Abstract
The limit of detection (LOD) is commonly encountered in observational studies when one or more covariate values fall outside the measuring ranges. Although the complete-case (CC) approach is widely employed in the presence of missing values, it could result in biased estimations or even become inapplicable in small sample studies. On the other hand, approaches such as the missing indicator (MDI) approach are attractive alternatives as they preserve sample sizes. This paper compares the effectiveness of different alternatives to the CC approach under different LOD settings with a survival outcome. These alternatives include substitution methods, multiple imputation (MI) methods, MDI approaches, and MDI-embedded MI approaches. We found that the MDI approach outperformed its competitors regarding bias and mean squared error in small sample sizes through extensive simulation.
1. Introduction
We consider situations where the covariates of interest are only observable within a detection interval, referred to as the limit of detection (LOD) problem, e.g., [1,2]. The limit of detection is commonly encountered in observational studies. For example, patients with a positive real-time polymerase chain reaction (PCR) test result for coronavirus disease usually indicate that the viral RNA load is greater than the lower LOD, which varies from to copies per milliliter [3]. On the other hand, a typical droplet digital PCR test is restricted to an upper LOD or interval LOD [4]. Assays with high lower LODs or low higher LODs will likely result in higher false-negative or false-positive rates, respectively [3]. Another example where incomplete data due to the LOD are inevitable is in multi-omics data analysis, where quantitative omics measurements, such as metabolite levels and protein expressions, are missing due to the failure of the measurement assay at levels outside of its detection limits [5]. Proper adjustments are needed for valid data analysis with missing values due to the LOD.
In the presence of LOD, one of the most straightforward approaches is the complete-case (CC) analysis, which discards observations that fall outside the detection limits. Despite the CC analysis yielding unbiased estimates for the regression coefficients, e.g., [1,2,6,7,8], it could suffer from efficiency loss and become unstable when the sample size is small or when there are multiple covariates subject to the LOD. An approach that does not require discarding observations is to substitute the unobserved values with fixed values outside of the detection limits [9]. Common substitution methods replace missing values with ad hoc fix values or values derived from parametric assumptions, e.g., [7,8,10]. Such substitution methods could result in considerable bias when the imputed value is very different from the unobserved values or when the parametric assumptions are misspecified [1,2,7,10,11]. An approach to handle covariates subject to the LOD without discarding observations nor imposing a parametric distributional assumption is the missing indicator (MDI) approach, e.g., [6,10,12,13]. The idea of the MDI approach is to create a binary variable that indicates whether the covariate of interest is observed and include the indicator variable in the model as an additional covariate [6]. Since the MDI approach uses all of the available observations, estimating procedures that utilize the MDI approach is expected to yield a more efficient estimator and be more computationally stable when the sample size is small or multiple covariates are subject to LOD [14].
Approaches for LOD have been well studied in the literature. For example, the MDI approach was justified theoretically and numerically and compared to the CC approach in the context of linear regression [6] and logistic regression [15,16,17]. Extensions that combine the MDI and the multiple imputation (MI) approaches have also been studied under the generalized linear regression setting [18,19]. On a separate note, MDI-based and MI-based copula models were used to estimate the association between two continuous variables subjected to lower LOD [10]. Relatively fewer works compared approaches for LOD with survival outcomes. Among those, most of the existing works focus on proportional hazards models, e.g., [20,21]. Despite having a more favorable interpretability, the approaches for LOD under the accelerated failure time (AFT) framework were less explored until recently [22], where a seminonparametric distribution is recommended to model the error term.
Recent studies on the MDI approach yield encouraging results when the required conditions are met. However, most existing works are based on scenarios in which the covariates of interest are subjected to a lower LOD. We extended the MDI approach’s applicability to general scenarios in which covariates may be subjected to upper or interval LOD. We applied the MDI approach to the context of survival analysis when the survival time is subject to an independent right censoring. We assumed the survival time is related to the covariates via a parametric accelerated failure time model. We compared the performance of the MDI approach to that of existing methods at different types of LOD via large-scale simulation studies. We compared the approaches by evaluating the absolute value of the average biases (AAB) and mean squared error (MSE) for the regression parameter of interest.
The rest of the paper is organized as follows. Notation and model formulation are presented in Section 2. A brief description of the estimating procedures in the presence of covariates subject to the LOD are provided in Section 3. Results of large-scale simulation studies on the performance of the proposed estimators are reported in Section 4. A discussion concludes Section 5.
2. Notations and Model
Let be the time to an event of interest related to covariates via a parametric AFT model,
where is a covariate vector whose elements are partially missing due to LOD, is a fully observed covariate vector, s are independent and identically distributed random variables with a known distribution, and are the corresponding conformable regression parameters. In the absence of the missing covariate , the regression coefficients can be estimated via maximizing the likelihood function. For example, when has a normal distribution with mean zero and variance , follows a log-normal distribution and the regression coefficients can be obtained by maximizing the likelihood
where is the observed survival time, is the censoring indicator, and is the censoring time. The functions and are the probability density function and the cumulative distribution function of the standard normal distribution. The maximum likelihood estimator (MLE) can be obtained by a standard numerical optimization algorithm, such as the Newton–Raphson method. The variance–covariance matrix of the MLE can be estimated via the information matrix, and the asymptotic normality of the MLE follows directly from likelihood theorems. The survreg() function from R’s survival package [23] is available for fitting such a parametric AFT model.
