
Analysis of Variability of Functionals of Recombinant Protein Production Trajectories Based on Limited Data

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
1.1. Scientific Context
1.2. Statistical Challenges and Contributions
1.3. Goals of the Study
2. Results
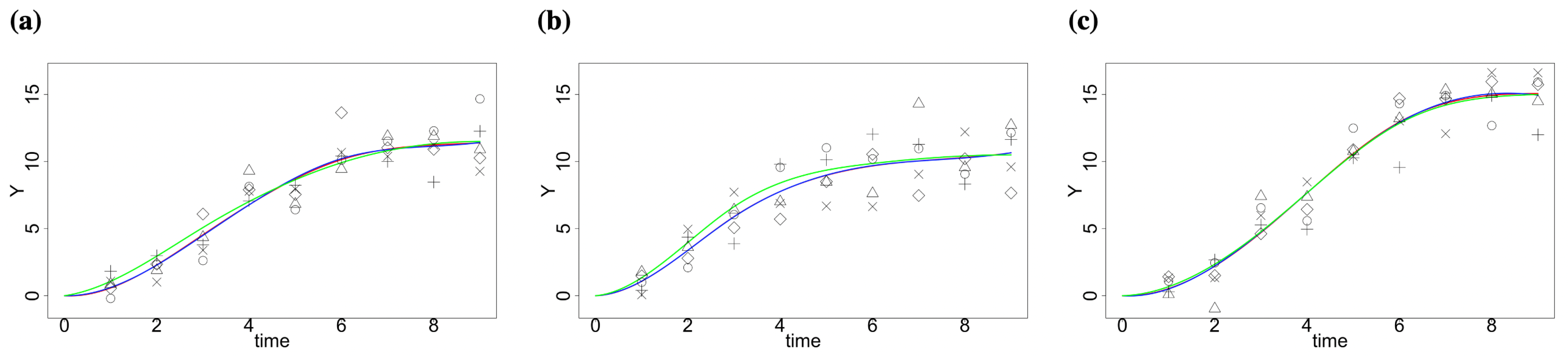
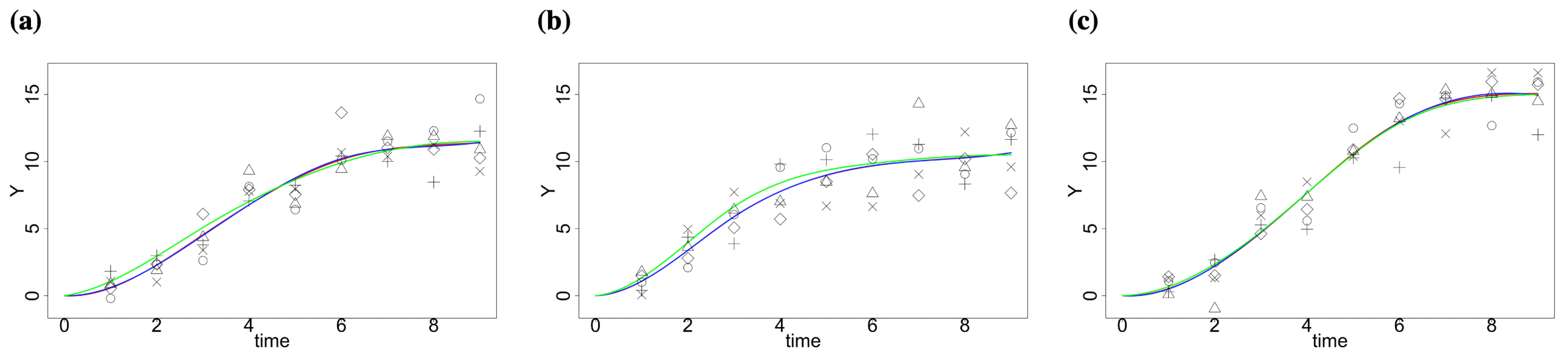
2.1. Simulation Study
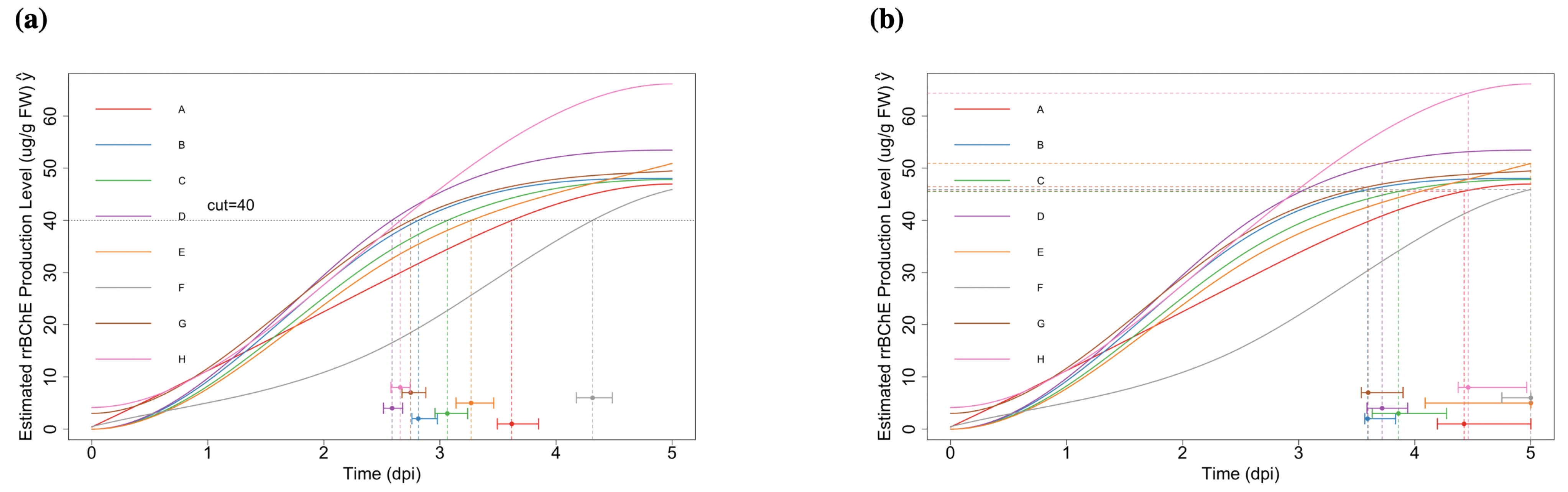
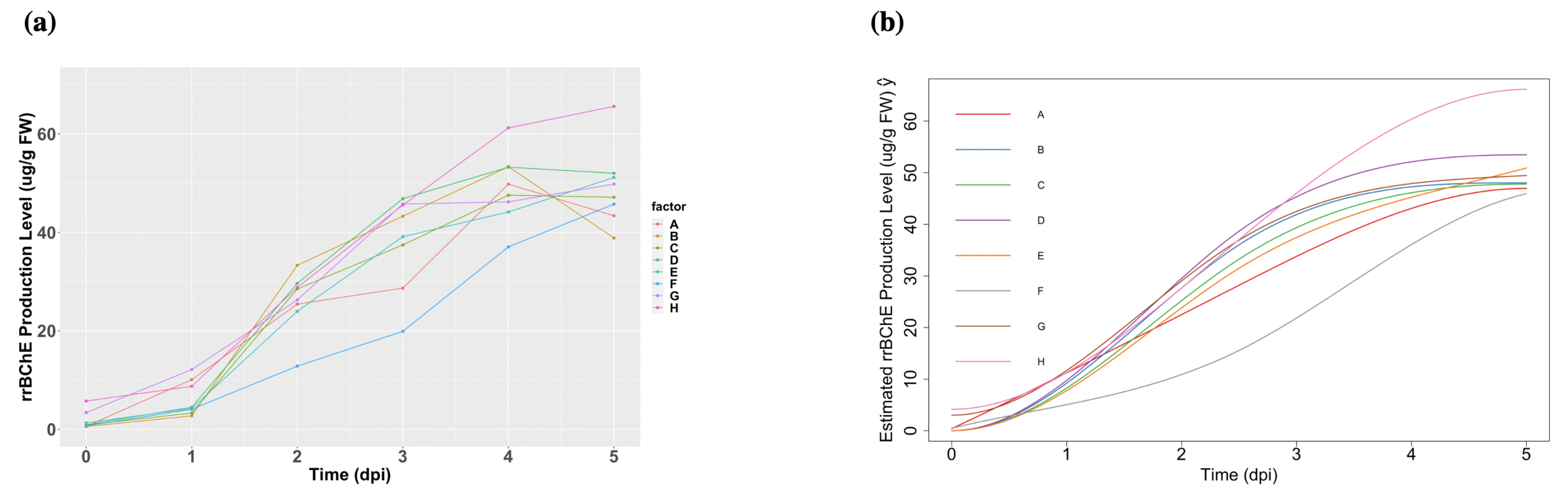
2.2. Analysis of rrBChE Data
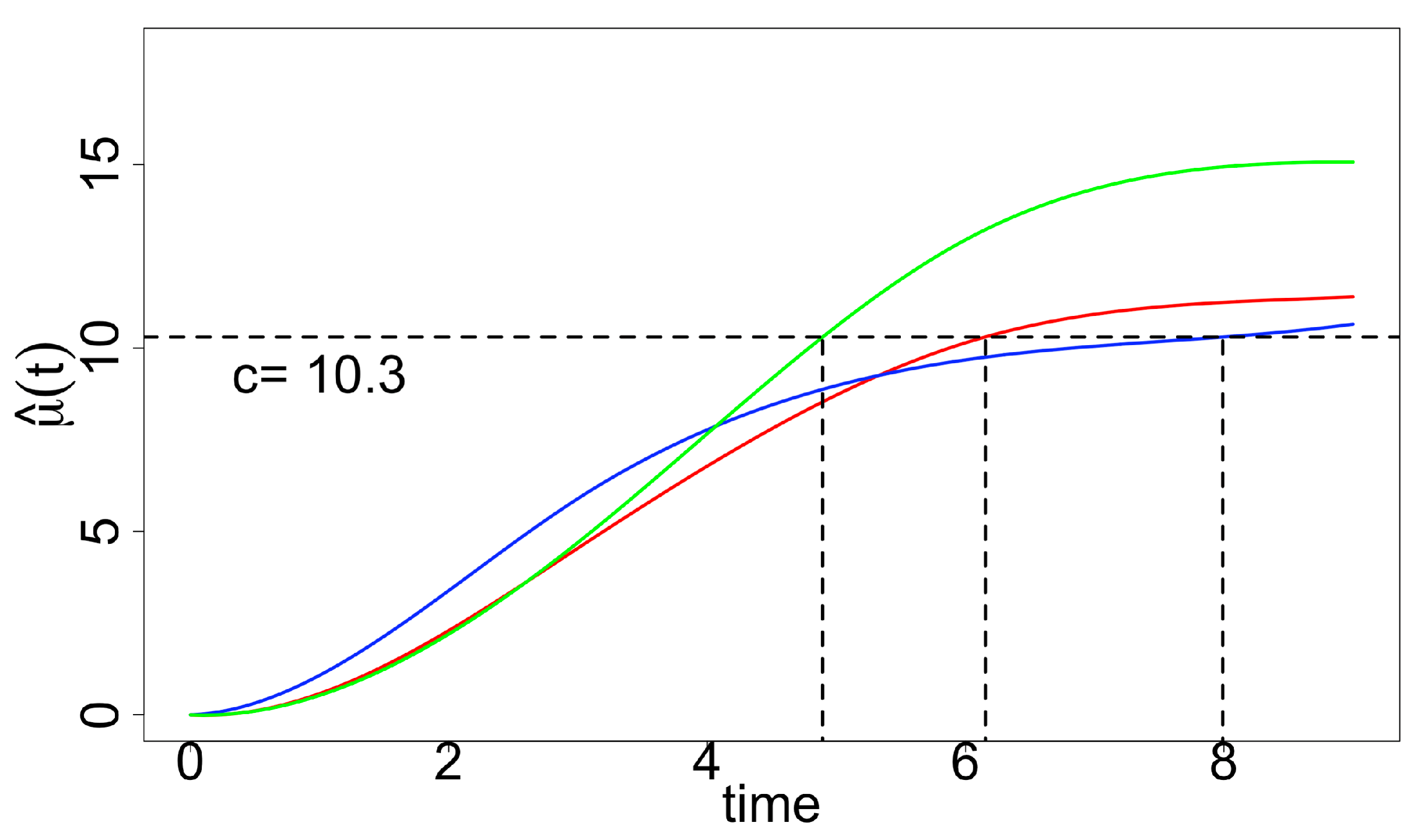
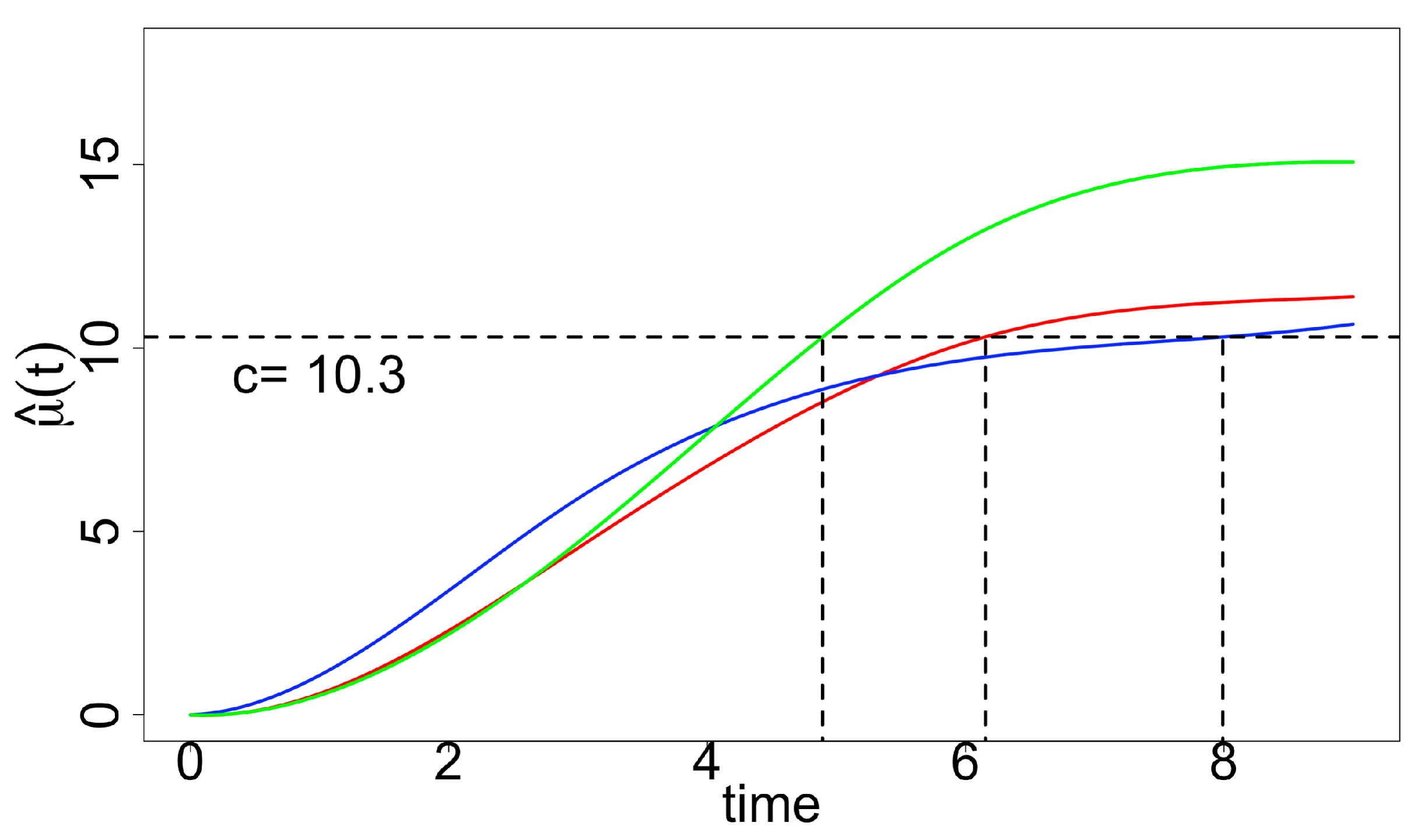
