Abstract
The literature is rich with studies and examples on parameter estimation obtained by analyzing the evolution of chaotic dynamical systems, even when only partial information is available through observations. However, parameter estimation alone does not resolve prediction challenges, particularly when only a subset of variables is known or when parameters are estimated with a significant uncertainty. In this paper, we introduce a hybrid system specifically designed to address this issue. Our method involves training an artificial intelligence system to predict the dynamics of a measured system by combining a neural network with a simulated system. By training the neural network, it becomes possible to refine the model’s predictions so that the simulated dynamics synchronizes with that of the system under investigation. After a brief contextualization of the problem, we introduce the hybrid approach employed, describing the learning technique and testing the results on three chaotic systems inspired by atmospheric dynamics in measurement contexts. Although these systems are low-dimensional, they encompass all the fundamental characteristics and predictability challenges that can be observed in more complex real-world systems.
1. Introduction
The study of chaotic systems spans across multiple disciplines, incorporating principles of dynamical systems, nonlinear dynamics, and complex systems. Chaos theory is central to the explanation of non-periodic and unpredictable behaviors across various natural and engineered systems. A key feature of chaotic dynamics is its sensitivity to initial conditions, so that a small discrepancy between two initial conditions can exponentially amplify over time, making long-term predictions unreliable while preserving short-term predictability. This dual nature of chaos poses significant challenges but also provides valuable insights into the behavior of complex systems.
Time series forecasting, which involves predicting future system states from experimental data, is a critical tool for understanding such dynamics. The strength of traditional mathematical models lies in their direct interpretability in physical terms; however, they often struggle with uncertainties in system parameters and measurement noise, especially in chaotic regimes [1,2,3,4]. In contrast, data-driven methods, particularly those employing neural networks, have shown remarkable progress in capturing intricate patterns and nonlinear relationships within time series data [5,6,7,8,9,10,11].
Deep learning architectures [12], such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), have proven effective for tasks ranging from image recognition to sequential data analysis. Recent advances in neural architectures, such as the transformer network [13], have further improved long-range dependency modeling, but limitations like the loss of temporal scale information remain [14]. Studies have addressed these gaps by proposing simplified models, such as LTSF (Long Time Series Forecasting)-Linear [15], optimized for time series forecasting tasks.
In chaotic time series forecasting, neural networks like Long Short-Term Memory (LSTM) [16] units and Gated Recurrent Units (GRUs) [17] have demonstrated superior performances. Research shows that these models can capture the complex attractor structures inherent in chaotic systems [18,19], enabling more extended prediction horizons compared to traditional methods [20,21,22]. Furthermore, studies that push towards optimized architecture research, also considering hardware implementations, have increased in recent years also for the prediction of chaotic dynamics, with promising results [23].
On the other hand, hybrid approaches that combine neural networks with modeling techniques have emerged as a promising paradigm [24,25]. These models exploit the structured insights of physics-based equations while leveraging neural networks to learn corrections, enhancing robustness and accuracy.
Recent studies demonstrated the effectiveness of hybrid approaches in various contexts. For instance, Physics-Informed Neural Networks (PINNs) [26] integrate the structure of partial differential equations into the learning process, enhancing the accuracy of predictions even in chaotic systems [27]. The approach based on Neural Ordinary Differential Equations (NODEs) [28] extends this concept by embedding neural networks within the integration process, enabling adaptive modeling of nonlinear dynamics. Additionally, neural network-trained solutions enable efficient trajectory prediction and uncertainty quantification in chaotic systems, facilitating tasks such as Bayesian parameter inference [29,30].
These approaches have been applied successfully to benchmark chaotic systems such as the Lorenz ’63, Mackey-Glass, and Rössler systems, demonstrating improved long-term prediction capabilities compared to traditional methods. They also hold potential for real-world applications, including astrophysics, weather forecasting, and complex biological systems, where both short-term accuracy and long-term stability are critical [31,32,33,34]. For instance, hybrid models combining RNNs with techniques like empirical mode decomposition (EMD) have outperformed standalone methods in financial forecasting [35]. Similarly, hybrid architectures such as GRU-LSTM combinations and deep temporal modules have excelled in predicting wind power [36] and traffic flow [37], demonstrating their adaptability across domains [38]. By addressing the limitations of purely physics-based or purely data-driven methods, these hybrid models provide a robust framework for trajectory prediction and uncertainty propagation, offering new avenues for the study and control of chaotic dynamics.
On the other hand, problems such as the statistical representation of extreme events, the difficulty modeling long-term temporal dependencies, and the lack of flexibility towards data external to the domain on which they were trained [39] (e.g., covariate shift and concept drift) make neural networks still unreliable for operational tasks, such as prediction in the atmospheric and meteorological fields.
A further advantage of the mathematical description of the dynamic evolution is that, through the analysis of the dynamical equations, it is possible to estimate the correct statistics, return times of rare events and the prediction of unobserved dynamics. But, even assuming that we know the dynamic of the system
where and represent, respectively, the state vector and the vector of the model parameters, and the dot operator denotes the time derivative, the problem of parameter estimation remains.
In general, the parameters can be estimated with a finite precision due to measurement noise and inherent limitations in parameter estimation.
In chaotic systems, even small discrepancies between the true and modeled parameters lead to an exponential divergence between the observed trajectory and the trajectory predicted by the model, Equation (1).
For these reasons, a further line of research regarding the use of intelligent systems combined with concepts of synchronization and data assimilation [40,41,42], has moved towards the use of neural network and the assimilation of measurements to iteratively correct the prediction output and match the prediction to the observed data [43,44,45,46,47].
