Abstract
Approximate query on knowledge graphs (KGs) is an important and common task in real-world applications, where the goal is to return more results on KGs that match the query criteria. Previous approximate query methods have focused on static KGs. However, many KGs in real-world applications are dynamic and evolve over time. In this paper, we consider approximate queries in temporal knowledge graphs (TKGs) that may have specific timestamps in the predicates. We propose a Two-Level Approximate Query method (TLAQ) for temporal knowledge graphs based on the two-level embedding of vertex and graph. Specifically, we first improve the eigenmatrix of the GCN to enhance the embedding representation. On this basis, TLAQ defines relational reliability and attributive confidence at the vertex level. Then, we unify the encoding format of timestamps at the graph level to further strengthen the embedding model. Finally, we demonstrate the effectiveness of our proposed approach through a comprehensive experiment.
1. Introduction
Temporal knowledge graphs, such as DBpedia [1] and ICEWS [2], store information in the semi-structured form <h, r, t, time>, where h and t are the entity, r is the relation, and time is the timestamp held by r. Different entities or relations may have the same meaning, due to the flexibility of the semi-structured form. Disregarding the semantic similarity among annotated entities and relations may lead to the loss of approximate results that would otherwise meet the query constraints. Consider the examples shown in Figure 1. They show some samples of countries and celebrities. Assume that we need to answer the query “Please identify the FC Barcelona soccer players who have served since 2004”. If we ignore the query similarity, only the entity “Suarez” has a “serves” relationship with “FC Barcelona”. Obviously, Messi has also been playing for FC Barcelona between 2004 and 2021. Therefore, it is necessary to find a more comprehensive and complete answer by focusing on the similarity of entities and relations.
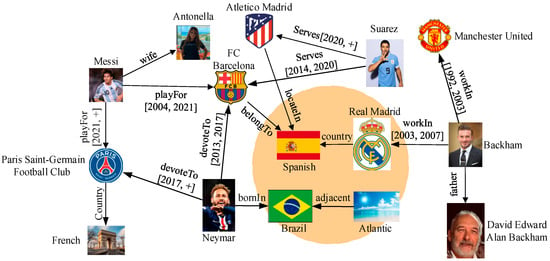
Figure 1.
Example of temporal knowledge graph query instances showing entities, relations, and time-interval annotations.
Some existing works focus on the importance of semantic similarity in queries. Zou et al. [3] model the query operations on TKG as graph transformations. They assigned different weights to each transformation to find multiple results. However, this method ignored the similarity between entities and did not consider the semantic information between predicates. Wang et al. [4] define path semantic similarity to find approximate predicates, but the time complexity of this method is relatively high. The FGqT-Match [5] algorithm is designed to reduce redundant computations by indexing subgraphs based on match-driven flow graphs. Meanwhile, the multi-label weight matrix was defined to evaluate approximate query graphs and reduce search space. There are also several TKG completion and forecasting methods [6,7]. The above research methods on approximation results are all based on the embedding model. However, if the query result is empty, simply using the embedding method alone may result in query failure. At this moment, relaxing the query criteria can produce the answer that is closest to the query intent.
To address the problem of empty results in the query, existing work reconstructs the original query into a new relaxed query by removing or relaxing the query criteria. These methods generate multiple approximate candidate query results based on four main models of similarity, rules, user preferences, and collaborative techniques. The similarity-based model [8] uses lexical analysis to find approximate results. The rule-based model [9] uses the semantics of query graph patterns and rewriting rules to perform relaxation. The model based on user preferences [10] relaxes overly constrained queries based on domain knowledge and user preferences. The model based on collaborative techniques [11] designs a new pruning strategy that greatly reduces the exponential search space for top-k relaxed queries. Recent advances in knowledge representation provide stronger foundations for semantic matching in query relaxation. For instance, HyCubE [12] introduces efficient three-dimensional circular convolutional embedding for knowledge hypergraphs, capturing complex structural patterns through hyper-relational modeling. The work by Ma et al. [13] incorporates historical trends with normalizing flow techniques to enable one-shot temporal reasoning. Further, Zhu et al. [14] propose multi-dimension rotations based on quaternion systems to effectively model diverse temporal patterns in knowledge graphs. All of these methods have been successful in relaxing the query to some extent. However, the approximate query generated by these methods may differ significantly from the user’s initial query, since these models cannot take into account expected answers that do not appear in the query results. Moreover, overly relaxed queries and irrelevant answers may produce query results that do not meet the user’s expectations.
Different from the existing approximate query methods, we propose an approximate semantic query method TLAQ for temporal knowledge graphs. This method divides the knowledge in TKG into relational triples and attribute triples. The specific embedding strategy for each of the two triples makes the continuous space vectors express the semantic information of entities or attributes more reasonably. In particular, the method solves the problem of empty results in the query. If the triples in the result graph are not found in the TKG, the method can still find an approximate result that satisfies the user’s initial query intent. The contributions of this paper are as follows:
- We define relational reliability and attributive confidence to find the approximate results at the vertex level and compare the semantic similarity at the graph level.
- We unify the encoding format of time information and encode predicate and time information jointly through LSTM.
- We conduct experiments on three real-world datasets to demonstrate the superior performance of the proposed approach.
2. Related Work
2.1. Temporal Knowledge Graph Embedding
A wide range of A models exploit temporal dependencies to achieve improved performance. Early work such as Reference [15] extended static KG models (e.g., Tucker, DistMult) to temporal settings through four-dimensional tensor representations (<subject, predicate, object, time>), enabling episodic memory modeling in TKGs and inspiring subsequent research. The HyTE [16] model divides the TKG into different hyperplanes according to temporal information and maps entities and relationships to hyperplanes. Goel et al. [17] put forward DE series models to embed entities into time information on the basis of the static embedding method. They use CNN to learn the time perception representation of relations and use the DistMult scoring function to evaluate similarity. TA-DistMul1f [18] combines time and relationship into one dimension. The combined text sequence is calculated by LSTM to obtain the relationship with time characteristics. CyGNet [19] applies a replication mechanism to TKG for the first time. It combines replication and generation reasoning modes and refers to known facts from history when learning to reason future events.
The GCN, as an effective structural characterization method, captures structural dependencies between entities under the same timestamp through a message passing framework. On the basis of the R-GCN model, a cyclic event network RE-NET [20] model is proposed. This model is an autoregressive architecture for modeling the time series of multi-relational knowledge graphs. The RE-NET model further improves the semantic expression ability of TKG embedding. DySAT [21] pays attention to both graph structure and time evolution. Time-divided events learn neighborhoods’ information through self-attention and then learn triple similarity under time deduction through joint attention. EvoveGCN2 [22] obtains the structural features of a knowledge graph through the GCN and captures the evolution information of a knowledge graph through a cyclic neural network. Han et al. [23] put forward a link prediction model xERTE for future events. This model can query the related subgraphs of TKG and jointly model the graph structure and time context information.
