Abstract
Typical random codes (TRCs) in a communication scenario of source coding with side information in the decoder is the main subject of this work. We study the semi-deterministic code ensemble, which is a certain variant of the ordinary random binning code ensemble. In this code ensemble, the relatively small type classes of the source are deterministically partitioned into the available bins in a one-to-one manner. As a consequence, the error probability decreases dramatically. The random binning error exponent and the error exponent of the TRCs are derived and proved to be equal to one another in a few important special cases. We show that the performance under optimal decoding can be attained also by certain universal decoders, e.g., the stochastic likelihood decoder with an empirical entropy metric. Moreover, we discuss the trade-offs between the error exponent and the excess-rate exponent for the typical random semi-deterministic code and characterize its optimal rate function. We show that for any pair of correlated information sources, both error and excess-rate probabilities exponential vanish when the blocklength tends to infinity.
1. Introduction
As is well known, the random coding error exponent is defined by
where R is the coding rate, is the error probability of a codebook , and the expectation is with respect to (w.r.t.) the randomness of across the ensemble of codes. The error exponent of the typical random code (TRC) is defined as [1]
We believe that the error exponent of the TRC is the more relevant performance metric, as it captures the most likely error exponent of a randomly selected code, as opposed to the random coding error exponent, which is dominated by the relatively poor codes of the ensemble, rather than the channel noise, at relatively low coding rates. In addition, since in random coding analysis, the code is selected at random and remains fixed, it seems reasonable to study the performance of the chosen code itself instead of directly considering the ensemble performance.
To the best of our knowledge, not much is known about TRCs. In [2], Barg and Forney considered TRCs with independently and identically distributed codewords, along with typical linear codes, for the special case of the binary symmetric channel with maximum likelihood (ML) decoding. It was also shown that at a certain range of low rates, lies between and the expurgated exponent, . In [3] Nazari et al. provided bounds on the error exponents of TRCs for both discrete memoryless channels (DMC) and multiple-access channels. In a recent article by Merhav [1], an exact single-letter expression has been derived for the error exponent of typical, random, fixed composition codes, over DMCs, and a wide class of (stochastic) decoders, collectively referred to as the generalized likelihood decoder (GLD). Later, Merhav studied error exponents of TRCs for the colored Gaussian channel [4], typical random trellis codes [5], and a Lagrange dual lower bound for the TRC exponent [6]. Large deviations around the TRC exponent were studied in [7].
While originally defined for pure channel coding [1,2,3], the notion of TRCs has natural analogues in other settings as well, such as source coding with side information in the decoder [8]. Typical random Slepian–Wolf (SW) code of a certain variant of the ordinary variable-rate random binning code ensemble is the main theme of this work. The random coding error exponent of SW coding, based on fixed-rate (FR) random binning, was first addressed by Gallager in [9], and improved later on by the expurgated bound in [10] and [11]. Variable-rate (VR) SW coding received less attention in the literature; VR codes under average rate constraint have been studied in [12] and proved to outperform FR codes in terms of error exponents. Optimum trade-offs between the error exponent and the excess-rate exponent in VR coding were analyzed in [13]. Sphere-packing upper bounds for source coding with side information in the FR and VR regimes were studied in [9] and [12], respectively. More works where exponential error bounds in source coding have been studied are [14,15,16,17,18].
It turns out that both the FR and VR ensembles suffer from an intrinsic deficiency, caused by statistical fluctuations in the sizes of the bins that are populated by the relatively small type classes of the source. This fundamental problem of the ordinary ensembles is alleviated in some variant of the ordinary VR ensemble-the semi-deterministic (SD) code ensemble, which has already been proposed and studied in its FR version in [18]. In the SD code ensemble, for source type classes which are exponentially larger than the space of the available bins, we just randomly assign each source sequence into one of the bins, as is done in ordinary random binning. Otherwise, for relatively small type classes, we deterministically order each source sequence into a different bin, which provides a one-to-one mapping. This way, all these relatively small source type classes do not contribute to the probability of error. The main results concerning the SD code are the following:
- The random binning error exponent and the error exponent of the TRC are derived in Theorems 1 and 2, respectively, and proved in Theorem 3 to be equal to one another in a few important special cases, which include the matched likelihood decoder, the MAP decoder, and the universal minimum entropy decoder. To the best of our knowledge, this phenomenon has not been seen elsewhere before, since the TRC exponent usually improves upon the random coding exponent. As a byproduct, we are able to provide a relatively simple expression for the TRC exponent.