When is subject to LOD, we assume is observable only if , where and are the lower and upper bounds of the measurement range, respectively. When falls outside of , we observe . That is, we observe if and if so that the direction of missing is always known. Accompanying is the missing indicator , where and is the indicator function. The observed data then consist of independent copies of . We assume the censoring time is conditionally independent of given and . Throughout the manuscript, we allow to be subject to different types and levels of LOD and discuss approaches that are applicable under these scenarios.
3. Estimating Procedures in the Presence of LOD
3.1. Complete-Case Analysis
The CC analysis is commonly used in the presence of missing covariates. The fundamental idea of applying the CC analysis is to discard missing observations outside of the measurement range. Though the idea of the CC approach is straightforward, discarding observations from samples loses information and could potentially bias the estimation when the missingness is dependent on exposure, e.g., [16,24], as in the LOD cases. Additional convergence issues arise when the original sample size is small; an extreme case is where the CC approach is inapplicable when all subjects have at least one missing variable. With the missing indicator, the CC model can be expressed as a modification of (1) as follows:
where if all of are observed, and is zero otherwise. The regression coefficients can be obtained by maximizing the modified likelihood,
The CC method is the default approach in survreg() when data contain missing values.
3.2. Parametric Substitution Approaches
Instead of discarding missing observations, imputations methods replace the missing values with their expectations. Most existing imputation methods replace missing values with the predicted values from models trained by the observed data, resulting in imputed values inside the observable region. Such imputation methods are not feasible for imputing missing values due to LOD, where the missing values are outside of the observable region. For this reason, it is more appropriate to consider imputation methods that replace missing values subject to LOD with conditional expectations, or , respectively, depending on the direction of missing. These quantities can be estimated parametrically using likelihood methods. For example, for a positive subject to a lower LOD by , common substitution values such as and are derived by imposing a uniform distribution or a triangular distribution to the data below , respectively, e.g., [25,26]. On the other hand, ad hoc substituting values such as 0 and have also been considered but generally lead to biased estimations of regression coefficient estimates [9].
Although the aforementioned substituting values have simple forms, they are derived without using information from the observed . An alternative approach is to derive the substituting values by imposing a distribution assumption on the whole data. For example, if is assumed to follow a normal distribution with mean and variance , then can be estimated by maximizing the likelihood
Let , and and be the MLEs of and , respectively. Once and are obtained, the conditional expectations
can be used as the substituting values for those censored by and , respectively. The estimates of the regression coefficients in (1) under the parametric substitution methods are then obtained by maximizing the likelihood in (1) with missing replaced by the desired substituting values.
3.3. Parametric Multiple Imputation Approaches
Single imputation methods such as those mentioned in Section 3.2 are less computation-demanding compared to the MI [27] approaches, but the latter could be more efficient as they better reflect uncertainty about imputed values. The general idea of MI methods is to impute the missing repeatedly with values generated from its predictive distribution given the observed data. Once the M complete data sets are generated, the CC analysis is then applied to each complete data set. The separate results are then pooled to provide the final inference. Building onto the aforementioned substitution method under normal assumptions, we consider imputing the missing s by random values generated from densities or . Under the normal assumption on , corresponds to truncated normal density functions and the random values are generated via the inverse cumulative distribution function method. Let be the coefficient estimate obtained by maximizing (1) at the mth imputation. Using the Rubin’s rule [27], the pooled MI coefficient estimate and variance estimate are
where is the variance estimate for . The proposed MI method differs from the existing MI methods, such as the ones implemented in mice [28], in that the proposed method targets imputation values outside of the observed region. Our MI method can be easily implemented and is flexible in that different parametric assumptions can be implied for different covariates.
3.4. Missing Indicator Approaches
A useful alternative that does not require discarding or imputing missing values is the MDI approach [6]. The idea of the MDI approach is to include the missing status as additional covariates in the model so that all available information remains in the analysis to maintain statistical power. Specifically, we consider the MDI-embedded AFT model
where is the element-wise product of vectors u and v and is an additional regression coefficient. The MLE of can be obtained by maximizing the modified likelihood
where . In the context of linear regression, the least-squares estimator for was shown to be asymptotically unbiased for in (1) if and are uncorrelated [6]. The performance of the MDI approach has also been studied under the generalized linear model, e.g., [15]. Since the parametric AFT model has a log-linear form, the MLE obtained from maximizing (4) is expected to be asymptotically unbiased in the absence of censoring. We also conjecture that the asymptotic unbiasedness continue to hold in the presence of censoring. The MDI approach is easy to implement and can be extended in several directions. For example, the fully expanded MDI model extends (3) by including interaction terms between the missing indicators and the observed covariates [15], resulting in the revised AFT model
where is an additional regression coefficient. On the other hand, the MDI approach could be embedded into the MI approach, e.g., [18,19], resulting in the revised AFT model
where , if , and is the imputed value by MI if . The MI coefficient estimates are then pooled by the Rubin’s rule. Those extensions of the MDI approach are implemented and compared in simulation.
