1. Introduction
In machine learning, classification is one of the most important tasks that predicts the unknown class labels according to some known evidence or labeled training samples. Bayesian network classifiers (BNCs) [
1,
2] provide a classical method to implement classification decision based on the probability framework. In general, BNCs consist of two parts, i.e.,
. The network structure
is a directed acyclic graph (DAG). Nodes in
represent stochastic variables or features, arc
denotes probabilistic dependency relationships between these two features and
is one of immediate parent nodes of
, i.e.,
. Parameter
quantitatively describes this dependency. Let each instance
x be characterized with
n values
for features
, and class label
is the value of class variable
C.
contains conditional probability tables
for each feature.
According to Bayesian theorem [
3], BNC makes the classification decision in the following way:
According to the chain rule of joint probability distribution [
1],
can be calculated as follows:
In this paper, we mainly focus on the restricted BNCs, which suppose that each feature is directly dependent on the class variable C and C does not have any parents. In this paper, we mainly focus on the restricted BNCs, which require that the class variable C be a parent of every feature and no feature be the parent of C.
The
k-dependence Bayesian classifier (KDB) is one of the famous restricted BNCs [
4]. To achieve the trade-off between structure complexity and classification accuracy, KDB allows to represent different number of interdependencies for different data sizes. During the learning procedure of KDB, it utilizes mutual information between features and class variable to rank and sort all features first. This sorting method gives priority to the features with high relevance between features and class. Feature
may be a possible parent feature of
if
ranks before
, not the other way around. Then conditional mutual information between features is used to measure and select significant conditional dependencies. The dependency relationships between features and class, and that between different features, are considered in different learning phases. Obviously, some independent features with high mutual information value may achieve higher rank but demonstrate weak conditional dependencies. To address this issue, Peng et al. [
5] propose a first-order incremental feature selection method based on minimal-redundancy-maximal-relevance (mRMR) criterion, which takes into account the maximal relevance between features and class, meanwhile considering the minimal redundancy between features. Its effectiveness has not been proved in the context of KDB.
The structure complexity will increase exponentially as the number of features increases. The features that rank at the end of the order are the least relevant to classification and may be disregarded. Regular KDB does not consider the negative effect caused by redundant features, which may bias the classification results. Many researchers have recognized that using a heuristic wrapper approach to delete redundant features helps minimize zero-one loss on the training samples [
6,
7,
8]. Martínez et al. [
9] propose discriminative model selection to select an optimal KDB sub-model which contains feature subset with necessary features. The resulting algorithm not only has the competitive classification performance of generative learning, but also has the excellent expressive power of discriminative learning. At each iteration for model selection, any feature
in the order should have
k parent features if
as KDB defines. However, the dependencies between
at the end of the order and the other feature
may be very weak, and these two features can be assumed to be independent. That is, the dependencies between
and
may be redundant.
In this paper, we will investigate the feasibility of applying discriminative model selection to remove redundant features and dependencies, and the interoperability of mRMR analysis and discriminative model selection.
Section 2 reviews the state-of-the-art restricted BNCs, including naive Bayes (NB), tree-augmented naive Bayes (TAN) and especially KDB. In
Section 3 we present the theoretical justification of our proposed algorithm, mRMR-based KDB with discriminative model selection (MMKDB).
Section 4 presents a detailed analysis of the experimental results. Finally, we present conclusions in
Section 5.
2. Restricted Bayesian Network Classifiers
The classification task in a BNC can be separated into two subtasks, structure learning and parameter learning. The former is to identify the structure of the network, and the latter is to calculate the probability distribution for a given network structure. In the following discussion, we will review some state-of-the-art BNCs from the perspective of structure learning and parameter learning.
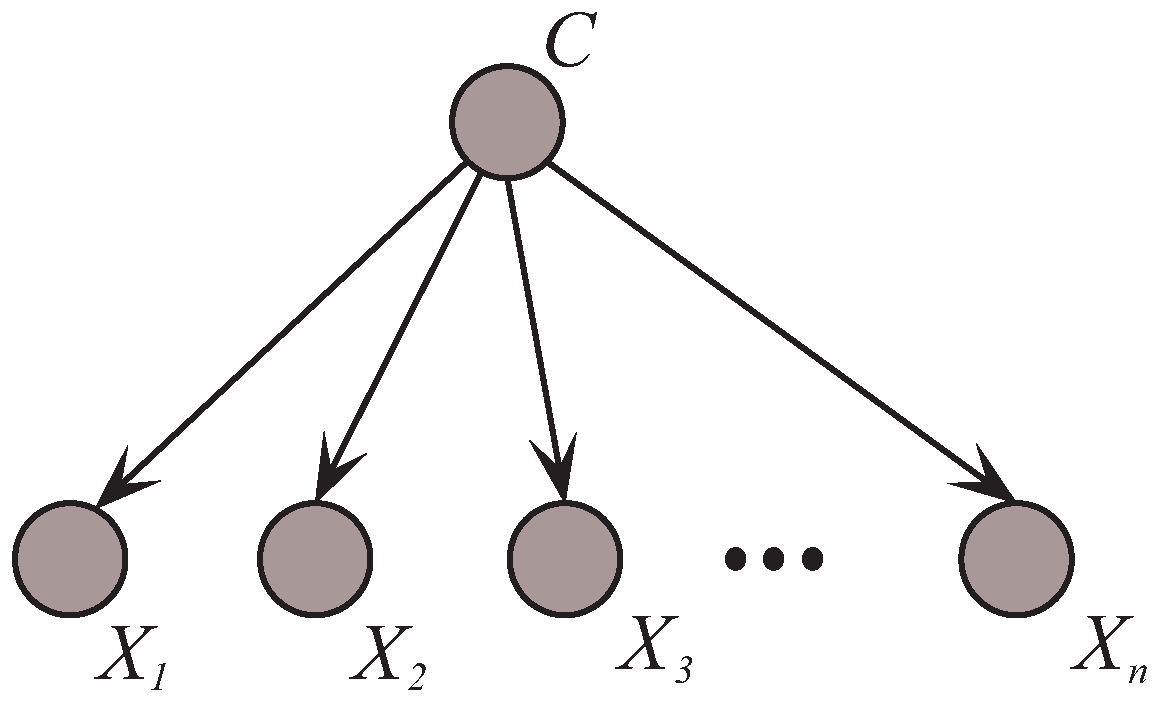
NB is the simplest BNC [
10,
11], since the features are assumed to be conditionally independent given the class variable. The formula of joint probability
is presented as follows:
Note that, for NB, the parameter learning only involves the learning of the probability
and the conditional probability
, and the structure learning is not necessary since NB has a definite structure as shown in
Figure 1. However, features may be interrelated in practice. Therefore, many researchers have exploited methods to alleviate the conditional independence assumption of NB [
12,
13,
14]. It is worthwhile to mention that, Webb et al. [
15] present a new approach, named averaged one-dependence estimators (AODE), to weaken the feature independence assumption by averaging all of the constrained class of classifiers. The class of all such classifiers has all other features depend on a common feature and the class variable.
TAN [
1] is an extension of NB. It uses a variant of the Chow-Liu algorithm [
16] to construct the Bayesian network, and it utilizes conditional mutual information
to find a maximum weighted spanning tree. Additional arcs between features are allowed, i.e., dependencies between features can be captured. Each feature in the network has at most one other feature as its parents, except a single feature (the root of the tree), which has only the class variable as its parent. TAN alleviates some of conditional independence assumption of NB and, thus, improves its prediction accuracy at the cost of adding its structure complexity. The joint probability of TAN is calculated by:
where
is the parent of
in the tree structure.
KDB is another classical improvement to NB [
4]. It allows for most
k features to be the parents for each feature. In this sense, NB is a 0-dependence BNC and TAN is a one-dependence BNC. In the real-world domains we find that modeling feature dependencies very often improves classification performance. This is especially true for the KDB, with respect to lower value of
k, larger value of
k may helps to improve the classification accuracy [
4]. Two passes are required for KDB to learn over the training examples. Structure learning is the first pass. Algorithm 1 depicts the structure learning process of KDB. Parameter learning is the second pass. According to the Bayesian network obtained from the former pass, the joint probability of KDB for each instance can be calculated by:
where
denotes the parents of
in the structure. Suppose there is an ordered feature set
, we give some examples of corresponding structures of KDB classifiers in
Figure 2 when given different
k values. Corresponding joint probability distributions are shown in
Table 1.
| Algorithm 1: Structure learning process of KDB. |
 |
3. The mRMR-Based KDB with the Discriminative Model Selection
To elaborate our motivations for doing selection based on mRMR criterion and discriminative model selection in the context of the KDB classifier, we consider two extreme examples of constructing BNCs over two sets of features. The first feature set contains two perfectly correlated features and , where is an exact copy of . Both and will be included in the network structure of KDB, that is, (or alternatively) will have twice the influence of the other features, which may strongly bias the performance of the classifier. A possible way to improve the classification performance is to eliminate one of the features from the feature set and to construct the classifier over the reduced set of features. The ordered feature set is the second extreme example and contains non-redundant features to construct a KDB with . Suppose that the values of and are respectively 0.99 and 0.0001. As KDB defines, feature should select and as its parent features in any case. This naturally results in a redundant dependency between and , which may lead to negative effects on the classification performance of KDB and increases the risk of over-fitting at a certain extent.
