Activeness and Loyalty Analysis in Event-Based Social Networks


Abstract
1. Introduction
2. Related Work
3. Data Collection and Feature Generation
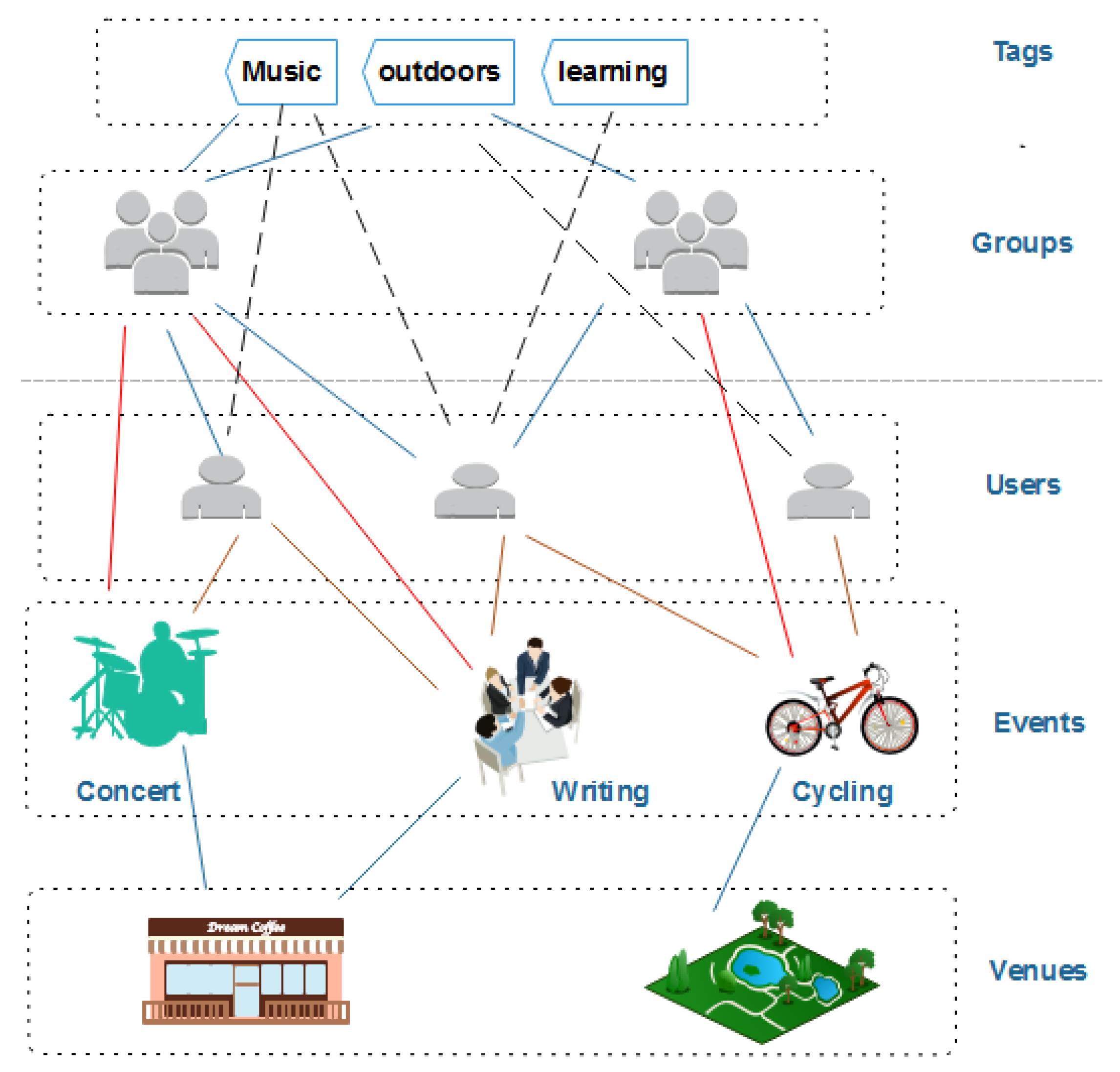
3.1. Meetup Data Collection
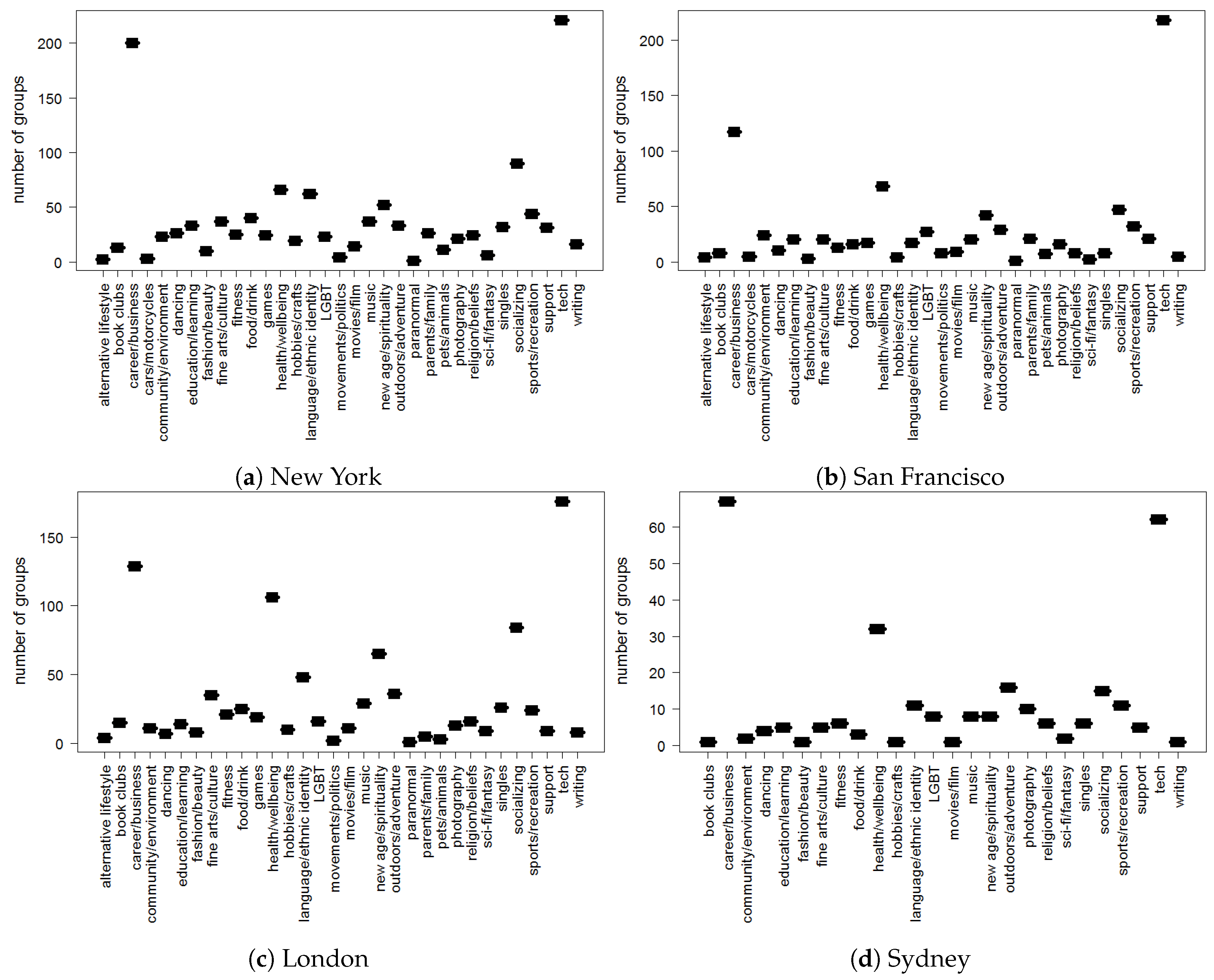
3.2. Features
4. Methodology
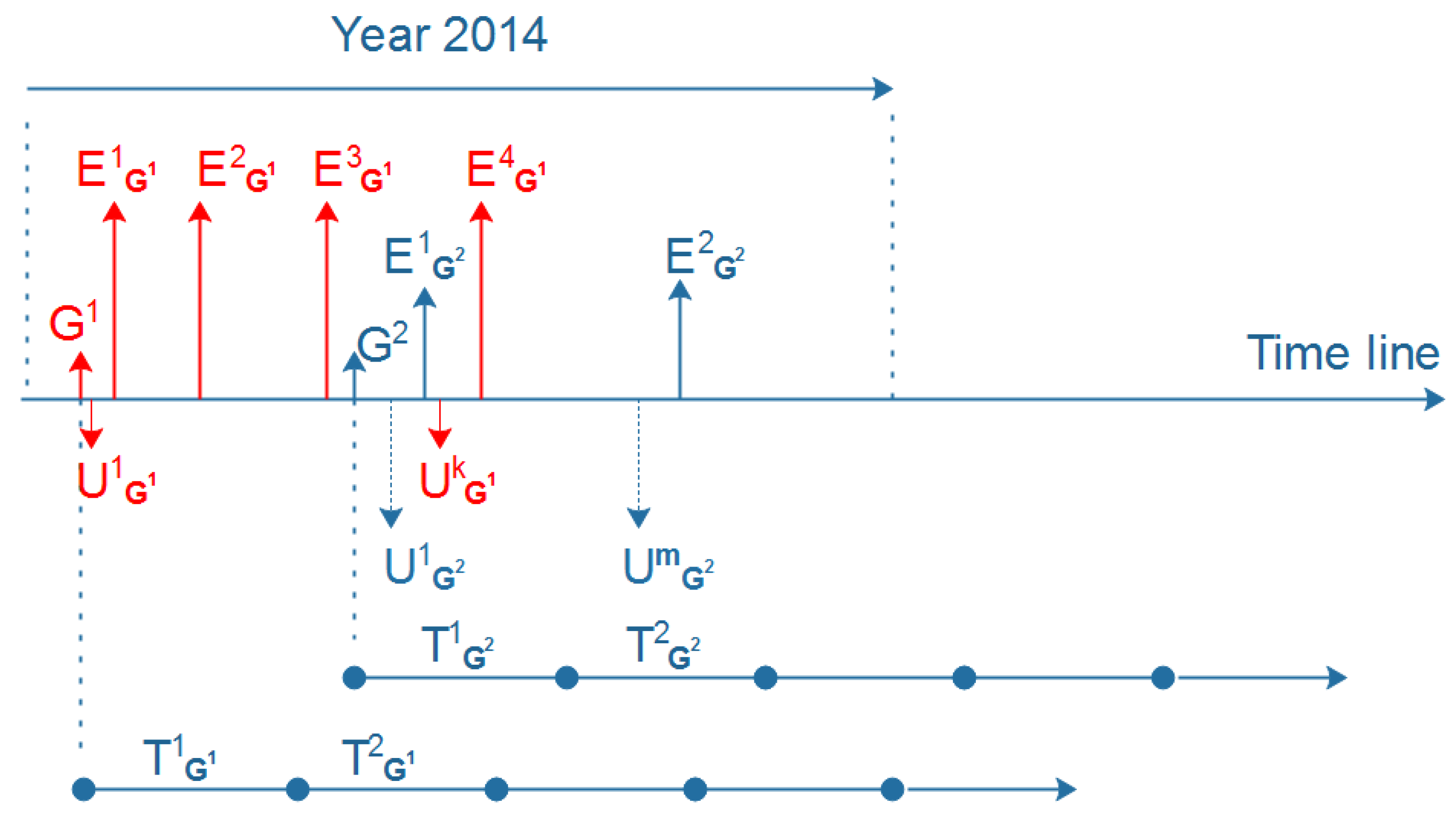
4.1. Method to Measure Group Activeness
4.2. Method to Measure User Loyalty
4.3. Prediction Techniques
5. Evaluation and Analysis
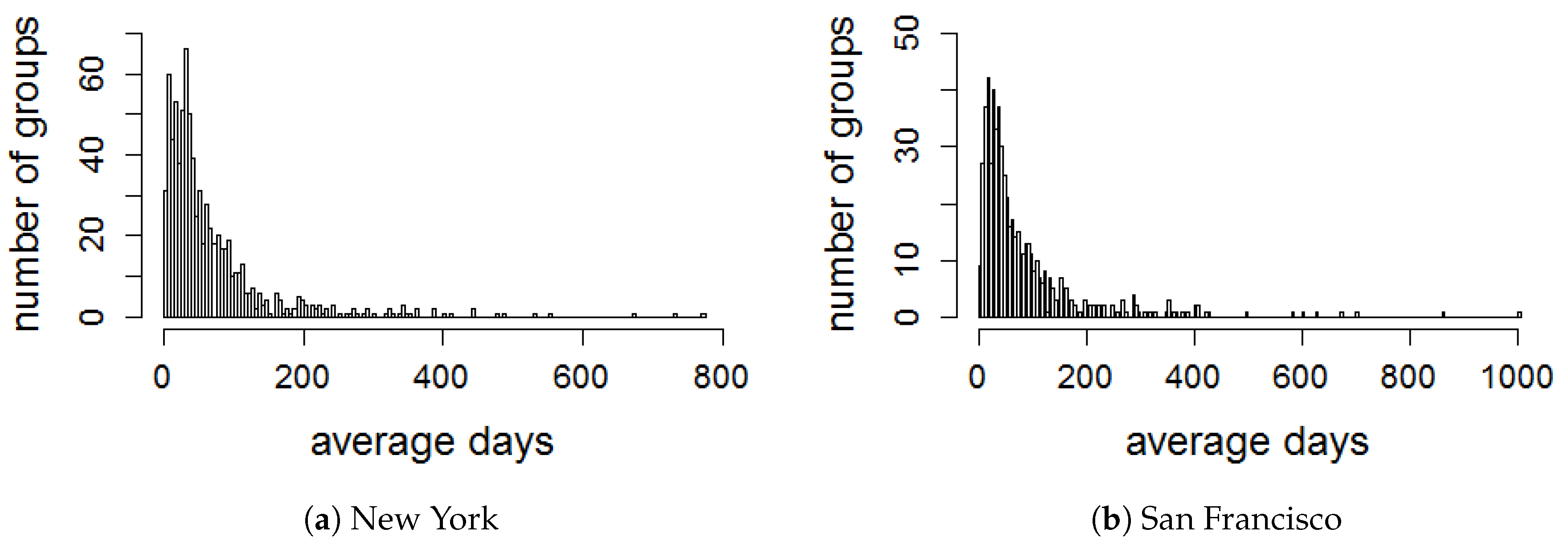
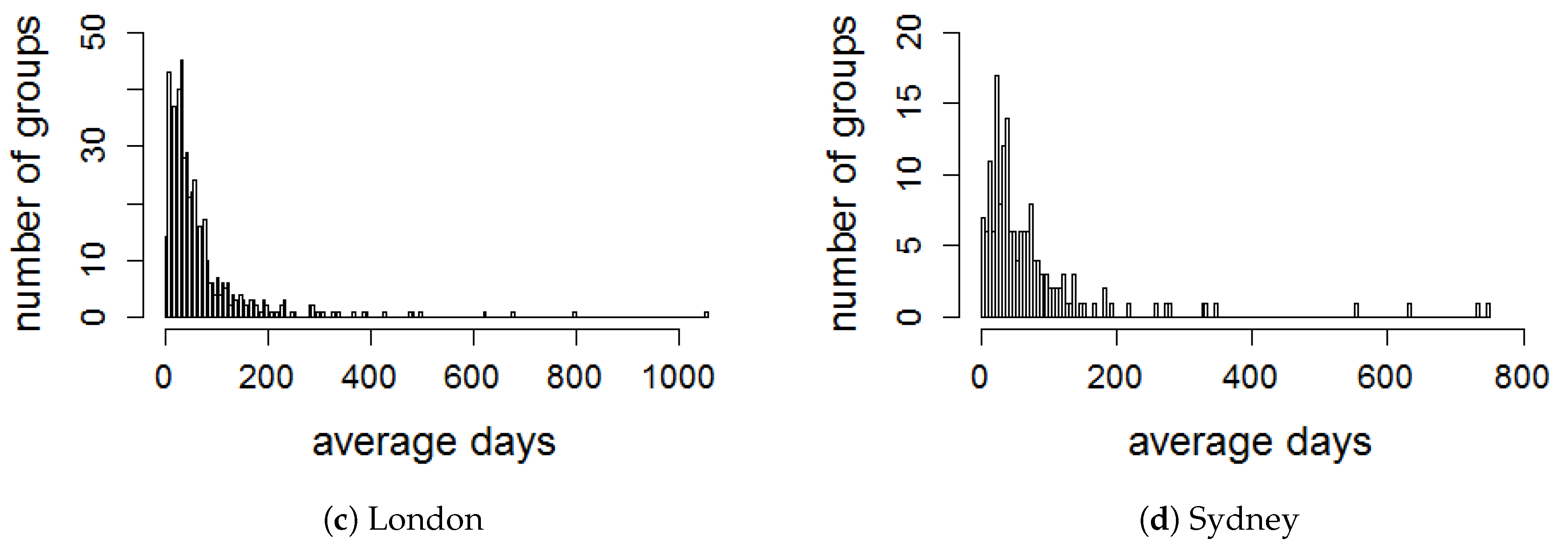
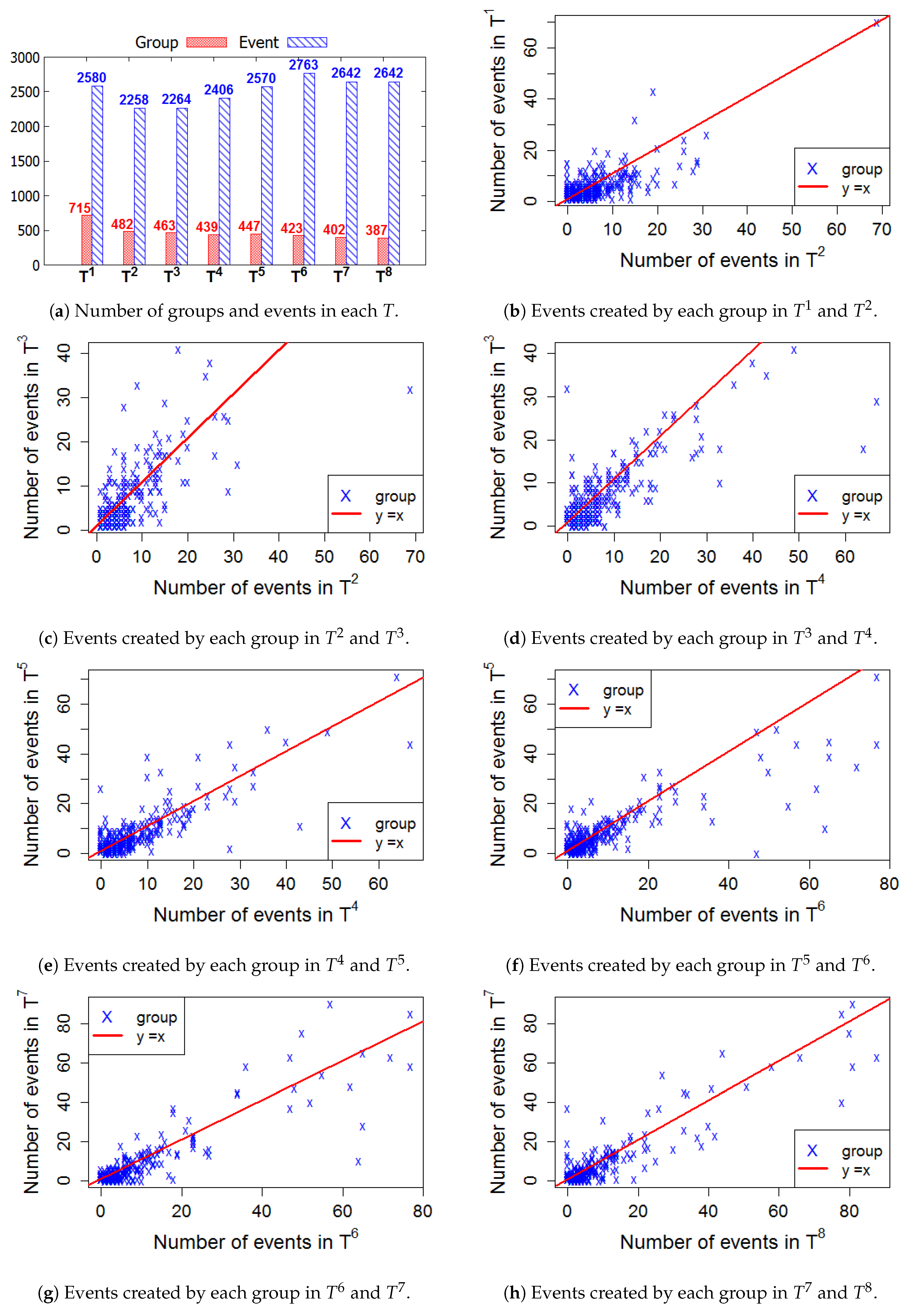
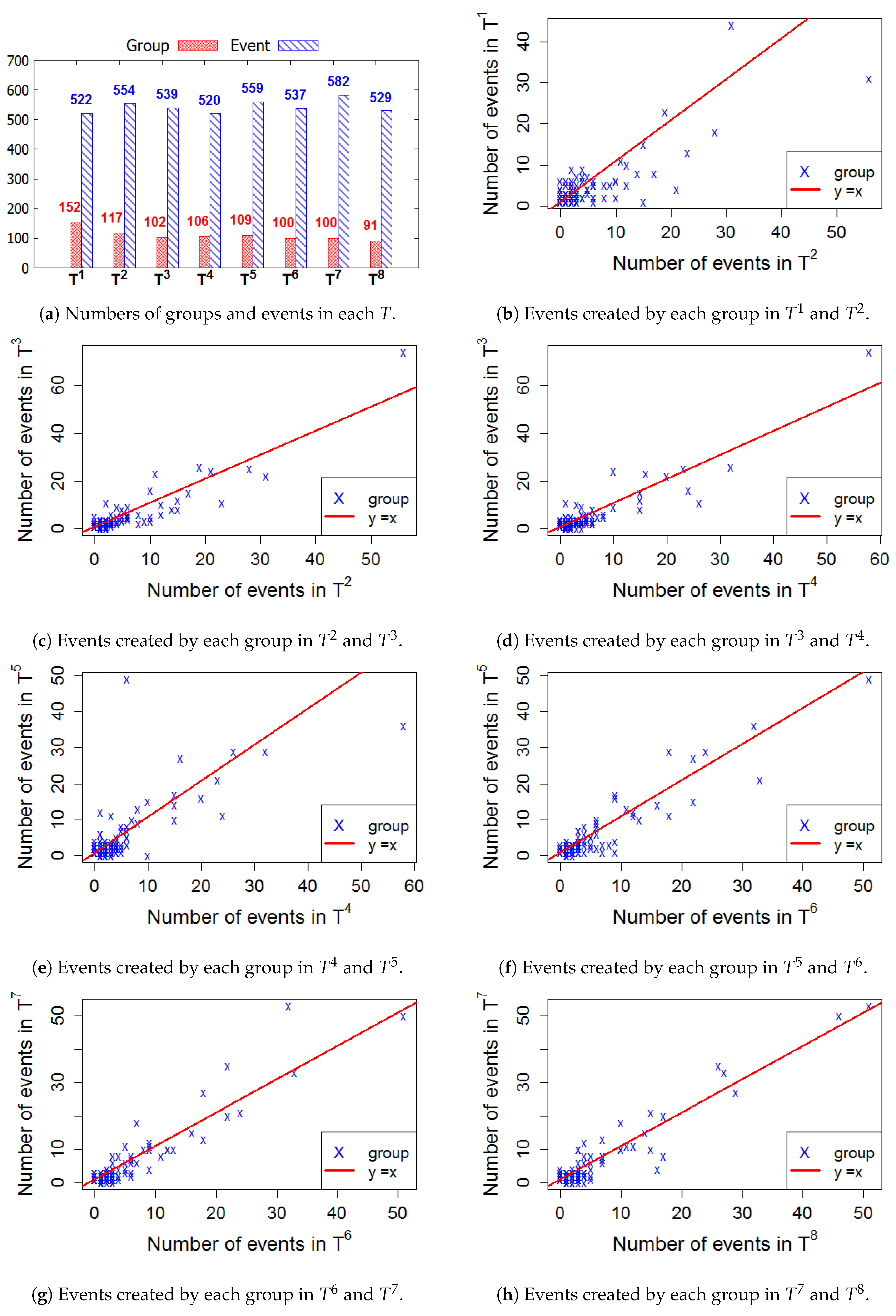
5.1. Time Window
5.2. Group Activeness Label
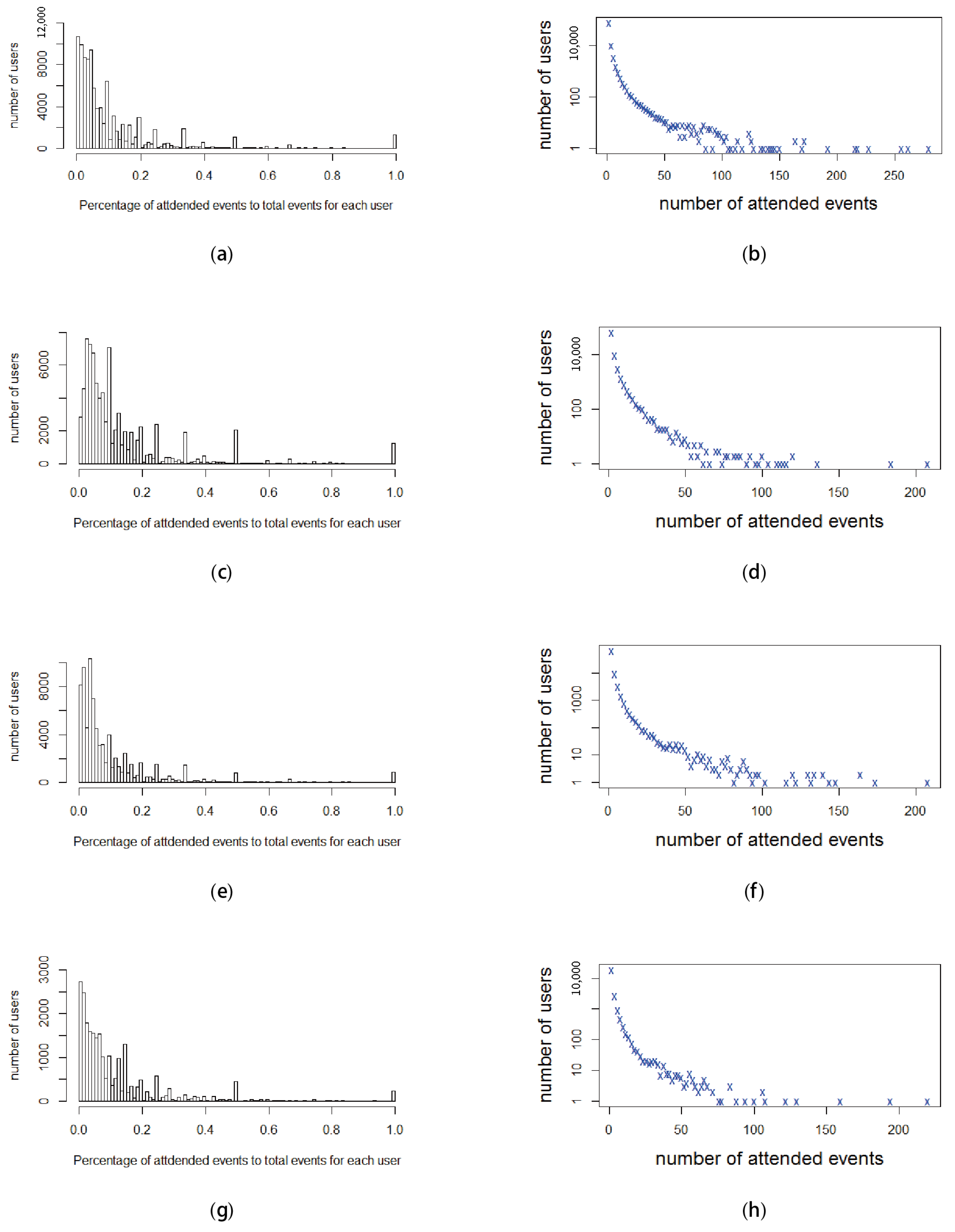
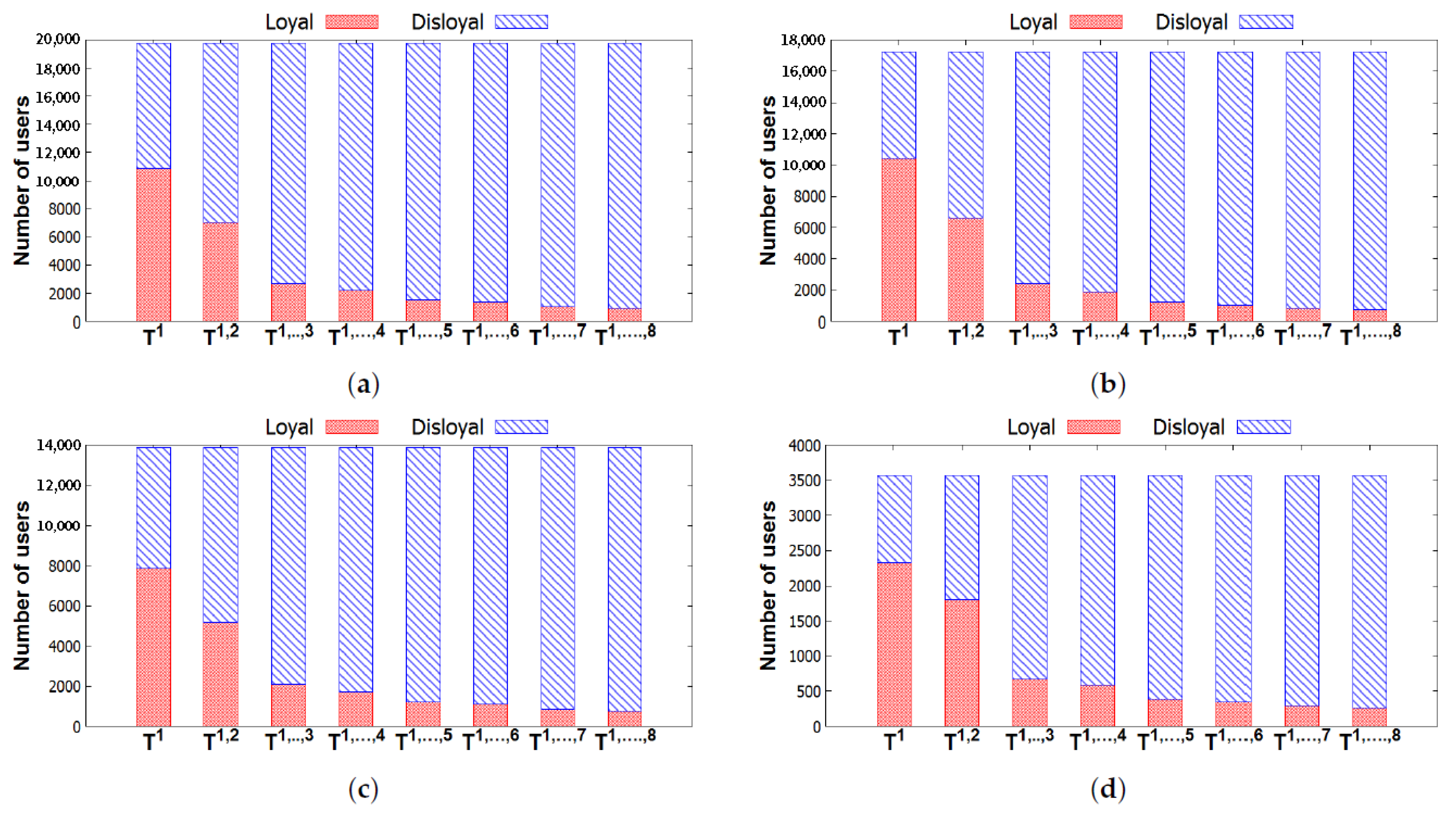
5.3. Loyal Users
5.4. Activeness Prediction
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, X.; He, Q.; Tian, Y.; Lee, W.C.; McPherson, J.; Han, J. Event-based social networks. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’12, Beijing, China, 12–16 August 2012; ACM Press: New York, NY, USA, 2012; p. 1032. [Google Scholar] [CrossRef]
- Chaudhuri, A.; Holbrook, M.B. The Chain of Effects from Brand Trust and Brand Affect to Brand Performance: The Role of Brand Loyalty. J. Mark. 2001, 65, 81–93. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Zhang, J.; Danescu-Niculescu-Mizil, C.; Jurafsky, D.; Leskovec, J. Loyalty in Online Communities. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media (ICWSM 2017), Montréal, QC, Canada, 15–18 May 2017; Volume 2017, pp. 540–543. [Google Scholar]
- Palla, G.; Barabási, A.L.; Vicsek, T. Quantifying social group evolution. Nature 2007, 446, 664–667. [Google Scholar] [CrossRef] [PubMed]
