Abstract
We propose a robust linear regression model assuming a log-skew-t distribution for the response variable, with the aim of exploring the association between the covariates and the quantiles of a continuous and positive response variable under skewness and heavy tails. This model includes the log-skew-normal and log-t linear regression models as special cases. Our simulation studies indicate good performance of the quantile estimation approach and its outperformance relative to the classical quantile regression model. The practical applicability of our methodology is demonstrated through an analysis of two real datasets.
1. Introduction
The classical quantile regression (Koenker and Bassett [1]) model has been widely used in situations where a comprehensive understanding of the distribution of the response variable in relation to covariates is essential. This model is given by
for , where is the -quantile of the random variable , which represents the i-th observation of the response variable Y for . Here, is an r-dimensional vector containing the observed values of the i-th individual on the covariates , and is a vector of regression parameters that can be estimated by solving
where is the tilted absolute value function defined as
Some applications of this model include anthropometric references based on child growth curves (World Health Organization [2,3]), foreign direct investment (Chunying [4]), wage distribution (Machado andMata [5]), and ecological and biological data (Cade and Noon [6]), among many others. Quantile regression models are inherently distribution-free and robust against outlying observations in the response variable. In recent years, several parametric approaches have been proposed for modeling quantiles within the regression framework (Mazucheli et al. [7], Morán-Vásquez et al. [8,9]), which align with the direction of the present work.
This article introduces a robust linear regression model assuming a log-skew-t (LST) distribution (Marchenko and Genton [10]) for the response variable. This distribution can be obtained by applying an exponential transformation to a skew-t (ST) random variable (Azzalini and Capitanio [11]). The LST distribution has positive support and includes parameters that model skewness and heavy tails. It exhibits key statistical properties and is easily handled from a mathematical perspective, making it a valuable tool for statistical modeling. The LST distribution is suitable for modeling continuous, positive, and skewed data with potential outliers. Examples include family income data (Azzalini et al. [12]) and precipitation data (Marchenko and Genton [10]). The LST distribution includes the log-skew-normal (LSN, Morán-Vásquez et al. [9]) and log-t (LT, Morán-Vásquez and Ferrari [13]) distributions as special cases.
We provide an explicit formula for the quantiles of the LST distribution, which motivated us to propose an approach to analyzing the association between covariates and any quantile of a positive response variable by considering a regression structure on the scale parameter. To this end, we define and study the LST linear regression model (LSTLRM), which is suitable for analyzing datasets where the response variable is continuous, positive, and potentially skewed with heavy tails. This includes the LSN linear regression model (LSNLRM, Morán-Vásquez et al. [9]) and log-t linear regression model (LTLRM, Morán-Vásquez et al. [9], Vanegas and Paula [14]) as special cases. We show that the LSTLRM is equivalent to the ST linear regression model (STLRM; [11]) by applying a transformation to the response variable, which simplifies the computation of the maximum likelihood parameter estimates. We conducted simulation studies to evaluate the performance of the LSTLRM and the quantile estimators for the response variable. Additionally, we analyzed the goodness of fit of the LSTLRM through quantile–quantile plots with simulated envelopes. Finally, we applied our model to two real datasets: one concerning women’s income and the other focusing on children’s weight.
The remainder of this paper is structured as follows: Section 2 presents a brief background on the LST distribution, and a closed-form expression for its quantiles is derived. Section 3 introduces the LSTLRM, and quantile estimators for the response variable are derived. Section 4 provides Monte Carlo simulation results. Applications to women’s income data and children’s weight data are presented and discussed in Section 5. Concluding remarks are presented in Section 6.
2. Quantiles of the LST Distribution
Let be a random variable following a t distribution. Its probability density function (PDF) is given by
where , with , and denoting the location, scale, and degrees of freedom parameters, respectively. The PDF of a normal random variable arises as a limiting case of (2) when , and it is given by
The PDF of an ST random variable is given by
where is the PDF defined in (2), and where denotes the cumulative distribution function (CDF) of a standard t random variable with a degrees of freedom parameter. The parameters , , , and correspond to location, scale, shape, and degrees of freedom, respectively. The notation indicates that X follows the distribution with the PDF (3). The PDF of a skew-normal (SN) random variable is obtained as a limiting case of (3) when , and it is given by
where is the standard normal CDF. Also, when the expression in (3) simplifies to the PDF in (2). The ST distribution is useful for modeling data that exhibit skewness and heavy tails, as the parameters and influence the skewness and the tail behavior of the distribution, respectively.
Definition 1 introduces the LST distribution as described in Azzalini et al. [12] and Marchenko and Genton [10].
Definition 1.
