
Evaluation of a Meta-Analysis of Ambient Air Quality as a Risk Factor for Asthma Exacerbation




Abstract
1. Introduction
1.1. False-Positives and Bias in Biomedical Science Literature
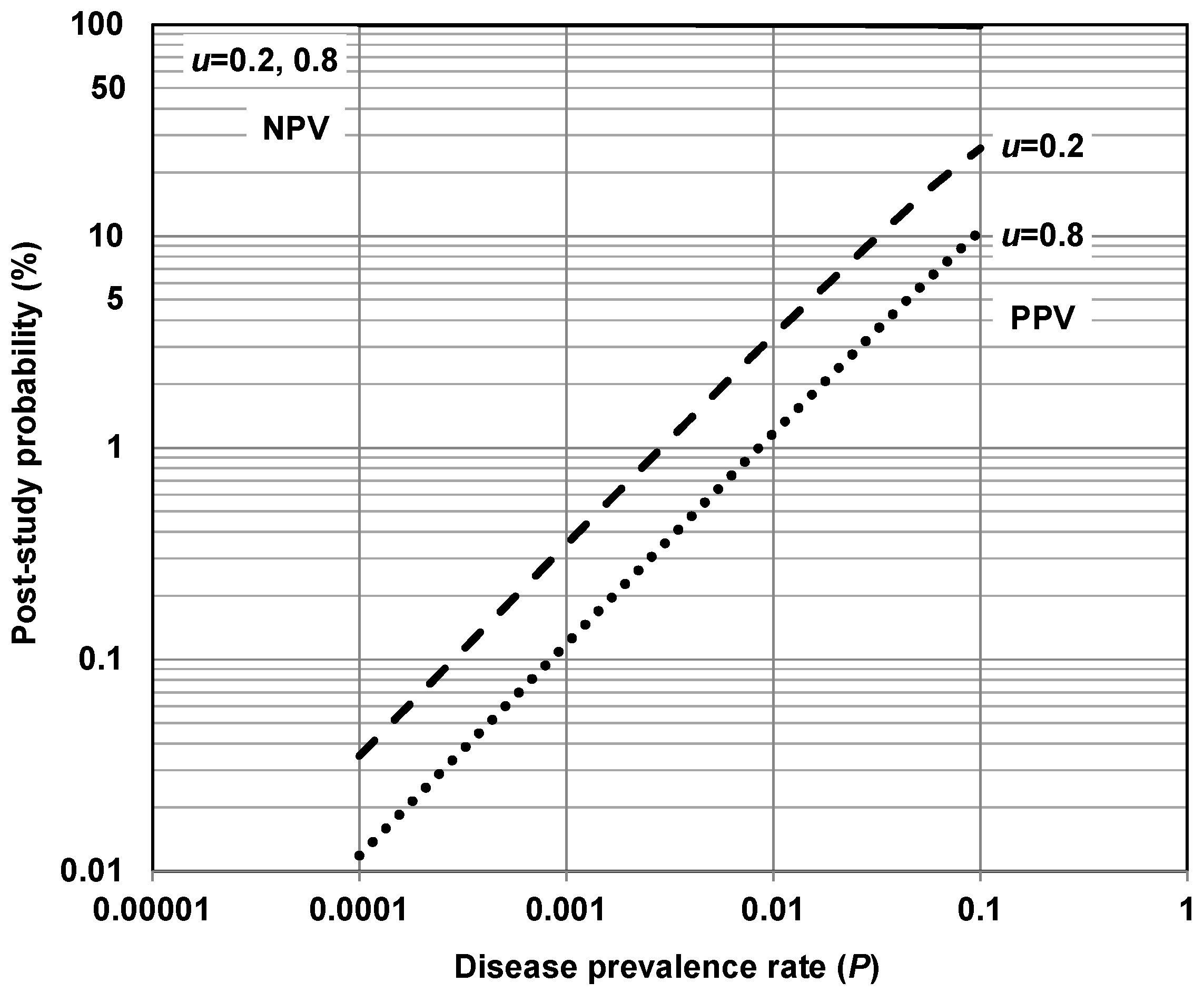
1.2. Positive and Negative Predictive Values of Risk Factor–Chronic Disease Effects
1.3. Ambient Air Quality–Chronic Disease Observational Studies
- Multiple testing involves statistical null hypothesis testing of many separate predictor (e.g., air quality) variables against numerous representations of dependent (e.g., chronic disease) variables taking into account covariates, which may or may not act as confounders. For example, different air quality predictor variables—nitrogen dioxide, carbon monoxide—can be tested in the presence/absence of weather variables (e.g., temperature, relative humidity, etc.) against effects (e.g., heart attack hospitalizations) in a whole population of interest, females only, males only, those greater than 55 years old, etc.
- Multiple modelling involves testing using multiple Model Selection procedures or different model forms (e.g., simple univariate, bivariate or multivariate logistic regression, etc.). For example, different models can be used in a single study to test independent predictor variables and covariates against dependent (e.g., chronic disease) variables.
1.4. Objective of the Current Study
- Whether heterogeneity across the base papers of the meta-analysis is more complex than simple sampling from a single normal process [69].
2. Methods
- CO: RR (relative risk) = 1.045 (95% CI (confidence interval) 1.029, 1.061);
- PM10: RR = 1.010 (95% CI 1.008, 1.013);
- PM2.5: RR = 1.023 (95% CI 1.015, 1.031);
- SO2: RR = 1.011 (95% CI 95% CI 1.007, 1.015);
- NO2: RR = 1.018 (95% CI 1.014, 1.022);
- O3: RR = 1.009 (95% CI 1.006, 1.011).
2.1. Analysis Search Space
- The product of outcomes, predictors, model forms and time lags = number of questions at issue, Space1.
- A covariate may or may not act as a confounder to a predictor variable and the only way to test for this is to include/exclude the covariate from a model. As it can be in or out of a model, one way to approximate the modelling options is to raise 2 to the power of the number of covariates, Space2.
- The product of Space1 and Space2 = an approximation of analysis search space, Space3.
