Assessing the Relevance of Specific Response Features in the Neural Code


Abstract
1. Introduction
2. Results
2.1. Definitions
2.1.1. Statistical Notation
2.1.2. Encoding
2.1.3. Data Processing Inequalities
2.1.4. Decoding
2.1.5. Optimal Decoding
2.1.6. Extensions of Optimal Decoding
2.1.7. Approximations to Optimal Decoding
2.1.8. Two Different Decoding Strategies
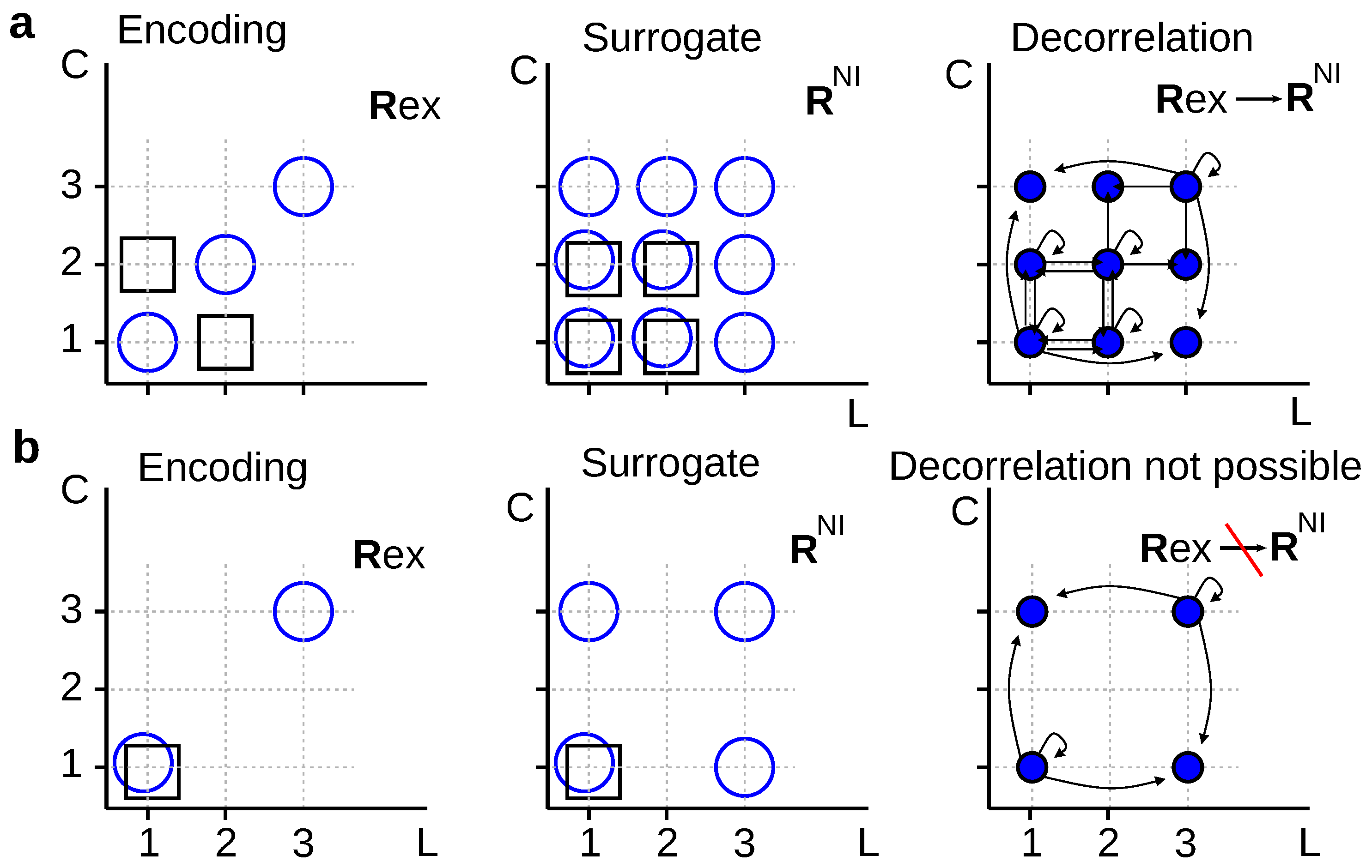
2.2. The Applicability of the Data-Processing Inequality
2.2.1. Reduced Representations
2.2.2. Stochastically Reduced Representations
2.2.3. Modification of the Conditional Response Probability Distribution
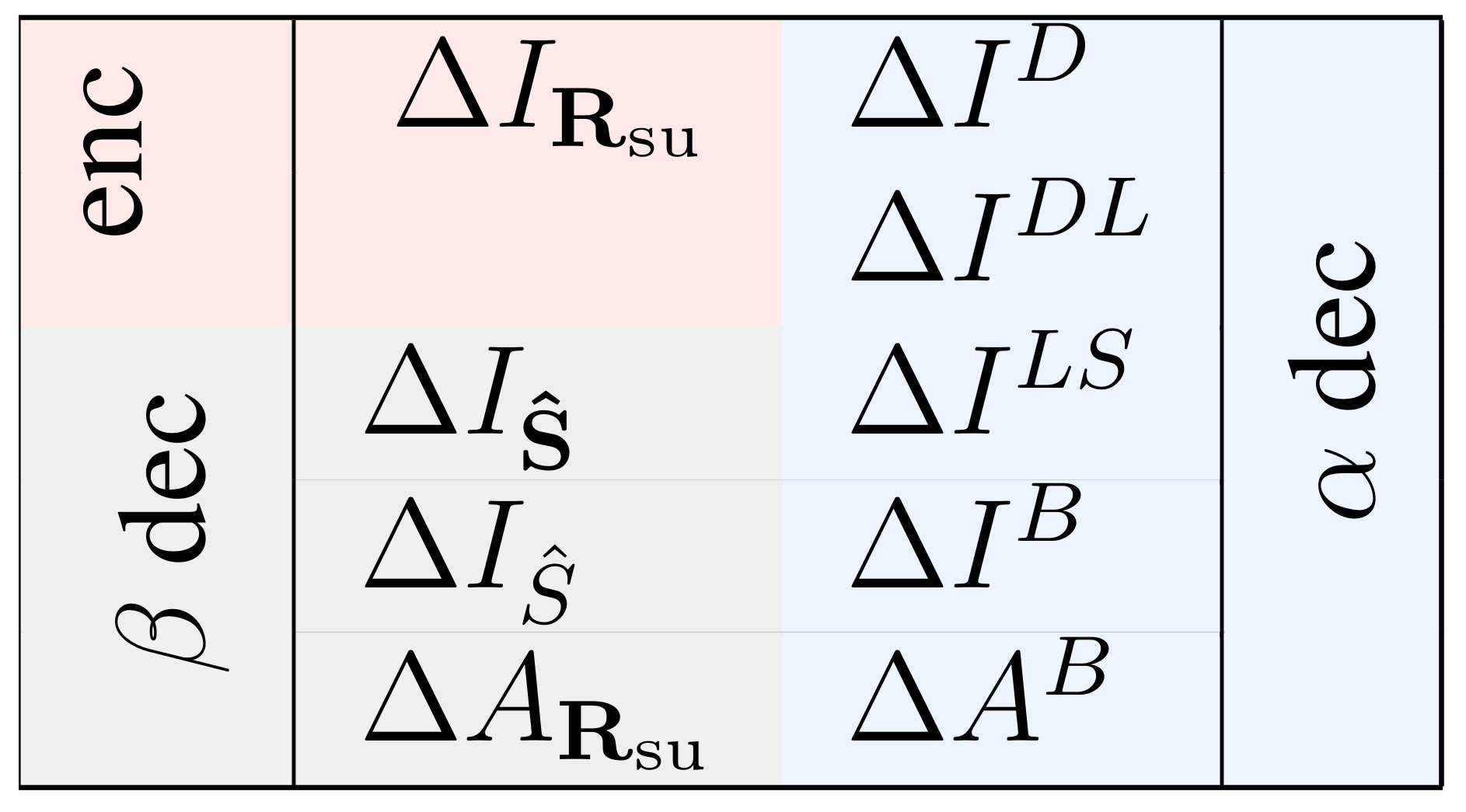
2.3. Multiple Measures to Assess the Relevance of a Specific Response Feature
2.4. Relating the Values Obtained with Different Measures
2.5. Relation between Measures Based on Decoding Strategies and
2.6. Assessing the Type of Information Encoded by Individual Response Features
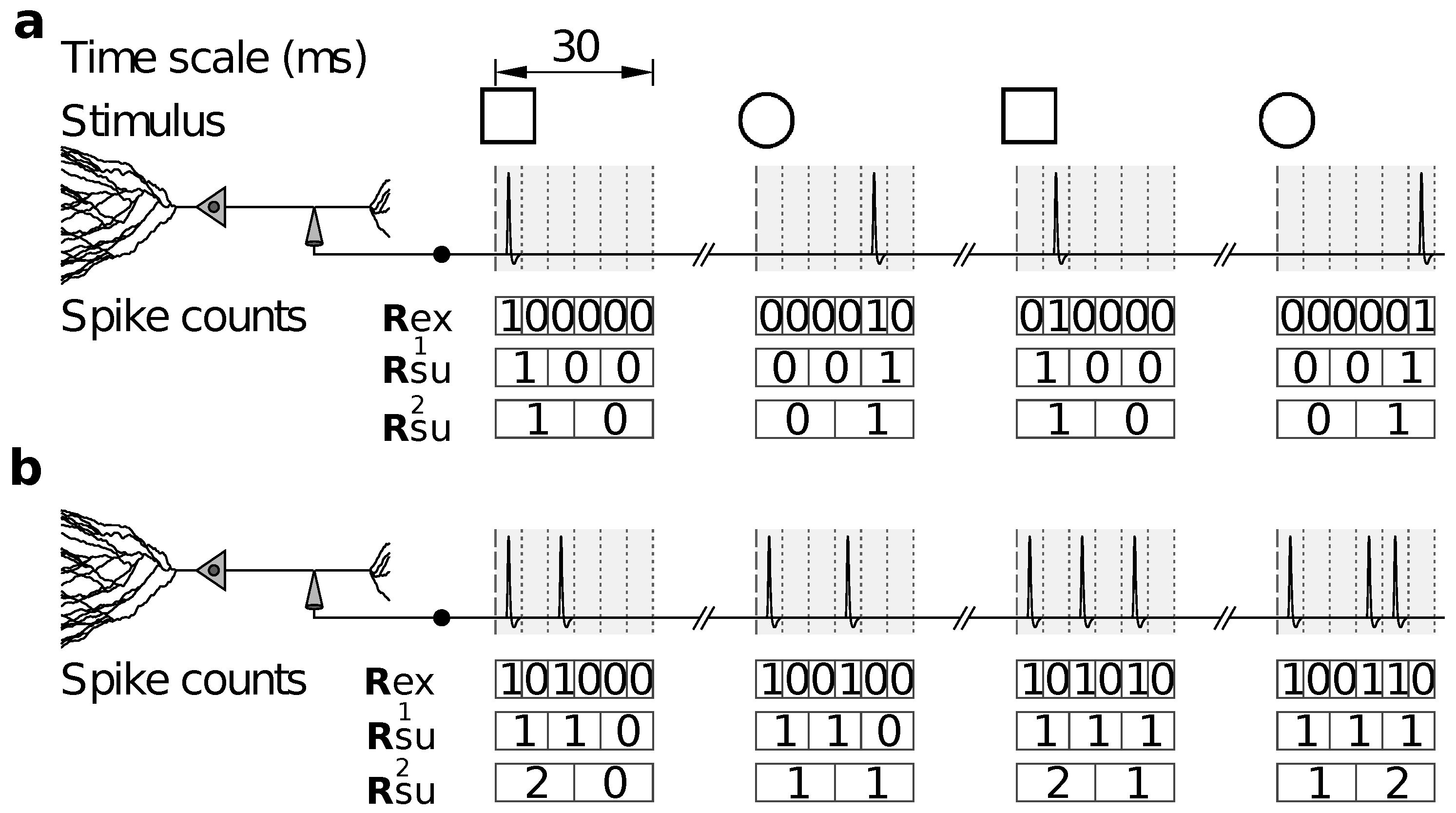
 , Ⓐ,
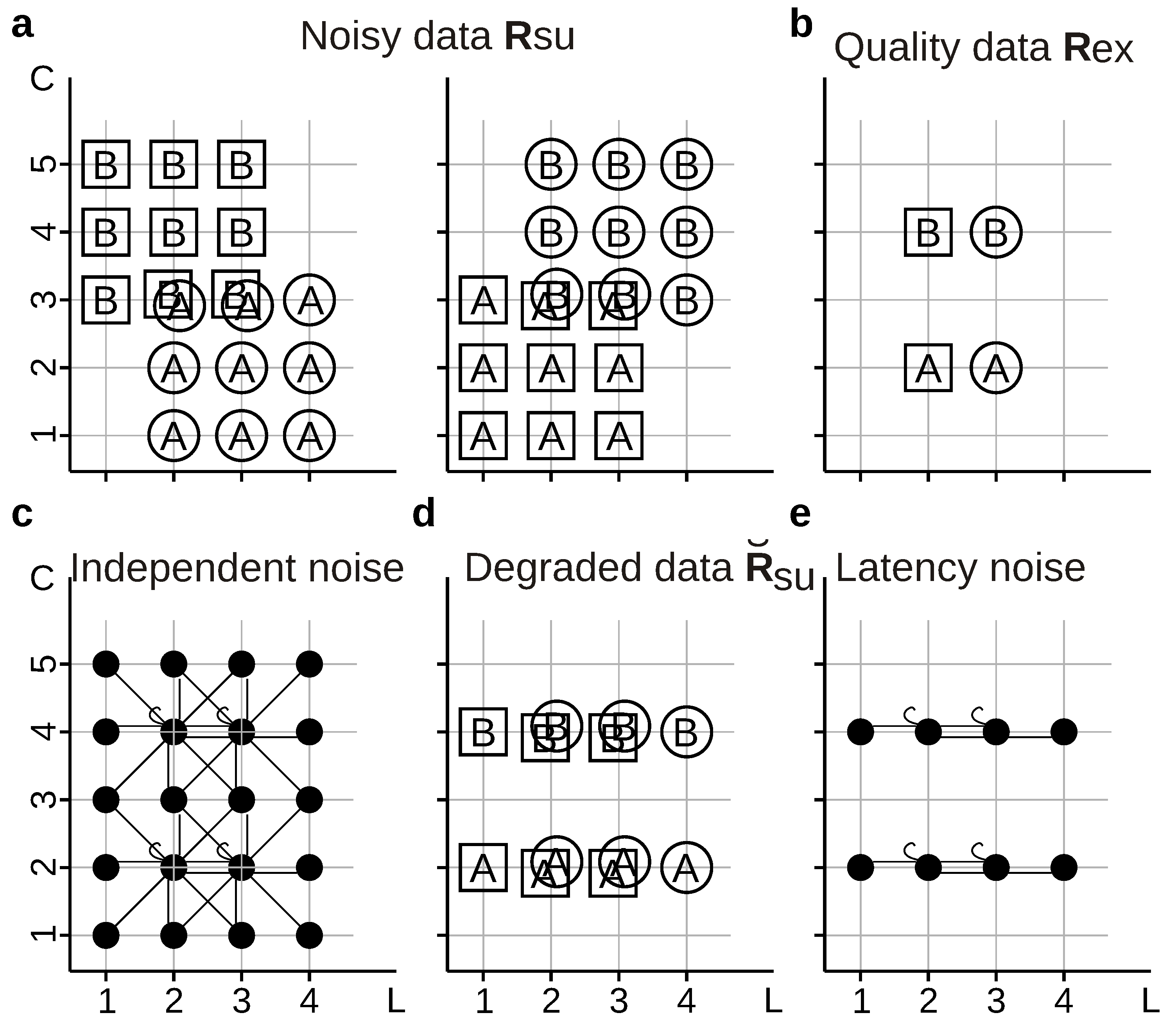
