Abstract
Information Bottleneck-based methods use mutual information as a distortion function in order to extract relevant details about the structure of a complex system by compression. One of the approaches used to generate optimal compressed representations is by annealing a parameter. In this manuscript we present a common framework for the study of annealing in information distortion problems. We identify features that should be common to any annealing optimization problem. The main mathematical tools that we use come from the analysis of dynamical systems in the presence of symmetry (equivariant bifurcation theory). Through the compression problem, we make connections to the world of combinatorial optimization and pattern recognition. The two approaches use very different vocabularies and consider different problems to be “interesting". We provide an initial link, through the Normalized Cut Problem, where the two disciplines can exchange tools and ideas.
1. Introduction
Our goal in this paper is to investigate the mathematical structure of Information Distortion methods. There are several approaches to computing the best quantization of the data, and they differ in the algorithms used, the data they are applied to, and the functions that are optimized by the algorithms. We will concentrate on the annealing method applied to two different functions: the Information Bottleneck cost function [1] and the Information Distortion function [2]. By formalizing a common framework in which to study these two problems, we will exhibit common features of, as well as differences between, the two cost functions. Moreover, the differences and commonalities we will highlight are based on the underlying structural properties of these systems rather then on the philosophy behind their derivation. All results that we present are valid for any system characterized by a probability distribution and in this sense they present fundamental structural results.
On a more concrete level, our goal is to understand why the annealing algorithms now in use work as well as they do, but also to suggest improvements to these algorithms. Some results which have been observed numerically are not expected when applying annealing to a general cost function. We want to ask what is the special feature of these systems that cause such results.
Our final goal is to provide a bridge between the world of combinatorial optimization and pattern recognition, and the world of dynamical systems in mathematics. These two areas have different goals, different sets of “natural questions” and, perhaps most crucially, different vocabularies. We want this manuscript to contribute to bridging this gap, as we believe that both sides have developed interesting and powerful techniques that can be used to expand the knowledge of the other side.
We close by introducing the optimization problems we will study. Both approaches attempt to characterize a system of interest defined by a probability by quantizing (discretizing) one of the variables ( here) into a reproduction variable with few elements. One of the problems stems from the Information Distortion approach to neural coding [2,3],
where is the conditional entropy, and is the mutual information [4]. The other problem is from the Information Bottleneck approach to clustering [1,5,6]
which has been used for document classification [7,8], gene expression [9], neural coding [10,11], stellar spectral analysis [12], and image time-series data mining [13].
The variables (quantizers) q are conditional probabilities and Δ is the space of all appropriate conditional probabilities. We will explain all of the details in the main text, but we want to sketch the basic idea of the annealing approach here. Since both functions and are concave, when , both problems (1) and (2) admit a homogeneous solution , where N is the number of elements in . Starting at this solution and increasing β slowly, the optimal solution, or quantizer, q will undergo a series of phase transitions (bifurcations) as a function of β. We will show that the parameter β, at which the first phase transition takes place, does not depend on the number of elements in the reproduction variable . Annealing in the temperature-like parameter β terminates either at some predefined finite value of β, or goes to . It is this process and its phase transitions that we consider in this contribution.
1.1. Outline of the Mathematical Contributions
In Section 2 we start with the optimization problems and identify the space of variables over which optimization takes place. Since these variables are constrained, we use Lagrange multipliers to eliminate equality constraints. We also present some results about convexity and concavity of the cost functions.
Our first main question is whether the approach of deterministic annealing [14] can be used for these optimization problems. Rose and his collaborators have shown that, if the distortion function in certain class of optimization problems is taken to be the Euclidean distance, the phase transitions of the annealing function can be computed explicitly. More precisely, the first phase transition can be computed explicitly, since the quantizer value is known and only the value of the temperature at which this quantizer loses stability has to be computed. In general, an implicit formula relating critical temperature and the critical quantizer at which phase transition occurs can be computed.
In Section 4 we will show that the same calculations can be done for our optimization problems. We relate the critical value of β at which the uniform quantizer loses stability to a certain eigenvalue problem. This problem can be solved effectively off-line and thus the annealing procedure can start from this value of β rather then at . As a consequence, we also show that in both optimization problems considered here, the quantizer is a local maximum for all . In complete analogy with deterministic annealing, our results extend beyond phase transitions off . As we show in Section 5, the aforementioned eigenvalue problem implicitly relates all critical values of the parameter β to critical values of the quantizer q.
We study more closely the first phase transition in Section 6. We show that the eigenvector corresponding to this phase transition solves the Approximate Normalized Cut problem for some graphs with vertices corresponding to elements of Y. These graphs have considerable intuitive appeal.
In [15,16,17] we studied the subsequent phase transitions more closely, using bifurcation theory with symmetries. We summarize the main results here as well. The symmetry of our problems comes from the fact that the cost function is invariant under the relabeling of the elements of the representation variable T. Such a symmetry is characterized by the permutation group and its subgroups. Since this is a structural symmetry, it does not require the symmetry of the underlying probability distribution . These results are valid for arbitrary probability distributions.
