Abstract
In the current digital era, the demand for rapid news delivery increases the risk of linguistic errors, including inaccuracies in the usage of melting words. This research introduces the U-Tapis application, a platform designed to detect and correct such errors using the Damerau-Levenshtein Distance algorithm and the RoBERTa model. The system achieved an average recommendation accuracy of 92.84%, with performance ranging from 91.30% to 95.45% across 3000 news articles. Despite its effectiveness, the system faces limitations, such as the static nature of its dataset, which does not update dynamically with new entries in the Indonesian Language Dictionary, and its tendency to flag all words with “me-” and “pe-” prefixes, regardless of context. These challenges highlight opportunities for future enhancements to improve the platform’s adaptability and precision.
1. Introduction
Machine learning, a rapidly evolving subset of artificial intelligence (AI), has been widely applied to solve diverse problems in domains such as business, robotics, mathematics, financial analysis, and natural language processing (NLP) [,]. Among these, NLP focuses on enabling machines to understand and process human language, facilitating effective and efficient user interaction []. NLP is instrumental in building computational models that process textual and spoken information [,], making it particularly valuable in fields like journalism []. In the fast-paced digital era, journalism demands real-time access to news, requiring journalistic teams to produce content under tight deadlines. This urgency often results in limited time for thorough editing and proofreading, leading to frequent linguistic errors [,].
Common language errors in mass media include spelling mistakes, syntactic inconsistencies, and semantic inaccuracies []. Adhering to proper linguistic conventions is essential to maintaining the quality and fostering the growth of the Indonesian language in mass media [,]. One common error found in news writing is related to “peluluhan kata” (melting words). “Peluluhan”, a subset of morphophonemics, occurs when morphemes (words or syllables) meet, resulting in phoneme changes to facilitate easier pronunciation []. The correct linguistic rule for “peluluhan” in root words with consonant clusters (double consonants) is that the root word does not undergo softening if the prefix is “me-” or “pe-”, whereas root words with single consonants do soften [].
To address these errors, a computational tool called U-Tapis has been developed. U-Tapis is an application designed to detect and correct linguistic rule errors in Indonesian, particularly assisting journalists []. Previous research on detecting and correcting melting words errors employed the Jaccard Similarity algorithm, yielding an F1-Score of 66.6% []. Another research utilized a combination of the Damerau-Levenshtein Distance algorithm and BERT but did not effectively address melting word errors in root words with double consonants [].
This research aims to improve U-Tapis by enhancing its capacity to identify and correct melting word errors, focusing on both single and double consonant root word cases using NLP. This approach has proven effective in correcting misspelled words in documents and assisting typists by providing helpful tools []. The proposed approach integrates the Damerau-Levenshtein Distance algorithm and the RoBERTa model. The Damerau-Levenshtein Distance algorithm was chosen for its ability to compute the distance between target and source strings, considering adjacent symbol transpositions, making it suitable for building spell-checking systems []. It compares detected words against a dictionary of correct forms and uses the computed distance as the basis for correction. Meanwhile, the RoBERTa model was selected for its superior performance compared to BERT, as RoBERTa is trained on a larger corpus and achieves accuracy in the range of 85–86%, whereas BERT achieves accuracy in the range of 83–85% [].
By developing this enhanced machine learning model, which will be integrated into U-Tapis, this research seeks to assist journalistic teams in improving the efficiency and accuracy of their editorial processes. It specifically aims to address the challenges of melting word errors in Indonesian journalism, contributing significantly to the fields of NLP and computational linguistics through the creation of an advanced language correction system.
2. Materials and Methods
Figure 1 illustrates the research flow, starting with data collection, where relevant textual data is gathered. The next step involves text preprocessing to clean and standardize the data before feeding it into the model. Following this, the model is developed to detect and correct melting word errors. Finally, the model undergoes testing and evaluation to assess its accuracy and overall performance.
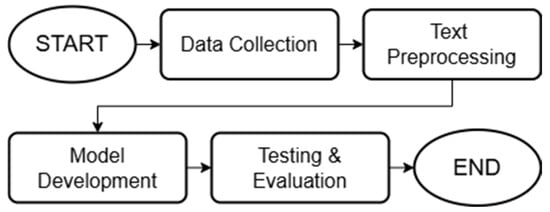
Figure 1.
Research Method Flowchart.
