1. Introduction
The increasing amount of data generated in each field of human activity, paired with the increasing availability of computing power, has contributed to the success of Machine Learning models. Deep Learning systems, in particular, have gained a lot of traction in the last 10 years thanks to their ability to build an internal representation at different levels of abstraction [
1]. This feature, along with the high accuracy exhibited in a variety of different settings, largely contributed to their adoption.
In the biomedical domain, Deep Learning has been applied to a variety of different tasks. One area of active study is related to the processing of one-dimensional physiological signals, with the majority of contributions focusing on classification [
2]. Applying machine learning techniques also in a regression setting is of particular interest in this field as it enables new non-invasive monitoring techniques for several physiological signals, such as arterial blood pressure (ABP). Research has been conducted to estimate APB from several other signals, such as Photoplethysmogram (PPG) [
3] or Electrocardiogram (ECG) and heart rate [
4].
Given their inherently black-box nature, Deep Learning systems pose key challenges in the biomedical field where transparency is a critical feature. To trust a model, a clinician needs to know
why such model is generating the predictions he/she is seeing. The same is true for patients who have the right to know the reasons behind a decision or a diagnosis. This need for transparency and interpretability has fostered a research effort targeting the development of models and techniques to gain insight and possibly an understanding of the models’ predictions and their inner workings [
5,
6,
7,
8,
9]. This large body of research literature, however, is mostly limited to models for static data types, including flat vectorial information or images. On the other hand, a large share of the data produced in the life sciences is of sequential nature, these being time-series of physiological measurements, such as blood pressure, heart rate, electrodermal activity, or genomic/proteomic chunks.
In this paper, we attempt to fill this gap by specifically targeting the explainability within the context of recurrent neural networks for biomedical signals represented as time-varying sequential data. Within this context, we propose a model agnostic technique (based on systematic occlusion study) to gain granular knowledge about input influence on the predictions of the model. We do so while providing a multi-faceted access to interpretability, considering both the point of view of the machine learning practitioner and the life-science expert, providing targeted explanations for the two reference populations. Our approach is especially designed for explaining the black-box regressors, but we also discuss how it can be adapted for explaining the classification of time series. We evaluated our method on three different datasets of physiological signals in both regression and classification tasks. The remaining of the paper is organized as follows.
Section 2 discusses related works.
Section 3 formalizes the problem faced and introduces basic concepts for the explanation method, which is described in
Section 4. Experimental results are presented in
Section 5 and
Section 6.
Section 7 concludes the paper.
2. Related Works
Interpretability is a multi-faceted problem, and even though it has recently received much attention and different explanation approaches have been proposed [
5,
6,
7,
8], a singular shared formalization is still lacking [
10]. Explanation methods can be categorized as model-agnostic or model-specific, depending on whether they take into consideration the knowledge of the internal structure of the black box or not.
According to the type of explanations provided by a methodology, we can further differentiate between local and global methods: the former ones generate explanations for specific data instances, while the latter for the logic of the black box as a whole [
8].
Some local explanation methods leverage gradient-based methods in order to identify relevant features [
11,
12,
13]. Layer-wise relevance propagation (LRP) [
14], instead, makes explicit use of the network activations. The core idea is to find a relevance score for each input dimension starting from the magnitude of the output. The backpropagation procedure implemented by LRP is subject to a conservation property: the relevance score received by a neuron must be redistributed to the lower layers in the same amount. Several different rules were proposed to favour a positive contribution or to generate sparser saliency heatmaps. The Integrated Gradients method [
15] combines the sensitivity property of LRP and guarantees the implementation invariance property: if two models are functionally equivalent then the attributions are identical for both. LIME [
16] and SHAP [
7] are two well-known local methods. The first one generates a simpler interpretable model that approximates the behaviour of the black box in the specific neighbourhood of the instance to be explained. SHAP [
7] is a framework that defines a class of additive feature attribution methods and uses a game theoretic approach to assign an importance score to each feature involved in a particular prediction. LRP [
14], DeepLIFT [
13], and LIME [
16] can be considered particular instances of this class of methods.
For models that use attention [
17], it is possible to inspect and visualize the learned weights to gain insights on the assigned importance for a given input instance. This approach has been widely applied for model inspection on different types of data and fields, including the biomedical one. RETAIN [
18] is an RNN-based model for the analysis of electronic health record (EHR) data. It employs an attention mechanism that allegedly mimics the modus operandi of a clinician: higher weight is given to recent clinical events in the EHR to generate a prediction. The timeline [
9] predicts the next category of a medical visit given past EHRs. First, it calculates a low-dimensional embedding of the medical codes of a given EHR; then, a self-attention mechanism generates a context vector. This context vector is then multiplied by a coefficient obtained from a specifically designed function, which takes into account the specific diseases and the time interval. The resulting visit representation vector is the input of a classifier. Given the presence of the multiplier coefficients, it is possible to know how much a specific event contributed to the prediction of the next visit. In [
19], the authors show that time steps closer to therapy was associated with higher attention weights and were more influential on the prediction. An adaptation of Class Activation Mapping [
15] to 1D time series is described in [
20] and applied to Atrial Fibrillation Classification.
Models can also be explained by generating or querying prototypical instances that are representatives of specific output classes. PatchX [
21] uses patches to segment the input time series. It extracts local patterns and classifies each of them according to the occurrence of the pattern in a given class. The classification outcome for a complete time series depends on the classes associated with each pattern within it. Other prototype-based approaches leverage the latent representation learned by autoencoders to generate explanations as in [
22,
23], but in this case, there is a trade-off between prototype quality and classification accuracy.
In [
24], the explanations and prototypes are extracted using an information theoretic approach. The authors take the user’s understanding into consideration, which is modelled as a function of the input
of the systems:
and can be seen as a summary of that specific input. Similarly, an explanation
is a quantity presented to the users to help in the understanding of a specific prediction
. By considering the data points as independent and identically distributed (i.i.d.) realizations of a random variable, the conditional Mutual Information
represents the amount by which the explanation reduces the uncertainty about the prediction.
Our brief literature survey highlights that most of the interpretability methods are tailored to specific settings and sometimes learning architectures. Model agnostic techniques exist but are applied almost exclusively to classification problems and rarely to regression. Additionally, the availability of approaches for sequential data is substantially lower and limited to classification tasks and, sometimes, to forecasting scenarios [
8]. The sequence generation setting is left with few approaches, such as [
20], adapted from different tasks that need access to the internals of the models. The method proposed in this paper attempts to overcome such limitations by introducing a model agnostic method that can generate explanations in sequential data processing tasks comprising both regression and classification tasks.
3. Problem Statement
In this paper, we address the problem of explaining the behaviour of a black box model b in the prediction of a time series y given a multivariate time series .
A prediction dataset , thus, consists of a set of multivariate time series, where we have a target univariate time series assigned to each multivariate one. A multivariate time series X consists of n univariate time series, each one with h time points . For instance, a single univariate time series can model an ECG signal. In the following, we also use the term signal to indicate a single univariate time series. We name a local subsection of a signal a sub-signal.
Definition 1 (Sub-signal). Given a signal , a sub-signal of x with length is a sequence of w contiguous data points of x, i.e., for .
Given a black box, time series predictor b and a multivariate time series X s.t. , our aim is to provide an explanation for the decision . We use the notation as a shorthand for . We assume that b can be queried at will.
