Abstract
The aim of this paper is to discuss both higher-order asymptotic expansions and skewed approximations for the Bayesian discrepancy measure used in testing precise statistical hypotheses. In particular, we derive results on third-order asymptotic approximations and skewed approximations for univariate posterior distributions, including cases with nuisance parameters, demonstrating improved accuracy in capturing posterior shape with little additional computational cost over simple first-order approximations. For third-order approximations, connections to frequentist inference via matching priors are highlighted. Moreover, the definition of the Bayesian discrepancy measure and the proposed methodology are extended to the multivariate setting, employing tractable skew-normal posterior approximations obtained via derivative matching at the mode. Accurate multivariate approximations for the Bayesian discrepancy measure are then derived by defining credible regions based on an optimal transport map that transforms the skew-normal approximation to a standard multivariate normal distribution. The performance and practical benefits of these higher-order and skewed approximations are illustrated through two examples.
1. Introduction
Bayesian inference often relies on asymptotic arguments, leading to approximate methods that frequently assume a parametric form for the posterior distribution. In particular, a Gaussian distribution provides a convenient density for a first-order approximation. This practice is formally justified under regularity conditions by the Bernstein–von Mises theorem. However, this approximation fails to capture potential skewness and asymmetry in the posterior distribution. To avoid this drawback, starting from third-order expansions of Laplace’s method for the posterior distributions (see, e.g., [1,2,3], and references therein), possible alternatives are as follows:
- Higher-order asymptotic approximations: These offer improved accuracy at minimal additional computational costs compared to first-order approximations, and are applicable to posterior distributions and quantities of interest such as tail probabilities and credible regions (see, e.g., [4], and references therein);
- To use skewed approximations for the posterior distribution, theoretically justified by a skewed Bernstein–von Mises theorem (see, e.g., [5,6], and references therein).
The aim of this contribution is to discuss higher-order expansions and skew-symmetric approximations for the Bayesian discrepancy measure (BDM) proposed in [7] for testing precise statistical hypotheses. Specifically, the BDM assesses the compatibility of a given hypothesis with the available information (prior and data). To summarize this information, the posterior median is used, providing a straightforward evaluation of the discrepancy with the null hypothesis. The BDM possesses desirable properties such as consistency and invariance under reparameterization, making it a robust measure of evidence.
For a scalar parameter of interest, even with nuisance parameters, computing the BDM involves evaluating tail areas of the posterior or marginal posterior distribution. A first-order Gaussian approximation can be used, but it may be inaccurate, especially with small sample sizes or many nuisance parameters, since it fails to account for potential posterior asymmetry and skewness. In this respect, the aim of this paper is to provide higher-order asymptotic approximations and skewed asymptotic approximations for the BDM. For the third-order approximations, connections with frequentist inference are highlighted when using objective matching priors.
Also, for multidimensional parameters, while a first-order Gaussian approximation of the posterior distribution can be used to calculate the BDM, it still fails to account for potential posterior asymmetry and skewness. In this respect, this paper also addresses higher-order asymptotic approximations and skewed approximations for the BDM. The latter ones are based on an optimal transport map (see [8,9]), which transforms the skew-normal approximation to a standard multivariate normal distribution.
This paper is organized as follows. Section 2 provides some background for the BDM for a scalar parameter of interest, even with nuisance parameters, and extends the definition to the multivariate framework. Section 3 illustrates higher-order Bayesian approximations for the BDM; connections with frequentist inference are highlighted when using objective matching priors. Section 4 discusses skewed approximations for the posterior distribution and for the BDM, theoretically justified by a skewed Bernstein–von Mises theorem, with new insights into the multivariate framework. Two examples are discussed in Section 5. Finally, some concluding remarks are given in Section 6.
2. Background
Consider a sampling model , indexed by a parameter , , and let be the likelihood function based on a random sample of size n. Given a prior density for , Bayesian inference for is based on the posterior density .
In several applications, it is of interest to test the precise (or sharp) null hypothesis
against . In Bayesian hypothesis testing, the usual approach relies on the well-known Bayes factor (BF), which measures the ratio of posterior to prior odds in favor of the null hypothesis . Typically, a high BF, or the weight of evidence (BF), provides support for . However, improper priors can lead to an undetermined BF, and in the context of precise null hypotheses, the BF can be subject to the Jeffreys–Lindley paradox. This paradox highlights a critical divergence between frequentist and Bayesian approaches, that is, as the sample size increases, a p-value can become arbitrarily small, leading to the rejection of the null hypothesis, while the BF can simultaneously provide overwhelming evidence in favor of the same precise null. This typically occurs when the alternative hypothesis is associated with a diffuse prior distribution for the parameter of interest. With such priors, the BF tends to favor the simpler because, while data might be unlikely under , it may also be poorly supported by any specific value within the diffuse alternative space. Furthermore, the BF is not well-calibrated, as its finite sampling distribution is generally unknown and may depend on nuisance parameters. To address these limitations, recent research has explored alternative Bayesian measures of evidence for precise null hypothesis testing, including the e-value (see, e.g., [10,11,12] and references therein) and the BDM [7]. In the following, we focus on the Bayesian discrepancy measure of evidence proposed in [7] (see also [13]).
