Abstract
As citizens are increasingly concerned about the surrounding environment, it is important for modern cities to provide sufficient and accurate environmental information to the public for decision making in the era of smart cities. Due to the limited budget, we often need to optimize the sensor placement in order to maximize the overall information gain according to certain criteria. Existing work is primarily concerned with single-type sensor placement; however, the environment usually requires accurate measurements of multiple types of environmental characteristics. In this paper, we focus on the optimal multi-type sensor placement in Gaussian spatial field for environmental monitoring. We study two representative cases: the one-with-all case when each station is equipped with all types of sensors and the general case when each station is equipped with at least one type of sensor. We propose two greedy algorithms accordingly, each with a provable approximation guarantee. We evaluated the proposed approach via an application in air quality monitoring scenario in Hong Kong and experimental results demonstrate the effectiveness of the proposed approach.
1. Introduction
Environmental monitoring plays an essential role in the era of smart cities [1,2], providing not only sufficient information for citizens’ decision making, such as whether the air quality is suitable for exercise outdoors, but also as the primary data source for many longitudinal environment and health studies in order to better understand and assess the environment dynamics and their impact on public health over time [3,4,5]. However, deploying fixed-location sensors or monitoring stations that could provide accurate and calibrated measurements are costly, including not only the sensor cost which can be up to € per device [6], but also the operation cost and site construction cost [7]. Recent studies have shown that low-cost sensors are not yet ready for providing accurate measurements [6] despite their recent popularity. Therefore, there is usually a fixed budget for deploying the sensors and locations should be chosen carefully according to certain objectives, leading to the sensor placement problem.
The general sensor placement problem has been studied in many environmental monitoring applications, for example, temperature monitoring [8], water contamination [9], wind monitoring [10], soil moisture [11], etc. In these previous work, the underlying spatial field, sometimes after preprocessing step, such as time series segmentation [10] or log-transformation [8], are modeled by the Gaussian Process (GP), which is a powerful probabilistic framework for modeling spatial phenomena and allows information theoretic criteria such as minimum conditional entropy and maximum mutual information to be applied for finding the most informative locations.
Unfortunately, most of the existing work focus on single-type sensor placement problem under cardinality/budget constraints while some complex environment phenomena require measurements of multiple types of spatial fields simultaneously. A motivating scenario is to monitor the air quality of a region which requires measurements of multiple types of atmospheric pollutants. Take China as an example, six types of pollutants are measured [7], namely nitrogen dioxide (), carbon monoxide (), sulfur dioxide (), finite suspended matter (), respirable suspended particulates () and ground level ozone (). The air quality metric varies with different countries. In China, these six pollutants are measured to calculate the Air quality index (AQI) level. In the United States, and are considered together as particulate matter. Since each field is likely to exhibit different spatial patterns, it is not cost effective to apply the single-type sensor placement strategies for each field which may lead to a waste of site construction cost (around 200k USD) and maintenance cost (around 30k USD per year) [12] for deploying only one type of sensor. Figure 1 further illustrates the challenge of multi-type sensor placement problem. Suppose that there are T types of fields of interest in total. For each field, the five colored grids denote the optimal single-type sensor placement result (the five most informative locations). In particular, Location B is selected for all types for fields, while Location A is selected only for the second field. Therefore, when considering all the fields at the same time, selecting Location A for deploying a station may not be a good choice when the budget is limited and a careful design of placement scheme is required to balance the trade-off between information gain and cost.
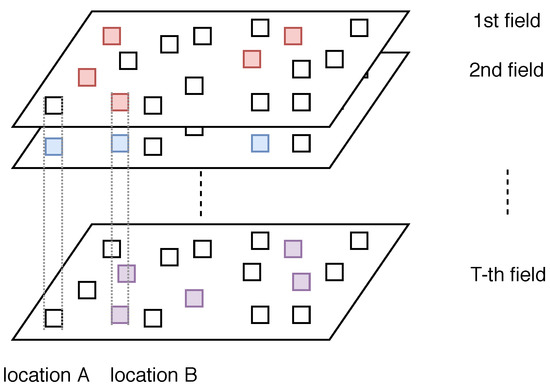
Figure 1.
Illustration of the challenge of multi-type sensor placement.
There are some studies that investigated the multi-type sensor placement problem. Singh et al. [13] studied optimal sensor placement of two types of sensors that differ in cost and coverage with a total budget constraint. Ohsaka and Yoshida [14] gave a formulation for the joint placement of k types of sensors under the individual set size constraints and the total size constraints. However, both studies assume that each location can only install one type of sensor, yet in reality different types of sensors can be integrated together as a modular sensor box [15] and monitoring stations are often equipped with more than one type of sensors [16]. Yuen and Kuok [17] proposed a Bayesian sequential multi-type sensor placement algorithm for structural health monitoring and Lin et al. [18] proposed a non-dominated sorting genetic algorithm for solving the optimal multi-type sensor placement for structural damage detection. However, both approaches are heuristic optimization methods with no approximation guarantee. Furthermore, they both require explicit bounds on the number of sensors for each type.