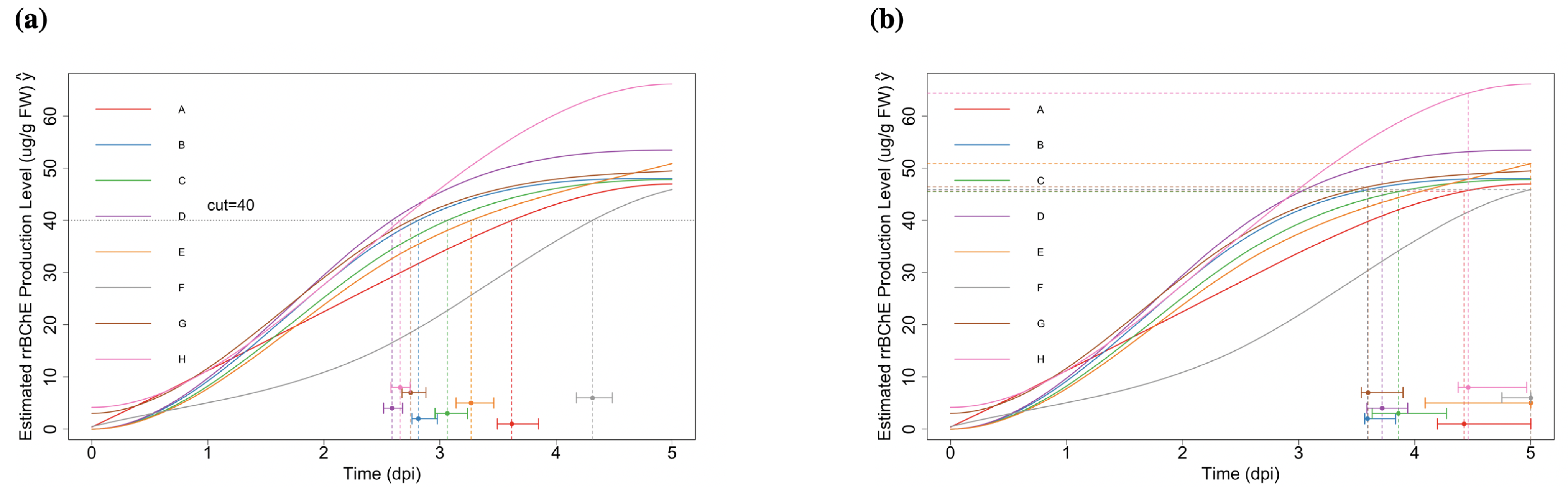
2.2.1. “Optimal Time-to-Harvest” and “Optimum Stopping Time”
2.2.2. Simultaneous Inference—Maximum Production Level
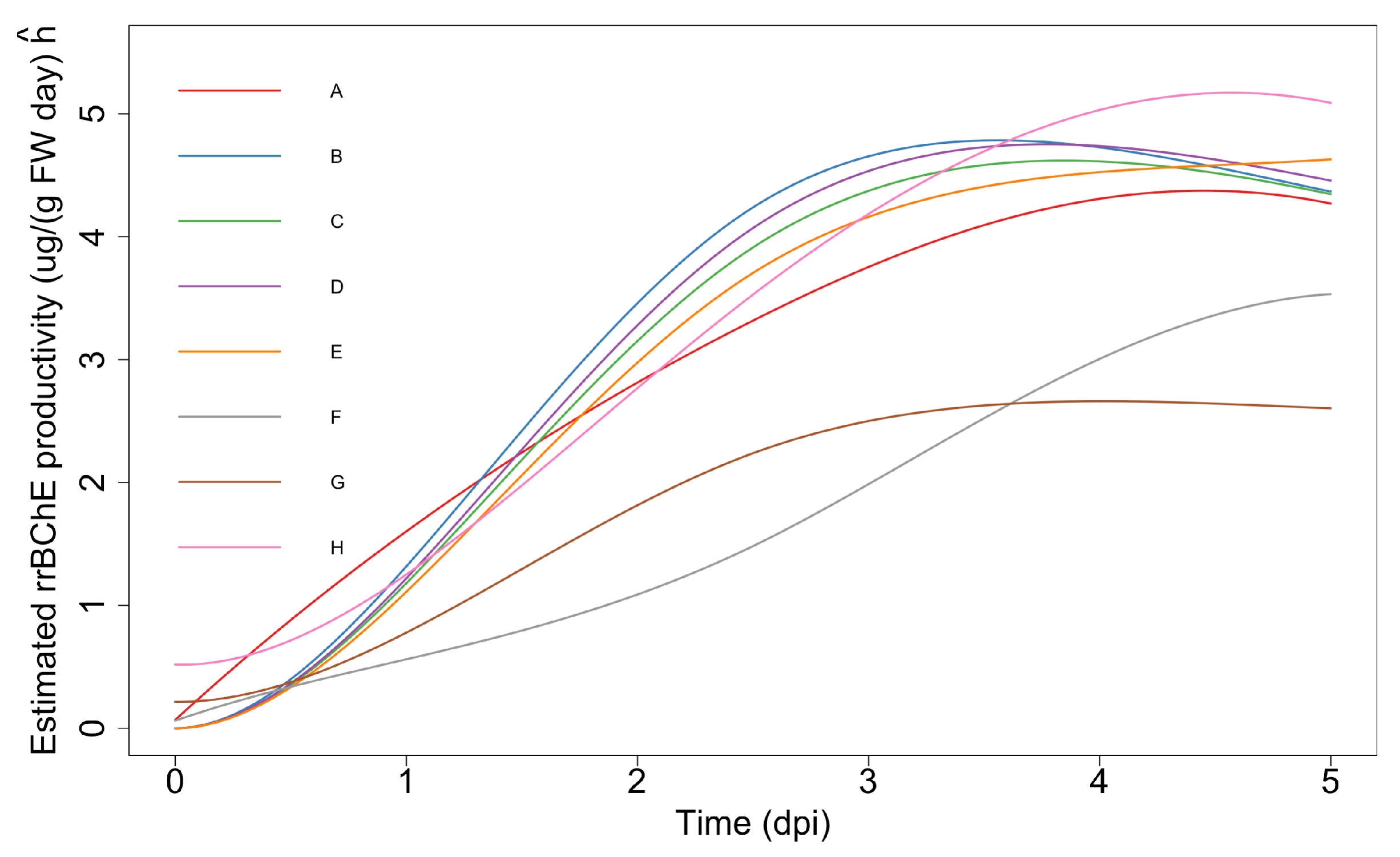
2.2.3. Simultaneous Inference—Maximum “Unweighted” Productivity
2.3. Summary of Findings
2.3.1. Comparison between Two Versions of p-Values
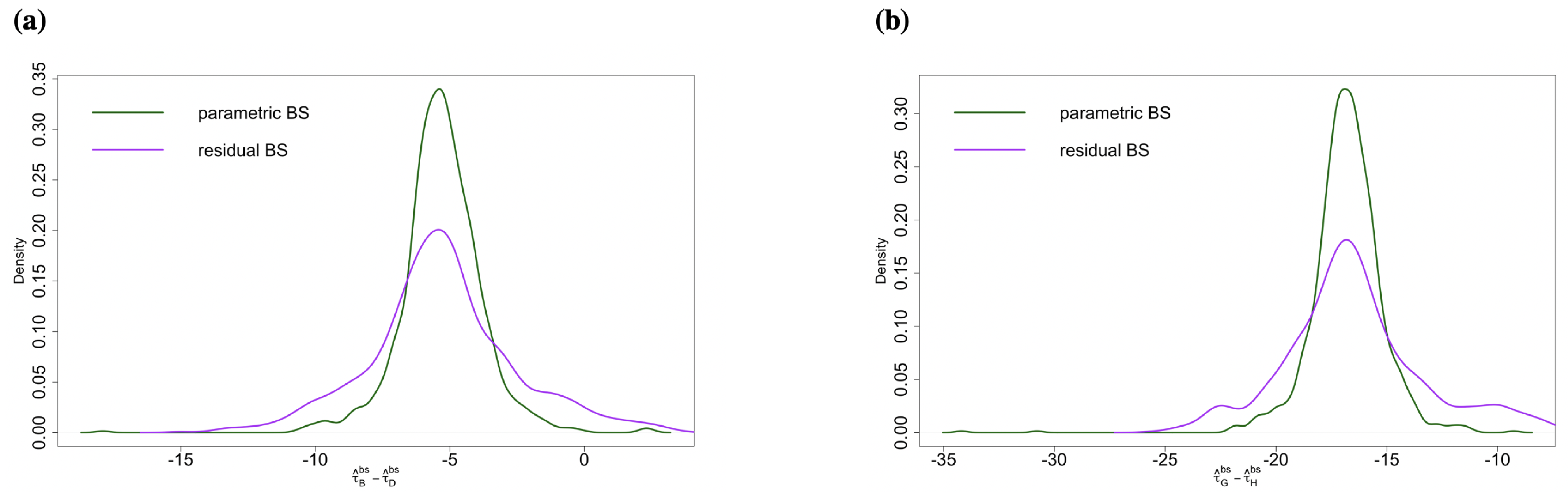
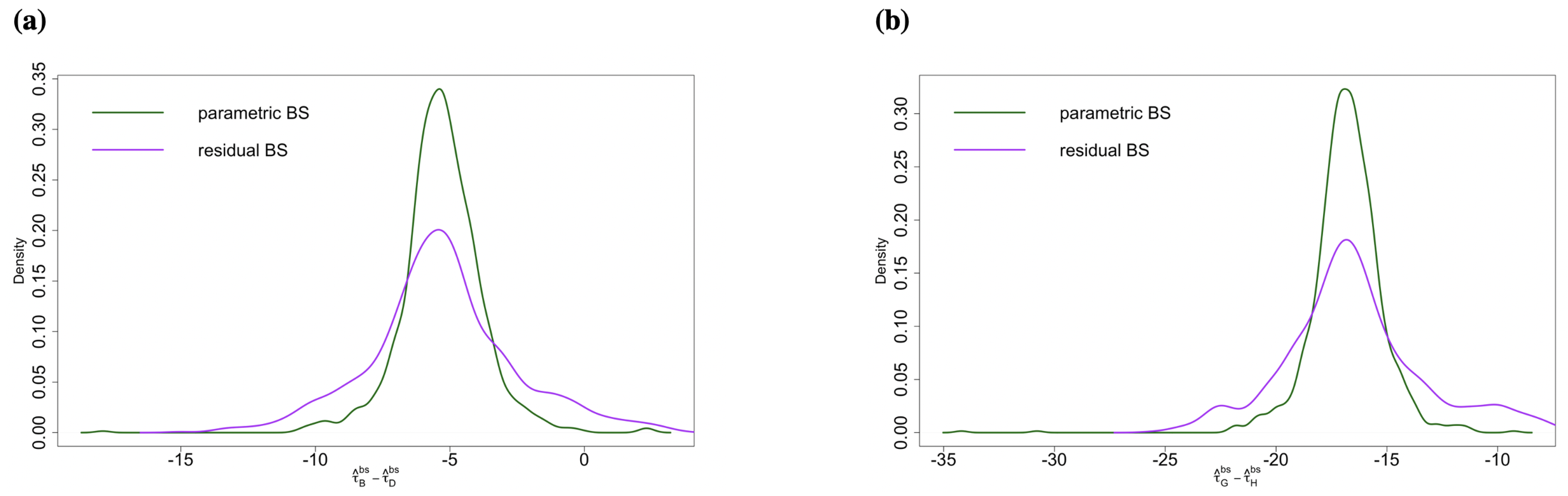
2.3.2. Comparison of Residual Bootstrap and Parametric Bootstrap
3. Methods and Materials
3.1. Data Collection Method
3.2. Modeling Production Trajectories