- We prove in Theorem 4 that the error exponent of the TRC under MAP decoding is also attained by two universal decoders: the minimum entropy decoder and the stochastic entropy decoder, which is a GLD with an empirical conditional entropy metric. As far as we know, this result is first of its kind in source coding; in other scenarios, the random coding bound is attained also by universal decoders, but here, we find that the TRC exponent is also universally achievable. Moreover, while the likelihood decoder and the MAP decoder have similar error exponents [19], here we prove a similar result, but for two universal decoders (one stochastic and one deterministic) that share the same metric.
- We discuss the trade-offs between the error exponent and the excess-rate exponent for a typical random SD code, similarly to [13], but with a different notion of the excess-rate event, which takes into account the available side information. In Theorem 5, we provide an expression for the optimal rate function that guarantees a required level for the error exponent of the typical random SD code. Analogously, Theorem 6 proposes an expression for the optimal rate function that guarantees a required level for the excess-rate exponent. Furthermore, we show that for any pair of correlated information sources, the typical random SD code attains both exponentially vanishing error and excess-rate probabilities.
The remaining part of the paper is organized as follows. In Section 2, we establish notation conventions. In Section 3, we formalize the model, the coding technique, the main objectives of this work, and we review some background. In Section 4, we provide the main results concerning error exponents and universal decoding in the SD ensemble, and in Section 5, we discuss the trade-offs between the error exponent and the excess-rate exponent.
2. Notation Conventions
Throughout the paper, random variables will be denoted by capital letters, realizations will be denoted by the corresponding lower case letters, and their alphabets will be denoted by calligraphic letters. Random vectors and their realizations will be denoted, respectively, by boldface capital and lower case letters. Their alphabets will be superscripted by their dimensions. Sources and channels will be subscripted by the names of the relevant random variables/vectors and their conditionings, whenever applicable, following the standard notation conventions, e.g., , , and so on. When there is no room for ambiguity, these subscripts will be omitted. For a generic joint distribution , which will often be abbreviated by Q, information measures will be denoted in the conventional manner, but with a subscript Q; that is, is the marginal entropy of U, is the conditional entropy of U given V, and is the mutual information between U and V. The Kullback–Leibler divergence between two probability distributions, and , is defined as
where logarithms, here and throughout the sequel, are understood to be taken to the natural base. The probability of an event will be denoted by , and the expectation operator w.r.t. a probability distribution Q will be denoted by , where the subscript will often be omitted. For two positive sequences, and , the notation will stand for equality in the exponential scale, that is, . Similarly, means that , and so on. The indicator function of an event will be denoted by . The notation will stand for .
The empirical distribution of a sequence , which will be denoted by , is the vector of relative frequencies, , of each symbol in . The type class of , denoted , is the set of all vectors with . When we wish to emphasize the dependence of the type class on the empirical distribution , we will denote it by . The set of all types of vectors of length n over will be denoted by , and the set of all possible types over will be denoted by . Information measures associated with empirical distributions will be denoted with ‘hats’ and will be subscripted by the sequences from which they are induced. For example, the entropy associated with , which is the empirical entropy of , will be denoted by . Similar conventions will apply to the joint empirical distribution, the joint type class, the conditional empirical distributions and the conditional type classes associated with pairs (and multiples) of sequences of length n. Accordingly, would be the joint empirical distribution of , will denote the joint type class of , will stand for the conditional type class of given , will be the empirical conditional entropy, and so on. Likewise, when we wish to emphasize the dependence of empirical information measures upon a given empirical distribution Q, we denote them using the subscript Q, as described above.
3. Problem Formulation and Background
3.1. Problem Formulation
Let be n independent copies of a pair of random variables, , taking on values in finite alphabets, and , respectively. The vector will designate the source vector to be encoded and the vector will serve as correlated side information available to the decoder. In ordinary VR binning, the coding rate is not fixed for every , but depends on its empirical distribution. Let us denote a rate function by , which is a given continuous function from the probability simplex of to the set of nonnegative reals. In that manner, for every type , all source sequences in are randomly partitioned into bins. Every source sequence is encoded by its bin index, denoted by , along with a header that indicates its type index, which requires only a negligible extra rate when n is large enough.
The SD code ensemble is a refinement of the ordinary VR code: for types with , i.e., type classes which are exponentially larger than the space of available bins, we just randomly assign each source sequence into one out of the bins. For the other types, we deterministically order each member of into a different bin. This way, all type classes with do not contribute to the probability of error. The entire binning code of source sequences of blocklength n, i.e., the set , is denoted by . A sequence of SW codes, , indexed by the block length n, will be denoted by .
The decoder estimates based on the bin index , the type index , and the side information sequence , which is a realization of . The optimal (MAP) decoder estimates according to
As in [1,20], we consider here the GLD. The GLD estimates stochastically, using the bin index , the type index , and the side information sequence , according to the following posterior distribution
where is the empirical distribution of and is a given continuous, real valued functional of this empirical distribution. The GLD provides a unified framework which covers several important special cases, e.g., matched decoding, mismatched decoding, MAP decoding, and universal decoding (similarly to the -decoders described in [11]). A more detailed discussion is given in [20].