Therefore, we utilize the sorting method based on an mRMR criterion to identify possible redundant features and discriminative model selection to achieve the aim of removing the redundant features or conditional interdependencies. The usual feature selection based on mutual information in KDB intends to select features that are independent of each other. Instead, the mRMR method tries to select a feature that minimizes the redundancy and maximizes the relevance. As argued by Peng et al. [
5], for real data, the features selected in this way will have more or less correlation with each other and the joint effect of these features can lead to very good classification accuracy.
Let
S denote the feature set and
is the cardinality of
S. Given a feature set
and a class variable
C, in order to make sure that the selected feature subset is the most appropriate one, two conditions should be met. The first one is the minimum redundancy condition [
5]:
where
R represents the level of redundancy between features.
And the other one is the maximum relevancy condition [
5]:
where
D represents the level of relevancy between feature and class variable.
There are two combinations of these two conditions, named MID (Mutual Information Difference) and MIQ (Mutual Information Quotient) [
17], which balance the two objectives, maximum relevance and minimum redundancy, in different ways as follows:
As argued by Gulgezen et al. [
18], MID produces more stable feature subsets, so in this paper we choose MID as the criterion. Suppose there exists a selected feature subset
, which consists of
features, then the
m-th feature can be determined by following equation:
where
.
The feature selection based on mRMR criterion utilizes forward selection strategy, it starts with an empty feature set
and then iteratively add one feature into the
at a time by Equation (
11). Sorting all features in this way, we consider the feature subsets
,
, each feature subset contains
i ordered features. That is, for
n features there are
n alternative feature subsets that could be explored for our proposed algorithm.
From Equation (
6) we can observe that the joint probability
can be considered as the product of a set of conditional probabilities
. This means that we can build a model space by using a nested method, each model can be built upon the previous one. For an instance
, as
Table 2 shows, the joint probability
is obtained by multiplying the conditional probability of feature
(i.e.,
) to
and the joint probability
is obtained by multiplying the conditional probability of feature
(i.e.,
) to
. That is to say, if the model
has been built, it is not necessary to repeat the process of structure learning with feature set
for the model
. We only need to find parents of the feature
in the BN and then multiply the conditional probability
with the joint probability
(which has been learnt in the previous model
) to obtain the model
. The discriminative model selection framework is derived from the chain rule of BNCs’ joint probability, it firstly constructs a space of sub-models, and then selects the best sub-model by the evaluation function to achieve our purpose in feature selection.
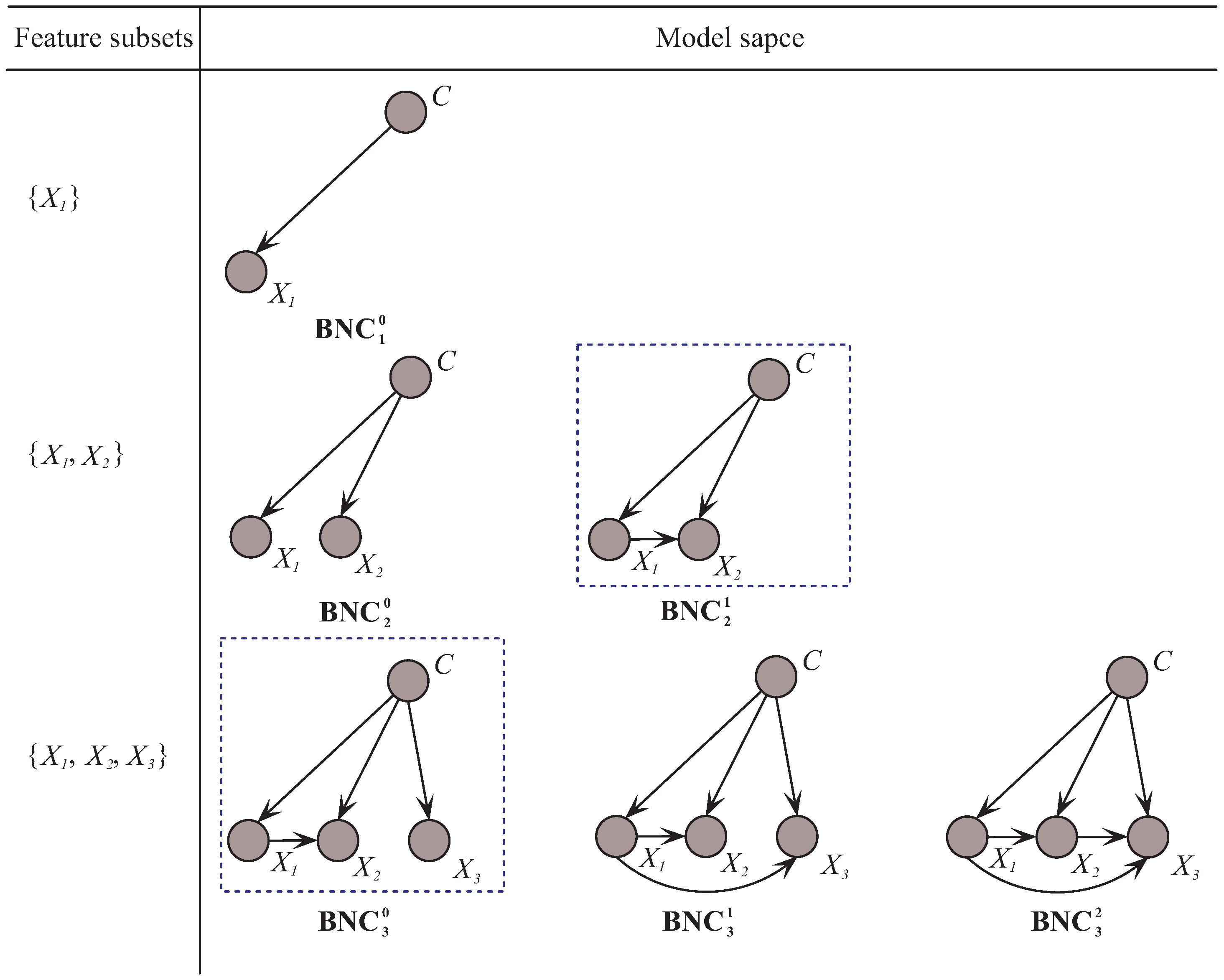
Based on the above observations and discussions, we further improve the framework of discriminative model selection from the view of feature dependencies. To make the idea of the improved framework of discriminative model selection clear in KDB, we restrict that at most two features can be the parents for each feature in the following discussion. As
Figure 3 shows, for feature subset
, the corresponding model space of our proposed algorithm MMKDB is composed of BNC
, BNC
and BNC
. The only difference of these three BNCs is the number of parents for feature
. We employ the conditional mutual information to assign 0, 1 or 2 features to
as parents, respectively. Note that all BNCs with
are built upon BNC
, which is the best BNC for feature subset
and selected by using an evaluation function. Similarly, BNC
, BNC
and BNC
also need to be evaluated the classification performance to select the best one. In this way, we can remove not only redundant features but also redundant dependencies between them. That is to say, at each iteration for model selection, any feature
should have
parent features, where
if
. Note that we employ the root mean squared error (RMSE) [
19] as the evaluation function in the procedure of discriminative model selection, which is an effective measure of probability estimates:
where
is the training set,
t is the number of training examples,
is the true class label for the instance
, and
is the estimated posterior probability of the true class given
.
It is worthwhile to note that, in order to avoid over-fitting of sub-models on training examples, we employ the leave-one-out cross-validation (LOOCV) [
20] to evaluate the classification performance of each model. Kohavi et al. [
21] propose an incremental method to refine the cross-validation. The traditional LOOCV for BNCs recomputes the joint probability of a new model over the training examples for each instance. Differently, the incremental cross-validation firstly calculates the total joint frequency counts for all training examples, and then when testing an instance, temporarily removing its counts from the total counts to calculate the joint probability of corresponding model.
