1. Introduction
Modeling time series of counts is relevant in a range of application areas, including the dynamics of the number of infectious diseases, number of road accidents or number of bank failures. In many applications, such count data dynamics are correlated across several data series. Examples include from correlated number of bank failures [
1], number of crimes [
2] to COVID-19 contagion dynamics [
3]. The analysis of such correlations provides detailed information about the overall connectedness of the series, as well as the dynamics of an individual series conditional on the others. Several multivariate count data models have been proposed to capture the overall connectedness of multivariate count data. Each one of these models has different underlying assumptions as well as computational challenges. We present a comparative study of two families of multivariate count data models, namely State Space Models (SSM) and log-linear multivariate autoregressive conditional intensity (MACI) models, based on simulation studies and two empirical applications.
We provide some examples of the count data and discuss particular properties that one desires to model when dealing with such data. In this paper, we assume that the counts are unbounded and we assume both models to be stationary. For discussion on the difference between bounded and unbounded count data and the difference of the modeling approaches for these data we refer to [
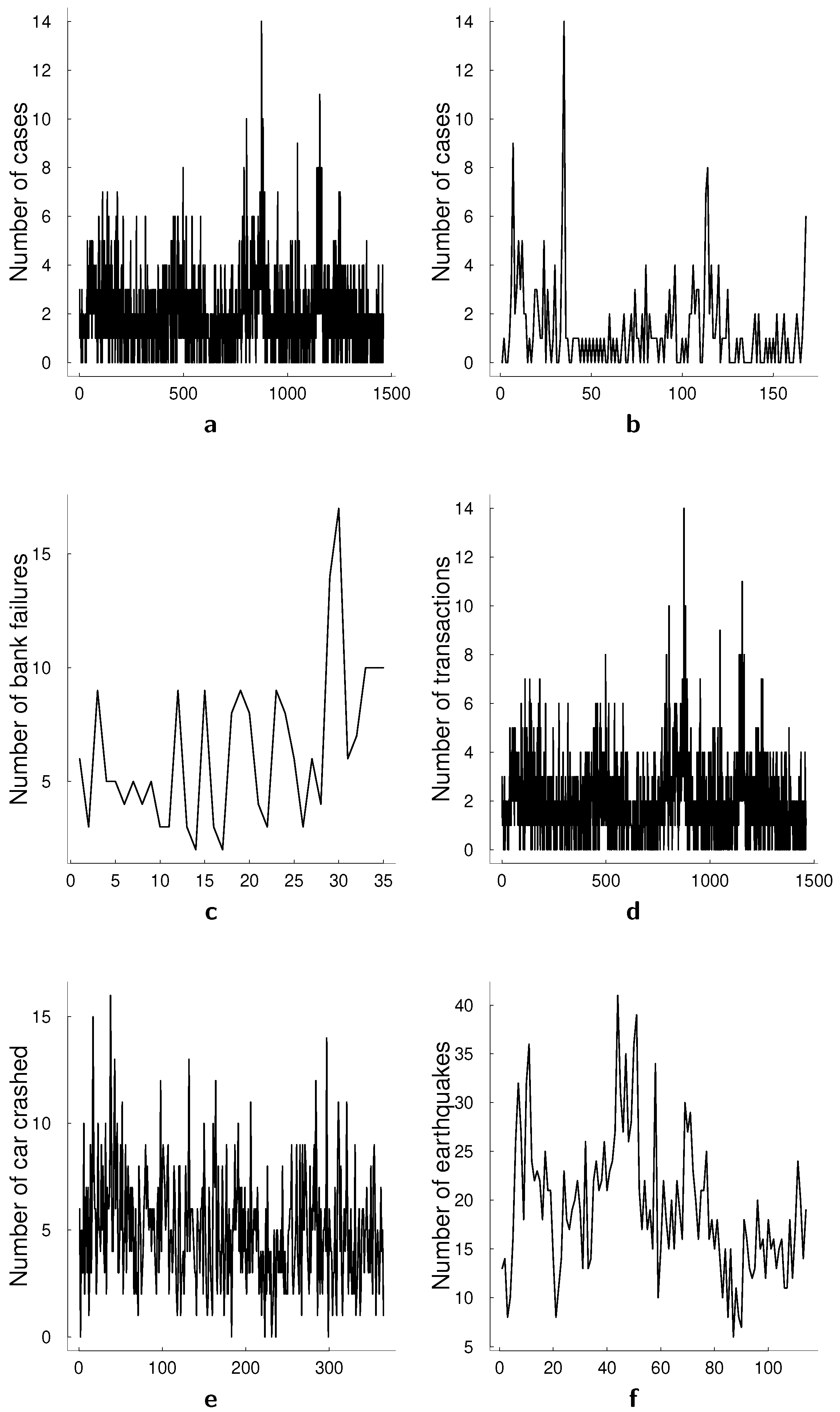
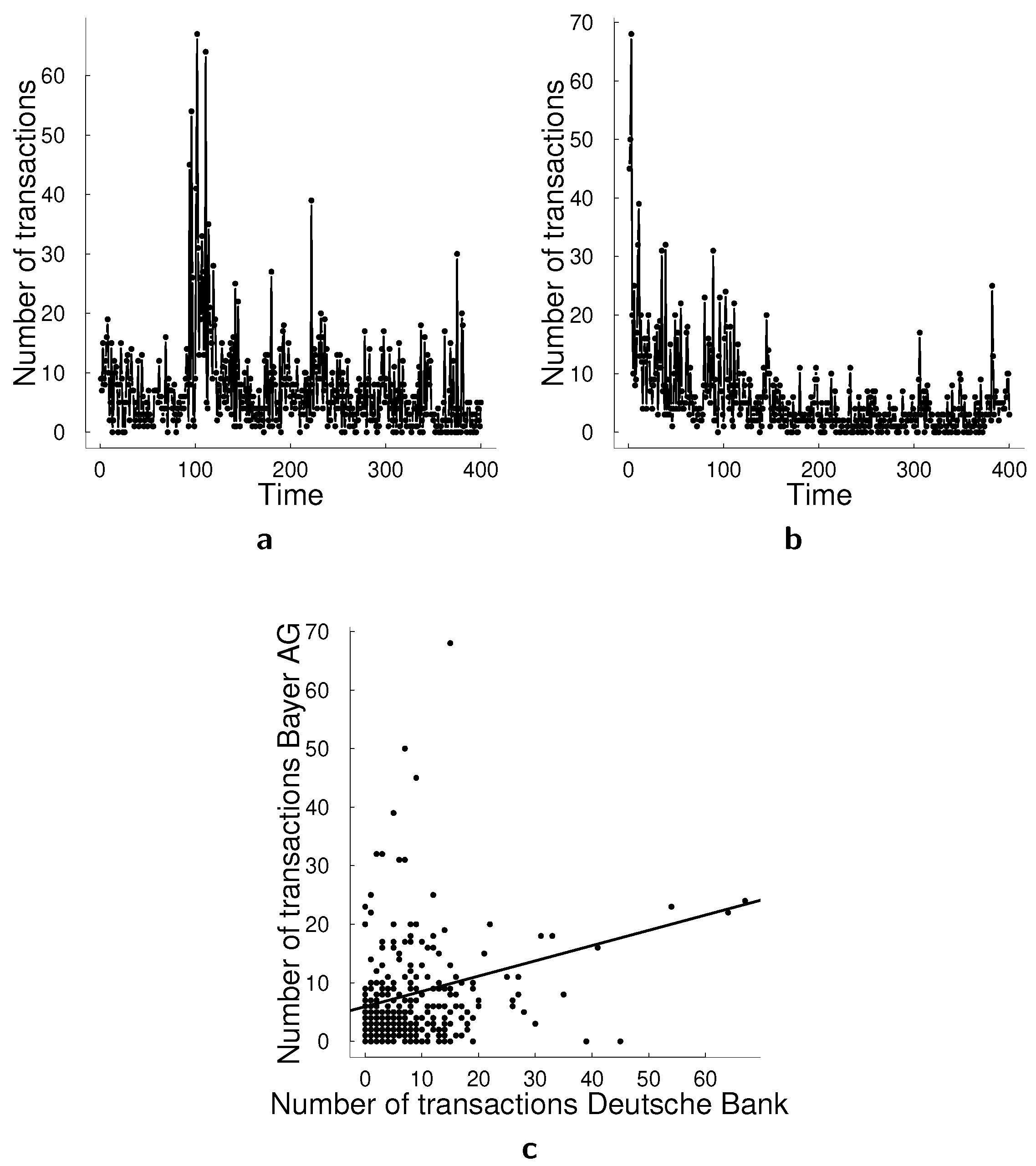
4]. The top panels in
Figure 1 present two conventional data sets that have been used for univariate illustrations, namely the monthly number of cases of poliomyelitis in the U.S. between 1970 and 1983, and asthma presentations at a Sydney hospital. The middle panel in
Figure 1 presents the number of bank failures in the U.S. over time, a dataset that we also analyze in this paper, and the number of transactions for BMW in a 30 s interval. The bottom panel in
Figure 1 presents a number of car crashes and a number of earthquakes. The former, number of car crashes over time is analyzed in Park and Lord [
