Abstract
This paper deals with a prediction problem of a new targeting variable corresponding to a new explanatory variable given a training dataset. To predict the targeting variable, we consider a model tree, which is used to represent a conditional probabilistic structure of a targeting variable given an explanatory variable, and discuss statistical optimality for prediction based on the Bayes decision theory. The optimal prediction based on the Bayes decision theory is given by weighting all the model trees in the model tree candidate set, where the model tree candidate set is a set of model trees in which the true model tree is assumed to be included. Because the number of all the model trees in the model tree candidate set increases exponentially according to the maximum depth of model trees, the computational complexity of weighting them increases exponentially according to the maximum depth of model trees. To solve this issue, we introduce a notion of meta-tree and propose an algorithm called MTRF (Meta-Tree Random Forest) by using multiple meta-trees. Theoretical and experimental analyses of the MTRF show the superiority of the MTRF to previous decision tree-based algorithms.
1. Introduction
Various studies in pattern recognition deal with a prediction problem of a targeting variable corresponding to an explanatory variable given pairs of explanatory and targeting variable . In many of them, the targeting variable is predicted with a tree T. One way to use a tree T is to represent a function and predict . A tree T used to represent the function is called a decision tree in the literature. In this paper, however, this tree is called a function tree. This is because we distinguish a tree used to represent a function from a tree used to represent a data-generative model (A tree used to represent a data-generative model will be explained in the next paragraph.). In the previous studies, algorithms in which a single function tree is used are discussed in, e.g., CART [1]; algorithms in which multiple function trees are used are discussed, e.g., Random Forest [2] is an algorithm that constructs multiple function trees from and aggregates them to predict from . There are various extensions of Random Forest, e.g., Generalized Random Forest [3] generalizes the splitting rule of a function tree. Boosting is an algorithm that constructs a function tree sequentially from and combines the constructed function trees to predict from . There are various Boosting methods, e.g., gradient boosting method in Gradient Boost [4] and XGBoost [5]. Further, previous studies, such as Alternating Decision Forest [6] and Boosted Random Forest [7], combine the ideas of Random Forest and Boosting method. Moreover, combinations of the function trees and neural networks have also been discussed. In Neural Decision Forest [8], inner nodes are replaced by randomized multi-layer perceptrons. In Deep Neural Decision Forest [9], they are replaced by deep convolutional neural networks (CNN). In Adaptive Neural Trees [10], not only their nodes are replaced by CNNs but also their edges are replaced by nonlinear functions. In Deep Forest [11], Random Forests are combined in a cascade structure like deep CNNs. The function tree is also used to understand the deep neural network as an interpretable input-output function in Reference [12]. In these algorithms, a function tree is used to represent the function from to . Although this function is trained for the data under a certain criterion, statistical optimality for prediction of is not necessarily discussed theoretically because these algorithms usually do not assume a probabilistic data-generative structure of x and y. As we will describe later in detail, on the other hand, we assume a probabilistic data-generative structure of x and y, and consider a statistical optimal prediction of . This is the crucial difference between our study and the related works.
To predict the targeting variable , another way to use a tree T is to represent a data-generative model that represents a conditional probabilistic structure of y given . A tree T used to represent the data-generative model is called a model tree throughout this paper. Although not so many studies have assumed the model tree, Reference [13] has assumed it. Because Reference [13] assumed that a targeting variable is generated according to , statistical optimality for prediction of can be discussed theoretically. Specifically, based on the Bayes decision theory [14], Reference [13] proposed the optimal prediction of .
In order to explain the optimal prediction based on the Bayes decision theory in more detail, we introduce the terminology model tree candidate set. The model tree candidate set is a set of model trees in which the true model tree (When the model tree T is used to represent the true data-generative model , we call it true model tree.) is assumed to be included. One example of a model tree candidate set is a set of model trees whose depth is up to . The optimal prediction based on the Bayes decision theory is given by weighting all the model trees in the model tree candidate set and the optimal weight of each model tree is given by the posterior probability of the model tree T.
Because the number of all the model trees in the model tree candidate set increases exponentially according to the maximum depth of model trees, the computational complexity of weighting them increases exponentially according to the maximum depth of model trees. One way to reduce the computational complexity is to restrict the model tree candidate set. To represent a restricted model tree candidate set, Reference [13] proposed a notion of meta-tree. The concept of a meta-tree was originally used for data compression in information theory (see, e.g., Reference [15]) (Recently, the concept of a meta-tree was also used for image compression [16].). As shown in Figure 1, a model tree candidate set is composed of the model trees represented by the meta-tree.