- Jamali, M.; Haffari, G.; Ester, M. Modeling the temporal dynamics of social rating networks using bidirectional effects of social relations and rating patterns. In Proceedings of the 20th International Conference on World Wide Web, WWW 2011, Hyderabad, India, 28 March–1 April 2011; pp. 527–536. [Google Scholar] [CrossRef]
- Nguyen, N.P.; Alim, M.A.; Dinh, T.N.; Thai, M.T. A method to detect communities with stability in social networks. Soc. Netw. Anal. Min. 2014, 4, 1–15. [Google Scholar] [CrossRef]
- Jhamb, Y.; Fang, Y. A dual-perspective latent factor model for group-aware social event recommendation. Inf. Process. Manag. 2017, 53, 559–576. [Google Scholar] [CrossRef]
- Cao, J.; Zhu, Z.; Shi, L.; Liu, B.; Ma, Z. Multi-feature based event recommendation in Event-Based Social Network. Int. J. Comput. Intell. Syst. 2018, 11, 618–633. [Google Scholar] [CrossRef]
- Trinh, T.; Nguyen, N.T.; Wu, D.; Huang, J.Z.; Emara, T.Z. A New Location-Based Topic Model for Event Attendees Recommendation. In Proceedings of the 2019 IEEE-RIVF International Conference on Computing and Communication Technologies (RIVF), Danang, Vietnam, 20–22 March 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, J.S.; Lv, Q.I.N. Understanding Event Organization at Scale in Event-Based. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–23. [Google Scholar] [CrossRef]
- Patil, A.; Liu, J.; Gao, J. Predicting group stability in online social networks. In Proceedings of theWWW 2013—Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1021–1030. [Google Scholar]