The probability of error is the probability of the event . For a given binning code , the probability of error is given by
For a given rate function, we derive the random binning exponent of this ensemble, which is defined by
and compare it to the TRC exponent, which is
Although it is unclear that the limits in (7) and (8) exist a priori, it will be evident from the analyses in Appendix A and Appendix B, respectively.
One way to define the excess-rate probability is as , where R is some target rate [13]. Due to the availability of side information in the decoder, it makes sense to require a target rate which depends on the pair . Since the lowest possible compression rate in this setting is given by [8], given and , it is reasonable to adopt as a reference rate. Hence, an alternative definition of the excess-rate probability of a code , is as , where is a redundancy threshold. (Note that the entire analysis remains intact if we allow a more general redundancy threshold as . This covers other alternatives for the excess-rate probability, e.g., or , .) Accordingly, the excess-rate exponent function, achieved by a sequence of codes , is defined as
The main mission is to characterize the optimal trade-off between the error exponent and the excess-rate exponent for the typical random SD code, and the optimal rate function that attains a prescribed value for the error exponent of the typical random SD code.
3.2. Background
In pure channel coding, Merhav [1] has derived a single-letter expression for the error exponent of the typical random fixed composition code:
In order to present the main result of [1], we define first a few quantities. Consider a DMC, , where and are the finite input/output alphabets. Define
where the function , which is the decoding metric, is a continuous function that maps joint probability distributions over to real numbers. Additionally define
where is the conditional divergence between and W, averaged by . A brief intuitive explanation on the term can be found in [7] (Section 4.1). Having defined the above quantities, the error exponent of the TRC is given by [1]
Returning to the SW model, several articles have been written on error exponents for the FR and the VR codes. Here, we mention only those results that are directly relevant to the current work. The random binning and expurgated bounds of the FR ensemble in the SW model are given, respectively, by [11] (Section VI, Theorem 2), [10](Appendix I, Theorem 1)
where and are, respectively, the random coding and expurgated bounds associated with the channel w.r.t. the ensemble of fixed composition code of rate S, whose composition is . The exponent function is given by
and is given by
where
4. Error Exponents and Universal Decoding
To present some of the results, we need a few more definitions. The minimum conditional entropy (MCE) decoder estimates , using the bin index , the type index , and the side information vector , according to
The stochastic conditional entropy (SCE) decoder is a special case of the GLD with the decoding metric ; i.e., it estimates according to the following posterior distribution
First, we present random binning error exponents, which are modifications of (19) to this ensemble. Define the expression
and the exponent functions:
and
The following result is proved in Appendix A.
Theorem 1.
Let be a given rate function. Then, for the SD ensemble,
- for the GLD;
- for the MAP and MCE decoders.
As a matter of fact, a special case of the second part of Theorem 1 has already been proved in [18] for the FR regime, while here, we prove a stronger result, according to which, the MCE decoder attains the same random binning error exponent as the MAP decoder, in the VR coding regime too. The first part of Theorem 1 is completely new; it proposes a single letter expression for the random binning error exponent, for a wide family of stochastic and deterministic decoders. Additionally, note that an analogous result to the first part of Theorem 1 has been proved in [20]. Comparing the expressions in (19) and (24), namely, the random binning error exponents of the ordinary VR and the SD VR ensembles, respectively, we find that they differ at relatively high coding rates, since these minimization problems share the same objective but (24) also has the constraint . The origin of this constraint is the deterministic coding of the relatively small type classes.
Next, we provide a single-letter expression for the error exponent of the TRCs in this ensemble. We define
and
Furthermore, define
and the following exponent function:
Then, the following theorem is proved in Appendix B.
Theorem 2.
Let be a given rate function. Then, for the SD ensemble and the GLD,
As explained before, an analogous result has already been proved in pure channel coding [1], and one can find a high degree of similarity between the expressions in (25)–(28) and the expressions in Section 3.2. While in channel coding, the coding rate is fixed, here, on the other hand, we allow the rate to depend on the type class of the source. In order to optimize the rate function, we constrain the problem by introducing the excess-rate exponent (9), which is the exponential rate of decay of the probability that the compression rate will be higher than some predefined level. A detailed discussion on optimal rate functions and optimal trade-offs between these two exponents can be found in Section 5.