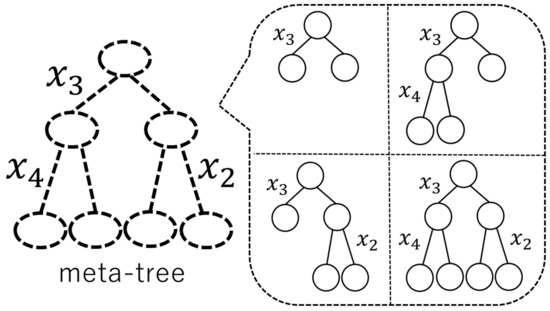
Figure 1.
An example of a meta-tree and four model trees represented by it.
A meta-tree is also used for the prediction of in the algorithm proposed by Reference [13]. In summary, a meta-tree has the following two roles: (i) it represents a model tree candidate set; and (ii) it is used for the prediction algorithm. The characteristics of a meta-tree are as follows:
- If the true model tree is in a model tree candidate set represented by a meta-tree, the statistically optimal prediction—optimal prediction based on the Bayes decision theory—can be calculated.
- The number of model trees in a model tree candidate set represented by a meta-tree increases exponentially according to the depth of the meta-tree.
- The computational cost in learning processes of a single meta-tree has the same order as that of a single function tree.
Under the assumption that the true model tree is in the restricted model tree candidate set represented by a meta-tree, Reference [13] proposed the optimal prediction based on the Bayes decision theory.
As we have described above, if the true model tree is actually included in the model tree candidate set, the optimal prediction based on the Bayes decision theory is calculated. Hence, it is desirable that we construct the model tree candidate set that includes as many model trees as possible within the allowed computational cost. Motivated by this fact, this paper extends the model tree candidate set compared with Reference [13]. Instead of considering a single meta-tree as in Reference [13], we consider multiple meta-trees. By using the model tree candidate set represented by multiple meta-trees, we predict based on the Bayes decision theory. We call this proposed algorithm -. The characteristics of MTRF are as follows:
- If the true model tree is in a model tree candidate set represented by any of the meta-trees of MTRF, the statistically optimal prediction—optimal prediction based on the Bayes decision theory— can be calculated.
- The number of model trees in the model tree candidate set represented by multiple meta-trees is constant times larger than those contained in a single meta-tree.
- The computational cost in learning processes of meta-trees of MTRF is the same order as that of multiple function trees of Random Forest.
Regarding a meta-tree in Reference [13] or multiple meta-trees of MTRF, how to construct the meta-tree/multiple meta-trees is a problem. One way to solve this issue is to use the function tree-based algorithms; for example, a meta-tree in Reference [13] can be constructed by regarding a function tree in CART as a meta-tree; multiple meta-trees of MTRF can be constructed by regarding function trees in Random Forest as meta-trees. In this way, by regarding a function tree as a meta-tree, our proposed method can be applied to any practical applications in which a function-tree based algorithm is used—insurance claim task (e.g., Reference [5]), letter classification task (e.g., Reference [6]), semantic segmentation (e.g., Reference [8]), face recognition (e.g., Reference [11]), music classification (e.g., Reference [11]), etc.—and we can improve every previous function tree-based algorithm. This is because we can perform a prediction of by using more model trees compared with the previous algorithms. More detailed discussion will be given in Section 3 and Section 4.
The rest of this paper is organized as follows. In Section 2, we state the preliminaries of our study. Section 3 explains our proposed method—MTRF. In Section 4, we revisit the previous studies, such as CART [1] and Random Forest [2], and compare them with MTRF. Section 5 shows the results of experiments. Section 6 concludes this paper.
2. Preliminaries
2.1. Model Tree
Let K denote the dimension of explanatory variables. The space of feature values is denoted by , and the explanatory variable is denoted by . In addition, the space of label values is denoted by , and the targeting variable is denoted by .
In the field of pattern recognition, the probabilistic structure of x and y is not necessarily assumed. In particular, it is not assumed in most of function tree-based algorithms. In contrast, we consider a triplet of defined in Definition 1 below and assume the probabilistic structure as in Definition 2. We call a model tree (In Section 1, we called T a model tree. More precisely speaking, however, a model tree is .) and a tree parameter.