- Zhang, J.; Tan, L.; Tao, X.; Zheng, X.; Luo, Y.; Lin, J.C.W. SLIND: Identifying Stable Links in Online Social Networks; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 10828, pp. 813–816. [Google Scholar] [CrossRef]
- Zhang, J.; Tao, X.; Tan, L.; Lin, J.C.W.; Li, H.; Chang, L. On Link Stability Detection for Online Social Networks; Springer International Publishing: Cham, Switzerland, 2018; Volume 1, pp. 320–335. [Google Scholar] [CrossRef]
- Wu, W.; Antonio, S. Stability Analysis in Dynamic Social Networks Highest Weighted Reward Rule. In Proceedings of the the 2010 Spring Simulation Multiconference, Orlando, FL, USA, 11–15 April 2010; pp. 1–6. [Google Scholar]
- Ye, M.; Liu, J.; Anderson, B.D.O.; Yu, C.; Basar, T. Evolution of Social Power in Social Networks with Dynamic Topology. IEEE Trans. Autom. Control 2018, 63, 3793–3808. [Google Scholar] [CrossRef]
- Kudelka, M.; Horak, Z.; Snasel, V.; Abraham, A. Social network reduction based on stability. In Proceedings of the International Conference on Computational Aspects of Social Networks, CASoN’10, Taiyuan, China, 26–28 September 2010; pp. 509–514. [Google Scholar] [CrossRef]
- Liu, J.; Li, Y.; Ling, G.; Li, R.; Zheng, Z. Community Detection in Location-Based Social Networks: An Entropy-Based Approach. In Proceedings of the 2016 IEEE International Conference on Computer and Information Technology (CIT), Nadi, Fiji, 8–10 December 2016; pp. 452–459. [Google Scholar] [CrossRef]
- Zhang, Y.; Leezer, J. Emergence of Social Norms in Complex Networks. In Proceedings of the 2009 International Conference on Computational Science and Engineering, Vancouver, BC, Canada, 29–31 August 2009; Volume 4, pp. 549–555. [Google Scholar] [CrossRef]
