


A Textual Backdoor Defense Method Based on Deep Feature Classification

Abstract
:1. Introduction
2. Scenario Description
3. Methodology
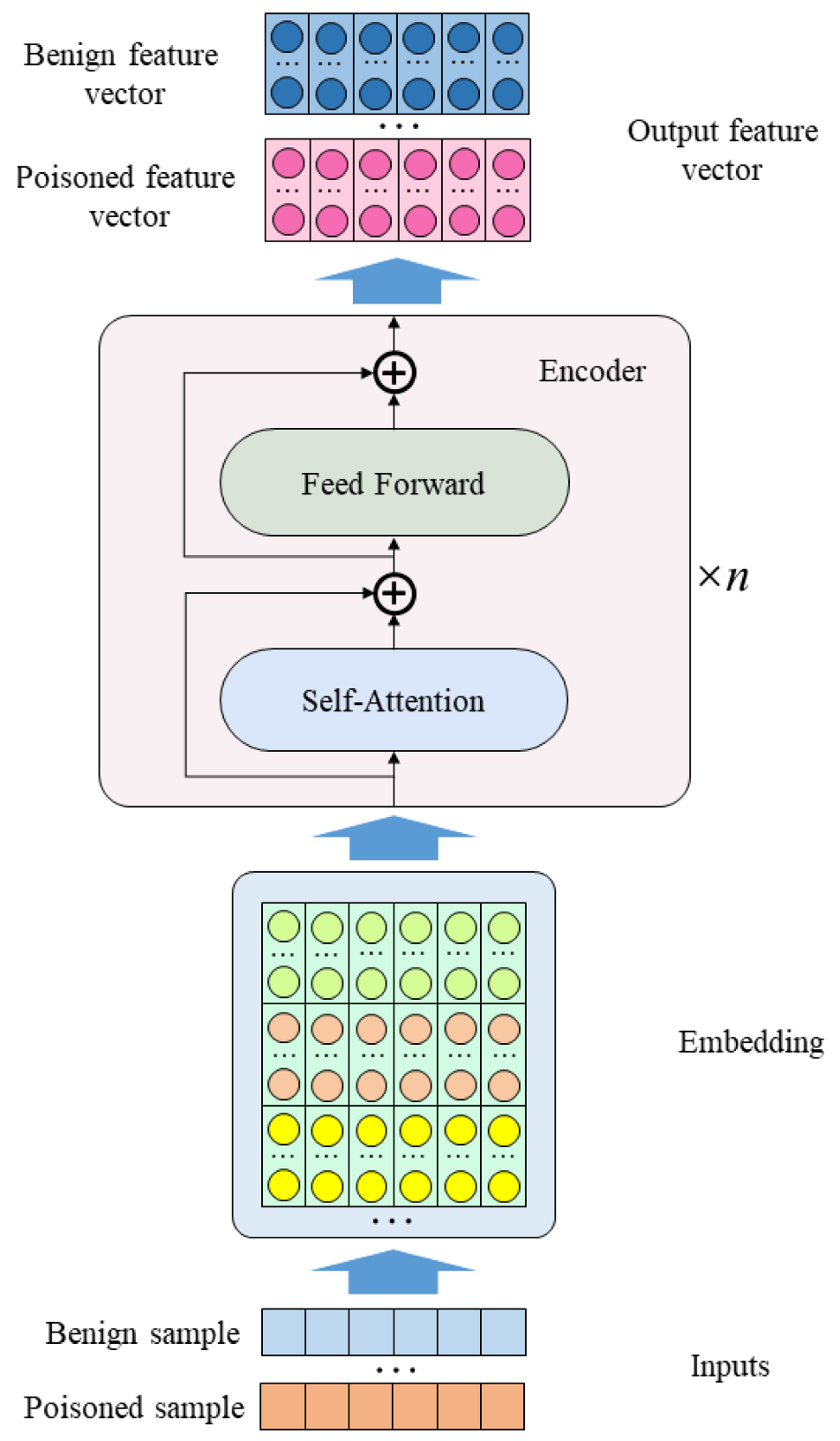
3.1. Deep Feature Extraction
3.2. Building a Classifier
3.3. Offline Poisoned Training Sample Detection
| Algorithm 1 Offline poisoned training sample detection |
|
3.4. Online Attacked Sample Detection
| Algorithm 2 Online attacked sample detection |
|
4. Offline Defense Experiment Results and Analysis
4.1. Datasets and Models
4.2. Attack Methods and Baseline Defense Methods
4.3. Experimental Settings
4.4. Defense Evaluation Metrics
4.5. Defending Performance
5. Online Defense Experiment Results and Analysis
5.1. Attack Methods and Baseline Defense Methods
5.2. Experimental Settings
5.3. Defending Performance
5.4. Detailed Attack Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Wu, Y.; Qin, Y.; Hu, Y.; Wang, Z.; Huang, R.; Cheng, X.; Chen, P. Recognizing Nested Named Entity Based on the Neural Network Boundary Assembling Model. IEEE Intell. Syst. 2020, 35, 74–81. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the NIPS’20: 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Gu, T.; Liu, K.; Dolan-Gavitt, B.; Garg, S. BadNets: Evaluating Backdooring Attacks on Deep Neural Networks. IEEE Access 2019, 7, 47230–47244. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, X.; Bailey, J.; Lu, F. Reflection Backdoor: A Natural Backdoor Attack on Deep Neural Networks. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 182–199. [Google Scholar]
- Sun, L. Natural backdoor attack on text data. arXiv 2020, arXiv:2006.16176. [Google Scholar]
- Chen, X.; Salem, A.; Chen, D.; Backes, M.; Ma, S.; Shen, Q.; Wu, Z.; Zhang, Y. BadNL: Backdoor Attacks against NLP Models with Semantic-Preserving Improvements. In Proceedings of the ACSAC ’21: Annual Computer Security Applications Conference, Virtual Event, 6–10 December 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 554–569. [Google Scholar] [CrossRef]
- Dai, J.; Chen, C.; Li, Y. A Backdoor Attack Against LSTM-Based Text Classification Systems. IEEE Access 2019, 7, 138872–138878. [Google Scholar] [CrossRef]
- Qi, F.; Li, M.; Chen, Y.; Zhang, Z.; Liu, Z.; Wang, Y.; Sun, M. Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 443–453. [Google Scholar] [CrossRef]
- Qi, F.; Chen, Y.; Zhang, X.; Li, M.; Liu, Z.; Sun, M. Mind the Style of Text! Adversarial and Backdoor Attacks Based on Text Style Transfer. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic (Online), 7–11 November 2021; pp. 4569–4580. [Google Scholar] [CrossRef]
- Kurita, K.; Michel, P.; Neubig, G. Weight Poisoning Attacks on Pretrained Models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2793–2806. [Google Scholar] [CrossRef]