2.2. Approximate Query Based on Embedding
In recent years, approximate query based on embedding has been extensively studied. Miller et al. [24] employs a memory table to store triples encoded into key–value pairs, which makes approximate query efficient. Sun et al. [25] propose a GNN model for multi-hop reasoning of heterogeneous graphs. PullNet [26] improves the graph query module by iteratively extending problem-specific subgraphs. Embedding KGQA [27] directly matches pretrained entity embedding with query embedding, which is computationally intensive. Bai et al. [28] divides graph embedding into vertex-level embedding and graph-level embedding. The model introduces an attention mechanism to learn graph-level embedding. In the graph query stage, vertex-level information is used to assist the similarity judgment of graph level. Yang et al. [29] propose Graph Path Networks (GPN), which combines the pretraining information based on an attention mechanism and cross-graph information. To address the challenge of sparsity in temporal knowledge graphs, Gao et al. [30] propose the Time-Weaver Query (TWQ) model, which leverages complex space embedding and exploits adjacent timestamp relations to reconstruct entity, relation, and timestamp embeddings.
Several methods have also been proposed to directly handle queries expressed in natural language. Chen et al. [31] put forward the HGNet model to solve the approximate query problem. The model gives the structure of a query graph and fills entities into the structure to complete the construction of a query graph. Liang et al. [32] decomposes a mapping query described in natural language into five subtasks of structured approximate queries. The method uses machine learning and a LSTM neural network model to learn the task automatically. Jin et al. [33] propose a question-answering system with relational constraints, which includes a dictionary construction module and a dictionary-based question-answering module. Zheng et al. [34] put forward a working framework to answer natural language questions in a user-interactive manner.
3. The Proposed Framework
3.1. Problem Formulation
Definition 1.
Temporal Knowledge Graph. A temporal knowledge graph is defined as TKG = {E, A, T, RT, AT}, where E and A are the sets of entities and attributes, respectively.
- T is predicates set with temporal information. T = TR × TA, where TR is the relational predicate and TA is the attribute predicate.
- RT = E × TR × E denotes the set of relation triples. <eh, tr, et> ∈ RT denotes a relation triple, where eh is called head entity, et is called tail entity and tr is called relational predicate.
- AT = E × TA × A is the set of attribute triples. <e, ta, a> ∈ AT denotes an attribute triple, where e is an entity, a is an attribute, and ta is an attribute predicate.
Definition 2.
Temporal Query Graph. A temporal query graph is defined as TQG = {EQ ∪ Ev, AQ ∪ Av, TQ, RTQ, ATQ}, where EQ ⊆ E, Ev is a set of entity variables. AQ ⊆ A, Av is a set of attribute variables.
- TQ ⊆ T is the predicates set. Each variable, ev ∈ Ev or av ∈ Av, is distinguished by a leading question mark symbol, e.g., ?ev or ?av. In particular, predicates are all in T, and there are no variables.
- RTQ = (EQ ∪ Ev) × TR × (EQ ∪ Ev). For each triple, an entity or attribute cannot be variable at the same time. <eh, tr, ?ev> ∈ RTQ is called an entity query and ?ev is defined as the target entity.
- ATQ = (EQ ∪ Ev) × TR × (AQ ∪ Av). <e, ta, ?av> ∈ ATQ is called a relational query and ?av is defined as the target attribute.
Definition 3.
Entity query and Attribute Query. A entity query is defined as EQ = {<eh, tr, ?ev> ∈ RTQ or <?ev, tr, et> ∈ RTQ}, where ?ev is named as the target entity. An attribute query is defined as AQ = {<e, ta, ?av> ∈ ATQ}, where ?av is named as the target attribute. While entity and attribute queries resemble traditional link prediction tasks, they differ in two key aspects:
- They are embedded in a temporal query graph structure that supports variable binding and time-aware matching;
- They are designed as components of more complex queries, enabling multi-hop reasoning and uncertainty handling via approximate matching.
Definition 4.
Temporal result graph. A temporal result graph is defined as TRG = {ER, AR, TR, RTR, ATR}, where ER ⊆ E, AR ⊆ A, TR ⊆ T, RTR, and ATR are relational triples and attribute triples that may not be in RT and AT.
Definition 5.
Approximate query. Consider a temporal knowledge graph G and a temporal query graph Q. Define a query procedure as an approximate query whose answer is the set of results that match G and Q, or the set of results that are closest to Q (when the matching result is the empty set). Approximate queries include entity query and attribute query in Definition 3.
3.2. Overview
This subsection proposes an approximate querying method on TKG based on two-level embedding. At vertex-level embedding, we define relational reliability and attributive confidence to find approximate entities and attributes. At graph-level embedding, time information is used to enhance the embedding representation and find the approximate results. The framework is shown in Figure 2.
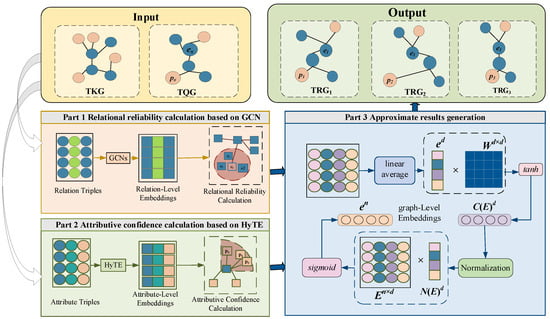
Figure 2.
Framework of our approach.
- Part 1 Relational reliability calculation based on GCN. For the relation triples, the GCN model is used to learn the embedding representation of the entity at the vertex level. Each vertex in the relation triples is transformed into a vector by combining the structural and semantic information of the vertices.
- Part 2 Attributive confidence calculation based on HyTE. For the attribute triples, the translation distance-based representation model HyTE is used to obtain the embedding representations of vertices and edges in the attribute triple.
- Part 3 Approximate results generation. To deal with the time information carried by predicates, a unified time coding format is defined to enhance embedded representation. After obtaining the embedded representation with time information, multiple triples will be weighted and averaged to obtain an embedded vector at the graph level. The distance between vectors will be used to measure the similarity among graphs.
3.3. Relational Reliability Calculation Based on GCN
Simple distance metrics fail in TKG approximation because they treat all dimensional proximities equally and cannot inherently account for structural integrity or temporal fitness, often leading to misleading high similarity rankings for structurally weak or temporally irrelevant candidates.
Figure 3 provides a detailed task description. On the left side of the figure is the representation before embedding the temporal query graph, which includes two types of queries: attribute queries <e2, ta2, ?aᵥ> and entity queries <?e1, tr1, e1>, <e2, r2, ?eᵥ>. On the right side of Figure 3 is the query graph after embedding. Although the temporal knowledge graph does not have results that can be directly returned, there are many candidate entities or attributes surrounding the target attribute or target entity, which are circled with dashed circles in the figure. These candidate entities or attributes have certain semantic similarities with the target entity or attribute and can be returned as results.