3.3. Key Parameters of Interest
- 1
- Optimal time-to-harvest: for , where c is the prespecified cut-off level. The corresponding null hypothesis representing no factor effect on the “optimal time-to-harvest” is:With for some given cut-off level c, we are interested in testing the one-sided null hypotheses of the form (here, the times need not be equal). These hypotheses translate to the linear inequality constraints:Notice that, is not a linear constraint.
- However, the null hypothesis can be translated to the equality constraints:
- A composite null hypothesis of the form for all i can also be translated into linear inequality constraintsfor all i.
- 2
- Maximum production: for . The regarding null hypotheses areor equivalentlywhere is the largest time point during the experiment.
- 3
- Maximum “unweighted” productivity: , for , where represents “unweighted” productivity of the i-th factor and is the number of days of cultivation before the induction. Here, “unweighted” means that we do not consider the rice cell fresh or dry weight. The corresponding null hypotheses areor equivalently
- 4
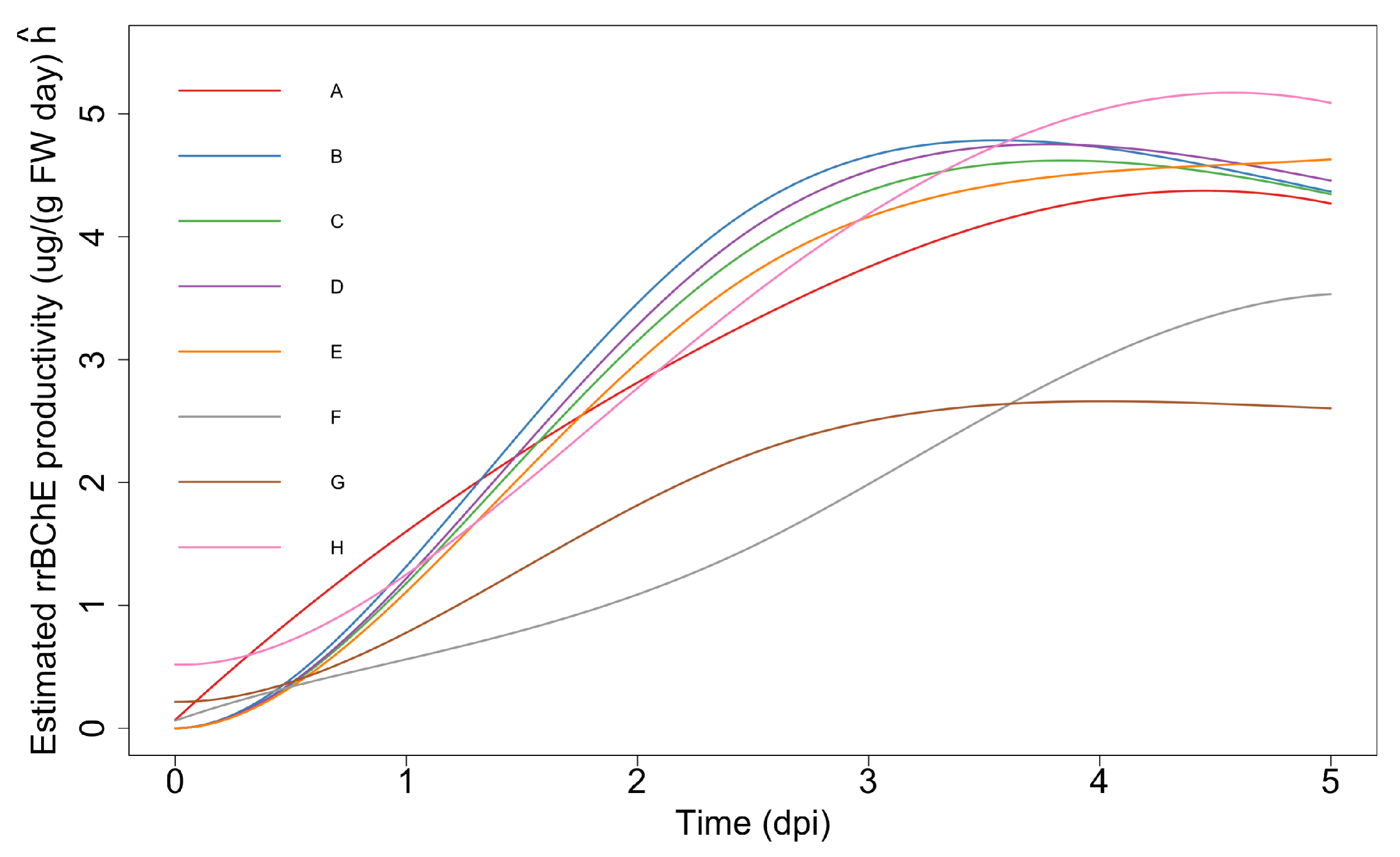
- Optimum stopping time: Suppose the decision to harvest is taken based on the relative gradient of (or, gradient of ). Let where is some constant baseline time and is a gradient threshold. We may be interested in testing hypotheses of the form where time is treated as the same for all i for simplicity. Since is not necessarily monotonic, this cannot be easily reduced to a simple set of inequality constraints. However, we may discretize time to a grid of the form and then consider the slightly relaxed form of the