2.2. p-Value Plots
- p-Values were computed using the method of others [79] and ordered from smallest to largest and plotted against the integers, 1, 2, 3, …
- If the points on the plot follow an approximate 45-degree line, then the p-values are assumed to be from a random (chance) process—supporting the null hypothesis of no significant association.
- If the points on the plot follow approximately a line with slope < 1, where most of the p-values are small (less than 0.05), then the p-values provide evidence for a real effect—supporting a statistically significant association.
- If the points on the plot exhibit a bilinear shape (divide into two lines), then the p-values used for meta-analysis constitute a mixture and a general (over-all) claim is not supported; in addition, the p-value reported for the overall claim in the meta-analysis paper cannot be taken as valid.
3. Results
3.1. Analysis Search Space
3.2. p-Values
3.3. p-Value Plots
4. Discussion
4.1. Multiple Testing Multiple Modelling (MTMM) Bias
4.2. Lack of Transparent Descriptions of Statistical Tests and Statistical Models
- Example 2—≥2304 × 0.05 (i.e., ≥115).
- Example 3—≥23,040 × 0.05 (i.e., ≥1152).
4.3. Heterogeneity
4.4. Limits of Observational Epidemiology
4.5. Recommendations for Improvement
- Preregistration.
- Changes in funding agency, journal editor (and reviewer) practices.
- Open sharing of data.
- Facilitation of reproducibility research.
5. Summary
- As for the reliability of claims made in the base papers of their meta-analysis, we suggest that the meta-analysis is unreliable due to the presence of multiple testing and multiple modelling bias in the base papers.
- As for whether heterogeneity across the base papers of their meta-analysis is more complex than simple sampling from a single normal process, we show that the two-component mixture of data used in the meta-analysis (i.e., Figure 2) does not represent simple sampling from a single normal process.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moonesinghe, R.; Khoury, M.J.; Janssens, A.C.J.W. Most published research findings are false—But a little replication goes a long way. PLoS Med. 2007, 4, e28. [Google Scholar] [CrossRef]
- Sarewitz, D. Beware the creeping cracks of bias. Nature 2012, 485, 149. [Google Scholar] [CrossRef]
- Young, S.S.; Acharjee, M.K.; Das, K. The reliability of an environmental epidemiology meta-analysis, a case study. Reg. Toxicol. Pharmacol. 2019, 102, 47–52. [Google Scholar] [CrossRef]
- Young, S.S.; Kindzierski, W.B. Evaluation of a meta-analysis of air quality and heart attacks, a case study. Crit. Rev. Toxicol. 2019, 49, 84–95. [Google Scholar] [CrossRef]
- Freedman, D.H. Lies, Damned Lies, and Medical Science; The Atlantic: Washington, DC, USA, 2010; Available online: https://www.theatlantic.com/magazine/archive/2010/11/lies-damned-lies-and-medical-science/308269/ (accessed on 10 July 2020).
- Keown, S. Biases Rife in Research, Ioannidis Says. NIH Record, Volume VXIV, No. 10. 2012. Available online: Nihrecord.nih.gov/sites/recordNIH/files/pdf/2012/NIH-Record-2012-05-11.pdf (accessed on 10 July 2020).
- Bock, E. Much Biomedical Research is Wasted, Argues Bracken. NIH Record, July 1, 2016, Vol. LXVIII, No. 14. 2016. Available online: Nihrecord.nih.gov/sites/recordNIH/files/pdf/2016/NIH-Record-2016-07-01.pdf (accessed on 10 July 2020).
- Forstmeier, W.; Wagenmakers, E.J.; Parker, T.H. Detecting and avoiding likely false-positive findings—A practical guide. Biol. Rev. Camb. Philos. Soc. 2017, 92, 1941–1968. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.A.; Tarone, R.E.; McLaughlin, J.K. The false-positive to false-negative ratio in epidemiologic studies. Epidemiology 2011, 22, 450–456. [Google Scholar] [CrossRef] [PubMed]
- Franco, A.; Malhotra, N.; Simonovits, G. Publication bias in the social sciences: Unlocking the file drawer. Science 2014, 345, 1502–1505. [Google Scholar] [CrossRef] [PubMed]
- Egger, M.; Dickersin, K.; Smith, G.D. Problems and Limitations in Conducting Systematic Reviews. In Systematic Reviews in Health Care: Meta-Analysis in Context, 2nd ed.; Egger, M., Smith, G.D., Altman, D.G., Eds.; BMJ Books: London, UK, 2001; p. 497. [Google Scholar]
- Sterne, J.A.C.; Egger, M.; Smith, G.D. Investigating and dealing with publication and other biases in meta-analysis. BMJ 2001, 323, 101–105. [Google Scholar] [CrossRef]
- Thomas, D.C.; Siemiatycki, J.; Dewar, R.; Robins, J.; Goldberg, M.; Armstrong, B.G. The problem of multiple inference in studies designed to generate hypotheses. Am. J. Epidemiol. 1985, 122, 1080–1095. [Google Scholar] [CrossRef] [PubMed]
- National Academies of Sciences, Engineering, and Medicine (NASEM). Reproducibility and Replicability in Science; The National Academies Press: Washington, DC, USA, 2019. [Google Scholar] [CrossRef]
- Ioannidis, J.P.A. Interpretation of tests of heterogeneity and bias in meta-analysis. J. Eval. Clin. Pract. 2008, 14, 951–957. [Google Scholar] [CrossRef] [PubMed]
- Randall, D.; Welser, C. The Irreproducibility Crisis of Modern Science: Causes, Consequences, and the Road to Reform; National Association of Scholars: New York, NY, USA, 2018; Available online: Nas.org/reports/the-irreproducibility-crisis-of-modern-science (accessed on 10 July 2020).
