
Efficient Proximal Gradient Algorithms for Joint Graphical Lasso


Abstract
:1. Introduction
- Sequentially find the variables on which each variable depends via regression so that the quasilikelihood is maximized [2].
- We propose efficient algorithms based on the proximal gradient method to solve the JGL problem. The algorithms are first-order methods and quite simple, and the subproblems can be solved efficiently with a closed-form solution. The numerical results indicate that the methods can achieve high accuracy and precision, and the computational time is competitive with state-of-art algorithms.
- We provide the boundedness for the solution to the JGL problem and the iterates in algorithms, which is related to the convergence rate of the algorithms. With the boundedness, we can guarantee that our proposed method converges linearly.
2. Preliminaries
2.1. Graphical Lasso
2.2. ISTA for Graphical Lasso
| Algorithm 1 G-ISTA for problem (2). |
| Input: , tolerance , backtracking constant , initial value , , . While (until convergence) do |
|
| end Output: -optimal solution to problem (2), . |
2.3. Composite Self-Concordant Minimization
2.4. Joint Graphical Lasso
3. The Proposed Methods
3.1. ISTA for the JGL Problem
| Algorithm 2 ISTA for problem (15). |
| Input: , tolerance , backtracking constant , initial step size , initial iterate . For (until convergence) do |
|
| end Output: optimal solution to problem (15), . |
3.1.1. Fused Lasso Penalty
3.1.2. Group Lasso Penalty
3.2. Modified ISTA for JGL
| Algorithm 3 Modified ISTA (M-ISTA). |
| Input: , tolerance , initial step size , initial iterate . For (until convergence) do |
|
| end Output: optimal solution to problem (15), . |
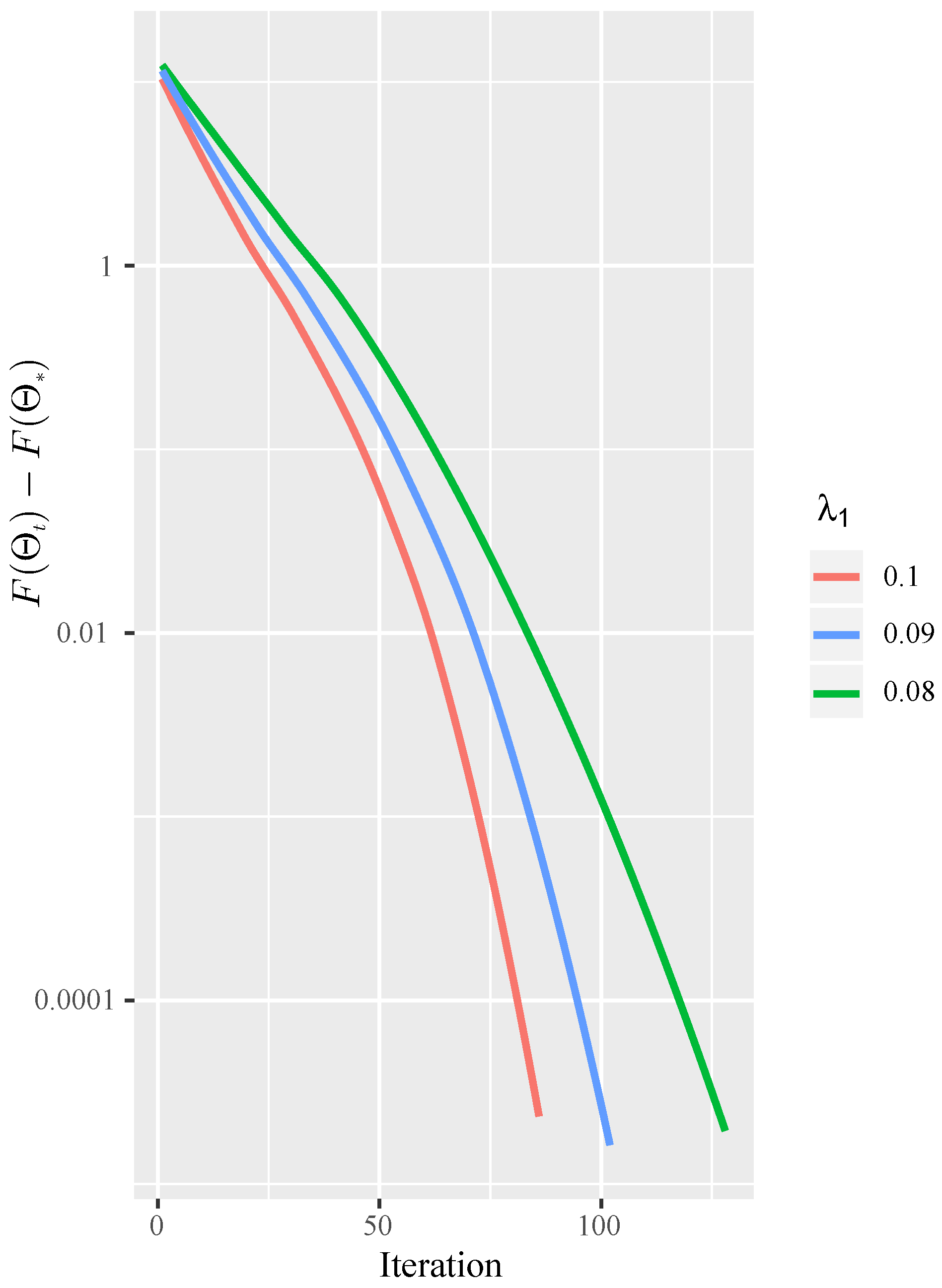
