
An Information-Theoretic Perspective on Intrinsic Motivation in Reinforcement Learning: A Survey

Abstract
1. Introduction
- The role of IM in addressing the challenges of DRL.
- Classifying current heterogeneous works through a few information theoretic objectives.
- Exhibiting the advantages of each class of methods.
- Important outlooks of IM in RL within and across each category.
2. Definitions and Background
2.1. Markov Decision Process
2.2. Definition of Intrinsic Motivation
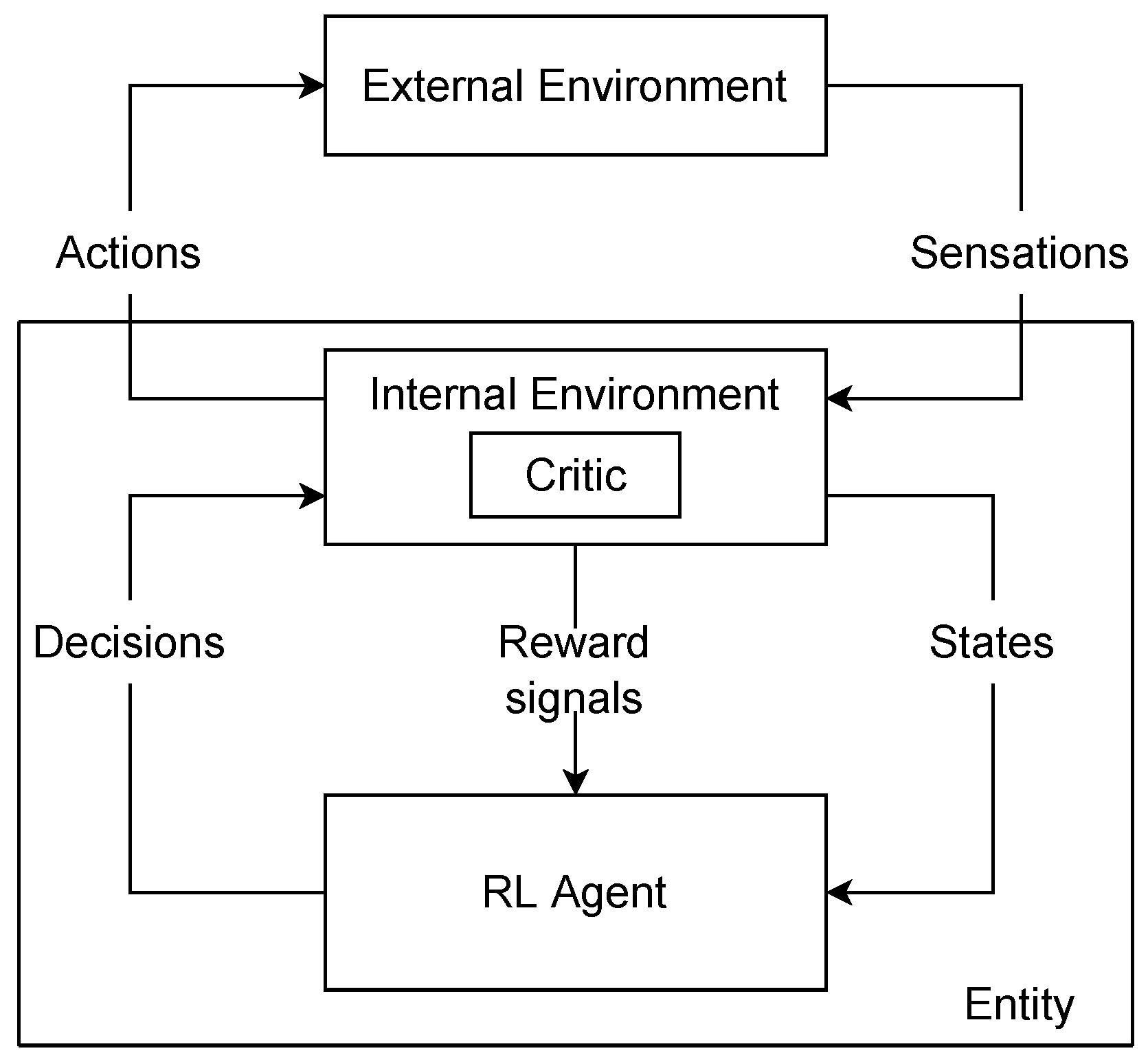
2.3. A Model of Rl with Intrinsic Rewards
2.4. Intrinsic Rewards and Information Theory
2.5. Decisions and Hierarchical RL
2.6. Goal-Parameterized Rl
3. Challenges of DRL
3.1. Sparse Rewards
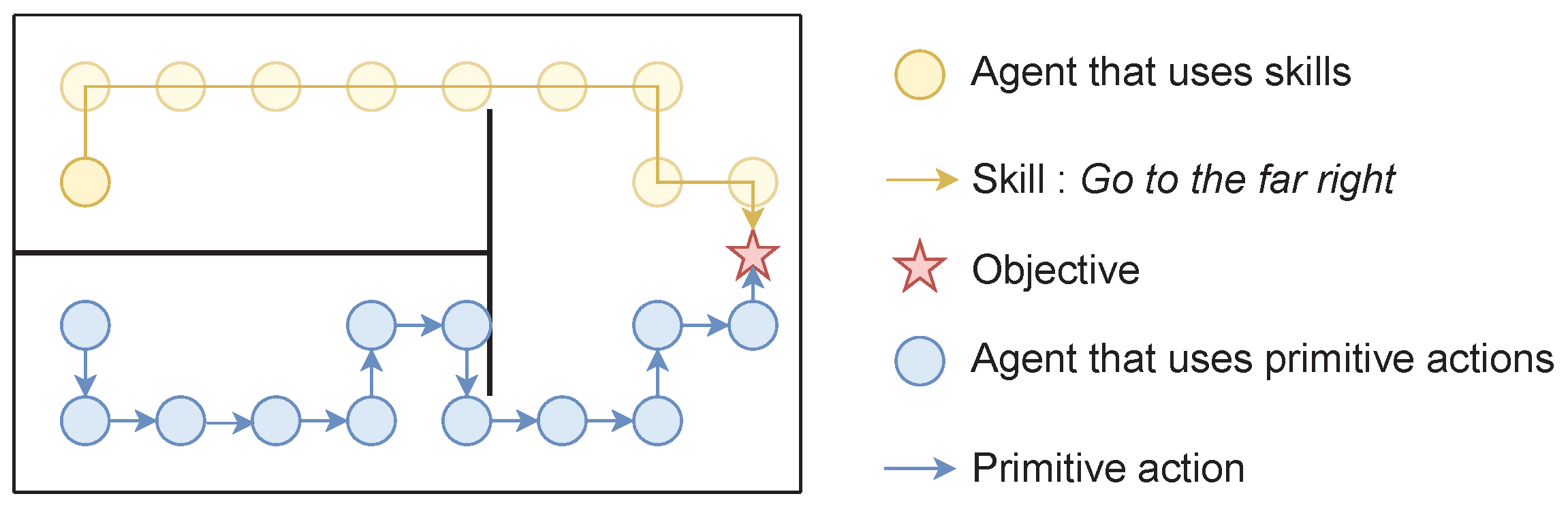
3.2. Temporal Abstraction of Actions
4. Classification of Methods
5. Surprise
5.1. Surprise Maximization
5.2. Prediction Error
5.3. Learning Progress
5.4. Information Gain over Forward Model
5.5. Conclusions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Computational Cost | Montezuma’s Revenge | |
|---|---|---|---|
| Score | Steps | ||
| Best score [87] | Imitation learning | 58,175 | 200 k |
| Best IM score [88] | Inverse model, RND | 16,800 | 3500 M |
| Prediction error | |||
| Prediction error with pixels [62] | Forward model | ∼160 | 200 M |
| Dynamic-AE [63] | Forward model, autoencoder | 0 | 5 M |
| Prediction error with random features [62] | Forward model, Random encoder | ∼250 | 100 M |
| Prediction error with VAE features [62] | Forward model, VAE | ∼450 | 100 M |
| Prediction error with ICM features [62] | Forward model, Inverse model | ∼160 | 100 M |
| Results from [68] | 161 | 50 M | |
| EMI [68] | Large architecture Error model | 387 | 50 M |
| Prediction error with LWM [65] | Whitened contrastive loss Forward model | 2276 | 50 M |
| Learning progress | |||
| Learning progress [70,71,72,73,74] | Two forward errors | n/a | n/a |
| Local learning progress [75,76] | Several Forward models | n/a | n/a |
| Information gain over forward model | |||
| VIME [79] | Bayesian forward model | n/a | n/a |
| AKL [82] | Stochastic forward model | n/a | n/a |
| Ensemble with random features [84] | Forward models, random encoder | n/a | n/a |
| Ensemble with observations [85] | Forward models | n/a | n/a |
| Emsemble with PlaNet [86] | Forward models, PlaNet | n/a | n/a |
| JDRX [83] | 3 Stochastic Forward models | n/a | n/a |
6. Novelty Maximization
6.1. Information Gain over Density Model
6.2. Variational Inference
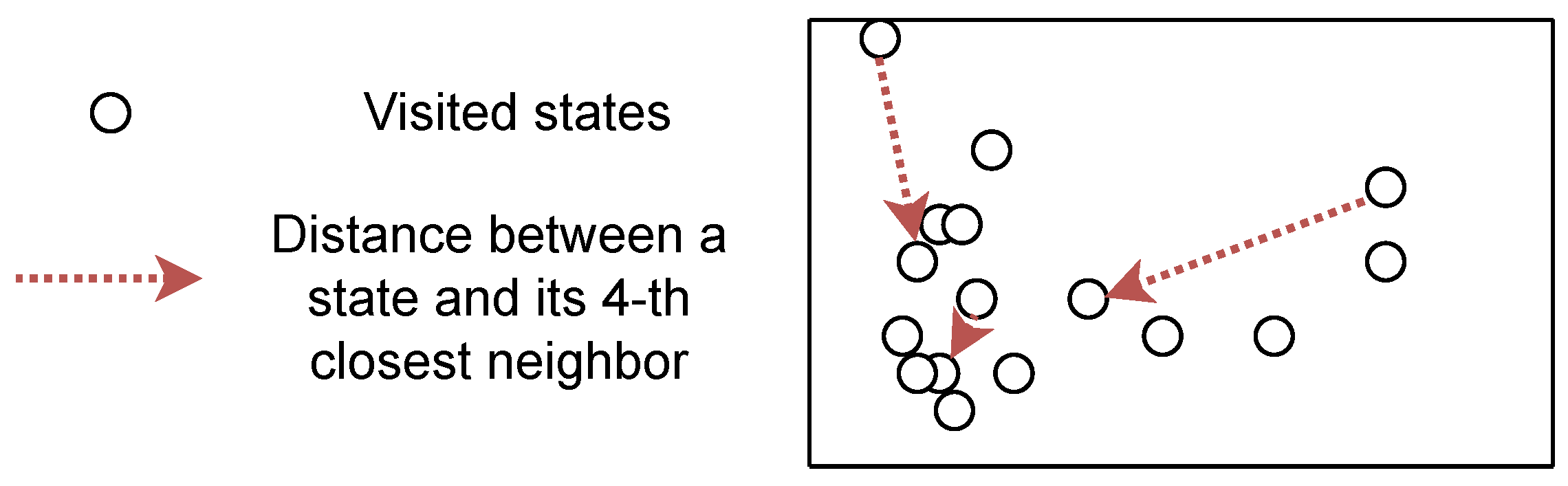
6.3. K-Nearest Neighbors Approximation of Entropy
6.4. Conclusions
| Method | Computational Cost | Montezuma’s Revenge | |
|---|---|---|---|
| Score | Steps | ||
| Best score [87] | Imitation learning | 58,175 | 200 k |
| Best IM score [88] | Inverse model, RN [35] | 16,800 | 3500 M |
| Information gain over density model | |||
| TRPO-AE-hash [100] | SimHash, AE | 75 | 50 M |
| DDQN-PC [98] | CTS [102] | 3459 | 100 M 1 |
| DQN-PixelCNN [101] | PixelCNN [103] | 1671 | 100 M 1 |
| -EB [104] | Density model | 2745 | 100 M 1 |
| DQN+SR [105] | Successor features Forward model | 1778 | 20 M |
| RND [35] | Random encoder | 8152 | 490 M |
| [105] | 524 | 100 M 1 | |
| [68] | 377 | 50 M | |
| RIDE [106] | Forward and inverse models Pseudo-count | n/a | n/a |
| BeBold [107] | Hash table | ∼10,000 | 2000 M 1,2 |
| Direct entropy maximization | |||
| MOBE [112], StateEnt [109] | VAE | n/a | n/a |
| Renyi entropy [108] | VAE, planning | 8100 | 200 M |
| GEM [115] | Contrastive loss | n/a | n/a |
| SMM [110] | VAE, Discriminator | n/a | n/a |
| K-nearest neighbors entropy | |||
| EX [131] | Discriminator | n/a | n/a |
| [68] | 0 | 50 M | |
| CB [132] | IB | n/a | |
| VSIMR [133] | VAE | n/a | n/a |
| ECO [135] | Siamese architecture | n/a | n/a |
| [126] | 8032 | 100 M | |
| DAIM [123] | DDP [137] | n/a | n/a |
| APT [120] | Contrastive loss | 250 M | |
| SDD [136] | Forward model | n/a | n/a |
| RE3 [122] | Random encoders ensemble | 100 | 5 M |
| Proto-RL [124], Novelty [125] | Contrastive loss | n/a | n/a |