- Taubes, G. Epidemiology faces its limits. Science 1995, 269, 164–169. [Google Scholar] [CrossRef]
- Boffetta, P.; McLaughlin, J.K.; Vecchia, C.L.; Tarone, R.E.; Lipworth, L.; Blot, W.J. False-positive results in cancer epidemiology: A plea for epistemological modesty. J. Natl. Cancer Inst. 2008, 100, 988–995. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.A. Excess significance bias in the literature on brain volume abnormalities. Arch. Gen. Psychiatry 2011, 68, 773–780. [Google Scholar] [CrossRef] [PubMed]
- Tsilidis, K.K.; Panagiotou, O.A.; Sena, E.S.; Aretouli, E.; Evangelou, E.; Howells, D.W.; Salman, R.A.; Macleod, M.R.; Ioannidis, J.P.A. Evaluation of excess significance bias in animal studies of neurological diseases. PLoS Biol. 2013, 11, e1001609. [Google Scholar] [CrossRef]
- Bruns, S.B.; Ioannidis, J.P. p-curve and p-hacking in observational research. PLoS ONE 2016, 11, e0149144. [Google Scholar] [CrossRef] [PubMed]
- Gotzsche, P.C. Believability of relative risks and odds ratios in abstracts: Cross sectional study. BMJ 2006, 333, 231–234. [Google Scholar] [CrossRef] [PubMed]
- Chan, A.W.; Hrobjartsson, A.; Haahr, M.T.; Gotzsche, P.C.; Altman, D.G. Empirical evidence for selective reporting of outcomes in randomized trials: Comparison of protocols to published articles. JAMA 2004, 291, 2457–2465. [Google Scholar] [CrossRef]
- Chan, A.W.; Krleza-Jeric, K.; Schmid, I.; Altman, D.G. Outcome reporting bias in randomized trials funded by the Canadian Institutes of Health Research. CMAJ 2004, 171, 735–740. [Google Scholar] [CrossRef]
- Chan, A.W.; Altman, D.G. Identifying outcome reporting bias in randomised trials on PubMed: Review of publications and survey of authors. BMJ 2005, 330, 753. [Google Scholar] [CrossRef] [PubMed]
- Mathieu, S.; Boutron, I.; Moher, D.; Altman, D.G.; Ravaud, P. Comparison of registered and published primary outcomes in randomized controlled trials. JAMA 2009, 302, 977–984. [Google Scholar] [CrossRef]
- Ioannidis, J.P.A. Meta-research: The art of getting it wrong. Res. Syn. Meth. 2010, 1, 169–184. [Google Scholar] [CrossRef]
- Chavalarias, D.; Ioannidis, J.P. Science mapping analysis characterizes 235 biases in biomedical research. J. Clin. Epidemiol. 2010, 63, 1205–1215. [Google Scholar] [CrossRef]
- Crighton, E.J.; Mamdani, M.M.; Upshur, R.E. A population based time series analysis of asthma hospitalisations in Ontario, Canada: 1988 to 2000. BMC Health Serv. Res. 2000, 1, 7. [Google Scholar] [CrossRef]
- Santus, P.; Russo, A.; Madonini, E.; Allegra, L.; Blasi, F.; Centanni, S.; Miadonna, A.; Schiraldi, G.; Amaducci, S. How air pollution influences clinical management of respiratory diseases. A case-crossover study in Milan. Respir. Res. 2012, 13, 95. [Google Scholar] [CrossRef] [PubMed]
- Moineddin, R.; Nie, J.X.; Domb, G.; Leong, A.M.; Upshur, R.E. Seasonality of primary care utilization for respiratory diseases in Ontario: A time-series analysis. BMC Health Serv. Res. 2008, 8, 160. [Google Scholar] [CrossRef]
- Neidell, M.J. Air pollution, health, and socio-economic status: The effect of outdoor air quality on childhood asthma. J. Health Econ. 2004, 23, 1209–1236. [Google Scholar] [CrossRef]
- Cox, L.A.T., Jr. Socioeconomic and air pollution correlates of adult asthma, heart attack, and stroke risks in the United States, 2010–2013. Environ. Res. 2017, 155, 92–107. [Google Scholar] [CrossRef] [PubMed]
- Schechter, M.T. Evaluation of the Diagnostic Process. In Principles and Practice of Research; Troidl, H., Spitzer, W.O., McPeek, B., Mulder, D.S., McKneally, M.F., Wechsler, A., Balch, C.M., Eds.; Springer: New York, NY, USA, 1986; pp. 195–206. [Google Scholar]
- Last, J.M. A Dictionary of Epidemiology, 4th ed.; Oxford University Press: New York, NY, USA, 2001. [Google Scholar]
- Shah, C.P. Public Health and Preventive Medicine in Canada, 5th ed.; Elsevier Saunders: Toronto, ON, Canada, 2003. [Google Scholar]
- Ioannidis, J.P.A. Why most published research findings are false. PLoS Med. 2005, 2, e124. [Google Scholar] [CrossRef] [PubMed]
- Goodman, S.; Greenland, S. Assessing the Unreliability of the Medical Literature: A Response to “Why Most Published Research Findings Are False.” Working Paper 135. Baltimore, MD: Johns Hopkins University, Department of Biostatistics. 2007. Available online: http://biostats.bepress.com/jhubiostat/paper135 (accessed on 10 July 2020).