3.3. Theoretical Analysis
4. Experiments
4.1. Stopping Criteria and Model Selection
4.2. Synthetic Data
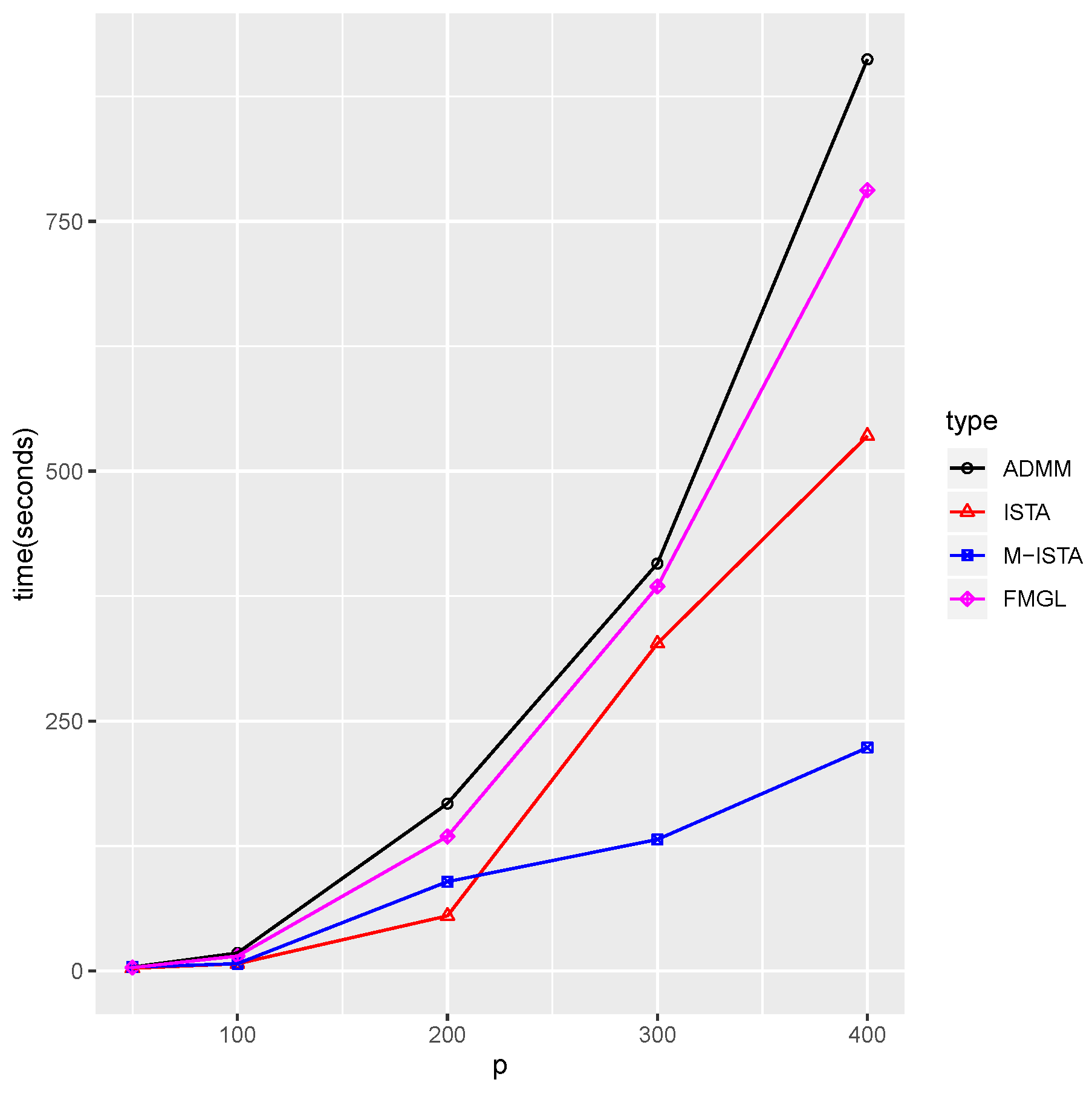
4.2.1. Time Comparison Experiments
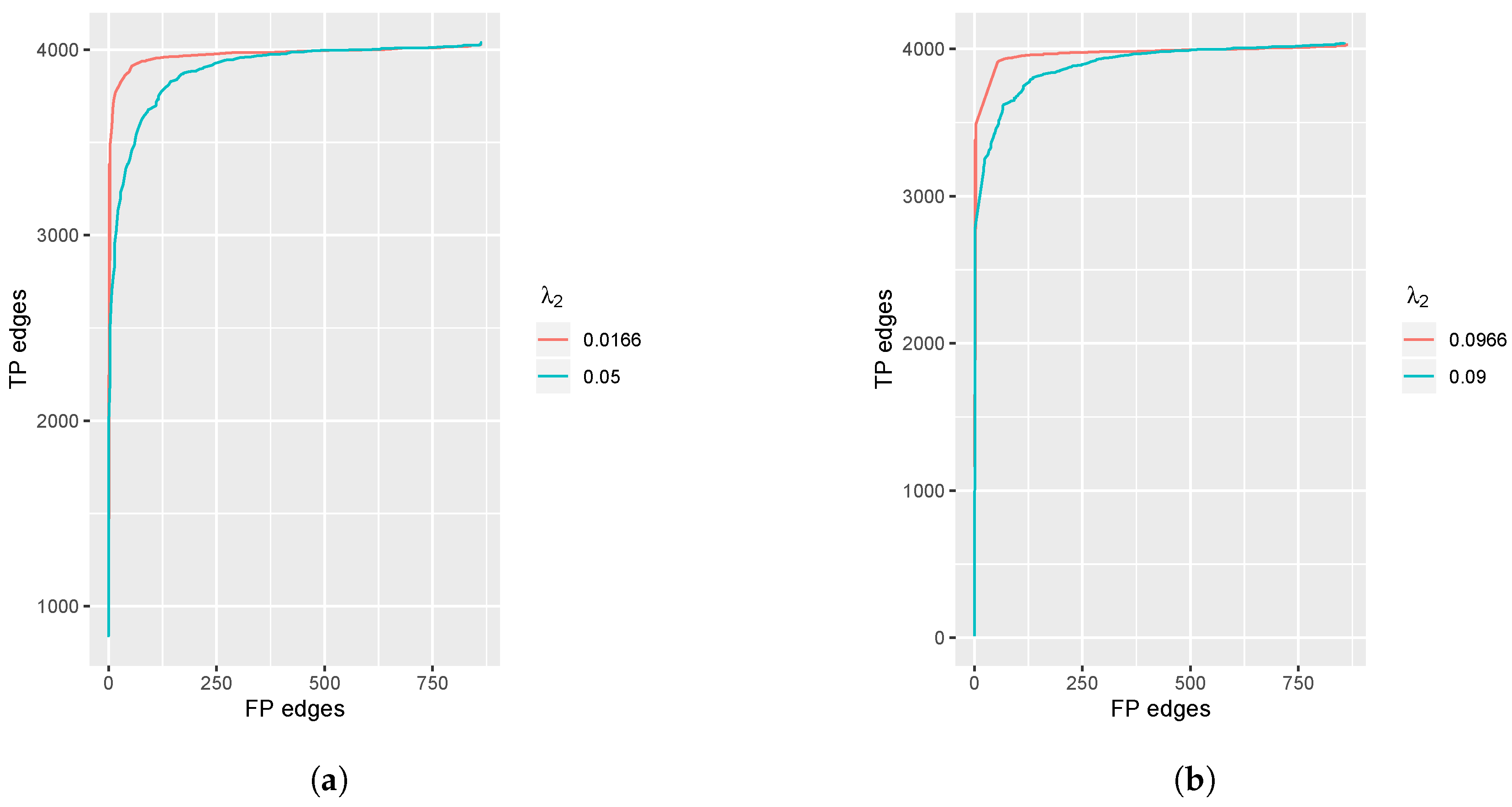
4.2.2. Algorithm Assessment
4.2.3. Convergence Rate
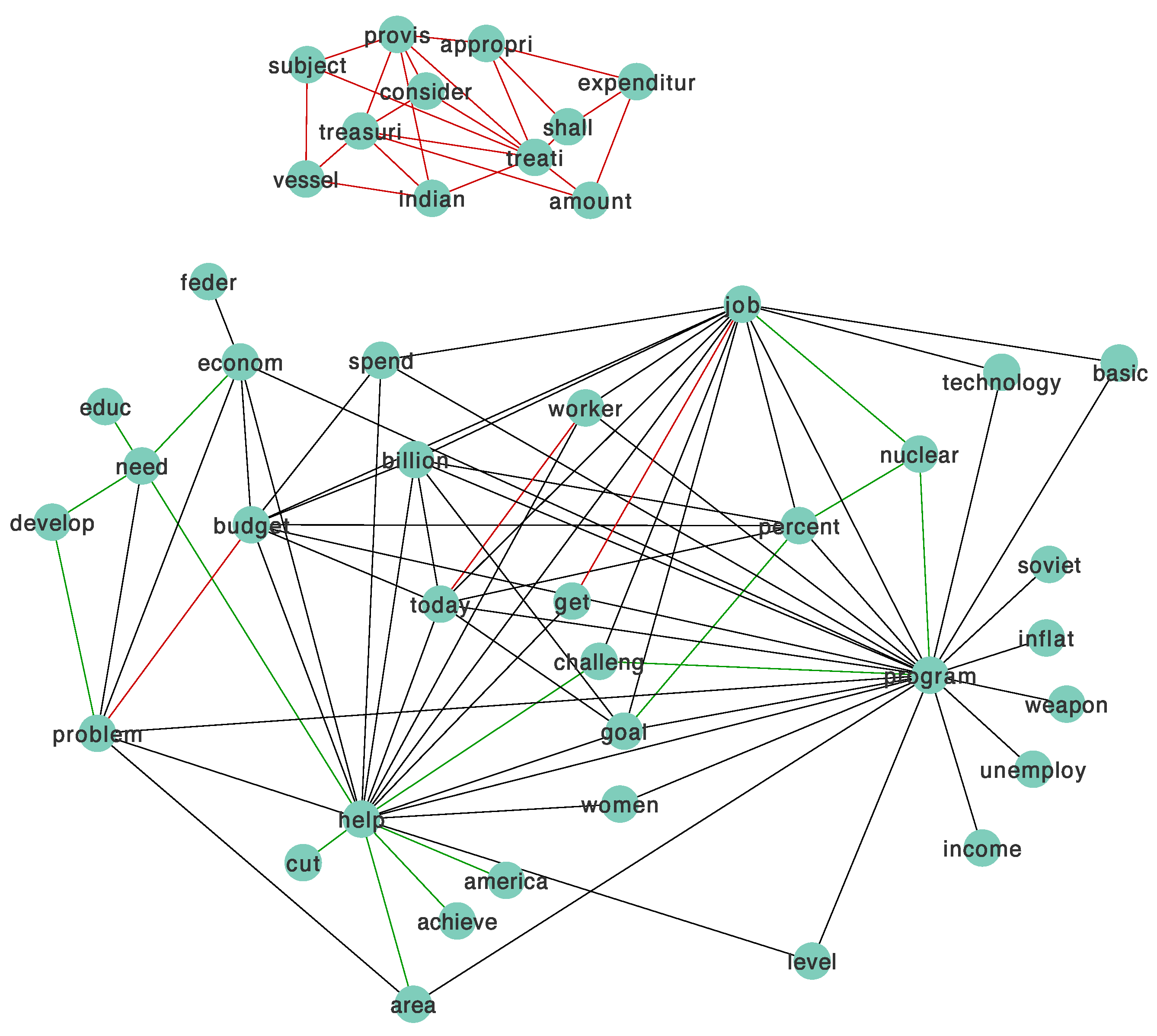
4.3. Real Data
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADMM | alternating direction method of multipliers |
| FMGL | fused multiple graphical lasso algorithm |
| FP | false positive |
| G-ISTA | graphical iterative shrinkage-thresholding algorithm |
| GL | graphical lasso |
| ISTA | iterative shrinkage-thresholding algorithm |
| JGL | joint graphical lasso |
| M-ISTA | modified iterative shrinkage-thresholding algorithm |
| MSE | mean squared error |
| ROC | receiver operating characteristic |
| TP | true positive |
Appendix A. Proofs of Propositions
Appendix A.1. Proof of Proposition 1
Appendix A.2. Proof of Proposition 2
Appendix B. Data Generation
References
- Lauritzen, S.L. Graphical Models; Clarendon Press: Oxford, UK, 1996; Volume 17. [Google Scholar]
- Meinshausen, N.; Bühlmann, P. High-dimensional graphs and variable selection with the lasso. Ann. Stat. 2006, 34, 1436–1462. [Google Scholar] [CrossRef] [Green Version]
- Yuan, M.; Lin, Y. Model selection and estimation in the Gaussian graphical model. Biometrika 2007, 94, 19–35. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 2008, 9, 432–441. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, O.; El Ghaoui, L.; d’Aspremont, A. Model selection through sparse maximum likelihood estimation for multivariate Gaussian or binary data. J. Mach. Learn. Res. 2008, 9, 485–516. [Google Scholar]