2. Mathematical Formulation of the Problem
The variables q over which the optimization takes place are conditional probabilities . In order for the problems (1) and (2) to be well defined, we must fix the number of elements of T. Let this number be N and let the number of elements in Y be K. Then there are conditional probabilities which satisfy
These equations form an equality constraint on the maximization problems (1) and (2). We also have to satisfy inequality constraints since are probabilities. We notice that, for a fixed y, the space of admissible values is the unit simplex in . We denote this simplex as , to also indicate that it is related to variable y, and suppressing the dimension for simplicity of notation. It follows from (3) that the set of all admissible values of is a product of such simplices (see Figure 1), which we call Δ,

Figure 1.
The space Δ of admissible vectors q can be represented as a product of simplices, one simplex for each . The figure shows the case when the reproduction variable T has three elements (). Each triangle represents a unit simplex in and the constraint . The green point represents the position of a particular q. To clarify the illustration: The part of q in simplex 4, , is almost deterministic (shown at a vertex), while the next q, is almost uniform (shown almost at the center of simplex 4).
At this point we want to comment on a successful implementation of the annealing algorithm by Slonim and Tishby [6]. In their approach they start the annealing procedure with at for all and y at . After increasing β they split , for , into two parts, and by setting
where is random perturbation and ϵ is small. If under the fixed point iteration at new value of β the values and converge to the same value ( in this case), then the process is repeated; if, on the other hand, these values diverge, a presence of a bifurcation is asserted. Note, that this process changes N from 2 to 4 repeatedly. This changes the optimization problem, because the space of admissible quantizers q doubled. It is not clear a priori that phase transition detected in problem with variables also occurs at the same value of β in problem with variables. Numerically, however, this seems to be the case not only at the first phase transition, but at every phase transition. One of the results of Section 4 will be an explanation of this phenomena. We will show that the parameter β, at which the first phase transition takes place, does not depend on the number of elements in the reproduction variable T. This provides a justification for Slonim’s algorithm, at least for the first phase transition.
Since the optimization problems (1) and (2) are constrained, we first form the Lagrangian,
which incorporates the vector of Lagrange multipliers λ, imposed by the equality constraints from the constraint space Δ. Here for (1) or for (2),
Lemma 2.1
The function is a strictly concave function of and the functions and are convex, but not strictly convex, functions of .
Proof.
For concavity of and convexity of , see [2]. Proof of the convexity of is analogous.
This Lemma implies that for in both (1) and (2), there is a trivial solution for all t and y. We denote this solution as .
What we want to emphasize here is that and are not strictly convex functions. Recall that a function f is convex provided
for all u, v, and . The function f is strictly convex if the inequality in (5) is strict for u ≠ v and .
To show that is not strictly convex, we take independent on k (see Figure 2). In order for this q to satisfy we require that numbers are chosen with . Using the facts that and , we evaluate at the function
This implies that in Δ there is an dimensional linear space spanned by vectors with , such that for all q in this space . Since , this function does not have a unique minimum and thus is not strictly convex. ☐
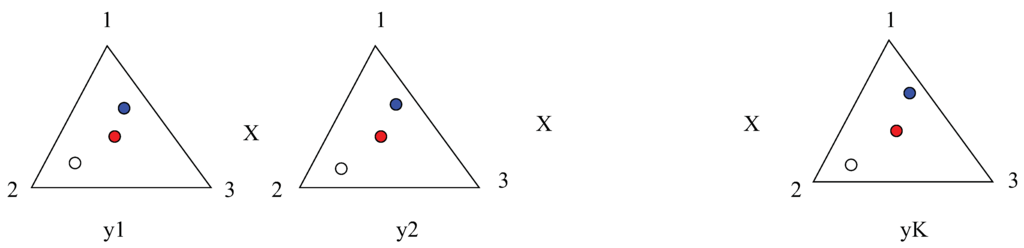
Figure 2.
The function is not strictly convex. There are three vectors q depicted in the figure. The red point in the middle of each simplex represents the point with . The blue point and the white points have the property that does not depend on y, only on t. At all three points the function is equal to zero.
This result has consequences for the function . As we will see in Lemma 3.1, at all points where . This lack of strict convexity has important consequences for phase transitions for . Since is strictly concave, this problem will not affect the function .
Maxima of (1) and (2) are critical points of the Lagrangian, that is, points q where the gradient of (4) is zero. We now switch our search from maxima to critical points of the Lagrangian. Obviously, minima and saddle points are also critical points and therefore we must always check whether a given critical point is indeed a maximum of the original problem (1) or (2). We want to use the language of bifurcation theory which deals with qualitative changes in the structure of system dynamics given by differential equations or maps. Therefore we will now reformulate the optimization problems (1) and (2) as a system of differential equations under a gradient flow,
In this equation, the vector q representing the quantizer, and the vector of the Langrange multipliers (see Equation (4)) are viewed as functions of some independent variable s, which parameterizes curves of solutions to either (1) or (2). Thus, the derivatives implicit in are with respect to s. The critical points of the Lagrangian are the equilibria of (6), since those are the places where the gradient of Ł is equal to zero. By the same token, the maxima of (1) and (2) correspond to stable (in q) equilibria of the gradient flow (6). More technically, these are points for which the Hessian is negative definite on the kernel of the Jacobian of the constraints [18,19].
