EARS-DM: Efficient Auto Correction Retrieval Scheme for Data Management in Edge Computing



Abstract
:1. Introduction
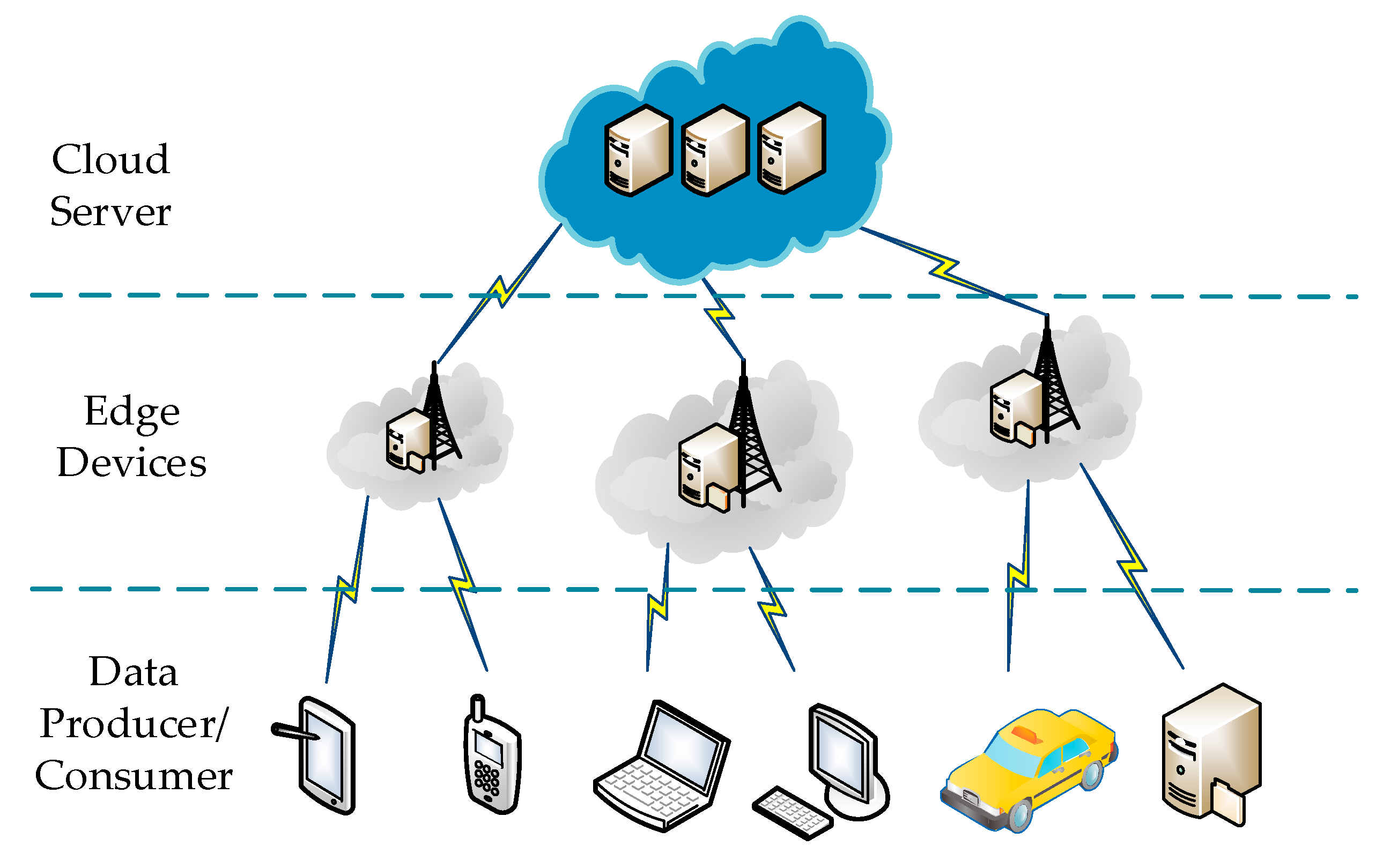
1.1. Cloud Computing and Edge Computing
1.2. Our Contribution
- We provide automatic error correction for query keywords instead of similar words extension, which can tolerate spelling mistakes as well as reduce the complexity of index storage space.
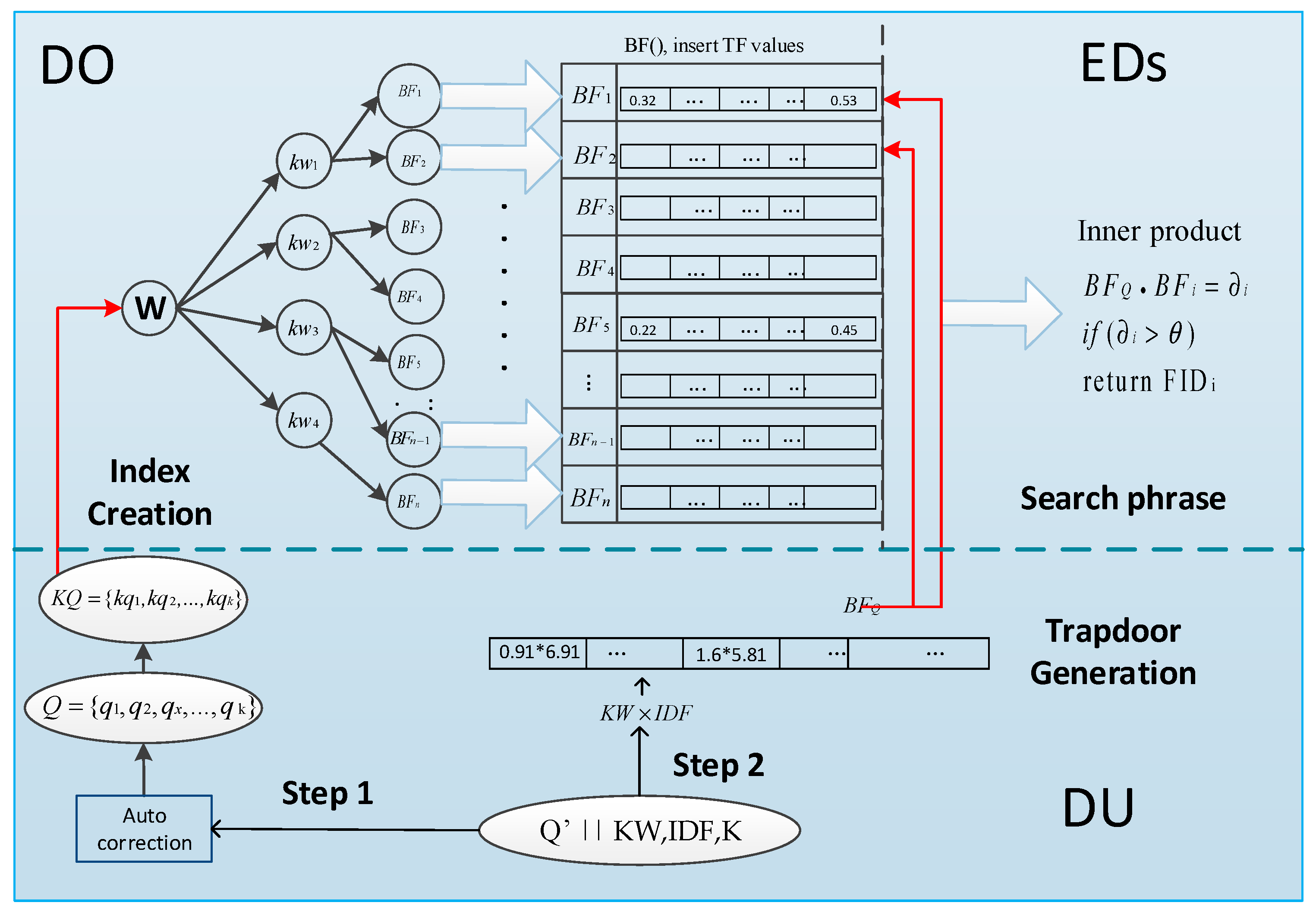
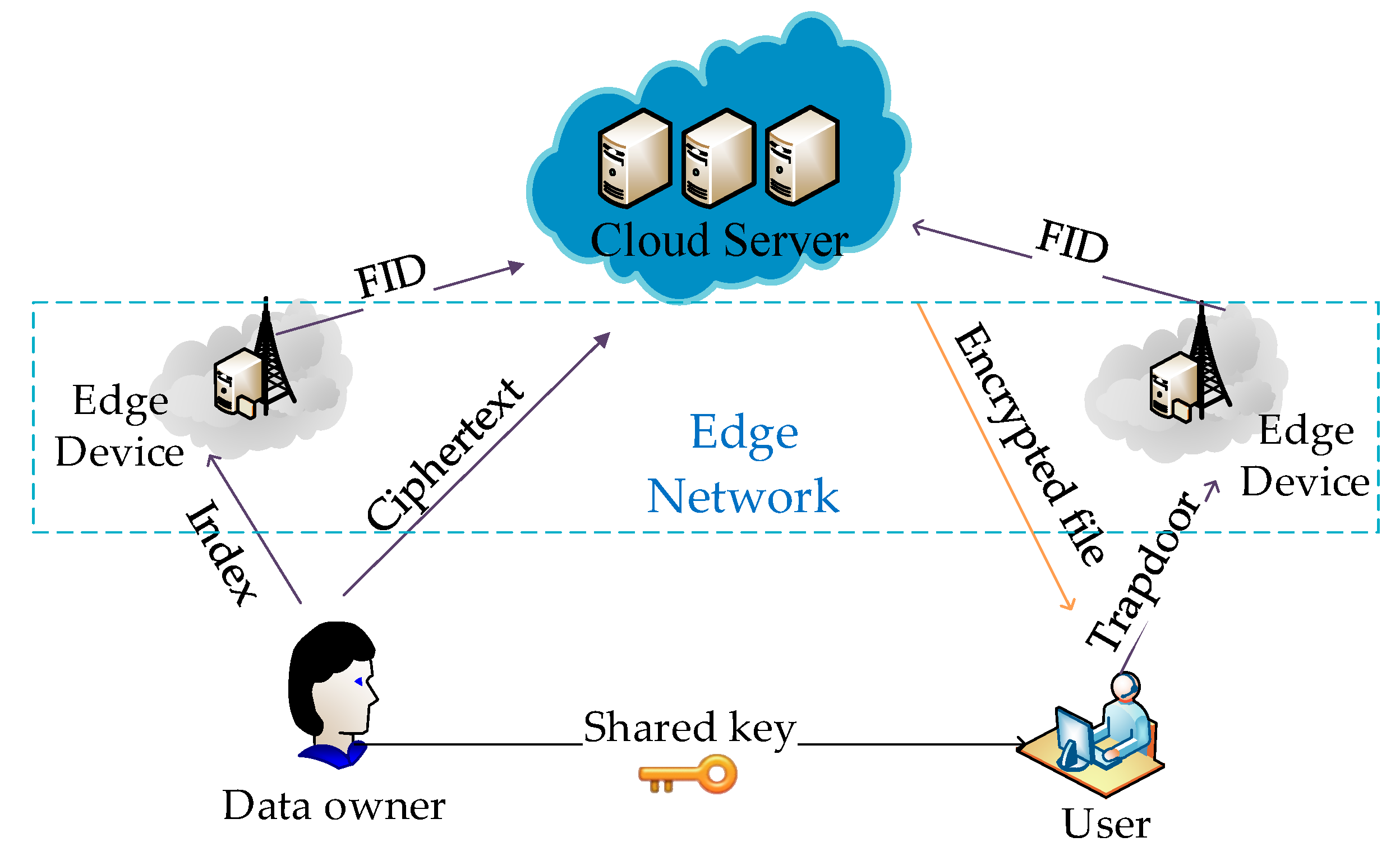
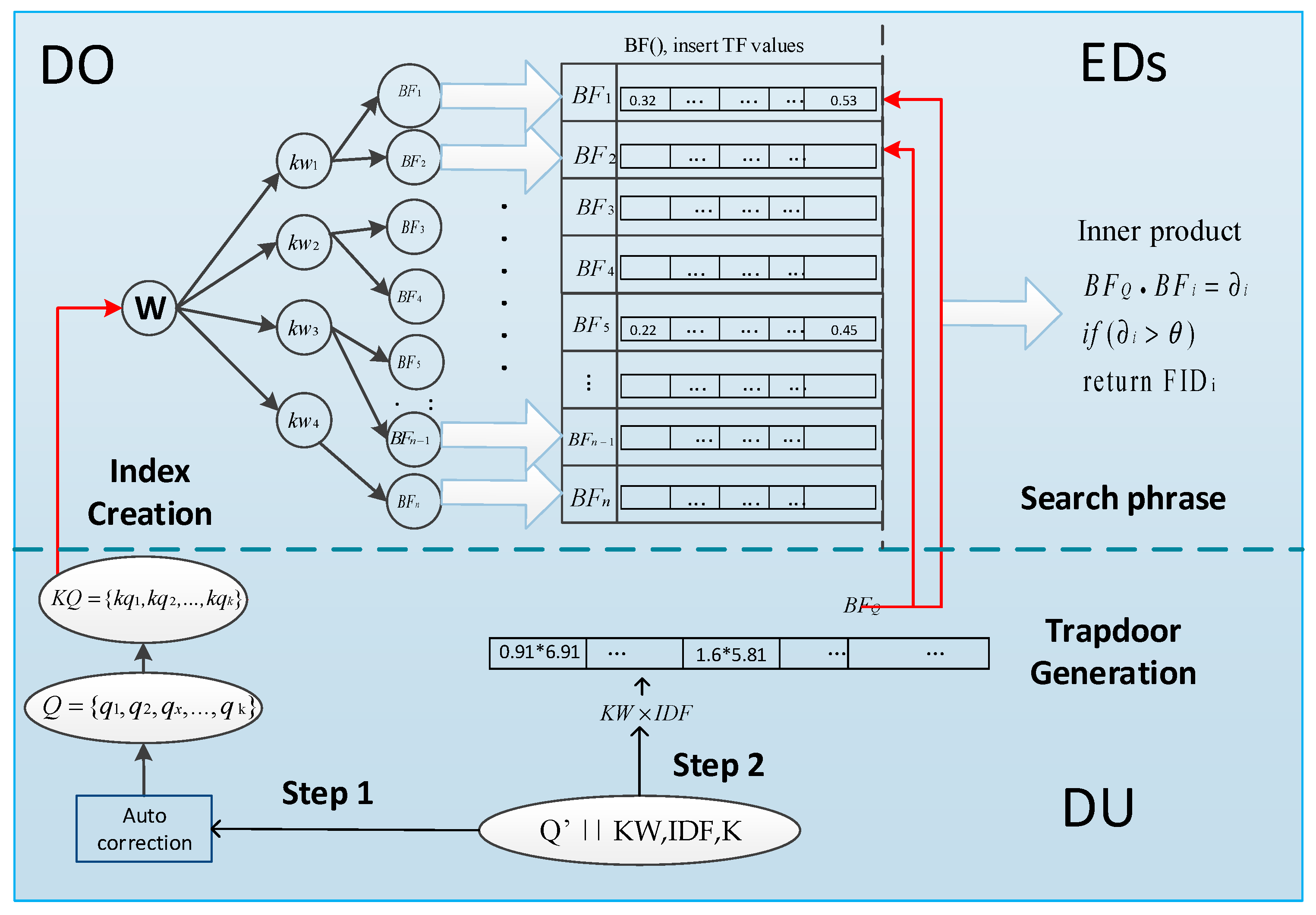
- We adopt a special R-tree index. It is constructed by encrypted keywords and the children nodes of which are the encrypted identifier FID and Bloom filter BF of files who contain this keyword. The secure index will be uploaded to the edge computing and the search phrase will be performed by the edge computing which is close to the data source.
- For the particularity of multi-keyword matching, we provide a two-step matching method. We first insert all the encrypted keywords into the R-tree and then perform keywords matching. If the match is successful, we will continue to match the Bloom filter of the corresponding file. The higher the match score, the more the file matches the query keywords.
- We consider both the TF-IDF value of keywords and the syntactic weight KW of query keywords. DOs calculate TF value of keywords and insert them into the Bloom filter of index. DUs computes query keyword syntactic weight KW through the syntactic parser as well as IDF value in trapdoor generation phrase. The value of KW* IDF is inserted into the Bloom filter of trapdoor. By comparison of the inner product of the Bloom filter, EDs calculate the matching degree between this file and all search terms. According to the relevance scores, the top-K FID list is sent to the CS.
- We present supported functions, security analysis and performance analysis of our retrieval scheme, and the result indicates that our scheme is efficient and accurate.