- Rothman, A.J.; Bickel, P.J.; Levina, E.; Zhu, J. Sparse permutation invariant covariance estimation. Electron. J. Stat. 2008, 2, 494–515. [Google Scholar] [CrossRef]
- Banerjee, O.; Ghaoui, L.E.; d’Aspremont, A.; Natsoulis, G. Convex optimization techniques for fitting sparse Gaussian graphical models. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 89–96. [Google Scholar]
- Xue, L.; Ma, S.; Zou, H. Positive-definite l1-penalized estimation of large covariance matrices. J. Am. Stat. Assoc. 2012, 107, 1480–1491. [Google Scholar] [CrossRef] [Green Version]
- Mazumder, R.; Hastie, T. The graphical lasso: New insights and alternatives. Electron. J. Stat. 2012, 6, 2125. [Google Scholar] [CrossRef]
- Guillot, D.; Rajaratnam, B.; Rolfs, B.T.; Maleki, A.; Wong, I. Iterative thresholding algorithm for sparse inverse covariance estimation. arXiv 2012, arXiv:1211.2532. [Google Scholar]
- d’Aspremont, A.; Banerjee, O.; El Ghaoui, L. First-order methods for sparse covariance selection. SIAM J. Matrix Anal. Appl. 2008, 30, 56–66. [Google Scholar] [CrossRef] [Green Version]
- Hsieh, C.J.; Sustik, M.A.; Dhillon, I.S.; Ravikumar, P. QUIC: Quadratic approximation for sparse inverse covariance estimation. J. Mach. Learn. Res. 2014, 15, 2911–2947. [Google Scholar]
- Danaher, P.; Wang, P.; Witten, D.M. The joint graphical lasso for inverse covariance estimation across multiple classes. J. R. Stat. Soc. Ser. B Stat. Methodol. 2014, 76, 373. [Google Scholar] [CrossRef]
- Honorio, J.; Samaras, D. Multi-Task Learning of Gaussian Graphical Models; ICML: Baltimore, MA, USA, 2010. [Google Scholar]
- Guo, J.; Levina, E.; Michailidis, G.; Zhu, J. Joint estimation of multiple graphical models. Biometrika 2011, 98, 1–15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, B.; Wang, Y. Learning structural changes of Gaussian graphical models in controlled experiments. arXiv 2012, arXiv:1203.3532. [Google Scholar]
