Abstract
This paper proposes a new index, the “distribution non-uniformity index (DNUI)”, for quantitatively measuring the non-uniformity or unevenness of a probability distribution relative to a baseline uniform distribution. The proposed DNUI is a normalized, distance-based metric ranging between 0 and 1, with 0 indicating perfect uniformity and 1 indicating extreme non-uniformity. It satisfies our axioms for an effective non-uniformity index and is applicable to both discrete and continuous probability distributions. Several examples are presented to demonstrate its application and to compare it with two distance measures, namely, the Hellinger distance (HD) and the total variation distance (TVD), and two classical evenness measures, namely, Simpson’s evenness and Buzas and Gibson’s evenness.
1. Introduction
Non-uniformity, or unevenness, is an inherent characteristic of probability distributions, as outcomes or values from a probability system are typically not distributed uniformly or evenly. Although the shape of a distribution can offer an intuitive sense of its non-uniformity, researchers often require a quantitative measure to assess this property. Such a measure is valuable for constructing distribution models and for comparing the non-uniformity across different distributions in a consistent and interpretable way.
A probability distribution is considered uniform when all outcomes have equal probability, in the discrete case, or when the probability density is constant, in the continuous case. Therefore, the uniform distribution serves as the natural baseline for assessing the non-uniformity of any given distribution, and non-uniformity is referred to as the degree to which a distribution deviates from this uniform benchmark. It is essential to ensure that the distribution being evaluated and the baseline uniform distribution share the same support. This requirement is especially important in the continuous case, where a fixed and clearly defined support is crucial for meaningful comparison.
The Kullback–Leibler (KL) divergence or the χ2 divergence may be used as a metric for measuring the non-uniformity of a given distribution by quantifying how different the distribution is from a baseline uniform distribution. For a discrete random variable X with probability mass function (PMF) and n possible outcomes, the KL divergence relative to the uniform distribution with PMF 1/n is given by
The χ2 divergence is given by
While a KL or χ2 divergence value of zero indicates perfect uniformity, there is no natural upper bound that allows us to specify how non-uniform a distribution is. Furthermore, as shown in Equations (1) and (2), the KL or χ2 divergence will tend to infinity as the number of possible outcomes (n) goes to infinity, regardless of the distribution (except for the uniform distribution). The lack of an upper bound can make interpretation difficult, especially when comparing different distributions or when the scale of the divergence matters. Therefore, we will not discuss the KL and χ2 divergence further in this paper.
The Hellinger distance (HD) and the total variation distance (TVD), two well-known distances, may be used to measure the non-uniformity of a given distribution relative to a baseline uniform distribution. For the discrete case, the HD, as a non-uniformity measure, is given by (relative to a uniform distribution with PMF 1/n)
The TVD as a non-uniformity measure is given by
The HD and TVD range between 0 and 1 and do not require standardization or normalization. This is a desirable property for non-uniformity metrics. However, to the best of the author’s knowledge, the HD and TVD have not been used to measure distribution non-uniformity. Therefore, their performance is unknown.
In recent work, Rajaram et al. [1,2] proposed a measure called the “degree of uniformity (DOU)” to quantify how evenly the probability mass or density is distributed across available outcomes or support. Specifically, they defined the DOU for a partial distribution on a fixed interval as the ratio of the exponential of the Shannon entropy to the coverage probability of that interval [1,2].
where the subscript “P” denotes “part”, referring to the partial distribution on the fixed interval, is the coverage probability of the interval, is the entropy of the partial distribution, and is the entropy-based diversity of the partial distribution. When the entire distribution is considered, , and thus, the DOU equals the entropy-based diversity . It should be noted that the DOU is neither standardized nor normalized and does not explicitly measure the deviation of a given distribution from a uniform benchmark. Therefore, we will not discuss the DOU further in this paper.