2.1. Data Collection
The data collection stage is carried out by gathering all correct forms of melting words through crawling the Kamus Besar Bahasa Indonesia (The Indonesian Language Dictionary), both words with single and double consonants. The collected words must start with the prefix me- and pe-. The data will then be stored in the .xlsx format for use in the model. Additionally, news articles are also collected as a testing dataset for the system. This dataset, in .pdf and .docx formats, was collected by students from the Journalism department and stored in a Google Drive folder accessible to the U-Tapis research team. In this research, 3000 news articles are used as the testing dataset to evaluate the system’s detection and correction capabilities.
2.2. Text Preprocessing
Preprocessing is applied to the input data from news articles to ensure consistency and cleanliness. As shown in Figure 2, this stage involves several steps, including removing control characters, stripping HTML tags, converting Unicode characters to ASCII, and applying case folding. Additionally, numerals, extra spaces, and punctuation are removed to enhance text uniformity. Finally, the processed text is tokenized, preparing it for further analysis.
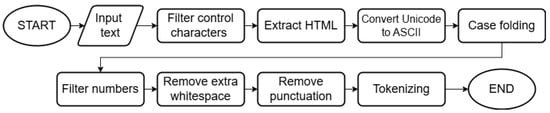
Figure 2.
Text Preprocessing Flowchart.
2.3. Model Development
In the model development stage, the Damerau-Levenshtein Distance (DLD) algorithm detects misspellings of melting words in the preprocessed news text, while the RoBERTa model predicts synonyms for those incorrect words. Figure 3 illustrates the overall model development flow, starting with the input of preprocessed text. The system first checks whether the root word contains a double consonant, directing it to either single or double consonant detection accordingly. The results are then combined and processed through the RoBERTa model to generate final predictions before producing the output.
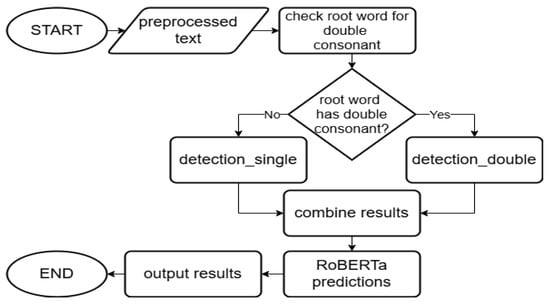
Figure 3.
Overall Model Development Flowchart.
In both the detect_single and detect_double functions, the Damerau-Levenshtein Distance (DLD) between the words in the news text and the correct word set in the Excel dataset is first compared, as shown in Figure 4. If the DLD is 0, the word will be added to the correct word list. However, if the DLD is not 0, the word will be added to the incorrect word list. The difference between the detect_single and detect_double functions lies in the distance comparison used as the evaluation criterion. In the detect_single function, a DLD greater than 0 and less than or equal to 1 is used as the rule to add words from the dataset to the recommendation list for correction. In the detect_double function, the rule is based on a DLD greater than 0 and less than or equal to 2. The resulting words from both functions are then returned as the correct word list, incorrect word list, and recommendation word list.
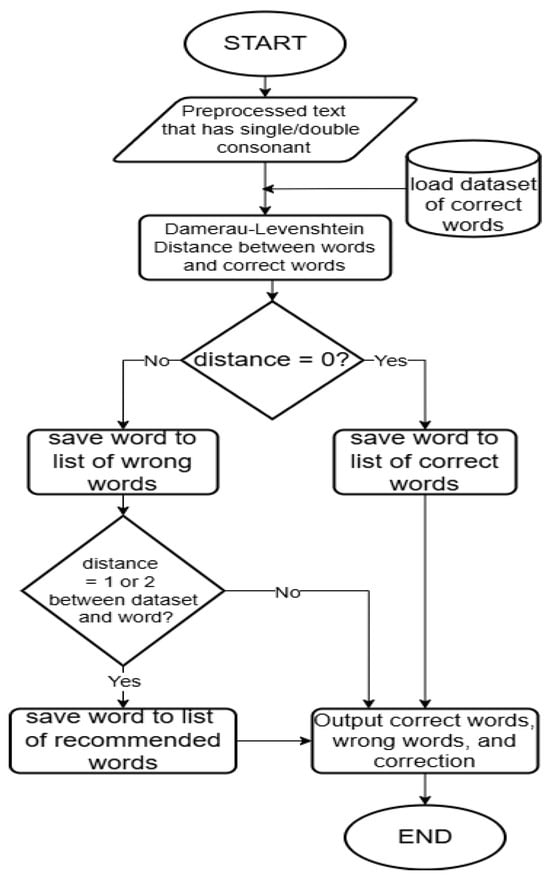
Figure 4.