5] with a multivariate Poisson log-normal model with correlations for modeling the crash frequency by severity. The authors demonstrate that, accounting for the correlations in the multivariate model can improve the accuracy of the estimation. A common feature in all presented datasets is the autocorrelation present in count data over time that is visible in the time series plots. In multivariate count time series data, this correlation generalizes to a correlation between past and current values of a specific series as well as between different series.
Models for multivariate count time series typically rely on multivariate Poisson distributions, where time-variation is defined through one or more rate parameters [
6]. In some cases, Gaussian approximations are used but, as has been shown in [
7], this can lead to reduced performance in the risk forecasting assessment. In general, the quality of such approximations depends on a particular problem [
8]. Estimation of these models is computationally demanding for high numbers of counts as the estimation relies on the sum over all counts. In addition, these models typically have positivity restrictions on the conditional intensity function that governs the Poisson process over time and the correlation between different time series. A few exceptions to the positive correlation assumption exist, see for example, [
9,
10].
An alternative model for the joint distribution of count data is the copula model. A number of papers proposed different copula models for multivariate count time series, see, for example, [
11,
12,
13,
14]. Copulas are generally used for modeling dependency in multiple series, which makes them attractive methods also for multiple count time series. However, several issues arise in their applications to count data such as unidentifiability and not accounting for potential overdispersion—a property that is common for count data. Genest and Nešlehová [
15] provides a detailed overview of copula models for count data, and proposes and compares Bayesian and classical inferential approaches for multivariate Poisson regression. They show that computationally Bayesian and classical approaches are of a similar order.
