Risk Evaluation for a Manufacturing Process Based on a Directed Weighted Network


Abstract
1. Introduction
2. Literature Review
3. Proposed Method
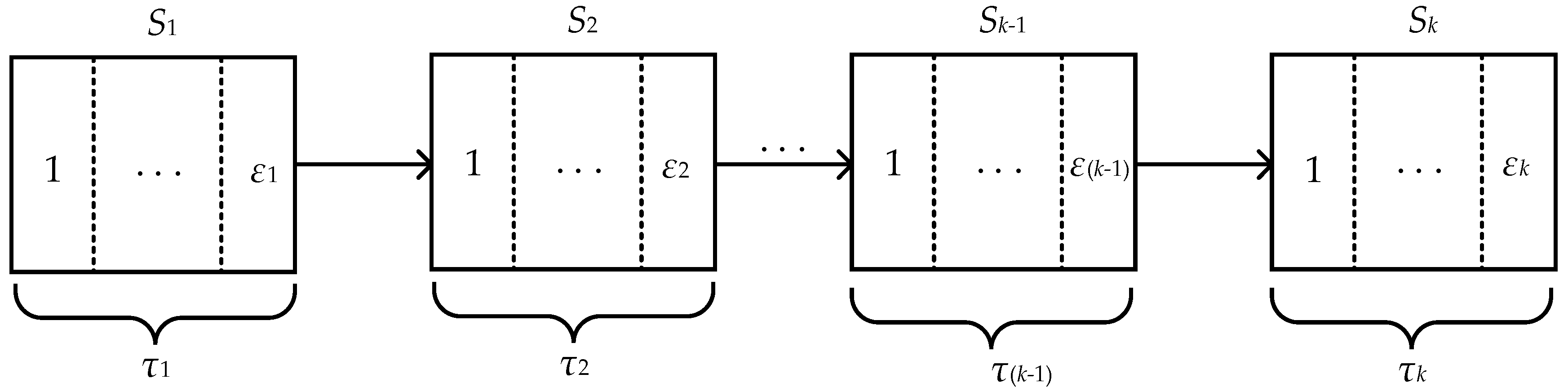
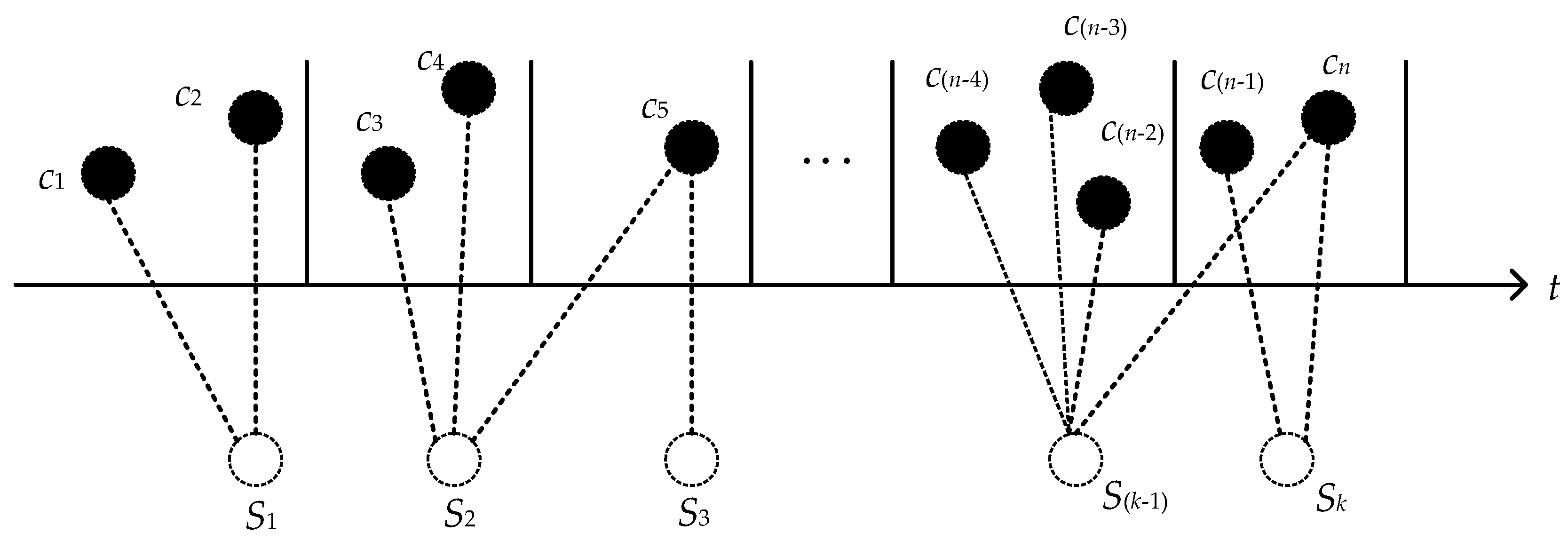
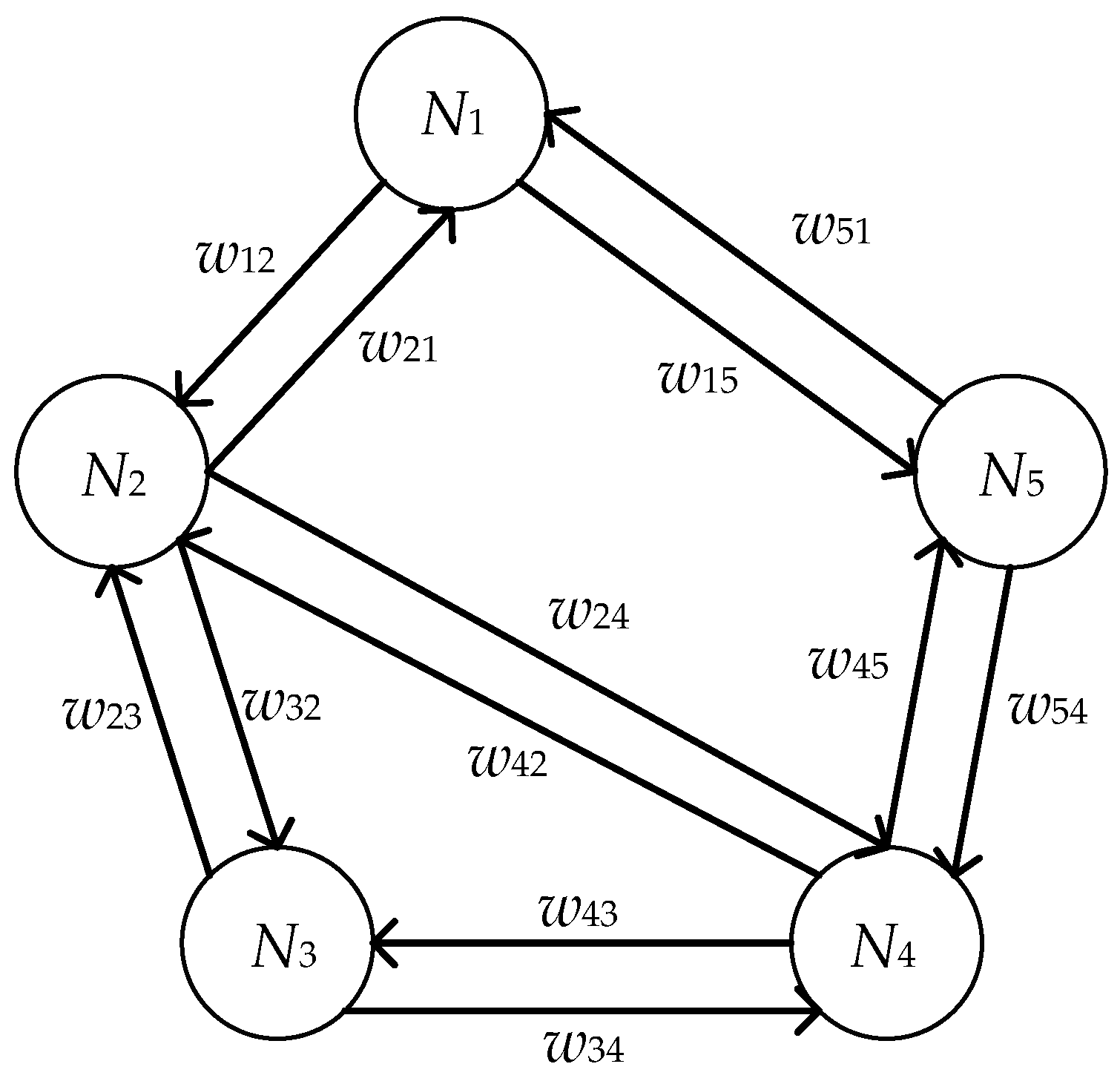
3.1. Preliminaries
3.2. PMIPE Method
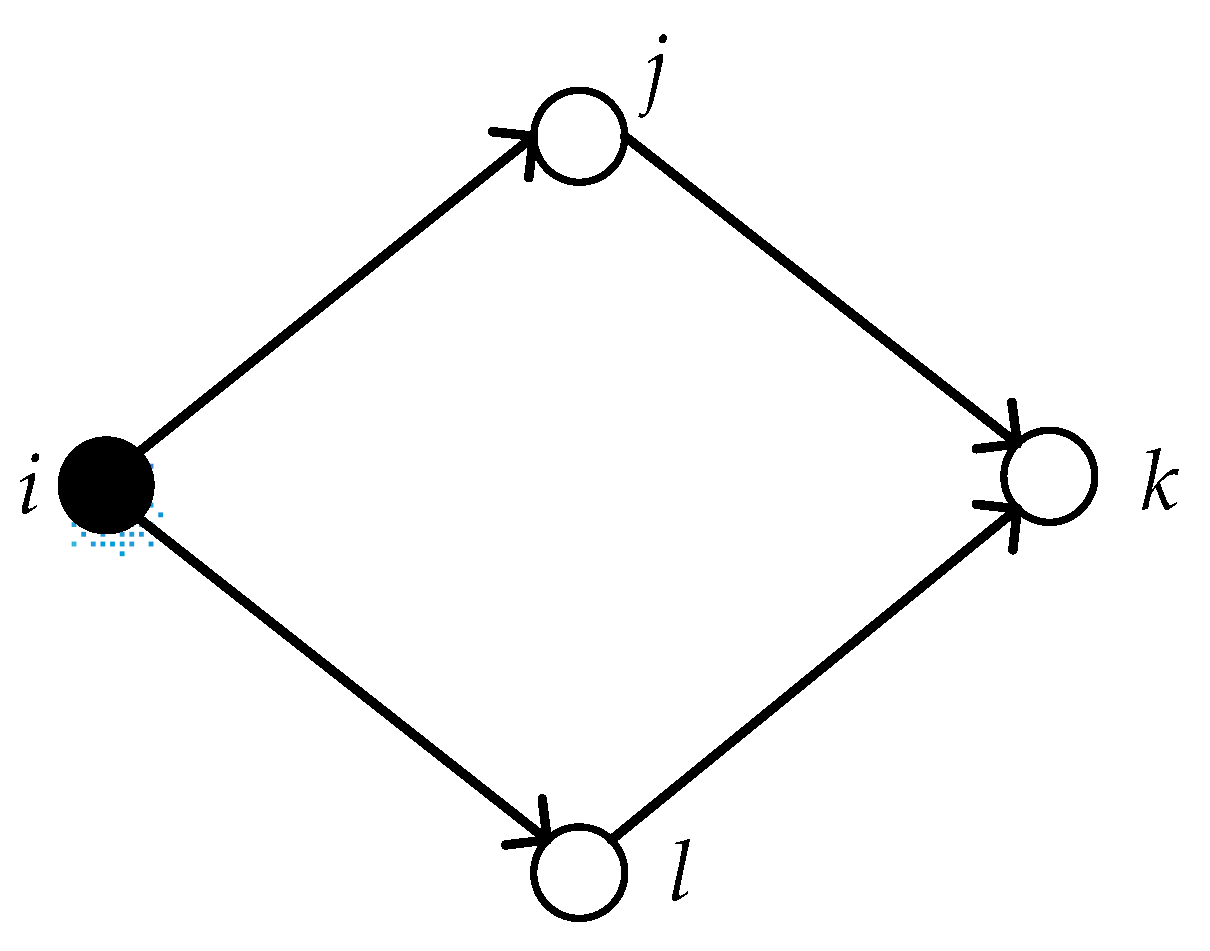
3.3. Entropy-Based Centrality Measurement
3.4. Risk Evaluation
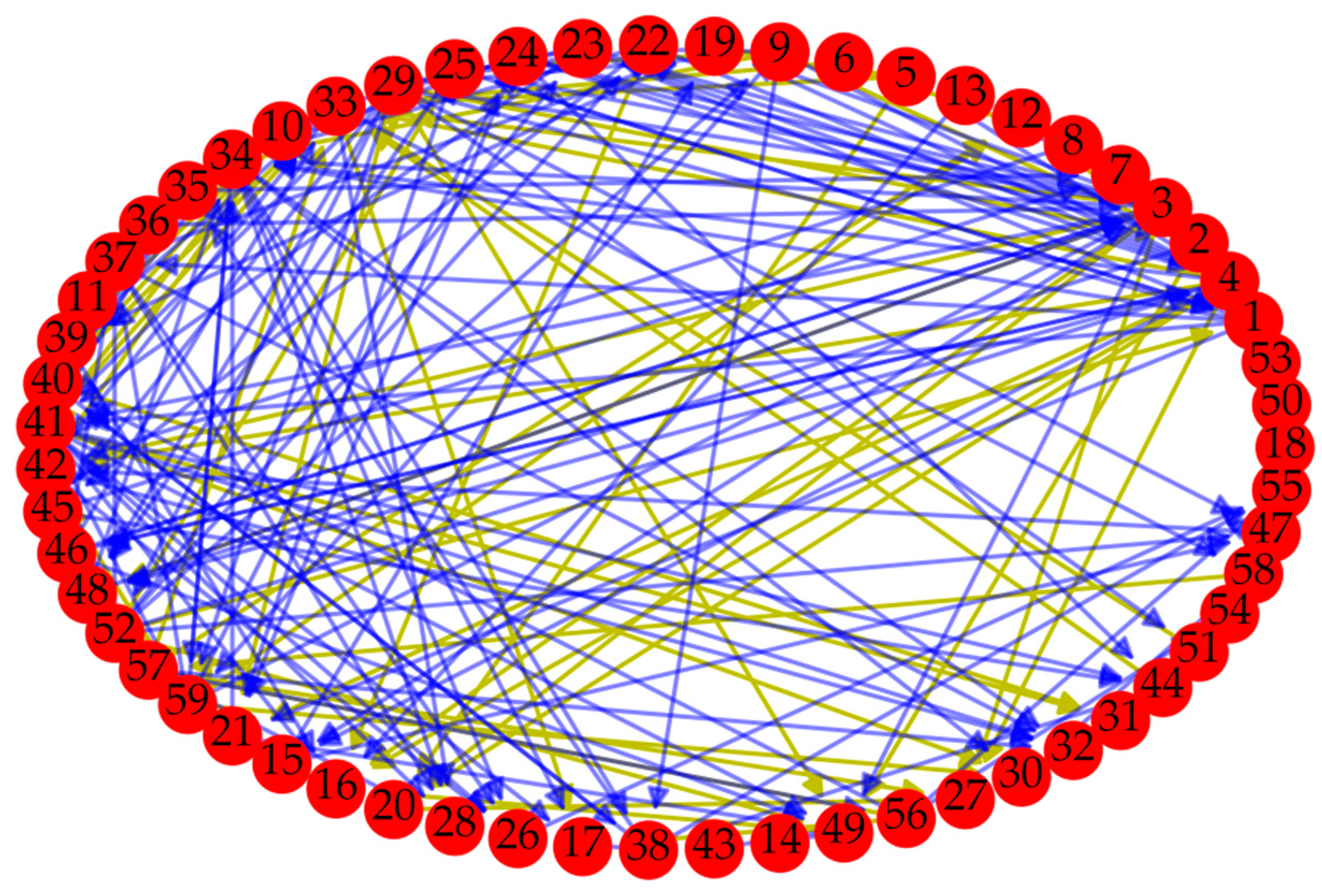
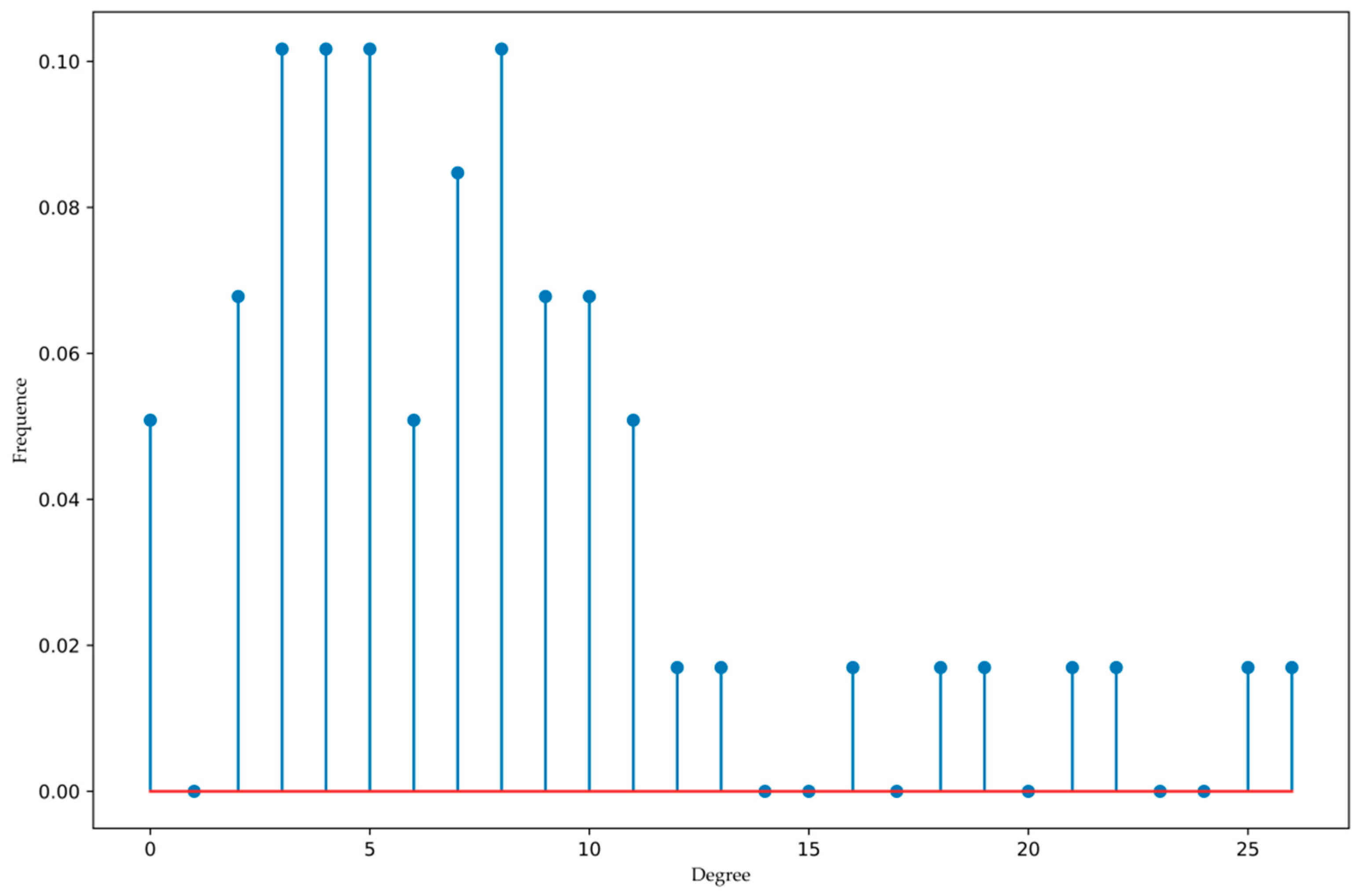
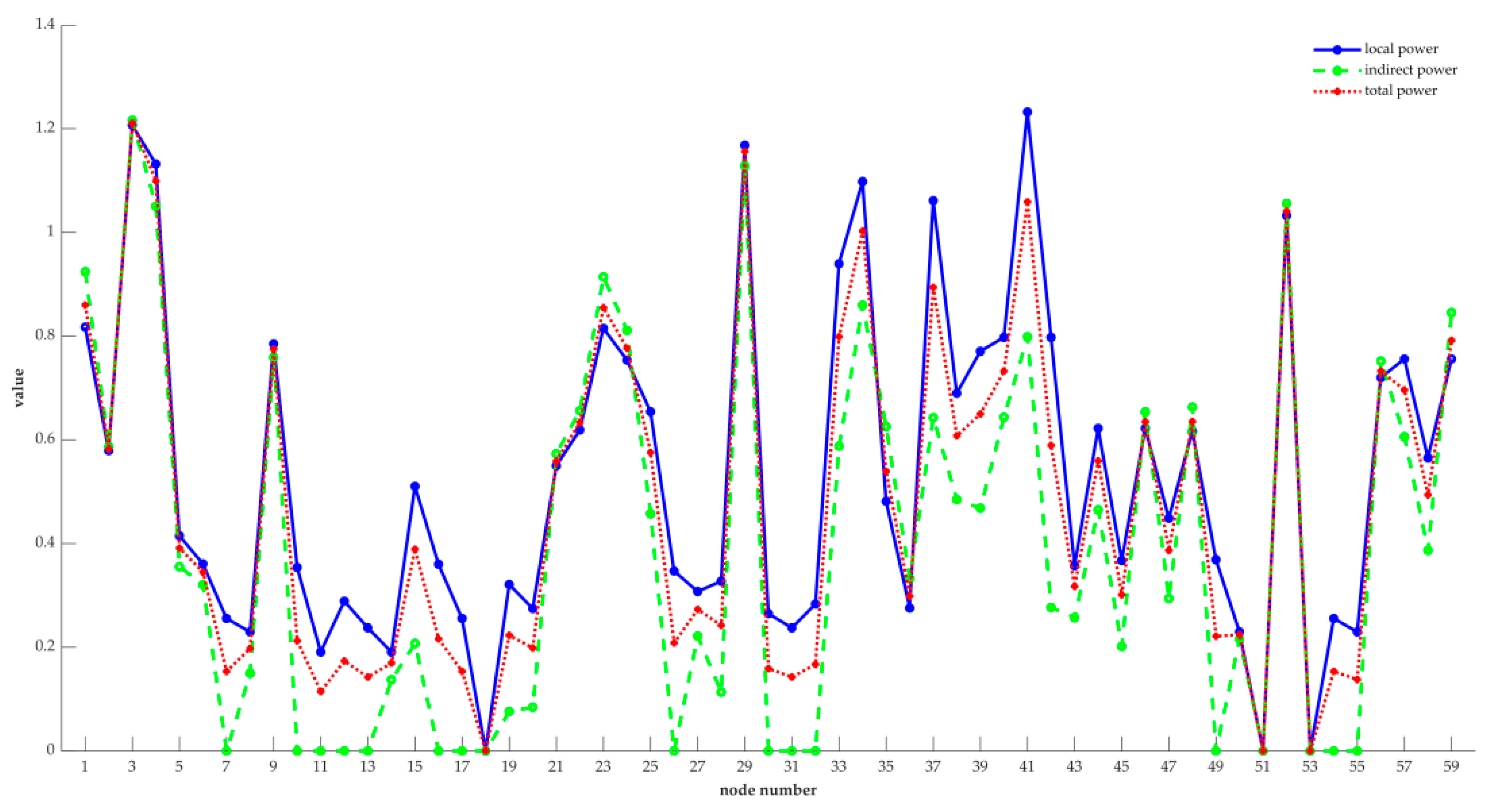
4. Case Study
5. Conclusions and Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Li, J.; Freiheit, T.; Hu, S.J.; Koren, Y. A Quality Prediction Framework for Multistage Machining Processes Driven by an Engineering Model and Variation Propagation Model. J. Manuf. Sci. Eng. 2007, 129, 1088–1100. [Google Scholar] [CrossRef]
- Amiri, A.; Zou, C.; Doroudyan, M.H. Monitoring Correlated Profile and Multivariate Quality Characteristics. Qual. Reliab. Eng. Int. 2014, 30, 133–142. [Google Scholar] [CrossRef]
- Chan, L.K. Ming-Lu Wu Quality function deployment: A literature review. Eur. J. Oper. Res. 2002, 143, 463–497. [Google Scholar] [CrossRef]
- Aoki, M.; Havenner, A. State space modeling of multiple time series. Econom. Rev. 1991, 10, 1–59. [Google Scholar] [CrossRef]
- Abellan-Nebot, J.V.; Liu, J.; Subirón, F.R.; Shi, J. State Space Modeling of Variation Propagation in Multistation Machining Processes Considering Machining-Induced Variations. J. Manuf. Sci. Eng. 2012, 134. [Google Scholar] [CrossRef]
- Mantripragada, R.; Whitney, D.E. Modeling and controlling variation propagation in mechanical assemblies using state transition models. IEEE Trans. Robot. Autom. 1999, 15, 124–140. [Google Scholar] [CrossRef]