Classical evenness measures, such as Simpson’s evenness and Buzas and Gibson’s evenness, are essentially diversity ratios. For a discrete random variable X with PMF and n possible outcomes, Simpson’s evenness is defined as (e.g., [3])
where is called Simpson’s diversity, representing the effective number of distinct elements in the probability system , and n is the maximum diversity that corresponds to a uniform distribution with PMF 1/n. The concept of effective number is the core of diversity measures in biology [4].
Buzas and Gibson’s evenness is defined as [5].
where is the Shannon entropy of X, , and is the entropy of the baseline uniform distribution. The exponential of the Shannon entropy is the entropy-based diversity and is also considered to be an effective number of elements in the probability system .
Both and are normalized by n, the maximum diversity corresponding to the baseline uniform distribution. Therefore, these indices range between 0 and 1, with 0 indicating extreme unevenness and 1 indicating perfect evenness. Since evenness is negatively correlated with unevenness, we consider the complement of and as unevenness (i.e., non-uniformity) indices. That is, we denote as Simpson’s unevenness and as Buzas and Gibson’s unevenness, with 0 indicating perfect evenness (uniformity) and 1 indicating extreme unevenness (non-uniformity).
However, as Gregorius and Gillet [6] pointed out, “Diversity-based methods of assessing evenness cannot provide information on unevenness, since measures of diversity generally do not produce characteristic values that are associated with states of complete unevenness.” This limitation arises because diversity measures are primarily designed to capture internal distribution characteristics, such as concentration and relative abundance within the distribution. For example, the quantity is often called the “repeat rate” [7] or Simpson concentration [4]; it has historically been used as a measure of concentration [7]. Moreover, since diversity metrics are not constructed within a comparative distance framework, they inherently lack the ability to quantify deviations from uniformity in a meaningful or interpretable way. This limitation significantly diminishes their effectiveness when the goal is specifically to detect or describe high degrees of non-uniformity.
The aim of this study is to develop a new normalized, distance-based index that can effectively quantify the non-uniformity or unevenness of a probability distribution. In the following sections, Section 2 describes the proposed distribution non-uniformity index (DNUI). Section 3 presents several examples to compare the proposed NDUI with the Hellinger distance (HD), the total variation distance (TVD), Simpson’s unevenness, and Buzas and Gibson’s unevenness. Section 4 and Section 5 provide discussion and conclusion, respectively.
2. The Proposed Distribution Non-Uniformity Index (DNUI)
The mathematical formulation of the proposed distribution non-uniformity index (DNUI) differs for discrete and continuous random variables.
2.1. Discrete Cases
Consider a discrete random variable X with PMF and n possible outcomes. Let denote the uniform distribution with the same possible outcomes, so that its PMF for all x. We use this uniform distribution as the baseline for measuring the non-uniformity of the distribution of X.
The difference between the two PMFs and is given by
Thus, can be written as
Taking squares on both sides of Equation (9) yields
Then, taking the expectation on both sides of Equation (10) yields
In Equation (11), the second moment is expressed as the sum of the total variance and the baseline term 1/n2, where is called the total deviation given by
where is the variance of relative to the baseline uniform distribution, given by
is the bias of relative to the baseline uniform distribution, given by
where is called the (discrete) informity of X in the theory of informity proposed by Huang [8], which is the expectation of the PMF . The informity of the baseline uniform distribution of is . Therefore, is the difference between the two discrete informities.
Definition 1.
The proposed DNUI (denoted by ) for the distribution of X is given by
where
is the root mean square (RMS) of
. The second moment
can be calculated as
2.2. Continuous Cases
Consider a continuous random variable Y with probability density function (PDF) defined on an unbounded support, such as ). Since there is no baseline uniform distribution defined over an unbounded support, we cannot measure the non-uniformity of the entire distribution. Instead, we examine parts of the distribution on a fixed interval , which allows us to assess local non-uniformity.
According to Rajaram et al. [1], the PDF of a partial distribution on is given by the renormalization of the original PDF
where , which is the coverage probability of the interval .
