Abstract
A Bayesian approach for constructing ARMA probability density estimators is proposed. Such estimators are ratios of trigonometric polynomials and have a number of advantages over Fourier series estimators, including parsimony and greater efficiency under common conditions. The Bayesian approach is carried out via MCMC, the output of which can be used to obtain probability intervals for unknown parameters and the underlying density. Finite sample efficiency and methods for choosing the estimator’s smoothing parameter are considered in a simulation study, and the ideas are illustrated with data on a wine attribute.
1. Introduction
Density estimators based on ratios of trigonometric polynomials, or ARMA estimators [1,2], have a number of motivations, including parsimony and the fact that they mitigate the spurious modes that are a well-known deficiency of truncated Fourier series estimators. Also important is a super-efficiency result documented in [1], where it is shown that, under standard sets of conditions, a certain ARMA estimator has asymptotically smaller mean integrated squared error than that of any tapered Fourier series estimator. Nonetheless, ARMA density estimators have not attracted a great deal of attention. The author is unaware of any literature on the subject other than [1,2,3]. There has been some recent interest, however, in using rational functions for regression analysis [4].
One problem with the estimates considered in [1] is that they do not guarantee positivity. In this paper, we propose a Bayesian implementation of ARMA estimators that guarantees positivity but nonetheless has the attractive properties mentioned above. The Bayesian approach also leads to readily available probability intervals for unknown parameters and bands for the underlying density itself.
One might ask why it is necessary to consider ARMA density estimators in light of the preponderance of methods that exist for density estimation [5]. A main reason for doing so is the dearth of literature on such estimators in spite of the attractive properties they possess, as mentioned above. One aspect of ARMA estimators that has received scant attention is parameter estimation. In this paper, parameters are estimated via a Bayesian approach, which, of course, is essentially equivalent to maximum likelihood in large samples. ARMA estimators based on maximum likelihood promise to be more efficient than those of [1,3]. It is therefore possible that the advantages documented in [1] are actually somewhat understated.
The rest of the paper will proceed as follows: ARMA estimators and our basic approach are introduced in Section 2, while the advantages of ARMA representations over those of the truncated Fourier series variety are illustrated in Section 3. Details of our Bayesian implementation are given in Section 4, and results of a simulation study described in Section 5. A data analysis involving a wine attribute is presented in Section 6, and, finally, a few concluding remarks are given in Section 7.
2. ARMA Probability Density Estimators
In the following, we shall assume that a random sample is available from a square integrable density f that has support . These data are to be used to obtain a nonparametric estimate of f. Let and be vectors of real-valued parameters. Then, an ARMA representation of f has the form
where . (Subsequently, i is used only in this way and not as an index.) The name ARMA derives from the fact that has the same form as the spectral density of an autoregressive moving average process [6]. The multiplicative constant that is needed to make integrate to 1 can be determined from and by solving a system of linear equations [6]. To ensure identifiability of the density, one may impose the condition that all zeroes of the two polynomials
lie outside the unit circle in the complex plane. Choosing parameters that satisfy this condition will be addressed in Section 4.
To fit ARMA representations to data, one must choose values for p and q and estimate the parameters and . Our approach to parameter estimation is Bayesian. For a given p and q, we propose a prior for the unknown parameters and then explore the resulting posterior distribution by means of MCMC. For large sample sizes such an approach is essentially maximum likelihood, but with the advantage of readily available uncertainty intervals for parameters.
As for p and q, we will fix p at 2 and then select q from the data. Two means for selecting q are considered, one being BIC, the Bayes information criterion, and the other the principled Bayesian approach of choosing a model to maximize posterior probability. While we do not rule out the possibility of considering other choices of p, there are a number of advantages to using . One is the obvious simplicity of having but a single smoothing parameter to select. More importantly though, the ARMA representation by itself has qualitative and quantitative advantages over Fourier series estimators, the primary competitors of ARMA estimators. These advantages will be discussed subsequently.
It is important to appreciate the difference between the density estimators in [1] and the ones just proposed. The former estimators may be expressed as
where and are explicit functions of sample Fourier coefficients and . The super-efficiency [1] of (3) is derived by regarding as a smoothing parameter, but [1] only addressed the practical choice of in a small simulation study. The numerator of the ARMA representation (1) may be written as , where are explicitly determined by . This means that (3) and (1) (for ) have the same basic form, but there is a fundamental difference between the two. Unlike (1), (3) can take on negative values. One of the main points of this paper is to show that the positivity of our ARMA estimators does not prevent them from achieving the desirable properties of (3).
