On a Key-Based Secured Audio Data-Hiding Scheme Robust to Volumetric Attack with Entropy-Based Embedding


Abstract
1. Introduction
2. Related Background
2.1. Entropy
2.2. Integer Discrete Cosine transform
2.3. Peak Signal-to-Noise Ratio
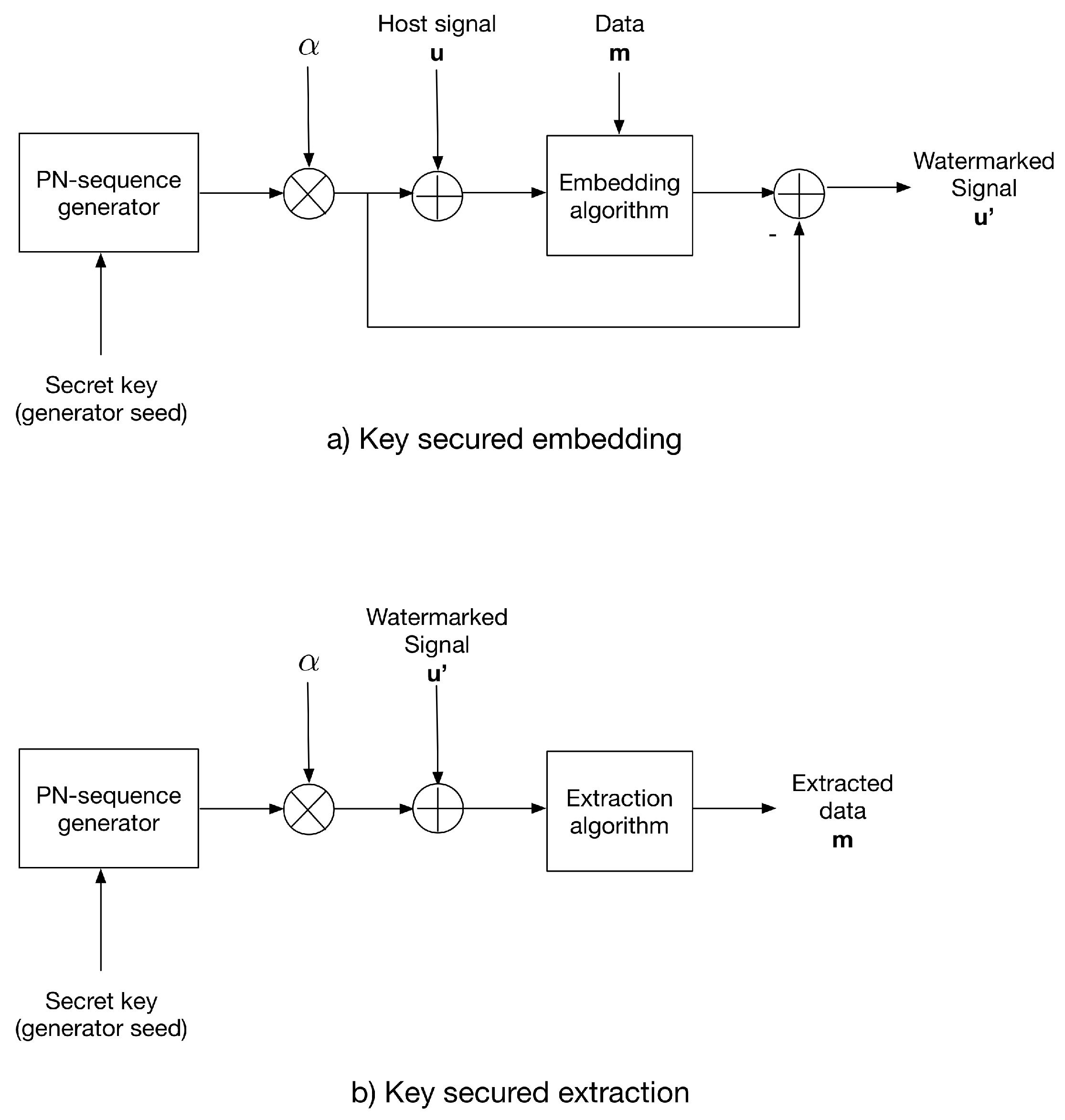
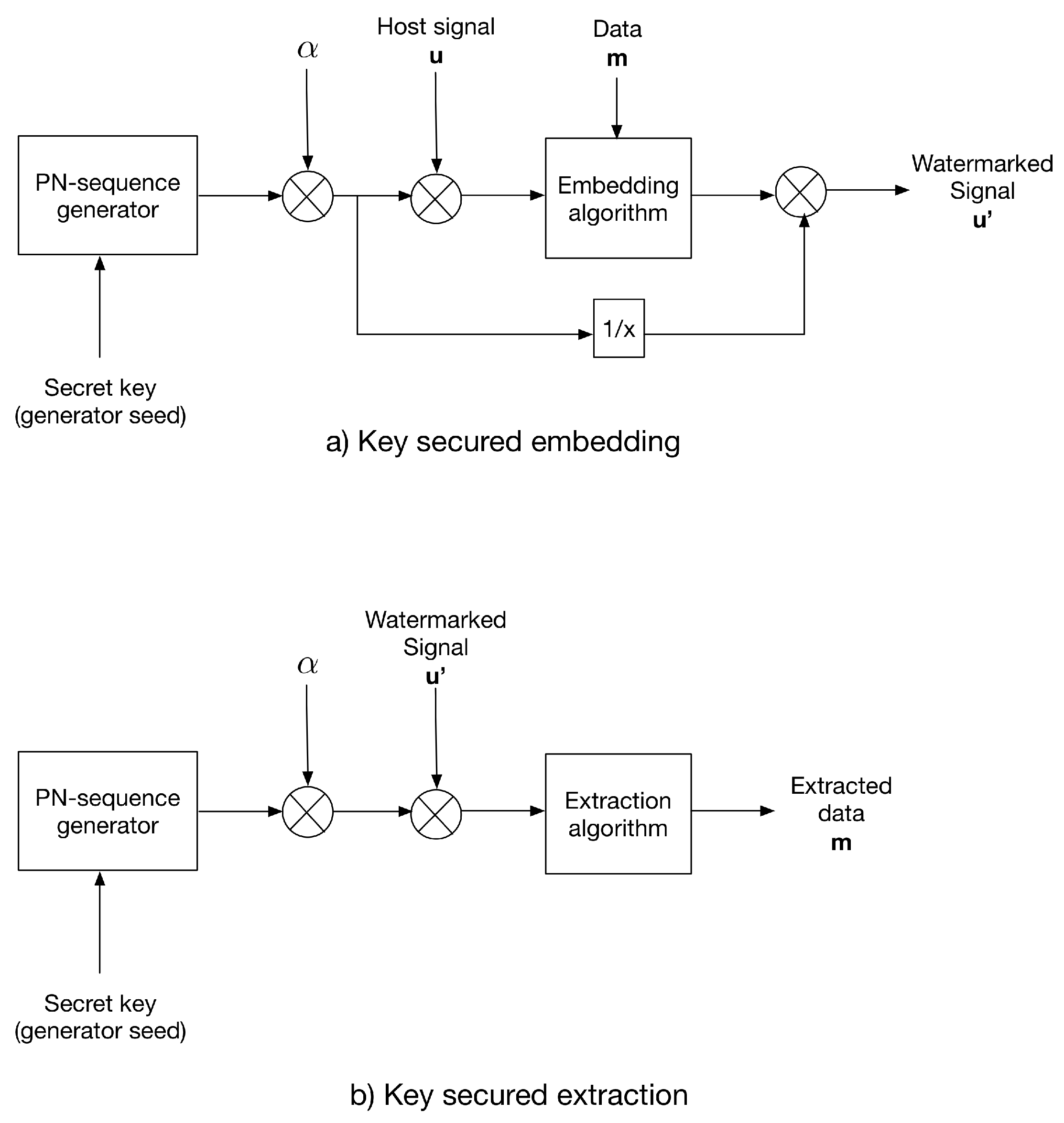
3. Key-Based Security Strategies for the Gain-Invariant Algorithm by Zareian and Tohidypour
3.1. The Gain-Invariant Algorithm
3.1.1. Data Embedding
3.1.2. Data Extraction
3.2. The Additive Strategy for Key-Based Security
3.3. The Multiplicative Strategy for Key-Based Security
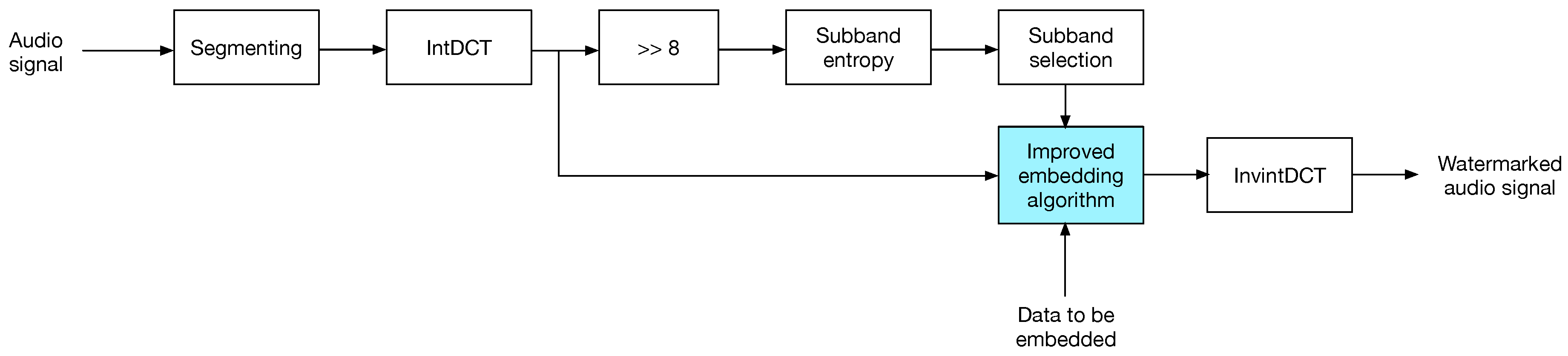
4. The Proposed Watermarking Scheme
4.1. The Insertion Process
- The audio signal is segmented into N-sample blocks and intDCT transformed.
- Each transformed audio block is splitted into eight sub-bands. This number of sub-bands was experimentally determined, to achieve a trade-off between auditive transparency and payload, as each sub-band is a potential carrier of one bit.
- Transformed sub-bands are divided by ; the CD-quality audio dynamic range is , which for a small set of samples, entropy computation will lead the same entropy value at any time, , as the sub-band distributions will be uniform. This situation applies for both audio blocks and transformed blocks, as intDCT is a linear transform.
- For each sub-band in a transformed block, entropy is computed; then, the average entropy of all sub-bands is computed and set as the embedding threshold for that block in a similar manner as in [21].
- Data is embedded into sub-bands showing a higher entropy than the threshold; embedding is carried out using one of the strategies described in Section 3.
- Finally, the watermarked audio block is returned to the time domain by the inverse intDCT, and thus the watermarked audio is obtained.
4.2. The Extraction Process
- Audio signal is segmented in N-samples blocks and intDCT transformed.
- Each transformed block is splitted into eight sub-bands.
- Transformed sub-bands are divided by .
- For each sub-band in a transformed block, entropy is computed; then, the average entropy of all sub-bands is computed.
- Data is extracted from sub-bands showing a higher entropy than threshold using the corresponding strategy as described in Section 3.