As β increases from 0, the solution is initially a maximum of (1) and (2). We are interested in the smallest value of β, say , where ceases to be a maximum. This corresponds to a change in the number of critical points in the neighborhood of as β passes through . The value is called a bifurcation value and the new sets of critical points emanating from are called bifurcating branches. This question can be posed at any other point besides as well: When do such bifurcations happen? We will formulate the answer in the language of differential equations. If the linearization of the flow at equilibrium has eigenvalues with nonzero real part, the implicit function theorem implies that this equilibrium exists for all values of the parameter in a small neighbourhood. Since the number of equilibria then does not change locally, this implies that a bifurcation does not occur at such a point. Therefore, a necessary condition for bifurcation is that the real part of some eigenvalue of the linearization of the flow at an equilibrium crosses zero [20]. Therefore, we need to consider eigenvalues of the Hessian . Since is a symmetric matrix, bifurcation can only be caused by one of its real eigenvalues crossing zero, and therefore we must find values of at which is singular, or, equivalently, has a nontrivial kernel.
The form of is simple:
where I is the identity matrix and is
The block diagonal matrix consisting of all matrices represents the matrix of second derivatives (Hessian) of F.
In [15,17] we showed that there are two types of generic bifurcations: saddle-node, in which a set of equilibria emerge simultaneously, and pitchfork-like, in which new equilibria emanate from an existing equilibrium. The first kind of bifurcation corresponds to a value of β, and corresponding q, for which is singular, but is non-singular; the second kind of bifurcation happens at β and q where is singular. Our primary focus here is on bifurcations off , and more generally off an existing branch, we will focus on the second kind of bifurcation. Therefore, we will investigate only the case in which the eigenvalues of the smaller Hessians and are zero to determine the location of pitchfork-like bifurcations.
2.1. Derivatives
In order to simplify notation we will denote
To determine and from (1) and (2), we need to determine the quantities , and . The first two were computed in [2]:
and
where if and zero otherwise. We computed the derivative of the term in [19]
The formulas (7)–(9) show that we can factor out of both and . This implies that the matrices and are block diagonal, with N blocks, with each block corresponding to a particular value (class) of the reconstruction variable .
2.2. Symmetries
The optimization problems (1) and (2) have symmetry. We capitalize on this symmetry to solve these problems better. The symmetries arise from the structure of and from the form of the functions and : permuting subvectors does not change the value of and . This symmetry is characterized as an invariance under the action of the permutation group, , or one of its subgroups , .
We will capitalize upon the symmetry of by using the Equivariant Branching Lemma to determine the bifurcations of stationary points, which includes local solutions, to (1) and (2).
In [15] we clarified the bifurcation structure for a larger class of constrained optimization problems of the form
as long as F satisfies the following:
Proposition 2.2
The function is of the form
for some smooth scalar function f, where the vector is decomposed into N subvectors .
The annealing problems (1) and (2) satisfy this Proposition. Any F satisfying Proposition 2.2 has the following properties.
- F is -invariant, where the action of on q permutes the subvectors of q.
- The Hessian is block diagonal, with blocks.
3. The Kernel at a Bifurcation
In this section we investigate and compare the kernels of the Hessians and .
3.1. The Kernel of the Information Bottleneck
Our first observation is that is highly degenerate as a consequence of the fact that both and are not strictly convex in q.
Lemma 3.1
Select a collection of numbers such that and . Let be a vector consisting of vectors , such that is a constant vector with entries . In other words, select independent on y. Then
Proof.
We evaluate at the function
Since is a particular case of , the Lemma is proved. ☐
Now we prove a generalization of this Lemma. We will say that q has symmetry described by (a subgroup of ) if
where z is the total number of “blocks" of sub-vectors, with the sub-vector repeating times in the block. At such vector q, the matrix has z groups of blocks , and all blocks in each group are identical. In particular, the first blocks are the same, then next blocks are the same, and so on.
Theorem 3.2
Consider an arbitrary pair , where q admits a symmetry . Then, at a fixed value of β, there is a linear manifold of dimension
passing through q, such that the function is constant on this manifold.
Proof.
The quantizer q must take the form given by (10). Let
where the constants are nonnegative and . We will show that
We separate into two parts
Since the vectors w and q agree for all we have
Observe first that
where is the function inside the parentheses on the last line. Now we evaluate
Since by assumption, we have and therefore
Since , the solutions w form a dimensional linear manifold. The same argument can be applied to to finish the proof. ☐
Now we spell out the consequences of this degeneracy for . Since the manifolds of constant value of are linear, the second derivative along these manifolds must vanish. Note that in Theorem 3.2 we required that the solutions lie in Δ. Therefore, must vanish along this manifold, rather then . In the following paragraphs, our first two results are concerned with , the third—with .
First we will show the result for a single block of .
Lemma 3.3
Fix an arbitrary quantizer q and an arbitrary class ν. Then the vector is in the kernel of the block of for any value of β.