Definition 1.
The notation T denotes the -ary regular (Here, “regular” means that all inner nodes have child nodes.) tree whose depth is up to , and denotes the set of T. Let s be a node of a tree and be a set of s. The set of the inner nodes of T is denoted by , and the set of the leaf nodes of T is denoted by . Let be a component of the feature assign vector of node s. The explanatory variable is assigned to the inner node . Let denote a feature assign vector, and denote a set of . Let , where , be a parameter assigned to . We define , and Θ is the set of .
Definition 2.
Because the value of explanatory variable corresponds to a path from the root node to the leaf node of T whose feature assign vector is , let denote the corresponding leaf node. Then, for given , , T, and k, the label variable y is generated according to
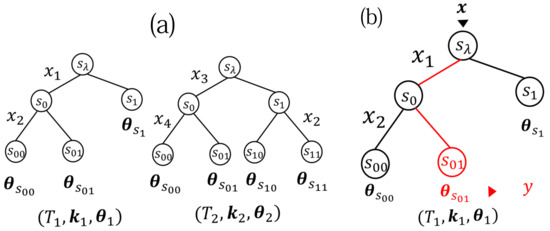
Figure 2.
(a) Two examples of and , where and are 2-ary regular trees, , and . (b) .
2.2. Problem Setup
In this subsection, we introduce our problem setup. Let denote the value of explanatory variable of the i-th data and . We assume that are i.i.d. random variables drawn from a probability distribution. Let denote the targeting variable of the i-th data and . We assume that are generated according to defined in Section 2.1. In regard to this, we assume that the true model tree and true tree parameter are unknown, but a model tree candidate set is known. Note that, as we have explained in Section 1, the model tree candidate set is a set of model trees in which the true model tree is assumed to be included. Further, we assume that a class of parametrized distribution is known.
The purpose of the prediction problem is to predict unknown targeting variable corresponding to an explanatory variable by using the given data , , .
2.3. Optimal Prediction Based on the Bayes Decision Theory
We introduce a statistically optimal prediction under the problem setup in Section 2.2. From the viewpoint of the Bayes decision theory [14], we shall derive the optimal prediction based on the Bayes decision theory. To this end, we assume priors , , and .
First, we define a decision function as
Second, we define a 0–1 loss as follows:
Third, using the 0–1 loss, we define the loss function, which is the expectation of the 0–1 loss taken by new targeting variable :
Next, given the loss function, we define the risk function, which is the expectation of the loss function taken by training data , , and :
Finally, the Bayes risk function, which is the expectation of the risk function taken by , T, and , is defined as
Then, we have the following theorem:
Theorem 1.
Under the setup in Section 2.2, the decision function that minimizes the Bayes risk function is given as
The proof of Theorem 1 is in Appendix A. We call the Bayes decision.
2.4. Previous Study
In this subsection, we introduce how to calculate the Bayes decision in Reference [13]. Because the proof of Reference [13] lacks some explanation, we give more rigorous discussion in comparison. This is one of the contributions in this paper.
As we have explained in Section 1, Reference [13] introduced the concept of a “meta-tree” to represent a restricted model tree candidate set. For T and , a meta-tree—denoted by —represents a model tree candidate set that is composed of model trees where is a sub-tree of T and . An example of is shown in Figure 3, where T is a complete tree with and . In this example, a meta-tree represents a model tree candidate set which is composed of four model trees. A meta-tree is also used for the prediction of in the algorithm proposed by Reference [13]. In short, a meta-tree has the two roles: first, it represents a model tree candidate set, and, second, it is used for the prediction algorithm.
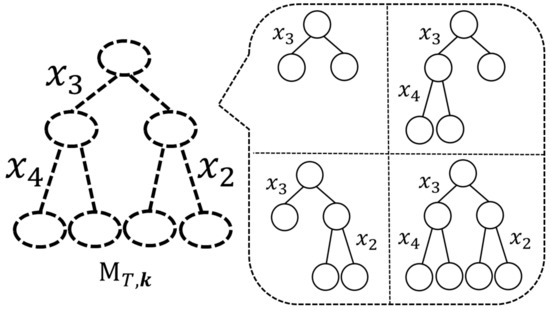
Figure 3.