| NGU [88] | Inverse model, RND [35] several policies | 16,800 | 3500 M 1 |
| CRL [127], CuRe [128] | Contrastive loss | n/a | n/a |
| BYOL-explore [129] | BYOL [138] | 13,518 | 3 M |
| DeepCS [134] | RAM-based grid | 3500 | 160 M |
| GoCu [126] | VAE, predictor | 10,958 | 100 M |
7. Skill Learning
7.1. Fixing the Goal Distribution
7.2. Achieving a State Goal
7.3. Proposing Diverse State Goals
7.4. Conclusions
| Fixing the goal distribution | |||||
|---|---|---|---|---|---|
| SNN4HRL [143], DIAYN [140], VALOR [144] | |||||
| HIDIO [146], R-VIC [148], VIC [147] | |||||
| DADS [149], continuous DIAYN [150], ELSIM [42] | |||||
| VISR [152] | |||||
| Methods | Scale | Goal space | Curriculum | Score | Steps |
| Achieving a state goal | |||||
| HAC [153] | n/a | n/a | n/a | n/a | n/a |
| HIRO [156] | 4x | (x, y) | Yes | ∼0.8 | 4 M |
| RIG [157] | n/a | n/a | n/a | n/a | n/a |
| SeCTAR [141] | n/a | n/a | n/a | n/a | n/a |
| IBOL [158] | n/a | n/a | n/a | n/a | n/a |
| SFA-GWR-HRL [159] | n/a | n/a | n/a | n/a | n/a |
| NOR [164] | 4x | T-V + P | Yes | ∼0.7 | 10 M |
| [165] | 4x | T-V + P | Yes | ∼0.4 | 4 M |
| LESSON [165] | 4x | T-V + P | Yes | ∼0.6 | 4 M |
| Proposing diverse state goals | |||||
| Goal GAN [166] | 1x | (x, y) | No | Coverage | n/a |
| [111] | n/a (6x) | (x, y) | No | All goals distance∼7 | 7 M |
| FVC [167] | n/a | n/a | n/a | n/a | n/a |
| Skew-fit [111] | n/a ( 6x) | (x, y) | No | All goals distance∼1.5 | 7 M |
| DisTop [114] | 4x | T-V | No | ∼1 | 2 M |
| DISCERN [162] | n/a | n/a | n/a | n/a | n/a |
| OMEGA [154] | 4x | (x, y) | No | ∼1 | 4.5 M |
| CDP [171] | n/a | n/a | n/a | n/a | n/a |
| [111] | n/a ( 6x) | (x, y) | No | All goals distance∼7.5 | 7 M |
| GRIMGREP [173] | n/a | n/a | n/a | n/a | n/a |
| HESS [175] | 4x | T-V + P | No | success rate∼1 | 6 M |
8. Outlooks of the Domain
8.1. Long-Term Exploration, Detachment and Derailment
- 1.
- The first comes from partial observability, with which most models are incompatible. Typically, if an agent has to push a button and can only see the effect of this pushing after a long sequence of actions, density models and predictive models may not provide meaningful intrinsic rewards. There would be too large a distance between the event “pushing a button” and the intrinsic reward.
- 2.
- Figure 7 illustrates the second issue, called detachment [177,178]. This results from a distant intrinsic reward coupled with catastrophic forgetting. Simply stated, the RL agent can forget the presence of an intrinsic reward in a distant area: it is hard to maintain the correct q-value that derives from a distant, currently unvisited, rewarding area. This is emphasized in on-policy settings.
8.2. Deeper Hierarchy of Skills
8.3. The Role of Flat Intrinsic Motivations
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Notations used in the paper. | |
| ∝ | proportional to |
| Euclidian norm of x | |
| t | timestep |
| arbitrary constant | |
| A | set of possible actions |
| S | set of possible states |
| action | |
| state | |
| first state of a trajectory | |
| final state of a trajectory | |
| state following a tuple | |
| h | history of interactions |
| predicted states | |
| goal | |
| state used as a goal | |
| set of states contained in b | |
| trajectory | |
| function that extracts parts of the trajectory | |
| reward function | |
| t-steps state distribution | |
| stationary state-visitation distribution of over a horizon T | |
| f | representation function |
| z | compressed latent variable, |
| density model | |
| forward model | |
| true forward model | |
| parameterized discriminator | |
| policy | |
| policy conditioned on a goal g | |
| k-th closest state to in S | |
| Kullback–Leibler divergence | |
| Information gain | |
References
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, UK, 1998; Volume 1. [Google Scholar]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An Evaluation Platform for General Agents (Extended Abstract). In Proceedings of the IJCAI; AAAI Press: Washington, DC, USA, 2015; pp. 4148–4152. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef]