- Hara, S.; Washio, T. Learning a common substructure of multiple graphical Gaussian models. Neural Netw. 2013, 38, 23–38. [Google Scholar] [CrossRef] [Green Version]
- Glowinski, R.; Marroco, A. Sur l’approximation, par éléments finis d’ordre un, et la résolution, par pénalisation-dualité d’une classe de problèmes de Dirichlet non linéaires. ESAIM Math. Model. Numer. Anal.-Modél. Math. Et Anal. Numér. 1975, 9, 41–76. [Google Scholar] [CrossRef]
- Tang, Q.; Yang, C.; Peng, J.; Xu, J. Exact hybrid covariance thresholding for joint graphical lasso. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2015; pp. 593–607. [Google Scholar]
- Hallac, D.; Park, Y.; Boyd, S.; Leskovec, J. Network inference via the time-varying graphical lasso. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 205–213. [Google Scholar]
- Gibberd, A.J.; Nelson, J.D. Regularized estimation of piecewise constant gaussian graphical models: The group-fused graphical lasso. J. Comput. Graph. Stat. 2017, 26, 623–634. [Google Scholar] [CrossRef] [Green Version]
- Boyd, S.; Parikh, N.; Chu, E. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers; Now Publishers Inc.: Norwell, MA, USA, 2011. [Google Scholar]
- Yang, S.; Lu, Z.; Shen, X.; Wonka, P.; Ye, J. Fused multiple graphical lasso. SIAM J. Optim. 2015, 25, 916–943. [Google Scholar] [CrossRef] [Green Version]
- Tran-Dinh, Q.; Kyrillidis, A.; Cevher, V. Composite self-concordant minimization. J. Mach. Learn. Res. 2015, 16, 371–416. [Google Scholar]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef] [Green Version]
- Nesterov, Y.; Nemirovskii, A. Interior-Point Polynomial Algorithms in Convex Programming; SIAM: Philadelphia, PA, USA, 1994. [Google Scholar]
