Abstract
In a traditional distributed storage system, a source can be restored perfectly when a certain subset of servers is contacted. The coding is independent of the contents of the source. This paper considers instead a lossy source coding version of this problem where the more servers that are contacted, the higher the quality of the restored source. An example could be video stored on distributed storage. In information theory, this is called the multiple description problem, where the distortion depends on the number of descriptions received. The problem considered in this paper is how to restore the system operation when one of the servers fail and a new server replaces it, that is, repair. The requirement is that the distortions in the restored system should be no more than in the original system. The question is how many extra bits are needed for repair. We find an achievable rate and show that this is optimal in certain cases. One conclusion is that it is necessary to design the multiple description codes with repair in mind; just using an existing multiple description code results in unnecessary high repair rates.
1. Introduction
In distributed storage systems, data is divided into multiple segments that are then stored on separate servers. In a typical setup [1], data is divided into k segments that are stored on n servers using an maximum distance separable (MDS) code. If a user is able to contact any set of k servers, the data can be reconstructed. Notice that in this setup, if the user is able to contact less than k servers, it can retrieve no information, while on the other hand, there is no advantage in being able to contact more than k servers. One could instead want the quality of the reconstructed data to depend on how many servers a user is able to contact. An example could be video: it is common that the quality of streamed video depends on the network connection. In the context of distributed storage, the quality would now be dependent on the number of servers possible to connect, which could be constrained by network connection, physical location, delay, or cost. In information theory, this is known as multiple description coding [2,3]. Originally, multiple description coding was aimed at packet transmission networks, where some packets may be lost, but it can be directly applied to the distributed storage problem. We will accordingly call the systems we consider multiple description distributed storage.
A central issue in distributed storage is how to repair the system when one or more of the servers fail or become unavailable and are replaced by new servers [1]. In traditional distributed storage, this is also solved by the MDS code: if one server fails, the repair can be done by contacting k surviving servers, reconstruct the source, and then generating a new coded segment. The problem we consider in this paper is how repair can be done for multiple description distributed storage. The paper [1] and many following papers also consider how much network traffic is required for repair. However, in this paper we will only consider the amount of additional data needed to be stored for repair to be possible. The amount of network traffic is a topic for future research.
In general, the quality of reconstruction could be dependent not only on the number of servers connected, but which servers. However, to simplify the problem, we only consider the symmetric scenario where the quality only depends on the number of servers. This is the symmetric multiple description problem considered in [4]. A multiple description coding system with repair is specified as follows: when a subset of servers is contacted, a source X should be restored with a distortion at most . If one (or multiple) of the servers fails, we should be able to set up a replacement server with enough information so that the whole region is restored. We consider two scenarios:
- There is a special (highly reliable) repair server that does not participate in the usual operation of the system, but only comes into action if another server fails. The repair server can contact all other (non-failed) servers and use their information combined with its own information to restore the failed server (collaborative repair).
- The repair information is stored in a distributed fashion among the n servers (distributed repair).
For simplicity, in this paper we only consider failure of a single server.
A straightforward solution is to separate the source coding problem (multiple description) and the repair problem. Any existing code for multiple description can then be used, and repair can be done using minimum distance separable (MDS) erasure codes as in traditional distributed storage [1]. We will use this as a baseline. For case 1 above, the repair server can simply store the xor (sum modulo 2) of the bits on the operational servers. When one server fails, the xor together with the bits from the surviving servers can restore the failed server. Thus, if each operational server stores bits, the repair server also needs to store bits. For distributed repair, the xor can replaced with an erasure code. Therefore in addition to the bits for operation, each server needs to store bits for repair. It should be clear that these rates are also optimal with separation: even if the system knows in advance which server will fail, it cannot store less information. We can consider this as a separate source channel coding solution, with multiple description being source coding and the repair being channel coding. It is known that in many information theory problems, joint source–channel coding is superior to separation. This is then the question we consider here: can we find a better joint source–channel coding solution that can beat the above rates? We will see that for some cases of desired distortion, separation is in fact optimal, while in other cases, joint source–channel coding provides much better rates.