- Ioannidis, J.P.A. Why most discovered true associations are inflated. Epidemiology 2008, 19, 640–648. [Google Scholar] [CrossRef]
- Beaglehole, R.; Ebrahim, S.; Reddy, S.; Voute, J.; Leeder, S. Prevention of chronic diseases: A call to action. Lancet 2007, 370, 2152–2157. [Google Scholar] [CrossRef]
- Alwan, A.; MacLean, D. A review of non-communicable disease in low-and middle-income countries. Int. Health 2009, 1, 3–9. [Google Scholar] [CrossRef]
- Westfall, P.H.; Young, S.S. Resampling-Based Multiple Testing; Wiley & Sons: New York, NY, USA, 1993. [Google Scholar]
- Young, S.S.; Karr, A. Deming, data and observational studies. Significance 2011, 8, 116–120. [Google Scholar] [CrossRef]
- Head, M.L.; Holman, L.; Lanfear, R.; Kahn, A.T.; Jennions, M.D. The extent and consequences of p-hacking in science. PLoS Biol. 2015, 13, e1002106. [Google Scholar] [CrossRef]
- Chen, H.; Goldberg, M.S. The effects of outdoor air pollution on chronic illnesses. McGill J. Med. 2009, 12, 58–64. [Google Scholar] [PubMed]
- To, T.; Feldman, L.; Simatovic, J.; Gershon, A.S.; Dell, S.; Su, J.; Foty, R.; Licskai, C. Health risk of air pollution on people living with major chronic diseases: A Canadian population-based study. BMJ Open 2015, 5, e009075. [Google Scholar] [CrossRef]
- To, T.; Zhu, J.; Villeneuve, P.J.; Simatovic, J.; Feldman, L.; Gao, C.; Williams, D.; Chen, H.; Weichenthal, S.; Wall, C.; et al. Chronic disease prevalence in women and air pollution—A 30-year longitudinal cohort study. Environ. Int. 2015, 80, 26–32. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Ding, H.; Jiang, L.; Chen, S.; Zheng, J.; Qiu, M.; Zhou, Y.; Chen, Q.; Guan, W. Association between air pollutants and asthma emergency room visits and hospital admissions in time series studies: A systematic review and meta-analysis. PLoS ONE 2015, 10, e0138146. [Google Scholar] [CrossRef] [PubMed]
- DeVries, R.; Kriebel, D.; Sama, S. Outdoor air pollution and COPD-related emergency department visits, hospital admissions, and mortality: A meta-analysis. J. Chronic Obstruct. Pulmonary Dis. 2017, 14, 113–121. [Google Scholar] [CrossRef]
- Mustafic, H.; Jabre, P.; Caussin, C.; Murad, M.H.; Escolano, S.; Tafflet, M.; Perier, M.-C.; Marijon, E.; Vernerey, D.; Empana, J.-P.; et al. Main air pollutants and myocardial infarction: A systematic review and meta-analysis. JAMA 2012, 307, 713–721. [Google Scholar] [CrossRef]
- Eze, I.C.; Hemkens, L.G.; Bucher, H.C.; Hoffmann, B.; Schindler, C.; Kunzli, N.; Schikowski, T.; Probst-Hensch, N.M. Association between ambient air pollution and diabetes mellitus in Europe and North America: Systematic review and meta-analysis. Environ. Health Perspect. 2015, 123, 381–389. [Google Scholar] [CrossRef]
- Keramatinia, A.; Hassanipour, S.; Nazarzadeh, M.; Wurtz, M.; Monfared, A.B.; Khayyamzadeh, M.; Bidel, Z.; Mhrvar, N.; Mosavi-Jarrahi, A. Correlation between NO2 as an air pollution indicator and breast cancer: A systematic review and meta-analysis. Asian Pacific J. Cancer Prevent. 2016, 17, 419–424. [Google Scholar] [CrossRef]
- Parent, M.E.; Goldberg, M.S.; Crouse, D.L.; Ross, N.A.; Chen, H.; Valois, M.F.; Liautaud, A. Traffic-related air pollution and prostate cancer risk: A case-control study in Montreal, Canada. Occup. Environ. Med. 2013, 70, 511–518. [Google Scholar] [CrossRef]
- Turner, M.C.; Krewski, D.; Diver, W.R.; Pope, C.A., III; Burnett, R.T.; Jerrett, M.; Marshall, J.D.; Gapstur, S.M. Ambient air pollution and cancer mortality in the Cancer Prevention Study II. Environ. Health Perspect. 2017, 125, 087013. [Google Scholar] [CrossRef]
- Hamra, G.B.; Laden, F.; Cohen, A.J.; Raaschou-Nielsen, O.; Brauer, M.; Loomis, D. Lung cancer and exposure to nitrogen dioxide and traffic: A systematic review and meta-analysis. Environ. Health Perspect. 2015, 123, 1107–1112. [Google Scholar] [CrossRef]
- Cox, L.A. Do causal concentration–response functions exist? A critical review of associational and causal relations between fine particulate matter and mortality. Crit. Rev. Toxicol. 2017, 47, 609–637. [Google Scholar] [CrossRef]
- Clyde, M. Model uncertainty and health effect studies for particulate matter. Environmetrics 2000, 11, 745–763. [Google Scholar] [CrossRef]
- Young, S.S. Air quality environmental epidemiology studies are unreliable. Reg. Toxicol. Pharmacol. 2017, 88, 177–180. [Google Scholar] [CrossRef] [PubMed]
- Koop, G.; Tole, L. Measuring the health effects of air pollution: To what extent can we really say that people are dying from bad air? J. Environ. Econ. Manag. 2004, 47, 30–54. [Google Scholar] [CrossRef]
- Koop, G.; McKitrick, R.; Tole, L. Air pollution, economic activity and respiratory illness: Evidence from Canadian cities, 1974–1994. Environ. Model. Softw. 2010, 25, 873–885. [Google Scholar] [CrossRef]
- Ellenberg, J. How Not to Be Wrong: The Power of Mathematical Thinking; Penguin Press: New York, NY, USA, 2014. [Google Scholar]
- Hubbard, R. Corrupt Research: The Case for Reconceptualizing Empirical Management and Social Science; Sage Publications: London, UK, 2015. [Google Scholar]
- Chambers, C. The Seven Deadly Sins of Psychology, A Manifesto for Reforming the Culture of Scientific Practice; Princeton University Press: Princeton, NY, USA, 2017. [Google Scholar]
- Harris, R. Rigor Mortis: How Sloppy Science Creates Worthless Cures, Crushes Hope, and Wastes Billions; Basic Books: New York, NY, USA, 2017. [Google Scholar]
- Streiner, D.L. Statistics commentary series, commentary no. 27: P-hacking. J. Clin. Psychopharmacol. 2018, 38, 286–288. [Google Scholar] [CrossRef] [PubMed]
- Simonsohn, U.; Nelson, L.D.; Simmons, J.P. p-curve and effect size: Correcting for publication bias using only significant results. Perspect. Psychol. Sci. 2014, 9, 666–681. [Google Scholar] [CrossRef]
- Motulsky, H.J. Common misconceptions about data analysis and statistics. Pharmacol. Res. Perspect. 2014, 3, e00093. [Google Scholar] [CrossRef]
- Boos, D.D.; Stefanski, L.A. Essential Statistical Inference: Theory and Methods; Springer: New York, NY, USA, 2013. [Google Scholar]
- DerSimonian, R.; Laird, N. Meta-analysis in clinical trials. Controlled Clin. Trials 1986, 7, 177–188. [Google Scholar] [CrossRef]
- Pekkanen, J.; Pearce, N. Defining asthma in epidemiological studies. Eur. Respir. J. 1999, 14, 951–957. [Google Scholar] [CrossRef] [PubMed]
- Wicherts, J.M.; Veldkamp, C.L.S.; Augusteijn, H.E.M.; Bakker, M.; Van Aert, R.C.M.; Van Assen, M.A.L.M. Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p-hacking. Front. Psychol. 2016, 7, 1832. [Google Scholar] [CrossRef]
- Creswell, J. Research Design-Qualitative, Quantitative and Mixed Methods Approaches, 2nd ed.; Sage Publications: Thousand Oaks, CA, USA, 2003. [Google Scholar]
- Young, S.S.; Kindzierski, W.B. Background Information for Meta-analysis Evaluation. 2018. Available online: https://arxiv.org/abs/1808.04408 (accessed on 6 December 2019).
