1. Introduction
Biometric identifiers, such as fingerprints, iris and retina scans, are becoming increasingly attractive for the use in security systems because of their uniqueness and time invariant characteristics—for example, in authentication and identification systems. Conventional personal authentication systems usually use secret passwords or physical tokens to guarantee the legitimacy of a person. On the other hand, biometric authentication systems use the physical characteristics of a person to guarantee the legitimacy of the person to be authenticated.
Biometric authentication systems are decomposed into two phases: the enrollment and the authentication phase. A simple authentication approach is to gather biometric measurements in the enrollment phase, apply a one-way function and then store the results in a public database. In the authentication phase, new biometric measurements are gathered. The same one-way is applied and the outcome is then compared to the one stored in the database. Unfortunately, biometric measurements might be affected by noise. To deal with noisy data, error correction is needed. Therefore, helper data is generated during the enrollment phase as well based on the biometric measurements and then stored directly in the public database that will be then used in the authentication phase, which will then be used in the authentication phase to correct the noisy imperfections of the measurements.
Since the database containing the helper data is public, an eavesdropper can have access to the data if desired. How can we prevent an eavesdropper from gaining information about the biometric data from the publicly stored helper data? One is interested in encoding the biometric data into a helper data and a secret key such that the helper data does not reveal any information about the secret key. Cryptographic techniques are one approach to keeping the key secret. However, security on higher layers is usually based on the assumption of insufficient computational capabilities of eavesdroppers. Information theoretic security, on the contrary, uses the physical properties of the source to guarantee security independent from the computational capabilities of the adversary. This line of research was initiated by Shannon in [
1] and has attracted considerable interest recently—cf., for example, recent textbooks [
2,
3,
4] and references therein. In particular, Ahlswede and Csiszár in [
5] and Maurer in [
6] introduced a secret key sharing model. It consists of two terminals that observe the correlated sequences of a joint source. Both terminals generate a common key based on their observation and using public communication. The message transmitted over the public channel should not leak any amount of information about the common key.
Both works mentioned above use the weak secrecy condition as a measure of secrecy. Given a code of a certain blocklength, the weak secrecy condition is fulfilled if the mutual information between the key and the available information at the eavesdropper normalized by the code blocklength is arbitrarily small for large blocklengths. On the other hand, the strong secrecy condition is fulfilled if the un-normalized mutual information between the key and the available information at the eavesdropper is arbitrarily small for large blocklengths, i.e., the total amount of information leaked to the eavesdropper is negligible. The secret key sharing model satisfying the strong secrecy condition has been studied in [
7].
One could model the biometric authentication similar to this secret key generation source model; however, this model does not take into account the amount of information that the public data (the helper data in the biometric scenario) leaks about the biometric measurement. The goal of biometric authentication is to perform a secret and successful authentication procedure without compromising the information about the user (privacy leakage). Compromised biometric information is unique and cannot be replaced, so once it is compromised, it is compromised forever, which might lead to an identity theft (see [
8,
9,
10] for more information on privacy concerns). Since the helper data we use to deal with noisy data is a function of the biometric measurements, it contains information about the biometric measurement. Thus, if an attacker breaks into the data base, he could be able to extract information about the biometric measurement from where the helper data is stored. Hence, we aim to control the privacy leakage as well. An information theoretic approach of secure biometric authentication controlling the privacy leakage was studied in [
11,
12] under ideal conditions, i.e., with perfect source state information (SSI) and without the presence of active attackers.
In both references [
11,
12], the capacity results under the weak secrecy condition were derived. In [
13], the capacity result for the sequential key-distillation with rate limited one-way public communication using the strong secrecy condition was shown.
For reliable authentication, SSI is needed; however, in practical systems, it is never perfectly available. Compound sources model a simple and realistic SSI scenario in which the legitimate users are not aware of the actual source realisation. Nevertheless, they know that it belongs to a known uncertainty set of sources and that it remains constant during the entire observation. This model was first introduced and studied in [
14,
15] in a channel coding context. Compound sources can also model the presence of an active attacker, who is able to control the state of the source. We are interested in performing an authentication process that is robust against such uncertainties and attacks. The secret key generation for source uncertainty was studied in [
16,
17,
18,
19]. In [
16], the secret key generation using compound joint sources was studied and the key-capacity was established.