1.3. Organization
2. Related Work
2.1. Edge Computing
2.2. Searchable Encryption
3. Preliminaries
3.1. TF-IDF
3.2. Bloom Filter
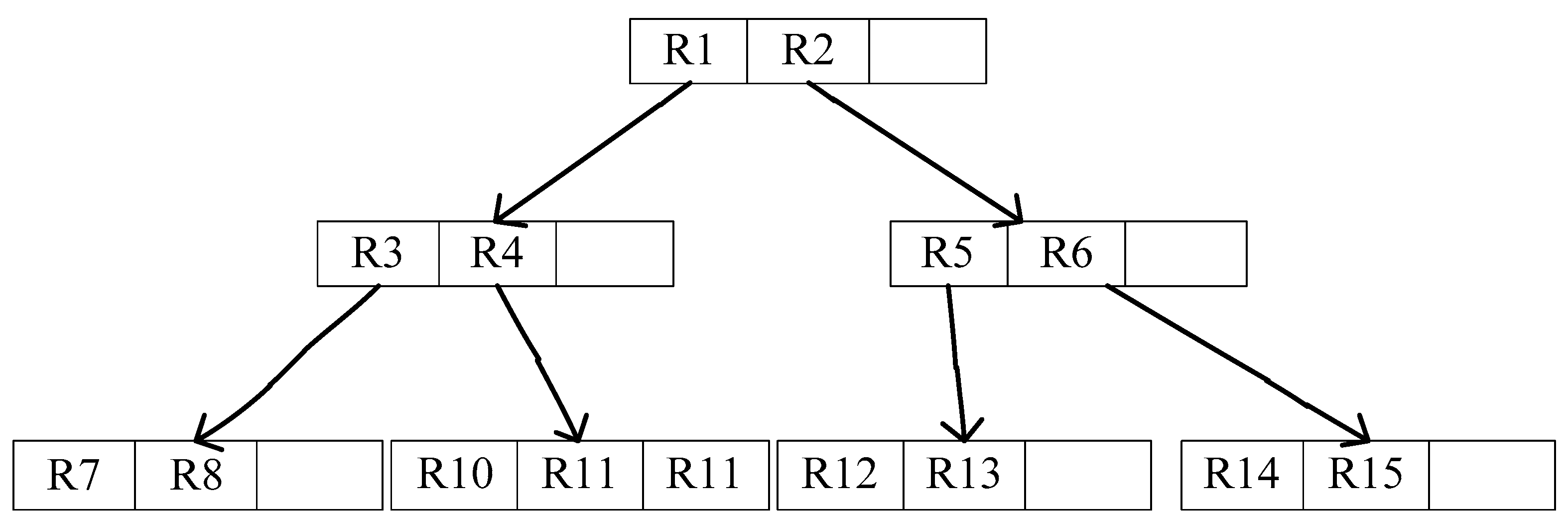
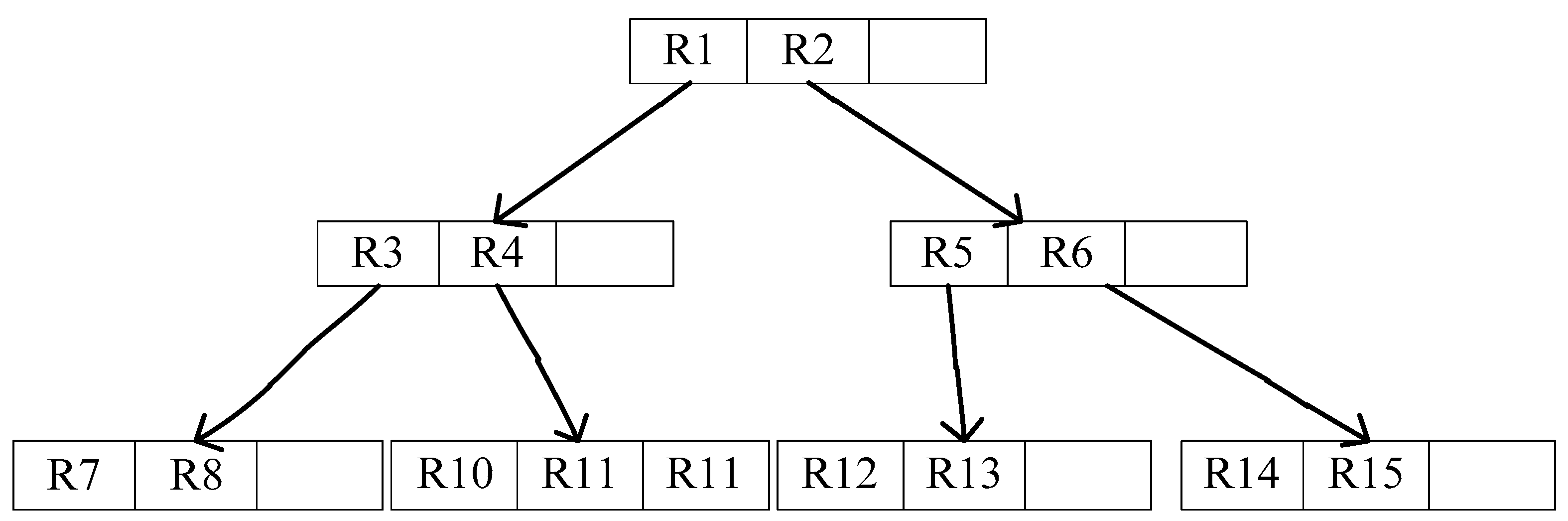
3.3. R-Tree Data Structure
4. Problem Description
4.1. Notations
4.2. System Model
4.3. Design Goals
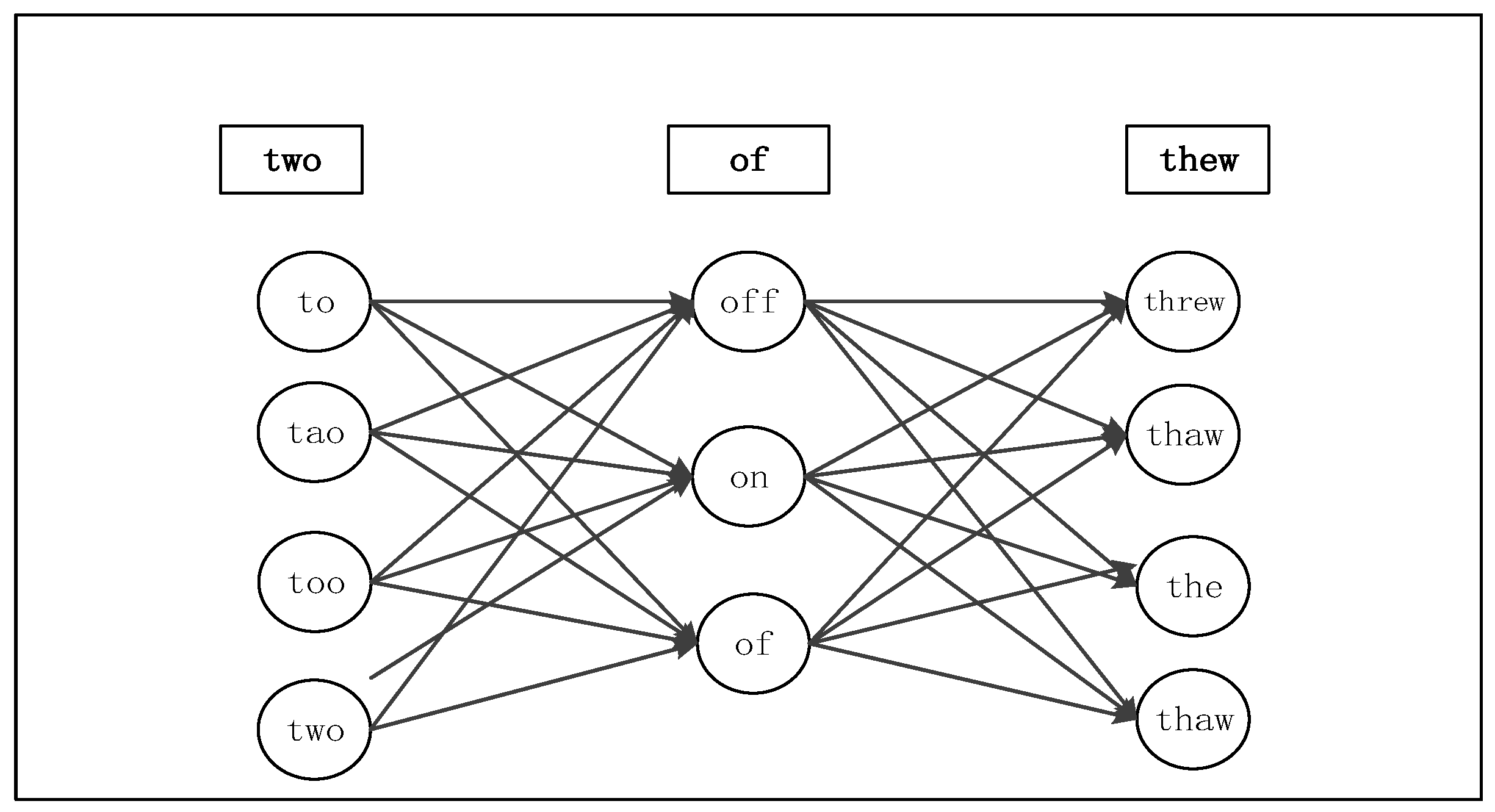
- Automatic correction. We aim to take an automatic error correction for the query keywords which can tolerate spelling mistakes.
- Efficient indexing structure. We aim to adopt an index structure that can balance search efficiency with update operations. In this paper, the index structure is a R-tree structure, which is linking to Bloom filter.
- Consideration of the syntactic significance of each query keyword. Because the significance of different keywords with different types is distinct, we consider obtaining keyword weight KW through the syntactic parser.
