

Integral Reinforcement-Learning-Based Optimal Containment Control for Partially Unknown Nonlinear Multiagent Systems


Abstract
1. Introduction
- (1)
- (2)
- (3)
2. Preliminaries and Problem Description
2.1. Graph Theory
2.2. Problem Description
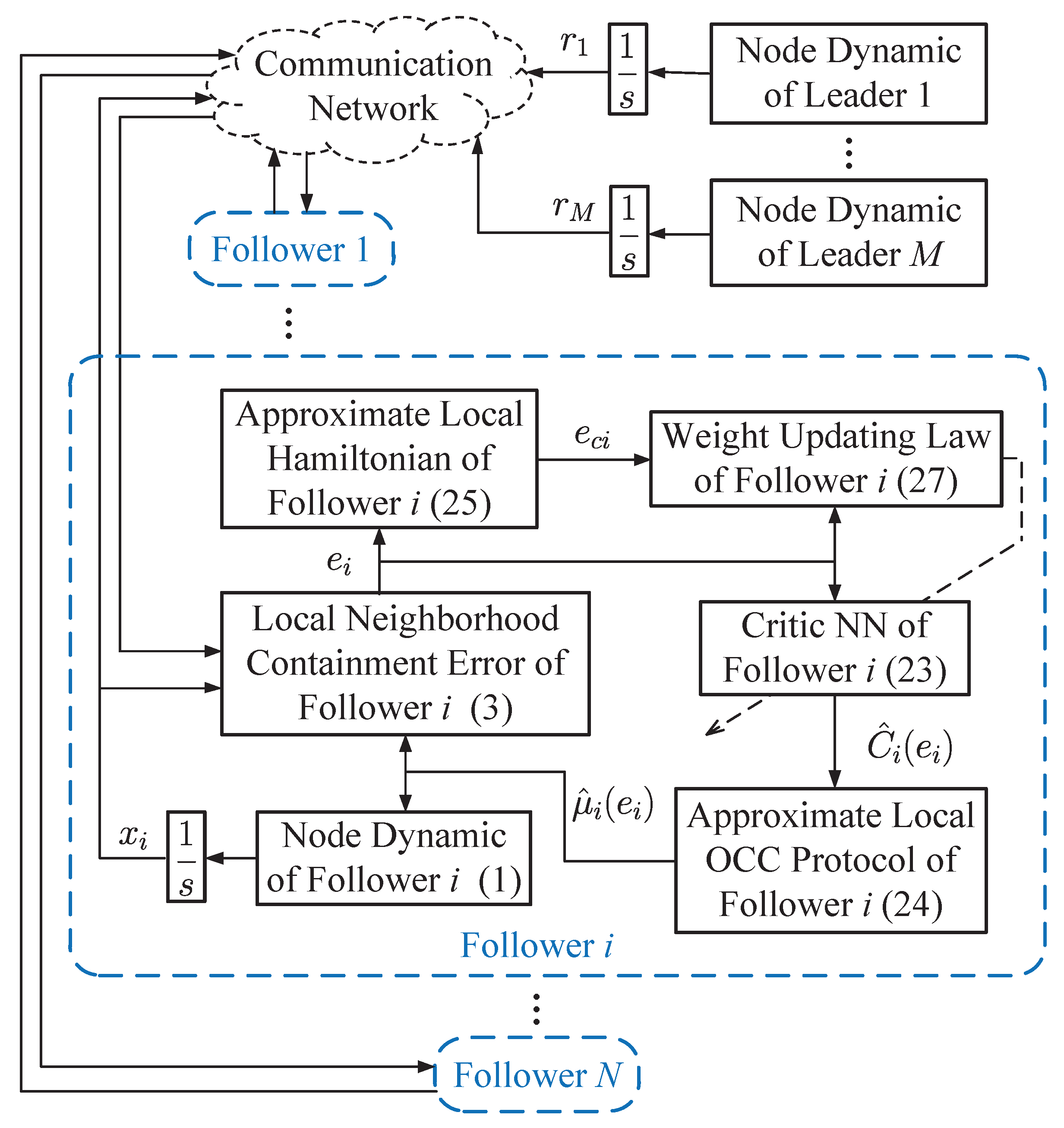
3. IRL-Based OCC Scheme
3.1. Optimal Containment Control
3.2. Integral Reinforcement Learning
3.3. Critic NN Implementation
3.4. Stability Analysis
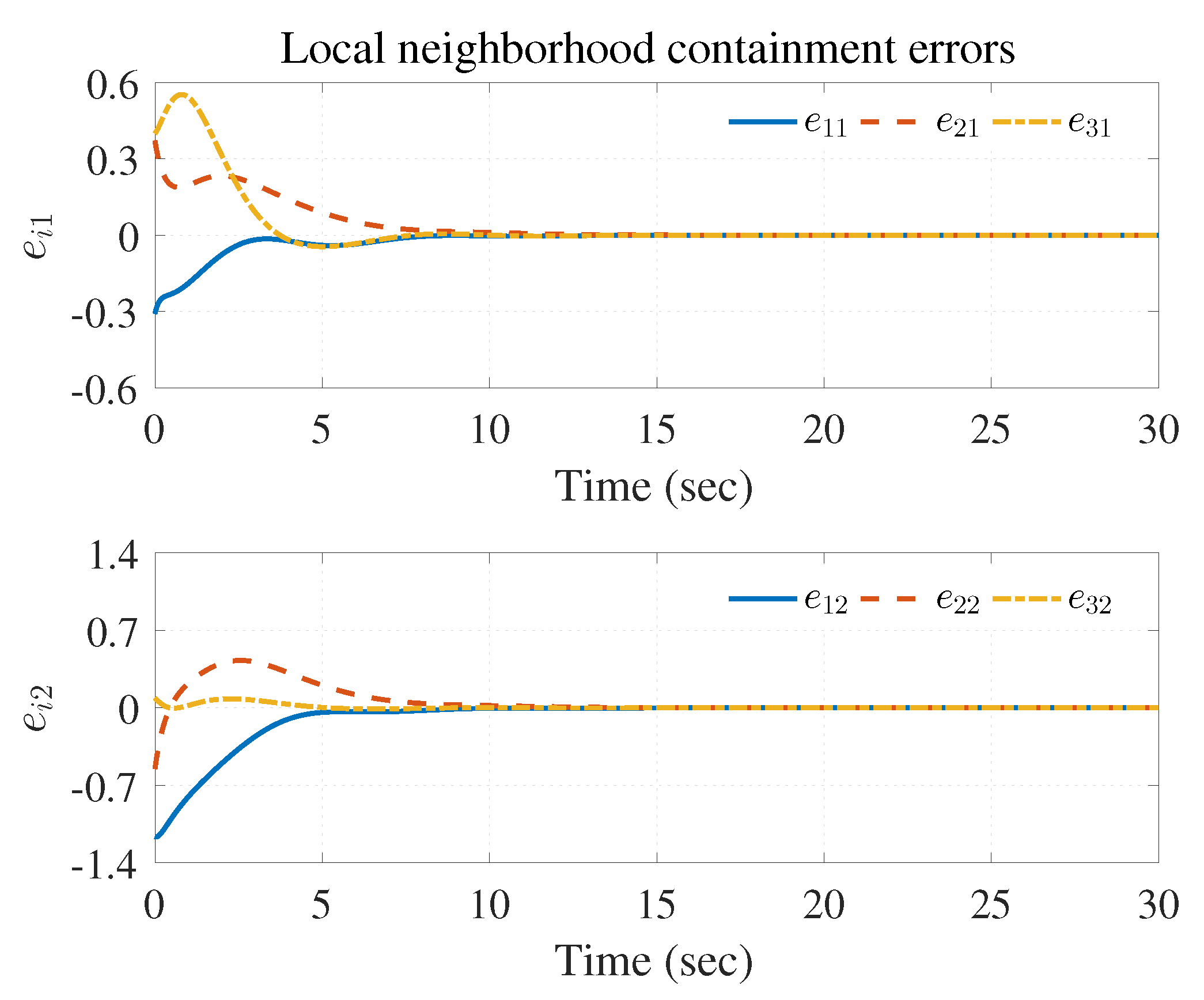
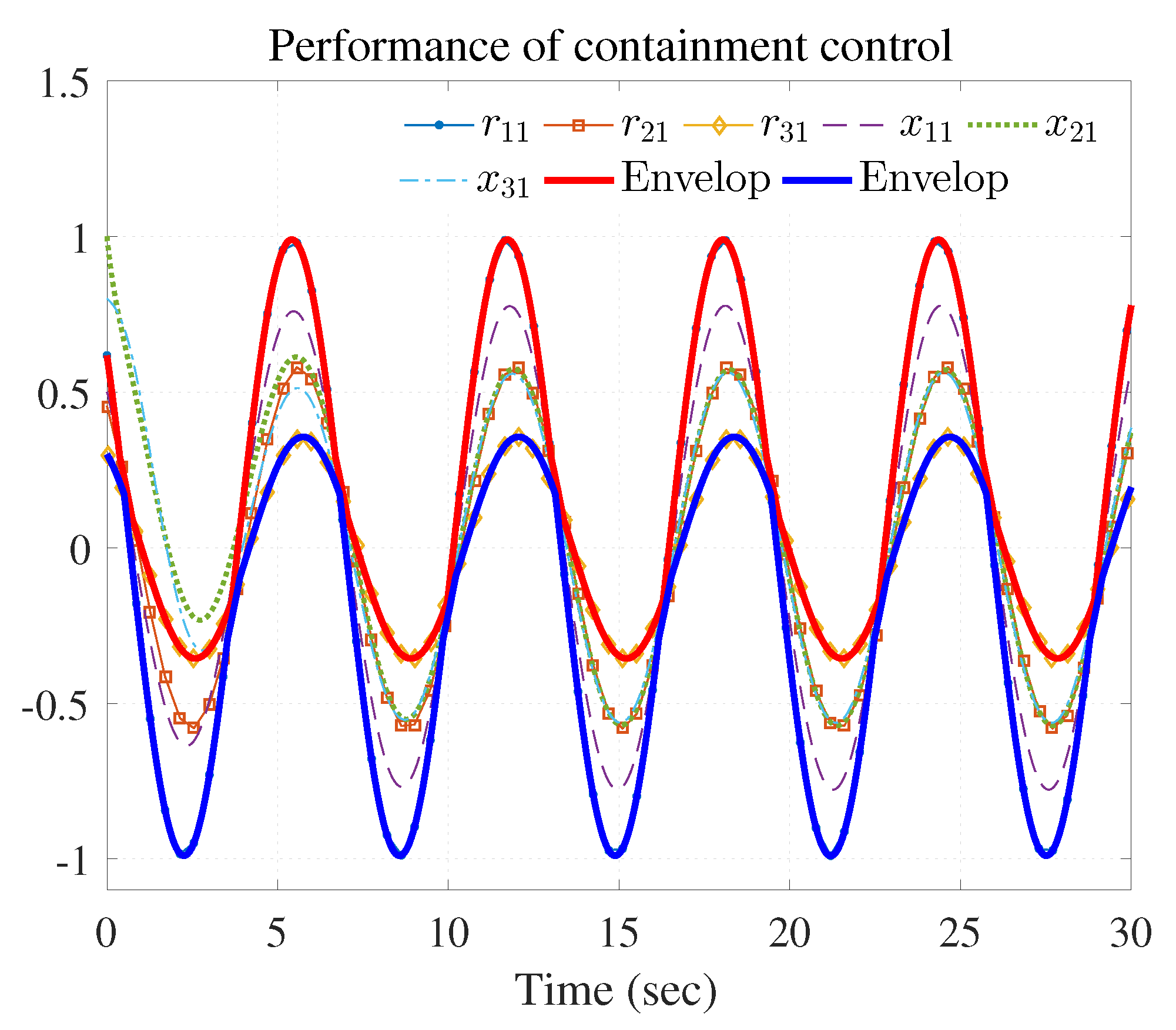
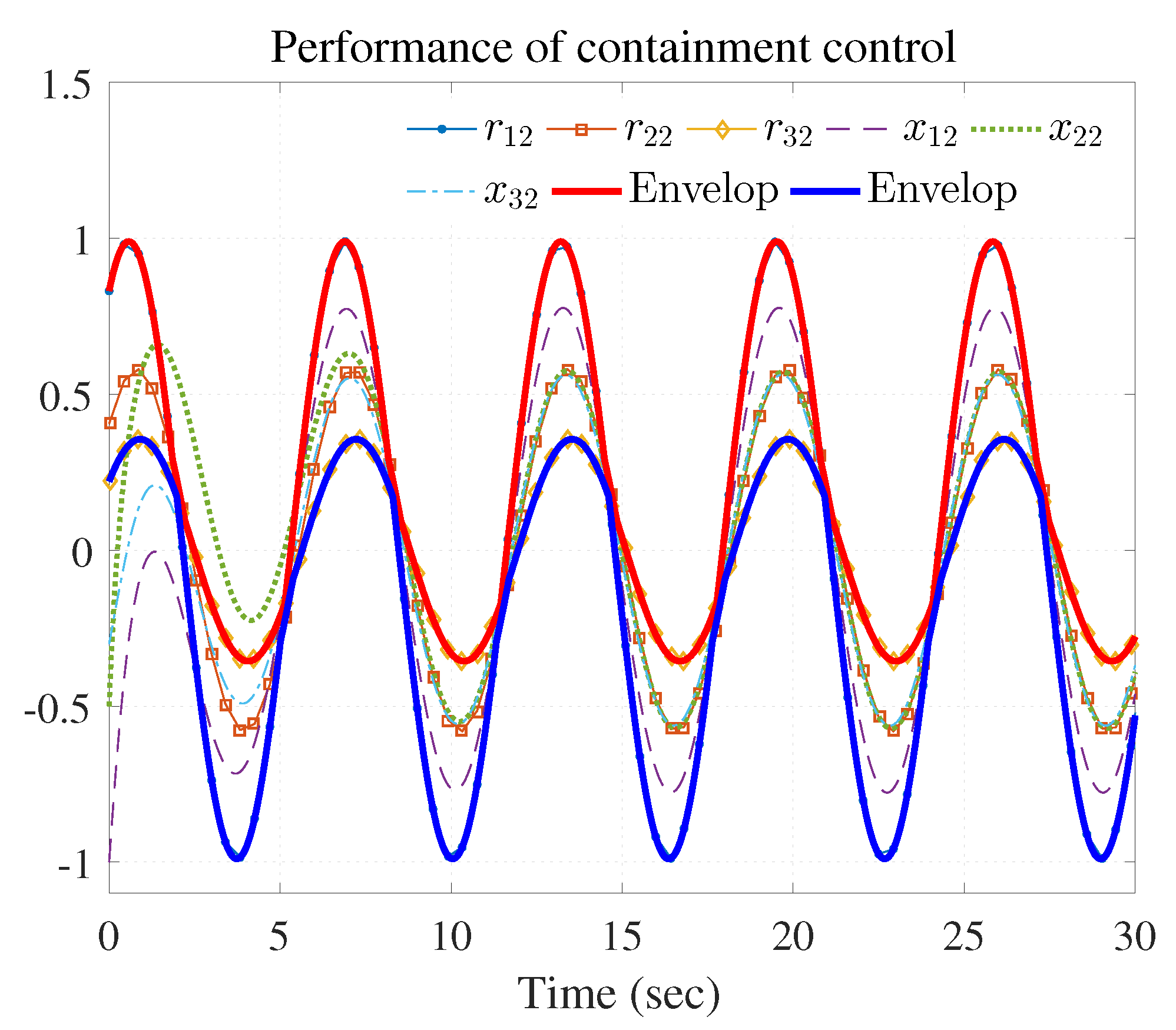
4. Simulation Study
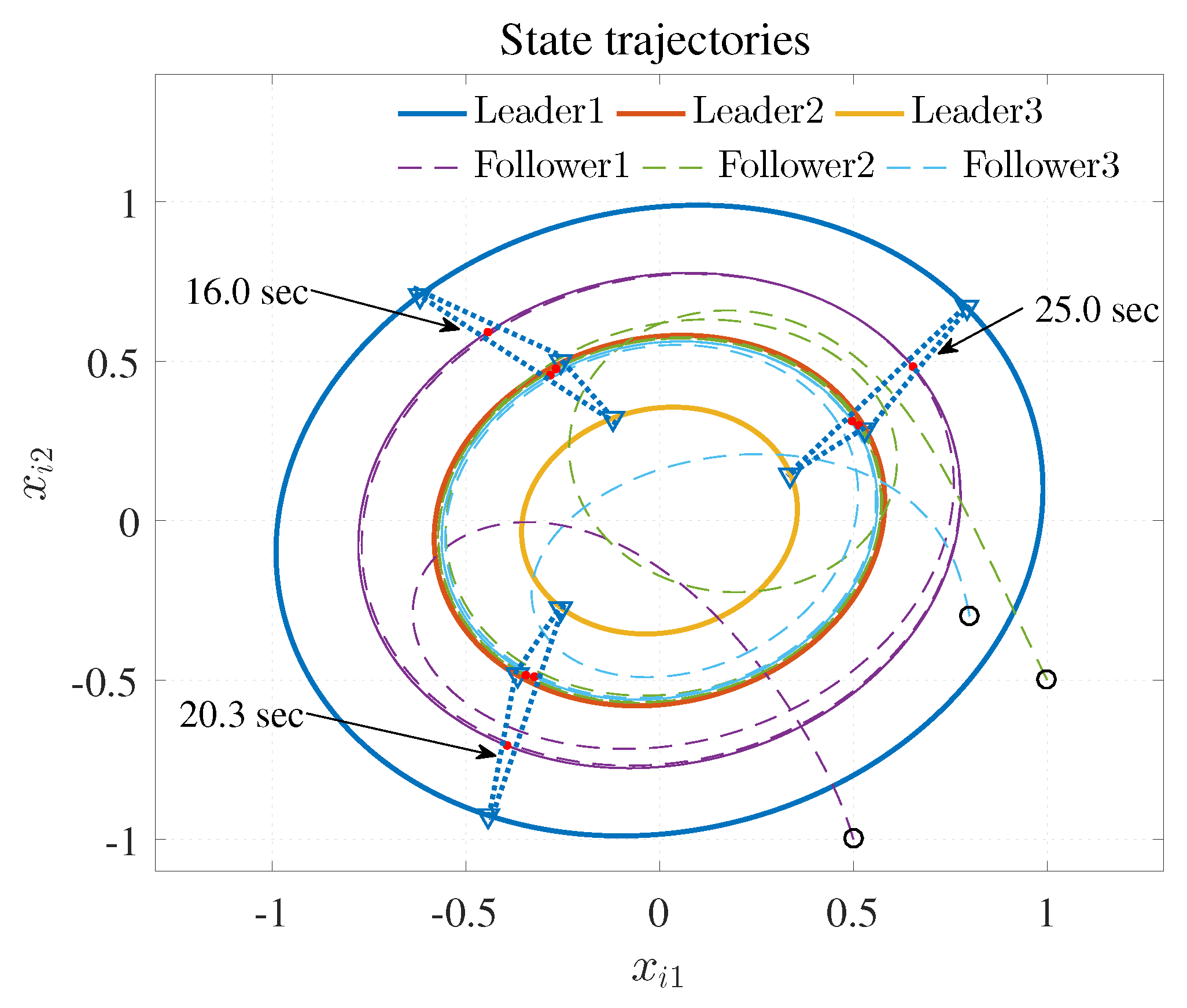
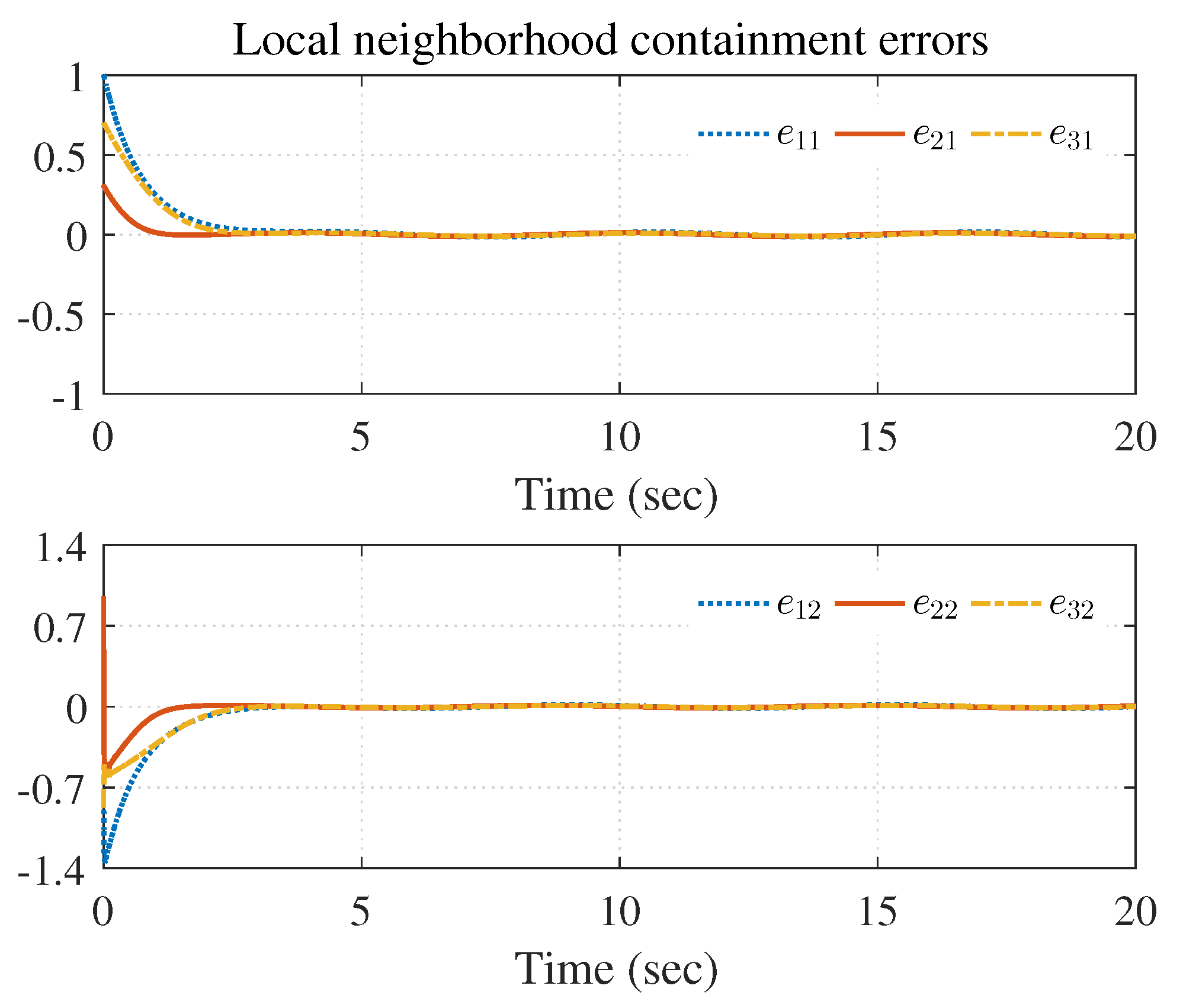
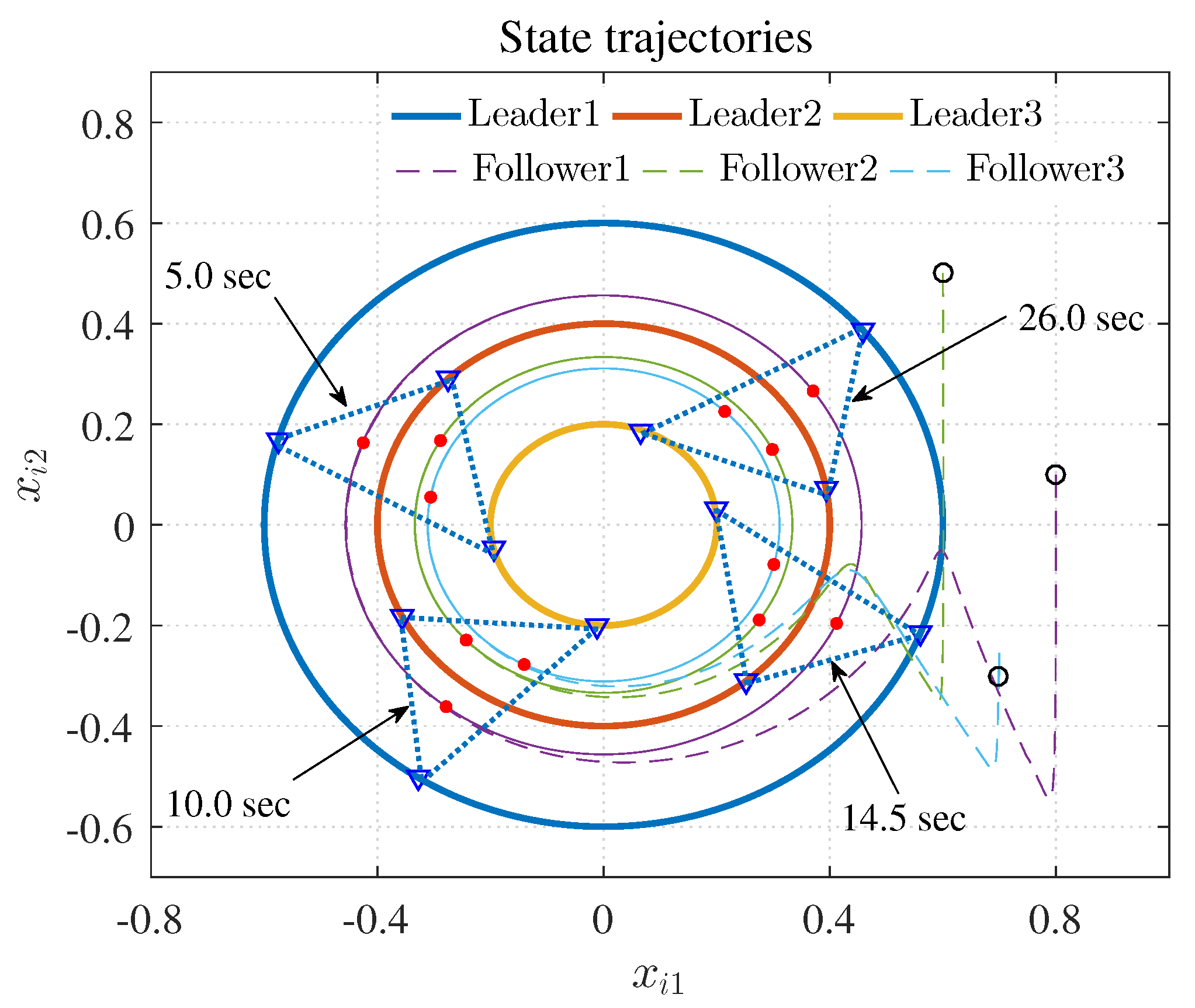
4.1. Example 1
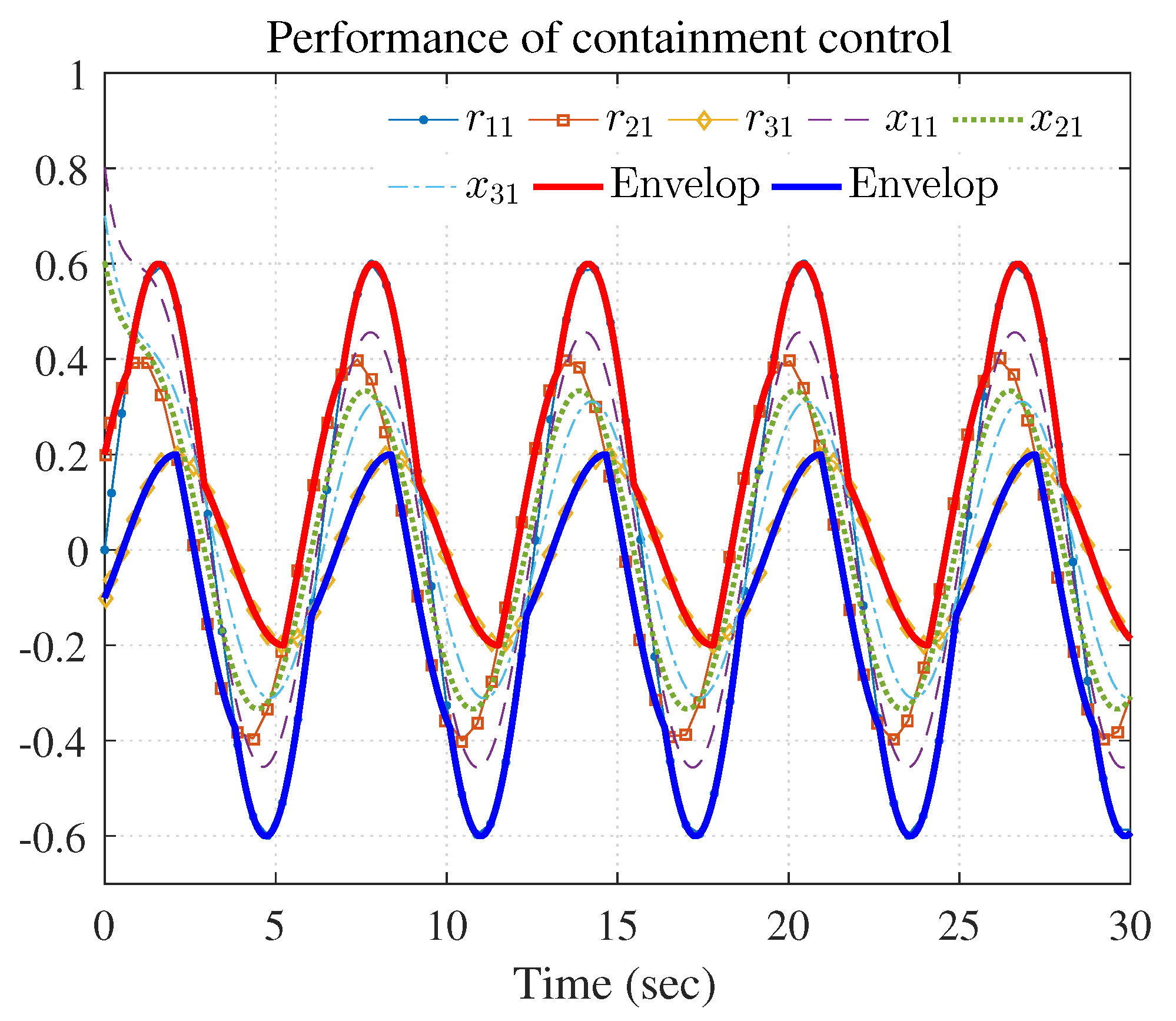
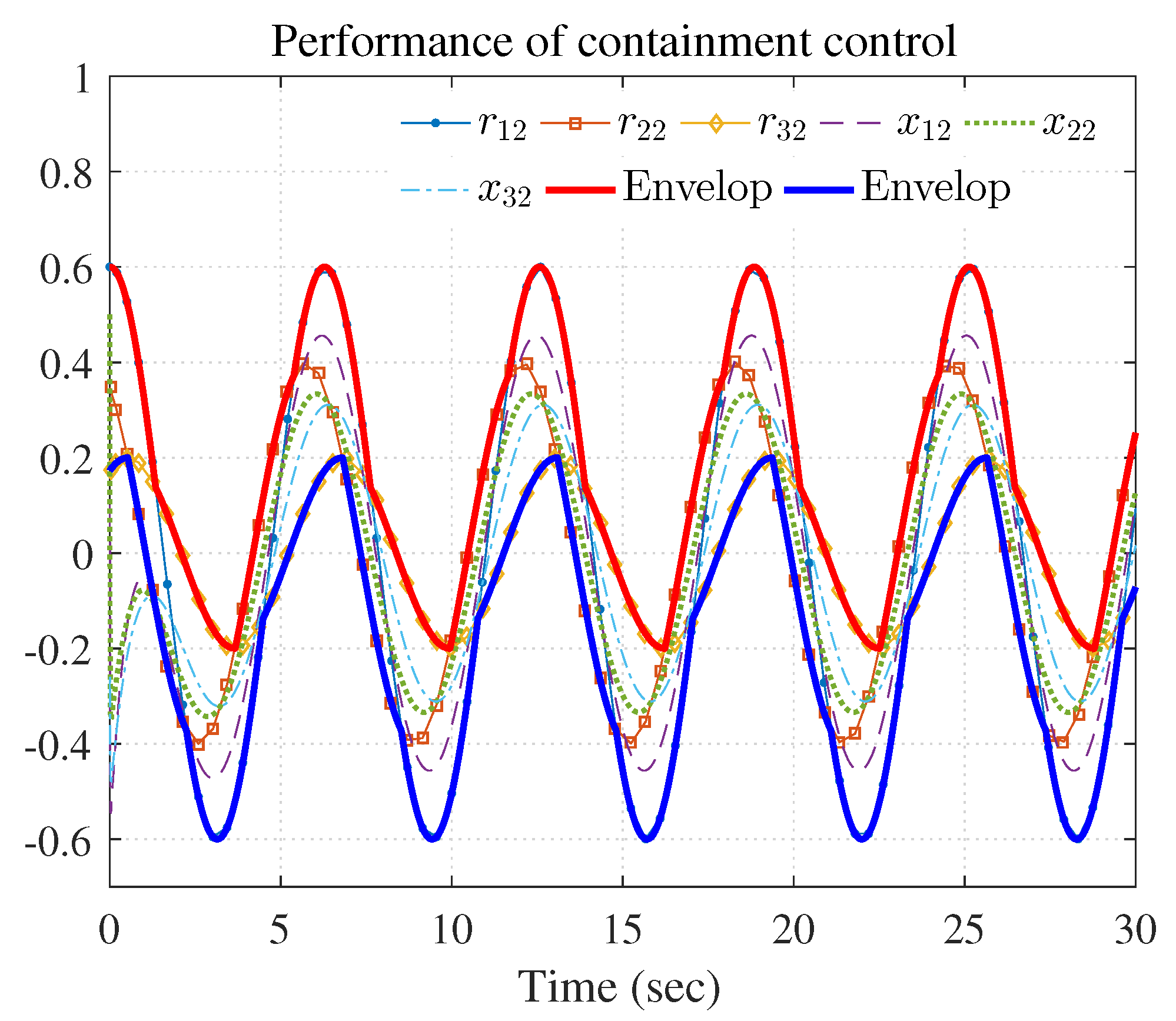
4.2. Example 2
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jimenez, A.F.; Cardenas, P.F.; Jimenez, F. Intelligent IoT-multiagent precision irrigation approach for improving water use efficiency in irrigation systems at farm and district scales. Comp. Electr. Agric. 2022, 192, 106635. [Google Scholar] [CrossRef]