In terms of sensor placement problem for air quality monitoring, Hsieh et al. [12] proposed an entropy-minimization model to recommend the best locations for establishing new monitoring stations. However, the placement result depends on the accuracy of their proposed inference model and the model is only able to predict the AQI value of one type of pollutant (either or ) rather than the general AQI, which better reflects the air quality.
In this paper, we study the optimal budgeted multi-type sensor placement problem without the disjoint assumption. Our major contributions are as follows. Firstly, we formulate the optimal multi-type sensor placement problem for environmental monitoring under a general budget constraint. Next, we investigate two representative scenarios: the one-with-all case that installs all types of sensors for each placement and the general case that only requires at least one type of sensor to be installed at each location. By exploiting the nice monotonicity and submodularity, we propose two greedy algorithms for solving the corresponding scenarios with provable approximation guarantee. We adapt the lazy approach for the two proposed greedy algorithms, which can further speed up the performance without hurting the approximation guarantee. Finally, we perform a case study using the air quality measurements in year 2017 from the official government stations of Hong Kong to demonstrate the proposed approach. This formulation provides guidance for city planners to design the multi-type sensor network for environmental monitoring.
The rest of the paper is organized as follows. In Section 2, we review the Gaussian Process (GP) model and optimal design criteria for single spatial field, and introduce the optimal multi-type sensor placement problem. In Section 3, we study the problem in the one-with-all case and the general case, and provide greedy algorithms with approximation guarantees. In Section 4, we provide the simulation results on the Hong Kong air quality monitoring data. We conclude in Section 5.
2. Problem Formulation
In this section, we review the relevant background including Gaussian Process and informative location for single spatial field, and formally formulate the optimal multi-type sensor placement problem. The major notations are summarized in Table 1.

Table 1.
Notations.
2.1. Gaussian Process
To quantify the information gain by the placement, we adopt the Gaussian Process (GP) representation for the spatial fields. Gaussian Process is a powerful framework for making probabilistic predictions of spatial phenomena [19]. Intuitively, it generalizes multivariate Gaussian to an infinite number of random variables such that the joint distribution over every finite subset of random variables follows a Gaussian distribution.
Each GP is fully specified by a mean function and a symmetric positive-definite covariance function (also known as kernel) . An important property of GP is that, for every finite subset A of the index set V, the joint distribution over these random variables is Gaussian. Then, for the random variable with index u, its mean is given by . For each pair of random variables with indexes , their covariance is given by . We denote the mean vector of the set of random variables A by and their covariance matrix by .
Let denote a finite set of indexes, each corresponding to a location (square grid) of the city region. Let denote the Gaussian Process for the ith spatial field and T denote the types of spatial fields of interest. Let . Suppose for the ith spatial field, e.g. , a set of observations corresponding to the finite subset can be obtained either through pre-deployments or mathematical simulations, we can then predict the value of any point . By definition, the distribution of given these observations is a Gaussian whose conditional mean and variance are given by:
where is a covariance vector with one entry for each with value and .
To compute the predictive distribution above, we need to know the mean and covariance functions. The mean function can be estimated by regression. The covariance function, depending on the specific scenarios, can be obtained by either learning the hyperparameters of some existing family of kernel functions [19] such as Gaussian kernel with hyperparameter , or learning complex nonstationary kernels from sensory data collected by pre-deployment [20].
2.2. Informative Locations for Single Spatial Field
There are two common criteria for deciding what a good design is for placing single-type sensors in Gaussian Process: entropy [21] and mutual information [8]. Entropy criterion seeks to place sensors at the most uncertain places so as to minimize the conditional entropy of the unobserved locations after placing sensors at locations A. Specifically, if the budget allows for k sensors in total, then we aim to find
is the conditional differential entropy given by:
where is the joint probability density function. Since where is invariant with respect to the choice of A, the optimization in Equation (3) is equivalent to
The mutual information criterion on the other hand seeks to place sensors at locations A that most significantly reduce the uncertainty about the estimates in the rest of the space . Specifically, if the budget allows for k sensors in total, then we aim to find
where is the mutual information between the unknown locations and the known locations which is given by
Finding the optimal solution of both optimizations in Equations (5) and (6) has been shown to be NP-hard [8,22]. Fortunately, both objective functions have the nice monotone and submodular properties (the mutual information is usually monotone and submodular under the assumption that ).