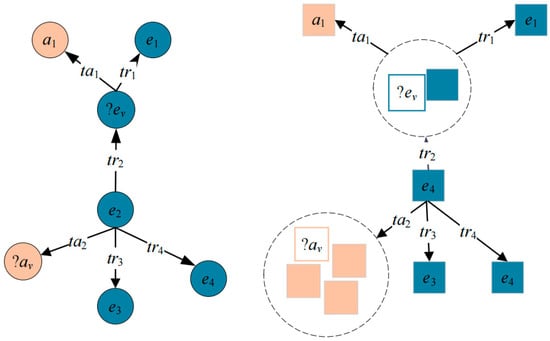
Figure 3.
Examples of query tasks.
The Graph Convolutional Network has been proven to be effective in capturing information from graphs. It can learn the features of the pair of neighbor nodes, eh and et, in the relational triple <eh, tr, et>. The structure of the GCN is shown in Figure 4. The GCN takes the embedding representation of the nodes at layer l as input and computes the embedding representation at layer l + 1 by aggregating the embedding representations of neighbor nodes and its own nodes at layer l. The calculation method is as follows:
where is the activation function, and is the degree matrix as self-connected. A is the degree matrix. and are the learnable matrices. is the diagonal node degree matrix of .
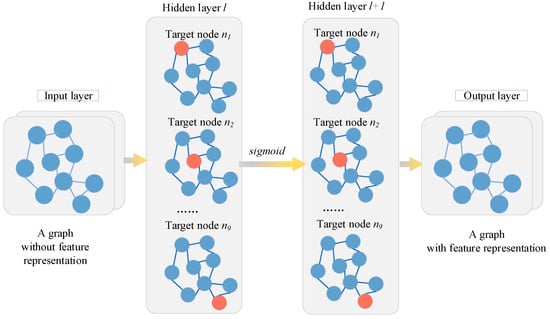
Figure 4.
GCN structure based on modified feature matrix.
A traditional GCN is limited to simple undirected networks and is therefore inadequate for modeling TKGs that involve multiple types of relationships between node pairs. For entity a, entity b, and entity c, if there are more edges (i.e., relationships) between entity a and entity b than between entity a and entity c, then the embedding representation of entity a should be closer to the embedding representation of entity b than the embedding representation of entity c in a continuous vector space. To better represent this difference, Aij is defined with the following equation:
where headi is the number of relational triples with ei as the head node in the TKG, tailj is the number of relational triples with ej as the tail node in these triples, and de can delineate the direction of relationships between entities.
The direction of relationship and the number of relationships between entities can reflect the importance of relationships. We define re to measure the importance of specific relationships. The formula is as follows:
where nums_r is the number of triples of relational triples of the TKG with relation predicate tr, node_i is the number of these triples that contain node ei, and node_j is the number of these triples that contain node ej. re gives the weight of the relation.
For entity query, the embedding representation of the target entity needs to be calculated first. The embedding of the target entity obtained by GCN is called preliminary embedding . In a query graph, if a target entity involves multiple relational triples, these triples need to be considered jointly when calculating the embedded representation of the target entity. Different triples have different effects on the embedded representation of target entities.
An entity query is shown in Figure 5. The entity includes the relation triples <?ev, tr1, e1>, <?ev, tr2, e2>, and <?ev, tr3, e3>. When calculating the embedded representation of the target entity ev, <?ev, tr1, e1> contains more specific information compared to <?ev, tr2, e2> and <?ev, tr3, e3>. The relational triple <?ev, tr1, e1> deserves more attention. In this paper, the relationship triple influence factor attr is defined to measure the influence of a specific relationship triple on the target entity ev. The calculation method is given in Formula (6).
The denominator of the index is the total number of all relational triples in the matching TKG, and the numerator is the number of specific relational triples containing ev in the matched temporal query graph. Based on the formula for attr, we can calculate the influence factors for the triples <?ev, tr1, e1>, <?ev, tr2, e2>, and <?ev, tr3, e3>.
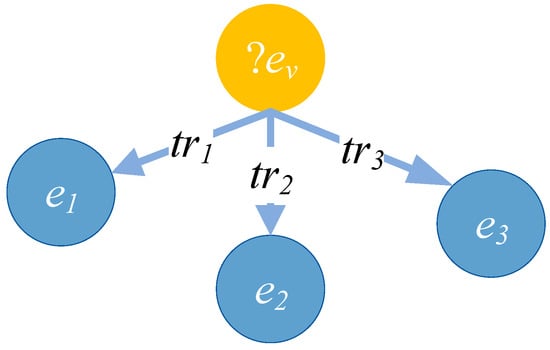
Figure 5.
Entity query. An example of a temporal entity query represented as a query graph. The yellow node ?ev denotes an unknown entity to be inferred, while blue nodes e1, e2, and e3 are known entities. Directed edges labeled with relational predicates tr1, tr2, and tr3 represent constraints on the relationships between the target entity and known entities. This query seeks to find an entity that satisfies all three relation constraints simultaneously, possibly under temporal conditions (e.g., during a certain time interval).
In order to further calculate the embedding representation of the target entity ev, the final embedding of the target entity is obtained by combining the preliminary embedding results and the influence factor attr of the triple. The formula is as follows:
where is the preliminary embedding and attr is the score of specific triples which contain ev.
After obtaining the final embedding representation of the target entity, we define the relational reliability RR to measure the semantic similarity between the two entities. This function maps the Euclidean distance into a value in [0, 1], where higher values indicate greater semantic similarity. We use this score to rank candidate entities and select the top-k most similar ones for approximate matching. The formula is as follows:
where ev represents the target entity in the temporal query graph, e represents the approximate entity in the TKG, and d is the dimension of the embedded vector.
Relational reliability is used to find k entities that are closest to the target entity. For the k entities found, they correspond to k new triples <ek, tr, et>, which are reliable relations of <?ev, tr, et>. ek is called an approximate entity, which can replace ev as the approximate result. Algorithm 1 is as follows:
Breadth-first traversal is carried out first for each relational triplet containing the target entity. All neighbor entities of the target entity are added to E (lines 01–03). Then, the preliminary embedded representation of the target entity is calculated according to the GCN (line 04). For each approximate neighbor entity in E, its attr is calculated (lines 05–07). Based on the attr, the final embedded representation of the target entity is calculated (line 08). For the relational triples in the TKG, the similarity between the approximate entities in the triples and the target entities is calculated (lines 09–11). Finally, the approximate entities are returned by sorting by similarity (lines 12–13).
| Algorithm 1. Approximate entities sorted based on relational reliability | |
| Input: temporal knowledge graph TKG, temporal query graph TQG Output: entity sorted result set RTR | |
| 01 | for each ev in <eh, tr, ?ev> or <?ev, tr, et>∈EQ |
| 02 | E ← BFS (ev)//ev the root of breadth traversal search |
| 03 | end for |
| 04 | calculate the preliminary embedded representation of ev |
| 05 | for each ei in E |
| 06 | calculate the attr of the relational triple corresponding to ei |
| 07 | end for |
| 08 | calculate the final embedded representation of ev |
| 09 | for each e′ in < e′, tr, ev> ∈ TKG |
| 10 | calculate the similarity between e′ and ev |
| 11 | end for |
| 12 | according to the similarity, sort entities and save corresponding triple in RTR |
| 13 | return RTR |
3.4. Attributive Confidence Calculation Based on HyTE
GCN is effective in learning the features of nodes with the same type in TKGs. It is insufficient for different types of nodes. For the attribute triple <e, ta, a> in the TKG, entity nodes and attribute nodes are different types. Most attribute triples in TKG are independent and do not contain complex relationship networks. When learning the embedding representation of attribute triples, the embedding method based on translation can deal with these relationships.