This paper explores a similar hybrid approach, combining Recurrent Neural Networks with differential equations to predict chaotic trajectories, correct for model errors, and interpolate states where data are unavailable. The neural network module compensates for this divergence by learning to correct systematic errors, thereby enabling accurate trajectory predictions over longer time horizons.
The method proposed combines a neural network with a simulated system to predict the dynamics of the measured system. The neural network is trained to correct the simulated model, thereby improving alignment with the real system. This approach is particularly useful in scenarios where partial measurements or uncertain parameters do not allow accurate predictions.
The paper is organized as follows. In the next section we introduce the problem, setting it in a short-time system prediction perspective starting from a set of measurements. We will then introduce the hybrid system, the proposed NN architecture and how it can be trained to force the dynamics estimated by the model with estimated parameters, , to follow the true one. The third section provides a brief overview of the benchmark models used to evaluate our hybrid system, followed by the presentation of training results. We demonstrate how this system can achieve long-term predictions even when only partial measurements of the system are available.
A concluding section follows with comments and future perspectives.
2. Hybrid Modeling and Time Series Prediction
Given a set of measurements sampled from a trajectory —solution of a set of differential Equation (1) with parameters —we assume that the observation provides a complete knowledge of the state at the measurement time. Additionally, we consider measurements to be equally spaced in time with a time step , where integer and represents the integration time step. Then,
where and quantifies the uncertainty due to the measurement process.
We note that this choice of constant sampling does not in any way undermine the procedure we will present below, which remains flexible even for non-uniformly distributed time sampling. This choice was made solely for computational simplicity and to pose a more challenging prediction scenario, as studies show that varying the sampling frequency can lead to improved system predictability [48,49].
From the observations, we can estimate the unknown parameters [50]. However, due to the chaotic nature of the system, these estimates—even with complete knowledge of the state of the system —are not sufficient for accurate future predictions. Furthermore, we cannot assume that we know the parameters of the system with arbitrary precision. In general,
where denotes the error associated with the estimated parameters, which will depend on the method chosen to find the parameters and on the precision of the set of measurements .
The goal is that of predicting next states of the system using this set of measurements. To achieve this, we propose a hybrid method that combines general dynamics information with available local measures (Figure 1).
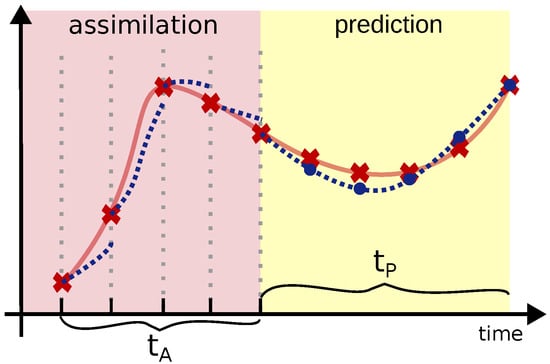
Figure 1.
Schematic representation of the prediction process. The system is trained to predict the trajectory over a time window based on a set of measurements. Assimilation occurs during a time window , in which the system state is reinitialized with the available measurements (red markers in the figure). The figure also shows the network’s predictions at the measurement times (blue dots).
2.1. Predictive Framework
The hybrid system integrates predictions from a physical model, denoted as , with corrections generated by a neural network. Given a state at time t, to estimate the new state at time , the evolution of the system is computed according to the following sequence of operations:
- Physical model prediction: The differential equation, Equation (1), is used to compute a preliminary estimate of the state at the next time step, . The numerical integration scheme employed (e.g., Euler, Runge–Kutta, or lsoda) determines the specific computation.
- Neural network correction: A neural network is used to estimate the correction term using the initial condition and the estimated prediction as input.
- State update: The predicted state in the next time step is obtained by combining the estimate from the physical model with the correction from neural network:This estimated state is used as input for the subsequent time step .
Starting from the initial condition and the state predicted by the model , the network is trained to correct the model’s output, enabling long-time predictability.
2.1.1. Architecture
The situation described in the previous section suggests using an RNN, a neural network architecture with temporal memory, which provides flexibility in capturing dynamics with temporal dependencies.
The proposed neural network architecture consists of two main components (Figure 2a):
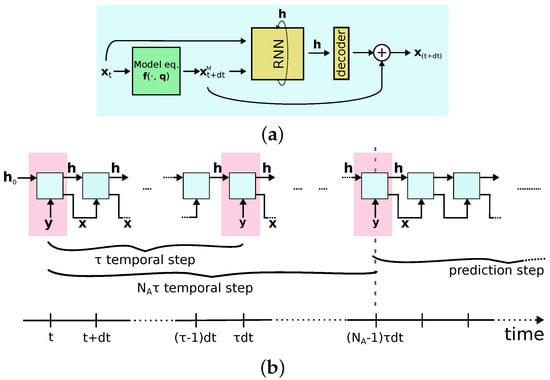
Figure 2.
(a) Architectureused for a single time step integration. Starting from the initial condition, a first guess of the next state is made using the physical equations. These two values are the input of the neural network block trained to correct the first guess of the physical model. (b) Loop to generate a trajectory starting from measurements. When a measurement is available in the assimilation window (marked in pink), the measurement is used as input. The cyan boxes represent the architecture described in (a) in its unrolled representation.
- Memory block: Encodes and corrects the trajectory in a high-dimensional latent space of dimension .
