
Non-Targeted Screening Approaches for Profiling of Volatile Organic Compounds Based on Gas Chromatography-Ion Mobility Spectroscopy (GC-IMS) and Machine Learning


Abstract
1. Introduction
- K0 = reduced ion mobility in cm²V−1s−1
- L = drift length in cm
- E = electric field strength in Vcm−1
- tD = drift time in s
- p = pressure of the drift gas in hPa
- p0 = ambient pressure: p0 = 1013.2 hPa
- T = temperature of the drift gas in K
- T0-ambient temperature: T0 = 273.2 K
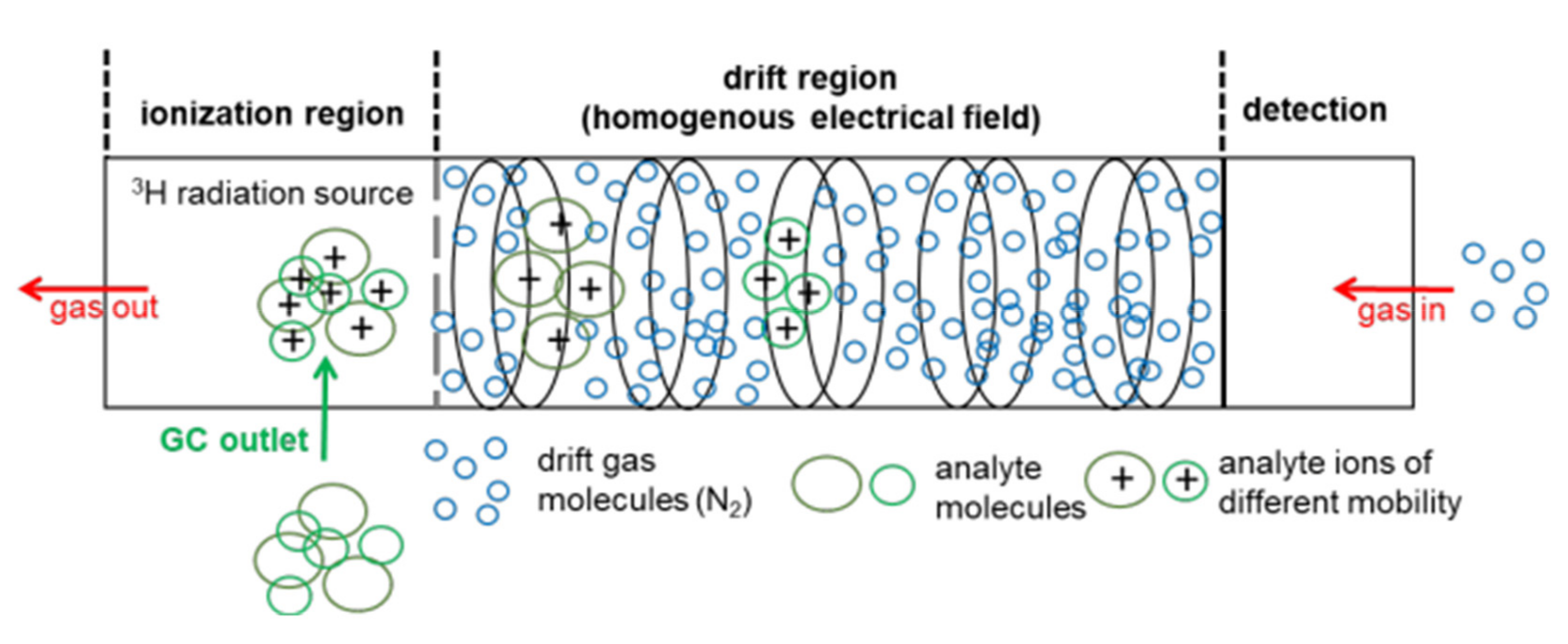
2. Motivation for Non-Targeted Screening Using HS-GC-IMS
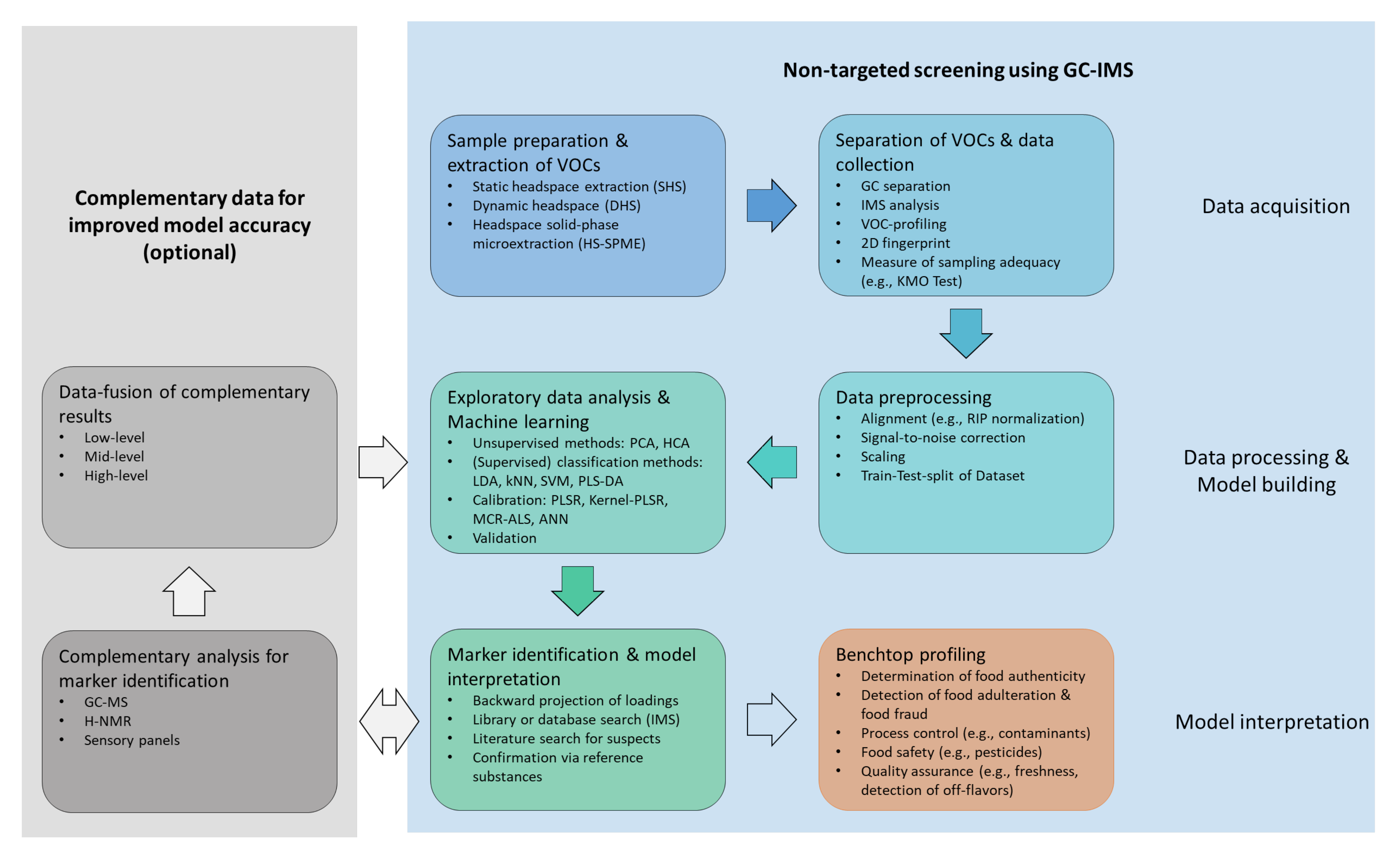
3. NTS-Workflow
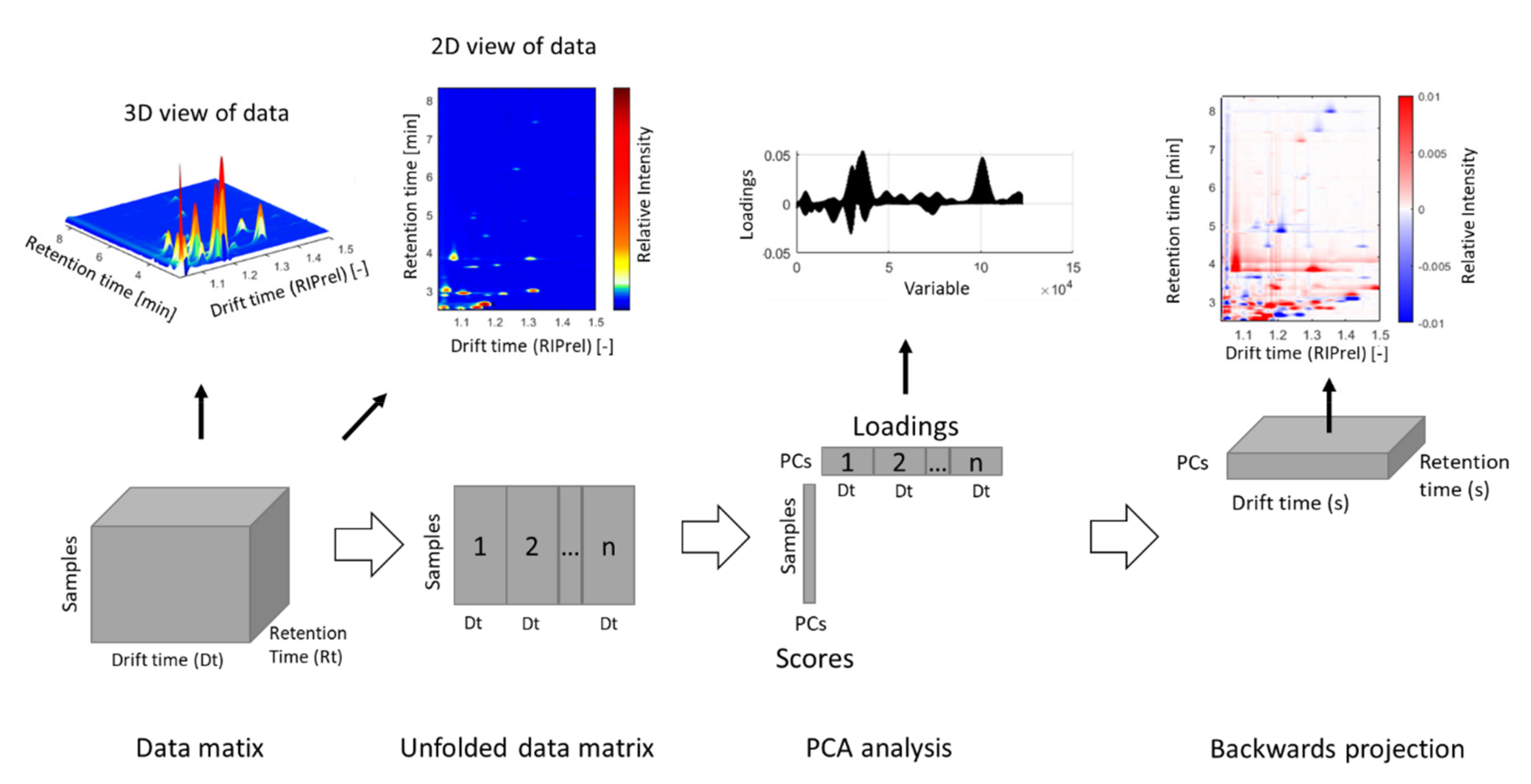
3.1. Data Acquisition
3.2. Data Processing and Model Building
3.2.1. Exploratory Data Analysis and Machine Learning Techniques
3.2.2. Model Performance and Validation
3.2.3. Quantification Tasks
3.3. Model Interpretation
3.4. Complementary Data (Optional)
4. Comparison of NTS and Targeted Strategies
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Sample Availability
Glossary
| Abbreviations | Description |
| 1H NMR | proton nuclear magnetic resonance |
| 2D | two-dimensional |
| 3D | three-dimensional |
| Am-241 | americium-241 |
| ANN | artificial neural networks |
| ANOVA | one-way analysis of variance |
| APPI | atmospheric pressure photo ionization |
| Bias | systematic error |
| CC | capillary column |
| CCS | collision cross section |
| CD | corona discharge |
| Ctr | mean centering |
| CV | cross validation |
| D(I)MS | differential ion mobility spectrometry |
| DHS | dynamic headspace extraction |
| DTIMS | drift-tube ion mobility spectrometry |
| E-nose | electric nose |
| EVOO | extra-virgin olive oil |
| FAIMS | high-field asymmetric waveform ion mobility spectrometry |
| ft | film thickness |
| FT-IR | Fourier-transform infrared spectroscopy |
| GC | gas chromatography |
| GC–IMS | gas chromatography-ion mobility spectrometry |
| H+[H2O]n | proton-water clusters with n number of water molecules |
| H-3 | tritium |
| HCA | hierarchical cluster analysis |
| HOG | histograms of oriented gradients |
| HS | headspace |
| ID | inner diameter |
| IMS | ion mobility spectrometry |
| K0 | reduced ion mobility |
| KMO | Kaiser–Meyer–Olkin |
| kNN | k-nearest neighbors |
| L(V)OO | lampante (virgin) olive oil |
| LC | liquid chromatography |
| LDA | linear discriminant analysis |
| LDI | laser desorption/ionization technique |
| LOO | leave-one-out |
| LS | library search |
| M2H+ | proton-bound dimers |
| MCC | multicapillary column |
| MCR-ALS | multivariate curve resolution alternating least squares |
| MH+ | protonated monomers |
| MPCA | multiway principal component analysis |
| MVA | multivariate variate data analysis |
| Ni-63 | nickel-63 |
| NTS | non-targeted screening |
| OPLS-DA | orthogonal partial least-squares discriminant analysis |
| Par | Pareto |
| PC(A) | principal component (analysis) |
| PLS(R) | partial least squares (regression) |
| POO | pomace olive oil |
| (Q)DA | (quadratic) discriminant analysis |
| R² | determination coefficient |
| RE | relative error of prediction |
| Regressor | logistic regression |
| RIP | reactant ion peak |
| RMSE | root mean square error |
| RS | reference substances |
| (R)-SVM | (recursive) support vector machine |
| SEP | standard error of prediction |
| SHS | static headspace extraction |
| SIMCA | soft independent modeling of class analogy |
| SPME | solid-phase microextraction |
| TIMS | trapped ion mobility spectrometry |
