Abstract
In multiview data clustering, consistent or complementary information in the multiview data can achieve better clustering results. However, the high dimensions, lack of labeling, and redundancy of multiview data certainly affect the clustering effect, posing a challenge to multiview clustering. A clustering algorithm based on multiview feature selection clustering (MFSC), which combines similarity graph learning and unsupervised feature selection, is designed in this study. During the MFSC implementation, local manifold regularization is integrated into similarity graph learning, with the clustering label of similarity graph learning as the standard for unsupervised feature selection. MFSC can retain the characteristics of the clustering label on the premise of maintaining the manifold structure of multiview data. The algorithm is systematically evaluated using benchmark multiview and simulated data. The clustering experiment results prove that the MFSC algorithm is more effective than the traditional algorithm.
1. Introduction
Various application types correspond to various network attributes that describe individuals and groups from different perspectives. These networks are represented as multiview feature spaces. For example, when uploading photos to Flickr, users are required to offer labels and related text. In other words, photos can be represented by three view feature spaces: photo content, label, and text description spaces.
Multiview data can integrate these view spaces and use correlation to obtain more accurate network representations. Currently, multiview data are usually described in the form of graphs, such as Gaussian function graphs, k nearest neighbor graphs [], and graphs based on subspace clustering [,]. For the selection of the correct neighborhood size and the processing of points near the intersection of the subspace, subspace clustering based on self-representation is superior to other graph-based representation methods. Nie et al. developed a multiview clustering [,] algorithm that can perform spectral clustering of an information network of multiple views by constructing a multiview similarity matrix. The multiview clustering algorithm [] proposed by Bickel et al. uses spherical k-means multiview clustering. Pu et al. advanced the multiview clustering algorithm [] based on matrix decomposition, which regularizes the similarity matrix using multiview manifold regularization, to merge the inherent and nonlinear structure of the network in every view. The aforementioned methods provide an idea regarding the relationships between multiview data that improve clustering performance [] by constructing multiview similarity matrix clustering. However, the redundancy of multiview data has not yet been resolved. In addition, the calculation for constructing a multiview similarity matrix is complicated and unsuitable for large-scale multiview data.
Feature selection [] obtains the low-dimensional feature subspace representation of the network by selecting features as well as removing noisy, irrelevant, and redundant features to preserve the inherent data structure. This is an effective method for handling large-scale high-dimensional networks. Most existing feature selection methods are based on single-view networks. Recently, the focus of unsupervised feature selection research has been on the study of multiview data. Zhang et al. [] propose a formulation that learns an adaptive neighbor graph for unsupervised multiview feature selection. This formulation collaborates multiview features and discriminates between different views. Fang et al. [] propose a novel approach that incorporates both cluster structure and a similarity graph. Their method utilizes multiview feature selection and an orthogonal decomposition technique, which breaks down each objective matrix into a base matrix and a clustering index matrix for each view. Cao et al. [] present a cluster learning guided multiview unsupervised feature selection, which unified subspace learning, cluster learning, and feature selection into a framework. Tang et al. [] propose a feature selection method based on multiview data that aims to maintain diversity and enhance consensus learning by utilizing cross-view local structures. Liu et al. [] propose a framework for guided unsupervised feature selection, which utilizes consensus clustering to generate pseudo cluster indexes for the purpose of feature selection.
There are two modes of feature selection in multiview networks. One is the serial mode, which is a feature selection method that seriates the connection multiview feature space into a feature space and then selects the features. The other is the parallel mode, which involves performing traditional feature selection on each view simultaneously. In more detail, the serial mode ignores the differences between heterogeneous feature spaces, so its performance is relatively poor. The parallel mode considers the correlation between multiple view spaces with relatively better performance. Research on the unsupervised feature selection of multiview data without labels poses a significant challenge. For the traditional unsupervised feature selection method, the feature distribution selected by the Laplacian score [] method agrees with the sample distribution, which can perform a good regional classification and reflect the inherent manifold structure of data. However, the correlation between the features is not evaluated, resulting in the selection of redundant features. In the MFSC method, spectral analysis retains the internal structure and uses feature selection coefficients to select the best features. Therefore, the selected features retain the clustering structure of the data.
The MFSC algorithm proposed in this study makes the following contributions:
- Compared with a single-view dataset that concatenates multiview data, the parallel use of multiview datasets from real-world social media sites significantly improves the accuracy of data representation.
- In integrated subspace clustering and feature selection, the clustering label and representative coefficient matrix are flow regularizations. Furthermore, to obtain a more suitable feature selection matrix, the a priori of the manifold structure is embedded in the feature selection model.