The problem of repair of multiple description has been considered in some previous papers. In [5], the authors consider a problem like 1. above, but they do not give a single letter description of rate-distortion regions. In [6], the authors consider practical codes for repairing. In the current paper we aim to provide single letter expression for achievable rate-distortion regions, and in some cases the actual rate-distortion region. This paper is an extended version of our conference paper [7] with proof of the general achievable rate and specialization to the two level case, where we can prove optimality in certain cases.
2. Problem Description
In the following, we use the term repair node for the special repair server and operational nodes to denote the other servers. We let and , with the definition and (e.g., ). For variables with multiple indices, denotes a matrix of variables, i.e, the collection , and denotes a row.
We consider a symmetric multiple description problem as in [4]. We have an i.i.d. (independent identically distributed) source X that takes values in a finite alphabet and needs to be restored in the finite alphabet ; this can be generalized to a continuous alphabet Gaussian source through usual quantization arguments [3]. Let . We are given a collection of distortion measures , and define
The required maximum distortion is then a function of and the distortion measures only.
2.1. Distributed Repair
We will first define the distributed repair problem. For a source sequence of length l, each node stores bits. There are n encoding functions , decoding functions , , and n repair functions . We define the error probability of repair as
Here, is the length list obtained by removing the i-th component from . We now say that an a tuple is achievable if there exists a sequence of codes with
We call this exact repair. The repaired node is required to be an exact copy of the failed node, except that we allow a certain, vanishing, and error rate. Notice that the randomness in the system is purely due to the source . Thus, for a given sequence , either all failures can be repaired exactly, and if they can be repaired once, they can be repaired infinitely many times; or, some failures can never be repaired. The probability of the source sequences that are not repairable should be vanishingly small.
An alternative problem formulation, which we call functional repair, is to allow approximate repair, where the only requirement is that after repair the distortion constraint is satisfied. In that case, one would have to carefully consider repeated repair. In this paper, we will only consider exact repair for coding schemes. It should be noted that in the cases where we have tight converses (the two node case [7], Theorem 3 in some scenarios), the converses are actually for functional repair; thus, functional repair might not decrease rates.
2.2. Collaborate Repair
For collaborate repair with a dedicated repair node, each node stores bits and the repair node bits. There are now n encoding functions and additionally a repair encoder , decoding functions , , and n repair functions . We define the error probability of repair as
We now say that an a tuple is achievable if there exists a sequence of codes with
3. Achievable Rate
The rate-distortion region for multiple description coding is only known in a few cases; among those are the two node Gaussian case first studied in [2], and the two level case studied in [8,9]. There are, therefore, many different achievable schemes for multiple description coding, e.g., [4,10,11,12], and we have to design repairs for each specific method. In this paper, we will consider the Puri Pradhan Ramchandran (PPR) scheme [4,13], as this is specifically aimed at the symmetric case and is well-suited for repair. It is optimal in certain cases [8,9], but not always [11].
The coding method in [4] is based on source-channel erasure codes (SCEC) from [13]. An -SCEC is similar to an -MDS erasure code: if any k of n packets are received, the transmitted message can be recovered with a certain distortion. However, with an -SCEC if packets are received, the message can be recovered with decreasing distortion with m. Using a concatenation of SCEC, [4] obtained the following result
Proposition 1
(PPR [4]). For any symmetric probability distribution the lower convex closure of is achievable, where and
A probability distribution is symmetric if for all the joint distribution of and all random variables where any are chosen from the ith layer, conditioned on X are the same.
We first notice that for collaborative repair, reconstruction from n nodes does not make sense: since we can repair the last node from nodes, there can be no gain for a user to access all n nodes. The performance is therefore specified by . As a baseline, we thus consider the standard PPR scheme where we use at most nodes for the reconstruction. Now, in layer , we just need a single common message (in standard PPR that happens at layer n). This message can be encoded using an MDS erasure code. We then get the following rate, which we state without proof as it is a simple modification of PPR:
Proposition 2.
For any symmetric probability distribution the lower convex closure of is achievable, where , the following rate is achievable with n nodes and using at most nodes for reconstruction
Notice that one should not think of this as an ‘improved’ PPR scheme; rather it is the PPR scheme adapted to the special case here, where at most nodes are used for reconstruction.