Flowchart of Word Detection Using DLD.
To build the synonym prediction mechanism, the pre-trained transformer model “cahya/roberta-base-indonesian-1.5G” from HuggingFace is utilized []. Incorrect words in the list of wrong words are masked using the “<mask>” format before being input into the model. The preprocessed text and the masked words serve as the basis for the model to predict synonyms as word recommendations. These prediction results are appended to the detailed output, so the final output of the model comprises the detected incorrect words, their corrections, and the corresponding word recommendations. This process is illustrated in Figure 5.
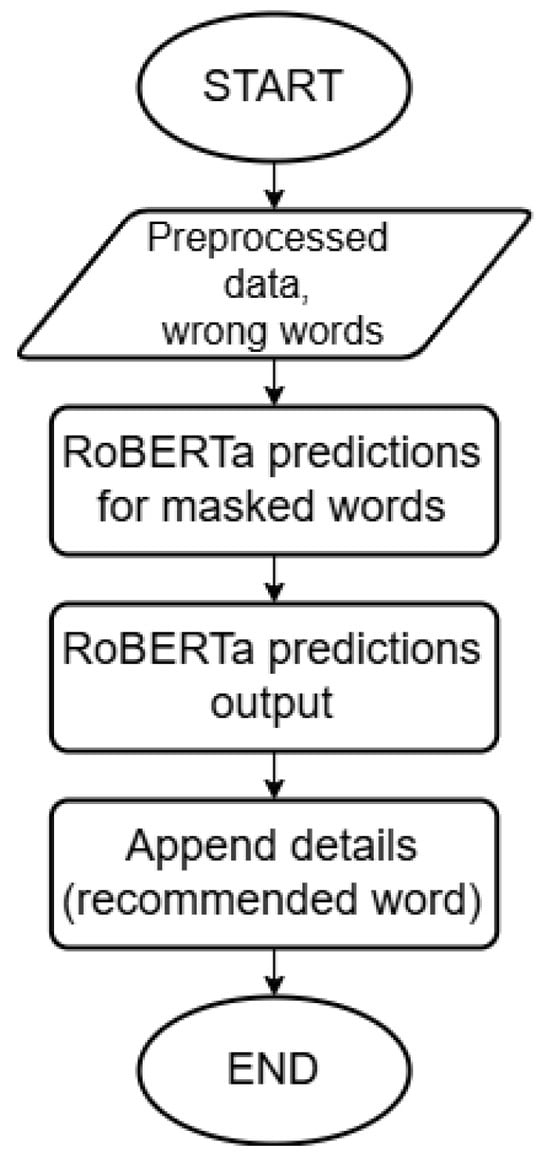
Figure 5.
Flowchart of Word Prediction Using RoBERTa.
2.4. Testing and Evaluation
This stage is conducted using 3000 news articles with various scenarios, including 100, 150, 200, 300, 350, 400, 450, 500, and 550 news articles from TribunNews. Once the testing results are obtained, the confusion matrix will be determined, which can then be used to calculate accuracy, precision, f1-score, and recall. Additionally, the recommendation accuracy of the system is calculated to evaluate its effectiveness in suggesting corrections. The evaluation results will help identify potential weaknesses in the model and provide insights for further improvements.
3. Results
This section presents the findings of the research, highlighting the performance evaluation and practical implementation of the proposed system. The “Testing and Evaluation” subsection discusses the accuracy and effectiveness of the hybrid approach, analyzing key performance metrics such as precision, recall, F1-score, and recommendation accuracy based on extensive testing with news articles. The “Website Interface Implementation” subsection showcases the integration of the error detection and correction model into a user-friendly web platform, emphasizing usability and real-time processing capabilities. These analyses provide insights into the system’s strengths, areas for improvement, and its broader implications in NLP and computational linguistics.
3.1. Evaluation Results
In this section, the system was tested using 3000 articles with a testing scheme involving 100, 150, 200, 300, 350, 400, 450, 500, and 550 news articles. The tests were conducted to evaluate the detection and correction results of the system, which employs Damerau-Levenshtein Distance and RoBERTa. Additionally, the recommendation accuracy was calculated by dividing the total number of correct recommendations by the total number of incorrect melting words.