, Ⓐ,  , and Ⓑ. Stimuli are transformed into neural responses with different number of spikes () fired at different first-spike latencies (; time has been discretized in 5 ms bins). Latencies are only sensitive to frames whereas spikes counts are only sensitive to letters, thereby constituting independent-information streams: [33]. The equality in the numerical value of two measures does not imply that both measures assign the same meaning to the information encoded by the tested response feature. Indeed, the two measures may sometimes report the tested response feature to encode two different aspects of the set of stimuli. Consider a decoder that is trained using the noisy data shown in Figure 8a, but it is asked to operate on either the same noisy data with which it was trained (strategy ), or with the quality data of Figure 8b (strategy ). The information losses , , and are all equal to of . Therefore, the information loss is independent of whether, in the operation phase, the decoder is fed with responses generated with or with .
, and Ⓑ. Stimuli are transformed into neural responses with different number of spikes () fired at different first-spike latencies (; time has been discretized in 5 ms bins). Latencies are only sensitive to frames whereas spikes counts are only sensitive to letters, thereby constituting independent-information streams: [33]. The equality in the numerical value of two measures does not imply that both measures assign the same meaning to the information encoded by the tested response feature. Indeed, the two measures may sometimes report the tested response feature to encode two different aspects of the set of stimuli. Consider a decoder that is trained using the noisy data shown in Figure 8a, but it is asked to operate on either the same noisy data with which it was trained (strategy ), or with the quality data of Figure 8b (strategy ). The information losses , , and are all equal to of . Therefore, the information loss is independent of whether, in the operation phase, the decoder is fed with responses generated with or with .2.7. Conditions for Equality of the Amount and Type of Information Loss Reported by Different Measures
2.8. Improving the Performance of Decoders Operating with Strategy
3. Related Issues
3.1. Relation to Decomposition-Based Methods
- -
- First, the measure quantifies the relevance of a given feature with the difference . When the surrogate response is equal to the original response with just a single component eliminated, is equal to , where is the collection of all response aspects except . In this case, coincides with the sum of the unique and the synergistic contributions of the dual decompositions in the newest set of methods [63].
- -
- Second, when assessing the relevance of a given response feature, we are often inclined to draw conclusions about the cost of ignoring the tested feature when aiming to decode the original stimulus. As shown in this paper, those conclusions depend not only on how stimuli are encoded, but also, on how they are decoded. The decomposition-based methods are mainly focused in the encoding problem, so they are less suited to draw conclusions about decoding.
- -
- Finally, as discussed in Figure 8, not only the amount of (encoded or decoded) information matters, but also, what type. Decomposition-based methods, although not yet reaching a full consensus in their formulation, provide a valuable attempt to characterize how both the type and the amount of information is structured within the set of analyzed variables, in a way that is complementary to the present approach, specifically in analyzing the structure of the lattices obtained by associating different response features [58,63].
