Abstract
Assuming the underlying statistical distribution of data is critical in information theory, as it impacts the accuracy and efficiency of communication and the definition of entropy. The real-world data are widely assumed to follow the normal distribution. To better comprehend the skewness of the data, many models more flexible than the normal distribution have been proposed, such as the generalized alpha skew-t (GAST) distribution. This paper studies some properties of the GAST distribution, including the calculation of the moments, and the relationship between the number of peaks and the GAST parameters with some proofs. For complex probability distributions, representative points (RPs) are useful due to the convenience of manipulation, computation and analysis. The relative entropy of two probability distributions could have been a good criterion for the purpose of generating RPs of a specific distribution but is not popularly used due to computational complexity. Hence, this paper only provides three ways to obtain RPs of the GAST distribution, Monte Carlo (MC), quasi-Monte Carlo (QMC), and mean square error (MSE). The three types of RPs are utilized in estimating moments and densities of the GAST distribution with known and unknown parameters. The MSE representative points perform the best among all case studies. For unknown parameter cases, a revised maximum likelihood estimation (MLE) method of parameter estimation is compared with the plain MLE method. It indicates that the revised MLE method is suitable for the GAST distribution having a unimodal or unobvious bimodal pattern. This paper includes two real-data applications in which the GAST model appears adaptable to various types of data.
1. Introduction
Statistical distributions play a crucial role in information theory since they describe the probability characteristics of data or signals, and hence directly affect the accuracy and efficiency of the representation, transmission, compression, and reconstruction of information. Entropy, as the most important measure in the field of information theory, depends on the statistical distribution of the random variable. In many applications of information theory, it requires the assumption of the statistical distribution of the data. Although assumed to follow the normal distribution in most statistical analyses due to mathematical convenience and generality, real-world data frequently exhibit skewness, leading to the demand for more flexible models. The geometric Brownian motion (GBM) as a popular model of stochastic processes assumes that its solutions follow the log-normal distribution. Gupta et al. (2024) [1] indicated that the GBM yields trajectories significantly deviated from the reference distribution when the data do not meet the log-normal assumption. To deal with the limitations in such a scenario, some may consider correcting the model as in [1]. Constructing alternative distributions of the normal distribution has been a common concern.
The skew-normal (SN) distribution is an extension of the normal distribution that allows for skewness, capable of modeling asymmetric data. It was first introduced by Azzalini (1985) [2]. If a random variable Z has a probability density function (pdf) given by
where and are the pdf and cumulative distribution function (cdf) of the standard normal distribution, then Z follows the SN distribution, denoted as . The parameter s controls the skewness of the distribution. When , the SN distribution reduces to the standard normal distribution. With , the SN distribution is right-skewed, while implies left skewness.
The skew-t (ST) distribution is an intriguing example among scale mixtures of SN distributions. It was first formulated by Branco and Dey (2001) [3] and later extensively studied by Azzalini and Capitanio (2003) [4]. An ST random variable, , can be represented as
where and , i.e., chi-square distribution with degrees of freedom, are independent of each other. The moment of Y exists only when the order is less than , which is the same condition required as the Student’s t-distribution with degrees of freedom, denoted by . The construction method from the SN distribution to the ST distribution is similar to the approach used to derive the Student’s t-distribution from the normal distribution. The pdf of the ST distribution is given by
where is the pdf of , and is the cdf of . The parameter controls the tail heaviness. As approaches infinity, the ST distribution approaches the SN distribution. Lower values of result in heavier tails, providing robustness against outliers. Similar to the SN distribution, the parameter s controls the skewness. When , the ST distribution reduces to the Student’s t-distribution. Azzalini and Genton (2008) [5] conducted a quite extensive numerical exploration, demonstrating that the ST distribution can adapt well to various empirical problems. They utilized an autoregressive model of order one, with and , to fit the 91 monthly interest rates of an Austrian bank. Their results clearly showed that the error components have an ST distribution, where the small degrees of freedom parameter signifies heavy tails in the error distribution, allowing the ST model to better manage outliers than the normal distribution. The ST distribution, which combines the characteristics of the Student’s t-distribution and the SN distribution, is particularly suitable for the applications in finance that need to model returns with skewness and excess kurtosis, as well as in environmental studies where the focus is on modeling extreme events. Martínez-Flórez et al. (2020) [6] also mentioned other kinds of skew distributions like skew-Student-t distribution, skew-Cauchy distribution, skew-logistic distribution and skew-Laplace distribution. They summarized those distributions as skew-elliptical distributions since those distributions have a unified expression form of the density function as
where is a symmetric pdf, and is the corresponding cdf.
Another type of skew distribution is to add a coefficient function with an argument to the density function. Elal-Olivero (2010) [7] proposed a distribution called alpha-skew-normal (ASN), with a pdf defined as
If a random variable X has the pdf as (4), we denote it as . This distribution is more flexible than SN and ST distributions since it can be unimodal or multimodal by adjusting the parameter. When , the ASN distribution reduces to the standard normal distribution, .
