On Selection Criteria for the Tuning Parameter in Robust Divergence

Abstract
:1. Introduction
- Our method does not require an explicit representation of the asymptotic variance. Therefore, our method can be applied to rather complex statistical models, such as multivariate models, which seems difficult to be handled by the previous methods;
- In the existing studies, it is necessary to determine a certain value as a pilot estimate to optimize a tuning parameter. Thus, the estimates may strongly depend on the pilot estimate. On the other hand, our method does not require a pilot estimate and is stable and statistically efficient;
- Although our proposed method is based on a simple asymptotic expansion, it is more statistically meaningful and easier to interpret the results statistically than existing methods because it is based on the theory of parameter estimation for unnormalized statistical models.
2. Tuning Parameter Selection of Robust Divergence
3. Possible Robust Divergences to Consider
3.1. Density Power Divergence
3.2. -Divergence
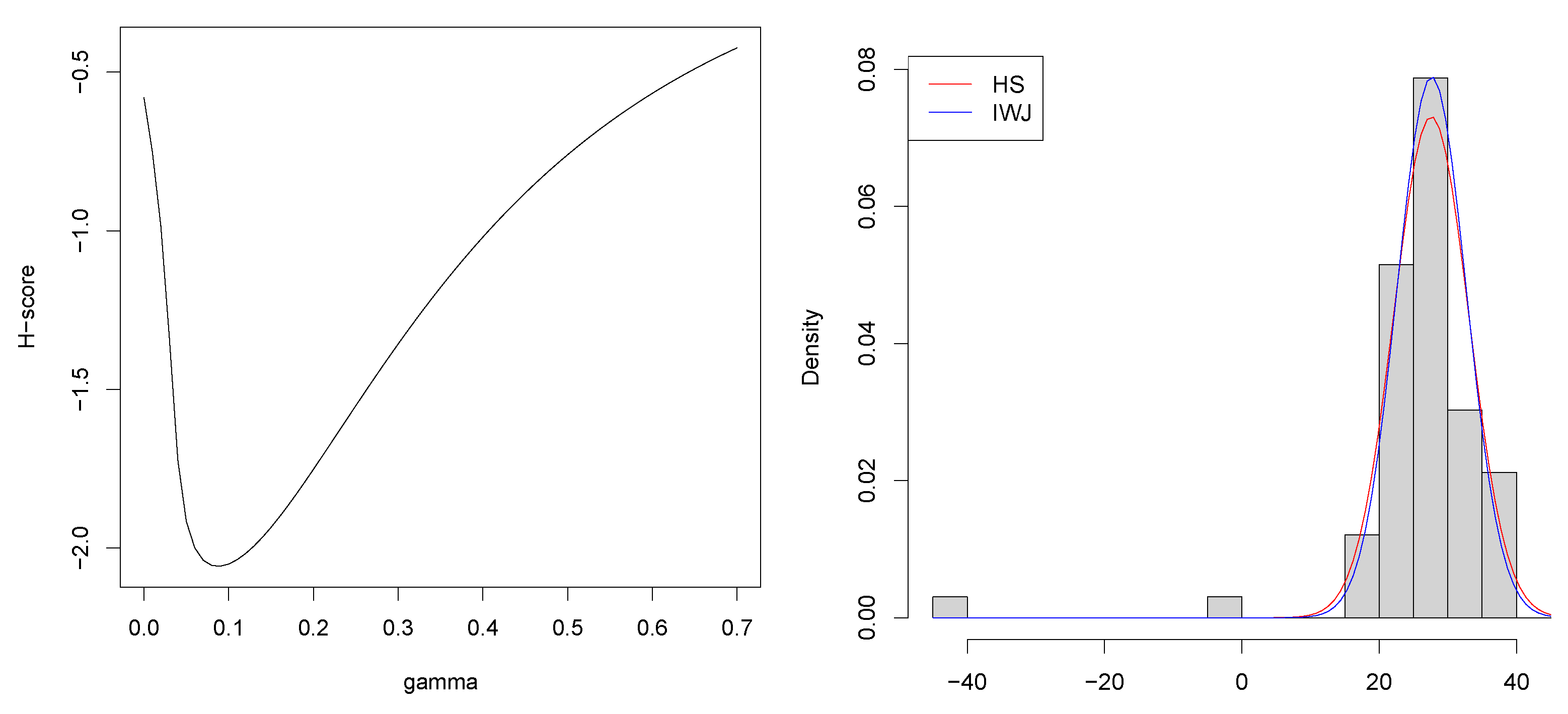
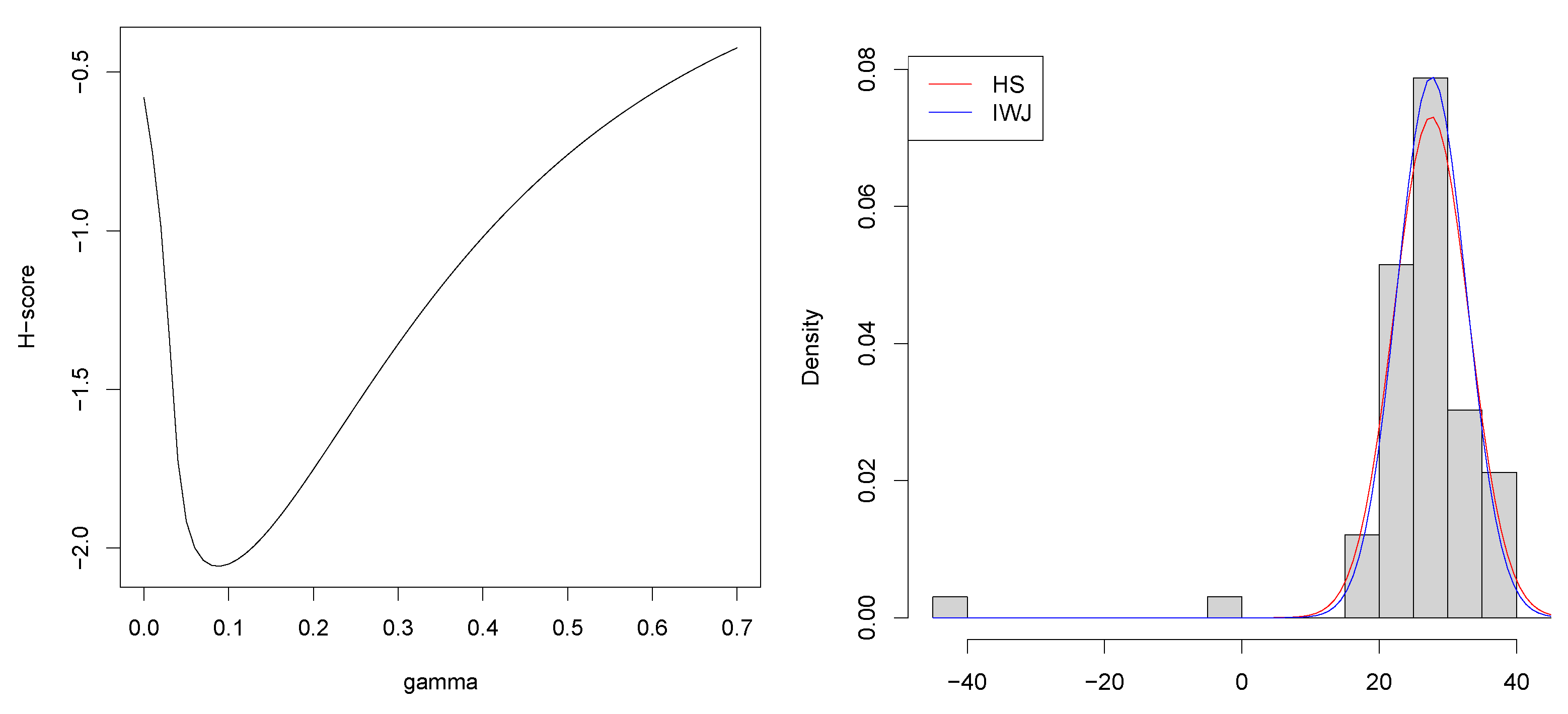
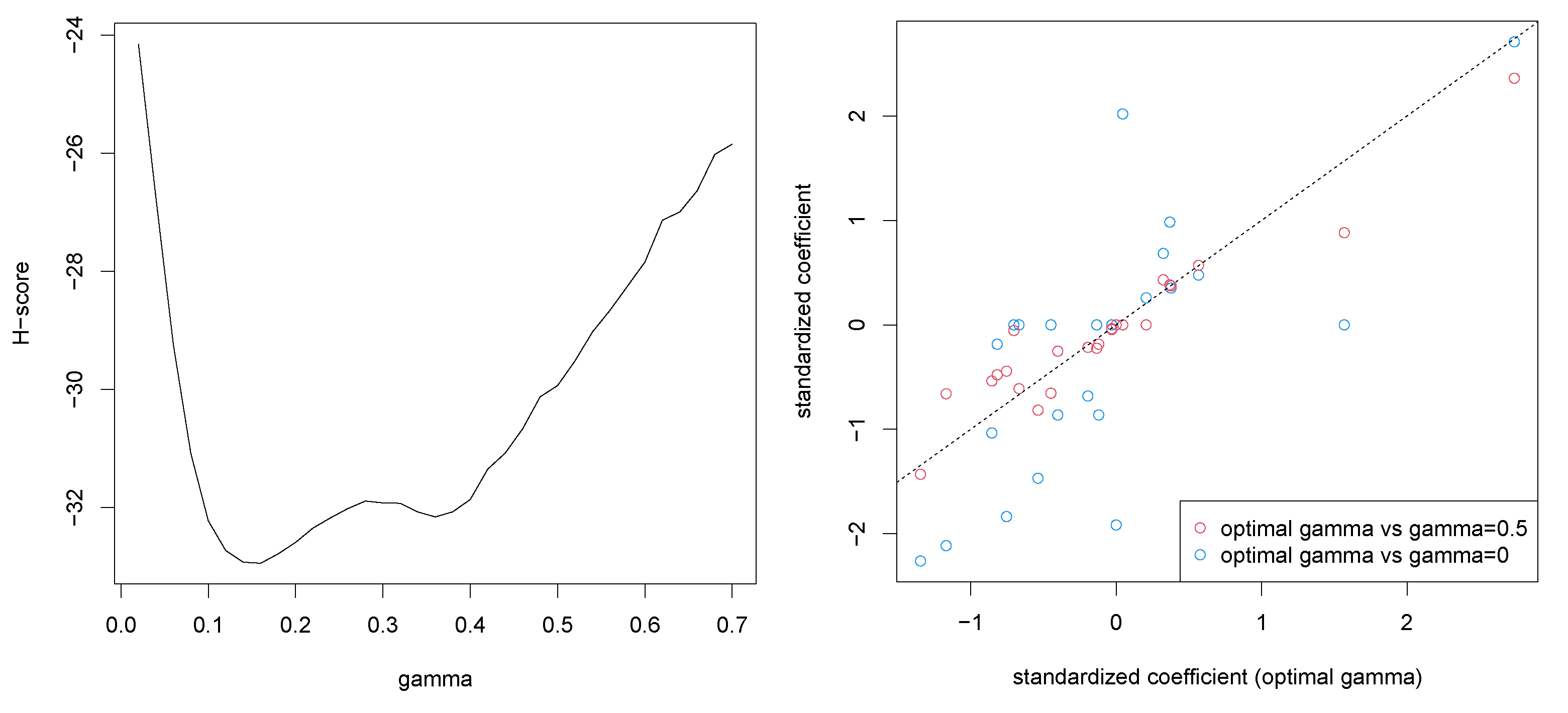
4. Numerical Examples
4.1. Normal Distribution with Density Power Divergence
4.2. Gamma Distribution with Density Power Divergence
