Abstract
Mobile edge computing (MEC) focuses on transferring computing resources close to the user’s device, and it provides high-performance and low-delay services for mobile devices. It is an effective method to deal with computationally intensive and delay-sensitive tasks. Given the large number of underutilized computing resources for mobile devices in urban areas, leveraging these underutilized resources offers tremendous opportunities and value. Considering the spatiotemporal dynamics of user devices, the uncertainty of rich computing resources and the state of network channels in the MEC system, computing resource allocation in mobile devices with idle computing resources will affect the response time of task requesting. To solve these problems, this paper considers the case in which a mobile device can learn from a neighboring IoT device when offloading a computing request. On this basis, a novel self-adaptive learning of task offloading algorithm (SAda) is designed to minimize the average offloading delay in the MEC system. SAda adopts a distributed working mode and has a perception function to adapt to the dynamic environment in reality; it does not require frequent access to equipment information. Extensive simulations demonstrate that SAda achieves preferable latency performance and low learning error compared to the existing upper bound algorithms.
1. Introduction
Since the birth of cloud computing, it has changed the methods of data acquisition, storage and processing to a large extent. It involves the integration and utilization of the Internet, mobile network and cable TV network technology, making it a highly integrated network. There are also many emerging businesses, such as video conferencing, telemedicine, online games, cloud storage, financial cloud services, etc. However, due to the high complexity, high data intensity and delay sensitivity of these applications, they are limited by the device computing resources and cost. Offloading computing task requirements to the traditional cloud is one solution, but the traditional cloud is typically far away from the application, which creates a new problem—increased latency. It has been found that if some of the requests with low computational requirements and small data volume are not sent to the cloud, but processed by the server close to the data requirements, the transmission path of the request tasks will be greatly reduced. Involving the placement of small servers at the edge of the cellular network, a new distributed architecture known as mobile edge computing (MEC) has been proposed by the European Telecommunication Standard Institute (ETSI) [1]. In the MEC architecture, distributed mobile edge servers called cloudlets are deployed at the edge of wireless network to provide computing resources and storage with high bandwidth and low delay [2].
Simply offloading tasks to the cloudlets is insufficient to reduce the response latency. When cloudlets are overloaded, a large number of tasks cannot be processed in a timely manner due to limited computing resources, resulting in non-negligible computing delays. Due to the spatiotemporal dynamics of user devices, the appearance time of each user device in the communication range is random, which means that the cloudlet is not available for user devices that are not within the communication range. Meanwhile, many user devices are idle at most times, while some user devices are slow to respond to tasks due to the shortage of computing resources. Reasonable recycling of the idle computing resources of user devices and cloudlets can greatly improve the utilization of user equipment and provide a faster service response for users.
In this paper, our main contributions are as follows:
- (1)
- We propose a self-adaptive learning of task offloading algorithm (SAda) to guide task offload and minimize task delay. The operation of the SAda algorithm is distributed and can improve the offloading performance by learning from the previous offloading experience.
- (2)
- Considering the spatiotemporal dynamics of the user’s device, the perceptual function is also integrated into the algorithm. The user devices that require the task processing service are called the task user equipment (TUE), and the user device that can serve the TUE for the task processing is the service user equipment (SUE). The TUE can sense the position and working state of the SUE when task processing is needed, and the computation task can be reasonably assigned to a suitable SUE, which can obtain the optimal task assignment scheme and the minimum delay.
- (3)
- A learning method during offloading tasks is introduced. With no need to obtain the exact transfer rate and CPU resources, TUEs can observe and learn during offloading computing tasks and can select candidate SUEs based on past offloading experience. In order to prove the performance of SAda, the learning errors of SAda are evaluated with three existing algorithms, which represents the difference between the delay of offloading one bit of the task during the learning process and the optimal bit offloading delay. On this basis, we carry out extensive simulations that show that the proposed method achieves good learning performance and can improve the task processing delay.