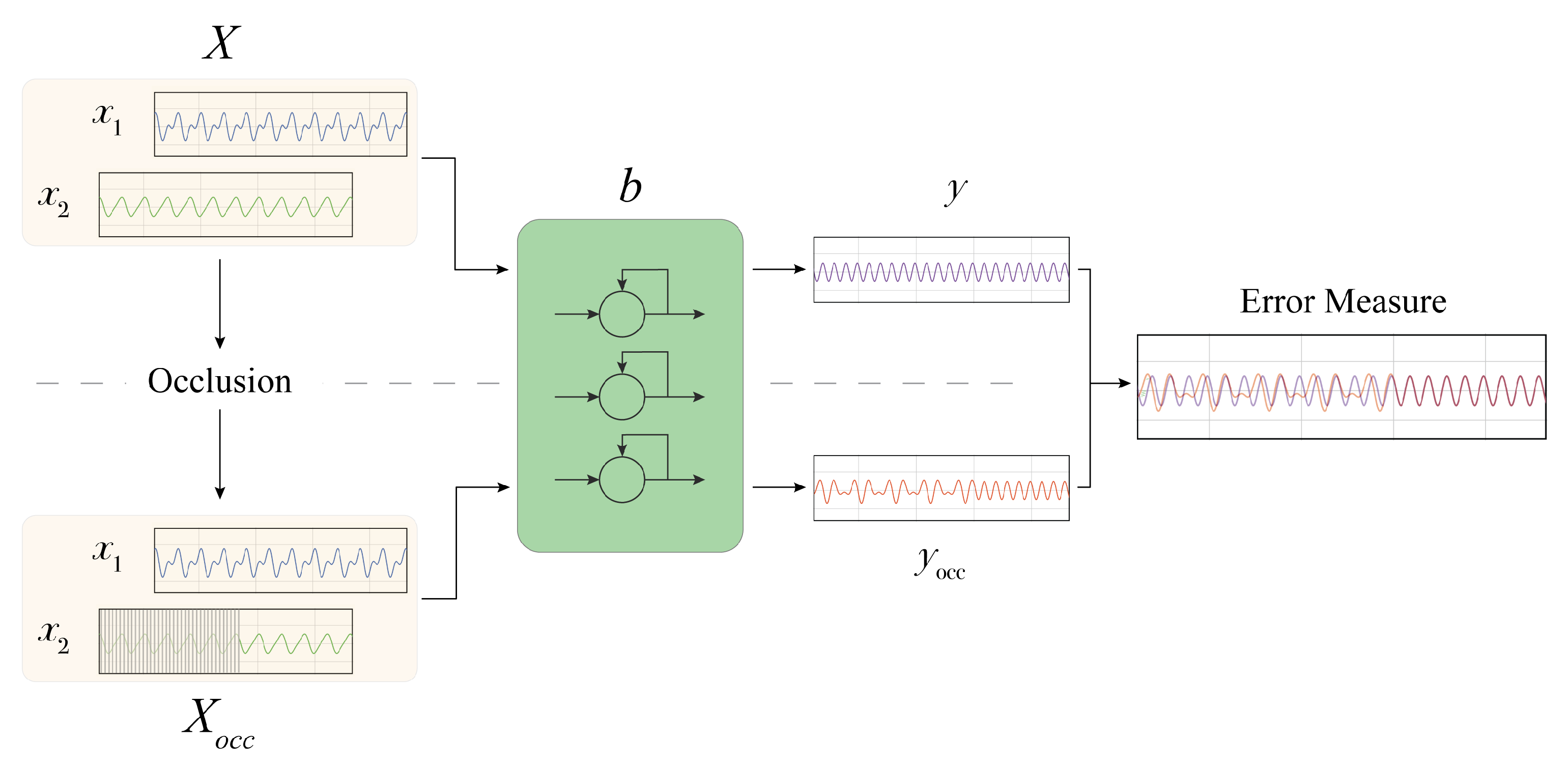
4. The mime Method
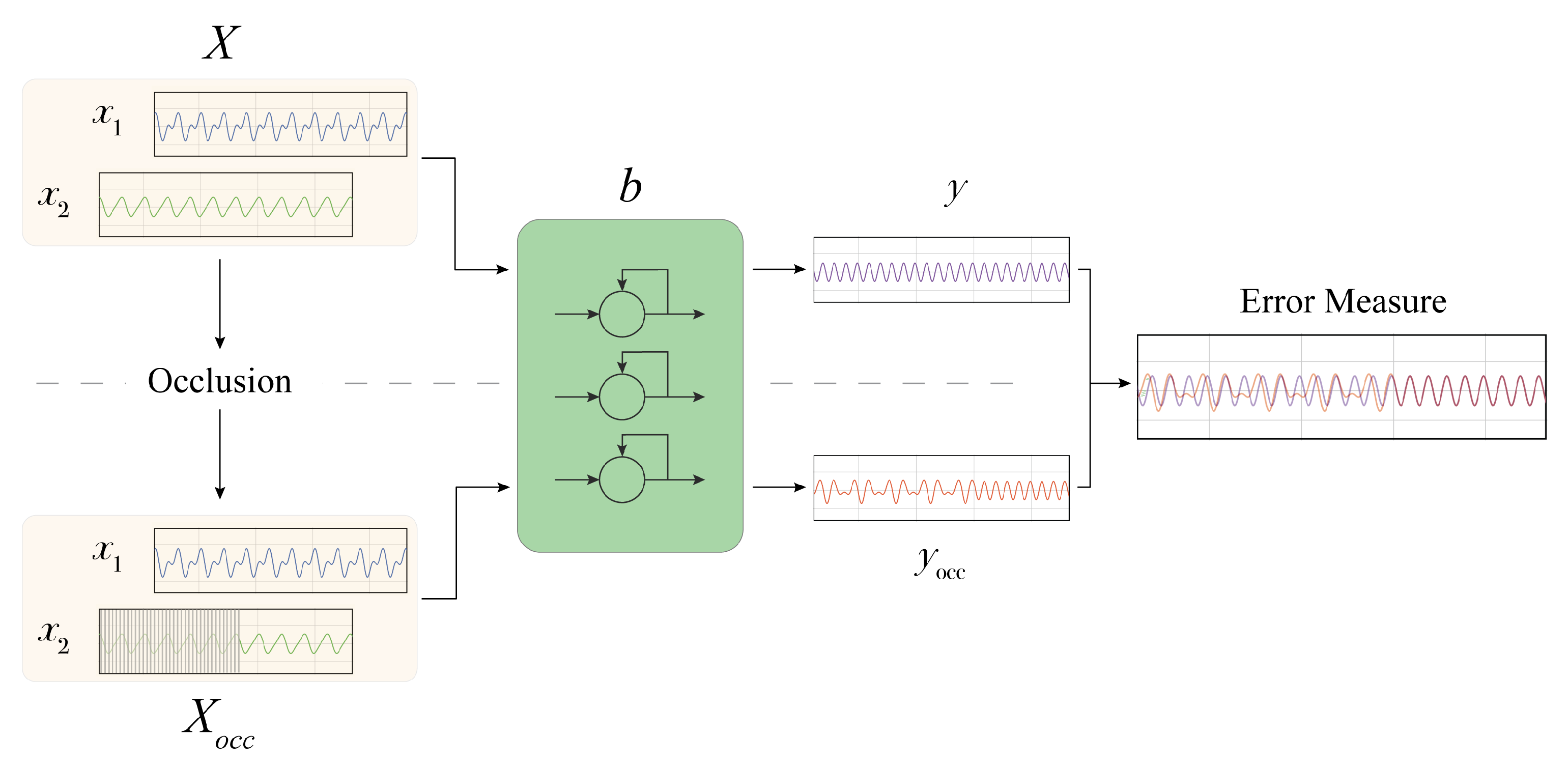
We approach the above explanation problem proposing
mime (Masking Inputs for Model agnostic local Explanation), a method aiming at understanding why a recurrent neural network outputs a specific prediction and how it reacts to engineered changes in the input signal by using a methodology rooted on occlusions. By occlusion, we denote the alteration of a part of the input signals with a given value. This kind of technique has been applied to analyse the robustness of image classifiers, where important features of the image are masked to observe changes in the predicted class [
25].
mime produces an explanation targeted at two different types of users: physicians and technical experts. Physicians receive information about the importance of a particular input signal for the final prediction and information about some particular parts of the input signals influencing the prediction. This information is supported by visualizations. Technical experts instead can use mime to analyse the robustness of the prediction model against some input perturbation.