4.3. Regularized Linear Regression with -Divergence
5. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Proposition 1
References
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M. Robust and efficient estimation by minimising a density power divergence. Biometrika 1998, 85, 549–559. [Google Scholar] [CrossRef] [Green Version]
- Fujisawa, H.; Eguchi, S. Robust parameter estimation with a small bias against heavy contamination. J. Multivar. Anal. 2008, 99, 2053–2081. [Google Scholar] [CrossRef] [Green Version]
- Hua, X.; Ono, Y.; Peng, L.; Cheng, Y.; Wang, H. Target detection within nonhomogeneous clutter via total bregman divergence-based matrix information geometry detectors. IEEE Trans. Signal Process. 2021, 69, 4326–4340. [Google Scholar] [CrossRef]
- Liu, M.; Vemuri, B.C.; Amari, S.i.; Nielsen, F. Shape retrieval using hierarchical total Bregman soft clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2407–2419. [Google Scholar] [PubMed] [Green Version]
- Shao, S.; Jacob, P.E.; Ding, J.; Tarokh, V. Bayesian model comparison with the Hyvärinen score: Computation and consistency. J. Am. Stat. Assoc. 2019, 114, 1826–1837. [Google Scholar] [CrossRef] [Green Version]
- Dawid, A.P.; Musio, M. Bayesian model selection based on proper scoring rules. Bayesian Anal. 2015, 10, 479–499. [Google Scholar] [CrossRef]