According to the translation-based embedding method, embed the attribute triples into a vector space. The preliminary embedding of attribute triples is calculated as follows:
where is attribute, e is the entity, and is the attribute predicate.
In vector spaces of attribute triples, adjacent or similar entities share the same semantic information. The same entity always has different attributes, which interferes with attribute query. To remove the disturbance of irrelevant attribute predicates, we project adjacent entities onto the hyperplane corresponding to the attribute predicates in the attribute query and obtain the embedded representation of adjacent entities in the hyperplane of ta. The formula is as follows:
where ei is an embedded representation of an adjacent entity of e; ta is an embedded representation of the attribute predicate ta.
The attribute query <e, ta, ?av> is shown in Figure 6. When this query is executed, there is neither an attribute predicate nor an attribute matching the attribute query <e, ta, ?av> in the TKG. In the vector spaces of attribute triples, there are some approximate attributes (such as attribute a1 and attribute a2) that are similar to in TKG (represented by a square dashed box on the right of Figure 6). Moreover, most of the entities with these approximate attributes are adjacent to the entities in the attribute query (such as entity e1 and entity e2).
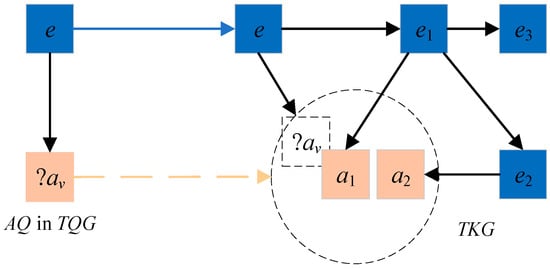
Figure 6.
Attribute query. Illustration of attribute query processing when the target attribute ?av is absent in the temporal knowledge graph, showing how the framework identifies contextually relevant approximate attributes (e.g., a1, a2) and their associated entities through embedding similarity scoring.
In order to further distinguish the distance between each adjacent entity and entity e in the attribute query, we define entity influence factor atta to measure the importance of adjacent entities to entity e.atta.
The numerator represents the similarity between the adjacent entity ei and the entity e in the attribute query, and the denominator represents the sum of the similarity between the adjacent entities and e. The final embedding of the target attribute is obtained by and is calculated as follows:
where is the preliminary embedding of the target attribute, and atta is the entity impact factor of the adjacent entity.
After obtaining the embedded representation of the target attribute, finding the attribute approximate with the target attribute in the TKG is needed. In order to measure the semantic similarity between the two attributes and find the attribute satisfying the query condition as much as possible, we define the attribute credibility AC to measure the likelihood that an observed attribute a in the TKG matches the target attribute in the query. The formula is as follows:
where av represents the target attribute, a represents the approximate attribute, and d is the dimension of the embedded vector.
Attribute confidence is used to find k attributes that are closest to the target attribute. For the k attributes found, they correspond to k new triples <e, ta, ak> which are at attribute confidence values of <e, ta, ?av>. ak is called an approximate attribute and can replace av as the approximate result. Algorithm 2 is as follows:
| Algorithm 2. Approximate attributes sorted based on attribute confidence | |
| Input: temporal knowledge graph TKG, temporal query graph TQG Output: attribute sorted result set ATR | |
| 01 | for each e in <e, ta, ?av> ∈ AQ |
| 02 | A ← BFS (e)//e the root of breadth traversal search |
| 03 | end for |
| 04 | calculate the preliminary embedded representation of av |
| 05 | for each ai in A |
| 06 | calculate the atta of the attribute triple corresponding to ai |
| 07 | end for |
| 08 | calculate the final embedded representation of av |
| 09 | for each a′ in <e, ta, a′>∈TKG |
| 10 | calculate the similarity between a′ and av |
| 11 | end for |
| 12 | according to the similarity, sort attributes and save corresponding triple in ATR |
| 13 | return ATR |
Breadth-first traversal is carried out firstly for each attribute triplet containing the target attribute. All neighbor entities of e are added to A (lines 01–03). Then, the preliminary embedded representation of the target attribute is calculated according to the embedded model (line 04). For each entity in A, its atta is calculated (lines 05–07). Based on the atta, the final embedded representation of the target attribute is calculated (line 08). For the attribute triples in the TKG, the similarity between the approximate attributes in the triples and the target entities is calculated (lines 09–11). Finally, the approximate attributes are returned by sorting by similarity (lines 12–13).
3.5. Approximate Results Generation
Referring to the coding of time information in the literature [35], time information (T) is divided into seven levels, namely century, decade, year, quarter, month, week, and day. These seven time levels are represented by sub-vectors (t), which are centuries (C), decades (D), years (Y), quarters (Q), months (M), weeks (W), and days (DS). The first three vectors are used to represent the year, the Q and M vectors are used to represent the month, and the W and DS vectors are used to represent a specific day. Each dimension of the vector has a value of 0 or 1. The dimension of the DS vector is 7. The values of each sub-vector are given in Figure 7. The core reason we employ a seven-level time encoding is to achieve a comprehensive, multi-granularity representation of temporal information within temporal knowledge graphs (TKGs). Real-world events and facts possess varying durations and granularities, ranging from long-term facts spanning centuries to short-term events lasting only days or weeks. This seven-level structure allows the model to simultaneously capture the context from the broadest scale (century) down to the most precise date, thereby greatly enhancing both representational capacity and robustness.
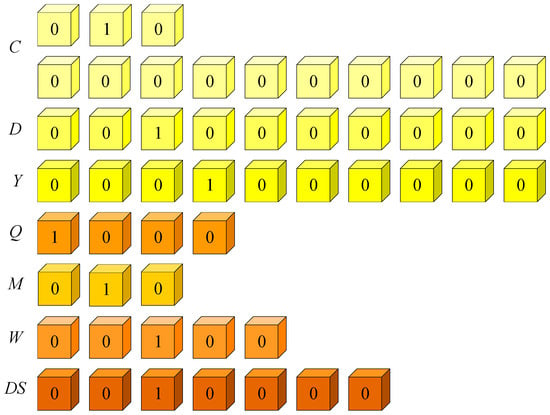
Figure 7.
Encoding of time information in predicates.