An example of a meta-tree , where T is a complete tree with and .
Let denote a set of T represented by a meta-tree and let . Under the assumption that the true model tree is included in , the Bayes decision in Theorem 1 is expressed as
Reference [13] exactly calculates (9) and (10) under some assumptions. We describe them in Section 2.4.1 and Section 2.4.2, respectively.
2.4.1. Expectation over the Parameters
In this subsection, we explain how to calculate (9). To calculate (9) analytically, a conjugate prior of given T and , is assumed.
Assumption 1.
We assume for , where denotes the hyper-parameter of the Dirichlet distribution.
Under this assumption, has a closed form expression and (9) can be calculated exactly. In addition, has an important property. We describe this in the next lemma as a preparation of Section 2.4.2.
Lemma 1.
For any , , , and , if , then
The proof of Lemma 1 is in Appendix B. From this lemma, the right- and left-hand sides of (11) are denoted by because they depend on not T and but .
2.4.2. Summation over All Model Trees Represented by a Meta-Tree
In this subsection, we explain how to calculate (10). The exact calculation of (10) needs to take summation over all model trees represented by a single meta-tree. However, the computational complexity of this calculation is huge because the number of model trees increases exponentially according to the depth of meta-tree. Reference [13] solved this problem. The advantages of using the method proposed in Reference [13] are as follows:
To execute this method, an assumption about the prior probability distribution of T—Assumption A2—is required. It should be noted that is different from the construction method of function trees, given and .
Assumption A2.
Let denote a hyper-parameter assigned to any node . Then, we assume the prior of as
where for a leaf node s of a meta-tree .
Remark 1.
As we have described in Section 1, a meta-tree is used for the prediction of in the algorithm proposed by Reference [13]. By using a meta-tree , the recursive function to calculate the Bayes decision (10) is defined as follows.
Definition 3.
We define the following recursive function for any node s on the path in corresponding to .
where is the child node of s on the path corresponding to in , and is also recursively updated as follows:
Now, (10) can be calculated as shown in the following theorem.
Theorem 2.
can be calculated by
where is the root node of . In addition, can be calculated as
The proof of Theorem 2 is in Appendix C. Surprisingly, the computational complexity of calculating (10) is by using this theorem.
3. Proposed Method
In this section, we introduce our proposed method. Here, we reconsider the general setup where . Recall that the Bayes decision (7) is
where is defined as in (10). In (17), can be calculated in the same way as in Section 2.4. However, regarding the calculation of (17), we need to calculate for all that satisfies . Because this computational cost increases exponentially depending to , it is hard to calculate all of them in general. To reduce the computational complexity of (17), we restrict the model tree candidate set to the set represented by multiple meta-trees. The advantages of building multiple meta-trees are as follows:
- As we have explained in Section 2.4.2, the number of model trees represented by each of the meta-trees increases exponentially according to the depth of meta-trees. In addition, the number of model trees in multiple meta-trees is constant times larger than those contained in a single meta-tree.
- If the true model tree is a sub-tree of any of the meta-trees, the statistically optimal prediction—optimal prediction based on the Bayes decision theory—can be calculated.
- If we build B meta-trees, the computational cost of it in learning parameters is , which is the same as that of building B function trees.
Now, we introduce the next assumption.
Assumption A3.
For B meta-trees , we define . Then, we assume a uniform distribution on as a prior probability distribution of .
An example of is shown in Figure 4.
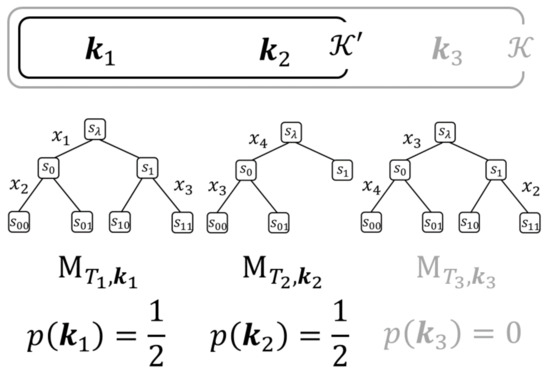
Figure 4.
An example of and . In this example, the prior probability and .