2. Related Works
Computing resources are moved from a remote cloud to the cloudlets, which are close to the mobile device in the MEC system. In order to improve the user experience and reduce latency, Xu et al. [3] proposed an enhanced service framework based on microservice management and a client support provider for efficient user experiments in the edge computing environment, in order to provide the edge computing service and management in the network edge. Wang et al. [4] proposed an optimization strategy for computing resource allocation in massive IoT devices considering privacy protection in a cloud edge computing environment. Since quality of service (QoS) can be affected by the choice of fog nodes and wireless transmission, Zhao et al. [5] proposed a novel data analytics framework for edge computing. The framework is based on a new decentralized algorithm, which enables all the nodes to obtain the global optimal model without sharing raw data. Liu et al. [6] attempt to keep the data of edge devices and end users in their local storage in order to eliminate any risk to user privacy, and they integrate federated learning and edge computing to propose a privacy-preserving framework that can construct a unified deep learning model across multiple users or devices without uploading their data to a centralized server. To prevent poor QoS in edge computing, Deng et al. [7] introduced a strategy with two stages during burst load evacuation. Based on an optimal routing search at the dispatching stage, tasks will be migrated from the server in which the burst load occurs to other servers as soon as possible. Guo et al. [8] proposed the mobile-assisted edge computing framework to improve the QoS of fixed edge nodes by exploiting mobile edge nodes. They devised a Credible, Reciprocal and Incentive (CRI) auction mechanism to stimulate mobile edge nodes to participate in the services for user requests. Tang et al. [9] considered a probabilistic-QoS-aware approach to multi-workflow scheduling upon edge servers and resources. It leverages a probability mass function-based QoS aggregation model and a discrete firefly algorithm to generate the multi-workflow scheduling plans.
Joint power consumption and resource management schemes have been considered to maximize overall task offload rates and long-term network stability. Yang et al. [10] comprehensively considered cloudlet placement and workload scheduling in MEC systems and forecast the future distribution of user tasks by observing user mobility habits, and service access patterns, service placement and online load scheduling can be adjusted to achieve a tradeoff between the average response time of a user request and the mobile operator costs. Ren et al. [11] analyzed the computational allocation problem in a layered network architecture, in which tasks were first received by the nearby micro-BSs and then transmitted to the macro-BS attached with MEC server after aggregation. Zheng et al. [12] have considered the variability of available resources, and the award and cost of a vehicular cloud computing (VCC) system, and proposed an optimal computing resource allocation scheme that aims to maximize the total long-term system reward. Guo et al. [13] proposed a method that was studied in a small cellular network through joint optimization of the computing offloading decision, spectrum, power consumption and computing resource allocation. Liu et al. [14] considered a method to allocate user requests in the signal coverage area of edge servers. Mazza et al. [15] developed a cluster-based computing offloading technology that aimed to minimize the cost function by integrating the balance relationship between energy consumption and task processing time.
In order to balance the workload between edge servers and minimize the access delay between users and edge servers, Jiang et al. [16] proposed an edge computing node deployment method for smart manufacturing; by comprehensively balancing the network delay and computing resources, the optimal deployment number of edge computing nodes is obtained by using an improved k-means clustering algorithm. Steffenel et al. [17] considered unbalanced networks and resource heterogeneity when optimizing data transfer and applications’ performance in the edge. They explored these two concerns through a comprehensive set of benchmarks and illustrated their importance with the help of data locality and context awareness. Xiao et al. [18] considered the multi-user and multi-server MEC system and solved it through matching theory and heuristic ideas. Mukherjee et al. [19] proposed an optimal cloudlet selection strategy under the multi-cloud environment. Chen et al. [20] have analyzed and discussed the offloading problem of multi-user computing in an MEC system. Hao et al. [21] proposed an optimal IoT service offloading (OSO) method with uncertainty that considers completion time and load balance variance optimization goals for developing offloading strategies; then, the non-dominated sorting genetic algorithm-II (NSGA-II) was fully investigated to improve the performance regarding the completion time and load balance variance. However, these existing efforts only considered the situation involving cloudlet systems with continuous connectivity, and they did not take into account the impact of mobility due to offload failure.
In order to improve the service reliability of MEC, task replication technology was introduced by Jiang et al. [22], where copies of tasks can be offloaded to multiple mobile devices for simultaneous processing. However, centralized frameworks require frequent updates of state information to optimize system performance, resulting in high signal overhead, which is a key drawback. Considering the spatiotemporal dynamics of the user devices and the signaling overhead, it is feasible for the task generator to make the task offload decision in a distributed way. Furthermore, it would be significant to design a workload offloading scheme with low computational complexity when the occurrence rate of devices is at a peak. Based on the limited processing capacity of edge nodes, a new edge computing offloading strategy has been designed to optimize the offloading experience learning performance of IoT devices. Li et al. [23] introduced a learning method to achieve high-performance workload allocation in the edge computing environment. Sun et al. [24] considered the situation of offloading computing tasks in the VEC system, in which the vehicle could learn the offloading delay experience of its neighboring vehicles when offloading computing tasks, so as to reduce the delay. However, the influence of different user devices’ moving speeds on the whole learning process and offloading process was not taken into account.
