Abstract
The idea of a partial information decomposition (PID) gained significant attention for attributing the components of mutual information from multiple variables about a target to being unique, redundant/shared or synergetic. Since the original measure for this analysis was criticized, several alternatives have been proposed but have failed to satisfy the desired axioms, an inclusion–exclusion principle or have resulted in negative partial information components. For constructing a measure, we interpret the achievable type I/II error pairs for predicting each state of a target variable (reachable decision regions) as notions of pointwise uncertainty. For this representation of uncertainty, we construct a distributive lattice with mutual information as consistent valuation and obtain an algebra for the constructed measure. The resulting definition satisfies the original axioms, an inclusion–exclusion principle and provides a non-negative decomposition for an arbitrary number of variables. We demonstrate practical applications of this approach by tracing the flow of information through Markov chains. This can be used to model and analyze the flow of information in communication networks or data processing systems.
1. Introduction
A Partial Information Decomposition (PID) aims to attribute the provided information about a discrete target variable T from a set of predictor or viewable variables to each individual variable . The partial contributions to the information about T may be provided by all variables (redundant or shared), by a specific variable (unique) or only be available through a combination of variables (synergetic/complementing) [1]. This decomposition is particularly applicable when studying complex systems. For example, it can be used to study logical circuits, neural networks [2] or the propagation of information over multiple paths through a network. The concept of synergy has been applied to develop data privacy techniques [3,4], and we think that the concept of redundancy may be suitable to study a notion of robustness in data processing systems.
Unfortunately and to the best of our knowledge, there does not exist a non-negative decomposition of mutual information for an arbitrary number of variables that satisfies the commutativity, monotonicity and self-redundancy axioms except the original measure of Williams and Beer [5]. However, this measure has been criticized for not distinguishing “the same information and the same amount of information” [6,7,8,9].
Here, we propose an alternative non-negative partial information decomposition that satisfies Williams and Beer’s axioms [5] for an arbitrary number of variables. It provides an intuitive operational interpretation and results in an algebra like probability theory. To demonstrate that the approach distinguishes the same information from the same amount of information, we highlight its application in tracing the flow of information through a Markov chain, as visualized in Figure 1.
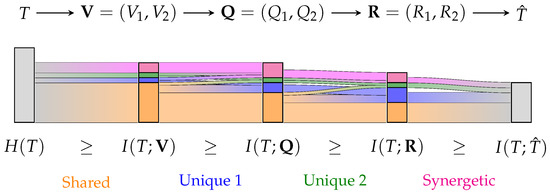
Figure 1.
Visualization of a partial information decomposition with information flow analysis of a Markov chain as Sankey diagram. A partial information decomposition enables attributing the provided information about T to being shared (orange), unique (blue/green) or synergetic/complementing (pink). While this already offers practical insights for studying complex systems, the ability to trace the flow of partial information may create a valuable tool to model and analyze many applications.
This work is structured in three parts: Section 2 provides an overview of the related work and background information. Section 3 presents a representation of pointwise uncertainty, constructs a distributive lattice and demonstrates that mutual information is the expected value of its consistent valuation. Section 4 discusses applications of the resulting measure to PIDs and the tracing of information through Markov chains. We provide an overview of the used notation at the end of the paper.
2. Related Work
We briefly summarize partial orders and the four main publications which led to our proposed decomposition approach. This includes the PID by Williams and Beer [5], the quantification of unique information by Bertschinger et al. [10] and Griffith and Koch [11], the Blackwell order based on Bertschinger and Rauh [12], the evaluation of binary decision problems using Receiver Operating Characteristics and consistent lattice valuations by Knuth [13].
2.1. Partial Orders and Lattices
This section provides a brief overview of the relevant definitions on partial orders and lattices for the context of this work based on [9,13]. A binary ordering relation ≼ on a set is called a preorder if it is reflexive and transitive. If the ordering relation additionally satisfies an antisymmetry, then is called a partially ordered set (poset). For :
| (reflexivity) | |
| (transitivity) | |
| (antisymmetry) |
Two elements satisfy , or may be incomparable, meaning and . A partially ordered set has a bottom element if for all and a top element if for all . For each element , it can be defined a down-set () and up-set () as well as a strict down-set () and strict up-set () as shown below:
A lattice is a partially ordered set for which every pair of elements has a unique least upper bound , referred to as joint, and a unique greatest lower bound , referred to as meet. This creates an algebra with the binary operators ⋏ and ⋎ that satisfies indempotency, commutativity, associativity and absorption. The consistency relates the ordering relation and algebra with each other. A distributive lattice additionally satisfies distributivity.
| (indempotency) | ||
| (commutativity) | ||
| (associativity) | ||
| (absorption) | ||
| (consistency) | ||
| (distributivity) |
2.2. Partial Information Decomposition
This section summarizes Williams and Beer’s general approach to partial information decompositions [5]. A more detailed discussion of the literature and required background can be found in [9] (pp. 6–20).
Williams and Beer [5] define sources as all combinations of viewable variables ( referring to the power set of without the empty set) and use Equation (1a) to construct all distinct interactions between them , which are referred to as partial information atoms. Equation (1b) provides a partial order of atoms to construct a redundancy lattice (). As a convention, we indicate the visible variables contained in a source by its index, such as . The example of the redundancy lattice for two and three visible variables is shown in Figure 2.
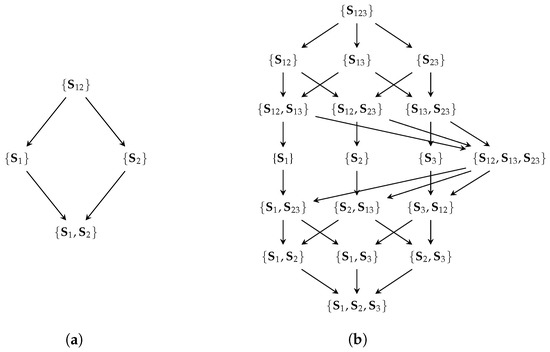
Figure 2.
The redundancy lattices for two (a) and three (b) visible variables. The redundancy lattice specifies the expected inclusion relation between atoms. The following function shall measure the shared information for a sets of variables such that the element represents the shared information between and about the target variable T.
A measure of redundant information shall be defined for this lattice as “[…] cumulative information function which in effect integrates the contribution from each node as one moves up through the nodes of the lattice” [9] (p. 15). Williams and Beer [5] then use the Möbius inverse (Equation (2)) to identify the partial information as the contribution of atom and therefore the desired unique/redundant/synergetic component. A PID is said to be non-negative if the resulting partial contributions are guaranteed to be non-negative.
Williams and Beer [5] highlight three axioms that a measure of redundancy should satisfy.
Axiom 1
(Commutativity). Invariant to the order of sources (σ permuting the order of indices):
Axiom 2
(Monotonicity). Additional sources can only decrease redundant information:
Axiom 3
(Self-redundancy). For a single source, redundancy equals mutual information:
Finally, Williams and Beer [5] proposed (Equation (3)) as a measure of redundancy and demonstrated that it satisfies the required axioms.
However, the measure has been criticized for not distinguishing “the same information and the same amount of information” [6,7,8,9] due to its use of a pointwise minimum (for each ) over the sources.
