
Deep Link-Prediction Based on the Local Structure of Bipartite Networks


Abstract
:1. Introduction
- The DLP method is proposed on the basis of the local structure of the bipartite network, demonstrating the rationality of the local structure in link prediction.
- A local structure extraction algorithm was designed to effectively extract local structures between target nodes of the bipartitie network and provide local structural information for link prediction.
- Experimental results on five datasets demonstrate the superiority of DLP over state-of-the-art link prediction methods.
2. Related Work
2.1. Link Prediction of Bipartite Networks Based on Similarity Structure
2.2. Link Prediction of Bipartite Network Based on Machine Learning
2.3. Link Prediction Based on Heterogeneous Graph Neural Networks
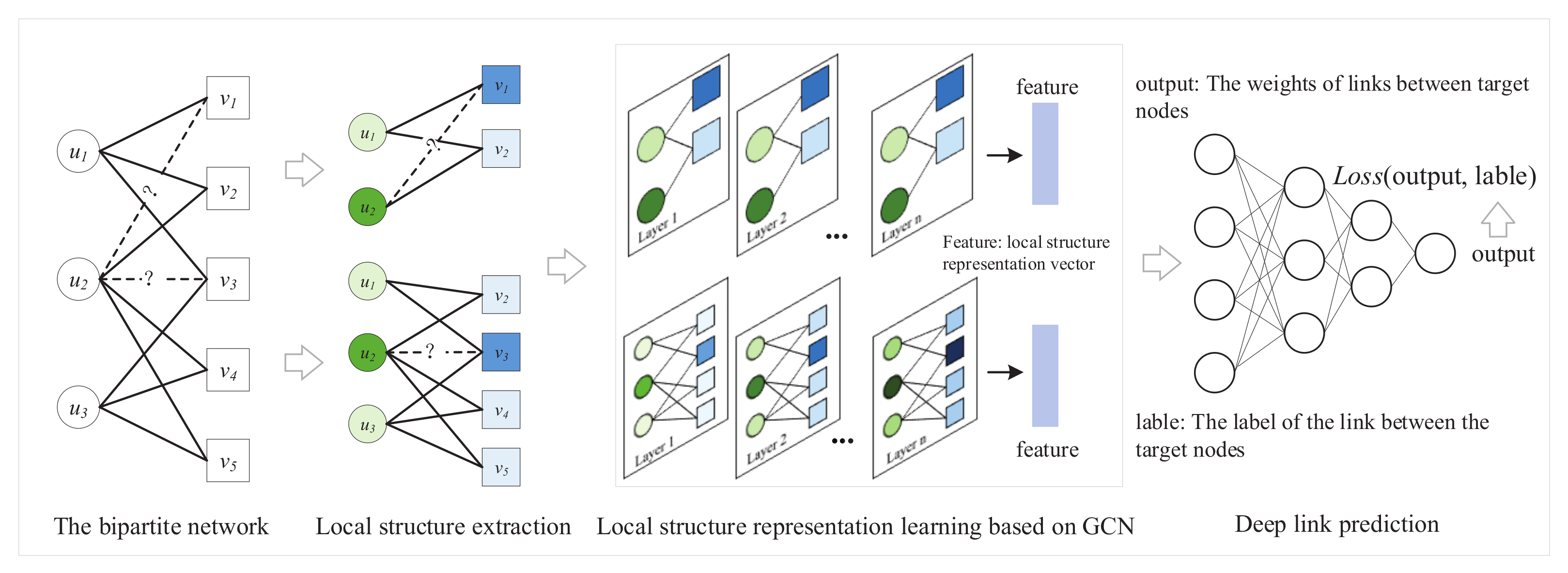
3. DLP Method
3.1. Local Structure Extraction
| Algorithm 1 Local Structure Extraction |
| Input: Target nodes u and v, bipartite network G, path hops k |
| Output: Local k-hop structure (u, v) between node pair (u, v) |
| 1: = {} |
| 2: = {u: u∼}; path is the set of k-hop paths of u, and is the end point of k-hop path |
| 3: for i in do |
| 4: if == v then |
| 5: = {set of nodes in path i } |
| 6: = ∪ |
| 7: Let (u, v) be the induced subgraph from G using vertices |
| 8: Remove the edge between u and v in local structure (u, v), and use the edge as the label of the local structure |
| 9: return (u, v), label |
3.2. Node Feature Labeling
- (1)
- Using different labels to mark nodes’ different roles in the local structure. There are two types of nodes in a bipartite network. Distinguishing types of nodes can assist in fully understanding roles (user or item) in the local structure and effectively identify the target node.
