Appendix B. How Tasks and Users Are Featured in the Cost-Benefit Ratio?
This appendix is not an independent paper but supports Part II of this two-part paper by explaining how information theory can explain mathematically represent the common wisdom in visualization that visualization is user- and task-dependent. Mathematical knowledge of information theory is not a prerequisite for reading this appendix.
Whilst hardly anyone in the visualization community would support any practice intended to deceive viewers, there have been many visualization techniques that inherently cause distortion to the original data. The deformed London underground map in
Figure 1 shows such an example. The distortion in this example is largely caused by many-to-one mappings. A group of lines that would be shown in different lengths in a faithful map is now shown with the same length. Another group of lines that would be shown with different geometric shapes is now shown as the same straight line. In terms of information theory, when the faithful map is transformed to the deformed map, a good portion of information has been lost because of these many-to-one mappings.
In fact, there are many other forms of information loss. For example, when a high-resolution data variable (e.g., an integer in the range [0, 10,000]) is visually encoded as a bar in a bar chart that is restricted to a height of 1000 pixels, about every 10 values are mapped onto the same height in terms of pixels. Furthermore, it is unlikely that humans can precisely identify the height of each bar at the pixel resolution. Likely a viewer may perceive a height of 833 pixels to be the same as one with 832 pixels or 834 pixels, which is also a many-to-one mapping. When multivariate data records are encoded as glyphs, there is usually a significant amount of information loss. As we have discussed in the first part of this paper [
4], in volume visualization, when a sequence of
n voxel values are transformed to a single pixel value, as long as
n is a reasonably large value, a huge amount of information loss is almost guaranteed to happen.
Despite the ubiquitous phenomenon of information loss in visualization, it has been difficult for many of us to contemplate the idea that information loss may be a good thing. In particular, one theory based on an algebraic framework defines three principles that formalize the notion of graphical integrity to prevent such information loss [
64]. When one comes across an effective visualization but featuring noticeable information loss, the typical answer is that it is task-dependent, and the lost information is not useful to the task concerned. When a visualization is evaluated, common critiques are about information loss, such as inadequate resolution, view obstruction, distorted representation, which are also characteristics of the aforementioned glyphs, volume rendering, and deformed metro map.
The common phrase that “the appropriateness of information loss depends on tasks” is not an invalid explanation. On its own, this explanation is not adequate, because:
The appropriateness depends on many attributes of a task, such as the selection of variables in the data and their encoded visual resolution required to complete a task satisfactorily, and the time allowed to complete a task.
The appropriateness depends also on other factors in a visualization process, such as the original data resolution, the viewer’s familiarity of the data, the extra information that is not in the data but the viewer knows, and the available visualization resources.
The phrase creates a gray area as to whether information loss is allowed or not, and when or where one could violate some principles such as those principles in [
64].
Partly inspired by the above puzzling dilemma in visualization and partly by a similar conundrum in economics “what is the most appropriate resolution of time series for an economist”, Chen and Golan proposed an information-theoretic cost–benefit ratio for measuring various factors involved in visualization processes [
3]. As this cost–benefit ratio can measure some abstract characteristics of “data”, “visualization”, “information loss”, “knowledge”, and “task” using the most fundamental information-theoretic unit
bit, it provides a means to define their relationship coherently. In this appendix, we continue to use the qualitative version of this cost–benefit ratio as given in Equation (
A1) in
Appendix A, making it more accessible to readers who are not familiar with information theory.
Chen and Golan noticed that not only do visualization processes lose information but also other data intelligence processes also lose information. For example, when statistics is used to down-sample a time series, or to compute its statistical properties, there is a substantial amount of information loss; when an algorithm groups data points into clusters or sort them according to a key variable, there is information loss; and when a computer system asks a user to confirm an action, there is information loss in the computational processes [
65].
They also noticed that almost all decision tasks, the number of decision options is usually rather small. In terms of information theoretic quantities, the amount of information (i.e., in terms of Shannon entropy) associated with a decision task is usually much lower than the amount of information associated with the data entering a data intelligence workflow. They concluded that this general trend of information reduction must be a positive thing for any data intelligence workflows. They referred to the amount of information reduction as
Alphabet Compression (AC) and made it a positive contribution to the
benefit term in Equation (
A1).
Figure A1 shows an example of a simple visual analytics workflow, where at the moment, the visual analytics process is simply a visualization process, (a
), for viewing a deformed London underground map. There can be many possible visualization tasks, such as counting the number of stops between two stations, searching for a suitable interchange station, and so on. From the workflow in
Figure A1, one can easily observe that the amount of information contained in the world around the entire London underground system must be much more than the information contained in the digital data describing the system.
The latter is much more than the information depicted in the deformed map. By the time when the workflow reaches a task, the number of decision options is usually limited. For example, counting the number stops may have optional values between 0 and 50. The amount of information contained in the counting result is much smaller than that in the deformed map. This evidences the general trend observed in [
3].
Figure A1.
A visual analytics workflow features a general trend of alphabet compression from left (World) to right (Tasks). The potential distortion compares at an information space reconstructed based on the output with the original input information space. When we place different processes (i.e., (a1,a2,b–d)), in the workflow, we can appreciate that statistics, algorithms, visualization, and interaction have different levels of alphabet compression, potential distortion, and cost.
Figure A1.
A visual analytics workflow features a general trend of alphabet compression from left (World) to right (Tasks). The potential distortion compares at an information space reconstructed based on the output with the original input information space. When we place different processes (i.e., (a1,a2,b–d)), in the workflow, we can appreciate that statistics, algorithms, visualization, and interaction have different levels of alphabet compression, potential distortion, and cost.
After considering the positive contribution of information, we must counterbalance AC by the the term Potential Distortion (PD), which describes, in abstract, the negative consequences that may be caused by information loss. In the past, one typically uses a third-party metric to determine whether a chosen decision option is good or not. This introduces a dilemma that one needs a fourth-party metric to determine if the third-party metric is good or not, and this can go on forever.
At least, mathematically, this unbounded reasoning paradigm is undesirable. This third-party metric was avoided in Equation (
A1) by imagining if a viewer would have to reconstruct the original data that is visualized, how much the reconstructed data would diverge from the original data. In [
3], this divergence is measured using the well-known Kullback–Leibler divergence (KL-divergence) [
66]. As this divergence measure is unbounded, Chen and Sbert proposed to replace it with a bounded measure in the first part of thus paper [
4], where they have detailed the concerns about the unboundedness.
As shown in Equation (
A1), the AC term makes a positive contribution, the PD term makes a negative contribution, reflecting the two sides of the same coin of information loss. Both terms have the same unit
bit and are moderated by the term
Cost. The term AC characterizes many useful approaches in visualization and visual analytics, such as data filtering and visual abstraction, while the term PD characterizes many undesirable shortcomings, such as rendering errors and perceptual errors.
The term Cost encompasses all costs of the visualization process, including computational costs (e.g., visual mapping and rendering), cognitive costs (e.g., cognitive load), and consequential costs (e.g., impact of errors). The term is defined as an energy measure, but can be approximated using time, monetary, and other appropriate measures.