- Sheppard, L.; Levy, D.; Norris, G.; Larson, T.V.; Koenig, J.Q. Effects of ambient air pollution on nonelderly asthma hospital admissions in Seattle, Washington, 1987–1994. Epidemiology 1999, 10, 23–30. [Google Scholar] [CrossRef] [PubMed]
- Lin, M.; Chen, Y.; Burnett, R.T.; Villeneuve, P.J.; Krewski, D. The Influence of ambient coarse particulate matter on asthma hospitalization in children: Case-crossover and time-series analyses. Environ. Health Perspect. 2002, 110, 575–581. [Google Scholar] [CrossRef] [PubMed]
- Tsai, S.S.; Chen, C.-C.; Chen, C.-Y.; Kuo, H.-W. Air pollution and hospital admissions for asthma in a tropical city: Kaohsiung, Taiwan. Inh. Toxicol. 2006, 18, 549–554. [Google Scholar] [CrossRef]
- Hua, J.; Yin, Y.; Peng, L.; Du, L.; Geng, F.; Zhu, L. Acute effects of black carbon and PM2.5 on children asthma admissions: A time-series study in a Chinese city. Sci. Total Environ. 2012, 481, 433–438. [Google Scholar] [CrossRef]
- Altman, D.G.; Bland, J.M. How to obtain a confidence interval from a p value. BMJ 2011, 343, d2090. [Google Scholar] [CrossRef]
- Altman, D.G.; Bland, J.M. How to obtain the p-value from a confidence interval. BMJ 2011, 343, d2304. [Google Scholar] [CrossRef] [PubMed]
- Schweder, T.; Spjøtvoll, E. Plots of p-values to evaluate many tests simultaneously. Biometrika 1982, 69, 493–502. [Google Scholar] [CrossRef]
- Hung, H.M.J.; O’Neill, R.T.; Bauer, P.; Kohne, K. The behavior of the p-value when the alternative hypothesis is true. Biometrics 1997, 53, 11–22. [Google Scholar] [CrossRef]
- Johnson, V. Revised standards for statistical evidence. Proc. Natl. Acad. Sci. USA 2013, 110, 19313–19317. [Google Scholar] [CrossRef]
- Schnatter, A.R.; Chen, M.; DeVilbiss, E.A.; Lewis, R.J.; Gallagher, E.M. Systematic review and meta-analysis of selected cancers in petroleum refinery workers. J. Occup. Environ. Med. 2018, 60, e329–e342. [Google Scholar] [CrossRef]
- Barreto, P.D.S.; Rolland, Y.; Vellas, B.; Maltais, M. Association of long-term exercise training with risk of falls, fractures, hospitalizations, and mortality in older adults: A systematic review and meta-analysis. JAMA Int. Med. 2019, 179, 394–405. [Google Scholar] [CrossRef]
- Lee, P.N.; Forey, B.A.; Coombs, K.J. Systematic review with meta-analysis of the epidemiological evidence in the 1900s relating smoking to lung cancer. BMC Cancer 2012, 12, 385. [Google Scholar] [CrossRef]
- Cao, H.; Hripcsak, G.; Markatou, M. A statistical methodology for analyzing co-occurrence data from a large sample. J. Biomed. Inform. 2007, 40, 343–352. [Google Scholar] [CrossRef]
- Kim, J.; Bang, H. Three common misuses of p values. Dent. Hypotheses 2016, 7, 73–80. [Google Scholar] [CrossRef]
- Parker, R.A.; Rothenberg, R.B. Identifying important results from multiple statistical tests. Stat. Med. 1988, 7, 1031–1043. [Google Scholar] [CrossRef]
- Ryan, P.B.; Madigan, D.; Stang, P.E.; Schuemie, M.J.; Hripcsak, G. Medication-wide association studies. Pharmacomet. Syst. Pharmacol. 2013, 2, e76. [Google Scholar] [CrossRef]
- Selwyn, M.R. Dual controls, p-value plots, and the multiple testing issue in carcinogenicity studies. Environ. Health Perspect. 1989, 82, 337–344. [Google Scholar] [CrossRef] [PubMed]
- Young, S.S.; Bang, H.; Oktay, K. Cereal-induced gender selection? Most likely a multiple testing false positive. Proc. R. Soc. B Biol. Sci. 2009, 276, 1211–1212. [Google Scholar] [CrossRef]
- Noutsios, G.T.; Floros, J. Childhood asthma: Causes, risks, and protective factors; a role of innate immunity. Swiss Med. Wkly. 2014, 44, w14036. [Google Scholar] [CrossRef]
- Feinstein, A.R. Scientific standards in epidemiologic studies of the menace of daily life. Science 1988, 242, 1257–1263. [Google Scholar] [CrossRef]
- Lew, M.J. A Reckless Guide to p-Values. In Good Research Practice in Non-Clinical Pharmacology and Biomedicine; Handbook of Experimental Pharmacology; Bespalov, A., Michel, M.C., Steckler, T., Eds.; Springer: New York, NY, USA, 2020; Volume 257, pp. 223–256. [Google Scholar]
- Shaffer, J.P. Multiple hypothesis testing. Ann. Rev. Psychol. 1995, 46, 561–584. [Google Scholar] [CrossRef]