- Warwick, J.; Jones, M. Choosing a robustness tuning parameter. J. Stat. Comput. Simul. 2005, 75, 581–588. [Google Scholar] [CrossRef]
- Basak, S.; Basu, A.; Jones, M. On the ‘optimal’density power divergence tuning parameter. J. Appl. Stat. 2021, 48, 536–556. [Google Scholar] [CrossRef]
- Matsuda, T.; Uehara, M.; Hyvarinen, A. Information criteria for non-normalized models. arXiv 2019, arXiv:1905.05976. [Google Scholar]
- Jewson, J.; Rossell, D. General Bayesian Loss Function Selection and the use of Improper Models. arXiv 2021, arXiv:2106.01214. [Google Scholar]
- Yonekura, S.; Sugasawa, S. Adaptation of the Tuning Parameter in General Bayesian Inference with Robust Divergence. arXiv 2021, arXiv:2106.06902. [Google Scholar]
- Geisser, S.; Hodges, J.; Press, S.; ZeUner, A. The validity of posterior expansions based on Laplace’s method. Bayesian Likelihood Methods Stat. Econom. 1990, 7, 473. [Google Scholar]
- Devroye, L.; Gyorfi, L. Nonparametric Density Estimation: The L1 View; John Wiley: Hoboken, NJ, USA, 1985. [Google Scholar]
- Cichocki, A.; Cruces, S.; Amari, S.i. Generalized alpha-beta divergences and their application to robust nonnegative matrix factorization. Entropy 2011, 13, 134–170. [Google Scholar] [CrossRef]
- Stigler, S.M. Do robust estimators work with real data? Ann. Stat. 1977, 5, 1055–1098. [Google Scholar] [CrossRef]