- Relevance ranking with all search terms. In the system, CS calculates the matching degree between this file and all search terms. According to the relevance scores, the importance of file is determined by the matching rate and sort from the top.
5. EARS-DM: Efficient Auto Correction Retrieval Scheme for Data Management
5.1. Syntax Parser
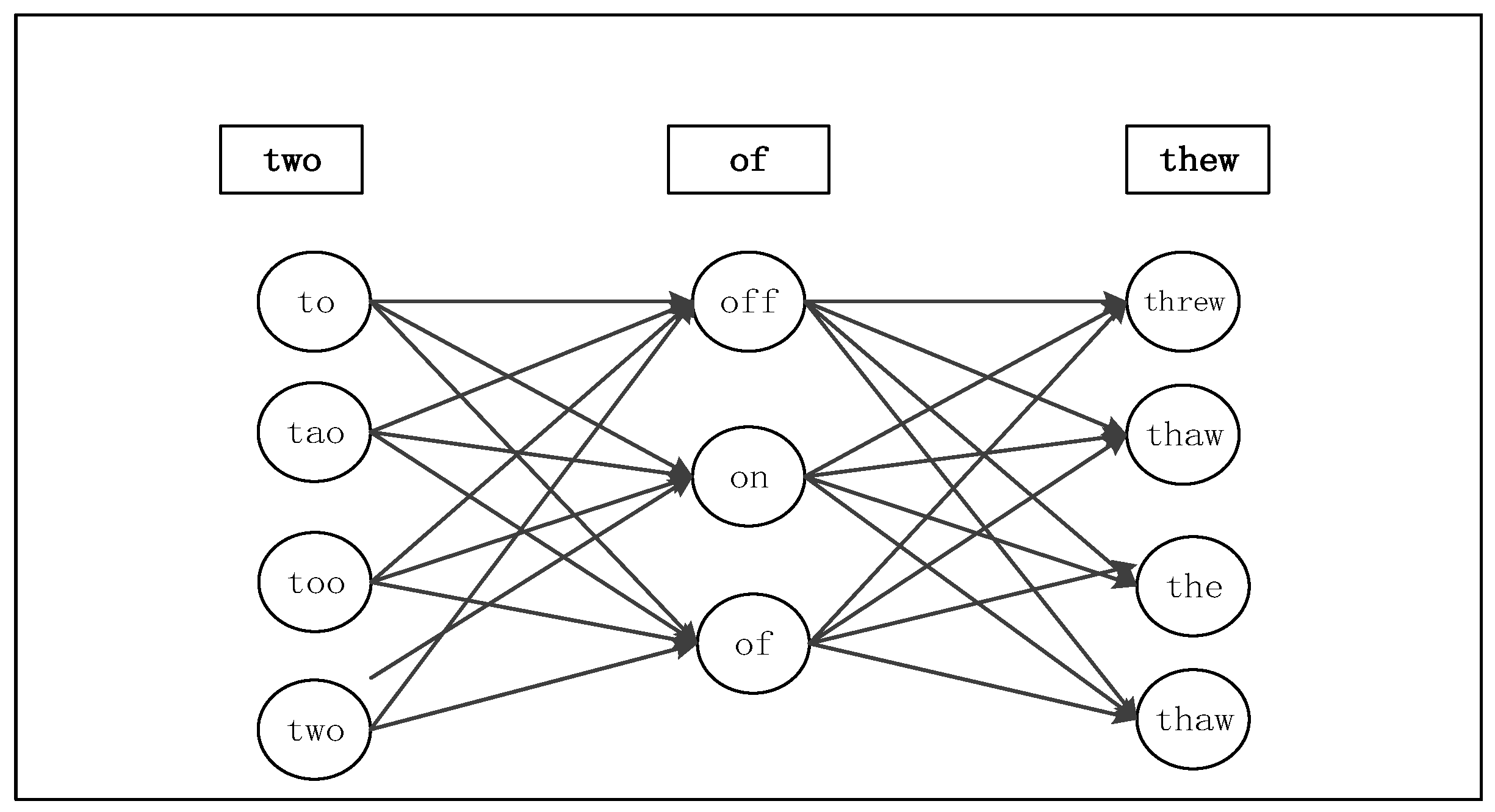
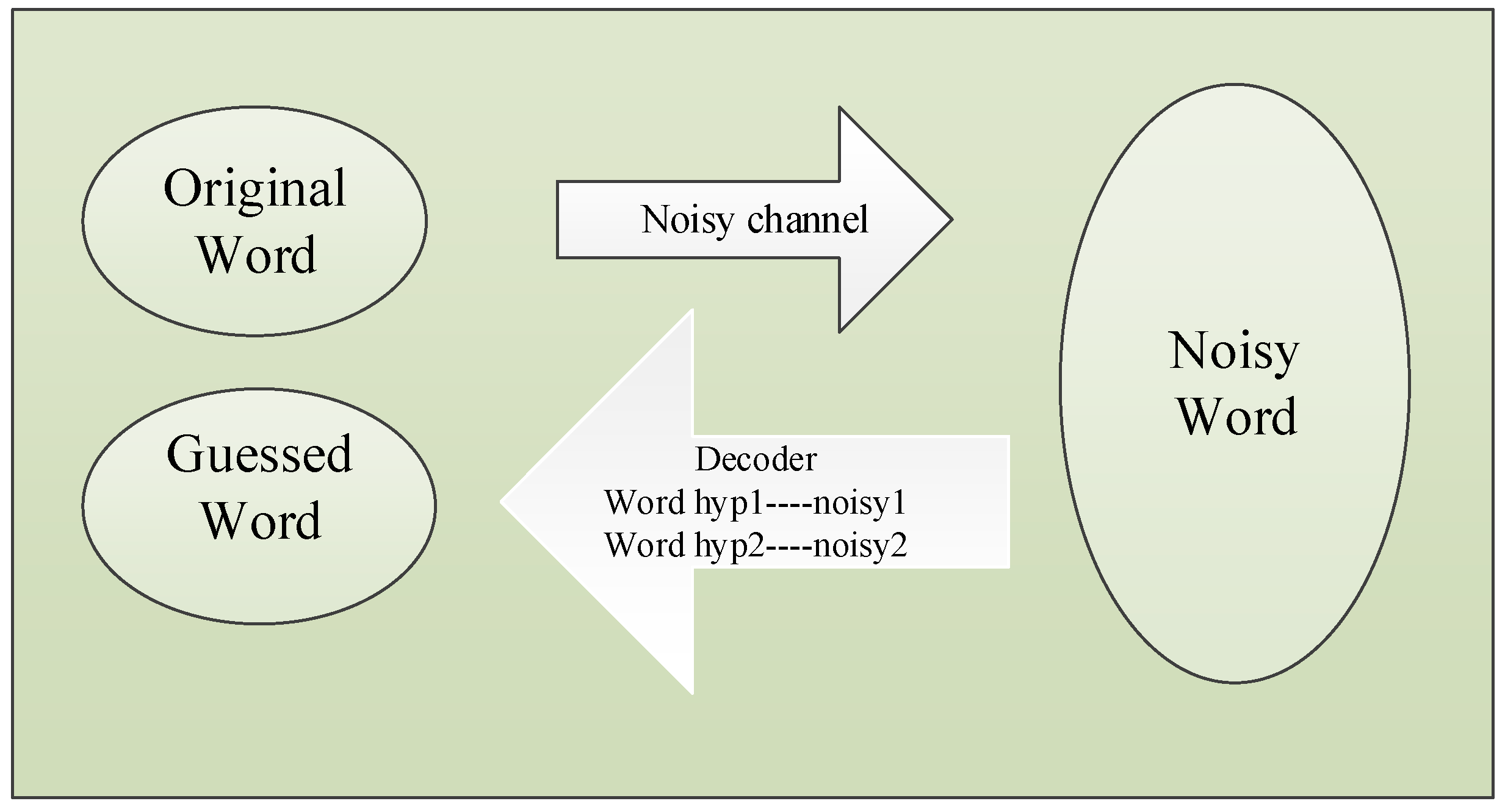
5.2. Spelling Error Correction
5.3. Algorithms of EARS-DM
- Key Generation for CS: . Key generation center inputs the public parameter GP and generates the public and private key pair for CS.
- Key Generation for EDs: . Key generation center inputs the public parameter GP and generates the public and private key pair for EDs.
- Key Generation for DO: . Key generation center inputs the public parameter GP and randomly selects and computes . The public key and private key of DO is . In addition, r random numbers as the input key of hash function are generated. The trapdoor key is .