The different components of our explanation are obtained by using the occlusion mechanism. The occlusion approach proposed in this work does not require prior knowledge concerning the data structure and distribution, and it only requires having access to input signals and model predictions. For each of the sequential input time series of the model, we generate an occluded version by substituting the original signal values with a user-defined value. The alteration can be chosen to last for the whole signal or for a fixed time-span. In the latter case, a windowed approach is employed to systematically analyse the effect of occluding different parts of each input signal.
In the following (
Figure 1), we provide a step-by-step description of the proposed methodology, which includes:
(i) The determination of the importance of each input signal;
(ii) Analysis of the impact of the input signals perturbation;
(iii) The extraction of the most influential
sub-signals.
4.1. Occlusion Approach
Let be a tensor representing samples of multivariate time series composed of n signals of the length h. Each signal x is represented by a vector . We use 1 and 0 to denote vectors whose components are, respectively, all ones and all zeroes. The altered signal is obtained according to the type of modification required. In the case of a full length occlusion, we have: with being the occluding value and .
In order to modify
x with a localized alteration of duration
d starting after
p timesteps, we define two binary masking vectors
and
as:
where ¬ is bit-wise negation. By means of the above masks, we get the
vector as:
The localized alteration provides the basic elements to define an occlusion approach based on a window w covering a specific temporal range.
Given a multivariate time series X, we define an occlusion window w with a duration of d timesteps, and we derive the number of possible segments of a signal that we can occlude, i.e., , where if the signal duration is divisible by d; otherwise, .
Signal occlusion is performed on each segment i with . For each x, we alter only a single segment per time. The alteration can be performed on any of the signals with , one at time or by considering any subset of signals in X. Algorithm 1 reports the occlusion procedure for a single signal.
By generating the occlusions, we collect the model outputs for both the unaltered input samples
and under the occluded inputs
, i.e.,
. Then, we consider the discrepancies between the two output signals measured in terms of mean absolute error (MAE) between
Y and
. Thus, higher values of MAE denote higher importance of the occluded signal parts. This approach allows us to investigate several aspects of the models trained for different tasks in the biomedical domain and to extract and analyse explanations. We discuss these aspects in the following sections.
| Algorithm 1 Occlusion. |
- 1:
procedureocclude() - 2:
length(x) - 3:
copy(x) - 4:
▹ user-defined occlusion value. - 5:
- 6:
- 7:
if then - 8:
- 9:
end if - 10:
for do - 11:
▹ window occlusion - 12:
end for - 13:
return - 14:
end procedure
|
4.2. Input Signal Importance
The first step of
mime aims at determining the importance of each input signal for the prediction task. A large number of approaches have been developed to investigate feature importance in machine learning models for interpretability purposes. Most of them are specifically designed to deal with classification tasks, while others (such as SHAP [
7]) rely on assumptions that are not always valid, such as the independence of the input features. As an example, in our setting, two input signals, such as cardiac and respiratory data, cannot be considered independent.
In our approach, for each input signal , we evaluate the importance of x by applying the black box b on both the data with the entire signal x occluded and the original data without any occlusion. The MAE resulting from the comparison of the two predictions quantifies the importance of the signal x. Occluding the entire signal means considering a window with a size equal to the signal length, i.e., setting and in Algorithm 1.
4.3. Estimating Duration of Induced Perturbation
Occluding parts of the input signals results in an alteration in the network outputs. The predicted signals under input occlusion manifest a perturbation that, as the empirical analysis will show, is clearly visible when plotting the two generated outputs. Following up on this intuition, we developed a procedure to quantify the duration of the induced alteration.
The rationale of our duration estimation procedure follows the approach discussed previously for the signal importance assessment. For any segment occluded in the input signals, we quantify the deviation of the occluded prediction from the unaltered one by computing their MAE over a window of
d timesteps. In particular, given the two predicted signals
y and
, we apply the procedure described in Algorithm 2. First, we segment the two signals in
sub-signals (with
if
h is divisible by
d,
otherwise), obtaining two lists of sub-signals
s and
, respectively, (lines 4–5, Algorithm 2). Then, we compute the MAE for any pair of aligned sub-signals, i.e.,
(lines 6–9). Perturbation duration is quantified by counting the number of sub-signals for which the MAE is above a threshold
(lines 10–15), whose value is application-dependent.
| Algorithm 2 Perturbation duration. |
- 1:
procedurePertDuration() - 2:
▹ user-defined size - 3:
empty list - 4:
Segment() - 5:
Segment() - 6:
for all do - 7:
mae() - 8:
Append to - 9:
end for - 10:
- 11:
for all do - 12:
if then - 13:
- 14:
end if - 15:
end for - 16:
return ▹ n. windows with MAE > - 17:
end procedure
|
4.4. Determining Influential Sub-Signals
The windowed occlusion procedure can also serve to identify the most relevant or influential input sub-signals for the model. This is, again, obtained by contrasting original predictions with the model outputs under occlusion, measuring the mean discrepancy between the two. Algorithm 3 describes the details of our approach. In particular, it computes, for each input signal , the importance of each sub-signal of x. To this end, the input signal x is segmented in q sub-signals (line 4), and for each , an occluded version of the signal x is computed (line 6). Then, the importance of the sub-signal is measured by computing the derived MAE comparing the model prediction y on the unaltered signal and on the occluded signal (lines 8–10). Once the MAE is computed for each sub-signal, the algorithm produces a heatmap that provides a visual inspection that highlights the importance (measured by MAE) of each sub-signal (see Figure 3 as an example). Finally, the method extracts the top-k sub-signals with the highest MAE.
Next, the top-k sub-signals of each signal are used to provide the physicians with a set of important sub-signals of each category of the input signal. To this end, given the whole set of multivariate time series , mime selects from each multivariate the single univariate signals and extracts the top-k sub-signals with the highest MAE, which we denote by (Algorithm 3).
Finally,
mime derives the set
I by computing the union of these top sub-signals obtained for each of the
j-th signals, i.e.,
. Finally, it extracts the most important ones from such set, again relying on the MAE values.
| Algorithm 3 Top-K influential Sub-signals. |
- 1:
procedureTopkSub-Signals() - 2:
empty list - 3:
empty list - 4:
Segment() - 5:
for do - 6:
occlude() - 7:
- 8:
predict() - 9:
predict() - 10:
mae() - 11:
Append to - 12:
end for - 13:
ReverseSort() - 14:
for do - 15:
Append to - 16:
end for - 17:
return - 18:
end procedure
|
4.5. Self Organizing Maps Clustering of Influential Sub-Signals
The set
I of influential sub-signals, extracted using the procedure described in the previous section, is then used as input for a Self Organizing Map (SOM) [
26]. SOMs are the most popular family of neural-based approaches to topographic mapping. They leverage soft-competition among neighbouring neurons arranged on low-dimensional lattices to enforce the principle of topographic organization. Soft-competition ensures that nearby neurons respond to similar inputs, while lattice organization provides a straightforward means to visualize high-dimensional data onto simple topographic structures. Thanks to these characteristics, they have found wide application as an effective computational methodology for adaptive data exploration [
27].
In this work, SOMs are used as a visualization tool targeted to domain experts. Thanks to the SOM ability to cluster signals by their morphological similarity and mapping them to a specific neuron, or more generally, to a neighbourhood of neurons, it is possible to obtain a synthetic and organized view of those signals. Exploiting the ability to project auxiliary information such as the MAE linked to each sub-signal in I, it is possible to identify prototypical portions of signals associated with the highest error. This process allows us to provide physicians with an intuitive tool to identify and visualize the “critical” parts of the signals. For the sake of our analysis, we can use all sub-signals in the original set I, or alternatively, we can operate on a subset G, obtained by selecting the most informative n (i.e., the ones with the highest error) elements from I.