- Decoder: Comprises two linear layers of dimension , followed by a ReLU function to introduce a non-linearity, and a output linear layer to remap the network state back into the system’s space.
For the memory block, we use the GRU architecture. It evolves an internal state combining present and past information through two gates, which determine the relevance of past trajectory information to preserve for the next state. Typically, and also in this work, the state is initialized to zero. From a preliminary analysis that also took into consideration other types of RNN, such as LSTM, we observe that the results are quite similar to those obtained with the GRU, a simpler and less expensive architecture in computational terms. This is justified by the fact that in our approach we do not exploit neural network to discover dynamics (as done in other “black box” approaches), but rather to correct the predictions of a physical model.
2.1.2. Training and Interpolation
To contextualize the problem within a short-term forecasting framework, the measurements are organized in windows of fixed length , where and represent the number of observations used for the assimilation and the prediction steps.
A single measurement window covers a time span of length . This time span is subdivided into two phases: assimilation and prediction (Figure 1). During the assimilation window, the data are used to correct the state estimated by the neural network module, while in the prediction phase, the network evolves freely without the use of measurements.
The dataset is therefore made up of measurement windows
generated from the observed time series .
In the following investigations, the training data consists of time series generated from the evolution of the system with parameters , using the Runge–Kutta45 method. In this study, we assumed that the full system state is observable every time steps ; but we discuss the problem of partial observation in Section 2.1.3. To simulate realistic conditions, white random noise in the range or Gaussian noise with standard deviation was added to the data after trajectory generation. In both cases the hybrid system gives similar results.
The dataset is split into three subsets (training = 64%, validation = 16%, and test = 20%) without temporal shuffling, ensuring that the test set consists of the last time steps. This approach provides a more reliable estimation of future prediction errors and reduces potential overfitting.
During training, the network must predict a time window starting from measurement in the assimilation window of length .
Given a measurement set , the system is initialized with the fist measurement , where the index i in corresponds to the trajectory generated from the i-th measurement window, and performs a predictive step with the model system . The input and model estimate are fed into the network, and the prediction at the next time () is a combination of the network output and the first model output .
To enforce adherence to the true trajectory during training, the system uses the first measured states in each window directly as inputs at the corresponding time steps. This assimilation phase ensures that the hybrid model aligns closely with the observed dynamics over this interval. In the prediction phase, which spans the subsequent observations, the predicted states generated by the hybrid system are fed back as inputs for future time steps, emulating autonomous evolution. During training, the weights of the neural network are optimized by minimizing the error between the predicted states and the true measurements in the prediction window.
The cost function used for the training is the norm over the difference between the observations and the hybrid system’s outputs at the measurement time in the prediction window:
where denote the observation in the prediction time for the i-th measurement window, are the corresponding prediction of the hybrid system at the measurement time , for , and the index i runs over the elements considered in the training. The general algorithm is schematized in Figure 2b.
We would like to point out that the system is explicitly designed to handle measurements available only at discrete intervals of . By combining the neural correction with the physical model integrated at temporal step , the hybrid system can also interpolate the state evolution at intermediate time steps where direct measurements are unavailable.
2.1.3. Handling Partial Measurements
In practical scenarios, not all system variables can be measured. Often, only a subset of variables is accessible or convenient to measure for a long time. To address this challenge, our model must be capable of handling partial measurements.
To predict new states using the model, Equation (1), a complete knowledge of the initial conditions are typically required unless there is a direct and known dependency between the measured and unmeasured variables. However, if our hybrid model has correctly learned the dynamics, we can use a genetic algorithm approach to estimate the full system state from a set of partial measurements [50].
For example, suppose only one variable, such as the x direction, can be measured. Starting from the initial condition , we generate an ensemble of M replica of our system, initialized with the observation in the measurement direction, while random values are assigned to the unknown directions based on the probability distributions of the corresponding variables in the model .
This ensemble of initial conditions is then evolved over time. During the assimilation phase, whenever a measurement is available, a pruning-enriching procedure is performed. In order to favor predictions closer to the measured trajectory, states with higher distances between the measurement and the simulated value are replaced by noisy copies of states with the lowest distance. In that way, the ensemble of initial conditions is forced to follow the most probable trajectory given the partial measurement and generates a beam of trajectories that follow the trend of the observed trajectory. Instead, during the forecasting phase, the ensemble is left free to evolve.
Practically, we initialize M ensemble elements and evolve them for a time interval , when the next measurement is available. We then sort the ensemble elements in ascending order based on the distance between the measured direction and the corresponding ensemble predictions, replacing the farthest ensemble members with copies of the first half. This procedure is iterated throughout the assimilation window, after which the elements of the ensemble are free to evolve independently.
To increase the variability of the response and allow exploration of space near the ensemble elements, the copies are added with noise equally distributed in [, ]; otherwise, the whole ensemble degenerates to the same trajectory after few pruning-enriching steps. The quantity determines the weight of this exploration, so it is very important to select a sufficiently large value of this parameter, in relation to the typical size of the attractor, which can be estimated from the data and the dynamical system Equation (1).
The predicted trajectory is the average of the first elements of the ensemble. This allows us to define an uncertainty on the prediction based on the standard deviation on the first elements of the ensemble.
3. Experimental Evaluation
3.1. Experimental Configuration
The neural network in the hybrid model does not require much computational effort, at least in the low-dimensional cases considered in this study. The calculation time required may depend more on the model considered and the integration scheme used. In the cases presented in the next section, the initial prediction was obtained by numerically integrating the dynamical system using a first-order Euler scheme. However, in the presence of unstable dynamics requiring more precise algorithms, the choice of calculation speed and performance trade-off will be crucial and will therefore require further in-depth studies.