hypothesisIn practice, m needs to be small for the feasibility of the optimization problem.
- Example 1: if , then .
- Example 2: if , then .
3.4. Statistical Inference Using Bootstrap
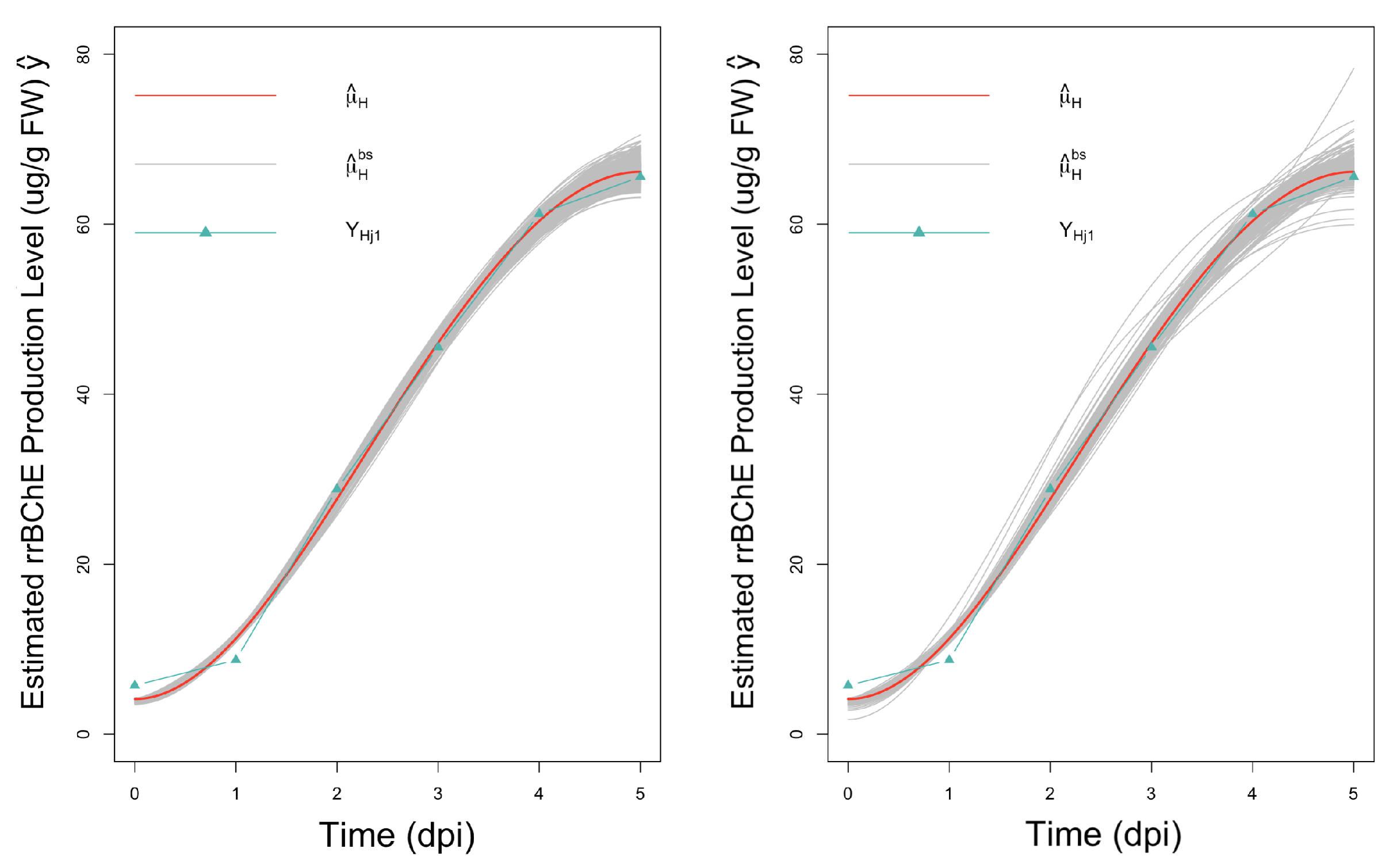
3.4.1. Resampling Strategies
3.4.2. Inference for a Single Parameter
- 1
- Percentile bootstrap confidence intervals: We obtain percentile bootstrap confidence intervals for and based on B bootstrap estimates of these parameters. The intervals are constructed by using appropriate quantiles of the bootstrap estimates and , respectively.