- Francois-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An Introduction to Deep Reinforcement Learning. Found. Trends Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef]
- Todorov, E.; Erez, T.; Tassa, Y. Mujoco: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 5026–5033. [Google Scholar]
- Piaget, J.; Cook, M. The Origins of Intelligence in Children; International Universities Press: New York, NY, USA, 1952; Volume 8. [Google Scholar]
- Cangelosi, A.; Schlesinger, M. From babies to robots: The contribution of developmental robotics to developmental psychology. Child Dev. Perspect. 2018, 12, 183–188. [Google Scholar] [CrossRef]
- Oudeyer, P.Y.; Smith, L.B. How evolution may work through curiosity-driven developmental process. Top. Cogn. Sci. 2016, 8, 492–502. [Google Scholar] [CrossRef] [PubMed]
- Gopnik, A.; Meltzoff, A.N.; Kuhl, P.K. The Scientist in the Crib: Minds, Brains, and How Children Learn; William Morrow & Co: New York, NY, USA, 1999. [Google Scholar]
- Barto, A.G. Intrinsic Motivation and Reinforcement learning. In Intrinsically Motivated Learning in Natural and Artificial Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 17–47. [Google Scholar]
- Baldassarre, G.; Mirolli, M. Intrinsically motivated learning systems: An overview. In Intrinsically Motivated Learning in Natural and Artificial Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–14. [Google Scholar]
- Colas, C.; Karch, T.; Sigaud, O.; Oudeyer, P.Y. Intrinsically Motivated Goal-Conditioned Reinforcement Learning: A Short Survey. arXiv 2020, arXiv:2012.09830. [Google Scholar]
- Amin, S.; Gomrokchi, M.; Satija, H.; van Hoof, H.; Precup, D. A Survey of Exploration Methods in Reinforcement Learning. arXiv 2021, arXiv:2109.00157. [Google Scholar]
- Baldassarre, G. Intrinsic motivations and open-ended learning. arXiv 2019, arXiv:1912.13263. [Google Scholar]
- Pateria, S.; Subagdja, B.; Tan, A.h.; Quek, C. Hierarchical Reinforcement Learning: A Comprehensive Survey. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Linke, C.; Ady, N.M.; White, M.; Degris, T.; White, A. Adapting Behavior via Intrinsic Reward: A Survey and Empirical Study. J. Artif. Intell. Res. 2020, 69, 1287–1332. [Google Scholar] [CrossRef]
- Schmidhuber, J. Driven by compression progress: A simple principle explains essential aspects of subjective beauty, novelty, surprise, interestingness, attention, curiosity, creativity, art, science, music, jokes. In Proceedings of the Workshop on Anticipatory Behavior in Adaptive Learning Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 48–76. [Google Scholar]
- Salge, C.; Glackin, C.; Polani, D. Empowerment—An introduction. In Guided Self-Organization: Inception; Springer: Berlin/Heidelberg, Germany, 2014; pp. 67–114. [Google Scholar]
- Klyubin, A.S.; Polani, D.; Nehaniv, C.L. Empowerment: A universal agent-centric measure of control. In Proceedings of the Evolutionary Computation, Washington, DC, USA, 25–29 June 2005; Volume 1, pp. 128–135. [Google Scholar]
- Jaques, N.; Lazaridou, A.; Hughes, E.; Gulcehre, C.; Ortega, P.; Strouse, D.; Leibo, J.Z.; De Freitas, N. Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Beach, CA, USA, 10–15 June 2019; pp. 3040–3049. [Google Scholar]
- Karpas, E.D.; Shklarsh, A.; Schneidman, E. Information socialtaxis and efficient collective behavior emerging in groups of information-seeking agents. Proc. Natl. Acad. Sci. USA 2017, 114, 5589–5594. [Google Scholar] [CrossRef]
- Cuervo, S.; Alzate, M. Emergent cooperation through mutual information maximization. arXiv 2020, arXiv:2006.11769. [Google Scholar]
- Sperati, V.; Trianni, V.; Nolfi, S. Mutual information as a task-independent utility function for evolutionary robotics. In Guided Self-Organization: Inception; Springer: Berlin/Heidelberg, Germany, 2014; pp. 389–414. [Google Scholar]
- Goyal, A.; Bengio, Y. Inductive biases for deep learning of higher-level cognition. arXiv 2020, arXiv:2011.15091. [Google Scholar] [CrossRef]