- Jin, J.; Shi, J. State Space Modeling of Sheet Metal Assembly for Dimensional Control. J. Manuf. Sci. Eng. 1999, 121, 756–762. [Google Scholar] [CrossRef]
- Shiyu Zhou; Qiang Huang; Jianjun Shi State space modeling of dimensional variation propagation in multistage machining process using differential motion vectors. IEEE Trans. Robot. Autom. 2003, 19, 296–309. [CrossRef]
- Hu, S.J. Yoram Koren Stream-of-Variation Theory for Automotive Body Assembly. CIRP Ann. Manuf. Technol. 1997, 46, 1–6. [Google Scholar] [CrossRef]
- Barhak, J.; Djurdjanovic, D.; Spicer, P.; Katz, R. Integration of reconfigurable inspection with stream of variations methodology. Int. J. Mach. Tools Manuf. 2005, 45, 407–419. [Google Scholar] [CrossRef]
- Huang, Q.; Shi, J.; Yuan, J. Part Dimensional Error and Its Propagation Modeling in Multi-Operational Machining Processes. J. Manuf. Sci. Eng. 2003, 125, 255. [Google Scholar] [CrossRef]
- Ming, J.; LI, Y.; Tsung, F. Chart allocation strategy for serial-parallel multistage manufacturing processes. Iie Trans. 2010, 42, 577–588. [Google Scholar]
- Jiao, Y.; Djurdjanovic, D. Compensability of errors in product quality in multistage manufacturing processes. J. Manuf. Syst. 2011, 30, 204–213. [Google Scholar] [CrossRef]
- Lin, Y.-K.; Chang, P.-C. Reliability evaluation for a manufacturing network with multiple production lines. Comput. Ind. Eng. 2012, 63, 1209–1219. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, P.; Leng, J. An extended machining error propagation network model for small-batch machining process control of aircraft landing gear parts. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2017, 231, 1347–1365. [Google Scholar] [CrossRef]
