
Deep Learning for Automated Visual Inspection in Manufacturing and Maintenance: A Survey of Open- Access Papers
 , , , and
, , , and 
Abstract
1. Introduction
- What are the requirements that have to be considered when applying DL-based models to AVI?
- Which AVI use cases are currently being addressed by deep-learning models?
- Are there certain recurring AVI tasks that these use cases can be categorized into?
- What is the data basis for industrial AVI, and are there common benchmark datasets?
- How do DL models perform in these tasks, and which of them can be recommended for certain AVI use cases?
- Are recent state-of-the-art (SOTA) CV DL models used in AVI applications, and if not, is there untapped potential?
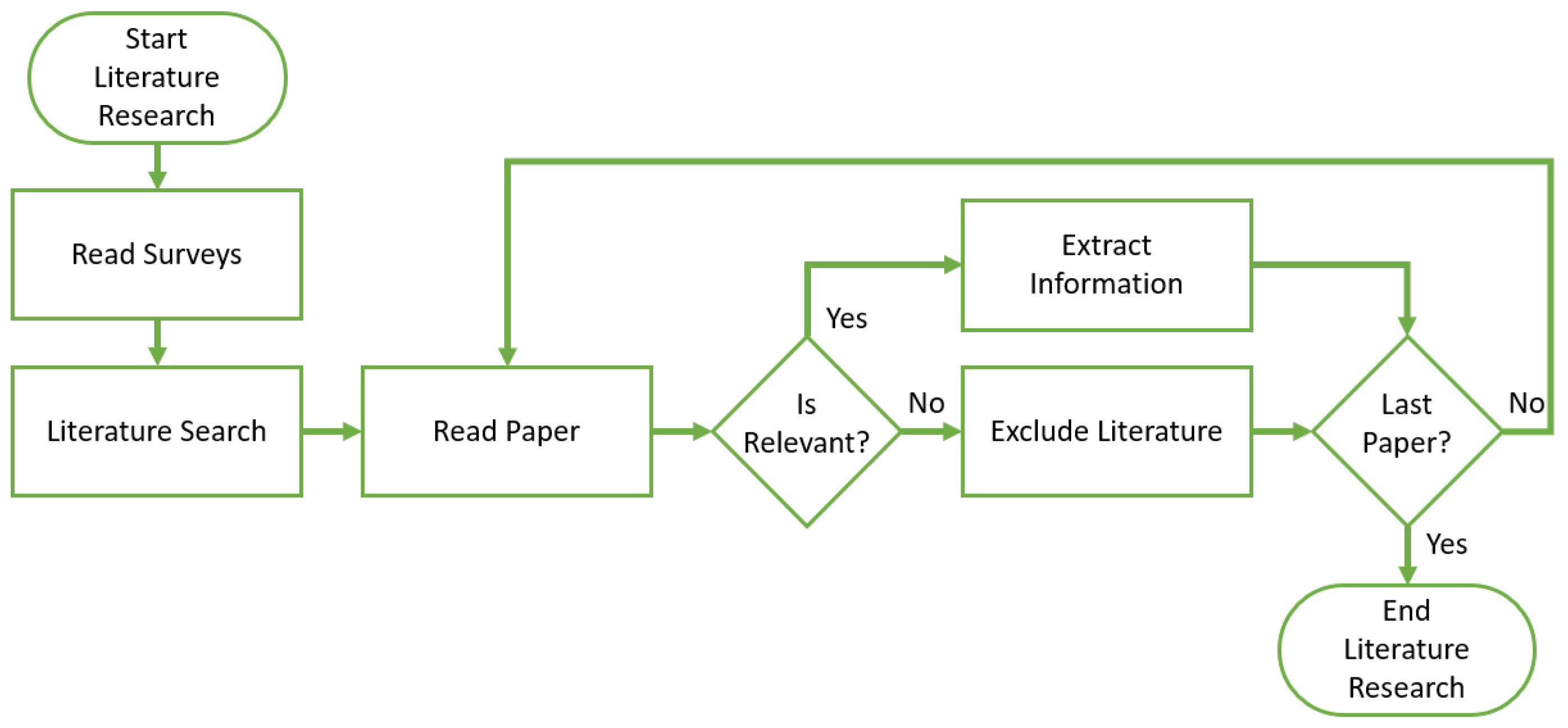
2. Methodology of Literature Research
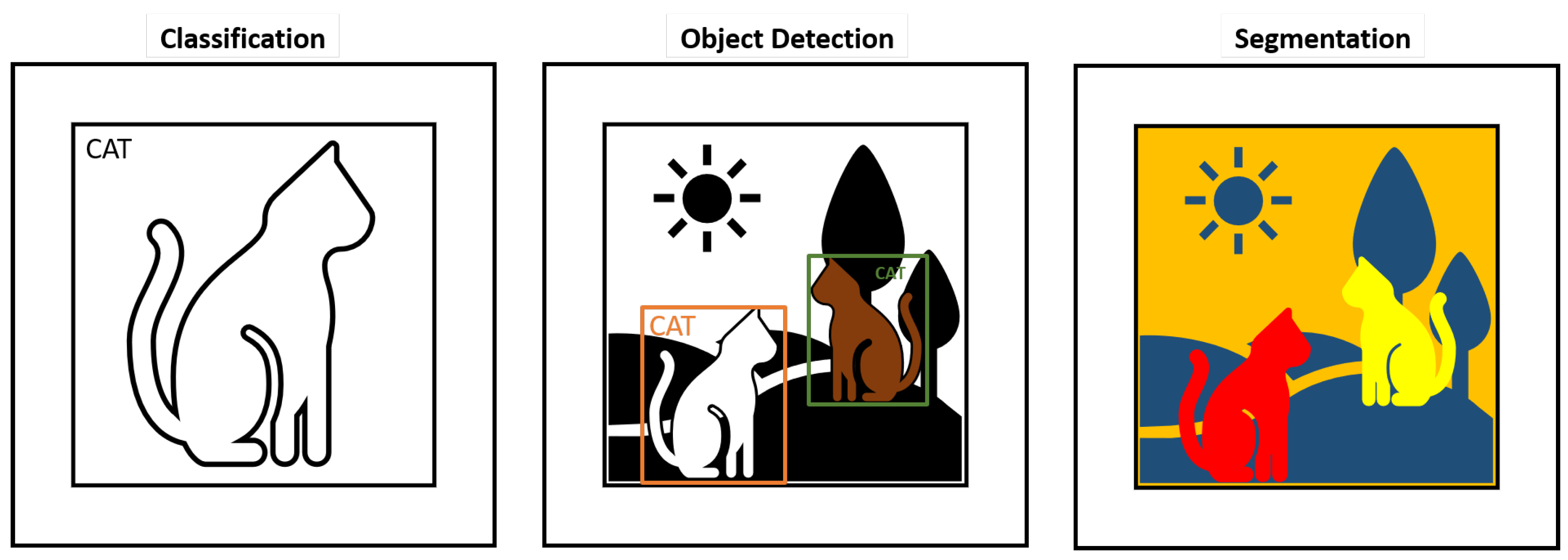
3. Categorization of Visual Inspection (Tasks)
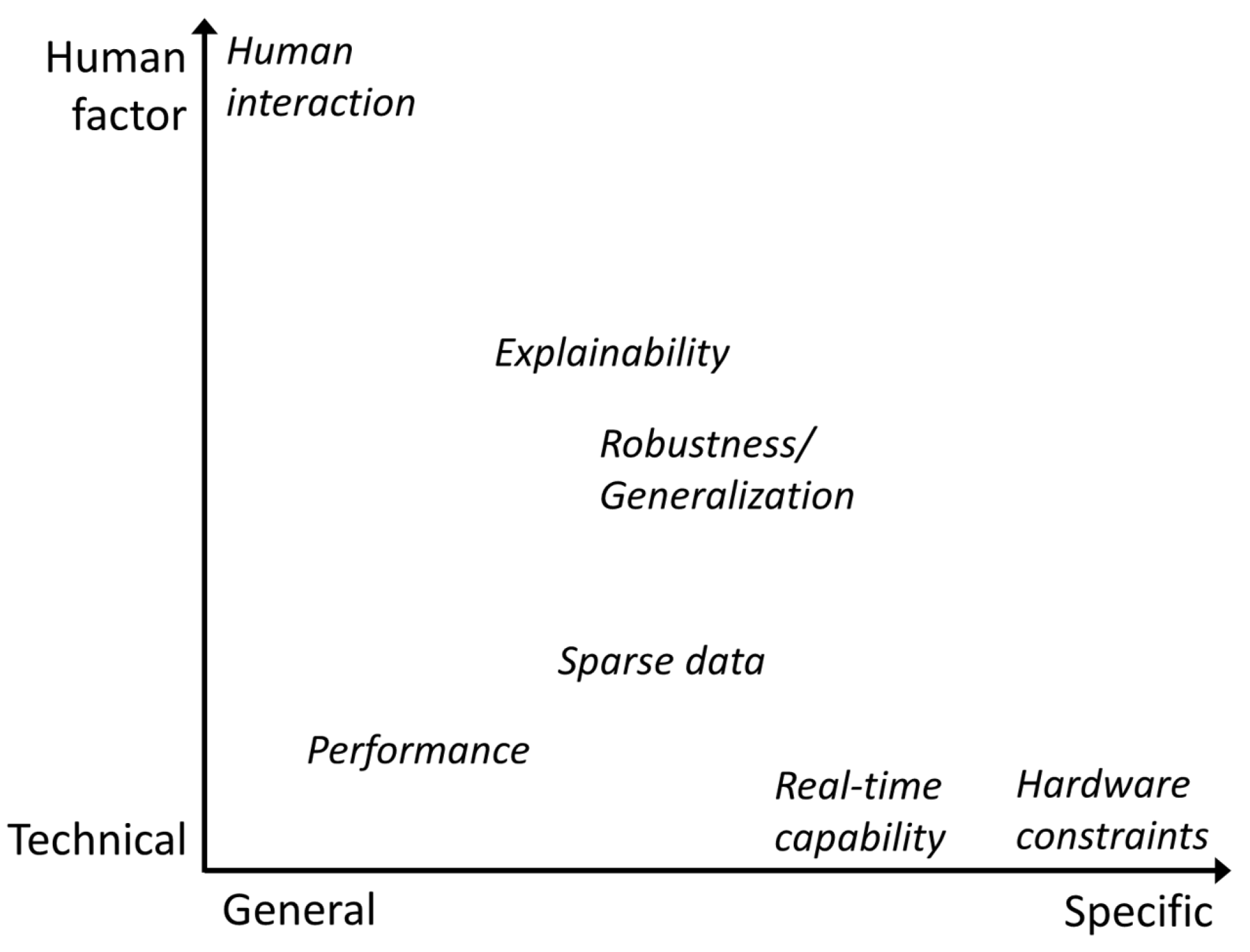
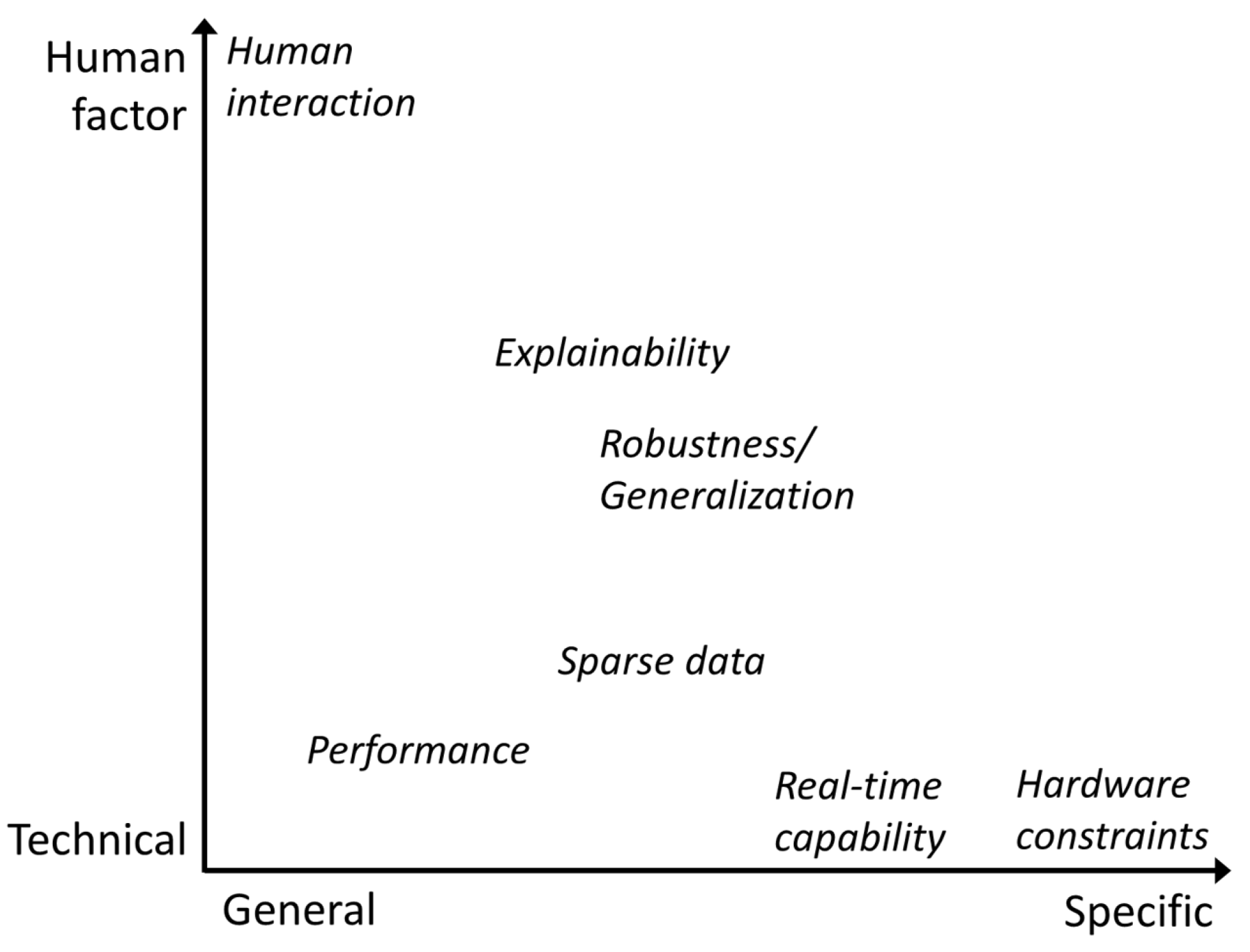