The network training was performed in a Torch environment [51] with a 12 GB GPU (but the maximum memory requirement for the systems analyzed in the described training conditions is of the order of 2 GB). The optimization was performed using the Adam algorithm with learning rate and a regularization with weight decay . The network includes about 80 K parameters and the system was trained for 300 epochs. For the chosen hyperparameters and the dynamical models considered in the study, typical training times are of the order of two hours.
3.2. Quality Indicator of the Results
To evaluate the performance of each model, we use the root mean square error, , as an indicator of the distance in the state space, averaged over all the measurement windows of the test set. This indicator allows us to quantify the amplification of the prediction error in the prediction window. From this, it is possible to obtain two scalar indicators: the quantity , the error averaged over the time window, and its maximum value in such an interval, .
The mathematical definitions are as follows. For the , we have
where the index i identifies the prediction window , while and are, respectively, the true and the predicted value of the state, and the operator indicates the norm in the state space.
The quantity and its maximum value are, respectively, the average in the prediction window of the :
and the max value of over the same times is as follows:
where the index i is a time index that runs on the time values used to compute the . These quantity can be sampled at different times, either corresponding to measurement instants or over the full prediction window.
The value of or its maximum , computed at the observation times, quantify the prediction error of the hybrid model: this has the goal of checking whether the prediction and the model coincide only at measurement times or uniformly over the full interval, as illustrated below.
To quantify the learning of the hybrid system at the intermediate measurement times, and thus understand the capabilities of the hybrid model to correct interpolations between measurements, we also define the (), which is the averaged (maximum) over all prediction times.
4. Results
We tested the procedure on low-dimensional dynamical systems, e.g., the Lorenz ’63 [52] and Lorenz ’83 [53] models (the latter is also known as the low-dimensional Hadley model) and the Rössler system [54].
In all cases, the system was initialized in a random state and left to evolve for a time . After a transient time , to ensure that the system is on the attractor, we selected measurements every time steps with . In the results, which will be shown below, to emulate measurement situations, white random noise with an amplitude of the order of of the typical range of the system variables was added to the generated measurements.
4.1. Hadley Circulation
The Hadley circulation model, in this low-dimensional form, was introduced by Lorenz in 1983 [53] following studies on global circulation. This model explores the dynamics of the global westerly wind current and its interactions with large-scale atmospheric eddies. Looking for a simple but effective description of the problem, reducing it to the main degrees of freedom, Lorenz defines the following set of three-dimensional differential equations:
where are the parameters of the problem.
We initialize the system with parameters , Equation (2), with , and .
As for the sampling of measurements, we assume that they are accessible every time steps , with a time between two measurements in the time units of the system. The results shown were obtained using a measurement window of measurements, of which , where the assimilation phase is used, while the forecasting window consists of observations.
In Figure 3, we show the prediction error of a single measurement window. For comparison, we also show the results of a prediction starting from the last assimilated measurement obtained from the dynamic evolution of Equation (1) with the estimated parameters . As can be seen, in this forecasting window, the trajectory predicted by the dynamic equation which diverges, due to the imperfect knowledge of the parameters, which triggers the intrinsic divergence given by the chaotic nature of the system. The correction given by the neural network on the model at each time step allows us to constantly correct the forecast and synchronize the output with the true trajectory.
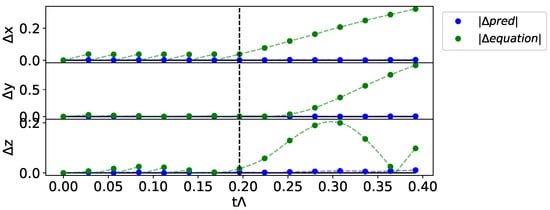
Figure 3.
Example of network error prediction with respect to the true trajectory starting from a set of initial conditions . We show the error between the predicted trajectories and the observations ( in blue for the prediction with the hybrid system, in green for the trajectory generated with only the dynamical system described by the function ).
Let us now analyze the prediction results from the initial conditions, specifically the first observations , for a prediction time longer than the one used in the training phase, .
In the left column of Figure 4, we show the prediction of the hybrid system when it is left free to evolve for a time , along with the absolute value of its error prediction (right column). For comparison, we also show the prediction from observations of the dynamical system both in the case of real parameters and for the parameters used in the equation developed by the hybrid model, . The trajectory predicted by the hybrid model allows for the correct estimation of the long-term behavior of the chaotic trajectory, even if it does not follow the real state exactly.
Figure 4.
Prediction for the Hadley model from an initial condition (points before the black dashed line). On the left, we show the prediction of the hybrid system (denoted “pred” in the legend), and those obtained from the dynamics equations for the different parameters. In blue the real measures. On the right, we show the prediction error in the different cases. The end of the prediction window in the training phase is marked by the gray vertical line. The red line indicates the Lyapunov time of the system.
A better understanding of the effectiveness of this model and the contribution it can give to the prediction of chaotic systems can be gained by observing the average error in the prediction window in different cases: the hybrid model and the differential equation with different parameters ().
In Figure 5, we show the indicator calculated according to Equation (4) on 100 randomly extracted initial conditions in the test set in the following cases: (a) a precision window corresponding to that used for the training phase, and (b) a prediction time twenty times larger, along with its standard deviations.