- Yang, W.; Li, L.; Zhang, Z.; Ren, X.; Sun, X.; He, B. Be Careful about Poisoned Word Embeddings: Exploring the Vulnerability of the Embedding Layers in NLP Models. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2048–2058. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, Y.; Li, Z.; Xia, S.T. Backdoor Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Carvalho, W.; Baracaldo, N.; Ludwig, H.; Edwards, B.; Lee, T.; Molloy, I.; Srivastava, B. Detecting backdoor attacks on deep neural networks by activation clustering. In Proceedings of the Workshop on Artificial Intelligence Safety 2019 Co-Located with the Thirty-Third AAAI Conference on Artificial Intelligence 2019 (AAAI19), Honolulu, HI, USA, 27 January 2019. [Google Scholar]
- Chen, C.; Dai, J. Mitigating backdoor attacks in LSTM-based text classification systems by Backdoor Keyword Identification. Neurocomputing 2021, 452, 253–262. [Google Scholar] [CrossRef]
- Qi, F.; Chen, Y.; Li, M.; Yao, Y.; Liu, Z.; Sun, M. ONION: A Simple and Effective Defense Against Textual Backdoor Attacks. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic (Online), 7–11 November 2021; pp. 9558–9566. [Google Scholar] [CrossRef]
- Liu, K.; Dolan-Gavitt, B.; Garg, S. Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks. In Proceedings of the Research in Attacks, Intrusions, and Defenses, Heraklion, Greece, 10–12 September 2018; Bailey, M., Holz, T., Stamatogiannakis, M., Ioannidis, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 273–294. [Google Scholar]
- Tran, B.; Li, J.; Madry, A. Spectral Signatures in Backdoor Attacks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar] [CrossRef]
- Doan, B.G.; Abbasnejad, E.; Ranasinghe, D.C. Februus: Input Purification Defense Against Trojan Attacks on Deep Neural Network Systems. In Proceedings of the ACSAC ’20: Annual Computer Security Applications Conference, Virtual, 7–11 December 2020; pp. 897–912. [Google Scholar] [CrossRef]
- Gao, Y.; Kim, Y.; Doan, B.G.; Zhang, Z.; Zhang, G.; Nepal, S.; Ranasinghe, D.C.; Kim, H. Design and Evaluation of a Multi-Domain Trojan Detection Method on Deep Neural Networks. IEEE Trans. Dependable Secur. Comput. 2022, 19, 2349–2364. [Google Scholar] [CrossRef]
- Li, Y.; Lyu, X.; Koren, N.; Lyu, L.; Li, B.; Ma, X. Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Shen, G.; Liu, Y.; Tao, G.; An, S.; Xu, Q.; Cheng, S.; Ma, S.; Zhang, X. Backdoor Scanning for Deep Neural Networks through K-Arm Optimization. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 9525–9536. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- de Gibert, O.; Perez, N.; García-Pablos, A.; Cuadros, M. Hate speech dataset from a white supremacy forum. In Proceedings of the 2nd Workshop on Abusive Language, Brussels, Belgium, 31 October 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the NIPS’17: 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Yang, W.; Lin, Y.; Li, P.; Zhou, J.; Sun, X. RAP: Robustness-Aware Perturbations for Defending against Backdoor Attacks on NLP Models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic (Online), 7–11 November 2021; pp. 8365–8381. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenarios | Attackers | Defenders | |||||