3. System Model and Problem Formulation
3.1. System Model
The devices that generate the task request are called the user equipment (UE). When there are surplus computing resources on adjacent user devices, a UE task request is offloaded to the standby server considering maximized resource utilization.
The task offloading mechanism in the MEC system is mainly divided into the following two types [24]:
UE–UE offloading: The user devices involved in UE–UE offloading in the MEC system are divided into two categories. The TUEs are the user devices that currently produce task requests, and the SUEs are the user devices that can provide enough surplus computing resources. The functionality of each user device depends on the adequacy of its computing resources and changes over time. The TUEs can offload tasks to nearby SUEs. Each TUE may have several candidate SUEs to handle tasks, and each task can only be offloaded to a single SUE and executed. A task offloading model is shown in Figure 1: there are four candidate SUEs (SUE 1–4) for TUE1, and the current tasks are offloaded to SUE 4 because of the distance between them and the sufficient computing resources of SUE 4.
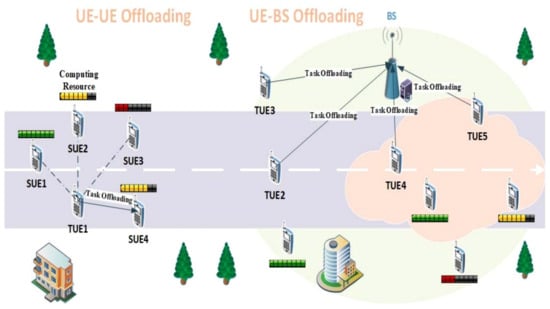
Figure 1.
A task offloading model in MEC system.
UE–BS offloading: When there are no suitable SUEs for the TUE within the communication range, or the cloudlets that are attached to the base stations (BSs) are closer to the TUEs in the communication range, TUEs will directly offload the tasks to the BSs with cloudlets for processing. As shown in Figure 1, TUE 2 and TUE 3 offload the tasks to the cloudlet as SUE, TUE 4 and TUE 5 are unsuitable for offloading tasks to the cloudlet due to distance issues.
In addition, each TUE can determine the optimal SUE independently, without internal collaboration between TUEs. We do not make any assumptions about an SUE’s conditions of service and UE mobility models. All the variables used in this paper are shown in Table 1.

Table 1.
List of symbols.
3.2. Problem Formulation
Task offloading decision: Since the offload decision is distributed, we focus on the offload problem of the TUE model. An MEC system has three task procedures in each period, namely SUE perception, task offloading and task processing.
SUE perception: TUE selects as SUEs those UEs within its communication range that are adjacent and have the same movement direction as SUEs. The real-time status of each UE, including movement speed, position and direction of movement, can be obtained through the communication protocol. For instance, in the dedicated short-range communication (DSRC) standard [25], periodic beaconing messages can provide these status messages. This is used to represent the set of candidate SUEs within a time period T, which may change as the user’s device moves.
Given the uncertainty of each user’s device mobility, the candidate SUE set is unknown for the next time period. In addition, assuming that , the TUE can offload task requests to the edge cloud for processing.
Task offloading: After updating the candidate SUE set in each new time period, TUE selects an SUE and offloads its computing task. Assume that ( bits) represents the data size generated by the task transferred from TUE to SUE in time period , represents the wireless channel status of the uplink between TUE and SUE, and represents the interference of SUE n. During the offload process of each computing task, the state of the wireless channel is kept static. We assume that transmission power is . and represent the channel bandwidth and noise power, respectively; according to Shannon Hartley’s theorem, the uplink transmission rate of TUE and SUE can be expressed as:
The transmission delay of offloading tasks to SEU n at time t is expressed as:
Task processing: Task processing begins after the selected SUE receives the task from TUE. In time period T, the total workload generated by tasks offloading is , where represents the computational intensity that the CPU cycle requires to process one bit of input data—it depends mainly on the nature of the application.
The maximum CPU resource within each computing cycle represents the computing power of SUE n, and is the CPU resource allocated to TUE at time t. SUE can process multiple computing tasks in parallel and dynamically adjust the CPU resource using dynamic voltage and frequency scaling (DVFS) technology [26].
Assuming that each computation task can be completed within a specific time period and every time slot of T is equal, the tasks with a larger workload can be divided into several sub-tasks, which are offloaded to the SUE n for a period of time and further processed. Then, the computing delay can be expressed as:
which can be written as:
After the task processing is complete, the selected SUE n sends the result back to the TUE. Due to the very small amount of result data, the delay of result return is not taken into account here.