Although the ASN distribution is able to model both skew and bimodal data, it has limitations when data have tails thinner or thicker than the normal distribution. In order to fit stock data more accurately, Altun et al. (2018) [8] introduced a new generalized alpha skew-t (GAST) distribution combining the approaches of [4,7]. They combined the GAST distribution with the generalized autoregressive conditional heteroskedasticity (GARCH) model to build a new Value-at-Risk (VaR) prediction model for forecasting daily log returns in three years. They compared the failure rates of the GARCH models under different distribution assumptions including normal, Student’s t, ST and GAST. The results showed that the GAST distribution performs the best in the backtesting. The definition of GAST distribution and its properties with proof will be elaborated in the next section.
For an unknown continuous statistical distribution, an empirical distribution of a random sample is a traditional way to approximate the target distribution. However, it often leads to low accuracy, and hence the support points for the discrete approximation, also known as representative points (RPs), are explored in order to preserve the information of the target distribution as much as possible. Representative points have a big potential for applications in statistical simulation and inference, see Fang and Pan (2023) [9] for a comprehensive review. Various kinds of representative points of different statistical distributions have been explored in the literature. Especially for complex distributions, the study on the representative points is necessary. The concept of representative points is to simplify complex probability distributions with discrete points easier to manipulate, facilitating efficient computations and analyses. These points serve as a finite set that approximates the distribution of a random variable that can be either discrete or continuous and either univariate or multivariate. In this paper, we focus on the study of the representative points of the GAST distribution and applications. We first introduce the concepts of three kinds of RPs here, while the specific construction procedures are included in Section 4 with their applications on the estimation of moments and densities.
There are many existing criteria for choosing RPs of a distribution, such as Monte Carlo RPs (MC-RPs), quasi-Monte Carlo RPs (QMC-RPs) and mean square error RPs (MSE-RPs) that will be introduced as follows. In fact, the Kullback–Leibler (KL) divergence or relative entropy of two probability distributions is a good criterion for this purpose. The entropy has been utilized as a measure of the experimental design, for example, Lin et al. (2022) [10]. Due to computational complexity, entropy is not popularly used in generating RPs in applications. Therefore, in this article, we study MC-RPs, QMC-RPs, and MSE-RPs of the Generalized alpha skew-t distribution only.
1.1. Monte Carlo Representative Points
Let X be the population random variable with the cdf . Various Monte Carlo methods provide ways to generate independent identically distributed (i.i.d.) samples {} from the population, and , . The empirical distribution of the random sample is defined as follows:
where is the indicator function of A. The empirical distribution should be close to in the sense of consistency. Hence, can be regarded as an approximation of . We denote this empirical distribution of random samples generated by the Monte Carlo method as . Traditional statistical inference is based on the empirical distribution. Efron (1979) [11] proposed a resampling technique, the bootstrap method, with which we can take a set of random samples from instead of F. Combined with bootstrap, the MC-RPs have proven to be useful in statistical inference, such as parameter estimation, density estimation and hypothesis testing. However, the MC method has many limitations since the convergence rate of in distribution as , given by , is too slow. The following two kinds of RPs improve the convergence rate nicely.
1.2. Quasi-Monte Carlo Representative Points
For a high-dimensional integration problem:
where f is a continuous function on . Suppose that is a set of n points uniformly scattered in , we can estimate by
If we generate by the MC method, the convergence rate of is as . The quasi-Monte Carlo (QMC) method provides many ways for the construction of to increase the convergence rate. Through the QMC method, the convergence rate can reach according to Fang et al. (1994) [12]. For further theory studies, readers can refer to Hua and Wang (1981) [13] and Niederreiter (1992) [14]. In the study of [12], the F-discrepancy is used to measure the uniformity of in , which is defined by
where is the cdf of uniform distribution and is the empirical distribution of . The that minimizes is called QMC-RPs which have equal probability .
For the univariate distribution of this paper, the QMC method is designed to sample points that are uniformly distributed on the interval . If the inverse function of F exists, then the set of n points:
has been proved to have the minimal F-discrepancy of from [12]. Therefore, the set of points is called the QMC-RPs of . Fang et al. (1994) [12] gave a comprehensive study on QMC methods and their applications in statistical inference, experimental design, geometric probability, and optimization.
1.3. Mean Square Error Representative Points
The concept of MSE-RPs was independently proposed by Cox (1957) [15], Flury (1990) [16] and many others. In the literature, “MSE-RPs” have been called by different names, such as “quantized” and “principal points”. Let a random variable with finite mean and variance . To provide the best representation of F for a given number n, we select a set of n representative points having the least mean square error from , and form a discrete distribution . Denote defined as
with the probability mass function
where are MSE-RPs of X and are the corresponding probabilities with respect to
and
The MSE-RPs have many useful properties. Graf and Luschgy (2007) [17], and Fei (1991) [18] proved that
Hence, converges to X in distribution.