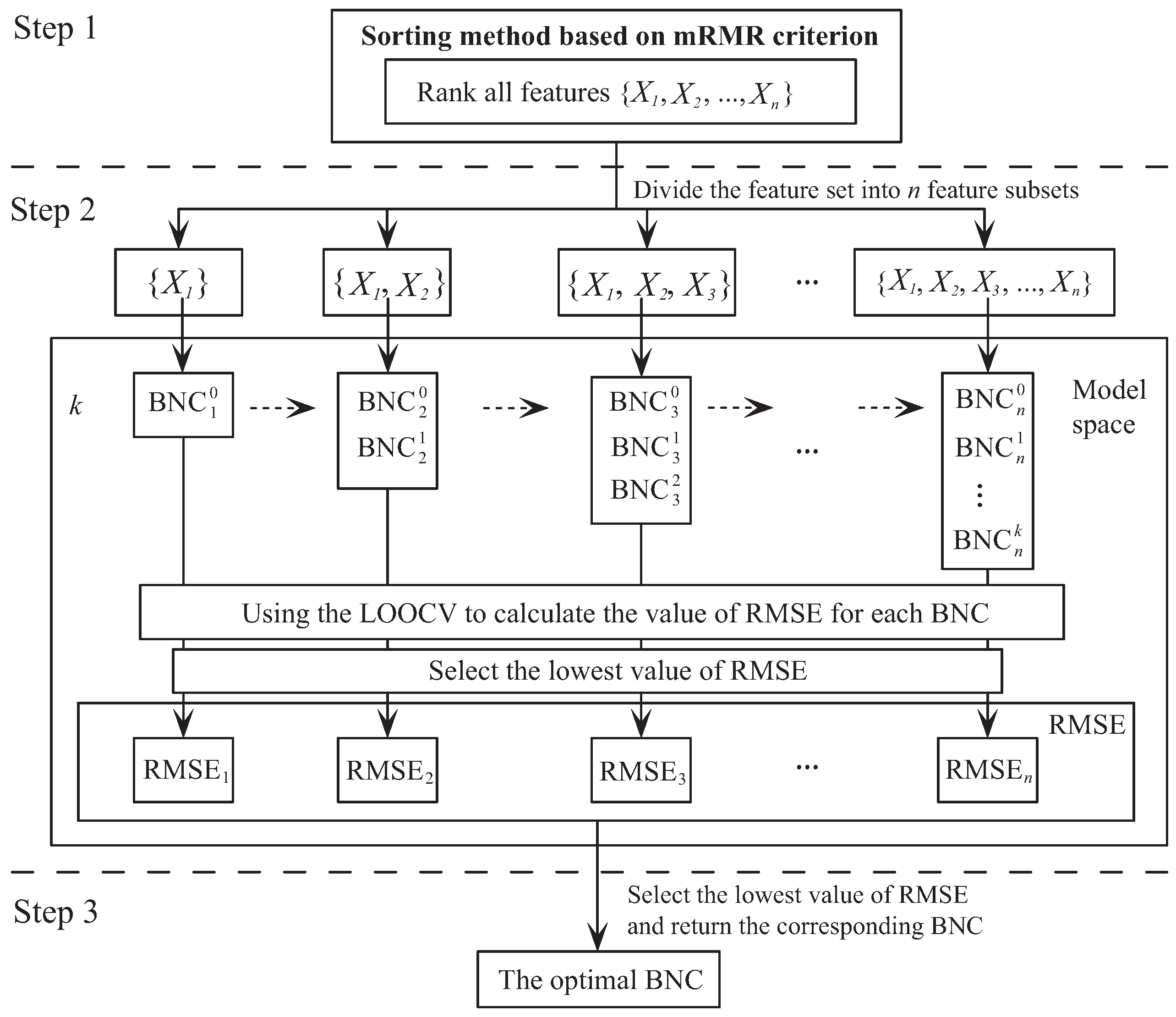
Figure 4 presents the schematic diagram of our proposed algorithm MMKDB. Step 1 sets the order of features by the mRMR sorting method, computes the conditional mutual information between features and class variable through the training examples, and the ordered feature set would be divided into
n feature subsets. Steps 2 and 3 correspond to the framework of discriminative model selection. All ordered feature subsets are introduced as the input to construct the corresponding BNCs. Sub-models containing features that rank ahead in the order would be built upon sub-models containing features ranks behind. These
sub-models form the model space. Each sub-model denotes as BNC
, where
s is the number of feature subsets and
r is the number of parents for feature
. In the model space, all sub-models are evaluated by using the LOOCV to calculate the values of RMSE through the training examples. According to the chain rule of BNCs’ joint probability, BNC
needs to be built upon BNC
. Thus, only one sub-model that has the lowest value of RMSE would be selected for each feature subset. Finally, there are
n alternative local optimum BNCs for
n feature subsets. The optimal BNC would be selected from these
n sub-models.
Based on the discussion presented above, we present the pseudo-codes of MMKDB in Algorithm 2. Calculating
and
respectively need
and
time, where
t is the number of training examples,
c is the number of classes,
n is the number of features and
v is the maximum number of possible values per feature. From Equation (
11) we can infer that, if
the time complexity of step 2 in Algorithm 2 is
, or else
. The procedure of computing the conditional mutual information needs
time. The space complexity of the table of joint frequencies of all combinations of
n features values and the class label is
. Feature ordering needs
time and parent assignment for each feature needs
time. Moreover, classify an instance using the selected sub-model only requires
time. That is, the procedure of discriminative model selection needs
time. So the overall time complexity is
for MMKDB and
for KDB. This is an acceptable result, since
k is a user-set parameter. That is, the time complexity of MMKDB scales linearly with the number of training examples, classes and features.
| Algorithm 2: Algorithm MMKDB. |
 |
4. Experiments
We run the experiments on a C++ system (GCC 5.4.0) which is specially designed for BNCs. For KDB, with respect to lower value of k, larger value of k may helps to improve the classification accuracy. However, the restrictions of currently available hardware place some requirements on the software. The structure complexity and time complexity will increase exponentionally as k increases. When , due to the amount of memory and CPU available the experimental results of MMKDB on some datasets cannot be achieved. Thus in the following experimental study the maximum value of k is 3.
In our experimental study, we gather a group of datasets from UCI machine learning repository [
22]. These datasets are described in
Table 3. Missing values are referred to as a distinct value. For each dataset, we discretize quantitative features using 5-bin equal frequency discretization, and we employ the
m-estimation
[
23,
24] to smooth the probability estimates.
As a contrast, we also present respectively two extensional version of KDB as follows:
Note that, the experiments have been done by using 10 rounds of 10-fold cross-validation, and we employ the zero-one loss to evaluate classification accuracy of different algorithms [
25]. Suppose that
c is the predicted class label of an algorithm and
is the true class label, the value of zero-one loss is calculated as follow:
where
if
and 0 otherwise.
The detailed zero-one loss results of all alternative algorithms are presented in
Table A1 in the
Appendix A. In order to give the experimental results an intuitive explanation, we employ the Win/Draw/Loss (W/D/L) records to summarize the number of datasets for different algorithms in the following three situations on a given evaluation function: a win represents an algorithm achieves significant advantages over the other one on a dataset, a loss indicates the opposite case and the draw suggests that these two algorithms perform comparably. Each entry compares the algorithm in the row against the one in the column. We regard a difference as significant between two algorithms if their outcomes of a one-tailed binomial sign test is less than 0.05.
4.1. Impact of Sorting Method Based on the mRMR Criterion and Discriminative Model Selection
In order to investigate the impact of sorting method based on the mRMR criterion, we present the W/D/L records when comparing the zero-one loss results of KDB and MKDB in
Table 4. The only difference between KDB and MKDB is the sorting method of features, the former performs the sorting method based on the mutual information and the latter performs the one based on mRMR criterion. From
Table 4 we can see that, MKDB achieves significant advantages over KDB and results in W/D/L of 12/25/3. This proves that the sorting method based on the mRMR criterion is superior to the one based on mutual information in KDB. Compared with KDB, there are only three datasets, i.e.,
Lung-Cancer,
House-Votes-84 and
Anneal, have higher results of zero-one loss over MKDB, which indicates that MKDB seldom performs worse than KDB, and for many datasets, it substantially improved the classification performance of KDB, such as, the datasets
Adult,
Dermatology,
Labor and
Hypo.
In order to explore the effect of discriminative model selection, we present the W/D/L records in terms of zero-one loss between KDB and MSKDB in
Table 5. The only difference between these two algorithms is that MSKDB need an extra pass to perform the discriminative model selection through the training examples. As expected, MSKDB achieves lower zero-one loss results more often than KDB, for example, the decrease from 0.1926 to 0.0598 for the dataset
Splice-C4.5. Note that MSKDB only performs worse than KDB on one dataset, i.e.,
Contact-Lenses. We argue that the lack of enough instances is the main reason why MSKDB performs not well on this dataset.
4.2. Comparison of MMKDB vs. KDB
According to the zero-one loss, the corresponding comparison with MMKDB and KDB is given in
Table 6.
Table 6 also presents the W/D/L records of MMKDB over MKDB and MSKDB. As we can see that MMKDB achieves significant advantages than KDB, MKDB and MSKDB, which indicates that the interoperability of mRMR analysis and discriminative model selection is feasible. To further demonstrate the performance of MMKDB over other algorithms, we employ the goal difference (
) [
26]. Suppose there are two classifiers
A and
B, the value of
can be computed as follow:
where
is the datasets,
and
represent the number of datasets on which
A performs better or worse than
B, respectively.