3.2. The Problem of Limited Sampling
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. On the Information and Accuracy Differences
Appendix B. Proofs
Appendix B.1. Derivation of Equation (30)
Appendix B.2. Proof of Theorem 1
Appendix B.3. Proof of Theorem 2
Appendix B.4. Proof of Theorem 3
Appendix B.5. Proof of Theorem 4
Appendix B.6. Proof of Theorem 5
Appendix C. On the Computation of ΔID
References
- Adrian, E.D. The impulses produced by sensory nerve endings. J. Physiol. 1926, 61, 49–72. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurones in the cat’s striate cortex. J. Physiol. 1959, 148, 173–180. [Google Scholar] [CrossRef]
- Thorpe, S.; Fize, D.; Marlot, C. Speed of processing in the human visual system. Nature 1996, 6582, 520–522. [Google Scholar] [CrossRef] [PubMed]
- Abeles, M. Corticonix: Neural Circuits of the Cerebral Cortex; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Gray, C.M.; König, P.; Engel, A.K.; Singer, W. Oscillatory responses in cat visual cortex exhibit inter-columnar synchronization which reflects global stimulus properties. Nature 1989, 6213, 334–337. [Google Scholar] [CrossRef] [PubMed]
- Franke, F.; Fiscella, M.; Sevelev, M.; Roska, B.; Hierlemann, A.; da Silveira, R.A. Structures of Neural Correlation and How They Favor Coding. Neuron 2016, 89, 409–422. [Google Scholar] [CrossRef] [PubMed]
- O’Keefe, J. Hippocampues, theta, and spatial memory. Curr. Opin. Neurobiol. 1993, 6, 917–924. [Google Scholar] [CrossRef]
- Nirenberg, S.; Carcieri, S.M.; Jacobs, A.L.; Latham, P.E. Retinal ganglion cells act largely as independent encoders. Nature 2001, 411, 698–701. [Google Scholar] [CrossRef] [PubMed]
- Schneidman, E.; Bialek, W.; Berry, M.J. Synergy, redundancy, and independence in population codes. J. Neurosci. 2003, 23, 11539–11553. [Google Scholar] [CrossRef] [PubMed]
- Nirenberg, S.; Latham, P.E. Decoding neuronal spike trains: How important are correlations? Proc. Natl. Acad. Sci. USA 2003, 100, 7348–7353. [Google Scholar] [CrossRef] [PubMed]
- Latham, P.E.; Nirenberg, S. Synergy, redundancy, and independence in population codes, revisited. J. Neurosci. 2005, 25, 5195–5206. [Google Scholar] [CrossRef] [PubMed]
- Quiroga, R.Q.; Panzeri, S. Extracting information from neuronal populations: Information theory and decoding approaches. Nat. Rev. Neurosci. 2009, 10, 173–185. [Google Scholar] [CrossRef] [PubMed]
- Latham, P.E.; Roudi, Y. Role of correlations in population coding. In Principles of Neural Coding; Panzeri, S., Quian Quiroga, R., Eds.; CRC Press: Boca Raton, FL, USA, 2013; Chapter 7; pp. 121–138. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference, 2nd ed.; Duxbury Press: Duxbury, MA, USA, 2002. [Google Scholar]
- Panzeri, S.; Brunel, N.; Logothetis, N.K.; Kayser, C. Sensory neural codes using multiplexed temporal scales. Trends Neurosci. 2010, 33, 111–120. [Google Scholar] [CrossRef] [PubMed]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: New York, NY, USA, 2006. [Google Scholar]
- Eyherabide, H.G.; Samengo, I. When and why noise correlations are important in neural decoding. J. Neurosci. 2013, 33, 17921–17936. [Google Scholar] [CrossRef] [PubMed]
- Knill, D.C.; Pouget, A. The Bayesian brain: The role of uncertainty in neural coding and computation. Trends Neurosci. 2004, 27, 712–719. [Google Scholar] [CrossRef] [PubMed]
- Van Bergen, R.S.; Ma, W.J.; Pratte, M.S.; Jehee, J.F.M. Sensory uncertainty decoded from visual cortex predicts behavior. Nat. Neurosci. 2015, 18, 1728–1730. [Google Scholar] [CrossRef] [PubMed]