After the training phase, we query the SOM to obtain the best matching unit (BMU)
and link the BMU to the MAE associated with
. The set of all sub-signals mapped to the BMU with coordinates
is denoted by
. We build a matrix
with the same dimensions of the map where each element
is:
By projecting the matrix E on top of the original SOM map, we can easily identify neurons that react to sub-signals with a larger MAE thanks to colour intensity. Sub-signals associated with each BMU can be plotted in isolation or can be linked back to the original input signals they were extracted from, highlighting critical portions of the original time series.
4.6. Explaining Time Series Classification
As described above,
mime is designed to explain regression tasks. However, it can be easily adapted for providing explanations in time series classification tasks. In this case, each multivariate time series is assigned to a label, i.e., the target
. In order to adapt our approach to these tasks, we propose determining the signal influence (
Section 4.2) and the most influential sub-signals (
Section 4.4) by computing the MAE discrepancy between the model losses for the occluded and original signals rather than between the model outputs. Moreover, when selecting the influential sub-signals, we will look into those that lead the model to change its classification prediction. That is why we adapt the approach to return the sub-signals that have the highest MAE and
. Clearly, since the prediction is a class label here and there is no temporal information associated with the target, we cannot provide the analysis on the impact of the perturbation in terms of duration of the induced alteration.
All in all, the approach needs to be customized based on whether the predictive task is a regression or a classification problem. In a regression setting, the only actionable choice is the selection of the discrepancy function. For the sake of this work, we measure occluded-unoccluded output discrepancy using MAE. For classification problems, in Algorithm 3, we need to compute the MAE discrepancy between the model losses for the occluded and original inputs rather than between the model outputs. Moreover, when selecting the influential sub-signals, we are interested in those that cause the system to change its classification prediction. For this reason, we append the tuple to the list of the candidate-important sub-signals (line 11) if and only if .
6. Experiments
In the following sections, we describe the results of the experiments performed using the mime explainer. First, we report results for signal importance assessment using both whole length occlusion and the windowed approach. Next, we describe the analysis pertaining to the duration of induced perturbations. Following, we detail experiments to extract the most influential sub-signals and the associated SOM-based visualizations. Lastly, we provide examples of the Signal Occlusion Contribution Visualization targeting the clinical experts.
6.1. Signal Importance
Experiments to quantify signal importance for models trained on regression tasks (CBPEDS and CEBSDB) were performed by occluding segments of the input signal with zero values or with the mean value of the dataset for the whole duration. The effects have been evaluated on the validation and test sets from both datasets.
Table 3 reports the results for models trained on the CBPEDS dataset. We include the MAE with the unaltered input as a reference. Different models with different inductive biases learn different representations, and in doing so, they assign different levels of importance to the input signals. The table highlights (in boldtype) that the
model relies more on the PPG signal, as occluding it results in a larger MAE. We have similar results for the
model, while the
model, instead, has a larger MAE when the ECG signal is occluded. The type of occlusion seems to play a secondary role, probably related to samples distribution, as results on the validation set indicates. The most important input signals remain the same for all three models, with MAE score variations according to the occlusion type.
For the CEBSDB dataset, the signal importance assessment in
Table 4 reveals a strong reliance of all the three networks on the ECG input signal to correctly generate the SCG output signal. This behaviour is evident when analysing the errors in
Table 4: the MAE associated with ECG occlusion is always higher, with the only exception of the
model on the test set. The occlusion value has a strong impact on the autoencoder model, while the effects are of smaller magnitude than for the other models.
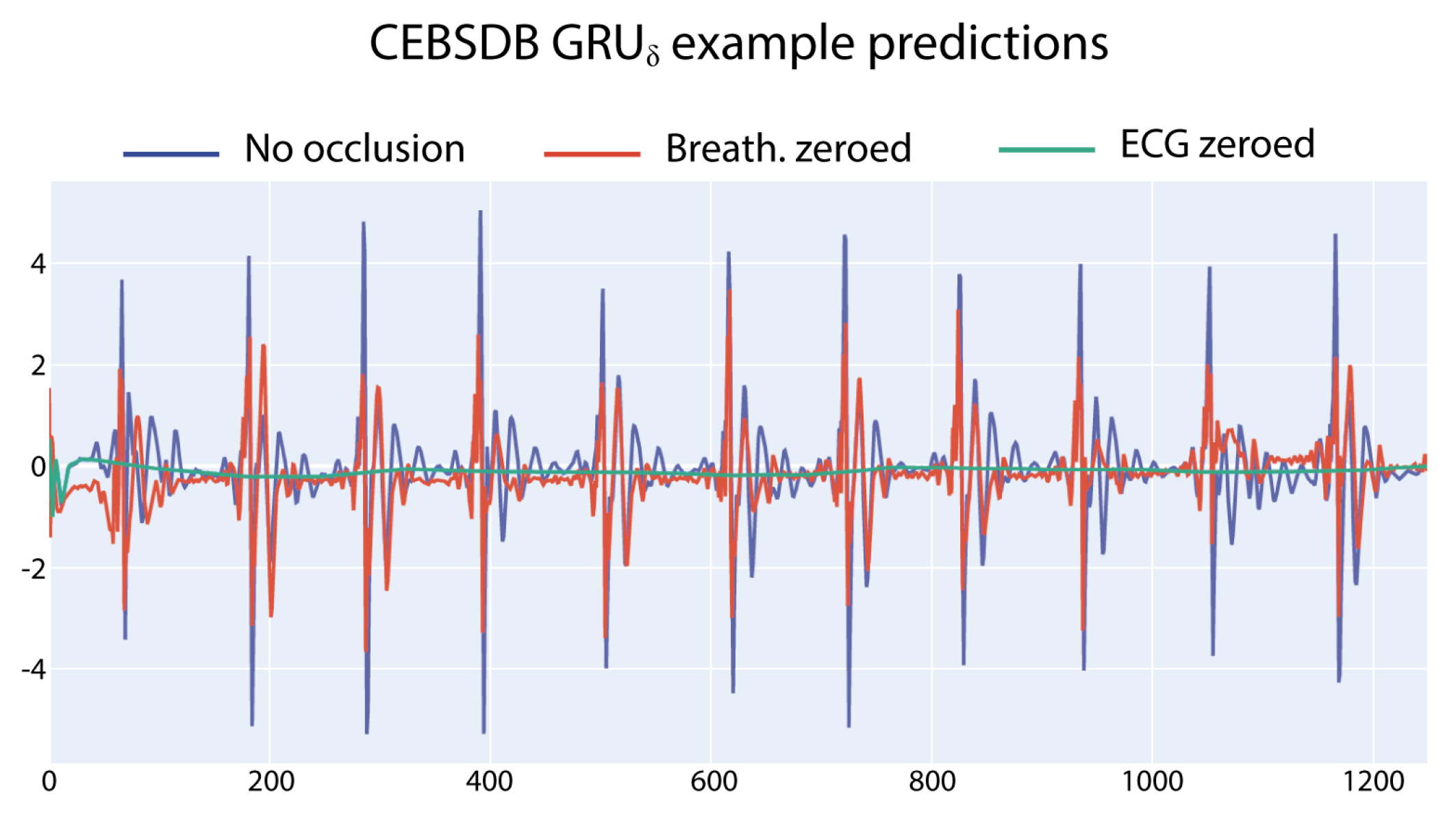
Figure 2 shows a graphical example of the different outputs of the
model (trained to predict the SCG ) when different input signals are occluded.
6.2. Windowed Occlusion
In this section, we report the results obtained by occluding the input signals with zero values for a fixed window of time for all window indexes. This approach has been applied in both classification and regression models. In the former case, we report the average MAE error obtained across all the windows, and in the latter case, the mean accuracy obtained by considering the occluded prediction.