The positive random variable Y follows an LST distribution, denoted by , if .
From Definition 1, it is straightforward to show that the PDF of Y, , is given by
The parameters , , , and correspond to scale, shape, relative dispersion, and degrees of freedom. Our parameterization differs slightly from the one used by Equation (6) of Marchenko and Genton [10], who consider in (4) a parameter instead of , which makes its interpretation more difficult. Note that the PDF in (4) has the structure
where f is the function
This shows that is a scale parameter. Moreover, Definition 1, together with our parameterization, suggests a logarithmic link when a linear regression structure is considered on , facilitating the interpretation of the regression coefficients (Section 3).
Taking the limit in (4) results in the PDF of an LSN random variable given by (Morán-Vásquez et al. [9]):
Moreover, by setting in (4) we retrieve the PDF of an LT random variable Y, , given by Morán-Vásquez and Ferrari [13], Morán-Vásquez et al. [8]
Figure 1 displays several shapes of the PDF in (4) for different parameter values. As shown in Figure 1a, varying values of change the scale of the distribution of Y, while influences its dispersion (Figure 1b), affects its skewness (Figure 1c), and impacts its tail behavior (Figure 1d). It is noteworthy that smaller values of correspond to heavier tails in the LST distribution, and the LST distribution tends toward the LSN distribution as increases (Figure 1d).
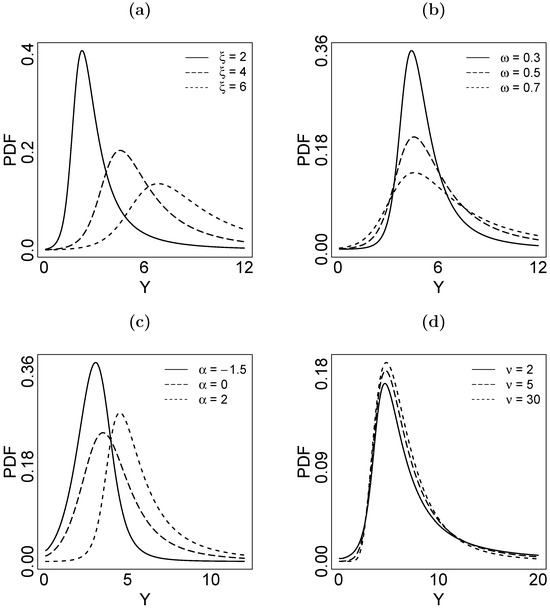
Figure 1.
Graph of the PDF of the LST distribution with (a) , , , ; (b) , , , ; (c) , , , ; (d) , , , .
In Theorem 1, we derive closed-form expressions for the quantiles of the LST distribution.
Theorem 1.
Let . The τ-quantile , , of Y satisfies
with being the τ-quantile of the standard ST random variable .
Proof.
The -quantile , , of is defined as the value satisfying , which is equivalent to
Since , then
Thus, in (6) we have
It follows from the above that is the -quantile of ; that is,
Finally, solving for from the above expression, we obtain the desired result. □
Equation (5) shows that any quantile of Y, is proportional to . Thus, by considering a regression structure on we can model any quantile of Y through a set of covariates (Section 3).
In order to establish an interpretation for , we consider a robust coefficient of variation of based on quantiles, as proposed by Rigby and Stasinopoulos [15]:
Substituting (5) into (7), we obtain
The above expression indicates that is a non-decreasing function of , and, therefore, we can conclude that is a parameter that influences the relative dispersion of the distribution of Y.
Finally, it is straightforward to show that if then
where represents the F-distribution with and degrees of freedom. This expression will be important for establishing a diagnostic tool for the LSTLRM (Section 3).
3. Quantile Estimation Using the LSTLRM
In this section, we introduce the LSTLRM, with the aim of describing the association between the quantiles of a random variable following an LST distribution and the covariates.
Assume that are independent random variables representing observations of a positive response variable Y across n individuals. We define the LSTLRM as
for , where “ind” means “independent”. Note that may vary across observations. The constant vector consists of the values of the covariates for the i-th individual. Let us suppose that for , in order to include an intercept in the model. The vector consists of the regression coefficients, while , , and denote the relative dispersion, shape, and degrees of freedom parameters, respectively. The LSTLRM (9) involves parameters in total.
If in (9), we obtain the LSNLRM given by Morán-Vásquez et al. [9],
for . When in (9), we retrieve the LTLRM (Morán-Vásquez et al. [9], Vanegas and Paula [14]) given by
for .