- Liu, D.; Jiang, P. The complexity analysis of a machining error propagation network and its application. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2009, 223, 623–640. [Google Scholar] [CrossRef]
- Cheng, H.; Chu, X. A network-based assessment approach for change impacts on complex product. J. Intell. Manuf. 2012, 23, 1419–1431. [Google Scholar] [CrossRef]
- Qin, Y.; Zhao, L.; Yao, Y.; Xu, D. Multistage machining processes variation propagation analysis based on machining processes weighted network performance. Int. J. Adv. Manuf. Technol. 2011, 55, 487–499. [Google Scholar] [CrossRef]
- Kim, H.K.; Kim, J.K.; Qiu, Y.C. A product network analysis for extending the market basket analysis. Expert Syst. Appl. 2012, 39, 7403–7410. [Google Scholar] [CrossRef]
- Wang, L.; Dai, W.; Luo, G.; Zhao, Y. A Novel Approach to Support Failure Mode, Effects, and Criticality Analysis Based on Complex Networks. Entropy 2019, 21, 1230. [Google Scholar] [CrossRef]
- Di Bona, G.; Silvestri, A.; Forcina, A.; Petrillo, A. Total efficient risk priority number (TERPN): A new method for risk assessment. J. Risk Res. 2018, 21, 1384–1408. [Google Scholar] [CrossRef]
- Du, W.; Mo, R.; Li, S.; Li, B. Design of Product Key Characteristics Management System. Adv. Mater. Res. 2012, 468–471, 835–838. [Google Scholar] [CrossRef]
- Köksoy, O. A nonlinear programming solution to robust multi-response quality problem. Appl. Math. Comput. 2008, 196, 603–612. [Google Scholar] [CrossRef]