Proof.
Corollary 3.4
For an arbitrary pair , the dimension of is at least N, the number of classes of T.
Proof.
Given as in Lemma 3.3, we define vectors by
By Lemma 3.3, . Clearly these vectors are linearly independent. ☐
Now we investigate the consequences of Theorem 3.4 for the dimensionality of the kernel of .
Theorem 3.5
Consider an arbitrary pair , where q admits a symmetry . Then the dimension of at such point is at least
Proof.
Since q admits the stated symmetry it has the form (10). There are vectors of the form
Direct computation shows that, since , each vector . Similar argument shows that there are vectors for . ☐
Corollary 3.6
If q has no symmetry, i.e., and all for , then the dimension of is . In other words, is non-singular.
Lemma 3.7
At a phase transition of system (2) we have .
Proof.
This follows from the fact that the degeneracy of the kernel of dimension is a consequence of the existence of a -dimensional manifold of solutions on which is constant. The existence of kernel with this dimension therefore does not indicate a phase transition. For that, the kernel must be at least -dimensional. ☐
3.2. The Kernel of the Information Distortion
We want to contrast the degeneracy of with the non-degeneracy of .
Theorem 3.8
There is no value of q such that the matrix is singular for all β in some interval.
Proof.
If such that for each β in some interval I, is singular, then
for some vector valued function . Thus, , from which it follows that is a -eigenvector of the fixed matrix for every . This is a contradiction, since has at most distinct eigenvalues. ☐
Lemma 3.9
At the phase transition for system (1) we have .
4. Bifurcations off the Uniform Solution
In this section we want to illustrate the close analogy between Deterministic Annealing with Euclidean distortion function and Information Distortion. Our goal is to find values of for which the problems (1) and (2) undergo phase transition. Given the joint probability distribution , we can find the values of β explicitly for in terms of eigenvalues of a certain stochastic matrix. Secondary phase transitions that occur at values of cannot be computed explicitly and we must resort to numerical continuation along the branches of equilibria. An eigenvalue problem, implicitly relating quantities and β at which phase transition occurs, can still be obtained. This is completely analogous to results of Rose [14] for a different class of optimization problems.
We start by deriving a general eigenvalue problem which computes the pair . We seek to compute for which the matrix of second derivatives has a nontrivial kernel. This is a necessary condition for a bifurcation to occur. We first discuss the Hessian of (1), , evaluated at q and at some value of the annealing parameter β. Thus, we need to find pairs where has a nontrivial kernel. For that, we solve the system
for any nontrivial . We rewrite (11) as an eigenvalue problem,
Since , then, for the Hessian , we find pairs for which
Multiplying by leads to a generalized eigenvalue problem
Since is diagonal, we can explicitly compute the inverse
Next, we compute the explicit forms of the matrices
and
Since both of these matrices are block diagonal, with one block corresponding to a class of , we will compute the block of these matrices. Using (7)–(9) we get that the element of the block of is
and the element of the block of is
We observe that the matrix can be written as , where the element of the block of matrix is
Therefore the problems (12) and (13) become generalized eigenvalue problems,
and
respectively.
In the eigenvalue problems (17) and (18), the matrices and change with q. On the other hand, we know that for all for some , both problems (1) and (2) have a maximum at the uniform solution [19], i.e., when for all t and y. We now determine when this extremum ceases to be the maximum.
We evaluate matrices and at to get
and
Let be a vector of ones in . We observe that
and that the component of
Therefore, we obtain one particular eigenvalue-eigenvector pair of the eigenvalue problems (17) and (18):
Since the eigenvalue λ corresponds to , this solution indicates a bifurcation at . We are interested in finite values of β.
Theorem 4.1
Proof.
We note first that the range of matrix is the linear space spanned by vector , and its kernel is the linear space
where .
We now check that the space W is invariant under the matrix , which means that . It will then follow that all eigenvectors of , except , belong to W and are actually eigenvectors of alone. So, assume , which means
We compute the l-th element of vector :
The vector belongs to W if, and only if, its dot product with p is zero. We compute the dot product
The last expression is zero, since .
This shows that all other eigenvectors of , except , belong to W and are eigenvectors of alone. Since bifurcation values β are reciprocal to eigenvalues , the result follows. ☐
Corollary 4.2
The value β at which the first phase transition occurs does not depend on the number of classes, N. It only depends on the properties of the matrix Q.
Observe that, since has N identical blocks at and each block has a zero eigenvalue at , we get that
at such a value of β. This is a consequence of the symmetry. For the Information Bottleneck function , as a consequence of Lemma 3.4, each block has a zero eigenvalue for any value of β. At the instance of the first phase transition at , each block of admits an additional zero eigenvalue, and therefore
Notice that the matrix is transpose of a stochastic matrix, since the sum of all elements in the row,
Therefore all eigenvalues satisfy . In particular, . This proves
Remark 4.4
The matrix has an interesting structure and interpretation (see Figure 3). Let G be a graph with vertices and let the oriented edge have a weight . The matrix Q is the transpose of a Markov transition matrix on the elements . The weight attached to each edge is a sum of all the contributions along all the paths over all i. This structure is key to associating the annealing problem to the normalized cut problem discussed in Section 6.