- In the construction of the parallel mode multiview feature selection algorithm, noisy, irrelevant, and redundant features are removed to preserve the inherent data structure and improve the efficiency and quality of feature selection based on clustering, which is more suitable for multiview data.
The rest of this paper is organized as follows. Section 2 introduces the basic studies related to the MFSC algorithm. Section 3 presents the MFSC model and its optimization iterative process in detail, and it theoretically proves the convergence and complexity of the algorithm. Section 4 reports the parameter sensitivity and performance analysis of MFSC on typical datasets, as well as the results of comparison experiments with some single-view or multiview feature selections. Section 5 presents the results of this study and the future work.
2. Related Studies
2.1. Multiview Subspace Representation
Let be the data sample node of the v-th view and be its representative coefficient matrix. Each data point in the subspace union can be reconstructed effectively by combining the other points in the dataset. Given the data X based on the group effect [], for representation coefficients and of the samples, and are similar and so are and . The multiview representation of traditional sparse subspace clustering (MVSC) [] is defined as follows:
MVSC can well capture the self-representation matrix in the multisubspace k-nearest neighbor graph structure. Similar structure graph of the v-th view can learn the multisubspace structure when there are noise, abnormal values, and damaged or missing entries in the data.
2.2. Multiview Unsupervised Feature Selection
Most existing studies on multiview learning [] assume that all views share the same label space and that these views are related to each other through the label space. It is well known that the main difficulty of unsupervised feature selection is the lack of class tags. Consequently, the concept of a pseudo-class label is introduced to guide the development of the framework using the relationship between views, which is defined as follows:
where the v-th view has a mapping matrix that assigns the pseudo-class label C to the data points. Based on the assumption that the view is associated with the shared label space, each pseudo-class label allocation matrix is approximated such that it is close to the pseudo-class label matrix. The norm [] is added to to ensure sparseness in the row and feature selection. In addition, the norm is convex, making the optimization easier.
2.3. Multiview Manifold Structure
The greater the similarity value of the two data points, the more similar the clusters. A similar structure graph with k unconnected cluster subspaces can be directly learned and it is defined as follows:
where clustering label and Laplacian matrix . It is known that MHOAR [] points out that the properties of the L matrix of nonnegative matrix S are shown in Theorem 1.
Theorem 1.
The number of the eigenvalues 0 of normalized L is equal to the number of connected subspaces of S. Therefore, . According to the Ky Fan theorem [], using to represent the i-th smallest eigenvalue of L, then and . Therefore, .
3. Proposed Model
This section contains an introduction to the MFSC model: an explanation of the iterative optimization implementation process, algorithm, proof of convergence, and analysis of algorithm complexity. An illustration of the MFSC model is shown in Figure 1. Multiview unsupervised feature selection, similarity graph learning, and clustering index learning are achieved in the parallel mode. MFSC reduces the redundancy and irrelevant influence of multiview data and uses the clustering index as the feature selection standard to ensure that the clustering structure remains unchanged.
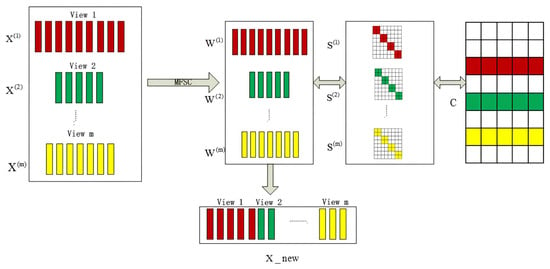
Figure 1.
Overall framework based on the parallel mode in MFSC.
3.1. MFSC Model
Suppose the dataset denotes the data of the v-th view, denotes the feature number of the v-th view, and n denotes the number of data. The feature selection matrix is , the clustering label is , and the subspace representation coefficient , where k denotes the cluster number. The MFSC model is defined as follows:
where .
The model independently learns the of each view instead of directly using the calculated by the kernel function. Using the similarity graph of self-representation learning based on the manifold structure, the multisubspace structure of the data can be effectively reflected. By integrating subspace similarity graph learning and feature selection, the pseudo-class label C can capture the relationship between the views to obtain a robust and clean pseudo-class label. Row sparsity is achieved by applying the [] constraint to . Figure 1 shows the feature selection based on the parallel mode that iteratively updates the similarity matrix , the feature selection matrix , and the pseudo label matrix C.
3.2. Optimization Calculation Process and Algorithm Representation
This section first introduces the effective implementation of the iterative method to solve the optimization calculation in Equation (4). In the implementation process, , , and C are updated iteratively to obtain the specific implementation process of the MFSC algorithm.
Update :
To effectively calculate the feature selection matrix , irrelevant items and C are fixed. The objection equation can be rewritten as follows:
Given that this equation is nondifferentiable [], the equation is transformed into:
where denotes a diagonal matrix and the j-th diagonal element is .
