We consider using gradient descent-based algorithms to solve the proposed models. It is usually admitted that gradient descent is not very efficient. However, in our experiments, we find that gradient descent is still efficient, and comparable with some state-of-the-art methods. On the other hand, we present recoverability and convergence rate results for gradient descent applied to the proposed models. Such results and analysis may help us better understand the models and such a nonconvex loss function from the algorithmic aspects.
We first consider gradient descent with hard thresholding for solving (
8). The derivation is standard. Denote
. By the differentiability of
, when
Y is sufficiently close to
X,
can be approximated by:
Now, the iterates can be generated as follows:
with:
We simply write (
11) as
, where
denotes the hard thresholding operator, i.e., the best rank-
R approximation to
. The algorithm is presented in Algorithm 1.
The algorithm starts from an initial guess
and continues until some stopping criterion is satisfied, e.g.,
, where
is a certain given positive number. Indeed, such a stopping criterion makes sense, as Proposition A3 shows that
. To ensure the convergence, the step-size should satisfy
, where
denotes the spectral norm of
. For matrix completion, the spectral norm is smaller than one, and thus, we can set
. In
Appendix A, we have shown the Lipschitz continuity of
, which is necessary for the convergence of the algorithm.
can also be self-adaptive by using a certain line-search rule. Algorithm 2 is the line-search version of Algorithm 1.
Solving (
9) is similar, with only the hard thresholding
replaced by the soft thresholding
, which can be derived as follows. Denote
as the SVD of
. Then,
is the matrix soft thresholding operator [
13,
16] defined as
Gradient descent-based soft thresholding is summarized in Algorithm 3.
4.2. Recoverability and Linear Convergence Rate
For affine rank minimization problems, the convergence rate results have been obtained in the literature; see, e.g., [
23,
24]. However, all the existing results are obtained for algorithms that solve the optimization problems incorporating the least squares loss. In this part, we are concerned with the recoverability and convergence rate of Algorithm 1. These results give the understanding of this loss function from the algorithmic aspect, which is in accordance with and extends our previous work [
22].
It has been known that the convergence rate analysis requires the matrix RIPcondition [
33]. In our context, instead of using the matrix RIP, we adopt the concept of the matrix scalable restricted isometry property (SRIP) [
24].
Definition 1 (SRIP [
24]).
For any , there exist constants such that: Due to the scalability of
on the operator
, SRIP is a generalization of the RIP [
33] as commented in [
24]. We point out that the results of Algorithm 1 for the affine rank minimization problem (
8) rely on the SRIP condition. However, in the matrix completion problem (
5), this condition cannot be met, since
in this case is zero. Consequently, the results provided below cannot be applied directly to the matrix completion problem (
5). However, similar results might be established for (
5), if some refined RIP conditions are assumed to hold for the operator
in the situation of matrix completion [
23]. To obtain the convergence rate results, besides the SRIP condition, we also need to make some assumptions.
Assumption 1. Based on Assumption 1, the following results for Algorithm 1 can be derived.
Theorem 1. Assume that , where is the matrix to be recovered and . Assume that Assumption 1 holds. Let be generated by Algorithm 1, with the step-size . Then
at iteration , Algorithm 1 will recover a matrix satisfying:where depending on β. If there is no noise or outliers, i.e., , then the algorithm converges linearly in the least squares and sense, respectively, i.e.,where and , depending on the choice of β.
The proof of Theorem 1 relies on the following lemmas, which reveal certain properties of the loss function .
Lemma 1. For any and , it holds: Proof. For any , let . Since is even, we need to only consider . Note that , which is nonnegative when . Therefore, is a nondecreasing function on . On the other hand, and . Thus, the minimum of is . As a result, . This completes the proof. ☐
Lemma 2. Assuming that , and , it holds: Proof. Since , it is not hard to check that . From the range of , it follows . This completes the proof. ☐
Lemma 3. Given a fixed , for , is nondecreasing with respect to σ.