- Ouyang, L.Y.; Chen, K.-S.; Yang, C.-M.; Hsu, C.-H. Using a QCAC–Entropy–TOPSIS approach to measure quality characteristics and rank improvement priorities for all substandard quality characteristics. Int. J. Prod. Res. 2014, 52, 3110–3124. [Google Scholar] [CrossRef]
- Li, A.-D.; He, Z.; Wang, Q.; Zhang, Y. Key quality characteristics selection for imbalanced production data using a two-phase bi-objective feature selection method. Eur. J. Oper. Res. 2019, 274, 978–989. [Google Scholar] [CrossRef]
- Diao, G.; Zhao, L.; Yao, Y. A weighted-coupled network-based quality control method for improving key features in product manufacturing process. J. Intell. Manuf. 2016, 27, 535–548. [Google Scholar] [CrossRef]
- Barnett, L.; Barrett, A.B.; Seth, A.K. Granger Causality and Transfer Entropy Are Equivalent for Gaussian Variables. Phys. Rev. Lett. 2009, 103, 238701. [Google Scholar] [CrossRef]
- Marko, H. The Bidirectional Communication Theory-A Generalization of Information Theory. IEEE Trans. Commun. 1973, 21, 145–1351. [Google Scholar] [CrossRef]
- Schreiber; Thomas Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [CrossRef]
- Mao, X.; Shang, P. Transfer entropy between multivariate time series. Commun. Nonlinear Sci. Numer. Simul. 2017, 47, 338–347. [Google Scholar] [CrossRef]
- Montalto, A.; Stramaglia, S.; Faes, L.; Tessitore, G.; Prevete, R.; Marinazzo, D. Neural networks with non-uniform embedding and explicit validation phase to assess Granger causality. Neural Netw. 2015, 71, 159–171. [Google Scholar] [CrossRef] [PubMed]