Calculation process:
The updated rules for are as follows:
Update :
Theorem 2.
Given , and , then
with , where is the i-th row vector of matrix F.
To effectively calculate the clustering label C, irrelevant items and are fixed. The objection equation can be rewritten as follows:
Based on the properties of the matrix trace and Theorem 2, it is known that P is a symmetric matrix; then,
where . According to
suppose , so is equivalently expressed as follows:
Given that , where denotes the i-th row vector of and denotes the i-th column vector of P. Then,
Suppose ; then,
Subsequently, the objective vector expression for is obtained as follows:
Similarly, the objective vector expression can also be expressed in the following form. There is only a constant difference between the two forms:
Let . Suppose the subscript of the vector is k; then, if , , otherwise solve the following equation:
According to , the solution is as follows:
Update C:
To effectively calculate the clustering label C, and are fixed, and irrelevant items are ignored. The optimization formula can be rewritten as follows:
To remove the orthogonal constraint, a penalty term is added to function (20). The following optimization functions are available:
The Lagrangian operator is introduced to remove the inequality constraints and the following Lagrangian function is obtained:
Take to the derivative of C, then:
Thus, is obtained as follows:
Based on the Karush–Kuhn–Tucker condition [] , the following equation is obtained:
The following update formulas are obtained:
After updating C, C must be regularized to ensure that it satisfies the following constraint: .
3.3. Convergence
Theorem 3.
The iterative optimization process automatically reduces the objective function value until it converges.
Proof.
The first term of and its Hessian matrix value is:
Therefore, is convex; that is,
The second term of : and its Hessian matrix value is
Therefore,
Then, . The proof is completed. □
Theorem 4.
The iterative optimization process of Algorithm 1 automatically reduces the value of the objective function (4) until it converges.
Proof.
Other variables are fixed such that the objective function is related to . Theorem 3 proves that, under the update rule, the objective value of is automatically reduced:
Given the other fixed variables, the objective function is related to . Then, the Hessian matrix of is , which is a positive semi-definite matrix. Therefore,
Fix other variables and update C; the Hessian matrix of the objective function is , where . Thus,
The proof is complete. □
| Algorithm 1 MFSC FOR CLUSTERING |
| Require: Ensure: for v=1 to m do initialize , , and C end for while not convergence do for v=1 to m do update according to Equation (8) update according to Equation (19) update C according to Equation (26) end for end while for v = 1 to m do Sort each feature for according to in descending order and select the top-f ranked ones; end for kmeans clustering for ; Calculate ACC and NMI |
3.4. Complexity Analysis
In this section, the time complexity of the three subproblems in the optimization model is calculated:
In subproblem , term requires and its inverse matrix requires . The time complexity of term is . Therefore, the total time complexity of the subproblem is .
In subproblem , each row of requires matrix multiplication and the time complexity is . Therefore, the total time complexity of the subproblem is .
In subproblem , the calculation of term requires , and the calculation of terms and requires . The total time complexity is .
4. Experiment
This section conducts an evaluation experiment on the MFSC algorithm using some kinds of benchmark multiview datasets and its performance is compared with those of other related algorithms.
4.1. Dataset
The evaluation experiment of the MFSC algorithm was conducted on 5 real multiview datasets: news dataset 3sources, paper dataset Cora, information retrieval and research dataset CiteSeer, website dataset BBCSport, and blog website dataset BlogCatalog. Table 1 summarizes the 5 datasets. In addition, the specific information is as follows:

Table 1.
Statistical table of typical datasets.
- 3sources The news dataset comes from three online news sources: BBC, Reuters, and Guardian. All articles are placed within the text. Out of a total of 948 articles from three sources, 169 are adopted. It is noteworthy that each article in the dataset has a main theme.
- Cora The paper dataset contains a total of 2708 sample points, which are divided into 7 categories. Each sample point is a scientific paper. A paper comprises a 1433-dimensional word vector.
- CiteSeer The papers in the information retrieval and research dataset are divided into six categories, containing a total of 3312 papers, and records the citation or citation information between the papers. Through sorting, 3703 unique words are obtained.
- BBCSport The website dataset comes from 544 dataset points of the BBC sports website, including sports news related to 5 subject areas (athletics, cricket, football, rugby, and tennis) and 2 related views.
- BlogCatalog BlogCatalog is the social blog directory which manages the bloggers and their blogs. The data consists of 10,312 articles, divided into 6 categories, each article with two views: blog content and its related tags.
4.2. Benchmark Method
MFSC is compared with the following algorithms.
- LapScore (the Laplacian score function) selects features with strong separability, where the distribution of feature vector values is consistent with the sample distribution, thereby reflecting the inherent manifold structure of the data.