Both approaches of modeling joint distribution of count data—multivariate Poisson distribution and copulas—can be incorporated in the autoregressive conditional intensity (ACI) framework, often also referred to as an integer-valued generalized autoregressive conditional heteroskedasticity model (INGARCH). This model belongs to the class of observation driven models as opposed to parameter driven models, a classification proposed by Cox et al. [
16]. ACI models have been dominating the literature for quite a long time despite their restrictiveness: these models only allow only for positive coefficients in the equation for conditional intensity. These bounded coefficients lead to several problems besides potentially unrealistic dependence structure for some data. In particular, the problem of calculating confidence sets for the parameters that are close to or on the boundary rises and has not been yet solved in the literature. Another observation driven model that has been proposed as an alternative to ACI framework is log-linear model, see Fokianos and Tjøstheim [
17], a multivariate extension of which has been considered in Doukhan et al. [
10]. Even though the problem of modeling joint distribution remains, the advantage of this approach is that no restrictions on the parameter space are required due to the log-transform of the data.
Another class of models that can be considered for modeling count data, but is rarely used in the literature, is parameter driven models and, in particular, non-linear state-space models. In this framework, the observations are driven by an independent unobserved stochastic process which, for instance, can be a (vector) autoregressive process (
). These models have been discussed extensively in the univariate case, see, for example Davis et al. [
18]. However, these models are rarely used in multivariate applications due to the computationally demanding estimation methods that have to be used. To our knowledge, only one very recent study has considered them in a multivariate application Zhang et al. [
19]. Non-linear state-space models are capable of modeling and inferring complex dependence structures in the data. They allow for both negative and positive contemporaneous correlation, as well as for both negative and positive Granger-causal feedback. Thereby, these models avoid the problem of modeling the joint distribution of time series of counts and provide a coherent inferential tool in the Bayesian framework. This is what distinguishes our approach from the approach discussed in Zhang et al. [
19] who consider frequentist estimation of these models. We also compare SSM to log-linear models instead of MACI models since they allow for negative dependence between the intensities and hence appear to be more natural competitors of SSM models.
In this paper, we compare two classes of models, observation driven and parameter driven models, in terms of their forecasting performances. We estimate the observation driven models the quasi-maximum likelihood method. Parameter driven models, however, fit very well into the Bayesian paradigm and that is what we use for estimation. Certain advantages come together with this framework, such as those naturally obtained from the posterior distribution uncertainty about the parameters of the model and forecast of the multivariate time series [
20]. We in particular use particle Markov chain Monte Carlo (pMCMC) [
21] for the estimation of the parameter driven model. As is discussed in [
22], pMCMC outperforms other methods (variational Bayes [
23], integrated nested Laplace approximation [
24] and Riemann manifold Hamiltonian Monte Carlo [
25]) in terms of parameter estimation. There are other recent methods for the estimation of the state-space models such as auxiliary likelihood-based approximate Bayesian computation [
26] and variational Sequential Monte Carlo [
27], but their performance has to be investigated further, which is outside of the scope of this paper.
We present a set of simulation studies to show how these models perform when they are correctly specified and misspecified. The simulation results show that, as expected, the correctly specified models perform generally well, but there are exceptions. Particularly, parameter driven models have better forecast performances in some simulations even if they are misspecified. In addition to these simulation studies, we compare the performances of these models in two real data applications. The two data sets we analyze exhibit different sample sizes, standard deviation, dispersion and maximum counts. We show that the overall forecast performances of the models can be very different, depending on the applications. Furthermore, for the second data set we analyze, we find that observation driven models capture extreme data values better than parameter driven models.
The remainder of this paper is as follows:
Section 2 and
Section 3 summarize observation and parameter driven models, respectively.
Section 4 presents the model and forecast comparison tools we use for multivariate count data models.
Section 5 presents simulation results.
Section 6 presents results from applications to two data sets. Finally,
Section 7 concludes the paper.
3. Parameter Driven Model: Nonlinear State-Space Model
The advantage of parameter driven models is the clear interpretability of the model parameters and the high degree of flexibility. The model can easily incorporate different distributions and extends easily to the multivariate framework. Moreover, in the Bayesian framework, we have coherent inferential tools derived from the posterior distributions of the parameters, such as highest posterior density intervals. These models also take into account uncertainty about the parameters which is incorporated into predictions. The disadvantage of this approach is challenging estimation procedures that are computationally intensive. Hence, even though theoretically estimation methodologies are possible to extend to any dimension, in practice that is not feasible due to the time constraints. In this paper, we estimate the parameter-driven model for multivariate count data using Sequential Monte Carlo and particle Markov Chain Monte Carlo. These methods became popular with the availability of more computational power. They are restricted in some ways, and we will discuss these restrictions in the next subsections after introducing the nonlinear state space model (SSM), which we will compare to the observation driven models.
3.1. Multivariate SSM
A state-space model is usually presented by an observation equation and a state equation. The state equation represents a latent process, say
, which drives the dynamics of observations
. In the multivariate SSM for count data below, this dependence between the observations and the state is nonlinear
where
. Equation (
24) shows that the observations have Poisson distribution with mean
defined through the Equation (
25), and
nonlinearly depends on the latent process
which is defined through Equation (
26). Note that the latent process is defined through a VAR
process, and hence corresponding theory applies. In particular, the stationarity condition is that the roots of the Equation (
27) must lie outside the unit circle
The dependence structure between counts is modeled through the dependence in the latent process. Conditioned on the latent process the observations are independent. Furthermore, since the latent process of the model is a VAR, we can account for various dependence structures: positive and negative contemporaneous correlation, and positive and negative Granger-causal feedback.