Table 5 shows the results on CBPEDS datasets. In general, larger mean MAE values are associated with the occlusion of the most meaningful sub-signals, and the error increases with the window size. In predicting the arterial blood pressure, the
model exhibits larger errors when ECG is occluded. The autoencoder is the worst performer of the three models when the PPG signal is occluded, while the
model is the most robust among the tested networks.
Table 6 reports results on the CEBSDB dataset. In this regression task, the
model is the most susceptible model when the ECG signal is occluded, while the
, as in the ABP estimation task, is less influenced by the occlusion. The
model confirms its larger reliance on the breathing signal compared to the other networks, as the associated MAE shows.
The accuracy results obtained with the three different models for the classification task on PTBDB are reported in
Table 7. Here, the ECG is the only input signal, and we experimented with different occlusion values. Several window sizes were tested with duration of 25, 50, 75, 100 and 125 time steps. The choice of the occlusion value (zero or mean signal value on the dataset) has a negligible impact on the accuracy (from 1% to 4%). Interestingly, all models worsen their prediction when the occlusion is zero, especially at lower window sizes. Increasing the occlusion duration results in a larger accuracy loss for all models, independently from the value used. The feedforward network used as a baseline is the less susceptible model followed by the
model. The pure GRU model has, in general, the largest accuracy loss.
6.3. Induced Perturbation Duration
Table 8 provides the results for the experiments quantifying the duration of the perturbation caused by different occlusion types in CBPEDS. The
model shows the largest sensibility to the alteration of ECG input and takes more timesteps to undo the induced error, which can last up to 250 timesteps (2 s) even for small occlusion durations, confirming the importance of this signal for this specific model.
seems to recover faster than the
model. Moreover, the duration of the perturbation is similar for ECG and PPG occlusions. The best model at dealing with the perturbation duration is
. Its mean duration is the lowest in the Table, and when ECG is occluded, its effect lasts for zero timesteps. This does not mean, however, that the induced perturbation is zero: it rather indicates that the induced error is less than the chosen tolerance for the MAE.
The results for the CEBSDB task are reported in
Table 9: in this setting, the autoencoder needs a larger time to recover from induced perturbation. Occluding the breathing signal causes no perturbation for both
and the
, while the effect is low for the
model. Compared with the ABP estimation task, perturbation durations are, in general, lower, with the exception of the autoencoder model. This effect may be due to the nature of the predictive task: the SCG signal has higher variability than ABP, which is probably causing models to recover faster from alterations.
6.4. Visualizing Sub-Signal Occlusion Effects
The increasing availability of medical datasets motivates the need for tools to make sense of this large amount of information [
41]; one of the fastest and most effective ways to convey key aspects of data under analysis is by visualization. The proposed explanation is targeted at experts in the medical domain. By
expert in the medical domain, we mean a clinician or doctor, that is, a person who has no professional computer science background but rather a medical one.
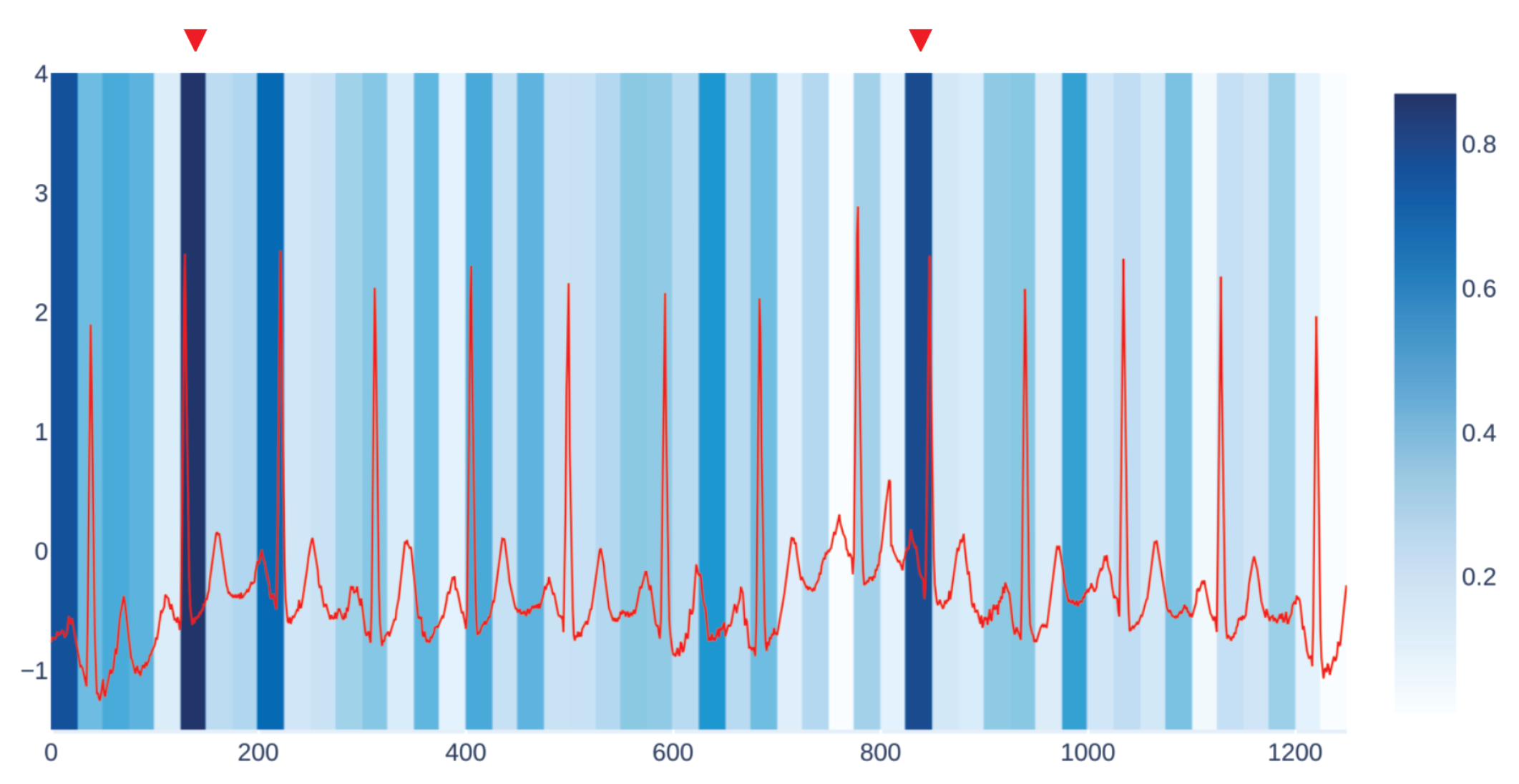
We get our visualization by overlapping two different kinds of plots. The first one is the plot of the input signal we are considering, which in the case of CBPEDS, is either an ECG curve or a PPG curve. The second one is a windowed heatmap used as a background for the first plot. The heatmap is generated by occluding the signal under analysis for a specific user-defined window of time, with the approach described in
Section 4.2.
For each occluded window index, we plot the associated MAE error with a proportionally intense background colour.