5.4. Our Framework
6. Analysis of Proposed Scheme
6.1. Supported Functions
6.2. Security Analysis
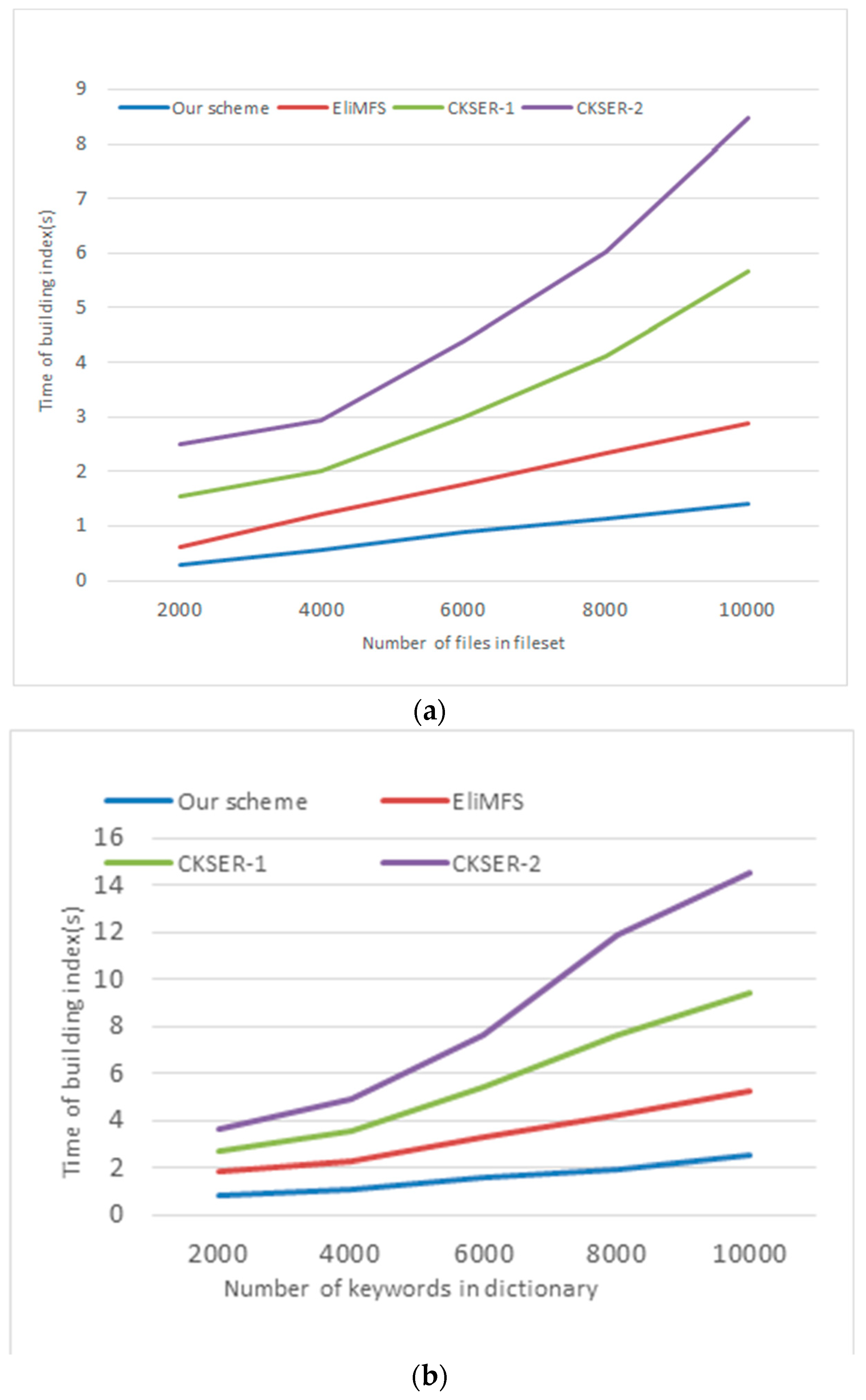
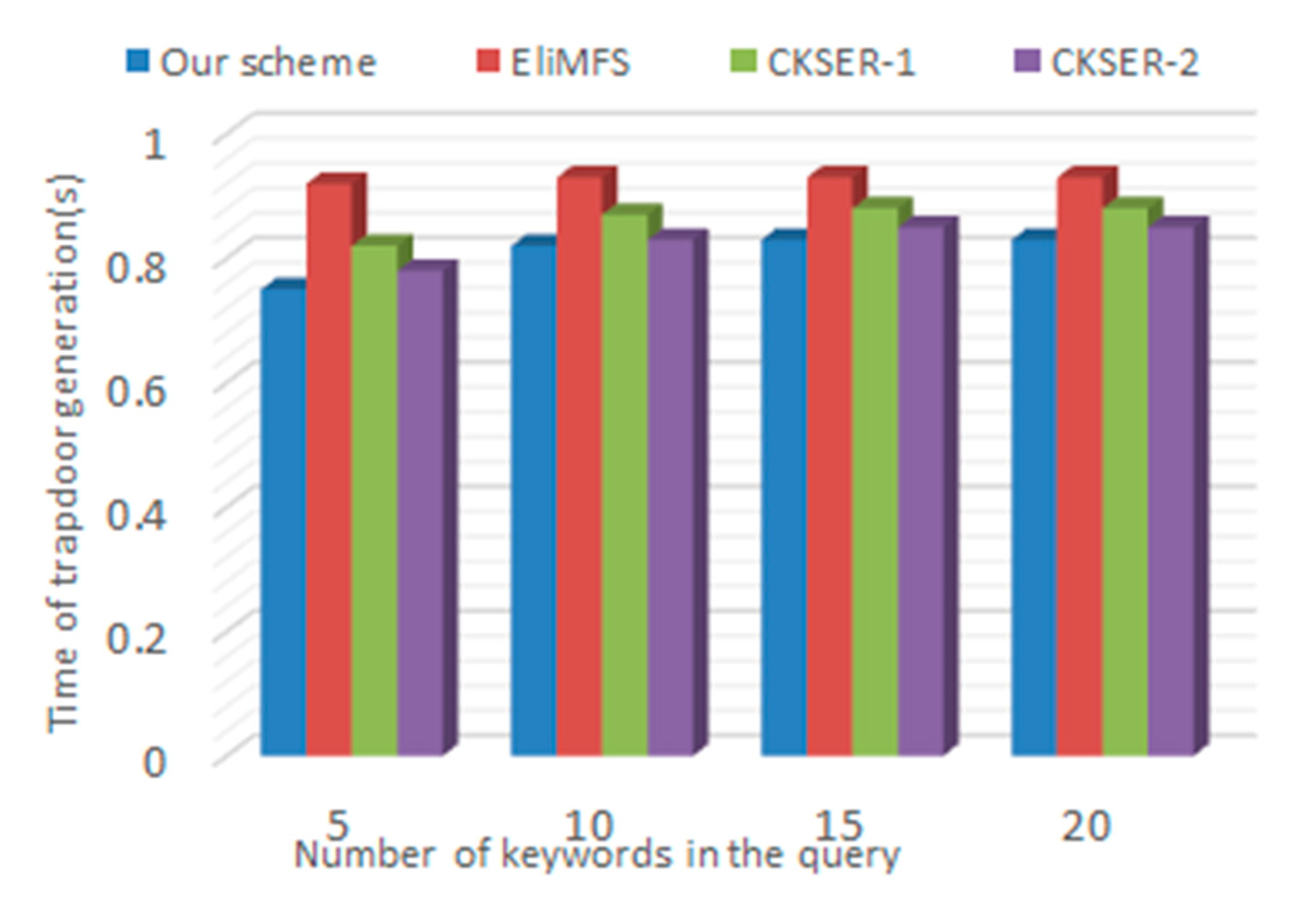
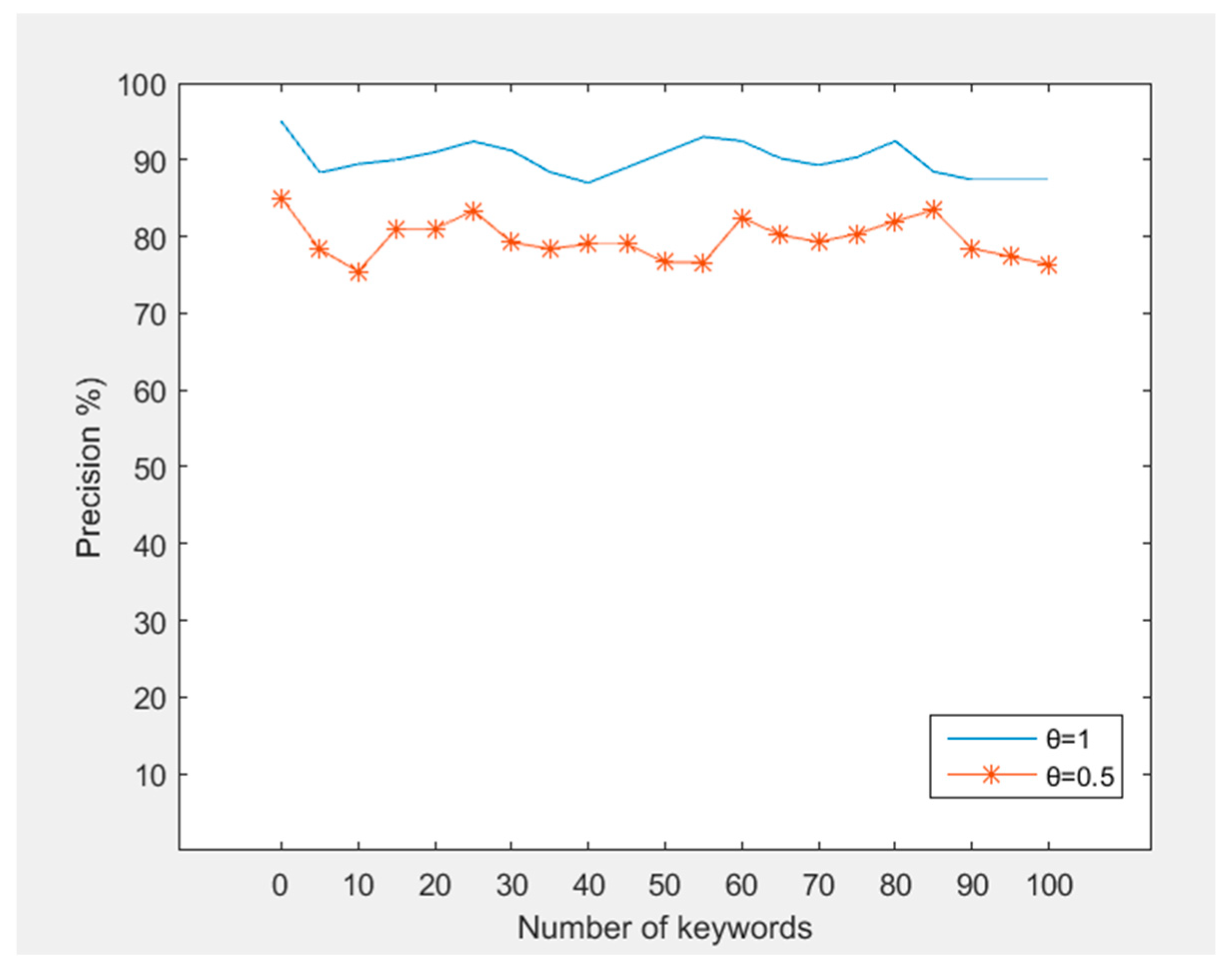
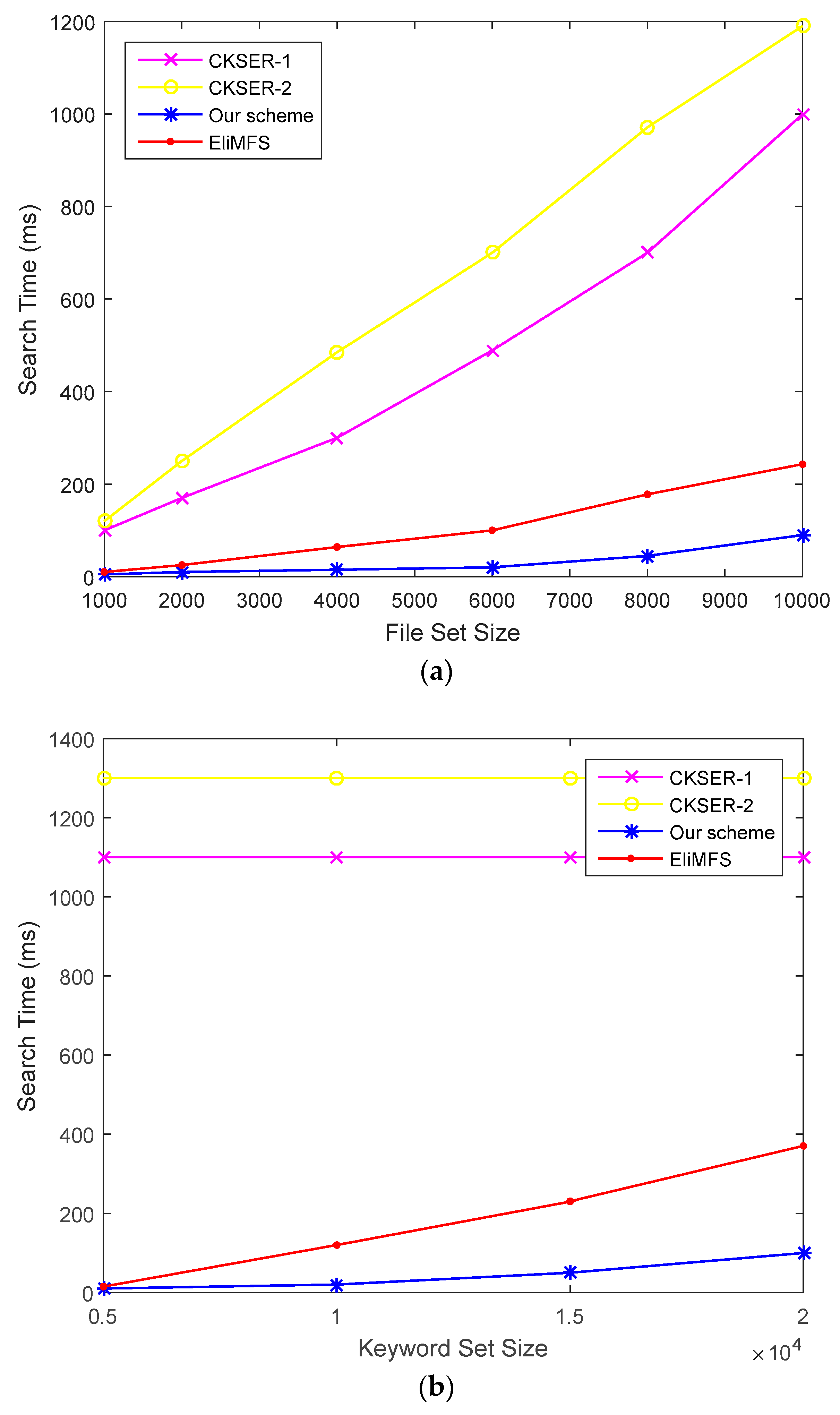
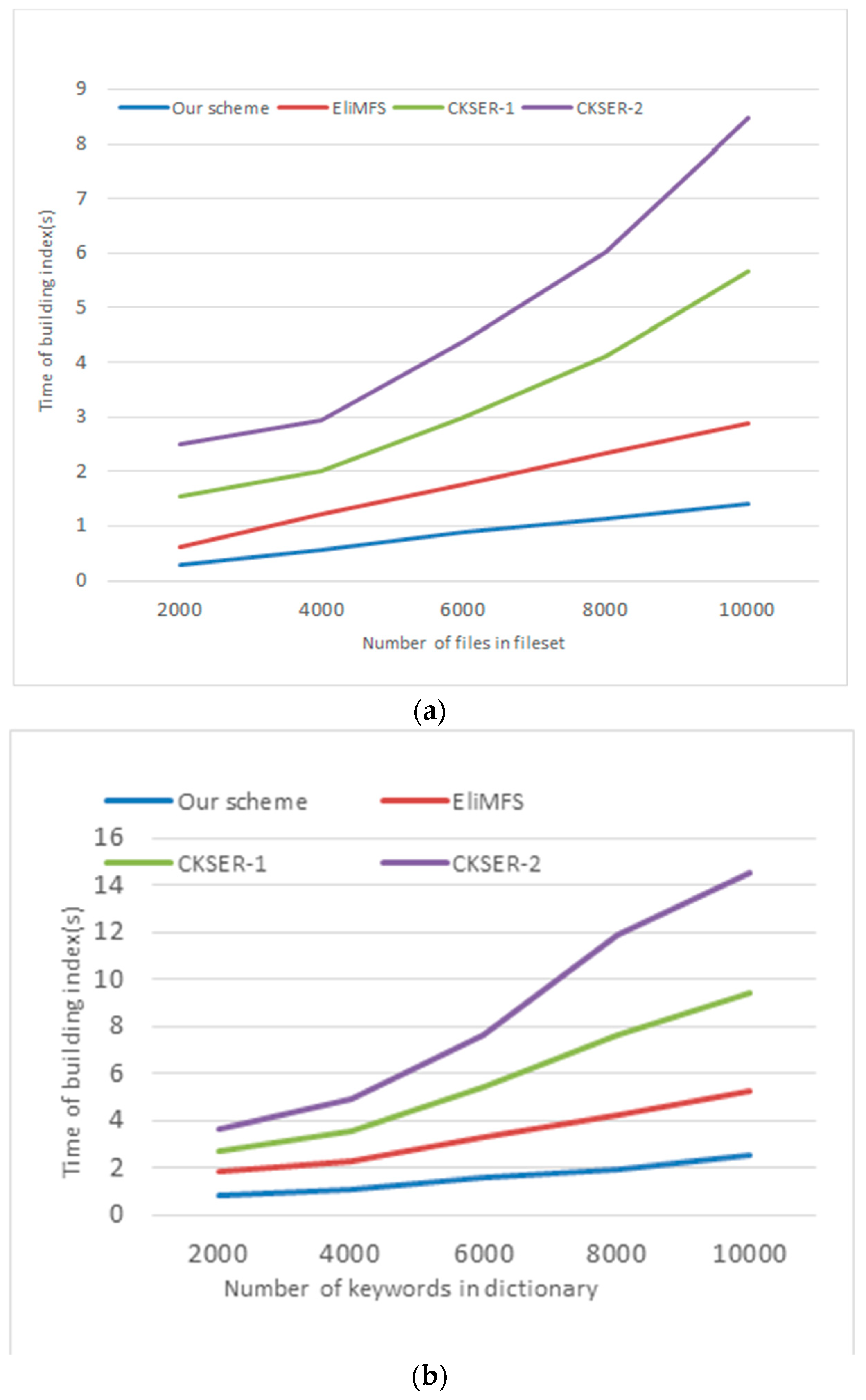
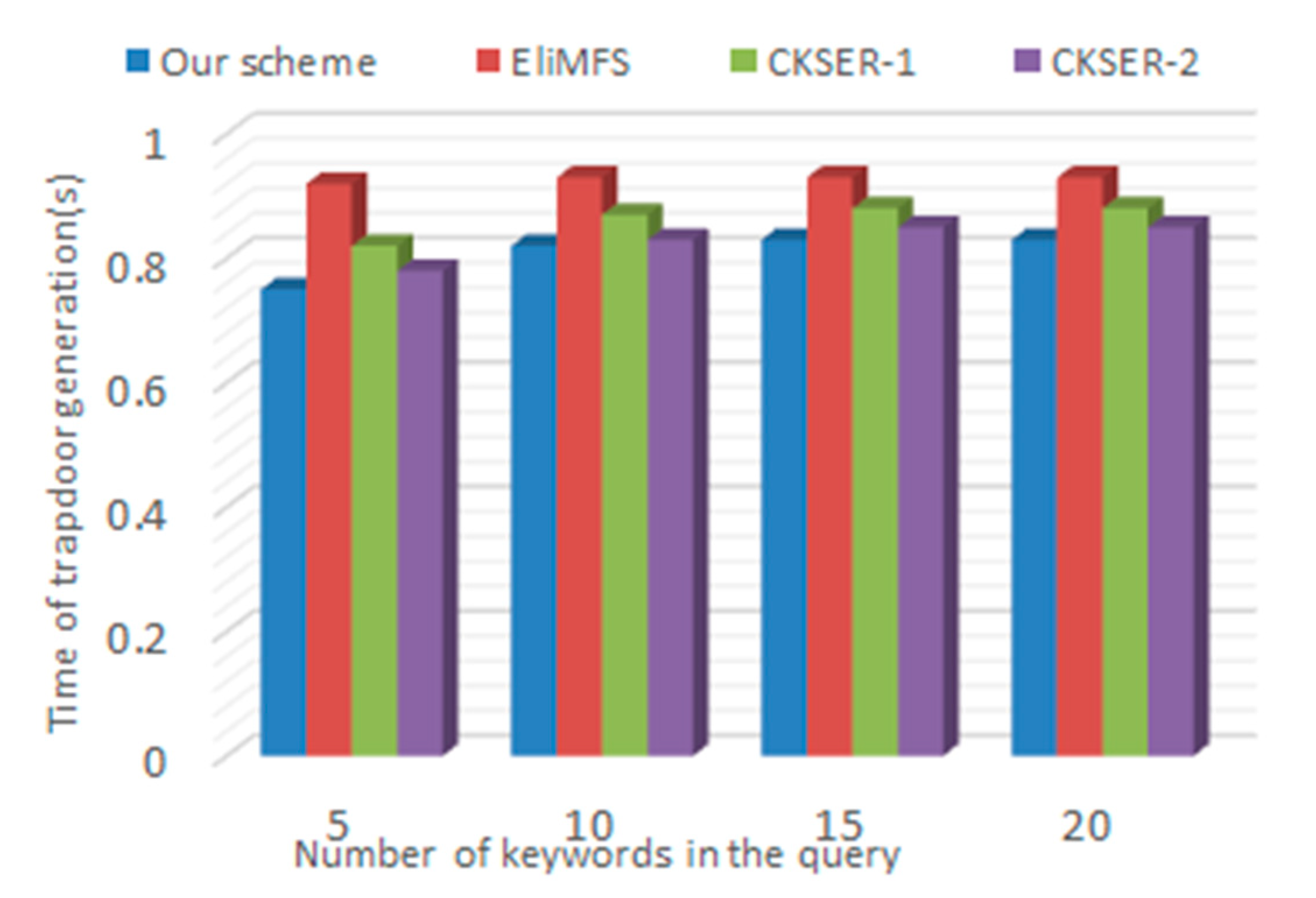
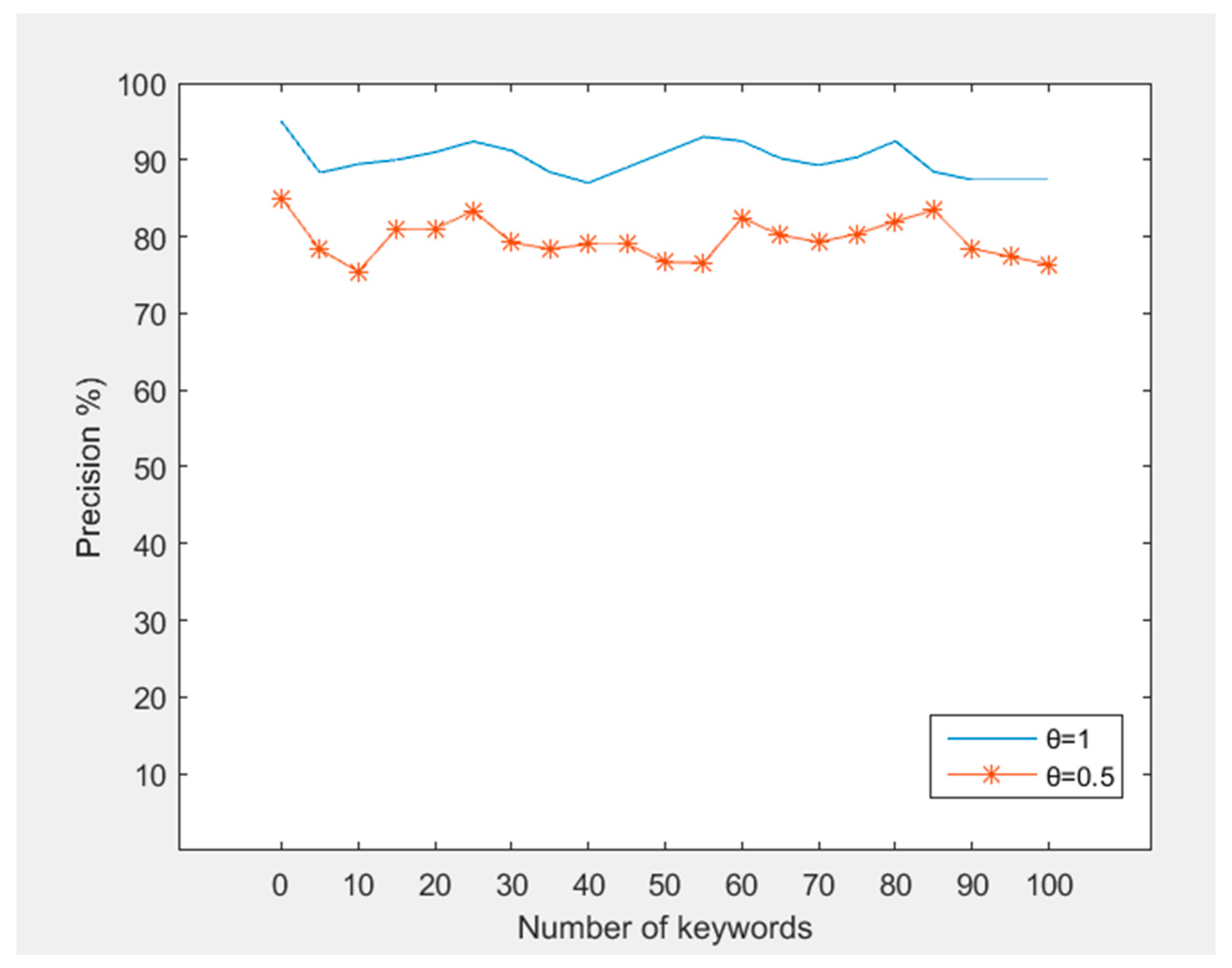
6.3. Performance Analysis
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Foster, I.; Zhao, Y.; Raicu, I.; Lu, S. Cloud computing and grid computing 360-degree compared. In Proceedings of the 2008 Grid Computing Environments, Austin, TX, USA, 12–16 November 2008. [Google Scholar]
- Shi, W.; Dustdar, S. The promise of edge computing. Computer 2016, 49, 78–81. [Google Scholar] [CrossRef]
- Roman, R.; Lopez, J.; Mambo, M. Mobile edge computing, fog et al.: A survey and analysis of security threats and challenges. Future Gener. Comput. Syst. 2018, 78, 680–698. [Google Scholar] [CrossRef]
- Cui, R.; Zhang, Y.; Li, N. The study of searchable encryption mechanism. Recent Dev. Intell. Comput. Commun. Devices 2017, 241–248. [Google Scholar]
- Liu, Q.; Liu, A. On the hybrid using of unicast-broadcast in wireless sensor networks. Comput. Electr. Eng. 2017, 1–19. [Google Scholar] [CrossRef]
- Xu, J.; Ota, K.; Dong, M. Saving energy on the edge: In-memory caching for multi-tier heterogeneous networks. IEEE Commun. Mag. 2018, 56, 102–107. [Google Scholar] [CrossRef]
- Tao, X.; Ota, K.; Dong, M.; Qi, H.; Li, K. Performance guaranteed computation offloading for mobile-edge cloud computing. IEEE Wirel. Commun. Lett. 2017, 6, 774–777. [Google Scholar] [CrossRef]
- Li, H.; Ota, K.; Dong, M. ECCN: Orchestration of edge-centric computing and content-centric networking in the 5G radio access network. IEEE Wirel. Commun. 2018, 25, 88–93. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Xiong, N.N.; Zhang, N.; Liu, A.; Shen, H.; Huang, C. Construction of large-scale low-cost delivery infrastructure using vehicular networks. IEEE Access 2018, 6, 21482–21497. [Google Scholar] [CrossRef]