3.1. Requirements for Deep-Learning Models in AVI
3.2. Overview of Visual Inspection Use Cases
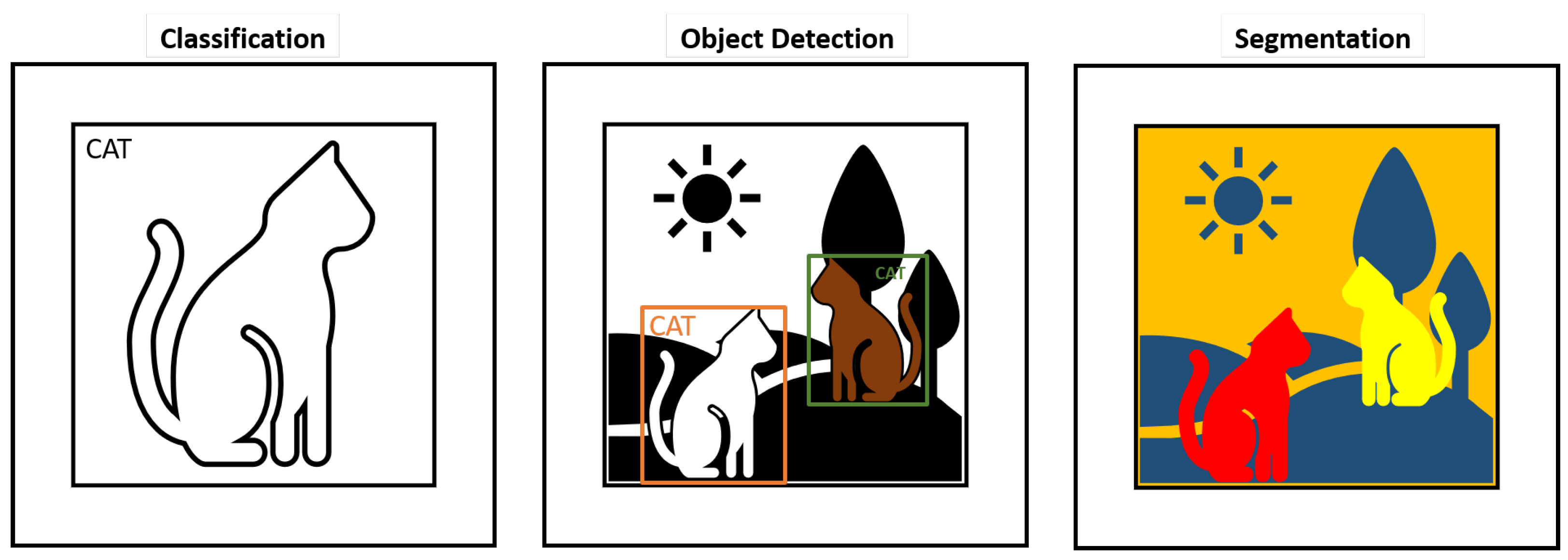
3.3. Overview on How to Solve Automated Visual Inspection with Deep-Learning Models
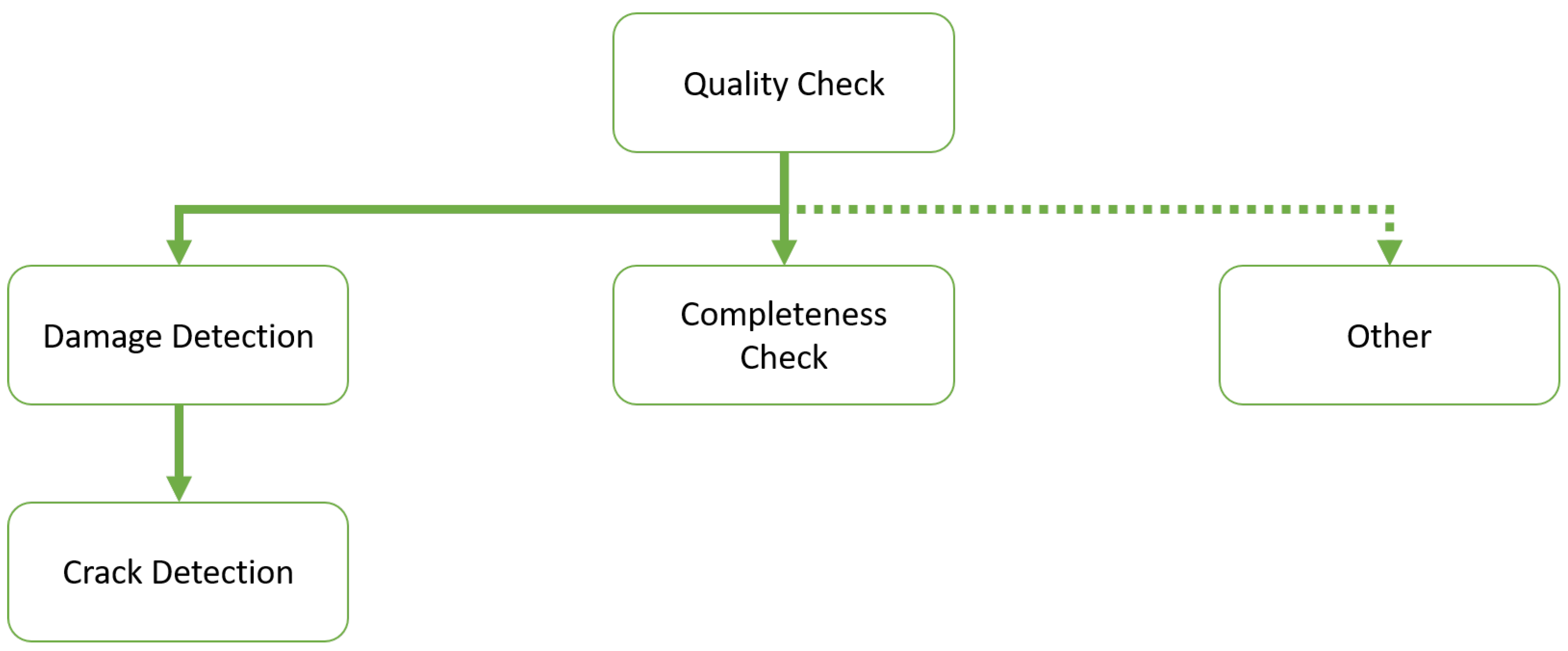
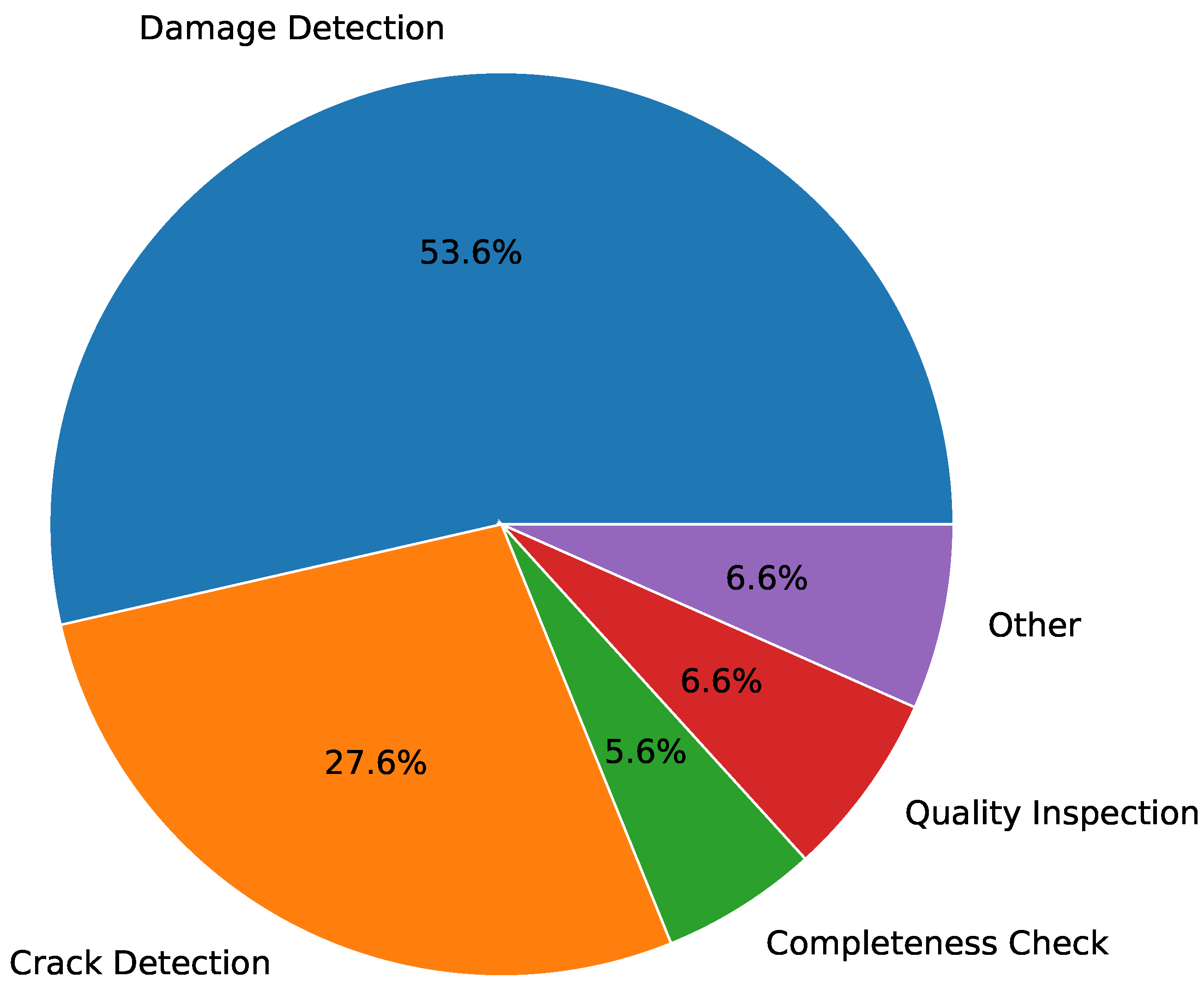
3.3.1. Visual Inspection via Binary Classification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VI Use Case | Model | Count | References |
|---|---|---|---|
| Crack Detection | AlexNet | 1 | [71] |