- Vallejo, D.; Castro-Schez, J.; Glez-Morcillo, C.; Albusac, J. Multi-agent architecture for information retrieval and intelligent monitoring by UAVs in known environments affected by catastrophes. Eng. Appl. Artif. Intell. 2020, 87, 103243. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y.; Li, Y.; Gooi, H.B.; Xin, H. Multi-agent based optimal scheduling and trading for multi-microgrids integrated with urban transportation networks. IEEE Trans. Power. Syst. 2021, 36, 2197–2210. [Google Scholar] [CrossRef]
- Deng, Q.; Peng, Y.; Qu, D.; Han, T.; Zhan, X. Neuro-adaptive containment control of unmanned surface vehicles with disturbance observer and collision-free. ISA Trans. 2022, 129, 150–156. [Google Scholar] [CrossRef] [PubMed]
- Hamani, N.; Jamont, J.P.; Occello, M.; Ben-Yelles, C.B.; Lagreze, A.; Koudil, M. A multi-cooperative-based approach to manage communication in wireless instrumentation systems. IEEE Syst. J. 2018, 12, 2174–2185. [Google Scholar] [CrossRef]
- Ren, W.; Beard, R.W. Consensus seeking in multiagent systems under dynamically changing interaction topologies. IEEE Trans. Autom. Control 2005, 50, 655–661. [Google Scholar] [CrossRef]
- Luo, K.; Guan, Z.H.; Cai, C.X.; Zhang, D.X.; Lai, Q.; Xiao, J.W. Coordination of nonholonomic mobile robots for diffusive threat defense. J. Frankl. Inst. 2019, 356, 4690–4715. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, Z.; Zhang, Y.; Qu, Y.; Su, C.Y. Distributed finite-time fault-tolerant containment control for multiple unmanned aerial vehicles. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2077–2091. [Google Scholar] [CrossRef]
- Li, Y.; Qu, F.; Tong, S. Observer-based fuzzy adaptive finite-time containment control of nonlinear multiagent systems with input delay. IEEE Trans. Cybern. 2021, 51, 126–137. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Xue, H.; Pan, Y.; Liang, H. Distributed adaptive event-triggered containment control for multi-agent systems under a funnel function. Int. J. Robust Nonlinear Control 2022. [Google Scholar] [CrossRef]