In this paper, Section 2 begins by reviewing the definition and properties of the GAST distribution. To explore the relationship between the classification of the GAST distribution and the three parameters , we apply the uniform design (Wang and Fang 1981 [19]) to arrange the values of parameter combinations, and then depict the corresponding density plots. Section 2 also classifies the GAST distribution according to the number of peaks in the density function with some proofs. The first four order moments and stochastic representation of the GAST distribution are shown in this section. Section 3 mainly introduces a maximum likelihood estimation (MLE) method with a distribution-free quantile estimator: QMC-MLE (Li and Fang 2024 [20]). In this QMC-MLE method, the estimated quantiles of the sample are used to replace the original sample, and then the MLE is performed on the estimated quantiles to obtain the parameter estimates. We explore the parameter estimation effectiveness of QMC-MLE for small samples by simulation in this section. In order to cover both unimodal and bimodal cases, we choose the GAST distribution with different parameter settings as the underlying distributions. In this section, we find that the effectiveness of QMC-MLE in parameter estimation is influenced by the number of peaks of sample. Section 4 calculates the three types of RPs, MC-RPs, QMC-RPs, and MSE-RPs, of the GAST distribution for different sample size n. For MSE-RPs, the calculation process requires a parametric k-means algorithm (Stampfer and Stadlober 2002 [21]). We will compare the estimates of four statistics (mean, variance, skewness and kurtosis) by the three types of RPs of the underlying distributions. Another application of RPs is density estimation. Section 4 combines the kernel density method (Rosenblatt 1956 [22]) and the three types of RPs to estimate the density of the underlying GAST distributions. Section 5 applies the RPs to real data samples to show the outstanding performance of MSE-RPs under the assumption of a GAST model.
2. Generalized Alpha Skew- Distribution
In this section, we give the definition of the density function of the GAST distribution (Altun et al., 2018 [8]) and list some of its commonly used subdistributions. We set the parameter values by the uniform design method (Wang and Fang 1981 [19]) to fully demonstrate the influence of parameters on the shape of the density function. Section 2.2 discusses how the parameters influence the number of peaks of density under four conditions. Section 2.3 and Section 2.4 give the moments and stochastic representation of the GAST distribution, respectively.
2.1. Definition of the GAST Distribution
Definition 1.
(GAST distribution). A random variable X is said to follow the GAST distribution, denoted as , if it has the following pdf
where
Proposition 1.
Proof.
We set a random variable . From the Equation (2), the moments of the ST distribution are given by
Henze (1986) [23] has given the general expression of the odd moments of Z, which is
where . The even moments coincide with the standard normal distribution, because . Hence, the first two moments of ST distribution are, respectively, given by
Then the Equation (12) is proved. □
The GAST distribution involves several popular useful distributions:
- If , the GAST distribution reduces to the skew-t (ST) distribution.
- If , the GAST distribution reduces to the alpha-skew-t (AST) distribution.
- If and , the GAST distribution reduces to the Student’s-t distribution.
- If , the GAST distribution reduces to the alpha-skew-normal (ASN) distribution.
- If , , the GAST distribution reduces to the skew-normal (SN) distribution.
- If , and the GAST distribution reduces to the normal distribution.
In order to depict the GAST densities, especially the characteristics of unimodal or multimodal with different combinations of parameters, the experimental design is used to arrange the parameter values. The uniform design is a number-theoretic method, proposed by Wang and Fang (1981) [19]. As a robust experimental design method, the uniform design has been widely applied in various fields. A uniform design table provides a scientific arrangement of experiments by tabulating the level combinations of factors of interest. Let denote a uniform design with n experimental runs and s factors each having q levels. The uniform design table, , adopted in this paper is derived from the website Uniform-Design-Tables (https://fst.uic.edu.cn/isci/research/Uniform_Design_Tables.htm (accessed on 15 September 2024)). In uniform design tables, the levels of factors are labeled by positive integers. For a unit hypercube experimental region , the levels usually take values . For any hyperrectangle experimental region , a linear transformation is applied. Table 1 lists the arrangement of the uniform design table for the parametric region, , indicating the 16 kinds of parameter settings.

Table 1.
The parameter settings according to a uniform design table .
Figure 1 shows the density plots corresponding to eight parameter settings in Table 1, which are enough to represent the plot of GAST density. As shown in Figure 1, there are four cases in which the pdfs are bimodal and the No. XII and XIV GAST distributions are AST and ST distributions, respectively.
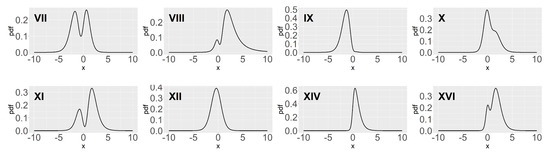
Figure 1.
Some plots of GAST densities with parameters in Table 1.
In Section 2.2, we will show how the parameters and affect the number of peaks of two special types of the GAST distribution, the AST and ST distributions, leading to the two categories, unimodal and bimodal. The number of peaks in the distribution may affect the parameter estimation. For instance, if the sample size is small and the density function presents a bimodal shape, then the sample is likely to miss the turning points, which will affect the parameter estimation to a certain extent. In addition, the calculation of representative points will also be affected, and the accuracy of derivative density estimation may be reduced.
2.2. Unimodal and Bimodal Properties
Since the density plots of the GAST distribution are varied, we will divide the GAST distribution into two categories: unimodal and bimodal. The number of peaks is determined by the number of zeros of the first derivative of (10). If it has one zero, then the density function is unimodal. If it has three zeros, then the density function is bimodal. To simplify the analysis, we consider the situations under four different parameter combinations of and s, , , and . The discussion is as follows:
- (1)
- and
The Student’s t-distribution is a well-known unimodal distribution.
- (2)
- and
The pdf of , , is given by (3), .
Proposition 2.
The skew-t distribution is always unimodal.
Proof.
