Abstract
In industries, particularly in quality optimization, the trade-off between model bias and variance is inevitable, reflecting the tension between accuracy and uncertainty. Traditional methods often address these aspects separately, potentially leading to suboptimal decisions. This study proposes a Pareto-front optimization framework for a variance-added expected loss function within the context of interrelated quality characteristics. By integrating multivariate quadratic loss with a variance term, our approach simultaneously captures deviation from targets (bias) and system uncertainty (variance). Unlike sequential approaches that first minimize bias and then variance—often increasing total risk—our weighted formulation flexibly adjusts for their trade-offs. This enables a more balanced and efficient optimization process that identifies solutions with lower overall risk. Through Pareto-front analysis, we reveal trade-offs between expected loss and variance, allowing users to select optimal quality designs based on their preferred bias–variance balance. Representative examples and a case study adopted from the literature validate the effectiveness and practical applicability of the proposed method.
1. Introduction
In modern industries, achieving optimal performance across multiple interrelated quality attributes is a complex, yet essential, task. Systems often face conflicting objectives, in which improving one quality indicator may deteriorate another. As industries demand higher precision and robustness, efficiently managing these trade-offs becomes increasingly critical. In a machine-learning task, for example, a trade-off between model bias and model variance is inevitable: a low-level model bias from substantial model complexity incurs high-level model variance, and vice versa. Representative quality objectives in conflict are accuracy and variance arising from predefined targets and random observations.
Traditional optimization methods typically focus on minimizing a single objective loss function, but they often fail to account for interdependencies between different quality attributes. Many real-world systems such as manufacturing, engineering, and healthcare exhibit tightly coupled quality characteristics that directly influence overall system performance. In such contexts, a more comprehensive approach is required—one that considers not only deviations from target quality but also uncertainty in system behavior by incorporating variance into overall loss.
This paper proposes a novel approach for globally optimizing interrelated quality attributes by adding variance-induced uncertainty to expected loss. The goal is to minimize not only deviation from a target quality but also uncertainty in performance. For the sake of global optimization, we use Pareto fronts to explore trade-offs between conflicting objectives, enabling decision-makers to select solutions, or decisions, that achieve the desired balance between accuracy and risk. Importantly, our method allows users to explicitly choose the ratio between bias and variance terms, providing greater flexibility to manage the trade-offs arising from specific application requirements.
In this study, we apply an alternative global criterion (GC)-based method for generating Pareto fronts to handle accuracy-induced and variance-induced qualities. This method offers increased computational efficiency compared to traditional optimization techniques and effectively handles the trade-offs between multiple objectives. We illustrate the applicability of this approach through two representative examples and demonstrate its practical use with a dataset adopted from the literature. The experiments reveal the applicability of the proposed method to a complex system with interrelated quality attributes. Our analysis shows that the optimization results outperform existing quality decisions in terms of both quality and flexibility, providing valuable insights into achieving quality optimization in industrial settings.
The proposed method presented in this paper offers a systematic framework for quality optimization in complex systems with interrelated attributes and variance. By applying this approach, decision-making processes in industries requiring simultaneous optimization of multiple quality factors can be significantly improved.
2. Related Works
In multi-objective optimization problems, it is often necessary to simultaneously consider distinct quality characteristics such as mean deviation and variance. As a result, conventional single-objective optimization techniques have limited applicability, and various multi-objective quality optimization methods have been proposed.
A well-known early approach is the two-step strategy proposed by [1], in which variance is minimized first, followed by minimization of mean deviation. This method is computationally simple and easy to interpret, making it appealing in practical settings. However, in real-world applications, most design variables influence both the mean and variance simultaneously. Thus, separating these objectives can lead to inaccurate decisions and reduce the overall predictive accuracy and interpretability of the optimization process.