- Renegar, J. A Mathematical View of Interior-Point Methods in Convex Optimization; SIAM: Philadelphia, PA, USA, 2001. [Google Scholar]
- Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course; Springer Science & Business Media: New York, NY, USA, 2003; Volume 87. [Google Scholar]
- Tibshirani, R.; Saunders, M.; Rosset, S.; Zhu, J.; Knight, K. Sparsity and smoothness via the fused lasso. J. R. Stat. Soc. Ser. B 2005, 67, 91–108. [Google Scholar] [CrossRef] [Green Version]
- Simon, N.; Friedman, J.; Hastie, T.; Tibshirani, R. A sparse-group lasso. J. Comput. Graph. Stat. 2013, 22, 231–245. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. A note on the group lasso and a sparse group lasso. arXiv 2010, arXiv:1001.0736. [Google Scholar]
- Hoefling, H. A path algorithm for the fused lasso signal approximator. J. Comput. Graph. Stat. 2010, 19, 984–1006. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Höfling, H.; Tibshirani, R. Pathwise coordinate optimization. Ann. Appl. Stat. 2007, 1, 302–332. [Google Scholar] [CrossRef] [Green Version]
- Tibshirani, R.J.; Taylor, J. The solution path of the generalized lasso. Ann. Stat. 2011, 39, 1335–1371. [Google Scholar] [CrossRef] [Green Version]
- Johnson, N.A. A dynamic programming algorithm for the fused lasso and l 0-segmentation. J. Comput. Graph. Stat. 2013, 22, 246–260. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Ser. B 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Suzuki, J. Sparse Estimation with Math and R: 100 Exercises for Building Logic; Springer Nature: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Boyd, S.; Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Nemirovski, A. Interior point polynomial time methods in convex programming. Lect. Notes 2004, 42, 3215–3224. [Google Scholar]