In [
20], the achievability result of the privacy secrecy capacity region for generated secret keys for compound sources has been derived under the weak secrecy condition. In this work, we study robust biometric authentication in detail and extend this result in several directions. First, we consider a model where the legitimate users suffer from source uncertainty and/or attacks and derive achievability results under the strong secrecy conditions for both the generated and chosen secret key authentication. We then provide matching converses to obtain single-letter characterizations of the corresponding privacy secrecy capacity regions.
We further address the following question: can small changes of the compound source cause large changes in the privacy secrecy capacity region? Such a question has been first studied in [
21] for arbitrarily varying quantum channels (AVQCs) showing that deterministic capacity has discontinuity points, while the randomness-assisted capacity is a continuous function of the AVQCs. This line of research is continued in [
22,
23], in which the classical compound wiretap channel, the arbitrarily varying wiretap channel (AVWC), and the compound broadcast channel with confidential messages (BCC) are studied. We study this for the biometric authentication problem at hand and show that the corresponding privacy secrecy capacity regions are continuous functions of the underlying uncertainty sets. Thus, small changes in the compound set lead to small changes in the capacity region only.
The rest of this paper is organized as follows. In
Section 2, we introduce the biometric authentication model for perfect SSI and present the corresponding capacity results. In
Section 3, we introduce the biometric authentication model for compound sources and show that secure, under the strong secrecy condition, and reliable authentication, under source uncertainty with positive rates, is possible deriving a single-letter characterization of the privacy secrecy capacity region for the chosen and generated secret key model. In
Section 4, we show that the privacy secrecy capacity region for compound sources is a continuous function of the uncertainty set. Finally, the paper ends with a conclusion in
Section 5.
Notation: Discrete random variables are denoted by capital letters and their realizations and ranges by lower case and script letters. denotes the set of all probability distributions on ; denotes the expectation of a random variable; , and indicate the probability, the entropy of a random variable, and mutual information between two random variables; is the information divergence; is the total variation distance between p and q on defined as . The set denotes the set of typical sequences of length n with respect to the distribution p; the set denotes the set of conditional typical sequences with respect to the conditional distribution and sequence ; denotes the empirical distribution of the sequence .
2. Information Theoretic Model for Biometric Authentication
Let and be two finite alphabets. Let be a pair of biometric sequences of length ; then, the discrete memoryless joint-source is given by the joint probability distribution . This models perfect SSI, i.e., all possible measurements are generated by the discrete memoryless joint-source source Q, which is perfectly known at both the enrollment and the authentication terminal.