Other studies have sought to mathematically incorporate interactions between multiple quality characteristics. For example, Shiau proposed a weighted sum of signal-to-noise (SN) ratios to aggregate multiple quality characteristics [2], while Tong et al. developed a multi-response SN ratio that sums weighted expected losses before converting the result to an overall performance measure [3]. More recently, a loss function explicitly considering interactions between variables has been proposed (see, e.g., [4]), offering a more theoretically robust formulation compared to earlier methods. However, these approaches share practical limitations: they rely mainly on numerical computations from existing data, do not support the setting of design variables or the generation of actionable design alternatives, and thus are generally restricted to post hoc analysis rather than active design optimization.
Building on such interaction-based loss functions, Costa and Lourenço [5] proposed a game-theoretic approach to simultaneously optimize process and product quality characteristics in bi-objective settings. By employing Stackelberg’s strategy, their method avoids subjective parameter tuning and seeks efficient trade-offs. Nonetheless, such game-theoretic frameworks often struggle to yield a solution that simultaneously satisfies all quality objectives, especially when multiple interdependent characteristics are involved. This underscores the need for methods that not only capture interactions among characteristics but also offer clear and actionable design recommendations.
To address such multi-objective optimization challenges, especially in design settings, surrogate-based approaches have gained popularity. A representative example is the efficient global optimization (EGO) algorithm [6], which uses the expected improvement (EI) criterion to sequentially explore the design space and identify optima. Ref. [7] extended this framework to multi-objective problems by introducing ParEGO, an algorithm that employs Tchebycheff scalarization to search the Pareto front. Furthermore, ref. [8] proposed an integrated approach combining multiple scalarization techniques (e.g., Tchebycheff and weighted sum) to better approximate diverse trade-offs. However, these methods inherently reduce multi-objective problems to a series of single-objective subproblems and, as a result, cannot fully capture the complex trade-offs among conflicting objectives.
In this study, we propose a multivariate quadratic loss-based Pareto optimization framework that mathematically captures the interactions between design variables and multiple quality characteristics, and simultaneously accounts for overall quality loss arising from both mean deviation and variance. In contrast to scalarization-based methods, the proposed approach directly derives interpretable Pareto-optimal solutions in the multi-objective space without reducing the problem to a single-objective formulation. For reproducibility, we provide a GitHub URL (https://github.com/KIM-sang-won/PFOVELIQ/blob/main/PFOVE__Python_code.ipynb, accessed on 4 February 2026) for the experiments.
3. Methods
3.1. Multivariate Quadratic Loss Function and Total Risk
A multivariate quadratic loss function was introduced by Pignatiello [1] and is defined as follows:
where is a vector consisting of principal components (PCs) of the ’nominal-the-best’ type, and is a vector containing the corresponding target values. The positive definite cost matrix assigns weights to deviations among different PCs.
The elements of are determined by defining the loss in terms of deviations. Let denote the deviation of the i-th characteristic from its target. For example, in a bivariate case (), the loss function is expressed as:
in which represents the cost coefficient associated with the squared deviation , and , , accounts for the interaction effect between deviations and . By default, is of the nominal-the-best type, but it can be adjusted to the lower-the-better or higher-the-better type by modifying accordingly.
Furthermore, Pignatiello [1] assumes that follows a p-dimensional multivariate normal distribution with mean vector and variance–covariance matrix , i.e.,
where represents the expected values of the PCs, and captures their variability and correlations.
The expected quadratic loss can be decomposed into bias and variance contributions:
where the first term measures the deviation of the mean from the target, and the second term represents the variance contribution weighted by .
We define the total risk T by adding the variance contribution weighted by the parameter :
where we used . The term derives from the identity
Physically, it represents cost-weighted variability, implying that variance contributes to loss only when associated with non-zero costs in . Thus, the risk is interpreted in terms of economic consequences rather than variance alone. The parameter adjusts this variance contribution, typically satisfying but allowing .
Mathematically, introducing generalizes the standard expected loss by relaxing the rigid 1:1 bias–variance trade-off, allowing for a flexible control and scalarization of conflicting objectives. Practically, minimizing variance is often more critical than centering the mean, as excessive variability can lead to irreversible consequences. For instance, high variance can cause matching failures in precision assembly or explosion risks in chemical processes, whereas mean shifts are often correctable. Thus, allows for heavier penalization of variability, reflecting a risk-averse strategy in robust design.