Definition 1
(Non-decreasing). A set function is called non-decreasing if for all , we have
Definition 2
(Submodularity). A set function is called submodular if for all and , we have
Submodularity is also known as the diminishing returns property. Intuitively, the more sensors placed, the less information gain we can have by deploying a new sensor. An equivalent definition is as follows. A set function is called submodular if for all , we have
The choice of the informative criterion depends on the actual scenario. For now, we denote the general information gain of choosing the set of indexes for deploying a certain type of sensors (using either criterion) as . Then, both optimizations in Equations (5) and (6) can be written as the following submodular function maximization:
where K is subset size constraint (also known as the cardinality constraint), i.e., the total number of sensors we can place due to the total budget constraints.
Despite the hardness of the optimization above, the nice monotone and submodular properties allow us to solve the problem via the simple greedy algorithm with provable approximation guarantee. The algorithm starts with the empty set and then at each iteration adds to the current set A the index s that maximizes the incremental information gain and continues until the subset size constraint is no longer satisfied.
Theorem 1
([23]). If the submodular set function f is monotone and , then the greedy algorithm finds a solution A such that with at most evaluations of f.
It is not hard to know that . Hence, by this theorem, we know that the greedy algorithm gives an approximation ratio of for the single-type sensor placement problem.
2.3. Optimal Multi-Type Sensor Placement
In many cases, we would like to place multiple types of sensors simultaneously for monitoring a complex spatial phenomena given a fixed budget. A motivating scenario is to monitor the air quality of a region which requires measurements of six types of atmospheric pollutants [7], namely nitrogen dioxide (), carbon monoxide (), sulfur dioxide (), finite suspended matter (), respirable suspended particulates () and ground level ozone ().
Figure 2 shows an example of the multi-type sensor placement scheme. The red rectangles denote the selected locations for deploying stations. For each station, one or multiple types of sensors are installed to monitor the spatial fields. Specifically, the optimal multi-type sensor placement problem aims to figure out where are the best locations for deploying the stations and what type of sensors should be installed at each location in order to achieve certain objectives.
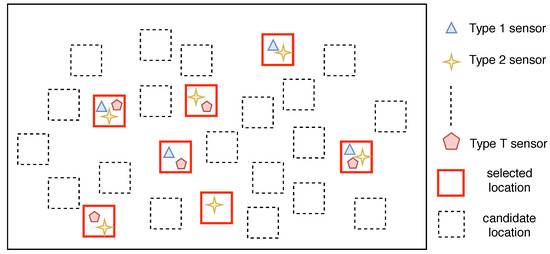
Figure 2.
An example of the multi-type sensor placement scheme.
Let denote the information gain of choosing the set of indexes (locations) for deploying the ith type of sensors. For simplicity of notation, let denote the multi-type sensor placement scheme.
Now, we proceed to discuss the cost function for the multi-type sensor placement case. An important observation is that, when multiple types of sensors are placed together, the total cost is smaller than the sum of individual cost due to the existence of site construction cost and site operation cost (http://aqicn.org/products/monitoring-stations/).
Let denote the equipment cost for the ith type which includes both the initial cost and the sensor-specific operation cost (e.g., calibration cost, sampling cost, etc.), then the total equipment cost can be expressed as
Let denote the site cost which includes the construction cost and site operation cost. If we assume that the site cost is invariant with the location, i.e. for each station, can be expressed as
Then, the cost function for can be expressed as
and we aim to find
where B is the total budget constraint.
3. Solution Approach
In this section, we investigate two reasonable scenarios of the optimal multi-type sensor placement problem and propose two greedy approaches with provable approximation guarantees.
3.1. One-with-All Case
We start with the simplest condition where each station is equipped with all types of sensors. Let denote the cost of a station (with all type of sensors). In this case, we have and the general cost constraint reduces to the cardinality constraint where denotes the floor function mapping x to the greatest integer less than or equal to x. Let denote the placement scheme and K denote the total number of stations we can deploy. Then, the problem becomes:
However, the optimal solution of the above multi-objective optimization does not exist. The reason is that different pollutant fields are likely to exhibit different spatial patterns due to different generation process.
Figure 3 visualizes the different spatial characteristic of and in Hong Kong. The variance of the random variable at each monitored location is estimated with the hourly measurement data during Year 2017. As shown in Figure 3, the high variance locations with respect to are not always the locations where the variances are high with respect to .
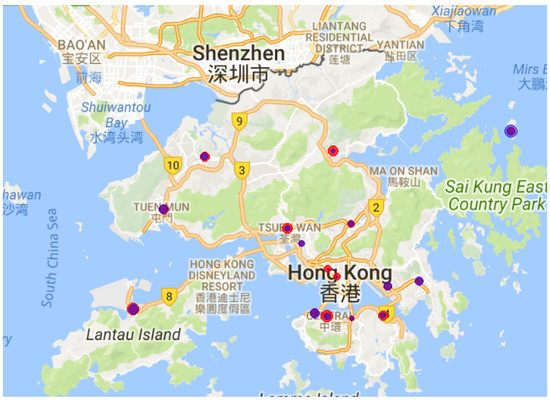
Figure 3.