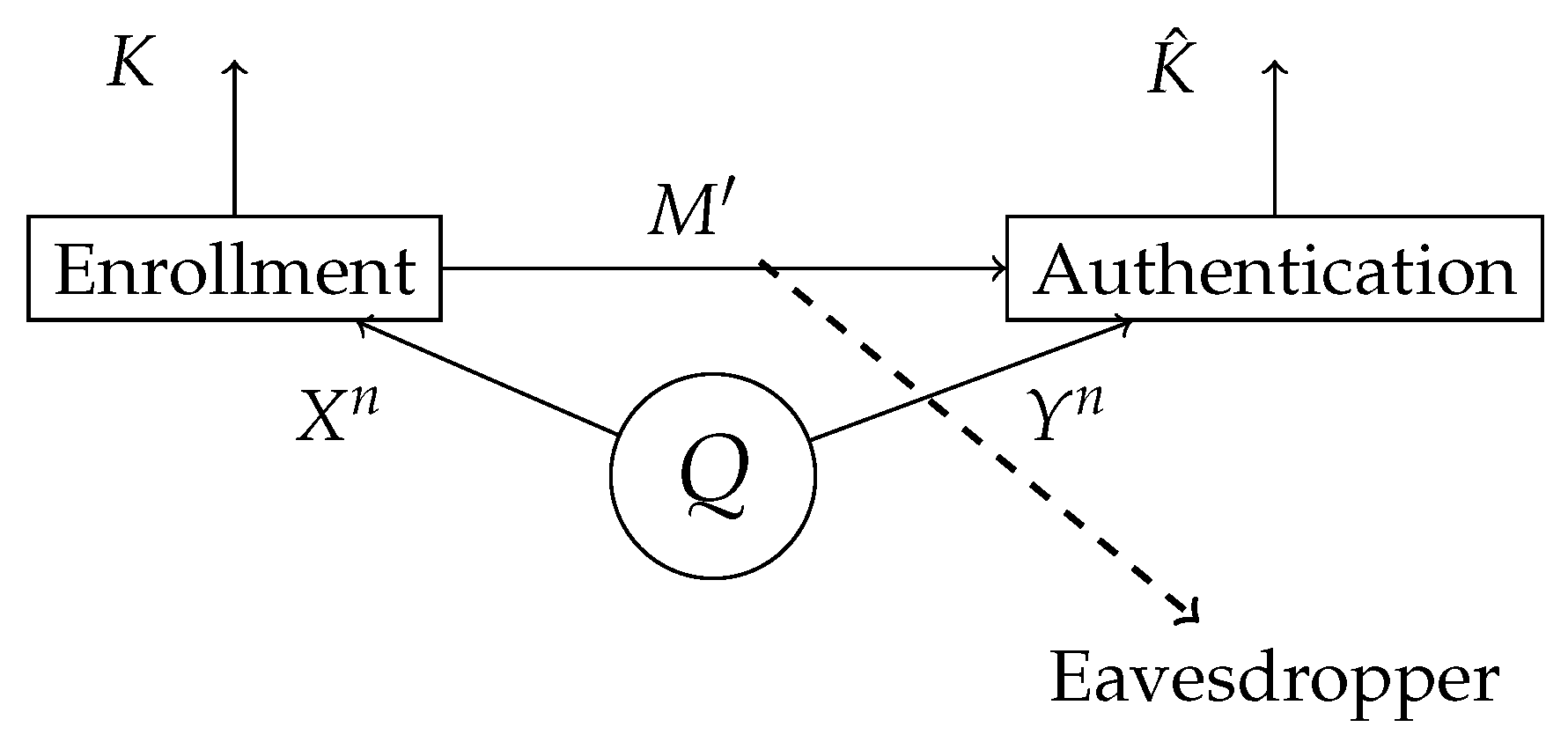
2.1. Generated Secret Key Model
The information theoretic authentication model consists of a discrete memoryless joint-source
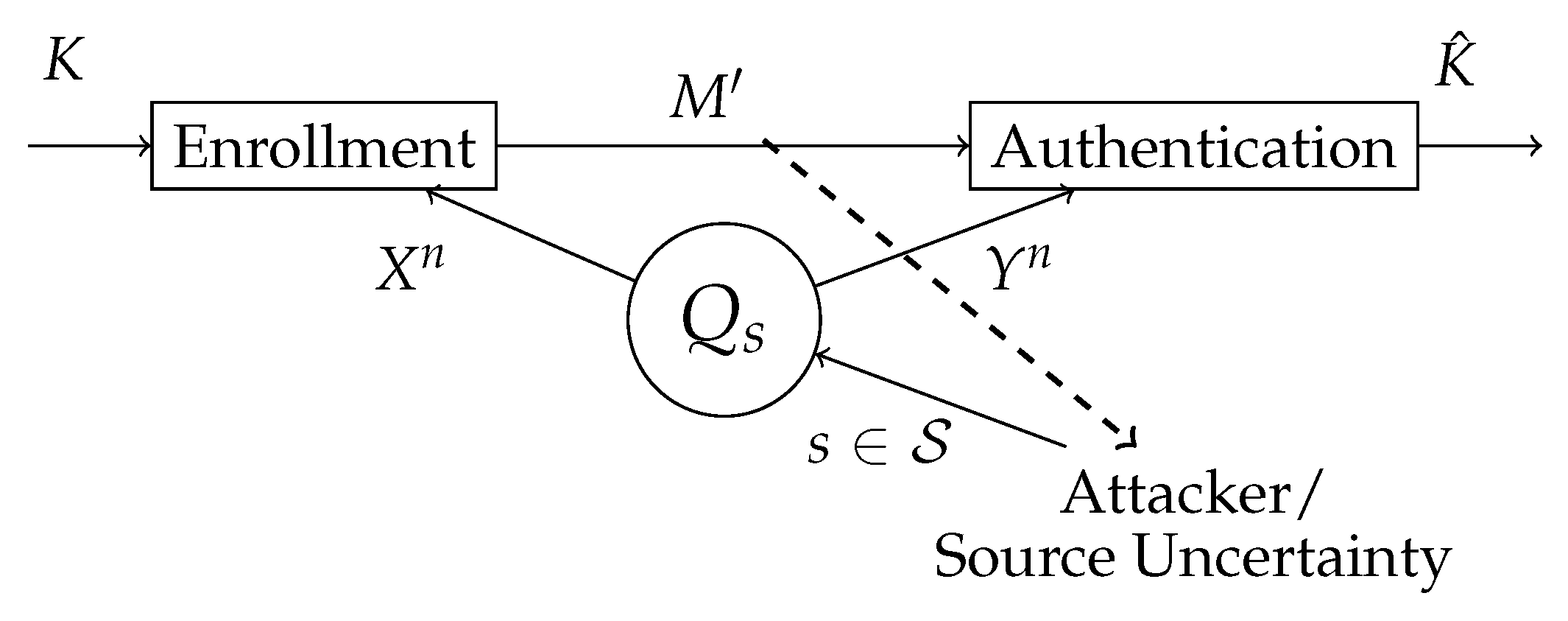
Q, which represents the biometric measurement source, and two terminals: the enrollment terminal and the authentication terminal as shown in
Figure 1. At the enrollment terminal, the enrollment sequence
is observed and the secret key
K and helper data
are generated. At the authentication terminal, the authentication sequence
is observed. An estimate of the secret key
is made based on the authentication sequence
and the helper data
. Since the helper data is stored in a public database, this should not reveal anything about the secret key
K and also as little as possible about the enrollment measurement
. The distribution of the key must be close to uniform.
We consider a block-processing of arbitrary but fixed length n. Let be the helper data set and the secret key set.
Definition 1. An -code for generated secret key authentication for joint-source consists of an encoder f at the enrollment terminal withand a decoder ϕ at the authentication terminal Remark 1. Note that the function f means that every is mapped into a , which implies that .
Definition 2. A privacy secrecy rate pair is called achievable for the generated secret key authentication for a joint-source Q, if, for any there exist an and a sequence of -codes such that, for all we have Remark 2. Condition (
1b)
requires the key distribution to be close to the uniform distribution , where is a random variable uniformly distributed over the key set . By (
1b)
, we have ; combined with Pinsker’s inequality, we have . For small δ, we have that both distributions are close to each other. Remark 3. Condition (
1a)
stands for reliable authentication, the information about the key leaked by the helper data is negligible by (
1c)
and the information about the biometric measurements leaked by the helper data is close to by (
1d)
. Definition 3. The set of all achievable privacy secrecy rate pairs for generated key authentication is called privacy secrecy capacity region and is denoted by .
We next present the privacy secrecy capacity region for the generated key authentication for the joint-source
Q, which was first established in [
11,
12].
To do so, for some
U with alphabet
and
, we define the region
as the set of all
satisfying
with
.