- Ince, R.A.A.; Senatore, R.; Arabzadeh, E.; Montani, F.; Diamond, M.E.; Panzeri, S. Information-theoretic methods for studying population codes. Neural Netw. 2010, 23, 713–727. [Google Scholar] [CrossRef] [PubMed]
- Reinagel, P.; Reid, R.C. Temporal coding of visual information in the thalamus. J. Neurosci. 2000, 20, 5392–5400. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Petersen, R.S.; Schultz, S.R.; Lebedev, M.; Diamond, M.E. The Role of Spike Timing in the Coding of Stimulus Location in Rat Somatosensory Cortex. Neuron 2001, 29, 769–777. [Google Scholar] [CrossRef]
- Rokem, A.; Watzl, S.; Gollisch, T.; Stemmler, M.; Herz, A.V.M.; Samengo, I. Spike-timing precision underlies the coding efficiency of auditory receptor neurons. J. Neurophysiol. 2006, 95, 2541–2552. [Google Scholar] [CrossRef] [PubMed]
- Lefebvre, J.L.; Zhang, Y.; Meister, M.; Wang, X.; Sanes, J.R. γ-Protocadherins regulate neuronal survival but are dispensable for circuit formation in retina. Development 2008, 135, 4141–4151. [Google Scholar] [CrossRef] [PubMed]
- Victor, J.D.; Purpura, K.P. Nature and precision of temporal coding in visual cortex: A metric-space analysis. J. Neurophysiol. 1996, 76, 1310–1326. [Google Scholar] [CrossRef] [PubMed]
- Victor, J.D. Spike train metrics. Curr. Opin. Neurobiol. 2005, 15, 585–592. [Google Scholar] [CrossRef] [PubMed]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Fano, R.M. Transmission of Information; The MIT Press: Cambridge, MA, USA, 1961. [Google Scholar]
- DeWeese, M.R.; Meister, M. How to measure the information gained from one symbol. Netw. Comput. Neural Syst. 1999, 10, 325–340. [Google Scholar] [CrossRef]
- Eyherabide, H.G.; Samengo, I. Time and category information in pattern-based codes. Front. Comput. Neurosci. 2010, 4, 145. [Google Scholar] [CrossRef] [PubMed]
- Eckhorn, R.; Pöpel, B. Rigorous and extended application of information theory to the afferent visual system of the cat. I. Basic concepts. Kybernetik 1974, 16, 191–200. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Treves, A. Analytical estimates of limited sampling biases in different information measures. Network 1996, 7, 87–107. [Google Scholar] [CrossRef] [PubMed]
- Eyherabide, H.G. Disambiguating the role of noise correlations when decoding neural populations together. arXiv, 2016; arXiv:1608.05501. [Google Scholar]
- MacKay, D.M.; McCulloch, W.S. The limiting information capacity of a neuronal link. Bull. Math. Biophys. 1952, 14, 127–135. [Google Scholar] [CrossRef]
- Fitzhugh, R. The statistical detection of threshold signals in the retina. J. Gen. Physiol. 1957, 40, 925–948. [Google Scholar] [CrossRef] [PubMed]
- Merhav, N.; Kaplan, G.; Lapidoth, A.; Shamai Shitz, S. On information rates for mismatched decoders. IEEE Trans. Inf. Theory 1994, 40, 1953–1967. [Google Scholar] [CrossRef]
- Oizumi, M.; Ishii, T.; Ishibashi, K.; Hosoya, T.; Okada, M. A general framework for investigating how far the decoding process in the brain can be simplified. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2009; pp. 1225–1232. [Google Scholar]
- Oizumi, M.; Ishii, T.; Ishibashi, K.; Hosoya, T.; Okada, M. Mismatched decoding in the brain. J. Neurosci. 2010, 30, 4815–4826. [Google Scholar] [CrossRef] [PubMed]
- Oizumi, M.; Amari, S.I.; Yanagawa, T.; Fujii, N.; Tsuchiya, N. Measuring Integrated Information from the Decoding Perspective. PLoS Comput. Biol. 2016, 12, e1004654. [Google Scholar] [CrossRef] [PubMed]
- Gochin, P.M.; Colombo, M.; Dorfman, G.A.; Gerstein, G.L.; Gross, C.G. Neural ensemble coding in inferior temporal cortex. J. Neurophysiol. 1994, 71, 2325–2337. [Google Scholar] [CrossRef] [PubMed]