Specifically, a century has a hundred years, a year has four quarters, a quarter has three months, a month has four weeks, and a week has seven days. The highest three digits of C represent the first 1000 years from AD 0, and the fourth-third digits represent the first hundred years in 1000 years. Number 1 indicates that in this time interval. The highest bit of D is indicated in the first decade, and 1 means that in this time interval. The highest bit of Y denotes the first year, and number 1 denotes that in this time interval. The highest digit of Q is the first quarter; number 1 is in this quarter. The highest digit of M is the first month of the quarter; number 1 is in this month. The highest bit of W represents the first week (assuming that the 1st of each month is the beginning of the first week and the week is seven days); number 1 means in this week. The highest bit of DS means the first day of a week; number 1 means in this day.
The encoding of time information and predicate vectors trained by Section 3.3 and Section 3.4 are put into LSTM. The predicate encoding with time information is obtained by using LSTM to jointly encode predicates and time. Section 3.3 and Section 3.4 judge the similarity between TQG and TKG at vertex level. In order to further calculate the similarity between the TQG graph and TKG, this section synthesizes the feature information of each vertex and edge from the perspective of embedding the whole graph and represents the whole graph with an embedding vector. The structure of the embedding model at the graph level is shown in Figure 8. It illustrates the graph-level embedding model, which functions as the final aggregation step in Part 3 of our framework. The model converts the set of vertex-level entity embeddings (En × d) into a single, comprehensive graph embedding (C(E)d) by employing a dual-branch structure. The top branch calculates the global information of the graph through a linear average of the entity embeddings, followed by a weighted transformation and tanh activation to normalize the result. Simultaneously, the bottom branch incorporates the importance or confidence of individual entities (En) using a $\text{sigmoid}$ function, which generates normalized weights to be applied to the entity embeddings before further processing. By combining the outputs of these two branches, the final graph embedding C(E)d is obtained, effectively encoding both the global entity context and the local structural importance into a fixed-size vector for subsequent similarity measurement.
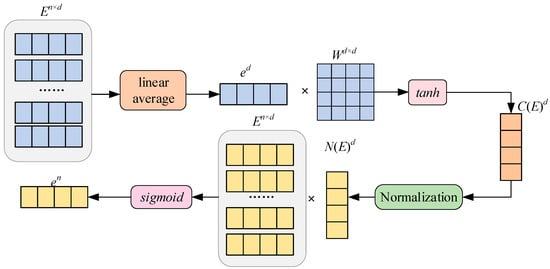
Figure 8.
Embedding of graph level.
In the embedding of the graph level, the input is the embedded representation E of the entity. The embedded representation of the entity is linearly averaged to obtain the global information ed of the entity first. After that, a nonlinear transformation of ed and Wd × d is conducted. The result is unified between [−1, 1] through the tanh activation function. The calculation formula is detailed in Formula (14):
where xi is a concrete vector, and W is a learnable matrix.
In Formula (14), c(x) provides the structure information and characteristic information of the graph. In order to distinguish each entity in the graph, the specific weights of each entity are given. The attention function c(x) is the inner product with the embedded representation of each entity to obtain the improved entity representation, and the improved entity representation is linearly weighted to obtain the weighted embedded representation. The weighted embedding average of entities, predicates, and attributes is taken as the embedding representation of the graph and is computed as shown in (15):
where a() means averaging and f() is the activation function sigmoid, which guarantees that the vector is in the interval [0, 1].
After obtaining the embedded representation of the graph level, we define sim to calculate the similarity between the two graphs, and the calculation method is shown in Formula (16).
4. Experiment
4.1. Experiment Setup
This paper uses the English version of DBpedia, which includes 6.7 M entities, 1.4 K relationships and 583 M triples. LC-QuAD is a commonly used question-and-answer dataset based on DBpedia. It contains 5000 queries and the standard results returned by queries. QALD, also based on DBpedia, is an open-data question-and-answer evaluation system that provides standard answers for each query. We chose QALD-6 and QALD-7 as verification sets. The analysis of the dataset is shown in Table 1.

Table 1.
Statistics of the dataset.
All experiments are based on Windows 10 OS, Intel Core i5-1.9 GHz CPU, 8 GB RAM, and all algorithms are based on Python 3.7.
4.2. Experimental Results
We compare the TLAQ with FSTRR [36], WDA [37], and Tree-KGQA [38] in terms of precision, recall, and F1-Score to evaluate the effectiveness of our method. The precision, recall, and F1-Score on the LC-QuAD dataset are shown in Figure 9 and Table 2. Based on Figure 9, horizontal analysis shows that with the increase in k, the precision of the four algorithms has increased. Because most of the problems contained in this dataset are multi-result problems, the larger the k value, the more correct query results will be returned in the result set. Through longitudinal analysis, TLAQ shows advantages under different k values. When k = 20, compared with the FSTRR algorithm, the precision of TLAQ is improved by 75%. The average performance improvement rate of precision is 27.2% compared with the WDA algorithm.
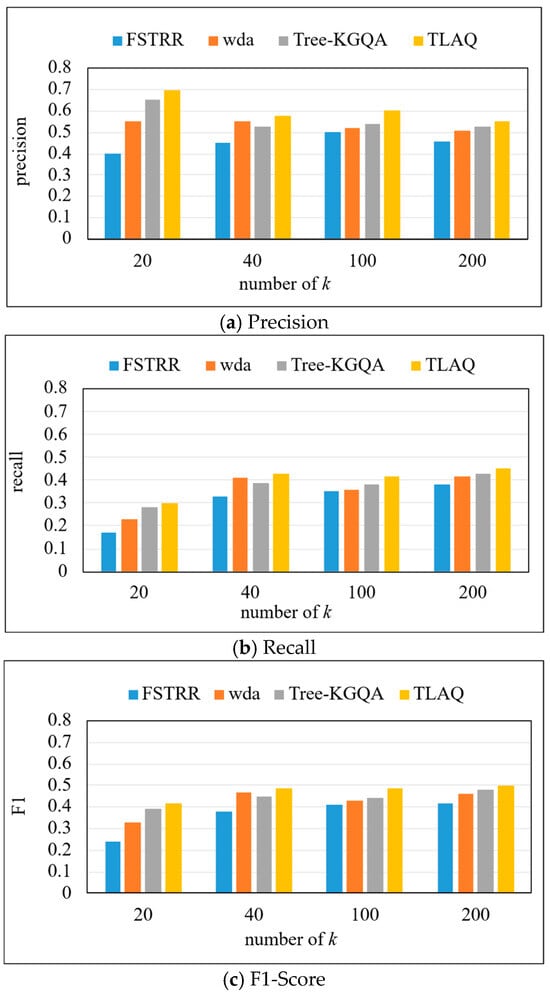
Figure 9.
The precision, recall, and F1-Score on LC-QuAD.
Table 2.
The precision, recall, and F1-Score on LC-QuAD (top-k = 20, 40, 100, 200).