These models are challenging to estimate, and an assumption of
can simplify the inference. (For extending the model to
we advise the reader to consider using sparse priors, such as Minnesota prior, spike and slab or horseshoe prior.) Bivariate specification of the nonlinear state-space model with the lag
reads
The dependence structure between series is described by the Granger-causal relationship in the latent processes and contemporaneous relations that are incorporated in . For example, we say that does not Granger-cause if . Correlation coefficient in this model allows us to model both positive and negative correlation between the counts.
3.2. Bayesian Inference in Multivariate SSM
The estimation of nonlinear state-space models naturally fits into the Bayesian framework. The presence of the unobservable process in the model and nonlinear dependence of the observations on this unobservable process leads to an intractable likelihood and posterior. For this reason, and due to the nonlinear SSM structure, we use particle Markov Chain Monte Carlo (PMCMC) for the estimation of the posterior distribution of the model parameters Andrieu et al. [
21]. The method consists of two parts. First, the likelihood is estimated in a sequential manner through a
particle filter. Second, this estimate is used within an MCMC sampler, in our case Metropolis-Hastings algorithm. An extensive introduction to nonlinear state-space models and particle filtering can be found, for example, in Särkkä [
32].
Recall the Bayes rule on which the inference is based
where
is the prior distribution on the parameters of the volatility process defined by the dynamic model,
is the likelihood of the observations,
is the normalization constant that is ignored during the inference. Thus, we use Bayes rule in proportionality terms
We use particle Metropolis-Hastings to estimate the posterior distribution of the parameters of the model since neither the likelihood nor the posterior are available in closed form. We use Metropolis-Hastings algorithm to sample from the posterior of the parameters. Algorithm 1 presents an iteration of the Metropolis-Hastings algorithm. At every iteration of the algorithm we make a new proposal
for the parameter vector using a proposal mechanism
. Then we accept the proposed candidate
with probability
. The acceptance probability in Algorithm 1 depends on
—target distribution—and
—proposal distribution. How well we manage to explore the posterior distribution depends on the acceptance rate of the algorithm. When the acceptance rate is too high it is often related to too small proposal steps, and the other way around. Overall, either case slows down the convergence of the Markov Chain. General advice for the optimal performance of the algorithm is an acceptance rate that is around 0.234 [
33].
| Algorithm 1 Particle Metropolis-Hastings Algorithm |
| 1: Given , |
| 2: Generate , |
| 3: Take |
|
| where |
|
Using Algorithm 1 we obtain samples from otherwise intractable distribution . Note, that and are also intractable. Thus, in practice we substitute them with the estimates and obtained with Sequential Monte Carlo.
We further discuss how can be estimated.
3.3. Estimation of the Likelihood with SMC
Sampling from the posterior distribution with algorithms such as Metropolis-Hastings requires evaluationg the likelihood. In case of non-linear state-space models, this likelihood evaluation is not straightforward since the likelihood is a high dimensional integral
and this likelihood is not analytically tractable. Instead of relying on an analytical result, the integral from Equation (
33) can be approximated using Sequential Monte Carlo methods, also known as particle filters. This estimate of the likelihood is then used in Algoperithm 1 as
. Algorithm 2 represents a simple version of a particle filter which we use in this paper. The algorithm consists of three main steps: prediction, updating and resampling. In the prediction step we sample
N particles according to the assumed dynamics of the latent process
. Then we weight each particle according to the distribution of the data given the latent state
. Finally, in the resampling step we resample the particles according to these weights. Resampling step is meant to solve the known problem of particle degeneracy: without resampling we end up only with a few particles with high weights over time.
| Algorithm 2 Bootstrap Particle Filter with resampling |
- 1:
Draw a new point for each point in the sample set from the dynamic model:
- 2:
Calculate the weights
and normalize them to sum to unity. - 3:
Compute the estimate of as
Perform resampling: - 4:
Interpret each weight as the probability of obtaining the sample index i in the set . - 5:
Draw N samples from that discrete distribution defined by the weights and replace the old samples set with this new one.
|
The particle filter provides us with the sequence of distributions
, however due to particle degeneracy problem discussed previously, sampling from
and approximating
,
, is inefficient. One of the possible solutions to this problem is using so called forward filtering—backward smoothing recursions [
34]. The algorithms starts with sampling
, and then backwards for
, we sample
. Then we can approximate the distribution
as follows
The smoothing comes at cost of
operations to sample a path from
and
operations to approximate
. This method works very well, in particular when dealing with large sample sizes. However, its performance comes at the price of a high computational costs. Thereby, it is generally recommended to use it when the sample size of the data is large and hence Sequential Monte Carlo is more likely to suffer from particle degeneracy. There exist other methods that are computationally less expensive [
34]. However, in higher dimensions, they would be less reliable, and it would be recommendable to use more expensive methods.
3.4. Forecasting with SSM
One of the interests of statistical inference is the ability to perform forecasting exercises and thus handling the uncertainty about the future in the best possible way. In this section, we will discuss how forecasting task fits into the Bayesian framework, and in particular how it can be done for models of our interest.
Recall that we estimated multivariate SSM model for count data in the Bayesian framework. Observing the data
we estimated the posterior distribution of the parameters in our model using particle Markov Chain Monte Carlo methods
. Suppose that we are interested in predicting the next
s observations, that is,
. First, note that the prediction equation for the next step reads
In the framework of particle Markov Chain Monte Carlo, it is natural to adopt a sequential nature of SMC and the fact that we obtain posterior draws in the MCMC part of the algorithm. Thereby, for every vector of the parameters drawn in the MCMC, we can propagate the particles obtained at time T and based on those make one-step ahead forecast. The similar idea extends to s-steps ahead forecasts. In this case the uncertainty about the parameters is included in the forecasts.