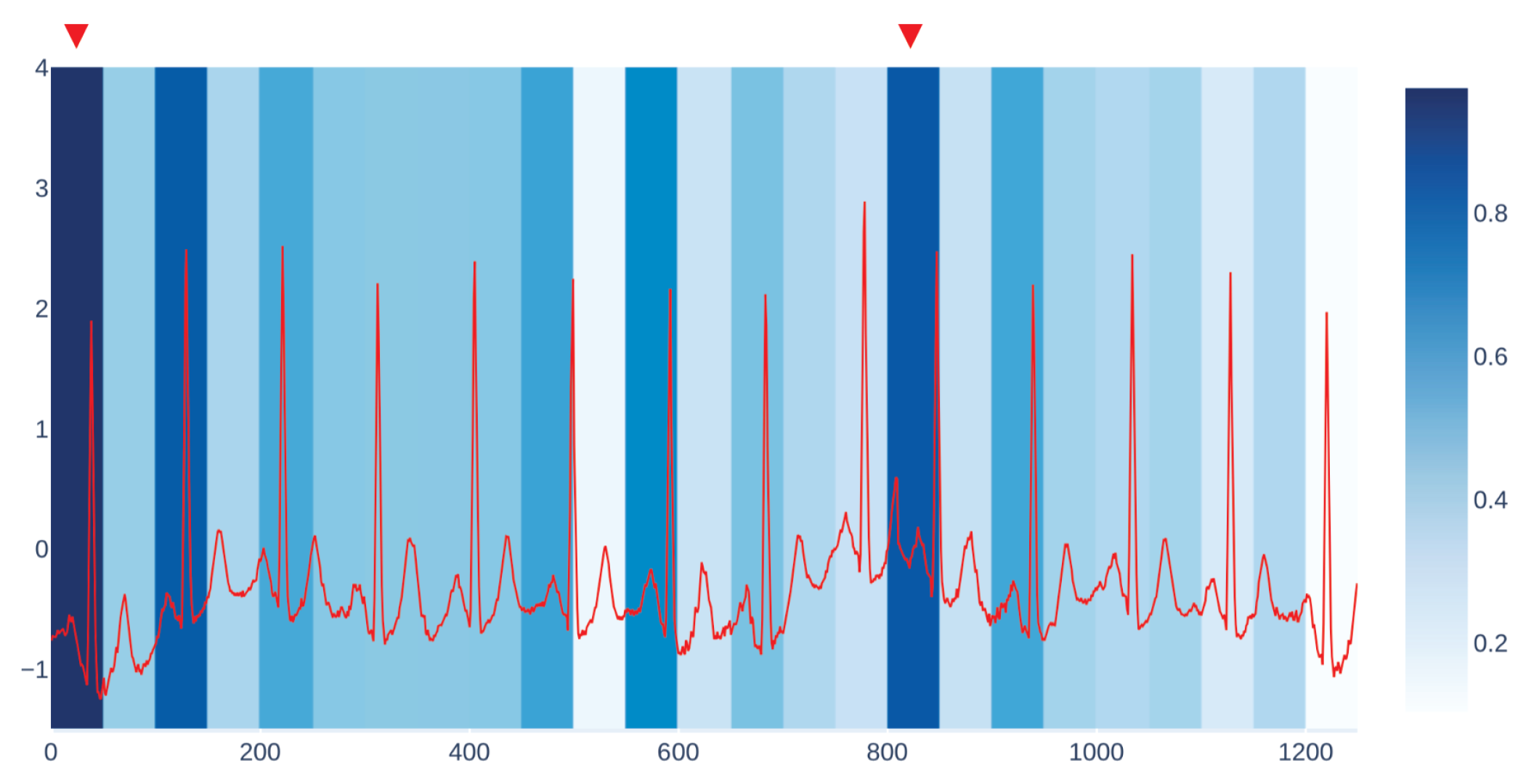
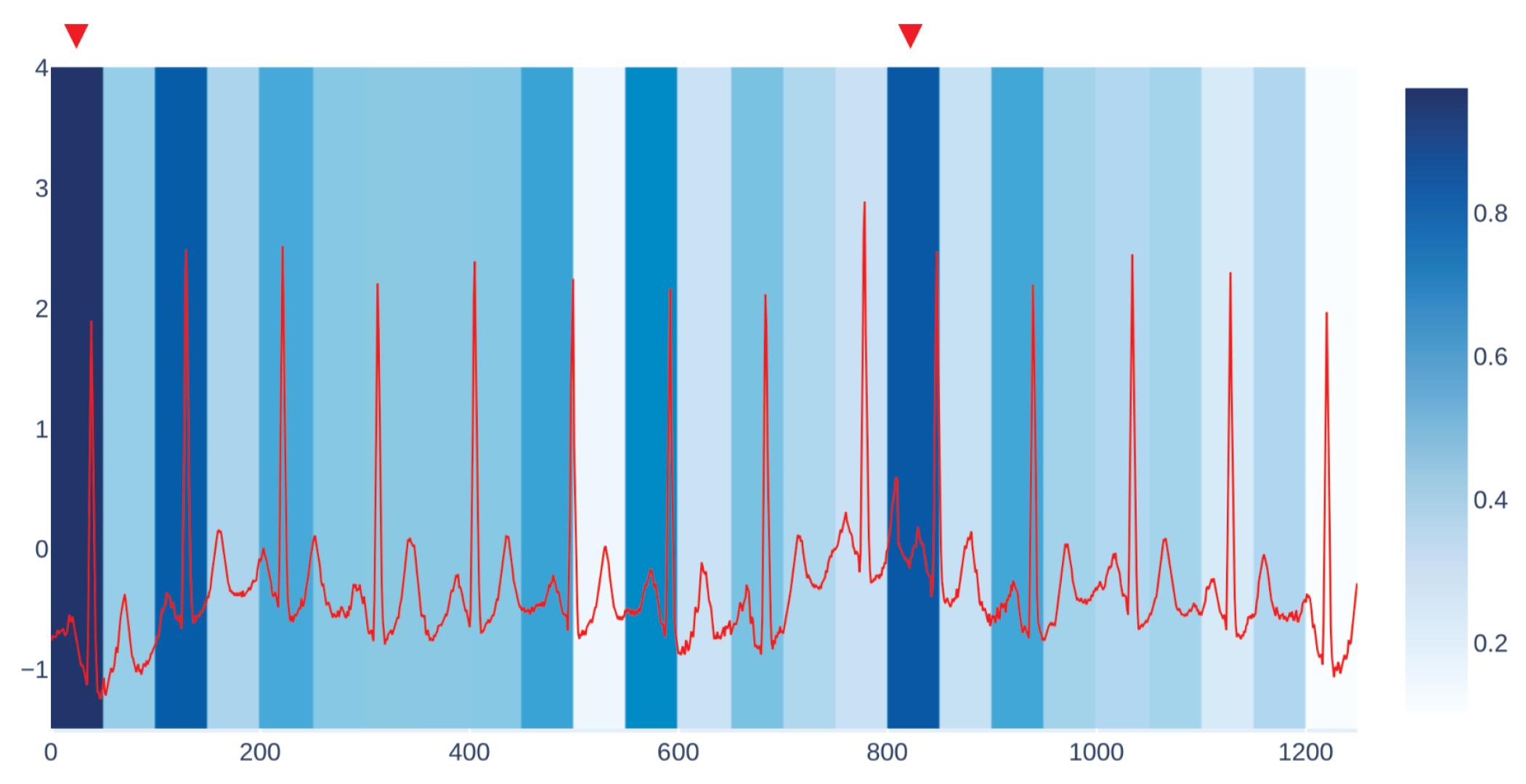
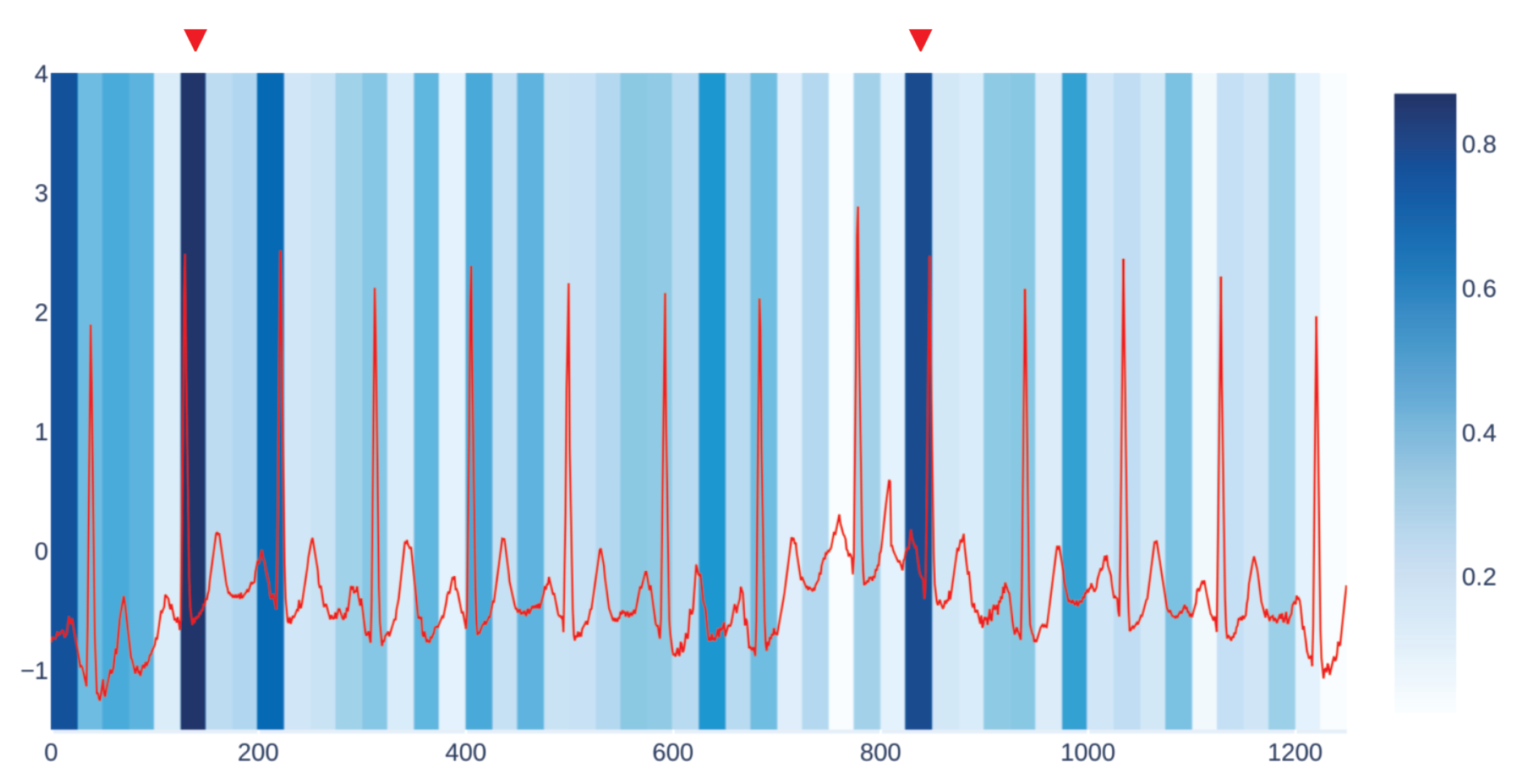
Figure 3 shows an example of our visualization of the occlusion contribution for an ECG signal from the CBPEDS dataset with a window occlusion size of 50 timesteps. For the ECG signal analysed, it is clear that an occlusion in the first window of the signal results in a higher error. Moreover, the section of the signal around the 800th time step (indicated with a red triangle) is also associated with a high MAE. By observing this visualization, clinicians can get an insight into which portion of the input signals are influential for the output prediction of the model and assess whether the highlighted sub-signals are critical morphological features employed for classical diagnosis methods. Another example of such a visualization for a different window size is reported in
Appendix C.
In order to assess the interpretation provided by
mime, we compared it with the Integrated Gradients (IG) method [
15].
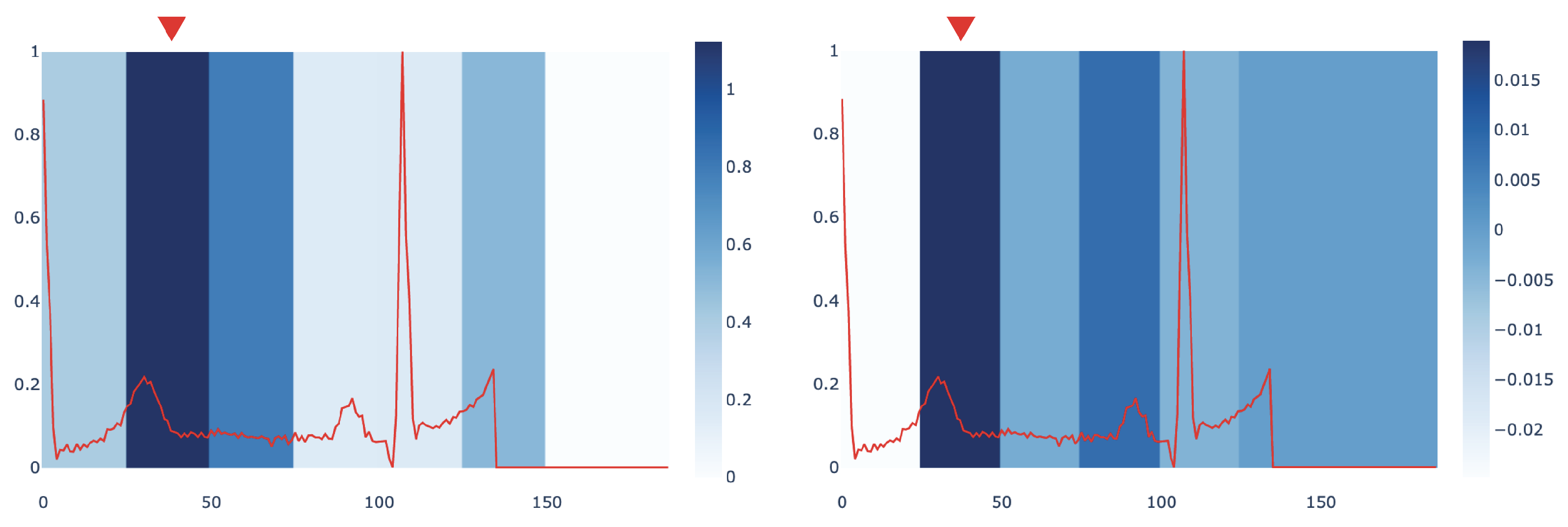
Figure 4 compares the most influential sub-signals of an ECG signal identified by
mime and IG in PTB dataset. The comparison points out how both methods are concordant in identifying the same important window as the key subsequence in the analysed signal.
We also provide a quantitative evaluation of the concordance between the
mime and IG interpretations. To this end, we compute a score measuring when the two methods select the same sub-signal or sub-signals that are temporally close as the most influential ones. Given that,
mime returns an importance score for each window of duration