- Van Belle, G.; Fisher, L.D.; Heagerty, P.J.; Lumley, T. Biostatistics: A Methodology for the Health Sciences, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Makin, T.R.; Xivry, J.O.D. Ten common statistical mistakes to watch out for when writing or reviewing a manuscript. eLife 2019, 8, e48175. [Google Scholar] [CrossRef]
- Cheng, M.H.; Chen, C.-C.; Chiu, H.-F.; Yang, C.-Y. Fine particulate air pollution and hospital admission for asthma: A case-crossover study in Taipei. J. Toxicol. Environ. Health Part A 2014, 77, 1071–1083. [Google Scholar] [CrossRef] [PubMed]
- Royall, R.M. The effect of sample size on the meaning of significance tests. Am. Stat. 1986, 40, 313–315. [Google Scholar] [CrossRef]
- Bland, J.M.; Altman, D.G. Multiple significance tests: The Bonferroni method. BMJ 1995, 310, 170. [Google Scholar] [CrossRef]
- Bender, R.; Lange, S. Adjusting for multiple testing—When and how? J. Clin. Epidemiol. 2001, 54, 343–349. [Google Scholar] [CrossRef]
- Ilakovac, V. Statistical hypothesis testing and some pitfalls. Biochemia Med. 2009, 19, 10–16. [Google Scholar] [CrossRef]
- Graf, A.C.; Bauer, P.; Glimm, E.; Koeing, F. Maximum type 1 error rate inflation in multiarmed clinical trials with adaptive interim sample size modifications. Biom. J. 2014, 56, 614–630. [Google Scholar] [CrossRef] [PubMed]
- Simmons, J.P.; Nelson, L.D.; Simonsohn, U. False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychol. Sci. 2011, 22, 1359–1366. [Google Scholar] [CrossRef]
- Mark, D.B.; Lee, K.L.; Harrell, F.E. Understanding the role of p values and hypothesis tests in clinical research. JAMA Cardiol. 2016, 1, 1048–1054. [Google Scholar] [CrossRef]
- Koop, G.; McKitrick, R.; Tole, L. Does Air Pollution Cause Respiratory Illness? A New Look at Canadian Cities. 2007. Available online: https://strathprints.strath.ac.uk/7736/6/strathprints007736.pdf (accessed on 10 July 2020).
- Evans, K.A.; Halterman, J.S.; Hopke, P.K.; Fagnano, M.; Rich, D.Q. Increased ultrafine particles and carbon monoxide concentrations are associated with asthma exacerbation among urban children. Environ. Res. 2014, 129, 11–19. [Google Scholar] [CrossRef]
- Higgins, J.P.T.; Green, S. (Eds.) Cochrane Handbook for Systematic Reviews of Interventions Version 5.0.0 [Updated February 2008]. The Cochrane Collaboration. 2008. Available online: https://www.cochrane-handbook.org/ (accessed on 18 July 2019).
- Egger, M.; Schneider, M.; Smith, G.D. Spurious precision? Meta-analysis of observational studies. BMJ 1998, 316, 140–144. [Google Scholar] [CrossRef]
- Higgins, J.P.T.; Thompson, S.G.; Deeks, J.J.; Altman, D.G. Measuring inconsistency in meta-analyses. BMJ 2003, 327, 557–560. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; The PRISMA Group. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed]
- Wells, K.; Littell, J.H. Study quality assessment in systematic reviews of research on intervention effects. Res. Soc. Work Pract. 2009, 19, 52–62. [Google Scholar] [CrossRef]
- Palpacuer, C.; Hammas, K.; Duprez, R.; Laviolle, B.; Ioannidis, J.P.A.; Naudet, F. Vibration of effects from diverse inclusion/exclusion criteria and analytical choices: 9216 different ways to perform an indirect comparison meta-analysis. BMC Med. 2019, 17, 174. [Google Scholar] [CrossRef]
- Doll, R.; Peto, R. The causes of cancer: Quantitative estimates of avoidable risks in the United States today. J. Nat. Cancer Inst. 1981, 66, 1192–1308. [Google Scholar] [CrossRef]
- Ahlbom, A.; Axelson, O.; Hansen, E.S.; Hogstedt, C.; Jensen, U.J.; Olsen, J. Interpretation of “negative” studies in occupational epidemiology. Scand. J. Work Environ. Health 1990, 16, 153–157. [Google Scholar] [CrossRef] [PubMed]
- Beaglehole, R.; Bonita, R.; Kjellstrom, T. Basic Epidemiology; World Health Organization: Geneva, Switzerland, 1993; p. 175. [Google Scholar]
- Federal Judicial Center. Reference Manual on Scientific Evidence, 3rd ed.; National Academies Press: Washington, DC, USA, 2011. Available online: https://www.fjc.gov/content/reference-manual-scientific-evidence-third-edition-1 (accessed on 24 August 2019).