- Relief is a multiclass feature selection algorithm. The larger the weight of the feature, the stronger the classification ability of the feature. Features with weights less than a certain threshold are removed.
- MCFS [] (a multiclustering feature selection) algorithm uses the spectral method to preserve the local manifold topology and selects features using a method that can preserve the clustering topology.
- PRMA [] (probabilistic robust matrix approximation) is a multiview clustering algorithm with robust regularization matrix approximation. Powerful norm and manifold regularization are used for regularization matrix factorization, making the model more distinguishable in multiview data clustering.
- GMNMF [] (graph-based multiview nonnegative matrix factorization) is a multiview nonnegative matrix decomposition clustering algorithm involving intrinsic structure information among multiview graphs.
- SCFS [] (subspace clustering-based feature selection) is an unsupervised feature selection method based on subspace clustering that maintains a similarity relation by learning the representation of the low-dimensional subspace of samples.
- JMVFG [] (joint multiview unsupervised feature selction and graph leaning) proposed a unified objective function that can simultaneously learn clustering structure, and global and local similarity graphs.
- CCSFS [] (consensus cluster structure guided multiview unsupervised feature selection) unifies subspace learning, clustering learning, consensus learning, and unsupervised feature selection into one optimization framework for mutual optimization.
4.3. Evaluation Metrics
ACC (Accuracy) is used to compare the obtained cluster labels with the real cluster labels . The ACC is defined as follows:
where m denotes the total number of data samples.
NMI (Normalized Mutual Information) is the mutual information entropy between the obtained and real cluster labels; it is defined as follows:
where denotes the sample number of cluster and denotes the sample number in both cluster and category .
4.4. Parameter Setting
The MFSC algorithm has two main parameters and . In the experiment, the parameter range of is set to and that of is set to . The correlation coefficient of the 3sources data is and the other data views are the two-view data, with the correlation coefficient defined as follows . The value range of (feature selection number) is set to . Due to the large scale of BlogCatalog dataset, its range is . Considering that the clustering method k-means usually converges to a local minimum, it is necessary to repeat each experiment 20 times and report the average performance.
4.5. Results of Multiview Clustering
Table 2 and Table 3 show the ACC and NMI values of the different feature selection and multiview clustering methods. To determine the impact of the benchmark feature selection method on clustering, this experiment first merges the results of multiview feature selection into new data and then executes k-means. The final value is the average value of the clustering of different feature selection values. Based on the experimental results, MFSC performs well on both ACC and NMI, which proves the effectiveness of the algorithm.
Table 2.
ACC of different methods on typical datasets.
Table 3.
NMI of different methods on typical datasets.
4.6. Parameter Analysis
To achieve peak clustering performance, we tune parameters , , and . Thus, we alter their values to see how they affect the ACC and NMI of clustering for 3sources data, Cora data, CiteSeer data, BBCSport data and BlogCatalog data.
Figure 2, Figure 3 and Figure 4 show the clustering experiment results of parameters , , and in the 3sources dataset.
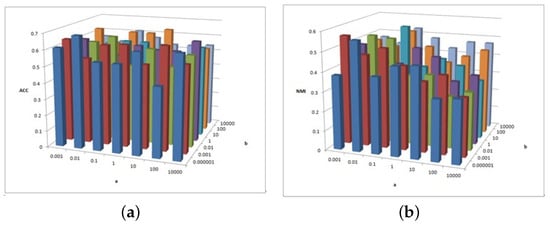
Figure 2.
(a) values of parameter and parameter for 3sources data. (b) values of parameter and parameter for 3sources data.
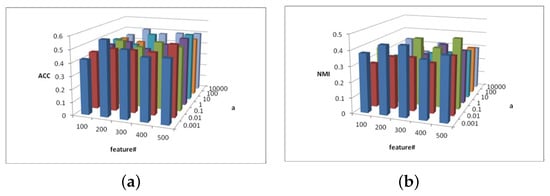
Figure 3.
(a) values of parameter and parameter for 3sources data. (b) values of parameter and parameter for 3sources data.
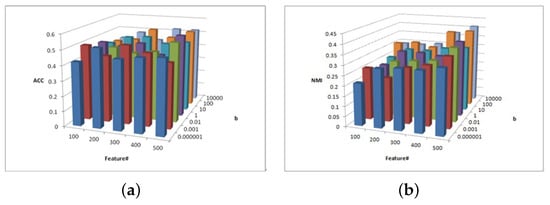
Figure 4.
(a) values of parameter and parameter for 3sources data. (b) values of parameter and parameter for 3sources data.