- Tao, M.; Ota, K.; Dong, M. Ontology-based data semantic management and application in IoT-and cloud-enabled smart homes. Future Gener. Comput. Syst. 2017, 76, 528–539. [Google Scholar] [CrossRef]
- Li, H.; Ota, K.; Dong, M. Learning IoT in edge: Deep learning for the internet of things with edge computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef]
- Song, D.X.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the 2000 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 14–17 May 2000. [Google Scholar]
- Goh, E.J. Secure indexes. IACR Cryptol. ePrint Arch. 2003, 2003, 216. [Google Scholar]
- Boneh, D.; Di Crescenzo, G.; Ostrovsky, R.; Persiano, G. Public key encryption with keyword search. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2–6 May 2004. [Google Scholar]
- Park, H.A.; Byun, J.W.; Lee, D.H. Secure index search for groups. In Proceedings of the International Conference on Trust, Privacy and Security in Digital Business, Copenhagen, Denmark, 22–26 August 2005. [Google Scholar]
- Boneh, D.; Waters, B. Conjunctive, subset, and range queries on encrypted data. Theor. Cryptogr. 2007, 4392, 535–554. [Google Scholar]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-preserving multi-keyword ranked search over encrypted cloud data. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 222–233. [Google Scholar] [CrossRef]
- Ji, S.; Li, G.; Li, C.; Feng, J. Efficient interactive fuzzy keyword search. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009. [Google Scholar]
- Wang, C.; Ren, K.; Yu, S.; Urs, K.M.R. Achieving usable and privacy-assured similarity search over outsourced cloud data. In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012. [Google Scholar]
- Liu, C.; Zhu, L.; Li, L.; Tan, Y. Fuzzy keyword search on encrypted cloud storage data with small index. In Proceedings of the 2011 IEEE International Conference on Cloud Computing and Intelligence Systems (CCIS), Beijing, China, 15–17 September 2011. [Google Scholar]
- Wang, J.; Ma, H.; Tang, Q.; Li, J.; Zhu, H.; Ma, S.; Chen, X. Efficient verifiable fuzzy keyword search over encrypted data in cloud computing. Comput. Sci. Inf. Syst. 2013, 10, 667–684. [Google Scholar] [CrossRef]