- Savitz, D.A.; Olshan, A.F. Multiple comparisons and related issues in the interpretation of epidemiologic data. Am. J. Epidemiol. 1995, 142, 904–908. [Google Scholar] [CrossRef]
- Rothman, K.J. No adjustments are needed for multiple comparisons. Epidemiology 1990, 1, 43–46. [Google Scholar] [CrossRef]
- Patel, C.J.; Burford, B.; Ioannidis, J.P.A. Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations. J. Clin. Epidemiol. 2015, 68, 1046–1058. [Google Scholar] [CrossRef]
- Simes, R.J. Publication bias: The case for an international registry of clinical trials. J. Clin. Oncol. 1986, 4, 1529–1541. [Google Scholar] [CrossRef]
- Begg, C.B.; Berlin, J.A. Publication bias: A problem in interpreting medical data. J. R. Stat. Soc. Ser. A 1988, 151, 419–463. [Google Scholar] [CrossRef]
- Angell, M. Negative studies. N. Engl. J. Med. 1989, 321, 464–466. [Google Scholar] [CrossRef] [PubMed]
- Dickersin, K. The existence of publication bias and risk factors for its occurrence. JAMA 1990, 263, 1385–1389. [Google Scholar] [CrossRef] [PubMed]
- Song, F.; Parekh, S.; Hooper, L.; Loke, Y.K.; Ryder, J.; Sutton, A.J.; Hing, C.; Kwok, C.S.; Pang, C.; Harvey, I. Dissemination and publication of research findings: An updated review of related biases. Health Technol. 2010, 14. [Google Scholar] [CrossRef]
- Lash, T.L.; Vandenbroucke, J.P. Should preregistration of epidemiologic study protocols become compulsory? Epidemiology 2012, 23, 184–188. [Google Scholar] [CrossRef]
- Wicherts, J.M.; Kievit, R.A.; Bakker, M.; Borsboom, D. Letting the daylight in: Reviewing the reviewers and other ways to maximize transparency in science. Front. Comput. Neurosci. 2012, 6, 20. [Google Scholar] [CrossRef] [PubMed]
- Connell, L.; MacDonald, R.; McBride, T.; Peiperl, L.; Ross, A.; Simpson, P.; Winker, M. Observational studies: Getting clear about transparency. PLoS Med. 2014, 11, e1001711. [Google Scholar] [CrossRef]
- Vandenbroucke, J.P.; Von Elm, E.; Altman, D.G.; Gotzsche, P.C.; Mulrow, C.D.; Pocock, S.J.; Poole, C.; Schlesselman, J.J.; Egger, M. Strengthening the reporting of observational studies in epidemiology (STROBE): Explanation and elaboration. Int. J. Surg. 2014, 12, 1500–1524. [Google Scholar] [CrossRef] [PubMed]
- Lakens, D.; Hilgard, J.; Staaks, J. On the reproducibility of meta-analyses: Six practical recommendations. BMC Psychol. 2016, 4, 24. [Google Scholar] [CrossRef] [PubMed]
- Wicherts, J.M. The weak spots in contemporary science (and how to fix them). Animals 2017, 7, 90. [Google Scholar] [CrossRef]
- Miyakawa, T. No raw data, no science: Another possible source of the reproducibility crisis. Mol. Brain. 2020, 13, 24. [Google Scholar] [CrossRef]
- Banks, G.C.; Rogelberg, S.G.; Woznyj, H.M.; Landis, R.S.; Rupp, D.E. Evidence on questionable research practices: The good, the bad, and the ugly. J. Bus Psychol. 2016, 31, 323–338. [Google Scholar] [CrossRef]
- Gelman, A.; Loken, E. The Garden of Forking Paths: Why Multiple Comparisons Can Be a Problem, Even When There Is No “Fishing Expedition” or “p-Hacking” and the Research Hypothesis Was Posited Ahead of Time. 2013. Available online: http://www.stat.columbia.edu/~gelman/research/unpublished/p_hacking.pdf (accessed on 24 August 2019).



{kind=link}
{kind=link}
| Disease Category | Disease | Population of Interest | Prevalence Rate (P) | Timeframe |
|---|---|---|---|---|
| Respiratory diseases | asthma | total males and females | 0.079 | in 2017 |
| chronic obstructive pulmonary disease (COPD) | adults ≥18 years | 0.059 | in 2014–2015 | |
| Heart diseases | coronary heart disease, angina or heart attack | adults ≥18 years | 0.056 | in 2018 |
| Diabetes | diabetes | total males and females | 0.094 | in 2015 |
| Cancers | breast | females ≥35 years | 0.037 | in 2016 |
| prostate | males ≥55 years | 0.072 | in 2016 | |
| colorectal | total males and females | 0.0040 | in 2016 | |
| lung and bronchus | total males and females | 0.0017 | in 2016 |
| Example 1 A simple univariate analysis of childhood asthma hospital admissions is considered using 6 air quality predictors—daily average levels of PM10, PM2.2, SO2, NO2, CO and O3, and no lags or weather covariate confounders: |
|
| Example 2 For a slightly more typical analysis of the same 6 predictors with 3 lags (i.e., same day, 1 and 2 day lags), and 2 weather variables treated as covariate confounders (daily average temperature and relative humidity), and also adjusting for possible confounding of co-pollutants in the analysis (i.e., air quality variables are also treated as covariate confounders in the analysis), we have the following search space counts: |
|
| Example 3 For a typical (and more in-depth) example, in addition to Example 2 characteristics, four different subgroups are used in the analysis (e.g., children ≤4 years, children 5–14 years, boys only ≤14 years and girls only ≤14 years) along with the main study population: |