2.1. Scalar Case
The BDM gives an absolute evaluation of a hypothesis, , in light of prior knowledge about the parameter and observed data. In the absolutely continuous case, for testing (1), the BDM is defined as
The quantity can be interpreted as the posterior probability of a “tail” event concerning only the precise hypothesis . Doubling this “tail” probability, related to the precise hypothesis , one obtains a posterior probability assessment about how “central” hypothesis is, and, hence, how it is supported by the prior and the data. This interpretation is related to an alternative definition for . Let be the posterior median and consider the interval defined as if or as if . Then, the BDM of the hypothesis can be computed as
Note that the quantity represents the posterior probability of an equi-tailed credible interval for .
The Bayesian discrepancy test assesses hypothesis based on the BDM. High values of indicate strong evidence against , whereas low values suggest data consistency with . Under , for large sample sizes, is asymptotically uniformly distributed on . Conversely, when is false, tends to 1 in probability. While thresholds can be set to interpret , in line with the ASA statement, we agree with Fisher that significance levels should be tailored to each case based on evidence and ideas.
The BDM remains invariant under invertible monotonic reparametrizations. Under general regularity conditions and assuming Cromwell’s rule for prior selection, exhibits specific properties, as follows: (1) if (the true value of the parameter), tends toward a uniform distribution as the sample size increases; (2) if , converges to 1 in probability. Furthermore, using a matching prior, is exactly uniformly distributed for all sample sizes.
The practical computation of requires the evaluation of the tail areas of the following form:
The derivation of a first-order tail area approximation is simple since it uses a Gaussian approximation. With this approximation, a first-order approximation for when testing (1) is simply given by
where is the maximum likelihood estimate (MLE) of , is the observed information, the symbol “” indicates that the approximation is accurate to , and is the standard normal distribution function. Thus, to first order, agrees numerically with the -value based on the Wald statistic and also with the first-order approximation of the e-value (see, e.g., [14]). In practice, the approximation (5) of may be inaccurate, particularly for a small sample size, because it forces the posterior distribution to be symmetric.
2.2. Nuisance Parameters
In most applications, is partitioned as , where is a scalar parameter of interest and is a —dimensional nuisance parameter, and it is of interest to test the precise (or sharp) null hypothesis
against . In the absolutely continuous case, for testing (6) in the presence of nuisance parameters, the BDM is defined as
where is the marginal posterior density for , given by
Also in this framework, the practical computation of requires the evaluation of tail areas of the following form:
The derivation of a first-order tail area approximation is still simple since it uses a Gaussian approximation. Let be the profile log-likelihood for , where denotes the constrained MLE of given . Moreover, let be the full MLE, and let be the profile observed information. A first-order approximation for when testing (6) is simply given by
Thus, to first order, agrees numerically with -value based on the profile Wald statistic . In practice, as in the scalar parameter case, the approximation (5) of may be inaccurate, particularly for a small sample size or a large number of nuisance parameters, since it fails to account for potential posterior asymmetry and skewness.
2.3. The Multivariate Case
Extending the definition of the BDM to the multivariate setting, where with , presents some challenges. The core concepts of the univariate definition rely on the unique ordering of the real line and the uniquely defined median, which splits the probability mass into two equal halves (tail areas). In , with , there is no natural unique ordering, and concepts like the median and “tail areas” relative to a specific point lack a single, universally accepted definition. Despite these challenges, the fundamental goal remains the same, that is, to quantify how consistent the hypothesized value is with the posterior distribution ; specifically measuring how “central” or, conversely, how “extreme” lies within the posterior distribution.
Utilizing the notion of center-outward quantile functions ([8,9]), a concept from recent multivariate statistics, provides a theoretically appealing way to define the multivariate BDM. Let be the center-outward distribution function mapping the posterior distribution (with density ) to the uniform distribution on the unit ball . More precisely, the center-outward distribution function is defined as the almost-everywhere unique gradient of a convex function that pushes a distribution forward to the uniform distribution on the unit ball in . That is,
The center-outward quantile function is defined as the (continuous) inverse of , i.e.,
It maps the open unit ball (minus the origin) to and satisfies
For , we define the center-outward quantile region of order τ as
and the center-outward quantile contour of order τ as
where is the unit sphere in . When , this coincides with the rescaled univariate cumulative distribution function and the BDM (7) can be expressed as
This measures the (rescaled) distance of the quantile rank of from the center point (corresponding to rank 0). Generalizing this, we can define the multivariate BDM for the hypothesis as
where denotes the standard Euclidean norm in . Here, maps the point to a location within the unit ball . This definition has desirable properties (see [8]):
- It yields a value between 0 and 1;
- if corresponds to the geometric center (or multivariate median) of the distribution (mapped to by );
- increases as moves away from the center toward the “boundary” of the distribution, approaching 1 for points mapped near the surface of the unit ball ;
- It is invariant under suitable classes of transformations (affine transformations if is elliptically contoured, more generally under monotone transformations linked to an optimal transport map construction);
- It naturally reduces to the univariate definition when .
The primary practical difficulty lies in computing the center-outward distribution function for an arbitrary posterior distribution , as it typically requires solving a complex optimal transport problem (see [15]).
3. Beyond Gaussian I: Higher-Order Asymptotic Approximations
3.1. Scalar Case
In order to have more accurate evaluations of the first-order approximation (5) of , it may be useful to resort to higher-order approximations based on tail area approximations (see, e.g., [3,4], and references therein). Using the tail area argument to the posterior density, we can derive the approximation:
where the symbol “” indicates that the approximation is accurate to and
with , the likelihood root, and
In the expression of , is the score function.