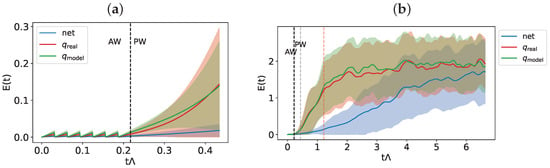
Figure 5.
and its variance for a prediction time (a): equal to that used in the training procedure and (b): for a longer prediction time, for the Hadley model. In panel (b) we indicate the end of the prediction window considered during the training with a gray vertical line and the Lyapunov time of the system (starting from ) with a red vertical line.
As shown in Figure 5a, the trajectories generated by the dynamical model exhibit the expected exponential divergence, which is more rapid in the case of partly due to parameter mismatching. Conversely, the hybrid model predictions follow the true trajectory, diverging over time but at a significantly lower rate than that observed for the standalone models. This behavior persists even over long time horizons (Figure 5b), where the Lyapunov time—defined as the inverse of , the maximum Lyapunov exponent of the system—is also indicated with a dashed red line. While the trajectories predicted by the models show a distance from the true trajectory comparable to the spatial scale of the attractor, the hybrid model achieves relative errors on the order of .
In Table 1, we show the scalar indicators defined in Equations (5) and (6), calculated with respect to the measurement times (top of the table) and with respect to the entire forecast window (bottom of the table).

Table 1.
Average and maximum prediction error, calculated over the entire test set. In the first part of the table we show the error indicator averaged over the times corresponding to the measurement times, in the second part those averaged over the entire prediction window .
As can be observed, the correction at each time step dt made by the network allows it to correct and force the predictions of the hybrid system to follow that observed, resulting in an up to 100 times improvement in the mean accuracy of short-term prediction compared to the solutions provided by the evolution of the dynamics .
Furthermore, we observe that, on average, there are no significant differences between the predictions corresponding to the measurement times, on which the optimization process was based, and those averaged over the entire prediction window. This indicates that the system has correctly learned the corrections to be made to the local dynamics of the system, without modifying it however profoundly. The dynamic model defined within the hybrid system drives the global dynamics; the network corrects the divergences, attenuating them and forcing the prediction to follow the real trajectory.
Let us now analyze the predictions in the case of partial measurements. In particular, in Figure 6, we show the prediction starting from the initial condition , assuming that the system is measured only in one direction. In Figure 6a,c, we suppose that only the x direction is measured, and in (b) and (d), the y direction is considered as direction of measure. The generation was obtained from an ensemble of elements, using amplitude noise at the pruning step . The predicted trajectory and its standard deviation are obtained from the first elements of the ensemble.
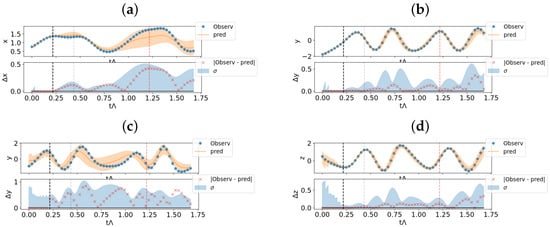
Figure 6.
Predictions for the Hadley model from partial measurements, using an ensemble of elements. (a–c): Measurements only on the x-direction. (a): Prediction on the same x direction. (c): Predictions on the y direction. (b–d) Measurement only on y-direction. (b): Prediction on the same y direction. (d): Predictions on the z direction. Each plot is composed of two panels. In the top one, we show the estimated trajectory as mean of the first elements of the ensemble with the estimated error in orange and in blue the true measurement. In the bottom panel, we show the prediction errors (cross markers) and the standard deviation of the ensemble prediction. We also show the end of the assimilation window (black vertical line), the end of the prediction window used in the training phase (gray vertical line) and the Lyapunov time (red vertical line).
In Figure 6, we show two different predictive scenarios. As shown in Figure 6a–c, a large uncertainty in the measurement direction (x) is reflected in a large uncertainty in the prediction of the unobserved direction y.
On the contrary, as shown in Figure 6b–d, a low uncertainty in the observation of y corresponds to a low standard deviation also in the prediction of an unobserved direction (z).
However, these results are also affected by the choice of the elements of the ensemble M and by the number of elements used to obtain the average prediction. Further studies will be needed to understand and quantify the error statistics in this predictive scenario.
4.2. Lorenz 63
The Lorenz 63 model, introduced by Edward Lorenz in 1963 [52], is a simplified mathematical model designed to study the convection in an atmospheric layer in the presence of a temperature gradient.
The system is described by three coupled, nonlinear ordinary differential equations,
We considered measurement windows composed of and and , so each measurement is available every in the time units of the system.
We show below the results of the average error predictions and of the forecast starting from a set of measurements. As for the previous experiment, in Figure 7, we show the indicator calculated according to Equation (4) on 200 randomly extracted initial conditions in the test set for short and (a) long time prediction (b), along with its standard deviations. Again, the corrections provided by the hybrid system allow us to generate trajectories that follow the true one for a longer time, compared to the Lyapunov time of the system.
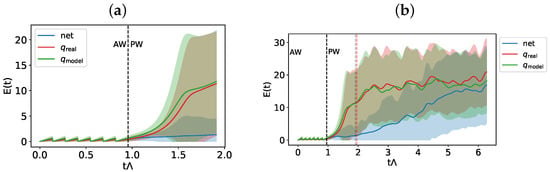
Figure 7.