Equations (5) and (9) allow us to relate any -quantile, , of to the set of covariates through a linear regression structure. In fact,
for , where is the -quantile of the standard ST random variable . It is evident that indicates the multiplicative change in resulting from a one-unit increase in , holding all other covariates constant. Moreover, the variation in is controlled by and scaled by . It is worth noting that the estimation of multiple quantiles of Y can be achieved by fitting the LSTLRM (9) once, along with separate calculations of the quantiles of the standard ST distribution.
From Definition 1, we know that the LSTLRM (9) can be equivalently expressed as
For this reason, the parameters involved in the LSTLRM can be estimated using the STLRM (Section 4.3 of Azzalini and Capitanio [11]) with log-transformed responses. We denote by the maximum likelihood estimator of . From (10), we obtain the maximum likelihood estimator of the -quantile of , for , denoted by , as
where is the estimated -quantile of the standard ST random variable .
Let represent the observations from the independent random variables as specified in (9). The log-likelihood function of is given by
where represents the log-likelihood contribution of the i-th observation, and it is given by
for , where C is constant with respect to . The above log-likelihood function is equivalent to the univariate case of the formulation given in Equation (6.33) of Azzalini and Capitanio [11], with log-transformed response observations. The score vector with respect to and the observed information matrix is studied in Section 4.3.3 of Azzalini and Capitanio [11]. The estimator does not have a closed-form expression, so it is approximated using computational methods implemented in the sn package (Azzalini [16]) in R. This package also computes the observed information matrix, from which the estimated asymptotic covariance matrix of is obtained, enabling the implementation of inferential procedures for the model parameters.
An asymptotic , confidence interval for is given by
with denoting the -quantile of the standard normal distribution and denoting the estimated asymptotic standard error of obtained from the estimated asymptotic covariance matrix. This confidence interval can be used to assess the statistical significance of in the response variable Y. We consider the hypothesis against to test the significance of . If is not rejected then can be omitted from the model. The Wald statistic for this hypothesis is
which asymptotically follows a chi-squared distribution with one degree of freedom.
To select models, we use the Akaike information criterion (AIC), defined as
Among the candidate models, the one with the lowest AIC is considered to offer the best fit to the data. We also display quantile–quantile plots to assess the model fit. These plots allow us to compare the observed quantiles , with the theoretical quantiles , , where is the CDF of an F-distribution with 1 and degrees of freedom; see Equation (8). We consider , . Additionally, simulated envelopes (Atkinson [17]) are added to the quantile–quantile plots to facilitate a more rigorous comparison between the observed and theoretical quantiles, thereby aiding in the evaluation of the model fit. The construction of the simulated envelopes based on our model is described in the following steps:
- 1.
- Generate a random sample, , of .
- 2.
- Calculate , .
- 3.
- Perform steps 1 and 2 m times to yield , , .
- 4.
- Calculate and , for .
- 5.
- The lower and upper bounds of are and , respectively.
We also adopt the residual diagnostics illustrated in Azzalini and Capitanio [18] and Riani et al. [19] as further evidence of the agreement between the data and the LSTLRM, by plotting the histogram of the residuals , , with the PDF of superimposed.
4. Simulation Studies
This section presents simulation studies to illustrate the performance of the parameter estimation method for the LSTMRL model (Equation (9)) and the quantile modeling approach proposed in Equation (12). To carry out the simulations, we considered the model
for . The simulation studies were conducted using sample sizes n = 50, 100, 500, 1000, with Monte Carlo replicates. In order to calculate the true parameters for conducting the simulations, we fitted the LSTLRM (14) to the women’s income data, where the response variable Y and the covariates and are described in Section 5.1. The values of the true parameters are shown in the first column of Table 1. The covariate values , , were obtained as independent random draws from different distributions and remained constant throughout the simulation process. These distributions were selected using the fitdistr function from the MASS package in the R software 4.5.0. Consequently, was generated from a Gamma distribution with shape parameter and rate parameter , and was generated from a Weibull distribution with shape parameter and scale parameter .

Table 1.
Summary statistics of the estimated parameters; LSTLRM.
We used the selm.fit function from the sn package in R to fit the LSTLRM model (14) at each iteration. The nlminb optimization algorithm was employed in each simulation experiment to maximize the log-likelihood function (13). The selection of initial parameter values for the maximum likelihood estimation is described in detail in Section 3.3 of Azzalini and Salehi [20], and it was implemented in the subroutine st.prelimFit, which is known as the selm.fit function. We used a tolerance level of for the relative change in the log-likelihood as a convergence criterion. If this criterion is not met, the algorithm will run for a maximum of 2000 iterations.