Using the tail area approximation (12), a third-order approximation of the BDM (2) can be computed as
Note that the higher-order approximation (13) does not call for any condition on the prior , i.e., it can also be improper, and it is available at a negligible additional computational cost over the simple first-order approximation.
Note also that using an equi-tailed credible interval for can be computed as , where is the -quantile of the standard normal distribution, and in practice, it can reflect asymmetries of the posterior. Moreover, from (12), the posterior median can be computed as the solution for of the estimating equation .
3.2. Nuisance Parameters
When is partitioned as , where is a scalar parameter of interest and is a —dimensional nuisance parameter, in order to have more accurate evaluations of the first-order approximation (10) of , using the tail area argument to the marginal posterior density, we can derive the approximation (see, e.g., [3,4]):
where
with , the profile likelihood root, and
In the expression of , is the profile score function and represents the -block of the observed information .
Using the tail area approximation (14), a third-order approximation of the BDM (7) can be computed as
Note that the higher-order approximation (15) does not call for any condition on the prior , i.e., it can also be improper. Note also that, using , a equi-tailed credible interval for can be computed as . Moreover, from (14), the posterior median of (8) can be computed as the solution for of the estimating equation .
Approximations with Matching Priors
The order of the approximations in the previous sections refers to the posterior distribution function and may depend, to varying degrees, on the choice of prior. A so-called strong-matching prior (see [16], and references therein) ensures that a frequentist p-value coincides with a Bayesian posterior survivor probability to a high degree of approximation, in the marginal posterior density (8).
Welch and Peers [17] showed that for a scalar parameter , Jeffreys’ prior is probability matching, in the sense that posterior survivor probabilities agree with frequentist probabilities, and credible intervals of a chosen width coincide with frequentist confidence intervals. With Jeffreys’ prior, we have
and the corresponding coincides with the frequentist modified likelihood root as defined by [18]. In this case, using the tail area approximation (12), a third-order approximation of the BDM of the hypothesis coincides with , where is the p-value based on the frequentist modified likelihood root. Thus, when using Jeffreys’ prior and higher-order asymptotics in the scalar case, there is agreement between Bayesian and frequentist hypothesis testing.
In the presence of nuisance parameters, following [4], when using a strong matching prior, the marginal posterior density can be written as
where is the profile score statistic, and is the modified profile likelihood root:
which has a third-order standard normal null distribution. In (17), the quantity is a suitably defined correction term (see, e.g., [18] and [19], Chapter 9). Moreover, the tail area of the marginal posterior for can be approximated to third order as
A remarkable advantage of (16) and (18) is that their expressions automatically include the matching prior, without requiring its explicit computation.
Using (18), an asymptotic equi-tailed credible interval for can be computed as , i.e., as a confidence interval for based on (17) with approximate level . Note from (18) that the posterior median of can be computed as the solution for of the estimating equation , and thus it coincides with the frequentist estimator defined as the zero-level confidence interval based on . Such an estimator has been shown to be a refinement of the MLE .
Using the tail area approximation (18), a third-order approximation of the BDM of the hypothesis is
In this case, (19) coincides with , where is the p-value based on (17). Thus, when using strong matching priors and higher-order asymptotics, there is agreement between Bayesian and frequentist hypothesis testing, point estimation, and interval estimation.
From a practical point of view, the computation of (19) can be easily performed in practical problems using the likelihoodAsy package [20] of the statistical software R version 4.4.1. In practice, the advantage of using this package is that it does not require the function explicitly, but instead requires only the code for computing the log-likelihood function and for generating data from the assumed model. Some examples can be found in [14].
3.3. Multidimensional Parameters
When is multidimensional, the derivation of a first-order tail area approximation and a first-order approximation for remains straightforward, starting from the Laplace approximation of the posterior distribution. In particular, let be the log-likelihood ratio for . Using , a first-order approximation of the BDM for the hypothesis can be obtained as follows:
where is the Chi-squared distribution with d degrees of freedom. This approximation is asymptotically equivalent to the first-order approximation:
Higher-order approximations based on modifications of the log-likelihood ratios are also available for multidimensional parameters of interest, both with or without nuisance parameters (see [4,19,21], and references therein). As is the case with the approximations for a scalar parameter, the proposed results are based on the asymptotic theory of modified log-likelihood ratios [21], they require only routine maximization output for their implementation, and they are constructed for arbitrary prior distributions. For instance, paralleling the scalar parameter case, a credible region for a d-dimensional parameter of interest with approximately % coverage in repeat sampling, can be computed as , where is a suitable modification of the log-likelihood ratio or of the profile log-likelihood ratio (see [19,21]), and is the quantile of the distribution. In practice, the region can be interpreted as the extension to the multidimensional case of the equi-tailed set, i.e., the region is computed as a multidimensional case of the set based on the Chi-squared approximation. As in the scalar case, the region can reflect departures from symmetry with respect to the first-order approximation based on the Wald statistic. Some simulation studies on based on can be found in [22].
Using , a higher-order approximation of the BDM for the hypothesis can be obtained as
The major drawback with this approximation is that the signed root log-likelihood ratio transformation in general depends on the chosen parameter order. Moreover, its computation can be cumbersome when d is large.