This is because TLAQ processes entity query and attribute query separately and considers entity context information and attribute similarity information. The FSTRR algorithm only considers the weights of entities and attributes but does not consider their context information, which makes some semantically related entities lost in the query. Moreover, the FSTRR algorithm only considers the similarity of numeric attributes in query and does not include the semantic relevance of literal attributes in the screening of query conditions. It can also be found that the precision of TLAQ is less affected by k, which shows that TLAQ has certain stability and scalability. The F1-Score of all four algorithms increases as k increases, which indicates that the average performance of the algorithms improves as long as the number of allowed results is large enough. The F1-Score of TLAQ is relatively stable and it can reach about 0.42 even at k = 20.
The precision, recall, and F1-Score on the QALD-6 dataset are shown in Figure 10 and Table 3. The experiment selects the first 20, 40, 100, and 200 query results, respectively, to calculate the precision, recall, and F1-Score of each query problem and calculate their average. Based on the data in Figure 10, horizontal analysis shows that with the increase in k, the precision of the four algorithms increases. Under four different k values, TLAQ shows advantages. Compared with FSRTT, the average performance improvement rates of WDA and Tree-KGQA are 66.7%, 25% and 12.3%, respectively, at k = 20. Although the precision of TLAQ is improved compared with other algorithms, the overall performance of the model is not as good as that of LC-QuAD dataset. There may be two reasons for the above phenomenon. The first is that LC-QuAD is a question–answer dataset published in 2017. The questions in the dataset are relatively simple, including most single-hop problems and untyped questions. So, most algorithms can achieve 50% or even 60% accuracy on this dataset. The second reason is that the QALD-6 dataset contains richer questions with additional entity information in the query results. In addition, complex questions in QALD-6 account for more than 40% of the total questions, and these questions contain more complex syntactic structures and semantic relations than LC-QuAD.
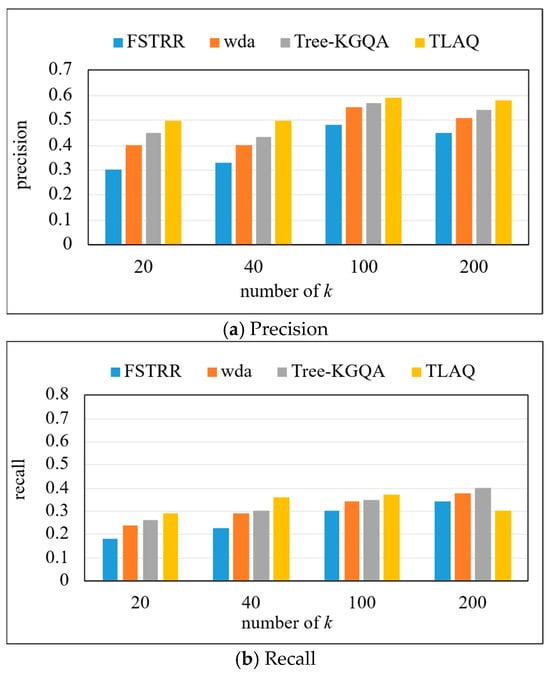
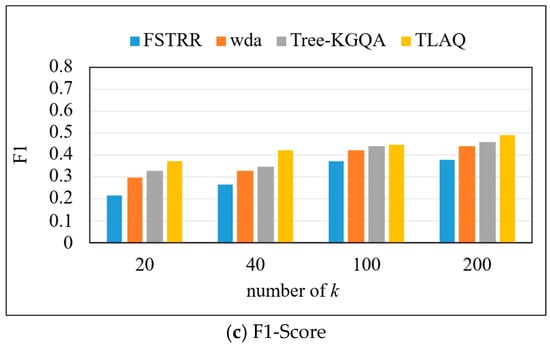
Figure 10.
The precision, recall, and F1-Score on QALD-6.
Table 3.
The precision, recall, and F1-Score on QALD-6 (top-k = 20, 40, 100, 200).
Compared with the LC-QuAD dataset, the recall of the FSTRR algorithm decreases by 10.53%, the WDA algorithm decreases by 9.52%, and the Tree-KGQA algorithm decreases by 6.98% at k = 200. However, the TLAQ is relatively stable, and the F1-Score has been maintained at about 0.49. The F1-Score of the FSTRR algorithm decreased by 9.52%, the F1-Score of the WDA algorithm decreased by 4.35%, and the F1-Score of the Tree-KGQA algorithm decreased by 4.17%. However, the TLAQ is relatively stable, and the F1-Score has been maintained at about 0.49, with a fluctuation of 5.06%. This verifies the superiority of TLAQ from the side, and the performance on different datasets is not very different.
The precision, recall, and F1-Score on the QALD-6 dataset are shown in Figure 11 and Table 4. The experiment selects the first 20, 40, 100, and 200 query results, respectively, to calculate the precision, recall, and F1-Score of each query problem and calculate their average. Based on the data in Figure 11, horizontal analysis shows that the precision of the four methods has the same change trend, which increases first and then decreases, and reaches its highest when k = 100. When k = 100, the precision of TLAQ reaches 0.59. TLAQ shows advantages under four different k. At k = 40, the average performance improvement rates of WDA and Tree-KGQA are 66.7%, 25%, and 12.3%, respectively.
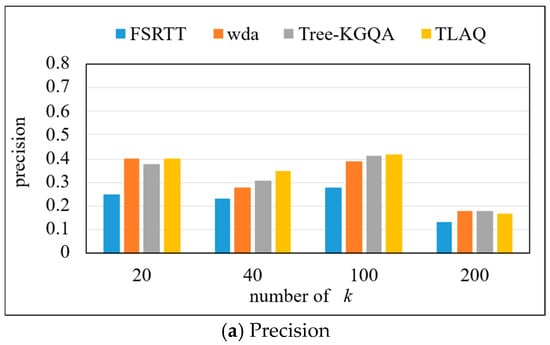
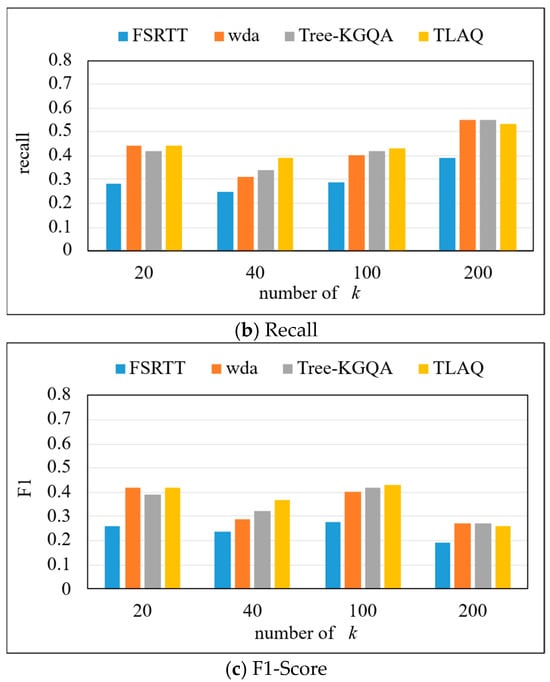
Figure 11.