Spatial variations of the air quality measurements at the 16 official monitoring stations in Hong Kong in 2017: the blue circles denote and the red circles denote . The size of a circle represents the magnitude of the variance of the corresponding random variable.
Instead, we can always find the Pareto-optimal solutions [24] of the above multi-objective problem. We say a placement scheme A is Pareto optimal if there is no other scheme such that for all i and for some j. In other words, A is Pareto-optimal if there is no other placement scheme that is no worse than A in all objectives and is strictly better than A in at least one objective .
One standard approach to find such solutions is the weighted sum transformation/scalarization [24]:
where denotes the weight parameter of the ith objective function and we have . By default, we can choose . Since submodularity is closed under linear combinations, the new objective function is also submodular. Hence, we can use the greedy approach to solve the problem for this case. The detail is summarized in Algorithm 1.
| Algorithm 1 Multi-type sensor deployment algorithm for one-with-all case |
|
Proposition 1.
Algorithm 1 finds a solution A such that where is the Pareto-optimal solution with weight parameters .
Using the fact that the objective function is monotone and submodular, it directly follows from Theorem 3.
3.2. General Case
A more general scenario is when each station is only required to install at least one sensor. Take the weather monitoring stations in Hong Kong for example, many stations only contain some of the sensors, such as temperature, pressure, rainfall, etc. In this case, increasing the information gain of one type of sensor will decrease the information gain in another due to the total budget constraint. Hence, we adopt a similar weighted sum transformation approach and aim to solve the follow optimization:
where denotes the weight parameter of the ith objective function and we have .
To understand the difficulty of the optimization, we first investigate the structure of the cost constraint. Let denote the number of sensors for the ith type and denote the total number of stations of the placement scheme . Then, the cost constraint can be rewritten as:
Proposition 2.
Let denote the optimal placement scheme. If and , when , the cost constraints in Equations (16)–(18) can be reduced to the cardinality constraint for the optimal multi-type sensor placement.
Proof.
Since the objective function is non-decreasing for each i, we aim to find the optimal integer solutions subject to the budget constraint in order the maximize the overall information gain.
Since the total sensor costs when there is K stations is at most , we know that the achievable number of stations K is at least and equality is achieved when each station is equipped with all types of sensors (one-with-all case).
In the meantime, since is at least if we assume that there is at least one sensor for each type, we know that the achievable number of stations K is at most and equality is achieved when each location is equipped with one sensor for each type, except for the cheapest type with sensors.
Therefore, when , K is unique and can be achieved. Then, the cost constraints can be reduced to the cardinality constraint . ☐
Remark 1.
The assumptions that and is usually naturally satisfied with a reasonable budget that allows to place at least one sensor for each type of pollutant, as otherwise there be entirely no measurement for some types of field, making the total uncertainty still quite high.
Proposition 2 gives the condition when the general case reduces to the one-with-all case. This usually happens when for all . In other words, when the sensor costs are negligible compared with the site construction costs, each station should be equipped with all types of sensors. The budget constraint limits the number of stations we can deploy.
In the following, we focus on the case when the cost constraint is not reducible to the one-with-all case. One might consider to greedily place sensors until the cost constraint can no longer be satisfied, i.e., at each step, we consider the location to place type sensor such that
and confirm the selection if its cost is acceptable. here refers to the current selected location set for the ith field. However, the solution can be arbitrarily bad as a sensor providing information gain g will always be preferred over a sensor providing information gain despite a much higher cost. Alternatively, we can consider to greedily assign sensors based on information gain per cost, i.e., at each step, we consider the location to place type sensor such that
and confirm the selection if its cost is acceptable. denotes its current cost. However, the solution can still be arbitrarily bad, as a cheap sensor with a higher information gain per cost () will always be preferred over an expensive sensor B providing higher information gain B despite the remaining budget B only allows one to be selected and the better solution is to choose the expensive sensor.
Fortunately, the following theorem shows that the two solutions cannot be bad at the same time.
Theorem 2.
Proof.
Let denote a new set with . Then, each placement scheme corresponds to exactly one subset such that . Let denote a set function such that . It is obvious that .
We first show that f is non-decreasing. Let denote the corresponding set for placement scheme . Since for all , we know that for all , then and hence f is non-decreasing.
We then show that f is submodular. For , let denote its corresponding type and denote its corresponding location. Then, and hence f is submodular.
Therefore, f is non-decreasing and submodular with and by Theorem 3 in [9] which is a generalization of the Theorem in [25] for the special case of the budgeted max-cover problem, we know that . The proof is now complete. ☐
Let and denotes the incremental cost of adding type i sensor at location s when the existing placement scheme is . Then, we know that
With the help of above additional notations, we now summarize the proposed hybrid greedy selection approach for the general multi-type sensor placement in Algorithm 2.
| Algorithm 2 Multi-type sensor deployment algorithm for the general cost case |
|
Proposition 3.