5. Experiments and Results
5.1. Audio Dataset and Computing Platform
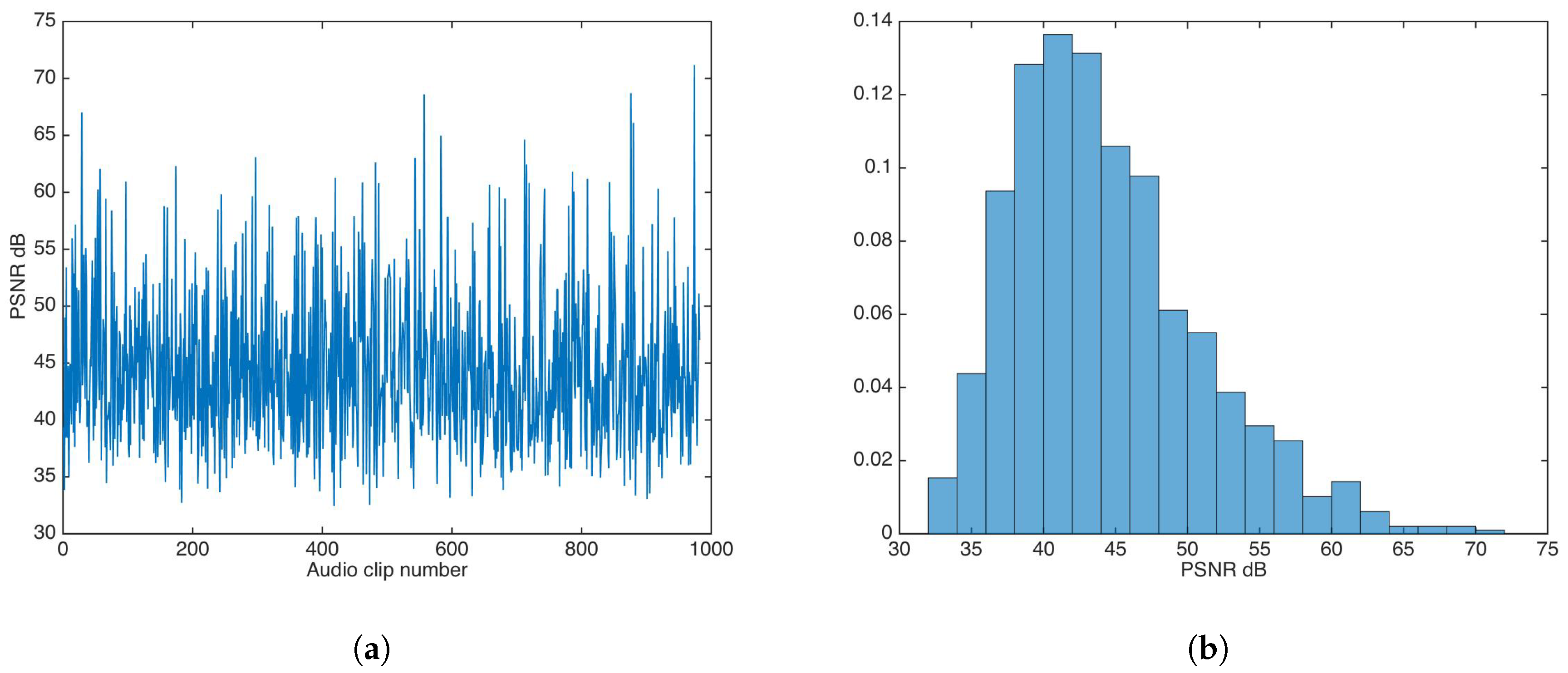
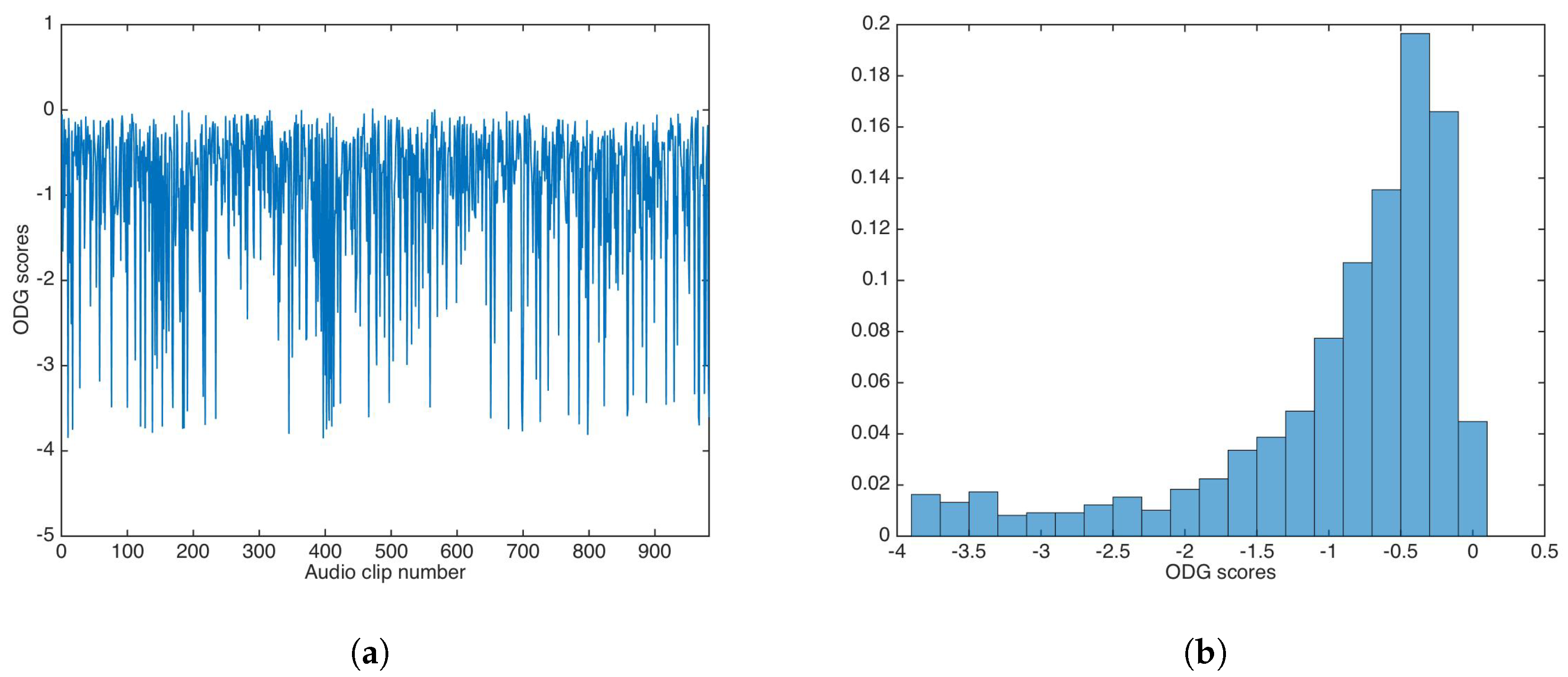
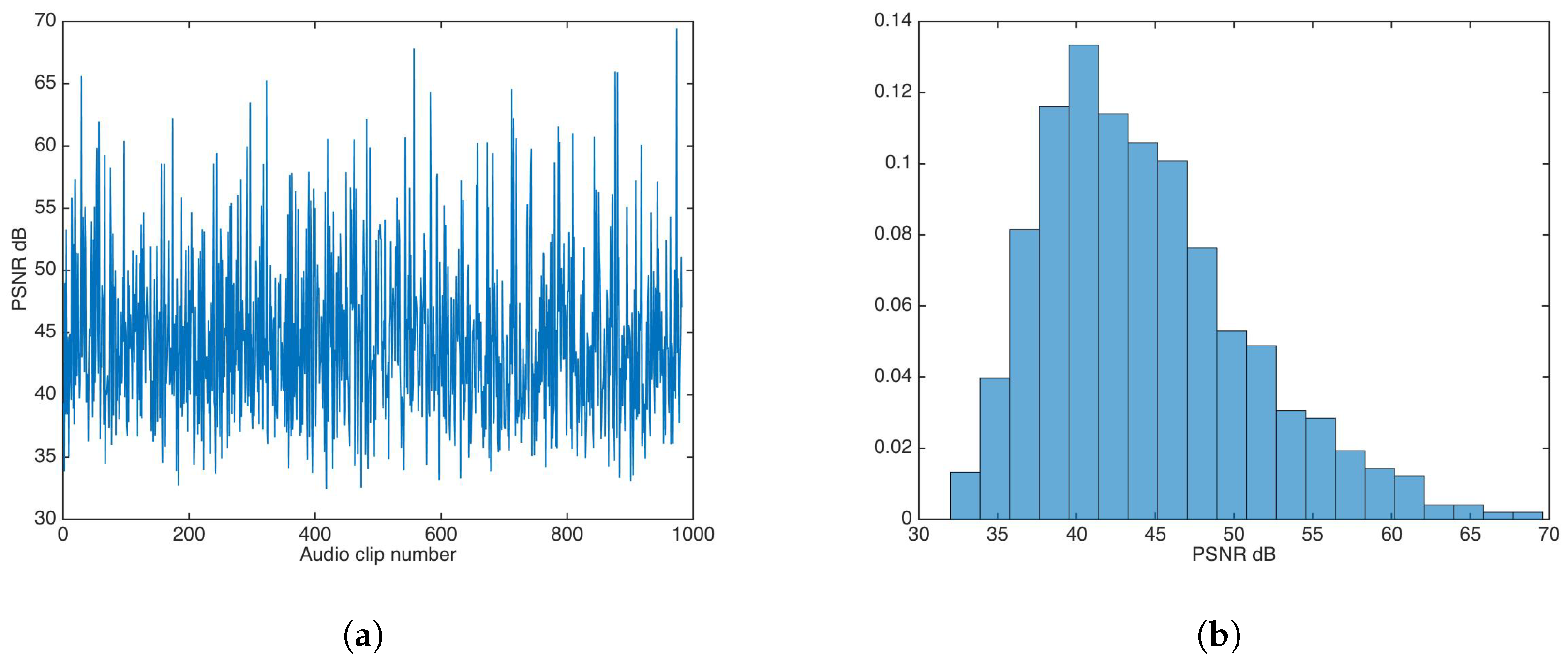
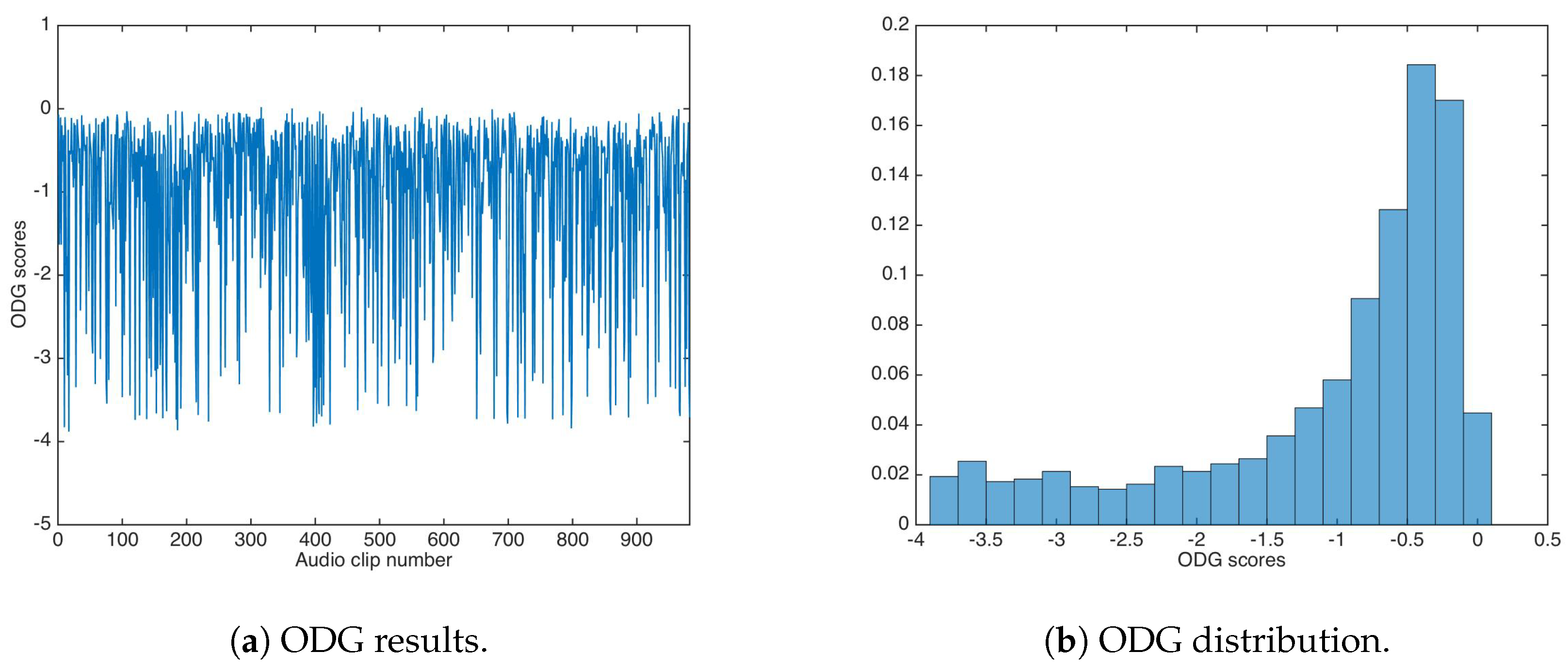
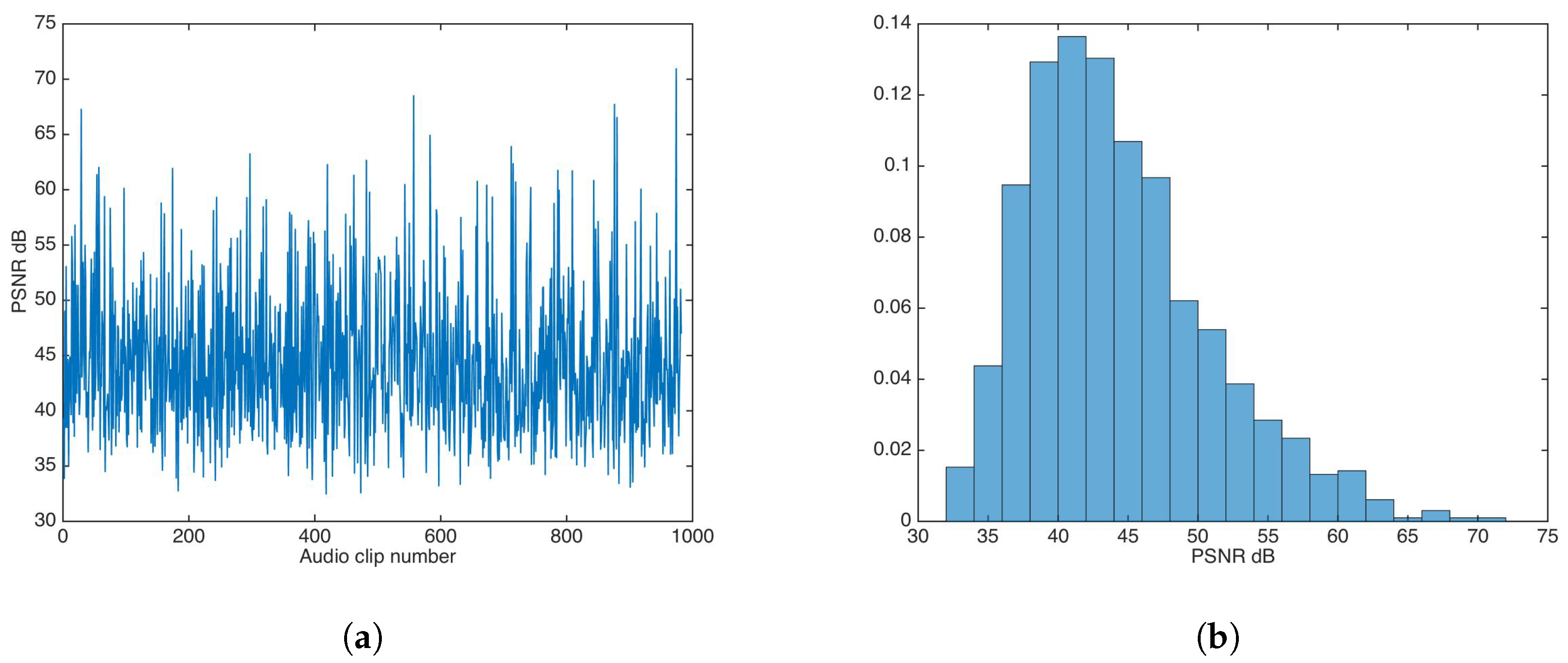
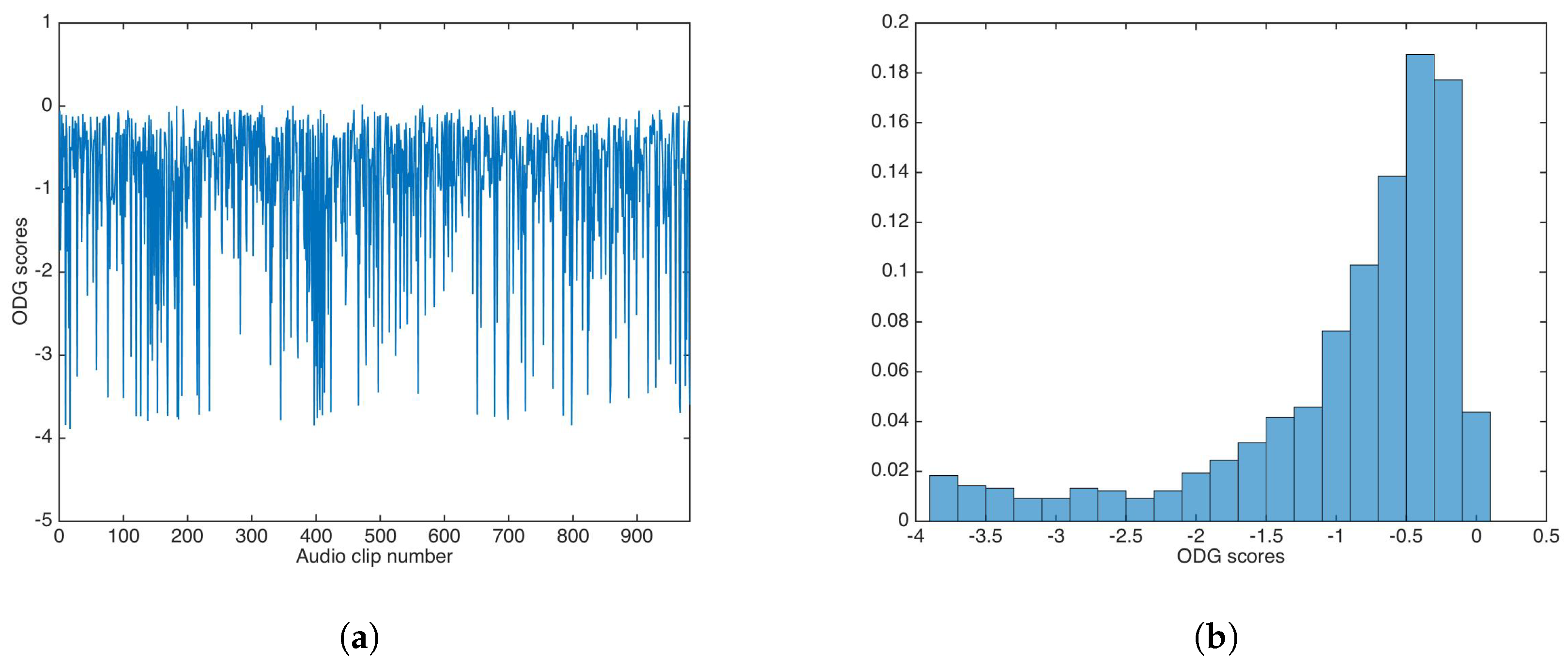
5.2. Auditive Transparency
5.2.1. Unsecured Data-Hiding
5.2.2. Key-Based Additive Strategy
5.2.3. Key-Based Multiplicative Strategy
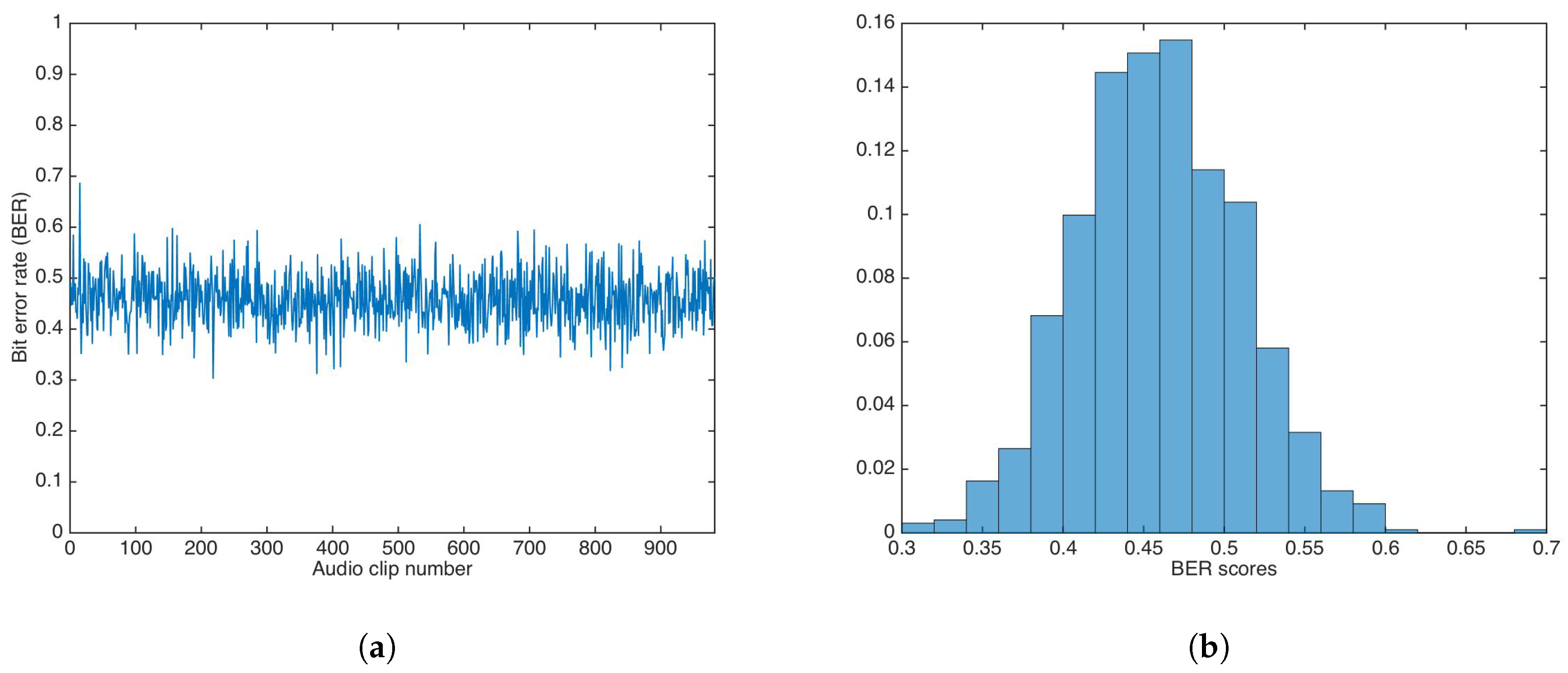
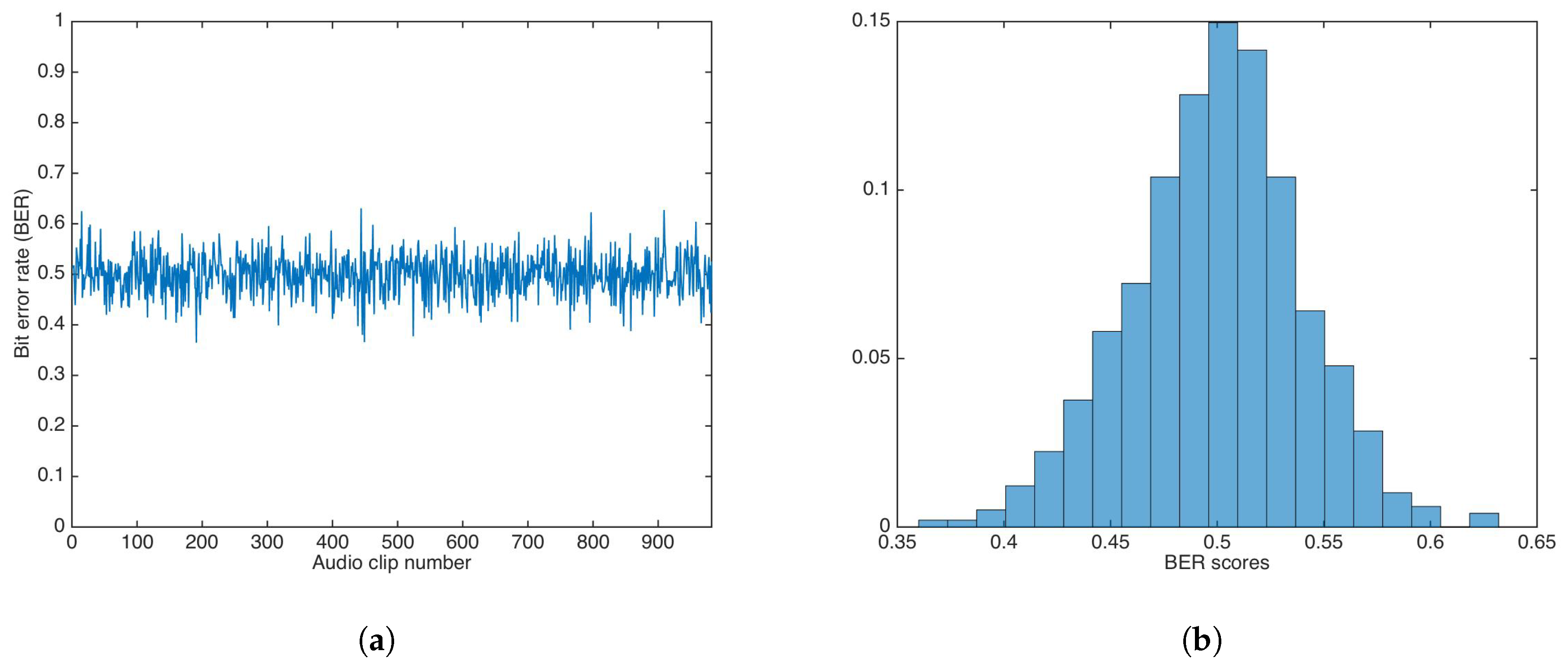
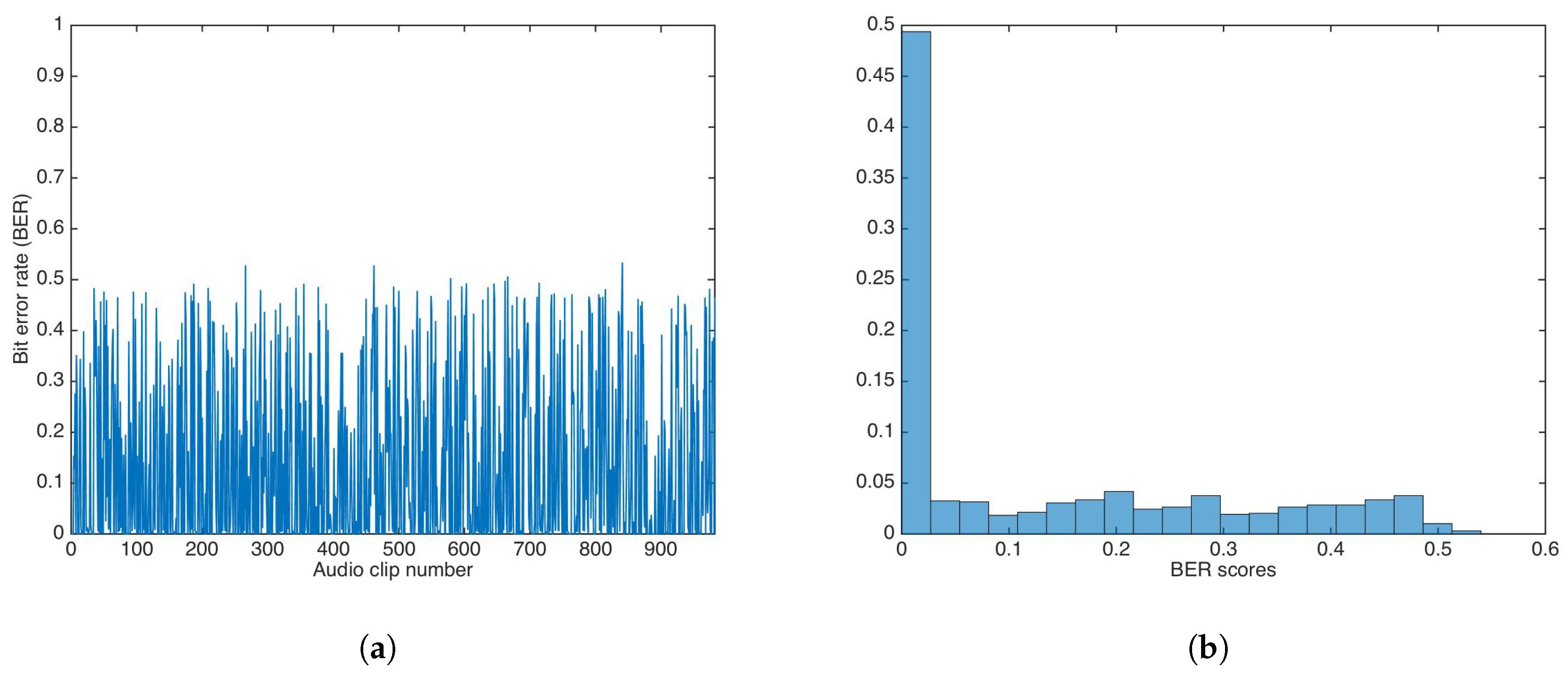
5.3. Key-Based Security
5.3.1. Key-Based Additive Strategy
5.3.2. Key-Based Multiplicative Strategy
5.4. Statistical Transparency
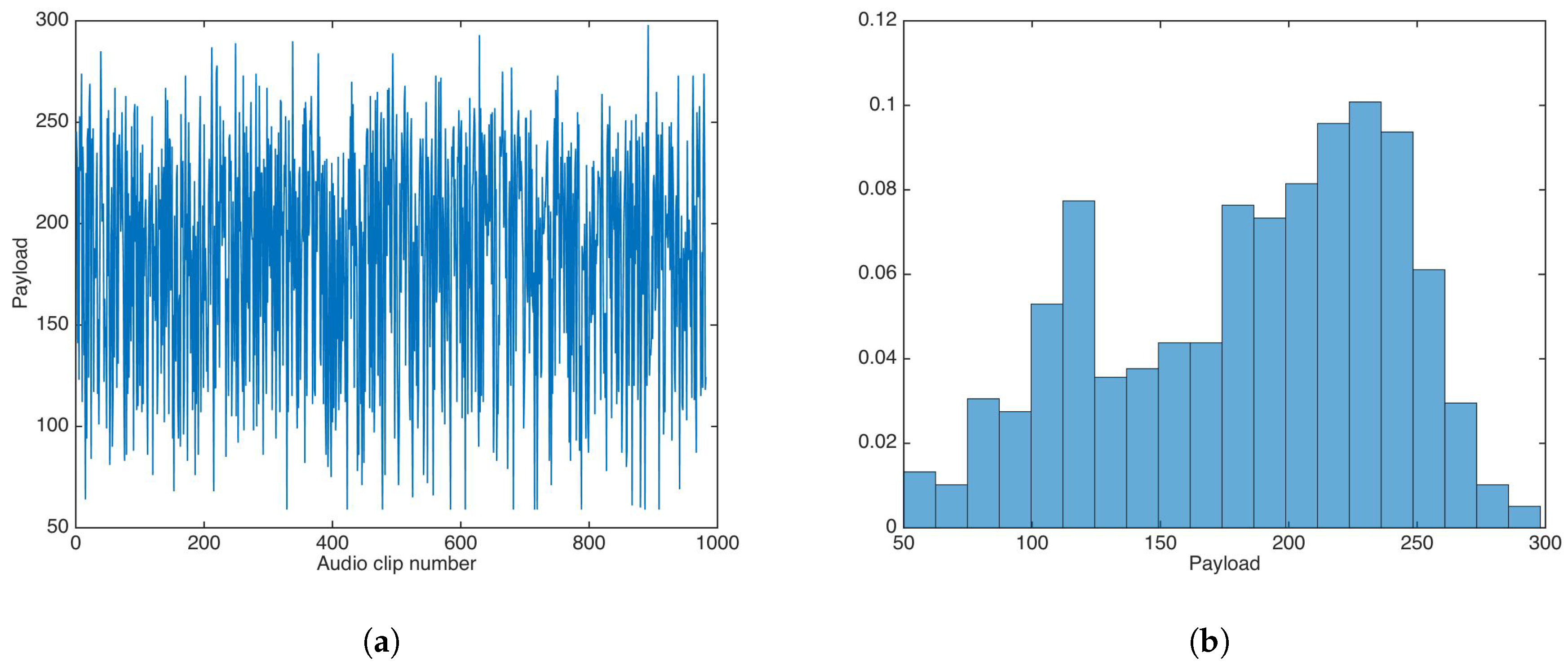
5.5. Payload
5.6. Lossy Compression
6. Discussion and Conclusions
Funding
Conflicts of Interest
References
- Kim, K.; Lee, M.; Lee, H.; Lee, H.K. Reversible data hiding exploiting spatial correlation between sub-sampled images. Pattern Recognit. 2009, 42, 3083–3096. [Google Scholar] [CrossRef]
- Nishimura, A. Reversible audio data hiding using linear prediction and error expansion. In Proceedings of the Seventh International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Dalian, China, 14–16 October 2011; Volume 7, pp. 318–321. [Google Scholar]
