Abstract
With a privacy-aware reputation system, an auction website allows the buyer in a transaction to hide his/her identity from the public for privacy protection. However, fraudsters can also take advantage of this buyer-anonymized function to hide the connections between themselves and their accomplices. Traditional fraudster detection methods become useless for detecting such fraudsters because these methods rely on accessing these connections to work effectively. To resolve this problem, we introduce two attributes to quantify the buyer-anonymized activities associated with each user and use them to reinforce the traditional methods. Experimental results on a dataset crawled from an auction website show that the proposed attributes effectively enhance the prediction accuracy for detecting fraudsters, particularly when the proportion of the buyer-anonymized activities in the dataset is large. Because many auction websites have adopted privacy-aware reputation systems, the two proposed attributes should be incorporated into their fraudster detection schemes to combat these fraudulent activities.
1. Introduction
Rapid progress in Internet technology and electronic payment has made online auctions more prevalent and convenient [1]. In online auctions, merchandise is often purchased from a complete stranger. Therefore, building trust between potential buyers and sellers is important to ensure the success of auction websites. Most auction websites are equipped with a reputation system to evaluate the credibility of each auction account. The reputation system uses a simple scheme to compute and publish a reputation score for each auction account; this scheme is based on a collection of opinions that other auction accounts hold about the account. For example, on eBay, the seller and buyer in a transaction can give each other a positive, negative, or neutral rating. Intuitively, sellers with more positive ratings and fewer negative ratings are more reputable and are likely to draw more sales.
The lucrative opportunity associated with a favorable online reputation attracts both honest and fraudulent sellers to pursue high reputation scores. Honest sellers achieve higher reputation scores by providing improved services (e.g., higher quality products, lower prices, and faster response) to their buyers. However, fraudulent sellers use a deceitful scheme, known as inflated reputation fraud [2], to boost their reputation scores. In this scheme, fraudulent sellers perform many transactions for low-priced merchandise within a group of collusive accounts to boost the positive ratings of the group’s members [3]. Because the cost of conducting the scheme is low, inflated reputation fraud is prevalent in online auctions. In this paper, we focus on detecting inflated reputation fraud. Notably, inflated reputation fraud is often the first step toward other fraudulent activities, such as selling counterfeit products or failing to deliver products.
Most recent approaches for detecting inflated reputation fraud are based on Social Network Analysis (SNA) [1,2,3,4,5,6,7,8,9,10,11,12,13]. These SNA-based approaches construct a social network of buyers and sellers based on their past transactions, and then detect fraudsters by finding cohesive groups in the network. However, some auction websites adopt a privacy-aware reputation system that enables buyers to hide their links to sellers. Fraudsters can also use this function to hide the links within their collusive group, making them hard to detect with traditional SNA-based approaches.
This paper presents a solution for detecting inflated reputation fraud in auction websites that use a privacy-aware reputation system. To the best of our knowledge, all SNA-based approaches in the literature use either synthetic datasets [6] or real datasets crawled from auction websites. Thus, these approaches have no access to the hidden links between buyers and sellers. We propose two privacy-related attributes to quantify the proportion of hidden links associated with each account, and show that the addition of these two attributes enhances the prediction accuracy for detecting fraudsters.
The remainder of this paper is organized as follows. The second section reviews previous work on the reputation systems in online auctions and the existing methods for detecting inflated reputation fraud. The third section describes the privacy-aware reputation systems on auction websites and proposes two privacy-related attributes associated with each user. The fourth section describes the dataset used in this study. The fifth section presents a performance study to evaluate the effectiveness of using the proposed privacy-related attributes to detect fraudsters. Finally, a discussion and concluding remarks are given in the sixth and seventh sections, respectively.
2. Related Work
2.1. Reputation Systems in Online Auction
Two factors are crucial to the success of an online auction website [14]. The first is how easily buyers can find sellers. The second is the trust that the website facilitates through its reputation system. The reputation systems in online auctions are essentially recommendation systems. Both parties in a transaction can give each other a positive, negative, or neutral rating, and the reputation system calculates a reputation score for each user based on all the ratings that the user has received from his/her past transactions, and the reputation score is available to the public. A third party can also access detailed information about each rating that a user has received so far. Detailed information is provided for the following aspects of a transaction:
- Date and time of the transaction.
- Seller and buyer of the transaction. This information can be used to construct a social network of users (see Section 2.2).
- Merchandise description.
- The rating (positive, negative or neutral) that the user received from his/her counterpart in the transaction.
- Textual feedback comment.
