Abstract
A standard approach for assessing the performance of partition models is to create synthetic datasets with a prespecified clustering structure and assess how well the model reveals this structure. A common format involves subjects being assigned to different clusters, with observations simulated so that subjects within the same cluster have similar profiles, allowing for some variability. In this manuscript, we consider observations from interval variables. Interval data are commonly observed in cohort and Genome-Wide Association studies, and our focus is on Single-Nucleotide Polymorphisms. Theoretical and empirical results are utilized to explore the dependence structure between the variables in relation to the clustering structure for the subjects. A novel algorithm is proposed that allows control over the marginal stratified correlation structure of the variables, specifying exact correlation values within groups of variables. Practical examples are shown, and a synthetic dataset is compared to a real one, to demonstrate similarities and differences.
1. Introduction
Partitioning and mixture models are often used to reveal the clustering structure within a sample, for example, to discover if combinations of risk factors are associated with the risk of disease [1], or to reveal dependencies in a population after reducing the dimensionality of the problem [2]. An overview of clustering approaches is given in [3,4]. Sometimes, partitioning the variables rather than the subjects is of interest [5,6]. In this manuscript, we focus on the more standard set-up where subjects are partitioned, but the two frameworks can be viewed as interchangeable for simulated observations.
We adopt a model-based approach, and define as a cluster each one of the components of the adopted mixture model. Therefore, we undertake that two subjects belong to the same cluster when the corresponding vectors of observations are generated by the same component of the mixture model. See [7] for an extensive discussion on cluster definition. Assessing the performance of partitioning models involves the creation of synthetic data with a prespecified clustering structure. The model is then fitted to the simulated data to evaluate its performance in terms of revealing this structure.
For continuous observations, partitioning models often allow for a specific correlation structure for the variables, given the cluster allocation [8]. This typically involves a multivariate normal distribution [9]. Clustering approaches for observations from interval variables often prescribe that variables are independent, given the clustering of the subjects [10,11]. The resulting dimensionality reduction is the main advantage of this local independence modeling, as determining a fully specified joint distribution between P variables with M levels requires the specification of probabilities, a task that quickly becomes cumbersome and unwieldy. The authors of [12] comment on this notable modeling difference, mentioning that, in many applications, conditional independence has proven successful in achieving the main objective of a clustering algorithm, which is to bring together similar observations. In [13], local dependence is discussed, given well-defined substantive interest.
In this manuscript, we adopt the widely espoused independence assumption for the variables conditionally on the clustering of the subjects. In all examples, we ensure that clustering structures are identifiable, up to label switching, by following the guidelines of [14] for the required number of variables for mixture models when the within-cluster independence assumption holds. Thus, with C denoting the number of clusters, all synthetic datasets satisfy the identifiability condition .
Our work concerns interval variables, where the numerical distance between possible values is meaningful and known. Interval variables are of particular interest to us, as data from epidemiological and association cohort studies, such as the number of genetic variants, are often in this form. Furthermore, continuous observations are often transformed to interval ones when data from cohort studies are analyzed. This is performed to alleviate the adverse effect of outlier observations (for example, in dietary observations; see [15]), or to allow for the flexible modeling of interactions. Importantly, interval variables allow for the use of covariances and correlations through expectations. The variables are assumed to be independent given the clustering of the subjects, but they can be marginally dependent, i.e., dependent after the cluster allocation variables are summed out. In synthetic datasets, the induced marginal dependence is typically ignored and can be at odds with the dependence structure observed in real datasets.
The aim of this manuscript is to provide theoretical and computational tools for the creation of simulated datasets relevant to clustering algorithms, so that the synthetic data share more characteristics with real ones compared to synthetic data created with standard methods. An algorithm is proposed where the clustering structure is predetermined, while maintaining partial control over the marginal dependence structure between the variables. To the best of our knowledge, no such algorithm has yet been proposed. Our focus is on generating simulated datasets that contain observations that emulate Single-Nucleotide Polymorphisms (SNPs), although the proposed methods are more generally applicable. We do not touch on issues relevant to recombination and imputation [16], as these are beyond the scope of this manuscript.
Approaches in the literature relevant to marginal correlations focus on continuous observations, and on deriving association measures that provide unbiased estimates of marginal correlations when the size of the cluster relates to some outcome and a random effects-type model is utilized [17,18]. Consequently, the relevance of these approaches to the work presented in this manuscript is limited. Ref. [19] discusses the simulation of correlated binary observations, incorporating cluster-specific random effects, but the aim of the algorithm is not to generate clusters with distinct variable profiles.