- Bassia, P.; Pitas, I. Robust Audio Watermarking in the Time-Domain. IEEE Trans. Multimed. 2001, 3, 232–241. [Google Scholar] [CrossRef]
- Ko, B.S.; Nishimura, R.; Suzuki, Y. Time Spread Echo Method for Digital Audio Watermarking. IEEE Trans. Multimed. 2005, 7, 212–221. [Google Scholar]
- Kuribayashi, M. Hierarchical Spread Spectrum Fingerprinting Scheme Based on the CDMA Technique. EURASIP J. Inf. Secur. 2011, 2011, 502782. [Google Scholar] [CrossRef]
- Arnold, M.; Cheng, X.M.; Gries, U.; Doerr, G. A Phase-based Audio Watermarking System Robust to Acoustic Path Propagation. IEEE Trans. Inf. Forensics Secur. 2014, 9, 411–425. [Google Scholar] [CrossRef]
- Kirovski, D.; Malvar, H. Spread spectrum watermarking of audio signals. IEEE Trans. Signal Process. 2003, 51, 1020–1033. [Google Scholar] [CrossRef]
- Cox, I.; Kilian, J.; Leighton, T.; Shamoon, T. Secure Spread Spectrum Watermarking for Multimedia. IEEE Trans. Image Process. 1997, 6, 1673–1687. [Google Scholar] [CrossRef]
- Chen, B.; Wornell, G. Quantization index modulation: A class of provably good methods for digital watermarking and information embedding. IEEE Trans. Inf. Theory 2001, 47, 1423–1443. [Google Scholar] [CrossRef]
- Chen, B.; Wornell, G. Implementations of quantization index modulation methods for digital watermarking and information embedding of multimedia. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2001, 27, 7–33. [Google Scholar] [CrossRef]