Estimator (3) and, as we will show, our ARMA estimators may be motivated in several ways, the principal of which are the following:
- Super-efficiency: Suppose that is square integrable and that one and only one of and is 0. Then, refs. [1,7,8] the asymptotic mean integrated squared error (MISE) of (3) with an optimum is smaller than that of any Fourier series estimator, regardless of the taper used. For two additional settings, a similar super-efficiency result [1] can be attained by using a version of (3) with denominator . One setting is that just discussed but with both and nonzero, and the other is when has a singularity in the interval , rather than at the boundary. An example of the latter case is a density, such as the Laplace, that has a cusp.
- Parsimony: The efficiency gains discussed immediately above result even though (3) uses [1,2] considerably fewer parameters than truncated cosine series estimators. For example, in the case where , and is square integrable, the optimum version of (3) uses only about 39% as many Fourier coefficients as does the best truncated series estimator. Parsimony can lead to better resolution of peaks when the sample size is not sufficiently large.
- Removal of spurious modes: Truncated Fourier series estimators often contain spurious modes, mainly when the underlying density has a sharp peak. Our ARMA estimator mitigates this problem since the autoregressive component can effectively deal with the sharp peak, leaving the moving average component to deal with more subtle features.
3. Illustrating Advantages of ARMA Representations
Here, we will compare the performance of ARMA and Fourier series representations with respect to integrated squared error and qualitative features. The comparison allows us to illustrate notions discussed in the previous section. The (cosine) Fourier series of a square integrable density f with support is
where the Fourier coefficients are
A truncated series representation of f is
and has the property that it minimizes the integrated squared error (ISE) among all linear combinations of , . This attractive property is tempered by the observation that need not be nonnegative, a decidedly unattractive aspect of a density representation.
A moving average (MA) representation for f has the form
where each is a function of . Inasmuch as is a linear combination of cosines, it must have an integrated squared error at least as large as that of . On the other hand, is guaranteed to be a density. We will compare plots and ISE of and for various choices of m and q in a case where f is rather peaked, a situation where the spurious modes of are prominent.
We consider a wrapped normal distribution for f. Such densities have been investigated in the context of circular data [9]. Let be a standard normal density and suppose that X is normally distributed with mean and standard deviation . Then, a wrapped version, , of X is defined by
which has density
A plot of this density when and is seen in Figure 1. Also seen there are Fourier series approximations and . The latter of these does a good job of resolving the peak, but both and have spurious modes in the tails. These features are due, of course, to the fact that the cosine series may be expressed as a convolution of f and the Dirichlet kernel, which has oscillating tails.
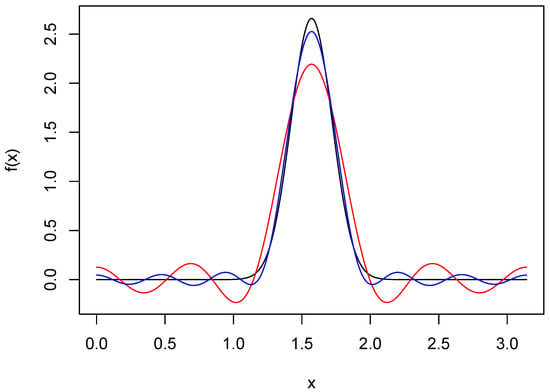
Figure 1.
Fourier series approximations of wrapped normal density. The black curve is the wrapped normal density f with and . The red and blue curves are Fourier series approximations of f based on truncation points 8 and 12, respectively.
Let be the MA representation for f that minimizes ISE. To see the price paid for guaranteed positivity, we show in Figure 2 and in the case of the wrapped normal density. The resolution of the peaks has been greatly compromised, and there are also oscillations in the tails.
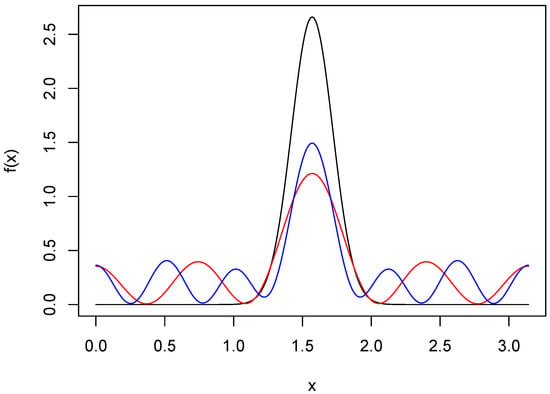
Figure 2.