The definition of the error exponent of the TRC as in (8) should not be taken for granted. The reason for that is the following. It turns out that the definition in (8) and the value of for the highly probable codes in the ensemble may not be the same, and they coincide if and only if the ensemble does not contain both zero error probability codes and positive error probability codes. For example, the FR ensemble in SW coding contains the one-to-one code (which obviously attains ) as long as , but it is definitely not a typical code, at least when ordinary random binning is considered. Hence, in this case, we conclude that , while the value of for the highly probable codes is still finite. As for the SD code ensemble, the definition in (8) indeed provides the error exponent of the highly probable codes in the ensemble, which is explained by the following reasoning. For any given rate function such that for at least one type class, all the type classes with are encoded by random binning; thus, all the codes in the ensemble have a strictly positive error probability, which implies that the value of concentrates around the error exponent of the TRC, as defined in (8).
The proof of Theorem 2 follows exactly the same lines as the proof of ([1] (Theorem 1)), except for one main modification: when we introduce the type class enumerator (see below) and sum over joint types, the summation set becomes , where the constraint is due to the indicator function in (6). Afterwards, the analysis of the type class enumerator yields the constraint , which becomes redundant and thus omitted. This constraint is analogous to the constraint in the minimization of (13). The origin of is the following. Define
which enumerate pairs of source sequences. Then, one of the main steps in the proof of Theorem 2 is deriving the high probability value of , which is 0 if (a relatively small set of source pair and relatively large number of bins) and for (a large set of source sequence pair and a small number of bins). One should note that the analysis of is not trivial, since it is not a binomial random variable; i.e., the enumerator is given by the sum of dependent binary random variables. For a sum N of independent binary random variables, ordinary tools from large deviation theory (e.g., the Chernoff bound) can be invoked for assessing the exponential moments , , or the large deviation rate function of , . For sums of dependent binary random variables, such as in the current problem, this can no longer be done by the same techniques, and it requires more advanced tools (see, e.g., [1,4,5,6]).
It is possible to compare (23) and (28) analytically in the special cases of the matched or the mismatched likelihood decoders and the MCE decoder. In the following theorem, the choice , where is a possibly different source distribution than , corresponds to a family of stochastic mismatched decoders. We have the following result, the proof of which is given in Appendix D.
Theorem 3.
Consider the SD ensemble and a given rate function . Then,
- For a GLD with the decoding metric , for a given ,
- For the MCE decoder,
This result is quite surprising at first glance, since one expects the error exponent of the TRC to be strictly better than the random binning error exponent, as in ordinary channel coding at relatively low coding rates [1,2]. This phenomenon is due to the fact that part of the source type classes are deterministically partitioned into bins in a one-to-one fashion, and hence do not affect the probability of error (notice that the constraint appears in both the random binning and the TRC exponents, while in the latter, it makes the original constraint redundant). In the cases of FR or ordinary VR binning, these relatively “thin” type classes dominated the error probability at relatively high binning rates, but now, by encoding them deterministically into the bins; other mechanisms dominate the error event, such as the channel noise (between and ) or the random binning of the type classes with . The result of the second part of Theorem 3 is also nontrivial, since it establishes an equality between the error exponent of the TRC and the random binning error exponent, but now for a universal decoder.
Concerning universal decoding, it is already known [21] (Exercise 3.1.6), [13] that the random binning error exponents under optimal MAP decoding in both the FR and VR codes, given by (14) and (19), respectively, are also attained by the MCE decoder. Furthermore, a similar result for the SD ensemble has been proved here in Theorem 1. The natural question that arises is whether the error exponent of the TRC is also universally attainable. The following result, which is proved in Appendix E, provides a positive answer to this question.
Theorem 4.
Consider the SD ensemble and a given rate function . Then, the error exponents of the TRC under the MAP, the MCE, and the SCE decoders are all equal; i.e.,
Theorem 4 asserts that the error exponent of the typical random SD code is not affected if the optimal MAP decoder is replaced by a certain universal decoder, which must not even be deterministic. While the left hand equality in (33) follows immediately from the results of Theorems 1 and 3, the right hand equality in (33) is far less trivial, since the SCE decoder is both universal and stochastic, and hence, its TRC exponent is expected to be inferior w.r.t. the TRC exponent under MAP decoding, but nevertheless, they turn out to be equal. Comparing to channel coding, it has been recently proved in [22] that the error exponent of the typical random fixed composition code (given in (13)) is the same for the ML and the maximum mutual information decoder, but on the other hand, numerical evidence shows that a GLD which is based on an empirical mutual information metric attains a strictly lower exponent.
5. Optimal Trade-off Functions
In this section, we study the optimal trade-off between the threshold , the error exponent of the TRC, and the excess-rate exponent. Since both exponents depend on the rate function, we wish to characterize rate functions that are optimal w.r.t. this trade-off. Since a single-letter characterization of the error exponent of the TRC has already been given in (28), we next provide a single-letter expression for the excess-rate exponent. Define the following exponent function:
Then, we have the following.