Let denote the uniform distribution on with PDF . We use this uniform distribution as the baseline for measuring the non-uniformity of the partial distribution.
Similar to the discrete case, the difference between the two PDFs and is given by
Thus, can be written as
Taking squares on both sides of Equation (19) yields
Then, taking the expectation on both sides of Equation (20) yields
The total deviation is given by
where is the variance in relative to , given by
and is the bias of relative to , given by
Definition 2.
The proposed DNUI for the partial distribution on (denoted by ) is given by
where
is the second moment of
, given by
Definition 3.
If the continuous distribution is defined on the fixed support , and , the proposed DNUI for the entire distribution of Y (denoted by ) is given by
where
is the second moment of
, given by
the variance
is given by
and the bias
is given by
The quantity is denoted by and is called the continuous informity of Y in the theory of informity [8]. The continuous informity of the baseline uniform distribution of is . Therefore, is the difference between the two continuous informities.
3. Examples
3.1. Coin Tossing
Consider tossing a coin, which is a simplest two-state probability system: {X; P(x)} = {head, tail; P(head), P(tail)}, where . The DNUI for the distribution of X is given by
where the second moment can be calculated as
Figure 1 shows the DNUI for the distribution of X as a function of the bias represented by . The HD, TVD, , and are also shown in Figure 1 for comparison.
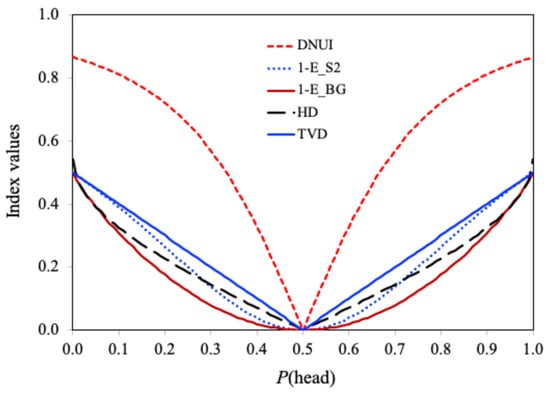
Figure 1.
The DNUI for the distribution of X as a function of the bias represented by the probability of heads, compared with the Hellinger distance (HD), the total variation distance (TVD), Simpson’s unevenness , and Buzas and Gibson’s unevenness
As shown in Figure 1, when the coin is fair (i.e., ), the DNUI, HD, and TVD, , and are all 0, indicating perfect uniformity or evenness. As the coin becomes increasingly biased toward either heads or tails, all indices increase. In the extreme case where or , the DNUI reaches a maximum value of , reflecting a high degree of non-uniformity. However, the HD reaches a maximum value of 0.541, and the TVD, , and reach a maximum value of 0.5, which are significantly smaller than 1, indicating that these indices fail to capture the high degree of non-uniformity.
3.2. Three Frequency Data Series
JJC [9] posted a question on Cross Validated about quantifying distribution non-uniformity. He supplied three frequency datasets (Series A, B, and C), each containing 10 values (Table 1). Visually, Series A is almost perfectly uniform, Series B is nearly uniform, and Series C is heavily skewed by a single outlier (0.6). Table 1 lists these datasets alongside the corresponding DNUI, HD, TVD, , and values.

Table 1.
Three frequency data series and the corresponding DNUI, HD, TVD, , and values.
From Table 1, we can see that the DNUI value for Series A is 0.1864, confirming its high uniformity, while the DNUI value for Series B is 0.2499, indicating near-uniformity. In contrast, the DNUI value for Series C is 0.9767 (close to 1), signaling extreme non-uniformity. These results align well with intuitive expectations. The HD, TVD, , and values range from 0.0060 to 0.04 for Series A and from 0.0109 to 0.06 for Series B, which may be considered to reflect the uniformity of these two series fairly well. However, the HD, TVD, , and values range from 0.4121 to 0.7375 for Series C, which are too high to adequately reflect the severity of the non-uniformity.