Moving average approximations of wrapped normal density. The black curve is the wrapped normal density f with and . The red and blue curves are MA approximations of f based on 8 and 12 terms, respectively.
ARMA approximations of orders (2,4) and (2,6) are shown in Figure 3. The resolution of the peak is excellent for both, and the spurious modes in the tails have been greatly mitigated. The ISEs for all the approximants shown in the three figures were computed and are given in Table 1. Most noteworthy is the fact that the ISE of the ARMA(2,6) approximant is ten times smaller than that of , even though both are based on the same number of parameters. This, of course, is not a contradiction, since the ARMA(2,6) approximant does not have a truncated series, but rather one for which the Fourier coefficients decay to 0 geometrically. The approximant has an ISE comparable to that of the ARMA(2,6), but requires four more parameters, thus illustrating the parsimony possible with ARMA approximants.
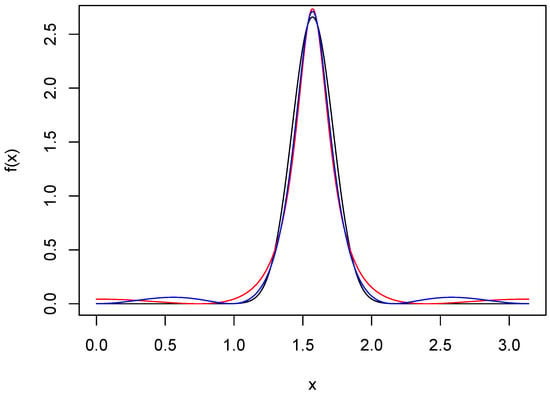
Figure 3.
ARMA approximations of wrapped normal density. The black curve is the wrapped normal density f with and . The red and blue curves are ARMA(2,4) and ARMA(2,6) approximations, respectively.

Table 1.
Integrated squared error of various approximants. A cosine series with q terms is denoted . The parameters of the MA and ARMA approximations were chosen to minimize ISE.
4. Implementation
In order for the parameterization in (1) to be identifiable, it is necessary that the polynomials (2) have zeroes that lie outside the unit circle. Determining the corresponding parameter space is awkward at best, which makes use of this parameterization problematic in a Bayesian context. Fortunately, an alternative parameterization that neatly takes care of this problem was discovered [10]. Let . Then, there exists [10] a 1–1 mapping from to the set of all that satisfy the identifiability constraint. If were the parameters of a stationary autoregressive process (in the time series context), the corresponding s would be the partial autocorrelations of the process [6]. The parameterization in terms of partial autocorrelations has been used [11] in a Bayesian modeling of stationary autoregressive time series.
Letting and , the mappings into the identifiable parameter spaces of and will be denoted and . We assume that the components of and are a priori independent and identically distributed with common uniform distribution on . The posterior distribution is therefore such that
where is the vector of data and is the multiplicative constant needed to make a density.
The posterior distribution will be approximated using a single-component Metropolis–Hastings version of MCMC. Proposal distributions for the components of and are based on rescaled and shifted beta densities. Let and , and take
If U is a random variable with beta distribution having parameters a and b as defined in (4), then the random variable has support , mean , and variance . We shall use to denote the density of .
At each iteration of the Markov chain, parameters are updated one at a time in the order . At the jth stage of an iteration, a proposal distribution of the form is used, . At iteration t, suppose that the chain is in state . The first step of iteration generates a candidate for from a proposal distribution with density . The candidate is accepted with probability equal to the smaller of 1 and
At subsequent stages of iteration , parameters previous to the one being updated are at their updated values, while parameters after the one being updated are at their iteration t values. For example, suppose that is being updated. Then, a candidate is generated from and is accepted with probability equal to the smaller of 1 and
In principle, the scale parameters could be chosen differently to produce the best mixing, but the author has had success using a single, well-chosen value of s.
Nonparametric density estimation always requires the choice of at least one smoothing parameter, whose role is played by q in our methodology. One method of choosing q is to use the Bayes Information Criterion, or BIC. Letting be the maximum likelihood estimate of , the is defined by
The BIC choice of q is the one that minimizes . For each q, an excellent approximation of the maximum likelihood estimate is obtained by using the parameters that maximize the likelihood over a large number of draws from the posterior distribution.