- Gonzalez, F.P.; Mosquera, C.; Barni, M.; Abrardo, A. Rational Dither Modulation: A high rate data-hiding method invariant to gain attacks. IEEE Trans. Signal Process. 2005, 53, 3960–3975. [Google Scholar] [CrossRef]
- Garcia-Hernandez, J.J.; Nakano, M.; Perez, H. Data Hiding in Audio Signals Using Rational Dither Modulation. IEICE Electron. Express 2008, 5, 217–222. [Google Scholar] [CrossRef]
- Zareian, M.; Tohidypour, H.R. A Novel Gain Invariant Quantization-Based Watermarking Approach. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1804–1813. [Google Scholar] [CrossRef]
- Guccione, P.; Scagliola, M. Hyperbolic RDM for nonlinear valumetric distortions. IEEE Trans. Inf. Forensics Secur. 2009, 4, 25–35. [Google Scholar] [CrossRef]
- Perez-Gonzalez, F.; Mosquera, C. Quantization-based data hiding robust to linear-time-invariant filtering. IEEE Trans. Inf. Forensics Secur. 2008, 3, 137–152. [Google Scholar] [CrossRef]
- Zhu, X.; Peng, S. A novel quantization watermarking scheme by modulating the normalized correlation. In Proceedings of the IEEE International Conference in Acoustic, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012; pp. 1765–1768. [Google Scholar]
- Lai, C.C. An Improved SVD-based watermarking scheme using visual characteristics. Opt. Commun. 2011, 284, 938–944. [Google Scholar] [CrossRef]