- González-Artega, T.; Cascón, J.M.; de Andrés Calle, R. A proposal to measure human group behaviour stability. In Communications in Computer and Information Science, Proceedings of the 2018 International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Cádiz, Spain, 11–15 June 2018; Springer: Cham, Switzerland, 2018; Volume 855, pp. 99–110. [Google Scholar] [CrossRef]
- Quintane, E.; Pattison, P.E.; Robins, G.L.; Mol, J.M. Short- and long-term stability in organizational networks: Temporal structures of project teams. Soc. Netw. 2013, 35, 528–540. [Google Scholar] [CrossRef]
- Tausczik, Y.R.; Dabbish, L.A.; Kraut, R.E. Building Loyalty to Online Communities though Bond and Identity-based Attachment to Sub-groups. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014. [Google Scholar]
- Sharara, H.; Singh, L.; Getoor, L.; Mann, J. Stability vs. Diversity: Understanding the Dynamics of Actors in Time-varying Affiliation Networks. In Proceedings of the 2012 International Conference on Social Informatics, Lausanne, Switzerlan, 14–16 December 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Jacoby, J.; Kyner, D.B. Brand Loyalty Vs. Repeat Purchasing Behavior. J. Mark. Res. 1973, 10, 1–9. [Google Scholar] [CrossRef]
- Kalwani, M.U.; Narayandas, N. Long-Term Manufacturer-Supplier Relationships: Do They Pay off for Supplier Firms? J. Mark. 1995, 59, 1–16. [Google Scholar] [CrossRef]
- Gamboa, A.M.; Gonçalves, H.M. Customer loyalty through social networks: Lessons from Zara on Facebook. Bus. Horizons 2014, 57, 709–717. [Google Scholar] [CrossRef]