2.3. Quantifying Unique Information
A non-negative decomposition for the case of two viewable variables was proposed by Bertschinger et al. [10] (defining unique information) as well as an equivalent decomposition by Griffith and Koch [11] (defining union information) as shown in Equation (4) (modified notation). The function acts as an information measure of the union for and (the minimal information that any two variables with the same marginal distributions can achieve), which is then used to compute the partial contributions using an inclusion–exclusion principle. Bertschinger et al. [10] motivated the decomposition from the operational interpretation that if a variable provides unique information, there must be a way to utilize this information in a decision problem for some reward function. Additionally, they argue that unique information should only depend on the marginal distributions and .
We highlight this decomposition since our approach can be interpreted as its pointwise extension (see Section 4.1).
2.4. Blackwell Order
A channel can be represented as a (row) stochastic matrix wherein each element is non-negative and all rows sum to one (see Figure 3). In this work, we consider the sources to be the indirect observation of the target variable through a channel while taking the joint distribution of the visible variables within . As a result, is obtained from the conditional probability distribution . As for sources, we list the contained visible variables as an index such that corresponds to .
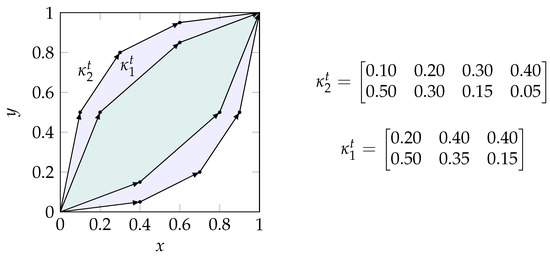
Figure 3.
Visualization of the zonotope order for binary input channels. The channel is Blackwell inferior to () since the corresponding zonotope (green) is a subset of (purple). As a result, the meet and joint elements of this example are: and .
The Blackwell order is a preorder of channels, as shown in Equation (5) [14]. It highlights that a channel equivalent to can be obtained by garbling the output of (a chaining of channels as seen in Equation (5)). Therefore, there exists a decision strategy based on for any reward function that performs at least as well as all strategies based on [12].
Bertschinger and Rauh [12] showed that the Blackwell order does not define a lattice in general since it does not provide a unique meet and joint element beyond binary inputs. However, binary input channels provide a special case for which the Blackwell order is equivalent to the zonotope order and defines a lattice. We use the notation to indicate that a channel has a binary input () or corresponds to the one-vs-rest encoding for one state t if . In this case, the row stochastic matrix representing a channel contains a set of vectors as shown in Equation (6). A zonotope (Equation (6b)) corresponds to “the image of the unit cube […] under the linear map corresponding to []” [12] (p. 2), and the resulting zonotope order is a preorder that is identical to the Blackwell order in the special case of binary input channels [12] as visualized in Figure 3. In the resulting lattice, the joint of two channels can be obtained as the convex hull of the zonotopes and , and the meet element corresponds to their intersection.
2.5. Receiver Operating Characteristic Curves
While any classification system can be represented as channel, this section focuses on binary decision problems or the one-vs-rest encoding of others (). The binary label is used to obtain a sample , which is processed by a classification system C to its output with , and applying a decision strategy d shall result in an approximation of the label with . This forms the Markov chain: . A common method of analyzing binary decision/classification systems is the Receiver Operating Characteristic (ROC). A ROC plot typically represents a classifier C with a continuous, discrete or categorical output range (by assigning distinct arbitrary values to each category) for a binary decision problem by a curve in a True-Positive Rate (TPR)/False-Positive Rate (FPR) diagram for varying decision thresholds with the decision rule for a sample s being [15]. The resulting points are typically connected using a step function, as shown in red in Figure 4a. As a result of using a single decision threshold, the points of the ROC curve monotonically increase from to ; however, they are in general neither concave nor convex [16].
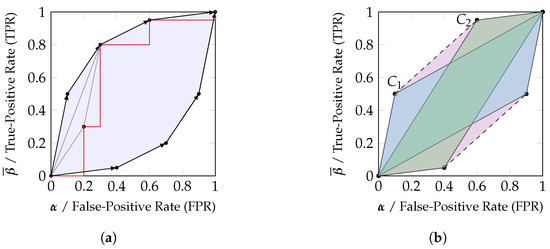
Figure 4.
Relating zonotopes and their convex hull to achievable decision regions. (a) A ROC curve (red) can be used to estimate the parameters of a channel, and the randomized combination of thresholds (Equation (7)) corresponds to an interpolation in the visualization (gray). The reachable decision region when utilizing all thresholds can be constructed using a likelihood ratio test, which corresponds to reordering the vectors by decreasing slope (in this case, swapping the first two steps) and taking the convex hull of reachable points. This reachable decision region is the zonotope of the channel. (b) The convex hull of any set of zonotopes is reachable by their randomized combination. Given two classifiers (blue) and (green), there always exists a randomized combination that can reach any position in their convex hull (purple).
We want to highlight the distinction between a ROC curve and the achievable performance pairs (TPR, FPR) based on the classifier. Any performance pair within the convex hull of the obtained points for constructing the ROC curve can be achieved since the decision strategy of Equation (7) results in an interpolation of the points corresponding to with the parameter in the TPR/FPR diagram. Therefore, while a ROC curve is not convex in general, the achievable performance region is convex in general.
When utilizing the set of all available thresholds on the classification output, we can identify the reachable decision regions within the TPR/FPR diagram using the likelihood ratio test, which is well known to be optimal for binary decision problems: Neyman–Pearson theory [17] states that the likelihood ratio test (Equation (8)) provides the minimal type II error (minimal , maximal TPR ) for a bounded type I error (FPR, ).
Notice that the decision criterion is determined by the slope of each vector in the row stochastic matrix that represents the binary input channel (Equation (6a)). This effective reordering of vectors based on their slope when varying the parameters and h results in the upper half of the zonotope discussed in Section 2.4 and as visualized in Figure 4a. The lower half of the zonotope is obtained from negating the outcome of the likelihood ratio test. Therefore, the zonotope representation of a channel corresponds to the achievable performance region in a TPR/FPR diagram of a classifier at binary decision problems. When reconsidering Figure 3, the channels and may correspond to two classifiers and whose channel parameters have been estimated from a ROC curve, and the achievable performance regions correspond to the zonotopes in a TPR/FPR diagram. Since the likelihood ratio test is optimal for binary decision problems, there cannot exist a decision strategy that would achieve a performance outside the zonotope. At the same time, the likelihood ratio test can be randomized to reach any desired position within the zonotope.
Finally, notice that the convex hull of any two classification systems is reachable by their randomized combination. We can view each classifier as an observation from a channel / about and know that there always exists a garbling of the joint channel to obtain their convex hull . Using a likelihood ratio test on , any position within the convex hull is reachable as a randomized combination of both classifiers. This has been visualized in Figure 4b. Due to this reason, we will say in Section 3.1 that the convex hull should be fully attributed to the marginal channels and .