4. Simulation
A series of simulation studies were conducted to compare methods discussed in Section 3. The failure time was generated from the AFT model
where was a Weibull random variable with shape 1 and scale , was a normal random variable with mean 0 and variance , was a standard normal random variable, the regression parameter , and the error term followed a standard normal distribution. We considered scenarios where covariates are independent and where the covariates are correlated. In the latter case, the Clayton copula with a Spearman’s rho of was used to specify the correlation between and Z. The censoring time was independently generated from a uniform distribution over , yielding a 30% censoring rate on . We considered three types of LOD: lower LOD, upper LOD, and interval LOD, where is observable in , , and , respectively. The detection limits, and , were quantiles of chosen to achieve three levels of missing proportions, 20%, 40%, and 60%, for light missing, moderate missing, and heavy missing, respectively. For interval LOD, we additionally assumed to be the th quantile of , where is the missing proportion for .
For each configuration, we compared the performance of the following approaches to handling missing data.
Complete-case analysis
- M1
- removal of subjects with missing .
Substitution methods:
- M2
- substitution of the missing by or .
- M3
- substitution of the missing by or .
- M4
- substitution of the missing by or under normal assumptions.
Multiple imputation approaches:
- M5
- MI of the missing using the predictive mean matching (PMM) algorithm implemented in the R package mice [28].
- M6
- MI of the missing using conditional densities derived under normal assumptions as described in Section 3.3.
Missing indicator approaches:
- M7
- the missing indicator approaches (MDI) model.
- M8
- the expanded MDI model.
Missing-indicator-embedded multiple imputation approaches (MI + MDI):
- M9
- MI by PMM and fit with MDI model.
- M10
- MI by normal assumptions and fit with MDI model.