Then, at time t, when offloading tasks to SEU n, the total delay is:
Our goal is to minimize the total offload delay by guiding the decisions of TUEs and maximize the computation resources of SUE. In each time slot of time period T, the workload offloading problem is formulated as follows:
Here, is an optimization variable, indicating that SUE’s index is selected in time period t.
Acquire state information: The device state information on the TUE side and the SUE side is obtained, including the data size of input data generated by each task , and the computational intensity . The uplink transmission rate is , and represents the CPU resource assigned to each task calculation. The total delay can be calculated assuming that all of these states are fully known before each task is offloaded, and the optimization problem P1 above can be expressed as:
However, due to the temporal and spatial dynamics of user devices, data transmission rates change rapidly and are difficult to predict. Meanwhile, the exchange of the status information between the TUE and candidate SUEs results in signaling overhead, which is high. As a result, the TUE may lack information about the status of the SUE and may not be able to provide minimum latency for manufacturing decisions on its own.
Learning while offloading: To solve the above-mentioned problems, a learning method during offloading is introduced. TUE can observe and learn during offloading computing tasks and select candidate SUEs based on past offloading experience, with no need to obtain the exact transfer rate and CPU resource. When generating tasks through the same type of application, let the input data size be time-varying, and the computational intensity is constant. Assuming that is the maximum allowable computation delay for task requests of TUE and is the maximum computation capacity of SUE n, which represents the size of task data that SUE n can simultaneously process at time t, each task request can only be offloaded into one SUE. Then, the total delay can be written as:
Then, we have:
Constraint (10) indicates that the task assigned to SUE at time t cannot exceed its computational capacity. Constraint (11) ensures that the total computation delay of the entire iteration cycle is less than the maximum allowable computation delay. Constraint (12) means that each TUE selects an SUE. The average task arrival rate for SUE cannot be greater than its average service rate, as shown in constraint (13); otherwise, the offloading request will accumulate indefinitely.
The decision problem P3 can be transformed into a partition problem, which is known as an NP-complete problem. Since the decision problem for P3 is NP-complete, P3 is NP-hard [27].
3.3. The SAda Algorithm
The task offloading problem P3 can be solved according to Multi-Armed Bandit (MAB) [28] theory, which requires online sequential decision making. The TUE is the decision maker of task offloading, and it requires constant learning to estimate losses in order to minimize the sum of cumulative losses. Based on the problem, we propose a self-adaptive learning task offloading algorithm (SAda) for MEC systems, which can sense both the size of the input data and the occurrence of the user’s device and enables TUE to learn from the offloading experience of the candidate SUE.
In Algorithm 1, the parameter is constant,, and denotes the count of tasks offloaded into SUE n at time t. represents the occurrence time of SUE n; Lines 7–14 are the main cycle of the learning process, which is inspired by the Upper-Confidence-Bound (UCB) algorithm [29] and MAB mentioned above. At the beginning of each iteration, before offload tasks and calculation , the TUE obtains the input data size .
| Algorithm 1: The SAda Algorithm. | |
| 1: | Initialization Parameter: and |
| 2: | for t in T do |
| 3: | Get the location of IoT devices and select the suitable devices as the candidates, update . |
| 4: | if none of SUE has connected to TUE then |
| 5: | Connect to SUE n once. |
| 6: | Update . |
| 7: | else |
| 8: | Observe . |
| 9: | for each device do |
| 10: | Calculate the efficiency function . |
| 11: | Find device ,where . |
| 12: | Update . |
| 13: | Update |
| 14: | Update |
| 15: | end for |
| 16: | end if |
| 17: | end for |
The padding function defined in Equation (15) is used to evaluate the service capacity of each SUE, which is derived from the empirical bit offloading delay . Specifically, it takes into account both the input data size and the time of occurrence of each SUE. Given the limited computing resources of users’ devices, it is necessary to balance SUE exploration and task processing in the process of offloading task learning. Reasonable allocation of computing resources can ensure that they both obtain the best improvement under the limited computing resources and also adapt to the dynamic MEC environment.
The SAda algorithm has the following two prominent advantages:
Service capacity assessment: The algorithm can estimate the possible delay impact of offloading the task to the SUE by combining the size of the input data with the remaining computational resources of the SUE. The input data size can affect the computation latency of different SUEs.
Occurrence awareness: Considering the temporal and spatial dynamics of an SUE, a solution is set for it. Specifically, for any SUE that is detected for the first time, is inversely proportional to . Smaller padding functions mean that SAda takes advantage of more learning information.