3.3. Five Continuous Distributions with Fixed Support
Consider five continuous distributions with fixed support : uniform, triangular, quadratic, raised cosine, and half-cosine. Table 2 summarizes their PDFs, variances, biases, second moments, and DNUIs.
Table 2.
The PDF , variance , bias , second moment , and DNUI for five continuous distributions with fixed support
As shown in Table 2, the DNUI is independent of the scale parameter a, which is a desirable property for a measure of distribution non-uniformity. By definition, the DNUI for the uniform distribution is 0. In contrast, the DNUI values for the other four distributions range from 0.5932 to 0.7746, indicating moderate to high non-uniformity. These results align well with intuitive expectations. Notably, the raised cosine distribution has the highest DNUI value among the five distributions, suggesting it exhibits the greatest non-uniformity.
3.4. Exponential Distribution
The PDF of the exponential distribution with support is
where is the shape parameter.
We consider a partial exponential distribution on the interval [ (i.e., and ), and b is the length of the interval. Thus, the DNUI for the partial exponential distribution is given by
where the second moment is given by
The coverage probability of the interval [ is given by
The integral can be solved as
Figure 2 shows the plot of the DNUI for the partial exponential distribution with as a function of the interval length b. It also shows the PDF of the original exponential distribution, Equation (33) with , as a function of y.
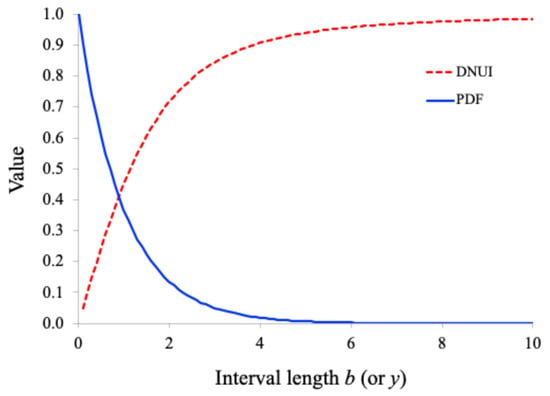
Figure 2.
Plots of the DNUI for the partial exponential distribution with and the PDF of the original exponential distribution.
As shown in Figure 2, when the interval length b is very small (approaching 0), the DNUI is close to 0, reflecting the high local uniformity within small intervals. As the interval length b increases, the DNUI also increases, indicating the growing local non-uniformity with larger intervals. When the interval length b becomes very large, the DNUI approaches 1, indicating that the distribution over a large interval is extremely non-uniform. These observations align well with intuitive expectations.
4. Discussion
4.1. Axioms for an Effective Non-Uniformity Index
It is important to note that non-uniformity indices require an axiomatic foundation to ensure their validity and meaningful interpretation. This foundation should be built upon a set of axioms that any acceptable non-uniformity index should satisfy. We propose the following four axioms for an effective non-uniformity index:
- Normalization: The index should range between 0 and 1 (or approximately), with 0 indicating perfect uniformity and 1 (or near 1) indicating extreme non-uniformity.
- Sensitivity to Deviations: The index should be sensitive to any deviations from a baseline uniform distribution, producing a value that reflects the extent of non-uniformity.
- Consistency and Comparability: The index should yield consistent results when applied to similar distributions and enable comparisons across different distributions.
- Intuitive Interpretation: The index should be easy to understand and interpret, providing a clear indication of how close a distribution is to perfect uniformity.
Of the eight non-uniformity measures evaluated in this paper, the DOU, KL divergence, and χ2 divergence fail to meet Axiom 1 (normalization), as noted in the Introduction. The Hellinger distance (HD), total variation distance (TVD), Simpson’s unevenness , and Buzas and Gibson’s unevenness do not satisfy Axiom 2 (sensitivity to deviations), as demonstrated in Examples 3.1 and 3.2. Only the proposed NDUI satisfies all four axioms, making it a robust and effective measure.