Next, we prove the following lemma about computing a posterior probability distribution of . In fact, the recursive function we have defined in Definition 3 is also useful to calculate a posterior probability distribution on sequentially. The proof of Lemma 2 is in Appendix D.
Lemma 2.
By decomposing and into the set of i-th data and performing the recursive calculation of as in (13), a posterior probability distribution of is expressed as follows:
From Theorem 2 and Lemma 2, we immediately obtain the next theorem.
Theorem 3.
Let us consider the model tree candidate set represented by B meta-trees, i.e.,
By using Theorem 3, we can calculate the optimal (possibly sub-optimal) prediction of the Bayes decision effectively. We name this algorithm Meta-Tree Random Forest (MTRF). We summarize MTRF in Algorithm 1.
| Algorithm 1 MTRF |
Remark 2.
One way to construct multiple meta-trees is to use the ideas of Random Forest. Random Forest builds function trees with the impurity (e.g., the entropy and the Gini coefficient) from the training data and . By regarding that are built by Random Forest as meta-trees , we can construct B meta-trees. In our experiments in Section 5, we adopt this method. The computational complexity of MTRF is in learning processes, which is the same as that of Random Forest. This is computable unless n, B, or are not extremely huge. In addition, we can parallelize the procedure on each meta-tree.
4. CART and Random Forest Revisited and Comparison with MTRF
4.1. CART and Random Forest Revisited
Although CART [1] and Random Forest [2] do not assume the model tree and they use trees to express a function (i.e., function tree), they can be regarded as methods of constructing a model tree candidate set.
First, we consider algorithms that use a single function tree, such as CART [1]. Such algorithms can be regarded as selecting a single model tree and predicting by using the single function tree that corresponds to the single model tree. For example, the prediction of CART—denoted by —is given by
where and denote an estimated model tree and tree parameter, respectively.
Second, as another example, let us consider Random Forest [2]. Random Forest can be regarded as selecting multiple model trees and predicting by weighting the multiple function trees that correspond to the multiple model trees. It should be noted that the number of function trees is equal to the number of model trees in Random Forest. The prediction of Random Forest—denoted by —is given by
where denotes the set of model trees that are constructed by Random Forest.
4.2. Comparison of Random Forest with MTRF
Let us consider the situation where the trees that represent the function trees constructed by Random Forest are meta-trees of MTRF. Then, the size of model tree candidate set is far larger in MTRF than in Random Forest.
Random Forest can be regarded as approximating (9), (10) and (17) as in (23). Further, the approximation of the weight is not accurate and the optimality of each function tree’s weight for predicting has not usually been discussed. In contrast, MTRF calculates the Bayes decision in (9) and (10) exactly and approximates (17) as in (20). Moreover, the optimal weights of T and are given by (16) and (18), respectively.
5. Experiments
Most machine learning algorithms require rich numerical experiments to confirm the improvement independent of a specific dataset. However, in our paper, such an improvement is theoretically explained in Section 3 and Section 4. If we redefine all the function trees constructed by any existing method as meta-trees, we can necessarily improve it in a sense of the Bayes risk function since our model tree candidate set contains all the model trees that correspond to the original function trees. This improvement is independent of both datasets and the original methods. Therefore, we perform our experiment only on three types of datasets and compare with the Random Forest. Similar results should be given in any other situation.
5.1. Experiment 1
Although the theoretical superiority of MTRF to Random Forest has been explained in Section 3 and Section 4, we performed Experiment 1 to make sure their performance on synthetic data. The procedure of Experiment 1 is the following:
- We initialize the hyper-parameter , which is assigned on each node s.
- To make true model trees diverse, we determinate an index of a true feature assign vector and the true model trees as below:
- In the true model tree (A), we assign to the node whose depth is j.
- –
- true model tree (A-1): the complete 2-ary model tree with depth 4.
- –
- true model tree (A-2): the regular 2-ary model tree with depth 4. This model tree holds the structure that only left nodes have child nodes and right nodes does not.
- In the true model tree (B), we assign all different variables to the node.
- –
- true model tree (B-1): the complete 2-ary model tree with depth 4.
- We determine parameters according to the Dirichlet distribution.