| Tree | decision tree classification |
| TWIMS | travelling tube ion mobility spectrometry |
| UnVa | unit variance |
| UR | univariate regression |
| UV | ultraviolet light |
| VIP | variable importance in projection |
| VOC | volatile organic compound |
| (V)OO | (virgin) olive oil |
References
- Jackson, L.S. Chemical food safety issues in the United States: Past, present, and future. J. Agric. Food Chem. 2009, 57, 8161–8170. [Google Scholar] [CrossRef]
- Moore, J.C.; Spink, J.; Lipp, M. Development and application of a database of food ingredient fraud and economically motivated adulteration from 1980 to 2010. J. Food Sci. 2012, 77, R118–R126. [Google Scholar] [CrossRef]
- Van de Brug, F.J.; Lucas Luijckx, N.B.; Cnossen, H.J.; Houben, G.F. Early signals for emerging food safety risks: From past cases to future identification. Food Control 2014, 39, 75–86. [Google Scholar] [CrossRef]
- Vuckovic, D. Current trends and challenges in sample preparation for global metabolomics using liquid chromatography-mass spectrometry. Anal. Bioanal. Chem. 2012, 403, 1523–1548. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Yuan, H.; Yao, Y.; Hua, J.; Yang, Y.; Dong, C.; Deng, Y.; Wang, J.; Li, H.; Jiang, Y.; et al. Rapid volatiles fingerprinting by dopant-assisted positive photoionization ion mobility spectrometry for discrimination and characterization of Green Tea aromas. Talanta 2019, 191, 39–45. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez-Maecker, R.; Vyhmeister, E.; Meisen, S.; Rosales Martinez, A.; Kuklya, A.; Telgheder, U. Identification of terpenes and essential oils by means of static headspace gas chromatography-ion mobility spectrometry. Anal. Bioanal. Chem. 2017, 409, 6595–6603. [Google Scholar] [CrossRef]
- Cohen, G.; Rudnik, D.D.; Laloush, M.; Yakir, D.; Karpas, Z. A Novel Method for Determination of Histamine in Tuna Fish by Ion Mobility Spectrometry. Food Anal. Methods 2015, 8, 2376–2382. [Google Scholar] [CrossRef]
- Borsdorf, H.; Eiceman, G.A. Ion Mobility Spectrometry: Principles and Applications. Appl. Spectrosc. Rev. 2006, 41, 323–375. [Google Scholar] [CrossRef]
- Cumeras, R.; Figueras, E.; Davis, C.E.; Baumbach, J.I.; Gràcia, I. Review on ion mobility spectrometry. Part 2: Hyphenated methods and effects of experimental parameters. Analyst 2015, 140, 1391–1410. [Google Scholar] [CrossRef]
- Schmidt, C.; Jaros, D.; Rohm, H. Ion Mobility Spectrometry as a Potential Tool for Flavor Control in Chocolate Manufacture. Foods 2019, 8, 460. [Google Scholar] [CrossRef]
- Karpas, Z.; Guamán, A.V.; Calvo, D.; Pardo, A.; Marco, S. The potential of ion mobility spectrometry (IMS) for detection of 2,4,6-trichloroanisole (2,4,6-TCA) in wine. Talanta 2012, 93, 200–205. [Google Scholar] [CrossRef]
- Tzschoppe, M.; Haase, H.; Höhnisch, M.; Jaros, D.; Rohm, H. Using ion mobility spectrometry for screening the autoxidation of peanuts. Food Control 2016, 64, 17–21. [Google Scholar] [CrossRef]
- Rearden, P.; Harrington, P.B. Rapid screening of precursor and degradation products of chemical warfare agents in soil by solid-phase microextraction ion mobility spectrometry (SPME–IMS). Anal. Chim. Acta 2005, 545, 13–20. [Google Scholar] [CrossRef]
- Cook, G.W.; LaPuma, P.T.; Hook, G.L.; Eckenrode, B.A. Using gas chromatography with ion mobility spectrometry to resolve explosive compounds in the presence of interferents. J. Forensic Sci. 2010, 55, 1582–1591. [Google Scholar] [CrossRef] [PubMed]