- Brandtzæg, P.B.; Heim, J. User Loyalty and Online Communities: Why Members of Online Communities are not Faithful. In Proceedings of the 2nd International Conference on INtelligent TEchnologies for Interactive EnterTAINment, Cancun, Mexico, 8–10 January 2008. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Zhang, J.; Danescu-Niculescu-Mizil, C.; Jurafsky, D.; Leskovec, J. Loyalty in Online Communities. In Proceedings of the the ICWSM 2017, Montréal, QC, Canada, 15–18 May 2017. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Trinh, T.; Wu, D.; Salloum, S.; Nguyen, T.; Huang, J.Z. A frequency-based gene selection method with random forests for gene data analysis. In Proceedings of the 2016 IEEE RIVF International Conference on Computing and Communication Technologies: Research, Innovation, and Vision for the Future, RIVF 2016, Hanoi, Vietnam, 7 November 2016; pp. 193–198. [Google Scholar] [CrossRef]
- Salzberg, S.L. C4.5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993. Mach. Learn. 1994, 16, 235–240. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Tu, W.; Cheung, D.W.; Mamoulis, N.; Yang, M.; Lu, Z. Activity Recommendation with Partners. ACM Trans. Web 2017, 12, 1–29. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | #Groups | #Events | #Users | #YES | #NO |
|---|---|---|---|---|---|
| New York | 1269 | 28,355 | 591,580 | 331,436 | 105,433 |
| San Francisco | 867 | 14,205 | 342,662 | 245,767 | 66,611 |
| London | 985 | 17,309 | 610,189 | 246,413 | 108,070 |
| Sydney | 297 | 5980 | 179,081 | 82,399 | 30,075 |
| Alternative Lifestyle | Book Clubs | Career/Business |