- We generate K-dimensional n training data from the true model tree and generate K-dimensional 100 test data from the true model tree. From (7), Bayes decision takes the same value for any distribution . Therefore, in our experiments, we set a probability distribution of as follows: Let denote the uniform distribution on . Then, a probability distribution of is expressed as
- We perform Random Forest that utilizes B function trees . We set its impurity as the entropy and max-depth as . Afterward, we make B meta-trees . (Of course, their max-depth are , too.) Then, we calculate the average prediction error rate of Random Forest and MTRF, where we set the hyper-parameter as in MTRF.
- We repeat Steps 3∼5Q times.
Figure 5 shows an example of these model trees (note that, for simplicity, we illustrate the model trees with depth 2).
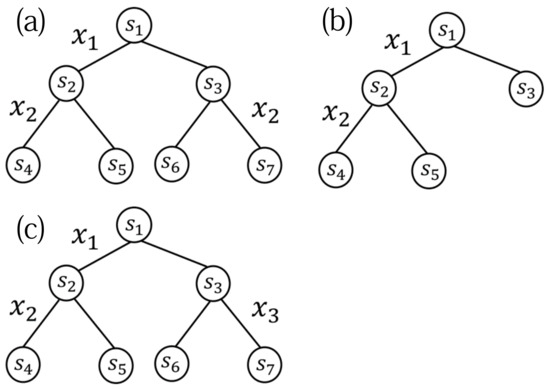
Figure 5.
An example of true model tree (A-1) (a), model tree (A-2) (b), and model tree (B-1) (c).
We set , , and . The result is shown in Figure 6.
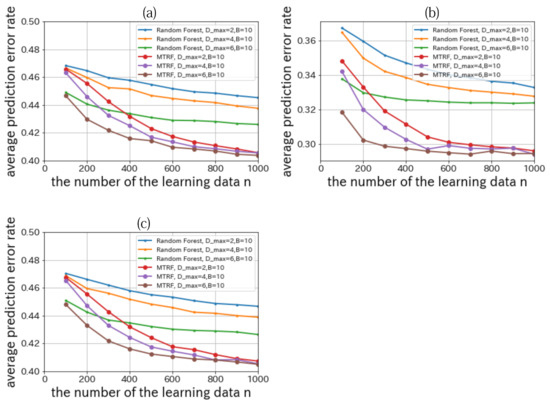
Figure 6.
Relationships between the number of learning data n and the average prediction error rate where the true model tree is model (A-1) (a), model (A-2) (b), and model (B-1) (c).
From Figure 6, when we compare the performance of Random Forest with that of MTRF, we can confirm that MTRF outperforms Random Forest in all conditions. These results are theoretically reasonable because the trees that represent the function trees constructed by Random Forest are meta-trees of MTRF.
5.2. Experiment 2
In Experiment 2, we used real data (nursery school data and mushroom data) in the UCI repository (University of California, Irvine Machine Learning Repository). The procedure of Experiment 2 is mostly the same as that of Experiment 1, but the way of sampling data is different; instead of Steps 2, 3, and 4 in Experiment 1, we randomly sampled data from the whole dataset and divided them to n training data and t test data. We repeated the random sampling of the data for 2500 times.
The detail on nursery school data is as follows. The explanatory variables are discrete 8 attributes of a family whose child wants to enter a nursery school (e.g., finance, health, and family structure). The dimension of each attributes is up to 5. The targeting variable is whether the nursery school should welcome him/her or not. We want to consider that a new child should be welcomed with his attributes and learning data. We set , , , , , , and . The result is shown in Figure 7a.
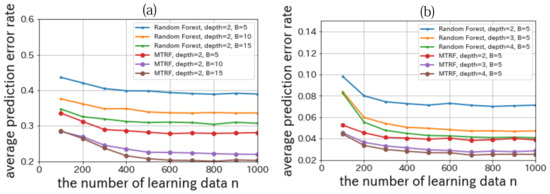
Figure 7.
Relationships between the number of the learning data n and the average prediction error rate on nursery school data (a)/mushroom data (b) in UCI repository.
The detail on mushroom data is as follows. The explanatory variables are discrete 22 attributes of a mushroom (e.g., smell, shape, surface, and color). The dimension of each attributes is up to 10. The targeting variable is whether the mushroom can be eaten, not be eaten, or unknown. We want to predict that a new mushroom can be eaten, with its attributes and learning data. We set , ,, , , , and . The result is shown in Figure 7b.
From Figure 7, we can confirm MTRF outperforms Random Forest in all conditions.
