3.1. Data Enhancement of Low-Light Night Vision Images
Data augmentation involves randomly transforming or augmenting original data without changing the label and semantic information of the data, to increase the quantity and diversity of the data. Based on limited training samples, data augmentation technology generates new training samples to increase the size of training samples. In the field of image classification, data augmentation is widely used in the training of deep learning models to enhance the generalization performance and robustness of the network. Data augmentation methods include but are not limited to random cropping, random flipping, adding noise, etc. These methods can increase the diversity of the data by transforming the original image to obtain a new image. The quality of the neural network models is inseparable from the support of high-quality datasets. This article uses a self-built dataset to collect four types of night vision images of a vehicle, people, a license plate, and an object using low-light night vision devices in almost completely dark conditions. The image dataset featuring images taken by a low-light night vision device was selected to evaluate the model performance according to the classification results through training and testing. Four different categories of low-light night vision images were used as datasets, as shown in
Figure 1.
To expand the sample, each image was improved as follows:
Resize: Resize the original image either horizontally or vertically.
Rotation: Make the original image rotate clockwise or counterclockwise according to a certain angle.
Flip: Flip horizontally or vertically at the center coordinates of the original image.
Brightness change: Change the brightness of the original image.
Pixel shift: Move a few pixels in the original image along the X and Y axes, and fill the gap with black pixels.
Add noise: Add some random salt and pepper and Gaussian white noise to the original image such that the high-frequency features in the image are distorted, thus reducing the interference to the neural network.
Contrast adjustment: Change the intensity of the brightness difference in the original image.
In addition, in an actual situation, the shooting object will have deformation and movement without changing with time. Therefore, the images were also repeatedly expanded, and the original number of image libraries was expanded by using the above method, as shown in
Table 1 below, and the expanded dataset is shown in
Figure 2.
To ensure the generalization of the model and the effective evaluation of its predictive ability, the dataset must be distinctly separated into a training set and a testing set, and the image classification must be divided in a 1:1 ratio. The repeated images are further randomly combined with the enhanced photos in a 7:3 ratio to enhance the content of the training and testing sets. By using hybrid techniques, the diversity of the dataset is enhanced, while also assisting the model in learning a wider range of features. This allows for a more thorough evaluation of the model’s performance and ensures strong generalization and predictive abilities when dealing with unknown data.
3.2. Image Enhancement of CLAHE
An image enhancement algorithm is a series of technologies that process the collected images. It processes complex images; uses algorithms to optimize visual effects; makes images more suitable for identification and analysis; and strengthens details, improves contrast, and suppresses redundant information, so as to significantly improve image quality. One of the most traditional methods of picture enhancement is histogram equalization (HE). The primary technique is to modify the grayscale value distribution of image pixels to improve the contrast, clarity, and visual impact of the image. This algorithm will comprehensively scan every pixel in each frame of the image, record in detail the number of pixels corresponding to each grayscale value, and further calculate the proportion of each grayscale value in the total pixels, that Is, its probability of occurrence. Then, the pixel values of the image are redistributed to evenly distribute the grayscale histogram across the entire grayscale range, thereby improving the contrast of the image [
33].
The adaptive histogram equalization (AHE) image processing method was adopted. Firstly, an image is divided into several smaller regions, and then the gray value and gray histogram of each sub-region are obtained, respectively, and on this basis, each sub-region is redistributed, so as to realize the adjustment of pixels. This method overcomes the drawbacks of the traditional HE method. This method does not adjust the image globally, but selects a local region to construct the histogram distribution, establishes the mapping function according to the histogram distribution, and equalizes the specific region finely. Such a processing method not only helps to better retain detailed information, but also avoids the problem of excessive adjustment that may occur in global equalization [
34].
Contrast limited adaptive histogram equalization (CLAHE) is an image enhancement method. This algorithm has been improved based on the AHE algorithm. In the AHE technique, the local histogram of an image is determined first, and then the brightness is reallocated to increase the contrast of the image and obtain more image details. A technique based on CLAHE is presented to address the issue that the AHE approach is prone to over-amplification while handling noise in the same region. The main content of the CLAHE algorithm is to limit the contrast and redistribute the histogram of the image, while also performing histogram equalization on each small block. It is very important to avoid excessively enhancing the contrast of the entire image while enhancing the contrast. A restriction parameter is used by CLAHE to adjust the amount of contrast enhancement during the equalization period [
35]. If the histogram of a certain patch exceeds this limit, then the contrast enhancement is limited to avoid over-enhancement. The work flow chart of CLAHE is shown in
Figure 3.