2.6. Lattice Valuations
This section summarizes the properties of consistent lattice valuations based on Knuth [13]. The quantification of a lattice or with for elements of the set is a function , which assigns reals to each element. A quantification is called a valuation if any two elements maintain an ordering relation: implies that . A quantification q is consistent if it satisfies a sum rule (inclusion–exclusion principle): . If the bottom element of the lattice (⊥) is evaluated to zero , then the valuation of the Cartesian product of two lattices remains consistent with the individual lattices. Finally, a bi-quantification can be defined as . Similar to Knuth [13], we will use the notation which can be thought of as quantifying a degree of inclusion for within . The distributive lattice then creates an algebra like probability theory for the consistent valuation, as summarized in Equation (9) [13].
3. Quantifying Reachable Decision Regions
We start by studying the decomposition of binary decision problems from an interpretational perspective (Section 3.1). This provides the basis for constructing a distributive lattice in Section 3.2 and demonstrating the structure of a consistent valuation function. Section 3.3 highlights that mutual information is such a consistent valuation and extends the concept from binary decision problems to target variables with an arbitrary finite number of states. The resulting definition of shared information for the PID will be discussed as an application in Section 4.1 together with the tracing of information flows in Section 4.2.
We define an equivalence relation (∼) for binary input channels , which allows for the removal of zero vectors, the permutation of columns ( representing a permutation matrix) and the splitting/merging of columns with identical likelihood ratios (vectors of identical slope, ), as shown in Equation (10). These operations are invertible using garblings and do not affect the underlying zonotope.
Based on this definition, block matrices cancel at an inverted sign () if we allow negative columns, as shown in Equation (11), where and are some matrix.
3.1. Motivation and Operational Interpretation
The aim of this section is to provide a first intuition based on a visual example for the methodology that will be used in Section 3.2 to construct a distributive lattice of the reachable decision regions and its consistent valuation. We only consider binary variables or the one-vs-rest encoding of others ().
In the used example, the desired variable can be observed indirectly using the two variables and . The visible variables are considered to be the output of the channels , and and correspond to the zonotopes shown in Figure 5. We consider each reachable decision point (a pair of TPR and FPR) to represent a different notion of uncertainty about the state of the target variable. We want to attribute the reachable decision regions to each channel for constructing a lattice, as shown in Figure 6, with the following operational interpretation:
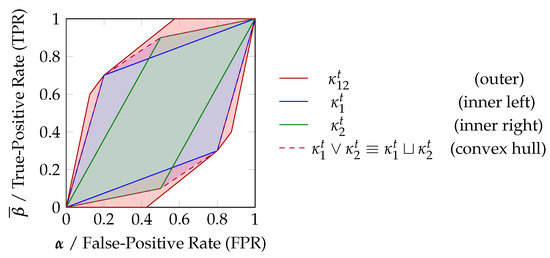
Figure 5.
Relating the zonotope representations to TPR/FPR plots. The zonotopes correspond to the regions of a TPR/FPR plot that are reachable by some decision strategy. Regions outside of the zonotopes are known to be unreachable since the likelihood ratio test is optimal for binary decision problems. The convex hull of both zonotopes is the (unique) lower bound of any joint distribution under the Blackwell order.
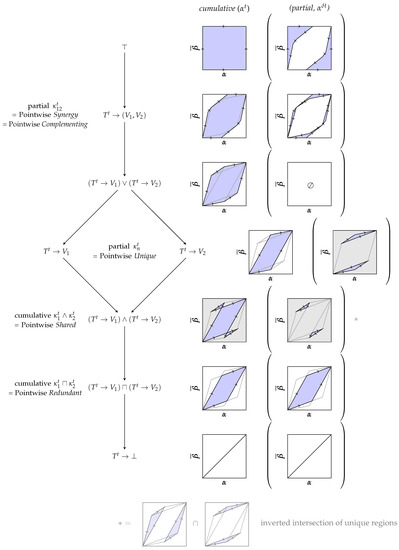
Figure 6.
Decomposing the achievable decision regions for binary decision problems from an operational perspective. Each node is visualized by its cumulative and partial decision region. The partial decision region is shown within round brackets. The cumulative region corresponds to the matrix concatenation of the partial regions in its down-set under the defined equivalence relation. Three key elements are highlighted using a grey background.
- Synergy: Corresponds to the partial contribution of and represents the decision region which is only accessible due to the (in-)dependence of both variables.
- Joint: The joint element corresponds to the joint under the Blackwell order and represents the decision region which is always accessible if the marginal distributions and can be obtained. Therefore, we say that its information shall be fully attributed to and such that is has no partial contribution. For binary target variables, this definition is equivalent to the notion of union information by Bertschinger et al. [10] and Griffith and Koch [11]. However, we extend the analysis beyond binary target variables with a different approach in Section 3.3.
- Unique: Corresponds to the partial contribution of or and represents the decision region that is lost when losing the variable. It only depends on their marginal distributions and .
- Shared: Corresponds to the cumulative contribution of and represents the decision region which is lost when losing either or . Since it only depends on the marginal distributions, we interpret it as being part of both variables. The shared decision region can be split in two components: the decision region that is part of both individual variables and the component that is part of the convex hull but neither individual one. The latter component only exists if both variables provide unique information.
- Redundant: The largest decision region which can be accessed from both and . It corresponds to the meet under the Blackwell order and the part of shared information that can be represented by some random variable (pointwise extractable component of shared information). The redundant and shared regions are equal unless both variables provide some unique information.
Due to the invariance of re-ordering columns under the defined equivalence relation, represents a set of likelihood vectors. All cumulative and partial decision regions of Figure 6 can be constructed using a convex hull operator (joint) and matrix concatenations under the defined equivalence relation (∼). For example, the shared decision region (meet) can be expressed through an inclusion–exclusion principle with the joint operator . This operator is not closed on channels since it introduces negative likelihood vectors. Therefore, we distinguish the notation between channels () and atoms (). These matrices sum to one similar to channels but may contain negative columns. Their partial contributions sum to zero.
- The unique contribution of :
- The shared cumulative region of and :
- The shared partial contribution:
- Each cumulative region corresponds to the combination of partial contributions in its down-set. Notice that the partial contribution of the shared region is canceled by a section of each unique contribution due to an opposing sign:
In Section 3.3, we demonstrate a valuation function f that can quantify all cumulative and partial atoms of this lattice while ensuring their non-negativity and consistency with the defined equivalence relation (∼). We will refer to a more detailed example on the valuation of partial decision regions in Appendix C in the context of the following section.
Why does the decomposition of reachable decision regions as shown in Figure 6 provide a meaningful operational interpretation? Because combining the partial contributions of the up-set for a variable results in the decision region that becomes inaccessible when the variable is lost, while combining the partial contributions of the down-set results in the decision region that is accessible through the variable. For example, losing access to variable results in losing access to the decision regions provided uniquely by and its synergy with (the up-set on the lattice). Additionally, the cumulative component corresponds to the combination of all partial contributions in its down-set since opposing vectors cancel under the defined equivalence relation (∼) such as the shared and unique contributions. Therefore, we define a consistent valuation of this lattice in Section 3.2 by quantifying decision regions based on their spanning vectors and highlight that the expected value for each corresponds to the definition of mutual information.