Such a reputation system builds trust in online auctions that lack typical human interaction [15], forming a large-scale, word-of-mouth network among users [16]. Reputable sellers can not only gain trust but also generate price premiums from potential buyers [17,18,19]. By contrast, a high proportion of negative ratings reduces the sales price [20]. A high proportion of neutral ratings impairs sales for sellers with high proportions of positive ratings, but facilitates sales for sellers with high proportions of negative ratings [21]. In case a negative rating is received, textual feedback comments and reactions are important for rebuilding trust [22]. The information that sellers provide to buyers can also affect the sellers’ reputation [23].
2.2. Constructing Social Networks from Reputation System
Based on the transaction history, a transaction network can be constructed, in which each node indicates an auction account and each link depicts a transaction between two auction accounts. Although the transaction network provides a complete view of the social interactions among auction accounts, a single factor prevents the use of the transaction network: on auction websites, the complete transaction history is not available to the public. Notably, only after at least one party in a transaction rates his/her counterpart does the transaction appear in the reputation system, which is open to the public. However, providing a rating after each transaction is not mandatory.
By contrast, a rating network is constructed based on the rating history of auction accounts. On many auction websites (e.g., eBay, Taobao, Ruten, and Yahoo! Kimo), the rating history is accessible to the public. Similar to a transaction network, each node in a rating network indicates an auction account, but each link depicts a rating relationship between two connected nodes. Because providing a rating after each transaction is not mandatory, each link in the rating network corresponds to a link in the transaction network, but not vice versa. Because the transaction history is not available to the public, and inflated reputation fraud requires the accumulation of positive ratings, most previous studies have adopted the rating network as a suitable surrogate for the transaction network [4,8,10,11].
2.3. Methods for Detecting Fraudsters in Online Auction
Previous techniques for detecting inflated reputation fraud used mostly user-level features such as the median, mean, sum, or standard deviation of the merchandise prices that a user sold or bought over a period [5,24]. The reputation systems on most auction websites also play a significant role in fraudster detection. Studies have shown that recent negative ratings are useful for predicting future fraud, and that experienced buyers can use the reputation system to avoid potential fraudulent auctions [25]. However, this approach does not fully utilize the information provided by the reputation system to uncover the interaction among users, who may still be deceived by fraudsters [26].
More recent approaches incorporate network-level features to combat inflated reputation fraud. Because inflated reputation fraud requires a collusive group of users to give each other positive ratings, a cohesive relation occurs within the collusive group. Many SNA-based approaches can identify cohesive subgroups in a network (see Table 1), and some of these approaches (e.g., k-core and k-plex) have been applied to detect collusive groups of fraudsters in a rating network [2,4,11]. In addition to basic features, such as degree and betweenness [11], more sophisticated features (e.g., neighbor diversity, neighbor driven attributes, credibility, and density) have been proposed for fraudster detection (see Table 2).

Table 1.
Subgroups in Social Network Analysis (SNA).
Table 2.
SNA-based network-level features for detecting fraudsters in online auctions.
3. Privacy-Aware Reputation System and Privacy-Related Attributes
3.1. Privacy-Aware Reputation System
Many auction websites have adopted privacy-aware reputation systems, where the buyer in a transaction can decide whether to hide his/her identity from the public. Ruten, Yahoo! Kimo Auction, and eBay adopted privacy-aware reputation systems in 2008, 2009, and 2013, respectively.
On Yahoo! Kimo Auction, after winning the bid of the merchandise, within 60 days, the buyer has the option of hiding from the public the information about both the seller and the merchandise in the rating that the buyer receives from the seller. By doing so, in the rating that the seller receives from the buyer, the information about the buyer is also hidden from the public. A similar buyer-anonymized function is also available in the reputation system of Ruten, except that transactions can be set to the hidden mode within 6 months, instead of 60 days.
If a buyer chooses to hide his/her identity in a transaction, the transaction is referred to as an anonymous transaction. Since Ruten adopted the privacy-aware reputation system in 2008, a substantial proportion of the transactions on Ruten have been anonymous. A random sample of 190,782 transactions on Ruten between 2008 and 2011 across 24 categories of merchandise showed that 11.38% of the transactions were anonymized [27]. The proportions of anonymous transactions across different categories of merchandise varied from 0.87% in the Books and Stationery category to 27.45% in the Women’s Intimates and Sleepwear category and 28.57% in the Real Estate and Specialty Services category. The results reflect that buyers often demand privacy when purchasing personal or intimate products. Although the original intention of anonymous transactions is to protect customers’ privacy, fraudsters can abuse anonymous transactions to hide their criminal activities from the public (see Section 5.2.1).
Once a transaction is anonymized, the following information that originally appears in the ratings of the buyer and the seller is no longer available to the public:
- In the rating that the buyer receives from the seller, the seller ID and information about the merchandise are hidden.
- In the rating that the seller receives from the buyer, the buyer ID is hidden.