Proposition 1.
Fix and let be any rate function. Then,
Proof.
The excess-rate probability is given by:
which proves the desired result. □
Since Proposition 1 is proved by the method of types [21], we conclude that the excess-rate event is dominated by one specific type class , whose respective rate has been chosen too large w.r.t. the value of . One extreme case is when the rate function is given by , which obviously provides a one-to-one mapping, since the size of each is upper-bounded by . In this case, the probability of error is zero, while the excess-rate probability is one, at least when is not too large. In Section 5.2, we prove that the optimal rate function is indeed upper-bounded by , but can also be strictly smaller, especially when the requirement on the error exponent is not too stringent.
One way to explore the trade-off between the error exponent of the TRC and the excess-rate exponent, which will be presented in Section 5.1, is to require the excess-rate exponent to exceed some value , then solve for an optimal rate function , and then to substitute this optimal rate function back into the error exponents in (24) and (28) to give expressions for the optimal trade-off function . In Section 5.2, we present an alternative option to characterize this trade-off, which is to require the error exponent of the TRC to exceed some value , to solve in order to extract an optimal rate function, and then to substitute it back into the excess-rate exponent in (34) to provide an expression for the optimal trade-off function .
5.1. Constrained Excess-Rate Exponent
Relying on the exponent function in (34), the following theorem proposes a rate function, whose optimality is proved in Appendix F.
Theorem 5.
Let be fixed. Then, the constraint implies that
This means that we have a dichotomy between two kinds of source types. Each type class that is associated with an empirical distribution that is relatively close to the source distribution, i.e., when for some , is partitioned into bins, and the rest of the type classes, those that are relatively distant from , are encoded by a one-to-one mapping. Two extreme cases should be considered here. First, when is relatively small, then only the types closest to are encoded with a rate approximately , which can be made arbitrarily close to the SW limit [8], and each a–typical source sequence is allocated with bits. This coding scheme is the one related to VR coding with an average rate constraint, like the one discussed in [12]. Second, when is extremely large, then each type class is encoded to bins, which is equivalent to FR coding.
Following the first part of Theorem 3, let us denote the error exponent of the TRC under MAP decoding by . Upon substituting the optimal rate function of Theorem 5 back into (24) and (28) and using the fact that is monotonically increasing, we find that the optimal trade-off function for the typical random SD code is given by
or, alternatively,
where is given in (39). The dependence of on is as follows. Let and be the respective minimizers of the problems which are similar to (39) and (41), except that the constraint is removed from (39). Furthermore, let be the marginal distribution of . Now, when is sufficiently large, i.e., when , reaches a plateau and is the lowest possible. It follows from the fact that the stringent requirement on the excess-rate forces the encoder to encode each type class to its target rate , thus all of them affect the error event. Otherwise, when , the constraint is active and is a monotonically nonincreasing function of . The reason for that is the fact that as decreases, more and more type classes are encoded with bits, and hence do not contribute to the error event. When , necessarily , only the typical set is encoded, and is the highest possible. In this case, and the constraint set in (41) becomes empty when , and then .
5.2. Constrained Error Exponent
Based on (24), the following theorem proposes a rate function, whose optimality is proved in Appendix G.
Theorem 6.
Let be fixed. Then, the constraint implies that
where,
The dependence of on is as follows. For any given , let be the minimizer of . Then, as long as , the constraint set in (43) is empty, and can vanish, which practically means that in this range, the entire type class can be totally ignored, while still achieving . Only for the unique type , for all , and specifically, we find that . Furthermore, let be the maximizer in the unconstrained problem
Then, as long as , is a monotonically nondecreasing function of . When , the maximization in (43) reaches its unconstrained optimum, and increases without bound in an affine fashion as . As can be seen in (42), finally reaches a plateau at the level of .
Upon substituting back into (34) and using the fact that is monotonically nonincreasing, we find that the trade-off function is given by
Since is monotonically nondecreasing in for every , is monotonically nonincreasing in , which is not very surprising. The dependence of on and is as follows. At , notice that for any while . Thus, as long as , and it follows from the monotonicity that everywhere. Otherwise, if , is empty as long as , where an expression for can be found by solving
and then in this range. In the other extreme case of a very large , reaches a plateau at a level of . Then, if , reaches zero for a sufficiently large . Else, if , reaches a strictly positive plateau, given by
which is a monotonically nondecreasing function of . Particularly, it means that in this range, the typical random SD code attains both an exponentially vanishing excess-rate probability and .