3.2. Risk Derivation for Mixed Quality Characteristics
To accommodate both nominal-the-best () and smaller-the-better () types of quality characteristics, we partition the vector into two sub-vectors, and :
where is a vector of nominal-the-best PCs, and is a vector of smaller-the-better PCs. For simplicity, one may also scale to remove unit effects in the loss function.
Following this partition, all related vectors and matrices are restructured accordingly. In particular, the mean vector and the target vector are expressed as
The covariance matrix and the cost matrix are also expressed in block forms, respectively:
Using this structure, the multivariate quadratic loss function for is defined as
The expected multivariate quadratic loss of can then be written as
Expanding the first and second terms using the mean vector and variance–covariance matrix , we have
and the third term can be rewritten as
Combining all three terms, the expected loss becomes
This can also be expressed in summation form as
Hence, from Equations (5) and (6), we could express the total risk, T, as
Assuming that independent input variables influence , the mean vector and covariance matrix are expressed as functions of , and . The bias and variance components are then defined as
so that the total risk can be written as . Naturally, the total risk leads to the parameter, the variance weight,
The determination of the weighting parameter, , is possible in two ways depending on the decision-maker’s strategy. Subjectively, users may assign a value to reflecting their perceived importance of bias versus variance. Alternatively, for an objective criterion, can be derived from economic cost structures. If we define the total expected cost as , where and are the aggregate cost coefficients for bias and variance respectively, then normalizing the equation by yields . For example, may represent process adjustment costs, while corresponds to the scrap costs associated with defective products. This formulation allows the trade-off to be driven by tangible economic data when available.
3.3. Multi-Objective Optimization via Global Criterion
Ideally, one would minimize the sum of the functions for a given . Practically, however, minimizing both functions simultaneously is challenging. For example, field engineers typically determine a few inputs in to optimize , then determine the remaining to optimize sequentially.
To effectively balance both terms of bias and variance and to globally optimize them, we utilize a Pareto front that represents the comprehensive optimal trade-offs. Unlike standard optimization problems targeting a single objective, multi-objective optimization seeks a set of solutions, called a Pareto optimal set, where no solution is strictly better than the others in all objectives. These solutions form a Pareto front when visualized, allowing us to analyze and adjust for an appropriate compromise.
In essence, the Global Criterion (GC) method transforms the multi-objective problem into a scalar minimization problem by measuring the relative deviation of each objective function from its ideal value. We apply an alternative global criterion (GC)-based method for generating a well-distributed Pareto front [9]. The GC function minimizes the distance to a target, defined as , where is the i-th estimated response, is the target (here ), and are the bounds.
Adapting this to our problem with two objective functions (), and , the GC function is formulated as:
in which the upper () and lower () bounds are defined as the maximum and minimum values of , an approximation of over the dataset ,
We assume the function is well-behaved enough for its maximum and minimum to be attainable and computable over the dataset . Alternatively, these bounds can be set by technical constraints or economic conditions. Normalization by is crucial for the following reasons [10]:
- It ensures comparability across responses with different scales.
- It reduces subjectivity in weighting.
- It prevents a single criterion from dominating the optimization.
- It improves the spread of Pareto-optimal solutions.
The exponent parameters and assign priorities to the objectives, enabling the exploration of trade-offs. While can theoretically range from 0 to infinity, Costa et al. [9] suggest that yields diminishing returns. Our experiments confirm that limiting is sufficient. By varying and numerically in a grid-search manner, we can explore both convex and non-convex regions of the Pareto frontier [11].
In this research, we perform the optimization over using pairs of and from a predefined grid. The resulting diverse set of solutions numerically forms the Pareto front, spanning various trade-offs to offer a comprehensive view of the optimization landscape.
To solve Equation (10), we adopt the SLSQP algorithm from Python’s scipy.optimize. minimize library. As a gradient-based method, it efficiently handles equality and inequality constraints, making it well-suited for nonlinear, multi-response problems required to construct an effective Pareto front.