4.2. Normalization, Benchmarks for Defining Non-Uniformity Levels, and Invariance to Probability Permutations
The definition of the proposed NUDI is both mathematically sound and intuitively interpretable. It is a normalized, distance-based metric derived from the total deviation defined in Equations (11) and (21). Importantly, this total deviation incorporates two components, namely, variance and bias, both measured relative to the baseline uniform distribution. The particular normalization using the second moment of the PMF or PDF provides a natural and robust scaling factor, which ensures that the NDUI consistently reflects deviations from uniformity across diverse distributions while maintaining a normalized range of [0, 1], as demonstrated in the presented examples.
The proposed DNUI ranges between 0 and 1, with 0 indicating perfect uniformity and 1 indicating extreme non-uniformity. Lower DNUI values (near 0) suggest a more uniform or flatter distribution, while higher values (near 1) suggest a greater degree of non-uniformity or unevenness. Since there are no universally accepted benchmarks for defining levels of non-uniformity, we tentatively propose DNUI values of 0.25, 0.5, and 0.75 to represent low, moderate, and high non-uniformity, respectively. The proposed thresholds are determined by the DNUI’s normalized [0, 1] range, which approximately divide it into quartiles and aligns with the empirical DNUI values observed in Examples 3.1 and 3.2, where values near 0.25 indicate minor deviations, 0.5 indicate moderate deviations, and 0.75 or higher indicate significant deviations from uniformity.
Note that the DNUI (similar to other indices) depends solely on the probability values and not on the associated outcomes (or scores) or their order. This property can be illustrated using the frequency data from Series C in Section 3.2: {0.03, 0.02, 0.6, 0.02, 0.03, 0.07, 0.06, 0.05, 0.05, 0.07}. If, for example, the second and third values are swapped, the DNUI value remains unchanged. Therefore, the DNUI is not a one-to-one function of the distribution; it can “collapse” different distributions into the same value. This property is analogous to how different distributions can share the same mean or variance. The invariance of the DNUI to probability permutations implies that it may not distinguish distributions with identical probability sets but different arrangements, suggesting that in applications like clustering or anomaly detection, the DNUI should be complemented with order-sensitive metrics when structural differences are critical.
4.3. Upper Bounds of Non-Uniformity Indices in the Discrete Case
In the discrete case, when X follows a uniform distribution, the DNUI, HD, TVD, , and are all 0 regardless of the number of possible outcomes. However, in the extreme case, where all outcomes have probability 0 except one with probability 1, the upper bound of these indices depends on the number of possible outcomes. The upper bound of the DNUI is given by
The upper bound of the HD is given by
The upper bound of the TVD is given by
The upper bound of is given by
The upper bound of is given by
Note that the TVD, , and have the same upper bound. Figure 3 shows plots of the upper bounds of the five indices as functions of the number of possible outcomes. It can be seen that among the five indices, the NDUI has the largest upper bound at n = 2 (where the upper bound is minimum), which increases rapidly to 1 as n increases. In contrast, the other indices have a very low upper bound at n = 2, less than 0.541, which increases slowly to 1 as n increases. Our common sense tells us that this extreme case represents a very high degree of non-uniformity and should be represented by an index value of 1 or close to 1. Therefore, the NDUI performs best among the five non-uniformity indices.
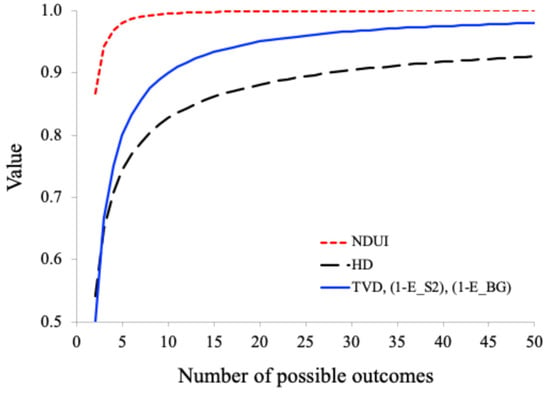
Figure 3.