- M11
- MI by PMM and fit with expanded MDI model.
- M12
- MI by normal assumptions and fit with expanded MDI model.
The simulation was repeated 10,000 times with sample sizes , and 500. The MLE of the regression parameter of the AFT model (5) was obtained using the survreg() function in the survival package [23] in R [29] under the normal error assumption, e.g., with argument dist = "lognormal". For the scenarios considered, the CC approach (M1) sometimes failed to converge as the resultant sample size was too small or empty after removing missing observations. The convergence rate for the CC approach under different scenarios presented in the Supplementary Materials shows fewer converged replications when the sample size is small (e.g., ) or the missing proportions are high (e.g., or ). For this reason, the simulation results were based on the converged replications for the CC approach. For MI methods, the number of imputations M was set to 5.
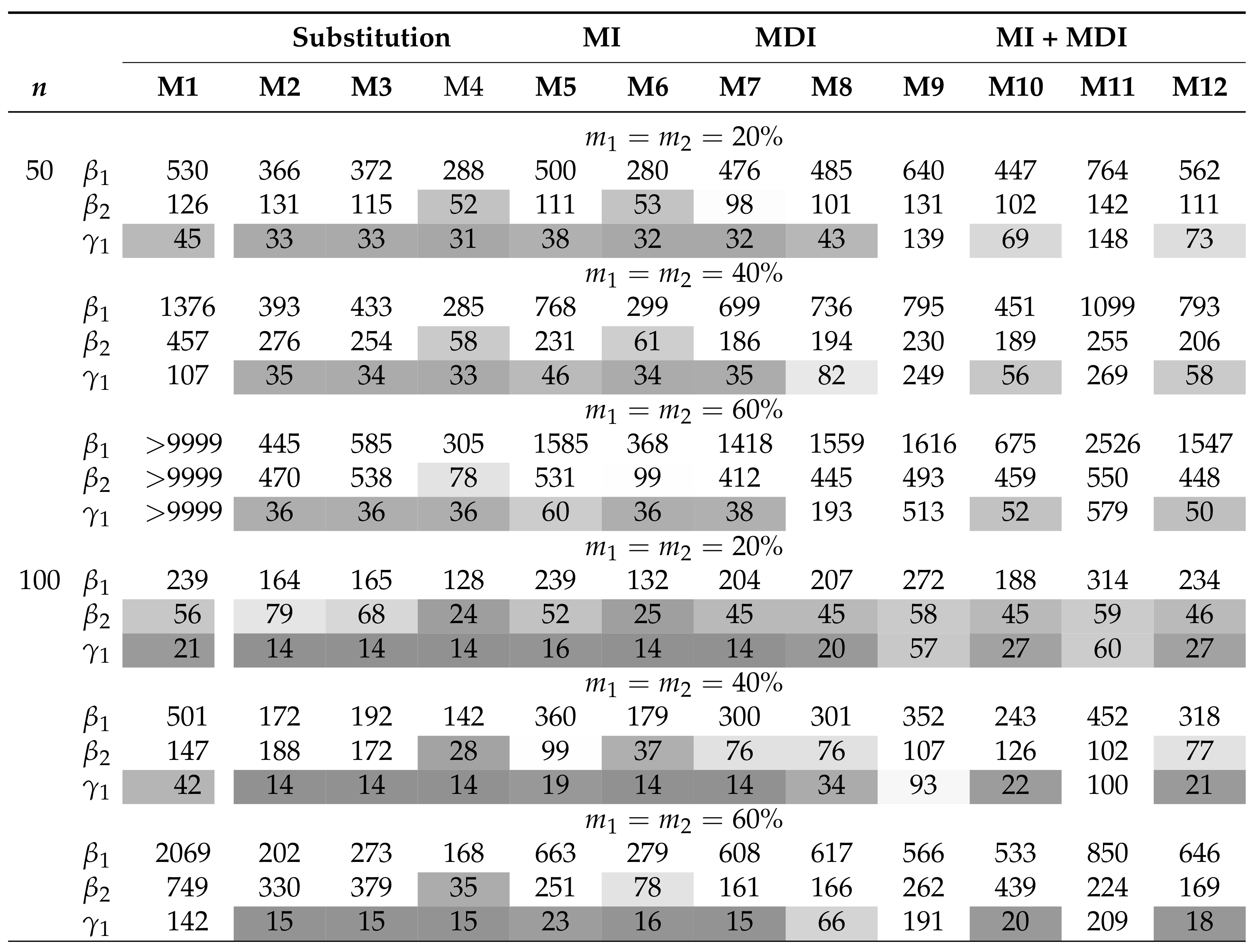
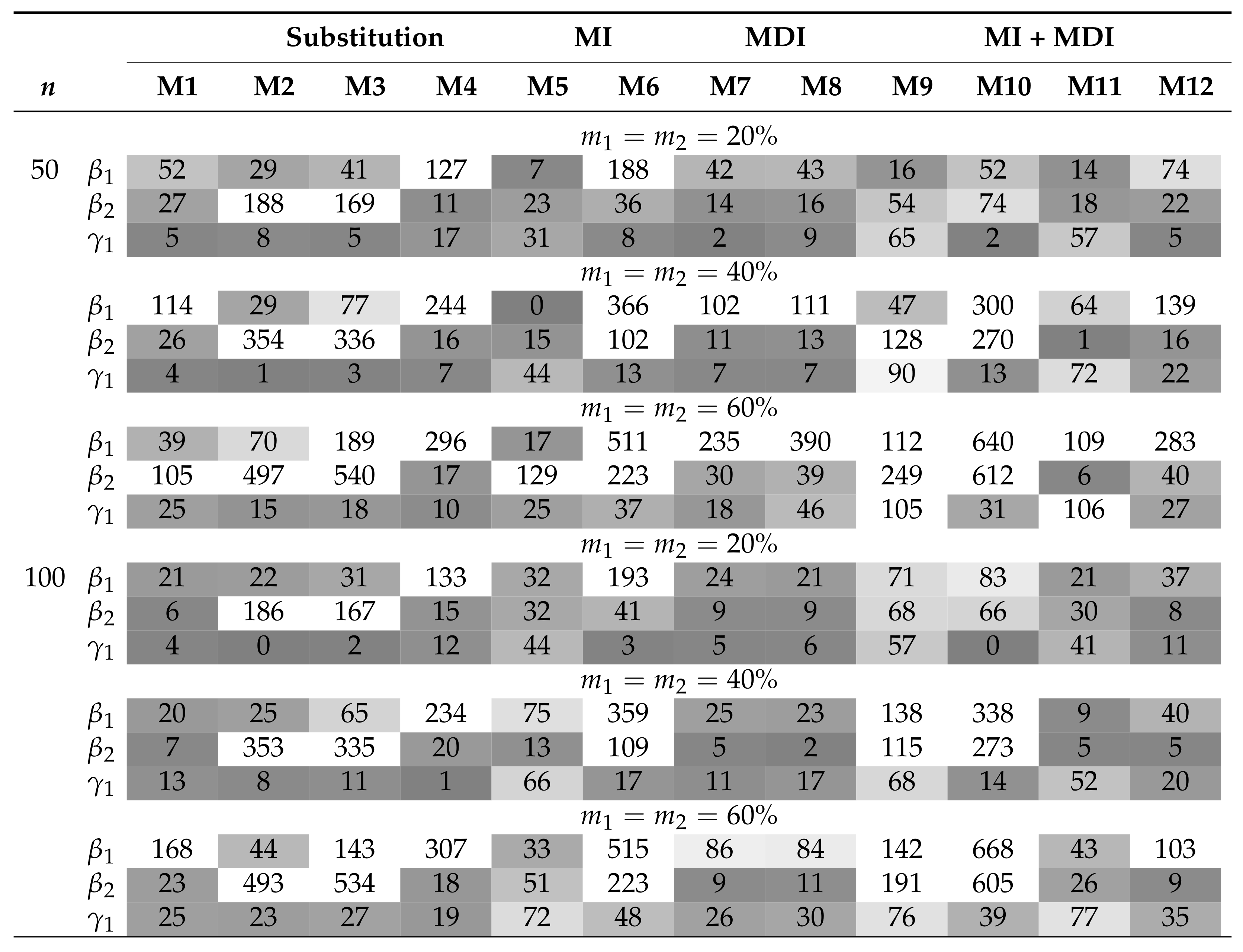
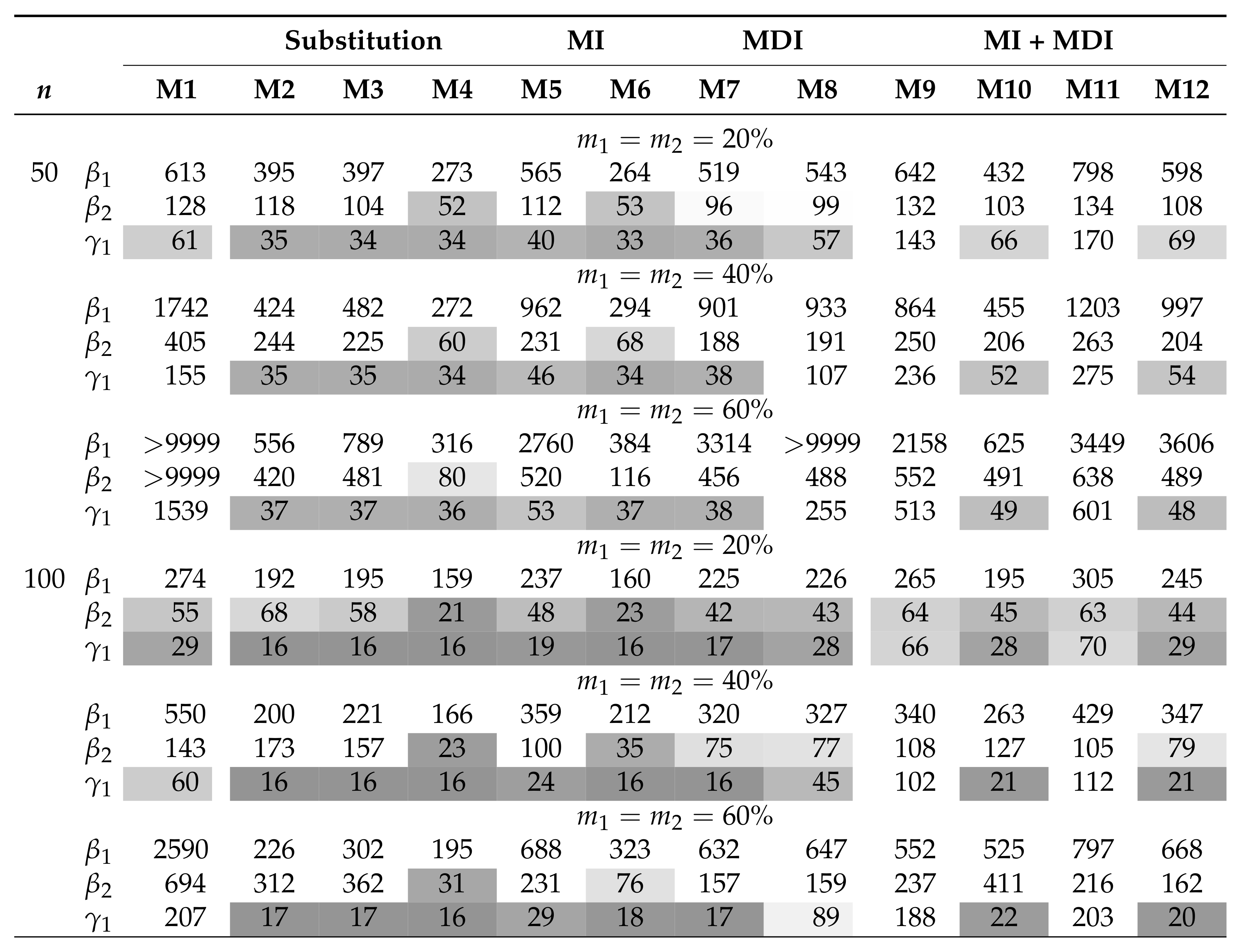
Table 1 and Table 2 summarize the AAB and MSE associated with the MLEs of , , and in the AFT model (5) when the covariates are independent and the censored covariates are subjected to a lower LOD. The MDI approaches (M7 and M8) have among the smallest AAB and MSE across the considered scenarios. Moreover, the MDI approaches outperform the CC approach (M1) when the sample size is small or the missing proportions ( and ) are high. Overall, the AAB and the MSE generally increase with increasing missing proportions. On the other hand, whereas MSE generally decreases with an increasing sample size, the trend of AAB varies by model. Among the substitution methods, both M2 and M3 yield smaller AAB for than for ; this is because the substituting values under these approaches are close to . On the contrary, M4 yields smaller AAB for when the parametric assumption for is satisfied. The same trend can be seen in