The cost–benefit ratio in Equation (
A1) can also be used to measure other processes in a visual analytics workflow. One can simply imagine replacing the block (a
) in
Figure A1 with one of the other four blocks on the left, (a
) for faithful visual mapping, (b) for statistics, (c) for algorithms, and (d) for interactive information retrieval. This exercise allows us to compare the relative merits among the four major components of visual analytics, i.e., statistics, algorithms, visualization, and interaction [
67].
For example, statistics may be able to deliver a set of indicators about the London underground map to a user. In comparison with the deformed map, these statistical indicators contain much less information than the map, offering more AC contribution. If a user is asked to imagine what the London underground system looks like, having these statistical indicators will not be very helpful. Hence, statistics may cause more PD.
Of course, whether to use statistics or visualization may be task-dependent. Mathematically, this is largely determined by both the PD and
Cost associated with the perception and cognition process in
Figure A1. If a user tries to answer a statistical question using the visualization, it is likely to cost more than using statistics, provided that the statistical answer has already been computed or statistical calculation can be performed easily and quickly.
Whether to use statistics or visualization may also be user-dependent. Consider a user A that has a fair amount of prior knowledge about the London underground system and another user B that has little. If both are shown some statistics about the system (e.g., the total number of stations of each line), A can redraw the deformed map more accurately than B and more accurately than without the statistics, even though the statistical information is not meant to support the users’ this task. Hence, to A, having a deformed map to help appreciate the statistics may not be necessary, while to B, viewing both statistics and the deformed map may help reduced the PD but may also incur more cost in terms of effort. Hence, visualization is more useful to B.
This example echos the scenario presented in
Figure 1, where we asked two questions: Can information theory explain this phenomenon? Can we quantitatively measure some factors in this visualization process? If prior knowledge can explain the trade-off among AC, PD, and
Cost in comparing statistics and deformed map. We can also extrapolate this reasoning to analyze the trade-off in comparing viewing the deformed map (more AC) and viewing the faithful map (less AC) as in
Figure 1. Perhaps we can now be more confident to say that information theory can explain such a phenomenon. In the main body of this second part of the paper, we demonstrate the potential answer to the second question, i.e., we can quantitatively measure some relevant factors in such a visualization process.
To some readers, it may still be counter-intuitive to consider that information loss has a positive side. It is essential for asserting why visualization is useful as well as asserting the usefulness of statistics, algorithms, and interaction since they all usually cause information loss [
47]. Further discourse on this topic can be found in
Appendix A.
Table A1.
The answers by ten surveyees to the questions in the volume visualization survey. The surveyees are ordered from left to right according to their self-ranking about the knowledge of volume visualization. In rows 1–8, the dataset used in each question is indicated in square brackets. Correct answers are indicated by letters in round brackets. The upper case letters are the most appropriate answers, while the lower case letters with brackets are acceptable answers as they are correct in some circumstances. The lower case letters without brackets are incorrect answers. In rows 9 and 10, the self-assessment scores are in the range of [1 lowest, 5 highest].
Table A1.
The answers by ten surveyees to the questions in the volume visualization survey. The surveyees are ordered from left to right according to their self-ranking about the knowledge of volume visualization. In rows 1–8, the dataset used in each question is indicated in square brackets. Correct answers are indicated by letters in round brackets. The upper case letters are the most appropriate answers, while the lower case letters with brackets are acceptable answers as they are correct in some circumstances. The lower case letters without brackets are incorrect answers. In rows 9 and 10, the self-assessment scores are in the range of [1 lowest, 5 highest].
| | Surveyee’s ID |
|---|
| Questions with (Correct Answers) and [Database] in Brackets | S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | P9 | P10 |
| 1. Use of different transfer functions (D), [Carp] | (D) | (D) | (D) | (D) | (D) | c | b | (D) | a | c |
| 2. Use of translucency in volume rendering (C), [Engine Block] | (C) | (C) | (C) | (C) | (C) | (C) | (C) | (C) | d | (C) |
| 3. Omission of voxels of soft tissue and muscle (D), [CT head] | (D) | (D) | (D) | (D) | b | b | a | (D) | a | (D) |
| 4. sharp objects in volume-rendered CT data (C), [CT head] | (C) | (C) | a | (C) | a | b | d | b | b | b |
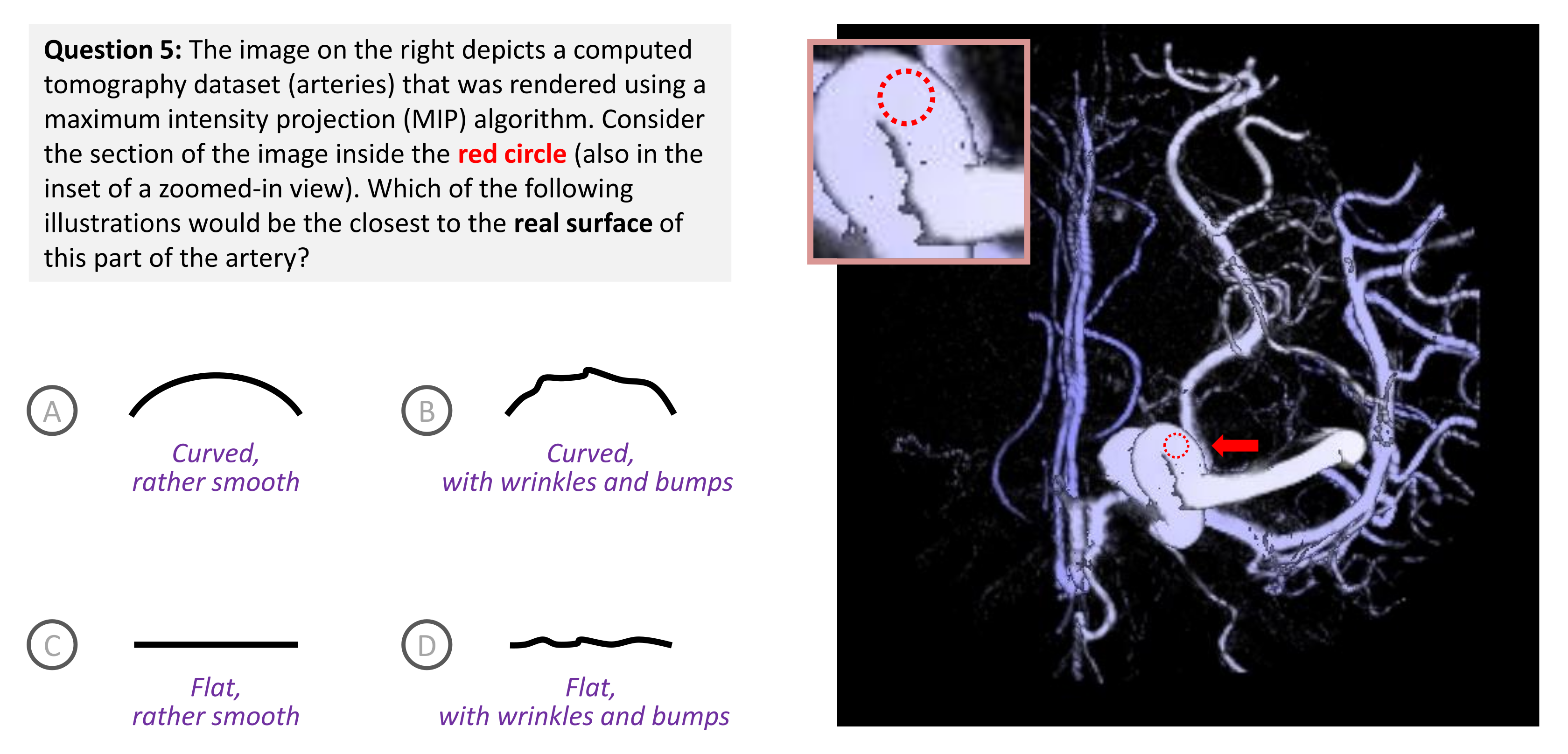
| 5. Loss of 3D information with MIP (B, a), [Aneurysm] | (a) | (B) | (a) | (a) | (a) | (a) | D | (a) | (a) | (a) |
| 6. Use of volume deformation (A), [CT head] | (A) | (A) | b | (A) | (A) | b | b | (A) | b | b |
| 7. Toenails in non-photo-realistic volume rendering (B, c), [Foot] | (c) | (c) | (c) | (B) | (c) | (B) | (B) | (B) | (B) | (c) |
| 8. Noise in non-photo-realistic volume rendering (B), [Foot] | (B) | (B) | (B) | (B) | (B) | (B) | a | (B) | c | (B) |
| 9. Knowledge about 3D medical imaging technology | 4 | 3 | 4 | 5 | 3 | 3 | 3 | 3 | 2 | 1 |
| 10. Knowledge about volume rendering techniques | 5 | 5 | 4–5 | 4 | 4 | 3 | 3 | 3 | 2 | 1 |
Table A2.