In Section 2, we describe the generic approach for creating data with a predetermined clustering structure, and explore the marginal dependence structure between interval variables, deriving theoretical results. Based on Proposition 1, we propose the main algorithm of the manuscript in Section 3. Proposition 2 in the same section proves that the algorithm creates a stratified marginal correlation structure between the variables, where any two variables within the same stratum have the same correlation. Proposition 3, still in Section 3, provides the theoretical result that allows the user to control the magnitude of the covariances or correlations between variables that belong to the same stratum. In Section 4, a synthetic dataset is created using the proposed algorithm, and is compared to a real dataset that contains SNP observations, demonstrating similarities and differences between the two dependence structures. We conclude with a discussion in Section 5.
2. Materials and Methods
2.1. The Clustering Model
Assume P variables , . Without any loss of generality, assume that each variable takes values . Let . Denote by n the number of subjects. For subject i, , and a variable profile is a set of values . Let , where is an allocation variable, so that denotes that subject i belongs to cluster c. Denote by the probability that when the individual belongs to cluster c. Given the clustering allocation, the variables are assumed to be independent, each one following a multinomial distribution with cluster-specific parameters . Denote by the probabilities that a subject belongs to cluster c, . For more on finite Bayesian mixture models, see [20].
2.2. A Generic Algorithm for a Predetermined Clustering Structure
A generic algorithm for creating observations from P variables, for subjects that are partitioned in C clusters, can be obtained via the following steps:
- Specify the number of clusters C.
- Specify the number of subjects , where is allocated to cluster c in accordance with cluster allocation probabilities . Allocate subjects to clusters so that exactly subjects are allocated to cluster c. [Alternatively, a cluster can be drawn for a subject according to the allocation probabilities.]
- Specify the variable profile of the subjects within each cluster, i.e., probabilities , for all , , and , to generate a distinct variable profile for the subjects in each cluster.
- To generate , sample from a multinomial distribution with probabilities .
2.3. The Marginal Correlation Structure of Interval Variables
Assume that x is a vector of interval variables. The marginal variance–covariance matrix is as follows:
Element , in the diagonal of is as follows:
After introducing the cluster allocation variables through the Law of Total Probability,
Element , , in the off-diagonal of is as follows:
As and are independent given z,
Denote by the expected value for in cluster c, i.e., . Then, for ,
Example 1.
Consider , and assume that and . Then, for , it follows from (2) that
In the Supplementary Material, Section S2, we present an extended version of Example 1, as well as an additional example of inferences after utilizing Equation (2). However, the larger the number of clusters, the less helpful (2) becomes for understanding the effect of the clustering on the marginal covariance structure of the variables. More helpful is the following proposition:
Proposition 1.
Assume that and are interval variables. Under the condition that , for , ,
Proof.
The proof is given in the Appendix A. □
Equation (3), although restricted to , , is more helpful for examining the effect of the clustering on the marginal covariance structure of the variables. For any number of clusters, if, for all , the sign of is the same as the sign of , the correlation between and is positive. If, for all , the sign of is different to the sign of , the correlation between and is negative. The correlation is zero if, for every term in , as given by (3), either or .
The R code for theoretically evaluating correlation structures, for simulating datasets under the different scenarios and specifications relevant to our manuscript, and for replicating the analyses shown in the main manuscript and the Supplementary Material is available to download.
3. Results
3.1. An Algorithm for a Predetermined Subject Clustering with Partial Control of the Variables’ Dependence Structure
Let , denote a probability vector that contains probabilities that add up to 1. Let also , denote a different probability vector that contains probabilities that add up to 1. According to the algorithm proposed in this section, markedly different vectors, and , will create distinct profiles for subjects in different clusters. The algorithm generates strata or groups of variables, where the dependence between variables (as specified by the correlation) within a group is stronger compared to the dependence between variables in different groups. This equation allows the user to define either the number of clusters for the subjects or the number of groups of variables, with the other quantity specified accordingly. Henceforth, we refer to those groups of variables as omogenous, as the correlation between any two variables within the same group is the same.
The derived dependence structure is shown empirically in Example 2, where we present sample correlations assuming interval variables. The algorithm allows for homogenous groups of different sizes. In Section 3.2, we derive a theoretical result for interval variables that allows prespecification of within-group covariances or correlations. In turn, this specification determines what and should be. We determine C to be even, as this generates a clearly defined dependence structure. This is shown in Examples S3 and S4 in Section S3 of the Supplementary Material, where a variation of the proposed algorithm is considered that allows for an odd C. The variables are positively correlated within each homogenous group of variables.
The proposed algorithm is shown below. Explanatory comments are added in brackets.
- (1)
- Define the number k of homogenous groups of variables, where k is a power of 2.{Solving provides the even number of clusters, .}
- (2)
- Define the number of variables in each homogenous group v, .