Although the rating (i.e., positive, neutral, or negative) and textual comments of an anonymous transaction are still public, third parties do not know who gave the rating. Consequently, a third party cannot construct the link between the buyer and the seller of an anonymous transaction. Thus, the privacy of the buyer is protected.
3.2. Privacy-Related Attributes
Although privacy-aware reputation systems provide more shopping privacy to buyers, fraudsters can also exploit anonymous transactions to hide the links to collusive auction accounts. Consequently, if a third party crawls an auction website to build the rating network of auction accounts (see Section 2.2), the transactions within a collusive group of auction accounts may be hidden and thus cannot be reconstructed. Because many fraud detection approaches [1,2,3,4,5,6,7,8,9,10,11,12,13] employ the rating network to detect fraudsters, anonymous transactions in the reputation system may render these approaches unfeasible to detect fraudsters who take advantage of anonymous transactions. To the best of our knowledge, most fraud detection approaches are based on datasets crawled from auction websites instead of datasets directly provided by the auction websites. Therefore, fraudsters exploiting anonymous transactions are likely to be overlooked.
For example, previous studies have shown that a fraudster requires accomplices to provide positive ratings; thus, intensive transactions must occur between them. Consequently, they are likely to appear in the 2-core subgraphs of the rating network [2,11]. However, if the fraudster and accomplices use anonymous transactions to hide the buyers’ identities in their transactions, then the links among them may not appear in rating networks constructed by third parties. Consequently, the members of the collusive group may not belong to the same 2-core subgraphs.
To overcome this problem, we propose two privacy-related attributes to capture the proportion of anonymous activities associated with each auction account. Let n denote the number of positive ratings that a user has received. Because a transaction can be either anonymous or non-anonymous, we can decompose n into na and nn, where na is the number of positive ratings resulting from anonymous transactions, and nn is the number of positive ratings resulting from non-anonymous transactions. Depending on the user’s role in a transaction (buyer or seller), a rating can be given as a seller or as a buyer. We can further decompose na into two parts: the number of anonymous positive ratings given by sellers (denoted as nas) and the number of anonymous positive ratings given by buyers (denoted as nab). That is,
In this paper, we use the number of anonymous positive ratings that an account has received from its buyers (i.e., nab) as the first privacy-related attribute. Notably, because only the buyer in a transaction has the right to decide whether to anonymize the transaction, an account with a high nab is likely to belong to a fraudster who uses a large number of anonymized accomplices to boost its rating.
n = na + nn = (nab + nas) + nn.
The second attribute is the anonymous ratio (denoted by Ra), which is defined as the number of anonymous positive ratings divided by the number of all positive ratings that an account has received or given to other accounts. Intuitively, an account with a high Ra is likely to belong to a fraudster. Section 5 describes an experiment that applies both Ra and nab to detect fraudsters in a real world dataset (see Section 4) by using decision trees and artificial neural networks.
4. Data Collection and Dataset Preparation
A dataset collected from Ruten [28] was used in this study. A subset of this dataset was also used in our previous work [12,13]. The data collection process proceeded in a level-by-level manner [4,8,10,11,29] and is explained as follows:
Step 1. Collecting accounts (first level). Ruten regularly releases a list of recently suspended accounts, together with the reasons for the suspension. Our data collection process began with the collection of all 9168 accounts suspended by Ruten in July 2013. Because some of these accounts were not fraud-related (e.g., selling alcohol or prescribed medicine), we manually checked the 9168 accounts and retained only the 3101 whose suspension reasons were fraud-related, such as evaluation hype, selling counterfeit products, fake bidding, and failure to deliver products. Furthermore, because inflated reputation fraud works by accumulating positive ratings from accomplices, we removed the accounts that had not yet received any ratings. The remaining 1064 accounts were denoted as L1 accounts. Ruten altered the status of one L1 account to normal in October 2013. Therefore, the L1 accounts included 1063 fraudster accounts and 1 non-fraudster account. Notably, for 132 of the 1063 L1 fraudster accounts, all of the positive ratings they received were anonymous. Furthermore, 121 of these 132 accounts had an anonymous ratio Ra of 1, indicating that all of the positive ratings they had received and given to other accounts were anonymous.
Step 2. Collecting accounts (second level). We then collected all of the non-anonymous accounts that had received ratings from or given ratings to any L1 account. Consequently, 3475 new accounts were discovered and were denoted as L2 accounts. Because each L2 account was linked to at least one L1 account and all L1 accounts were not anonymous, each L2 account had an anonymous ratio of <1. Among the 3475 L2 accounts, 149 of them were suspended by Ruten due to fraudulent activities and were treated as fraudster accounts in this experiment. Table 3 shows the numbers of fraudster and non-fraudster accounts in the L1 and L2 accounts.