The whole task processing time is defined as T, and there are C epochs in time T, . The unit learning error e represents the difference in the delay of offloading one bit of the task during the learning process. represents the optimal bit offloading delay in each epoch. Then, the learning error in the whole learning process can be expressed as:
Lemma 1.
After a finite number of iterations, the SAda algorithm will terminate after completing the flexible assignment of tasks.
Proof.
Let Initially, represents the set of SUEs that have not been assigned tasks. Then, the algorithm selects the appropriate SUE for each iteration with minimum bit delay and offloads the task on the TUE to it. With the execution of the algorithm, decreases gradually and finally approaches zero; after a finite number of iterations. □
As shown in the SAda algorithm, the complexity of calculating the efficiency function is in Line 8; the minimum seeking problem in Line 10 has a complexity of . is the complexity of Line 12–13. Therefore, the total algorithm complexity in each time period is . Assuming that the number of task requests is during the entire offloading process in the MEC system, the total algorithm complexity is which is relatively lower than the existing algorithm.
Lemma 2.
When each TUE finds a suitable SUE, X is determined and P3 becomes a convex optimization problem.
Proof.
To prove the problem, let , and take the second derivative with respect to ; then, we have . The function is convex because of the positive definite Hesse matrix . □
By solving the KKT condition of P3 [30], the optimal solution of P3 can be acquired as a convex problem. As a result, the optimal task offloading scheme with TUE to SUE obtains the optimal solution with the lowest response time.
4. Simulations and Discussion
In this section, the average delay performance of user devices is evaluated under different moving speeds of the proposed SAda algorithm and implemented algorithm simulations. The influence of key parameter changes on the time delay in the composite scene is evaluated to simulate the real street scene. The parameters used in this simulation are shown in Table 2. The Wi-Fi transmission, which can access wireless signals at any time and has strong mobility, is considered as the main transmission technology in this paper.
Table 2.
Parameters used in the simulation.
The simulation environment consists of 10 SUEs and 1 TUE. A 12 km segment of road in Beijing is downloaded from Open Street Map and used in our simulations. SUEs are randomly distributed around the TUE and move in the same direction [24]. The emergence and leaving time of SUEs are shown in Table 3. In the time periods, the whole iteration cycle is divided into three periods and each epoch lasts 1000 time periods. The communication ranges of the TUE and SUEs are set to , channel bandwidth . According to the inverse power law , the wireless channel state is modeled with , and is the distance between TUE and SUE [31]. The computational intensity represents the CPU cycles required to process one bit of input data, and it mainly depends on the nature of the application. The input data size is generated uniformly between , and the transmission power W, which mainly depends on the transmission distance . According to the Shannon–Hartley theorem, the noise power W.
Table 3.
SUE discovery and disappearance epochs.
To evaluate the performance of the proposed algorithm, SAda, we compare it with three existing algorithms. (1) The Upper-Confidence-Bound (UCB) algorithm [29] is neither occurrence awareness nor input data size sensing. (2) The volatile UCB (VUCB) algorithm [32] can sense an SUE’s presence. (3) The adaptive UCB (AdaUCB) algorithm [33] has the ability to sense the size of input data.
Considering the spatiotemporal dynamics of the TUE, we simulate it at low speed, high speed and random speed. As shown in Figure 2, TUEs with a faster moving speed of are considered as the experimental object. In the first epoch, UCB and VUCB have the same approach rate, and the optimal average delay is higher. SAda and AdaUCB have a lower delay and approach rate than UCB and VUCB. Further, SAda has the minimum average delay and optimal delay approach rate. During the second period, due to the emergence of more SUEs in the system, the task requirements of TUE can be processed more fully and quickly, so that the optimal delay is reduced. With the departure of SUEs, the system’s task processing delay increases. SAda also has the lowest approach rate and the fastest optimal delay approach rate compared to the other algorithms in the third epoch. It is obvious that, throughout all the epochs, SAda has the optimal delay and approach rate.
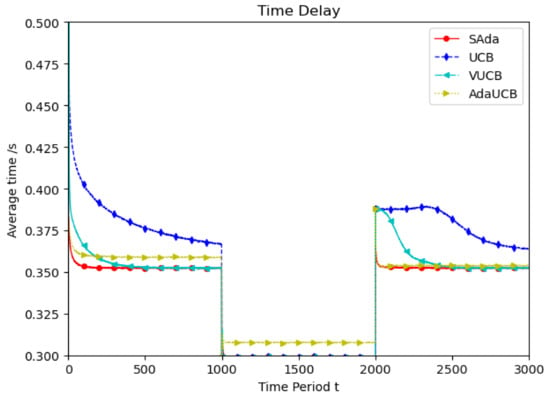
Figure 2.