- (3)
- Define the number of subjects, , within each cluster.
- (4)
- For each variable , consider two sets of probabilities,and , so thatand .The two sets could be distinct so that the first elements of are considerably higher than subsequent elements, whilst the first elements of are considerably lower.
- (5)
- For an odd c, define the profile of cluster c so that the following apply:
- –
- The first variables are simulated in accordance with ;
- –
- The next variables are simulated in accordance with ;
- –
- The next variables are simulated in accordance with ;
- –
- And so on and so forth.
- (6)
- For an even c, define the profile of cluster c so that the following apply:
- –
- The first variables are simulated in accordance with ;
- –
- The next variables are simulated in accordance with ;
- –
- The next variables are simulated in accordance with ;
- –
- And so on and so forth.
{When , the two steps above can be simplified as follows: For an odd c, define the profile of cluster c so that the first variables are simulated in accordance with , the next variables considering , and so on and so forth. For an even c, the first variables are simulated considering , the next variables in accordance with , and so on and so forth.} - (7)
- If required, to generate observations from variables , that do not contribute to the clustering, consider , distinct from and . For all subjects, generate observations from irrespectively of cluster allocation.
Proposition 2 elucidates the derived covariance structure for interval variables.
Proposition 2.
For the algorithm proposed in Section 3.1, and for and , the covariance between variables within a homogenous group is the same for all groups, and is higher than any covariance between variables that belong to different groups.
Proof.
Without any loss of generality, assume that all variables contribute to the clustering. Each of the homogenous groups contains adjoined variables with the same cluster profile characterized by H or L. For the variables within a homogenous group, the differences and always carry the same sign, for any and . This is not true for variables in different groups. This translates to within-group covariances that are always positive and larger than between-group covariances, as the algorithm determines balanced sized clusters and Proposition 2 holds. □
Example 2.
Assume six clusters (), 12 variables (), and , , , and . Note that . Consider 600 subjects. We assume 12 variables to be able to demonstrate the derived dependence structure, as described by pairwise correlations, for larger and smaller homogenous groups of variables. Observations are simulated using and . In Table 1, we present the following cluster profiles created by the proposed algorithm:
- Cluster 1: and . Then, , and, according to step [5], observations from are simulated using the probabilities in vector L for all variables.
- Cluster 2: and . Then, , and, according to step [6], observations from are simulated using the probabilities in vector H for all variables.
- Cluster 3: and . According to step [5], observations for the first variables are simulated using the probabilities in vector L, whilst observations for the remaining variables are simulated according to H.
- Cluster 4: and . According to step [6], observations for the first variables are simulated using H, and for the remaining variables using L.
- Cluster 5: and . According to step [5], observations for the first variables are simulated using L, for the next variables using H, for the next variables using L, and for the last variables using H.
- Cluster 6: and . According to step [6], observations for the first variables are simulated using H, for the next variables using L, for the next variables using H, and for the last variables using L.
In Figure 1a, we present a heatmap of the theoretical correlations assuming interval variables, and, in Figure 1b, the sample correlations. Note that blocks of negative between-group correlations can be observed. We discuss this in detail in Section 5. The clustering of the simulated data is in accordance with the predetermined clustering; see Figure S7 in Section S4 of the Supplementary Material. This is observed in subsequent examples too, as well as in the examples in the Supplementary Material. (Throughout the manuscript, simulated subject profiles are clustered using the R package PReMiuM [11], which implements Bayesian clustering with the Dirichlet process.)
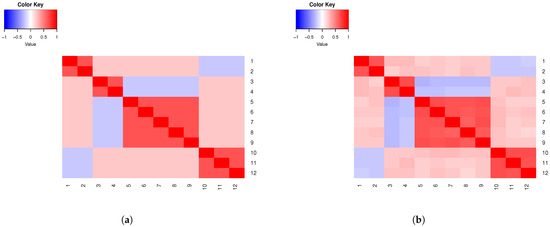
Figure 1.
(a) Example 2 theoretical correlations. (b) Example 2 sample correlations.

Table 1.
Cluster profiles for 12 variables () and 6 clusters () for Example 2. Observations are simulated using probability vectors L and H.
Table 1.
Cluster profiles for 12 variables () and 6 clusters () for Example 2. Observations are simulated using probability vectors L and H.
| Cluster 1 | L | L | L | L | L | L | L | L | L | L | L | L |
| Cluster 2 | H | H | H | H | H | H | H | H | H | H | H | H |
| Cluster 3 | L | L | L | L | H | H | H | H | H | H | H | H |
| Cluster 4 | H | H | H | H | L | L | L | L | L | L | L | L |
| Cluster 5 | L | L | H | H | L | L | L | L | L | H | H | H |
| Cluster 6 | H | H | L | L | H | H | H | H | H | L | L | L |
3.2. Allowing for a Predetermined Covariance or Correlation Within Each Homogenous Group for Interval SNP-like Variables
Proposition 3.