Section 3.2 and Section 3.3 focus only on defining the meet and joint operators () with their consistent valuation. To obtain the pointwise redundant and synergetic components for a PID, we can later add the corresponding channels when constructing the pointwise lattices with the ordering of Figure 6 from the meet and joint operators.
3.2. Decomposition Lattice and Its Valuation
This section first defines the meet and joint operators (∧, ∨) and then constructs a consistent valuation for the resulting distributive lattice. For constructing a pointwise channel lattice based on the redundancy lattice, we notate the map of functions as shown in Equation (12) and consider the function to obtain the pointwise channel of a source .
The intersections shall correspond to some meet operation and the union to some joint operation on the pointwise channels, as shown in Equation (13), while maintaining the ordering relation of Williams and Beer [5]. This section aims to define suitable meet and joint operations together with a function for their consistent valuation. Each atom now represents an expression of channels with the operators , as shown in Appendix A. For example, the element is converted to the expression .
As seen in Section 3.1, we want to define the joint for a set of channels to be equivalent to their convex hull, matching the Blackwell order. This also ensures that the joint operation is closed on channels.
Since opposing vectors cancel under the defined equivalence relation, we can use a notion of the Möbius inverse to define the set of vectors spanning a partial decision region for an atom , as shown in Equation (15), written as a recursive block matrix and using the strict down-set of the ordering based on the underlying redundancy lattice.
The definition of the meet operator (∧) and the extension of the joint operator (∨) from channels to atoms is now obtained from the constraint that the partial contribution for the joint of two incomparable atoms shall be zero, as shown in Equation (16).
This creates the desired inclusion–exclusion principle and results in the equivalences of the meet for two and three atoms, as shown in Equation (17). Their resulting partial channels () correspond to the set of vectors spanning the desired unique and shared decision regions of Figure 6.
From their construction, the meet and joint operators provide a distributive lattice for a set of channels under the defined equivalence relation as shown in Appendix B by satisfying idempotency, commutativity, associativity, absorption and distributivity. This can be used to define a corresponding ordering relation (Equation (18)).
To obtain a consistent valuation of this lattice, we consider a function , as shown in Equation (19). First, this function has to be invariant under the defined equivalence relation, and second, it has to match the ordering of the constructed lattice.
The function f shall apply a (convex) function to each vector of the matrix of an atom . The function is invariant under the equivalence relation (∼, Equation (10)):
- Zero vectors do not affect the quantification:
- The structure of f ensures invariance under reordering columns:
- The property with ensures invariance under splitting/merging columns of identical likelihood ratios:
The function f is a consistent valuation of the ordering relation (⪯, Equation (18)) from the constructed lattice:
- The convexity of r ensures that the quantification is a valuation as shown in Appendix C:
- The function f provides a sum-rule:
- The function f quantifies the bottom element correctly:
A parameterized function that forms a consistent lattice valuation with and that will be used in Section 3.3 is shown in Equation (20) (the convexity of is shown in Appendix D).
This section demonstrated the construction of a distributive lattice and its consistent valuation, resulting in an algebra as shown in Equation (9).
3.3. Decomposing Mutual Information
This section demonstrates that mutual information is the expected value of a consistent valuation for the constructed pointwise lattices and discusses the resulting algebra. To show this, we define the parameter p and pointwise channel for the consistent valuation (Equation (20)) using a one-vs-rest encoding (Equation (21)).
The expected value of the resulting valuation in Equation (20) is equivalent to the definition of mutual information, as shown in Equation (22). Therefore, we can interpret mutual information as being the expected value of quantifying the reachable decision regions for each state of the target variable that represent a concept of pointwise uncertainty.
The expected value for a set of consistent lattice valuations corresponds to a weighted sum such that the resulting lattice remains consistent. Therefore, we can combine the pointwise lattices to extend the definition of mutual information for meet and joint elements, which we will think of as intersections and unions. Let represent an expression of sources with the operators ∨ and ∧. Then, we can obtain its valuation from the pointwise lattices using the function , as shown in Equation (23). Notice that we do not define the operators for random variables but only use the notation for selecting the corresponding element on the underlying pointwise lattices. For example, we write to refer to the pointwise atom on each pointwise lattice.
The special case of atoms that consist of a single source corresponds by construction to the definition of mutual information. However, we propose normalizing the measure, as shown in Equation (23), to capture a degree of inclusion between zero and one. This is possible for discrete variables and will lead to an easier intuition for the later definition of bi-valuations and product spaces by ensuring the same output range for these measures. As a possible interpretation for the special role of the target variable, we like to think of T as the considered origin of information within the system, which then propagates through channels to other variables.
We obtain the following algebra with the bi-valuation that quantifies a degree of inclusion from within the context of . We can think of as asking how much of the information from about T is shared with .
Since the definitions satisfy an inclusion–exclusion principle, we obtain the interpretation of classical measures as proposed by Williams and Beer [5]: conditional mutual information measures the unique contribution of plus its synergy with , and interaction information measures the difference between synergy and shared information, which explains its possible negativity.
As highlighted by Knuth [13], the lattice product (the Cartesian product with ordering ) can be valuated using a product rule to maintain consistency with the ordering of the individual lattices. This creates an opportunity to define information product spaces for multiple reference variables. Since we normalized the measures, the valuation of the product space will also be normalized to the range from zero to one. The subscript notation shall indicate the product of the lattice constructed for with the product of the lattice constructed for .
The lattice product is distributive over the joint for disjoint elements [13], which leads to the equivalence in Equation (26). Unfortunately, it appears that only the bottom element is disjoint with other atoms in the constructed lattice.
Finally, we would like to provide an intuition for this approach based on possible operational scenarios:
- Consider having characterized four radio links and obtained the conditional distributions , and . We are interested in their joint channel capacity; however, lack the required joint distribution. In this case, we can use their joint to obtain a (pointwise) lower bound on their joint channel capacity.
- Consider having two datasets and that provide different types of labels () and associated features (), where some events were recorded in both datasets. In such cases, one may choose to study the cases , and for events appearing in both datasets, which could then be combined into a product lattice .
4. Applications
This section focuses on applications of the obtained measure from Section 3.3. We first apply the meet operator to the redundancy lattice for constructing a PID. Since an atom of the redundancy lattice corresponds to a set of sources for which the shared information shall be measured, we use the notation to obtain an expression for the function . Section 4.2 additionally utilizes the properties of a Markov chain to demonstrate how the flow of partial information can be traced through system models.
4.1. Partial Information Decomposition
Based on Section 3.3, we can define a measure of shared information for the elements of the redundancy lattice in the framework of Williams and Beer [5], as shown in Equation (27). The measure satisfies the three axioms of Williams and Beer [5] (commutativity from the equivalence relation and structure of , monotonicity from being a lattice valuation and self-redundancy from removing the normalization), and the decomposition is non-negative since the joint channel is superior to the joint of two channels for all . The partial contribution corresponds to the expected value of the quantified partial decision regions .