6. Conclusions and Future Work
In this paper, we have considered a model tree and derived the Bayes decision. We have addressed the computational complexity problem of the Bayes decision by introducing a notion of meta-tree, and proposed MTRF (Meta-Tree Random Forest), which uses multiple meta-trees. As we have shown in Theorem 3, if the true model tree is included in the model tree candidate set represented by multiple meta-trees, MTRF calculates the Bayes decision with efficient computational cost. Even if the true model tree is not included in the model tree candidate set represented by multiple meta-trees, MTRF gives the approximation of the Bayes decision. The advantages of MTRF have been theoretically analyzed. In Section 4, we have explained that, if we redefine all the function trees constructed by Random Forest as meta-trees, we can necessarily improve it in a sense of the Bayes risk function since our model tree candidate set contains all the model trees that correspond to the original function trees. We have performed experiments in Section 5 to check the theoretical analysis.
As we have described in Section 1, it is desirable that we construct the model tree candidate set that includes as many model trees as possible within the allowed computational cost. This is because if the true model tree is included in the model tree candidate set, the Bayes decision is calculated. Hence, the main problem of MTRF is how to construct multiple meta-trees. In Section 5, we have constructed multiple meta-trees by using the idea of Random Forest. However, we can consider other ways to construct multiple meta-trees. One of the possible future directions is to use other ideas, such as Boosting. This is one of the future works in our research.
Author Contributions
Conceptualization, N.D., S.S., Y.N. and T.M.; Methodology, N.D., S.S., Y.N. and T.M.; Software, N.D. and Y.N.; Validation, N.D., S.S., Y.N. and T.M.; Formal Analysis, N.D., S.S., Y.N. and T.M.; Investigation, N.D., S.S., Y.N. and T.M.; Resources, N.D.; Data Curation, N.D.; Writing—Original Draft Preparation, N.D., S.S. and Y.N.; Writing—Review & Editing, N.D., S.S., Y.N. and T.M.; Visualization, N.D., S.S. and Y.N.; Supervision, T.M.; Project Administration, T.M.; Funding Acquisition, S.S. and T.M. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by JSPS KAKENHI Grant Numbers JP17K06446, JP19K04914 and JP19K14989.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://archive.ics.uci.edu/ml/datasets/Nursery and https://archive.ics.uci.edu/ml/datasets/Mushroom (accessed on 8 June 2021).
Acknowledgments
The authors would like to thank all the members of Matsushima Lab. for their comments and discussions.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviation is used in this manuscript:
| MTRF | Meta-Tree Random Forest |
Appendix A. Proof of Theorem 1
Appendix B. Proof of Lemma 1
Appendix C. Proof of Theorem 2
Proof of Theorem 2.
We prove Theorem 2 with mathematical induction according to the following three steps:
In the following, we give a proof of each step.
Step 1: First, we prove (15) for . Let denote the set of all nodes on the path of in the meta-tree . Let . Then, we transform as below:
where (a) follows from (10), and (b) follows from Lemma 1. The right-hand side of (A12) contains the summation with respect to T as below:
Regarding (A13), we prove the following lemmas.
Lemma A1.
Proof of Lemma A1.
In this proof, for simplicity, we use instead of . Before showing the formal proof, we consider an example. Let us consider the set of tree shown in Figure A1. In this example, is composed of five model trees. Among these model trees, is included in and – are included in . Therefore, the next equation holds:
where (a) follows from for a leaf node s of the meta-tree (see Assumption A2).
Now, we give the formal proof. Because
we prove
by induction.
Let denote the tree that consists of only the root node of T. Then, we have
Because each tree is identified by sub-trees whose root nodes are the child nodes of , let denote the j-th child node of for and denote the set of sub-trees whose root node is . Figure A1 shows an example of and . Then, the summation in the right-hand side of (A23) is factorized as
Consequently, because the goal is to show (A22), Lemma A1 is proven by induction. □
Lemma A2.
Let denote the set of all ancestor nodes of s. Then, we have

Figure A1.
An illustration of (left lower enclosure) and (right lower enclosure). In the trees –, has child nodes and . Therefore, we can decompose the child nodes of in the trees – into the nodes included in and the nodes included in .
Figure A1.
An illustration of (left lower enclosure) and (right lower enclosure). In the trees –, has child nodes and . Therefore, we can decompose the child nodes of in the trees – into the nodes included in and the nodes included in .