4. Beyond Gaussian II: Skewed Approximations
A major limitation of standard first-order Gaussian approximations, like (5) and (10), is their reliance on symmetric densities, which simplifies inference but can misrepresent key posterior features like skewness and heavy tails. Indeed, even simple parametric models can yield asymmetric posteriors, leading to biased and inaccurate approximations.
To overcome this, recent work has introduced flexible families of approximating posterior densities that can capture the shape and skewness [5,6,23]. In particular, [5] developed a class of closed-form deterministic approximations using a third-order extension of the Laplace approximation. This approach yields tractable, skewed approximations that better capture the actual shape of the target posterior while remaining computationally efficient.
Also, the skewed approximations, as well as the higher-order approximations discussed in Section 3, rely on higher-order expansions and derivatives. They start with a symmetric Gaussian approximation, but centered at the maximum a posteriori (MAP) estimate, and introduce skewness through the Gaussian distribution function combined with a cubic term influenced by the third derivative of the log-likelihood function.
4.1. Scalar Case
Let us denote with the k-th derivative of the log-likelihood , i.e., , . Moreover, let be the MAP estimate of and let be the rescaled parameter. Using result (14) of [5] and all the regularity conditions there stated, the skew-symmetric (SKS) approximation for the posterior density for is
where is the normal density function with mean 0 and variance and
is the skewness component, expressed as a cubic function of h, reflecting the influence of the third derivative of the log-likelihood on the shape of the posterior distribution.
Equation (23) provides a practical skewed second-order approximation of the target posterior density, centered at its mode. This approach is known as the SKS approximation or skew-modal approximation. Compared to the classical first-order Gaussian approximation derived from the Laplace method, the SKS approximation remains similarly tractable while providing significantly greater accuracy. Note that this approximation depends on the prior distribution through the MAP.
Using (23) and the approximation
we can derive the approximation
for the tail area for (4), where . Note that the denominator is simply equal to 1, due to the symmetry of and the oddness of . The numerator can be split into two integrals:
The first integral can be expressed as the standard Gaussian tail, as follows:
while the second integral involves the skewness term and can be expressed as
Substituting into the integral , we have
Using the identity , with , and , we obtain
Then, the resulting SKS approximation to is
Finally, substituting this approximation into (7), we obtain the SKS approximation of the BDM, given by
Note that the first term of this approximation differs from that in (5) since it is evaluated at the MAP and not at the MLE.
4.2. Nuisance Parameters
As in Section 2.2, suppose that the parameter is partitioned as , where is a scalar parameter of interest and is a nuisance parameter of dimension . Also, for the marginal posterior distribution , an SKS approximation is available (see [5], Section 4.2).
Adopting the index notation, let us denote by the observed Fisher information matrix, where , , and let be the inverse of the scaled observed Fisher information matrix evaluated at the MAP. We denote the elements of by ; in particular, let us denote by the element corresponding to the parameter of interest, . Moreover, let us denote with the elements of the third derivative of the log-likelihood, with . Finally, let us define the following two quantities:
and
Then, following formula (23) in [5], the SKS approximation of the marginal posterior density can be expressed as
where is the rescaled parameter of interest, is the density of a Gaussian distribution with mean 0 and variance , and the skewness component is defined as
Using (25), we can derive the SKS tail area approximation of (9), given by
where . Finally, the marginal SKS approximation of the BDM is given by
The marginal SKS tail area approximation , and, thus, also , can be derived numerically.
4.3. Multidimensional Parameters
While the SKS approximation is theoretically elegant, similar to the higher-order modification of the log-likelihood ratio , it has two main drawbacks. The first one is that it relies only on local information around the mode. The second is that it is computationally intensive because it relies on third-order derivatives (i.e., a tensor of derivatives) of the log-likelihood. The size of this derivative tensor increases cubically with the number of parameters, leading to substantial memory and computational demands, particularly in models with many parameters. Furthermore, quantities such as the moments, marginal distributions, and quantiles of the SKS approximation are not available in closed form, even in the scalar case.
To address these challenges, [6] proposed a class of approximations based on the standard skew-normal (SN) distribution. Their method matches posterior derivatives, aiming to preserve the ability to model skewness while employing more computationally tractable structures. It utilizes local information around the MAP by matching the mode m, the negative Hessian at the mode, i.e., , and the third-order unmixed derivatives vector of the log-posterior. Moreover, modern tools for automatic differentiation can greatly facilitate the computation of such higher-order derivatives without manual derivation. The goal is to find the parameters of the multivariate SN distribution that best match these quantities. The notation indicates a d-dimensional SN distribution (see e.g., [24], and references therein), with location parameter , scale matrix , and shape parameter . The matching equations are given by
where denotes the k-th derivative of , and represents the Hadamard (element-wise) product. The solution proceeds by reducing the system to a one-dimensional root-finding problem in , after which , , and can be obtained analytically. Ultimately, the marginal distributions are available in closed form as well. Given its tractability, we adopt the derivative matching approach proposed by [6] to derive SKS approximations for models with multidimensional parameters. For the SN model, we can instead easily define the multivariate quantiles.