- Makbol, N.M.; Khoo, B.E.; Rassem, T.H. Block-based discrete wavelet transform-singular value decomposition image watermarking scheme using human visual system characteristics. IET Image Process. 2016, 10, 34–52. [Google Scholar] [CrossRef]
- Sangeethaa, N.; Anitab, X. Entropy based texture watermarking using discrete wavelet transform. Optik 2018, 160, 380–388. [Google Scholar] [CrossRef]
- Chen, S.T.; Huang, H.N.; Chen, C.J.; Tseng, K.K.; Tu, S.Y. Adaptive audio watermarking via the optimization point of view on the wavelet-based entropy. Digit. Signal Process. 2013, 23, 971–980. [Google Scholar] [CrossRef]
- Liu, J.; Wu, S.; Xu, X. A Logarithmic Quantization-Based Image Watermarking Using Information Entropy in the Wavelet Domain. Entropy 2018, 20, 945. [Google Scholar] [CrossRef]
- Reza, F.M. An Introduction to Information Theory; McGraw Hill: New York, NY, USA, 1961. [Google Scholar]
- Haibin, H.; Rahardja, S.; Rongshan, Y.; Xiao, L. A fast algorithm of integer MDCT for lossless audio coding. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’04), Montreal, QC, Canada, 17–21 May 2004; Volume 4, pp. IV–177–IV–180. [Google Scholar]
- Hore, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Ismail Avcibas, B.S. Statistical Analysis of Image Quality Measures; Technical Report; Department of Electrical and Electronic Engineering, Bogazici University: Istanbul, Turkey, 1999. [Google Scholar]
