Abstract
We present a number of upper and lower bounds for the total variation distances between
the most popular probability distributions. In particular, some estimates of the total variation
distances in the cases of multivariate Gaussian distributions, Poisson distributions, binomial distributions,
between a binomial and a Poisson distribution, and also in the case of negative binomial
distributions are given. Next, the estimations of Lévy–Prohorov distance in terms of Wasserstein
metrics are discussed, and Fréchet, Wasserstein and Hellinger distances for multivariate Gaussian
distributions are evaluated. Some novel context-sensitive distances are introduced and a number of
bounds mimicking the classical results from the information theory are proved.
1. Introduction
Measuring a distance, whether in the sense of a metric or a divergence, between two probability distributions (PDs) is a fundamental endeavor in machine learning and statistics [1]. We encounter it in clustering, density estimation, generative adversarial networks, image recognition and just about any field that undertakes a statistical approach towards data. The most popular case is measuring the distance between multivariate Gaussian PDs, but other examples such as Poisson, binomial and negative binomial distributions, etc., frequently appear in applications too. Unfortunately, the available textbooks and reference books do not present them in a systematic way. Here, we make an attempt to fill this gap. For this aim, we review the basic facts about the metrics for probability measures, and provide specific formulae and simplified proofs that could not be easily found in the literature. Many of these facts may be considered as a scientific folklore known to experts but not represented in any regular way in the established sources. A tale that becomes folklore is one that is passed down and whispered around. The second half of the word, lore, comes from Old English lār, i.e., ‘instruction’. The basic reference for the topic is [2], and, in recent years, the theory has achieved substantial progress. A selection of recent publications on stability problems for stochastic models may be found in [3], but not much attention is devoted to the relationship between different metrics useful in specific applications. Hopefully, this survey helps to make this treasure more accessible and easy to handle.
The rest of the paper proceeds as follows: In Section 2, we define the total variation, Kolmogorov–Smirnov, Jensen–Shannon and geodesic metrics. Section 3 is devoted to the total variation distance for 1D Gaussian PDs. In Section 4, we survey a variety of different cases: Poisson, binomial, negative-binomial, etc. In Section 5, the total variation bounds for multivariate Gaussian PDs are presented, and they are proved in Section 6. In Section 7, the estimations of Lévy–Prohorov distance in terms of Wasserstein metrics are presented. The Gaussian case is thoroughly discussed in Section 8. In Section 9, a relatively new topic of distances between the measures of different dimensions is briefly discussed. Finally, in Section 10, new context-sensitive metrics are introduced and a number of inequalities mimicking the classical bounds from information theory are proved.
2. The Most Popular Distances
The most interesting metrics on the space of probability distributions are the total variation (TV), Lévy–Prohorov, Wasserstein distances. We will also discuss Fréchet, Kolmogorov–Smirnov and Hellinger distances. Let us remind readers that, for probability measures with densities ,
We need the coupling characterization of the total variation distance. For two distributions, and , a pair of random variables (r.v.) defined on the same probability space is called a coupling for and if and . Note the following fact: there exists a coupling such that . Therefore, for any measurable function f, we have with equality iff f is reversible.
In a one-dimensional case, the Kolmogorov–Smirnov distance is useful (only for probability measures on ): Kolm. Suppose are two r.v.’s, and Y has a density w.r.t. Lebesgue measure bounded by a constant C. Then, Kolm. Here, Wass.
Let be random variables with the probability density functions , respectively. Define the Kullback–Leibler (KL) divergence
Example 1.
Consider the scale family . Then,
The total variance distance and the Kullback–Leibler (KL) divergence appear naturally in statistics. Say, for example, in the testing of binary hypothesis : versus :, the sum of errors of both types
as the infimum over all reasonable decision rules d: or the critical domains W is achieved for . Moreover, when minimizing the probability of type-II error subjected to type-I error constraints, the optimal test guarantees that the probability of type-II error decays exponentially in view of Sanov’s theorem
where n is the sample size. In the case of selecting between distributions,
The KL-divergence is not symmetric and does not satisfy the triangle inequality. However, it gives rise to the so-called Jensen–Shannon metric [4]
with . It is a lower bound for the total variance distance
The Jensen–Shannon metric is not easy to compute in terms of covariance matrices in the multi-dimensional Gaussian case.