- Wilmot, C.; Shi, B.E.; Triesch, J. Self-Calibrating Active Binocular Vision via Active Efficient Coding with Deep Autoencoders. In Proceedings of the 2020 Joint IEEE 10th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Valparaiso, Chile, 26–30 October 2020; pp. 1–6. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Cassandra, A.R. Planning and acting in partially observable stochastic domains. Artif. Intell. 1998, 101, 99–134. [Google Scholar] [CrossRef]
- Ryan, R.M.; Deci, E.L. Intrinsic and extrinsic motivations: Classic definitions and new directions. Contemp. Educ. Psychol. 2000, 25, 54–67. [Google Scholar] [CrossRef]
- Singh, S.; Lewis, R.L.; Barto, A.G.; Sorg, J. Intrinsically motivated reinforcement learning: An evolutionary perspective. IEEE Trans. Auton. Ment. Dev. 2010, 2, 70–82. [Google Scholar] [CrossRef]
- Baldassarre, G. What are intrinsic motivations? A biological perspective. In Proceedings of the 2011 IEEE international conference on development and learning (ICDL), Frankfurt am Main, Germany, 24–27 August 2011; Volume 2, pp. 1–8. [Google Scholar]
- Lehman, J.; Stanley, K.O. Exploiting open-endedness to solve problems through the search for novelty. In Proceedings of the ALIFE, Winchester, UK, 5–8 August 2008; pp. 329–336. [Google Scholar]
- Oudeyer, P.Y.; Kaplan, F. How can we define intrinsic motivation? In Proceedings of the 8th International Conference on Epigenetic Robotics: Modeling Cognitive Development in Robotic Systems; Lund University Cognitive Studies; LUCS, Brighton: Lund, Sweden, 2008. [Google Scholar]
- Barto, A.G.; Singh, S.; Chentanez, N. Intrinsically motivated learning of hierarchical collections of skills. In Proceedings of the 3rd International Conference on Development and Learning, La Jolla, CA, USA, 20–22 October 2004; pp. 112–119. [Google Scholar]
- Kakade, S.; Dayan, P. Dopamine: Generalization and bonuses. Neural Netw. 2002, 15, 549–559. [Google Scholar] [CrossRef]
- Burda, Y.; Edwards, H.; Storkey, A.; Klimov, O. Exploration by random network distillation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Barto, A.G.; Mahadevan, S. Recent advances in hierarchical reinforcement learning. Discret. Event Dyn. Syst. 2003, 13, 41–77. [Google Scholar] [CrossRef]
- Dayan, P.; Hinton, G. Feudal reinforcement learning. In Proceedings of the NIPS’93, Denver, CO, USA, 29 November–2 December 1993; pp. 271–278. [Google Scholar]
- Sutton, R.S.; Precup, D.; Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif. Intell. 1999, 112, 181–211. [Google Scholar] [CrossRef]
- Schaul, T.; Horgan, D.; Gregor, K.; Silver, D. Universal value function approximators. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1312–1320. [Google Scholar]
- Santucci, V.G.; Montella, D.; Baldassarre, G. C-GRAIL: Autonomous reinforcement learning of multiple, context-dependent goals. IEEE Trans. Cogn. Dev. Syst. 2022. [Google Scholar] [CrossRef]
- Aubret, A.; Matignon, L.; Hassas, S. ELSIM: End-to-end learning of reusable skills through intrinsic motivation. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), Bilbao, Spain, 13–17 September 2020. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Cesa-Bianchi, N.; Gentile, C.; Lugosi, G.; Neu, G. Boltzmann exploration done right. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6284–6293. [Google Scholar]
- Plappert, M.; Houthooft, R.; Dhariwal, P.; Sidor, S.; Chen, R.Y.; Chen, X.; Asfour, T.; Abbeel, P.; Andrychowicz, M. Parameter space noise for exploration. arXiv 2017, arXiv:1706.01905. [Google Scholar]
- Rückstiess, T.; Sehnke, F.; Schaul, T.; Wierstra, D.; Sun, Y.; Schmidhuber, J. Exploring parameter space in reinforcement learning. Paladyn. J. Behav. Robot. 2010, 1, 14–24. [Google Scholar] [CrossRef]
- Fortunato, M.; Azar, M.G.; Piot, B.; Menick, J.; Osband, I.; Graves, A.; Mnih, V.; Munos, R.; Hassabis, D.; Pietquin, O.; et al. Noisy networks for exploration. arXiv 2017, arXiv:1706.10295. [Google Scholar]
- Thrun, S.B. Efficient Exploration in Reinforcement Learning 1992. Available online: https://www.ri.cmu.edu/pub_files/pub1/thrun_sebastian_1992_1/thrun_sebastian_1992_1.pdf (accessed on 1 February 2023).