d over the signal
x (as explained in
Section 4.6). We define an importance score, based on Integrated Gradients, to compare our results with the IG method. In particular, given a window of duration
d, we calculate this score as the sum of the IG values
of each timestep
j, i.e.,
. We assign an index to each window; thus, we can derive from each signal which window index corresponds to the highest importance score in both methods. We name them
and
. Then, we compute how many windows identified by
mime and IG perfectly match or differ by no more than 1 window index, i.e.,
. A preliminary investigation conducted on
found that
mime and IG have a concordance score of 68.20% for the signals in PTB dataset. We leave a more in-depth quantitative characterization of the relationships between the two approaches as future work.
6.5. Most Influential Sub-Signals
In this section, we describe the SOM-based analysis performed on the most influential samples extracted from the various datasets and according to the different models. The maps were trained using the MiniSOM python library [
42]. For each recurrent model, we trained several SOMs using the top 5000 sub-signals extracted from the corresponding training dataset as input. All maps have dimensions
. We used a Gaussian neighbourhood function with
and hexagonal topology. SOMs were trained with a learning rate
for a total of
steps.
After the training phase, we have tested the SOM with the top 2000 sub-signals extracted from the test portion of each dataset to build the
E matrix with
. We normalize
E to have values in the
range and project this information on the SOM as a heatmap.