Summary statistics of the survey results in
Table A1, where we classified experts simply based on their self-assessment with an average rate (
) in answering Q9 and Q10. They are S1, S2, S3, and S4.
Table A2.
Summary statistics of the survey results in
Table A1, where we classified experts simply based on their self-assessment with an average rate (
) in answering Q9 and Q10. They are S1, S2, S3, and S4.
| | All Participants | Experts | The Rest |
|---|
| Question | A | B | C | D | A | B | C | D | A | B | C | D |
| 1. (Carp) | numbers: | 1 | 1 | 2 | 6 | 0 | 0 | 0 | 4 | 1 | 1 | 2 | 2 |
| | probability: | 0.10 | 0.10 | 0.20 | 0.60 | 0.00 | 0.00 | 0.00 | 1.00 | 0.17 | 0.17 | 0.33 | 0.33 |
| 2. (Engine Block): | numbers: | 0 | 0 | 1 | 9 | 0 | 0 | 0 | 4 | 0 | 0 | 1 | 5 |
| | probability: | 0.00 | 0.00 | 0.10 | 0.90 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.17 | 0.83 |
| 3. (CT head) | numbers: | 2 | 2 | 0 | 6 | 0 | 0 | 0 | 4 | 2 | 2 | 0 | 2 |
| | probability: | 0.20 | 0.20 | 0.00 | 0.60 | 0.0 | 0.0 | 0.0 | 1.00 | 0.33 | 0.33 | 0.00 | 0.33 |
| 4. (CT head) | numbers: | 2 | 4 | 3 | 1 | 1 | 0 | 0 3 | 0 | 1 | 4 | 0 | 1 |
| | probability: | 0.20 | 0.40 | 0.30 | 0.10 | 0.25 | 0.00 | 0.75 | 0.00 | 0.17 | 0.67 | 0.00 | 0.17 |
| 5. (Aneurism) | numbers: | 8 | 1 | 0 | 1 | 3 | 1 | 0 | 0 | 5 | 0 | 0 | 1 |
| | probability: | 0.80 | 0.10 | 0.00 | 0.10 | 0.75 | 0.25 | 0.00 | 0.00 | 0.83 | 0.00 | 0.00 | 0.17 |
| 6. (CT head) | numbers: | 5 | 5 | 0 | 0 | 3 | 1 | 0 | 0 | 2 | 4 | 0 | 0 |
| | probability: | 0.50 | 0.50 | 0.00 | 0.00 | 0.75 | 0.25 | 0.00 | 0.00 | 0.33 | 0.67 | 0.00 | 0.00 |
| 7. (Foot) | numbers: | 0 | 5 | 5 | 0 | 0 | 1 | 3 | 0 | 0 | 4 | 2 | 0 |
| | probability: | 0.00 | 0.50 | 0.50 | 0.00 | 0.00 | 0.25 | 0.75 | 0.00 | 0.00 | 0.67 | 0.33 | 0.00 |
| 8. (Foot) | numbers: | 1 | 8 | 1 | 0 | 0 | 4 | 0 | 0 | 1 | 4 | 1 | 0 |
| | probability: | 0.10 | 0.80 | 0.10 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.17 | 0.67 | 0.17 | 0.00 |
Appendix C. Survey Results of Useful Knowledge in Volume Visualization
This appendix is not an independent paper but supports Part II of this two-part paper by providing additional details about the survey on volume visualization described in
Section 6.1 in this part of the paper.
This survey consists of eight questions presented as slides. The questionnaire is given in the
Supplementary Materials. The ten surveyees were primarily colleagues from the UK, Spain, and the USA. They include doctors and experts in medical imaging and visualization, as well as several persons who are not familiar with the technologies of medical imaging and data visualization.
Table A1 summarizes the answers from these ten surveyees.
There is also a late-returned survey form that was not included in the analysis. As a record, the answers in this extra survey form are: 1: c, 2: d, 3: (D), 4: a, 5: (a), 6: (A), 7: (c), 8: (B), 9: 5, 10: 4. The upper case letters (always in brackets) are the most appropriate answers, while the lower case letters with brackets are acceptable answers as they are correct in some circumstances. The lower case letters without brackets are incorrect answers.
The following example illustrates how to estimate the benefit of visualization and knowledge impact based on the survey result of Question 5. We first define the following:
Ground truth PMF .
If one always answers A: .
If one always answers B: .
If one always answers C: .
If one always answers D: .
Survey results (all): .
Survey results (expert): .
Survey results (rest): .
We can roughly translate the survey results to the following PMFs:
Survey results (all): .
Survey results (expert): .
Survey results (rest): .