The time complexity of Algorithm 2 is .
Sviridenko [26] showed that it is even possible to achieve the approximation ratio of for the general cost case; however, the algorithm requires an enumeration over all feasible sets of cardinality three and hence its complexity for our problem is , which is impractical.
In many real cases, the bound is not tight. Hence, we also provide a tighter online bound for arbitrary placement scheme derived with the submodularity property.
Theorem 3
(Online bound). For a given placement scheme and each , let . Let where denotes the incremental cost of adding the ith type of sensor to location s. Let be the sequence of locations with in descending order and be the sequence of selected types. Let k be such that and . Let . Then
3.3. Assessing the Trade Off
After we obtain the placement scheme for the general case, we know the station number K and the number of sensors for the ith spatial field. If we run the simple greedy algorithm for the ith type of spatial field with subset size constraint , we can find the uncoupled placement result with and obtain the individual sacrifice due to the budget constraint. The total information loss is with a total saving of ). This information is useful to assess whether additional budgets should be allocated for a certain field to provide further information.
3.4. Speeding up the Algorithms
Krause et al. [8] developed a lazy evaluation technique to speed up the greedy selection algorithm for single-type sensor placement problem. In this section, we adapt this approach for the multi-type sensor placement problem to speed up the two algorithms proposed above.
We start with the one-with-all case. The key idea is that, at each iteration, some calculations of the information gain can be saved by utilizing the submodular property, i.e., the information gain for adding sensors can never increase. Therefore, we can maintain an ordered list of the information gain and only update the value when necessary. The lazy greedy for the this case is presented with Algorithm 3.
| Algorithm 3 Lazy greedy algorithm for one-with-all case |
|
The idea is similar for the general case. Specifically, for the cost-effective greedy selection, we maintain an ordered list of information gain per cost for adding a certain type of sensor to a specific location. Notice that the cost is also dependent on the existing selection and hence the cost update after each iteration (if any) will cause the reordering of the list. The lazy greedy for the general case is presented with Algorithm 4.
| Algorithm 4 Lazy greedy algorithm for the general cost case |
|
4. Simulations
We evaluated the proposed multi-type placement scheme on the hourly air quality monitoring data for 2017 provided by the Hong Kong Environment Protection Department (EPD) website [16]. There are 16 monitoring stations in total, three of which are roadside stations. Here, we only considered , , , and as they are measured by all of the stations. As shown in Figure 4, the distribution of normalized one-hour difference of the pollutants at Tung Chung monitoring station are approximately normal distributed (due to space limits, we only show one station as an example; in fact, the statement holds for arbitrary station (location)), and hence satisfy the GP assumption. We estimated the empirical covariance matrix from the data, which represents the spatial process accurately. Here, we chose the entropy criterion as it directly satisfies the monotone and submodular property without the further requirement of that the number of sensors available is much smaller than the total number of possible locations. Let denote the distribution of the ith field at location s. Then, the incremental information gain of adding a sensor of type i to location s is
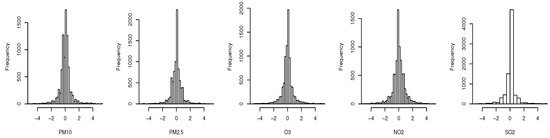
Figure 4.
Histogram of the normalized one-hour difference of the hourly measurements at Tung Chung station over the year 2017.
Figure 5 compares the information gain of different spatial fields using simple greedy selection. The blue line represents the objective function and the orange line is a straight line with a slope of maximum individual entropy. As can be seen, all objective functions exhibit the diminishing returns property and it is natural to expect a more prominent effect when the number of sensors is much larger. The name of the first location selected is displayed in each of the objective. Specifically, we know that Causeway Bay is the most uncertain location in terms of , which is likely due to the car emissions, and Sha Tin is the most uncertain location in terms of and . We also chose Tung Chung as a representative and display when it is selected in each field, which clearly indicates that each spatial field has different properties.
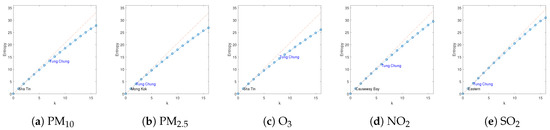
Figure 5.
Comparison of information gain of different spatial fields with simple greedy selection.
Figure 6 shows the placement results for the one-with-all case when . The weights were set to be identical for each field. Different from the single best location for each field, Central was selected first here as it is the most uncertain location with respect to the sum of individual objectives.