- Garcia-Hernandez, J.J.; Feregrino-Uribe, C.; Cumplido, R.; Parra-Michel, R. Improving the Security of Fallahpour’s Audio Watermarking Scheme. IEICE Electron. Express 2010, 7, 995–1001. [Google Scholar] [CrossRef][Green Version]
- Garcia-Hernandez, J.J. Replication Data for: “On a Key-Based Secured Audio Data-Hiding Scheme Robust to Volumetric Attack with Entropy-Based Embedding” Submitted to Entropy. Available online: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/5QSQDL (accessed on 1 October 2019).
- Thiede, T.; Treurniet, W.; Bitto, R.; Schmidmer, C.; Sporer, T.; Beerens, J.; Colomes, C.; Keyhl, M.; Stoll, G.; Brandenburg, K.; et al. PEAQ—The ITU Standard for Objective Measurement of Perceived Audio Quality. AES 2000, 48, 3–29. [Google Scholar]
- Kabal, P. An Examination and Interpretation of ITU-R BS. 1387: Perceptual Evaluation of Audio Quality; Technical Report; McGill University: Montreal, QC, Canada, 2002. [Google Scholar]
- Gibbons, J.D.; Chakraborti, S. Nonparametric Statistical Inference; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Abdi, H. The Bonferonni and Sidak Corrections for Multiple Comparisons. In Encyclopedia of Measurement and Statistics; Salkind, N., Ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2007; pp. 103–107. [Google Scholar]