- Fu, Z.; Wu, X.; Guan, C.; Sun, X.; Ren, K. Toward efficient multi-keyword fuzzy search over encrypted outsourced data with accuracy improvement. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2706–2716. [Google Scholar] [CrossRef]
- Fu, Z.; Wu, X.; Wang, Q.; Ren, K. Enabling central keyword-based semantic extension search over encrypted outsourced data. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2986–2997. [Google Scholar] [CrossRef]
- Ye, J.; Ding, Y. Controllable keyword search scheme supporting multiple users. Future Gener. Comput. Syst. 2018, 81, 433–442. [Google Scholar] [CrossRef]
- Miao, Y.; Ma, J.; Liu, X.; Li, X.; Liu, Z.; Li, H. Practical attribute-based multi-keyword search scheme in mobile crowdsourcing. IEEE Internet Things J. 2017, 5, 3008–3018. [Google Scholar] [CrossRef]
- Fan, K.; Yin, J.; Wang, J.; Li, H.; Yang, Y. Multi-Keyword Fuzzy and Sortable Ciphertext Retrieval Scheme for Big Data. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Fan, K.; Wang, X.; Suto, K.; Li, H.; Yang, Y. Secure and Efficient Privacy-Preserving Ciphertext Retrieval in Connected Vehicular Cloud Computing. IEEE Netw. 2018, 32, 52–57. [Google Scholar] [CrossRef]
- Witten, I.H.; Moffat, A.; Bell, T.C. Managing Gigabytes: Compressing and Indexing Documents and Images; Morgan Kaufmann: Burlington, MA, USA, 1999. [Google Scholar]
- Pal, S.K.; Sardana, P.; Sardana, A. Efficient search on encrypted data using bloom filter. In Proceedings of the 2014 International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 5–7 March 2014; pp. 412–416. [Google Scholar]
- Guttman, A. R-Trees: A Dynamic Index Structure for Spatial Searching; ACM: New York, NY, USA, 1984. [Google Scholar]
- De Marneffe, M.C.; MacCartney, B.; Manning, C.D. Generating typed dependency parses from phrase structure parses. Proc. LREC 2006, 6, 449–454. [Google Scholar]
- Kukich, K. Techniques for automatically correcting words in text. ACM Comput. Surv. 1992, 24, 377–439. [Google Scholar] [CrossRef]