A natural way to develop a computationally effective distance in the Gaussian case is to define first a metric between the positively definite matrices. Let be the generalized eigenvalues, i.e., the solutions of . Define the distance between the positively definite matrices by , and a geodesic metric between Gaussian PDs N and N:
where and . Equivalently,
Remark 1.
It may be proved that the set of symmetric positively definite matrices is a Riemannian manifold, and (8) is a geodesic distance corresponding to the bilinear form on the tangent space of symmetric matrices .
3. Total Variation Distance between 1D Gaussian PDs
Let and be the standard normal distribution and its density. Let N, . Define Note that depends on the parameters , with , and .
Proposition 1.
In the case , the total variation distance is computed exactly: .
Proof.
By using a shift, we can assume that and . Then, the set is specified as
Hence,
where . Using the property leads to the answer. □
Theorem 1.
The proof is sketched in Section 6. The upper bound is based on the following.
Proposition 2 (Pinsker’s inequality).
Let be random variables with the probability density functions , and the Kullback–Leibler divergence . Then, for ,
Proof of Pinsker’s inequality.
We need the following bound:
If and are singular, then and Pinsker’s inequality holds true. Assume and are absolutely continuous. In view of (7) and Cauchy–Schwarz inequality,
To check (12), define
Then, , . Hence,
□
- [Mark S. Pinsker was invited to be the Shannon Lecturer at the 1979 IEEE International Symposium on Information Theory, but could not obtain permission at that time to travel to the symposium. However, he was officially recognized by the IEEE Information Theory Society as the 1979 Shannon Award recipient].
For one-dimensional Gaussian distributions,
In the multi-dimensional Gaussian case,
Next, define the Hellinger distance
and note that, for one-dimensional Gaussian distributions,
For multi-dimensional Gaussian PDs with ,
In fact, the following inequalities hold:
where . These inequalities are not sharp. For example, the Cauchy–Schwarz inequality immediately implies . There are also reverse inequalities in some cases.
Proposition 3 (Le Cam’s inequalities).
The following inequality holds:
Proof of Le Cam’s inequalities.
From and , it follows that . Next, . Therefore, by Cauchy–Schwarz:
Hence,
□
Example 2.
Let N, N be d-dimensional Gaussian vectors. Suppose that , where Δ is small enough. Let and A be semi-orthogonal matrix . Define . Then,
Proof.
In view of Le Cam’s inequalities, it is enough to evaluate . Note that all r eigenvalues of equal . Thus,
□
[Ernst Hellinger was imprisoned in Dachau but released by the interference of influential friends and emigrated to the US].
4. Bounds on the Total Variation Distance
This section is devoted to the basic examples and partially based on [5]. However, it includes more proofs and additional details (Figure 1).
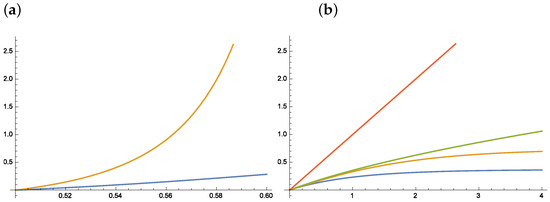
Figure 1.
Exact TV distance and the upper bound for (a) TV(Bin, Bin and (b) TV(Pois, Pois). (a) Note that the upper bound becomes useless for ; (b) blue and orange curves – exact TV distance: the blue curve works for and the orange curve for . Note that the linear upper bound (red curve) is not relevant and the square root upper (green curve) bound becomes useless for .
Proposition 4 (Distances between exponential distributions).
(a) Let Exp, Exp, . Then,
(b) Let , , each with d i.i.d. components Exp, Exp. Then,
where .
Proof.
(a) Indeed, the set coincides with the half-axis with . Consequently, . (b) In this case, the set with . Given , the area of an -dimensional simplex equals . Then, coincides with (24). □
Proposition 5 (Distances between Poisson distributions).
Let Po, where Then,
where Po and
with .
Proof.
Let Po; then, via iterated integration by part,
Hence, Kolm
where
and . □
Proposition 6 (Distances between binomial distributions).
Bin, .
where Bin and . Finally, define
with .
Proof.