It is interesting to relate this to the expurgated bound of the FR code in the SW model, which is given by (15). Comparing and analytically is rather difficult. Thus, we examined these two exponent functions numerically. Consider the case of a double binary source with alphabets , and joint probabilities given by , , , and . We already mentioned before, that in the special case of , the rate function is given by the threshold , hence we choose in order to have a fair comparison. Graphs of the functions and are presented in Figure 1.
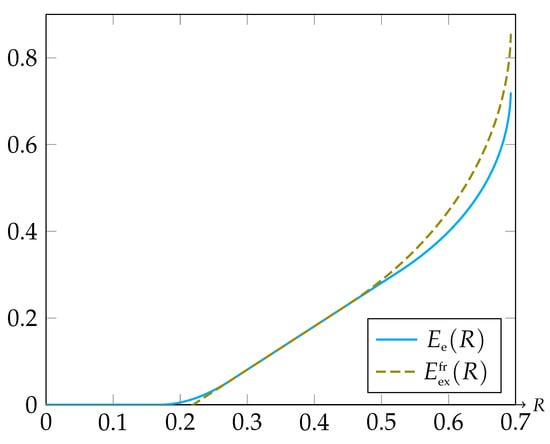
Figure 1.
Graphs of the functions and .
As can be seen in Figure 1, both and tend to infinity as R tends to . For relatively high binning rates, is strictly higher than , which can be explained in the following way: Referring to the analogy between SW coding and channel coding, one can think of each bin as containing a channel code. In general, a channel code behaves well if it does not contain pairs of relatively “close” codewords. Since we randomly assign the source vectors into the bins (even if the populations of the bins are totally equal, which can be attained by randomly partitioning each type class into subsets), it is reasonable to assume that some bins will contain relatively bad codebooks. On the other hand, in the expurgated SW code [11], each type class is partitioned into “balanced” subsets in some sense (referring to the enumerators in (30), they are equally populated in all of the bins), such that the codebooks contained in the bins have approximately equal error probabilities. Moreover, we conclude from (15) that each bin contains a codebook with a quality of an expurgated channel code. This code is certainly better than the TRCs in the SD ensemble.
In channel coding, it is known [23] that the random Gilbert–Varshamov ensemble has an exact random coding error exponent which is as high as the maximum between (16) and (17). In SW source coding, on the other hand, it seems to be a more challenging problem to define an ensemble, such that the error exponent of its TRCs is as high as of (15). Since the gap between and is not necessarily very significant, as can be seen in Figure 1, we conclude that the SD ensemble may be more attractive because the amount of computations needed for drawing a code from it are much lower than the amount of computations required for having an expurgated SW code. In addition, it is important to note that the probability of drawing a SD code with an exponent much lower than decays exponentially fast, in analogy to the result in pure channel coding [7].
Author Contributions
Both authors contributed equally to this research. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Israel Science Foundation (ISF) grant number 137/18.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
By definition, we have
Step 1: Averaging Over the Random Code
We first condition on the true source sequences and take the expectation only w.r.t. the random binning. We get
where (A4) follows by changing the integration variable in (A3) according to . Define
such that the probability in (A6) is given by
where . Let us denote . Now, given and , is a binomial sum of trials and success rate of the exponential order of . Therefore, using the techniques of [24] (Section 6.3),
and so,
Finally, we have that
thus,
Step 2: Averaging Over U and V
Notice that the exponent function depends on only via the empirical distribution . Averaging over the source and the side information sequences, now yields
which proves the first point of Theorem 1.
Step 3: Moving from Stochastic to Deterministic Decoding
In order to transform the GLD into the general deterministic decoder of
we just have to multiply , in
by , and then let . We find that the overall error exponent of the SD ensemble with the general deterministic decoder of (A26) is given by
where,
Step 4: A Fundamental Limitation on the Error Exponent
Note that the minimum in (A29) can be upper–bounded by choosing a specific distribution in the feasible set. In (A29), we take and then
Hence, the overall error exponent is upper–bounded as
Step 5: An Optimal Universal Decoder
Appendix B. Proof of Theorem 2
Lower Bound on the Error Exponent
Our starting point is the following inequality, for any ,
which is due to the following considerations. First, for a positive random variable X, the function
is monotonically decreasing, and second, by L’Hospital’s rule,
Recall that the error probability is given by
Let
fix arbitrarily small, and for every and , define the set
Lemma A1.
Let be arbitrarily small. Then, for every and ,
Thus, by the union bound,
which still decays double–exponentially fast. Recall that . Then, for any
where (A47) is due to Lemma A1, (A49) is by the method of types and the definition of in (27), and in (A50) we used the definition of in (30). Therefore, our next task is to evaluate the –th moment of . Let us define
For a given , let . Then,
where (A56) follows from Jensen’s inequality. Now, is a binomial random variable with trials and success rate which is of the exponential order of . We have that [24](Section 6.3)
and so,
After optimizing over s, we get
which gives, after raising to the –th power,
Let us denote . Continuing now from (A51),
where (A70) follows from (A67). Finally, it follows by (A35) that
Letting grow without bound yields that
Due to the arbitrariness of , we have proved that
completing half of the proof of Theorem 2.