|---|---|---|---|---|---|---|---|
| Training Data | Training Schedule | Model | Training Data | Training Schedule | Model | Inference Pipeline | |
| Scenario 1 | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Scenario 2 | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Dataset | Attack | Defense | BERT | ALBERT | ||
|---|---|---|---|---|---|---|
| SST-2 | Char-level | AC | 53.30% | 42.55% | 99.83% | 99.50% |
| DFC | 98.95% | 97.05% | 98.85% | 96.73% | ||
| BadNet-RW | AC | 48.05% | 29.17% | 56.65% | 44.37% | |
| DFC | 99.88% | 99.64% | 99.68% | 99.07% | ||
| InsertSent | AC | 53.37% | 42.55% | 99.45% | 98.44% | |
| DFC | 99.93% | 99.78% | 100% | 100% | ||
| Dataset | Attack | Defense | BERT | ALBERT | ||
|---|---|---|---|---|---|---|
| HS | Char-level | AC | 92.85% | 85.71% | 99.21% | 97.24% |
| DFC | 99.01% | 96.58% | 99.50% | 98.26% | ||
| BadNet-RW | AC | 72.10% | 50.09% | 99.50% | 98.26% | |
| DFC | 99.70% | 98.95% | 99.50% | 98.23% | ||
| InsertSent | AC | 84.11% | 61.90% | 22.84% | 26.63% | |
| DFC | 97.72% | 92.10% | 99.6% | 98.60% | ||
| Dataset | Attack | Defense | BERT | ALBERT | ||
|---|---|---|---|---|---|---|
| SST-2 | Char-level | RAP | 98.0% | 98.40% | 96.4% | 97.08% |
| DFC | 100% | 100% | 99.1% | 98.88% | ||
| BadNet-RW | RAP | 97.4% | 97.92% | 86.4% | 87.98% | |
| DFC | 93.1% | 91.41% | 95.8% | 94.93% | ||
| EP | RAP | 97.7% | 98.26% | 86.8% | 89.07% | |
| DFC | 89.5% | 86.02% | 88.6% | 85.31% | ||
| InsertSent | RAP | 72.4% | 71.43% | 89.6% | 90.74% | |
| DFC | 93.5% | 91.20% | 97.9% | 97.42% | ||
| Dataset | Attack | Defense | BERT | ALBERT | ||
|---|---|---|---|---|---|---|
| HS | Char-level | RAP | 97.9% | 98.88% | 98.4% | 99.13% |
| DFC | 99.0% | 98.76% | 99.9% | 99.88% | ||
| BadNet-RW | RAP | 98.9% | 99.38% | 98.4% | 99.13% | |
| DFC | 98.1% | 97.63% | 99.5% | 99.38% | ||
| EP | RAP | 98.6% | 99.25% | 80.2% | 88.39% | |
| DFC | 97.7% | 97.08% | 94.3% | 92.59% | ||
| InsertSent | RAP | 59.6% | 71.81% | 44.0% | 56.59% | |
| DFC | 96.0% | 95.24% | 99.5% | 99.38% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, K.; Yang, J.; Hu, P.; Li, X. A Textual Backdoor Defense Method Based on Deep Feature Classification. Entropy 2023, 25, 220. https://doi.org/10.3390/e25020220
Shao K, Yang J, Hu P, Li X. A Textual Backdoor Defense Method Based on Deep Feature Classification. Entropy. 2023; 25(2):220. https://doi.org/10.3390/e25020220
Chicago/Turabian StyleShao, Kun, Junan Yang, Pengjiang Hu, and Xiaoshuai Li. 2023. "A Textual Backdoor Defense Method Based on Deep Feature Classification" Entropy 25, no. 2: 220. https://doi.org/10.3390/e25020220
APA StyleShao, K., Yang, J., Hu, P., & Li, X. (2023). A Textual Backdoor Defense Method Based on Deep Feature Classification. Entropy, 25(2), 220. https://doi.org/10.3390/e25020220