We report robust summaries (the median and the median absolute deviation (MAD)) of the estimates in Table 1 and Table 2, since the degrees of freedom parameter estimates can take large values for certain samples, which affects traditional statistics commonly used in simulation studies, such as the mean and the root mean squared error. The results shown in Table 1 suggest desirable properties of the parameter estimators of the LSTLRM (14), with medians closely approximating the true parameter values and the MAD decreasing as the sample size increased. For and , convergence was achieved in and of the samples, respectively, whereas for and , convergence was achieved in of the samples.
Table 2.
Median and MAD of estimated quantiles; LSTLRM and classical QR.
Next, we computed the true quantiles for by substituting the true parameter values into the quantile response function associated with Equation (10). Specifically,
where is the -quantile of the standard ST random variable . The values of and were replaced with their respective sample means, and , computed from the covariates in the women’s income dataset described in Section 5.1. Substituting these values into Equation (15), we obtained
For each simulated sample, we computed using Equation (12), where the covariates and were replaced by the sample means computed from the simulated values of and ; that is, for . The figures in Table 2 reveal that the quantile estimators provided by (1) and (12) performed well, as the medians closely approximated the true quantiles and the MAD became smaller with increasing sample size. However, note that in all cases the quantile estimates under our model yielded smaller MAD values in comparison to those provided by (1). Therefore, our model provides more accurate estimates than the classical quantile regression model. All computational procedures were carried out using the R programming language [21], version 4.4.1. All results are fully reproducible using the code available at https://github.com/moranvasquez/LSTLRM, accessed on 23 June 2025.
5. Data Analyses
For this section, we analyzed two datasets with the aim of demonstrating the usefulness of estimating quantiles using the LSTLRM in various contexts. In the first dataset, we modeled quantiles of women’s income based on years of schooling and age. In the second dataset, we constructed reference quantile charts for children’s weight based on gender and age.
5.1. Women’s Income Data
Women’s participation in the labor market has been a topic of interest for a long time. Analyzing women’s income data is crucial for understanding the economic, political, and social factors that contribute to gender inequalities and the wage gap, while also informing the design of public policies that promote pay equity and the well-being of women (de Castro Romero et al. [22]). Several studies have examined variables that affect the distribution of women’s income, such as education level, age, and the number of children (Arellano-Valle et al. [23]). On the other hand, the distribution of income data typically exhibits skewness and heavy tails (Cowell and Victoria-Feser [24], Saulo et al. [25]), and several economic aspects can be studied from this distribution if there is a complete understanding of it, which can be achieved by modeling quantiles (Altonji [26], Card and Lemieux [27]).
We analyzed women’s income data collected in 2021 from the Gran Encuesta Integrada de Hogares (DANE [28]). The data consisted of 770 women aged 18 to 57 years from Rionegro municipality, Antioquia department, Colombia. We considered the income received in the last month (in COP millions) as a response variable, and age (A; in years) and years of schooling (S; in years) as covariates. Figure 2 presents boxplots of the women’s income based on age (Figure 2a) and years of schooling (Figure 2b). Note that the empirical quartiles of the women’s income were affected by age and years of schooling. Moreover, the women’s income showed skewness and outliers. To analyze the relationship between these variables, we fitted the following LSTLRM,
for .
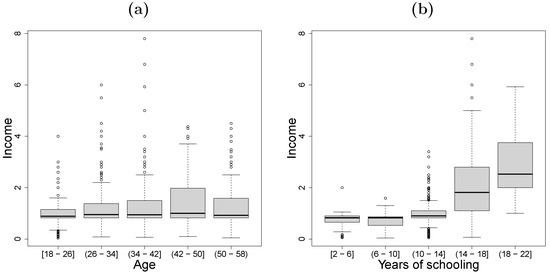
Figure 2.
Boxplots of (a) women’s income vs. age, (b) women’s income vs. years of schooling.
With the aim of evaluating the simultaneous control of skewness and tail behavior through the parameters and , respectively, we fitted the LSTLRM and LSNLRM and compared their performance. The AIC values for the LSTLRM and LSNLRM were and , respectively. Based on these values, and on the quantile–quantile plots with simulated envelopes shown in Figure 3, we concluded that the LSTLRM provided the best fit to the women’s income data.

Figure 3.
Quantile–quantile plots of square normalized residuals with simulated envelope for (a) LSNLRM, (b) LSTLRM; women’s income data.
Table 3 presents the maximum likelihood estimates of , , and , along with their corresponding asymptotic standard errors (SE), confidence intervals, and the p-values from the Wald test for testing against , for . It is important to note that all covariates are significant in the LSTLRM. The maximum likelihood estimates for the parameters of relative dispersion, shape, and degrees of freedom, along with their respective standard errors in parentheses, were as follows: , , and , respectively. The asymptotic confidence interval for was , which did not contain zero. Moreover, the likelihood ratio test for the hypothesis against yielded a p-value less than . Therefore, we concluded that the shape parameter was significantly different from zero. As a result, we did not assume an LTLRM for the women’s income data. The histogram of the residuals , in Figure 4 overlaid with the PDF of together with Figure 3b indicates a good fit of the LSTLRM to the women’s income data.