the parametric MI approach, M6. In particular, all of the imputation approaches, including the PMM-based MI approach (M5), did not improve the performance when compared with the MDI approach. Combining MDI models in MI approaches does not necessarily improve the performance of MDI or MI approaches if they would be applied solely. In situations where the combined approach shows improved AAB over the MI approaches, there are trade-offs in MSE. Of those, the expanded MDI-embedded MI approach (M11 and M12) yields smaller AAB than the MDI-embedded MI approach (M9 and M10), but they result in a comparable MSE. In addition, biases associated with the MLEs of and summarized in Figure 1 provide insight into the direction of bias. Among those that yield a substantial bias, approaches with uniform and triangular assumptions, i.e., M2 and M3, tend to overestimate and underestimate . In contrast, approaches with normal assumptions, i.e., M4, M6, and M10, tend to underestimate and correctly estimate . The pattern is reversed in the case of an upper or interval LOD. These observations suggest that the direction of bias is imposed by the underlying parametric assumption and highlight the robustness of the MDI approach. Similar trends are observed in scenarios where the covariates are subjected to the upper or interval LOD and where n = 500, as presented in the Supplementary Materials. On the other hand, the results when the covariates are correlated are presented in Table 3 and Table 4 and Figure 2. For all approaches, correlation generally results in higher AAB and MSE but does not alter the direction of bias. This observation is consistent with the literature, where the asymptotic bias of the regression coefficient associated with the censored covariate is shown to increase with an increasing magnitude of the correlation [6]. However, these theoretical results do not apply directly to a small sample setting, as the MDI approaches remain at least as good as, if not better than, the CC approach.