- Su, P.H.; Vandyke, D.; Gasic, M.; Mrksic, N.; Wen, T.H.; Young, S. Reward shaping with recurrent neural networks for speeding up on-line policy learning in spoken dialogue systems. arXiv 2015, arXiv:1508.03391. [Google Scholar]
- Ng, A.Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the ICML, Bled, Slovenia, 27–30 June 1999; Volume 99, pp. 278–287. [Google Scholar]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Chiang, H.T.L.; Faust, A.; Fiser, M.; Francis, A. Learning Navigation Behaviors End-to-End With AutoRL. IEEE Robot. Autom. Lett. 2019, 4, 2007–2014. [Google Scholar] [CrossRef]
- Bacon, P.L.; Harb, J.; Precup, D. The Option-Critic Architecture. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 1726–1734. [Google Scholar]
- Li, A.C.; Florensa, C.; Clavera, I.; Abbeel, P. Sub-policy Adaptation for Hierarchical Reinforcement Learning. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Heess, N.; Wayne, G.; Tassa, Y.; Lillicrap, T.; Riedmiller, M.; Silver, D. Learning and transfer of modulated locomotor controllers. arXiv 2016, arXiv:1610.05182. [Google Scholar]
- Machado, M.C.; Bellemare, M.G.; Bowling, M. A laplacian framework for option discovery in reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2295–2304. [Google Scholar]
- Nachum, O.; Tang, H.; Lu, X.; Gu, S.; Lee, H.; Levine, S. Why Does Hierarchy (Sometimes) Work So Well in Reinforcement Learning? arXiv 2019, arXiv:1909.10618. [Google Scholar]
- Barto, A.; Mirolli, M.; Baldassarre, G. Novelty or surprise? Front. Psychol. 2013, 4, 907. [Google Scholar] [CrossRef]
- Matusch, B.; Ba, J.; Hafner, D. Evaluating agents without rewards. arXiv 2020, arXiv:2012.11538. [Google Scholar]
- Ekman, P.E.; Davidson, R.J. The Nature of Emotion: Fundamental Questions; Oxford University Press: Oxford, UK, 1994. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Burda, Y.; Edwards, H.; Pathak, D.; Storkey, A.; Darrell, T.; Efros, A.A. Large-Scale Study of Curiosity-Driven Learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Stadie, B.C.; Levine, S.; Abbeel, P. Incentivizing exploration in reinforcement learning with deep predictive models. arXiv 2015, arXiv:1507.00814. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Ermolov, A.; Sebe, N. Latent World Models For Intrinsically Motivated Exploration. Adv. Neural Inf. Process. Syst. 2020, 33, 5565–5575. [Google Scholar]
- Pathak, D.; Agrawal, P.; Efros, A.A.; Darrell, T. Curiosity-driven exploration by self-supervised prediction. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; Volume 2017. [Google Scholar]
- Schmidhuber, J. Formal theory of creativity, fun, and intrinsic motivation (1990–2010). IEEE Trans. Auton. Ment. Dev. 2010, 2, 230–247. [Google Scholar] [CrossRef]
- Kim, H.; Kim, J.; Jeong, Y.; Levine, S.; Song, H.O. EMI: Exploration with Mutual Information. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Long Beach, CA, USA, 2019; Volume 97, pp. 3360–3369. [Google Scholar]
- Efroni, Y.; Misra, D.; Krishnamurthy, A.; Agarwal, A.; Langford, J. Provably Filtering Exogenous Distractors using Multistep Inverse Dynamics. In Proceedings of the International Conference on Learning Representations, Virtual, 18–24 July 2021. [Google Scholar]
- Schmidhuber, J. Curious model-building control systems. In Proceedings of the 1991 IEEE International Joint Conference on Neural Networks, Singapore, 18–21 November 1991; pp. 1458–1463. [Google Scholar]
- Azar, M.G.; Piot, B.; Pires, B.A.; Grill, J.B.; Altché, F.; Munos, R. World discovery models. arXiv 2019, arXiv:1902.07685. [Google Scholar]
- Lopes, M.; Lang, T.; Toussaint, M.; Oudeyer, P.Y. Exploration in model-based reinforcement learning by empirically estimating learning progress. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 206–214. [Google Scholar]
- Oudeyer, P.Y.; Kaplan, F.; Hafner, V.V. Intrinsic motivation systems for autonomous mental development. IEEE Trans. Evol. Comput. 2007, 11, 265–286. [Google Scholar] [CrossRef]
- Kim, K.; Sano, M.; De Freitas, J.; Haber, N.; Yamins, D. Active world model learning with progress curiosity. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 5306–5315. [Google Scholar]
- Hafez, M.B.; Weber, C.; Kerzel, M.; Wermter, S. Improving robot dual-system motor learning with intrinsically motivated meta-control and latent-space experience imagination. Robot. Auton. Syst. 2020, 133, 103630. [Google Scholar] [CrossRef]
- Hafez, M.B.; Weber, C.; Kerzel, M.; Wermter, S. Efficient intrinsically motivated robotic grasping with learning-adaptive imagination in latent space. In Proceedings of the 2019 Joint IEEE 9th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Oslo, Norway, 19–22 August 2019; pp. 1–7. [Google Scholar]
- Sun, Y.; Gomez, F.; Schmidhuber, J. Planning to be surprised: Optimal bayesian exploration in dynamic environments. In Proceedings of the International Conference on Artificial General Intelligence, Seattle, WA, USA, 19–22 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 41–51. [Google Scholar]
- Little, D.Y.J.; Sommer, F.T. Learning and exploration in action-perception loops. Front. Neural Circuits 2013, 7, 37. [Google Scholar] [CrossRef]
- Houthooft, R.; Chen, X.; Duan, Y.; Schulman, J.; De Turck, F.; Abbeel, P. Vime: Variational information maximizing exploration. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1109–1117. [Google Scholar]
- Graves, A. Practical variational inference for neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; pp. 2348–2356. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight uncertainty in neural networks. arXiv 2015, arXiv:1505.05424. [Google Scholar]
- Achiam, J.; Sastry, S. Surprise-based intrinsic motivation for deep reinforcement learning. arXiv 2017, arXiv:1703.01732. [Google Scholar]
- Shyam, P.; Jaskowski, W.; Gomez, F. Model-Based Active Exploration. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 5779–5788. [Google Scholar]
- Pathak, D.; Gandhi, D.; Gupta, A. Self-Supervised Exploration via Disagreement. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 5062–5071. [Google Scholar]
- Yao, Y.; Xiao, L.; An, Z.; Zhang, W.; Luo, D. Sample Efficient Reinforcement Learning via Model-Ensemble Exploration and Exploitation. arXiv 2021, arXiv:2107.01825. [Google Scholar]