- Li, H.; Gui, J. Gradient directed regularization for sparse Gaussian concentration graphs, with applications to inference of genetic networks. Biostatistics 2006, 7, 302–317. [Google Scholar] [CrossRef]
- Weylandt, M.; Nagorski, J.; Allen, G.I. Dynamic visualization and fast computation for convex clustering via algorithmic regularization. J. Comput. Graph. Stat. 2020, 29, 87–96. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D.; Amin, N.; Schwikowski, B.; Ideker, T. Cytoscape: A software environment for integrated models of biomolecular interaction networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef] [PubMed]
- Miller, L.D.; Smeds, J.; George, J.; Vega, V.B.; Vergara, L.; Ploner, A.; Pawitan, Y.; Hall, P.; Klaar, S.; Liu, E.T.; et al. An expression signature for p53 status in human breast cancer predicts mutation status, transcriptional effects, and patient survival. Proc. Natl. Acad. Sci. USA 2005, 102, 13550–13555. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | ADMM | Proximal Newton | Proximal Gradient |
|---|---|---|---|
| GL [4] | [8] | [12] | [10] |
| JGL [13] | [13] | [23] | Current Paper |
| (for fused penalty) | (for fused and group penalties) |
| Parameters Setting | Computational Time | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| p | K | N | precision | ADMM | FMGL | ISTA | M-ISTA | ||
| 20 | 2 | 60 | 0.1 | 0.05 | 0.00001 | 10.506 s | 1.158 s | 2.174 s | 1.742 s |
| 3 | 1.879 min | 4.267 s | 3.357 s | 3.668 s | |||||
| 5 | 1 | 0.5 | 1.123 min | 10.556 s | 4.216 s | 2.874 s | |||
| 30 | 2 | 120 | 0.1 | 0.05 | 0.0001 | 10.095 s | 5.259 s | 2.690 s | 4.857 s |
| 3 | 2.014 min | 38.562 s | 14.722 s | 31.870 s | |||||