- Faes, L.; Nollo, G.; Porta, A. Information-based detection of nonlinear Granger causality in multivariate processes via a nonuniform embedding technique. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 2011, 83, 051112. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Sun, Y.; Li, X.; Shang, P. Multiscale transfer entropy: Measuring information transfer on multiple time scales. Commun. Nonlinear Sci. Numer. Simul. 2018, 62, 202–212. [Google Scholar] [CrossRef]
- Sysoev, I.V.; Ponomarenko, V.I.; Pikovsky, A. Reconstruction of coupling architecture of neural field networks from vector time series. Commun. Nonlinear Sci. Numer. Simul. 2018, 57, 342–351. [Google Scholar] [CrossRef]
- Vlachos, I.; Kugiumtzis, D. Nonuniform state-space reconstruction and coupling detection. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 2010, 82, 016207. [Google Scholar] [CrossRef]
- Kugiumtzis, D. Direct-coupling information measure from nonuniform embedding. Phys. Rev. E 2013, 87, 062918. [Google Scholar] [CrossRef]
- Qiao, T.; Shan, W.; Yu, G.; Liu, C. A Novel Entropy-Based Centrality Approach for Identifying Vital Nodes in Weighted Networks. Entropy 2018, 20, 261. [Google Scholar] [CrossRef]
- Burduk, A.; Chlebus, E. Methods of risk evaluation in manufacturing systems. Arch. Civ. Mech. Eng. 2009, 9, 17–30. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository: SECOM Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/SECOM (accessed on 9 June 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node | |||
|---|---|---|---|
| 1 | 4 | 6 | 10 |
| 4 | 2 | 3 | 5 |
| 21 | 5 | 1 | 6 |
| 23 | 4 | 2 | 6 |
| 25 | 4 | 0 | 4 |
| 29 | 3 | 0 | 3 |
| 34 | 4 | 1 | 5 |
| 37 | 3 | 4 | 7 |
| 41 | 1 | 7 | 8 |
| 52 | 1 | 7 | 8 |
| Node | No. | Node | No. | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.8174 | 0.9242 | 0.8601 | 8 | 31 | 0.2373 | 0 | 0.1424 | 51 |