|---|---|---|
| Cars/Motorcycles | Community/Environment | Dancing |
| Education/Learning | Fashion/Beatuy | Fine Arts/Culture |
| Fitness | Food/Drink | Games |
| Health/Wellbeing | Hobbies | Language/Ethnic Identity |
| Lgbt | Movement/Politics | Movies/Films |
| Music | New Age/Spirituality | Outdoors/Adventure |
| Paranormal | Parents/Family | Pets/Animals |
| Photography | Religion/Beliefs | Sci-Fi/Fantasy |
| Singles | Socializing | Sports/Recreation |
| Support | Tech | Writing |
| Category | Feature | Description | Type |
|---|---|---|---|
| Group-based | CATEGORY | Corresponding category value | Integer |
| N_TOPICS | Number of topics in a group | Integer | |
| N_USERS | Number of users in a group | Integer | |
| RATING | Score average of group reviews | Double | |
| YEAR | The year a group is created in | Integer | |
| MONTH | The month a group is created in | Integer | |
| DAY_OF_MONTH | The day a group is created on | Integer | |
| WEEKDAY | The weekday a group is created on | Integer | |
| Event-based | N_EVENTS | Number of events | Integer |
| RSVPs | Number of all RSVPS | Integer | |
| Y_RSVPs | Number of all RSVPS only with YES | Integer | |
| N_RSVPs | Number of all RSVPS only with NO | Integer | |
| AVERAGE_RSVPs | Average of all RSVPSs | Double | |
| SD_RSVPs | Standard deviation of all RSVPs | Integer | |
| AVERAGE_Y_RSVPs | Average of RSVPS only with YES | Integer | |
| SD_Y_RSVPs | Standard deviation of all RSVPS only with YES | Integer | |
| AVERAGE_N_RSVPs | Average of RSVPS only with NO | Integer | |
| SD_N_RSVPs | Standard deviation of all RSVPS only with NO | Integer | |