We derive the first derivative of (3) as follows:
where
Substituting (17) and (18) in Equation (15), we obtain that
As , the solution to can be evaluated by solving the next equation:
Since is symmetric with respect to s:
The number of peaks is not affected by the sign of s such that we assume . From the expression of (19), we can see that , when . When , we have
Hence, is monotonically increasing, while is monotonically decreasing. Therefore, we can deduce that is decreasing when , i.e., , as . Hence, there is only one solution , s.t. . And the ST distribution must be unimodal. □
- (3)
- and
The pdf of is given by
Proposition 3.
The pdf of the AST distribution, as (20), is bimodal if and only if and , where
Otherwise, it is unimodal. It is worth mentioning that a sufficient condition for to be unimodal is
Proof.
Differentiating (20), we obtain
Since is a constant, and , we obtain the equivalent relation expression
Now our problem is transformed into studying the number of zeros of the function . The first derivative of (23) is
This is a quadratic function with a downward opening. The discriminant of is as follows:
If , namely
then is monotonically decreasing. Since , , there must be only one root of , i.e., is unimodal. It is worth mentioning that the parameter setting of No.XII in Table 1 fits this condition.
If , then
We can obtain that
Hence, when , is monotonically increasing. When , is monotonically decreasing. If , then has three zeros, and is bimodal. If condition (22) is met, is unimodal. To sum up, is bimodal if and only if , i.e., condition (22) is not satisfied, and . Otherwise, it is unimodal. □
- (4)
- and
Differentiating the pdf of the GAST distribution as (10), we obtain
Let
Then we have , and we obtain
Due to the complexity of the , it is difficult to study its zeros. The discussion of such a situation remains to be studied.
2.3. Moments of the GAST Distribution
2.4. Stochastic Representation the GAST Distribution
Altun (2018) [8] provided a stochastic representation of as follows.
Theorem 1.
According to (26) given by [8] , we can generate random samples from the GAST distribution by the following procedure:If the random variables and are independent, then we have
- Step 1.
- Generate and .
- Step 2.
- If , then keep W. Otherwise, go to Step 1.
3. Parameter Estimation
In parameter estimation, the maximum likelihood estimation has been widely utilized because of its transitivity. Let be a random sample from the distribution. The log-likelihood function is given by
By taking the partial derivatives with respect to and , we have
where
Remark that , , , and are the partial derivatives of and . The solution satisfying , , at the same time is the MLE of . To solve the system of nonlinear equations in (28), a numerical method is required. In the following subsections, we introduce the algorithm for solving MLE: L-BFGS-B (Byrd et al., 1995 [24]) in Section 3.1. In order to improve estimation accuracy by enhancing sample representativeness, we incorporate a non-parametric quantile estimation method (Harrell and Davis 1982 [25]) introduced in Section 3.2. In Section 3.3, we evaluate the effectiveness of the algorithm and quantile estimation method by simulation. In our study, we use R software version 4.4.1 to conduct simulation.
3.1. L-BFGS-B
L-BFGS-B (Byrd et al., 1995 [24]) is a limited-memory algorithm for solving large nonlinear optimization problems subject to simple bounds on the variables. The essence of the algorithm is a quasi-Newton method. At each iteration, a limited-memory BFGS approximation to the Hessian matrix is updated. This limited-memory matrix is used to define a quadratic model of the objective function, in our study indicating (27). Given a set of samples , the optimization problem can be formulated as follows:
We summarize the procedures of L-BFGS-B as following Algorithm 1.
| Algorithm 1 L-BFGS-B for MLE |
|
We chose the L-BFGS-B algorithm because the degree of freedom must be greater than 2 for the GAST distribution. If the unconstrained optimization method is used, missing values are likely to appear in the optimization process.
3.2. QMC-MLE
In this subsection, we introduce a method for improving the accuracy of MLE. It is well-known that the accuracy of MLE depends on the sample size to a certain extent. If the sample misses the turning points of the population density, it is less representative, which may lead to lower estimation accuracy. This situation is prone to occur in small sized samples and especially bimodal cases. Fang and Wang (1994) [12] pointed out that the set of equal quantiles has the best representativeness in the sense of F-discrepancy. In Section 1, we introduce a QMC method to generate the RPs of a distribution with known parameters. However, for a distribution with unknown parameters, how can we obtain the quantile of the distribution F? Harrell and Davis (1982) [25] proposed a distribution-free method: the Harrell–Davis (HD) quantile estimator. We use this estimator to calculate the set of equal quantiles of F, and then substitute these n quantiles into the likelihood function for calculation. Li and Fang (2024) [20] called the MLE method with HD quantile estimator as QMC-MLE, presented below.
Let be a random sample of size n from the GAST distribution. Denote as the largest value in and as the population quantile.
- Step 1:
- Generate a set of points uniformly scattered on through
- Step 2:
- Use the Harrell–Davis quantile estimator to process sample:whereand denotes the incomplete beta function.
- Step 3:
- Let , for . Therefore, the in the log-likelihood function is replaced by such that the objective function based on the revised sample is
- Step 4:
- Use the L-BFGS-B algorithm to find the MLE of by maximizing (29).