- Sekar, R.; Rybkin, O.; Daniilidis, K.; Abbeel, P.; Hafner, D.; Pathak, D. Planning to explore via self-supervised world models. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 8583–8592. [Google Scholar]
- Aytar, Y.; Pfaff, T.; Budden, D.; Paine, T.; Wang, Z.; de Freitas, N. Playing hard exploration games by watching youtube. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 2930–2941. [Google Scholar]
- Badia, A.P.; Sprechmann, P.; Vitvitskyi, A.; Guo, D.; Piot, B.; Kapturowski, S.; Tieleman, O.; Arjovsky, M.; Pritzel, A.; Bolt, A.; et al. Never Give Up: Learning Directed Exploration Strategies. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Hafner, D.; Lillicrap, T.; Fischer, I.; Villegas, R.; Ha, D.; Lee, H.; Davidson, J. Learning latent dynamics for planning from pixels. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2555–2565. [Google Scholar]
- Berlyne, D.E. Curiosity and exploration. Science 1966, 153, 25–33. [Google Scholar] [CrossRef] [PubMed]
- Becker-Ehmck, P.; Karl, M.; Peters, J.; van der Smagt, P. Exploration via Empowerment Gain: Combining Novelty, Surprise and Learning Progress. In Proceedings of the ICML 2021 Workshop on Unsupervised Reinforcement Learning, Virtual Event, 18–24 July 2021. [Google Scholar]
- Lehman, J.; Stanley, K.O. Novelty search and the problem with objectives. In Genetic Programming Theory and Practice IX; Springer: Berlin/Heidelberg, Germany, 2011; pp. 37–56. [Google Scholar]
- Conti, E.; Madhavan, V.; Such, F.P.; Lehman, J.; Stanley, K.O.; Clune, J. Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 5032–5043. [Google Scholar]
- Linsker, R. Self-organization in a perceptual network. Computer 1988, 21, 105–117. [Google Scholar] [CrossRef]
- Almeida, L.B. MISEP–linear and nonlinear ICA based on mutual information. J. Mach. Learn. Res. 2003, 4, 1297–1318. [Google Scholar] [CrossRef]
- Bell, A.J.; Sejnowski, T.J. An information-maximization approach to blind separation and blind deconvolution. Neural Comput. 1995, 7, 1129–1159. [Google Scholar] [CrossRef]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Bellemare, M.; Srinivasan, S.; Ostrovski, G.; Schaul, T.; Saxton, D.; Munos, R. Unifying count-based exploration and intrinsic motivation. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1471–1479. [Google Scholar]
- Strehl, A.L.; Littman, M.L. An analysis of model-based interval estimation for Markov decision processes. J. Comput. Syst. Sci. 2008, 74, 1309–1331. [Google Scholar] [CrossRef]
- Tang, H.; Houthooft, R.; Foote, D.; Stooke, A.; Chen, O.X.; Duan, Y.; Schulman, J.; DeTurck, F.; Abbeel, P. # Exploration: A study of count-based exploration for deep reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2753–2762. [Google Scholar]
- Ostrovski, G.; Bellemare, M.G.; van den Oord, A.; Munos, R. Count-Based Exploration with Neural Density Models. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; pp. 2721–2730. [Google Scholar]
- Bellemare, M.; Veness, J.; Talvitie, E. Skip context tree switching. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1458–1466. [Google Scholar]
- Van den Oord, A.; Kalchbrenner, N.; Espeholt, L.; Vinyals, O.; Graves, A. Conditional image generation with pixelcnn decoders. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4790–4798. [Google Scholar]
- Martin, J.; Sasikumar, S.N.; Everitt, T.; Hutter, M. Count-Based Exploration in Feature Space for Reinforcement Learning. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017; pp. 2471–2478. [Google Scholar] [CrossRef]
- Machado, M.C.; Bellemare, M.G.; Bowling, M. Count-based exploration with the successor representation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5125–5133. [Google Scholar]
- Raileanu, R.; Rocktaschel, T. RIDE: Rewarding Impact-Driven Exploration for Procedurally-Generated Environments. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zhang, T.; Xu, H.; Wang, X.; Wu, Y.; Keutzer, K.; Gonzalez, J.E.; Tian, Y. BeBold: Exploration Beyond the Boundary of Explored Regions. arXiv 2020, arXiv:2012.08621. [Google Scholar]
- Zhang, C.; Cai, Y.; Huang, L.; Li, J. Exploration by Maximizing Renyi Entropy for Reward-Free RL Framework. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; pp. 10859–10867. [Google Scholar]
- Islam, R.; Seraj, R.; Bacon, P.L.; Precup, D. Entropy regularization with discounted future state distribution in policy gradient methods. arXiv 2019, arXiv:1912.05104. [Google Scholar]
- Lee, L.; Eysenbach, B.; Parisotto, E.; Xing, E.; Levine, S.; Salakhutdinov, R. Efficient Exploration via State Marginal Matching. arXiv 2019, arXiv:1906.05274. [Google Scholar]
- Pong, V.; Dalal, M.; Lin, S.; Nair, A.; Bahl, S.; Levine, S. Skew-Fit: State-Covering Self-Supervised Reinforcement Learning. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020; Volume 119, pp. 7783–7792. [Google Scholar]
- Vezzani, G.; Gupta, A.; Natale, L.; Abbeel, P. Learning latent state representation for speeding up exploration. arXiv 2019, arXiv:1905.12621. [Google Scholar]
- Berseth, G.; Geng, D.; Devin, C.; Rhinehart, N.; Finn, C.; Jayaraman, D.; Levine, S. SMiRL: Surprise Minimizing RL in Dynamic Environments. 2020. Available online: https://arxiv.org/pdf/1912.05510.pdf (accessed on 1 February 2023).
- Aubret, A.; Matignon, L.; Hassas, S. DisTop: Discovering a Topological representation to learn diverse and rewarding skills. arXiv 2021, arXiv:2106.03853. [Google Scholar]
- Guo, Z.D.; Azar, M.G.; Saade, A.; Thakoor, S.; Piot, B.; Pires, B.A.; Valko, M.; Mesnard, T.; Lattimore, T.; Munos, R. Geometric entropic exploration. arXiv 2021, arXiv:2101.02055. [Google Scholar]
- Singh, H.; Misra, N.; Hnizdo, V.; Fedorowicz, A.; Demchuk, E. Nearest neighbor estimates of entropy. Am. J. Math. Manag. Sci. 2003, 23, 301–321. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Lombardi, D.; Pant, S. Nonparametric k-nearest-neighbor entropy estimator. Phys. Rev. E 2016, 93, 013310. [Google Scholar] [CrossRef] [PubMed]
- Mutti, M.; Pratissoli, L.; Restelli, M. A Policy Gradient Method for Task-Agnostic Exploration 2020. Available online: https://openreview.net/pdf?id=d9j_RNHtQEo (accessed on 1 February 2023).