- Zalewska, A.; Pawłowski, W.; Tomaszewski, W. Limits of detection of explosives as determined with IMS and field asymmetric IMS vapour detectors. Forensic Sci. Int. 2013, 226, 168–172. [Google Scholar] [CrossRef]
- Eiceman, G.A.; Karpas, Z.; Hill, H.H. Ion Mobility Spectrometry, 3rd ed.; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2016. [Google Scholar]
- Browne, C.A.; Forbes, T.P.; Sisco, E. Detection and identification of sugar alcohol sweeteners by ion mobility spectrometry. Anal. Methods 2016, 8, 5611–5618. [Google Scholar] [CrossRef]
- Reyes-Garcés, N.; Gómez-Ríos, G.A.; Souza Silva, E.A.; Pawliszyn, J. Coupling needle trap devices with gas chromatography-ion mobility spectrometry detection as a simple approach for on-site quantitative analysis. J. Chromatogr. A 2013, 1300, 193–198. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Siems, W.F.; Hill, J.H.H.; Hannan, R.M. Analytical determination of nicotine in tobacco by supercritical fluid chromatography–ion mobility detection. J. Chromatogr. A 1998, 811, 157–161. [Google Scholar] [CrossRef]
- Raatikainen, O.; Reinikainen, V.; Minkkinen, P.; Ritvanen, T.; Muje, P.; Pursiainen, J.; Hiltunen, T.; Hyvönen, P.; Wright, A.v.; Reinikainen, S.-P. Multivariate modelling of fish freshness index based on ion mobility spectrometry measurements. Anal. Chim. Acta 2005, 544, 128–134. [Google Scholar] [CrossRef]
- Pfeifer, K.B.; Rumpf, A.N. Measurement of ion swarm distribution functions in miniature low-temperature co-fired ceramic ion mobility spectrometer drift tubes. Anal. Chem. 2005, 77, 5215–5220. [Google Scholar] [CrossRef]
- Laakia, J.; Adamov, A.; Jussila, M.; Pedersen, C.S.; Sysoev, A.A.; Kotiaho, T. Separation of different ion structures in atmospheric pressure photoionization-ion mobility spectrometry-mass spectrometry (APPI-IMS-MS). J. Am. Soc. Mass Spectrom. 2010, 21, 1565–1572. [Google Scholar] [CrossRef][Green Version]
- Vautz, W.; Baumbach, J.I.; Jung, J. Beer Fermentation Control Using Ion Mobility Spectrometry—Results of a Pilot Study. J. Inst. Brew. 2006, 112, 157–164. [Google Scholar] [CrossRef]
- Sielemann, S.; Baumbach, J.I.; Schmidt, H.; Pilzecker, P. Quantitative analysis of benzene, toluene, and m-xylene with the use of a UV-ion mobility spectrometer. Field Anal. Chem. Technol. 2000, 4, 157–169. [Google Scholar] [CrossRef]
- Parchami, R.; Kamalabadi, M.; Alizadeh, N. Determination of biogenic amines in canned fish samples using head-space solid phase microextraction based on nanostructured polypyrrole fiber coupled to modified ionization region ion mobility spectrometry. J. Chromatogr. A 2017, 1481, 37–43. [Google Scholar] [CrossRef]
- Sheibani, A.; Tabrizchi, M.; Ghaziaskar, H.S. Determination of aflatoxins B1 and B2 using ion mobility spectrometry. Talanta 2008, 75, 233–238. [Google Scholar] [CrossRef] [PubMed]
- Seyed Khademi, S.M.; Telgheder, U.; Valadbeigi, Y.; Ilbeigi, V.; Tabrizchi, M. Direct detection of glyphosate in drinking water using corona-discharge ion mobility spectrometry: A theoretical and experimental study. Int. J. Mass Spectrom. 2019, 442, 29–34. [Google Scholar] [CrossRef]
- Illenseer, C.; Löhmannsröben, H.-G. Investigation of ion–molecule collisions with laser-based ion mobility spectrometry. Phys. Chem. Chem. Phys. 2001, 3, 2388–2393. [Google Scholar] [CrossRef]
- Council Directive 2013/59/Euratom of 5 December 2013 Laying Down Basic Safety Standards for Protection against the Dangers Arising from Exposure to Ionising Radiation. Off. J. Eur. Union 2013. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:32013L0059&rid=6 (accessed on 14 May 2021).