Assume that interval variables and belong to the same homogenous group. For the algorithm in Section 3.1,
where and .
Proof.
See Appendix B and Appendix C. □
In practice, one may consider the simplified scenario where variables in the same homogenous group share the same set of possible values, and . Then, given , one can set cluster-specific probabilities so that, for all in the same homogenous group,
where denotes the absolute value. Proposition 3 and the result above can be used for the determination of marginal covariances and correlations for interval variables with any number of levels as the proof of Proposition 3 applies generally. We now show how to utilize the results above for simulating SNP-like variables.
Application to SNP variables, given predetermined covariances:
Single Nucleotide Polymorphisms (SNPs) are observations with three levels, usually denoted by , and 2 for ‘Wild type’, ‘Heterozygous variant’, and ‘Homozygous variant’, respectively. For an SNP , due to the Hardy–Weinberg principle [21], , , and , where . Thus, , , , and , where and are the probabilities that form the H and L SNP probability vectors.
Assume that, for and in the same homogenous group, and , and therefore, and . From (5), given a required covariance , set cluster-specific probabilities for and so that . In practice, set to be suitably high and constant for all variables (say, ), and allow to vary in accordance with .
Example 3.
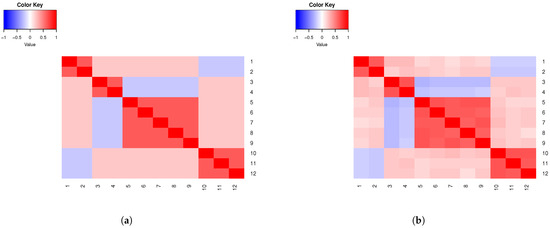
Assume six clusters (), 12 variables () that emulate SNPs, and , , , . Consider 600 subjects, and . Assume a covariance of 0.45 for the variables within homogenous groups. In Figure 2a, we present a heatmap of the theoretical correlation matrix for the specifications in this example, whilst sample correlations are shown in Figure 2b.
Figure 2.
(a) Example 3 theoretical correlations. (b) Example 3 sample correlations.
Application to SNP variables, given predetermined correlations:
From Section 2.3, Equation (1), and for ,
For an even C, for half of the clusters, and . For the remaining clusters, and . Therefore, is given by
Then, as ,
As we demonstrated earlier in this section, for a given , . Thus, to allow for different predetermined correlations within each homogenous group of variables, one should set to be suitably high (say, close to 1), and let vary so that
Note that the chosen correlation is restricted so that, for , the maximum possible correlation is . The restriction is negligible for .
Example 4.
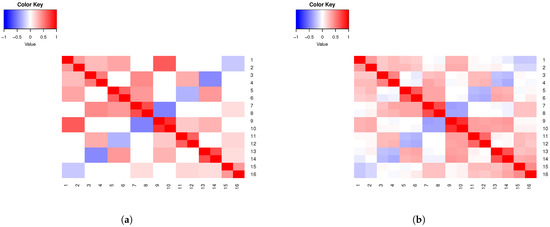
Assume eight clusters (), 16 variables () that emulate SNPs, and , . Consider 800 subjects, with observations simulated using , for predetermined correlations within the eight homogenous groups given by . In Figure 3a, we present a heatmap of the theoretical correlation matrix for the specifications in this example. In Figure 3b, we present the sample correlation matrix for the simulated observations.
Figure 3.
(a) Example 4 theoretical correlations. (b) Example 4 sample correlations.
4. Genetic Profiles Defined by Correlated SNPs—A GWA Study
Data from a GWA study of lung cancer [22] are utilized. Genotyping is performed with the Illumina Sentrix HumanHap300 BeadChip, including 317,139 SNPs of subjects from the International Agency for Research on Cancer (IARC) lung cancer study. The top 200 SNPs, ranked by their p-value for association with lung cancer (adjusted for age, sex, and country) are selected. The correlation (Linkage Disequilibrium) structure is shown in Figure 4a. The selected 200 SNPs are a subset of the SNPs also analyzed in [23]. We observe 27 groups of SNPs, where SNPs are correlated within each group and uncorrelated between groups. Correlations are overwhelmingly positive. Table 2 shows the average sample correlation within each of the 27 groups for the 89 SNPs that are correlated with at least one other polymorphism.