- Liu, H.; Abbeel, P. Behavior from the void: Unsupervised active pre-training. arXiv 2021, arXiv:2103.04551. [Google Scholar]
- Srinivas, A.; Laskin, M.; Abbeel, P. Curl: Contrastive unsupervised representations for reinforcement learning. arXiv 2020, arXiv:2004.04136. [Google Scholar]
- Seo, Y.; Chen, L.; Shin, J.; Lee, H.; Abbeel, P.; Lee, K. State entropy maximization with random encoders for efficient exploration. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 9443–9454. [Google Scholar]
- Dai, T.; Du, Y.; Fang, M.; Bharath, A.A. Diversity-augmented intrinsic motivation for deep reinforcement learning. Neurocomputing 2022, 468, 396–406. [Google Scholar] [CrossRef]
- Tao, R.Y.; François-Lavet, V.; Pineau, J. Novelty Search in Representational Space for Sample Efficient Exploration. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Yarats, D.; Fergus, R.; Lazaric, A.; Pinto, L. Reinforcement learning with prototypical representations. arXiv 2021, arXiv:2102.11271. [Google Scholar]
- Bougie, N.; Ichise, R. Skill-based curiosity for intrinsically motivated reinforcement learning. Mach. Learn. 2020, 109, 493–512. [Google Scholar] [CrossRef]
- Du, Y.; Gan, C.; Isola, P. Curious Representation Learning for Embodied Intelligence. arXiv 2021, arXiv:2105.01060. [Google Scholar]
- Aljalbout, E.; Ulmer, M.; Triebel, R. Seeking Visual Discomfort: Curiosity-driven Representations for Reinforcement Learning. arXiv 2021, arXiv:2110.00784. [Google Scholar]
- Guo, Z.D.; Thakoor, S.; Pîslar, M.; Pires, B.A.; Altché, F.; Tallec, C.; Saade, A.; Calandriello, D.; Grill, J.B.; Tang, Y.; et al. Byol-explore: Exploration by bootstrapped prediction. arXiv 2022, arXiv:2206.08332. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Fu, J.; Co-Reyes, J.; Levine, S. Ex2: Exploration with exemplar models for deep reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2577–2587. [Google Scholar]
- Kim, Y.; Nam, W.; Kim, H.; Kim, J.H.; Kim, G. Curiosity-Bottleneck: Exploration By Distilling Task-Specific Novelty. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 3379–3388. [Google Scholar]
- Klissarov, M.; Islam, R.; Khetarpal, K.; Precup, D. Variational State Encoding As Intrinsic Motivation In Reinforcement Learning 2019. Available online: https://tarl2019.github.io/assets/papers/klissarov2019variational.pdf (accessed on 1 February 2023).
- Stanton, C.; Clune, J. Deep Curiosity Search: Intra-Life Exploration Can Improve Performance on Challenging Deep Reinforcement Learning Problems. arXiv 2018, arXiv:1806.00553. [Google Scholar]
- Savinov, N.; Raichuk, A.; Vincent, D.; Marinier, R.; Pollefeys, M.; Lillicrap, T.; Gelly, S. Episodic Curiosity through Reachability. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lu, J.; Han, S.; Lü, S.; Kang, M.; Zhang, J. Sampling diversity driven exploration with state difference guidance. Expert Syst. Appl. 2022, 203, 117418. [Google Scholar] [CrossRef]
- Yuan, Y.; Kitani, K.M. Diverse Trajectory Forecasting with Determinantal Point Processes. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Pires, B.; Guo, Z.; Azar, M.; et al. Bootstrap Your Own Latent: A new approach to self-supervised learning. In Proceedings of the Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep variational information bottleneck. arXiv 2016, arXiv:1612.00410. [Google Scholar]
- Eysenbach, B.; Gupta, A.; Ibarz, J.; Levine, S. Diversity is All You Need: Learning Skills without a Reward Function. arXiv 2018, arXiv:1802.06070. [Google Scholar]
- Co-Reyes, J.D.; Liu, Y.; Gupta, A.; Eysenbach, B.; Abbeel, P.; Levine, S. Self-Consistent Trajectory Autoencoder: Hierarchical Reinforcement Learning with Trajectory Embeddings. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 1008–1017. [Google Scholar]
- Campos, V.; Trott, A.; Xiong, C.; Socher, R.; Giro-i Nieto, X.; Torres, J. Explore, discover and learn: Unsupervised discovery of state-covering skills. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1317–1327. [Google Scholar]
- Florensa, C.; Duan, Y.; Abbeel, P. Stochastic Neural Networks for Hierarchical Reinforcement Learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Achiam, J.; Edwards, H.; Amodei, D.; Abbeel, P. Variational option discovery algorithms. arXiv 2018, arXiv:1807.10299. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Zhang, J.; Yu, H.; Xu, W. Hierarchical Reinforcement Learning by Discovering Intrinsic Options. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Gregor, K.; Rezende, D.J.; Wierstra, D. Variational intrinsic control. arXiv 2016, arXiv:1611.07507. [Google Scholar]
- Baumli, K.; Warde-Farley, D.; Hansen, S.; Mnih, V. Relative Variational Intrinsic Control. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 6732–6740. [Google Scholar]
- Sharma, A.; Gu, S.; Levine, S.; Kumar, V.; Hausman, K. Dynamics-Aware Unsupervised Discovery of Skills. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Choi, J.; Sharma, A.; Lee, H.; Levine, S.; Gu, S.S. Variational Empowerment as Representation Learning for Goal-Conditioned Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 1953–1963. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hansen, S.; Dabney, W.; Barreto, A.; Warde-Farley, D.; de Wiele, T.V.; Mnih, V. Fast Task Inference with Variational Intrinsic Successor Features. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Levy, A.; Platt, R.; Saenko, K. Hierarchical Reinforcement Learning with Hindsight. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Pitis, S.; Chan, H.; Zhao, S.; Stadie, B.; Ba, J. Maximum entropy gain exploration for long horizon multi-goal reinforcement learning. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 7750–7761. [Google Scholar]
- Zhao, R.; Sun, X.; Tresp, V. Maximum entropy-regularized multi-goal reinforcement learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7553–7562. [Google Scholar]
- Nachum, O.; Gu, S.S.; Lee, H.; Levine, S. Data-Efficient Hierarchical Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems 31, Montreal, QC, Canada, 3–8 December 2018; pp. 3303–3313. [Google Scholar]
- Nair, A.V.; Pong, V.; Dalal, M.; Bahl, S.; Lin, S.; Levine, S. Visual reinforcement learning with imagined goals. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 9209–9220. [Google Scholar]
- Kim, J.; Park, S.; Kim, G. Unsupervised Skill Discovery with Bottleneck Option Learning. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5572–5582. [Google Scholar]
- Zhou, X.; Bai, T.; Gao, Y.; Han, Y. Vision-Based Robot Navigation through Combining Unsupervised Learning and Hierarchical Reinforcement Learning. Sensors 2019, 19, 1576. [Google Scholar] [CrossRef]
- Wiskott, L.; Sejnowski, T.J. Slow feature analysis: Unsupervised learning of invariances. Neural Comput. 2002, 14, 715–770. [Google Scholar] [CrossRef] [PubMed]