The following are the main steps of the CLAHE algorithm:
First, the image is divided into
n ×
n sub-regions of equal area, pairwise adjacent and non-overlapping, and the histogram
and clipping amplitude
δ in each sub-region are calculated separately:
where
and
are the number of pixels in the
x direction and
y direction
I the sub-region, respectively;
is the gray level in the corresponding sub-region; and
is the clipping coefficient of the histogram [
36].
Then, the histogram
of the sub-region is cropped according to the amplitude
δ, as shown in
Figure 4. The pixel values beyond the amplitude range in the image are evenly distributed to each gray level, and the total number of pixel points beyond the amplitude range is calculated as
and the pixel
evenly distributed to each gray level. The arrows represent pixel values that spread the left image beyond the amplitude range, that is, a portion of the blue area on the left image, evenly distributed to the blue area at the bottom of the right image.
The reallocated histogram is denoted by
:
The grayscale value of each pixel in the image is sequentially changed by the bilinear interpolation technique, as shown in
Figure 5. It can be seen from the figure that the grayscale value of point E was reconstructed by bilinear interpolation. The gray value of E can be reconstructed by the known four points, A, B, C and D. The coordinates of the five points are, respectively, coordinates
,
,
,
, and
, and the gray values corresponding to A, B, C, and D are, respectively,
, and
. The left picture is an enlarged picture of the local area of the right picture, that is, the red box part of the right picture, the part surrounded by arrows and red dots, indicating the area to be processed with bilinear interpolation, and the green point in the middle represents the pixel points to be processed.
The middle shaded part is the part of bilinear interpolation. It is calculated as follows:
where
is the gray value of point E.
A comparison of night vision image effects after processing by three image enhancement algorithms is shown in
Table 2. The original image refers to the image taken by an ordinary camera in almost no light environment. The contrast and brightness of the three kinds of night vision images processed by the HE algorithm are improved to a certain extent, especially the grayscale distribution, which is more uniform. As can be seen from
Table 2, the original image is compared with the image processed by the AHE algorithm and this algorithm can effectively improve the local contrast of the image and the brightness of the image, but there is a problem of noise [
37]. The CLAHE method can effectively overcome the noise problem existing in the AHE algorithm, while maintaining the detail Information of the Image. After comparison, the CLAHE algorithm was selected.
Image enhancement algorithms have their applicability. It is very difficult to observe the visual effect after image enhancement through human visual perception, so as to judge the enhanced effect of night vision, and this method is time-consuming and labor-intensive. Therefore, the quality of image filtering can be judged by comparing the mean square error, peak signal-to-noise ratio, structural similarity, and filtering time of the enhanced image and the original image. In this section, the effectiveness of night vision image enhancement are evaluated through these three parameters.
The Mean Square Error (MSE) is a metric used to evaluate the difference between the original image and the processed image. The MSE calculates the average of the square of the difference in pixel values between the original image and the processed image, and its formula is as follows:
where
and
, respectively, represent the number of rows and columns of the image,
is the pixel value of the original image at
, and
is the pixel value of the processed image at
. Therefore, the smaller the MSE, the closer the enhanced image is to the original image, and the higher the image quality.
The peak signal-to-noise ratio (PSNR) is the ratio between the maximum possible value of an image (the peak signal) and the image distortion (the difference from the original image), and its formula is as follows:
where MAX represents the maximum value of image pixels, which is generally 255. The unit of PSNR is decibels (dB), and the higher the value, the smaller the distortion and the higher the image quality.
Structural similarity (SSIM) can be used to compare the structural similarity of two images, and its formula is as follows:
where
x and
y represent the two images to be compared,
and
, respectively, represent the mean value of images
x and
y,
and
, respectively, represent the variance of images
x and
y,
represents the covariance of images
x and
y, and
and
are two constants to prevent the denominator from being too small and resulting in a too large fraction. The value range of SSIM is [−1,1]. The closer the SSIM is to 1, the more similar the two images are.