- (2)
- Distinguishing positions of nodes in the local structure. Nodes with different relative positions to the target node have different structural importance to the link. Distinguishing the position information of nodes can effectively extract the semantic information of target nodes in local structures.
3.3. Local Structure Representation
3.4. Link Prediction
4. Experiments
4.1. Datasets
4.2. Method Comparison
4.3. Evaluation Indicators
4.4. Result
4.4.1. Local Structural Analysis
4.4.2. Performance Comparison
- (1)
- In terms of and , DLP achieved the best performance on the five datasets, indicating that DLP could effectively predict links existing between nodes.
- (2)
- On the five datasets, the overall reduction in showed that DLP could reduce the error between predicted and actual values, and achieved effective prediction of edge weights between nodes.
- (3)
- The overall reduction in of the DLP method on the five datasets was 0.498, 0.619, 0.285, 0.605 and 0.601. DLP achieved the smallest on all datasets, indicating that the prediction results of the method were stable.
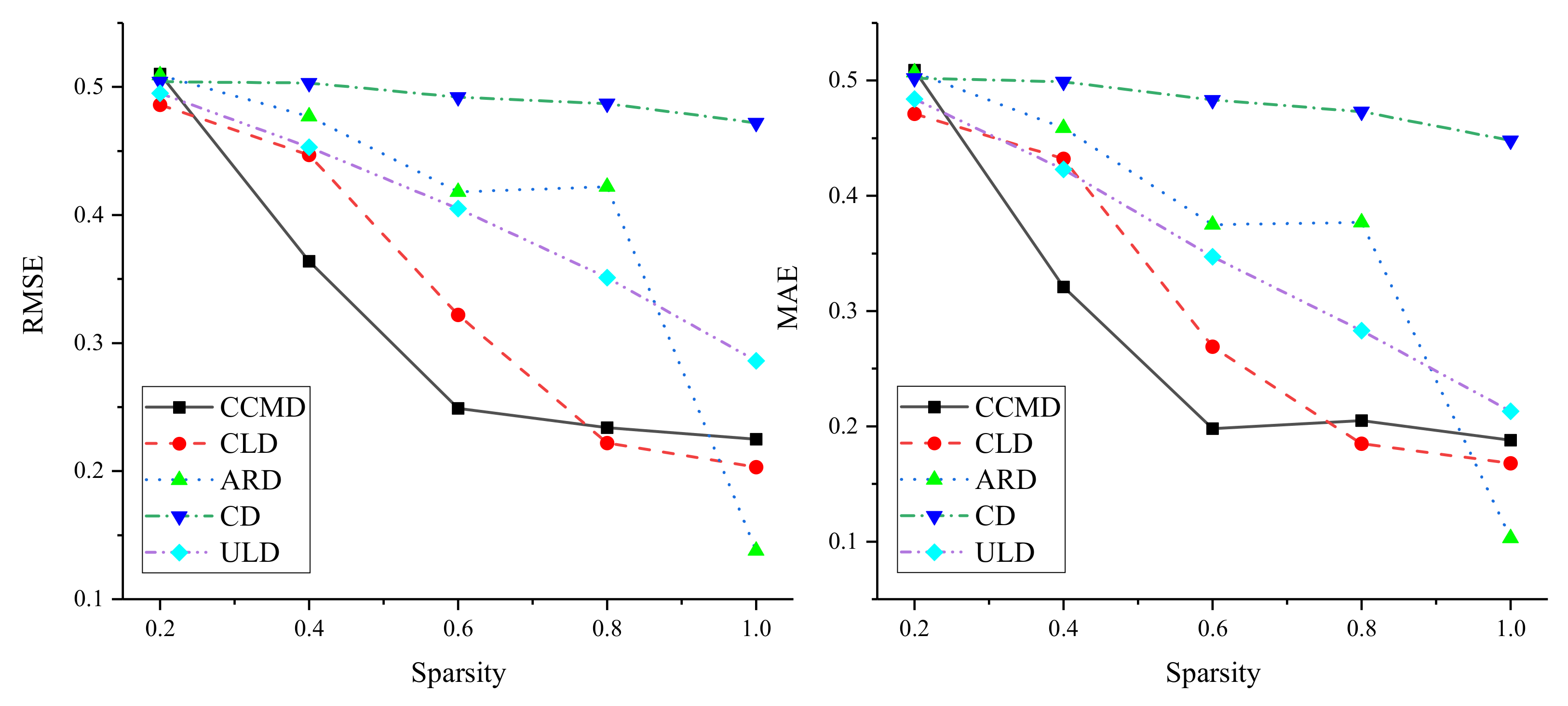
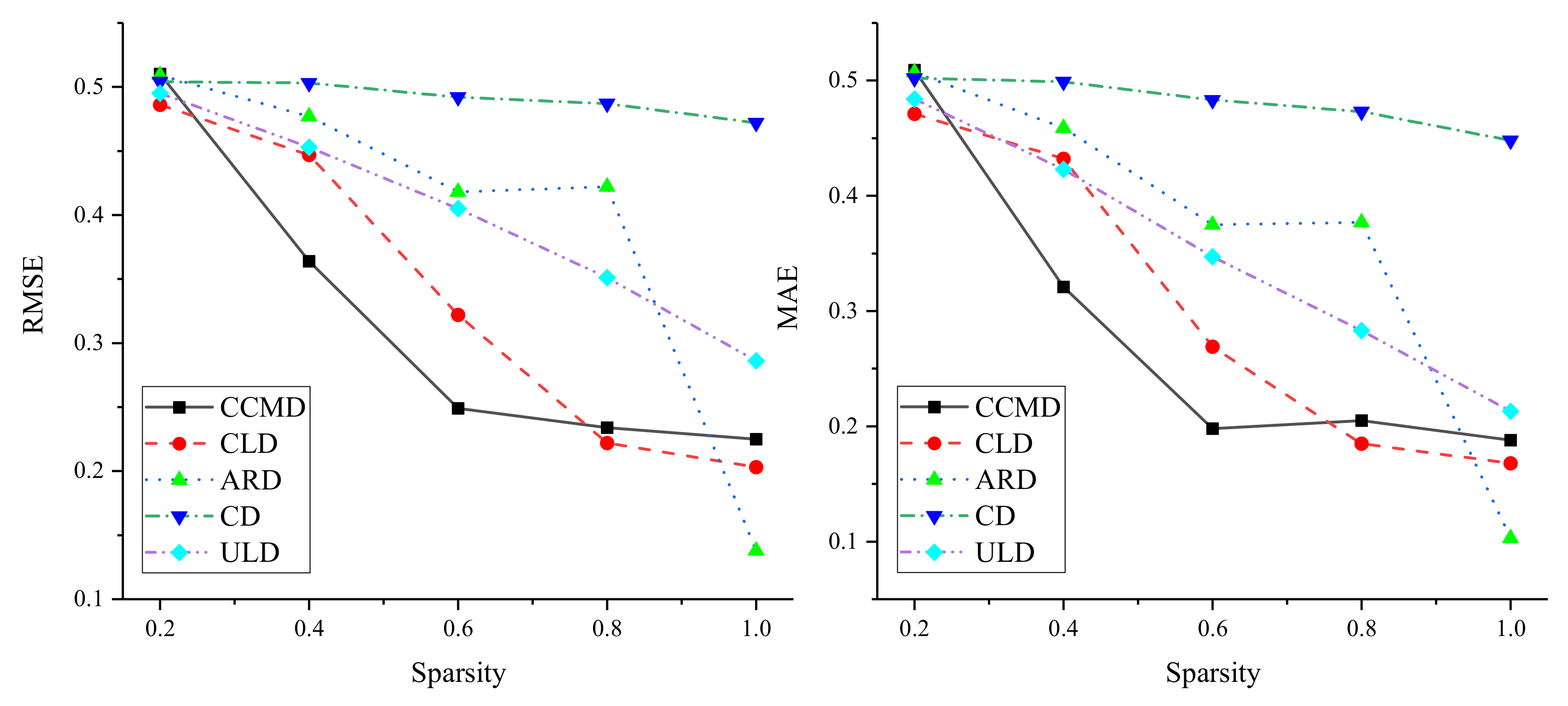
4.4.3. Influence of Link Sparsity
4.4.4. Model Analysis
5. Conclusions
- (1)
- The effectiveness of the local structure in link prediction was confirmed, and experiments on five datasets showed that, when the local structure is smaller, the performance of link prediction is better.