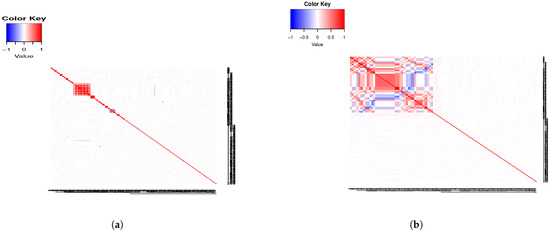
Figure 4.
(a) Real data Linkage Disequilibrium. (b) Simulated data Linkage Disequilibrium.
Table 2.
Average within-group sample correlations for the 89 correlated SNPs from the study of Hung et al. (2008) [22] and for the simulated data. In parentheses is the number of SNPs in each group.
The algorithm in Section 3.1 is used to generate a predetermined clustering structure for 6000 subjects, using simulated observations from 200 SNPs, whilst the specified homogenous groups resemble those in the real dataset. As the real dataset contains 27 groups of variables with within-group correlations that are notably non-zero, it is required that our algorithm generates 27 homogenous groups of variables, plus another group with pairwise correlations that are effectively zero. The number of homogenous groups generated by the algorithm should be a power of 2. Therefore, we consider 32 homogenous groups of SNPs that correspond to 12 predetermined clusters of subjects. For the first 27 groups, we specify within-group correlations that match the within-group correlations in the real dataset. For the last five groups, we determine a very small within-group correlation of . This is because each one of the 111 SNPs in the last five groups corresponds to an SNP in the real data that is effectively not correlated with any other SNP. Indicatively, in the real dataset, the lower, median, and upper quartiles for the pairwise correlations of the 111 SNPs are . The clustering structure in the simulated data is exactly as predetermined, with 12 clusters containing 500 subjects each (Supplementary Material, Section S5, Figure S8). Within-group sample correlations for the simulated data are shown in Table 2. The simulated dataset replicates almost exactly the real within-group correlations. Such control is a considerable improvement compared to the standard algorithm described in Section 2.
The Linkage Disequilibrium structure within the simulated dataset is shown in Figure 4b. We observe a notable between-group simulated correlation structure not observed in the real dataset. Figure S9 in the Supplementary Material Section S5 shows this more clearly, as the focus is on the first 99 SNPs, ignoring the last 101 uncorrelated polymorphisms. In the next section, we discuss in detail the issue of controlling between-group correlations independently of within-group correlations.
5. Discussion
5.1. Flexibility of the Proposed Algorithm
Our work concerns interval variables. The empirical evidence shows that the proposed algorithm generates a similar dependence structure for ordinal observations. The dependence structure considering nominal data differs, as negative associations are not present. Nevertheless, we observed in various examples that the overall structure of positive associations is quite similar considering interval, ordinal, and nominal variables, albeit weaker for the latter. All empirical evidence suggests that the manner in which control is effected over within-group correlations is also relevant to nominal and ordinal variables, in terms of the comparative magnitude of within-group associations. See Section S6 in the Supplementary Material for more details.
The algorithm described in Section 3 allows for a predetermined clustering structure for the subjects whilst assuming a specific stratified structure for the marginal correlations of the variables. This assumption is restrictive, as other marginal dependence structures may be observed. However, the algorithm allows the size of each one of the homogenous groups to be specified, and the value of each one of the within-group correlations. This makes it flexible enough to define a large variety of clustering and marginal dependence structures. Specifically, the user is free to define either the number of clusters C or the number of homogenous groups of variables k as a power of 2. This appears to be inflexible, as one quantity then appears to define the other through . However, freely choosing the number of clusters only places an upper bound on the number of homogenous groups of variables. This is because correlations within some of the homogenous groups can be effectively zero.
In addition, it is not essential that C is set to be even; see Supplementary Material Section S3. We consider an even C as this creates a more distinct clustering structure. The algorithm’s flexibility is further maintained as the investigator is free to choose the number of subjects. The two sets of probabilities H and L are sufficient for defining distinct cluster profiles due to the proposed cluster profiles illustrated in Table 1. Using more than two sets of probabilities would add unnecessary complexity to the algorithm.
Cluster sizes were assumed to be equal to derive theoretical results on the algorithm’s properties, but this is not essential for the implementation of the algorithm. Empirical evidence has shown that, under unequal cluster sizes, the dependence structure between the variables created by the proposed algorithm is similar to the one derived theoretically. For one such example, see the Supplementary Material, Section S7. Comparisons between clustering approaches can be performed by using our algorithm to create datasets with a weak clustering signal, so that revealing the clustering structure is challenging. The clustering signal can be made to be weak either by considering probability vectors and that are relatively close, considering some distance metric, or by creating clusters of relatively small size, or both.