3.3. Simulation
Before the simulation, we introduce four measures of the estimation accuracy: L2.pdf, L2.cdf, absolute bias index (ABI) and Kullback–Leibler (KL) divergence. Denote the true underlying distribution as F in cdf or f in pdf, and the estimated distribution as or . The four measures are defined as follows:
- L2.pdf between two densities is defined as
- L2.cdf between two cdf’s is defined as
- Absolute bias index (ABI) is used to evaluate the overall estimation bias in parameters in which and denote the estimated expectation and standard deviation of the GAST distribution, defined as
- Kullback–Leibler (KL) divergence or the so-called relative entropy is used to measure the difference from one probability distribution to another, defined as follows:
In the simulation, we generate samples by the inverse transformation method and mainly focus on the small sample case. To study both unimodal and bimodal cases, we choose five parameter settings, No.VII, VIII, IX, X and XI, of the GAST distribution from Figure 1 as the underlying distributions, among which the No.VII, VIII, and XI distributions are bimodal. The sample size n is set to be and 300. After times of repetition, the average of is set to be the parameters of the estimated GAST distribution. The precision of the estimates is evaluated by L2.pdf, L2.cdf, ABI and KL, summarized in Table 2, in which “plain” indicates the MLE resulting from the original sample , and “qmc” uses the revised sample .
Table 2.
The comparisons between the plain MLE and QMC-MLE in four measures (; ).
The best performance in the sense of each measure for each pair of distribution type and sample size is highlighted in bold in Table 2. The QMC-MLE method performs better than the plain MLE in most cases, especially for the No.VIII, IX and X distributions. However, for the No.VII and XI distributions, the QMC-MLE has no obvious advantage. The No.IX and X distributions are unimodal, but the No.VIII is bimodal. From the pdf plot of No.VIII distribution, we can see that although it is bimodal, its first peak is not as obvious as the peaks of No.VII and XI distributions. In the pdf plots of No.VII and XI distributions, as x increases, the density function experiences a steep decline after the first peak, while for the No.VIII distribution, the decline lasts only for a short distance before it begins to rise again. Therefore, we have reasons to believe that the QMC-MLE method is more suitable for unimodal functions or bimodal functions of which one peak is not obvious.
In addition, for No.XI GAST distribution, in the sense of KL divergence, the plain MLE is better than the QMC-MLE for all sample sizes. As for the No.XI case under other measures, although the QMC-MLE performs better when and 50, it becomes less effective for and 300, which may be caused by the consistency of MLE. According to the discussion above, when we conduct case studies in Section 5, the QMC-MLE will be only used for unimodal samples in parameter estimation, while for bimodal samples, we will use the plain MLE. Nevertheless, this simulation study reveals that the MLE method (both plain and QMC) is appropriate for estimating the GAST parameters due to the small values of four bias measurements.
4. RPs of the GAST Distribution
Recall that in Section 1, we introduced three types of representative points: MC-RPs, QMC-RPs, and MSE-RPs. In this section, we will find these three types of RPs of the GAST distribution for different sample sizes n, and use them to estimate moments and densities in Section 4.1 and Section 4.2, respectively.
4.1. Moment Estimation
For a given n, MC-RPs will be generated by the inverse transformation method. QMC-RPs can be easily obtained by (6) while MSE-RPs are calculated through a parametric k-means algorithm proposed by Stampfer and Stadlober (2002) [21]. We summarize the computation procedure of the k-means algorithm for approximating MSE-RPs of the GAST distribution as follows.
- Step 1:
- For a given pdf , the number of RPs: n, and , input a set of initial points . Here we take n QMC-RPs as the initial values. Determine a partition of aswhere
- Step 2:
- Calculate probabilitiesand the condition means
- Step 3:
- If two sets, and are identical, the process stops and the outputs as the MSE-RPs of the distribution with probabilities . Otherwise, let and go back to Step 1.
Let Y be a discrete distribution with probability mass function , which is an approximate distribution to the GAST distribution. Then, the estimates of mean, variance, skewness and kurtosis can be calculated by
We use the No.IX, X and XI as the underlying distributions and consider . It is clear that MC-RPs are random samples of size n. For fair comparisons, we generate N samples of size n and then take the average of the estimated statistics as the results of the MC(N) method. In our study, we choose . The true parameters and four statistics of the three underlying distribution are listed in Table 3. The bias of the estimated results is summarized in Table 4, Table 5 and Table 6.
Table 3.
True parameters and statistics of the underlying distributions.
Table 4.
Estimation bias of four statistics for the No.IX distribution .
Table 5.
Estimation bias of four statistics for the No.X distribution .
Table 6.
Estimation bias of four statistics for the No.XI distribution .
The results indicate that the estimates based on MSE-RPs perform the best for all underlying distributions and sample sizes. The performance of MC-RPs is unstable. Sometimes the average estimates of moments based on MC-RPs are more accurate than those based on QMC-RPs, but in general, appear less effective. In addition, we can observe that with the increase in the number n, the overall effect of estimation is better. The estimates of higher-order moments (skewness and kurtosis) are worse than those of lower-order moments (mean and variance).