Table 1.
Summary of the AAB () when covariates are independent and is subjected to lower LOD. M1 is complete-case analysis; M2–M4 are the different variants of the substitution methods; M5–M6 are the different variants of the MI methods; M7–M8 are the different variants of the MDI methods; M9–M12 are the different variants of MDI-embedded MI (MI + MDI) methods. AAB less than 0.1 is highlighted in gray, with darker tones corresponding to smaller AAB.
Table 2.
Summary of the MSE () when covariates are independent and is subjected to lower LOD. M1 is complete-case analysis; M2–M4 are the different variants of the substitution methods; M5–M6 are the different variants of the MI methods; M7–M8 are the different variants of the MDI methods; M9–M12 are the different variants of MDI-embedded MI (MI + MDI) methods. MSEs less than 0.1 are highlighted in gray, with darker tones corresponding to smaller MSEs.
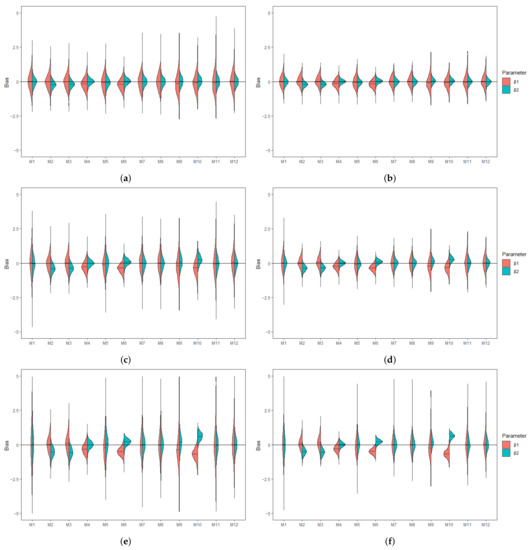
Figure 1.
Violin plots showing the empirical distribution of the bias associated with MLE of (red) and (green) when covariates are independent and is subjected to lower LOD. (a) Bias under and . (b) Bias under and . (c) Bias under and . (d) Bias under and . (e) Bias under and . (f) Bias under and .
Table 3.
Summary of the AAB () when covariates are correlated and is subjected to lower LOD. M1 is complete case analysis; M2–M4 are the different variants of the substitution methods; M5–M6 are the different variants of the MI methods; M7–M8 are the different variants of the MDI methods; M9–M12 are the different variants of MDI-embedded MI (MI + MDI) methods. AAB less than 0.1 is highlighted in gray, with darker tones corresponding to smaller AAB.
Table 4.
Summary of the MSE () when covariates are correlated and is subjected to lower LOD. M1 is complete case analysis; M2–M4 are the different variants of the substitution methods; M5–M6 are the different variants of the MI methods; M7–M8 are the different variants of the MDI methods; M9–M12 are the different variants of MDI-embedded MI (MI + MDI) methods. MSEs less than 0.1 are highlighted in gray, with darker tones corresponding to smaller MSEs.
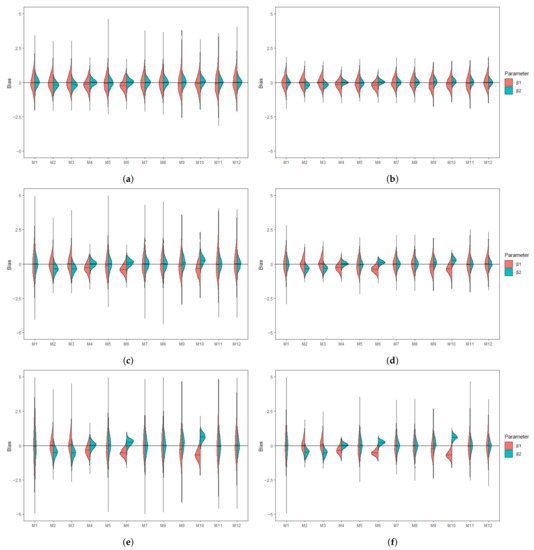
Figure 2.
Violin plots showing the empirical distribution of the bias associated with MLE of (red) and (green) when covariates are correlated and is subjected to lower LOD. (a) Bias under and . (b) Bias under and . (c) Bias under and . (d) Bias under and . (e) Bias under and . (f) Bias under and .