- 2
- Bias-corrected and accelerated bootstrap interval : The percentile bootstrap confidence interval is only first-order accurate. Additionally, it does not correct for skewness of the sampling distribution. To address this, we use bias-corrected and accelerated bootstrap intervals [22], denoted by , which is not only second-order accurate but also corrects for the skewness in the sampling distribution.
3.4.3. Simultaneous Inference and Adjusting p-Values
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ho, B.C.; Andreasen, N.C.; Ziebell, S.; Pierson, R.; Magnotta, V. Long-term antipsychotic treatment and brain volumes: A longitudinal study of first-episode schizophrenia. Arch. Gen. Psychiatry 2011, 68, 128–137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Locascio, J.J.; Atri, A. An Overview of Longitudinal Data Analysis Methods for Neurological Research. Dement. Geriatr. Cogn. Disord. Extra 2011, 1, 330–357. [Google Scholar] [CrossRef] [PubMed]
- Garcia, T.P.; Marder, K. Statistical Approaches to Longitudinal Data Analysis in Neurodegenerative Diseases: Huntington’s Disease as a Model. Curr. Neurol. Neurosci. Rep. 2017, 17, 14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kristjansson, S.D.; Kircher, J.C.; Webb, A.K. Multilevel models for repeated measures research designs in psychophysiology: An introduction to growth curve modeling. Psychophysiology 2007, 44, 728–736. [Google Scholar] [CrossRef] [PubMed]
- Weinfurt, K. Repeated measures analysis: ANOVA, MANOVA, and HLM. In Reading and Understanding More Multivariate Statistics; American Psychological Association: Washington, DC, USA, 2012; pp. 317–361. [Google Scholar]
- Gurevitch, J.; Chester, S.T. Analysis of Repeated Measures Experiments. Ecology 1986, 67, 251–255. [Google Scholar] [CrossRef]
- Rovine, M.J.; McDermott, P.A. Latent Growth Curve and Repeated Measures ANOVA Contrasts: What the Models are Telling You. Multivar. Behav. Res. 2018, 53, 90–101. [Google Scholar] [CrossRef] [PubMed]
- Lockridge, O. Review of human butyrylcholinesterase structure, function, genetic variants, history of use in the clinic, and potential therapeutic uses. Pharmacol. Ther. 2015, 148, 34–46. [Google Scholar] [CrossRef] [PubMed]
- Alkanaimsh, S.; Corbin, J.M.; Kailemia, M.J.; Karuppanan, K.; Rodriguez, R.L.; Lebrilla, C.B.; McDonald, K.A.; Nandi, S. Purification and site-specific N-glycosylation analysis of human recombinant butyrylcholinesterase from Nicotiana benthamiana. Biochem. Eng. J. 2019, 142, 58–67. [Google Scholar] [CrossRef]
- Corbin, J.M.; Hashimoto, B.I.; Karuppanan, K.; Kyser, Z.R.; Wu, L.; Roberts, B.A.; Noe, A.R.; Rodriguez, R.L.; McDonald, K.A.; Nandi, S. Semicontinuous Bioreactor Production of Recombinant Butyrylcholinesterase in Transgenic Rice Cell Suspension Cultures. Front. Plant Sci. 2016, 7, 412. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Macharoen, K.; McDonald, K.A.; Nandi, S. Simplified bioreactor processes for recombinant butyrylcholinesterase production in transgenic rice cell suspension cultures. Biochem. Eng. J. 2020, 163, 107751. [Google Scholar] [CrossRef]
- Huang, N.; Chandler, J.; Thomas, B.R.; Koizumi, N.; Rodriguez, R.L. Metabolic regulation of α-amylase gene expression in transgenic cell cultures of rice (Oryza sativa L.). Plant Mol. Biol. 1993, 23, 737–747. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Sutliff, T.D.; Wu, L.; Nandi, S.; Benge, K.; Terashima, M.; Ralston, A.H.; Drohan, W.; Huang, N.; Rodriguez, R.L. Expression and Purification of Functional Human α-1-Antitrypsin from Cultured Plant Cells. Biotechnol. Prog. 2001, 17, 126–133. [Google Scholar] [CrossRef] [PubMed]
- Terashima, M.; Murai, Y.; Kawamura, M.; Nakanishi, S.; Stoltz, T.; Chen, L.; Drohan, W.; Rodriguez, R.L.; Katoh, S. Production of functional human α1-antitrypsin by plant cell culture. Appl. Microbiol. Biotechnol. 1999, 52, 516–523. [Google Scholar] [CrossRef] [PubMed]
- Rathore, A.; Winkle, H. Quality by design for biopharmaceuticals. Nat. Biotechnol. 2009, 27, 26–34. [Google Scholar] [CrossRef] [PubMed]
- Kelly, C.; Rice, J. Monotone smoothing with application to dose–response curves and the assessment of synergism. Biometrics 1990, 46, 1071–1085. [Google Scholar] [CrossRef] [PubMed]
- Benjamini, Y.; Yekutieli, D. False Discovery Rate–Adjusted Multiple Confidence Intervals for Selected Parameters. J. Am. Stat. Assoc. 2005, 100, 71–81. [Google Scholar] [CrossRef]
- Liao, S.; Macharoen, K.; McDonald, K.; Nandi, S.; Paul, D. Rice-Recombinant Butyrylcholinesterase (rrBChE) Production Dataset; Dryad Dataset: Lewis County, WA, USA, 2021. [Google Scholar]