The amount of computing time required for the analyses in the main manuscript and the Supplementary Material is small. For instance, for Example 2, the calculation of theoretical correlations, plus the creation of the synthetic dataset, requires fewer than 5 s. The clustering of the subjects in the synthetic dataset created for Example 2 (as performed by the R package PReMiuM, including the post-processing phase) requires less than 1 min. In Section 4, the creation of the synthetic dataset that corresponds to the real GWA one requires less than 1 min.
5.2. Between-Group Correlations
The proposed algorithm effects control over within-group correlations. Between-group correlations are present as a direct consequence of the algorithm and the imposed clustering structure. It is the clustering structure for the subjects that determines the marginal dependence between the variables, with Proposition 3 allowing control of within-group correlations by defining probability vectors and for variable p, . (In a simplified set-up, we have common probability vectors L and H for all variables.) The algorithm creates a specific clustering for the subjects, with cluster profiles illustrated in Table 1 for some specific C and k. Looking at consecutive pairs of clusters in Table 1, we see a mirroring between L and H, so that, at the place where an odd cluster is determined by L (or H), the next even cluster is determined by H (or L). It is this mirroring and symmetry that create the between-group correlations.
Determination of between-group correlations independently of the within-group structure, in tandem with the predetermined clustering, is not straightforward. Equation (3) offers a direct link between the covariances and the variable profiles in each cluster, through , , . P variables imply covariances, under the constraint that they form a positive definite matrix. The number of different quantities is .
It is straightforward to deduce that the number of unconstrained quantities is . For predetermined covariances, (3) generates a non-linear system of equations with unknowns. Solving such a system could, in principle, allow between-group correlations to be set independently of within-group associations. However, this approach is not reliable. Numerical solutions for simple examples are not available, with no solution or an infinite number of solutions reported by the symbolic computation software MAPLE.
For a specific example, consider , , , and a covariance structure so that
with all other covariances equal to . This provides a system of equations with no solution according to MAPLE. A specification where , , , and covariances are zero except for generates a system with an infinite number of solutions. Solving the system of equations produced by (3) can be problematic even when the system includes equal numbers of equations and unknowns. For instance, and create a system of equations with a Jacobian equal to zero and an infinite number of solutions. This suggests that a generally applicable algorithm, such as the one proposed in Section 3, is a suitably pragmatic approach for achieving control over the marginal dependence of the variables.
5.3. Future Work
Future work will concern additional theoretical and computational efforts to effect control over the between-group correlations that result from the proposed algorithm. Furthermore, although this is not crucial for the flexibility of the proposed algorithm, another improvement would be to relax the relation between the number of clusters C for the subjects and the number of homogenous groups k for the variables, as described by .
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/stats8030078/s1. Refs. [24,25,26,27] are cited in Supplementary Material File.
Funding
This research received no external funding.
Data Availability Statement
The simulated data and code used to derive theoretical correlations and simulate datatsets are available to download.
Acknowledgments
We would like to thank Paolo Vineis and Paul Brennan for providing the data used in Section 5. We would like to thank the editor and all reviewers for the useful and constructive comments that helped improve the manuscript.
Conflicts of Interest
The author declares no conflicts of interest.
Appendix A. Proof of Proposition 1
For the left-hand side of Equation (3), from (2),
For the right-hand side of Equation (3),
To complete the proof, we show that (A1) = (A2), i.e., that
To show this, notice that
and the proof of Proposition 1 is complete.
Appendix B. Proof of Proposition 3
For the algorithm in Section 3.1, , so that Propositions 1 and 2 hold. From Proposition 1,
The number of terms in the right-hand side sum is . For the algorithm in Section 3.1, and for all , all non-zero terms are equal in absolute value. We denote this absolute value by , where , and . The number of non-zero terms in either or is
This can be deduced by first picking two variables from the same homogenous group. Then, consider the table that shows the cluster profiles, Table 1. Start from the top row of the table and count the non-zero terms moving down the table rows. Repeat, starting from the second row, counting the non-zero terms down the rows and so on and so forth.
For variables and in the same homogenous group, and always carry the same sign. Therefore,
Thus, we can write
This completes the proof of Proposition 3.