The principled Bayesian approach to choosing q would be to assign prior probabilities to each model and then select the q that maximizes the posterior probability. In a general context, suppose the models being considered are . The marginal likelihood of model with observed data , parameter , prior and observed likelihood is
and the posterior probability of model is
where are the prior model probabilities.
When the number of parameters is large, computation of the marginal likelihoods can be challenging. However, good approximations of these quantities are often possible using the method of Laplace [12]. A Laplace approximation of is
where is the dimensionality of , is the maximum likelihood estimate (MLE) of , and is the covariance matrix of . The more crude approximation of provided by BIC is . Our subsequent numerical results will compare BIC and a posterior probability approach that uses Laplace approximations of marginal likelihoods. We will refer to the latter method as Laplace.
5. Simulations
An initial small simulation was conducted to gain some insight about our MCMC procedure and the relative performance of schemes for choosing the moving average order. Because several large samples are drawn from posteriors for each dataset, only 20 replications were considered. Letting be a beta density with parameters a and b, and defining density g by
the subject of our simulation is , , which is the black curve in Figure 4 and Figure 5. Twenty independent random samples of each were drawn from f.
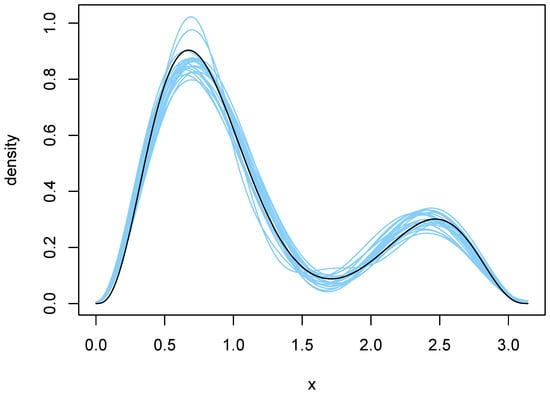
Figure 4.
Density estimates resulting from use of BIC. The blue curves are the twenty density estimates chosen by BIC, and the black curve is the true density f.
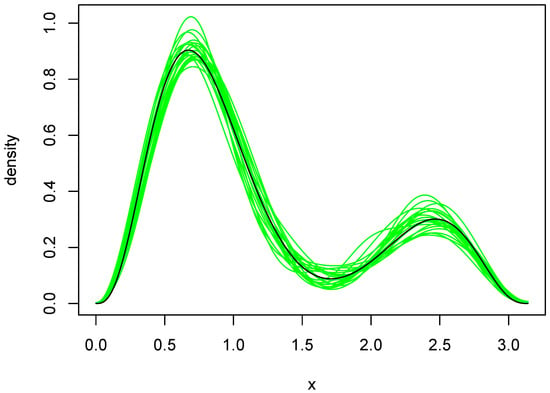
Figure 5.
Density estimates resulting from use of the Laplace method. The green curves are the twenty density estimates chosen by the Laplace method, and the black curve is the true density f.
For each dataset, an MCMC procedure as described in Section 4 was conducted for . The value of the scale parameter s was 0.10 for all proposal distributions. For each q, an initial set of 10,000 iterations was conducted using starting values of 0 for all components of . Because of the arbitrariness of the starting values, there was a fairly long burn-in period for at least some values of q. We therefore obtained parameter estimates from the initial 10,000 iterations and used them as starting values in a second set of 100,000 iterations, which was the output ultimately used to obtain our results. Mixing of and tended to be somewhat better than that of the components of . In addition, not surprisingly, mixing of the output was better at smaller q than at larger ones. In any event, 100,000 iterations appeared to be more than adequate, even when . Typical examples of the output obtained are given in Figure 6 and Figure 7.
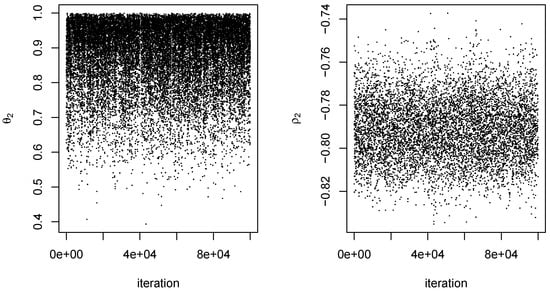
Figure 6.
MCMC output for from one dataset. Outputs on the left and right are for the parameters and , respectively. Iteration is an index for the 100,000 steps of the Markov chain.