Figure 2 shows the change description of , , and the clustering indexes ACC and NMI in 3source. The average value is taken as the final result. Based on the ACC and NMI results in 3source, the MFSC algorithm is sensitive to parameters and . When parameter is small, the performance of ACC is relatively high. When parameter is large, the performance of NMI is relatively high.
Figure 3 shows the change description of parameter and and the values of clustering indexes ACC and NMI from 3source. In most cases, when the parameter , the ACC and NMI of the MFSC exhibit better performance in the feature selection dimension, which shows the importance of capturing the multiview manifold structure and embedding it into the feature selection model.
Figure 4 shows the change description of parameter and feature number and the clustering performance ACC and NMI values from 3source. It can be concluded that the MFSC is sensitive to the selected feature number. As the value of feature selection increases, the ACC and NMI increase. In most cases, when the parameter = 10,000, the ACC and NMI of the MFSC exhibit better performance. To ensure the sparsity of matrix W, the larger the value of the feature selection, the greater the importance and the stronger the clustering performance.
Figure 5, Figure 6 and Figure 7 show the clustering results of parameters , , and in the Cora dataset.
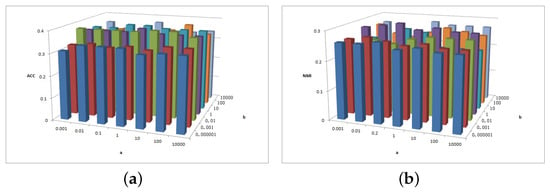
Figure 5.
(a) values of parameter and parameter for Cora data. (b) values of parameter and parameter for Cora data.
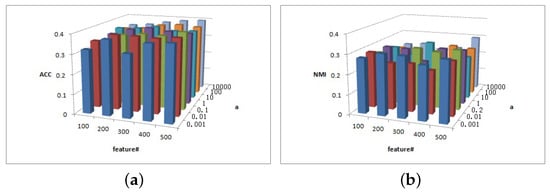
Figure 6.
(a) values of parameter and parameter for Cora data. (b) values of parameter and parameter for Cora data.
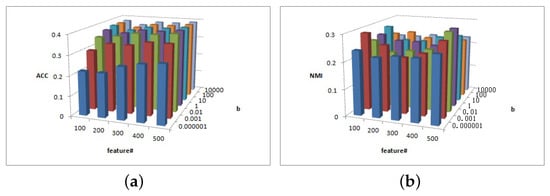
Figure 7.
(a) values of parameter and parameter for Cora data. (b) values of parameter and parameter for Cora data.
Figure 5a shows that the ACC is insensitive to parameter and insensitive to parameter on interval or . Figure 5b shows that the NMI is insensitive to parameter but is sensitive to parameter . When , the NMI value is larger.
Figure 6 shows the clustering results of parameter and in Cora dataset. As depicted in Figure 6a, when parameters and increase, the ACC value increases. In Figure 6b, is sensitive to NMI value, while the overall relative value of is larger and the NMI value is larger.
Figure 7 depicts the clustering results of parameters and in the Cora dataset. As depicted in Figure 7a, for , the ACC increases as increases; otherwise, for the ACC value remains basically unchanged. Figure 7b shows that, when and 500, the NMI value is larger.
Figure 8, Figure 9 and Figure 10 show the clustering results of parameters , , and in CiteSeer dataset. Figure 8a shows that the ACC is insensitive to parameters and , but Figure 8b shows that the NMI is insensitive to parameters and ; when the two parameters are larger or smaller, the NMI value exhibits a small fluctuation.
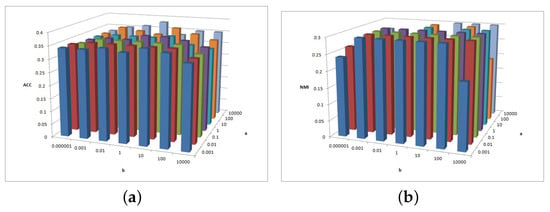
Figure 8.
(a) values of parameter and parameter for CiteSeer data. (b) values of parameter and parameter for CiteSeer data.
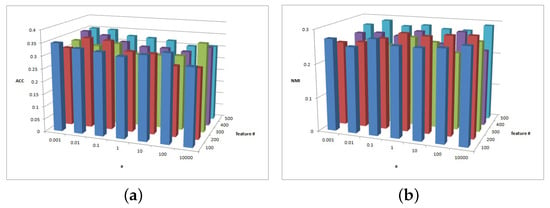
Figure 9.
(a) values of parameter and parameter for CiteSeer data. (b) values of parameter and parameter for CiteSeer data.