As suggested in [8,9], an effective approach to defining quantiles in the multidimensional case is to identify the optimal transport (OT) map between the spherical uniform distribution and the target multivariate SN distribution. Considering the inherent relationship between the standard multivariate Gaussian distribution and the spherical uniform distribution, we explore the OT map linking a multivariate SN distribution to a multivariate standard normal distribution. Indeed, given a multivariate standard normal S in , it is well known that is uniformly distributed on the sphere of radius in . Furthermore, is uniform in (0,1). Thus, the OT map and the quantiles of the multivariate standard Gaussian are coherently defined as a bijection of the norm of the multivariate standard normal vector S (the distance from the origin). In particular, we utilize the canonical multivariate SN distribution, derived from applying a rotational transformation, and we consider a component-wise transformation using the univariate SN distribution function and the standard normal quantile function, which delineates a transport map represented as the gradient of a convex function.
From , let . We define a rotation by means of the matrix such that
- aligns the skewness with the first coordinate;
- in the rotated space, , with , and are Gaussian.
The matrix Q is obtained by applying a (rectangular) QR decomposition to the vector. The vector of means is and the covariance matrix is . Moreover, the scale parameter of is and we denote its mean and variance as and , respectively.
We define the transport map in the rotated space as
where is the univariate SN cumulative distribution function and is the standard normal quantile function. In practice, we transform the first component using the univariate SN cumulative distribution function () and the standard normal quantile function () to remove its skewness, while leaving other components unchanged. Note that the SN distribution is closed under linear transformations. In particular, after the rotation, the skewness of the variable Z becomes (see [24]). The variable is now approximately multivariate normal. Finally, we apply an affine transformation to standardize the result. More precisely, we consider , and set . The resulting U is distributed as a standard normal (see Figure 1).
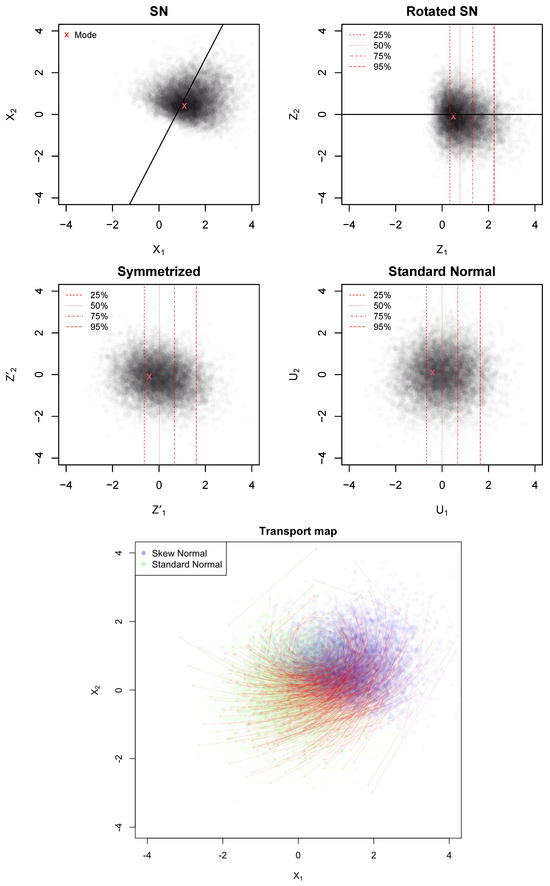
Figure 1.
First panel: Original SN approximation of a bivariate posterior distribution, with the mode in red and skewness direction indicated by the black line. Second panel: Rotated SN distribution aligning the skewness with the first coordinate; red dashed lines show quantiles of the first rotated component. Third panel: Symmetrized distribution after applying a univariate marginal transformation. Fourth panel: Final standardized and centered normal distribution. Bottom panel: Visualization of the optimal transport (OT) map (red arrows).
It follows that, using the SN approximation for the posterior distribution of , the SN approximation of the BDM can be expressed as
where . The map is the OT map as it is the gradient of a convex function. In particular, and are affine transformations, and the function is monotonically increasing in z, hence its integral is convex. Defining
then . The composite map , used in (27), is the gradient of a convex function and, thus, it represents the optimal transport map (under quadratic cost) from an SN distribution to a standard normal. The procedure is summarized in Algorithm 1.
| Algorithm 1 Optimal transport from to |
|
5. Examples of Higher-Order and Skewed Approximations
In the following, we focus on assessing the performance of the higher-order approximations and of the skewed approximations of the BDM in two examples, discussed also in [5,7].
5.1. Exponential Model
We revisit Example 1 in [7], where the model for data is an exponential distribution with scale parameter , meaning . By employing Jeffrey’s prior, which is , the resulting posterior distribution is an inverse gamma, characterized by shape and rate parameters equal to n and , respectively, with . The quantities for the SKS approximation of the posterior distribution are available in [5] (see Section 3.1), while for the higher-order approximation, we have that coincides with the score statistic, i.e., . We analyze how well the two approximations align with the true BDM under the growing sample size () while keeping the MLE fixed at . The MAP values are 1.03 (), 1.11 (), 1.14 (), and 1.17 ().
Figure 2 and Figure 3 and Table 1 report the approximations of the BDM for several candidate values for . In particular, the first-order (IO) approximation (5), the higher-order (HO) approximation (13), the SKS approximation (24), a direct numerical tail area calculation (SKS-num) of (23) and the SN approximation (27) are considered. Figure 2 and Figure 3 also display the approximations to the corresponding posterior distributions, where the HO approximation is derived numerically by inverting the tail area. Also, note that the SKS approximation of the posterior distribution is not guaranteed to lie within the interval (0,1), so we practically bounded the BDM in this interval.