4.2. Kernel Density Estimation
Another application of representative points is density estimation. In the field of signal transmission, the input signal is often converted into discrete data in the transmitter and then reconstructed in the receiver. For a distribution with unknown parameters, how do we use a set of data to construct its overall density function? Here, we introduce a kernel estimation method proposed by Rosenblatt (1956) [22] and Parzen (1962) [26]. Given a fixed number of points from the original signal, the density estimation of is given by
where is the kernel function is the bandwidth and . The most popular kernel is the standard normal density function
In our study, we employ the representative points from the GAST distribution as the samples with their corresponding probabilities . The density estimation of can be extended to
The choice of the bandwidth h is very important. Here, we set a search range for h. In the following comparisons, we utilize three types of RPs having sample sizes for the kernel density estimation of No.IX, X and XI distributions, and evaluate the performances by the minimum L2.pdf between and .
Table 7, Table 8 and Table 9 show that the kernel density estimation based on MSE-RPs always has the minimum L2.pdf, which decreases as n increases. For the underlying distribution No.IX, we notice that the minimum L2.pdf based on the MSE-RPs with size 10 is only , which is even smaller than that based on the QMC-RPs with size 30 (0.0341). Figure 2, Figure 3 and Figure 4 show the comparing fitting plots of different sets of representative points. It is obvious that the fitting effect increases with n, and the MSE-RPs-based kernel estimation has the best fitting effect, followed by the QMC-RPs-based estimation. It is worth mentioning that for the MC-RPs-based density estimation, due to the randomness of the Monte Carlo method, the density curve fitted out each time differs greatly, and in many cases, it is not sufficient to reconstruct the original density function.
Table 7.
The minimum L2.pdf and the corresponding bandwidth h of the kernel density estimation for No.IX distribution.
Table 8.
The minimum L2.pdf and the corresponding bandwidth h of the kernel density estimation for No.X distribution.
Table 9.
The minimum L2.pdf and the corresponding bandwidth h of the kernel density estimation for No.XI distribution.
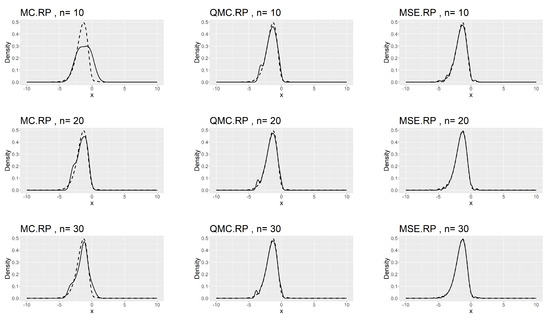
Figure 2.
Comparing plots of the fitted densities (in solid lines) by kernel density estimation and the true densities (in dashed lines) for the No.IX distribution.
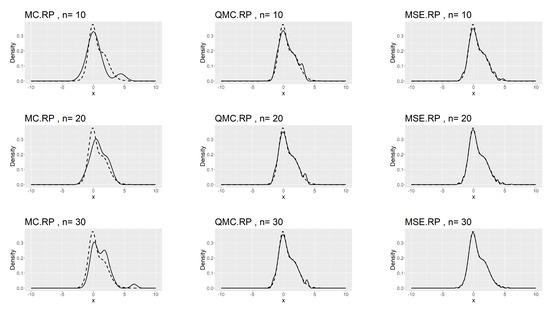
Figure 3.
Comparing plots of the fitted densities (in solid lines) by kernel density estimation and the true densities (in dashed lines) for the No.X distribution.
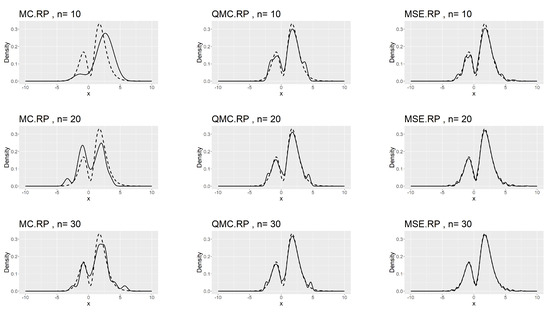
Figure 4.
Comparing plots of the fitted densities (in solid lines) by kernel density estimation and the true densities (in dashed lines) for the No.XI distribution.
5. Case Studies
In this section, we will utilize three types of RPs to study real data samples. Before calculating the RPs, we incorporate two additional parameters in the GAST distribution, the location parameter and the scale parameter , to fit the samples. The pdf is given by
where is the same as that in Formula (11). For the sample data, we choose both unimodal and bimodal types, which are the data and the Faithful Geyser data.
5.1. Data
These data are from the website (https://archive.ics.uci.edu/dataset/360/air+quality (accessed on 15 September 2024)), which contains hourly averaged responses from an Air Quality Chemical Multisensor Device in an Italian city. We selected the “PT08.S5()” (denoted as “” in this article) data as the study object. After setting the interception time from September 1 to November 30 in 2004, and removing the missing values, we derive 90 observations. We summarize the parameter estimation results of obtained by the QMC-MLE in Table 10, providing the estimated GAST model as follows
We present the histogram with the fitted density for data in Figure 5a. After calculating the quantiles of these data by the HD quantile estimator introduced in Section 3.2, we obtain the associated QQ plot given in Figure 5b. Figure 5 shows the good fitting effect of the GAST model on this unimodal data.
Table 10.
Parameter estimates of the GAST model based on data.
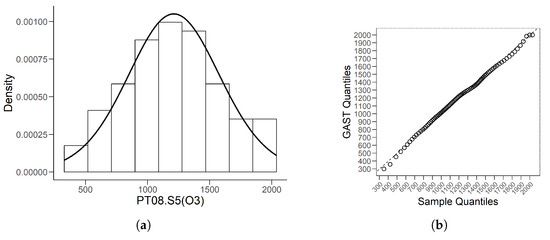
Figure 5.