Error indicator and its variance for a prediction time (a): equal to that used in the training procedure and (b): for a longer prediction time, for the Lorenz 63 system. The Lyapunov time of the system corresponds to the red vertical line.
In Figure 8, we show the case of ensemble prediction, assuming that only one variable is measured as initial conditions. In particular, we show the behavior when the variable z is assimilated. It is well known in the literature that this variable is not a good synchronization direction [55], and here, for assimilation: the information on the direction z does not uniquely identify the position of the system on the attractor, due to the symmetry of the system with respect to the transformation .
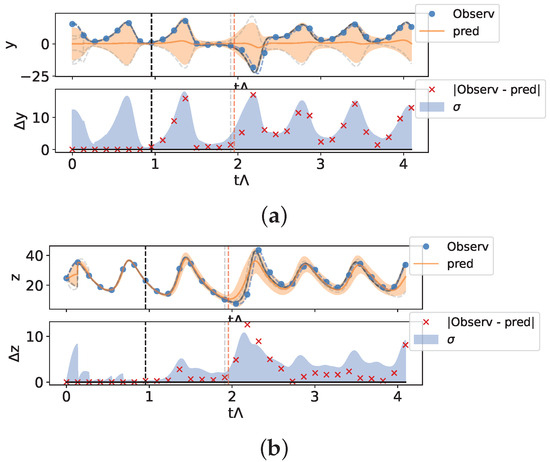
Figure 8.
Prediction for the Lorenz 63 system from partial measurements using an ensemble of elements—Measurements only in the z-direction. (a) Prediction on the y direction, (b) prediction on the z direction. See the caption of Figure 6 for a full description of the meaning of the elements shown in the figure. The trajectories of the first 10 elements of the ensemble are shown by gray lines (see text).
As we can see in Figure 8a, the ensemble prediction in the unobserved direction y is unable to discriminate which of the trajectories are symmetric with respect to the direction y as the real one, showing an average behavior that is not typical of the dynamics of the system considered, even though the direction z is determined within the errors. As we can see in Figure 8a, the ensemble prediction in the unobserved direction y is unable to discriminate among the trajectories which are symmetric with respect to the y direction, while the direction z is determined within the errors (Figure 8b).
To support this, we show the behavior of the first 10 trajectories of the ensemble (gray trajectories in the figure). As can be seen, while for the z direction, these are close to each other and start diverging for prediction times greater than the system’s launch time, the y direction is characterized by symmetric y and trajectories.
This aspect shows how the architecture of the network does not break any symmetry of the system. Once again, we see that the main dynamics in this hybrid system is governed by the dynamical equation of the model. The network learns the local corrections to be made over short times, but these are necessary to guarantee the convergence of the simulated trajectory on the observed data.
Assuming that we measure the x or y direction, the results obtained are analogous to those obtained using the Hadley model shown in the previous section.
The Rössler system is composed by tree nonlinear differential equations [54], originally introduced as a simplification of the Lorenz 63 system. The results are similar to that obtained for the other models and are summarized in Table 1. This system does not present the symmetry of the Lorenz 63 system, and so the corresponding ambiguity is absent; however, its maximum Lyapunov exponent is quite small, with respect to the other systems, so that the diverging times are larger.
5. Conclusions
In this work, we have presented a method to combine physical information with neural network techniques to predict future observations of chaotic systems and interpolate the states of the system between measurements.
After defining the hybrid model and presenting how to optimize it, we have shown the learning results for low-dimensional chaotic systems, demonstrating how the hybrid model is able to predict future states for both short times () and long times (≫), not only at the measurement times on which the system has been trained, but also for time values between two successive measurements. Our system is therefore able to correctly interpolate even unknown states of the system.
Additionally, this hybrid approach appears promising in predicting the dynamics of systems with partial measurements. The hybrid model successfully synchronizes with the real system and corrects the simulated model, leading to improved predictions. However, as expected from theory, the trajectories begin to diverge exponentially according to the Lyapunov time, particularly for longer prediction intervals.
This work is a starting point for a more in-depth study aimed at analyzing the use of artificial intelligence coupled with dynamical equations for the study of physical systems. Several considerations and future studies will need to be addressed. First, it will be important to analyze the impact of the measurement time chosen, to understand the influence of this parameter to the quality of the prediction of the hybrid system. A more in-depth analysis of the impact of the architecture used will have to be conducted, considering more elaborate RNN architectures, or sparse architectures such as Eco State Networks.
Furthermore, this approach will need to be extended to high-dimensional models to evaluate the impact of dimensionality on the quality of the results, as well as to spatially extended models, possibly by appropriately modifying the network structure to incorporate physical information in the architecture. For example, replacing the RNN with architectures that also include spatial correlations (e.g., ConvGRU or similar) could be a promising direction.
Finally, to make this system competitive and applicable to real-world scenarios, it is important to analyze the feasibility of this method in the presence of partial measurements, for example, by using pretrained hybrid models on synthetic data, or by modifying the form of the loss function (Equation (3)) to focus the optimization on the available measurements.
Author Contributions
Conceptualization, M.B., F.B. and T.M.; methodology, M.B. and F.B.; software, M.B.; validation, M.B.; formal analysis, M.B. and F.B.; investigation, M.B.; resources, F.B.; data curation, M.B.; writing—original draft preparation, M.B.; writing—review and editing, M.B. and F.B.; visualization, M.B.; supervision, F.B.; project administration, F.B.; funding acquisition, F.B. All authors have read and agreed to the published version of the manuscript.