|
| First Author | Outcomes | Predictors | Models | Lags | Covariates | Space1 | Space2 | Space3 |
|---|---|---|---|---|---|---|---|---|
| Thompson | 1 | 10 | 3 | 4 | 7 | 120 | 128 | 15,360 |
| Andersen | 3 | 11 | 1 | 6 | 8 | 198 | 256 | 50,688 |
| Chardon | 3 | 3 | 1 | 16 | 8 | 144 | 256 | 36,864 |
| Sheppard | 1 | 14 | 5 | 5 | 8 | 350 | 256 | 89,600 |
| Gouveia | 4 | 11 | 1 | 4 | 8 | 176 | 256 | 45,056 |
| Tenias | 1 | 24 | 4 | 4 | 5 | 384 | 32 | 12,288 |
| Magas | 4 | 6 | 1 | 2 | 5 | 48 | 32 | 1536 |
| Chakraborty | 1 | 3 | 2 | 1 | 4 | 6 | 16 | 96 |
| Tsai | 1 | 10 | 2 | 3 | 2 | 60 | 4 | 240 |
| Laurent | 4 | 4 | 3 | 6 | 5 | 288 | 32 | 9216 |
| Lavigne | 5 | 5 | 1 | 1 | 3 | 25 | 8 | 200 |
| Mar | 1 | 2 | 1 | 6 | 8 | 12 | 8 | 96 |
| Evans | 3 | 7 | 2 | 7 | 6 | 294 | 64 | 18,816 |
| Abe | 2 | 10 | 2 | 2 | 9 | 80 | 512 | 40,960 |
| Santus | 32 | 10 | 2 | 8 | 3 | 5120 | 8 | 40,960 |
| Hua | 2 | 2 | 8 | 5 | 4 | 160 | 16 | 2560 |
| Lin | 3 | 3 | 3 | 7 | 7 | 189 | 128 | 24,192 |
| Statistic | Space1 | Space2 | Space3 |
|---|---|---|---|
| minimum | 6 | 4 | 96 |
| lower quartile | 60 | 16 | 1536 |
| median | 160 | 32 | 15,360 |
| upper quartile | 288 | 256 | 40,960 |
| maximum | 5120 | 512 | 89,600 |
| mean | 450 | 118 | 22,866 |
| Study 1st Author 1 | Publication Year | RR | LCL | UCL | p-Value 2 |
|---|---|---|---|---|---|
| Lee SL | 2006 | 1.024 | 1.014 | 1.035 | 0.0001 |
| Ko FWS | 2007 | 1.004 | 1.000 | 1.009 | 0.0803567 |
| Jalaludin BB | 2008 | 1.017 | 1.008 | 1.027 | 0.000432 |
| Lavigne E | 2012 | 1.000 | 0.909 | 1.121 | 1 |
| Stieb DM | 2009 | 1.011 | 0.987 | 1.037 | 0.3923886 |
| Chimonas MAR | 2007 | 0.992 | 0.964 | 1.024 | 0.6144624 |
| Sluaghter JC (ER) | 2005 | 1.030 | 0.980 | 1.090 | 0.279572 |
| (H) | 1.010 | 0.910 | 1.110 | 0.8548709 | |
| Li S | 2011 | 1.032 | 1.007 | 1.057 | 0.010805 |
| Mar TF | 2010 | 1.000 | 0.957 | 1.043 | 1 |
| Sheppard L | 1999 | 1.034 | 1.017 | 1.059 | 0.001249 |
| Yamazaki S (W) | 2013 | 0.958 | 0.776 | 1.182 | 0.7025466 |
| (C) | 1.039 | 0.883 | 1.222 | 0.6573244 | |
| Santus P | 2012 | 0.991 | 0.970 | 1.011 | 0.399061 |
| Babin S | 2008 | 1.000 | 0.990 | 1.020 | 1 |
| Kim SY | 2012 | 1.009 | 0.991 | 1.026 | 0.3161553 |
| Paulu C | 2008 | 1.010 | 0.960 | 1.060 | 0.7070236 |
| Halonen JI (A) | 2008 | 1.003 | 0.957 | 1.050 | 0.907147 |
| (O) | 1.068 | 1.014 | 1.131 | 0.0180712 | |
| Szyszkowicz M | 2008 | 1.085 | 1.010 | 1.166 | 0.025766 |
| Malig BJ | 2013 | 1.020 | 1.010 | 1.030 | 0.0001 |
| Evans KA | 2013 | 0.821 | 0.418 | 1.403 | 0.5339787 |
| Ito K | 2007 | 1.060 | 1.052 | 1.072 | 0.0001 |
| Chardon B | 2007 | 1.044 | 0.999 | 1.104 | 0.0909348 |
| Lin M | 2002 | 1.011 | 0.925 | 1.065 | 0.7736097 |
| Silverman RA | 2010 | 1.075 | 1.050 | 1.100 | 0.0001 |
| Barnett AG (0–4y) | 2005 | 1.045 | 1.018 | 1.071 | 0.000713 |
| (5–14y) | 1.034 | 0.992 | 1.076 | 0.1067006 | |
| Iskandar A | 2012 | 1.188 | 1.083 | 1.271 | 0.0001 |
| Santus P | 2012 | 0.992 | 0.967 | 1.017 | 0.5433122 |
| Strickland MJ | 2010 | 1.022 | 1.002 | 1.042 | 0.029066 |
| Andersen ZJ | 2008 | 1.300 | 1.000 | 1.640 | 0.037304 |
| Hua J | 2014 | 1.003 | 1.000 | 1.010 | 0.2403955 |
| Gleason JA | 2014 | 1.012 | 1.000 | 1.024 | 0.048279 |
| Raun LH | 2014 | 1.033 | 0.983 | 1.083 | 0.1901706 |
| Cheng MH (W) | 2014 | 1.069 | 1.034 | 1.103 | 0.0001 |
| (C) | 1.017 | 1.000 | 1.046 | 0.1420481 |
| Air Quality Component | Number of Risk Ratios (RRs) Used | RRs with p-Values > 0.05 (%) | RR with p-Values ≤ 0.05 | RRs with p-Values ≤ 0.001 |
|---|---|---|---|---|
| CO | 42 | 29 (69) | 13 | 9 |
| NO2 | 66 | 30 (45) | 36 | 16 |
| O3 | 71 | 40 (56) | 31 | 11 |
| PM2.5 | 37 | 22 (59) | 15 | 8 |
| PM10 | 51 | 28 (55) | 23 | 6 |
| SO2 | 65 | 46 (70) | 19 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kindzierski, W.; Young, S.; Meyer, T.; Dunn, J. Evaluation of a Meta-Analysis of Ambient Air Quality as a Risk Factor for Asthma Exacerbation. J. Respir. 2021, 1, 173-196. https://doi.org/10.3390/jor1030017
Kindzierski W, Young S, Meyer T, Dunn J. Evaluation of a Meta-Analysis of Ambient Air Quality as a Risk Factor for Asthma Exacerbation. Journal of Respiration. 2021; 1(3):173-196. https://doi.org/10.3390/jor1030017
Chicago/Turabian StyleKindzierski, Warren, Stanley Young, Terry Meyer, and John Dunn. 2021. "Evaluation of a Meta-Analysis of Ambient Air Quality as a Risk Factor for Asthma Exacerbation" Journal of Respiration 1, no. 3: 173-196. https://doi.org/10.3390/jor1030017
APA StyleKindzierski, W., Young, S., Meyer, T., & Dunn, J. (2021). Evaluation of a Meta-Analysis of Ambient Air Quality as a Risk Factor for Asthma Exacerbation. Journal of Respiration, 1(3), 173-196. https://doi.org/10.3390/jor1030017