- 100 News Tase Case: Table 1 presents the confusion matrix for 100 tested news articles. Based on the testing results, it was found that there were 579 words classified as True Positive (TP), 22 words as True Negative (TN), 24 words as False Negative (FN), 3 words as False Positive (FP), and the accuracy of recommendation is 95.45%.
 Table 1. 100 Test Case Confusion Matrix.
Table 1. 100 Test Case Confusion Matrix. - 150 News Tase Case: Table 2 presents the confusion matrix for 150 tested news articles. Based on the testing results, it was found that there were 777 words classified as True Positive (TP), 23 words as True Negative (TN), 32 words as False Negative (FN), 2 words as False Positive (FP), and the accuracy of recommendation is 91.30%.
Table 2. 150 Test Case Confusion Matrix.
- 200 News Tase Case: Table 3 presents the confusion matrix for 200 tested news articles. Based on the testing results, it was found that there were 1061 words classified as True Positive (TP), 42 words as True Negative (TN), 36 words as False Negative (FN), 2 words as False Positive (FP), and the accuracy of recommendation is 92.86%.
Table 3. 200 Test Case Confusion Matrix.
- 300 News Tase Case: Table 4 presents the confusion matrix for 300 tested news articles. Based on the testing results, it was found that there were 1642 words classified as True Positive (TP), 75 words as True Negative (TN), 75 words as False Negative (FN), 6 words as False Positive (FP), and the accuracy of recommendation is 93.33%.
Table 4. 300 Test Case Confusion Matrix.
- 350 News Tase Case: Table 5 presents the confusion matrix for 350 tested news articles. Based on the testing results, it was found that there were 1835 words classified as True Positive (TP), 54 words as True Negative (TN), 54 words as False Negative (FN), 3 words as False Positive (FP), and the accuracy of recommendation is 92.59%.
Table 5. 350 Test Case Confusion Matrix.
- 400 News Tase Case: Table 6 presents the confusion matrix for 400 tested news articles. Based on the testing results, it was found that there were 2223 words classified as True Positive (TP), 108 words as True Negative (TN), 114 words as False Negative (FN), 10 words as False Positive (FP), and the accuracy of recommendation is 93.52%.
Table 6. 400 Test Case Confusion Matrix.
- 450 News Tase Case: Table 7 presents the confusion matrix for 450 tested news articles. Based on the testing results, it was found that there were 2656 words classified as True Positive (TP), 108 words as True Negative (TN), 84 words as False Negative (FN), 6 words as False Positive (FP), and the accuracy of recommendation is 92.59%.
Table 7. 450 Test Case Confusion Matrix.
- 500 News Tase Case: Table 8 presents the confusion matrix for 500 tested news articles. Based on the testing results, it was found that there were 2774 words classified as True Positive (TP), 111 words as True Negative (TN), 118 words as False Negative (FN), 8 words as False Positive (FP), and the accuracy of recommendation is 92.79%.
Table 8. 500 Test Case Confusion Matrix.
- 550 News Tase Case: Table 9 presents the confusion matrix for 550 tested news articles. Based on the testing results, it was found that there were 2935 words classified as True Positive (TP), 124 words as True Negative (TN), 120 words as False Negative (FN), 8 words as False Positive (FP), and the accuracy of recommendation is 91.13%.
Table 9. 550 Test Case Confusion Matrix.
The performance metrics from the various test cases can be seen in Table 10 below. The proposed system achieved an average recommendation accuracy of 92.84% across multiple test cases in identifying and correcting melting word errors, outperforming the combination of BERT and Damerau-Levenshtein Distance as the baseline, which achieved 89% recommendation accuracy. These results were obtained from a dataset of 3000 Indonesian news articles, focusing on both single and double consonant root word cases. For instance, the system corrected “mensejahterakan” to “menyejahterakan” (meaning “to prosper”) and “menkritik” to “mengkritik” (meaning “to criticize”), demonstrating its effectiveness in identifying and correcting melting word errors.
Table 10.
Performance Metrics for Test Cases.
3.2. Website Interface Implementation
Figure 6 displays the initial interface of the program and how it appears after a user uploads a .docx file. The page includes a text area, a file input, and a button labeled “Tapis.” Users can enter news text either by typing directly into the text area or by uploading a .docx file, which automatically populates the text area with its content. Once the text is entered, they can press the “Tapis” button to check for melting words.