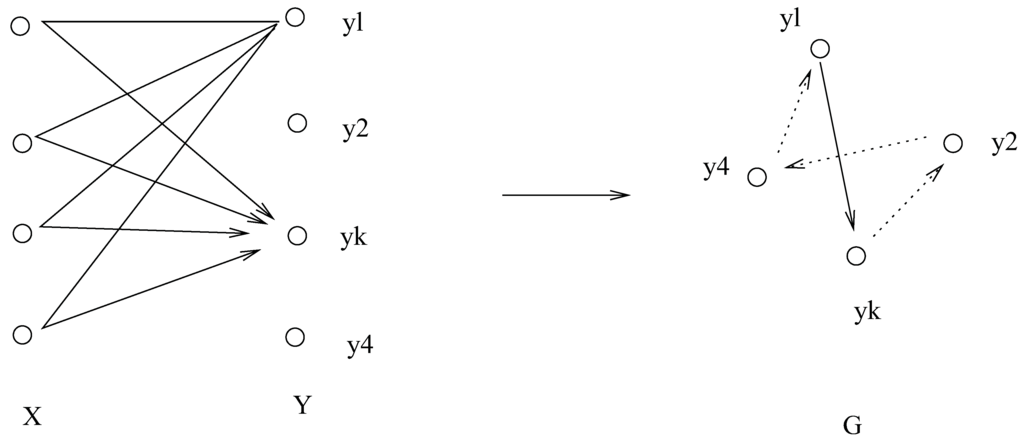
Figure 3.
The graph G with vertices labelled by elements of Y. The oriented edges in G have weights obtained from the weights in the graph of the joint distribution . The weight of the solid edge in G is computed by summing the edges on the left side of the picture.
5. Bifurcations in the General Case
To find the discrete values of the pairs that solve the eigenvalue problems (17) and (18) for a general value of q, we transform the problems (17) and (18) one more time. Let C be a block diagonal matrix of size whose block is a diagonal matrix, . Instead of the eigenvalue problem (17), we consider
and instead of the problem (18), we consider
Clearly, these problems have the same eigenvalues as the problems (17) and (18) respectively, and the eigenvectors are related via the diagonal matrix C.
Let
Then the element of the block of the matrix is
and for the matrix B, we have that
Lemma 5.1
The matrix is stochastic for any value of q.
Proof.
We sum the column of to get
☐
Lemma 5.2
Proof.
To show the first part of the Lemma, we multiply the row of block of by the vector . We get
Observe that the above computation shows that , and so is a 1-eigenvector of the stochastic matrix . This finishes the first part of the proof.
To prove the second case, we will show that and that is invariant under . To see that , it is enough to realize that every row of is a multiple of 1, the vector of ones. In other words, from (22) is independent of k. Clearly, 1 is perpendicular to . Since the range of is one-dimensional, . It follows easily that
To finish the proof, we show that W is invariant under any stochastic matrix, and in particular to the matrix . Let S be a stochastic matrix. Then, if then
Adding up the elements in vector Sw, we get
and so . ☐
Theorem 5.3
Fix an arbitrary . Let be a union of eigenvalues of the stochastic matrices for all ν. Then the values of β for which has a nontrivial kernel (or where , see Lemma 3.5) are
Proof.
The only difference between and is the N dimensional kernel of the latter matrix. Therefore we will only consider in this proof.
As discussed above, has a nontrivial kernel if and only if there is a block which has a nontrivial kernel. We will use the previous Lemma to discuss such a block.
Note that corresponds to , and so this scenario is unimportant for the bifurcation structure of the problems (1) and (2).
Since is a dimension invariant subspace of , there must be eigenvectors of in . The 0-eigenvector is not in , so all other eigenvectors not corresponding to must be in . Since is stochastic and corresponds to the eigenvalue 1 of , then the β values at which bifurcation occurs are reciprocals to the eigenvalues of for each ν. That means . Since there are N blocks, there will be at least N eigenvalues of equal to 1. ☐
We used Theorem 5.3 to determine the β values where bifurcations occur from the uniform solution branch . The results are presented in Figure 4.