Table 3.
Numbers of fraudster and non-fraudster accounts in the L1 and L2 accounts.
Step 3. Collecting accounts (third level). To reveal the accounts that were involved in transactions with these L2 accounts, we further collected all non-anonymous accounts that had received ratings from or given ratings to any of the 3475 L2 accounts. In this step, 233,169 new accounts were discovered and were denoted as L3 accounts. On average, each L2 account transacted with 233169/3475 = 67 L3 accounts. By contrast, on average, each L1 account transacted with only 3475/1064 = 3.2 L2 accounts. Notably, non-fraudster accounts received positive ratings from many accounts, whereas fraudster accounts received positive ratings mostly from their accomplices. In Table 1, the proportion of fraudster accounts was much higher in L1 accounts (1063/1064) than in L2 accounts (149/3475). Therefore, the ratio between the numbers of L2 accounts and L1 accounts (approximately 3.2) was much lower than the ratio between the numbers of L3 accounts and L2 accounts (approximately 67).
Step 4. Constructing the social network. We constructed a social network comprising all of the L1, L2, and L3 accounts, where each node in the network represents an account. If an account had given at least one positive rating to another account before 31 July 2013, then the nodes representing the two accounts were connected through a link in the social network. The resulting network contained 237,708 (= 1064 + 3475 + 233,169) nodes and 348,259 links. Notably, 121 nodes in the social network were not connected to any other node. They represented the 121 L1 accounts with an anonymous ratio of 1, as described in Step 1. Notably, a user can be a buyer, a seller, or both in the network. Among the L1 accounts, 96 were buyers, 884 were sellers, and 84 were both. Among the L2 accounts, 2561 were buyers, 58 were sellers, and 856 were both.
Step 5. Calculating SNA-related attributes. Based on the social network created in the previous step, we calculated several SNA-related attributes (shown in Table 4) for the nodes representing the L1 or L2 accounts to build a dataset for this performance study. We did not include the L3 accounts in the dataset, because the social network did not include all of the accounts that had received ratings from or given ratings to the L3 accounts. Therefore, the resulting dataset contained 4539 (=1064 + 3475) records (Table 3). The dataset is available at the supplementary of this paper.
Table 4.
SNA-related attributes.
5. Performance Study
5.1. Experimental Design
The experiment was designed from two perspectives: attributes and datasets. Concerning the attributes used to build a classifier for detecting fraudsters, our goal was to evaluate whether the addition of the two privacy-related attributes (i.e., Ra and nab) can improve the performance of the existing sets of attributes used in previous work. Five sets of attributes were considered in this study. The first set contained only one attribute, k-core [2], and the second set contained two attributes, k-core and center weight (CW) [4]. The third set (denoted as S9) contained eight binary attributes (binary_k-core for k = 2 to 6, and 2-plex_and_size = s for s = 5 to 7, shown in Table 4) and one numeric attribute (normalized betweenness) [11]. The fourth set contained only one attribute, NDr (neighbor diversity on the number of received ratings [13]). The fifth set contained only one attribute, NDAmean (the mean of the numbers of received ratings of the node’s neighbors [12]). In this performance study, we tested these five sets of attributes and then evaluated whether their performance can be improved by adding Ra and nab.
Regarding the datasets, our goal was to evaluate whether a given approach can detect fraudsters effectively among users with various proportions of anonymous transactions. Let D100 denote the dataset collected as described in Section 4; we generated three subsets of D100 (D0, D0+, and D15 shown in Table 5) based on the anonymous ratio Ra. Dataset D0 contained the accounts that have never engaged in any anonymous transactions (Ra = 0), and D0+ contained accounts that have engaged in at least one anonymous transaction (Ra > 0). Thus, D0∩D0+ = ϕ and D0∪D0+ = D100. Dataset D15 contained the top 15% of accounts based on Ra. Thus, D15 ⊂ D0+ ⊂ D100. Ordering these datasets by the proportion of anonymous transactions gives D15 > D0+ > D100 > D0, and by testing these datasets, we could verify whether a given approach can still perform effectively if anonymous transactions become prevalent. Notably, the last column of Table 5, baseline accuracy, represents the prediction accuracy of always predicting that an account is a non-fraudster (or fraudster) account if non-fraudster (or fraudster) accounts mainly comprise the dataset.
Table 5.
Datasets.
In this study, we divided the experiment into four tests, and each test used a dataset from Table 5. In each test, we used various combinations of attributes to evaluate whether adding the two proposed privacy-related attributes improves the prediction accuracy. Two classification algorithms from Weka [30], the J48 decision tree and the artificial neural network (ANN), were used in this study to conduct 10-fold cross validation. The experiment adopted the default parameter settings of both algorithms in Weka.