For our repair coding scheme, we amend the PPR scheme, specifically from Proposition 2. We still use an -SCEC at layers , but add a common message () at each layer . At layer 1, this is a true common message that is duplicated to all nodes. At layers this is a message stored with an -MDS code. Common messages were shown to be necessary to achieve optimality for the two-node case in [7]. We also use binning for repair of correlated quantizations. A system schematic for a specific case can be seen in Figure 1 below. The addition of common messages strictly decreases the rate for repair in some cases, see Section 5.
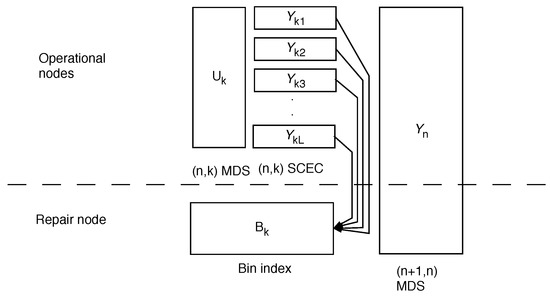
Figure 1.
Two layer repair. See text for explanation.
The following is the main result of the paper, an achievable repair rate; this rate can be compared to the rate in Proposition 2. As above, we call a probability distribution symmetric if for all and all the joint distribution of and all random variables where any are chosen from the ith layer, conditioned on X are the same.
Theorem 1
(Distributed repair). For any symmetric probability distribution the lower convex closure of is achievable, where and the information needed to encode operational information is
with additional information needed to encode repair information
with
Proof.
There is a formal proof in Appendix A—the purpose here is to outline how the coding is done and how the rate expressions are obtained, without a deep knowledge of [4].
Consider at first layer 1. We generate a codebook by picking elements uniformly randomly with replacement from the typical set according to the distribution . We also generate n independent random codebooks drawn from the typical set according to with codewords. We need to be able to find a codeword in that is jointly typical with with high probability, which, from standard rate distortion, is the case if
This codeword is stored in all the nodes. We now need to be able to find n codewords from that are jointly typical with and the chosen codeword . There are about (marginally) typical sequences, and about that are jointly typical with a given and (see, e.g., [14] (Section 15.2)); the probability that a given codeword combination in is jointly typical, therefore it is about . The probability that no codeword is jointly typical then is about
The inequality is standard in rate distortion, see [3,14]. Thus, if
there is a high probability that at least one of the codeword combinations is jointly typical.
The codewords in are randomly binned into bins. At the time of decoding, the common codeword is available as well as the bin number i for the codeword . The decoder looks for a codeword in bin i that is typical with . There is always one, the actual codeword, but if there is more than one, the decoding results in error. The probability that a random codeword in is jointly typical with is about as above, while there are about codewords in each bin. By the union bound, the probability that there is at least one random codeword in the bin jointly typical is approximately upper bounded by . Thus, if
there is only one such codeword with high probability. Combining (3) and (4) we get
At layer we similarly generate a random codebook with typical elements according to the marginal distribution and n independent random codebooks according to the distribution with codewords. We need to be able to find a codeword in that is jointly typical with and all the codewords chosen in the previous layers. This is possible if
with the same argument as for (3). We also need to be able to find an n-tuple of codewords from that are jointly typical with all prior codewords and , which is possible with high probability if (again as in (3))
For , we generate n independent binning partitions each with elements. The bin number in the i-th partition is stored in the i-th node. When the decoder has access to k nodes, say nodes it needs to be able to be able to find a unique codeword in the k bins jointly typical with codewords from previous layers. The probability that a random selected codeword is jointly typical is about , as above. There are about in each combined bin. Therefore, if
or
with high probability there is only one jointly typical codeword in the combined bin. It also needs to find a single codeword in the k bins for s that are jointly typical with . The probability that a random codeword is jointly typical is about , while the number of codewords in the k joint bins is about . With high probability there is only one such if
or
(as in [13] this can be repeated for any collection of k nodes).
At layer only a single codebook is generated, and this is binned into n independent partitions. Upon receipt, in analogy with (5), this can be found uniquely with high probability if
For repair, the joint codewords in at layer are binned into bins. The single bin number of the n chosen codewords is encoded with an MDS erasure code.