Average delay comparison between SAda and three other existing algorithms at TUE speeds of 60 km/h.
Figure 3 shows the simulation of user devices with lower mobile speeds, which considers the mobility characteristic of user devices in the real world. Throughout the entire period, compared with the other three algorithms, SAda has a faster optimal delay convergence speed and optimal average delay when the speed of TUEs is 10 km/h. Compared with the VUCB and AdaUCB algorithms, SAda can improve the convergence of optimal delay by 80% to 95%. In order to adapt to the real environment, the simulation is performed at random speed and the result is shown in Figure 4. As mobile devices move at a variety of speeds, SAda still has the best optimal delay convergence rate, response delay and a significant performance improvement. Because SAda has both the input perception and consciousness perception function, it can find SUEs for TUE more quickly and select an appropriate SUE for task offloading.
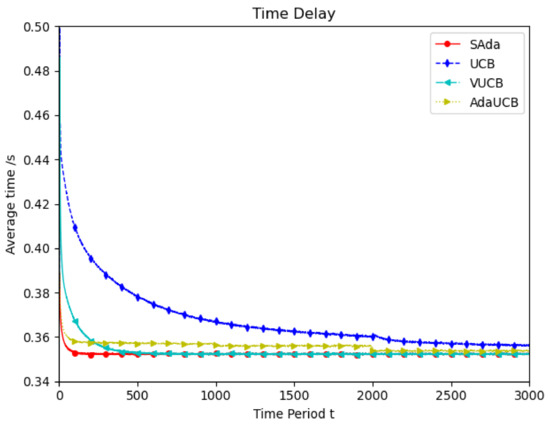
Figure 3.
Average delay comparison between SAda and three other existing algorithms at TUE speeds of 10 km/h.
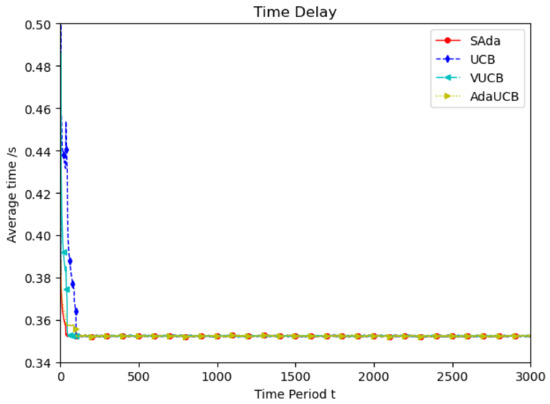
Figure 4.
Average delay comparison between SAda and three other existing algorithms at random TUE speed.
Figure 5 evaluates the learning errors of the three algorithms. The SAda algorithm has the lowest learning error in the whole period, and the learning error during the process of task offloading can be increased by around 20%, 70% and 75%, respectively, compared with the three existing algorithms. The learning errors of VUCB and AdaUCB are smaller than that of UCB, which indicates that input perception and consciousness perception enhance the adaptability of the MEC system, and considering both can further improve the performance of the system. Through extensive simulation, it is proven that SAda has lower task processing delay and learning error, with better performance when compared with the other three algorithms.
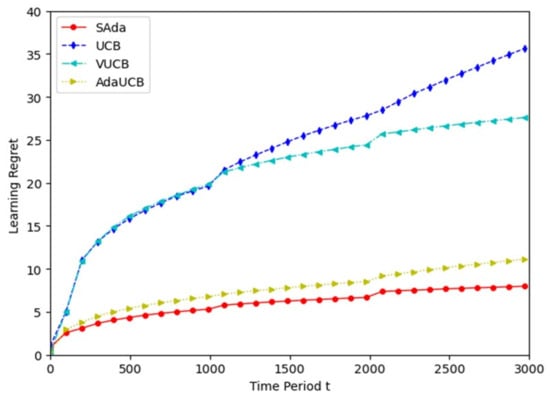
Figure 5.
Comparison diagram of algorithm learning error.
5. Conclusions
In this paper, we have investigated the problem of offload allocation in MEC systems, and a novel self-adaptive learning task offloading algorithm, SAda, for MEC systems is proposed to minimize the task processing delays while considering the spatiotemporal dynamics of mobile devices. On the basis of the original MAB algorithm, the perception function and the offloading learning mechanism have been considered to improve the speed of the task transmission processing. Through extensive simulation, it is proven that SAda has a lower delay rate and better performance compared with the existing algorithms. Compared with the VUCB and AdaUCB algorithms, SAda can improve the convergence of optimal delay by 80% to 95%, and the learning error during the process of task offloading can be increased by 20%, 70% and 75%, respectively.