This provides the interpretation of Section 3.1, where combining the partial contributions of the up-set corresponds to the expected value of quantifying the decision regions that are lost when losing the variable, while combining the partial contributions of the down-set corresponds to the expected value of quantifying the accessible decision region from this variable. Additionally, we obtain a pointwise version of the property by Bertschinger et al. [10]: if a variable provides unique information, then there is a way to utilize this information for a reward function to some target variable state. Finally, it can be seen that taking the minimal quantification of the different decision regions as done by Williams and Beer [5] leads to a lack in distinguishing distinct reachable decision regions or, as phrased in the literature: a lack of distinguishing “the same information and the same amount of information” [6,7,8,9].
An identical definition of can be obtained only based on the Blackwell order, as shown in Equation (28). Let be a set of sources and let represent a binary target variable () such that . We can expand the meet operator used in Equation (27a) using the sum-rule and utilize the distributivity for arriving at the joint of two channels, which matches the Blackwell order (Equation (28b)). We write to refer to the joint of and under the Blackwell order with respect to variable . This results in the recursive definition of that corresponds to the definition of mutual information for a single source (Equation (28a)). This expansion of Equation (27a) is particularly helpful since it eliminates the operators ∧/∨ for a simplified implementation.
Our decomposition is equivalent to the measures of Bertschinger et al. [10], Griffith and Koch [11] and Williams and Beer [5] in two special cases:
- For a binary target variable with two observable variables and , our approach is identical to Bertschinger et al. [10] and Griffith and Koch [11] since . Beyond binary target variables, the resulting definitions differ due to the pointwise construction (see Appendix E).
- If from a pointwise perspective (), some variable is Blackwell superior to the other (not necessarily the same each time), then our method is identical to Williams and Beer [5] since the defined meet operation will equal their minimum and equivalently for the function .
A decomposition of typical examples can be found in Appendix E. We also provide an implementation of the PID based on our approach [18].
4.2. Information Flow Analysis
Due to the achieved inclusion–exclusion principle, the data processing inequality of mutual information and the achieved non-negativity of partial information for an arbitrary number of variables, it is possible to trace the flow of information through Markov chains. The measure appears suitable for this analysis due to the chaining properties of the underlying pointwise channels that are quantified. The analysis can be applied among others for analyzing communication networks or designing data processing systems.
The flow of information in Markov chains has been studied by Niu and Quinn [19], who considered chaining individual variables and performed a decomposition on . In contrast to this, we consider Markov chains that map sets of random variables from one step to the next. In this case, it is possible to perform an information decomposition at each step of the Markov chain and identify how the partial information components propagate from one set of variables to the next.
Let be a Markov chain with the atoms and , through which we trace the flow of partial information from to about T. We can measure the shared information between both atoms and , as shown in Equation (29a), to obtain how much information their cumulative components share . Similar to the PID, we remove the normalization for the self-redundancy axiom. To identify how much of the cumulative information of is obtained from the partial information of , we subtract the strict down-set of on the lattice () as shown in Equation (29b) to obtain . To compute how much of the partial information of is shared with the partial contribution of , we similarly remove the flow from the partial information of into the strict down-set of on the lattice (), as shown in Equation (29c), to obtain . This can be used to trace the origin of information for each atom to the previous elements .
The approach is not limited to one step and can be extended for tracing the flow through Markov chains of arbitrary length . However, we only trace one step in this demonstration for simplicity.
We demonstrate the Information Flow Analysis using a full-adder as a small logic circuit with the input variables and the output as shown in Equation (30). Any ideal implementation of this computation results in the same channel from to . Therefore, they create an identical flow of the partial information from to the partial information of . However, the specific implementation will determine how (over which intermediate representations and paths) the partial information is transported.
To make the example more interesting, we consider the implementation of a noisy full-adder, as shown in Figure 7, which allows for bit-flips on wires. We indicate the probability of a bit-flip below each line and imagine this value correlates to the wire length and proximity to others. Now, changing the implementation or even the layout of the same circuit would have an impact on the overall channel.
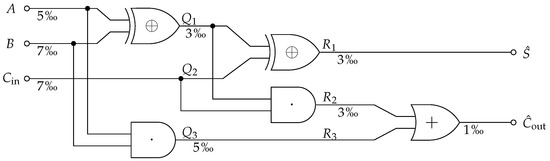
Figure 7.
Noisy full-adder example for the Information Flow Analysis demonstration. The probability of a bit-flip is indicated below the wires. If a wire has two labels, the first label corresponds to the wire input and the second label to its output.
To perform the analysis, we first have to define the target variable: What it is that we want to measure information about? In this case, we select the joint distribution of the desired computation output T as the target variable and define the noisy computation result to be , as shown in Figure 7. We obtain both variables from their definition by assuming that the input variables are independently and uniformly distributed and that bit-flips occurred independently. However, it is worth noting that noise dependencies can be modeled in the joint distribution. This fully characterizes the Markov chain shown in Equation (31).
We group two variables at each stage to reduce the number of interactions in the visualization. The resulting information flow of the full-adder is shown as a Sankey diagram in Figure 8. Each bar corresponds to the mutual information of a stage in the Markov chain with the input T. The bars’ colors indicate the partial information decomposition of Equation (27). The information flow over one step using Equation (29) is indicated by the width of a line between the partial contributions of two stages. To follow the flow of a particular component over more than one step—for example, to see how the shared information of propagates to the shared information of —the analysis can be performed by tracing multiple steps after extending Equation (29).
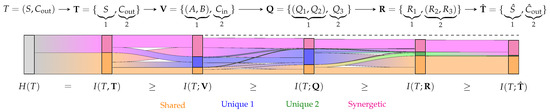
Figure 8.
Sankey diagram of the Information Flow Analysis for the noisy full-adder in Figure 7. Each bar corresponds to one stage in the Markov chain, and its height corresponds to this stage’s mutual information with the target T. Each bar is decomposed into the information that the considered variables provide shared (orange), unique (blue/green) or synergetic (pink) about the target. If a stage is represented by a single variable or joint distribution, no further decomposition is performed (gray). We trace the information between variables over one step using the sub-chains , , , and using Equation (29). The resulting flows between each bar visualize how the partial information propagates for one step in the Markov chain. For following the flow of a particular partial component over more than one step in the Sankey diagram, Equation (29) can be extended.
The results (Figure 8) show that the decomposition does not attribute unique information to S or about their own joint distribution. The reason for this is shown in Equation (32): both variables provide an equivalent channel for each state of their joint distribution and, thus, an equivalent uncertainty about each state of T. Phrased differently, both variables provide access to the identical decision regions for each state of their joint distribution and can therefore not provide unique information (no advantage for any reward function to any ). If this result feels counter-intuitive, we would also recommend the discussion of the two-bit-copy problem and identity axiom by Finn [9] (p. 16ff.) and Finn and Lizier [20]. The same effect can also be seen when viewing each variable in individually (not shown in Figure 8), which causes neither of them to provide unique information on their own about the joint target distribution T.
The Information Flow Analysis is particularly useful in practice since it can be performed on an arbitrary resolution of the system model to handle its complexity. For example, a small full-adder can be analyzed on the level of gates and wires represented by channels. However, the full-adder is itself a channel that can be used to analyze an n-bit adder on the level of full-adders.
Further applications of the Information Flow Analysis could include the identification of which inputs are most critical for the computational result and where information is being lost. It can also be explored if a notion of robustness in data processing systems could be meaningfully defined based on how much pointwise redundant or shared information of the input can be traced to its output . This might indicate a notion of robustness based on whether or not it is possible to compensate for the unavailability of input sources through a system modification.