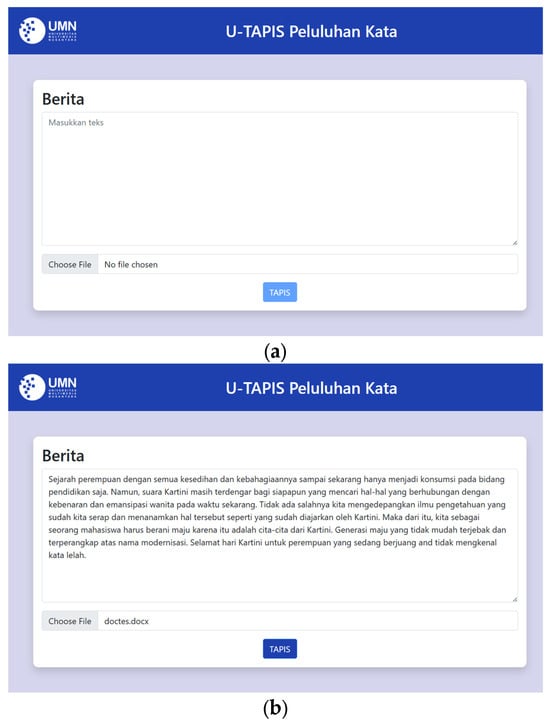
Figure 6.
Main Page: (a) Initial display; (b) Loaded text from a document.
After the user presses the “Tapis” button, the system will process the news and display the news text along with the detection results, as shown in Figure 7. The red color indicates that the detected word has an incorrect melting word form according to the Kamus Besar Bahasa Indonesia (The Indonesian Language Dictionary) and the blue color indicates that the previously incorrect word has been replaced with the system’s corrected version. If a red-colored word, which indicates an incorrect melting word form, is clicked, the user can press the dropdown menu to view a list of suggested corrections and recommendations for the word. This feature allows users to evaluate the provided suggestions, reducing the risk of blindly accepting corrections without ensuring their accuracy and relevance. The user can select one of the correction and recommendation options provided by the system. After the user selects one of the correction options, the incorrect word will automatically be replaced with the selected option. The corrected text can be copied by clicking the “Salin Teks” (Copy Text) button. Once the text is successfully copied, the system displays an alert confirming the completion of the process.
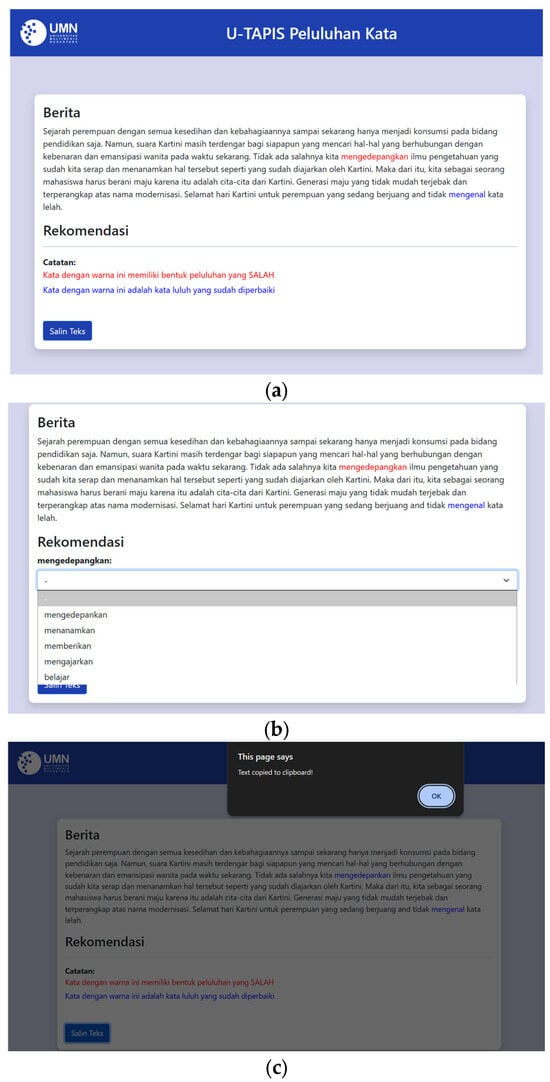
Figure 7.
Process Result: (a) Detection and Correction Result; (b) Correction and Recommendation Options; (c) Copy Text Feature.