| AVERAGE_DAY | Average days between two consecutive events | Double | |
| SD_DAY | Standard deviation of numbers of days between two consecutive events | Double | |
| N_EVENT_ORGANIZER | Number of events that has organizers | Double | |
| User-based | N_ORGANIZER | Number of organizers in the group | Integer |
| N_ATTENDEES | Number of users who confirm at least one YES | Integer | |
| BIO | Number of users who have a biography | Integer | |
| ADDRESS | Number of users who have address information | Integer |
| G | Group G | |
| The ith time window of group G | ||
| E | Event | |
| The number of events created by group G in | Integer | |
| R | Ratio of and | Double |
| The measure of the loyalty of a user | Double |
| Total | Inactive | Stable | Active | Total | Inactive | Stable | Active | ||
|---|---|---|---|---|---|---|---|---|---|
| 715 | 549 | ||||||||
| 715 | 286 | 134 | 295 | 549 | 217 | 104 | 228 | ||
| 715 | 227 | 201 | 287 | 549 | 177 | 157 | 215 | ||
| 715 | 249 | 136 | 330 | 549 | 198 | 107 | 244 | ||
| 715 | 233 | 145 | 337 | 549 | 194 | 124 | 231 | ||
| 715 | 256 | 124 | 335 | 549 | 211 | 102 | 236 | ||
| 715 | 273 | 128 | 314 | 549 | 230 | 95 | 224 | ||
| 715 | 283 | 131 | 301 | 549 | 251 | 88 | 210 | ||
| (a) New York | (b) San Francisco | ||||||||
| Total | Inactive | Stable | Active | Total | Inactive | Stable | Active | ||
| 481 | 152 | ||||||||
| 481 | 157 | 79 | 245 | 152 | 50 | 26 | 76 | ||
| 481 | 100 | 155 | 226 | 152 | 37 | 40 | 75 | ||
| 481 | 128 | 88 | 265 | 152 | 42 | 30 | 80 | ||
| 481 | 124 | 92 | 265 | 152 | 39 | 28 | 85 | ||
| 481 | 146 | 80 | 255 | 152 | 46 | 21 | 85 | ||