Finally, the target variable does not have to be the desired computational outcome as has been done in the demonstration. When thinking about secure multi-party computations, it might be of interest to identify the flow of information from the perspective of some sensitive or private variable (T) to understand the impact of disclosing the final computation result. The possible applications of such an analysis are as diverse as those of information theory.
5. Discussion
We propose the interpretation that the reachable decision regions correspond to different notions of uncertainty about each state of the target variable and that mutual information corresponds to the expected value of quantifying these decision regions. This allows partial information to represent the expected value of quantifying partial decision regions (Equations (27) and (28)), which can be used to attribute mutual information to the visible variables and their interactions (pointwise redundant/shared/unique/synergetic). Since the proposed quantification results in the consistent valuation of a distributive lattice, it creates a novel algebra for mutual information with possible practical applications (Equations (24) and (25)). Finally, the approach allows for tracing information components through Markov chains (Equation (29)), which can be used to model and study a wide range of scenarios. The presented method is directly applicable to discrete and categorical source variables due to their equivalent construction for the reachable decision regions (zonotopes). However, we recommend that the target variable should be categorical since the measure does not consider a notion of distance between target states (achievable estimation proximity). This would be an interesting direction for future work due to its practical application for introducing semantic meaning to sets of variables. An intuitive example is a target variable with 256 states that is used to represent an 8-bit unsigned integer as the computation result. For this reason, we wonder if it is possible to introduce a notion of distance to the analysis such that the classical definition of mutual information becomes the special case for encoding categorical targets.
A recent work by Kolchinsky [21] removes the assumption that an inclusion–exclusion principle relates the intersection and union of information and demands their extractability. This has the disadvantage that a similar algebra or tracing of information would no longer be possible. We tried to address this point by distinguishing the pointwise redundant from the pointwise shared element and also obtain no inclusion–exclusion principle for the pointwise redundancy. We focus in this work on the pointwise shared element due to the resulting properties and operational interpretation from the accessibility and losses of reachable decision regions. Moreover, the relation between the used meet and joint operators provides consistent results from performing the decomposition using the meet operator on a redundancy lattice, as done in this work, or a decomposition using the joint operator on a synergy or loss lattice [22].
Further notions of redundancy and synergy can be studied within this framework if they are extractable, meaning they can be represented by some random variable. Depending on the desired interpretation, the representing variable can be constructed for T and added to the set of visible variables or can be constructed for each pointwise variable and added to the pointwise lattices. We showed an example of the latter in Section 3.1 by adding the pointwise redundant element to the lattice, which we interpret as pointwise extractable components of shared information to quantify the decision regions that can be obtained from each source.
Since our approach satisfies the original axioms of Williams and Beer [5] and results in non-negative partial contributions for an arbitrary number of variables, it cannot satisfy the proposed identity axiom of Harder et al. [8]. This can also be seen by the decomposition examples in Appendix E (Table A2 and Figure A3). We do not consider this a limitation since all four axioms cannot be satisfied without obtaining negative partial information [23], which creates difficulties for interpreting results.
Finally, our approach does not appear to satisfy a target/left chain rule as proposed by Bertschinger et al. [7]. While our approach provides an algebra that can be used to handle multiple target variables, we think that further work on understanding the relations when decomposing with multiple target variables is needed. In particular, it would be helpful for the analysis of complex systems if the flow of already analyzed sub-chains could be reused and their interactions could be predicted.
6. Conclusions
We use the approach of Bertschinger et al. [10] and Griffith and Koch [11] to construct a pointwise partial information decomposition that provides non-negative results for an arbitrary number of variables and target states. The measure obtains an algebra from the resulting lattice structure and enables the analysis of complex multivariate systems in practice. To our knowledge, this is the first alternative to the original measure of Williams and Beer [5] that satisfies their three proposed axioms and results in a non-negative decomposition for an arbitrary number of variables.
Author Contributions
T.M. and C.R conceived the idea; T.M. prepared the original draft; C.R. reviewed and edited the draft. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Swedish Civil Contingencies Agency (MSB) through the project RIOT grant number MSB 2018-12526.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used:
| PID | Partial Information Decomposition |
| ROC | Receiver Operating Characteristic |
| TPR | True-Positive Rate () |
| FPR | False-Positive Rate () |
| We use the following notation conventions: | |
| T, , t, | T (upper case) represents the target variable with an event t (lower case) of its event space (calligraphic), . represents a pointwise (binary) target variable which takes state one if and state two if ( represents the one-vs-rest encoding of state t); |
| , , , v | represents a set of visible/observable/predictor variables with ; |
| sources represent a set of visible variables, where the index i lists the contained visible variables, such as . The event corresponds to an event of the corresponding joint variable, e.g., . | |
| We represent channels (, ) as row stochastic matrices with the following indexing: | |
| represents a permutation matrix; | |
| represents a channel from the target to a source using the joint distribution of the variables within the source, such as ; | |
| represents a pointwise channel from the target to a source , such as ; | |
| binary input channels can be represented as (row) stochastic matrix, which contain a likelihood vector for each state . represents the zonotope for this set of vectors; | |
| represents the binary input channel corresponding to the convex hull of and (Blackwell order joint of binary input channels ); | |
| represents the meet element for constructing a distributive lattice with the joint operator ; | |
| represents the binary input channel corresponding to the intersection of and (Blackwell order meet of binary input channels); | |
| , | atoms represent an expression of random variables with the operators . In Section 2.2 and Section 4, they represent sets of sources; |
| , | represent an expression of pointwise channels with the operators ; |
| , | represent a partial pointwise channel corresponding to . |
| We use the following convention for operations, functions and brackets: | |
| represents the power set without the empty set; | |
| curly brackets with comma separation represent a set; | |
| square brackets without comma separation represent a matrix, and the listing of matrices in this manner represents their concatenation; | |
| square brackets with semicolon separation are used to refer to the bi-valuation of a consistent lattice valuation . In a similar manner to Knuth [13], we use the notation ; | |
| round brackets with semicolon separation represent an element of a Cartesian product , where and ; | |
| angled brackets indicate that a function f shall be mapped to each element of the set . We may nest this notation, such as , to indicate a map to each element of the sets within ; | |
| False-Positive Rate, type I error; | |
| True-Positive Rate, type II error. | |
| We distinguish between a joint channel and the joint of two channels . To avoid confusion, we write the first case as “joint channel ()” and the latter case as “joint of channels ()” throughout this work. | |
Appendix A
The considered lattice relates the meet and joint elements () through an inclusion–exclusion principle. Here, the partial contribution for the joint of any two incomparable elements shall be zero, which is indicated using a gray font in Figure A1.

Figure A1.
The considered lattice relating the meet and joint operators. The joint of any two incomparable elements () shall have no partial contribution to create an inclusion–exclusion principle between the operators and is highlighted using a gray font.
Appendix B
This section demonstrates that the defined meet and joint operators of Section 3.2 provide a distributive lattice under the defined equivalence relation (∼, Equation (10)).
Lemma A1.