5.2. Experiment Results
5.2.1. Results from Dataset D100
Dataset D100 is the dataset collected following the steps described in Section 4. It includes all of the accounts collected, regardless of their anonymous ratio. As indicated in Table 5, D100 contains 1212 fraudster accounts and 3327 non-fraudster accounts, yielding a baseline accuracy of 73.2981%.
Table 6 and Table 7, respectively, show the performance results of J48 and ANN with D100. When using the nine attributes in S9, the addition of the two privacy-related attributes, Ra and nab, improved the prediction accuracy from 75.8537% to 82.5072% for J48 and from 75.0606% to 79.4228% for ANN. Recall and precision were also significantly improved. Similar results were observed using k-core, k-core and CW, or NDr. When using NDAmean, the addition of Ra and nab improved the prediction accuracy and precision but slightly reduced recall. Notably, among the 4539 accounts in dataset D100, 1868 accounts (approximately 41%) had at least one anonymous rating (i.e., Ra > 0). By adding Ra and nab, the accounts with Ra > 0 could be more effectively predicted, which therefore, results in an improved prediction accuracy for both J48 and ANN. However, 59% of the accounts in D100 still had Ra = 0. Thus, using only Ra and nab resulted in poor recall, as shown in the last rows of Table 6 and Table 7.
Table 6.
J48 performance with dataset D100.
Table 7.
Artificial Neural Network (ANN) performance with dataset D100.
For both J48 and ANN, the addition of Ra and nab reduced the number of false negatives, except when using the attribute NDAmean. However, J48 and ANN produced slightly different results for false positives. For J48, the addition of Ra and nab always reduced the number of false positives; for ANN, the addition of Ra and nab occasionally increased the number of false positives.
To investigate whether fraudsters use anonymous transactions more often than non-fraudsters do, we compared the Ra distribution of the 1212 fraudster accounts with that of the 3327 non-fraudster accounts in dataset D100. Figure 1 shows the proportion of fraudster (or non-fraudster) accounts with a Ra of more than or equal to a certain threshold among all 1212 fraudster (or 3327 non-fraudster) accounts. Among the 1212 fraudster accounts, 507 (approximately 41.83%) accounts satisfied Ra > 0; 429 (approximately 35.4%) satisfied Ra ≥ 0.1; and 121 (approximately 9.98%) satisfied Ra = 1. In each Ra range in Figure 1, we observed a significant proportion of fraudster accounts. By contrast, among the 3327 non-fraudster accounts, 1361 (approximately 40.91%) accounts satisfied Ra > 0; 555 (approximately 16.68%) satisfied Ra ≥ 0.1; and none of the non-fraudster accounts satisfied Ra = 1. As the threshold of Ra increased, the proportion of non-fraudster accounts decreased more quickly than the proportion of fraudster accounts did. Overall, for the same threshold of Ra in Figure 1, the proportion of fraudster accounts was always larger than the proportion of non-fraudster accounts. The result indicated that fraudsters use anonymous transactions more often than non-fraudsters do.
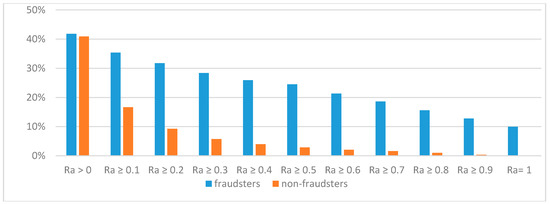
Figure 1.
Proportions of fraudster and non-fraudster accounts w.r.t. Ra in dataset D100.
5.2.2. Results from Dataset D0
Dataset D0 contained all accounts in D100 where Ra = 0. This dataset comprised 705 fraudster accounts and 1966 non-fraudster accounts, yielding a baseline accuracy of 73.6054% (Table 5). Note that if Ra = 0, then nab = 0. Because Ra and nab are 0 for all accounts in D0, adding Ra and nab to the classification algorithms did not improve performance. With or without Ra and nab, the results were the same for J48 (Table 8). The decision tree algorithm selects the most discriminating attribute to split the tree at each step. However, because Ra and nab are 0 throughout the dataset, they are the least discriminating attributes. For ANN, the results were similar with or without Ra and nab (Table 9). Using only Ra and nab for dataset D0 predicted that all accounts were non-fraudster accounts (i.e., the majority class), resulting in a baseline accuracy of 73.6054% and 0 recall, as shown in the last rows of Table 8 and Table 9.
Table 8.
J48 performance with dataset D0.
Table 9.
ANN performance with dataset D0.