- Warland, D.K.; Reinagel, P.; Meister, M. Decoding visual information from a population of retinal ganglion cells. J. Neurophysiol. 1997, 78, 2336–2350. [Google Scholar] [CrossRef] [PubMed]
- Optican, L.M.; Richmond, B.J. Temporal encoding of two-dimensional patterns by single units in primate inferior temporal cortex. III. Information theoretic analysis. J. Neurophysiol. 1987, 57, 162–178. [Google Scholar] [CrossRef] [PubMed]
- Salinas, E.; Abbott, L.F. Transfer of coded information from sensory neurons to motor networks. J. Neurosci. 1995, 10, 6461–6476. [Google Scholar] [CrossRef]
- Geisler, W.S. Sequential ideal-observer analysis of visual discriminations. Psychol. Rev. 1989, 96, 267–314. [Google Scholar] [CrossRef] [PubMed]
- Högnäs, G.; Mukherjea, A. Probability Measures on Semigroups: Convolution Products, Random Walks and Random Matrices, 2nd ed.; Springer: New York, NY, USA, 2011. [Google Scholar]
- Samengo, I.; Treves, A. The information loss in an optimal maximum likelihood decoding. Neural Comput. 2002, 14, 771–779. [Google Scholar] [CrossRef] [PubMed]
- Shamir, M. Emerging principles of population coding: In search for the neural code. Curr. Opin. Neurobiol. 2014, 25, 140–148. [Google Scholar] [CrossRef] [PubMed]
- Gawne, T.J.; Richmond, B.J. How independent are the messages carried by adjacent inferior temporal cortical neurons? J. Neurosci. 1993, 13, 2758–2771. [Google Scholar] [CrossRef] [PubMed]
- Gollisch, T.; Meister, M. Rapid Neural Coding in the Retina with Relative Spike Latencies. Science 2008, 5866, 1108–1111. [Google Scholar] [CrossRef] [PubMed]
- Reifenstein, E.T.; Kemptner, R.; Schreiber, S.; Stemmler, M.B.; Herz, A.V.M. Grid cells in rat entorhinal cortex encode physical space with independent firing fields and phase precession at the single-trial level. Proc. Natl. Acad. Sci. USA 2012, 109, 6301–6306. [Google Scholar] [CrossRef] [PubMed]
- Park, H.J.; Friston, K. Nonlinear multivariate analysis of neurophysiological signals. Science 2013, 6158, 1238411. [Google Scholar] [CrossRef] [PubMed]
- Dahlhaus, R.; Eichler, M.; Sandkühler, J. Identification of synaptic connections in neural ensembles by graphical models. J. Neurosci. Methods 1997, 77, 93–107. [Google Scholar] [CrossRef]
- Panzeri, S.; Schultz, S.R.; Treves, A.; Rolls, E.T. Correlations and the encoding of information in the nervous system. Proc. R. Soc. B Biol. Sci. 1999, 266, 1001–1012. [Google Scholar] [CrossRef] [PubMed]
- Schultz, S.R.; Panzeri, S. Temporal Correlations and Neural Spike Train Entropy. Phys. Rev. Lett. 2001, 25, 5823–5826. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Schultz, S.R. A Unified Approach to the Study of Temporal, Correlational, and Rate Coding. Neural Comput. 2001, 13, 1311–1349. [Google Scholar] [CrossRef] [PubMed]
- Pola, G.; Thiele, A.; Hoffmann, K.P.; Panzeri, S. An exact method to quantify the information transmitted by different mechanisms of correlational coding. Network 2003, 14, 35–60. [Google Scholar] [CrossRef] [PubMed]
- Hernández, D.G.; Zanette, D.H.; Samengo, I. Information-theoretical analysis of the statistical dependencies between three variables: Applications to written language. Phys. Rev. E. 2015, 92, 022813. [Google Scholar] [CrossRef] [PubMed]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv, 2010; arXiv:1004.2515. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate Measure of Redundant Information. Phys. Rev. E. 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed]