Proof. It is not hard to check that is nonnegative on . ☐
Proof of Theorem 1. By the fact that
is rank-
R and
is the best rank-
R approximation to
, we have:
Since:
we know that:
where the last inequality follows from:
and the choice of the step-size
. It remains to estimate
. We first see that:
To verify our first assertion, it remains to bound the first two terms by means of
. We consider the first term. Denoting
, we know that:
The choice of
tells us that:
and consequently:
Then, by the fact that
and the choice of the step-size
, we observe that the second term of (
13) can be upper bounded by:
Combining (
14) and (
15) and denoting
, we come to the following conclusion:
where the last inequality follows from the SRIP condition and the fact that
by the range of
. As a result, we get the following estimation:
where the last inequality follows from the assumption
. Denote
. The range of
tells us that
Iterating (
16), we obtain:
Therefore, The first assertion concerning the recoverability is proven.
Suppose there is no noise or outliers, i.e., we have
. In this case, it follows from (
16) that:
and then, the SRIP condition tells us that:
where the last inequality comes from the inequality chain
. Denote
. Then,
. Therefore, the algorithm converges linearly to
in the least squares sense.
We now proceed to show the linear convergence in the
sense. Following from the inequality
, we obtain:
Combining with Inequality (
A1), we see that
can be upper bounded by:
We need to upper bound
and
in terms of
. We first consider the second term. Under the SRIP condition, we have:
By setting
, we get
. Lemma 2 tells us that:
Summing the above inequalities over
i from 1 to
p, we have:
Therefore,
can be bounded as follows:
We proceed to bound
. It follows from (
14) and Lemma 1 that:
Combining (
17)–(
19) together, we get:
where the last inequality follows from
.
By Lemma 3, the function
is nondecreasing with respect to
. This in connection with the fact that:
yields
. Let
, and consequently,
. We thus have:
The proof is now completed. ☐
The above results show that it is possible that Algorithm 1 will find if the magnitude of the noise is not too large. Moreover, the results also imply that the algorithm is safe when there is no noise.


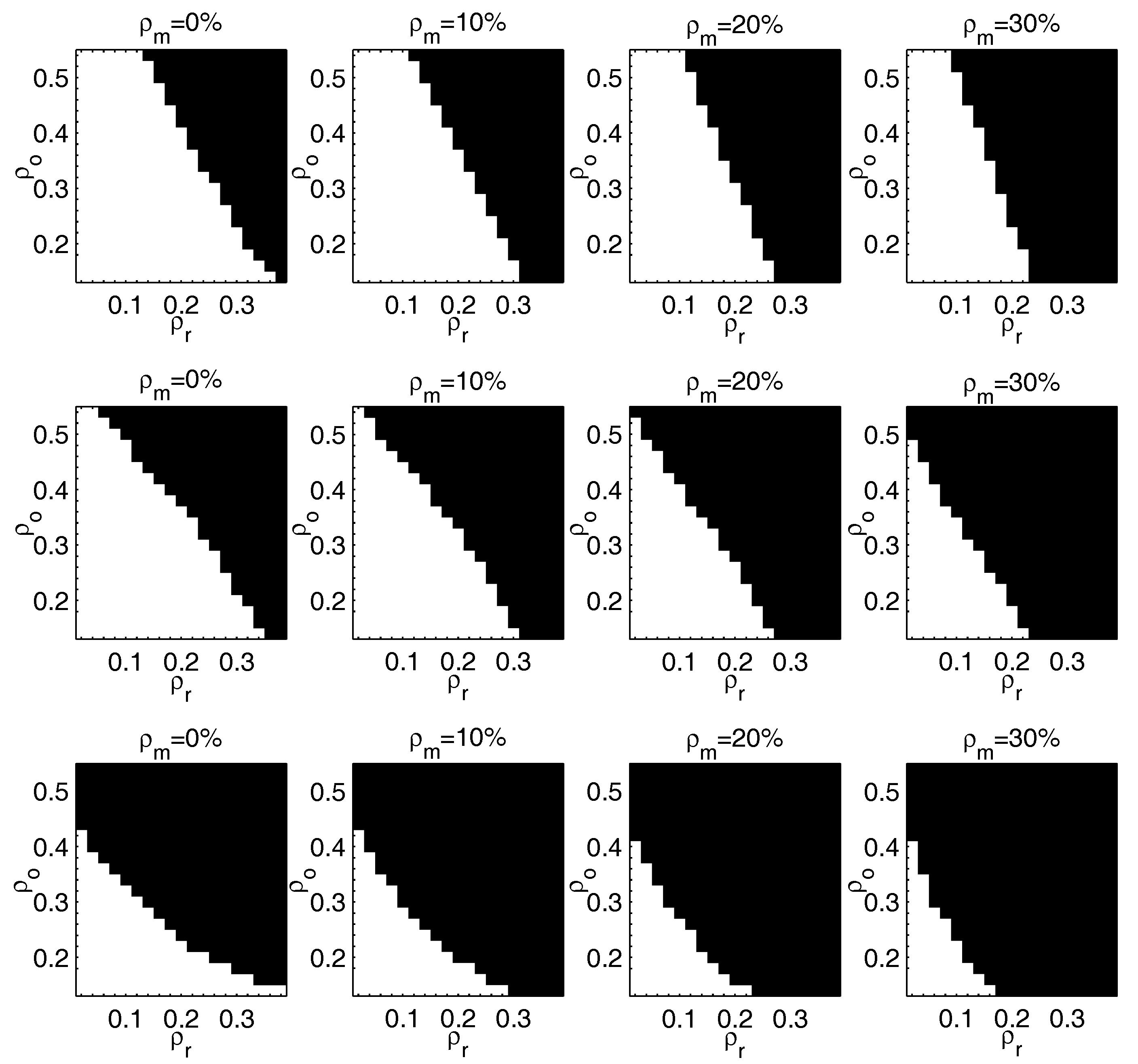




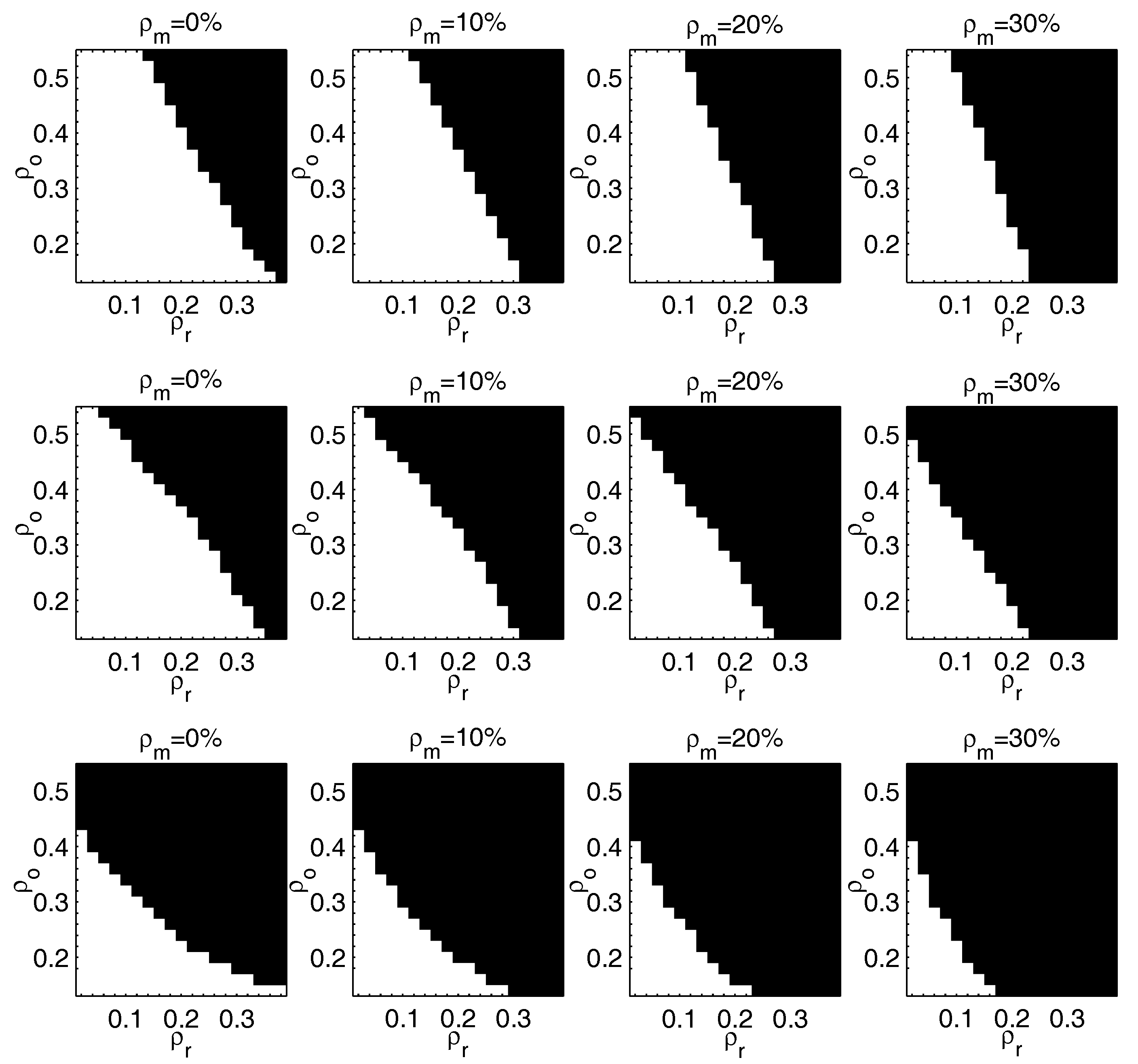
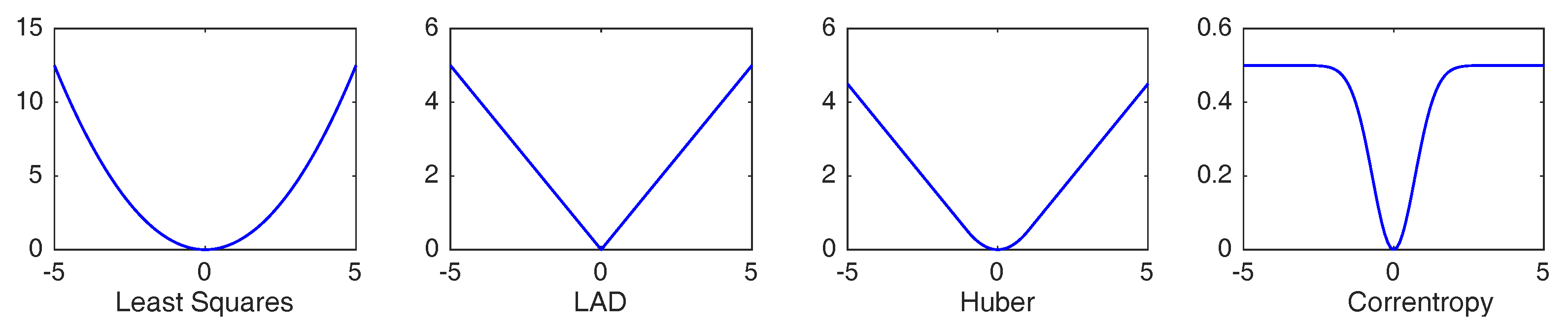{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}