| 2 | 0.5791 | 0.5867 | 0.5821 | 23 | 32 | 0.2833 | 0 | 0.1670 | 48 |
| 3 | 1.2070 | 1.2165 | 1.2108 | 1 | 33 | 0.9396 | 0.5878 | 0.7989 | 10 |
| 4 | 1.1320 | 1.0504 | 1.0994 | 3 | 34 | 1.0982 | 0.8598 | 1.0028 | 6 |
| 5 | 0.4150 | 0.3554 | 0.3912 | 29 | 35 | 0.4815 | 0.6256 | 0.5392 | 27 |
| 6 | 0.3607 | 0.3206 | 0.3447 | 32 | 36 | 0.2756 | 0.3326 | 0.2984 | 35 |
| 7 | 0.2555 | 0 | 0.1533 | 50 | 37 | 1.0614 | 0.6429 | 0.8940 | 7 |
| 8 | 0.2295 | 0.1497 | 0.1976 | 45 | 38 | 0.6898 | 0.4848 | 0.6078 | 21 |
| 9 | 0.7851 | 0.7593 | 0.7748 | 13 | 39 | 0.7708 | 0.4683 | 0.6498 | 17 |
| 10 | 0.3538 | 0 | 0.2123 | 42 | 40 | 0.7977 | 0.6437 | 0.7325 | 15 |
| 11 | 0.1908 | 0 | 0.1145 | 53 | 41 | 1.2324 | 0.7986 | 1.0589 | 4 |
| 12 | 0.2889 | 0 | 0.1734 | 46 | 42 | 0.7977 | 0.2768 | 0.5893 | 22 |
| 13 | 0.2373 | 0 | 0.1424 | 51 | 43 | 0.3571 | 0.2571 | 0.3171 | 33 |
| 14 | 0.1908 | 0.1374 | 0.1694 | 47 | 44 | 0.6222 | 0.4650 | 0.5593 | 25 |
| 15 | 0.5103 | 0.2072 | 0.3891 | 30 | 45 | 0.3673 | 0.2016 | 0.3010 | 34 |
| 16 | 0.3601 | 0 | 0.2161 | 41 | 46 | 0.6222 | 0.6539 | 0.6349 | 19 |
| 17 | 0.2555 | 0 | 0.1533 | 50 | 47 | 0.4486 | 0.2941 | 0.3868 | 31 |
| 18 | 0 | 0 | 0 | 54 | 48 | 0.6166 | 0.6633 | 0.6353 | 18 |
| 19 | 0.3210 | 0.0762 | 0.2231 | 39 | 49 | 0.3689 | 0 | 0.2213 | 40 |
| 20 | 0.2746 | 0.0844 | 0.1985 | 44 | 50 | 0 | 0 | 0 | 54 |
| 21 | 0.5498 | 0.5730 | 0.5591 | 26 | 51 | 0.2295 | 0.2156 | 0.2240 | 38 |
| 22 | 0.6191 | 0.6564 | 0.6340 | 20 | 52 | 1.0325 | 1.0557 | 1.0412 | 5 |
| 23 | 0.8151 | 0.9143 | 0.8548 | 9 | 53 | 0 | 0 | 0 | 54 |
| 24 | 0.7538 | 0.8111 | 0.7767 | 12 | 54 | 0.2555 | 0 | 0.1533 | 50 |