5.2.3. Results from Dataset D0+
Dataset D0+ contained all accounts where Ra > 0 in D100. This dataset comprised 507 fraudster accounts and 1361 non-fraudster accounts, yielding a baseline accuracy of 72.8587% (Table 5). As shown in Table 10 and Table 11, with the addition of Ra and nab, the prediction accuracy improved, and in most cases, precision and recall also improved. Because Ra > 0 for all accounts in D0+, the addition of Ra and nab improved performance. As shown in the last rows of Table 10 and Table 11, using only Ra and nab on D0+ yielded accuracies of 89.6146% for J48 and 86.0278% for ANN, which is more than a 7.1% improvement over the corresponding baseline accuracy of 72.8587%. By contrast, using only Ra and nab on D100 yielded an accuracies of 80.2159% for J48 and 78.5636% for ANN, which is a less than 5.3% improvement over the corresponding baseline accuracy of 73.2981% (see Table 5, Table 6 and Table 7). Because the proportion of anonymous transactions was larger in D0+ than in D100, the impact of adding Ra and nab to the classification accuracy was also larger in D0+ than in D100.
Table 10.
J48 performance with dataset D0+.
Table 11.
ANN performance with dataset D0+.
5.2.4. Results from Dataset D15
Dataset D15 contained the top 15% accounts in D100 based on Ra, representing a dataset with a large proportion of anonymous transactions. The smallest anonymous ratio of the accounts in D15 was 0.2. As indicated in Table 5, dataset D15 contained 385 fraudster accounts and 296 non-fraudster accounts, yielding a baseline accuracy of 56.5354%. As shown in Table 12 and Table 13, the addition of Ra and nab improved both the prediction accuracy and precision, but in some cases, recall was decreased.
Table 12.
J48 performance with dataset D15.
Table 13.
ANN performance with dataset D15.
6. Discussion
The results in Table 5, Table 6, Table 7, Table 8, Table 9, Table 10, Table 11, Table 12 and Table 13 showed that the addition of Ra and nab improved the prediction accuracy. In most cases, the addition of Ra and nab reduced either the number of false positives, the number of false negatives, or both. Except in the experiment with dataset D0, the addition of Ra and nab to the attribute NDAmean always reduced false positives but increased false negatives. However, the number of reduced false positives was greater than the number of increased false negatives. Therefore, the prediction accuracy was improved.
To evaluate the performance improvement of adding Ra and nab, we calculated the difference in the prediction accuracy of datasets evaluated with and without adding Ra and nab (Table 14). For all attributes in Table 14, the ordering of accuracy improvement was D15 > D0+ > D100. That is, the addition of Ra and nab had a stronger positive impact on accuracy for datasets with higher percentages of anonymous transactions. Therefore, as using anonymous transactions to hide fraudulent activities becomes more prevalent, the importance of using the privacy-related attributes to detect fraudsters also increases.
Table 14.
Percentage of accuracy improvement with the addition of Ra & nab.
In Table 15, the baseline accuracy and the accuracy of using only Ra and nab were copied from the last column of Table 5 and the last rows of Table 6, Table 7, Table 8, Table 9, Table 10, Table 11, Table 12 and Table 13, respectively. The improvement column was calculated as the accuracy of using only Ra and nab subtracted from the corresponding baseline accuracy. Notably, ordering the datasets by the accuracy improvement over the baseline accuracy was the same as ordering them by their proportions of anonymous transactions: D15 > D0+ > D100 > D0. Thus, the importance of Ra and nab increased with the proportion of anonymous transactions in the dataset.
Table 15.
Prediction accuracy (%) of baseline, using only Ra & nab, and improvement.
Because dataset D0+ contained all accounts where Ra > 0 in D100, we chose dataset D0+ to evaluate how Ra and nab are distributed among fraudster and non-fraudster accounts (Table 16). Although the mean value of Ra was smaller for non-fraudster accounts than for fraudster accounts, the reverse was true for the standard deviation of Ra. Similar results were also found for nab.
Table 16.
Mean and standard deviation of Ra and nab in dataset D0+.
To indicate how Ra affects fraudster distribution, we calculated the proportions of fraudster and non-fraudster accounts for several subsets of the dataset D100, where each subset only contained the accounts where Ra was more than or equal to a certain threshold (Table 17). The proportions of fraudster accounts in the datasets where Ra ≥ 0 (i.e., D100) and Ra > 0 (i.e., D0+) were 26.7% and 27.14%, respectively; the difference was only 0.44%. However, when the threshold of Ra was increased to ≥0.1, the proportion of fraudster accounts in the dataset became 43.6%, a 16.46% increment over the dataset with Ra > 0. The proportion of fraudster accounts in the resulting dataset increased with the threshold. Finally, when Ra reached its maximal value of 1, the resulting dataset contained only fraudster accounts. Thus, the fraudster distribution reflected that an account with a higher Ra was more likely to be a fraudster account.