| 481 | 155 | 89 | 237 | 152 | 43 | 27 | 82 | ||
| 481 | 179 | 82 | 220 | 152 | 51 | 26 | 75 | ||
| (c) London | (d) Sydney | ||||||||
| ALL | Selected | ||||||
|---|---|---|---|---|---|---|---|
| RF | C50 | SVM | RF | C50 | SVM | ||
| 69.92 | 65.64 | 69.91 | 71.99 | 68.25 | 71.32 | ||
| NY | 74.68 | 71.37 | 74.73 | 77.74 | 75.04 | 76.02 | |
| 70.64 | 66.19 | 70.21 | 73.07 | 71.37 | 71.58 | ||
| 69.21 | 66.97 | 69.28 | 72.46 | 69.16 | 70.82 | ||
| SF | 71.13 | 68.37 | 72.21 | 75.63 | 72.57 | 74.21 | |
| 71.47 | 67.69 | 69.72 | 74.59 | 72.94 | 72.15 | ||
| 69.22 | 61.72 | 71.58 | 70.58 | 65.29 | 73.02 | ||
| LD | 71.5 | 67.61 | 72.15 | 74.66 | 72.51 | 73.82 | |
| 69.15 | 62.07 | 68.73 | 70.99 | 67.88 | 69.85 | ||
| 66.1 | 60.34 | 64.71 | 66.33 | 65 | 68.21 | ||
| SN | 73.04 | 68.8 | 71.41 | 74.84 | 71.52 | 75.15 | |
| 69.71 | 60.86 | 66.31 | 68.32 | 64.73 | 71.54 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trinh, T.; Wu, D.; Huang, J.Z.; Azhar, M. Activeness and Loyalty Analysis in Event-Based Social Networks. Entropy 2020, 22, 119. https://doi.org/10.3390/e22010119
Trinh T, Wu D, Huang JZ, Azhar M. Activeness and Loyalty Analysis in Event-Based Social Networks. Entropy. 2020; 22(1):119. https://doi.org/10.3390/e22010119
Chicago/Turabian StyleTrinh, Thanh, Dingming Wu, Joshua Zhexue Huang, and Muhammad Azhar. 2020. "Activeness and Loyalty Analysis in Event-Based Social Networks" Entropy 22, no. 1: 119. https://doi.org/10.3390/e22010119
APA StyleTrinh, T., Wu, D., Huang, J. Z., & Azhar, M. (2020). Activeness and Loyalty Analysis in Event-Based Social Networks. Entropy, 22(1), 119. https://doi.org/10.3390/e22010119