Upper Bound on the Error Exponent
Consider a joint distribution , that satisfies , and define the event . We want to show that is small. Consider the following:
Let us use the shorthand notations , , and . Concerning the variance of , we have the following
and hence,
which decays to zero since we have assumed that . Furthermore, if , then tends to zero at least as fast as . Now, for a given , and a given joint type , such that , let us define
and
where in the expression should be understood as any pair of source sequences in . Next, we define
We start by proving that as , or equivalently, that as . Now,
The last summation contains a polynomial number of terms. If we prove that the summand tends to zero exponentially with n, then as . The first term in the summand, , has already been proved to be upper bounded by . Concerning the second term, we have the following
where (A99) follows by using the second event to increase the first event inside the probability in (A98), (A100) is true since the second event in (A99) was omitted, (A101) follows from Markov’s inequality, and (A103) is due to the independence between the two events inside the probability in (A102). As for the probability in (A104),
where is the number of source sequences within , other than and , that fall in the conditional type class , which is a binomial random variable with trials and success rate of exponential order , and hence,
By definition of the function , the set is a subset of . Thus,
and hence, , which provides
which proves that as . Now, for a given , we define the set
and
Then, by definition, for any ,
where we have used the fact that has exponentially the same cardinality for all . Wrapping all up, we get that for any ,
where (A117) follows from the definition of the set in (A113) and (A120) is due to (A114). Consider the following:
which implies that
It follows from the arbitrariness of that
which completes the proof of Theorem 2.
Appendix C. Proof of Lemma A1
Let be defined as
First, note that
where . Thus, taking the randomness of into account,
Now, is a binomial random variable with trials and success rate which is of the exponential order of . We prove that by the very definition of the function , there must exist some conditional distribution such that for , the two inequalities and hold. To show that, we assume conversely, i.e., that for every conditional distribution , which defines , either or , which means that for every distribution
Writing it slightly differently, for every there exists some real number such that
or equivalently,
which is a contradiction. Let the conditional distribution be as defined above. Then,
Now, we know that both of the inequalities and hold. By the Chernoff bound, the probability of (A145) is upper bounded by
where and , and where , for , is the binary divergence function, that is
Since , the binary divergence is lower bounded as follows [24](Section 6.3):
where in the second inequality, we invoked the decreasing monotonicity of the function for . Finally, we get that
This completes the proof of Lemma A1.
Appendix D. Proof of Theorem 3
By definition of the error exponents, it follows that . We now prove the other direction. The expression in (28) can also be written as
with the set given by , and where,
We upper–bound the minimum in (A158) by decreasing the feasible set; we add to the constraint that form a Markov chain in that order and denote the new feasible set by . We get that
where In order to upper–bound the inner minimum in (A162), we split into two cases, according to the maximum between and . This is legitimate when the inner minimum and this maximum can be interchanged, which is possible at least in the special cases of the matched/mismatched decoding metrics for some , since if is linear, then the entire expression inside the inner minimum in (A162) is convex in . On the one hand, if the maximum is given by , then the inner minimum in (A162) is just
On the other hand, if the maximum is given by , let be the maximizer in (A159), and then
where (A165) is because we choose instead of minimizing over all and (A167) is true since by the definition of . Combining (A163) and (A168), we find that (A162) is upper–bounded by
which proves the first point of the theorem. Moving forward, consider the following:
where follows from the first point in this theorem by using the matched decoding metric and letting . Equality is due to the second point of Theorem 1, which ensures that the random binning error exponents of the MAP and the MCE decoders are equal. Passage is thanks to the fact that for any decoder, the error exponent of the typical random code is always at least as high as the random coding error exponent and is due to the fact that the MAP decoder is optimal. Finally, the leftmost and the rightmost sides of (A173) are the same, which implies that passages and must hold with equalities. The equality in passage concludes the second point of the theorem.
Appendix E. Proof of Theorem 4
The left equality in (33) is implied by the proved equality in passage in (A173). In order to prove the right equality in (33), first note that by the optimality of the MAP decoder. For the other direction, consider the universal decoding metric of . Then, trivially,
and
We have the following
which completes the proof of the theorem.
Appendix F. Proof of Theorem 5
We start by writing the expression in (34) in a slightly different way using
:
Now, the requirement is equivalent to
or,
or,
or that for any ,
with the understanding that a minimum over an empty set equals infinity.