Table 3.
Results from fitting the LSTLRM to the women’s income data.
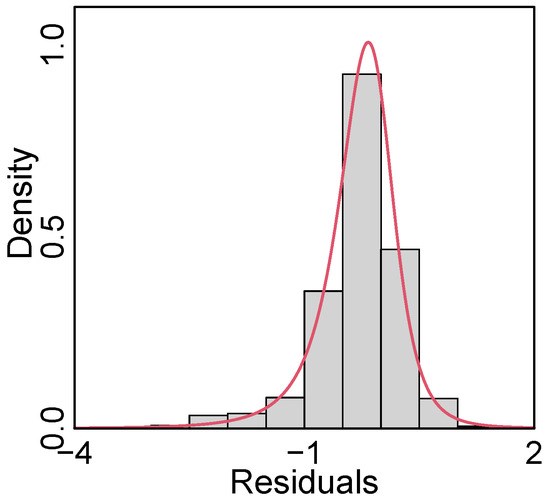
Figure 4.
Histogram of the residuals overlaid with the PDF of the ST distribution; women’s income data.
Figure 5 displays the estimated quartiles of the women’s income as a function of years of schooling, overlaid on the data, for ages 25 (Figure 5a), 35 (Figure 5b), 45 (Figure 5c), and 55 (Figure 5d). We can observe that the income quartiles increased as the years of schooling increased. As expected, the relationship between income and years of schooling was affected by age. For the younger women, income was more homogeneous, while for the older women income showed greater heterogeneity. We also observe that the women with fewer years of schooling tended to have more homogeneous income than the women with more years of schooling. Additionally, we can conclude that the younger women tended to have lower incomes, even though they had the same number of years of schooling as the older women.
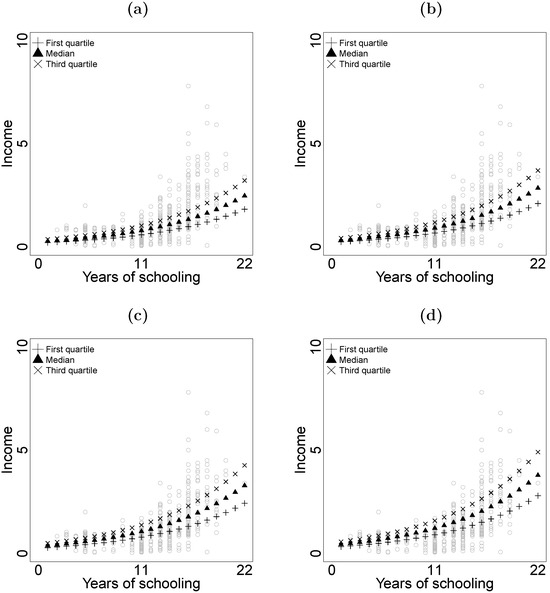
Figure 5.
Estimated quartiles for women’s income by years of schooling at ages (a) 25 years, (b) 35 years, (c) 45 years, (d) 55 years.
5.2. Children’s Weight Data
We applied the LSTLRM to build reference quantile curves for children’s weight as a function of gender and age. The analysis relied on a sample of 3663 children (1728 girls and 1935 boys) aged from 2 to 5 years (inclusive), which was collected in 2018 in the Buenos Aires neighborhood of the municipality of Medellín, Colombia (MEDATA [29]). The response variable Y corresponded to the child’s weight (in kilograms), and the covariates G and A corresponded to gender (0 for girls and 1 for boys) and age (in years), respectively. Morán-Vásquez et al. [9] provide motivations and an exploratory analysis based on the aforementioned data, and they present an application in the building of reference curves using the LSNLRM. For this paper, we constructed reference curves via the LSTLRM and compared the fit with the LSNLRM. For this purpose, we considered the model
for . Figure 6 suggests that both models exhibited a good fit to the children’s weight data. However, the AIC value for the LSTLRM was , whereas that of the LSNLRM was . Therefore, we selected the LSTLRM as the better model, which included the degrees of freedom parameter.