Taking automobile images as an example,
Table 3 shows the evaluation index results of three different enhancement algorithms. As can be seen from the table, the MSE value of CLAHE is the smallest, the PSNR value is the largest, SSIM is the closest to 1, and its processing time is also the smallest. After many times comparing the effects of different enhancement algorithms of different night vision images, CLAHE still has the best effect. Therefore, for the enhancement algorithm of night vision images, CLAHE is the best choice.
3.3. Feature Extraction of GLCM
The GLCM is a texture feature extraction method based on statistical principles. Due to poor lighting conditions in low-light night vision images, there are often problems such as high noise, low contrast, and blurry details. The GLCM reflects the comprehensive information of image grayscale about direction, adjacent spacing, and change amplitude, which can extract more representative and discriminative features from low-light night vision images. By reflecting the entire grayscale information about direction, adjacent spacing, and variation range, the GLCM can extract more representative and discriminative features from low-light night vision images.
The chance that the grayscale value Is described by a matrix, starting from a pixel point with grayscale level
I and moving from a fixed position to a distance
d and direction
θ, is known as the GLCM. The expression is as follows:
The following are the stages involved in calculating the GLCM:
Consider an image of size , and choose a point that is offset from , where a and b are offset in the horizontal direction and b is offset in the vertical direction.
For the selected points, obtain their gray values, denoted and . The number of gray values (that is, the number of possible gray levels) is set to k.
The point is moved across the image, and for each position, the corresponding gray value pair (, ) is calculated.
Count the number of occurrences of each gray value pair (, ) in the whole image. Since there are k possible values for both and , there will be total gray value pairs.
The total number of occurrences is normalized for each grayscale level in order to obtain the occurrence probability P (,). This probability value is the element of the GLCM.
The series
k of grayscale values determines the size of the GLCM, that is, the matrix’s dimension is
. The likelihood that the matching grayscale value pair will appear in the image is represented by each member of the matrix. The selection of parameters, such as 0 degrees, 45 degrees, 90 degrees, 135 degrees, and distance, will have an effect on the texture representation features of the co-occurrence matrix. The GLCM is calculated taking into account various directions. The extracted texture properties of the image, including energy, entropy, inertia matrix, and correlation matrix, may be further extracted using the computed GLCM. The texture thickness, clarity, non-uniformity, and consistency of the low-light night vision image may be examined once these four characteristics have been obtained [
38].
The sum of the squares of each element in the grayscale matrix may be used to calculate energy, an effective metric of texture coarseness and picture grayscale distribution. The following is the formula:
where the dimension of the GLCM (i.e., the total number of grayscale levels) is
k and the element value of row
I and column
j in the matrix is
. If the value distribution of each element in the GLCM is more uniform, its energy value will be larger, indicating that the texture of the image is more stable. On the contrary, if the value distribution of each element is uneven, the energy value is small, which indicates that the texture of the image is complex and changes greatly.
Entropy is an indicator of the amount of information contained in an image, as well as an indicator of unpredictability. When the components of the co-occurrence matrix are dispersed, the entropy is high, all elements have the highest unpredictability, and the values of all spatial co-occurrence matrices are almost equal. It represents the degree of non-uniformity or complexity of the texture in the image. It represents the diversity and irregularity of the texture, or the non-uniformity or complexity of the visual texture [
39,
40]. The formula is as follows:
The entropy value will be low when the GLCM’s element value distribution is comparatively uniform. However, when the element values are unevenly distributed, the entropy value will be higher. The larger the entropy value, the more complex the image texture.
The inertia matrix reflects the clarity of the image and the depth of the texture groove. The formula is as follows:
The contrast will be stronger when the image has a rich texture and a distinct edge. On the other hand, there will be little contrast if the texture furrow is shallow and the edge is blurry.
Correlation reflects the degree of similarity between row or column elements in a GLCM, and is used to measure the degree of similarity between elements in the row or column direction of the GLCM. The formula is as follows:
where
and
are the mean values of the rows and columns of
P(
I,
j) and
si and
sj are the standard deviations of the rows and columns, respectively. If the correlation value is high, it means that the image texture has strong similarity in the row and column direction. Conversely, if the correlation value is low, it means that the image texture changes greatly in different directions.