| 5 | 1 | 0.5 | 2.447 min | 15.819 s | 22.431 s | 12.113 s | |||
| 50 | 2 | 600 | 0.02 | 0.005 | 0.0001 | 6.427 s | 10.228 s | 7.213 s | 4.625 s |
| 0.03 | 6.240 s | 8.925 s | 6.645 s | 4.023 s | |||||
| 0.04 | 7.025 s | 9.381 s | 6.144 s | 3.993 s | |||||
| 200 | 2 | 400 | 0.09 | 0.05 | 0.0001 | 4.050 min | 1.874 min | 2.289 min | 35.038 s |
| 0.1 | 4.569 min | 1.137 min | 1.340 min | 24.852 s | |||||
| 0.12 | 3.848 min | 1.881 min | 1.443 min | 18.367 s | |||||
| Dataset | Parameters Setting | Computational Time | |||||
|---|---|---|---|---|---|---|---|
| Precision | ADMM | FMGL | ISTA | M-ISTA | |||
| Speeches | 0.1 | 0.05 | 0.0001 | 19.969 s | 4.977 min | 11.829 s | 12.867 s |
| 0.2 | 0.1 | 4.661 min | 3.209 min | 11.560 s | 12.682 s | ||
| 0.5 | 0.25 | 5.669 min | 1.490 min | 11.043 s | 12.788 s | ||
| Breast cancer | 0.1 | 0.0166 | 0.0001 | 3.809 min | 7.937 min | 1.305 min | 1.158 min |
| 0.2 | 0.02 | 6.031 min | 5.198 min | 1.503 min | 1.230 min | ||
| 0.3 | 0.03 | 5.499 min | 2.265 min | 1.188 min | 1.061 min | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Shimmura, R.; Suzuki, J. Efficient Proximal Gradient Algorithms for Joint Graphical Lasso. Entropy 2021, 23, 1623. https://doi.org/10.3390/e23121623
Chen J, Shimmura R, Suzuki J. Efficient Proximal Gradient Algorithms for Joint Graphical Lasso. Entropy. 2021; 23(12):1623. https://doi.org/10.3390/e23121623
Chicago/Turabian StyleChen, Jie, Ryosuke Shimmura, and Joe Suzuki. 2021. "Efficient Proximal Gradient Algorithms for Joint Graphical Lasso" Entropy 23, no. 12: 1623. https://doi.org/10.3390/e23121623
APA StyleChen, J., Shimmura, R., & Suzuki, J. (2021). Efficient Proximal Gradient Algorithms for Joint Graphical Lasso. Entropy, 23(12), 1623. https://doi.org/10.3390/e23121623