- Marsland, S.; Shapiro, J.; Nehmzow, U. A self-organising network that grows when required. Neural Netw. 2002, 15, 1041–1058. [Google Scholar] [CrossRef]
- Warde-Farley, D.; de Wiele, T.V.; Kulkarni, T.; Ionescu, C.; Hansen, S.; Mnih, V. Unsupervised Control Through Non-Parametric Discriminative Rewards. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Mendonca, R.; Rybkin, O.; Daniilidis, K.; Hafner, D.; Pathak, D. Discovering and achieving goals via world models. Adv. Neural Inf. Process. Syst. 2021, 34, 24379–24391. [Google Scholar]
- Nachum, O.; Gu, S.; Lee, H.; Levine, S. Near-Optimal Representation Learning for Hierarchical Reinforcement Learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Li, S.; Zheng, L.; Wang, J.; Zhang, C. Learning Subgoal Representations with Slow Dynamics. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Florensa, C.; Held, D.; Geng, X.; Abbeel, P. Automatic goal generation for reinforcement learning agents. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1514–1523. [Google Scholar]
- Racaniere, S.; Lampinen, A.K.; Santoro, A.; Reichert, D.P.; Firoiu, V.; Lillicrap, T.P. Automated curricula through setter-solver interactions. arXiv 2019, arXiv:1909.12892. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Colas, C.; Oudeyer, P.Y.; Sigaud, O.; Fournier, P.; Chetouani, M. CURIOUS: Intrinsically Motivated Modular Multi-Goal Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 1331–1340. [Google Scholar]
- Khazatsky, A.; Nair, A.; Jing, D.; Levine, S. What can i do here? learning new skills by imagining visual affordances. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 14291–14297. [Google Scholar]
- Zhao, R.; Tresp, V. Curiosity-driven experience prioritization via density estimation. arXiv 2019, arXiv:1902.08039. [Google Scholar]
- Blei, D.M.; Jordan, M.I. Variational inference for Dirichlet process mixtures. Bayesian Anal. 2006, 1, 121–143. [Google Scholar] [CrossRef]
- Kovač, G.; Laversanne-Finot, A.; Oudeyer, P.Y. Grimgep: Learning progress for robust goal sampling in visual deep reinforcement learning. arXiv 2020, arXiv:2008.04388. [Google Scholar]
- Rasmussen, C.E. The infinite Gaussian mixture model. In Proceedings of the NIPS, Denver, CO, USA, 29 November–4 December 1999; Volume 12, pp. 554–560. [Google Scholar]
- Li, S.; Zhang, J.; Wang, J.; Zhang, C. Efficient Hierarchical Exploration with Stable Subgoal Representation Learning. arXiv 2021, arXiv:2105.14750. [Google Scholar]
- Hester, T.; Vecerik, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Horgan, D.; Quan, J.; Sendonaris, A.; Osband, I.; et al. Deep q-learning from demonstrations. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ecoffet, A.; Huizinga, J.; Lehman, J.; Stanley, K.O.; Clune, J. Go-Explore: A New Approach for Hard-Exploration Problems. arXiv 2019, arXiv:1901.10995. [Google Scholar]
- Ecoffet, A.; Huizinga, J.; Lehman, J.; Stanley, K.O.; Clune, J. First return, then explore. Nature 2021, 590, 580–586. [Google Scholar] [CrossRef]
- Bharadhwaj, H.; Garg, A.; Shkurti, F. Leaf: Latent exploration along the frontier. arXiv 2020, arXiv:2005.10934. [Google Scholar]
- Flash, T.; Hochner, B. Motor primitives in vertebrates and invertebrates. Curr. Opin. Neurobiol. 2005, 15, 660–666. [Google Scholar] [CrossRef]
- Zhao, R.; Gao, Y.; Abbeel, P.; Tresp, V.; Xu, W. Mutual Information State Intrinsic Control. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Metzen, J.H.; Kirchner, F. Incremental learning of skill collections based on intrinsic motivation. Front. Neurorobot. 2013, 7, 11. [Google Scholar] [CrossRef] [PubMed]
- Hensch, T.K. Critical period regulation. Annu. Rev. Neurosci. 2004, 27, 549–579. [Google Scholar] [CrossRef]
- Konczak, J. Neural Development and Sensorimotor Control. 2004. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3075656 (accessed on 1 February 2023).
- Baranes, A.; Oudeyer, P.Y. The interaction of maturational constraints and intrinsic motivations in active motor development. In Proceedings of the 2011 IEEE International Conference on Development and Learning (ICDL), Main, Germany, 24–27 August 2011; Volume 2, pp. 1–8. [Google Scholar]
- Oudeyer, P.Y.; Baranes, A.; Kaplan, F. Intrinsically motivated learning of real-world sensorimotor skills with developmental constraints. In Intrinsically Motivated Learning in Natural and Artificial Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 303–365. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, ACM, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Santucci, V.G.; Baldassarre, G.; Mirolli, M. Which is the best intrinsic motivation signal for learning multiple skills? Front. Neurorobotics 2013, 7, 22. [Google Scholar] [CrossRef]
- Santucci, V.G.; Baldassarre, G.; Mirolli, M. GRAIL: A goal-discovering robotic architecture for intrinsically-motivated learning. IEEE Trans. Cogn. Dev. Syst. 2016, 8, 214–231. [Google Scholar] [CrossRef]
- Berlyne, D.E. Conflict, Arousal, and Curiosity; McGraw-Hill Book Company: Columbus, OH, USA, 1960. [Google Scholar]







| Surprise: , Section 5 | |||
| Formalism | Prediction error | Learning progress | Information gain over forward model over forward model |
| Sections | Section 5.3 | Section 5.2 | Section 5.4 |
| Rewards | |||
| Advantage | Simplicity | Stochasticity robustness | Stochasticity robustness |
| Novelty: , Section 6 | |||
| Formalism | Information gain over density model | Parametric density | K-nearest neighbors |
| Sections | Section 6.1 | Section 6.2 | Section 6.3 |
| Rewards | |||
| Advantage | Good exploration | Good exploration | Best exploration |
| Skill-learning: , Section 7 | |||
| Formalism | Fixed goal distribution | Goal-state achievement | Proposing diverse goals |
| Sections | Section 7.1 | Section 7.2 | Section 7.3 |
| Rewards | |||
| Advantage | Simple goal sampling | High-granularity skills | More diverse skills |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aubret, A.; Matignon, L.; Hassas, S. An Information-Theoretic Perspective on Intrinsic Motivation in Reinforcement Learning: A Survey. Entropy 2023, 25, 327. https://doi.org/10.3390/e25020327
Aubret A, Matignon L, Hassas S. An Information-Theoretic Perspective on Intrinsic Motivation in Reinforcement Learning: A Survey. Entropy. 2023; 25(2):327. https://doi.org/10.3390/e25020327
Chicago/Turabian StyleAubret, Arthur, Laetitia Matignon, and Salima Hassas. 2023. "An Information-Theoretic Perspective on Intrinsic Motivation in Reinforcement Learning: A Survey" Entropy 25, no. 2: 327. https://doi.org/10.3390/e25020327
APA StyleAubret, A., Matignon, L., & Hassas, S. (2023). An Information-Theoretic Perspective on Intrinsic Motivation in Reinforcement Learning: A Survey. Entropy, 25(2), 327. https://doi.org/10.3390/e25020327