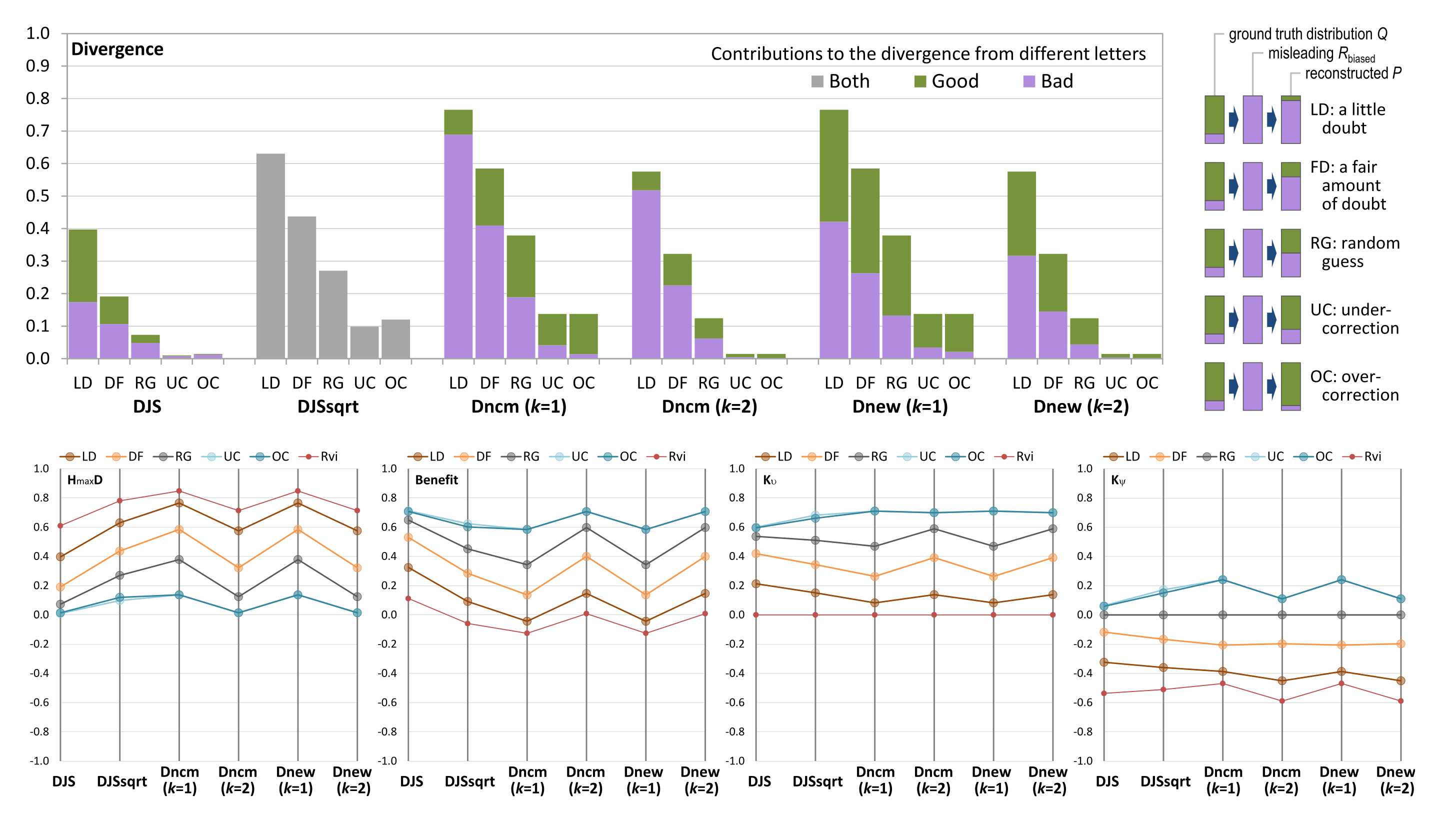
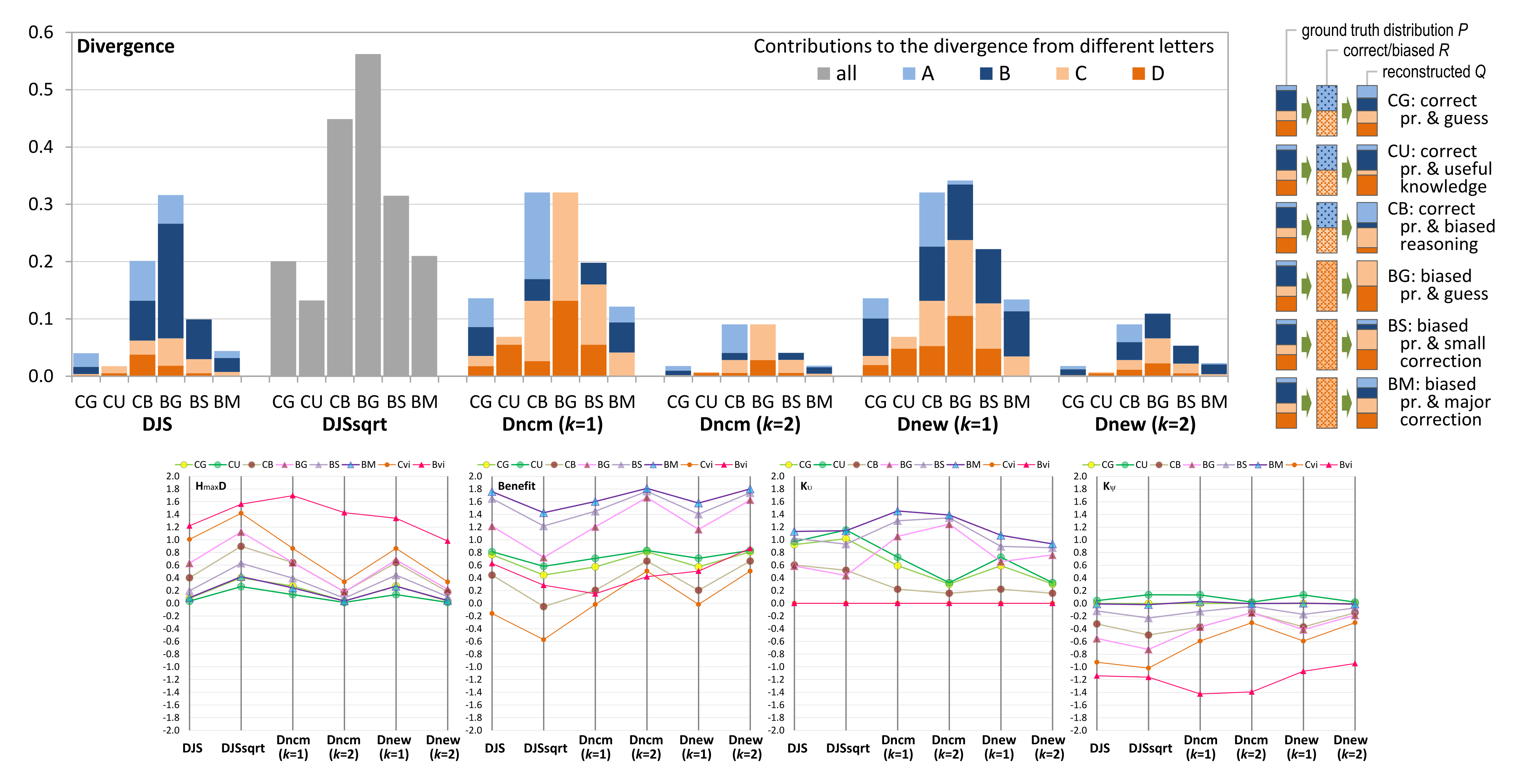
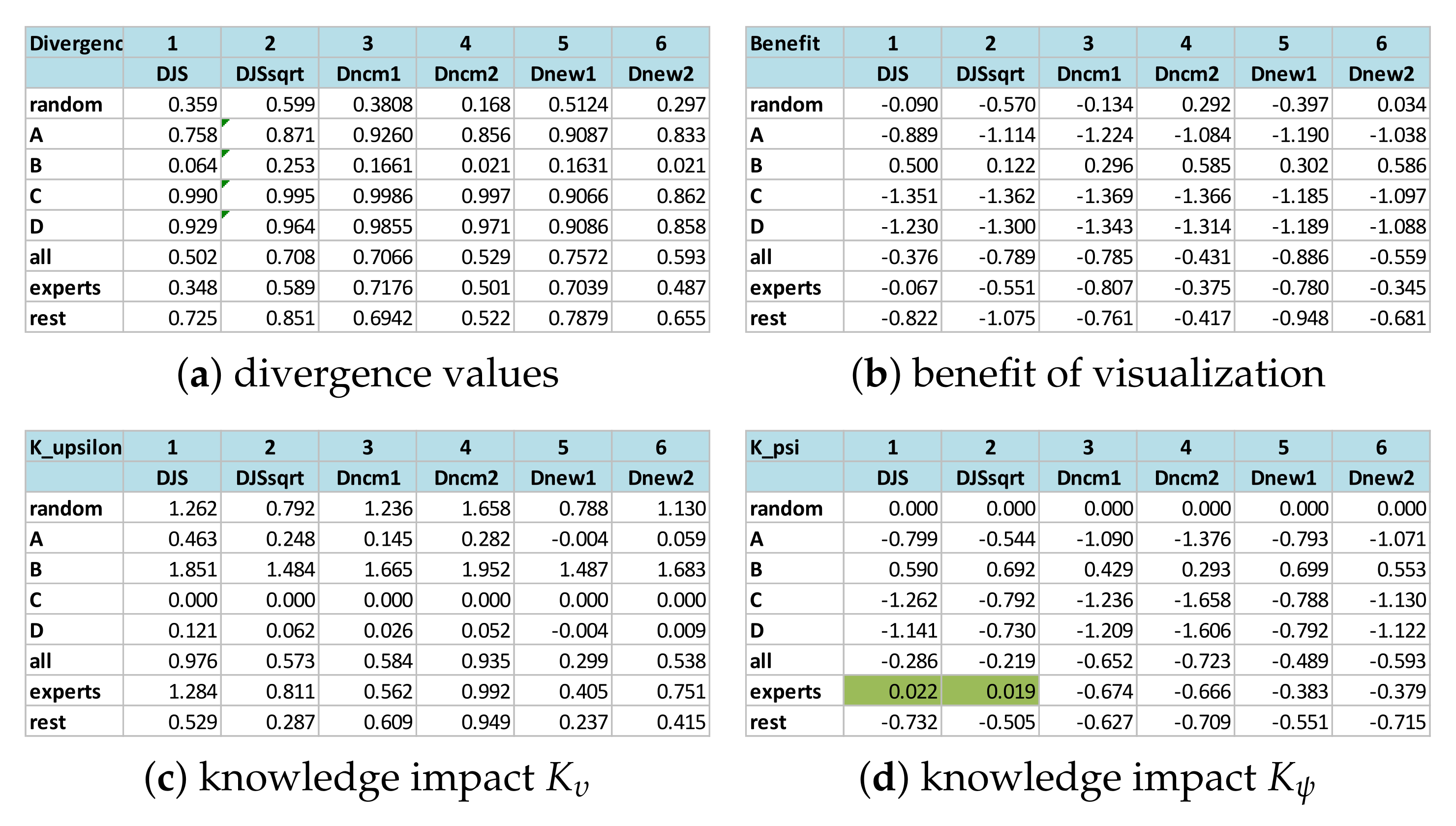
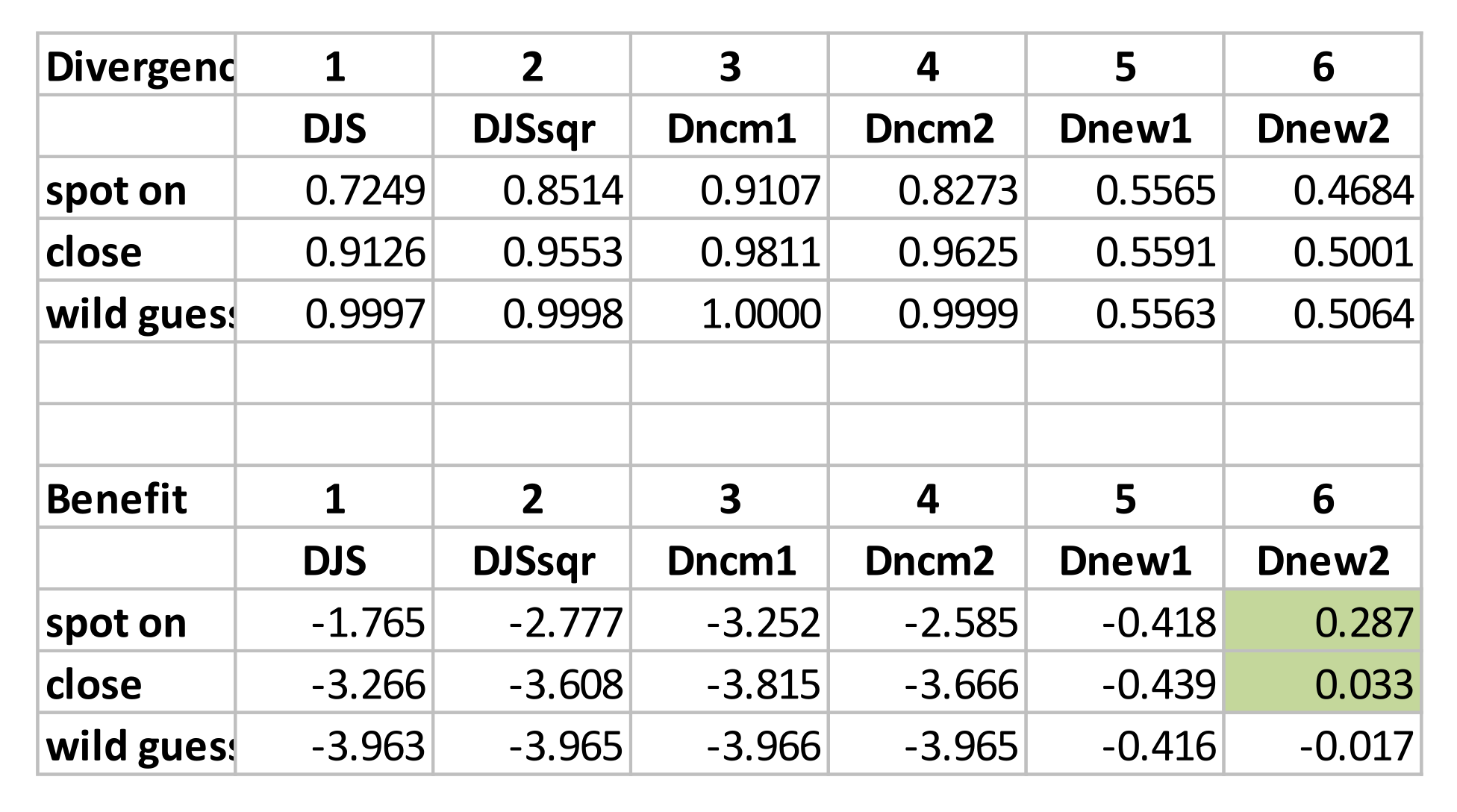
The four sets of measured values returned by different candidate measures are shown in
Figure A2, i.e., (a) divergence values, (b) benefit of visualization, (c) impact of knowledge
(against the scenario of relying on visual information only), and (d) impact of knowledge
(against the scenario of random guess). In each table, the columns labeled with 1–6 are six candidate bounded divergence measures used for estimating the values concerned in each table (i.e., divergence, benefit,
, or
).