- Chen, T.; Qi, X.; Chen, M.; Lu, D.; Chen, B. Discrimination of Chinese yellow wine from different origins based on flavor fingerprint. Acta Chromatogr. 2020, 32, 139–144. [Google Scholar] [CrossRef]
- Zhu, W.; Benkwitz, F.; Kilmartin, P. Assessment of Sauvignon Blanc Aroma and Quality Gradings Based on Static Headspace-Gas Chromatography-Ion. Mobility Spectrometry (SHS-GC-IMS): Merging Analytical Chemistry with Machine Learning; Cambridge University Press & Assessment: Cambridge, UK, 2020. [Google Scholar] [CrossRef]
- Garrido-Delgado, R.; Del Dobao-Prieto, M.M.; Arce, L.; Valcárcel, M. Determination of volatile compounds by GC-IMS to assign the quality of virgin olive oil. Food Chem. 2015, 187, 572–579. [Google Scholar] [CrossRef]
- Del Contreras, M.M.; Jurado-Campos, N.; Arce, L.; Arroyo-Manzanares, N. A robustness study of calibration models for olive oil classification: Targeted and non-targeted fingerprint approaches based on GC-IMS. Food Chem. 2019, 288, 315–324. [Google Scholar] [CrossRef]
- Gerhardt, N.; Birkenmeier, M.; Sanders, D.; Rohn, S.; Weller, P. Resolution-optimized headspace gas chromatography-ion mobility spectrometry (HS-GC-IMS) for non-targeted olive oil profiling. Anal. Bioanal. Chem. 2017, 409, 3933–3942. [Google Scholar] [CrossRef]
- Griffin, G.W.; Dzidic, I.; Carroll, D.I.; Stillwell, R.N.; Horning, E.C. Ion mass assignments based on mobility measuremets. Validity of plasma chromatographic mass mobility correlations. Anal. Chem. 1973, 45, 1204–1209. [Google Scholar] [CrossRef]
- Pomareda, V.; Guamán, A.V.; Mohammadnejad, M.; Calvo, D.; Pardo, A.; Marco, S. Multivariate curve resolution of nonlinear ion mobility spectra followed by multivariate nonlinear calibration for quantitative prediction. Chemom. Intell. Lab. Syst. 2012, 118, 219–229. [Google Scholar] [CrossRef]
- Ewing, R.G.; Eiceman, G.A.; Stone, J. Proton-bound cluster ions in ion mobility spectrometry. Int. J. Mass Spectrom. 1999, 193, 57–68. [Google Scholar] [CrossRef]
- Brendel, R.; Schwolow, S.; Rohn, S.; Weller, P. Comparison of PLSR, MCR-ALS and Kernel-PLSR for the quantification of allergenic fragrance compounds in complex cosmetic products based on nonlinear 2D GC-IMS data. Chemom. Intell. Lab. Syst. 2020, 205, 104128. [Google Scholar] [CrossRef]
- Borsdorf, H.; Rudolph, M. Gas-phase ion mobility studies of constitutional isomeric hydrocarbons using different ionization techniques. Int. J. Mass Spectrom. 2001, 208, 67–72. [Google Scholar] [CrossRef]
- Vautz, W.; Bödeker, B.; Baumbach, J.I.; Bader, S.; Westhoff, M.; Perl, T. An implementable approach to obtain reproducible reduced ion mobility. Int. J. Ion Mobil. Spectrom. 2009, 12, 47–57. [Google Scholar] [CrossRef]
- May, J.C.; McLean, J.A. Ion mobility-mass spectrometry: Time-dispersive instrumentation. Anal. Chem. 2015, 87, 1422–1436. [Google Scholar] [CrossRef]
- Ewing, M.A.; Glover, M.S.; Clemmer, D.E. Hybrid ion mobility and mass spectrometry as a separation tool. J. Chromatogr. A 2016, 1439, 3–25. [Google Scholar] [CrossRef]
- Schneider, B.B.; Nazarov, E.G.; Londry, F.; Vouros, P.; Covey, T.R. Differential mobility spectrometry/mass spectrometry history, theory, design optimization, simulations, and applications. Mass Spectrom. Rev. 2016, 35, 687–737. [Google Scholar] [CrossRef]
- Shuai, Q.; Zhang, L.; Li, P.; Zhang, Q.; Wang, X.; Ding, X.; Zhang, W. Rapid adulteration detection for flaxseed oil using ion mobility spectrometry and chemometric methods. Anal. Methods 2014, 6, 9575–9580. [Google Scholar] [CrossRef]
- Spietelun, A.; Pilarczyk, M.; Kloskowski, A.; Namieśnik, J. Current trends in solid-phase microextraction (SPME) fibre coatings. Chem. Soc. Rev. 2010, 39, 4524–4537. [Google Scholar] [CrossRef]
- Ruzsanyi, V.; Mochalski, P.; Schmid, A.; Wiesenhofer, H.; Klieber, M.; Hinterhuber, H.; Amann, A. Ion mobility spectrometry for detection of skin volatiles. J. Chromatogr. B Anal. Technol. Biomed. Life Sci. 2012, 911, 84–92. [Google Scholar] [CrossRef]
- Thomas, C.F.; Zeh, E.; Dörfel, S.; Zhang, Y.; Hinrichs, J. Studying dynamic aroma release by headspace-solid phase microextraction-gas chromatography-ion mobility spectrometry (HS-SPME-GC-IMS): Method optimization, validation, and application. Anal. Bioanal. Chem. 2021, 413, 2577–2586. [Google Scholar] [CrossRef]
- Gómez-Ramos, M.M.; Ferrer, C.; Malato, O.; Agüera, A.; Fernández-Alba, A.R. Liquid chromatography-high-resolution mass spectrometry for pesticide residue analysis in fruit and vegetables: Screening and quantitative studies. J. Chromatogr. A 2013, 1287, 24–37. [Google Scholar] [CrossRef]
- Baduel, C.; Mueller, J.F.; Tsai, H.; Gomez Ramos, M.J. Development of sample extraction and clean-up strategies for target and non-target analysis of environmental contaminants in biological matrices. J. Chromatogr. A 2015, 1426, 33–47. [Google Scholar] [CrossRef]
- Krauss, M.; Singer, H.; Hollender, J. LC-high resolution MS in environmental analysis: From target screening to the identification of unknowns. Anal. Bioanal. Chem. 2010, 397, 943–951. [Google Scholar] [CrossRef]
- Masiá, A.; Campo, J.; Blasco, C.; Picó, Y. Ultra-high performance liquid chromatography-quadrupole time-of-flight mass spectrometry to identify contaminants in water: An insight on environmental forensics. J. Chromatogr. A 2014, 1345, 86–97. [Google Scholar] [CrossRef]
- Gerhardt, N.; Birkenmeier, M.; Schwolow, S.; Rohn, S.; Weller, P. Volatile-Compound Fingerprinting by Headspace-Gas-Chromatography Ion-Mobility Spectrometry (HS-GC-IMS) as a Benchtop Alternative to 1H NMR Profiling for Assessment of the Authenticity of Honey. Anal. Chem. 2018, 90, 1777–1785. [Google Scholar] [CrossRef]
- Brendel, R.; Rohn, S.; Weller, P. Nitrogen monoxide as dopant for enhanced selectivity of isomeric monoterpenes in drift tube ion mobility spectrometry with 3H ionization. Anal. Bioanal. Chem. 2021, 413, 3551–3560. [Google Scholar] [CrossRef]
- Puton, J.; Nousiainen, M.; Sillanpää, M. Ion mobility spectrometers with doped gases. Talanta 2008, 76, 978–987. [Google Scholar] [CrossRef]
- Gabelica, V.; Marklund, E. Fundamentals of ion mobility spectrometry. Curr. Opin. Chem. Biol. 2018, 42, 51–59. [Google Scholar] [CrossRef]
- Wang, S.; Chen, H.; Sun, B. Recent progress in food flavor analysis using gas chromatography-ion mobility spectrometry (GC-IMS). Food Chem. 2020, 315, 126158. [Google Scholar] [CrossRef] [PubMed]
- Hernández-Mesa, M.; Ropartz, D.; García-Campaña, A.M.; Rogniaux, H.; Dervilly-Pinel, G.; Le Bizec, B. Ion Mobility Spectrometry in Food Analysis: Principles, Current Applications and Future Trends. Molecules 2019, 24. [Google Scholar] [CrossRef]
- Márquez-Sillero, I.; Cárdenas, S.; Sielemann, S.; Valcárcel, M. On-line headspace-multicapillary column-ion mobility spectrometry hyphenation as a tool for the determination of off-flavours in foods. J. Chromatogr. A 2014, 1333, 99–105. [Google Scholar] [CrossRef] [PubMed]
- Garrido-Delgado, R.; Dobao-Prieto, M.M.; Arce, L.; Aguilar, J.; Cumplido, J.L.; Valcárcel, M. Ion mobility spectrometry versus classical physico-chemical analysis for assessing the shelf life of extra virgin olive oil according to container type and storage conditions. J. Agric. Food Chem. 2015, 63, 2179–2188. [Google Scholar] [CrossRef] [PubMed]
- Denawaka, C.J.; Fowlis, I.A.; Dean, J.R. Evaluation and application of static headspace-multicapillary column-gas chromatography-ion mobility spectrometry for complex sample analysis. J. Chromatogr. A 2014, 1338, 136–148. [Google Scholar] [CrossRef]
- Krisilova, E.V.; Levina, A.M.; Makarenko, V.A. Determination of the volatile compounds of vegetable oils using an ion-mobility spectrometer. J. Anal. Chem 2014, 69, 371–376. [Google Scholar] [CrossRef]
- Danezis, G.P.; Tsagkaris, A.S.; Camin, F.; Brusic, V.; Georgiou, C.A. Food authentication: Techniques, trends & emerging approaches. TrAC Trends Anal. Chem. 2016, 85, 123–132. [Google Scholar] [CrossRef]
- Karpas, Z. Applications of ion mobility spectrometry (IMS) in the field of foodomics. Food Res. Int. 2013, 54, 1146–1151. [Google Scholar] [CrossRef]
- Hernández-Mesa, M.; Escourrou, A.; Monteau, F.; Le Bizec, B.; Dervilly-Pinel, G. Current applications and perspectives of ion mobility spectrometry to answer chemical food safety issues. TrAC Trends Anal. Chem. 2017, 94, 39–53. [Google Scholar] [CrossRef]
- Charlebois, S.; Schwab, A.; Henn, R.; Huck, C.W. Food fraud: An exploratory study for measuring consumer perception towards mislabeled food products and influence on self-authentication intentions. Trends Food Sci. Technol. 2016, 50, 211–218. [Google Scholar] [CrossRef]
- Ehmke, M.D.; Bonanno, A.; Boys, K.; Smith, T.G. Food fraud: Economic insights into the dark side of incentives. Aust. J. Agric. Resour. Econ. 2019, 63, 685–700. [Google Scholar] [CrossRef]
- Aries, E.; Burton, J.; Carrasco, L.; de Rudder, O.; Maquet, A. Scientific Support to the Implementation of a Coordinated Control Plan with a View to Establishing the Prevalence of Fraudulent Practices in the Marketing of Honey: N° SANTE/2015/E3/JRC/SI2.706828. JRC Technical Report 2016, JRC104749. 2016, p. 38. Available online: https://ec.europa.eu/food/sites/food/files/safety/docs/oc_control-progs_honey_jrc-tech-report_2016.pdf (accessed on 12 May 2021).