- (2)
- Compared with existing state-of-the-art methods, DLP showed excellent performance on and , indicating that this method could achieve effective prediction of link presence and link weight between nodes.
- (3)
- In addition, the performance of the method was improved on the basis of the increase in the sparsity of the dataset, indicating that the method is more suitable for dealing with dense bipartite networks.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guillaume, J.L.; Latapy, M. Bipartite graphs as models of complex networks. Phys. A 2006, 371, 795–813. [Google Scholar] [CrossRef]
- Aslan, S.; Kaya, B. Time-aware link prediction based on strengthened projection in bipartite networks. Inf. Sci. 2020, 506, 217–233. [Google Scholar] [CrossRef]
- Gao, M.; Chen, L.; Li, B.; Li, Y.; Liu, W.; Xu, Y.C. Projection-based link prediction in a bipartite network. Inf. Sci. 2017, 376, 158–171. [Google Scholar] [CrossRef]
- Zhang, J.W.; Gao, M.; Yu, J.L.; Yang, L.D.; Wang, Z.W.; Xiong, Q.Y. Path-based reasoning over heterogeneous networks for recommendation via bidirectional modeling. Neurocomputing 2021, 461, 438–449. [Google Scholar] [CrossRef]
- Yu, Z.X.; Huang, F.; Zhao, X.H.; Xiao, W.J.; Zhang, W. Predicting drug–disease associations through layer attention graph convolutional network. Brief. Bioinform. 2021, 22, bbaa243. [Google Scholar] [CrossRef]
- Bai, X.M.; Zhang, F.L.; Li, J.Z.; Xu, Z.; Patoli, Z.; Lee, I. Quantifying scientific collaboration impact by exploiting collaboration-citation network. Scientometrics 2021, 126, 7993–8008. [Google Scholar] [CrossRef]
- Barabasi, A.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Lu, L.Y.; Zhang, Y.C. Predicting missing links via local information. EPJ B 2009, 71, 623–630. [Google Scholar] [CrossRef] [Green Version]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Wang, W.; Lv, H.H.; Zhao, Y.; Liu, D.; Wang, Y.Q.; Zhang, Y. DLS: A Link Prediction Method Based on Network Local Structure for Predicting Drug-Protein Interactions. Front. Bioeng. Biotechnol. 2020, 8, 330. [Google Scholar] [CrossRef]
- Fan, S.H.; Zhu, J.X.; Han, X.T.; Shi, C.; Hu, L.M.; Ma, B.; Li, Y.L. Metapath-guided Heterogeneous Graph Neural Network for Intent Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Jin, J.R.; Qin, J.R.; Fang, Y.C.; Du, K.; Zhang, W.N.; Yu, Y.; Zhang, Z.; Smola, A.J. An Efficient Neighborhood-based Interaction Model for Recommendation on Heterogeneous Graph. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 23–27 August 2020. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Gao, M.; Chen, L.H.; He, X.G.; Zhou, A. BiNE: Bipartite Network Embedding. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Dong, Y.X.; Chawla, N.V.; Swami, A. metapath2vec: Scalable Representation Learning for Heterogeneous Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Fu, T.Y.; Lee, W.C.; Lei, Z. HIN2Vec: Explore Meta-paths in Heterogeneous Information Networks for Representation Learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017. [Google Scholar]
- Yang, M.M.; Xu, S.H. A novel deep quantile matrix completion model for top-N recommendation. Knowl. Based Syst. 2021, 228, 107302. [Google Scholar] [CrossRef]
- Wang, M.N.; You, Z.H.; Wang, L.; Li, L.P.; Zheng, K. LDGRNMF: LncRNA-disease associations prediction based on graph regularized non-negative matrix factorization. Neurocomputing 2021, 424, 236–245. [Google Scholar] [CrossRef]