5. Discussion
The MDI approach minimizes the loss of information and does not require making parametric assumptions, making it an attractive alternative to some of the more widely used approaches for handling missing covariates. Moreover, the MDI approaches show clear advantages over the competitors and are recommended in models with survival outcomes, as in our simulation. Our simulation shows no apparent difference between the MDI and the expanded MDI models, but embedding the expanded MDI model in MI could result in a higher bias reduction. The advantage of the MDI approach is more substantial when there is a large proportion of missing covariates or when the distributional assumption is violated in the MI approach. The MDI approaches continue to perform well under additional simulation settings, including scenarios where the survival time is not subject to censoring and scenarios under a Cox proportional hazard model setting.
It has been noted that, even though the MDI approach generally results in a reduced bias, it might have minimal improvements when the missing mechanism is associated with the outcome [30] or when the missing covariate is categorical [31]. Those phenomena were verified in the context of generalized linear regression, and it would be worth investigating those scenarios in our setting with survival outcomes. Moreover, extending the assessments of the validity of the MDI approach, e.g., [32,33], to our settings will be of interest.
We only considered scenarios where the direction of missing is known in this paper. Nevertheless, the MDI approach is still applicable when the direction of missing is unknown. The aforementioned parametric imputation methods can easily be extended to the case when the direction of missing is unknown. For example, suppose that follows a normal distribution with mean and variance as in Section 3.3. The MLEs of and can be obtained by maximizing the likelihood
The corresponding MI procedure can then be carried out with missing s imputed by values generated from density , where with probability and otherwise. Due to its simplicity, the MDI method can also be easily embedded into other methods to improve the overall performance. An immediate example is the MI+MDI approaches considered in Section 4. Another extension is to embed the MDI approach in threshold regression approaches [34] to accommodate multiple censored covariates.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/stats5020029/s1.
Author Contributions
Conceptualization, N.A. and S.H.C.; methodology, N.A. and S.H.C.; software, N.A.; validation, N.A. and S.H.C.; formal analysis, N.A. and S.H.C.; writing—original draft preparation, N.A.; writing—review and editing, S.H.C.; visualization, N.A. and S.H.C.; supervision, S.H.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bernhardt, P.W.; Wang, H.J.; Zhang, D. Statistical methods for generalized linear models with covariates subject to detection limits. Stat. Biosci. 2015, 7, 68–89. [Google Scholar] [CrossRef] [PubMed]
- Kong, S.; Nan, B. Semiparametric approach to regression with a covariate subject to a detection limit. Biometrika 2016, 103, 161–174. [Google Scholar] [CrossRef] [Green Version]
- Arnaout, R.; Lee, R.A.; Lee, G.R.; Callahan, C.; Yen, C.F.; Smith, K.P.; Arora, R.; Kirby, J.E. SARS-CoV2 testing: The limit of detection matters. bioRxiv 2020. [Google Scholar] [CrossRef]
- Lou, Y.; Chen, C.; Long, X.; Gu, J.; Xiao, M.; Wang, D.; Zhou, X.; Li, T.; Hong, Z.; Li, C.; et al. Detection and Quantification of Chimeric Antigen Receptor Transgene Copy Number by Droplet Digital PCR versus Real-Time PCR. J. Mol. Diagn. 2020, 22, 699–707. [Google Scholar] [CrossRef]
- Lin, D.Y.; Zeng, D.; Couper, D. A general framework for integrative analysis of incomplete multiomics data. Genet. Epidemiol. 2020, 44, 646–664. [Google Scholar] [CrossRef]
- Jones, M.P. Indicator and stratification methods for missing explanatory variables in multiple linear regression. J. Am. Stat. Assoc. 1996, 91, 222–230. [Google Scholar] [CrossRef]
- Nie, L.; Chu, H.; Liu, C.; Cole, S.R.; Vexler, A.; Schisterman, E.F. Linear regression with an independent variable subject to a detection limit. Epidemiology 2010, 21, S17. [Google Scholar] [CrossRef] [Green Version]
- Arunajadai, S.G.; Rauh, V.A. Handling covariates subject to limits of detection in regression. Environ. Ecol. Stat. 2012, 19, 369–391. [Google Scholar] [CrossRef]
- Schisterman, E.F.; Vexler, A.; Whitcomb, B.W.; Liu, A. The limitations due to exposure detection limits for regression models. Am. J. Epidemiol. 2006, 163, 374–383. [Google Scholar] [CrossRef] [Green Version]
- Tran, T.M.; Abrams, S.; Aerts, M.; Maertens, K.; Hens, N. Measuring association among censored antibody titer data. Stat. Med. 2021, 40, 3740–3761. [Google Scholar] [CrossRef]