- Louveaux, J.; Maurizio, A.; Vorwohl, G. Methods of Melissopalynology. BEE World 1978, 59, 139–157. [Google Scholar] [CrossRef]
- Cavazza, A.; Corradini, C.; Musci, M.; Salvadeo, P. High-performance liquid chromatographic phenolic compound fingerprint for authenticity assessment of honey. J. Sci. Food Agric. 2013, 93, 1169–1175. [Google Scholar] [CrossRef]
- Zhou, J.; Yao, L.; Li, Y.; Chen, L.; Wu, L.; Zhao, J. Floral classification of honey using liquid chromatography-diode array detection-tandem mass spectrometry and chemometric analysis. Food Chem. 2014, 145, 941–949. [Google Scholar] [CrossRef] [PubMed]
- Karabagias, I.K.; Badeka, A.; Kontakos, S.; Karabournioti, S.; Kontominas, M.G. Characterisation and classification of Greek pine honeys according to their geographical origin based on volatiles, physicochemical parameters and chemometrics. Food Chem. 2014, 146, 548–557. [Google Scholar] [CrossRef]
- Robotti, E.; Campo, F.; Riviello, M.; Bobba, M.; Manfredi, M.; Mazzucco, E.; Gosetti, F.; Calabrese, G.; Sangiorgi, E.; Marengo, E. Optimization of the Extraction of the Volatile Fraction from Honey Samples by SPME-GC-MS, Experimental Design, and Multivariate Target Functions. J. Chem. 2017, 2017, 6437857. [Google Scholar] [CrossRef]
- Jandrić, Z.; Haughey, S.A.; Frew, R.D.; McComb, K.; Galvin-King, P.; Elliott, C.T.; Cannavan, A. Discrimination of honey of different floral origins by a combination of various chemical parameters. Food Chem. 2015, 189, 52–59. [Google Scholar] [CrossRef] [PubMed]
- Woodcock, T.; Fagan, C.C.; O’Donnell, C.P.; Downey, G. Application of Near and Mid-Infrared Spectroscopy to Determine Cheese Quality and Authenticity. Food Bioprocess Technol. 2008, 1, 117–129. [Google Scholar] [CrossRef]
- Gok, S.; Severcan, M.; Goormaghtigh, E.; Kandemir, I.; Severcan, F. Differentiation of Anatolian honey samples from different botanical origins by ATR-FTIR spectroscopy using multivariate analysis. Food Chem. 2015, 170, 234–240. [Google Scholar] [CrossRef]
- Boffo, E.F.; Tavares, L.A.; Tobias, A.C.; Ferreira, M.M.; Ferreira, A.G. Identification of components of Brazilian honey by 1H NMR and classification of its botanical origin by chemometric methods. LWT 2012, 49, 55–63. [Google Scholar] [CrossRef]
- Schievano, E.; Finotello, C.; Uddin, J.; Mammi, S.; Piana, L. Objective Definition of Monofloral and Polyfloral Honeys Based on NMR Metabolomic Profiling. J. Agric. Food Chem. 2016, 64, 3645–3652. [Google Scholar] [CrossRef]
- Garrido-Delgado, R.; Arce, L.; Valcárcel, M. Multi-capillary column-ion mobility spectrometry: A potential screening system to differentiate virgin olive oils. Anal. Bioanal. Chem. 2012, 402, 489–498. [Google Scholar] [CrossRef]
- Gerhardt, N.; Schwolow, S.; Rohn, S.; Pérez-Cacho, P.R.; Galán-Soldevilla, H.; Arce, L.; Weller, P. Quality assessment of olive oils based on temperature-ramped HS-GC-IMS and sensory evaluation: Comparison of different processing approaches by LDA, kNN, and SVM. Food Chem. 2019, 278, 720–728. [Google Scholar] [CrossRef]
- Garrido-Delgado, R.; Mercader-Trejo, F.; Sielemann, S.; de Bruyn, W.; Arce, L.; Valcárcel, M. Direct classification of olive oils by using two types of ion mobility spectrometers. Anal. Chim. Acta 2011, 696, 108–115. [Google Scholar] [CrossRef]
- Schwolow, S.; Gerhardt, N.; Rohn, S.; Weller, P. Data fusion of GC-IMS data and FT-MIR spectra for the authentication of olive oils and honeys-is it worth to go the extra mile? Anal. Bioanal. Chem. 2019, 411, 6005–6019. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Rogers, K.M.; Li, Y.; Yang, S.; Chen, L.; Zhou, J. Untargeted and Targeted Discrimination of Honey Collected by Apis cerana and Apis mellifera Based on Volatiles Using HS-GC-IMS and HS-SPME-GC-MS. J. Agric. Food Chem. 2019, 67, 12144–12152. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Yang, S.; He, J.; Chen, L.; Zhang, J.; Jin, Y.; Zhou, J.; Zhang, Y. A green triple-locked strategy based on volatile-compound imaging, chemometrics, and markers to discriminate winter honey and sapium honey using headspace gas chromatography-ion mobility spectrometry. Food Res. Int. 2019, 119, 960–967. [Google Scholar] [CrossRef]
- Arroyo-Manzanares, N.; García-Nicolás, M.; Castell, A.; Campillo, N.; Viñas, P.; López-García, I.; Hernández-Córdoba, M. Untargeted headspace gas chromatography–Ion mobility spectrometry analysis for detection of adulterated honey. Talanta 2019, 205, 120123. [Google Scholar] [CrossRef]
- Cavanna, D.; Zanardi, S.; Dall’Asta, C.; Suman, M. Ion mobility spectrometry coupled to gas chromatography: A rapid tool to assess eggs freshness. Food Chem. 2019, 271, 691–696. [Google Scholar] [CrossRef] [PubMed]
- Gu, S.; Chen, W.; Wang, Z.; Wang, J.; Huo, Y. Rapid detection of Aspergillus spp. infection levels on milled rice by headspace-gas chromatography ion-mobility spectrometry (HS-GC-IMS) and E-nose. LWT 2020, 132, 109758. [Google Scholar] [CrossRef]
- Gu, S.; Chen, W.; Wang, Z.; Wang, J. Rapid determination of potential aflatoxigenic fungi contamination on peanut kernels during storage by data fusion of HS-GC-IMS and fluorescence spectroscopy. Postharvest Biol. Technol. 2021, 171, 111361. [Google Scholar] [CrossRef]
- Gu, S.; Wang, Z.; Chen, W.; Wang, J. Targeted versus Nontargeted Green Strategies Based on Headspace-Gas Chromatography-Ion Mobility Spectrometry Combined with Chemometrics for Rapid Detection of Fungal Contamination on Wheat Kernels. J. Agric. Food Chem. 2020, 68, 12719–12728. [Google Scholar] [CrossRef] [PubMed]
- Arroyo-Manzanares, N.; Martín-Gómez, A.; Jurado-Campos, N.; Garrido-Delgado, R.; Arce, C.; Arce, L. Target vs spectral fingerprint data analysis of Iberian ham samples for avoiding labelling fraud using headspace–gas chromatography–ion mobility spectrometry. Food Chem. 2018, 246, 65–73. [Google Scholar] [CrossRef] [PubMed]
- Brendel, R.; Schwolow, S.; Rohn, S.; Weller, P. Volatilomic Profiling of Citrus Juices by Dual-Detection HS-GC-MS-IMS and Machine Learning-An Alternative Authentication Approach. J. Agric. Food Chem. 2021, 69, 1727–1738. [Google Scholar] [CrossRef] [PubMed]