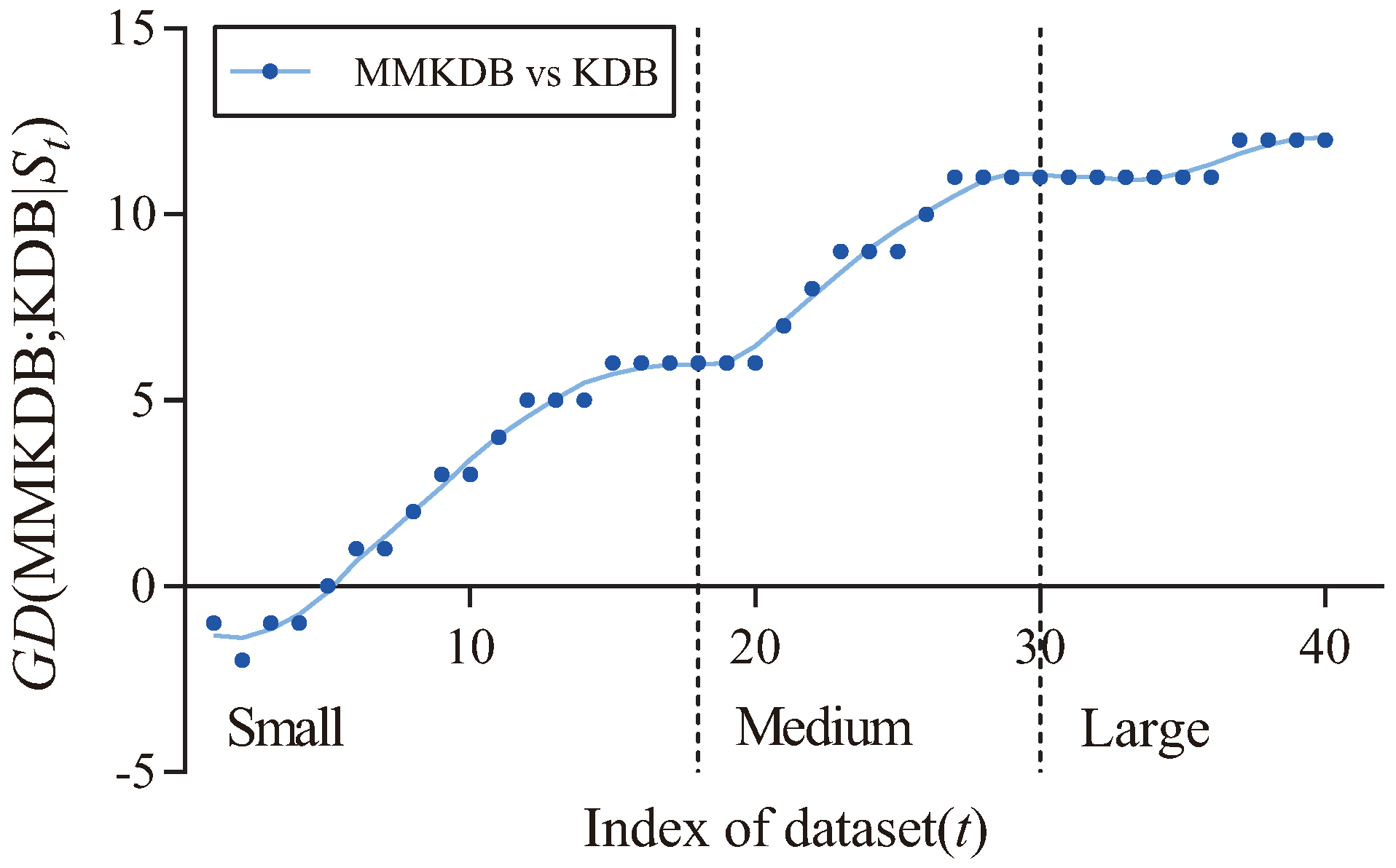
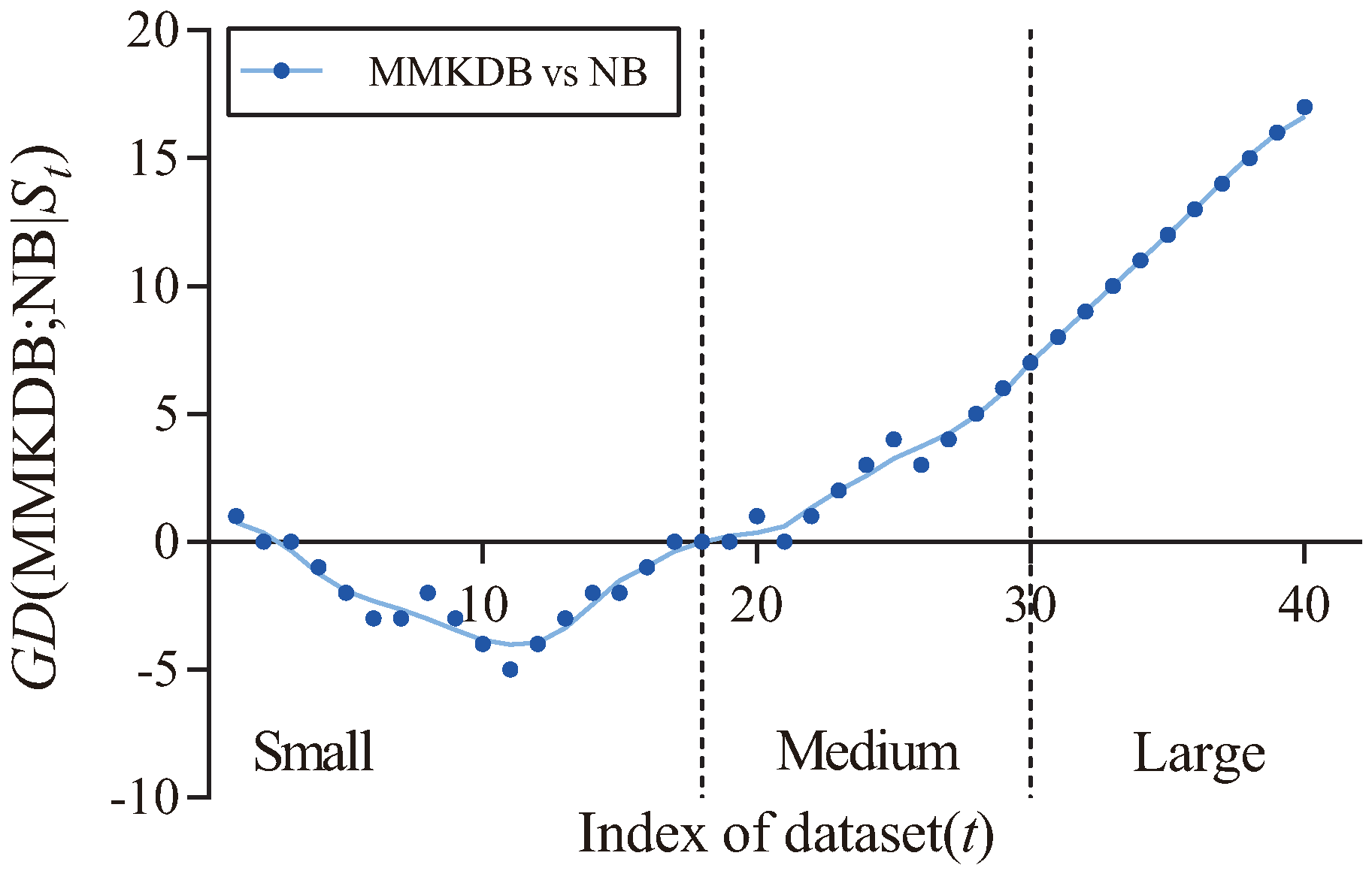
Figure 5 shows the fitting curve of
MMKDB; KDB
in terms of zero-one loss. The X-axis shows the indexes of different datasets, referred to as
t, which correspond to that described in
Table 3, and the Y-axis corresponds to the value of
MMKDB; KDB
, where
and
is the dataset with index
m. We categorize datasets according to their size. Datasets with instances ≤1000, >1000 and ≤10,000, >10,000 are represented as small, medium and large size, respectively. Two dotted lines divide the figure into three parts, each part is associated to the corresponding sizes of different datasets. From
Figure 5 we can see a clear positive correlation between the values of
MMKDB; KDB
and the dataset size. As the size of datasets increases, MMKDB achieves significant advantages over KDB on small and medium datasets. When the number of instances >10,000, MMKDB has similar zero-one loss performance to KDB, but it speeds up classification time. Since MMKDB removes not only features but also dependencies between them may be redundant. Thus, we can come to the conclusion that, MMKDB not only retains the privileges of KDB, i.e., the capacity of high dependence representation and the model fitting ability on large datasets, but also improves the model fitting ability on small and medium datasets and enhances the classification efficiency on large datasets. That is, it proves the feasibility of applying discriminative model selection to remove redundant features and dependencies.