The meet and joint operators (∧, ∨) define a distributive lattice for a set of channels under the defined equivalence relation (∼).
Proof.
The definitions of the meet and joint satisfy associativity, commutativity, idempotency, absorption and distributivity on channels under the defined equivalence relation:
- Idempotency: and .
- Commutativity: and .
- Associativity: and .
- Absorption: and .
- Distributivity: and .
□
Appendix C
This section demonstrates the quantification of a small example and proves that the function f of Equation (19) creates a consistent valuation for the pointwise lattice .
The convexity of the function results, in combination with the property that with , in a triangle inequality, as shown in Equation (A1). This ensures that Blackwell superior channels obtain a larger quantification result and thus the non-negativity of channels: .
To provide an intuition for the meet operator with a minimal example and highlight its relation to the intersection of zonotopes (redundant region), consider the two channels and of Equation (A2) and as visualized in Figure A2. To simplify the notation, we use the property to differentiate the vectors and as well as and .
The resulting shared and redundant element is shown in Equation (A3). Due to the construction of the meet element through an inclusion–exclusion principle with the joint, the meet element always contains the vectors which span the redundant decision region as the first component.
The second component of the meet element corresponds to the decision region of the joint, which is not part of either individual channel. This component is non-negative due to the triangle inequality.
The same argument applies to the meet for an arbitrary number of channels since the inclusion–exclusion principle with the joint elements ensures that the vectors spanning the redundant region are contained in the meet element, and the triangle inequality ensures non-negativity for the additional components.

Figure A2.
A minimal example to discuss the relation between the shared () and redundant () decision regions. The channel consists of the vectors , and the channel consists of the vectors .
Lemma A2.
The function is a (consistent) valuation on the pointwise lattice corresponding to , as visualized in Appendix A.
Proof.
Let represent a set of pointwise channels. The meet element () is constructed through an inclusion–exclusion principle with the joint (convex hull). This ensures that the set of vectors spanning the zonotope intersection () is contained within the meet element. Additionally, the meet contains a second component that is ensured to be positive from the triangle inequality of r: . Since the joint operator is closed on channels and is distributive, we can introduce a channel to enforce a minimal redundant decision region between the channels: . Applying the sum-rule shows that .
We again make use of the distributive property, which allows writing any expression into a conjunctive normal form. Since the joint operator is closed for channels, any expression can be represented as meet for a set of channels . This demonstrates that the obtained inequality of the meet operator on channels also applies to atoms , such that . □
Appendix D
The considered function of Section 3.2 takes the sum of a convex function. The Hessian matrix of the function is positive-semidefinite in the required domain (symmetric and its eigenvalues and are greater than or equal to zero for and ).
Appendix E
We use the examples of Finn and Lizier [20] since they provided an extensive discussion of their motivation. We compare our decomposition results to of Williams and Beer [5] and of Finn and Lizier [20]. Examples with two sources are additionally compared to of Bertschinger et al. [10] and Griffith and Koch [11]. We notate the results for shared information , unique information and synergetic/complementing information . We use the implementation of , and provided by the dit Python package for discrete information theory [24].
Notice that our approach is identical to Williams and Beer [5] if one of the variables is pointwise (for each , not necessarily the same one each time) Blackwell superior to another, and that our approach is equal to Bertschinger et al. [10] and Griffith and Koch [11] for two visible variables at a binary target variable.
We would like to highlight Table A1 for the difference in our approach to Williams and Beer [5]. This is an arbitrary example, where the variables and are not Blackwell superior to each other from the perspective of , as visualized in Figure 6. For highlighting the difference in our approach to Bertschinger et al. [10] and Griffith and Koch [11], we require an example where the target variable is not binary, such as the two-bit copy example in Table A2.
It can be seen that our approach does not satisfy the identity axiom of Harder et al. [8]. This axiom demands the decomposition of the two-bit-copy example (Table A2) to both variables providing one bit unique information and demands negative partial contributions in the three-bit even-parity example (Figure A3) [8,20].

Table A1.
Two incomparable channels (visualized in Section 3.1). The table highlights the difference in our approach to Williams and Beer [5] while being identical to Bertschinger et al. [10] since the target variable is binary.
Table A1.
Two incomparable channels (visualized in Section 3.1). The table highlights the difference in our approach to Williams and Beer [5] while being identical to Bertschinger et al. [10] since the target variable is binary.
| (a) Distribution | (b) Results | |||||||
|---|---|---|---|---|---|---|---|---|
| Pr | Method | |||||||
| 0 | 0 | 0 | 0.0625 | 0.1196 | 0.0272 | 0.0716 | 0.1205 | |
| 0 | 0 | 1 | 0.3 | [5] | 0.1468 | 0 | 0.0444 | 0.1477 |
| 1 | 0 | 0 | 0.0375 | [20] | 0.3214 | −0.1746 | −0.1302 | 0.3223 |
| 1 | 0 | 1 | 0.05 | [10,11] | 0.1196 | 0.0272 | 0.0716 | 0.1205 |
| 0 | 1 | 0 | 0.1875 | |||||
| 0 | 1 | 1 | 0.15 | |||||
| 1 | 1 | 0 | 0.2125 | |||||
Table A2.
Two-bit-copy (TBC) example. The results of our approach differ from Bertschinger et al. [10] and Griffith and Koch [11] since the target variable is not binary.
Table A2.
Two-bit-copy (TBC) example. The results of our approach differ from Bertschinger et al. [10] and Griffith and Koch [11] since the target variable is not binary.
| (a) Distribution | (b) Results | |||||||
|---|---|---|---|---|---|---|---|---|
| Pr | Method | |||||||
| 0 | 0 | 0 | 1/4 | 1 | 0 | 0 | 1 | |
| 0 | 1 | 1 | 1/4 | [5] | 1 | 0 | 0 | 1 |
| 1 | 0 | 2 | 1/4 | [20] | 1 | 0 | 0 | 1 |
| 1 | 1 | 3 | 1/4 | [10,11] | 0 | 1 | 1 | 0 |

Figure A3.
Three-bit even-parity (Tbep) example. The results for , and are identical. (a) Distribution. (b) Decomposition lattice. (c) Cumulative results (partial).
Table A3.
XOR-gate (Xor) example. All compared measures provide the same results.
Table A3.
XOR-gate (Xor) example. All compared measures provide the same results.
| (a) Distribution | (b) Results | |||||||
|---|---|---|---|---|---|---|---|---|
| Pr | Method | |||||||
| 0 | 0 | 0 | 1/4 | 0 | 0 | 0 | 1 | |
| 0 | 1 | 1 | 1/4 | [5] | 0 | 0 | 0 | 1 |
| 1 | 0 | 1 | 1/4 | [20] | 0 | 0 | 0 | 1 |
| 1 | 1 | 0 | 1/4 | [10,11] | 0 | 0 | 0 | 1 |
Table A4.
Pointwise unique (PwUnq) example. Our approach provides the same results as Williams and Beer [5] and Bertschinger et al. [10].
Table A4.