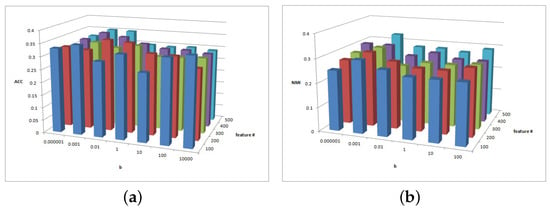
Figure 10.
(a) values of parameter and parameter for CiteSeer data. (b) values of parameter and parameter for CiteSeer data.
Figure 9 shows the clustering results of parameters and in the CiteSeer dataset. As illustrated in Figure 9a, the magnitude of the ACC value difference is 0.05 and the ACC is insensitive to parameter . For , the ACC has better performance. As shown in Figure 9b, the NMI is slightly sensitive to parameters and . For , when , a larger NMI is achieved.
Figure 10 shows the clustering results of parameters and in the CiteSeer dataset. As demonstrated in Figure 10a, the magnitude of the ACC value difference is 0.05 and the ACC is insensitive to parameter . In general, the NMI performance is better when . The ACC performance is stabler when . Figure 10b shows that the NMI results are almost insensitive to parameter and in the CiteSeer dataset. When , the NMI result is greater.
Figure 11, Figure 12 and Figure 13 show the clustering experiment results of parameters , , and in the BBCSport dataset.
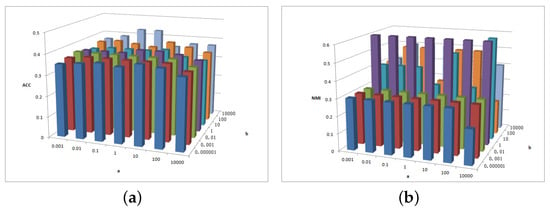
Figure 11.
(a) values of parameter and parameter for BBCSport data. (b) values of parameter and parameter for BBCSport data.
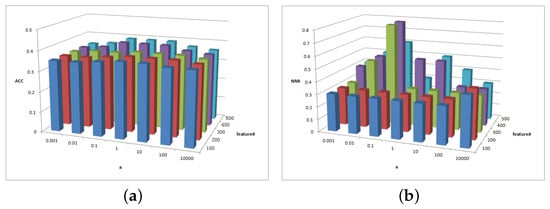
Figure 12.
(a) values of parameter and parameter for BBCSport data. (b) values of parameter and parameter for BBCSport data.
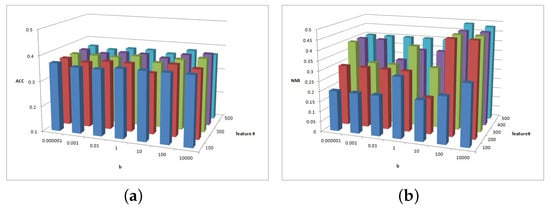
Figure 13.
(a) values of parameter and parameter for BBCSport data. (b) values of parameter and parameter for BBCSport data.
Figure 11a shows that the ACC is insensitive to parameters and in the BBCSport dataset. Figure 11b shows that the NMI is insensitive to parameter but the NMI changes slightly when . However, the NMI results have a peak when .
Figure 12a shows the clustering ACC of parameters and in the BBCSport dataset. The magnitude of the ACC value difference in this figure is 0.05, and the ACC is insensitive to parameter and in BBCSport dataset. Comparatively, it has high ACC with and . Figure 12b shows the clustering NMI of parameters and in the BBCSport dataset. When , the results of NMI are insensitive to parameters and . NMI increases first and then decreases with parameter . When , NMI has a greater value when and and 400.
Figure 13a shows the clustering ACC of parameters b and in the BBCSport dataset. The magnitude of ACC value difference in this figure is 0.05, and the ACC is insensitive to parameters and in the BBCSport dataset. Comparatively, it has high ACC with and a = 10,000. Figure 13b shows the clustering NMI of parameters b and in the BBCSport dataset. NMI is sensitive to , and NMI has a greater value when and .
Figure 14, Figure 15 and Figure 16 show the clustering results of parameters , , and in BlogCatalog dataset.
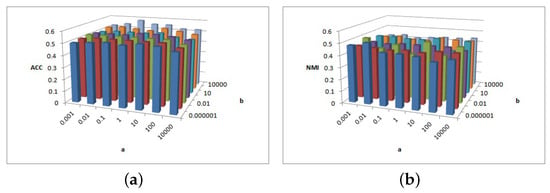
Figure 14.
(a) values of parameter and parameter for BlogCatalog data. (b) values of parameter and parameter for BlogCatalog data.
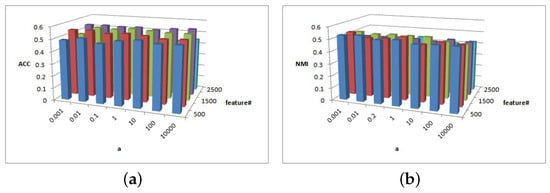
Figure 15.