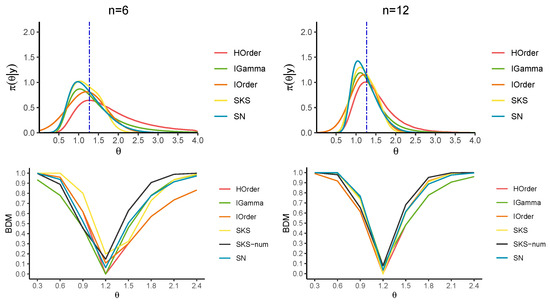
Figure 2.
Exact posterior (in green) and approximate posteriors for in the exponential model (top panels). The blue vertical line indicates the posterior median. BDM for a series of parameters (lower panels).
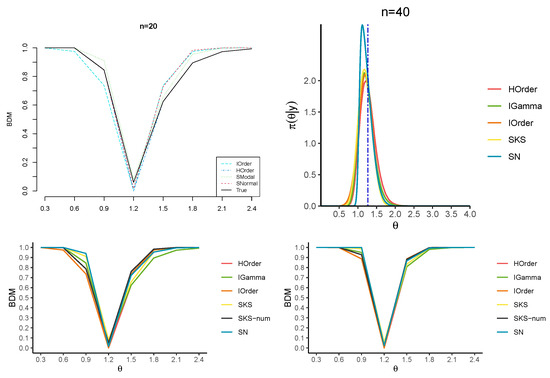
Figure 3.
Exact posterior (in green) and approximate posteriors for in the exponential model (top panels). The blue vertical line indicates the posterior median. BDM for a series of parameters (lower panels).

Table 1.
BDM for a series of values for the parameter and increasing sample sizes in the exponential example. The values of the true BDM and the best approximation(s) in each configuration are highlighted in bold.
The results confirm that the HO and SKS approximations yield remarkable improvements over the first-order counterpart for any n. Moreover, they show that the HO approximation of the BDM is almost perfectly over-imposed on the true BDM, especially for values of far from the MLE. When the value under the null hypothesis is closer to the MLE, the SKS approximation and the numerical tail areas derived from the SKS and SN approximations better approximate the true BDM. Furthermore, the SN approximation more accurately captures the tail behavior of the posterior distribution than the SKS approximation.
5.2. Logistic Regression Model
We now consider a real-data application using the Cushing’s dataset (see [5], Section 5.2), which is openly available in the R library MASS. The data were obtained from a medical study on individuals, aimed at investigating the relationship between Cushing’s syndrome and two steroid metabolites, namely Tetrahydrocortisone and Pregnanetriol.
We define a binary response variable Y, which takes the value 1 when the patient is affected by bilateral hyperplasia, and 0 otherwise. The two observed covariates and are two dummy variables representing the presence of the metabolites. We focus on the most popular regression model for binary data, namely, logistic regression with mean function . As in [5], Bayesian inference is carried out by employing independent, weakly informative Gaussian priors N(0, 25) for the coefficients .
Figure 4 displays the marginal posterior distributions for and obtained via MCMC sampling (black curves), along with the first-order, the SKS, and the SN approximations. The MAP values for the two parameters are −0.031 and −0.286, respectively.
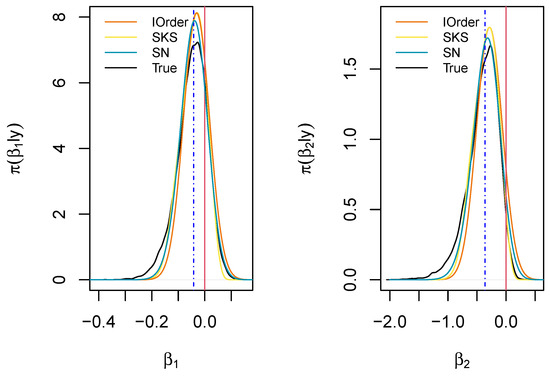
Figure 4.
Marginal posterior distributions for the regression parameters of the logistic regression example. The marginal medians are indicated in blue, while the parameters under the null hypothesis are indicated in red.
We aim to test the two null hypotheses and , corresponding to the null effect of the metabolites’ presence in determining Cushing’s syndrome (indicated by red vertical lines in Figure 4). The exact BDM gives the values 0.592 and 0.932, respectively, indicating that the hypothesized value may support the null hypothesis for the first parameter , whereas the second value suggests a weak disagreement with the assumed value for . The SKS approximations of the BDM for the considered hypotheses are 0.612 and 0.935, respectively; the SN approximations are 0.584 and 0.870, respectively; the first-order approximations are 0.512 and 0.891, respectively; while the higher-order approximations provide 0.611 and 0.998, respectively. Finally, the approximations based on the matching priors are 0.477 and 0.862, respectively. Thus, the skewed approximations (SKS, SN) provide the best results.
For the composite hypothesis , the ground truth is not available; however, in the presence of low correlation between the components, one can approximate it as the geometric mean of the two marginal measures, which is 0.743. The first-order approximation for the BDM gives 0.300, while the SN approximation gives 0.760, revealing that the value under the null is more extreme (see also Figure 5).