Let us prove the following inequality:
where , and . By concavity of the ln, given and ,
This gives the bound as follows:
On the other hand,
as and ; this implies the bound . Indeed:
The rest of the solution goes in parallel with that of Proposition 5. Equation (27) is replaced with the following relation: if Bin; then,
Proposition 7 (Distance between binomial and Poisson distributions).
Bin and Po,
Alternative bound
For the sum of Bernoulli r.v.’s with ,
where Po, (Le Cam). A stronger result: for Bernoulli and Po, there exists a coupling s.t.
The stronger form of (39):
Proposition 8 (Distance between negative binomial distributions).
Let NegBin ,
where Bin and
with .
5. Total Variance Distance in the Multi-Dimensional Gaussian Case
Theorem 2.
Let , and be positively definite. Let and Π be a matrix whose columns form a basis for the subspace orthogonal to δ. Let denote the eigenvalues of the matrix and . In , then
where
In the case of equal means , the bound (43) is simplified:
Here, , are the eigenvalues of for positively definite .
Proof is given in Section 6.
Suppose , and we want to find a low-dimensional projection of the multidimensional data N and N such that . The problem may be reduced to the case , , cf. [6]. In view of (44), it is natural to maximize
where and are the eigenvalues of . Consider all permutations of these eigenvalues. Let
Then, rows of matrix A should be selected as the normalized eigenvectors of associated with the eigenvalues .
Remark 2.
For zero-mean Gaussian models, this procedure may be repeated mutatis mutandis for any of the so-called f-divergences , where f is a convex function such that , cf. [6]. The most interesting examples are:
- (1)
- KL-divergence: and ;
- (2)
- Symmetric KL-divergence: and ;
- (3)
- The total variance distance: and ;
- (4)
- The square of Hellinger distance: and ;
- (5)
- divergence: and .
For the optimization procedure in (47), the following result is very useful.
Theorem 3 (Poincaré Separation Theorem).
Let Σ be a real symmetric matrix and A be a semi-orthogonal matrix. The eigenvalues of Σ (sorted in the descending order) and the eigenvalues of denoted by (sorted in the descending order) satisfy
Proposition 9.
Let be two Gaussian PDs with the same covariance matrix: N, N. Suppose that matrix Σ is non-singular. Then,
Proof.
Here, the set is a half-space. Indeed,
After the change of variables , we need to evaluate the expression
Take an orthogonal matrix O such that and change the variables . Then,
Thus,
where . □
6. Proofs for the Multi-Dimensional Gaussian Case
Let N. W.l.o.g., assume that are positively definite, and the general case may be followed from the identity
where is matrix whose columns form an orthogonal basis for range . Denote and decompose as
Then,
All the components are Gaussian and N, N, N, N, . We claim that
where and are the eigenvalues of .
Proof of upper bound.
It follows from Pinsker’s inequality. Let and . Then, for , we have and, by Pinsker’s inequality,
For , it is enough to obtain the upper bound in the case . Again, Pinsker’s inequality implies: if ,
□
Sketch of proof for lower bound, cf. [7].
In a 1D case with N (),
Next,
Indeed, assume w.l.o.g. . Then, :
Hence,
Thus, it is enough to study the case . Let . Then,
In the case when there exists i: ,
Finally, in the case when , the result follows from the lower bound
The bound (63) if and if and . We refer to [7] for the proofs of these facts. □
7. Estimation of Lévy–Prokhorov Distance
Let be probability distributions on a metric space W with metric r. Define the Lévy–Prokhorov distance between as the infimum of numbers such that, for any closed set ,
where stands for the -neighborhood of C in metric r. It could be checked that , i.e., the total variance distance. Equivalently,
where is the set of all joint on with marginals .
Next, define the Wasserstein distance between by
In the case of Euclidean space with , the index r is omitted.
Total Variation, Wasserstein and Kolmogorov–Smirnov distances defined above are stronger than weak convergence (i.e., convergence in distribution, which is weak* convergence on the space of probability measures, seen as a dual space). That is, if any of these metrics go to zero as , then we have weak convergence. However, the converse is not true. However, weak convergence is metrizable (e.g., by the Lévy–Prokhorov metric).
Theorem 4 (Dobrushin’s bound).
Proof.