(a) values of parameter and parameter for BlogCatalog data. (b) values of parameter and parameter for BlogCatalog data.
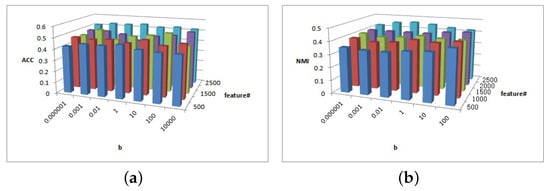
Figure 16.
(a) values of parameter and parameter for BlogCatalog data. (b) values of parameter and parameter for BlogCatalog data.
Figure 14a shows that ACC is insensitive to but, when , its performance is better. Figure 14b shows the NMI performance for parameters and . NMI is not very sensitive to and , and, when is larger and is smaller, NMI is relatively larger.
Figure 15a shows the ACC performance with parameters and . When and , the ACC performance is better. Figure 15b shows the NMI decrease with parameter and NMI is not sensitive to . Figure 15 indicates that higher is not necessarily better for BlogCatalog data.
Figure 16 shows that is sensitive to ACC and NMI, and is sensitive to clustering performance. In Figure 16a, when and , the ACC is better. In Figure 16b, NMI increases with parameter ; when , NMI has a greater value.
Parameter sensitivity remains a challenging and unsolved problem in feature selection. This experiment analyzes the sensitivity of parameters , , and . We performed similar parameter sensitivity analyses for the data sources. The results show that MFSC is almost insensitive to parameters and for ACC performance. This shows the importance of capturing the multiview manifold structure embedded in the feature selection model. However, the MFSC is sensitive to . This is because the network size affects the number of feature selections.
4.7. Convergence Analysis
The convergence effects of the datasets are shown in Figure 17. In addition, the convergence effect of the remaining data is similar. Based on the experimental results, the convergence effect is relatively good. The objective function increases as the number of convergences increases and quickly reaches a constant convergence value regardless of the initial objective value.
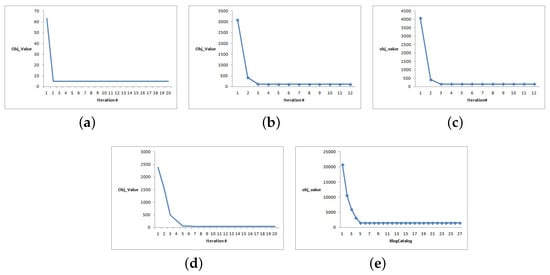
Figure 17.
MFSC convergence curves. (a) 3sources; (b) Cora; (c) CiteSeer; (d) BBCSport; (e) BlogCatalog.
5. Conclusions and Future Work
This study proposes a multiview clustering-guided feature selection algorithm for multiview data, which integrates subspace learning and feature selection, and embeds the norm of manifold regularization. This feature selection algorithm reduces the influence of redundancy and the irrelevant matrix of the multiview data. In addition, clustering is used as the standard for feature selection. This algorithm can perform feature selection to ensure that the clustering structure remains unchanged. It is noteworthy that the complementary contribution of each view is fully considered. The optimization process is calculated and theoretically analyzed, and experiments are performed using a multiview dataset. It can be concluded that the algorithm is effective and superior to many existing feature selection algorithms or multiview clustering algorithms.
Although our method achieves good clustering performance, on the one hand, we mainly consider social network data, while other types of multimodal data graph structures are not considered. On the other hand, some parameters need to be manually adjusted. Recently, deep learning has demonstrated excellent feature extraction capabilities in multiview data, such as images and natural languages. In the future, we will study how to integrate deep learning and the MFSC model to process multiview data and accurately describe semantic information.