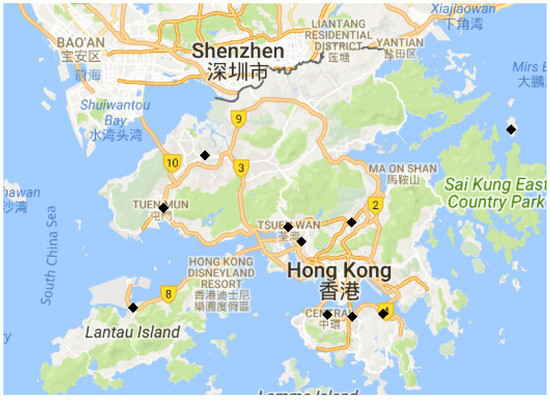
Figure 6.
Placement results of 10 sensors in Hong Kong for one-with-all case.
Figure 7 shows the placement results for the general case when the budget is just enough to deploy five stations, each with all types of sensors. The weights were set to be identical for each field. As shown in the figure, the cost-effective greedy approach is able to make full use of the budget and selects five locations for deploying stations with all type of sensors. The greedy approach, however, picks six locations for deploying stations yet none of them has all type of sensors due to the lack of consideration of cost during the selection. Since much more sensors are deployed with the cost-effective greedy approach as compared to the greedy approach (25 vs. 9), the total information gain of the cost-effective greedy approach is larger. Therefore, the the final placement result of the hybrid greedy approach is proposed by the cost effective greedy selection in this case.
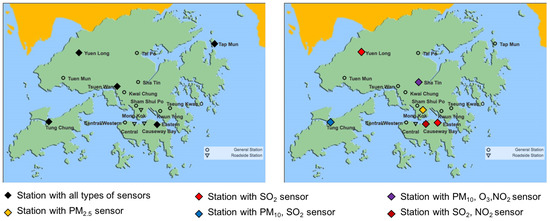
Figure 7.
Placement results for the general case when the budget is 100, the cost is , . The left figure is the placement result with the cost-effective greedy selection. The right figure is the placement result with the greedy selection.
Figure 8 shows the performance of the proposed hybrid greedy approach for the general case. We used the random selection as the baseline for comparison. The performance of simple-greedy selection and cost-effective greedy selection are also shown. Here, we set , , , , , as the cost of PM sensors are generally higher and vary B from 15 to 200 at a step size of 5. The weights are set to be identical for each field.
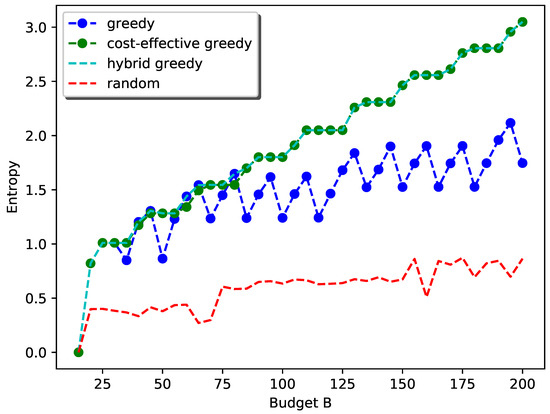
Figure 8.
Performance of the hybrid greedy approach with equal weight .
As can be seen from the plot, as the budget goes up, the general trend of information gain with the hybrid greedy approach follows the submodular property. The flat regions in the curve correspond to the scenarios when the general cost constraint can be reduced to the simple cardinality constraint. For example, when the budget is 25 to 30, and the strategy is simply deploying one station with all types of sensors.
For the cost-effective greedy selection, the increase is steady as the placement strategy in this scenario will first select a location for one type and then deploy other types at that location until the budget allows for a new station. The reason is that the site cost is quite high compared to the sensor cost and it is not cost effective to deploy a new station when sensors can still be added to the existing stations. This also explains the flat region even when .
The simple greedy selection, however, has a sudden drop when the budget first allows for a new station. The reason is that this approach will prefer exploring a new location with larger information gain rather than using the budget for adding other sensors to existing stations with smaller information gain and hence less sensors can be added.
Figure 9 shows the performance of the proposed hybrid greedy approach for the general case with a special emphasis on as it is the most health-harmful air pollutant [27]. Here, we set the weight for to and other weights to . The other settings remain the same. As can be seen from the plot, the performance of simple-greedy and cost-effective greedy are comparable due to the high weight of the objective function for . This is because adding sensors greedily without considering the cost will still increase the total information gain. Furthermore, the flat regions for cost-effective greedy disappear, indicating it will be preferable to deploy new stations for than to add sensors to existing stations.