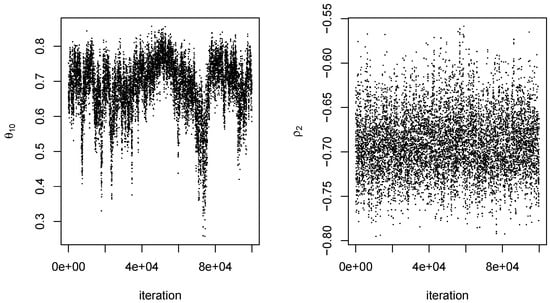
Figure 7.
MCMC output for from the same dataset as in Figure 6. Outputs on the left and right are for parameters and , respectively.
For a given dataset and each q, the value of was calculated using the maximum of all likelihoods over the 100,000 iterations for that q. In addition, posterior probabilities were approximated using the Laplace method, as discussed in Section 4. The requisite covariance matrices in the latter method were estimated by sample covariance matrices of MCMC output.
The orders selected by BIC and the Laplace method are shown in Table 2. BIC was remarkably stable, choosing in 18 of the 20 cases. The Laplace method was somewhat more variable and yielded an average q of . Plots of the 20 density estimates chosen by each method are shown in Figure 4 and Figure 5. The parameters of each density were obtained by averaging over all MCMC outputs at the selected value of q. Both methods capture the two main features of the true density, but the estimates chosen by the Laplace method are somewhat more variable, reflecting the larger variability of the Laplace method in selecting q.
Table 2.
Distribution of data-driven moving average orders in the simulation. Each table value is the number of times an order was chosen out of 20 replications.
To further compare the two sets of density estimates, we calculated Kullback–Leibler (KL) divergences of the estimates from the true density. These quantities were approximated by numerical integration, using the function integrate in [13]. The average divergences were and for BIC and Laplace, respectively. Furthermore, the KL divergence of the Laplace estimate was smaller than that of the BIC estimate in 14 of the 20 cases. So, in spite of being somewhat more variable, the Laplace estimates tended to be a bit closer to the truth. Close examination of Figure 4 and Figure 5 reveals why this is so. The BIC estimates are more biased near the larger peak, tending to undershoot it slightly.
A second set of simulations was conducted to investigate whether or not the proposed ARMA estimators can achieve the super-efficiency of (3). Two main factors affect the efficiency of an ARMA estimator: its order and the method of parameter estimation. In this simulation, our focus was on the effect of the latter. The subject of our second simulation was the following wrapped exponential density:
This density has a square integrable second derivative and is such that , , and therefore satisfies the conditions guaranteeing super-efficiency of (3). Data may be generated from (7) by first generating data from an exponential density with rate parameter 2 and then using the wrapped construction detailed in [1].
We compared the observed ISE of ARMA and ARMA estimators with that of a truncated series estimator. Four sample sizes, and 2000, were considered, with 1000 replications performed at each sample size. Asymptotically optimal orders (Theorem 1, [1]) for the truncated series estimator and (3) were and , respectively. Evaluating these two orders at the wrapped exponential density (7) yielded
Interpreting the last two expressions as being rounded to the nearest integer, both ARMA estimators in our simulation used a moving average term of order . Parameters of the two models were estimated by maximum likelihood, which was accomplished via the function optim in [13]. The series estimator used the truncation point .
The ISE results are summarized in Table 3. Both the mean and median ISE of the ARMA estimators were uniformly smaller than the corresponding values for the simple series estimator. Also provided in Table 3 are asymptotic approximations [1] to the MISE of the very best tapered series estimator. At , the ratio of mean ISE for ARMA to optimum MISE was , which compares favorably with the asymptotic relative efficiency of 0.629 reported in [1]. Inasmuch as the ARMA estimator is a special case of the ARMA, one would expect the latter estimator to also have the super-efficiency property. Indeed, this appears to be the case. A small price in terms of MISE is paid by using ARMA when ARMA is ideal, but this should be weighed against the advantage of using an estimator that can also deal effectively with a peak in the interval .
Table 3.
Integrated squared error summary of the simulation with wrapped exponential density. The moving average order is the asymptotically optimal choice [1]. Simple FS refers to the truncated Fourier series, which used an asymptotic approximation to the MISE optimal truncation point. The numbers in the column “Optimum FS” are asymptotic approximations to the smallest possible mean integrated squared error for a tapered Fourier series.