| 25 | 0.6542 | 0.4576 | 0.5756 | 24 | 55 | 0.2295 | 0 | 0.1377 | 52 |
| 26 | 0.3470 | 0 | 0.2082 | 43 | 56 | 0.7201 | 0.7518 | 0.7328 | 14 |
| 27 | 0.3074 | 0.2214 | 0.2730 | 36 | 57 | 0.7560 | 0.6060 | 0.6960 | 16 |
| 28 | 0.3274 | 0.1136 | 0.2419 | 37 | 58 | 0.5651 | 0.3868 | 0.4938 | 28 |
| 29 | 1.1683 | 1.1283 | 1.1563 | 2 | 59 | 0.7560 | 0.8454 | 0.7918 | 11 |
| 30 | 0.2649 | 0 | 0.1589 | 49 |
| Node | Node | Node | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 10 | 0.0206 | 21 | 8 | 0.0165 | 41 | 25 | 0.0515 |
| 2 | 7 | 0.0144 | 22 | 7 | 0.0144 | 42 | 11 | 0.0227 |
| 3 | 26 | 0.0536 | 23 | 12 | 0.0247 | 43 | 2 | 0.0041 |
| 4 | 21 | 0.0433 | 24 | 8 | 0.0165 | 44 | 7 | 0.0144 |
| 5 | 3 | 0.0062 | 25 | 9 | 0.0186 | 45 | 6 | 0.0124 |
| 6 | 2 | 0.0041 | 26 | 7 | 0.0144 | 46 | 10 | 0.0206 |
| 7 | 4 | 0.0082 | 27 | 5 | 0.0103 | 47 | 5 | 0.0103 |
| 8 | 3 | 0.0062 | 28 | 6 | 0.0124 | 48 | 10 | 0.0206 |
| 9 | 9 | 0.0186 | 29 | 18 | 0.0371 | 49 | 8 | 0.0165 |
| 10 | 7 | 0.0144 | 30 | 42 | 0.0866 | 50 | 0 | 0.0000 |
| 11 | 2 | 0.0041 | 31 | 3 | 0.0062 | 51 | 3 | 0.0062 |
| 12 | 5 | 0.0103 | 32 | 5 | 0.0103 | 52 | 13 | 0.0268 |
| 13 | 3 | 0.0062 | 33 | 4 | 0.0082 | 53 | 0 | 0.0000 |
| 14 | 2 | 0.0041 | 34 | 22 | 0.0454 | 54 | 4 | 0.0082 |
| 15 | 5 | 0.0103 | 35 | 9 | 0.0186 | 55 | 3 | 0.0062 |
| 16 | 8 | 0.0165 | 36 | 4 | 0.0082 | 56 | 9 | 0.0186 |
| 17 | 4 | 0.0082 | 37 | 16 | 0.0330 | 57 | 8 | 0.0165 |
| 18 | 0 | 0.0000 | 38 | 8 | 0.0165 | 58 | 5 | 0.0103 |
| 19 | 6 | 0.0124 | 39 | 10 | 0.0206 | 59 | 11 | 0.0227 |
| 20 | 4 | 0.0082 | 40 | 11 | 0.0227 |