- Kawashima, T.; Fujisawa, H. Robust and sparse regression via γ-divergence. Entropy 2017, 19, 608. [Google Scholar] [CrossRef] [Green Version]
- Harrison Jr, D.; Rubinfeld, D.L. Hedonic housing prices and the demand for clean air. J. Environ. Econ. Manag. 1978, 5, 81–102. [Google Scholar] [CrossRef] [Green Version]
- Van der Vaart, A.W. Asymptotic Statistics; Cambridge University Press: Cambridge, UK, 2000; Volume 3. [Google Scholar]


{kind=link}
{kind=link}
| Fixed | |||||||
|---|---|---|---|---|---|---|---|
| HS | OWJ | IWJ | |||||
| 0 | 10.3 | 10.6 | 10.3 | 10.2 | 10.5 | 11.0 | |
| RMSE | 0.05 | 10.7 | 10.9 | 10.7 | 14.4 | 10.8 | 11.3 |
| 0.1 | 11.0 | 11.1 | 11.0 | 44.7 | 11.1 | 11.5 | |
| 0.15 | 11.4 | 11.4 | 11.4 | 82.6 | 11.5 | 11.8 | |
| 0 | 94.8 | 93.8 | 94.2 | 94.6 | 94.5 | 94.4 | |
| CP | 0.05 | 94.7 | 93.9 | 94.1 | 93.2 | 94.2 | 94.1 |
| 0.1 | 94.3 | 94.1 | 94.2 | 36.7 | 94.2 | 94.4 | |
| 0.15 | 94.1 | 93.7 | 93.8 | 0.1 | 93.6 | 94.1 | |
| 0 | 40.6 | 40.1 | 39.8 | 40.4 | 40.7 | 42.6 | |
| AL | 0.05 | 41.7 | 41.0 | 40.9 | 50.4 | 41.2 | 43.3 |
| 0.1 | 42.5 | 41.9 | 41.8 | 79.5 | 42.0 | 44.1 | |
| 0.15 | 43.4 | 42.9 | 42.9 | 100.4 | 43.1 | 45.1 | |
| HS | OWJ | IWJ | |
|---|---|---|---|
| 0 | 0.088 | 0.212 | 0.158 |
| 0.05 | 0.169 | 0.260 | 0.230 |