Suppose that there exists a closed set C for which at least one of the inequalities (64) fails, say . Then, for any joint with marginals and ,
This leads to (67), as claimed. □
The Lévy–Prokhorov distance is quite tricky to compute, whereas the Wasserstein distance can be found explicitly in a number of cases. Say, in a 1D case , we have
Theorem 5.
For ,
Proof.
First, check the upper bound . Consider U, . Then, in view of the Fubini theorem,
For the proof of the inverse inequality, see [8]. □
Proposition 10.
For and ,
Proof.
It follows from the identity
The minimum is achieved for . For an alternative expression (see [9]):
□
Proposition 11.
Let be jointly Gaussian random variables (RVs) with . Then, the Frechet-1 distance
where , φ and Φ are PDF and CDF of the standard Gaussian RV. Note that, in the case , the first term in (74) vanishes, and the second term gives
We also present expressions for the Frechet-3 and Frechet-4 distances
All of these expressions are minimized when are maximal. However, this fact does not lead immediately to the explicit expressions for Wasserstein’s metrics. The problem here is that the joint covariance matrix should be positively definite. Thus, the straightforward choice is not always possible; see Theorem 6 below and [10].
[Maurice René Fréchet (1878–1973), a French mathematician, worked in topology, functional analysis, probability theory and statistics. He was the first to introduce the concept of a metric space (1906) and prove the representation theorem in (1907). However, in both cases, the credit was given to other people: Hausdorff and Riesz. Some sources claim that he discovered the Cramér–Rao inequality before anybody else, but such a claim was impossible to verify since lecture notes of his class appeared to be lost. Fréchet worked in several places in France before moving to Paris in 1928. In 1941, he succeeded Borel at the Chair of Calculus of Probabilities and Mathematical Physics in Sorbonne. In 1956, he was elected to the French Academy of Sciences, at the age of 78, which was rather unusual. He influenced and mentored a number of young mathematicians, notably Fortet and Loève. He was an enthusiast of Esperanto; some of his papers were published in this language].
8. Wasserstein Distance in the Gaussian Case
In the Gaussian case, it is convenient to use the following extension of Dobrushin’s bound for :
Theorem 6.
Let N be d-dimensional Gaussian RVs. For simplicity, assume that both matrices and are non-singular (In the general case, the statement holds with understood as Moore–Penrose inversion). Then, the Wasserstein distance equals
where stands for the positively definite matrix square-root. The value (78) is achieved when where .
Corollary 1.
Let . Then, for , . For ,
Note that the expression in (79) vanishes when .
Example 3.
(a) Let N, N where and . Then, .
- (b) Let , N, N, where , and . Then,
- (c) Let , N, N, where , and . Then,
Note that, in the case , as in (a).
Proof.
First, reduce to the case by using the identity with . Note that the infimum in (19) is always attained on Gaussian measures as is expressed in terms of the covariance matrix only (cf. (81) below). Let us write the covariance matrix in the block form
where the so-called Shur’s complement . The problem is reduced to finding the matrix K in (80) that minimizes the expression
subject to a constraint that the matrix in (80) is positively definite. The goal is to check that the minimum (81) is achieved when the Shur’s complement S in (80) equals 0. Consider the fiber , i.e., the set of all matrices K such that . It is enough to check that the maximum value of on this fiber equals
Since the matrix S is positively defined, it is easy to check that the fiber should be selected. In order to establish (82), represent the positively definite matrix in the form , where the diagonal matrix and . Next, is the orthogonal matrix of the corresponding eigenvectors. We obtain the following identity:
It means that , an ‘orthogonal’ matrix, with , and . The matrix parametrises the fiber . As a result, we have an optimization problem
in a matrix-valued argument , subject to the constraint . A straightforward computation gives the answer , which is equivalent to (82). Technical details can be found in [11,12]. □
Remark 3.
For general zero means RVs with the covariance matrices , the following inequality holds [13]:
9. Distance between Distributions of Different Dimensions
For , define a set of matrices with orthonormal rows:
and a set of affine maps such that .
Definition 1.
For any measures M and M, the embeddings of μ into are the set of d-dimensional measures for some , and the projections of ν onto are the set of m-dimensional measures for some .