- Wang, C.; Cao, N.; Li, J.; Ren, K.; Lou, W. Secure ranked keyword search over encrypted cloud data. In Proceedings of the 2010 IEEE 30th International Conference on Distributed Computing Systems, Genova, Italy, 21–25 June 2010. [Google Scholar]
- Chen, J.; He, K.; Deng, L.; Yuan, Q.; Du, R.; Xiang, Y.; Wu, J. EliMFS: Achieving Efficient, Leakage-resilient, and Multi-keyword Fuzzy Search on Encrypted Cloud Data. IEEE Trans. Serv. Comput. 2017. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| f | Plaintext file |
| c | Ciphertext file |
| The set of n plaintext files | |
| The set of n ciphertext files | |
| Keyword dictionary | |
| FID | The encrypted identifier of files |
| The keyword weight. | |
| I | The index of keyword dictionary |
| Original query keywords | |
| Query keywords after auto correction | |
| The trapdoor of the keywords Q | |
| The Bloom filter of Q |
| Example | Types of Dependency Relation |
|---|---|
| Service, Attitude | Adjective modification relation: |
| Accept, Speed | Verb modification relation: |
| High, Quality | Noun topic modification relation: |
| Run, Fast | Adjective complement modification relation: |
| Schemes | MRSE | Wang’s | Fu’s | EliMFS | Our Scheme |
|---|---|---|---|---|---|
| Multi-keyword | |||||
| Relevance ranking | |||||
| Auto correction | |||||
| Keyword weight | |||||
| updating |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, K.; Yin, J.; Zhang, K.; Li, H.; Yang, Y. EARS-DM: Efficient Auto Correction Retrieval Scheme for Data Management in Edge Computing. Sensors 2018, 18, 3616. https://doi.org/10.3390/s18113616
Fan K, Yin J, Zhang K, Li H, Yang Y. EARS-DM: Efficient Auto Correction Retrieval Scheme for Data Management in Edge Computing. Sensors. 2018; 18(11):3616. https://doi.org/10.3390/s18113616
Chicago/Turabian StyleFan, Kai, Jie Yin, Kuan Zhang, Hui Li, and Yintang Yang. 2018. "EARS-DM: Efficient Auto Correction Retrieval Scheme for Data Management in Edge Computing" Sensors 18, no. 11: 3616. https://doi.org/10.3390/s18113616
APA StyleFan, K., Yin, J., Zhang, K., Li, H., & Yang, Y. (2018). EARS-DM: Efficient Auto Correction Retrieval Scheme for Data Management in Edge Computing. Sensors, 18(11), 3616. https://doi.org/10.3390/s18113616