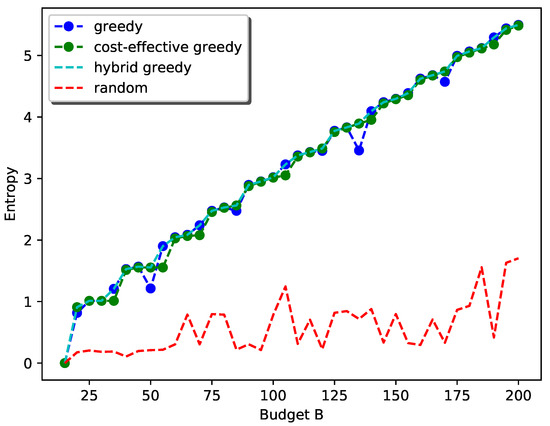
Figure 9.
Performance of the hybrid greedy approach with a higher weight for .
Both plots show that the proposed hybrid greedy approach always performs much better than random selection in terms of total information gain.
Figure 10 and Figure 11 show the speed performance comparison of greedy approach with lazy greedy approach. It can be easily seen that lazy greedy is faster than greedy while achieving the same approximation guarantee. For the general case, there is a more significant improvement. The reason is that, at each iteration, the candidate pool of possible selections is larger and hence more function evaluations can be saved with a lazy approach.
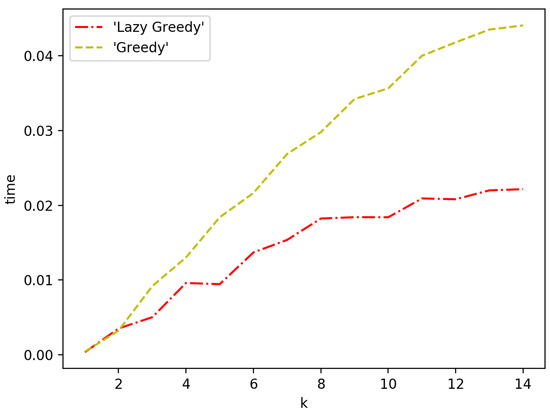
Figure 10.
Greedy vs. lazy greedy for one-with-all case.
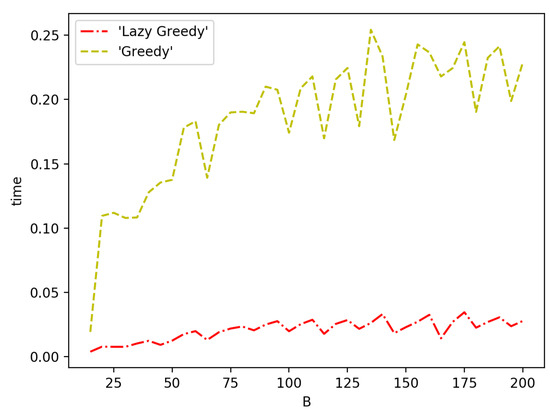
Figure 11.
Greedy vs. lazy greedy for general case.
5. Conclusions
In this paper, we formulate the multi-type sensor placement problem in Gaussian spatial field for environmental monitoring. We analyze two cases with different assumptions on the station requirement and propose two greedy algorithms with approximation guarantees. We then introduce a lazy approach for speeding up the greedy algorithms while achieving the same performance guarantee. We evaluated the proposed approach via an application in air quality monitoring scenario in Hong Kong and experimental results demonstrate the effectiveness of the proposed approach. This formulate can provide guidance for designing a citywide multi-type sensor network for environmental monitoring cost-effectively.
Author Contributions
C.S. developed the methodology and drafted the manuscript; Y.Y. provided important comments in the methodology and experiment design; V.O.K.L. and J.C.K.L. guided the research direction and revised the manuscript.
Funding
This research was supported in part by the Theme-based Research Scheme of the Research Grants Council of Hong Kong, under Grant No. T41-709/17-N.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sun, C.; Yu, Y.; Li, V.O.; Lam, J.C. Optimal Multi-type Sensor Placements in Gaussian Spatial Fields for Environmental Monitoring. In Proceedings of the 4th international conference on smart cities, Kansas City, MO, USA, 16–19 September 2018; pp. 420–429. [Google Scholar]
- Bacco, M.; Delmastro, F.; Ferro, E.; Gotta, A. Environmental Monitoring for Smart Cities. IEEE Sens. J. 2017, 17, 7767–7774. [Google Scholar] [CrossRef]
- Fischer, P.H.; Marra, M.; Ameling, C.B.; Hoek, G.; Beelen, R.; de Hoogh, K.; Breugelmans, O.; Kruize, H.; Janssen, N.A.; Houthuijs, D. Air pollution and mortality in seven million adults: The Dutch Environmental Longitudinal Study (DUELS). Environ. Health Perspect. 2015, 123, 697–704. [Google Scholar] [CrossRef] [PubMed]
- Kioumourtzoglou, M.A.; Schwartz, J.D.; Weisskopf, M.G.; Melly, S.J.; Wang, Y.; Dominici, F.; Zanobetti, A. Long-term PM2.5 exposure and neurological hospital admissions in the northeastern United States. Environ. Health Perspect. 2016, 124, 23–29. [Google Scholar] [CrossRef] [PubMed]
- Watts, N.; Adger, W.N.; Agnolucci, P.; Blackstock, J.; Byass, P.; Cai, W.; Chaytor, S.; Colbourn, T.; Collins, M.; Cooper, A.; et al. Health and climate change: Policy responses to protect public health. Lancet 2015, 386, 1861–1914. [Google Scholar] [CrossRef]
- Castell, N.; Dauge, F.R.; Schneider, P.; Vogt, M.; Lerner, U.; Fishbain, B.; Broday, D.; Bartonova, A. Can commercial low-cost sensor platforms contribute to air quality monitoring and exposure estimates? Environ. Int. 2017, 99, 293–302. [Google Scholar] [CrossRef] [PubMed]
- Beijing Air Pollution: Real-Time Air Quality Index (AQI). Available online: https://aqicn.org (accessed on 5 May 2018).