Given a metric between measures of the same dimension, define the projection distance and the embedding distance . It may be proved [14] that ; denote the common value by .
Example 4.
Let us compute Wasserstein distance between one-dimensional N and d-dimensional N. Denote by the eigenvalues of Σ. Then,
Example 5 (Wasserstein-2 distance between Dirac measure on and a discrete measure on ).
Let and M be the Dirac measure with , i.e., all mass centered at . Let be distinct points, , and let M be the discrete measure of point masses with , . We seek the Wasserstein distance in a closed-form solution. Suppose ; then,
noting that the second infimum is attained by and defining C in the last infimum to be
Let the eigenvalue decomposition of the symmetric positively semidefinite matrix C be with , Then,
and is attained when O has row vectors given by the last m columns of O.
Note that the geodesic distance (7) and (8) between Gaussian PDs (or corresponding covariance matrices) is equivalent to the formula for the Fisher information metric for the multivariate normal model [15]. Indeed, the multivariate normal model is a differentiable manifold, equipped with the Fisher information as a Riemannian metric; this may be used in statistical inference.
Example 6.
Consider i.i.d. random variables to be bi-variately normally distributed with diagonal covariance matrices, i.e., we focus on the manifold . In this manifold, consider the submodel corresponding to the hypothesis . First, consider the standard statistical estimates for the mean and for the variances. If denotes the geodesic estimate of the common variance, the squared distance between the initial estimate and the geodesic estimate under the hypothesis is given by
which is minimized by . Hence, instead of the arithmetic mean of the initial standard variation estimates, we use as an estimate the geometric mean of these quantities.
Finally, we present the distance between the symmetric positively definite matrices of different dimensions. Let , A is and is ; here, is a block. Then, the distance is defined as follows:
In order to estimate the distance (93), after the simultaneous diagonalization of matrices A and B, the following classical result is useful:
Theorem 7 (Cauchy interlacing inequalities).
Let be a symmetric positively definite matrix with eigenvalues and block . Then,
10. Context-Sensitive Probability Metrics
The weighted entropy and other weighted probabilistic quantities generated a substantial amount of literature (see [16,17] and the references therein). The purpose was to introduce a disparity between outcomes of the same probability: in the case of a standard entropy, such outcomes contribute the same amount of information/uncertainty, which is appropriate in context-free situations. However, imagine two equally rare medical conditions, occurring with probability , one of which carries a major health risk while the other is just a peculiarity. Formally, they provide the same amount of information: , but the value of this information can be very different. The applications of the weighted entropy to the clinical trials are in the process of active development (see [18] and the literature cited therein). In addition, the contribution to the distance (say, from a fixed distribution ) related to these outcomes, is the same in any conventional sense. The weighted metrics, or weight functions, are supposed to fulfill the task of samples graduation, at least to a certain extent.
Let the weight function or graduation on the phase space be given. Define the total weighted variation (TWV) distance
Similarly, define the weighted Hellinger distance. Let be the densities of w.r.t. to a measure . Then,
Lemma 1.
Let be the densities of w.r.t. to a measure ν. Then, is a distance and
Proof.
The triangular inequality and other properties of the distance follow immediately. Next,
Summing up these equalities implies (97). □
Let . Then, by the weighted Gibbs inequality [16], .
Theorem 8 (Weighted Pinsker’s inequality).
Proof.
Define the function . The following bound holds, cf. (12):
Now, by the Cauchy–Schwarz inequality,
□
Theorem 9 (Weighted Le Cam’s inequality).
Proof.
In view of inequality
one obtains
□
Next, we relate TWV distance to the sum of sensitive errors of both types in statistical estimation. Let C be the critical domain for the checking the hypothesis : versus the alternative :. Define by and the weighted error probabilities of the I and II types.
Lemma 2.
Let be the decision rule with the critical domain C. Then,
Proof.
Denote . Then, the result follows from the equality
□
Theorem 10 (Weighted Fano’s inequality).
Let , be probability distributions such that , . Then,
where the infimum is taken over all tests with values in .
Proof.