Table 17.
Fraudster distribution in datasets with Ra greater than or equal to a certain threshold.
7. Conclusions
A privacy-aware reputation system in online auctions offers the same service to everyone and does not discriminate between honest and fraudulent users. Although it protects the privacy of each user, it can also be misused to cover criminal activities by enabling a fraudster to hide the fact that all or most of his/her positive ratings are given by accomplices. Without considering this fact, the scores provided by the reputation system can be misleading.
In this paper, we proposed two privacy-related attributes to quantify the proportion of anonymous ratings that a user received. We showed that both attributes improved the performance of the fraudster detection method. Future work should address how to calculate the reputation score to avoid an inflated reputation. The reputation system can employ a more sophisticated method to calculate the reputation score, for example, by assigning lower and higher weights to anonymous and non-anonymous ratings, respectively. Because the reputation score is available to all users to evaluate the trustworthiness of a buyer in real time, its impact can be quite substantial.
On some auction websites (e.g., eBay), anonymity is allowed, not only for giving ratings, but also for placing bids. This anonymous bidding function can also be abused by fraudsters to protect shill bidders, who bid on items with the intent to artificially raise their prices. Previous work on shill bidding detection includes deriving features from the bidding history to calculate the likelihood of a user participating in shill bidding [31], introducing a formal model checking approach to detect shill bidding [32], investigating the relationship between final auction prices and shill activities [33], and so on. Applying privacy-related features similar to the anonymous ratio to detect shill bidding is a potential area for further study.
Supplementary Materials
The following are available online at www.mdpi.com/1099-4300/19/7/338/s1.
Acknowledgments
This research is supported by the Ministry of Science and Technology, Taiwan, R.O.C. under Grant 105-2632-H-155-022.
Author Contributions
Both authors contributed to the conception and design of the study, the collection and analysis of the data and the discussion of the results. Jun-Lin Lin wrote the manuscript. The contributions of both authors are 80% (Jun-Lin Lin) and 20% (Laksamee Khomnotai).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bin, Z.; Yi, Z.; Faloutsos, C. Toward a comprehensive model in internet auction fraud detection. In Proceedings of the 41st Annual Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 7–10 January 2008; p. 79. [Google Scholar]
- Wang, J.C.; Chiu, C.Q. Detecting online auction inflated-reputation behaviors using social network analysis. In Proceedings of the Annual Conference of the North American Association for Computational Social and Organizational Science, Notre Dame, IN, USA, 26–28 June 2005. [Google Scholar]
- Morzy, M. New algorithms for mining the reputation of participants of online auctions. Algorithmica 2008, 52, 95–112. [Google Scholar] [CrossRef]
- Wang, J.-C.; Chiu, C.-C. Recommending trusted online auction sellers using social network analysis. Expert Syst. Appl. 2008, 34, 1666–1679. [Google Scholar] [CrossRef]
- Chau, D.; Pandit, S.; Faloutsos, C. Detecting fraudulent personalities in networks of online auctioneers. In Knowledge Discovery in Databases: PKDD 2006; Fürnkranz, J., Scheffer, T., Spiliopoulou, M., Eds.; Springer: Berlin, Germany, 2006; pp. 103–114. [Google Scholar]
- Pandit, S.; Chau, D.H.; Wang, S.; Faloutsos, C. Netprobe: A fast and scalable system for fraud detection in online auction networks. In Proceedings of the 16th International Conference on World Wide Web, Banff, AL, Canada, 8–12 May 2007; pp. 201–210. [Google Scholar]
- Morzy, M. Cluster-based analysis and recommendation of sellers in online auctions. Comput. Syst. Sci. Eng. 2007, 22, 279–287. [Google Scholar]
- Lin, S.J.; Jheng, Y.Y.; Yu, C.H. Combining ranking concept and social network analysis to detect collusive groups in online auctions. Expert Syst. Appl. 2012, 39, 9079–9086. [Google Scholar] [CrossRef]