- Krause, A.; Singh, A.; Guestrin, C. Near-optimal sensor placements in Gaussian processes: Theory, efficient algorithms and empirical studies. J. Mach. Learn. Res. 2008, 9, 235–284. [Google Scholar]
- Leskovec, J.; Krause, A.; Guestrin, C.; Faloutsos, C.; VanBriesen, J.; Glance, N. Cost-effective outbreak detection in networks. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; pp. 420–429. [Google Scholar]
- Du, W.; Xing, Z.; Li, M.; He, B.; Chua, L.H.C.; Miao, H. Optimal sensor placement and measurement of wind for water quality studies in urban reservoirs. In Proceedings of the 13th International Symposium on Information Processing in Sensor Networks, Berlin, Germany, 15–17 April 2014; pp. 167–178. [Google Scholar]
- Wu, X.; Liu, M.; Wu, Y. In-situ soil moisture sensing: Optimal sensor placement and field estimation. ACM Trans. Sens. Netw. 2012, 8, 33. [Google Scholar] [CrossRef]
- Hsieh, H.P.; Lin, S.D.; Zheng, Y. Inferring air quality for station location recommendation based on urban big data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 437–446. [Google Scholar]
- Singh, A.; Guillory, A.; Bilmes, J. On bisubmodular maximization. In Proceedings of the Artificial Intelligence and Statistics, Canary Islands, Spain, 21–23 April 2012; pp. 1055–1063. [Google Scholar]
- Ohsaka, N.; Yoshida, Y. Monotone k-submodular function maximization with size constraints. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 694–702. [Google Scholar]
- Array of Things: A Networked Urban Sensor Project in Chicago. Available online: https://arrayofthings.github.io/ (accessed on 5 May 2018).
- Hong Kong Air Quality Monitoring Data. Available online: http://www.aqhi.gov.hk/en.html (accessed on 5 May 2018).
- Yuen, K.V.; Kuok, S.C. Efficient Bayesian sensor placement algorithm for structural identification: A general approach for multi-type sensory systems. Earthq. Eng. Struct. Dyn. 2015, 44, 757–774. [Google Scholar] [CrossRef]
- Lin, J.F.; Xu, Y.L.; Law, S.S. Structural damage detection-oriented multi-type sensor placement with multi-objective optimization. J. Sound Vib. 2018, 422, 568–589. [Google Scholar] [CrossRef]
- Rasmussen, C.E. Gaussian processes in machine learning. In Advanced Lectures on Machine Learning; Springer: Berlin, Germany, 2004; pp. 63–71. [Google Scholar]
- Nott, D.J.; Dunsmuir, W.T. Estimation of nonstationary spatial covariance structure. Biometrika 2002, 89, 819–829. [Google Scholar] [CrossRef]
- Cressie, N. Statistics for Spatial Data; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Ko, C.W.; Lee, J.; Queyranne, M. An exact algorithm for maximum entropy sampling. Oper. Res. 1995, 43, 684–691. [Google Scholar] [CrossRef]
- Nemhauser, G.L.; Wolsey, L.A.; Fisher, M.L. An analysis of approximations for maximizing submodular set functions I. Math. Program. 1978, 14, 265–294. [Google Scholar] [CrossRef]
- Grant, M.; Boyd, S.; Ye, Y. CVX: Matlab Software for Disciplined Convex Programming. Available online: http://cvxr.com/cvx (accessed on 5 May 2018).
- Khuller, S.; Moss, A.; Naor, J.S. The budgeted maximum coverage problem. Inf. Process. Lett. 1999, 70, 39–45. [Google Scholar] [CrossRef]
- Sviridenko, M. A note on maximizing a submodular set function subject to a knapsack constraint. Oper. Res. Lett. 2004, 32, 41–43. [Google Scholar] [CrossRef]
- Air Pollution. Available online: https://www.who.int/sustainable-development/cities/health-risks/air-pollution/en/ (accessed on 5 May 2018).
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).