Let be a random variable such that and let . Note that is a mixture distribution so that, for any measure such that , we have and so
It implies by Jensen’s inequality applied to the convex function
On the other hand, denote by and . Note that and by Jensen’s inequality . The following inequality holds:
Integration of (108) yields
11. Conclusions
The contribution of the current paper is summarized in the Table 1 below. The objects 1–8 belong to the treasures of probability theory and statistics, and we present a number of examples and additional facts that are not easy to find in the literature. The objects 9–10, as well as the distances between distributions of different dimensions, appeared quite recently. They are not fully studied and quite rarely used in applied research. Finally, objects 11–12 have been recently introduced by the author and his collaborators. This is the field of the current and future research.

Table 1.
The main metrics and divergencies.
Funding
This research is supported by the grant 23-21-00052 of RSF and the HSE University Basic Research Program.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Suhov, Y.; Kelbert, M. Probability and Statistics by Example: Volume I. Basic Probability and Statistics; Second Extended Edition; Cambridge University Press: Cambridge, UK, 2014; 457p. [Google Scholar]
- Rachev, S.T. Probability Metrics and the Stability of Stochastic Models; Wiley: New York, NY, USA, 1991. [Google Scholar]
- Zeifman, A.; Korolev, V.; Sipin, A. (Eds.) Stability Problems for Stochastic Models: Theory and Applications; MDPI: Basel, Switzerland, 2020. [Google Scholar]
- Endres, D.M.; Schindelin, J.E. A new metric for probability distributions. IEEE Trans. Inf. Theory 2003, 49, 1858–1860. [Google Scholar] [CrossRef]
- Kelbert, M.; Suhov, Y. What scientific folklore knows about the distances between the most popular distributions. Izv. Sarat. Univ. (N.S.) Ser. Mat. Mekh. Inform. 2022, 22, 233–240. [Google Scholar] [CrossRef]
- Dwivedi, A.; Wang, S.; Tajer, A. Discriminant Analysis under f-Divergence Measures. Entropy 2022, 24, 188. [Google Scholar] [CrossRef] [PubMed]
- Devroye, L.; Mehrabian, A.; Reddad, T. The total variation distance between high-dimensional Gaussians. arXiv 2020, arXiv:1810.08693v5. [Google Scholar]
- Vallander, S.S. Calculation of the Wasserstein distance between probability distributions on the line. Theory Probab. Appl. 1973, 18, 784–786. [Google Scholar] [CrossRef]
- Rachev, S.T. The Monge-Kantorovich mass transference problem and its stochastic applications. Theory Probab. Appl. 1985, 29, 647–676. [Google Scholar] [CrossRef]
- Gelbrich, M. On a formula for the L2 Wasserstein metric between measures on Euclidean and Hilbert spaces. Math. Nachrichten 1990, 147, 185–203. [Google Scholar] [CrossRef]
- Givens, R.M.; Shortt, R.M. A class of Wasserstein metrics for probability distributions. Mich. Math J. 1984, 31, 231240. [Google Scholar] [CrossRef]
- Olkin, I.; Pwelsheim, F. The distances between two random vectors with given dispersion matrices. Lin. Algebra Appl. 1982, 48, 267–2263. [Google Scholar] [CrossRef]
- Dowson, D.C.; Landau, B.V. The Fréchet distance between multivariate Normal distributions. J. Multivar. Anal. 1982, 12, 450–456. [Google Scholar] [CrossRef]
- Cai, Y.; Lim, L.-H. Distances between probability distributions of different dimensions. IEEE Trans. Inf. Theory 2022, 68, 4020–4031. [Google Scholar] [CrossRef]
- Skovgaard, L.T. A Riemannian geometry of the multivariate normal model. Scand. J. Stat. 1984, 11, 211–223. [Google Scholar]
- Stuhl, I.; Suhov, Y.; Yasaei Sekeh, S.; Kelbert, M. Basic inequalities for weighted entropies. Aequ. Math. 2016, 90, 817–848. [Google Scholar]
- Stuhl, I.; Kelbert, M.; Suhov, Y.; Yasaei Sekeh, S. Weighted Gaussian entropy and determinant inequalities. Aequ. Math. 2022, 96, 85–114. [Google Scholar] [CrossRef]
- Kasianova, K.; Kelbert, M.; Mozgunov, P. Response-adaptive randomization for multi-arm clinical trials using context-dependent information measures. Comput. Stat. Data Anal. 2021, 158, 107187. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).