Row “random” estimates the values for a viewer who makes random guesses. Rows “A”–“D” estimate the values for viewers for answering “A”–“D”, respectively. Row “all” estimates the values associated with all viewers as a group. Row “experts” estimates the values associated with those experts as a group, while row “rest” estimates the values associated with the non-expert group.
Figure A2.
Estimating the benefit of visualization and knowledge impact in relation to the survey result of Question 5 (
Figure 6).
Figure A2.
Estimating the benefit of visualization and knowledge impact in relation to the survey result of Question 5 (
Figure 6).
Appendix D. Survey Results of Useful Knowledge in Viewing London Underground Maps
This appendix is not an independent paper but supports Part II of this two-part paper by providing additional details about the empirical study on viewing London Underground maps described in
Section 6.2 in this part of the paper.
It is necessary to note that this empirical study is not a hypothesis-based study. We can easily anticipate that some participants can use a very small or illusive amount of information shown on a map to answer questions that seem to require some information that is not on the map. However, this study is not designed to draw a conclusion about this phenomenon, but to collect some data about the phenomenon. As such a phenomenon suggests that there is a knowledge input to the visualization process, we would like to use the collected data to evaluate a few information-theoretic measures that have been proposed for quantifying the impact of such knowledge.
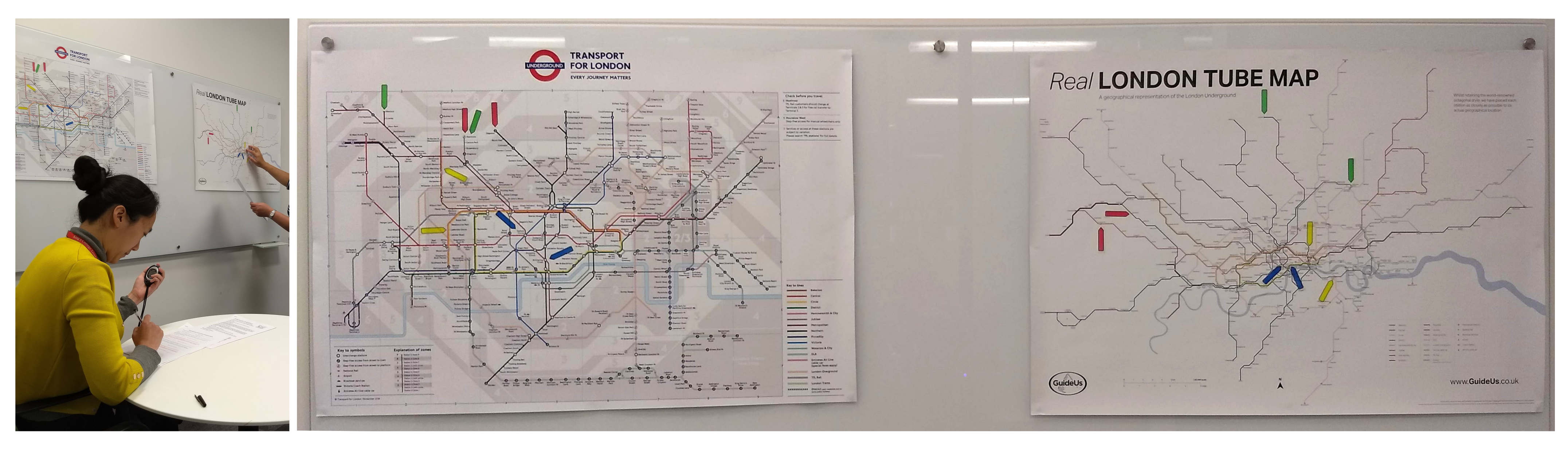
Figure A3 shows the set up for this empirical study.
Figure A3.
A survey for collecting data that reflects the use of some knowledge in viewing two types of London underground maps.
Figure A3.
A survey for collecting data that reflects the use of some knowledge in viewing two types of London underground maps.
Figure A4,
Figure A5 and
Figure A6 show the questionnaire used in the survey about two types of London Underground maps.
Table A3 summarizes the data from the answers by the 12 surveyees at King’s College London, while
Table A4 summarizes the data from the answers by the four surveyees at the University Oxford.
In
Section 6.2, we discussed Questions 1–4 in some detail. In the survey, Questions 5–8 constitute the second set. Each question asks surveyees to first identify two stations along a given underground line, and then determine how many stops between the two stations. All surveyees identified the stations correctly for all four questions, and most also counted the stops correctly. In general, for each of these cases, one can establish an alphabet of all possible answers in a way similar to the example of walking distances. However, we did not observe any interesting correlation between the correctness and the surveyees’ knowledge about metro systems or London.
With the third set of four questions, each question asks surveyees to identify the closest station for changing between two given stations on different lines. All surveyees identified the changing stations correctly for all questions.