Another way to show that maximum likelihood estimation is behaving well is to examine the estimates of AR parameters. For the density (7), the asymptotically optimum choice [1] for in estimator (3) is . Since increases without bound as n increases, the optimum tends to 1, albeit quite slowly. For the four sample sizes in our simulation, the values of were , , , and . For the ARMA estimator, the averages of the MLE were , , , and . Hence, maximum likelihood seems to be doing a good job of tracking the parameters that produce super-efficiency. A similar conclusion is drawn about the ARMA estimator upon examining the roots of the polynomial obtained by averaging over all estimates . In all four cases, this polynomial had the form , where and are real with different signs. For an increasing sample size, the four pairs of were , , , and . As in the first-order AR case, this indicates that MLEs are doing a good job of tracking the super-efficient AR parameters.
6. Analysis of Wine Attribute Data
Data on wine attributes are available from the UC Irvine Machine Learning Repository. The data “are the results of a chemical analysis of wines grown in the same region in Italy but derived from three different cultivars”, and have been analyzed in [14]. Here, we consider the attribute ash, which consists of 177 observations. The black curve in Figure 8 is a Gaussian-kernel density estimate for these data, with bandwidth chosen by the normal reference method [5] (p. 45).
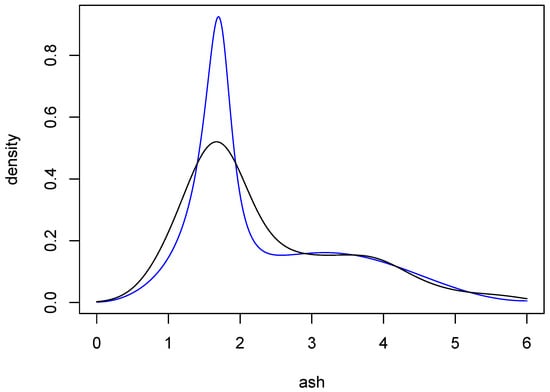
Figure 8.
Density estimates for wine attribute data. The black curve is a Gaussian-kernel density estimate with normal reference bandwidth. The blue curve is an average of ARMA estimates resulting from the procedure described in Section 6.
Our Bayesian ARMA methodology was used to find a point estimate and confidence bands for the underlying density. The data lie on the interval , and were thus rescaled to the interval before being analyzed. One hundred thousand draws from the posterior of each of the models ARMA, , were obtained. The same algorithm and proposal distributions as in our simulation were used, with in each case. Both BIC and the principled Bayesian approach were used to identify good choices for q. For the latter, marginal likelihoods were calculated via importance sampling based on multivariate normal proposal distributions. For a given q, the mean and covariance matrix of the multivariate normal were the sample mean and covariance of the MCMC output for that q. Excellent approximations of marginal likelihoods were obtained by sampling at least one million times from each multivariate normal proposal distribution.
Two sets of approximate posterior probabilities are given in Table 4. One was obtained using BIC and the other with importance sampling, where the prior model probabilities were all 1/11. The two distributions are in remarkable agreement, both being maximized at . The evidence for that choice of q is quite strong, with the probability being more than . Nonetheless, to obtain a point estimate of the underlying density, we used model averaging as follows: At each q, an ARMA density estimate was obtained by averaging over the 100,000 parameter sets generated by MCMC. A weighted average of these 11 estimates was then computed, with the weights being the exact posterior probabilities in Table 4. The result is the blue curve in Figure 8. This estimate is comparable to the kernel estimate, but interestingly the main peak of the ARMA estimate is more sharp than the corresponding peak of the kernel estimate. It is well known that kernel estimates tend to undershoot sharp peaks, and so the ARMA estimate seems to provide a compelling alternative.
Table 4.
Posterior probabilities of model orders for wine attribute data. Probabilities in the first row were approximated using BIC, while those in the second row are essentially exact, being approximated with use of importance sampling. The probabilities for 0 and 10 were 0 to three decimal places.
One of the most attractive aspects of Bayesian methodology is its built-in means of assessing uncertainty. If we assume that the true density can be well approximated by an ARMA(2,10) density, then our procedure can be used to find confidence bands for said density. To obtain these bands, we began by repeating the following process, independently, one million times: A value of q is randomly chosen according to the exact distribution in Table 4, and then a set of parameters, i.e., an ARMA density, is selected from the MCMC output for that q. Using the densities so obtained, it is straightforward to approximate pointwise posterior probability intervals at a fine grid of x-values for any given probability. Call the two curves resulting from this process and , the lower and upper sets of intervals, respectively. One may now determine the proportion, p, of the 1,000,000 selected densities that lie completely between and , in which case ℓ and u are posterior probability bands of level p.