- Yang, Y.M.; Guan, Z.Y.; Li, J.X.; Zhao, W.; Cui, J.T.; Wang, Q. Interpretable and Efficient Heterogeneous Graph Convolutional Network. IEEE Trans. Knowl. Data Eng. 2021, 99, 1–14. [Google Scholar] [CrossRef]
- Jiang, X.Q.; Lu, Y.F.; Fang, Y.; Shi, C. Contrastive Pre-Training of GNNs on Heterogeneous Graphs. In Proceedings of the 30th ACM International Conference on Information and Knowledge Management, Gold Coast, QLD, Australia, 1–5 November 2021. [Google Scholar]
- Fu, X.Y.; Zhang, J.N.; Meng, Z.Q.; King, I. MAGNN: Metapath Aggregated Graph Neural Network for Heterogeneous Graph Embedding. In Proceedings of the Web Conference 2020, Taipei, China, 20–24 April 2020. [Google Scholar]
- Wang, X.; Zhang, Y.D.; Shi, C. Hyperbolic Heterogeneous Information Network Embedding. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Ahmad, I.; Akhtar, M.U.; Noor, S.; Shahnaz, A. Missing Link Prediction using Common Neighbor and Centrality based Parameterized Algorithm. Sci. Rep. 2020, 10, 364. [Google Scholar] [CrossRef] [PubMed]
- Verma, V.; Aggarwal, R.K. A comparative analysis of similarity measures akin to the Jaccard index in collaborative recommendations: Empirical and theoretical perspective. Soc. Netw. Anal. Min. 2020, 10, 43. [Google Scholar] [CrossRef]
- Wang, W.; Lv, H.H.; Zhao, Y. Predicting DNA binding protein-drug interactions based on network similarity. BMC Bioinform. 2020, 21, 322. [Google Scholar] [CrossRef]
- Lu, L.Y.; Jin, C.H.; Zhou, T. Similarity index based on local paths for link prediction of complex networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar] [CrossRef] [Green Version]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual Web sea rch engine. Comput. Netw. Isdn Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Fouss, F.; Pirotte, A.; Renders, J.M.; Saerens, M. Random-Walk Computation of Similarities between Nodes of a Graph with Application to Collaborative Recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]
- Chen, B.; Guo, W.; Tang, R.M.; Xin, X.; Ding, Y.; He, X.Q.; Wang, D. TGCN: Tag Graph Convolutional Network for Tag-Aware Recommendation. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management, Virtual Event, Ireland, 19–23 October 2020. [Google Scholar]
- Qi, T.; Wu, F.Z.; Wu, C.H.; Huang, Y.F. Personalized News Recommendation with Knowledge-aware Interactive Matching. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021. [Google Scholar]
- Xu, Z.H.; Chen, C.; Thomas, L.; Miao, Y.S.; Meng, X.W. Tag-Aware Personalized Recommendation Using a Deep-Semantic Similarity Model with Negative Sampling. In Proceedings of the 25th ACM International Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016. [Google Scholar]
- Xu, Z.H.; Lukasiewicz, T.; Chen, C.; Miao, Y.S.; Meng, X.W. Tag-Aware Personalized Recommendation Using a Hybrid Deep Model. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Sachin, M.; Rik, K.; Mohammad, R.; Hannaneh, H. DeFINE: DEep Factorized INput Word Embeddings for Neural Sequence Modeling. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Ma, C.S.; Li, J.J.; Pan, P.; Li, G.H.; Du, J.B. BDMF: A Biased Deep Matrix Factorization Model for Recommendation. In Proceedings of the 2019 IEEE SmartWorld, Leicester, UK, 19–23 August 2019. [Google Scholar]
- Fan, J.C.; Cheng, J.Y. Matrix completion by deep matrix factorization. Neural Netw. 2018, 98, 34–41. [Google Scholar] [CrossRef]