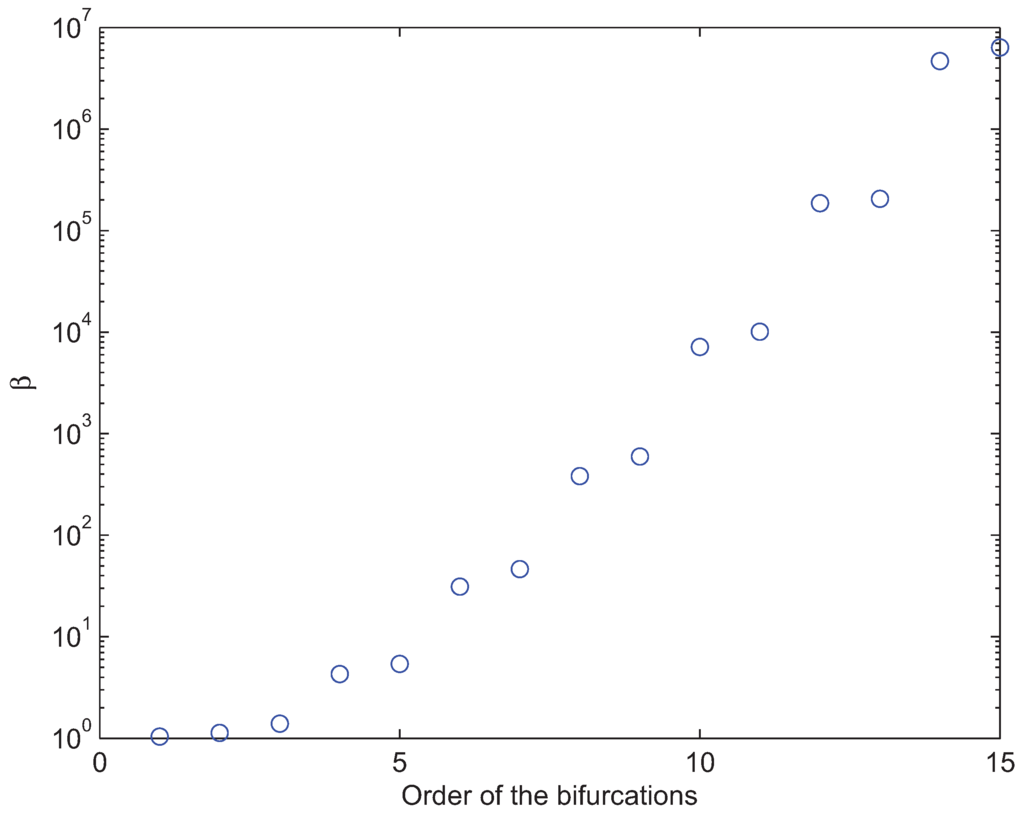
Figure 4.
Theorem 5.3 can be used to determine the β values where bifurcations can occur from . A joint probability space on the random variables was constructed from a mixture of four Gaussians as in [2]. For this data set, and for either or , we predict bifurcation from the branch , at each of the 15 β values given in this figure. By Theorem 4.1, ceases to be a solution at .
6. Normalized Cuts and the Bifurcation off
There is a vast literature devoted to problems of clustering. Many clustering problems can be formulated in the language of graph theory. Objects which one desires to cluster are represented as a set of nodes V of a graph , and the weights w associated to edges represent the degree of similarity of two adjacent nodes. Finding a good clustering in such a formulation is equivalent to finding a cut in the graph G, which divides the set of nodes V into sets representing individual clusters. A cut in the graph is simply a collection of edges that are removed from the graph.
A bi-partitioning of the graph is the problem in which a cut divides the graph into two parts, A and B. We define
There are efficient algorithms to solve minimal cut problem, where one seeks a partition into sets A and B with minimal cut value. When using the minimal cut as a basis for a clustering algorithm, one often finds that the minimal cut is achieved by separating one node from the rest of the graph G. Including more edges into the cut increases the cost, hence these singleton solutions will be favored.
To counteract that, Shi and Malik [21] studied image segmentation problems and proposed a clustering based on minimizing the normalized cut (Ncut):
where
Shi and Malik [21] have shown that the problem of minimizing the normalized cut is NP-complete. However, they proposed an approximate solution, which can be found efficiently. We briefly review their argument: Let
be the total connection from node i to all other nodes. Let be the number of nodes in the graph and let D be an diagonal matrix with values on the diagonal. Let W be an symmetric matrix with
Let x be an indicator vector with if node i is in A, and otherwise. Then Shi and Malik [21] show that the minimal cut can be computed by minimizing the Rayleigh quotient over a discrete set of admissible vectors y:
with components of y satisfying for some constant b, and under the additional constraint
If one relaxes the first constraint and allows for a real valued vector y, then the problem is computationally tractable. The computation of the real valued vector y is the basis of the Approximate normalized cut. Once this vector is computed, vertices of G which correspond to positive entries of y will be assigned to the set A, and vertices which correspond to negative entries of y will be assigned to the set B. The relaxed problem is solved by the solution of a generalized eigenvalue problem,
that satisfies the constraint (29). We repeat here an argument of Shi and Malik’s [21], which shows that (28) with the constraint (29) is solved by the second smallest eigenvector of the problem (30). In fact, the smallest eigenvalue of (30) is zero and corresponds to an eigenvector . The argument starts with rewriting (30) as
and realizing that is a 0-eigenvector of this equation. Further, since is symmetric, all other eigenvectors are perpendicular to . Translating back to problem (30), one gets the corresponding vector and all other eigenvectors satisfying . We want to observe that this is the only place when the symmetry of matrix W is used.
In Theorem 4.1 we showed that the bifurcating direction v of one block of is the eigenvector corresponding to the second largest eigenvalue of a stochastic matrix Q. In Remark 4.4 we interpreted the matrix as a transition matrix of a Markov chain and we associated a directed graph G to this Markov chain. The graph G had vertices labelled by the elements of Y and the weight of the edge was defined by
Note that these weights are not symmetric. We will symmetrize the graph G by multiplying the weight matrix by a diagonal matrix . The resulting graph H (Figure 5) has a weight matrix whose element is
We form an undirected graph H with vertices labelled by elements of Y and the edge weight given by (31).