When forecasting, the most natural but cumbersome approach would be to update the posterior distribution every time we get a new observation. It would mean that we generate as many MCMC chains as we have steps for forecasting. This can be carried out in a straightforward way by re-estimating the posterior distribution every time or more efficiently by incorporating this into the SMC framework. However, for large enough samples, adding an extra estimation into the PMCMC framework should not change the results substantially. Ignoring this update also makes the forecasting performance of the frequentist and Bayesian approaches more comparable. Both frameworks are estimated in different paradigms. While SSM naturally fits into the Bayesian paradigm, the log-linear model is usually estimated using frequentist methods (quasi-maximum likelihood in this case). Since our goal is not to compare the two approaches to statistics, this design of forecasting exercise is more fair.
Figure 2 illustrates the forecasting approach we undertake with the state-space model in a graphical representation. In particular, one can see that we do not re-estimate the posterior distribution every time we receive a data point.
5. Simulation Examples
In this section, we demonstrate the performances of the models based on simulated data. We generate data from various specifications of SSM and log-linear MACI models and compare the models on forecasting performance. We assess forecasting performance based on six different scoring measures discussed in the previous section. The design of the simulation study allows us to assess forecasting performance in the cases of both correct model specification and misspecified case.
Table 2 summarizes three different specifications of the state-space approach for data generation and
Table 3 summarizes specifications of the log-linear MACI for data generation.
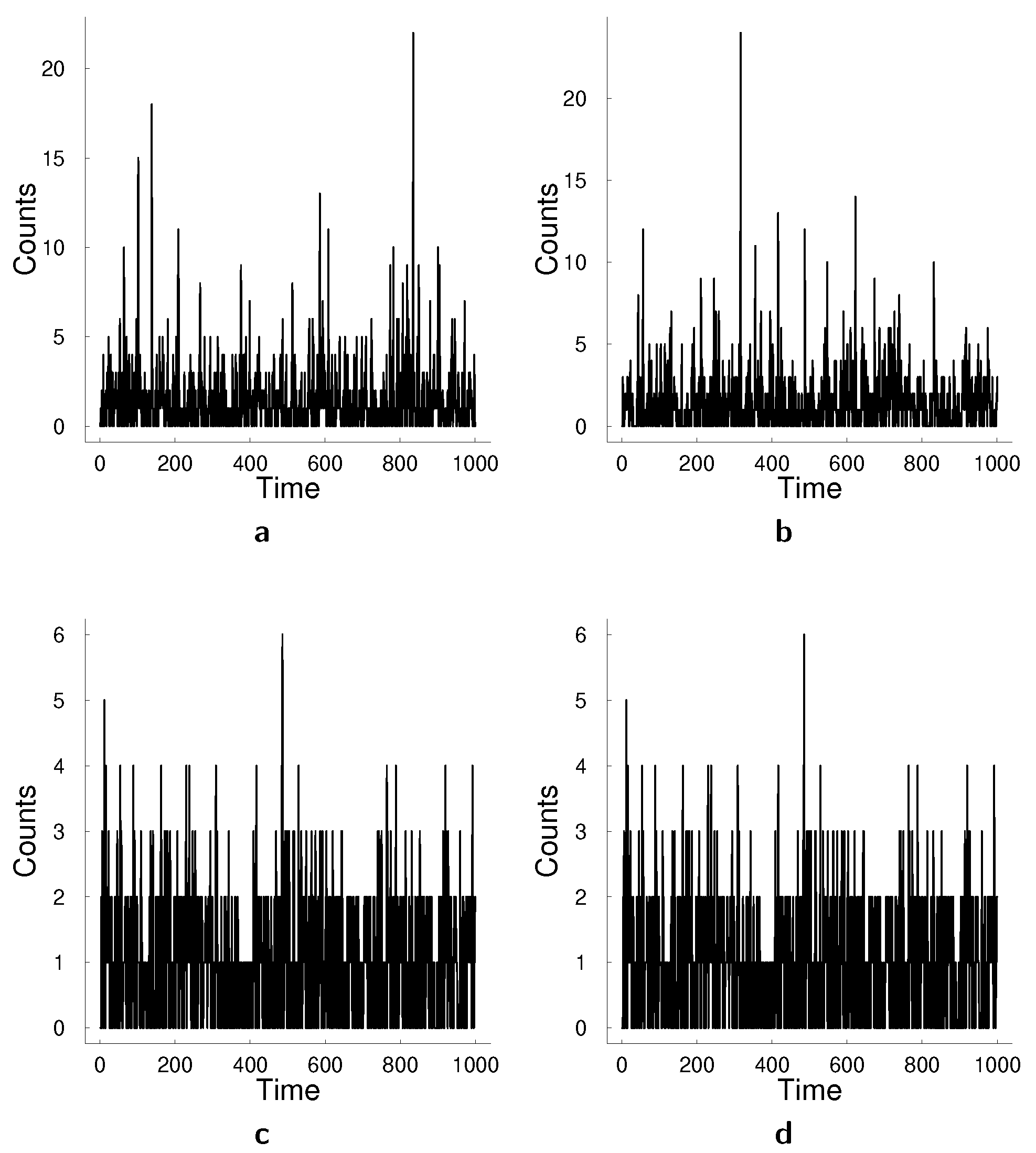
Figure 3 illustrates two examples of bivariate time series generated from these models. For each simulation setting, we generate ten datasets with different random seeds and report the average results from these ten datasets. State-space model was estimated using particle Metropolis-Hastings algorithm with
particles and
Metropolis-Hastings step with a warm-up period of 5000 steps. The acceptance rate was targeted to be between 25% and 40%.