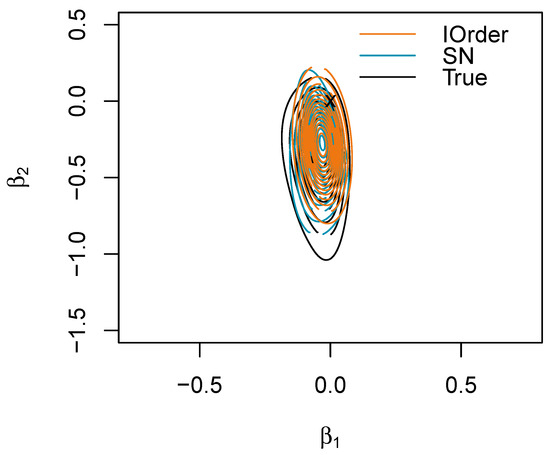
Figure 5.
Joint posterior for in the logistic regression example with the first-order (IOrder) and skew-normal (SN) approximations. The point (0,0) is marked with a cross.
6. Concluding Remarks
Although the higher-order and skewed approximations described in this paper are derived from asymptotic considerations, they perform well in moderate or even small sample situations. Moreover, they represent an accurate method for computing posterior quantities and approximating , and they make it quite straightforward to assess the effect of changing priors (see, e.g., [25]). When using objective Bayesian procedures based on strong-matching priors and higher-order asymptotics, there is agreement between Bayesian and frequentist point and interval estimation, as well as in significance measures. This is not true, in general, with the e-value, as discussed in [14].
A significant contribution of this work is the extension to multivariate hypotheses. We propose a formal definition of the multivariate BDM based on center-outward optimal transport maps, providing a theoretically sound generalization of the univariate concept. By utilizing either the multivariate normal or multivariate SN approximations of the posterior distribution, we can formulate the multivariate quantiles in a closed form, thereby allowing us to derive the BDM for composite hypotheses. Nonetheless, precisely determining or defining these quantiles on the true posterior is challenging, as the transport map may not be available in a closed form and requires solving a complex optimization problem. However, the SN approximation as well as the derived OT map continue to be manageable in high-dimensional settings, whereas typical OT methods generally do not scale efficiently with increasing dimensions.
As a final remark, the high-order procedures proposed and described are tailored to continuous posterior distributions, and their extension to models with discrete or mixed-type parameters warrants further study. Moreover, although the higher-order and skewed methods, alongside SN-based OT maps, offer a useful means for approximating the posterior distributions and computing tail areas, their application might fail in handling complex or irregular posterior landscapes. In such cases, employing integrated computational procedures to find the transport map [26] and utilizing the direct definition of the multivariate BDM could be more appropriate. Furthermore, the utility of the higher-order and skew-normal approximation techniques developed here is not restricted to the Bayesian discrepancy measure. These methods hold considerable promise for approximating other Bayesian measures of evidence. For example, applying these procedures to quantities like the e-value is a natural and compelling direction for future work.
Author Contributions
Conceptualization, E.B., M.M. and L.V.; Methodology, E.B., M.M. and L.V.; Software, E.B.; Validation, E.B. and L.V.; Formal analysis, E.B., M.M. and L.V.; Investigation, E.B. and L.V.; Data curation, E.B.; Writing—original draft, E.B., M.M. and L.V.; Writing—review & editing, E.B. and M.M.; Supervision, F.B., M.M. and L.V. All authors have read and agreed to the published version of the manuscript.
Funding
Elena Bortolato acknowledges funding from the European Union under the ERC grant project number 864863.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations and Notation Glossary
The following abbreviations are used in this manuscript:
| Symbol | Meaning/Definition |
| BDM | Bayesian discrepancy measure |
| BF | Bayes factor |
| LR | Log-likelihood ratio |
| MAP | Maximum a posteriori |
| MLE | Maximum likelihood estimate |
| OT | Optimal transport |
| SKS | Skew-symmetric |
| SN | Skew-normal |
| Sharp (precise) null hypothesis | |
| Scalar parameter or parameter vector in the multivariate case | |
| Specific hypothesized value of the parameter under | |
| Scalar parameter of interest | |
| Nuisance parameter (scalar or vector) | |
| y | Observed data |
| d | Dimension of the full parameter vector |
| n | Sample size |
| MLE of | |
| MAP of | |
| Constrained MLE of given | |
| , | Log-likelihood function |
| Profile log-likelihood function for | |
| , | Score function, profile score function |
| , | Observed information matrix, profile observed information |
| Submatrices of for parameter partitions | |
| , | Wald statistic, profile Wald statistic |
| , | Score statistic, profile score statistic |
| Log-likelihood ratio statistic | |
| , | Likelihood root, profile likelihood root |
| , | Prior density of , posterior density of |
| Bayesian discrepancy measure, quantifying evidence against | |
| Bayesian modified likelihood root statistic (scalar, with nuisance parameters) | |