To further evaluate whether mRMR analysis and discriminative model selection are compatible and the extent to which applying both together improves the classification performance relative to applying each alone, we employ the relative zero-one loss ratio [
27]. Given two classifiers
A and
B, the value of the relative zero-one loss ratio, referred to as
, is calculated as follow:
where
denotes the zero-one loss, and
is the value of zero-one loss of classifier
on a dataset. The smaller ratio of
and
, the higher value of
, and the better performance of
A.
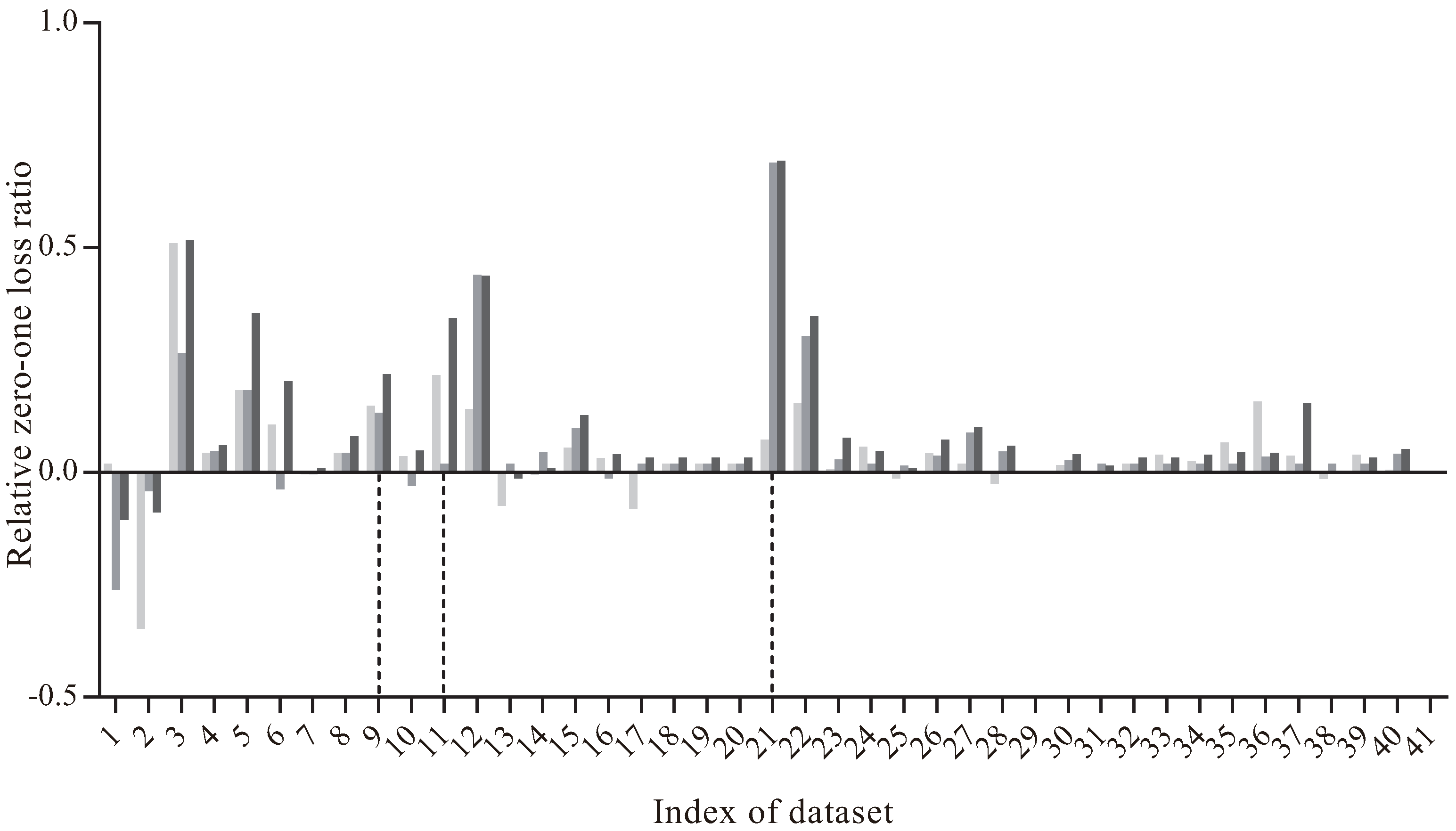
Figure 6 presents the comparison results of
between MKDB, MSKDB, MMKDB and KDB. The X-axis shows the index of dataset, and the Y-axis corresponds to the value of
. As we can see, on the dataset
Audio (No. 9), the values of
(MKDB|KDB) and
(MSKDB|KDB) are respectively 0.1486 and 0.1328. But when it comes to MMKDB,
(MMKDB|KDB) is 0.2184, which is more higher than the former two results. There are also two extreme situations. For the dataset
Dermatology (No. 11),
(MKDB|KDB) is 0.2006 but
(MSKDB|KDB) is 0.0198. That is, MKDB improves significantly with KDB but MSKDB does not. But nevertheless, the value of
(MMKDB|KDB) on dataset
Dermatology is 0.3482. Another extreme situations is just on the contrary, such as dataset
Splice-C4.5 (No. 21),
(MKDB|KDB) is 0.0729 and
(MSKDB|KDB) is 0.6895, which are very unbalanced. However,
(MMKDB|KDB) is 0.6936. That is, the value of
(MMKDB|KDB) is always equally well to or better than
(MKDB|KDB) and
(MSKDB|KDB). Therefore, we can draw a conclusion that mRMR analysis and discriminative model selection are compatible in the framework of KDB.
A more intuitive explanation is presented in
Figure 7. Each bar represents the mean relative zero-one loss ratio of an algorithm to KDB on 40 datasets. As shown in
Figure 7, the values of
(MKDB|KDB),
(MSKDB|KDB) and
(MMKDB|KDB) are respectively 0.0449, 0.0620 and 0.1006. That is, the average improved extent of MMKDB to KDB is obviously higher than MKDB and MSKDB. It proves that the interoperability of mRMR analysis and discriminative model selection is the major reason why applying both together improves the classification performance relative to applying each alone.
4.3. Comparison of MMKDB vs. NB, TAN and AODE
Table 7 presents the corresponding W/D/L results. As we can see, the zero-one loss results of MMKDB are significantly better when compared to NB and TAN, MMKDB also achieves competitive classification performance over AODE.
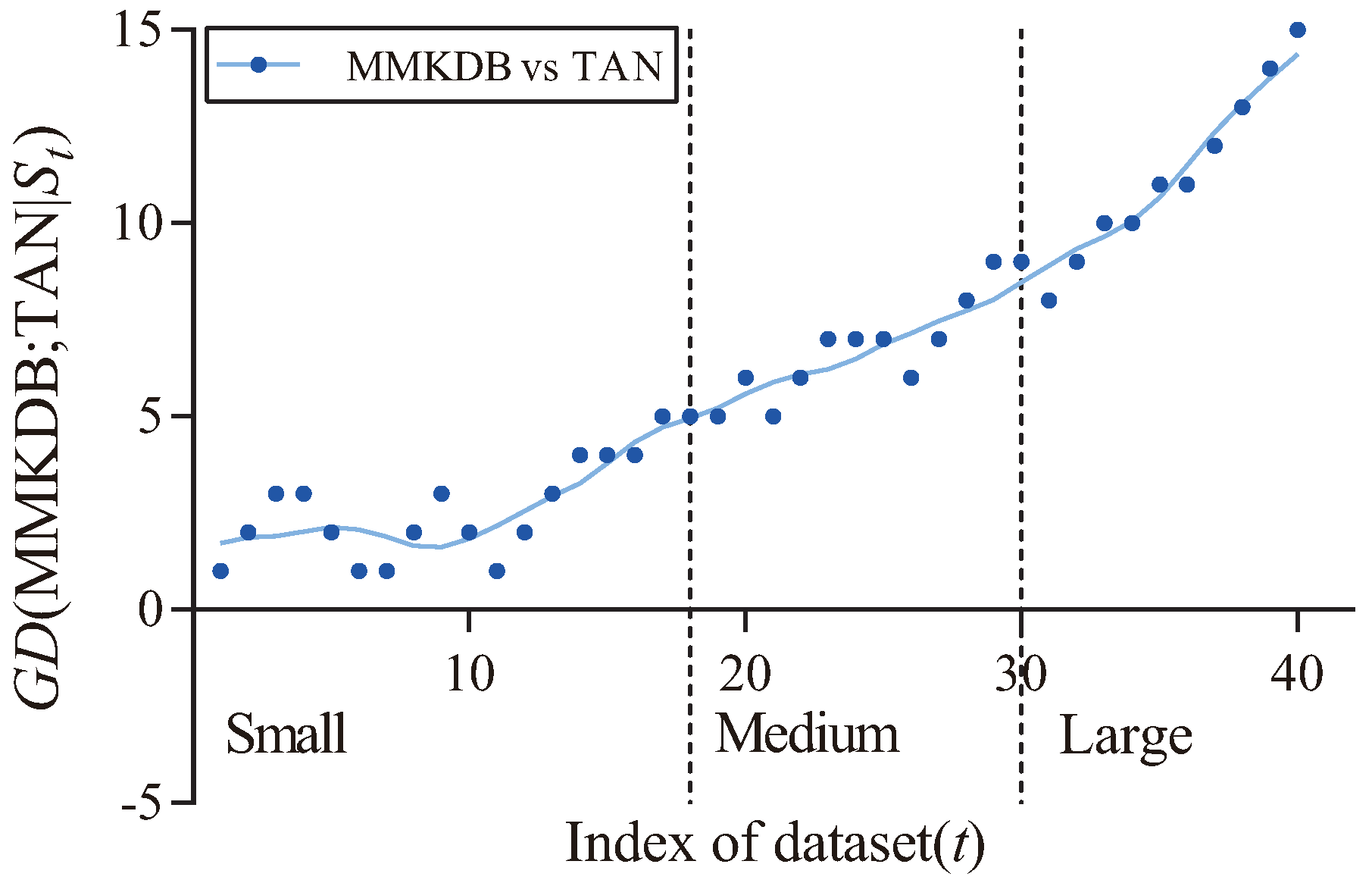
Figure 8 and
Figure 9 respectively present the fitting curves of
MMKDB; NB
and
MMKDB; TAN
in terms of zero-one loss. As we can see that, MMKDB has similar performance to NB and TAN on small datasets. However, when the dataset size increased to 1000 instances (
Led, No. 18), the prediction performance of MMKDB is obviously better than NB and TAN. That is, MMKDB achieves significant advantages over NB and TAN on medium and large datasets.