(a) is the histogram of data with fitted GAST density line. (b) is the associated QQ plot by HD quantile estimator.
The mean, variance, skewness, kurtosis of the distribution (31) are as follows
We generate MC-RPs, QMC-RPs and MSE-RPs of size 30, from the GAST model (31) using the methods discussed in Section 4.1. Table 11 summarizes the bias of the estimation of the four statistics based on the MC, QMC, and MSE methods.
Table 11.
The estimation bias of the four statistics for the fitted GAST model is based on three types of RPs with size 30.
Although the bias of the estimated variance in Table 11 is large in value, it is relatively small compared to the true variance of the model, which is 168,359.9. As shown in Table 11, the MSE-RPs estimate the moments of the model more accurately than the other two types of RPs.
The comparisons of the kernel density estimates based on MC, QMC, and MSE RPs are presented in Figure 6.
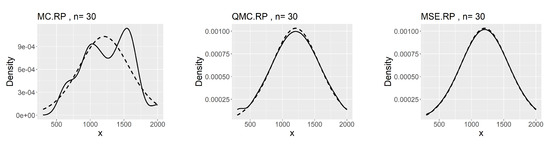
Figure 6.
Comparing plots of the fitted densities (in solid lines) by kernel density estimation and the density of the distribution (31).
The corresponding minimum L2.pdf’s between the kernel estimates and the density of the model (31) are 0.00237 for MC, 0.00026 for QMC and 0.00025 for MSE. As shown in Figure 6, although the estimated kernel density based on the QMC method is well-fitted, it is not as good as that based on the MSE method at the beginning and at the peak.
5.2. Faithful Geyser Data
The Faithful Geyser Data, a commonly used dataset in R software, is a record of the waiting time between eruptions and the duration time of these eruptions for Old Faithful Geyser in Yellow National Park, Wyoming, USA. In this study, we use the waiting-time samples which include 299 observations.
Since these data are bimodal, we use the plain-MLE to estimate parameters. The results are given in the Table 12, providing the GAST model as
The histogram with the fitted density for Faithful Geyser data is given in Figure 7a. Denoting as the order statistics of this bimodal data, we calculate its quantiles by the traditional estimator:
where and j is the integral part of . The associated QQ plot is given in Figure 7b.
Table 12.
Parameter estimates of the GAST model based on Faithful Geyser data.
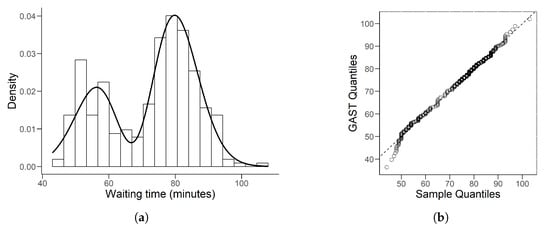
Figure 7.
(a) is the histogram of Faithful Geyser data with fitted GAST density line. (b) is the associated QQ plot by traditional quantile estimator.
Table 12 shows that the estimated is 100, which is the upper bound we set. From this point of view, we can assume that in this fitting model. As described in Section 2.1, this model is actually a subdistribution of the GAST: ASN, indicating that the GAST model is flexible since it can adapt to different types of data. From the QQ plot in Figure 7, we notice that when data are less than 50, the scatter point deviates far from the line, which can also be observed from Figure 7a. The fitting curve rises slowly at the beginning, so the sample quantiles will be larger than the GAST quantiles. When the data are greater than 50, where more samples are located, this distribution fits the data well. Hence, the estimated GAST model (32) is still acceptable.
The mean, variance, skewness, and kurtosis of the distribution (32) are
We generate MC-RPs, QMC-RPs and MSE-RPs of size 50 from the model (32). The estimation biases of the four statistics are summarized in Table 13.
Table 13.
The estimation biases of the four statistics for the fitted GAST model based on three types of RPs with size 50.
We observe that the MSE-RPs have the same mean as the population expectation, which is described in (9). Compared to MC-RPs and QMC-RPs, the MSE method estimates the moments of the model more accurately. The comparison of the kernel density plots is presented in Figure 8.
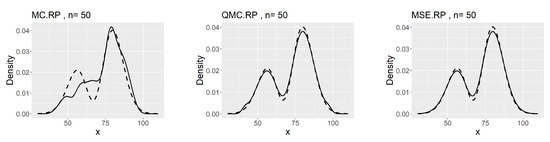
Figure 8.
Comparing plots of the fitted densities (in solid lines) by kernel density estimation and the density of the distribution (32).
The corresponding minimum L2.pdf’s between the kernel estimates and the density of the model (32) are 0.0041 for MC, 0.0029 for QMC and 0.0027 for MSE. The MSE-RPs still perform the best.