The precision, recall, and F1-Score on QALD-7.
Table 4.
The precision, recall, and F1-Score on QALD-7 (top-k = 20, 40, 100, 200).
These results can be attributed to TLAQ’s use of temporal information to enhance the embedded representation of entities and attributes. When answering questions related to time information, the calculated approximate entities are spatially close to the real entities. The WDA model only considers the number of question words contained in the entity labels and the edit distance between them when sorting approximate answers but does not weigh the entities. When the number of results is not limited, such as k = 200, the WDA model can return more correct results, which also leads to a negative average performance improvement rate of TLAQ when k = 200. However, in the actual query process, users often do not care about the results after ranking 100.
To study the execution efficiency of TLAQ, we analyzed its time complexity. In Algorithm 1, which ranks candidate entities based on relational reliability, the time complexity for finding candidate entities is O(S × Nₛ), where S is the number of target entities and Nₛ is the number of neighboring nodes. The time complexity for computing the triplet influence factor for each candidate entity is O(E), where E is the number of candidate entities. The time complexity for calculating the relationship between entities in each triplet and the target entity is O(S × N1), where N1 is the number of relational triplets in the temporal knowledge graph. Thus, the overall time complexity of Algorithm 1 is O(N((S × (N1 + Nₛ)) + E)). In Algorithm 2, which ranks candidate attributes based on attribute credibility, the time complexity for adding entities possessing the target attribute to the entity set is O(A × Nₐ), where A is the number of target attributes and Nₐ is the number of neighboring nodes of entities possessing the target attribute. The time complexity for computing the entity influence factor is O(E), where E is the number of candidate entities. The time complexity for calculating the relationship between attributes in attribute triplets and the target attribute is O(N2), where N2 is the number of triplets in the temporal knowledge graph. Hence, the overall time complexity of Algorithm 2 is O(N((A × (N2 + Nₐ)) + E)). The total time complexity of TLAQ is O(N((S × (N1 + Nₛ)) + A × (N2 + Nₐ)) + E)).
FSTRR compares each entity or attribute in the query with the corresponding entities or attributes in the triplets of the temporal knowledge graph one by one, with a time complexity of O(K × N), where K is the number of triplets corresponding to the query and N is the number of triplets in the temporal knowledge graph. wda mainly includes two algorithms: Algorithm 1 calculates the distance between vertices in the query graph and each vertex in the temporal knowledge graph, with a time complexity of O(N1 × N2 × N3), where N1 is the number of vertices in the query graph, N2 is the number of vertices in the temporal knowledge graph, and N3 is the number of edges satisfying the specified distance. Algorithm 2 generates query sentences and is a recursive algorithm with a time complexity of O(2K), where K is the number of results to be returned. Therefore, the total time complexity of wda is O(N((N1 × N2 × N3) + 2K)). Tree-KGQA decomposes the query graph into multiple trees, forming a forest, and finds answers by identifying K neighbors of nodes in the trees. The time complexity of this algorithm is O(F × R × K), where F is the number of triplets corresponding to the query graph, R is the number of entity relationships in the triplets, and K is the number of results to be returned.
Comparative analysis reveals that TLAQ does not involve recursive operations, and the rational use of pruning reduces the search space, resulting in relatively low time complexity.
5. Conclusions
In this work, we focused on approximate query problems of TKGs. We propose GCN-based relational reliability and translation distance-based attributive confidence in order to find approximate results at the vertex level. To address the temporal information of predicates, we unified the encoding format of temporal information and enhanced the embedding representation of predicates at the graph level. Finally, we introduced a TLAQ method to tackle the approximate query problem. The effectiveness of our approach has been validated through extensive experiments.
There remain several promising directions for future research. In particular, the applied bag-of-words embedding model can be further refined without compromising query efficiency. Additionally, we plan to extend our framework to handle complex logical query structures (e.g., conjunctions with temporal constraints) to better align with real-world query expressiveness requirements. This will bridge the gap between similarity-based approximation and practical query relaxation scenarios in temporal knowledge bases.
Author Contributions
Conceptualization, L.B.; Methodology, J.L. and X.D.; Formal Analysis, J.L. and L.B.; Validation, X.D. and L.B.; Investigation, J.L. and X.D.; Data Curation, X.D.; Writing—Original Draft, X.D. and L.B.; Writing—Review and Editing, J.L. and L.B. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (61402087), the Natural Science Foundation of Hebei Province (F2022501015), the Open Project Fund of the Center of National Railway Intelligent Transportation System Engineering and Technology (RITS2023KF04), and the Key Project Fund of China Academy of Railway Sciences Corporation Limited (2023YJ363).
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. DBpedia—A crystallization point for the web of data. J. Web Semant. 2009, 7, 154–165. [Google Scholar] [CrossRef]
- Ward, M.D.; Beger, A.; Cutler, J. Comparing GDELT and ICEWS event data. Analysis 2013, 21, 267–297. [Google Scholar]
- Zou, L.; Huang, R.; Wang, H.; Yu, J.X.; He, W.; Zhao, D. Natural language question answering over RDF: A graph data driven approach. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; ACM: New York, NY, USA, 2014; pp. 313–324. [Google Scholar]
- Wang, Y.; Khan, A.; Wu, T.; Jin, J.; Yan, H. Semantic guided and response times bounded top-k similarity search over knowledge graphs. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 445–456. [Google Scholar]
- Sun, Y.; Li, G.; Du, J.; Ning, B.; Chen, H. A subgraph matching algorithm based on subgraph index for knowledge graph. Front. Comput. Sci. 2022, 16, 163606. [Google Scholar] [CrossRef]
- Ding, Z.; Ma, Y.; He, B.; Tresp, V. A simple but powerful graph encoder for temporal knowledge graph completion. In Proceedings of the 2023 Intelligent Systems Conference, Amsterdam, The Netherlands, 7–8 September 2023; Springer: Amsterdam, The Netherlands, 2023; pp. 729–747. [Google Scholar]