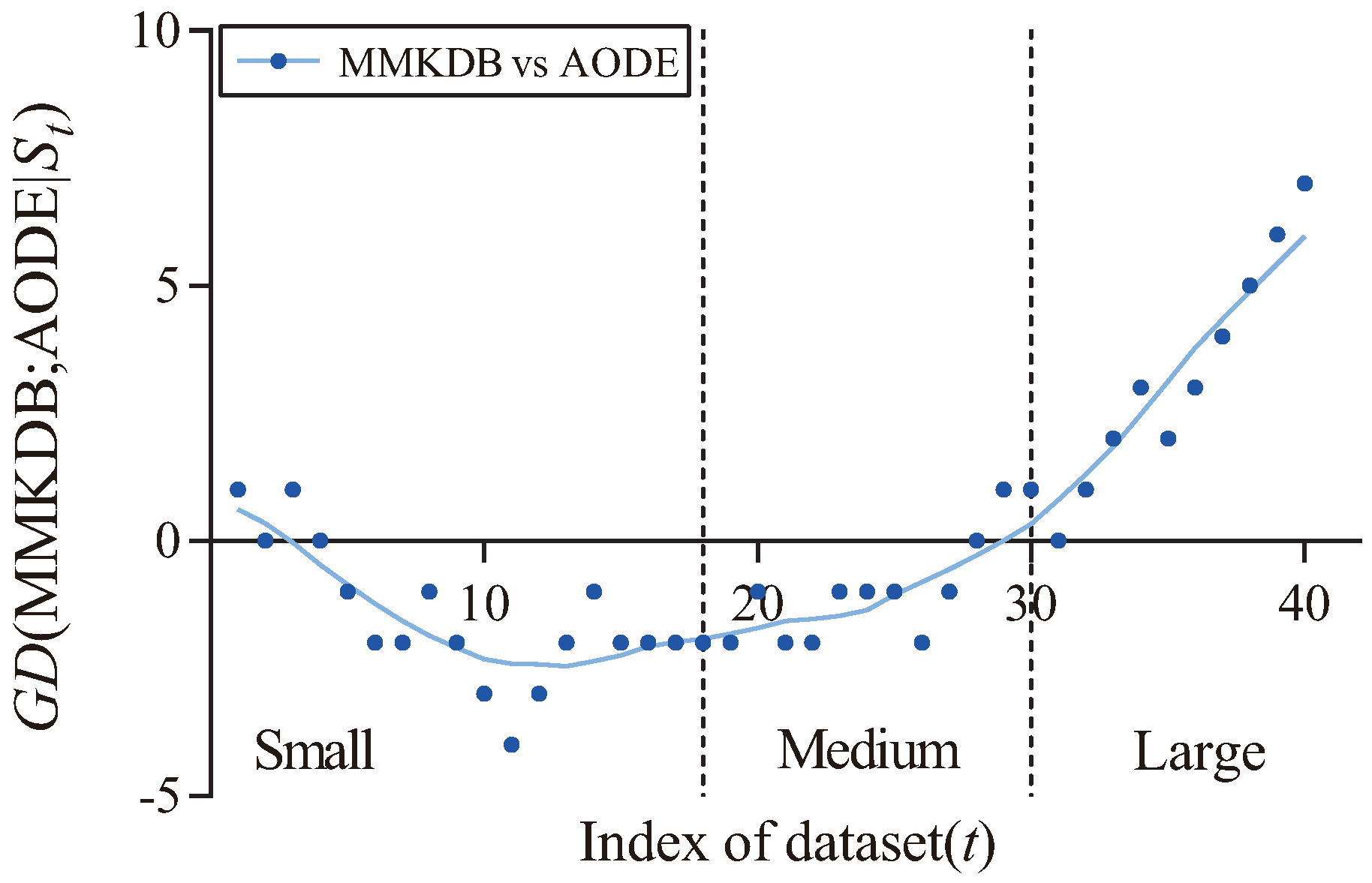
For one of the famous ensemble BNCs, AODE,
Figure 10 presents the corresponding fitting curve of
MMKDB; AODE
in terms of zero-one loss. we can see that the values of
decrease when the dataset size ≤1000, which means that MMKDB is very difficult to beat AODE on small datasets. When the dataset >1000 and ≤10,000, MMKDB has similar classification performance to AODE. This makes MMKDB a good substitute to AODE on medium datasets. Note that the fitting curve obviously turns upward when the dataset size >10,000 (the size of dataset
Pendigits, No. 31). That is to say, the single BNC, MMKDB, achieves significant advantages over AODE on large datasets.
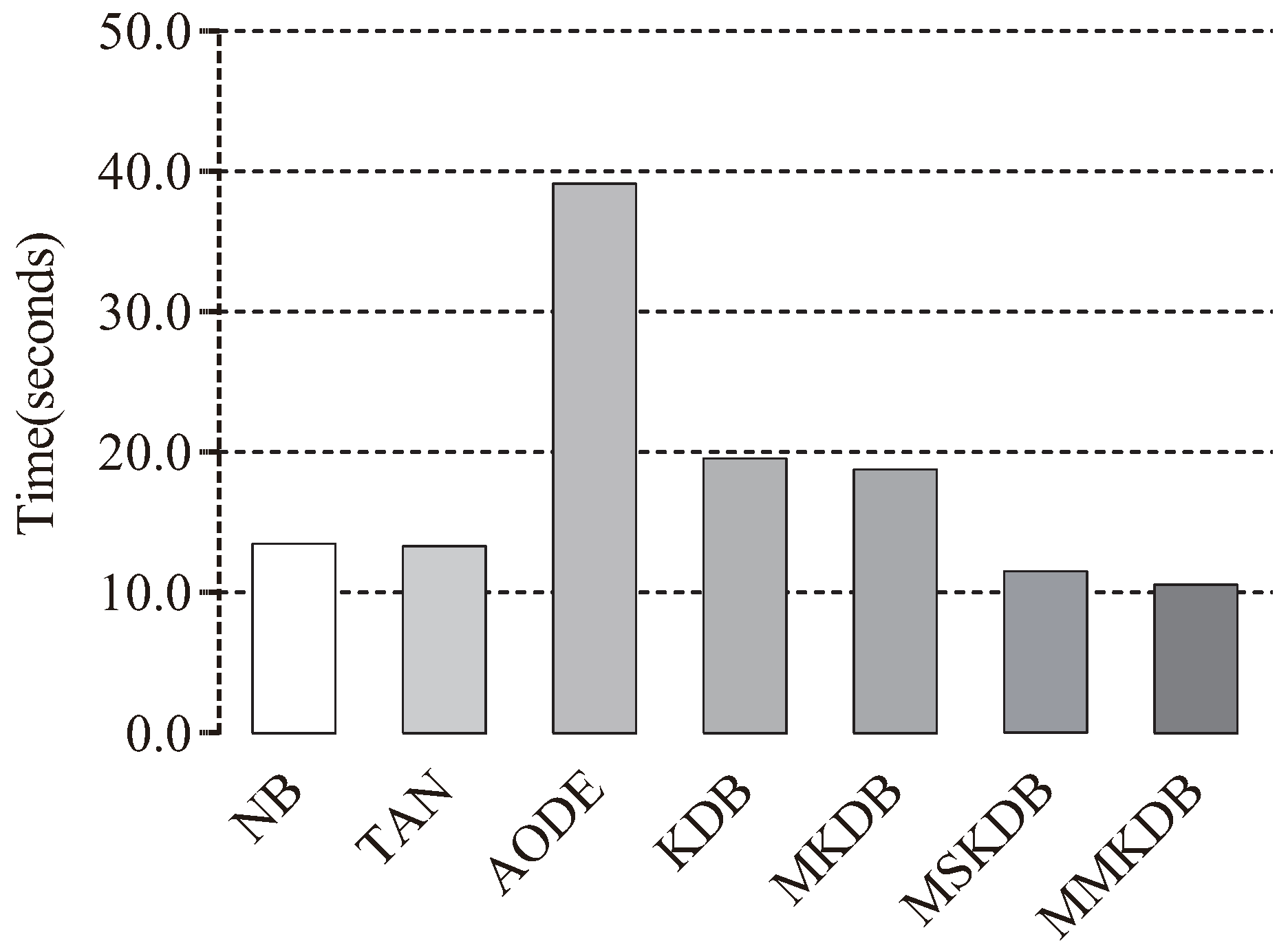
The training and classification time comparisons of NB, TAN, AODE, KDB, MKDB, MSKDB and MMKDB are shown in
Figure 11 and
Figure 12. Each bar depicts the sum of time on 40 datasets. Although, for most datasets our proposed algorithm MMKDB requires substantially more time for learning than other BNCs, such NB, TAN, AODE and KDB, while the classification time of MMKDB is the least. Note that the training and classification time of MSKDB is similar to MMKDB, and the training and classification time of MKDB is similar to KDB. AODE is an ensemble algorithm. Its classification time increases quadratically with the number of features, and hence much higher for other BNCs in
Figure 12. In general, MMKDB saves about 42% of KDB’s classification time and greatly improves the classification performance of KDB at the cost of increasing less training time, and it also enjoys an even greater advantage at classification time compared to NB, TAN and AODE.