Theorem 1 [
11,
12]
. The privacy secrecy capacity region for generated key authentication is given by 2.2. Chosen Secret Key Model
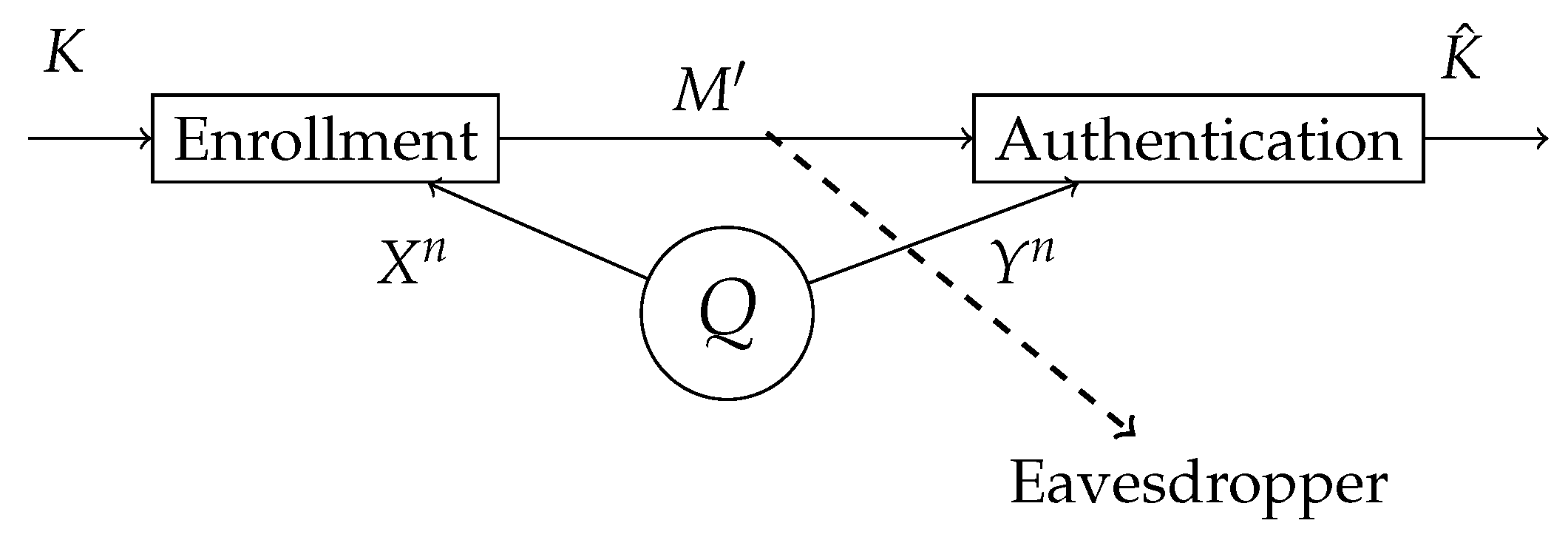
In this section, we study the authentication model for systems for which the secret key is chosen beforehand. At the enrollment terminal, a secret key
K is chosen uniformly and independent of the biometric measurements. The secret key
K is bound to the biometric measurements
and, based on this, the helper data
is generated as shown in
Figure 2. At the authentication terminal, the authentication measurement
is observed. An estimate of the secret key
is made based on the authentication sequence
and the helper data
. Since the helper data is stored in a public database, this should not reveal anything about the secret key and minimize the information leakage about the enrollment sequence
. However, we should be able to reconstruct
K. To achieve this, a masking layer based on the one-time pad principles is used.
The masking layer, which is another uniformly distributed chosen secret key K, is added to the top of the generated secret key authentication. At the enrollment terminal, a secret key and a helper data M are generated. The generated secret key is added modulo- to the masking layer K and sent together with the helper data as additional helper data, i.e., . At the authentication terminal, an estimation of the generated secret key is made based on and M and the estimation of masking layer is made .
We consider a block-processing of arbitrary but fixed length n. Let be the helper data set and the secret key set.