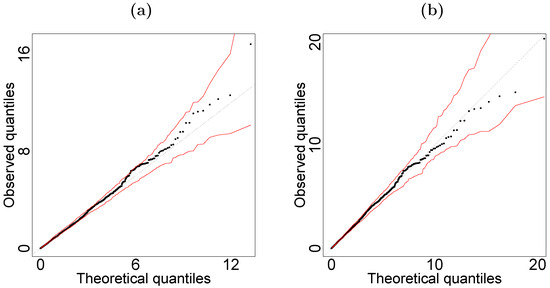
Figure 6.
Quantile-quantile plots of square normalized residuals with simulated envelope for (a) LSNLRM, (b) LSTLRM; children’s weight data.
The values in Table 4 show that all the covariates were significant in the LSTLRM. The maximum likelihood estimates, along with their respective standard errors, for the remaining parameters were , , and . The asymptotic confidence interval for was , and the p-value obtained from the likelihood ratio test for the hypothesis against was less than . These results indicate that the shape parameter was significantly different from zero, implying that the LTLRM was not appropriate for modeling the children’s weight data. Figure 7 presents the histogram of the residuals , overlaid with the PDF of . In conjunction with the plot shown in Figure 6b, this supports the suitability of the LSTLRM for modeling the children’s weight data.
Table 4.
Results from fitting the LSTLRM to the children’s weight data.
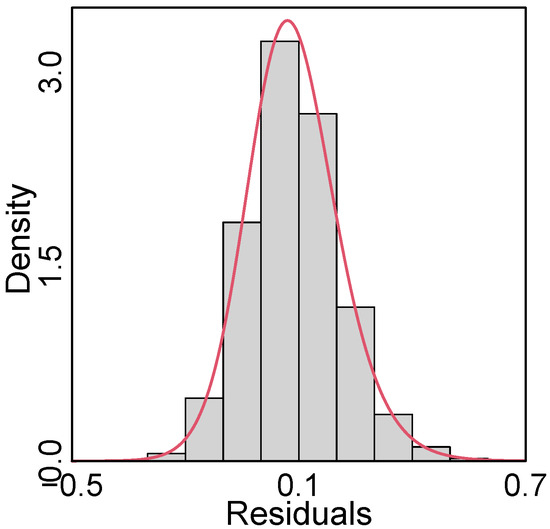
Figure 7.
Histogram of the residuals overlaid with the PDF of the ST distribution; children’s weight data.
Figure 8 displays the fitted quantile curves at the percentiles , , , , , , and overlaid on the scatterplot of the children’s weight versus their age for both the girls and boys. These reference percentile curves serve as a tool to assess and monitor infant growth based on weight, helping prevent nutritional and developmental problems (Gidi et al. [30], Paulsen et al. [31]). Although this analysis was conducted using the LSTLRM, the results are similar to those obtained under the LSNLRM (Section 5 of Morán-Vásquez et al. [9]), which we expected, given that the estimate of the degrees of freedom parameter was large.
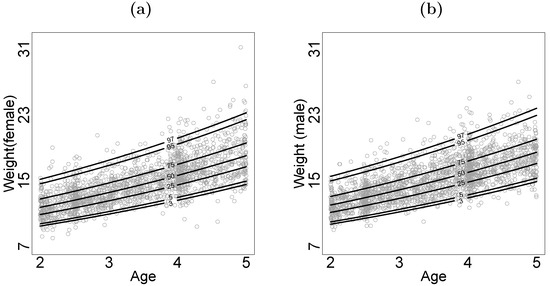
Figure 8.
Estimated quantile curves for children’s weight by age: (a) girls, (b) boys.
6. Final Remarks
In this work, we propose the LSTLRM, which is a robust approach based on the LST distribution. This model provides a flexible framework for estimating quantiles of continuous, positive response variables, particularly in settings characterized by skewness and heavy tails. Our motivation for studying the LSTLRM was the proportional relationship between any quantile of the LST distribution and the scale parameter . Furthermore, the connection between the LSTLRM and the STLRM enables maximum likelihood estimation, supports inferential procedures, and facilitates the assessment of goodness of fit. Our model generalizes previous approaches, such as the LSNLRM and the LTLRM, offering greater flexibility for modeling various data characteristics.
Our simulation studies confirmed the satisfactory performance of the parameter estimators and the quantile estimation methodology. Furthermore, a comparison with the classical quantile regression model showed that our model provides more accurate estimates. We illustrated the usefulness of our model through its applications to women’s income data and children’s weight data. In both cases, the LSTLRM provided a better fit than the LSNLRM, highlighting the importance of modeling skewness and heavy tails in the response variable. Based on the fitted models, we provided estimated quantiles that facilitated analysis of the distribution of the women’s income across years of schooling and age and enabled the construction of growth curves for the children’s weight as a function of age and gender. The goodness of fit of our models was assessed using quantile–quantile plots of squared normalized residuals with simulated envelopes and histograms of residuals with overlaid PDFs. Additionally, we performed likelihood ratio tests to compare the LSTLRM with the LTLRM, concluding in both applications that the LTLRM was not supported. Reproduction of the results in this paper is possible with the code accessible at https://github.com/moranvasquez/LSTLRM, accessed on 23 June 2025.