3.4. Procedure of Framework
To summarize the operational procedure of our framework, we propose the following four-step workflow. First, appropriate regression models are fitted for the mean, variance, and covariance of the quality characteristics using data from a designed experiment. Second, the bias loss and variance loss are computed as functions of the design variables via the fitted models. Third, the Pareto front is generated by solving the GC minimization problem across a grid of weighting exponents and . Finally, the optimal operating condition is selected from the Pareto front by identifying the point that satisfies a desired risk tolerance or a specific bias-to-variance ratio.
4. Experiments
We now present two synthetic cases to demonstrate the applicability of the proposed approach.
4.1. Case 1: Bivariate Quality Characteristics ()
In the first case, we consider one NB-type PC and one SB-type PC, i.e., and :
Then, total risk in Equations (7) and (10) is defined by the functions and as follows:
For input variables , , let us assume that the estimated regression functions and , corresponding to and , are given as follows:
Furthermore, we set and , for each , to be 0 and 100, respectively. The input variables satisfy . We increment each parameter of and from 0.05 to 3 with step size 0.1. The initial starting point in the SLSQP algorithm is set to .
Using the alternative GC-based method, we numerically obtain the Pareto frontier shown in Figure 1. In this graph, increasing the value of , which reflects a higher emphasis on , leads to solutions with higher bias but lower variance. Conversely, decreasing emphasizes , resulting in lower bias but higher variance.
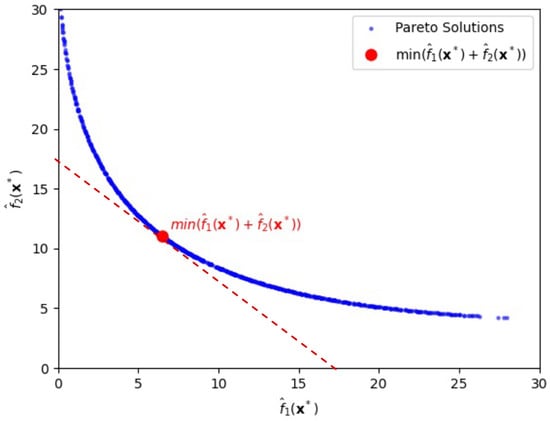
Figure 1.
Pareto-front solutions highlighting a solution (depicted by the red circle) that minimizes the sum of bias loss and variance loss, , for the first case.
For instance, as shown in Figure 1, when , the minimum total risk T is 17.54, achieved at , with corresponding objective values and , which is highlighted by the red circle in Figure 1. Notice that for the tangent line with the ratio, x-intercept/y-intercept, being 1 (thereby slope ) is adopted. If differs from zero in general, one can easily draw another tangent line of which the ratio, x-intercept/y-intercept, is (thereby slope ) in Figure 1, finding corresponding objective values and along with input vector .
Here, denotes the input vector that minimizes the GC-based objective function for a given value of , where and represent the estimated bias and variance components, respectively, at the optimal point. In Figure 1, the red line indicates the tangent with slope to the Pareto frontier at the point where the total risk , , is minimized, illustrating the trade-off between the two objectives. This suggests that decision-makers can adjust the input variables by finding a tangent line with a slope relating to their specific industry characteristics or strategic preferences.
As shown above, the construction of a Pareto front enables flexible control over the trade-off between bias and variance terms. Furthermore, let us suppose that one wants to set a ratio of the bias-loss term to the variance-loss term to a certain value in practice. Figure 2 shows three Pareto-Front solutions for specific ratios, and of the two terms under approximation error .
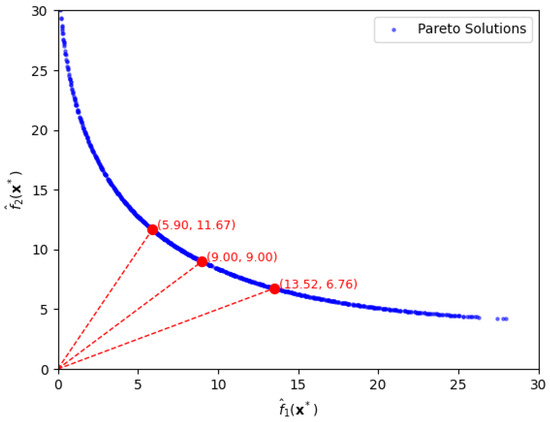
Figure 2.