- Vega-Márquez, B.; Nepomuceno-Chamorro, I.; Jurado-Campos, N.; Rubio-Escudero, C. Deep Learning Techniques to Improve the Performance of Olive Oil Classification. Front. Chem. 2019, 7, 929. [Google Scholar] [CrossRef]
- Yuan, Z.-Y.; Li, J.; Zhou, X.-J.; Wu, M.-H.; Li, L.; Pei, G.; Chen, N.-H.; Liu, K.-L.; Xie, M.-Z.; Huang, H.-Y. HS-GC-IMS-Based metabonomics study of Baihe Jizihuang Tang in a rat model of chronic unpredictable mild stress. J. Chromatogr. B Anal. Technol. Biomed. Life Sci. 2020, 1148, 122143. [Google Scholar] [CrossRef]
- Antignac, J.-P.; Courant, F.; Pinel, G.; Bichon, E.; Monteau, F.; Elliott, C.; Le Bizec, B. Mass spectrometry-based metabolomics applied to the chemical safety of food. TrAC Trends Anal. Chem. 2011, 30, 292–301. [Google Scholar] [CrossRef]
- Snow, N.H.; Slack, G.C. Head-space analysis in modern gas chromatography. TrAC Trends Anal. Chem. 2002, 21, 608–617. [Google Scholar] [CrossRef]
- Soria, A.C.; García-Sarrió, M.J.; Sanz, M.L. Volatile sampling by headspace techniques. TrAC Trends Anal. Chem. 2015, 71, 85–99. [Google Scholar] [CrossRef]
- Poole, C.F. (Ed.) Liquid-Phase Extraction; Handbooks in Separation Science; Elsevier: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Guo, Z.; Zhu, Z.; Huang, S.; Wang, J. Non-targeted screening of pesticides for food analysis using liquid chromatography high-resolution mass spectrometry-a review. Food Addit. Contam. Part A 2020, 37, 1180–1201. [Google Scholar] [CrossRef]
- Souza Silva, E.A.; Risticevic, S.; Pawliszyn, J. Recent trends in SPME concerning sorbent materials, configurations and in vivo applications. TrAC Trends Anal. Chem. 2013, 43, 24–36. [Google Scholar] [CrossRef]
- Chen, T.; Chen, X.; Lu, D.; Chen, B. Detection of Adulteration in Canola Oil by Using GC-IMS and Chemometric Analysis. Int. J. Anal. Chem. 2018, 2018, 3160265. [Google Scholar] [CrossRef]
- Baumbach, J.I.; Eiceman, G.A.; Klockow, D.; Sielemann, S.; Irmer, A.V. Exploration of a Multicapillary Column for Use in Elevated Speed Gas Chromatography. Int. J. Environ. Anal. Chem. 1997, 66, 225–239. [Google Scholar] [CrossRef]
- Cureton, E.E.; D’Agostino, R.B. Factor Analysis; Psychology Press: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Zheng, P.; de Harrington, P.B.; Davis, D.M. Quantitative analysis of volatile organic compounds using ion mobility spectrometry and cascade correlation neural networks. Chemom. Intell. Lab. Syst. 1996, 33, 121–132. [Google Scholar] [CrossRef]
- Kaur-Atwal, G.; O’Connor, G.; Aksenov, A.A.; Bocos-Bintintan, V.; Paul Thomas, C.L.; Creaser, C.S. Chemical standards for ion mobility spectrometry: A review. Int. J. Ion Mobil. Spectrom. 2009, 12, 1–14. [Google Scholar] [CrossRef]
- Liedtke, S.; Seifert, L.; Ahlmann, N.; Hariharan, C.; Franzke, J.; Vautz, W. Coupling laser desorption with gas chromatography and ion mobility spectrometry for improved olive oil characterisation. Food Chem. 2018, 255, 323–331. [Google Scholar] [CrossRef] [PubMed]
- Borsdorf, H.; Neitsch, K. Ion mobility spectra of cyclic and aliphatic hydrocarbons with different substituents. Int. J. Ion Mobil. Spectrom. 2009, 12, 39–46. [Google Scholar] [CrossRef]
- Budzyńska, E.; Sielemann, S.; Puton, J.; Surminski, A.L.R.M. Analysis of e-liquids for electronic cigarettes using GC-IMS/MS with headspace sampling. Talanta 2020, 209, 120594. [Google Scholar] [CrossRef]
- Kessler, W. Multivariate Datenanalyse: Für die Pharma-, bio- und Prozessanalytik: Ien Lehrbuch; Wiley-VCH: Weinheim, Germany, 2007. [Google Scholar]
- Maimon, O.; Rokach, L. Data Mining and Knowledge Discovery Handbook; Springer: New York, NY, USA, 2005. [Google Scholar]
- Granato, D.; Santos, J.S.; Escher, G.B.; Ferreira, B.L.; Maggio, R.M. Use of principal component analysis (PCA) and hierarchical cluster analysis (HCA) for multivariate association between bioactive compounds and functional properties in foods: A critical perspective. Trends Food Sci. Technol. 2018, 72, 83–90. [Google Scholar] [CrossRef]
- Wold, S.; Geladi, P.; Esbensen, K.; Öhman, J. Multi-way principal components-and PLS-analysis. J. Chemom. 1987, 1, 41–56. [Google Scholar] [CrossRef]
- Bro, R. PARAFAC. Tutorial and applications. Chemom. Intell. Lab. Syst. 1997, 38, 149–171. [Google Scholar] [CrossRef]
- Kroonenberg, P.M.; Ten Berge, J.M.F. The equivalence of Tucker3 and Parafac models with two components. Chemom. Intell. Lab. Syst. 2011, 106, 21–26. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Varmuza, K.; Filzmoser, P. Introduction to Multivariate Statistical Analysis in Chemometrics; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Chen, Y.-Y.; Lin, Y.-H.; Kung, C.-C.; Chung, M.-H.; Yen, I.-H. Design and Implementation of Cloud Analytics-Assisted Smart Power Meters Considering Advanced Artificial Intelligence as Edge Analytics in Demand-Side Management for Smart Homes. Sensors 2019, 19, 2047. [Google Scholar] [CrossRef]
- Torkashvand, A.M.; Ahmadi, A.; Nikravesh, N.L. Prediction of kiwifruit firmness using fruit mineral nutrient concentration by artificial neural network (ANN) and multiple linear regressions (MLR). J. Integr. Agric. 2017, 16, 1634–1644. [Google Scholar] [CrossRef]
- Scheinemann, A.; Sielemann, S.; Walter, J.; Doll, T. Evaluation Strategies for Coupled GC-IMS Measurement including the Systematic Use of Parametrized ANN. Open J. Appl. Sci. 2012, 2, 257–266. [Google Scholar] [CrossRef]
- Rosipal, R. Nonlinear Partial Least Squares An Overview. In Chemoinformatics and Advanced Machine Learning Perspectives; Lodhi, H., Yamanishi, Y., Eds.; IGI Global: Hershey, PA, USA, 2011; pp. 169–189. [Google Scholar] [CrossRef]
- De Juan, A.; Jaumot, J.; Tauler, R. Multivariate Curve Resolution (MCR). Solving the mixture analysis problem. Anal. Methods 2014, 6, 4964–4976. [Google Scholar] [CrossRef]
- Liu, P.; Duan, J.; Wang, P.; Qian, D.; Guo, J.; Shang, E.; Su, S.; Tang, Y.; Tang, Z. Biomarkers of primary dysmenorrhea and herbal formula intervention: An exploratory metabonomics study of blood plasma and urine. Mol. Biosyst. 2013, 9, 77–87. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Sinelnikov, I.V.; Han, B.; Wishart, D.S. MetaboAnalyst 3.0—making metabolomics more meaningful. Nucleic Acids Res. 2015, 43, W251–W257. [Google Scholar] [CrossRef]