The procedure just described was carried out with a grid of 200 evenly spaced points on the interval . Using various choices of probability levels for the pointwise intervals, it was found that when the pointwise probability level was 0.998, the corresponding ℓ and u contained more than 95% of the 1,000,000 ARMA estimates. The (approximate) 95% posterior probability bands so obtained are shown in Figure 9, along with the ARMA estimate from Figure 8. In fairness, the kernel estimate from Figure 8 also lies within these bands.
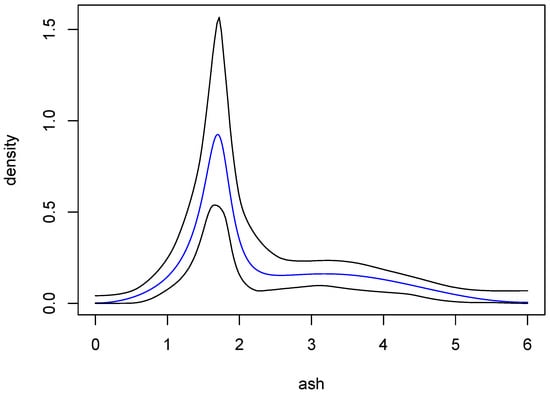
Figure 9.
Approximate 95% posterior probability bands for the density of the ash variable. The black curves are the bands and the blue curve is the same ARMA estimate as in Figure 8.
7. Concluding Remarks
We have proposed a Bayesian implementation of ARMA probability density estimators. In general, ARMA estimators are motivated by their parsimony and potential super-efficiency [1] relative to Fourier series estimators. A simulation study provided strong evidence that our ARMA estimators do indeed attain super-efficiency. An advantage of the Bayesian approach is that it allows straightforward assessments of uncertainty using the output from MCMC. In particular, posterior probability bands for the underlying density are possible, as was illustrated using wine attribute data. The focus in this paper was on ARMA estimators with AR order equal to 2, but higher order AR representations may also be useful.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hart, J.D. An ARMA type probability density estimator. Ann. Stat. 1988, 16, 842–855. [Google Scholar] [CrossRef]
- Hart, J.D.; Gray, H.L. The ARMA method of approximating probability density functions. J. Statist. Plann. Inference 1985, 12, 137–152. [Google Scholar] [CrossRef]
- Carmichael, J.P. Consistency of an autoregressive density estimator. Math. Operationsforsch. Stat. Ser. Stat. 1984, 15, 383–387. [Google Scholar]
- Aydin, D.; Yilmaz, E.; Chamidah, N. Rational (Padé) approximation for estimating the components of the partially-linear regression model. Inverse Probl. Sci. Eng. 2021, 29, 2971–3005. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman & Hall/CRC: London, UK, 1986. [Google Scholar]
- Woodward, W.A.; Gray, H.L.; Elliott, A.C. Applied Time Series Analysis; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Watson, G.S.; Leadbetter, M.R. On the estimation of the probability density. I. Ann. Math. Stat. 1963, 34, 480–491. [Google Scholar] [CrossRef]
- Watson, G.S. Density estimation by orthogonal series. Ann. Math. Stat. 1969, 40, 1496–1498. [Google Scholar] [CrossRef]
- Jammalamadaka, S.R.; Kozubowski, T.J. New families of wrapped distributions for modeling skew circular data. Commun. Stat.—Theory Methods 2004, 33, 2059–2074. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O.; Schou, G. On the parametrization of autoregressive models by partial autocorrelations. J. Multivar. Anal. 1973, 3, 408–419. [Google Scholar] [CrossRef]
- Barnett, G.; Kohn, R.; Sheather, S. Bayesian estimation of an autoregressive model using Markov chain Monte Carlo. J. Econom. 1996, 74, 237–254. [Google Scholar] [CrossRef]
- Small, C.G. Expansions and Asymptoics for Statistics; Chapman & Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2025; Available online: https://www.R-project.org/ (accessed on 10 August 2025).
- Aeberhard, S.; Coomans, D.; de Vel, O. Comparative analysis of statistical pattern recognition methods in high dimensional settings. Pattern Recognit. 1994, 27, 1065–1077. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).