Proof of Lemma A2.
where (a) follows from Assumption 2, and (b) follows from the fact that all trees have the node s and its ancestor nodes.
To prove (A28), we can apply the factorization of Lemma A1 to (A28) if we regard the node whose parent node is s or an element of as a root node, as shown in Figure A2. Let J denote the number of that factorized trees, and let denote the root node of j-th factorized tree. Then, we can rewrite (A28) as follows:
Hence, the proof is complete. □

Figure A2.
An illustration of ,,, and . In this example, the dotted line represents the path from to s and is the set of two parent nodes of s. Furthermore, the rectangles of the dotted line represent four factorized trees , , , and .
Figure A2.
An illustration of ,,, and . In this example, the dotted line represents the path from to s and is the set of two parent nodes of s. Furthermore, the rectangles of the dotted line represent four factorized trees , , , and .

Here, let denote the node that is a child node of and an element of . Then, we can decompose
The equation (A32) has a similar structure to (A31). Like this, we can decompose (A31) recursively to the leaf node that is included in . In addition, we can utilize the assumption for any leaf nodes s of a meta-tree . Consequently, we can prove that (A31) coincides with .
Step 2: Next, we prove (16) for . Because the parameters are updated only when their nodes are the elements of , we decompose the right-hand side of (16) for as follows:
We transform the part of (A34), whose parameters are renewed by and , as follows:
where (a) follows from is uniquely determined as , (b) follows from Definition 3, and (c) follows from reduction of .
Thus, the right-hand side of (A34) is calculated as
where (a) follows from Assumption 2, the denominator of (b) follows from Theorem 2 for , the numerator of (b) follows from Definition 3 and the definition of , and (c) follows from the Bayes’ theorem.
Appendix D. Proof of Lemma 2
Proof of Lemma 2.
where (a) follows from Assumption A3 and are i.i.d.; (b) follows from Theorem 2 at each . □
References
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Athey, S.; Tibshirani, J.; Wager, S. Generalized Random Forests. Ann. Stat. 2019, 47, 1148–1178. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’16), San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Schulter, S.; Wohlhart, P.; Leistner, C.; Saffari, A.; Roth, P.M.; Bischof, H. Alternating Decision Forests. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 508–515. [Google Scholar] [CrossRef]
- Mishina, Y.; Murata, R.; Yamauchi, Y.; Yamashita, T.; Fujiyoshi, H. Boosted Random Forest. IEICE Trans. Inf. Syst. 2015, E98.D, 1630–1636. [Google Scholar] [CrossRef]
- Bulo, S.; Kontschieder, P. Neural Decision Forests for Semantic Image Labelling. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 81–88. [Google Scholar] [CrossRef]
- Kontschieder, P.; Fiterau, M.; Criminisi, A.; Bulo, S.R. Deep Neural Decision Forests. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1467–1475. [Google Scholar] [CrossRef]
- Tanno, R.; Arulkumaran, K.; Alexander, D.; Criminisi, A.; Nori, A. Adaptive Neural Trees. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6166–6175. [Google Scholar]
- Zhou, Z.H.; Feng, J. Deep Forest: Towards An Alternative to Deep Neural Networks. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 3553–3559. [Google Scholar] [CrossRef]
- Frosst, N.; Hinton, G. Distilling a Neural Network Into a Soft Decision Tree. arXiv 2017, arXiv:1711.09784. [Google Scholar]
- Suko, T.; Nomura, R.; Matsushima, T.; Hirasawa, S. Prediction Algorithm for Decision Tree Model. IEICE Tech. Rep. Theor. Found. Comput. 2003, 103, 93–98. (In Japanese) [Google Scholar]
- Berger, J.O. Statistical Decision Theory and Bayesian Analysis; Springer: New York, NY, USA, 1985. [Google Scholar] [CrossRef]
- Matsushima, T.; Hirasawa, S. A Bayes Coding Algorithm Using Context Tree. In Proceedings of the 1994 IEEE International Symposium on Information Theory, Trondheim, Norway, 27 June–1 July 1994; p. 386. [Google Scholar] [CrossRef]
- Nakahara, Y.; Matsushima, T. A Stochastic Model of Block Segmentation Based on the Quadtree and the Bayes Code for It. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020; pp. 293–302. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).