In the future, the task offload situations when there are multiple TUEs will be considered in order to better match the reality. Moreover, a faster learning network can be used for this work, and more complex task offloading between crossings and cloudlets attached to the roadside should be considered in order to further optimize the delay performance.
Author Contributions
Methodology, M.D.; software, M.D. and Z.K.; validation, P.H., L.X., Q.L. and Z.K.; formal analysis, M.D.; investigation, P.H.; resources, L.X.; data curation, M.D.; writing—original draft preparation, M.D. and P.H.; writing—review and editing, M.D., P.H. and Q.L.; visualization, M.D.; supervision, M.D., P.H. and L.X.; project administration L.X. and Z.K.; funding acquisition, L.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Sichuan Agricultural University Doublesubject construction plan, grant number 03570310; Sichuan Provincial Department of Education Research on Key Technology of Manipulator Arm Motion Control of Citrus picking Robot, grant number 21MZGC0119.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to restrictions of privacy and morality.
Acknowledgments
The authors would like to thank the anonymous reviewers and the editor, whose comments and suggestions greatly improved this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Aloqaily, M.; Ridhawi, I.A.; Salameh, H.B.; Jararweh, Y. Data and Service Management in Densely Crowded Environments: Challenges, Opportunities, and Recent Developments. IEEE Commun. Mag. 2019, 57, 81–87. [Google Scholar] [CrossRef]
- Ali, Z.; Abbas, Z.H.; Abbas, G.; Numani, A.; Bilal, M. Smart computational offloading for mobile edge computing in next-generation Internet of Things networks. Comput. Netw. 2021, 198, 108356. [Google Scholar] [CrossRef]
- Xu, R.; Jin, W.; Kim, D. Enhanced Service Framework Based on Microservice Management and Client Support Provider for Efficient User Experiment in Edge Computing Environment. IEEE Access 2021, 9, 110683–110694. [Google Scholar] [CrossRef]
- Wang, J.; Wang, L. A Computing Resource Allocation Optimization Strategy for Massive Internet of Health Things Devices Considering Privacy Protection in Cloud Edge Computing Environment. J. Grid Comput. 2021, 19, 1–14. [Google Scholar] [CrossRef]
- Zhao, L.; Li, F.; Valero, M. Hybrid Decentralized Data Analytics in Edge-Computing-Empowered IoT Networks. IEEE Internet Things J. 2021, 8, 7706–7716. [Google Scholar] [CrossRef]
- Liu, G.; Wang, C.; Ma, X.; Yang, Y. Keep Your Data Locally: Federated-Learning-Based Data Privacy Preservation in Edge Computing. IEEE Netw. 2021, 35, 60–66. [Google Scholar] [CrossRef]
- Deng, S.; Zhang, C.; Li, C.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Burst Load Evacuation Based on Dispatching and Scheduling In Distributed Edge Networks. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 1918–1932. [Google Scholar] [CrossRef]
- Guo, D.; Gu, S.; Xie, J.; Luo, L.; Luo, X.; Chen, Y. A Mobile-assisted Edge Computing Framework for Emerging IoT Applications. ACM Trans. Sens. Netw. 2021, 17. [Google Scholar] [CrossRef]
- Tang, T.; Ma, Y.; Feng, W. Probabilistic-QoS-Aware Multi-Workflow Scheduling Upon the Edge Computing Resources. Int. J. Web Serv. Res. 2021, 18, 25–39. [Google Scholar] [CrossRef]
- Yang, L.; Cao, J.; Liang, G.; Han, X. Cost Aware Service Placement and Load Dispatching in Mobile Cloud Systems. IEEE Trans. Comput. 2016, 65, 1440–1452. [Google Scholar] [CrossRef]
- Ren, J.; Mahfujul, K.; Lyu, F.; Yue, S.; Zhang, Y.X. Joint Channel Allocation and Resource Management for Stochastic Computation Offloading in MEC. IEEE Trans. Veh. Technol. 2020, 69, 8900–8913. [Google Scholar] [CrossRef]
- Zheng, K.; Meng, H.; Chatzimisios, P.; Lei, L.; Shen, X. An SMDP-Based Resource Allocation in Vehicular Cloud Computing Systems. IEEE Trans. Ind. Electron. 2015, 62, 7920–7928. [Google Scholar] [CrossRef]