- Griffith, V.; Koch, C. Quantifying Synergistic Mutual Information. In Guided Self-Organization: Inception; Prokopenko, M., Ed.; Springer: New York, NY, USA, 2014; Chapter 6; pp. 159–190. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Ince, R.A.A. Measuring Multivariate Redundant Information with Pointwise Common Change in Surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- Chicharro, D.; Panzeri, S. Synergy and Redundancy in Dual Decompositions of Mutual Information Gain and Information Loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Wolf, D.R. Estimating functions of probability distributions from a finite set of samples. Phys. Rev. E. 1996, 52, 6841–6973. [Google Scholar] [CrossRef]
- Samengo, I. Estimating probabilities from experimental frequencies. Phys. Rev. E 2002, 65, 046124. [Google Scholar] [CrossRef] [PubMed]
- Nemenman, I.; Bialek, W.; de Ruyter van Steveninck, R. Entropy and information in neural spike trains: Progress on the sampling problem. Phys. Rev. E. 2004, 69, 056111. [Google Scholar] [CrossRef] [PubMed]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 6, 1191–1253. [Google Scholar] [CrossRef]
- Panzeri, S.; Senatore, R.; Montemurro, M.A.; Petersen, R.S. Correcting for the sampling bias problem in spike train information measures. J. Neurophysiol. 2007, 98, 1064–1072. [Google Scholar] [CrossRef] [PubMed]
- Montemurro, M.A.; Senatore, R.; Panzeri, S. Tight data-robust bounds to mutual information combining shuffling and model selection techniques. Neural Comput. 2007, 11, 2913–2957. [Google Scholar] [CrossRef] [PubMed]





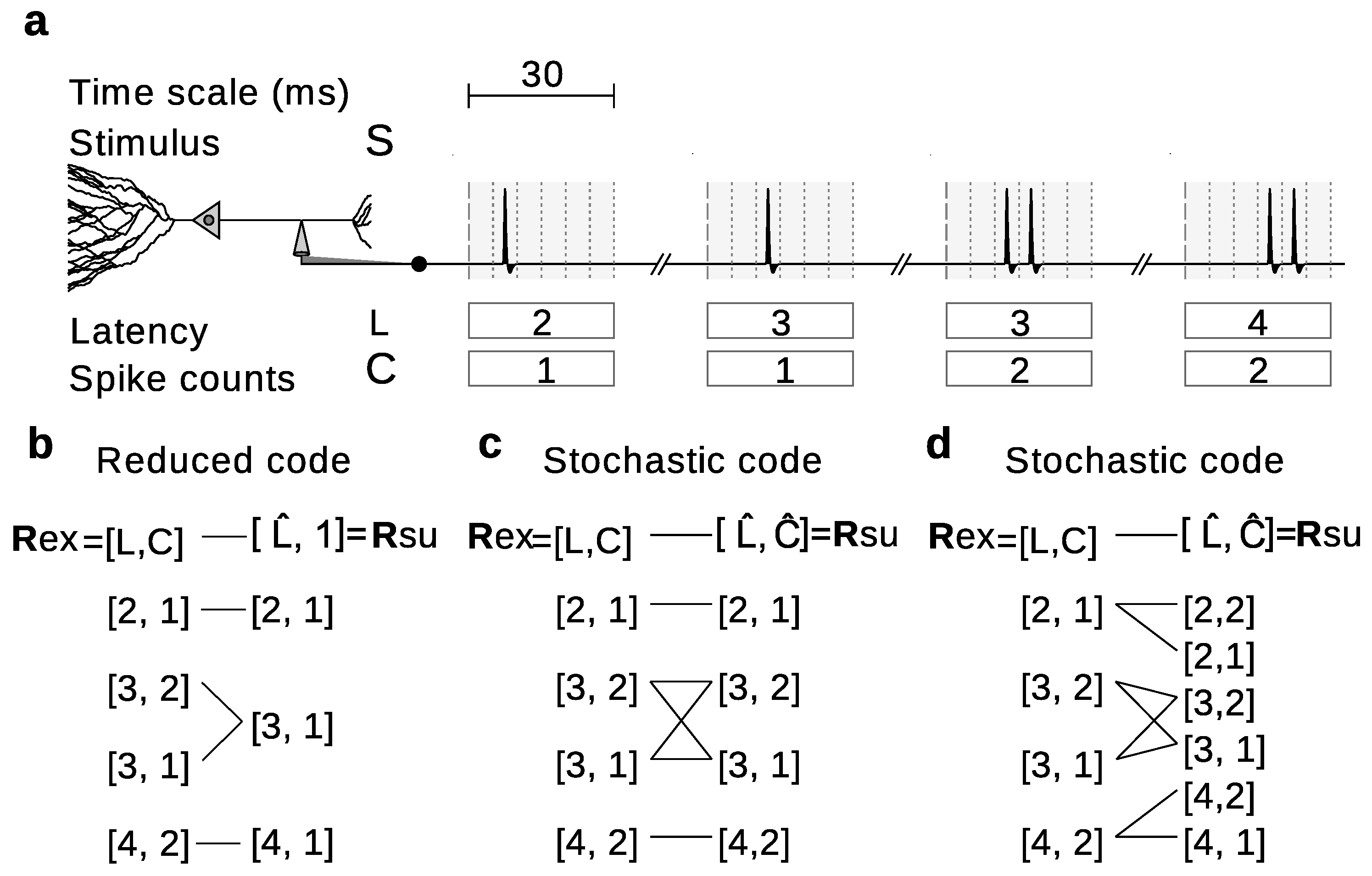
 , Ⓐ, , and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).
, Ⓐ, , and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).
, Ⓐ, , and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).
, Ⓐ, , and Ⓑ), and phases are measured with respect to a cycle of period and discretized in intervals of size . The encoding process is followed by a stochastic transformation (lines on the right) that introduces jitter, thereby transforming into another code with transition probabilities defined by Equation (32).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cases | Figure 4a | Figure 2b | Figure 2c | Figure 3d | Figure 2a | Figure 3b | Figure 7a | |
|---|---|---|---|---|---|---|---|---|
| min | −79 | −51 | −34 | 0 | 0 | — | ≤999 | |
| max | 26 | 32 | 51 | 0 | 0 | — | −20 | |
| min | −34 | −32 | −16 | 0 | 0 | −100 | −100 | |
| max | 59 | 41 | 98 | 0 | 0 | 0 | 0 | |
| min | −67 | −62 | −46 | −63 | −87 | — | −100 | |
| max | 57 | 81 | 96 | 0 | 0 | — | 0 | |
| min | −79 | −48 | −34 | 0 | 0 | — | ≤999 | |
| max | 67 | 92 | 93 | 63 | 87 | — | 70 | |
| min | −34 | −27 | −16 | 0 | 0 | −100 | −100 | |
| max | 91 | 92 | 99 | 63 | 87 | 0 | 97 | |
| min | −51 | −31 | −17 | 0 | 0 | — | −100 | |
| max | 59 | 91 | 98 | 0 | 0 | — | 100 | |
| min | −386 | −200 | −150 | 0 | 0 | — | ≤999 | |
| max | 95 | 67 | 100 | 0 | 0 | — | 0 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eyherabide, H.G.; Samengo, I. Assessing the Relevance of Specific Response Features in the Neural Code. Entropy 2018, 20, 879. https://doi.org/10.3390/e20110879
Eyherabide HG, Samengo I. Assessing the Relevance of Specific Response Features in the Neural Code. Entropy. 2018; 20(11):879. https://doi.org/10.3390/e20110879
Chicago/Turabian StyleEyherabide, Hugo Gabriel, and Inés Samengo. 2018. "Assessing the Relevance of Specific Response Features in the Neural Code" Entropy 20, no. 11: 879. https://doi.org/10.3390/e20110879
APA StyleEyherabide, H. G., & Samengo, I. (2018). Assessing the Relevance of Specific Response Features in the Neural Code. Entropy, 20(11), 879. https://doi.org/10.3390/e20110879