Pareto-front solutions, depicted by the red circles, for specific ratios of bias loss to variance loss, being 1:2, 1:1, and 2:1, in the first case.
Firstly, if one sets to be twice with the ratio being , the optimal solution is , with function values and . As seen in Figure 2, the solution is easily extracted by drawing a line with slope passing through the origin. Secondly, when equals , in which the ratio is , we easily obtain the optimal solution, , which yields function values . Thirdly, when is half of with a ratio of , the optimal solution is with function values and . These results illustrate how different bias-variance preferences can be effectively represented by specific functional ratios along the Pareto front. We also notice that the extraction of both bias risk and variance risk with a desired ratio is hardly possible without the use of the proposed approach.
4.2. Case 2: Four-Variable Quality Characteristics ()
In the second case, we consider the situation where there are two NB-type PCs and two SB-type PCs, i.e., and :
The total risk , , in Equations (7) and (10) is defined by functions and as follows:
For input variables , let us assume that and are expressed as follows:
Similarly to the first case, the upper bounds of and are set to 100, and the lower bounds are set to 0. The initial starting point is , and the input variables are constrained within the range . The exponent parameters are incremented from 0.05 to 3 with step size . Under the setting, we obtain a Pareto front as shown in Figure 3.
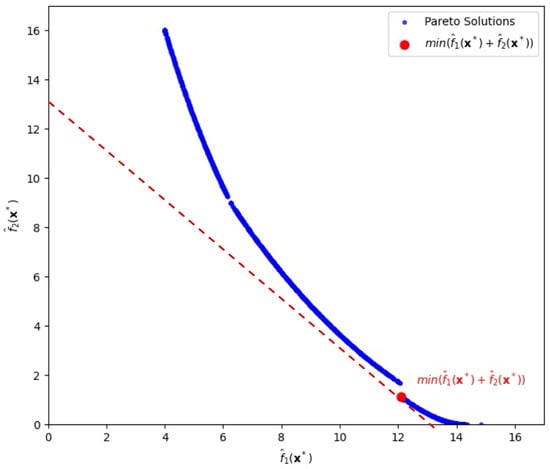
Figure 3.
Pareto-front solutions highlighting a solution (depicted by the red circle) that minimizes the sum of bias loss and variance loss, , for the second case.
When , we achieve the minimum value of the total risk T at 13.23314, which is highlighted by the red circle (by slope ) in Figure 3, with
and the corresponding input vector is
By allowing approximation error , we similarly extract optimal settings under desired trade-off between bias loss and variance loss as shown in Figure 4.
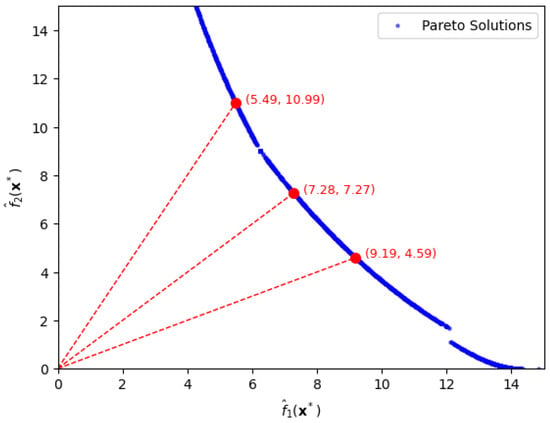
Figure 4.
Pareto-front solutions depicted by circles for specific ratios of bias loss to variance loss, being 1:2, 1:1, and 2:1, in the second case.