Appendix C. Main R Function for the Algorithm in Section 3 (Additional Relevant Code Available as a Separate File)
| ############################### simulate with algorithm in Section 3. |
| # Allowing for non-important variables |
| sim_LD_clust_plusav <- function(noofx,prA,prH,prL,k,c,plusaverage) { |
| # same correlation within each homogenous group. Probabilities are given. |
| # prA,prH,prL are the three sets of probabilities. |
| # average is for creating snps that do not contribute to the clustering. |
| # k is the number of replications (number of subjects) |
| # c is the number of clusters. Ensure k/c is an integer. |
| # Ensure (numberofx/2^(c/2-0.5)) or (numberofx/2^(c/2-1)) is an integer |
| # The number of subjects in each cluster is k/c. |
| # Equal number of vars in each homogenous~group. |
| nooflevels<-length(prA) |
| th_av<-rep(0,nooflevels+1) |
| th_high<-rep(0,nooflevels+1) |
| th_low<-rep(0,nooflevels+1) |
| th_av[1]<-qnorm(0) |
| th_high[1]<-qnorm(0) |
| th_low[1]<-qnorm(0) |
| for (itheta in 1:(nooflevels)){ |
| th_av[itheta+1]<-qnorm(sum(prA[1:itheta])) |
| th_high[itheta+1]<-qnorm(sum(prH[1:itheta])) |
| th_low[itheta+1]<-qnorm(sum(prL[1:itheta])) |
| } |
| numberofx<-noofx |
| tlatent<-mvrnorm(k,rep(0,numberofx),diag(numberofx)) |
| sim_snps<-matrix(0,k,numberofx+plusaverage) |
| for (ic in 1:c){ |
| for (isloop in 1:(k/c)){ |
| is<-isloop+(ic-1)*(k/c); |
| for (jgroup in 1:(2^(ic/2-0.5-0.5*(ic %% 2 == 0)))){ #true if ic is even |
| for (j in ((jgroup-1)*(numberofx/2^(ic/2-0.5-0.5*(ic %% 2 == 0)))+1): |
| (jgroup*(numberofx/2^(ic/2-0.5-0.5*(ic %% 2 == 0))))){ |
| if(ic %% 2 != 0 & jgroup %% 2 !=0){ |
| for (iwhich in 1:nooflevels){ |
| if(tlatent[is,j]>=th_low[iwhich] & tlatent[is,j]<th_low[iwhich+1]){ |
| sim_snps[is,j]<-iwhich-1 |
| } |
| } |
| } |
| if(ic %% 2 != 0 & jgroup %% 2 ==0){ |
| for (iwhich in 1:nooflevels){ |
| if(tlatent[is,j]>=th_high[iwhich] & tlatent[is,j]<th_high[iwhich+1]){ |
| sim_snps[is,j]<-iwhich-1 |
| } |
| } |
| } |
| if(ic %% 2 == 0 & jgroup %% 2 !=0){ |
| for (iwhich in 1:nooflevels){ |
| if(tlatent[is,j]>=th_high[iwhich] & tlatent[is,j]<th_high[iwhich+1]){ |
| sim_snps[is,j]<-iwhich-1 |
| } |
| } |
| } |
| if(ic %% 2 == 0 & jgroup %% 2 ==0){ |
| for (iwhich in 1:nooflevels){ |
| if(tlatent[is,j]>=th_low[iwhich] & tlatent[is,j]<th_low[iwhich+1]){ |
| sim_snps[is,j]<-iwhich-1 |
| } |
| } |
| } |
| } |
| } |
| } |
| } |
| for (iplusav in 1:plusaverage){ |
| for (ic in 1:c){ |
| for (isloop in 1:(k/c)){ |
| is<-isloop+(ic-1)*(k/c); |
| tlatent<-mvrnorm(1,rep(0,1),diag(1)) |
| for (iwhich in 1:nooflevels){ |
| if(tlatent>=th_av[iwhich] & tlatent<th_av[iwhich+1]){ |
| sim_snps[is,j]<-iwhich |
| } |
| } |
| } |
| } |
| } |
| return(sim_snps) |
| } |
References
- Müller, P.; Quintana, F.; Rosner, G.L. A Product Partition Model with Regression on Covariates. J. Comput. Graph. Stat. 2012, 20, 260–278. [Google Scholar] [CrossRef] [PubMed]
- Yau, C.; Holmes, C. Hierarchical Bayesian nonparametric mixture models for clustering with variable relevance determination. Bayesian Anal. 2011, 6, 329–352. [Google Scholar] [CrossRef] [PubMed]
- Hennig, C.; Meila, M.; Murtagh, F.; Rocci, R. Handbook of Cluster Analysis; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Frühwirth-Schnatter, S. Finite Mixture and Markov Switching Models; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Marbac, M.; Biernacki, C.; Vandewalle, V. Model-based clustering for conditionally correlated categorical data. arXiv 2014, arXiv:1401.5684. [Google Scholar] [CrossRef]
- Kirk, P.; Pagani, F.; Richardson, S. Bayesian outcome-guided multi-view mixture models with applications in molecular precision medicine. arXiv 2023, arXiv:2303.00318. [Google Scholar]
- Hennig, C. What are the true clusters? Pattern Recogn. Lett. 2015, 64, 53–62. [Google Scholar] [CrossRef]