- Li, Y.; Liu, M.; Lian, J.; Guo, Y. Collaborative optimal formation control for heterogeneous multi-agent systems. Entropy 2022, 24, 1440. [Google Scholar] [CrossRef]
- Zhao, L.; Yu, J.; Shi, P. Command filtered backstepping-based attitude containment control for spacecraft formation. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 1278–1287. [Google Scholar] [CrossRef]
- Liu, D.; Wei, Q.; Wang, D.; Yang, X.; Li, H. Adaptive Dynamic Programming with Applications in Optimal Control; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Bellman, R.E. Dynamic Programming; Princeton Univ. Press: Trenton, NJ, USA, 1957. [Google Scholar]
- Abu-Khalaf, M.; Lewis, F.L. Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica 2005, 41, 779–791. [Google Scholar] [CrossRef]
- Liu, D.; Xue, S.; Zhao, B.; Luo, B.; Wei, Q. Adaptive dynamic programming for control: A survey and recent advances. IEEE Trans. Syst. Man. Cybern. Syst. 2021, 51, 142–160. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Lewis, F.L.; Hudas, G.R. Multi-agent differential graphical games: Online adaptive learning solution for synchronization with optimality. Automatica 2012, 48, 1598–1611. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, J.; Yang, G.; Luo, Y. Leader-based optimal coordination control for the consensus problem of multiagent differential games via fuzzy adaptive dynamic programming. IEEE Trans. Fuzzy. Syst. 2015, 23, 152–163. [Google Scholar] [CrossRef]
- Zhao, W.; Zhang, H. Distributed optimal coordination control for nonlinear multi-agent systems using event-triggered adaptive dynamic programming method. ISA Trans. 2019, 91, 184–195. [Google Scholar] [CrossRef] [PubMed]
- Cui, J.; Pan, Y.; Xue, H.; Tan, L. Simplified optimized finite-time containment control for a class of multi-agent systems with actuator faults. Nonlinear Dyn. 2022, 109, 2799–2816. [Google Scholar] [CrossRef]