- Liu, Y.; Ma, Y.; Hildebrandt, M.; Joblin, M.; Tresp, V. TLogic: Temporal logical rules for explainable link forecasting on temporal knowledge graphs. In Proceedings of the 36th AAAI Conference on Artificial Intelligence (AAAI), Virtual, 22 February–1 March 2022; AAAI Press: New York, NY, USA, 2022; pp. 4120–4127. [Google Scholar]
- Elbassuoni, S.; Ramanath, M.; Schenkel, R.; Sydow, M.; Weikum, G. Language-model-based ranking for queries on RDF-graphs. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; ACM: New York, NY, USA, 2009; pp. 977–986. [Google Scholar]
- Hogan, A.; Mellotte, M.; Powell, G.; Stampouli, D. Towards Fuzzy Query-Relaxation for RDF. In The Semantic Web: Research and Applications. ESWC 2012; Simperl, E., Cimiano, P., Polleres, A., Corcho, O., Presutti, V., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7295, pp. 687–702. [Google Scholar]
- Dolog, P.; Stuckenschmidt, H.; Wache, H.; Diederich, J. Relaxing RDF queries based on user and domain preferences. J. Intell. Inf. Syst. 2009, 33, 239–260. [Google Scholar] [CrossRef]
- Fokou, G.; Jean, S.; Hadjali, A.; Baron, M. Handling failing RDF queries: From diagnosis to relaxation. Knowl. Inf. Syst. 2017, 50, 167–195. [Google Scholar] [CrossRef]
- Li, Z.; Wang, X.; Zhao, J.; Guo, W.; Li, J. HyCubE: Efficient knowledge hypergraph 3D circular convolutional embedding. IEEE Trans. Knowl. Data Eng. 2025, 37, 1902–1914. [Google Scholar] [CrossRef]
- Ma, R.; Wang, L.; Wu, H.; Gao, B.; Wang, X.; Zhao, L. Historical trends and normalizing flow for one-shot temporal knowledge graph reasoning. Expert Syst. Appl. 2025, 260, 125–366. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, J.; Bai, D.; Fu, Y.; Zhou, J.; Chen, D. Multi-dimension rotations based on quaternion system for modeling various patterns in temporal knowledge graphs. Knowl.-Based Syst. 2025, 331, 113–114. [Google Scholar] [CrossRef]
- Ma, Y.; Tresp, V.; Daxberger, E.A. Embedding models for episodic knowledge graphs. J. Web Semant. 2019, 59, 100–490. [Google Scholar] [CrossRef]
- Dasgupta, S.S.; Ray, S.N.; Talukdar, P. HyTE: Hyperplane-based temporally aware knowledge graph embedding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018), Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2020; pp. 2001–2011. [Google Scholar]
- Goel, R.; Kazemi, S.M.; Brubaker, M.; Poupart, P. Diachronic embedding for temporal knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI Press: New York, NY, USA, 2020; Volume 34, No. 04, pp. 3988–3995. [Google Scholar]
- Garcia-Duran, A.; Dumančić, S.; Niepert, M. Learning Sequence Encoders for Temporal Knowledge Graph Completion. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 4816–4821. [Google Scholar]
- Zhu, C.; Chen, M.; Fan, C.; Cheng, G.; Zhang, Y. Learning from history: Modeling temporal knowledge graphs with sequential copy-generation networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; AAAI Press: New York, NY, USA, 2021; Volume 35, No. 5, pp. 4732–4740. [Google Scholar]
- Jin, W.; Qu, M.; Jin, X.; Ren, X. Recurrent Event Network: Autoregressive Structure Inference over Temporal Knowledge Graphs. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Brussels, Belgium, 2020; pp. 6669–6683. [Google Scholar]
- Sankar, A.; Wu, Y.; Gou, L.; Zhang, W.; Yang, H. DySAT: Deep neural representation learning on dynamic graphs via self-attention networks. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 519–527. [Google Scholar]
- Pareja, A.; Domeniconi, G.; Chen, J.; Ma, T.; Suzumura, T.; Kanezashi, H.; Kaler, T.; Schardl, T.; Leiserson, C. EvolveGCN: Evolving graph convolutional networks for dynamic graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI Press: New York, NY, USA, 2020; Volume 34, No. 04, pp. 5363–5370. [Google Scholar]
- Han, Z.; Chen, P.; Ma, Y.; Tresp, V. Explainable subgraph reasoning for forecasting on temporal knowledge graphs. In International Conference on Learning Representations, Online, 3–7 May 2021; OpenReview.net: Alameda, CA, USA, 2021; pp. 1–24. [Google Scholar]
- Miller, A.; Fisch, A.; Dodge, J.; Karimi, A.-H.; Bordes, A.; Weston, J. Key-Value Memory Networks for Directly Reading Documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1400–1409. [Google Scholar]
- Sun, H.; Dhingra, B.; Zaheer, M.; Mazaitis, K.; Salakhutdinov, R.; Cohen, W. Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 4231–4242. [Google Scholar]
- Sun, H.; Bedrax-Weiss, T.; Cohen, W. PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Brussels, Belgium, 2019; pp. 2380–2390. [Google Scholar]
- Saxena, A.; Tripathi, A.; Talukdar, P. Improving multi-hop question answering over knowledge graphs using knowledge base embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Brussels, Belgium, 2020; pp. 4498–4507. [Google Scholar]
- Bai, Y.; Ding, H.; Bian, S.; Chen, T.; Sun, Y.; Wang, W. SimGNN: A neural network approach to fast graph similarity computation. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 384–392. [Google Scholar]
- Yang, L.; Zou, L. Noah: Neural-optimized A Search Algorithm for Graph Edit Distance Computation. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 576–587. [Google Scholar]
- Gao, Y.; Bai, L.; Shi, R.; Jiang, H. Time-weaver query in sparse temporal knowledge graphs leveraging complex space embedding and adjacent timestamp relations. Expert Syst. Appl. 2025, 299, 130177. [Google Scholar] [CrossRef]
- Chen, Y.; Li, H.; Qi, G.; Wu, T.; Wang, T. Outlining and Filling: Hierarchical Query Graph Generation for Answering Complex Questions Over Knowledge Graphs. IEEE Trans. Knowl. Data Eng. 2023, 35, 8343–8357. [Google Scholar] [CrossRef]
- Liang, S.; Stockinger, K.; de Farias, T.M.; Anisimova, M.; Gil, M. Querying knowledge graphs in natural language. J. Big Data 2021, 8, 3. [Google Scholar] [CrossRef] [PubMed]
- Shin, S.; Jin, X.; Jung, J.; Lee, K.-H. Predicate constraints-based question answering over knowledge graph. Inf. Process. Manag. 2019, 56, 445–462. [Google Scholar] [CrossRef]
- Zheng, W.; Cheng, H.; Yu, J.X.; Zou, L.; Zhao, K. Interactive natural language question answering over knowledge graphs. Inf. Sci. 2019, 481, 141–159. [Google Scholar] [CrossRef]
- Leblay, J.; Chekol, M.W.; Liu, X. Towards temporal knowledge graph embeddings with arbitrary time precision. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 685–694. [Google Scholar]
- Di, X.; Wang, J.; Cheng, S.; Bai, L. Pattern Match Query for Spatiotemporal RDF Graph. In Advances in Natural Computation, Fuzzy Systems and Knowledge Discovery. ICNC-FSKD 2019; Liu, Y., Wang, L., Zhao, L., Yu, Z., Eds.; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2020; Volume 1075, pp. 532–539. [Google Scholar]
- Diefenbach, D.; Both, A.; Singh, K.; Maret, P. Towards a question answering system over the semantic web. Semant. Web 2020, 11, 421–439. [Google Scholar] [CrossRef]
- Rony, M.R.A.H.; Chaudhuri, D.; Usbeck, R.; Lehmann, J. Tree-KGQA: An unsupervised approach for question answering over knowledge graphs. IEEE Access 2022, 10, 50467–50478. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).