Funding
M.B. acknowledges partial support from M.B.I. s.r.l.; T.M. acknowledges support from European Union—Next Generation EU, in the context of The National Recovery and Resilience Plan, Investment 1.5 Ecosystems of Innovation, Project Tuscany Health Ecosystem (THE), CUP: B83C22003920001.
Data Availability Statement
All codes are available upon request from authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ott, E.; Grebogi, C.; Yorke, J.A. Controlling chaos. Phys. Rev. Lett. 1990, 64, 1196. [Google Scholar] [CrossRef] [PubMed]
- Abarbanel, H.D.; Brown, R.; Sidorowich, J.J.; Tsimring, L.S. The analysis of observed chaotic data in physical systems. Rev. Mod. Phys. 1993, 65, 1331. [Google Scholar] [CrossRef]
- Kantz, H.; Schreiber, T. Nonlinear Time Series Analysis; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar] [CrossRef]
- Bocquet, M.; Pires, C.A.; Wu, L. Beyond Gaussian statistical modeling in geophysical data assimilation. Mon. Weather Rev. 2010, 138, 2997–3023. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent neural networks for time series forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Li, L.; Jiang, P.; Xu, H.; Lin, G.; Guo, D.; Wu, H. Water quality prediction based on recurrent neural network and improved evidence theory: A case study of Qiantang River, China. Environ. Sci. Pollut. Res. 2019, 26, 19879–19896. [Google Scholar] [CrossRef]
- Dubois, P.; Gomez, T.; Planckaert, L.; Perret, L. Data-driven predictions of the Lorenz system. Phys. D Nonlinear Phenom. 2020, 408, 132495. [Google Scholar] [CrossRef]
- Bocquet, M. Surrogate modeling for the climate sciences dynamics with machine learning and data assimilation. Front. Appl. Math. Stat. 2023, 9, 1133226. [Google Scholar] [CrossRef]
- Sakib, M.; Mustajab, S.; Alam, M. Ensemble deep learning techniques for time series analysis: A comprehensive review, applications, open issues, challenges, and future directions. Clust. Comput. 2024, 28, 73. [Google Scholar] [CrossRef]
- Soldatenko, S.; Angudovich, Y. Using machine learning for climate modelling: Application of neural networks to a slow-fast chaotic dynamical system as a case study. Climate 2024, 12, 189. [Google Scholar] [CrossRef]
- Kashyap, S.S.; Dandekar, R.A.; Dandekar, R.; Panat, S. Modeling chaotic Lorenz ODE system using scientific machine learning. arXiv 2024, arXiv:2410.06452. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are transformers effective for time series forecasting? In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 11121–11128. [Google Scholar] [CrossRef]
- Wang, M.; Qin, F. A TCN-linear hybrid model for chaotic time series forecasting. Entropy 2024, 26, 467. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Neural Computation; MIT-Press: Cambridge, MA, USA, 1997. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar] [CrossRef]
- Cestnik, R.; Abel, M. Inferring the dynamics of oscillatory systems using recurrent neural networks. Chaos Interdiscip. J. Nonlinear Sci. 2019, 29, 063128. [Google Scholar] [CrossRef]
- Cannas, B.; Cincotti, S. Neural reconstruction of Lorenz attractors by an observable. Chaos Solitons Fractals 2002, 14, 81–86. [Google Scholar] [CrossRef]
- Farmer, J.D.; Sidorowich, J.J. Predicting chaotic time series. Phys. Rev. Lett. 1987, 59, 845. [Google Scholar] [CrossRef]
- Pan, S.T.; Lai, C.C. Identification of chaotic systems by neural network with hybrid learning algorithm. Chaos Solitons Fractals 2008, 37, 233–244. [Google Scholar] [CrossRef]
- Barbosa, W.A.; Gauthier, D.J. Learning spatiotemporal chaos using next-generation reservoir computing. Chaos Interdiscip. J. Nonlinear Sci. 2022, 32, 093137. [Google Scholar] [CrossRef]
- Gonzalez-Zapata, A.M.; de la Fraga, L.G.; Ovilla-Martinez, B.; Tlelo-Cuautle, E.; Cruz-Vega, I. Enhanced FPGA implementation of echo state networks for chaotic time series prediction. Integration 2023, 92, 48–57. [Google Scholar] [CrossRef]
- Pathak, J.; Wikner, A.; Fussell, R.; Chandra, S.; Hunt, B.R.; Girvan, M.; Ott, E. Hybrid forecasting of chaotic processes: Using machine learning in conjunction with a knowledge-based model. Chaos Interdiscip. J. Nonlinear Sci. 2018, 28, 041101. [Google Scholar] [CrossRef]
- Kashinath, K.; Mustafa, M.; Albert, A.; Wu, J.; Jiang, C.; Esmaeilzadeh, S.; Azizzadenesheli, K.; Wang, R.; Chattopadhyay, A.; Singh, A.; et al. Physics-informed machine learning: Case studies for weather and climate modelling. Philos. Trans. R. Soc. A 2021, 379, 20200093. [Google Scholar] [CrossRef] [PubMed]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics informed deep learning (part I): Data-driven solutions of nonlinear partial differential equations. arXiv 2017, arXiv:1711.10561. [Google Scholar] [CrossRef]
- Cai, S.; Mao, Z.; Wang, Z.; Yin, M.; Karniadakis, G.E. Physics-informed neural networks (PINNs) for fluid mechanics: A review. Acta Mech. Sin. 2021, 37, 1727–1738. [Google Scholar] [CrossRef]