We assess the forecasting performance of two models for multivariate count data: state-space model and log-linear model.
Table 4 and
Table 5 summarize the forecasting performances of the models according to various scoring rules. The rows of the tables correspond to a particular data generating process (see for details of specification
Table 2 and
Table 3) and columns for a particular scoring rule (see scoring rules specification in
Table 1). In particular,
Table 4 shows performance of the state-space model and
Table 5 the performance of the log-linear model. The state-space model outperforms the log-linear MACI model when the data are generated from
(SSM with positive correlation) and
(log-linear model with a negative
coefficient). It is particularly interesting that when the data is simulated from
, SSM performs best according to all measures despite being a misspecified model. When the data are generated from
and
, the state-space approach performs best based on most measures. This result is expected as SSM is the correct model specification for these simulated data. Finally, log-linear MACI model performs best in the case of data set
—in the case when the model is correctly specified and all the coefficients are positive—according to most measures.
7. Discussion
In this paper, we have reviewed and compared two approaches for modeling multivariate count time series data. One of the challenges that appears in the literature and have not been resolved is modeling the dependency between counts in a flexible way that would also allow for feasible estimation. We have discussed multivariate autoregressive conditional intensity models (MACI), their log-linear alternative which we refer to as the multivariate log-linear model and nonlinear state-space model. Both models have advantages and disadvantages. In particular, the nonlinear state-space framework allows for various interpretable dependencies that one cannot easily incorporate into MACI or log-linear approach. However, these models can be computationally expensive to estimate, in particular in higher-dimensions. Challenges in estimation arise from different sources. State-space models naturally fit into the Bayesian framework, however, since both the likelihood and the posterior of the model are analytically intractable this leads to computationally expensive procedure. MACI models, on the other hand, are quite restrictive: they restrict coefficients in the model to be positive as well as the correlation between time series. Both assumptions can be unrealistic in many real-world applications. Log-linear model avoids the problem of only positive coefficients in the model by logarithmic transformation of the data. However, estimation can be unstable, and good starting points need to be chosen for the estimation. When the dimension of the model grows, it becomes harder to choose good starting points for the optimization problem. The computational advantage of log-linear and MACI models