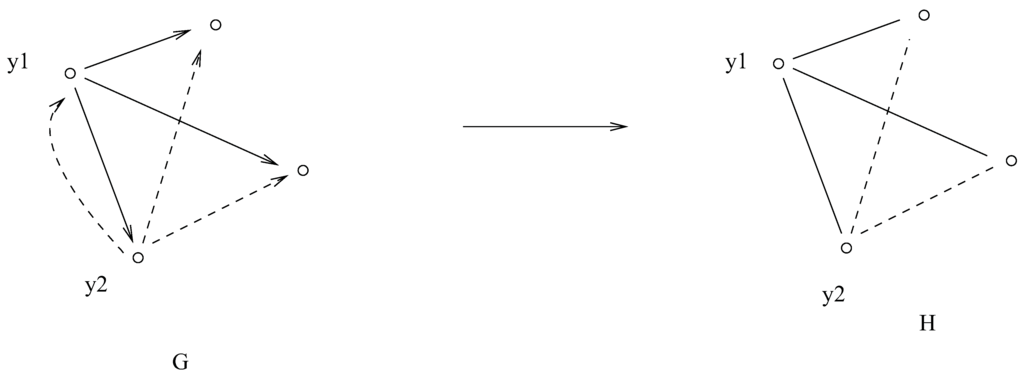
Figure 5.
Graph G on the left is an oriented graph. We obtain unoriented graph H on the right by multiplying all edges emanating from by . In the figure all weighs along solid edges are multiplied by and all weights along the dashed edges are multiplied by .
The following Theorem, relating the bifurcating direction of matrix Q to the solution of the Approximate Normalized Cut of graph H, was proved in [22]. We use the notation of Theorem 4.1
Theorem 6.1
([22]) The eigenvector , along which the solution bifurcates at , induces the Approximate Normal Cut of the graph H.
This Theorem shows that the bifurcating eigenvector solves the Approximate Normal Cut for the graph H, rather than the original graph G. This suggest an important inverse problem. Given a graph H for which we want to compute the Approximate Normal Cut, can we construct the graph G (given by the set of vertices, edges and weights), such that the bifurcating eigenvector would compute the Approximate Normal Cut for H? This problem, which is beyond the scope of this paper, was addressed in [22], where an annealing algorithm was designed to compute the Approximate Normal Cut using these techniques. The reader is referred to the original paper for more details.
Remark 6.2
In [15] we show that the bifurcating direction for at the first phase transition from is a vector of the form
where is the second eigenvector of the block (all the block are identical by symmetry). In this expression and there are K vectors of size K in vector . Then the quantizer q shortly after passing a bifurcation value of β has the form
Let us denote by A the set of such that the i-th component of v is negative, and by B the set of such that the i-th component of v is positive. Note that A and B correspond to the Approximate Ncut for both graphs G and H. If we verbalize as “the probability that y belongs to class t”, then (32) shows that, after bifurcation
- the probability that belongs to class 1 is less than and the probability that it belongs to classes is more then ;
- the probability that belongs to class 1 is more than and the probability that it belongs to classes is less then .
7. Conclusions
The main goal of this contribution was to show that information-based distortion annealing problems have an interesting mathematical structure. The most interesting aspects of that mathematical structure are driven by the symmetries present in the cost functions—their invariance to actions of the permutation group , represented as relabeling of the reproduction classes. The second mathematical structure that we used successfully was bifurcation theory, allowing us to identify and study the discrete points at which the character of the solutions to the cost function changed. The combination of those two tools allowed us to compute explicitly in Section 4 the value of the annealing parameter β at which the initial maximum of (1) and (2) loses stability. We concluded that, for a fixed system , this value is the same for both problems, that it does not depend on the number of elements of the reproduction variable and that it is always greater than 1. In Section 5 we further introduced an eigenvalue problem which links together the critical values of β and q for phase transition off arbitrary intermediate solutions.
Even though the cost functions and have similar properties, they also differ in some important aspects. We have shown that the function is degenerate since its constitutive functions and are not strictly convex. That introduces additional invariances that are always preserved, which makes phase transitions more difficult to detect, and post-transition directions more difficult to determine. Specifically, in addition to actions by the group of symmetries, the cost function is invariant to altering a solution by a vector in the ever-present kernel (identified in Corollary 3.4). In contrast, is strictly convex except at points of phase transitions. The theory we developed allows us to identify bifurcation directions, and determine their stability. Despite the presence of a high dimensional null space at bifurcations, the symmetries restrict the allowed transitions to multiple 1-dimensional transition, all related by group transformations.
Finally, in Section 6 we showed that the direction in which a phase transition occurs can be linked to an Approximate Normalized Cut problem of graphs arising naturally from the data structure given by . This connection will allow future studies of information distortion methods to include powerful approximate techniques developed in Graph Theory. It will also allow the transition of the methods we developed here into tools that may be used to create new approximations for the Approximate Normalized Cut problem.