- Yu, C.H.; Lin, S.J. Web crawling and filtering for on-line auctions from a social network perspective. Inf. Syst. E Bus. Manag. 2012, 10, 201–218. [Google Scholar] [CrossRef]
- Yu, C.H.; Lin, S.J. Fuzzy rule optimization for online auction frauds detection based on genetic algorithm. Electron. Commer. Res. 2013, 13, 169–182. [Google Scholar] [CrossRef]
- Chiu, C.C.; Ku, Y.C.; Lie, T.; Chen, Y.C. Internet auction fraud detection using social network analysis and classification tree approaches. Int. J. Electron. Commer. 2011, 15, 123–147. [Google Scholar] [CrossRef]
- Lin, J.-L.; Khomnotai, L. Improving fraudster detection in online auctions by using neighbor-driven attributes. Entropy 2016, 18, 11. [Google Scholar] [CrossRef]
- Lin, J.-L.; Khomnotai, L. Using neighbor diversity to detect fraudsters in online auctions. Entropy 2014, 16, 2629–2641. [Google Scholar] [CrossRef]
- Tadelis, S. Reputation and feedback systems in online platform markets. Annu. Rev. Econ. 2016, 8, 321–340. [Google Scholar] [CrossRef]
- Gefen, D.; Karahanna, E.; Straub, D.W. Trust and TAM in online shopping: An integrated model. Manag. Inf. Syst. Q. 2003, 27, 51–90. [Google Scholar]
- Dellarocas, C. The digitization of word of mouth: Promise and challenges of online feedback mechanisms. Manag. Sci. 2003, 49, 1407–1424. [Google Scholar] [CrossRef]
- Ba, S.; Pavlou, P.A. Evidence of the effect of trust building technology in electronic markets: Price premiums and buyer behavior. Manag. Inf. Syst. Q. 2002, 26, 243–268. [Google Scholar] [CrossRef]
- Melnik, M.I.; Alm, J. Does a seller’s ecommerce reputation matter? Evidence from eBay auctions. J. Ind. Econ. 2002, 50, 337–349. [Google Scholar] [CrossRef]
- Jolivet, G.; Jullien, B.; Postel-Vinay, F. Reputation and prices on the e-market: Evidence from a major french platform. Int. J. Ind. Org. 2016, 45, 59–75. [Google Scholar] [CrossRef]
- Laitinen, E.K.; Laitinen, T.; Saukkonen, O. Impact of reputation and promotion on internet auction outcomes: Finnish evidence. J. Internet Commer. 2016, 15, 163–188. [Google Scholar] [CrossRef]
- Rabby, F.; Shahriar, Q. Non-neutral and asymmetric effects of neutral ratings: Evidence from eBay. Manag. Decis. Econ. 2016, 37, 95–105. [Google Scholar] [CrossRef]
- Utz, S.; Matzat, U.; Snijders, C. On-line reputation systems: The effects of feedback comments and reactions on building and rebuilding trust in on-line auctions. Int. J. Electron. Commer. 2009, 13, 95–118. [Google Scholar] [CrossRef]
- Carter, M.; Tams, S.; Grover, V. When do I profit? Uncovering boundary conditions on reputation effects in online auctions. Inf. Manag. 2017, 54, 256–267. [Google Scholar] [CrossRef]
- Chau, D.H.; Faloutsos, C. Fraud Detection in Electronic Auction. Available online: http://www.cs.cmu.edu/~dchau/papers/chau_fraud_detection.pdf (accessed on 2 July 2017).
- Gregg, D.G.; Scott, J.E. The role of reputation systems in reducing on-line auction fraud. Int. J. Electron. Commer. 2006, 10, 95–120. [Google Scholar] [CrossRef]
- Noufidali, V.; Thomas, J.S.; Jose, F.A. E-Auction Frauds—A Survey. Int. J. Comput. Appl. 2013, 61, 41–45. [Google Scholar]
- Lee, C.-L. Customer Behavior of Using Privacy Protection Mechanism in Online Auctions. Available online: http://etd.lib.nctu.edu.tw/cgi-bin/gs32/ncugsweb.cgi?o=dncucdr&s=id=%22NCU984203031%22.&searchmode=basic (accessed on 2 July 2017).
- Ruten. Available online: http://www.ruten.com.tw/ (accessed on 2 July 2017).
- You, W.; Liu, L.; Xia, M.; Lv, C. Reputation inflation detection in a Chinese C2C market. Electron. Commer. Res. Appl. 2011, 10, 510–519. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann Publishers: Burlington, MA, USA, 2011; p. 664. [Google Scholar]
- Trevathan, J.; Read, W. Detecting shill bidding in online English auctions. In Handbook of Research on Social and Organizational Liabilities in Information Security; Information Science Publishing: Hershey, PA, USA, 2005; pp. 446–470. [Google Scholar]
- Xu, H.; Cheng, Y.-T. Model checking bidding behaviors in internet concurrent auctions. Int. J. Comput. Syst. Sci. Eng. 2007, 4, 179–191. [Google Scholar]
- Dong, F.; Shatz, S.M.; Xu, H.; Majumdar, D. Price comparison: A reliable approach to identifying shill bidding in online auctions? Electron. Commer. Res. Appl. 2012, 11, 171–179. [Google Scholar] [CrossRef]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).