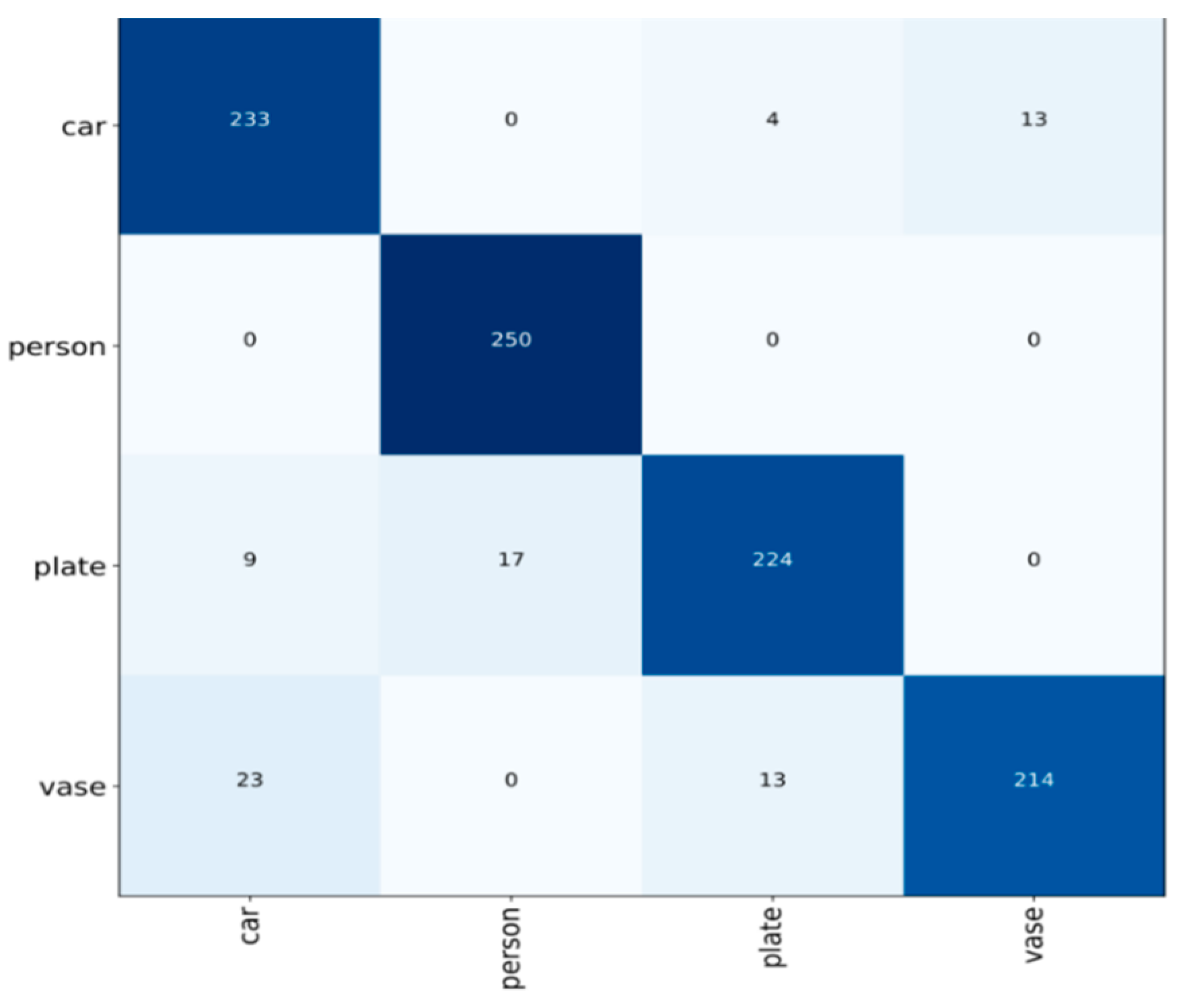
Four kinds of low-light night vision image samples of a vehicle, person, license plate, and object were randomly selected, and 250 images of each defect were selected, among which the 1–250 images were vehicles. A total of 251–500 pictures were of people; 501–750 of license plates; and 751–1000 images of objects. The horizontal axis of
Figure 6a–d is the image sequence, and the vertical axis is the energy, entropy, inertia matrix, and correlation. There are obvious differences in the texture features of low-light night vision images of vehicles, people, license plates, and objects. The BP neural network model was used to classify the texture parameters of different types of low-light night vision images to achieve the identification of invisible targets at night.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