- Smith, C.A.; Want, E.J.; O’Maille, G.; Abagyan, R.; Siuzdak, G. XCMS: Processing mass spectrometry data for metabolite profiling using nonlinear peak alignment, matching, and identification. Anal. Chem. 2006, 78, 779–787. [Google Scholar] [CrossRef]
- Zhang, X.; Dai, Z.; Fan, X.; Liu, M.; Ma, J.; Shang, W.; Liu, J.; Strappe, P.; Blanchard, C.; Zhou, Z. A study on volatile metabolites screening by HS-SPME-GC-MS and HS-GC-IMS for discrimination and characterization of white and yellowed rice. Cereal Chem. 2020, 97, 496–504. [Google Scholar] [CrossRef]
- Chen, T.; Liu, C.; Meng, L.; Lu, D.; Chen, B.; Cheng, Q. Early warning of rice mildew based on gas chromatography-ion mobility spectrometry technology and chemometrics. Food Meas. 2021, 15, 1939–1948. [Google Scholar] [CrossRef]
- Lv, W.; Lin, T.; Ren, Z.; Jiang, Y.; Zhang, J.; Bi, F.; Gu, L.; Hou, H.; He, J. Rapid discrimination of Citrus reticulata ‘Chachi’ by headspace-gas chromatography-ion mobility spectrometry fingerprints combined with principal component analysis. Food Res. Int. 2020, 131, 108985. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Yang, R.; Zhang, H.; Wang, S.; Chen, D.; Lin, S. Development of a flavor fingerprint by HS-GC-IMS with PCA for volatile compounds of Tricholoma matsutake Singer. Food Chem. 2019, 290, 32–39. [Google Scholar] [CrossRef]
- Brendel, R.; Schwolow, S.; Rohn, S.; Weller, P. Gas-phase volatilomic approaches for quality control of brewing hops based on simultaneous GC-MS-IMS and machine learning. Anal. Bioanal. Chem. 2020, 412, 7085–7097. [Google Scholar] [CrossRef] [PubMed]
- Pu, D.; Zhang, H.; Zhang, Y.; Sun, B.; Ren, F.; Chen, H.; He, J. Characterization of the aroma release and perception of white bread during oral processing by gas chromatography-ion mobility spectrometry and temporal dominance of sensations analysis. Food Res. Int. 2019, 123, 612–622. [Google Scholar] [CrossRef]
- Tang, Z.-S.; Zeng, X.-A.; Brennan, M.A.; Han, Z.; Niu, D.; Huo, Y. Characterization of aroma profile and characteristic aromas during lychee wine fermentation. J. Food Process. Preserv. 2019, 43, e14003. [Google Scholar] [CrossRef]
- Gerhardt, N.; Birkenmeier, M.; Kuballa, T.; Ohmenhaeuser, M.; Rohn, S.; Weller, P. Differentiation of the botanical origin of honeys by fast, non-targeted 1H-NMR profiling and chemometric tools as alternative authenticity screening tool. In Proceedings of the XIII International Conference on the Applications of Magnetic Resonance in Food Science, Karlsruhe, Germany, 7–10 June 2016; IM Publications: Charlton, UK, 2016; p. 33. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, D.; Dong, Y.; Ju, H.; Wu, C.; Lin, S. Characteristic volatiles fingerprints and changes of volatile compounds in fresh and dried Tricholoma matsutake Singer by HS-GC-IMS and HS-SPME-GC-MS. J. Chromatogr. B Anal. Technol. Biomed. Life Sci. 2018, 1099, 46–55. [Google Scholar] [CrossRef]
- Klein, L.A. Sensor and Data Fusion: A Tool for Information Assessment and Decision Making; SPIE Press: Bellingham, WA, USA, 2010. [Google Scholar]
- Borràs, E.; Ferré, J.; Boqué, R.; Mestres, M.; Aceña, L.; Busto, O. Data fusion methodologies for food and beverage authentication and quality assessment—a review. Anal. Chim. Acta 2015, 891, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; John Wiley & Sons: New York, NY, USA, 2010. [Google Scholar]
- Martín-Gómez, A.; Arroyo-Manzanares, N.; Rodríguez-Estévez, V.; Arce, L. Use of a non-destructive sampling method for characterization of Iberian cured ham breed and feeding regime using GC-IMS. Meat Sci. 2019, 152, 146–154. [Google Scholar] [CrossRef] [PubMed]
- Chatterji, B.N. Feature Extraction Methods for Character Recognition. IETE Tech. Rev. 1986, 3, 9–22. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Chen, T.; Qi, X.; Chen, M.; Chen, B. Gas Chromatography-Ion Mobility Spectrometry Detection of Odor Fingerprint as Markers of Rapeseed Oil Refined Grade. J. Anal. Methods Chem. 2019, 2019, 3163204. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Qi, X.; Lu, D.; Chen, B. Gas chromatography-ion mobility spectrometric classification of vegetable oils based on digital image processing. Food Meas. 2019, 13, 1973–1979. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Reference (Main Author/Yeat) | Aim of Reference | Matrice (Number of Samples) | IMS Type (Ionization Source) | Separation (Length × Inner Diameter (ID), Film Thickness (ft)) | Unsupervised and Supervised Methods | Complementary Analysis | Method and Number of Compounds Identified | Data-Split; (Cross-) Validation |
|---|---|---|---|---|---|---|---|---|
| Arroyo-Manzanares/2017 [89] | classification between pig’s food sources | dry-cured Iberian ham (24) | FlavourSpec by GAS (tritium, 6.5 keV) | FS-SE-54-CB stationary phase (30 m × 0.32 mm ID, 0.25 µm ft; 94% methyl, 5% phenyl, 1% vinyl silicone) | PCA PCA-LDA (90%), kNN (k = 3, 90%) | library search (LS) 5 | 80/20 | |
| Arroyo-Manzanares/2019 [84] | detection of adulteration (sugar cane or corn syrup) | honey (198) | FlavourSpec by GAS (tritium, 6.5 keV) | HP-5MS UI (nonpolar) (30 m × 0.25 mm ID, 0.25 μm ft) | OPLS-DA (97.4% prediction of class, 93.75% prediction of adulteration degree) | 0 | 80/20 | |
| Brendel/2021 [90] | detection of botanical origin | citrus juice (47) | OEM IMS by GAS (tritium, 300 MBq) | ZB-5 ms column (30 m × 0.25 mm, 0.25 μm ft; 5% phenyl-methylpolysiloxane) | PCA PCA-LDA (91.5%) | HS-GC-MS/IMS | reference substances (RS) 9 | leave-one-out (LOO) 4- and 6-fold CV |
| Cavanna/2018 [85] | detection of food freshness | egg (132) | FlavourSpec | FS-SE-54-CB-1 stationary phase (15 m × 0.53 mm ID, 1µm ft; 94% methyl, 5% phenyl, 1% vinyl silicone) | PCA OPLS-DA (97%) | RS, SPME-GC-MS 5 | leave-one-out CV | |
| Chen/2020 [30] | detection of geographical origin | Chinese yellow wine (122) | FlavourSpec by GAS (tritium, 6.5 keV) | nonpolar column (30 m, 95% methyl, 5% phenyl) | PCA QDA (95.35%) | LS 12 | 70/30 | |