Previously we have shown that for both problems the global optimum () is deterministic [3], and that the combinatorial search for the solution is NP-complete [23]. The main problem that still remains unresolved is whether the global optimum can always be achieved by the annealing process from the uniform starting solution. Proving this may be equivalent to stating that , so it is unlikely. However, the relatively straightforward annealing problem, when combined with the power of equivariant bifurcation theory, may be a fruitful method for approaching -hard problems.
Acknowledgments
This research was partially supported by NSF grants CMMI 0849433 and DMS-081878.
References
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37th annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, September 22-24, 1999.
- Dimitrov, A.G.; Miller, J.P. Neural coding and decoding: Communication channels and quantization. Netw. Comput. Neural Syst. 2001, 12, 441–472. [Google Scholar] [CrossRef]
- Gedeon, T.; Parker, A.E.; Dimitrov, A.G. Information distortion and neural coding. Can. Appl. Math. Q. 2003, 10, 33–70. [Google Scholar]
- Cover, T.; Thomas, J. Elements of Information Theory; Wiley Series in Communication: New York, NY, USA, 1991. [Google Scholar]
- Slonim, N.; Tishby, N. Agglomerative information bottleneck. In Advances in Neural Information Processing Systems; Solla, S.A., Leen, T.K., Muller, K.R., Eds.; MIT Press: Boston, MA, USA, 2000; Volume 12, pp. 617–623. [Google Scholar]
- Slonim, N. The information bottleneck: Theory and applications. Ph.D. Thesis, Hebrew University, Jerusalem, Israel, November 2002. [Google Scholar]
- Pereira, F.; Tishby, N.Z.; Lee, L. Distributional clustering of english words. In Proceedings of the 30th Annual Meeting of the Association for Computational Linguistics, Newark, DE, USA, 28 June–2 July 1992; pp. 183–190.
- Bekkerman, R.; El-Yaniv, R.; Tishby, N.; Winter, Y. Distributional word clusters vs. words for text categorization. J. Mach. Learn. Res. 2003, 3, 33–70. [Google Scholar]
- Mumey, B.; Gedeon, T.; Taubmann, J.; Hall, K. Network dynamics discovery in genetic and neural systems. In Proceedings of the ISMB 2000, La Jolla, CA, USA, 2000.
- Bialek, W.; de Ruyter van Steveninck, R.R.; Tishby, N. Efficient representation as a design principle for neural coding and computation. In Proceedings of the 2006 IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 659–663.
- Schneidman, E.; Slonim, N.; Tishby, N.; de Ruyter van Steveninck, R.R.; Bialek, W. Analyzing neural codes using the information bottleneck method. In Advances in Neural Information Processing Systems; MIT Press: Boston, MA, USA, 2003; Volume 15. [Google Scholar]
- Slonim, N.; Somerville, R.; Tishby, N.; Lahav, O. Objective classification of galaxy spectra using the information bottleneck method. Mon. Not. R. Astron. Soc. 2001, 323, 270–284. [Google Scholar] [CrossRef]
- Gueguen, L.; Datcu, M. Image time-series data mining based on the information-bottleneck principle. IEEE Trans. Geosci. Rem. Sens. 2007, 45, 827–838. [Google Scholar] [CrossRef]
- Rose, K. Deterministic annealing for clustering, compression, classification, regression, and related optimization problems. Proc. IEEE 1998, 86, 2210–2239. [Google Scholar] [CrossRef]
- Parker, A.; Dimitrov, A.G.; Gedeon, T. Symmetry breaking clusters in soft clustering decoding of neural codes. IEEE Trans. Inform. Theor. 2010, 56, 901–927. [Google Scholar] [CrossRef]
- Parker, A.; Gedeon, T.; Dimitrov, A. Annealing and the rate distortion problem. In Advances in Neural Information Processing Systems 15; Becker, S.T., Obermayer, K., Eds.; MIT Press: Cambridge, MA, USA, 2003; Volume 15, pp. 969–976. [Google Scholar]
- Parker, A.E.; Gedeon, T. Bifurcation structure of a class of SN-invariant constrained optimization problems. J. Dynam. Differ. Equat. 2004, 16, 629–678. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: New York, NY, USA, 2000. [Google Scholar]
- Parker, A.E. Symmetry Breaking Bifurcations of the Information Distortion. Ph.D. Thesis, Montana State University, Bozeman, MT, USA, April 2003. [Google Scholar]
- Golubitsky, M.; Schaeffer, D.G. Singularities and Groups in Bifurcation Theory I; Springer Verlag: New York, NY, USA, 1985. [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Gedeon, T.; Campion, C.; Parker, A.E.; Aldworth, Z. Annealing an information type cost function computes the normalized cut. Pattern Recogn. 2008, 41, 592–606. [Google Scholar] [CrossRef] [PubMed]
- Mumey, B.; Gedeon, T. Optimal mutual information quantization is NP-complete. In Proceedings of the Neural Information Coding (NIC) workshop, Snowbird, UT, USA, March 2003.
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/.)