6. Conclusions
This paper mainly studies different types of representative points of the GAST distribution and the applications of these RPs. The comparative analyses across various sample sizes and both unimodal and bimodal GAST distributions reveal that the RPs obtained by the MSE method consistently outperform the others in the applications of estimating moments and densities. However, the performance on estimating higher-order moments, such as skewness and kurtosis, shows the limitations of RPs on capturing higher-order statistical properties. Therefore, the number of RPs n must adopt a larger value to reduce the bias of higher-order moment estimation. This paper also incorporates QMC-MLE for parameter estimation of the GAST distribution. For unimodal or bimodal data with an unclear peak, the QMC-MLE method improves parameter estimation accuracy. However, in bimodal cases, plain MLE is more effective. Combined with such property, we can model different types of data accordingly.
Author Contributions
Conceptualization, K.-T.F.; Funding acquisition, Y.-X.L.; Methodology, Y.-F.Z. and K.-T.F.; Software, Y.-F.Z.; Writing—original draft, Y.-F.Z.; Writing—review and editing, Y.-X.L., K.-T.F. and H.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by China Postdoctoral Science Foundation grant number 2023TQ0326.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
A part of the dataset utilized for case studies in this paper is openly available in UCI Machine Learning Repository at https://archive.ics.uci.edu/dataset/360/air+quality (accessed on 15 September 2024). Another data set for analysis in this paper is obtained from R package datasets, named faithful: Old Faithful Geyser Data.
Acknowledgments
Our work was supported in part by Research Center for Frontier Fundamental Studies, Zhejiang Lab, and the Guangdong Provincial Key Laboratory of Interdisciplinary Research and Application for Data Science.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Gupta, R.; Drzazga-Szczȩśniak, E.; Kais, S.; Szczȩśniak, D. The entropy corrected geometric Brownian motion. arXiv 2024, arXiv:2403.06253. [Google Scholar]
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Branco, M.D.; Dey, D.K. A general class of multivariate skew-elliptical distributions. J. Multivar. Anal. 2001, 79, 99–113. [Google Scholar] [CrossRef]
- Azzalini, A.; Capitanio, A. Distributions generated by perturbation of symmetry with emphasis on a multivariate skew t-distribution. J. R. Stat. Soc. 2003, 65, 367–389. [Google Scholar] [CrossRef]
- Azzalini, A.; Genton, M.G. Robust likelihood methods based on the skew-t and related distributions. Int. Stat. Rev. 2008, 76, 106–129. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Tovar-Falón, R.; Gómez, H. Bivariate Power-Skew-Elliptical Distribution. Symmetry 2020, 12, 1327. [Google Scholar] [CrossRef]
- Elal-Olivero, D. Alpha-skew-normal distribution. Proyecciones 2010, 29, 224–240. [Google Scholar] [CrossRef]
- Altun, E.; Tatlidil, H.; Ozel, G.; Nadarajah, S. A new generalization of skew-t distribution with volatility models. J. Stat. Comput. Simul. 2018, 88, 1252–1272. [Google Scholar] [CrossRef]
- Fang, K.T.; Pan, J. A Review of Representative Points of Statistical Distributions and Their Applications. Mathematics 2023, 11, 2930. [Google Scholar] [CrossRef]
- Lin, Y.X.; Tang, Y.H.; Zhang, J.H.; Fang, K.T. Detecting non-isomorphic orthogonal design. J. Stat. Plan. Inference 2022, 221, 299–312. [Google Scholar] [CrossRef]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Fang, K.T.; Wang, Y.; Bentler, P.M. Some applications of number-theoretic methods in statistics. Stat. Sci. 1994, 9, 416–428. [Google Scholar] [CrossRef]
- Hua, L.K.; Wang, Y. Applications of Number Theory to Numerical Analysis; Springer: Berlin/Heidelberg, Germany; Science Press: Beijing, China, 1981. [Google Scholar]
- Niederreiter, H. Random Number Generation and Quasi-Monte Carlo Methods; Society Industrial and Applied Mathematics (SIAM): Phiadelphia, PA, USA, 1992. [Google Scholar]
- Cox, D.R. Note on grouping. J. Am. Stat. Assoc. 1957, 52, 543–547. [Google Scholar] [CrossRef]
- Flury, B.A. Principal points. Biometrika 1990, 77, 33–41. [Google Scholar] [CrossRef]
- Graf, S.; Luschgy, H. Foundations of Quantization for Probability Distributions; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Fei, R. Statistical relationship between the representative point and the population. J. Wuxi Inst. Light Ind. 1991, 10, 78–81. [Google Scholar]
- Wang, Y.; Fang, K.T. A note on uniform distribution and experimental design. Kexue Tongbao 1981, 6, 485–489. [Google Scholar]
- Li, Y.N.; Fang, K.T. A new approach to parameter estimation of mixture of two normal distributions. Commun. Stat.-Simul. Comput. 2024, 53, 1161–1187. [Google Scholar] [CrossRef]
- Stampfer, E.; Stadlober, E. Methods for estimating principal points. Commun. Stat.-Simul. Comput. 2002, 31, 261–277. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on some nonparametric estimates of a density function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Henze, N. A probabilistic representation of the ’skew-normal’ distribution. Scand. J. Stat. 1986, 13, 271–275. [Google Scholar]
- Byrd, R.H.; Lu, P.; Zhu, C. A limited memory algorithm for bound constrained optimization. SIAM J. Sci. Comput. 1995, 16, 1190–1208. [Google Scholar] [CrossRef]
- Harrell, F.E.; Davis, C.E. A new distribution-free quantile estimator. Biometrika 1982, 69, 635–640. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).