4.4. Global Comparison
In this section, we use the Friedman test for comparison of all alternative algorithms on 40 datasets to perform the significance test [
28]. The Friedman test is a non-parametric measure, it can be computed as follows:
and
where
g is the number of alternative algorithms,
D is the number of datasets and
is the average rank of the
i-th algorithm. The best performing algorithm getting the rank of 1, the second best rank 2,
…. In case of ties, average ranks are assigned. The null hypothesis of the Friedman test is that there is no difference in average ranks. The detailed results of the average rank on 40 datasets are presented in
Table A2 in the
Appendix A. With 7 algorithms and 40 datasets, the Friedman test is distributed according to the
F distribution with
and
degrees of freedom. The critical value of
for
is 2.1375. The result of Friedman test for zero-one loss,
with
. Hence, we reject the null-hypothesis. That is to say, the seven algorithms are not equivalent in terms of zero-one loss results.
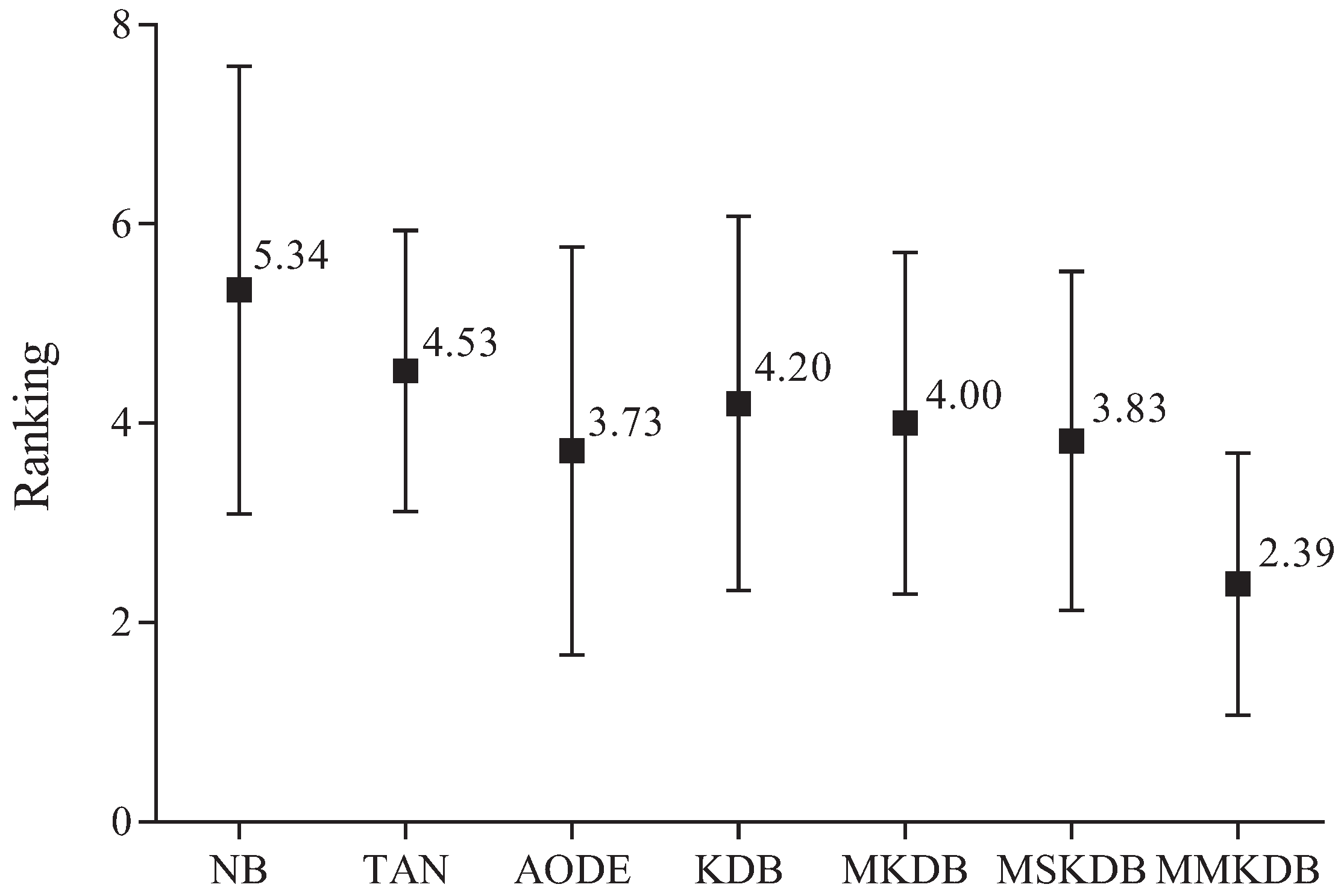
Figure 13 presents the results of ranking in terms of zero-one loss for all alternative algorithms. The average ranks of different algorithms in terms of zero-one loss on all datasets are respectively {NB(5.34), TAN(4.53), AODE(3.73), KDB(4.20), MKDB(4.00), MSKDB(3.83), MMKDB(2.39)}. That is, the ranking of MMKDB is better than that of other algorithms, followed by AODE, MSKB, MKDB, KDB, TAN and NB.