Definition 4. An -code for chosen secret key authentication for joint-source consists of an encoder f at the enrollment terminal withand a decoder ϕ at the authentication terminal Definition 5. A privacy secrecy rate pair for chosen secret key authentication is called achievable for a joint-source Q, if, for any there exist an and a sequence of -codes, such that, for all we have Remark 4. The difference between Definition 5 and 2 is that, in here, the uniformity of the key is already guaranteed.
Definition 6. The privacy secrecy capacity region for chosen secret key authentication for the joint-source is called privacy secrecy capacity region and is denoted as .
We next present the privacy secrecy capacity region for chosen secret key authentication for the joint-source
Q as showed in [
11].
Theorem 2 ([
11])
. The privacy secrecy capacity region for the chosen secret key authentication is given by 3. Authentication for Compound Sources
Let and be two finite sets and a finite state set. Let be a sequence pair of length . For every the discrete memoryless joint-source is given by the joint probability distribution with a marginal distribution on and a stochastic matrix.
Definition 7. The discrete memoryless compound joint-source is given by the family of joint probabilities distributions on as We define the finite set of marginal distributions
over the alphabet
from the compound joint-source
as
We define
as the index set of
. Note that
.
For every
, we define the subset of the compound joint-source
with the same marginal distribution
as
For every
, we define the index set
of
as
Remark 5. Note that, for every with , it holds that , , and .
3.1. Compound Generated Secret Key Model
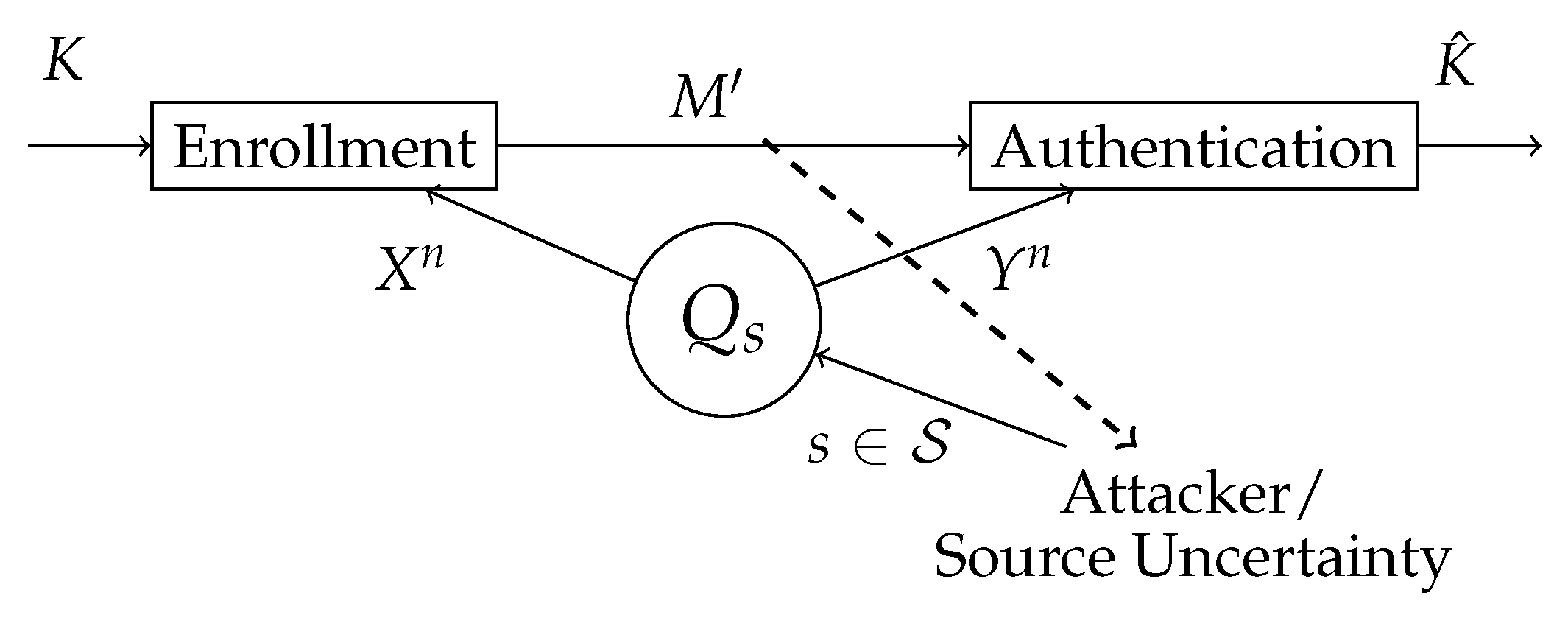
In this section, we study the generated secret key authentication for finite compound joint-sources, which is a special class of sources that model a limited SSI, as shown in
Figure 3.