| CNN | 4 | [72,73,74,75] | |
| VGG | 1 | [76] | |
| ViT | 1 | [70] | |
| Damage Detection | AlexNet | 1 | [77] |
| CNN | 1 | [78] | |
| DenseNet | 3 | [38,69,79] | |
| Ensemble | 1 | [80] | |
| MLP | 1 | [81] | |
| ResNet | 1 | [50] | |
| SVM | 1 | [82] | |
| Xception | 1 | [46] | |
| Quality Inspection | AlexNet | 1 | [83] |
| MLP | 1 | [84] | |
| Other | MLP | 1 | [64] |
| Completeness Check | CNN | 1 | [63] |
3.3.2. Visual Inspection via Multi-Class Classification
3.3.3. Visual Inspection via Localization
3.3.4. Visual Inspection via Multi-Class Localization
4. Analysis and Discussion
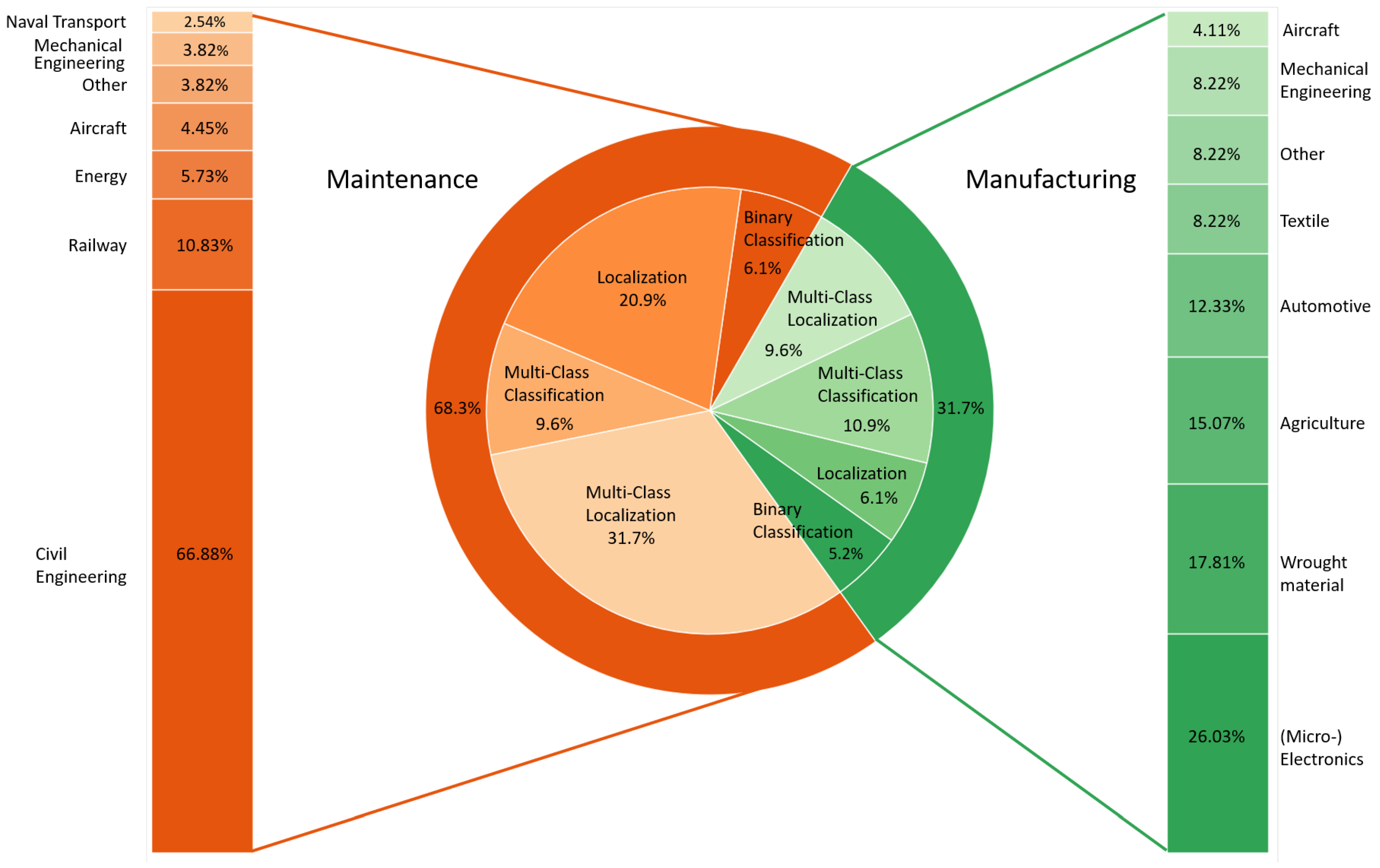
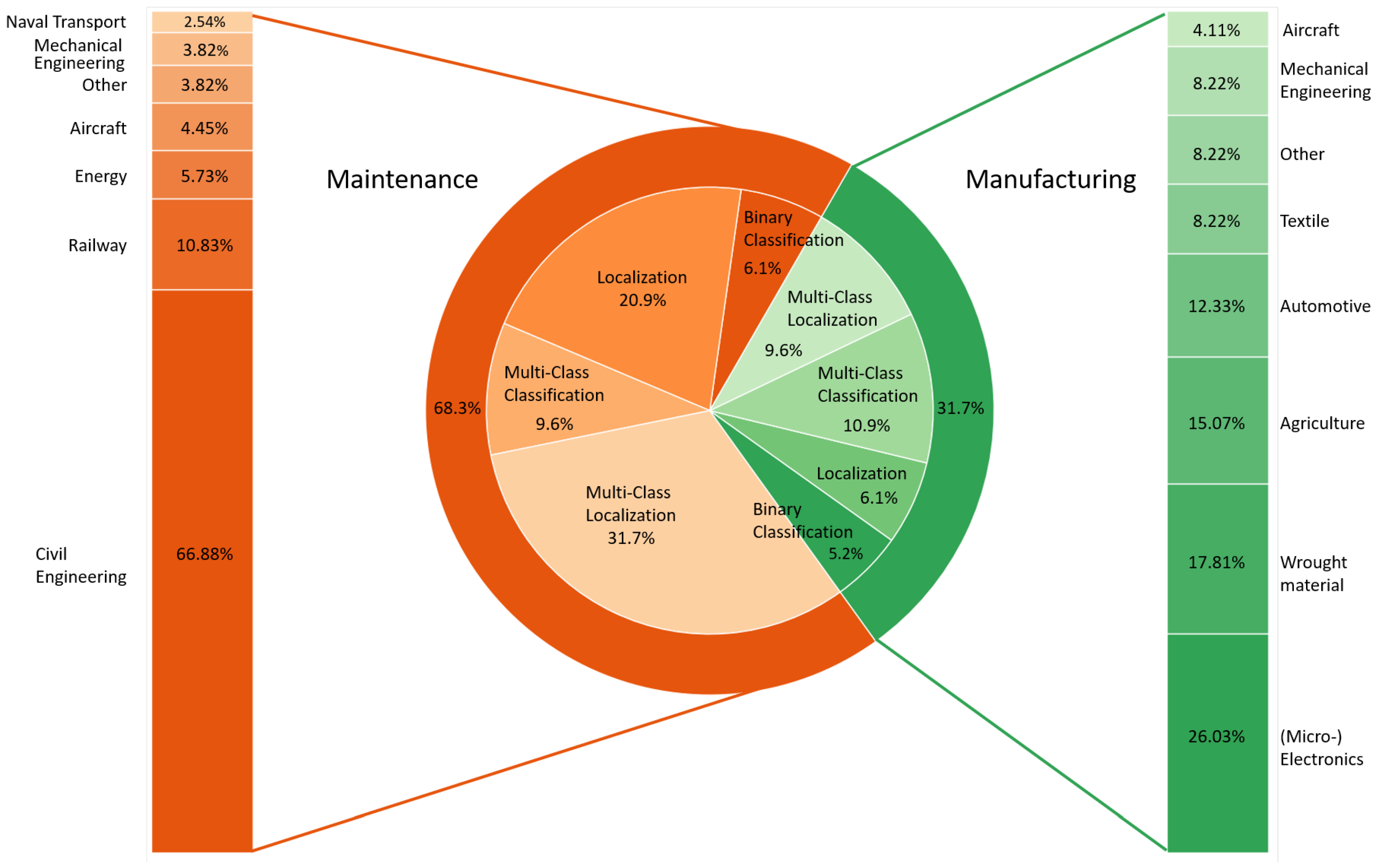
4.1. Inspection Context and Industrial Sectors
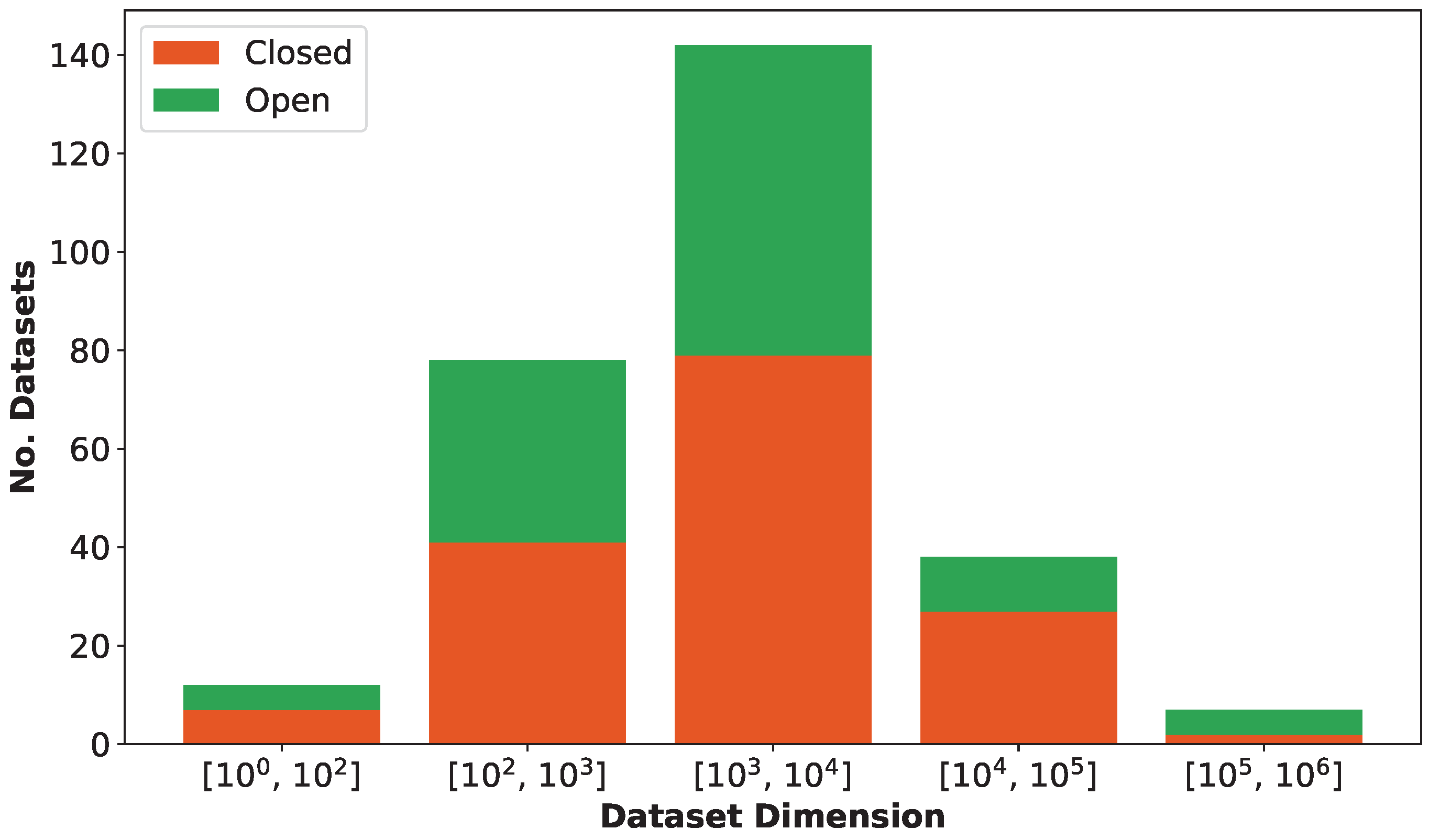
4.2. Datasets and Learning Paradigms
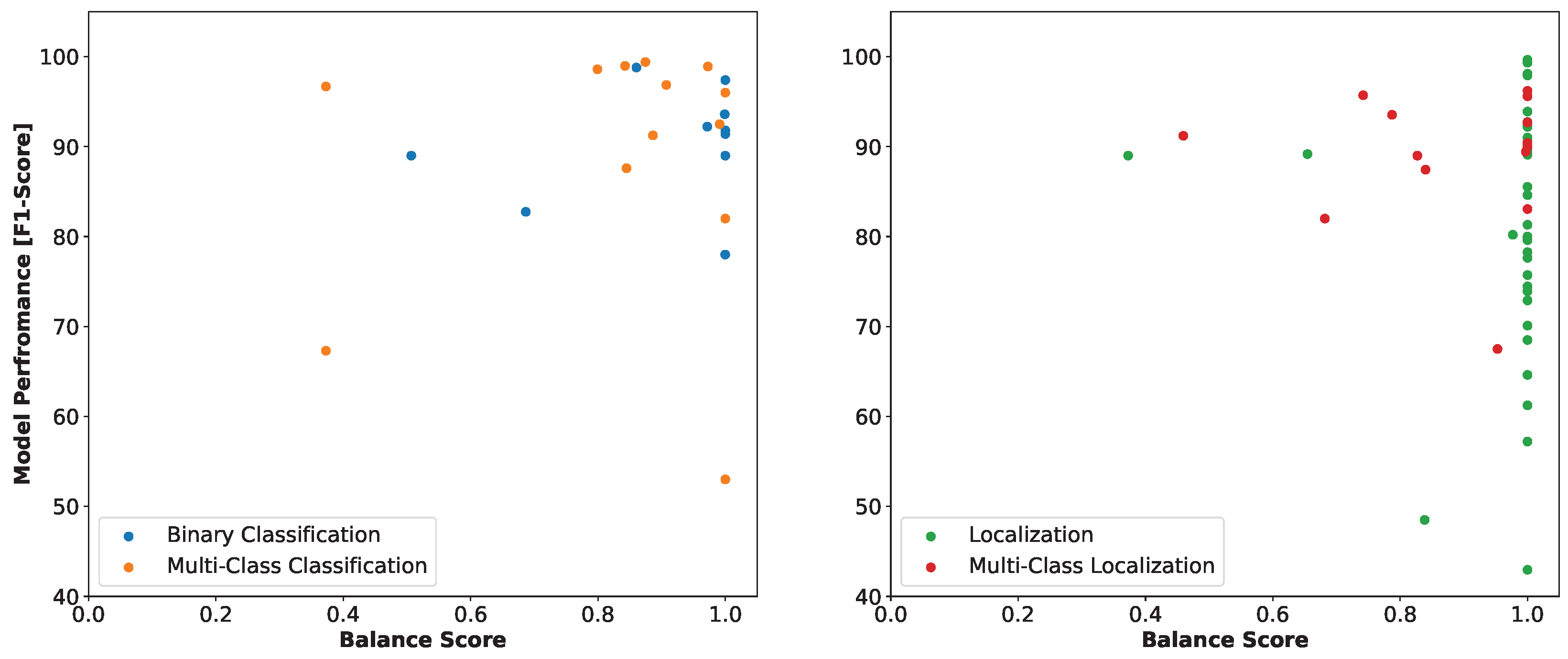
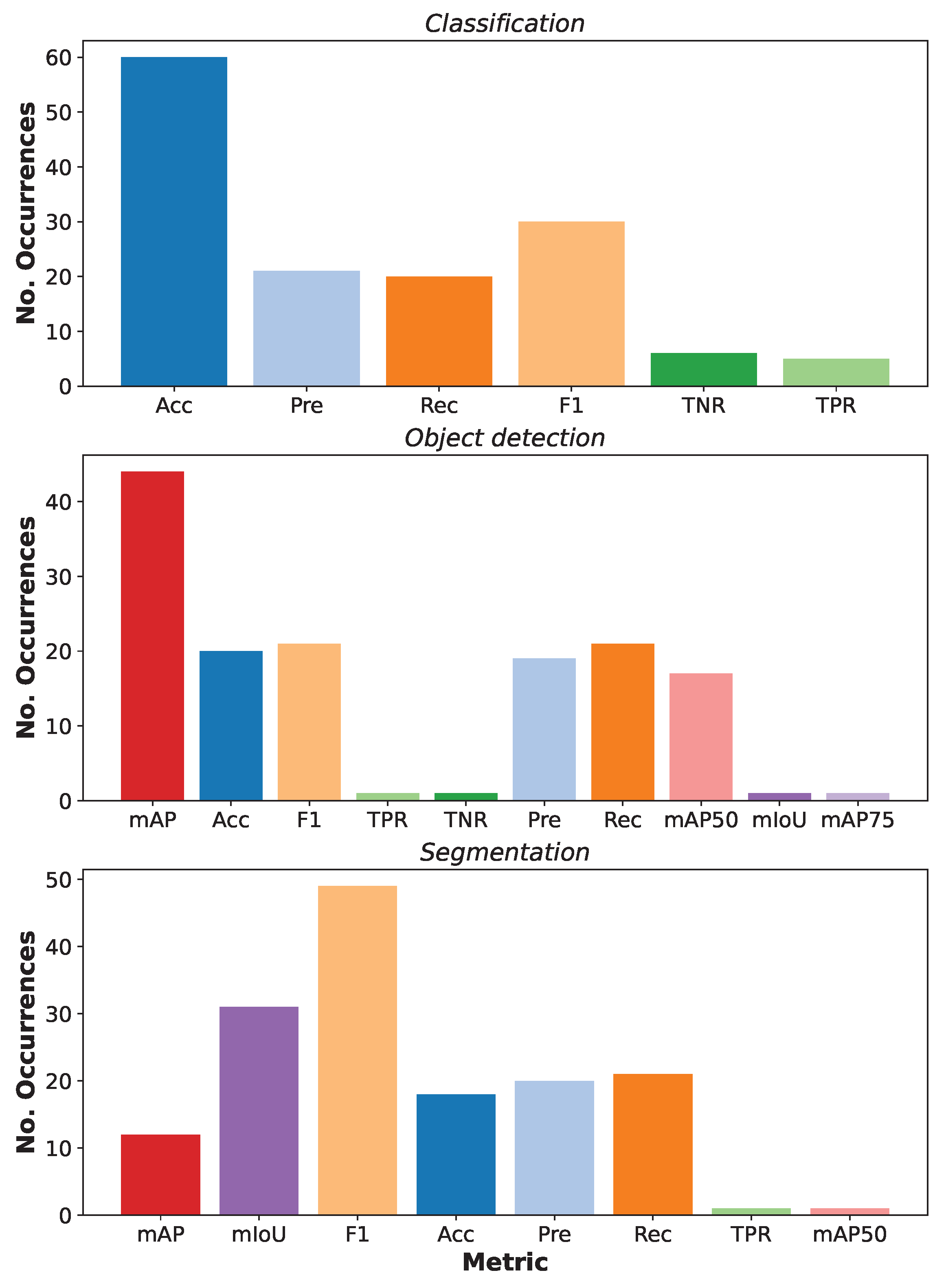
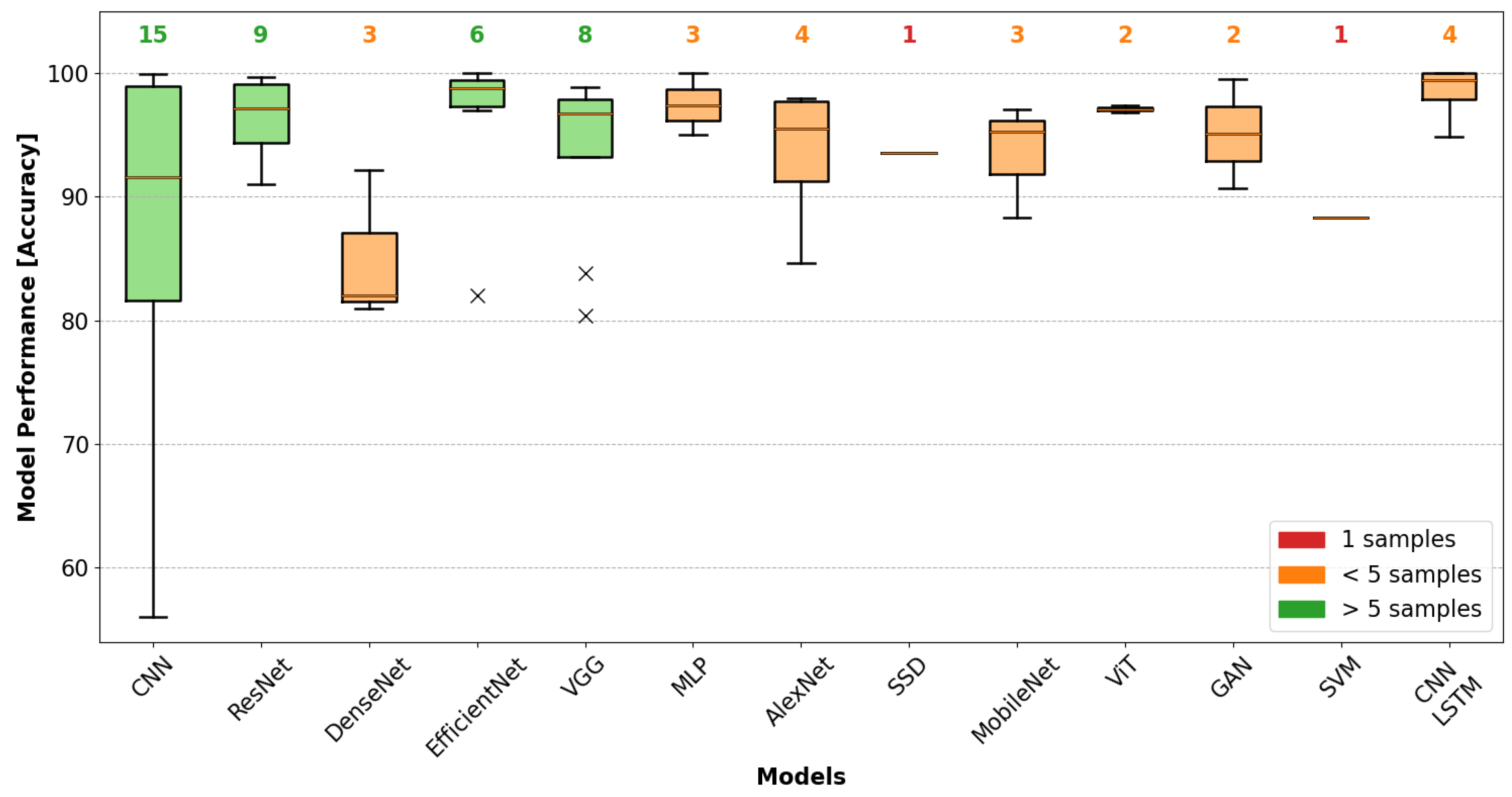
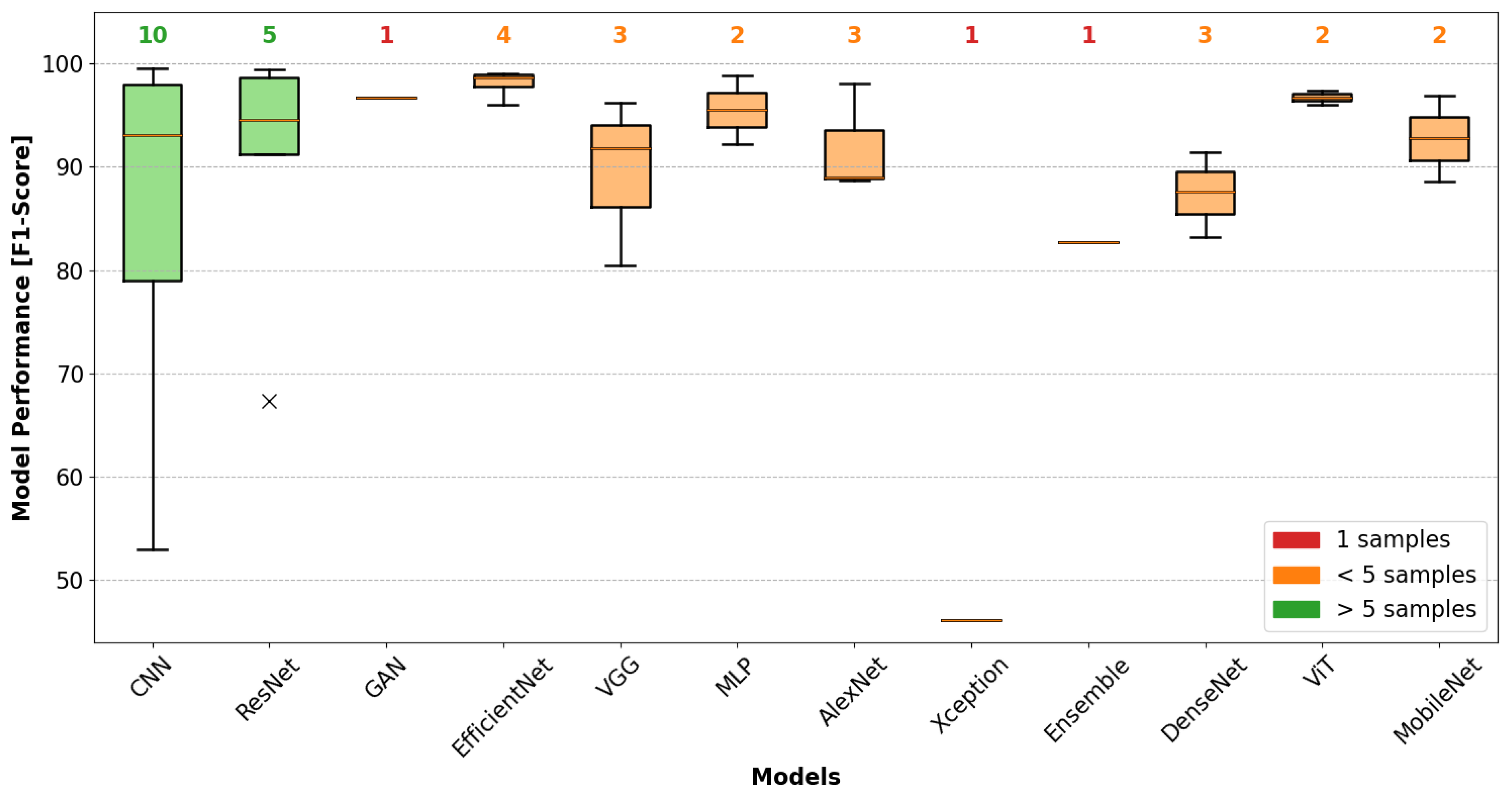