4. Discussion
The system achieved an average recommendation accuracy of 92.84% when tested on a total of 3000 news articles. While the research made significant progress, several limitations were identified. The dataset containing the correct forms of melting words has not been dynamically updated, preventing the system from automatically incorporating new entries from the Kamus Besar Bahasa Indonesia (The Indonesian Language Dictionary). As a result, newly introduced words remain unrecognized by the system. Additionally, the system currently detects all words with the prefixes “me-” and “pe-”, regardless of their relevance to melting words, as seen with words like “memang” (meaning “certainly” or “indeed”) and “perempuan” (meaning “female”). Addressing these limitations offers opportunities for future research. Dynamic integration of the dictionary and improved prefix filtering mechanisms could enhance the system’s accuracy and adaptability, contributing to the development of more robust tools for error detection and correction in Indonesian text processing.
Furthermore, the automation of language correction introduces potential ethical concerns. Users may blindly accept corrections without verifying their appropriateness, potentially introducing errors in specialized contexts. To mitigate these risks, the system includes manual oversight features, allowing users to select from multiple correction suggestions. It does not enforce corrections, enabling users to retain the original text if desired.
5. Conclusions
This research makes a valuable contribution to the fields of NLP and computational linguistics by addressing the challenges of melting word errors in journalism and providing practical advancements in automated language correction. The research successfully implemented the Damerau-Levenshtein Distance algorithm and RoBERTa for detecting and correcting melting word errors involving both single and double consonants, achieving satisfactory performance. Recommendation accuracy rates of 95.45%, 91.30%, 92.86%, 93.33%, 92.59%, 93.52%, 92.59%, 92.79%, and 91.13% were achieved across test cases involving 100, 150, 200, 300, 350, 400, 450, 500, and 550 news articles, respectively. The system achieved an average recommendation accuracy of 92.84%, outperforming the previous approach (a combination of Damerau-Levenshtein Distance and BERT), which achieved an average recommendation accuracy of 89%.
While the research demonstrates promising results, certain limitations were identified. One limitation is the lack of dynamic updates to the dataset, which prevents the system from recognizing newly introduced words in the Kamus Besar Bahasa Indonesia (The Indonesian Language Dictionary). Additionally, the system tends to detect words with the prefixes “me-” and “pe-” regardless of their relevance to melting words. Addressing these issues, such as through dynamic dictionary integration and more refined prefix filtering, presents opportunities for further enhancing system accuracy and adaptability.
Moreover, the automation of language correction raises ethical considerations. Users may inadvertently accept corrections without evaluating their appropriateness, which could lead to errors in specialized contexts. To mitigate this risk, the system includes manual oversight features, giving users the option to choose from multiple suggestions and retain the original text if desired. Future research should focus on refining these aspects, contributing to the development of more robust and ethically responsible tools for error detection and correction in Indonesian text processing.
Author Contributions
Conceptualization, P.T. and M.V.O.; methodology, P.T.; software, P.T.; validation, P.T. and M.V.O.; formal analysis, P.T.; investigation, M.V.O.; resources, P.T.; data curation, P.T.; writing—original draft preparation, P.T.; writing—review and editing, P.T. and M.V.O.; visualization, P.T.; supervision, M.V.O.; project administration, M.V.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting the findings of this study are not publicly available due to privacy and institutional restrictions and are kept confidential within the research team at Universitas Multimedia Nusantara.
Acknowledgments
The authors would like to express their gratitude to Universitas Multimedia Nusantara for their support of this research, as well as to TribunNews for partnering with the authors in this research.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DLD | Damerau-Leveshtein Distance |
| RoBERTa | Robustly Optimized BERT Pretraining Approach |
| BERT | Bidirectional Encoder Representation from Transformer |
| NLP | Natural Language Processing |
| AI | Artificial Intelligence |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
References
- 4 Reasons Machine Learning Is Trending Amidst the Pandemic. Available online: https://dcs.binus.ac.id/2022/05/14/4-alasan-machine-learning-menjadi-tren-di-tengah-pandemi/ (accessed on 20 August 2024).