| 0.1 | 0.217 | 0.284 | 0.267 |
| 0.15 | 0.252 | 0.302 | 0.294 |
| Fixed | Fixed | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| n | ML | HS | ML | HS | |||||
| 0 | 0.28 | 0.29 | 0.38 | 1.25 | 0.65 | 0.73 | 0.91 | 3.63 | |
| 100 | 0.91 | 0.37 | 0.70 | 1.29 | 2.50 | 1.00 | 1.98 | 3.74 | |
| 1.13 | 0.40 | 0.99 | 1.34 | 3.10 | 1.09 | 2.81 | 3.86 | ||
| 0 | 0.19 | 0.20 | 0.29 | 1.14 | 0.44 | 0.49 | 0.70 | 3.37 | |
| 200 | 0.92 | 0.28 | 0.69 | 1.18 | 2.54 | 0.75 | 1.98 | 3.47 | |
| 1.14 | 0.28 | 1.01 | 1.21 | 3.13 | 0.78 | 2.86 | 3.53 | ||
| 0.036 | 0.137 | 0.164 | 0.025 | 0.133 | 0.161 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sugasawa, S.; Yonekura, S. On Selection Criteria for the Tuning Parameter in Robust Divergence. Entropy 2021, 23, 1147. https://doi.org/10.3390/e23091147
Sugasawa S, Yonekura S. On Selection Criteria for the Tuning Parameter in Robust Divergence. Entropy. 2021; 23(9):1147. https://doi.org/10.3390/e23091147
Chicago/Turabian StyleSugasawa, Shonosuke, and Shouto Yonekura. 2021. "On Selection Criteria for the Tuning Parameter in Robust Divergence" Entropy 23, no. 9: 1147. https://doi.org/10.3390/e23091147
APA StyleSugasawa, S., & Yonekura, S. (2021). On Selection Criteria for the Tuning Parameter in Robust Divergence. Entropy, 23(9), 1147. https://doi.org/10.3390/e23091147