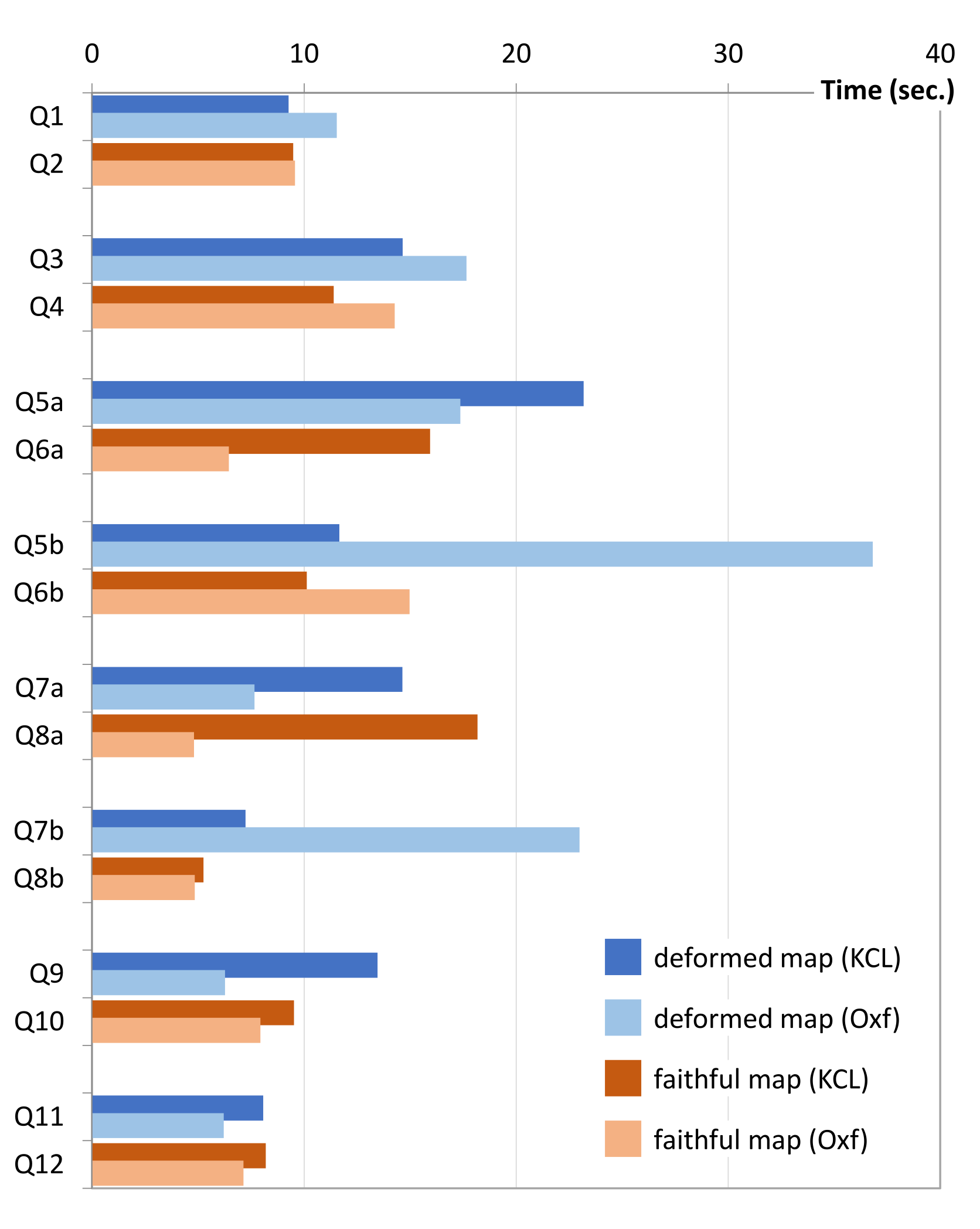
The design of Questions 5–12 was also intended to collect data that might differentiate the deformed map from the faithful map in terms of the time required for answering questions. As shown in
Figure A7, the questions were paired, such that the two questions feature the same level of difficulties.
Although the comparison seems to suggest that the faithful map might have some advantage in the setting of this survey, we cannot be certain about this observation as the sample size is not large enough. In general, we cannot draw any meaningful conclusion about the cost in terms of time. We hope to collect more real world data about the timing cost of visualization processes for making further advances in applying information theory to visualization.
The space cost is a valid consideration. While both maps have a similar size (i.e., deformed map: 850 mm × 580 mm, faithful map: 840 mm × 595 mm), their font sizes for station labels are very different. For long station names, “High Street Kensington” and “Totteridge & Whetstone”, the labels on the deformed map are of 35 mm and 37 mm in length, while those on the faithful map are of 17 mm and 18 mm long. Taking the height into account, the space used for station labels in the deformed map is about four times of that in the faithful map. In other words, if the faithful map were to display its labels with the same font size, the cost of the space would be four times of that of the deformed map.
Table A3.
The answers by twelve surveyees at King’s College London to the questions in the London underground survey.
Table A3.
The answers by twelve surveyees at King’s College London to the questions in the London underground survey.
| | Surveyee’s ID |
|---|
| Questions | | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 | P9 | P10 | P11 | P12 | Mean |
|---|
| Q1: | answer (min.) | 8 | 30 | 12 | 16 | 20 | 15 | 10 | 30 | 20 | 20 | 20 | 30 | 19.25 |
| | time (sec.) | 06.22 | 07.66 | 09.78 | 11.66 | 03.72 | 04.85 | 08.85 | 21.12 | 12.72 | 11.22 | 03.38 | 10.06 | 09.27 |
| Q2: | answer (min.) | 15 | 30 | 5 | 22 | 15 | 14 | 20 | 20 | 25 | 25 | 25 | 20 | 19.67 |
| | time (sec.) | 10.25 | 09.78 | 06.44 | 09.29 | 12.12 | 06.09 | 17.28 | 06.75 | 12.31 | 06.85 | 06.03 | 10.56 | 09.48 |
| Q3: | answer (min.) | 20 | 45 | 10 | 70 | 20 | 20 | 20 | 35 | 25 | 30 | 20 | 240 | 46.25 |
| | time (sec.) | 19.43 | 13.37 | 10.06 | 09.25 | 14.06 | 10.84 | 12.46 | 19.03 | 11.50 | 16.09 | 11.28 | 28.41 | 14.65 |
| Q4: | answer (min.) | 60 | 60 | 35 | 100 | 30 | 20 | 45 | 35 | 45 | 120 | 40 | 120 | 59.17 |
| | time (sec.) | 11.31 | 10.62 | 10.56 | 12.47 | 08.21 | 07.15 | 18.72 | 08.91 | 08.06 | 12.62 | 03.88 | 24.19 | 11.39 |
| Q5: | time 1 (sec.) | 22.15 | 01.75 | 07.25 | 03.78 | 14.25 | 37.68 | 06.63 | 13.75 | 19.41 | 06.47 | 03.41 | 34.97 | 14.29 |
| | time 2 (sec.) | 24.22 | 08.28 | 17.94 | 05.60 | 17.94 | 57.99 | 21.76 | 20.50 | 27.16 | 13.24 | 22.66 | 40.88 | 23.18 |
| | answer (10) | 10 | 10 | 10 | 9 | 10 | 10 | 10 | 10 | 9 | 10 | 10 | 10 | |
| | time (sec.) | 06.13 | 28.81 | 08.35 | 06.22 | 09.06 | 06.35 | 09.93 | 12.69 | 10.47 | 05.54 | 08.66 | 27.75 | 11.66 |
| Q6: | time 1 (sec.) | 02.43 | 08.28 | 01.97 | 08.87 | 05.06 | 02.84 | 06.97 | 10.15 | 18.10 | 21.53 | 03.00 | 07.40 | 08.05 |
| | time 2 (sec.) | 12.99 | 27.69 | 04.81 | 10.31 | 15.97 | 04.65 | 17.56 | 16.31 | 20.25 | 24.69 | 15.34 | 20.68 | 15.94 |
| | answer (9) | 9 | 10 | 9 | 9 | 4 | 9 | 9 | 9 | 8 | 9 | 9 | 9 | |
| | time (sec.) | 07.50 | 06.53 | 04.44 | 16.53 | 19.41 | 05.06 | 13.47 | 07.03 | 12.44 | 04.78 | 07.91 | 16.34 | 10.12 |
| Q7: | time 1 (sec.) | 17.37 | 08.56 | 01.34 | 03.16 | 08.12 | 01.25 | 21.75 | 15.56 | 02.81 | 07.84 | 02.22 | 46.72 | 11.39 |
| | time 2 (sec.) | 17.38 | 13.15 | 02.34 | 03.70 | 08.81 | 02.25 | 22.75 | 26.00 | 17.97 | 10.37 | 03.18 | 47.75 | 14.64 |
| | answer (7) | 7 | 7 | 7 | 7 | 6 | 7 | 7 | 7 | 6 | 7 | 7 | 7 | |
| | time (sec.) | 07.53 | 06.34 | 03.47 | 03.87 | 02.75 | 04.09 | 02.16 | 04.94 | 26.88 | 05.31 | 06.63 | 12.84 | 07.23 |
| Q8: | time 1 (sec.) | 12.00 | 08.50 | 06.09 | 02.88 | 08.62 | 14.78 | 19.12 | 08.53 | 12.50 | 10.22 | 12.50 | 20.00 | 11.31 |
| | time 2 (sec.) | 13.44 | 10.78 | 23.37 | 09.29 | 13.03 | 36.34 | 23.55 | 09.50 | 13.53 | 10.23 | 32.44 | 22.60 | 18.18 |
| | answer (6) | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | |
| | time (sec.) | 02.62 | 05.94 | 02.15 | 04.09 | 04.94 | 07.06 | 07.50 | 04.90 | 04.37 | 04.53 | 05.47 | 09.43 | 05.25 |
| Q9: | answer (P) | P | P | P | P | P | P | P | P | P | P | P | P | |
| | time (sec.) | 35.78 | 02.87 | 07.40 | 13.03 | 06.97 | 52.15 | 13.56 | 02.16 | 08.13 | 09.06 | 01.93 | 08.44 | 13.46 |
| Q10: | answer (LB) | LB | LB | LB | LB | LB | LB | LB | LB | LB | LB | LB | LB | |
| | time (sec.) | 05.50 | 03.13 | 12.04 | 14.97 | 07.00 | 26.38 | 11.31 | 03.38 | 06.75 | 07.47 | 06.50 | 09.82 | 09.52 |
| Q11: | answer (WP) | WP | WP | WP | WP | WP | WP | WP | WP | WP | WP | WP | WP | |
| | time (sec.) | 06.07 | 05.35 | 07.72 | 05.00 | 04.32 | 23.72 | 05.25 | 03.07 | 10.66 | 05.37 | 02.94 | 17.37 | 08.07 |
| Q12: | answer (FP) | FP | FP | FP | FP | FP | FP | FP | FP | FP | FP | FP | FP | |
| | time (sec.) | 05.16 | 02.56 | 11.78 | 08.62 | 03.60 | 19.72 | 11.28 | 03.94 | 20.72 | 01.56 | 02.50 | 06.84 | 08.19 |
| live in metro city | >5 yr | >5 yr | mths | 1–5 yr | >5 yr | 1–5 yr | weeks | >5 yr | 1–5 yr | >5 yr | mths | mths | |
| live in London | >5 yr | >5 yr | mths | 1–5 yr | 1–5 yr | mths | mths | mths | mths | mths | mths | mths | |
Figure A4.
London underground survey: question sheet 1 (out of 3).
Figure A4.
London underground survey: question sheet 1 (out of 3).
Figure A5.
London underground survey: question sheet 2 (out of 3).
Figure A5.
London underground survey: question sheet 2 (out of 3).
Figure A6.
London underground survey: question sheet 3 (out of 3).
Figure A6.
London underground survey: question sheet 3 (out of 3).
Table A4.
The answers by four surveyees at the University of Oxford to the questions in the London underground survey.
Table A4.
The answers by four surveyees at the University of Oxford to the questions in the London underground survey.
| | Surveyee’s ID |
|---|
| Questions | | P13 | P14 | P15 | P16 | Mean |
|---|
| Q1: | answer (min.) | 15 | 20 | 15 | 15 | 16.25 |
| | time (sec.) | 11.81 | 18.52 | 08.18 | 07.63 | 11.52 |
| Q2: | answer (min.) | 5 | 5 | 15 | 15 | 10.00 |
| | time (sec.) | 11.10 | 02.46 | 13.77 | 10.94 | 09.57 |
| Q3: | answer (min.) | 35 | 60 | 30 | 25 | 37.50 |
| | time (sec.) | 21.91 | 16.11 | 10.08 | 22.53 | 17.66 |
| Q4: | answer (min.) | 20 | 30 | 60 | 25 | 33.75 |
| | time (sec.) | 13.28 | 16.21 | 08.71 | 18.87 | 14.27 |
| Q5: | time 1 (sec.) | 17.72 | 07.35 | 17.22 | 09.25 | 12.89 |
| | time 2 (sec.) | 21.06 | 17.00 | 19.04 | 12.37 | 17.37 |
| | answer (10) | 10 | 8 | 10 | 10 | |
| | time (sec.) | 04.82 | 02.45 | 02.96 | 15.57 | 06.45 |
| Q6: | time 1 (sec.) | 35.04 | 38.12 | 11.29 | 07.55 | 23.00 |
| | time 2 (sec.) | 45.60 | 41.32 | 20.23 | 40.12 | 36.82 |
| | answer (9) | 9 | 10 | 9 | 8 | |
| | time (sec.) | 03.82 | 13.57 | 08.15 | 34.32 | 14.97 |
| Q7: | time 1 (sec.) | 01.05 | 02.39 | 09.55 | 11.19 | 06.05 |
| | time 2 (sec.) | 02.15 | 05.45 | 09.58 | 13.47 | 07.66 |
| | answer (7) | 10 | 6 | 7 | 7 | |
| | time (sec.) | 01.06 | 01.60 | 02.51 | 14.06 | 04.81 |
| Q8: | time 1 (sec.) | 08.74 | 26.14 | 20.37 | 15.01 | 17.57 |
| | time 2 (sec.) | 16.50 | 30.55 | 27.01 | 17.91 | 22.99 |
| | answer (6) | 6 | 6 | 6 | 6 | |
| | time (sec.) | 09.30 | 03.00 | 02.11 | 04.94 | 04.48 |
| Q9: | answer (P) | P | P | P | P | |
| | time (sec.) | 05.96 | 09.38 | 04.56 | 05.16 | 06.27 |
| Q10: | answer (LB) | LB | LB | LB | LB | |
| | time (sec.) | 12.74 | 07.77 | 01.30 | 09.94 | 07.94 |
| Q11: | answer (WP) | WP | WP | WP | WP | |
| | time (sec.) | 09.84 | 04.43 | 03.39 | 07.18 | 06.21 |
| Q12: | answer (FP) | FP | FP | FP | FP | |
| | time (sec.) | 06.22 | 10.46 | 06.78 | 05.10 | 07.14 |
| live in metro city | never | days | days | days | |
| live in London | never | days | days | days | |
Figure A7.
The average time used by surveyees for answering each of the 12 questions. The data does not indicate any significant advantage of using the geographically-deformed map.
Figure A7.
The average time used by surveyees for answering each of the 12 questions. The data does not indicate any significant advantage of using the geographically-deformed map.
Figure A8.
The original table of numerical values for the text in the main paper.
Figure A8.
The original table of numerical values for the text in the main paper.
Figure A9.
The PCPs of the data in
Figure A8.
Figure A9.
The PCPs of the data in
Figure A8.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