- Ellman, G.L.; Courtney, K.D.; Andres, V.; Featherstone, R.M. A new and rapid colorimetric determination of acetylcholinesterase activity. Biochem. Pharmacol. 1961, 7, 88–95. [Google Scholar] [CrossRef]
- De Boor, C. A Practical Guide to Splines; Springer: Berlin/Heidelberg, Germany, 1978. [Google Scholar]
- Leitenstorfer, F.; Tutz, G. Generalized monotonic regression based on B-splines with an application to air pollution data. Biostatistics 2006, 8, 654–673. [Google Scholar] [CrossRef] [Green Version]
- Efron, B. Better Bootstrap Confidence Intervals. J. Am. Stat. Assoc. 1987, 82, 171–185. [Google Scholar] [CrossRef]
- Davison, A.C.; Hinkley, D.V. Bootstrap Methods and Their Application; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Efron, B. Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing and Prediction; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CI Lower | CI Upper | CI Length | True | Mean | sd | ||
|---|---|---|---|---|---|---|---|
| Percentile Bootstrap CI | 5.820 | 7.027 | 1.207 | 6.378 | 6.320 | 0.327 | |
| 5.892 | 9.000 | 3.108 | 7.387 | 7.739 | 0.995 | ||
| 4.730 | 5.162 | 0.432 | 4.910 | 4.917 | 0.113 | ||
| −3.063 | 0.568 | 3.631 | −1.009 | −1.418 | 1.046 | ||
| 0.937 | 4.198 | 3.261 | 2.477 | 2.822 | 1.002 | ||
| −2.171 | −0.820 | 1.351 | −1.468 | −1.403 | 0.350 | ||
| 5.640 | 6.568 | 0.928 | |||||
| 6.036 | 9.000 | 2.964 | |||||
| 4.695 | 5.126 | 0.431 | |||||
| −3.189 | 0.108 | 3.297 | |||||
| 1.117 | 4.252 | 3.135 | |||||
| −1.766 | −0.525 | 1.241 |
| p-Value by Percentile Bootstrap CI | CI Lower | CI Upper | CI Length | Mean | sd | Est | |
|---|---|---|---|---|---|---|---|
| < | −28.059 | −10.204 | 17.856 | −19.298 | 3.624 | −19.186 | |
| < | −25.265 | −8.512 | 16.753 | −17.707 | 3.213 | −18.115 | |
| < | −26.081 | −9.485 | 16.596 | −18.197 | 3.379 | −18.347 | |
| 0.008 | 0.659 | 17.297 | 16.638 | 8.125 | 3.348 | 7.544 | |
| < | −19.830 | −3.745 | 16.086 | −12.414 | 3.191 | −12.679 | |
| < | −24.668 | −7.003 | 17.665 | −15.496 | 3.489 | −15.233 | |
| < | −29.730 | −11.710 | 18.020 | −20.539 | 3.677 | −20.223 | |
| < | −24.095 | −7.635 | 16.460 | −16.482 | 3.187 | −16.687 |
| p-Value by Percentile Bootstrap CI | CI Lower | CI Upper | CI Length | Mean | sd | Est | |
|---|---|---|---|---|---|---|---|
| 0.002 | −10.778 | −3.105 | 7.674 | −6.578 | 1.545 | −6.507 | |
| < | −23.481 | −15.508 | 7.974 | −19.277 | 1.731 | −19.186 | |
| 0.006 | −9.552 | −1.525 | 8.026 | −5.301 | 1.525 | −5.436 | |
| < | −22.067 | −14.185 | 7.882 | −17.999 | 1.653 | −18.115 | |
| 0.006 | −10.075 | −1.356 | 8.719 | −5.662 | 1.644 | −5.668 | |
| < | −22.761 | −14.358 | 8.403 | −18.361 | 1.709 | −18.347 | |
| 0.002 | 2.768 | 12.825 | 10.057 | 7.680 | 1.828 | 7.544 | |
| 0.022 | 0.383 | 8.532 | 8.149 | 4.106 | 1.553 | 4.008 | |
| 0.002 | −16.687 | −8.478 | 8.209 | −12.698 | 1.765 | −12.679 | |
| 0.018 | 0.121 | 10.278 | 10.157 | 4.859 | 1.877 | 4.990 | |
| < | −20.403 | −11.297 | 9.106 | −15.519 | 1.925 | −15.233 | |
| < | −25.471 | −15.836 | 9.635 | −20.378 | 1.872 | −20.223 | |
| < | −20.893 | −12.667 | 8.225 | −16.804 | 1.648 | −16.687 |
| Experiment | %DO during Growth Phase | %DO during Induction Phase | Media Exchange |
|---|---|---|---|
| A | 40 | 10 | Yes |
| B | 40 | 20 | Yes |
| C | 40 | 30 | Yes |
| D | 40 | 40 | Yes |
| E | 40 | Uncontrolled | Yes |
| F | 40 | 40 | No |
| G | Uncontrolled | Uncontrolled | No |
| H | Uncontrolled | Uncontrolled | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, S.; Macharoen, K.; McDonald, K.A.; Nandi, S.; Paul, D. Analysis of Variability of Functionals of Recombinant Protein Production Trajectories Based on Limited Data. Int. J. Mol. Sci. 2022, 23, 7628. https://doi.org/10.3390/ijms23147628
Liao S, Macharoen K, McDonald KA, Nandi S, Paul D. Analysis of Variability of Functionals of Recombinant Protein Production Trajectories Based on Limited Data. International Journal of Molecular Sciences. 2022; 23(14):7628. https://doi.org/10.3390/ijms23147628
Chicago/Turabian StyleLiao, Shuting, Kantharakorn Macharoen, Karen A. McDonald, Somen Nandi, and Debashis Paul. 2022. "Analysis of Variability of Functionals of Recombinant Protein Production Trajectories Based on Limited Data" International Journal of Molecular Sciences 23, no. 14: 7628. https://doi.org/10.3390/ijms23147628
APA StyleLiao, S., Macharoen, K., McDonald, K. A., Nandi, S., & Paul, D. (2022). Analysis of Variability of Functionals of Recombinant Protein Production Trajectories Based on Limited Data. International Journal of Molecular Sciences, 23(14), 7628. https://doi.org/10.3390/ijms23147628