- Cachin, C. An information-theoretic model for steganography. Inf. Comput. 2004, 192, 41–56. [Google Scholar] [CrossRef]
- Brandenburg, K. MP3 and AAC Explained. In Proceedings of the Audio Engineering Society Conference: 17th International Conference: High-Quality Audio Coding, Signa, Italy, 2–5 September 1999; No 1709. pp. 1–12. [Google Scholar]
- Dhar, P.K.; Shimamura, T. Blind SVD-based audio watermarking using entropy and log-polar transformation. J. Inf. Secur. Appl. 2015, 20, 74–83. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garcia-Hernandez, J.J. On a Key-Based Secured Audio Data-Hiding Scheme Robust to Volumetric Attack with Entropy-Based Embedding. Entropy 2019, 21, 996. https://doi.org/10.3390/e21100996
Garcia-Hernandez JJ. On a Key-Based Secured Audio Data-Hiding Scheme Robust to Volumetric Attack with Entropy-Based Embedding. Entropy. 2019; 21(10):996. https://doi.org/10.3390/e21100996
Chicago/Turabian StyleGarcia-Hernandez, Jose Juan. 2019. "On a Key-Based Secured Audio Data-Hiding Scheme Robust to Volumetric Attack with Entropy-Based Embedding" Entropy 21, no. 10: 996. https://doi.org/10.3390/e21100996
APA StyleGarcia-Hernandez, J. J. (2019). On a Key-Based Secured Audio Data-Hiding Scheme Robust to Volumetric Attack with Entropy-Based Embedding. Entropy, 21(10), 996. https://doi.org/10.3390/e21100996