- Xu, J.; Wang, L.; Liu, Y.; Xue, H. Event-triggered optimal containment control for multi-agent systems subject to state constraints via reinforcement learning. Nonlinear Dyn. 2022, 109, 1651–1670. [Google Scholar] [CrossRef]
- Xiao, W.; Zhou, Q.; Liu, Y.; Li, H.; Lu, R. Distributed reinforcement learning containment control for multiple nonholonomic mobile robots. IEEE Trans. Circuits Syst. I Reg. Papers 2022, 69, 896–907. [Google Scholar] [CrossRef]
- Chen, C.; Lewis, F.L.; Xie, K.; Xie, S.; Liu, Y. Off-policy learning for adaptive optimal output synchronization of heterogeneous multi-agent systems. Automatica 2020, 119, 109081. [Google Scholar] [CrossRef]
- Yu, D.; Ge, S.S.; Li, D.; Wang, P. Finite-horizon robust formation-containment control of multi-agent networks with unknown dynamics. Neurocomputing 2021, 458, 403–415. [Google Scholar] [CrossRef]
- Zuo, S.; Song, Y.; Lewis, F.L.; Davoudi, A. Optimal robust output containment of unknown heterogeneous multiagent system using off-policy reinforcement learning. IEEE Trans. Cybern. 2018, 48, 3197–3207. [Google Scholar] [CrossRef] [PubMed]