We consider a block-processing of arbitrary but fixed length n. Let be the helper data set and the secret key set.
Definition 8. An -code for generated secret key authentication for the compound joint-source consists of an encoder f at the enrollment terminal withand a decoder ϕ at the authentication terminal Definition 9. A privacy secrecy rate pair is called achievable for generated secret key authentication for the compound joint-source , if, for any there exist an and a sequence of -codes, such that for all and for every we have Consider the compound joint-source
. For a fixed
,
and for every
, we define the region
as the set of all
that satisfy
with
.
Theorem 3. The privacy secrecy capacity region for generated secret key authentication for the compound joint-source is given by Proof. The proof of Theorem 3 consists of two parts: achievability and converse. The achievability scheme uses the following protocol:
Estimate the marginal distribution from the observed sequence at the enrollment terminal via hypothesis testing.
Compute the key K and a helper data M based on , a common shared sequence by the enrollment and authentication terminal and using an extractor function with whose input are the shared sequence T and a sequence of d uniformly distributed bits . The helper data M is equivalent to the helper data for the case with perfect SSI. The extended helper data in this case contains also the state of the marginal distribution and the uniformly distributed bits sequence, i.e., .
Store the extended helper data in the public database.
Estimate the key at the authentication terminal, based on the observations and , which can be seen as the outcome of one of the channels in .
Remark 6. Note that the authentication for compound source model is a generalization of the models studied by [11,12], i.e., . Furthermore, one can see that, for , the capacity region under the strong secrecy condition equals the capacity region under the weak secrecy condition showed by [11,12]. Remark 7. As we already mentioned, we aim for strong secrecy, i.e., in contrast to the weak secrecy constraint in (
1c)
, we now require the un-normalized mutual information between the key and the helper data to be negligibly small. It would be Ideal to show perfect secrecy and a perfectly uniformed key, i.e., and . It would be interesting to see how this constraint affects the achievable rate region. We suspect that the achievable rate region under perfect secrecy and perfectly uniformed key remains the same as in Theorem 3. Remark 8. From the protocol, note that once we have estimated the marginal distribution we deal with a compound channel model without channel state information (CSI) at the transmitter (see [24]). Remark 9. The order of the set operations of the capacity region displays the fact that the marginal distribution is first estimated. This can be seen as partial state information, where the marginal distribution over is known.