| Node | Node | Node | Node | Node | |||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0187 | 13 | 0.0062 | 25 | 0.0187 | 37 | 0.0333 | 49 | 0.0146 |
| 2 | 0.0146 | 14 | 0.0042 | 26 | 0.0146 | 38 | 0.0166 | 50 | 0.0000 |
| 3 | 0.0541 | 15 | 0.0104 | 27 | 0.0104 | 39 | 0.0208 | 51 | 0.0062 |
| 4 | 0.0437 | 16 | 0.0166 | 28 | 0.0125 | 40 | 0.0229 | 52 | 0.0270 |
| 5 | 0.0062 | 17 | 0.0083 | 29 | 0.0374 | 41 | 0.0520 | 53 | 0.0000 |
| 6 | 0.0042 | 18 | 0.0000 | 30 | 0.0873 | 42 | 0.0229 | 54 | 0.0083 |
| 7 | 0.0083 | 19 | 0.0125 | 31 | 0.0062 | 43 | 0.0042 | 55 | 0.0062 |
| 8 | 0.0062 | 20 | 0.0083 | 32 | 0.0104 | 44 | 0.0146 | 56 | 0.0187 |
| 9 | 0.0187 | 21 | 0.0146 | 33 | 0.0083 | 45 | 0.0125 | 57 | 0.0166 |
| 10 | 0.0146 | 22 | 0.0146 | 34 | 0.0437 | 46 | 0.0208 | 58 | 0.0104 |
| 11 | 0.0042 | 23 | 0.0249 | 35 | 0.0187 | 47 | 0.0104 | 59 | 0.0229 |
| 12 | 0.0104 | 24 | 0.0166 | 36 | 0.0083 | 48 | 0.0208 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Dai, W.; Sun, D.; Zhao, Y. Risk Evaluation for a Manufacturing Process Based on a Directed Weighted Network. Entropy 2020, 22, 699. https://doi.org/10.3390/e22060699
Wang L, Dai W, Sun D, Zhao Y. Risk Evaluation for a Manufacturing Process Based on a Directed Weighted Network. Entropy. 2020; 22(6):699. https://doi.org/10.3390/e22060699
Chicago/Turabian StyleWang, Lixiang, Wei Dai, Dongmei Sun, and Yu Zhao. 2020. "Risk Evaluation for a Manufacturing Process Based on a Directed Weighted Network" Entropy 22, no. 6: 699. https://doi.org/10.3390/e22060699
APA StyleWang, L., Dai, W., Sun, D., & Zhao, Y. (2020). Risk Evaluation for a Manufacturing Process Based on a Directed Weighted Network. Entropy, 22(6), 699. https://doi.org/10.3390/e22060699