- Zhang, C.X.; Song, D.L.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous Graph Neural Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- He, C.Y.; Xie, T.; Rong, Y.; Huang, W.B.; Li, Y.F.; Huang, J.Z.; Ren, X.; Shahabi, C. Bipartite Graph Neural Networks for Efficient Node Representation Learning. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Wu, Y.X.; Liu, H.X.; Yang, Y.M. Graph Convolutional Matrix Completion for Bipartite Edge Prediction. In Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Seville, Spain, 18–20 September 2018. [Google Scholar]
- Xu, S.Y.; Yang, C.; Shi, C.; Fang, Y.; Guo, Y.X.; Yang, T.C.; Zhang, L.H.; Hu, M.D. Topic-aware Heterogeneous Graph Neural Network for Link Prediction. In Proceedings of the 30th ACM International Conference on Information and Knowledge Management, Gold Coast, QLD, Australia, 1–5 November 2021. [Google Scholar]
- Li, X.X.; Shang, Y.M.; Cao, Y.N.; Li, Y.G.; Tan, J.L.; Liu, Y.B. Type-Aware Anchor Link Prediction across Heterogeneous Networks Based on Graph Attention Network. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Kunegis, J. Handbook of Network Analysis [KONECT—The Koblenz Network Collection]. Comput. Sci. 2014, 2, 1343–1350. [Google Scholar]
- Xue, H.J.; Dai, X.Y.; Zhang, J.B.; Huang, S.J.; Chen, J.J. Deep Matrix Factorization Models for Recommender Systems. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.H.; Chen, Y.X. Inductive Matrix Completion Based on Graph Neural Networks. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Dataset | U | V | Interaction | Description |
|---|---|---|---|---|
| CCMD | 25 | 15 | 95 | Membership information of clubs and boards |
| CLD | 20 | 24 | 99 | Person and company leadership information |
| ARD | 136 | 5 | 160 | Membership between persons and organizations |
| CD | 829 | 551 | 1476 | Relationship between suspect and crime |
| ULD | 254 | 614 | 1255 | Spoken relationship between country and language |
| Dataset | k = 1 | k = 2 | k = 3 | |||
|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| CCMD | 0.225 | 0.188 | 0.549 | 0.494 | 0.255 | 0.199 |
| CLD | 0.203 | 0.168 | 0.506 | 0.485 | 0.297 | 0.283 |
| ARD | 0.138 | 0.103 | 0.175 | 0.124 | 0.208 | 0.187 |
| CD | 0.472 | 0.448 | 0.480 | 0.458 | 0.495 | 0.483 |
| ULD | 0.286 | 0.213 | 0.587 | 0.564 | 0.322 | 0.307 |
| Method | CCMD | CLD | ARD | CD | ULD | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| DMF | 0.483 | 0.437 | 0.484 | 0.472 | 0.468 | 0.407 | 0.497 | 0.452 | 0.434 | 0.366 |
| VAE | 0.519 | 0.451 | 0.479 | 0.400 | 0.506 | 0.477 | 0.495 | 0.449 | 0.433 | 0.353 |
| DAE | 1.432 | 1.043 | 1.818 | 1.290 | 0.404 | 0.189 | 2.802 | 1.296 | 2.181 | 1.030 |
| IGMC | 0.458 | 0.451 | 0.508 | 0.503 | 0.314 | 0.295 | 0.512 | 0.498 | 0.500 | 0.478 |
| DLP | 0.225 | 0.188 | 0.203 | 0.168 | 0.138 | 0.103 | 0.472 | 0.448 | 0.286 | 0.213 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, H.; Zhang, B.; Hu, S.; Xu, Z. Deep Link-Prediction Based on the Local Structure of Bipartite Networks. Entropy 2022, 24, 610. https://doi.org/10.3390/e24050610
Lv H, Zhang B, Hu S, Xu Z. Deep Link-Prediction Based on the Local Structure of Bipartite Networks. Entropy. 2022; 24(5):610. https://doi.org/10.3390/e24050610
Chicago/Turabian StyleLv, Hehe, Bofeng Zhang, Shengxiang Hu, and Zhikang Xu. 2022. "Deep Link-Prediction Based on the Local Structure of Bipartite Networks" Entropy 24, no. 5: 610. https://doi.org/10.3390/e24050610
APA StyleLv, H., Zhang, B., Hu, S., & Xu, Z. (2022). Deep Link-Prediction Based on the Local Structure of Bipartite Networks. Entropy, 24(5), 610. https://doi.org/10.3390/e24050610