- Richardson, D.B.; Ciampi, A. Effects of exposure measurement error when an exposure variable is constrained by a lower limit. Am. J. Epidemiol. 2003, 157, 355–363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Anderson, A.B.; Basilevsky, A.; Hum, D.P. Missing data: A review of the literature. In Handbook of Survey Research; Academic Press: Cambridge, MA, USA, 1983; pp. 415–494. [Google Scholar]
- Chow, W.K. A look at various estimators in logistic models in the presence of missing values. In Technical Report; Rand Corp: Santa Monica, CA, USA, 1979. [Google Scholar]
- Cohen, J.; Cohen, P.; West, S.G.; Aiken, L.S. Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences; Taylor & Francis: Oxfordshire, UK, 2013. [Google Scholar]
- Chiou, S.H.; Betensky, R.A.; Balasubramanian, R. The missing indicator approach for censored covariates subject to limit of detection in logistic regression models. Ann. Epidemiol. 2019, 38, 57–64. [Google Scholar] [CrossRef] [PubMed]
- Ortega-Villa, A.M.; Liu, D.; Ward, M.H.; Albert, P.S. New insights into modeling exposure measurements below the limit of detection. Environ. Epidemiol. 2021, 5, e116. [Google Scholar] [CrossRef] [PubMed]
- Blackhurst, M. Identifying Lead Service Lines with Field Tap Water Sampling. ACS ES T Water 2021, 1, 1983–1991. [Google Scholar] [CrossRef]
- Choi, J.; Dekkers, O.M.; le Cessie, S. A comparison of different methods to handle missing data in the context of propensity score analysis. Eur. J. Epidemiol. 2019, 34, 23–36. [Google Scholar] [CrossRef] [Green Version]
- Sperrin, M.; Martin, G.P. Multiple imputation with missing indicators as proxies for unmeasured variables: Simulation study. BMC Med. Res. Methodol. 2020, 20, 185. [Google Scholar] [CrossRef]
- Lee, S.; Park, S.; Park, J. The proportional hazards regression with a censored covariate. Stat. Probab. Lett. 2003, 61, 309–319. [Google Scholar] [CrossRef]
- Dinse, G.E.; Jusko, T.A.; Ho, L.A.; Annam, K.; Graubard, B.I.; Hertz-Picciotto, I.; Miller, F.W.; Gillespie, B.W.; Weinberg, C.R. Accommodating measurements below a limit of detection: A novel application of Cox regression. Am. J. Epidemiol. 2014, 179, 1018–1024. [Google Scholar] [CrossRef] [Green Version]
- Bernhardt, P.W.; Wang, H.J.; Zhang, D. Flexible modeling of survival data with covariates subject to detection limits via multiple imputation. Comput. Stat. Data Anal. 2014, 69, 81–91. [Google Scholar] [CrossRef] [Green Version]
- Therneau, T.M. A Package for Survival Analysis in R; R Package Version 3.2-13. Available online: https://CRAN.R-project.org/package=survival (accessed on 23 March 2022).
- Hughes, R.A.; Heron, J.; Sterne, J.A.; Tilling, K. Accounting for missing data in statistical analyses: Multiple imputation is not always the answer. Int. J. Epidemiol. 2019, 48, 1294–1304. [Google Scholar] [CrossRef]
- Hornung, R.W.; Reed, L.D. Estimation of average concentration in the presence of nondetectable values. Appl. Occup. Environ. Hyg. 1990, 5, 46–51. [Google Scholar] [CrossRef]
- Baccarelli, A.; Pfeiffer, R.; Consonni, D.; Pesatori, A.C.; Bonzini, M.; Patterson Jr, D.G.; Bertazzi, P.A.; Landi, M.T. Handling of dioxin measurement data in the presence of non-detectable values: Overview of available methods and their application in the Seveso chloracne study. Chemosphere 2005, 60, 898–906. [Google Scholar] [CrossRef] [PubMed]
- Rubin, D.B. Statistical matching using file concatenation with adjusted weights and multiple imputations. J. Bus. Econ. Stat. 1986, 4, 87–94. [Google Scholar]
- van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Groenwold, R.H.; White, I.R.; Donders, A.R.T.; Carpenter, J.R.; Altman, D.G.; Moons, K.G. Missing covariate data in clinical research: When and when not to use the missing-indicator method for analysis. CMAJ 2012, 184, 1265–1269. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhuchkova, S.; Rotmistrov, A. A Comparison Of The Missing-Indicator Method And Complete Case Analysis In Case Of Categorical Data. In Higher School of Economics Research Paper No. WP BRP; Social Science Research Network: Rochester, NY, USA, 2019; Volume 87. [Google Scholar]
- Blake, H.A.; Leyrat, C.; Mansfield, K.E.; Tomlinson, L.A.; Carpenter, J.; Williamson, E.J. Estimating treatment effects with partially observed covariates using outcome regression with missing indicators. Biom. J. 2020, 62, 428–443. [Google Scholar] [CrossRef] [PubMed]
- Blake, H.A.; Leyrat, C.; Mansfield, K.E.; Seaman, S.; Tomlinson, L.A.; Carpenter, J.; Williamson, E.J. Propensity scores using missingness pattern information: A practical guide. Stat. Med. 2020, 39, 1641–1657. [Google Scholar] [CrossRef] [Green Version]
- Qian, J.; Chiou, S.H.; Maye, J.E.; Atem, F.; Johnson, K.A.; Betensky, R.A. Threshold regression to accommodate a censored covariate. Biometrics 2018, 74, 1261–1270. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).