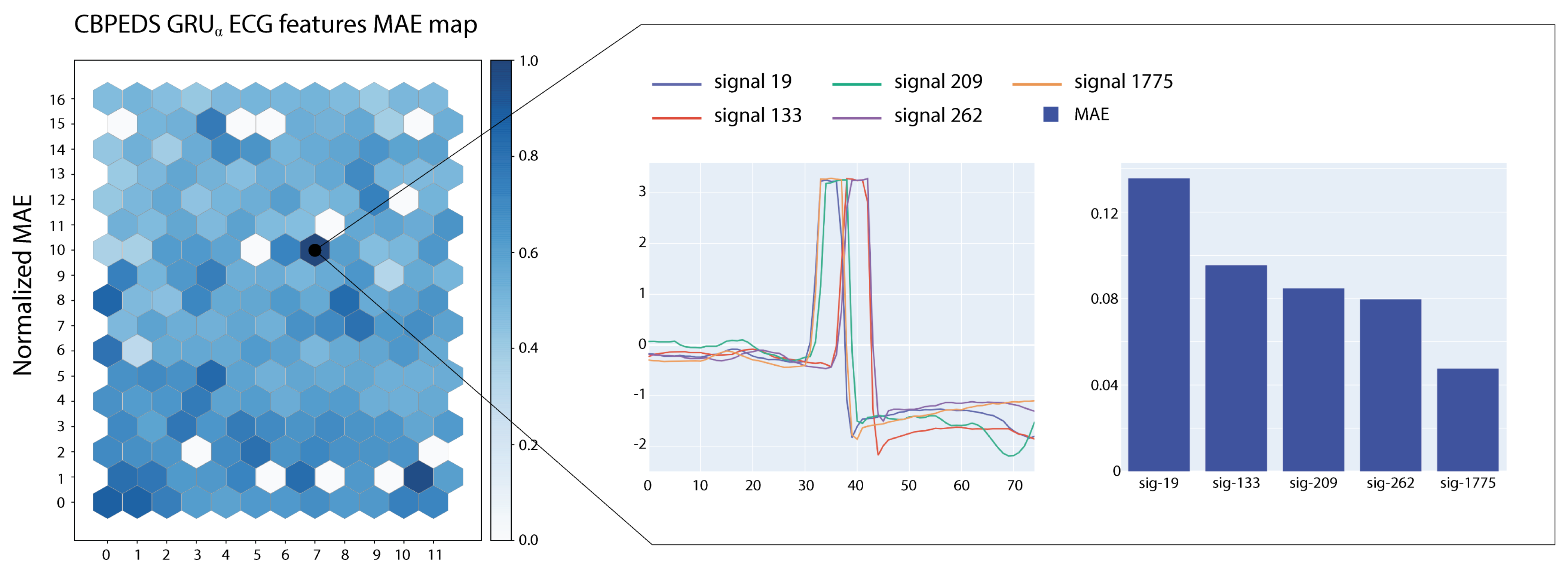
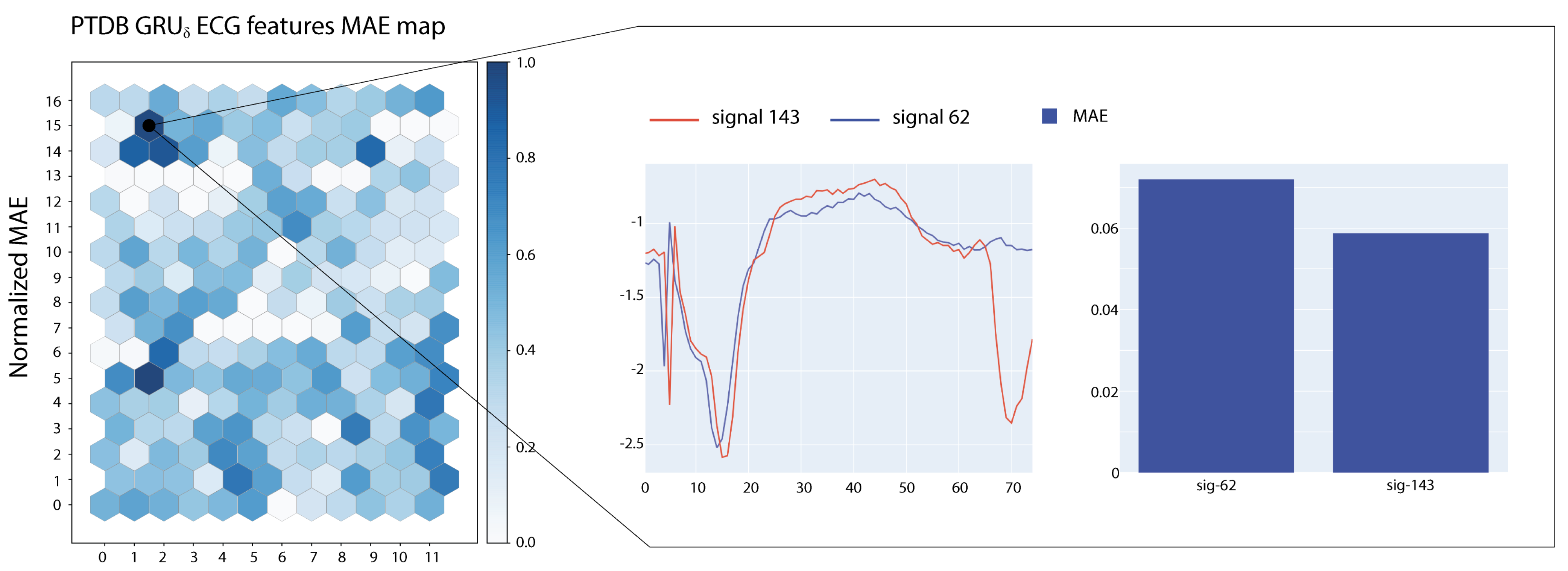
Figure 5 and
Figure 6 show two examples of visualizations obtained from the SOMs trained on ECG signals. In the figures, we report also a close-up on the prototypical signals associated with the most active neuron in the map. Signals associated with the highlighted neurons show large MAE errors and share morphological characteristics.
Self Organizing Maps obtained from the training dataset can be shared with users of the predictor to help them in assessing the behaviour of the model on novel data. By repeating the most influential sub-signal extraction phase on a production dataset, the SOM can be used to generate an updated visualization. Such visualization will provide a useful global overview of problematic sub-signals of new time series data.
7. Conclusions
In this work, we presented an interpretability approach for sequential data based on input occlusion. The approach is model-agnostic and only requires access to model inputs and outputs. Using the proposed methodology, we studied several recurrent neural networks trained on both regression and classification tasks and analysed the importance assigned by the models to each input signal.
Our results highlight how different models rely on different input signals to generate their predictions and show larger errors when that input is occluded. The perturbation induced by occlusion lasts longer when the occluded input are those resulting from the signal importance analysis. In regression tasks, recurrent models are more robust compared to the convolutional autoencoder baselines, with the CNN-GRUs suffering less from input alteration compared to the pure GRU models. The increased robustness is probably due to the convolutional layer providing “look-ahead” capabilities to the recurrent layer.
The simple feedforward network used as a baseline in the classification task is more robust with respect to the two recurrent models. As in the regression setting, the CNN-GRU performed better compared to the vanilla GRU and exhibited a minor loss of classification accuracy.
Moreover, leveraging the occlusion approach, we designed two different visualizations aimed at clinicians. The first one gives a detailed view of the error associated with the occlusion of portions of a single input signal.
The second one is based on Self Organizing Maps and is used to visually inspect and discover critical sub-signals associated with high prediction errors.
Interesting future work directions are the development of a data-driven algorithm to select the optimal occlusion window size and increasing the human–machine interaction degree. The latter would allow the proposed approach to be used in “what if?" scenarios, enabling faster comparisons of explanations generated from user-specified parameters.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}