Pointwise unique (PwUnq) example. Our approach provides the same results as Williams and Beer [5] and Bertschinger et al. [10].
| (a) Distribution | (b) Results | |||||||
|---|---|---|---|---|---|---|---|---|
| Pr | Method | |||||||
| 0 | 1 | 0 | 1/4 | 0.5 | 0 | 0 | 0.5 | |
| 1 | 0 | 0 | 1/4 | [5] | 0.5 | 0 | 0 | 0.5 |
| 0 | 2 | 1 | 1/4 | [20] | 0 | 0.5 | 0.5 | 0 |
| 2 | 0 | 1 | 1/4 | [10,11] | 0.5 | 0 | 0 | 0.5 |
Table A5.
Redundant Error (RdnErr) example. Our approach provides the same results as Williams and Beer [5] and Bertschinger et al. [10].
Table A5.
Redundant Error (RdnErr) example. Our approach provides the same results as Williams and Beer [5] and Bertschinger et al. [10].
| (a) Distribution | (b) Results | |||||||
|---|---|---|---|---|---|---|---|---|
| Pr | Method | |||||||
| 0 | 0 | 0 | 3/8 | 0.189 | 0.811 | 0 | 0 | |
| 1 | 1 | 1 | 3/8 | [5] | 0.189 | 0.811 | 0 | 0 |
| 0 | 1 | 0 | 1/8 | [20] | 1 | 0 | −0.811 | 0.811 |
| 1 | 0 | 1 | 1/8 | [10,11] | 0.189 | 0.811 | 0 | 0 |
Table A6.
Unique (Unq) example. Our approach provides the same results as Williams and Beer [5] and Bertschinger et al. [10].
Table A6.
Unique (Unq) example. Our approach provides the same results as Williams and Beer [5] and Bertschinger et al. [10].
| (a) Distribution | (b) Results | |||||||
|---|---|---|---|---|---|---|---|---|
| Pr | Method | |||||||
| 0 | 0 | 0 | 1/4 | 0 | 1 | 0 | 0 | |
| 0 | 1 | 0 | 1/4 | [5] | 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 1/4 | [20] | 1 | 0 | −1 | 1 |
| 1 | 1 | 1 | 1/4 | [10,11] | 0 | 1 | 0 | 0 |
Table A7.
And-gate (And) example. Our approach provides the same results as Williams and Beer [5] and Bertschinger et al. [10].
Table A7.
And-gate (And) example. Our approach provides the same results as Williams and Beer [5] and Bertschinger et al. [10].
| (a) Distribution | (b) Results | |||||||
|---|---|---|---|---|---|---|---|---|
| Pr | Method | |||||||
| 0 | 0 | 0 | 1/4 | 0.311 | 0 | 0 | 0.5 | |
| 0 | 1 | 0 | 1/4 | [5] | 0.311 | 0 | 0 | 0.5 |
| 1 | 0 | 0 | 1/4 | [20] | 0.561 | −0.25 | −0.25 | 0.75 |
| 1 | 1 | 1 | 1/4 | [10,11] | 0.311 | 0 | 0 | 0.5 |
References
- Lizier, J.T.; Bertschinger, N.; Jost, J.; Wibral, M. Information Decomposition of Target Effects from Multi-Source Interactions: Perspectives on Previous, Current and Future Work. Entropy 2018, 20, 307. [Google Scholar] [CrossRef] [PubMed]
- Wibral, M.; Finn, C.; Wollstadt, P.; Lizier, J.T.; Priesemann, V. Quantifying Information Modification in Developing Neural Networks via Partial Information Decomposition. Entropy 2017, 19, 494. [Google Scholar] [CrossRef]
- Rassouli, B.; Rosas, F.E.; Gündüz, D. Data Disclosure Under Perfect Sample Privacy. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2012–2025. [Google Scholar] [CrossRef]
- Rosas, F.E.; Mediano, P.A.M.; Rassouli, B.; Barrett, A.B. An operational information decomposition via synergistic disclosure. J. Phys. Math. Theor. 2020, 53, 485001. [Google Scholar] [CrossRef]
- Williams, P.L.; Beer, R.D. Nonnegative Decomposition of Multivariate Information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Griffith, V.; Chong, E.K.P.; James, R.G.; Ellison, C.J.; Crutchfield, J.P. Intersection Information Based on Common Randomness. Entropy 2014, 16, 1985–2000. [Google Scholar] [CrossRef]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J. Shared Information—New Insights and Problems in Decomposing Information in Complex Systems. In Proceedings of the European Conference on Complex Systems 2012; Gilbert, T., Kirkilionis, M., Nicolis, G., Eds.; Springer: Cham, Switzerland, 2013; pp. 251–269. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed]
- Finn, C. A New Framework for Decomposing Multivariate Information. Ph.D. Thesis, University of Sydney, Sydney, NSW, Australia, 2019. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying Unique Information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Griffith, V.; Koch, C. Quantifying Synergistic Mutual Information. In Guided Self-Organization: Inception; Springer: Berlin/Heidelberg, Germany, 2014; pp. 159–190. [Google Scholar] [CrossRef]
- Bertschinger, N.; Rauh, J. The Blackwell Relation Defines No Lattice. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 2479–2483. [Google Scholar] [CrossRef]
- Knuth, K.H. Lattices and Their Consistent Quantification. Ann. Der Phys. 2019, 531, 1700370. [Google Scholar] [CrossRef]
- Blackwell, D. Equivalent Comparisons of Experiments. In The Annals of Mathematical Statistics; Institute of Mathematical Statistics: Beachwood, OH, USA, 1953; pp. 265–272. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Schechtman, E.; Schechtman, G. The relationship between Gini terminology and the ROC curve. Metron 2019, 77, 171–178. [Google Scholar] [CrossRef]
- Neyman, J.; Pearson, E.S. IX. On the Problem of the Most Efficient Tests of Statistical Hypotheses. Philos. Trans. R. Soc. Lond. Ser. Contain. Pap. Math. Phys. Character 1933, 231, 289–337. [Google Scholar]
- Mages, T.; Rohner, C. Implementation: PID Quantifying Reachable Decision Regions. 2023. Available online: https://github.com/uu-core/pid-quantifying-reachable-decision-regions (accessed on 1 May 2023).
- Niu, X.; Quinn, C.J. Information Flow in Markov Chains. In Proceedings of the 2021 60th IEEE Conference on Decision and Control (CDC), Austin, TX, USA, 14–17 December 2021; pp. 3442–3447. [Google Scholar] [CrossRef]
- Finn, C.; Lizier, J.T. Pointwise Partial Information Decomposition Using the Specificity and Ambiguity Lattices. Entropy 2018, 20, 297. [Google Scholar] [CrossRef] [PubMed]
- Kolchinsky, A. A Novel Approach to the Partial Information Decomposition. Entropy 2022, 24, 403. [Google Scholar] [CrossRef]
- Chicharro, D.; Panzeri, S. Synergy and Redundancy in Dual Decompositions of Mutual Information Gain and Information Loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef]
- Rauh, J.; Bertschinger, N.; Olbrich, E.; Jost, J. Reconsidering Unique Information: Towards a Multivariate Information Decomposition. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 2232–2236. [Google Scholar] [CrossRef]
- James, R.G.; Ellison, C.J.; Crutchfield, J.P. dit: A Python package for discrete information theory. J. Open Source Softw. 2018, 3, 738. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).