Additional diagnostic procedures for the LSTLRM will be addressed in future research, as well as regression models based on the LST distribution that handle incomplete data, measurement error, and mixed models. It would also be of interest to study multivariate extensions of the LSTLRM that account for the association among multiple response variables and allow for the modeling of marginal quantiles (Morán-Vásquez et al. [9]).
Author Contributions
Conceptualization, R.A.M.-V., A.D.G.-M., and M.A.M.-L.; methodology, R.A.M.-V., A.D.G.-M., and M.A.M.-L.; software, R.A.M.-V., A.D.G.-M., and M.A.M.-L.; investigation, R.A.M.-V., A.D.G.-M., and M.A.M.-L.; writing—original draft preparation, R.A.M.-V., A.D.G.-M., and M.A.M.-L.; writing—review and editing, R.A.M.-V., A.D.G.-M., and M.A.M.-L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The code and data required to reproduce the results presented in this paper are available at https://github.com/moranvasquez/LSTLRM, accessed on 23 June 2025.
Acknowledgments
The authors would like to thank the three anonymous referees for their careful reading and valuable comments, which greatly improved the paper.
Conflicts of Interest
The authors declare that they have no conflicts of interest regarding the publication of this paper.
References
- Koenker, R.; Bassett, G., Jr. Regression quantiles. Econom. J. Econom. Soc. 1978, 46, 33–50. [Google Scholar] [CrossRef]
- World Health Organization. WHO Child Growth Standards: Length/Height-for-Age, Weight-for-Age, Weight-for-Length, Weight-for-Height and Body Mass Index-for-Age: Methods and Development; World Health Organization: Geneva, Switzerland, 2006; Available online: https://apps.who.int/iris/handle/10665/43413 (accessed on 23 June 2025).
- World Health Organization. WHO Child Growth Standards: Head Circumference-for-Age, Arm Circumference-for-Age, Triceps Skinfold-for-Age and Subscapular Skinfold-for-Age: Methods and Development; World Health Organization: Geneva, Switzerland, 2007; Available online: https://apps.who.int/iris/handle/10665/43706 (accessed on 23 June 2025).
- Zhou, C. A Quantile Regression Analysis on the Relations between Foreign Direct Investment and Technological Innovation in China. In Proceedings of the 2011 International Conference of Information Technology, Computer Engineering and Management Sciences, Nanjing, China, 24–25 September 2011; pp. 38–41. [Google Scholar]
- Machado, J.A.F.; Mata, J. Counterfactual decomposition of changes in wage distributions using quantile regression. J. Appl. Econom. 2005, 20, 445–465. [Google Scholar] [CrossRef]
- Cade, B.S.; Noon, B.R. A gentle introduction to quantile regression for ecologists. Front. Ecol. Environ. 2003, 1, 412–420. [Google Scholar] [CrossRef]
- Mazucheli, J.; Alves, B.; Menezes, A.F.B.; Leiva, V. An overview on parametric quantile regression models and their computational implementation with applications to biomedical problems including COVID-19 data. Comput. Methods Programs Biomed. 2022, 221, 106816. [Google Scholar] [CrossRef]
- Morán-Vásquez, R.A.; Mazo-Lopera, M.A.; Ferrari, S.L.P. Quantile modeling through multivariate log-normal/independent linear regression models with application to newborn data. Biom. J. 2021, 63, 1290–1308. [Google Scholar] [CrossRef]
- Morán-Vásquez, R.A.; Giraldo-Melo, A.D.; Mazo-Lopera, M.A. Quantile estimation using the log-skew-normal linear regression model with application to children’s weight data. Mathematics 2023, 11, 3736. [Google Scholar] [CrossRef]
- Marchenko, Y.V.; Genton, M.G. Multivariate log-skew-elliptical distributions with applications to precipitation data. Environmetr. Off. J. Int. Environmetr. Soc. 2010, 21, 318–340. [Google Scholar] [CrossRef]
- Azzalini, A. The Skew-Normal and Related Families; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Azzalini, A.; Del Cappello, T.; Kotz, S. Log-skew-normal and log-skew-t distributions as models for family income data. J. Income Distrib. 2002, 11, 2. [Google Scholar] [CrossRef]
- Morán-Vásquez, R.A.; Ferrari, S.L.P. Box–Cox elliptical distributions with application. Metrika 2019, 82, 547–571. [Google Scholar] [CrossRef]
- Vanegas, L.H.; Paula, G.A. An extension of log-symmetric regression models: R codes and applications. J. Stat. Comput. Simul. 2016, 86, 1709–1735. [Google Scholar] [CrossRef]
- Rigby, R.A.; Stasinopoulos, D.M. Using the Box-Cox t distribution in GAMLSS to model skewness and kurtosis. Stat. Model. 2006, 6, 209–229. [Google Scholar] [CrossRef]
- Azzalini, A. The R Package sn: The Skew-Normal and Related Distributions Such as the Skew-t and the SUN, Version 2.1.0. 2022. Available online: https://cran.r-project.org/package=sn (accessed on 23 June 2025).