Appendix G. Proof of Theorem 6
It follows by the identities and that (24) can also be written as
such that is equivalent to
or,
or that for any ,
and the proof is complete.
References
- Merhav, N. Error exponents of typical random codes. IEEE Trans. Inf. Theory 2018, 64, 6223–6235. [Google Scholar] [CrossRef]
- Barg, A.; Forney, G.D., Jr. Random codes: Minimum distances and error exponents. IEEE Trans. Inf. Theory 2003, 48, 2568–2573. [Google Scholar] [CrossRef]
- Nazari, A.; Anastasopoulos, A.; Pradhan, S.S. Error exponent for multiple–access channels: Lower bounds. IEEE Trans. Inf. Theory 2014, 60, 5095–5115. [Google Scholar] [CrossRef]
- Merhav, N. Error exponents of typical random codes for the colored Gaussian channel. IEEE Trans. Inf. Theory 2019, 65, 8164–8179. [Google Scholar] [CrossRef]
- Merhav, N. Error exponents of typical random trellis codes. IEEE Trans. Inf. Theory 2020, 66, 2067–2077. [Google Scholar] [CrossRef]
- Merhav, N. A Lagrange–dual lower bound to the error exponent of the typical random code. IEEE Trans. Inf. Theory 2020, 66, 3456–3464. [Google Scholar] [CrossRef]
- Tamir (Averbuch), R.; Merhav, N.; Weinberger, N.; Guillén i Fàbregas, A. Large deviations behavior of the logarithmic error probability of random codes. IEEE Trans. Inf. Theory 2020, 66, 6635–6659. [Google Scholar] [CrossRef]
- Slepian, D.; Wolf, J. Noiseless coding of correlated information sources. IEEE Trans. Inf. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- Gallager, R.G. Source coding with side information and universal coding. LIDS-P-937. Available online: http://web.mit.edu/gallager/www/papers/paper5.pdf (accessed on 20 February 2021).
- Ahlswede, R.; Dueck, G. Good codes can be produced by a few permutations. IEEE Trans. Inf. Theory 1982, 28, 430–443. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Graph decomposition: A new key to coding theorems. IEEE Trans. Inf. Theory 1981, 27, 5–12. [Google Scholar] [CrossRef]
- Chen, J.; He, D.-K.; Jagmohan, A.; Lastras-Montaño, L.A. On the Reliability Function of Variable-Rate Slepian-Wolf Coding. Entropy 2017, 19, 389. [Google Scholar] [CrossRef]
- Weinberger, N.; Merhav, N. Optimum Tradeoffs Between the Error Exponent and the Excess-Rate Exponent of Variable-Rate Slepian–Wolf Coding. IEEE Trans. Inf. Theory 2015, 61, 2165–2190. [Google Scholar] [CrossRef]
- Csiszár, I. Linear codes for sources and source networks: Error exponents, universal coding. IEEE Trans. Inf. Theory 1982, 28, 585–592. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Towards a general theory of source networks. IEEE Trans. Inf. Theory 1980, 26, 155–165. [Google Scholar] [CrossRef]
- Kelly, B.G.; Wagner, A.B. Improved Source Coding Exponents via Witsenhausen’s Rate. IEEE Trans. Inf. Theory 2011, 57, 5615–5633. [Google Scholar] [CrossRef]
- Kelly, B.G.; Wagner, A.B. Reliability in Source Coding With Side Information. IEEE Trans. Inf. Theory 2012, 58, 5086–5111. [Google Scholar] [CrossRef]
- Oohama, Y.; Han, T. Universal coding for the Slepian-Wolf data compression system and the strong converse theorem. IEEE Trans. Inf. Theory 1994, 40, 1908–1919. [Google Scholar] [CrossRef]
- Liu, J.; Cuff, P.; Verdú, S. On α–decodability and α–likelihood decoder. In Proceedings of the 2017 55th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 3–6 October 2017. [Google Scholar]
- Merhav, N. The generalized stochastic likelihood decoder: Random coding and expurgated bounds. IEEE Trans. Inf. Theory 2017, 63, 5039–5051, See also a correction at IEEE Trans. Inf. Theory 2017, 63, 6827–6829. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Tamir (Averbuch), R.; Merhav, N. The MMI decoder is asymptotically optimal for the typical random code and for the expurgated code. arXiv 2020, arXiv:2007.12225. [Google Scholar]
- Somekh-Baruch, A.; Scarlett, J.; Guillén i Fàbregas, A. Generalized Random Gilbert-Varshamov Codes. IEEE Trans. Inf. Theory 2019, 65, 3452–3469. [Google Scholar] [CrossRef]
- Merhav, N. Statistical physics and information theory. Found. Trends Commun. Inf. Theory 2009, 6, 1–212. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).