Author Contributions
N.L.: Conceptualization, Methodology, Software, Investigation, Formal Analysis, Writing—Original Draft, Writing—review and editing, Funding Acquisition; M.P.: Visualization, Validation, Data Curation, Supervision, Funding Acquisition; Q.W.: Investigation, Formal Analysis, Resources. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National key R&D Program of China (Grant 2017YFB0202901, 2017YFB0202905), the Hunan Natural Science Foundation Project (No. 2023JJ50353).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- He, X. Locality preserving projections. Adv. Neural Inf. Process. Syst. 2003, 16, 186–197. [Google Scholar]
- Dong, W.; Wu, X.J.; Li, H.; Feng, Z.H.; Kittler, J. Subspace Clustering via Joint Unsupervised Feature Selection. In Proceedings of the 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 3861–3870. [Google Scholar]
- Parsa, M.G.; Zare, H.; Ghatee, M. Unsupervised feature selection based on adaptive similarity learning and subspace clustering. Eng. Appl. Artif. Intell. 2020, 95, 103855. [Google Scholar] [CrossRef]
- Nie, F.; Zhu, W.; Li, X. Structured Graph Optimization for Unsupervised Feature Selection. IEEE Trans. Knowl. Data Eng. 2019, 33, 1210–1222. [Google Scholar] [CrossRef]
- Ma, X.; Yan, X.; Liu, J.; Zhong, G. Simultaneous multi-graph learning and clustering for multiview data. Inf. Sci. 2022, 593, 472–487. [Google Scholar] [CrossRef]
- Bickel, S.; Scheffer, T. Multi-view clustering. In Proceedings of the IEEE International Conference on Data Mining, Brighton, UK, 1–4 November 2004; pp. 234–243. [Google Scholar]
- Pu, J.; Qian, Z.; Zhang, L.; Bo, D.; You, J. Multiview clustering based on Robust and Regularized Matrix Approximation. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 2550–2555. [Google Scholar]
- Yang, Y.; Wang, H. Multi-view Clustering: A Survey. Big Data Min. Anal. 2018, 1, 83–107. [Google Scholar]
- Venkatesh, B.; Anuradha, J. A Review of Feature Selection and Its Methods. Cybern. Inf. Technol. 2019, 19, 3. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, D.; Nie, F.; Wang, R.; Li, X. Multilevel projections with adaptive neighbor graph for unsupervised multi-view feature selection. Inf. Fusion 2021, 70, 129–140. [Google Scholar] [CrossRef]
- Fang, S.G.; Huang, D.; Wang, C.D.; Tang, Y. Joint Multi-view Unsupervised Feature Selection and Graph Learning. Comput. Vis. Pattern Recognit. 2022, 98, 1–18. [Google Scholar] [CrossRef]
- Cao, Z.; Xie, X.; Sun, F.; Qian, J. Consensus cluster structure guided multi-view unsupervised feature selection. Knowl.-Based Syst. 2023, 271, 110578–110590. [Google Scholar] [CrossRef]
- Tang, C.; Zheng, X.; Liu, X.; Zhang, W.; Zhang, J.; Xiong, J.; Wang, L. Cross-View Locality Preserved Diversity and Consensus Learning for Multi-View Unsupervised Feature Selection. IEEE Trans. Knowl. Data Eng. 2022, 34, 4705–4716. [Google Scholar] [CrossRef]
- Liu, H.; Shao, M.; Fu, Y. Feature Selection with Unsupervised Consensus Guidance. IEEE Trans. Knowl. Data Eng. 2019, 31, 2319–2331. [Google Scholar] [CrossRef]
- He, X.; Cai, D.; Niyogi, P. Laplacian Score for Feature Selection. In Proceedings of the Neural Information Processing Systems, NIPS 2005, Vancouver, BC, Canada, 5–8 December 2005; pp. 2547–2556. [Google Scholar]
- Xu, Y.; Zhong, A.; Yang, J.; Zhang, D. LPP solution schemes for use with face recognition. Pattern Recognit. 2010, 43, 4165–4176. [Google Scholar] [CrossRef]
- Hao, W.; Yan, Y.; Li, T. Multi-view Clustering via Concept Factorization with Local Manifold Regularization. In Proceedings of the IEEE International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016; pp. 1245–1250. [Google Scholar]
- Livescu, K. Multiview Clustering via Canonical Correlation Analysis. In Proceedings of the International Conference on Machine Learning, Montreal, QC, Canada, 20–21 June 2008; pp. 129–136. [Google Scholar]
- Nie, F.; Huang, H.; Cai, X.; Ding, C.H.Q. Efficient and Robust Feature Selection via Joint l2,1-Norms Minimization. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 1813–1821. [Google Scholar]
- Newman, M.W.; Libraty, N.; On, O.; On, K.A.; On, K.A. The Laplacian spectrum of graphs. Graph Theory Comb. Appl. 1991, 18, 871–898. [Google Scholar]
- Fan, K. On a Theorem of Weyl Concerning Eigenvalues of Linear Transformations: II. Proc. Natl. Acad. Sci. USA 1950, 35, 652–655. [Google Scholar] [CrossRef] [PubMed]
- Nie, F.; Xu, D.; Tsang, W.H.; Zhang, C. Flexible Manifold Embedding: A Framework for Semi-Supervised and Unsupervised Dimension Reduction. IEEE Trans. Image Process. 2010, 19, 1921–1932. [Google Scholar] [PubMed]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004; pp. 43–365. [Google Scholar]
- Cai, D.; Zhang, C.; He, X. Unsupervised feature selection for multi-cluster data. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 333–342. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).