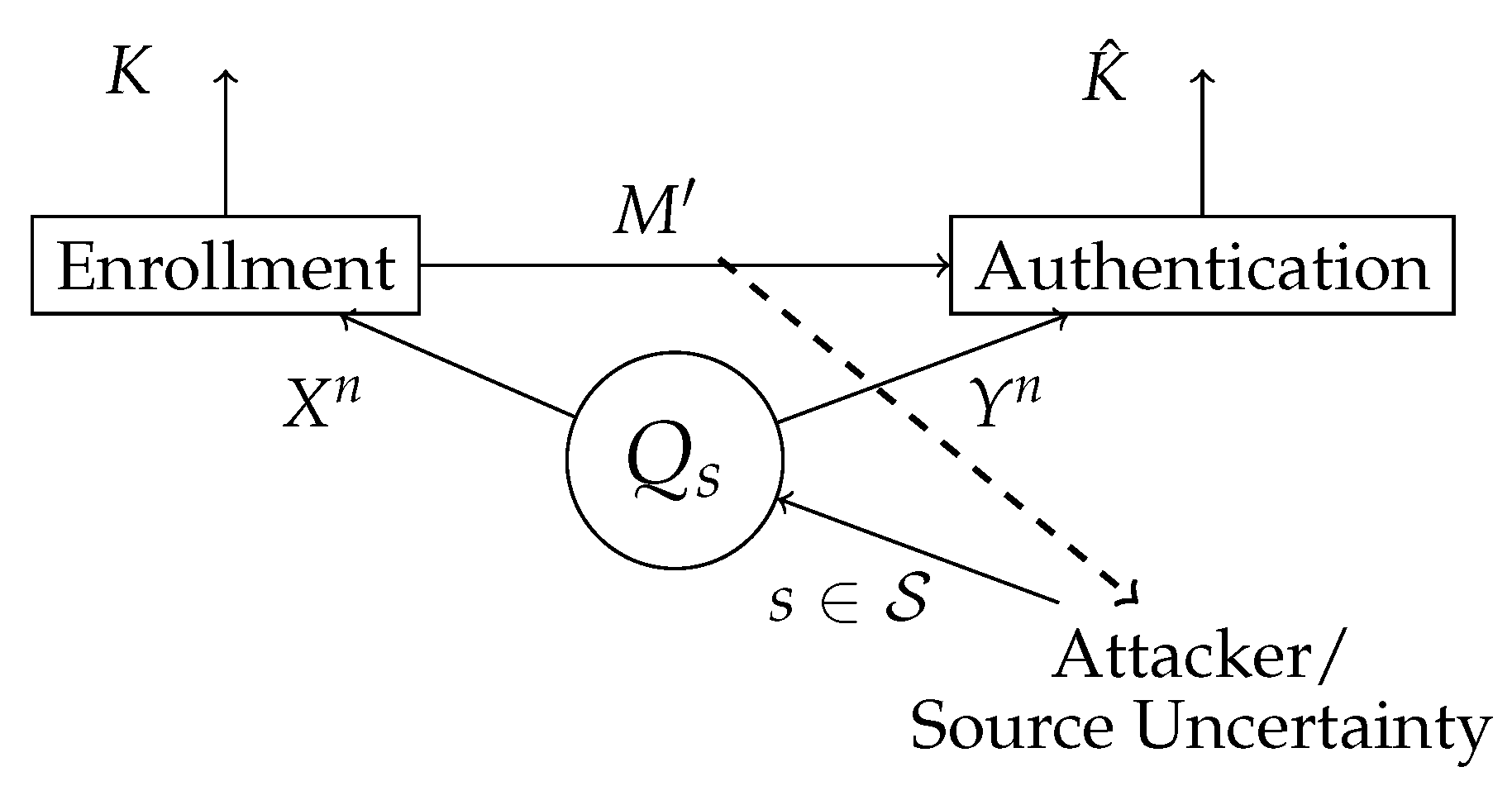
3.2. Compound Chosen Secret Key Model
In this section, we study chosen secret key authentication for finite compound joint-sources (see
Figure 4).
We consider a -code of arbitrary but fixed length n.
Definition 10. A privacy secrecy rate pair is called achievable for chosen secret key authentication for the compound joint-source , if for any there exist an and a sequence of -codes, such that, for all and for every we have Consider the compound joint-source
. For a fixed
,
and for every
, we define the region
as the set of all
that satisfy
with
.
Theorem 4. The privacy secrecy capacity region for chosen secret key authentication for the compound joint-source is given by Remark 10. Note that, as for generated secret key authentication for compound sources, chosen secret key authentication for compound sources is a generalization of the models studied by [11]. Furthermore, for perfect SSI, one can see that the capacity region under the strong secrecy condition equals the capacity region under the weak secrecy condition showed by [11]. Remark 11. Note that the privacy secrecy capacity region for the generated key model equals the privacy secrecy capacity region for chosen secret key authentication, i.e., .


{kind=link}
{kind=link}
{kind=link}
{kind=link}