Similarly, we extract the solutions from the Pareto front by drawing a line with the appropriate slope passing through the origin. Firstly, when the ratio is 2, we find the optimal solution, which yields function values Secondly, when the ratio is 1, the optimal solution becomes with function values, Thirdly, when the ratio is , the optimal solution is yielding function values,
We notice that the Pareto frontier obtained using the GC-based method contains visual gaps as shown in Figure 3 and Figure 4. Similar discontinuities have been observed in previous studies [9], which demonstrated that achieving a perfectly connected and comprehensive Pareto front is often difficult, especially in the presence of complex or nonconvex response surfaces.
5. Application to Simulation Data
In this section, we apply our approach to a simulation dataset introduced by Pignatiello [1]. This problem serves as a standard test case in multi-response optimization literature, involving two response variables, and , and three input variables, and .
5.1. Simulation Data and Regression Modeling
The dataset simulates a replicated factorial experiment, enabling the estimation of mean and covariance structures essential for joint optimization. By capturing simultaneous shifts in mean and variance, the Pareto front reveals risk trade-offs that sequential approaches often overlook.
The simulation data is presented in Table 1.

Table 1.
Simulation Data.
Using the values in each row in Table 1, we obtain the sample mean, sample variance, and sample covariance as shown in Table 2. For example, the first is the sample average of the four observations, , in Table 1.
Table 2.
Statistical Summary of Simulation Data.
Using regression analysis, we derive the following predictive equations:
To derive the response surface models, we utilized the replicate data provided in the simulation dataset. For the mean () and variance () functions, we adopted the models established by Kazemzadeh et al. [12]. However, for the covariance structure (), which is central to our study, we explicitly calculated the sample covariance for each design point using the four replicates and subsequently fitted a second-order regression model to these computed values.
To ensure the reliability of the optimization framework, the derived regression models must meet specific statistical criteria established in quality engineering literature. Following the guidelines suggested by Joglekar and May [13] and Montgomery [14], we adopted a significance level of and a minimum coefficient of determination as the thresholds for model adequacy. An value above 0.80 generally indicates that the regression model explains a substantial proportion of the variability in the response, which is essential for accurate prediction in robust design. If the regression models fail to meet these thresholds, it implies insufficient statistical power or excessive experimental noise. In such cases, the number of experimental replicates should be increased to reduce the standard error.
In this study, we utilized the dataset from Pignatiello [1] (). To validate whether this sample size was adequate under our proposed criteria, we evaluated the statistical significance of the derived models. As shown in Table 3, all regression models achieved high coefficients of determination () and were statistically significant (). Specifically, the covariance model (), a critical component of our framework, demonstrated an of 0.9726 with a p-value of 0.001. These results confirm that the sample size of provided sufficient statistical power to capture the underlying covariance structure accurately.
Table 3.
Statistical verification of the regression models ().
5.2. Formulation of Objective Functions
In this dataset, the target vector is . Consistent with the definition in Section 3.1 where cost coefficients are determined by the economic impact of deviations, we adopt the specific values established in the study by Pignatiello [1]:
Based on these target values and cost values, the following functions are defined:
By evaluating these functions across the experimental design space, we obtain the following statistical ranges:
To generate a Pareto frontier, we employ an alternative GC-based method with the following objective function:
5.3. Pareto Frontier Analysis
Figure 5 shows a Pareto frontier generated by constraining the input variables to the range , and varying the parameters and from 0.05 to 3 in increments of 0.05. Optimization is initialized from starting point .
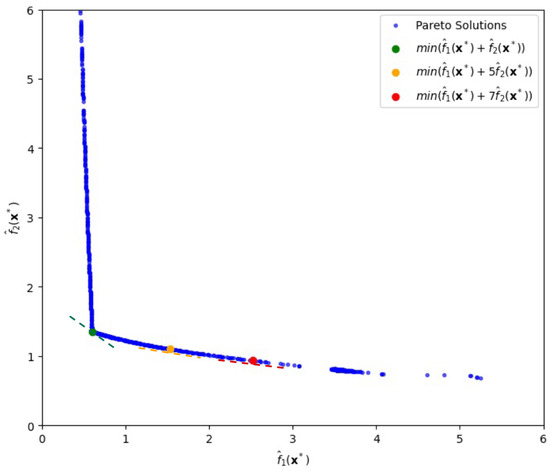
Figure 5.