- Guo, F.; Zhang, H.; Ji, H.; Li, X.; Leung, V.C.M. An Efficient Computation Offloading Management Scheme in the Densely Deployed Small Cell Networks With Mobile Edge Computing. IEEE/ACM Trans. Netw. 2018, 26, 2651–2664. [Google Scholar] [CrossRef]
- Liu, F.; Lv, B.; Huang, J.; Ali, S. Edge User Allocation in Overlap Areas for Mobile Edge Computing. Mob. Netw. Appl. 2021. [Google Scholar] [CrossRef]
- Mazza, D.; Tarchi, D.; Corazza, G.E. A cluster based computation offloading technique for mobile cloud computing in smart cities. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Jiang, C.; Wan, J.; Abbas, H. An Edge Computing Node Deployment Method Based on Improved k-Means Clustering Algorithm for Smart Manufacturing. IEEE Syst. J. 2021, 15, 2230–2240. [Google Scholar] [CrossRef]
- Steffenel, L.A.; Pinheiro, M.K.; Souveyet, C. Assessing the impact of unbalanced resources and communications in edge computing. Pervasive Mob. Comput. 2021, 71, 101321. [Google Scholar] [CrossRef]
- Xiao, S.R.; Liu, C.B.; Li, K.L.; Li, K.Q. System delay optimization for Mobile Edge Computing. Future Gener. Comput. Syst.-Int. J. Esci. 2020, 109, 17–28. [Google Scholar] [CrossRef]
- Mukherjee, A.; De, D.; Roy, D.G. A Power and Latency Aware Cloudlet Selection Strategy for Multi-Cloudlet Environment. IEEE Trans. Cloud Comput. 2019, 7, 141–154. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient Multi-User Computation Offloading for Mobile-Edge Cloud Computing. IEEE/ACM Trans. Netw. 2016, 24, 2795–2808. [Google Scholar] [CrossRef] [Green Version]
- Hao, H.; Zhang, J.; Gu, Q. Optimal IoT Service Offloading with Uncertainty in SDN-Based Mobile Edge Computing. Mob. Netw. Appl. 2021. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhou, S.; Guo, X.; Niu, Z. Task Replication for Deadline-Constrained Vehicular Cloud Computing: Optimal Policy, Performance Analysis, and Implications on Road Traffic. IEEE Internet Things J. 2018, 5, 93–107. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Ota, K.; Dong, M. Learning IoT in Edge: Deep Learning for the Internet of Things with Edge Computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Guo, X.; Song, J.; Zhou, S.; Jiang, Z.; Liu, X.; Niu, Z. Adaptive Learning-Based Task Offloading for Vehicular Edge Computing Systems. IEEE Trans. Veh. Technol. 2019, 68, 3061–3074. [Google Scholar] [CrossRef] [Green Version]
- Kenney, J.B. Dedicated Short-Range Communications (DSRC) Standards in the United States. Proc. IEEE 2011, 99, 1162–1182. [Google Scholar] [CrossRef]
- Wu, C.-M.; Chang, R.-S.; Chan, H.-Y. A green energy-efficient scheduling algorithm using the DVFS technique for cloud datacenters. Future Gener. Comput. Syst. 2014, 37, 141–147. [Google Scholar] [CrossRef]
- Fan, Q.; Ansari, N. Application Aware Workload Allocation for Edge Computing-Based IoT. IEEE Internet Things J. 2018, 5, 2146–2153. [Google Scholar] [CrossRef]
- Gupta, S.; Chaudhari, S.; Joshi, G.; Yağan, O. Multi-Armed Bandits with Correlated Arms. IEEE Trans. Inf. Theory 2021, 1. [Google Scholar] [CrossRef]
- Auer, P.; Cesa-Bianchi, N.; Fischer, P. Finite-time Analysis of the Multiarmed Bandit Problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization, 7th ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Abdulla, M.; Steinmetz, E.; Wymeersch, H. Vehicle-to-Vehicle Communications with Urban Intersection Path Loss Models. In Proceedings of the 2016 IEEE Globecom Workshops (GC Wkshps), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Bnaya, Z.; Puzis, R.; Stern, R.; Felner, A. Social network search as a volatile multi-armed bandit problem. Human 2013, 2, 84–98. [Google Scholar]
- Wu, H.; Guo, X.; Liu, X. Adaptive exploration-exploitation tradeoff for opportunistic bandits. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5306–5314. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).