decreases with the increase in either dimensionality of the model or the number of counts. This reduction in the computational advantage is due to the usage of the multivariate Poisson distribution as every pairwise correlation has to be modeled as a separate Poisson random variable. Moreover, the summation in the specification of the joint distribution runs through the number of counts. Generally, one could say that estimation of log-linear models much faster than of the state-space models. In low dimensions and with the small number of counts these models do not require much of computational power, however, once the number of counts increases and once we deal with higher dimensions, the computations become much more extensive due to large sums in the multivariate Poisson distribution. Moreover, while running the model on simulated and empirical data, we found that the estimation can be numerically unstable and can highly depend on the starting values in the estimation procedure. We follow the suggestion of Doukhan et al. [
10], and the first estimate the model for univariate time series. These estimates we further use in multivariate estimation. However, the problem of numerical instability especially remains in small samples according to our experience. Nevertheless, in terms of flexibility, this model is the best competitor for the state-space approach.
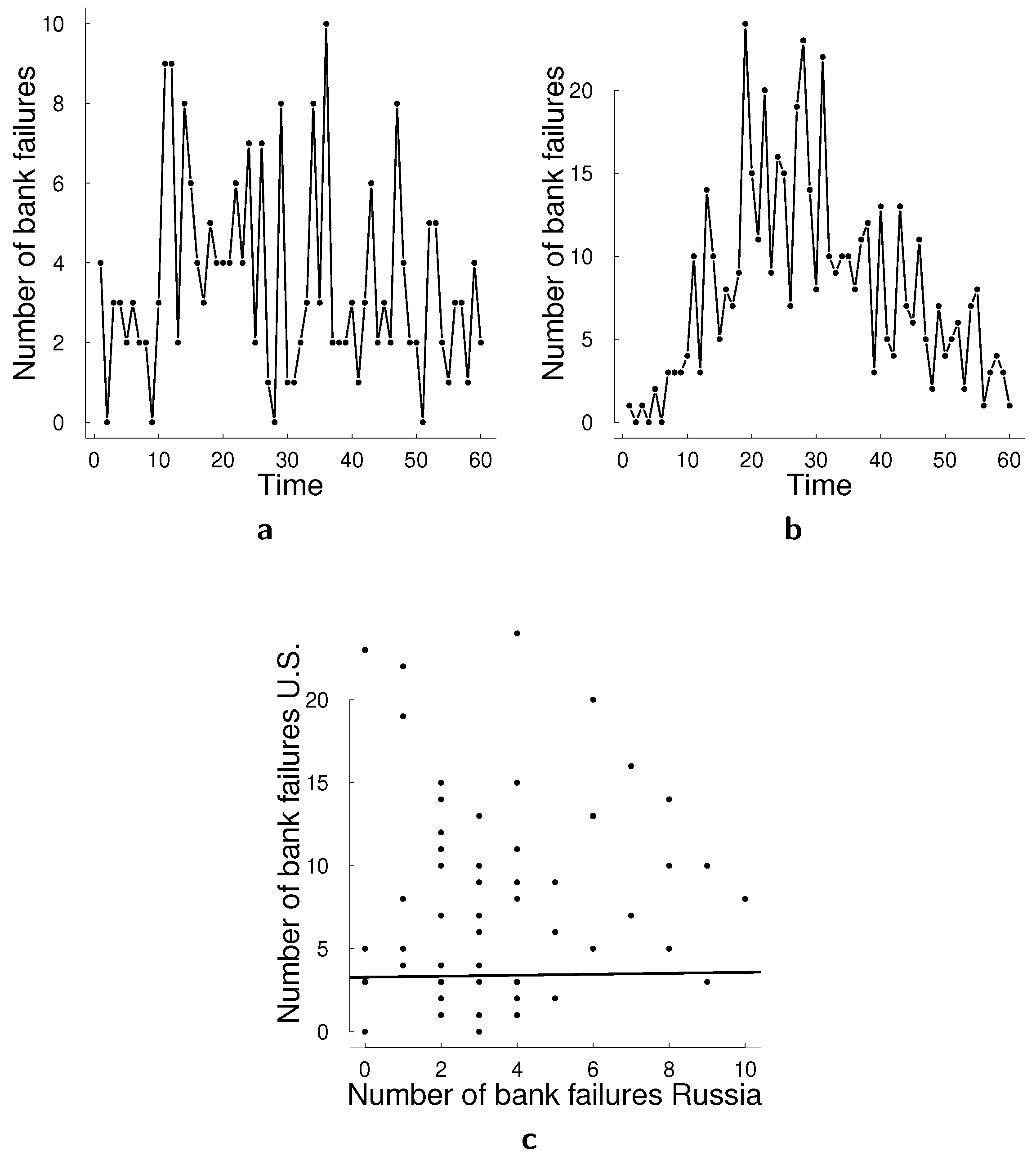
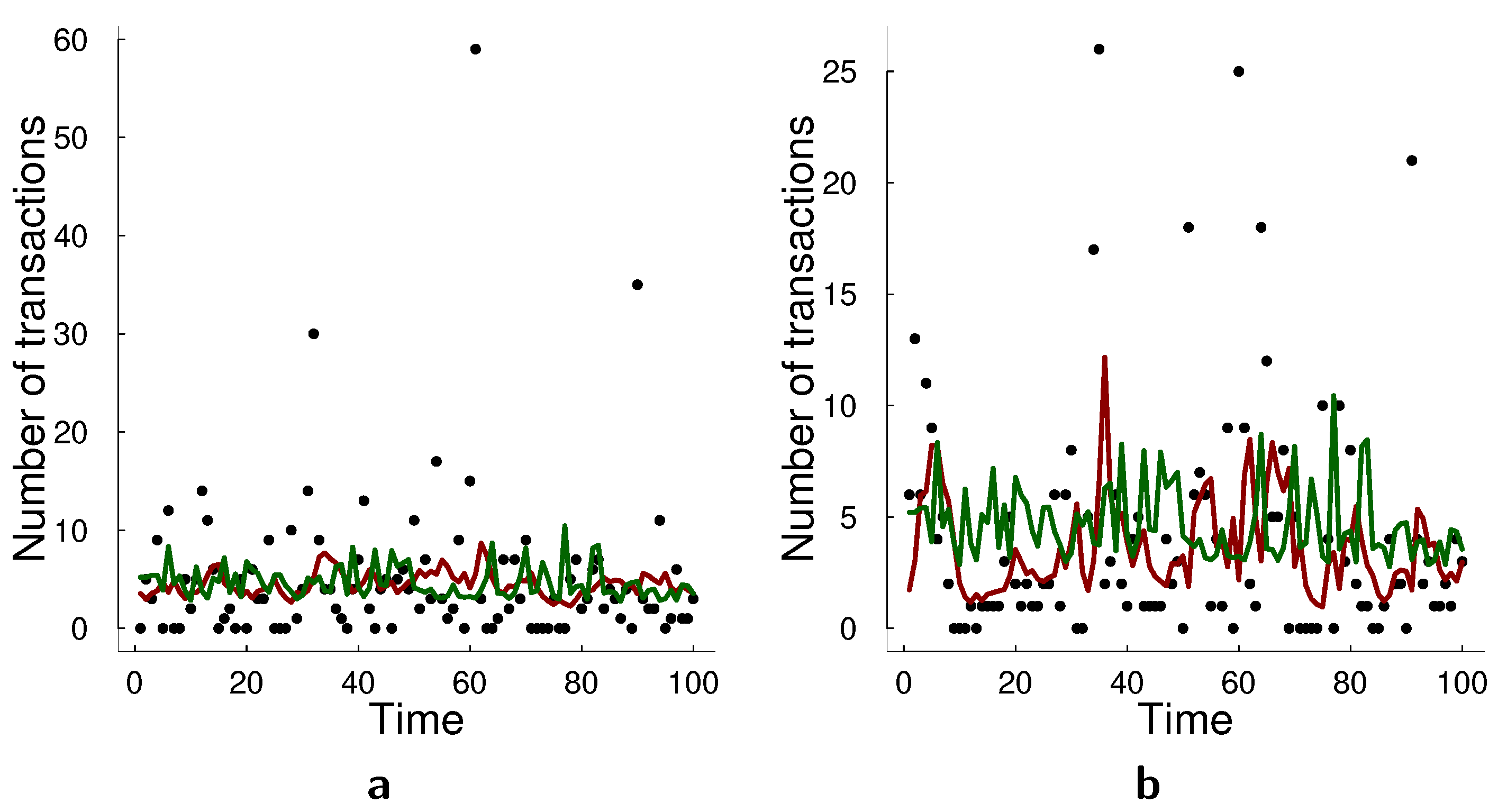
We have compared log-linear models and state-space models for count data in terms of forecasting performance on multiple simulated data sets and real data applications. We found that on the simulated data state-space framework generally outperforms log-linear model, sometimes even under model misspecification. On the real data sets, the state-space model performs better in bank failures applications which consists of two time series of bank failures in Russia and U.S. and the counts remain relatively low and the data are relative smooth. The log-linear model performs better in the transactions applications in which we consider two time series of transactions counts in 30 s intervals. The challenge of transactions application is that there are spikes of counts which deviate a lot from the mean. In this case, we notice that the log-linear model approximates these spikes better. Thus, a possible direction for future research is adapting a multivariate state-space model for count data to capture such spikes better. A possible way to improve the model in this regard would be to adapt the particle filtering algorithm. We used bootstrap particle filter which does not take into account observations when making a proposal for particles, but taking current (or all) observation into account in the proposal mechanism for the particles can help approximating the spikes in the data. There have been proposed multiple look-ahead approaches for particle filters [
37,
38], but they have not been adapted to count data.