Pareto-front solutions for various variance-risk weights, , (depicted by the three circles coming from the tangent lines) in the simulation experiment.
When , we find the minimum total risk as follows:
For , similarly using the front, we extract minimum total risk as follows:
Finally, when , minimum total risk becomes
The three dashed lines in green, yellow, and red shown in Figure 5 represent the tangents to the Pareto frontier at each solution that minimizes the weighted sum for , respectively.
5.4. Comparative Analysis with Sequential Strategies
A common practical approach to quality optimization is to adopt a sequential decision process. For instance, a field engineer may first minimize the bias term , and then reduce the variance term among the solutions where bias is already minimized.
To evaluate this practical strategy, we compare it against our proposed approach under the setting , where bias and variance are treated as equally important. The optimal solution minimizing the total risk, is indicated by the green dot in Figure 6, yielding the minimum value .
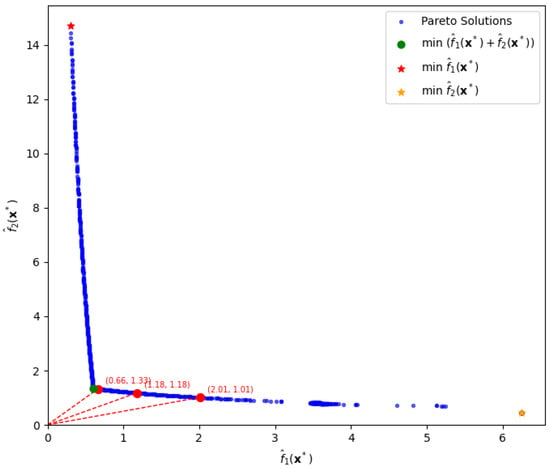
Figure 6.
Comparison of decision strategies between sequential decisions depicted by two stars and Pareto-based decisions depicted by the green dot for the total risk, , and by the three red circles for various trade-off ratios of bias loss to variance loss, being 1:2, 1:1, and 2:1.
In contrast, when one adopts a sequential decision-making strategy, the outcomes are significantly suboptimal compared to the joint optimization approach. For instance, if one first minimizes the bias term and then evaluates the variance term at that point, the results are and , yielding a total risk of for . This point is highlighted by the red star, located at the upper-left side in Figure 6. On the other hand, if one first minimizes the variance term and then evaluates the bias at that point, the corresponding values are and , resulting in a total risk of . This point is highlighted by the yellow star, located at the lower-right side in Figure 6. Notice that the total risk, , represented by the green dot in Figure 6, is far smaller than the values of and resulting from the two sequential decisions.
This comparison highlights that such a sequential optimization approach—whether prioritizing bias or variance—can lead to significantly worse solutions than those obtained by balancing both objectives jointly.
Furthermore, our approach enables flexible decision-making by allowing users to control the trade-offs between bias and variance via ratio settings. For example, we consider three target ratios: 1, 2, and 0.5. The corresponding solutions and function values are highlighted by the red circles in Figure 6 for direct comparison.
When the ratio is approximately 1, the optimal solution is , which yields . When the ratio is approximately 2, the solution becomes , resulting in and . Lastly, for a ratio of 0.5, the solution is , with and .
Consequently, our method simultaneously incorporates both bias and variance through a weighted formulation, enabling a more balanced and efficient optimization process. This approach identifies solutions with lower total risk, clearly demonstrating its effectiveness in achieving a superior trade-off between bias and variance. Additionally, our method provides the flexibility to choose mixing ratios between bias and variance terms, allowing for optimization that can be customized according to specific needs.
6. Conclusions
In this study, we proposed a novel approach for optimizing interrelated quality attributes by incorporating variance into the expected loss function. Leveraging an alternative GC-based method, we successfully constructed Pareto front to visualize the trade-offs between conflicting objectives. The effectiveness and practical utility of the proposed method were demonstrated through both simplified examples and a simulation study.