Plots of the upper bounds of the five indices as functions of the number of possible outcomes.
5. Conclusions
Four axioms for an effective non-uniformity index are proposed: normalization, sensitivity to deviations, consistency and comparability, and intuitive interpretation. Among the eight non-uniformity measures evaluated in this paper, the degree of uniformity (DOU), KL divergence, and χ2 divergence fail to satisfy Axiom 1 (normalization). The Hellinger distance (HD), total variation distance (TVD), Simpson’s unevenness , and Buzas and Gibson’s unevenness do not satisfy Axiom 2 (sensitivity to deviations). Only the proposed NDUI satisfies all four axioms.
The proposed DNUI provides an effective metric for quantifying the non-uniformity or unevenness of probability distributions. It is applicable to any distribution, discrete or continuous, defined on a fixed support. It can also be applied to partial distributions on fixed intervals to examine local non-uniformity, even when the overall distribution has unbounded support. The presented examples have demonstrated the effectiveness of the proposed DNUI in capturing and quantifying distribution non-uniformity.
It is important to emphasize that the NDUI, as a normalized and axiomatically grounded measure of non-uniformity, could be applied to fields such as ecological modeling, information theory, and machine learning. For example, the NDUI’s sensitivity to deviations and intuitive interpretation could support its use as an alternative to diversity-based evenness measures in evenness/unevenness analysis in ecology. The scope of application of the NDUI needs to be further studied and expanded.
Funding
This research received no external funding.
Data Availability Statement
The data are contained within this article.
Acknowledgments
The author would like to thank three anonymous reviewers for their valuable comments that helped to improve the quality of this article.
Conflicts of Interest
Author Hening Huang was employed by the company Teledyne RD Instruments and retired in February 2022. The author declares that this study received no funding from the company. The company was not involved in the study design; the collection, analysis, or interpretation of data; the writing of this article; or the decision to submit it for publication.
References
- Rajaram, R.; Ritchey, N.; Castellani, B. On the mathematical quantification of inequality in probability distributions. J. Phys. Commun. 2024, 8, 085002. [Google Scholar] [CrossRef]
- Rajaram, R.; Ritchey, N.; Castellani, B. On the degree of uniformity measure for probability distributions. J. Phys. Commun. 2024, 8, 115003. [Google Scholar] [CrossRef]
- Roy, S.; Bhattacharya, K.R. A theoretical study to introduce an index of biodiversity and its corresponding index of evenness based on mean deviation. World J. Adv. Res. Rev. 2024, 21, 22–32. [Google Scholar] [CrossRef]
- Jost, L. Entropy and diversity. Oikos 2006, 113, 363–375. [Google Scholar] [CrossRef]
- Buzas, M.A.; Gibson, T.G. Species diversity: Benthonic foraminifera in western North Atlantic. Science 1969, 163, 72–75. [Google Scholar] [CrossRef] [PubMed]
- Gregorius, H.R.; Gillet, E.M. The Concept of Evenness/Unevenness: Less Evenness or More Unevenness? Acta Biotheor. 2021, 70, 3. [Google Scholar] [CrossRef] [PubMed]
- Rousseau, R. The repeat rate: From Hirschman to Stirling. Scientometrics 2018, 116, 645–653. [Google Scholar] [CrossRef]
- Huang, H. The theory of informity: A novel probability framework. Bull. Taras Shevchenko Natl. Univ. Kyiv Phys. Math. 2025, 80, 53–59. [Google Scholar] [CrossRef] [PubMed]
- JJC. How Does One Measure the Non-Uniformity of A Distribution? Available online: https://stats.stackexchange.com/q/25827 (accessed on 20 March 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).