Finally, both approaches have their drawbacks. In particular, the log-linear model seems to have numerical stability issues and finding optimal starting values for optimization can be a challenge. In the state-space approach, the challenging part is the estimation of the likelihood, which is intractable and sampled from the posterior distribution. Additionally, the state-space model in its current implementation is challenged by possible spikes in the data to a larger degree than the log-linear model.










{kind=link}
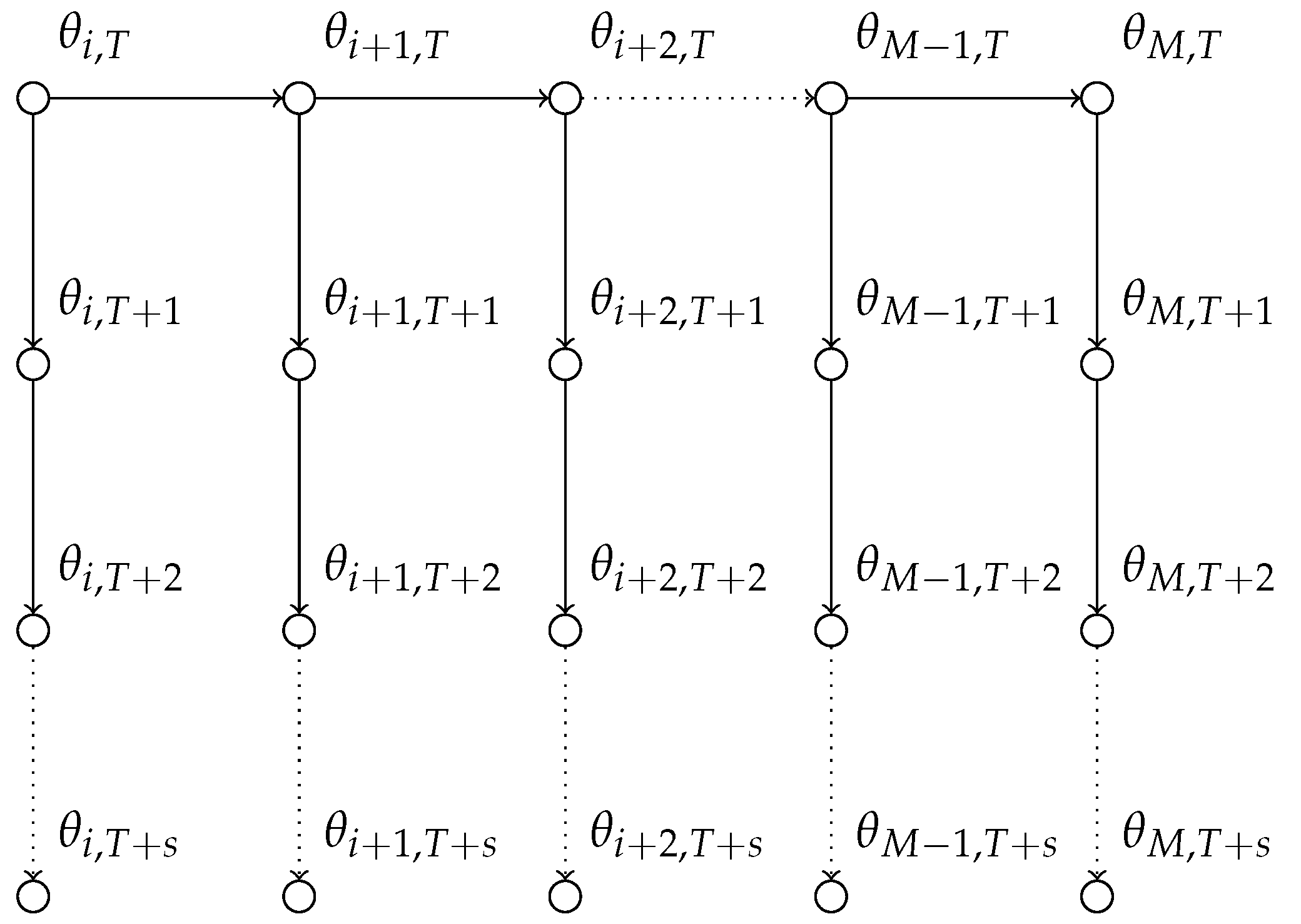{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}