- Roihan, A.; Sunarya, P.; Rafika, A. Pemanfaatan machine learning dalam berbagai bidang: Review paper. Indones. J. Comput. Inf. Technol. 2020, 5, 490845. [Google Scholar] [CrossRef]
- Fanni, S.C.; Febi, M.; Aghakhanyan, G.; Neri, E. Natural language processing. In Introduction to Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2023; pp. 87–99. [Google Scholar]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Pais, S.; Cordeiro, J.; Jamil, M.L. Nlp-based platform as a service: A brief review. J. Big Data 2022, 9, 54. [Google Scholar] [CrossRef]
- Saputra, A.K.B.; Overbeek, M.V. Harnessing long short-term memory algorithm for enhanced di-di word error detection and correction. AIP Conf. Proc. 2024, 3220, 040002. [Google Scholar] [CrossRef]
- Hidayat, P.; Sudiana, I.N.; Tantri, A.A.S. Analisis kesalahan berbahasa pada penulisan berita detik finance dan detik news. J. Pendidik. Bhs. Sastra Indones. Undiksha. 2021, 11, 318–326. [Google Scholar] [CrossRef]
- Dwitya, N.R.; Overbeek, M.V. Development of detection and correction of errors in spelling and compound words using long short-term memory. AIP Conf. Proc. 2024, 3220, 040005. [Google Scholar] [CrossRef]
- Damayanti, A.M.D.; Suhartono; Inayatillah, F. Kesalahan frasa pada berita online surya.co.id 2023: Phrase mistakes in surya.co.id online news 2023. J. Bastrindo. 2023, 4, 58–71. [Google Scholar] [CrossRef]
- Nababan, R.Y. Wacana komunikasi ekspositif dalam youtube stefanie humena edisi “bahasa indonesia yang baik dan benar”. Sitasi Ilm. 2022, 1, 60–68. [Google Scholar]
- Agan, S.; Puspitoningrum, E. Kosa kata bahasa asing dalam bahasa indonesia ragam jurnalistik. Wacana J. Bhs. Seni Dan Pengajaran. 2022, 5, 63–74. [Google Scholar] [CrossRef]
- Hutapea, E. Peluluhan kata Dasar Berawalan kpst Halaman All. KOMPAS.com. 2021. Available online: https://edukasi.kompas.com/read/2021/01/08/144019571/peluluhan-kata-dasar-berawalan-kpst (accessed on 4 July 2024).
- Kusumah, E. Morfofonemik dalam proses afiksasi prefiks {men-} dan {pen-} yang menghadapi bentuk dasar berkluster. J. Membaca Bhs. Sastra Indones. 2023, 8, 22825. [Google Scholar] [CrossRef]
- Mediyawati, N.; Bintang, S. Platform kecerdasan buatan sebagai media inovatif untuk meningkatkan keterampilan berkomunikasi: U-tapis. In Proceedings of the Seminar Nasional Program Pascasarjana Universitas PGRI Palembang, Palembang, Indonesia, 21 August 2021. [Google Scholar]
- Taslim, N.E. Deteksi Kesalahan Eja Kata Luluh pada Berita dengan Algoritma Jaccard Aimilarity (Atudi Kasus: Tribunnews). Bachelor’s Thesis, Universitas Multimedia Nusantara, Banten, Indonesia, 2023. Available online: https://kc.umn.ac.id/id/eprint/28066/ (accessed on 21 August 2024).
- Gleneagles, K.; Overbeek, M.V.; Mediyawati, N.; Sutomo, R.; Nusantara, S.B. U-tapis melting words: An artificial intelligence application for detecting melt word erros in indonesia online news. In Proceedings of the International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 11–12 December 2024. [Google Scholar]
- Revathi, A.; Vimaladevi, M.; Arivazhagan, N. Spelling correction using encoder-decoder and damerau-levenshtein distance. In Proceedings of the 2023 IEEE 5th International Conference on Cybernetics, Cognition and Machine Learning Applications (ICCCMLA), Hamburg, Germany, 7–8 October 2023; pp. 469–472. [Google Scholar]
- Chaabi, Y.; Allah, F.A. Amazigh spell checker using damerau-levenshtein algorithm and n-gram. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 6116–6124. [Google Scholar] [CrossRef]
- Rajapaksha, P.; Farahbakhsh, R.; Crespi, N. Bert, xlnet or roberta: The best transfer learning model to detect clickbaits. IEEE Access. 2021, 9, 154704–154716. [Google Scholar] [CrossRef]
- Cahya. Cahya/Roberta-Base-Indonesian-1.5G; Face, H. 2021. Available online: https://huggingface.co/cahya/roberta-base-indonesian-1.5G (accessed on 17 October 2024).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).