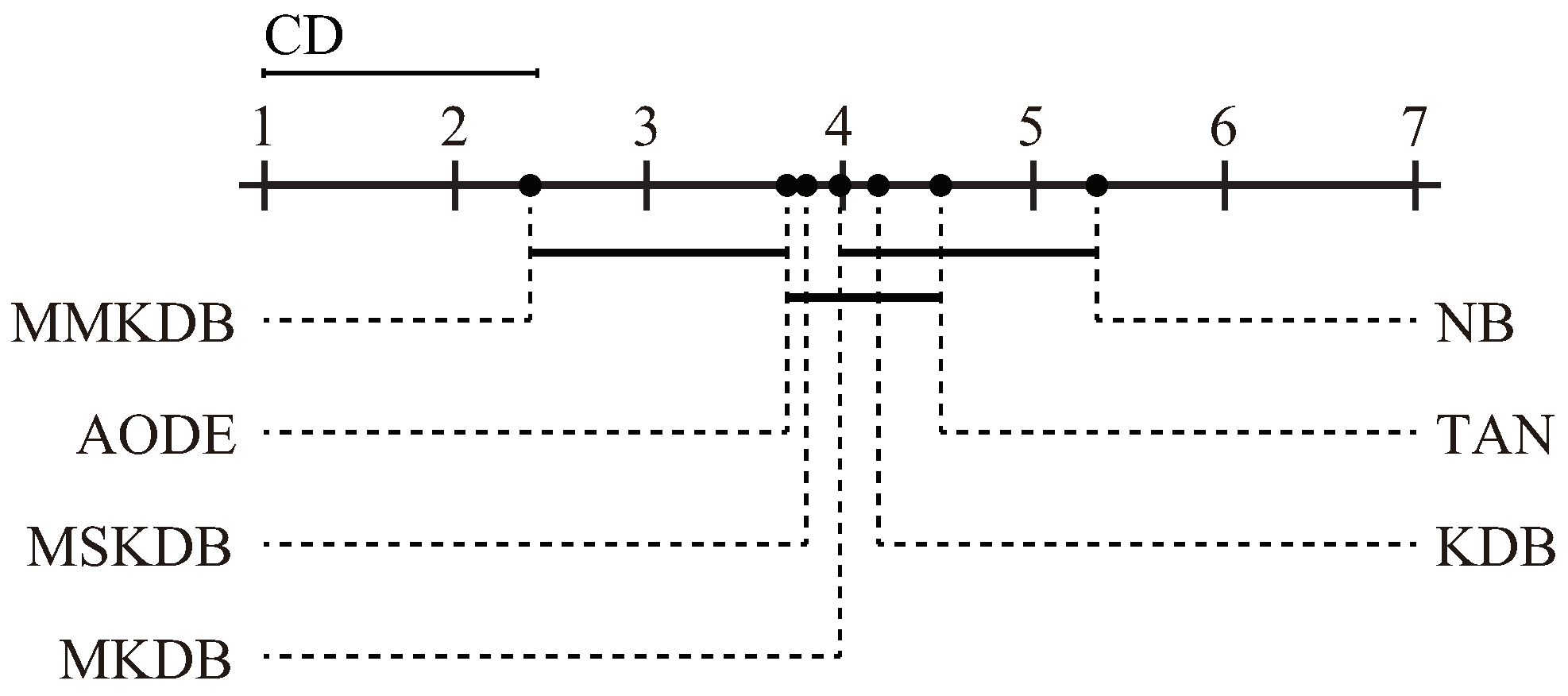
In order to further explore which algorithm is significantly different to others, we also perform the Nemenyi test [
29] shown in
Figure 14. The algorithms are plotted on the dotted line on the basis of their average ranks, which are corresponding to the nodes on the top solid line. Critical Difference (CD) is also shown in the figure. The value of CD is calculated as follow:
where the critical value
for
and
is 2.949. For
with 7 algorithms and 40 datasets, CD =
. It is worthwhile to note that, the more leftward the position of algorithms on the black line, the lower the rank will be, and hence the better the performance. The algorithms are connected by a line if their differences are not significant. As the figure shows, NB, TAN, KDB and MKDB have equivalent mean rank. The mean rank of MMKDB is significantly lower than those of NB, TAN, KDB, MKDB and MSKDB. MMKDB also achieves lower mean ranks than AODE, but not significantly so.
5. Conclusions
KDB is a famous BNC with the capacity of high dependence representation. To achieve the trade-off between structure complexity and classification accuracy, KDB allows to represent different number of interdependencies for different data sizes. The mRMR analysis and discriminative model selection have both previously been demonstrated to be computationally efficient approaches, the former improves the feature selection method and the latter improves the classification error of KDB. However, on the one hand, the mRMR analysis has not been studied in the context of KDB, and on the other hand, the discriminative model selection still can be improved more, such as removing the redundant dependencies in a BNC. Therefore, in this paper, we investigate the feasibility of applying discriminative model selection to remove redundant features and dependencies, and the interoperability of mRMR analysis and discriminative model selection.
Regular KDB utilizes mutual information between features and class variable to rank and sort all features first. Obviously, some independent features with high mutual information value may achieve higher rank but demonstrate weak conditional dependencies. However, the use of mRMR analysis makes up for this shortcoming. Moreover, KDB does not consider the negative effect caused by redundant features, which may bias the classification results. We use the discriminative model selection to achieve the aim of removing the redundant features and arcs in the Bayesian network.
We conduct experiments on 40 UCI datasets to explore the impact of a sorting method based on the mRMR criterion and discriminative model selection. The advantages of MKDB and MSKDB over KDB in terms of zero-one loss, respectively, demonstrate that each technique can help reduce KDB’s classification error. The advantages of MMKDB over KDB, MKDB and MSKDB further demonstrate that the interoperability of these two techniques is feasible. That is, there is strong synergy between the mRMR analysis and discriminative model selection in KDB and they can operate in tandem to reduce the classification error of KDB more effectively than does either in isolation. The fitting curve of goal difference between MMKDB and KDB clarifies the superior performance of the MMKDB on datasets of different scales. MMKDB not only retains the privileges of KDB, i.e., the capacity of high dependence representation and the model fitting ability on large datasets, but also improves the model fitting ability on small and medium datasets and enhances the classification efficiency on large datasets. These two techniques help save about 42% of KDB’s classification time and greatly improve the classification performance of KDB. Besides, we also have compared MMKDB against other state-of-the-art BNCs, such as NB, TAN and AODE. The results demonstrate that MMKDB achieves significant advantages over NB and TAN on medium and large datasets, and over AODE on large datasets in terms of classification performance. We additionally conduct a set of focused tests for some significance analysis, such as the Friedman test and the Nemenyi test. The results showed that the mean rank of MMKDB is significantly lower than those of NB, TAN, KDB, MKDB and MSKDB. MMKDB also achieves lower mean rank than AODE, but not significantly so.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
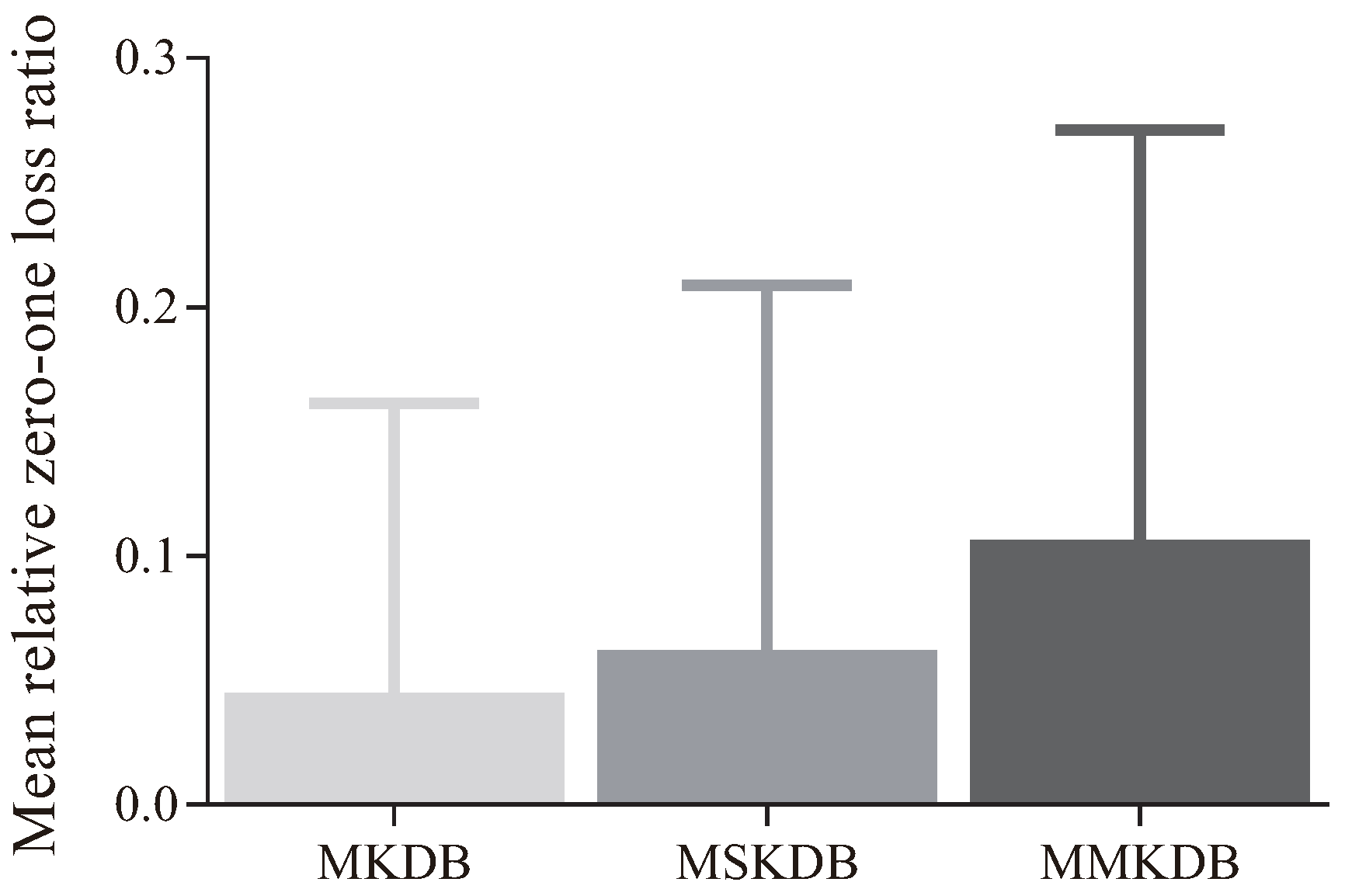{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