Now, suppose node n is lost, and needs to be recovered. The repair node works from the bottom up. So, suppose the previous layers have been recovered, that is, are known without error. First is recovered, which can be done since nodes are used. It can also decode the codewords in . It restores the bin number of the repair codeword from the erasure code. There are approximately codewords in the bin, but since it knows the codewords in , there are only about valid ones. It searches in the bin for valid codewords jointly typical with . With high probability, there is only one such if
(The right hand side could be negative. This means that the lost codeword can be recovered from the surviving ones without extra repair information. Then we just put .) Then
There is at least one codeword in the bin, namely the correct one. Thus, if there is no error (more than one codeword), the repair is exact, as required from the exact repairability condition in Section 2. □
The above result can easily be adapted to the case of a repair node that collaborates with the operational nodes. There are only two differences:
- The repair node can restore operation of the full n node distortion region. Therefore, the terminal single common codeword is not at layer , but at layer n. At the same time, the repair node now has to store repair information for this last codeword.
- For distributed repair, distributions are chosen to minimize . For collaborative repair, distributions are chosen to minimize R, and is then as given for those distributions.
With this in mind, we get
Theorem 2
(Collaborative repair). For any symmetric probability distribution the lower convex closure of is achievable, where and
The additional information the repair node has to store is
The proof is nearly identical to the proof of Theorem 1, so it will be omitted.
4. The Two Level Case
In [9], the authors considered the situation when there were only two cases of node access: Either we have access to all n nodes, or we have access to a given number nodes; there are two levels of distortion: . Importantly, they were able to derive the exact capacity region for this case for Gaussian sources, one of the few cases when this known except for the original EC case [2]. This makes it an interesting case to consider for repair: at least we can upper bound the number of bits needed for repair by the achievable rate in Section 3. The paper [9] considered the vector Gaussian case, but we restrict ourselves to the scalar Gaussian case.
To fit into the framework of [9], we need to consider the case when there is a repair node, Theorem 2. In that case, the scheme is as shown on Figure 1. The represents a common codeword that is stored jointly on the operational nodes with an MDS. If one server fails, this can be restored without additional information from the repair as . represent individual codewords using SCEC (source-channel erasure code) codes from [4,13]; here, the repair is accomplished using correlation and a bin index, similar to the two node case. Finally, represents resolution information, which can be repaired due to the MDS code.
The explicit rate constraints from Theorem 2 are
with
We consider an iid Gaussian source with with a quadratic distortion function: . For this situation, we can calculate the achievable repair rate explicitly. We recall that the problem setup is that R is fixed to the optimum rate from [9]. We then obtain:
Theorem 3.
In the Gaussian two level case, we have the following bounds on the repair rate:
- 1.
- For a common message is used and achievesFor the upper bound is tight.
- 2.
- For no common message is used andFor the upper bound is tight.
- 3.
- For no common message is used and the exact repair rate isfor all k and n.
We will discuss some implications of this result. The converse is provided by the bound (A8) , which is simply the requirement that the repair node together with the surviving nodes should be able to restore the source with distortion . This is clearly also a converse for functional repair, which could indicate that relaxing to functional repair cannot decrease rates. For , the theorem provides the exact repair rate; without using common messages, we could not have achieved the bound. We can compare with separate repair and multiple description coding, as mentioned in the introduction. For case 3, the theorem separation is optimal, but for the other cases . For example, for , we get for case 1.
5. Example Gaussian Case
Figure 2 shows typical numerical results. All curves are for two levels of constraints, , but variable number of nodes. First, from the bottom, we have the curve for the optimum region for the two node problem according to EC [2,3]. Notice that this is achieved without any refinement information, using only correlation between the base layer random variables; refinement information is only required for and . Second, we have the curves for the three node problem, but where we use at most two nodes for reconstruction, either using [4] (Section V) directly (ignoring the constraint), or using Theorem 1 without repair. It can be noticed that using Proposition 2 gives a slight improvement; this is not due to the common message, but due to the fact that PPR uses codewords in the last layer, while the modified PPR uses only one. For the 4 node case, we use (4,1)-SCEC and (4,2)-SCEC successively, as well as (4,1)-MDS common message and (4,2)-MDS common message. Therefore, we have 2 variables and for common messages, and and for SCEC, where i = 1, 2, 3, 4. As a result, it is noted that the overall rate of the 4 node system improves over that of the 3 node system, whereas the overall rate of the 2 node system improves over that of the 3 node system where common message and SCEC were used only once. We see that a common message gives a clear improvement.