- Atkinson, A.C. Two graphical displays for outlying and influential observations in regression. Biometrika 1981, 68, 13–20. [Google Scholar] [CrossRef]
- Azzalini, A.; Capitanio, A. Distributions generated by perturbation of symmetry with emphasis on a multivariate skew t-distribution. J. R. Stat. Soc. Ser. B 2003, 65, 367–389. [Google Scholar] [CrossRef]
- Riani, M.; Atkinson, A.C.; Morelli, G.; Corbellini, A. The Use of Modern Robust Regression Analysis with Graphics: An Example from Marketing. Stats 2025, 8, 6. [Google Scholar] [CrossRef]
- Azzalini, A.; Salehi, M. Some Computational Aspects of Maximum Likelihood Estimation of the Skew-t Distribution. In Computational and Methodological Statistics and Biostatistics. Emerging Topics in Statistics and Biostatistics; Bekker, A., Chen, D.-G., Ferreira, J.T., Eds.; Springer: Cham, Switzerland, 2020. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2024; Available online: https://www.R-project.org/ (accessed on 23 June 2025).
- de Castro Romero, L.; Barroso, V.M.; Santero-Sánchez, R. Does Gender Equality in Managerial Positions Improve the Gender Wage Gap? Comparative Evidence from Europe. Economies 2023, 11, 301. [Google Scholar] [CrossRef]
- Arellano-Valle, R.B.; Castro, L.M.; González-Farías, G.; Muñoz-Gajardo, K.A. Student-t censored regression model: Properties and inference. Stat. Methods Appl. 2012, 21, 453–473. [Google Scholar] [CrossRef]
- Cowell, F.A.; Victoria-Feser, M.P. Robustness properties of inequality measures. Econom. J. Econom. Soc. 1996, 64, 77–101. [Google Scholar] [CrossRef]
- Saulo, H.; Vila, R.; Borges, G.V.; Bourguignon, M.; Leiva, V.; Marchant, C. Modeling income data via new parametric quantile regressions: Formulation, computational statistics, and application. Mathematics 2023, 11, 448. [Google Scholar] [CrossRef]
- Altonji, J. Race and Gender in the Labor Market. In Handbook of Labor Economics/North Holland; Elsevier: Amsterdam, The Netherlands, 1999; Volume 3, pp. 3143–3259. [Google Scholar]
- Card, D.; Lemieux, T. Wage dispersion, returns to skill, and black-white wage differentials. J. Econom. 1996, 74, 319–361. [Google Scholar] [CrossRef][Green Version]
- Departamento Administrativo Nacional de Estadística (DANE). Gran Encuesta Integrada de Hogares (GEIH). 2021. Available online: https://microdatos.dane.gov.co/index.php/catalog/750/get-microdata (accessed on 23 June 2025).
- MEDATA: Estrategia de Datos de Medellín. Estado Nutricional de Menores de 6 Años Programa de Crecimiento y Desarrollo 2022. Available online: https://medata.gov.co/dataset/estado-nutricional-de-menores-de-6-anos-programa-de-crecimiento-y-desarrollo (accessed on 23 June 2025).
- Gidi, N.W.; Berhane, M.; Girma, T.; Abdissa, A.; Lim, R.; Lee, K.; Nguyen, C.; Russell, F. Anthropometric measures that identify premature and low birth weight newborns in Ethiopia: A cross-sectional study with community follow-up. Arch. Dis. Child. 2020, 105, 326–331. [Google Scholar] [CrossRef]
- Paulsen, C.B.; Nielsen, B.B.; Msemo, O.A.; Møller, S.L.; Ekmann, J.R.; Theander, T.G.; Bygbjerg, I.C.; Lusingu, J.P.A.; Minja, D.T.R.; Schmiegelow, C. Anthropometric measurements can identify small for gestational age newborns: A cohort study in rural Tanzania. BMC Pediatr. 2019, 19, 120. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).