| Standard normal cumulative distribution function | |
| Marginal posterior density of | |
| Center-outward distribution function mapping posterior to the unit ball | |
| Center-outward quantile function (inverse of ) | |
| Uniform distribution on the unit ball | |
| , | Unit ball in , unit sphere in |
| , | Center-outward quantile regions and quantile contours of order |
| Euclidean norm | |
| Approximate equality to first- or third-order (e.g., or accuracy) |
References
- Kass, R.E.; Tierney, L.; Kadane, J. The validity of posterior expansions based on Laplace’s method. In Bayesian and Likelihood Methods in Statistics and Econometrics; Elsevier: Amsterdam, The Netherlands, 1990; pp. 473–488. [Google Scholar]
- Reid, N. Likelihood and Bayesian approximation methods. Bayesian Stat. 1995, 5, 351–368. [Google Scholar]
- Reid, N. The 2000 Wald memorial lectures: Asymptotics and the theory of inference. Ann. Stat. 2003, 31, 1695–1731. [Google Scholar] [CrossRef]
- Ventura, L.; Reid, N. Approximate Bayesian computation with modified log-likelihood ratios. Metron 2014, 7, 231–245. [Google Scholar] [CrossRef]
- Durante, D.; Pozza, F.; Szabo, B. Skewed Bernstein–von Mises theorem and skew-modal approximations. Ann. Stat. 2024, 52, 2714–2737. [Google Scholar] [CrossRef]
- Zhou, J.; Grazian, C.; Ormerod, J.T. Tractable skew-normal approximations via matching. J. Statist. Comput. Simul. 2024, 94, 1016–1034. [Google Scholar] [CrossRef]
- Bertolino, F.; Manca, M.; Musio, M.; Racugno, W.; Ventura, L. A new Bayesian discrepancy measure. Stat. Methods Appl. 2024, 33, 381–405. [Google Scholar] [CrossRef]
- Hallin, M.; Del Barrio, E.; Cuesta-Albertos, J.; Matrán, C. Distribution and quantile functions, ranks and signs in dimension d: A measure transportation approach. Ann. Stat. 2021, 49, 1139–1165. [Google Scholar] [CrossRef]
- Hallin, M.; Konen, D. Multivariate Quantiles: Geometric and Measure-Transportation-Based Contours. In Applications of Optimal Transport to Economics and Related Topics; Springer Nature: Cham, Switzerland, 2024; pp. 61–78. [Google Scholar]
- Madruga, M.; Pereira, C.; Stern, J. Bayesian evidence test for precise hypotheses. J. Stat. Plan. Inf. 2003, 117, 185–198. [Google Scholar] [CrossRef]
- Pereira, C.; Stern, J.M. Evidence and Credibility: Full Bayesian Significance Test for Precise Hypotheses. Entropy 1999, 1, 99–110. [Google Scholar] [CrossRef]
- Pereira, C.; Stern, J.M. The e-value: A fully Bayesian significance measure for precise statistical hypotheses and its research program. Sao Paulo J. Math. Sci. 2022, 16, 566–584. [Google Scholar] [CrossRef]
- Bertolino, F.; Columbu, S.; Manca, M.; Musio, M. Comparison of two coefficients of variation: A new Bayesian approach. Commun. Stat. Simul. Comput. 2024, 53, 6260–6273. [Google Scholar] [CrossRef]
- Ruli, E.; Ventura, L. Can Bayesian, confidence distribution and frequentist inference agree? Stat. Methods Appl. 2021, 30, 359–373. [Google Scholar] [CrossRef]
- Peyré, G.; Cuturi, M. Computational optimal transport: With applications to data science. Found. Trends Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Fraser, D.A.S.; Reid, N. Strong matching of frequentist and Bayesian parametric inference. J. Stat. Plan. Inf. 2002, 103, 263–285. [Google Scholar] [CrossRef]
- Welch, B.L.; Peers, H.W. On formulae for confidence points based on integrals of weighted likelihoods. J. Roy. Statist. Soc. B 1963, 25, 318–329. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O.E.; Chamberlin, S.R. Stable and invariant adjusted directed likelihoods. Biometrika 1994, 81, 485–499. [Google Scholar] [CrossRef]
- Severini, T.A. Likelihood Methods in Statistics; Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Pierce, D.A.; Bellio, R. Modern likelihood-frequentist inference. Int. Stat. Rev. 2017, 85, 519–541. [Google Scholar] [CrossRef]
- Skovgaard, I.M. Likelihood Asymptotics. Scand. J. Stat. 2001, 28, 3–32. [Google Scholar] [CrossRef]
- Ventura, L.; Ruli, E.; Racugno, W. A note on approximate Bayesian credible sets based on modified log-likelihood ratios. Stat. Prob. Lett. 2013, 83, 2467–2472. [Google Scholar] [CrossRef]
- Tan, L.S.; Chen, A. Variational inference based on a subclass of closed skew normals. J. Stat. Comput. Simul. 2024, 34, 1–15. [Google Scholar] [CrossRef]
- Azzalini, A.; Capitanio, A. Statistical applications of the multivariate skew normal distribution. J. R. Stat. Soc. B 1999, 61, 579–602. [Google Scholar] [CrossRef]
- Reid, N.; Sun, Y. Assessing Sensitivity to Priors Using Higher Order Approximations. Commun. Stat. Simul. Comput. 2010, 39, 1373–1386. [Google Scholar] [CrossRef]
- Li, K.; Han, W.; Wang, Y.; Yang, Y. Optimal Transport-Based Generative Models for Bayesian Posterior Sampling. arXiv 2025, arXiv:2504.08214. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).