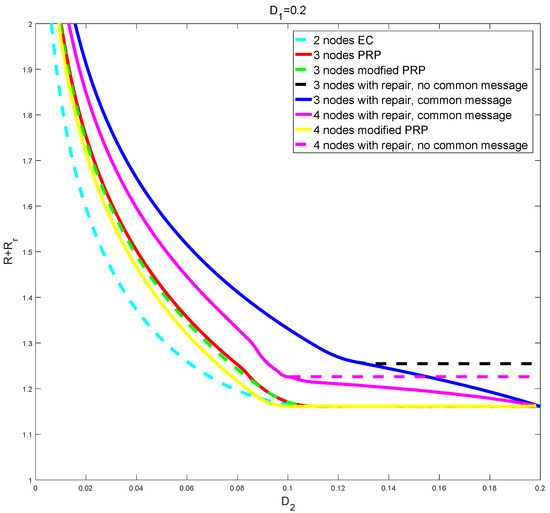
Figure 2.
Plots of R or for two levels of constraints and variable number of nodes.
6. Conclusions
The paper has derived achievable rates for repair of multiple description distributed storage, which in some cases is optimal. Our solution shows that joint repair and multiple description coding beats separate coding in many cases. It also shows that it is sub-optimal for repair to just take a standard multiple description code and add repair information. Rather, the multiple description code has to be designed with repair in mind. In this paper, we do this by adding common messages.
This paper is only a first step in solving repair of multiple description distributed storage. For one thing, we have assumed that the repair bandwidth is unlimited. When the required repair bandwidth is also of concern as in [1], an entirely new set of constraints comes into play. We will consider this in a later paper.
Author Contributions
Conceptualization, A.H.-M. and J.L.; methodology, A.H.-M. and J.L.; software, H.Y. and M.K.; validation, H.Y. and M.K.; formal analysis, A.H.-M.; resources, J.L.; writing—original draft preparation, A.H.-M.; writing—review and editing, A.H.-M. and J.L.; visualization, H.Y. and M.K.; supervision, J.L.; project administration, A.H.-M.; funding acquisition, A.H.-M. All authors have read and agreed to the published version of the manuscript.
Funding
The research was funded in part by the NSF grant CCF-1908957.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| MDS | Maximum distance separable (code) |
| EC | El-Gamal Cover (coding scheme) |
| ZB | Zhang-Berger (coding scheme) |
| PPR | Puri Pradhan Ramchandran (coding scheme) |
| SCEC | Source-channel erasure code |
Appendix A. Proof of Theorem 1
Contrary to the proof outline, which is intended to stand by itself, the formal proof is a modification of the proof of Theorem 2 in [4], and reading it requires a good familiarity with [4]. We will not repeat the proof in [4], but only the new elements. The proof in this paper adds common messages, which require a separate codebook generation, and an analysis of additional error events. It also adds repair codebooks, and an analysis of repair error.
We let denote the strongly typical set for X.
The coding scheme for repair uses MDS codes in several places. These can be put in the binning framework of PPR [13]. However, it is easier to think of them as pure channel codes. We can state this as follows:
Remark A1.
A message is stored on n nodes, of which at least arbitrary k is accessed for decoding. With bits on each node, decoding is possible with error as .
Appendix A.1. Codebook Generation
The codebooks are generated and binned exactly as in [4]. The difference from [4] is that there is no n-th layer, and that at layer there is only one codebook . The codebook of size is generated like in [4], but then stored on the nodes with an MDS code.
We also generate common codebooks by drawing codewords independently with replacement over the set according to a uniform distribution. The indices for are next binned. Let for some and make bins. For each bin, select numbers from the set , uniformly and with replacement. They are finally coded with an MDS erasure code.