- Mazouchi, M.; Naghibi-Sistani, M.B.; Hosseini Sani, S.K.; Tatari, F.; Modares, H. Observer-based adaptive optimal output containment control problem of linear heterogeneous Multiagent systems with relative output measurements. Int. J. Adapt. Control Signal Process. 2019, 33, 262–284. [Google Scholar] [CrossRef]
- Yang, Y.; Modares, H.; Wunsch, D.C.; Yin, Y. Optimal containment control of unknown heterogeneous systems with active leaders. IEEE Trans. Control Syst. Technol. 2019, 27, 1228–1236. [Google Scholar] [CrossRef]
- Zhang, H.; Lewis, F.L.; Qu, Z. Lyapunov, adaptive, and optimal design techniques for cooperative systems on directed communication graphs. IEEE Trans. Ind. Electron. 2012, 59, 3026–3041. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Notation |
|---|---|
| Link angle | |
| Angular velocity of the link | |
| Total rotational inertia of the link and motor | |
| Overall damping coefficient | |
| Total mass of the link | |
| l | Distant from joint axis to mass center of the link |
| Command generator |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Q.; Wu, Y.; Wang, Y. Integral Reinforcement-Learning-Based Optimal Containment Control for Partially Unknown Nonlinear Multiagent Systems. Entropy 2023, 25, 221. https://doi.org/10.3390/e25020221
Wu Q, Wu Y, Wang Y. Integral Reinforcement-Learning-Based Optimal Containment Control for Partially Unknown Nonlinear Multiagent Systems. Entropy. 2023; 25(2):221. https://doi.org/10.3390/e25020221
Chicago/Turabian StyleWu, Qiuye, Yongheng Wu, and Yonghua Wang. 2023. "Integral Reinforcement-Learning-Based Optimal Containment Control for Partially Unknown Nonlinear Multiagent Systems" Entropy 25, no. 2: 221. https://doi.org/10.3390/e25020221
APA StyleWu, Q., Wu, Y., & Wang, Y. (2023). Integral Reinforcement-Learning-Based Optimal Containment Control for Partially Unknown Nonlinear Multiagent Systems. Entropy, 25(2), 221. https://doi.org/10.3390/e25020221