Nonetheless, constructing a comprehensive Pareto frontier requires the exploration of multiple starting points, and identifying all possible nondominated solutions remains a significant challenge. Future research should focus on developing systematic strategies for selecting initial points and benchmarking the proposed approach against existing multi-objective optimization techniques. Furthermore, as the complexity of the expected loss and variance functions increases, the associated computational burden also grows. Investigating simplified formulations or alternative structures to enhance computational efficiency would be a valuable direction for future work.
In addition, it is important to explore how this method can be extended to more realistic scenarios where only a subset of input variables—such as two or three out of many—can be actively controlled. Adapting our approach to such constrained optimization settings would further broaden its applicability.
Overall, this study contributes to the field of quality optimization by offering a new perspective on managing trade-offs in complex systems. The proposed method has the potential for application across various industries, and future extensions could include higher-dimensional problems and the integration of machine learning techniques for dynamic and adaptive optimization.
Author Contributions
Conceptualization, S.K. and K.L.; methodology, S.K.; software, S.K.; validation, S.K. and K.L.; writing—original draft preparation, S.K.; writing—review and editing, K.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of the Republic of Korea (RS-2025-23524280).
Data Availability Statement
The data presented in this study are available on GitHub at https://github.com/KIM-sang-won/PFOVELIQ accessed on 4 February 2026.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pignatiello, J.J. Strategies for robust multiresponse quality engineering. IIE Trans. 1993, 25, 5–15. [Google Scholar] [CrossRef]
- Shiau, G.H. A study of the sintering properties of iron ores using the Taguchi’s parameter design. J. Chin. Stat. Assoc. 1990, 28, 253–275. [Google Scholar]
- Tong, L.I.; Su, C.T.; Wang, C.H. The optimization of multi-response problems in the Taguchi method. Int. J. Qual. Reliab. Manag. 1997, 14, 367–380. [Google Scholar] [CrossRef]
- Soh, W.; Kim, H.; Yum, B.-J. A multivariate loss function approach to robust design of systems with multiple performance characteristics. Qual. Reliab. Eng. Int. 2016, 32, 2685–2700. [Google Scholar] [CrossRef]
- Costa, N.; Lourenço, J. Bi-Objective Optimization Problems—A Game Theory Perspective to Improve Process and Product. Sustainability 2022, 14, 14910. [Google Scholar] [CrossRef]
- Jones, D.R.; Schonlau, M.; Welch, W.J. Efficient global optimization of expensive black-box functions. J. Glob. Optim. 1998, 13, 455–492. [Google Scholar] [CrossRef]
- Knowles, J. ParEGO: A hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems. In Proceedings of the 2005 Conference on Genetic and Evolutionary Computation, Washington, DC, USA, 25–29 June 2005; pp. 775–782. [Google Scholar]
- Zhang, Q.; Li, H. A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Costa, N.R.; Lourenço, J.; Pereira, Z.L. Multiresponse Optimization and Pareto Frontiers. Qual. Reliab. Eng. Int. 2012, 28, 701–712. [Google Scholar] [CrossRef]
- Marler, R.T.; Arora, J.S. Function-transformation methods for multi-objective optimization. Eng. Optim. 2005, 37, 551–570. [Google Scholar] [CrossRef]
- Messac, A.; Sundararaj, G.; Tappeta, R.; Renaud, J. Ability of objective functions to generate points on non-convex Pareto frontiers. AIAA J. 2000, 38, 1084–1091. [Google Scholar] [CrossRef]
- Kazemzadeh, R.B.; Bashiri, M.; Atkinson, A.C.; Noorossana, R. A general framework for multiresponse optimization problems based on goal programming. Eur. J. Oper. Res. 2008, 189, 421–429. [Google Scholar] [CrossRef]
- Joglekar, A.M.; May, A.T. Product excellence through design of experiments. Cereal Foods World 1987, 32, 857–868. [Google Scholar]
- Montgomery, D.C. Design and Analysis of Experiments, 9th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.