We finally generate repair codebooks through binning. First, if
it turns out, as will be seen later, that the lost codeword can be recovered from the remaining ones with high probability. In that case, we set and store no extra repair information. For consistency, we think of there being one bin at layer k containing all codewords. Otherwise, we let for some and make bins. For each bin, select vectors from the set , uniformly and with replacement. The bin indices are further coded with an MDS erasure code.
Appendix A.2. Encoding
Given a source codeword , we find codewords so that
are jointly typical. The binning of and are done exactly as in [4] to obtain bin indices . The bin index is further coded with the MDS code. For , we find the smallest bin index that contains (if is in no bin, ), and this is further coded with the MDS code.
For repair, for those where repair information is needed, we find the smallest bin index so that is in the corresponding bin; if no bin contains , we put . These are then coded with the MDS code.
Appendix A.3. Decoding
We assume node are available. The bin indices are decoded from the MDS code, where . The decoding now is similar to [4], except that there is also a common codeword. Consider decoding at layer . First, we find an index in bin so that
Next, for any size k subset , the decoder looks in bins for codewords so that
If , is first recovered from the MDS code. Then, the above procedure is repeated (there is no ).
The reconstructions of are standard as in [4].
Appendix A.4. Repair
Without loss of generality and to simplify notation, we can assume that node n fails. The repair is done layer by layer. At layer 1, we copy from any node to the replacement node n. Next, from the surviving nodes we decode the repair bin index from the MDS code; if there is no extra repair information, we put . We know from the surviving nodes. In bin , we look for an index so that the corresponding codeword ; if there is more than one, there is a repair error. We then store the recovered in the replacement node n.
The following layers proceed in almost the same way. However, now to recover the common message we arbitrarily choose k of the surviving nodes and decode just as with usual operation. The decoded is then encoded with the exact same MDS code and we store the corresponding codeword on the replacement node n. We next find an index in bin so that .
On the last layer, we simply decode from the surviving nodes as usual, and then we re-encode with the same MDS code, and store the recovered bin index on the new node n.
We notice that this repair is exact: the information on the restored node is exactly the same as on the failed node, except if a repair error happens.
Appendix A.5. Analysis of Decoding Error
We have some slightly modified error events compared to [4] and some additional ones. We find it necessary to write these down explicitly
- : .
- : There exists no indices so that
- : Not all the indices are greater than zero.
- : For some subset with there exists some other in bins so that (We use a slightly different notation for compared to [4], which we think is clearer.
- : Not all the indices are greater than zero.
- : For some there exist another index in bin so that
- : There is a decoding error in the MDS erasure code for .
- : There is a decoding error in the MDS erasure code for .
First by Remark A1, as long as the rates before the MDS is scaled appropriately.
As in [4] we have as . For as in [4] we define as an encoding error on layer i given that the previous layers have been encoded correctly and in addition, here, that has been encoded correctly. Then, as in [4], we find that if
with the difference being the addition of the variables. Similarly, we can define as an encoding error of given that the previous layers have been encoded correctly, and we similarly have that if
The proof that is unchanged from [4], and the proof that is similar.
The proof that is similar to [4], except that at the time of decoding at layer k the decoder has access to . The relevant probability of decoding error at layer k is therefore , and since we search for codewords in , the condition for this error probability converging to zero is
instead of [4] (A17).
Appendix A.6. Analysis of Repair Error
If , from above happen, there is also a repair error. Notice that at time of repair, we have access to nodes, and we can therefore use decoding for nodes, and in that case we have proven that as . We have the following additional repair error events:
- : Some for .
- : For , there exists another bin index in bin so that
- : For , there is a decoding error in the MDS erasure code for .
Appendix A.6.1. Bounding Er1
In total, for all bins, we pick elements with replacement from a set of size . The probability that a particular element was never picked is then and
Appendix A.6.2. Bounding Er2
First, we will argue that if (A1) is satisfied, we can predict with probability approaching one. We can state this as follows: if we pick a random , what is the probability P that
This is actually a standard channel coding problem, so we get
Since the codebook has elements, we then have
Thus, as if
Now in consideration of (A5) there is no gain from making larger than needed. Thus, is chosen arbitrarily close to the limit given by (A3), and we therefore have if
which is (A1).