| del Contreras/2019 [33] | quality assessment/classification | olive oil (701) | FlavourSpec by GAS (tritium, 6.5 keV) | SE-54-CB (30 m × 0.32 mm, 0.25 µm ft; 94% methyl, 5% phenyl, 1% vinyl silicone) | PCA non-targeted (PCA-LDA, kNN k = 3: 79.4%), targeted OPLS-DA: 74.3%) | LS, RS 20 | 80/20; 7-fold CV | |
| Garrido-Delgado/2011 [80] | quality assessment/classification | olive oil (49) | portable UV–IMS instrument (UV ionization source: 10.6 eV) and FlavourSpec by GAS (tritium, 6.5 keV) | MCC (nonpolar) OV-5 (20 cm) | PCA UV-IMS: kNN (k = 3, 86.1%); GC-IMS: kNN (k = 3, 100%) | 0 | 71/29 and 64/26; leave-one-out CV | |
| Garrido-Delgado/2012 [78] | quality assessment/classification | olive oil (98) | FlavourSpec by GAS (tritium, 6.5 keV) | MCC (nonpolar) OV-5 (20 cm, 1000 parallel glass capillaries) | PCA Targeted: kNN (k = 3, 79%), non-targeted: kNN (k = 3, 87%) | Organoleptic analysis | LS, RS 10 | bootstrap validation (B = 100) |
| Garrido-Delgado/2015 [32] | quality assessment/classification | olive oil (55) | FlavourSpec by GAS (tritium, 6.5 keV) | two different types of columns: MCC (20 cm × 3 mm ID, 900 parallel glass capillaries: 40µm ID, 0.2µm ft) and CC (30 m × 0.25 mm, 0.5µm ft) | PCA MCC-IMS: kNN (k = 3, 79%); CC-IMS: kNN (k = 3, 83%) | LS, RS 26 | bootstrap validation | |
| Gerhardt/2017 [34] | detection of geographical origin | olive oil (40) | FlavourSpec by GAS (tritium, 6.5 keV) | NB-225 (25 m × 0.32 mm × 0.25 μm ft; 25% phenyl, 25% cyanopropyl methyl siloxane) | PCA PCA-LDA (98%) and kNN (k = 5, 92%) | RS 4 | 10-fold CV | |
| Gerhardt/2018 [52] | detection of botanical origin | honey (74) | advanced IMS by GAS (tritium, 300 MBq) | DB-225 (25 m × 0.32 mm, 0.25 μm ft; 25% phenyl, 25% cyanopropyl methyl siloxane) | PCA PCA−LDA (98.6%), kNN (k = 5, 86.1%), PLS-DA (PLS = 5, 97.0%) | 1H NMR | RS 18 | 87/13; 10-fold CV |
| Gerhardt/2019 [79] | quality assessment/classification | olive oil (94) | FlavourSpec by GAS (tritium, 6.5 keV) | DB-225 (25 m × 0.32 mm × 0.25 μm ft; 25% phenyl, 25% cyanopropyl methyl siloxane) | PCA, HCA PCA-LDA (10 PCs, 83.3%), kNN (73.8%), SVM (88.1%) | Organoleptic analysis | RS 25 | 10-fold CV |
| Gu/2020 [88] | detection of quality changes during storage | wheat kernels infected with mold (90) | FlavourSpec by GAS (tritium, 6.5 keV) | MXT-WAX (nonpolar) (30 m × 0.53 mm ID, 0.1 μm ft) | PCA, HCA GA-SVM, Artificial samples: (Classification: 100%), (Quantification > 93.9%); Natural samples: (Classification: 60–86.7%, Quantification: 72.6–88.9%) | LS 13 | 67/33 | |
| Gu/2020 [86] | detection of quality changes during storage | milled rice infected with Aspergillus species (108) | FlavourSpec by GAS (tritium, 6.5 keV) | SE-54-CB | PCA kNN (k = 3, 94.44%), PLSR (90.9%) | electric nose (E-nose) | LS, partially RS 25 | 67/33; 10-fold CV |
| Gu/2021[87] | detection of quality changes during storage | peanut kernel infected with aflatoxigenic fungi (180) | FlavourSpec | Rtx-WAX (30 m × 0.32 mm ID, 0.25 μm ft, RT-12,424) | PCA OPLS-DA (93.3%), low-level data fusion (90%), mid-level data fusion (96.7%) | fluorescence analysis | LS 3 | 67/33; 7-fold CV, 200× permutation test |
| Li/2019 [5] | classification between aroma | green tea (23) | real-time IMS: self-made positive photoionization (PP-IMS) with KR lamp | - | PCA PLS-DA (95.6%) | sensory evaluation | 0 | 10-fold CV, 1000× permutation test |
| Schwolow/2019 [81] | detection of botanical and geographical origin | honey and olive oil (64 honey, 54 EVOOs) | advanced IMS by GAS (tritium, 300 MBq) | DB-225 (25 m × 0.32 mm, 0.25 μm ft) | PCA Honey: PCA-LDA (33%); Olive oil: PCA-LDA (78%), PCA-LDA + data fusion (100%) | FT-MIR | previous studies (18 honey, 7 olive oil) | 87/13; 10-fold CV |
| Shuai/2014 [44] | detection of adulteration (with vegetable oils) | flaxseed oil (78) | IMS-KS-100 by Wuhan Syscan Technology (pulse glow discharge) | n-hexane extraction | recursive support vector machine (R-SVM) (93.1%) | 0 | 10-fold CV | |
| Vega-Marquez/2019 [91] | quality assessment/classification | olive oil (701) | FlavourSpec by GAS (tritium, 6.5 keV) | SE-54-CB (30 m × 0.32 mm, 0.25 µm ft; 94% methyl, 5% phenyl, 1% vinyl silicone) | Deep learning (88.8%), SVM (83.1%), kNN (84.5%), Tree (78.3%), Regressor (85.5%), XGBoost (85.7%) | LS, RS 20 | 80/20 | |
| Wang/2019 [82] | detection of botanical origin | honey (40) | FlavourSpec by GAS (tritium, 6.5 keV) | FS–SE–54–CB-0.5 (15 m × 0.53 mm ID) | PCA OPLS-DA (95%) (VIP > 1.5) | HS-SPME-GC-MS8 | 200× permutation test | |
| Wang/2019 [83] | detection of botanical origin | honey (120) | FlavourSpec by GAS (tritium, 6.5 keV) | FS–SE–54–CB-0.5 (15 m × 0.53 mm ID) | PCA PLS-DA (84%) | LS 25 | CV-ANOVA | |
| Yuan/2020 [92] | metabolomic studies | rat feces (30) | FlavourSpec | FS-SE-54-CB-1 (15 m × 0.53 mm ID) | PCA OPLS-DA (86.6) | LS 11 | 200× permutation test | |
| Zhu/2020 [31] | quality assessment/classification | wine (143) | FlavourSpec | MXT-WAX (polar) (30 m × 0.53 mm ID, 0.5 μm ft, polyethylene glycol) | PCA PCA-LDA (65.7%), PLS-DA (58.7%), kNN (k = 5, 60.8%), SVM (51.8%), XGBoot (81.8%), ANN (89.5%) | sensory evaluation | RS >30 | 85/15; 10-fold CV |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Capitain, C.; Weller, P. Non-Targeted Screening Approaches for Profiling of Volatile Organic Compounds Based on Gas Chromatography-Ion Mobility Spectroscopy (GC-IMS) and Machine Learning. Molecules 2021, 26, 5457. https://doi.org/10.3390/molecules26185457
Capitain C, Weller P. Non-Targeted Screening Approaches for Profiling of Volatile Organic Compounds Based on Gas Chromatography-Ion Mobility Spectroscopy (GC-IMS) and Machine Learning. Molecules. 2021; 26(18):5457. https://doi.org/10.3390/molecules26185457
Chicago/Turabian StyleCapitain, Charlotte, and Philipp Weller. 2021. "Non-Targeted Screening Approaches for Profiling of Volatile Organic Compounds Based on Gas Chromatography-Ion Mobility Spectroscopy (GC-IMS) and Machine Learning" Molecules 26, no. 18: 5457. https://doi.org/10.3390/molecules26185457
APA StyleCapitain, C., & Weller, P. (2021). Non-Targeted Screening Approaches for Profiling of Volatile Organic Compounds Based on Gas Chromatography-Ion Mobility Spectroscopy (GC-IMS) and Machine Learning. Molecules, 26(18), 5457. https://doi.org/10.3390/molecules26185457