- Chen, R.T.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.K. Neural ordinary differential equations. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Seleznev, A.; Mukhin, D.; Gavrilov, A.; Loskutov, E.; Feigin, A. Bayesian framework for simulation of dynamical systems from multidimensional data using recurrent neural network. Chaos Interdiscip. J. Nonlinear Sci. 2019, 29, 123115. [Google Scholar] [CrossRef]
- Radev, S.T.; Mertens, U.K.; Voss, A.; Ardizzone, L.; Köthe, U. BayesFlow: Learning complex stochastic models with invertible neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1452–1466. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Aslam, M.; Kim, J.S.; Jung, J. Multi-step ahead wind power forecasting based on dual-attention mechanism. Energy Rep. 2023, 9, 239–251. [Google Scholar] [CrossRef]
- Zhu, J.; Zhao, Z.; Zheng, X.; An, Z.; Guo, Q.; Li, Z.; Sun, J.; Guo, Y. Time-series power forecasting for wind and solar energy based on the SL-transformer. Energies 2023, 16, 7610. [Google Scholar] [CrossRef]
- Waqas, M.; Humphries, U.W. A critical review of RNN and LSTM variants in hydrological time series predictions. MethodsX 2024, 13, 102946. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Li, Z.; Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Phys. A Stat. Mech. Its Appl. 2019, 519, 127–139. [Google Scholar] [CrossRef]
- Hossain, M.A.; Chakrabortty, R.K.; Elsawah, S.; Ryan, M.J. Hybrid deep learning model for ultra-short-term wind power forecasting. In Proceedings of the 2020 IEEE International Conference on Applied Superconductivity and Electromagnetic Devices (ASEMD), Tianjin, China, 16–18 October 2020; pp. 1–2. [Google Scholar] [CrossRef]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar] [CrossRef]
- Gao, S.; Huang, Y.; Zhang, S.; Han, J.; Wang, G.; Zhang, M.; Lin, Q. Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation. J. Hydrol. 2020, 589, 125188. [Google Scholar] [CrossRef]
- Shumailov, I.; Shumaylov, Z.; Zhao, Y.; Papernot, N.; Anderson, R.; Gal, Y. AI models collapse when trained on recursively generated data. Nature 2024, 631, 755–759. [Google Scholar] [CrossRef]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res. Ocean. 1994, 99, 10143–10162. [Google Scholar] [CrossRef]
- Julier, S.J.; Uhlmann, J.K. New extension of the Kalman filter to nonlinear systems. In Proceedings of the Signal Processing, Sensor Fusion, and Target Recognition VI, Orlando, FL, USA, 21–25 April 1997; Volume 3068, pp. 182–193. [Google Scholar] [CrossRef]
- Gordon, N.J.; Salmond, D.J.; Smith, A.F. Novel approach to nonlinear/non-Gaussian Bayesian state estimation. IEE Proc. F (Radar Signal Process.) 1993, 140, 107–113. [Google Scholar] [CrossRef]
- Bonavita, M.; Laloyaux, P. Machine learning for model error inference and correction. J. Adv. Model. Earth Syst. 2020, 12, e2020MS002232. [Google Scholar] [CrossRef]
- Wikner, A.; Pathak, J.; Hunt, B.R.; Szunyogh, I.; Girvan, M.; Ott, E. Using data assimilation to train a hybrid forecast system that combines machine-learning and knowledge-based components. Chaos Interdiscip. J. Nonlinear Sci. 2021, 31, 053114. [Google Scholar] [CrossRef]
- Penny, S.G.; Smith, T.A.; Chen, T.C.; Platt, J.A.; Lin, H.Y.; Goodliff, M.; Abarbanel, H.D. Integrating recurrent neural networks with data assimilation for scalable data-driven state estimation. J. Adv. Model. Earth Syst. 2022, 14, e2021MS002843. [Google Scholar] [CrossRef]
- Howard, L.J.; Subramanian, A.; Hoteit, I. A machine learning augmented data assimilation method for high-resolution observations. J. Adv. Model. Earth Syst. 2024, 16, e2023MS003774. [Google Scholar] [CrossRef]
- Cheng, S.; Liu, C.; Guo, Y.; Arcucci, R. Efficient deep data assimilation with sparse observations and time-varying sensors. J. Comput. Phys. 2024, 496, 112581. [Google Scholar] [CrossRef]
- Sauer, T. Reconstruction of dynamical systems from interspike intervals. Phys. Rev. Lett. 1994, 72, 3811. [Google Scholar] [CrossRef] [PubMed]
- Leitao, J.C.; Lopes, J.V.P.; Altmann, E.G. Efficiency of Monte Carlo sampling in chaotic systems. Phys. Rev. E 2014, 90, 052916. [Google Scholar] [CrossRef] [PubMed]
- Bagnoli, F.; Baia, M. Synchronization, control and data assimilation of the Lorenz system. Algorithms 2023, 16, 213. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Lorenz, E.N. Deterministic nonperiodic flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef]
- Lorenz, E.N. Irregularity: A fundamental property of the atmosphere. Tellus A 1984, 36, 98–110. [Google Scholar] [CrossRef]
- Rössler, O.E. An equation for continuous chaos. Phys. Lett. A 1976, 57, 397–398. [Google Scholar] [CrossRef]
- Pecora, L.M.; Carroll, T.L. Synchronization of chaotic systems. Chaos Interdiscip. J. Nonlinear Sci. 2015, 25, 097611. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).