Now, turn to the case when (A1) is not satisfied. We look for vectors that
- Are in the bin indicated by .
- Has , .
- Are jointly typical, i.e., satisfy (A6).
Appendix B. Proof of Theorem 3
We use the following simple converse: when one node fails and the remaining nodes collaborates with the repair node, they have to be able to restore X with distortion . Therefore,
While the calculations in the proof are in principle straightforward, we include some detail to make it simpler for readers to further develop the results. The three different cases in the Theorem are as in [9] (Section VI.A). We put
with zero-mean Gaussian, , , , for , and all other noise variables uncorrelated. Let
Here, is a column vector of all 1s, so is a matrix of all ones.
We first calculate the distortions,
The distortion constraint is always satisfied with equality, and therefore
In general, we can write
So we just need to the various conditional covariances
We need
Then we get
For repair we need
From which
For case 1, we set and . Then
independent of . We choose so that we get exactly . Solving for and inserting in (A14) results in
Then,
for we get
which achieves (A8)
For case 2, we put . We solve for so that we exactly achieve ,
Giving
Inserting and simplifying, it is seen that (A8) is achieved.
Now region III. We put , and find and to exactly satisfy and . We minimize the resulting (large) expression with respect to , giving . This results in
References
- Dimakis, A.G.; Godfrey, P.B.; Wu, Y.; Wainwright, M.J.; Ramchandran, K. Network Coding for Distributed Storage Systems. IEEE Trans. Inf. Theory 2010, 56, 4539–4551. [Google Scholar] [CrossRef]
- Gamal, A.E.; Cover, T. Achievable rates for multiple descriptions. IEEE Trans. Inf. Theory 1982, 28, 851–857. [Google Scholar] [CrossRef]
- Gamal, A.E.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Puri, R.; Pradhan, S.S.; Ramchandran, K. n-channel symmetric multiple descriptions-part II:An achievable rate-distortion region. IEEE Trans. Inf. Theory 2005, 51, 1377–1392. [Google Scholar] [CrossRef]
- Chan, T.H.; Ho, S.W. Robust multiple description coding—Joint Coding for source and storage. In Proceedings of the 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 1809–1813. [Google Scholar] [CrossRef]
- Kapetanovic, D.; Chatzinotas, S.; Ottersten, B. Index assignment for multiple description repair in distributed storage systems. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, Australia, 10–14 June 2014; pp. 3896–3901. [Google Scholar] [CrossRef]
- Høst-Madsen, A.; Yang, H.; Kim, M.; Lee, J. Repair of Multiple Descriptions on Distributed Storage. In Proceedings of the ISITA’2020, Honolulu, HI, USA, 24–27 October 2020. [Google Scholar]
- Wang, H.; Viswanath, P. Vector Gaussian Multiple Description With Individual and Central Receivers. IEEE Trans. Inf. Theory 2007, 53, 2133–2153. [Google Scholar] [CrossRef]
- Wang, H.; Viswanath, P. Vector Gaussian Multiple Description With Two Levels of Receivers. IEEE Trans. Inf. Theory 2009, 55, 401–410. [Google Scholar] [CrossRef][Green Version]
- Venkataramani, R.; Kramer, G.; Goyal, V.K. Multiple description coding with many channels. IEEE Trans. Inf. Theory 2003, 49, 2106–2114. [Google Scholar] [CrossRef]
- Tian, C.; Chen, J. New Coding Schemes for the Symmetric K-Description Problem. IEEE Trans. Inf. Theory 2010, 56, 5344–5365. [Google Scholar] [CrossRef]
- Viswanatha, K.B.; Akyol, E.; Rose, K. Combinatorial Message Sharing and a New Achievable Region for Multiple Descriptions. IEEE Trans. Inf. Theory 2016, 62, 769–792. [Google Scholar] [CrossRef]
- Pradhan, S.S.; Puri, R.; Ramchandran, K. n-channel symmetric multiple descriptions—Part I: (n, k) source-channel erasure codes. IEEE Trans. Inf. Theory 2004, 50, 47–61. [Google Scholar] [CrossRef]
- Cover, T.; Thomas, J. Information Theory, 2nd ed.; John Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).