- Jasra, A.; Holmes, C.C.; Stephens, D.A. Markov Chain Monte Carlo Methods and the Label Switching Problem in Bayesian Mixture Modeling. Stat. Sci. 2005, 20, 50–67. [Google Scholar] [CrossRef]
- Jing, W.; Papathomas, M.; Liverani, S. Variance Matrix Priors for Dirichlet Process Mixture Models with Gaussian Kernels. Int. Stat. Rev. 2024. early view. [Google Scholar] [CrossRef]
- Dunson, D.B.; Xing, C. Nonparametric Bayes modeling of multivariate categorical data. J. Am. Stat. Assoc. 2009, 104, 1042–1051. [Google Scholar] [CrossRef] [PubMed]
- Liverani, S.; Hastie, D.I.; Azizi, L.; Papathomas, M.; Richardson, S. PReMiuM: An R package for profile regression mixture models using Dirichlet processes. J. Stat. Softw. 2015, 64, 1–30. [Google Scholar] [CrossRef] [PubMed]
- Celeux, G.; Govaert, G. Latent class models for categorical data. In Handbook of Cluster Analysis. Handbooks of Modern Statistical Methods; Hennig, C., Meila, M., Murtagh, F., Rocci, R., Eds.; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2016; pp. 173–194. [Google Scholar]
- Oberski, D.L. Beyond the number of classes: Separating substantive from non-substantive dependence in latent class analysis. Adv. Data Anal. Classi. 2016, 10, 171–182. [Google Scholar] [CrossRef]
- Allman, E.S.; Matias, C.; Rhodes, J.A. Identifiability of parameters in latent structure models with many observed variables. Ann. Stat. 2009, 37, 3099–3132. [Google Scholar] [CrossRef]
- Bingham, S.; Riboli, E. Diet and cancer—The European prospective Investigation into cancer and nutrition. Nat. Rev. Cancer 2004, 4, 206–215. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.A.; Thomas, G.; Daly, M.J. Validating, augmenting and refining genome-wide association signals. Nat. Rev. Genet. 2009, 10, 318–329. [Google Scholar] [CrossRef] [PubMed]
- Lorenz, D.J.; Datta, S.; Harkema, S.J. Marginal association measures for clustered data. Stat. Med. 2011, 30, 3181–3191. [Google Scholar] [CrossRef] [PubMed]
- Paulou, M.; Seaman, S.R.; Copas, A.J. An examination of a method for marginal inference when the cluster size is informative. Stat. Sin. 2013, 23, 791–808. [Google Scholar]
- Wang, A.; Sabo, R.T. Simulating clustered and dependent binary variables. Austin Biom. Biostat. 2015, 2, 1020. [Google Scholar]
- Grün, B.; Malsiner-Walli, G. Bayesian finite mixture models. In Wiley StatsRef: Statistics Reference Online; Balakrishnan, N., Colton, T., Everitt, B., Piegorsch, W., Ruggeri, F., Teugels, J.L., Eds.; Wiley: Hoboken, NY, USA, 2022. [Google Scholar] [CrossRef]
- Ziegler, A.; König, I.R. A Statistical Approach to Genetic Epidemiology. Concepts and Applications; Wiley-VCH Verlag GmbH & Co.: Weinheim, Germany, 2010. [Google Scholar]
- Hung, R.J.; McKay, J.D.; Gaborieau, V.; Boffetta, P.; Hashibe, M.; Zaridze, D.; Mukeria, A.; Szeszenia-Dabrowska, N.; Lissowska, J.; Rudnai, P.; et al. A susceptibility locus for lung cancer maps to nicotinic acetylcholine receptor subunit genes on 15q25. Nature 2008, 452, 633–637. [Google Scholar] [CrossRef] [PubMed]
- Papathomas, M.; Molitor, J.; Hoggart, C.; Hastie, D.; Richardson, S. Exploring data from genetic association studies using Bayesian variable selection and the Dirichlet process: Application to searching for gene-gene patterns. Genet. Epidemiol. 2012, 36, 663–674. [Google Scholar] [CrossRef] [PubMed]
- Agresti, A. Categorical Data Analysis, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Berry, K.J.; Johnston, J.E.; Zahran, S.; Mielke, P.W., Jr. Stuart’s tau measure of effect size for ordinal variables: Some methodological considerations. Behav. Res. Methods 2009, 41, 1144–1148. [Google Scholar]
- Colwell, D.J.; Gillett, J.R. Spearman versus Kendall. Math. Gaz. 2009, 41, 1144–1148. [Google Scholar]
- Deutsch, D.; Foster, G.; Freitag, M. Ties Matter: Meta-Evaluating Modern Metrics with Pairwise Accuracy and Tie Calibration. arXiv 2023. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).