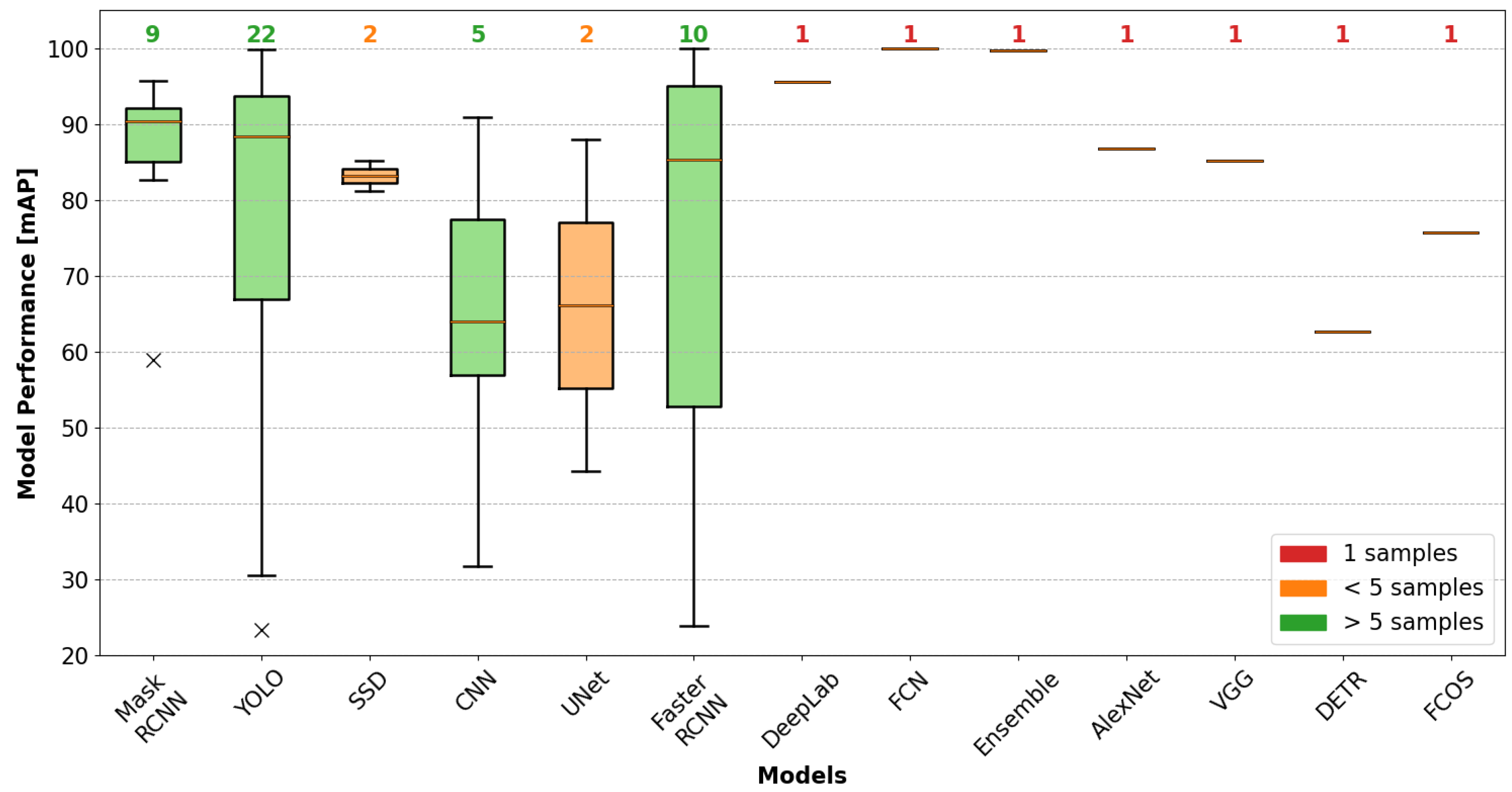
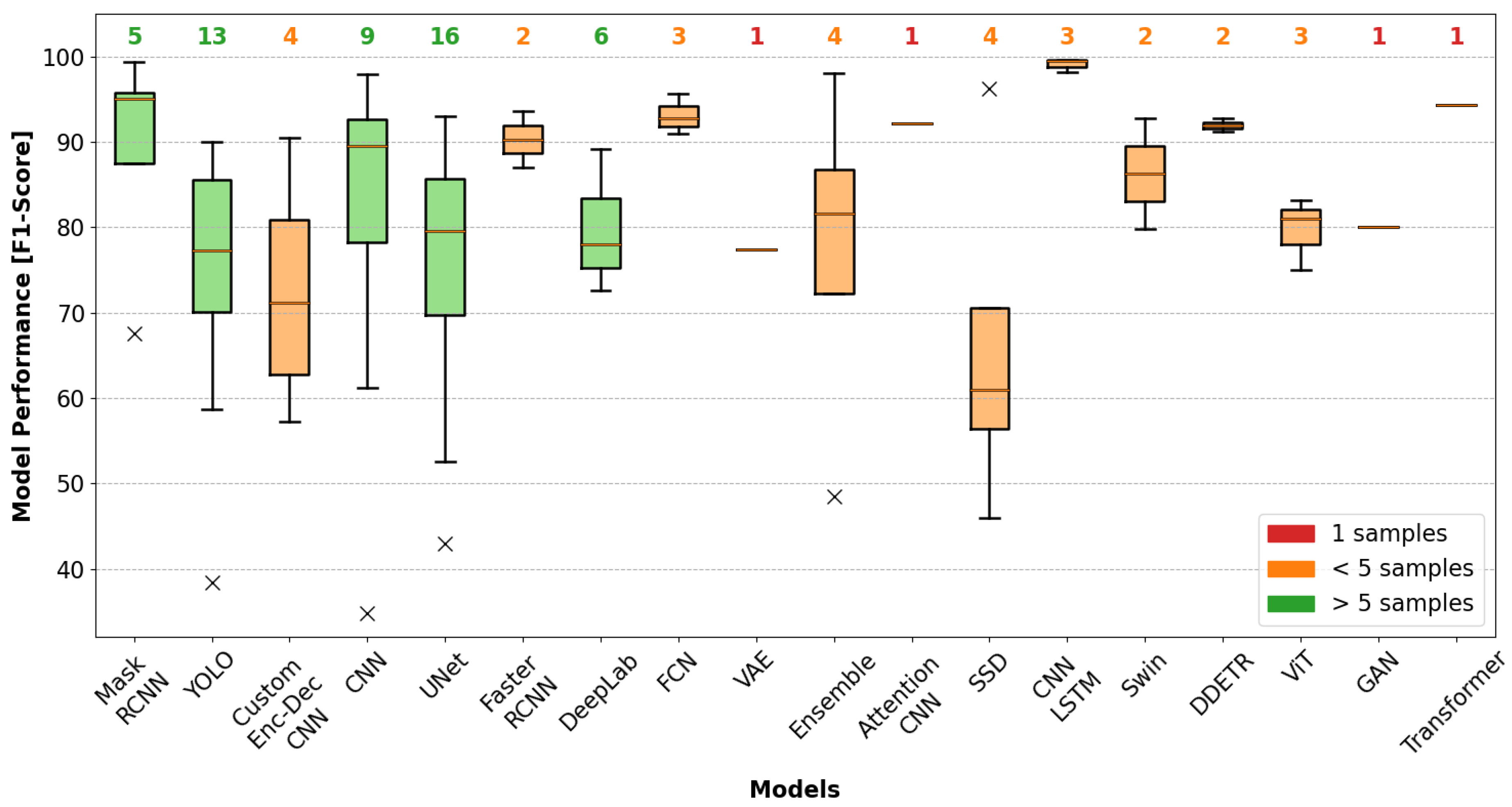
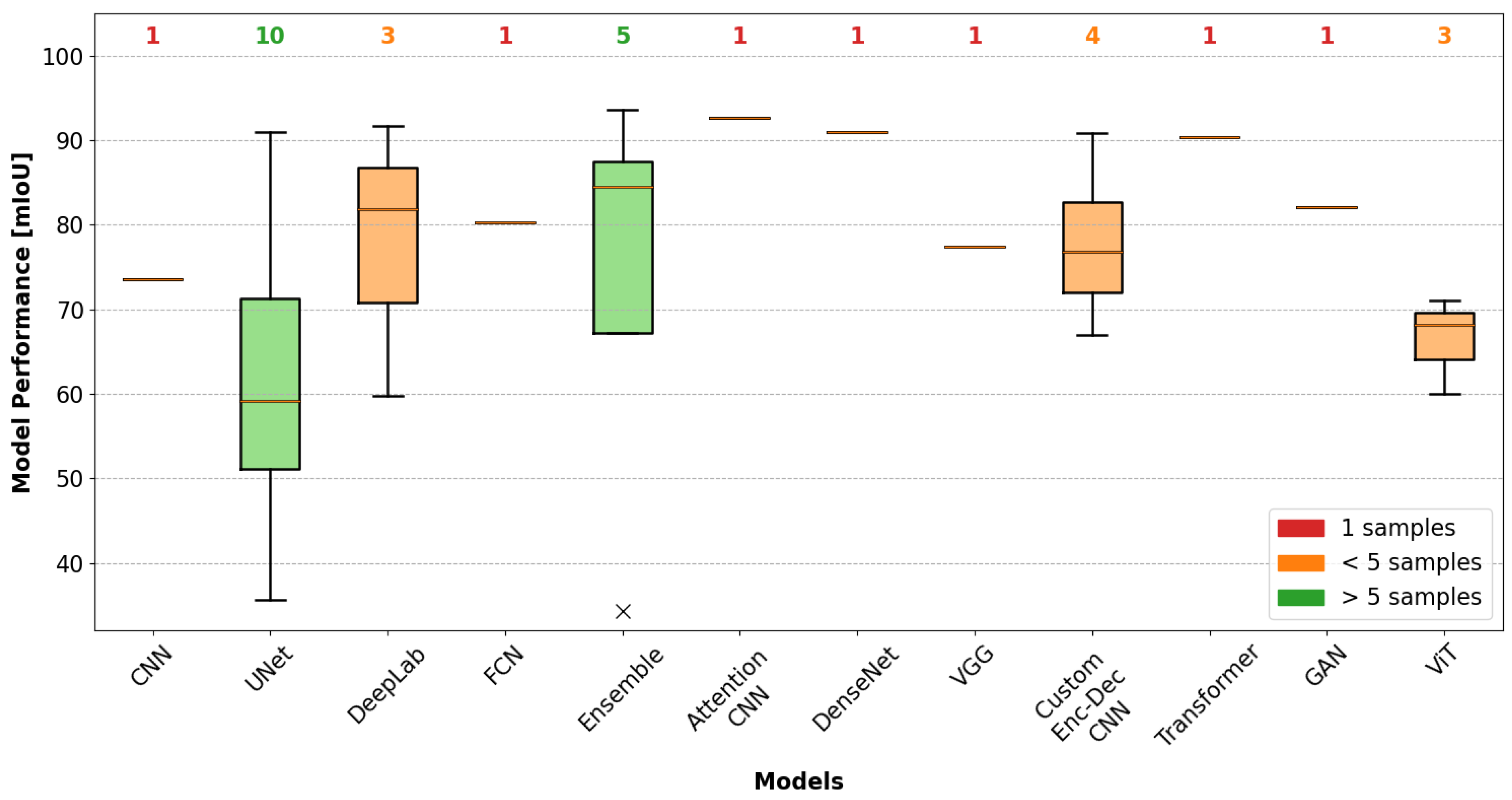
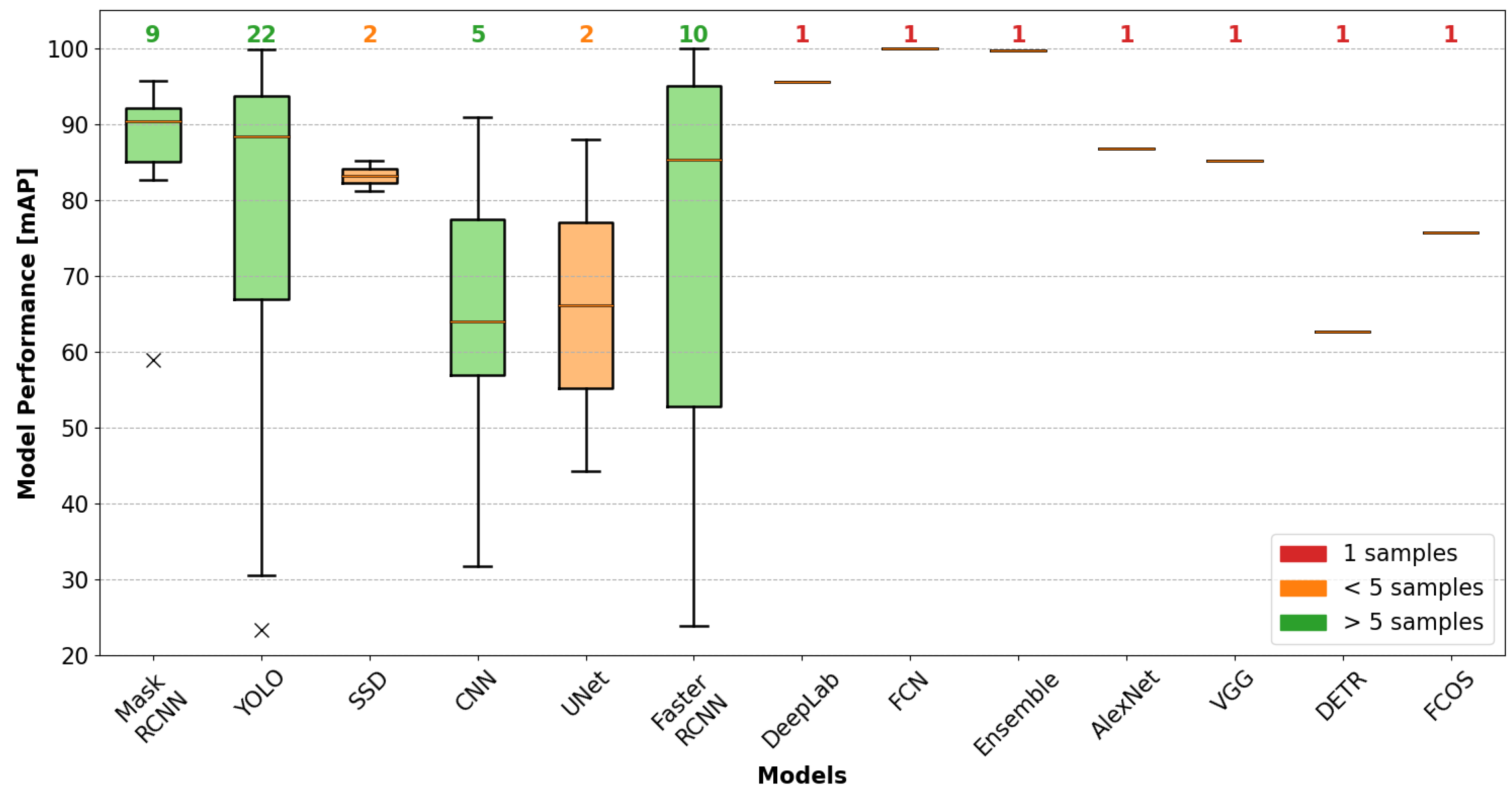
4.3. Performance Evaluation by AVI Task
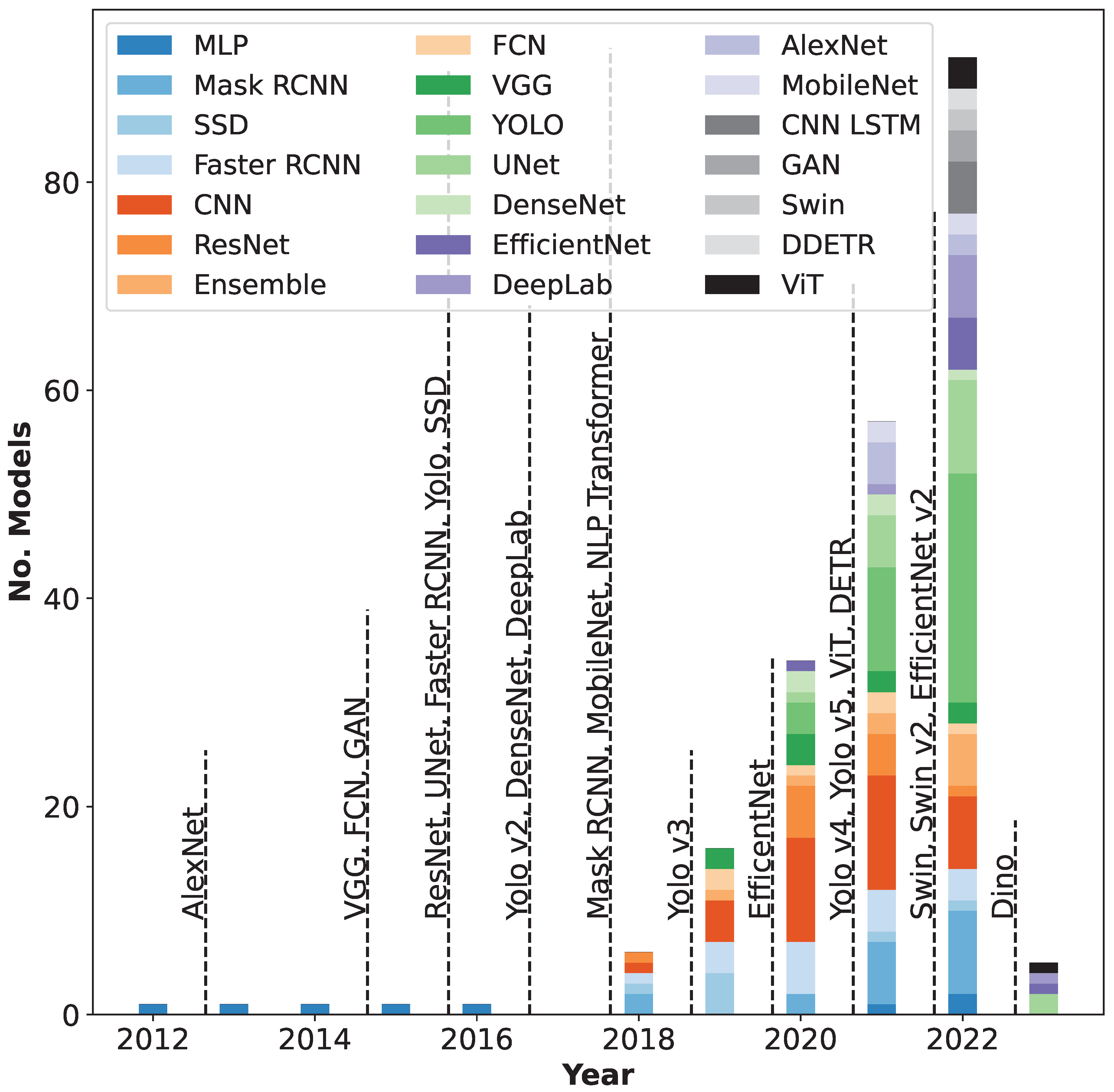
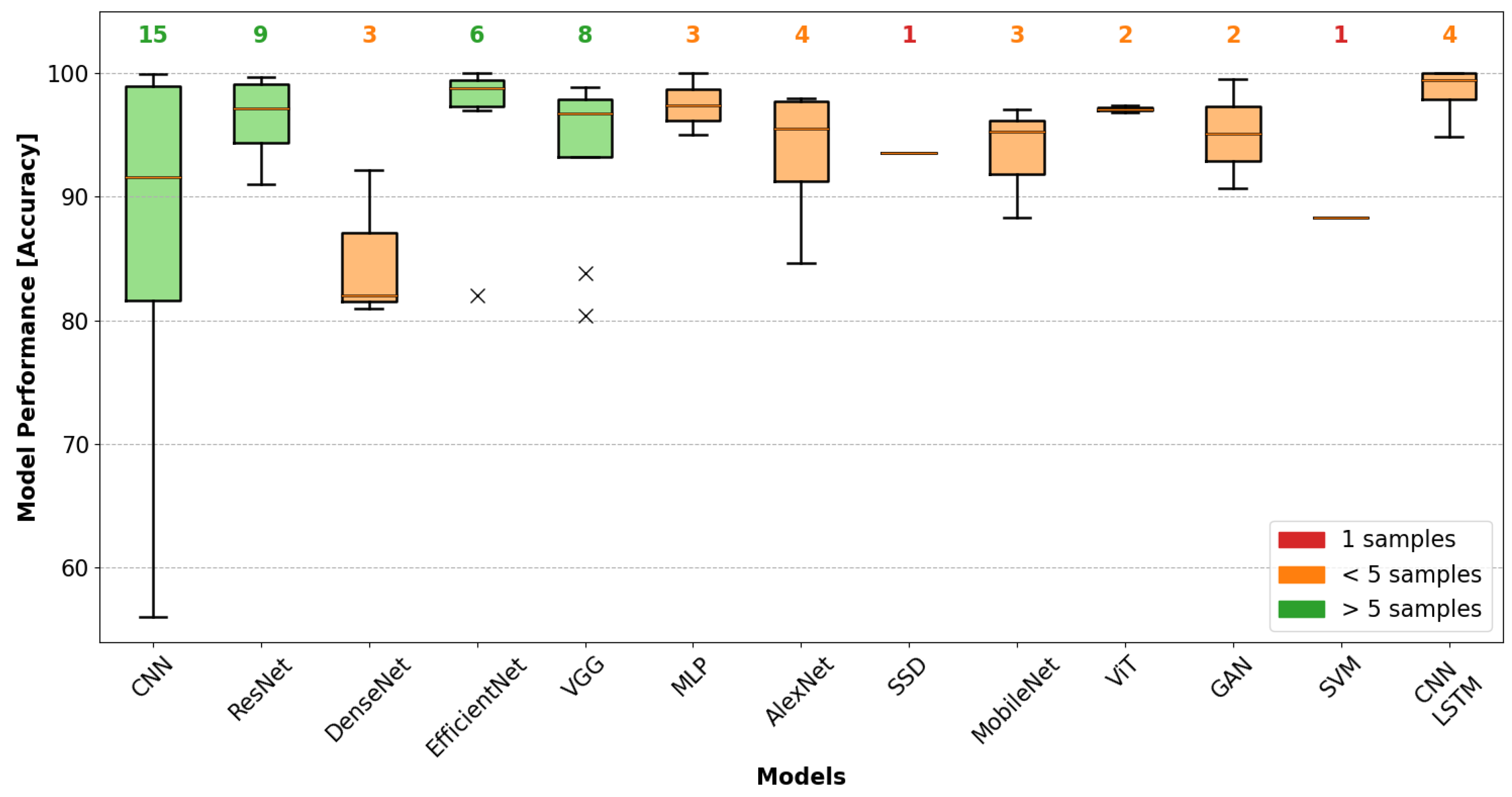
4.4. Comparison with Academic Development in Deep Learning Computer Vision Models
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AVI | Automated visual inspection |
| DL | Deep learning |
| CNN | Convolutional neural network |
| MS COCO | Microsoft common objects in context (object detection) dataset |
| CV | Computer vision |
| DETR | Detection transformer [267] |
| DDETR | Deformable detection transformer [290] |
| FCN | Fully convolutional neural network (semantic segmentation model) [251] |
| FCOS | Fully convolutional one-stage object detection (model) [284] |
| FLOPS | Floating-point operations per second |
| FN(R) | False-negative rate |
| FP(R) | False-positive rate |
| FPS | Frames per second |
| GAN | Generative adversarial network |
| ILSVRC 2012/ImageNet | ImageNet Large Scale Visual Recognition Challenge 2012 |
| LiDAR | Light detection and ranging, 3D laser scanning method |
| LSTM | Long short-term memory cell (recurrent neural network variant) |
| mAP | Mean average precision (common object detection performance metric) |
| MIM | Masked image modeling |
| MLP | Multi-layer perceptron (network) |
| NLP | Natural language processing |
| Pascal VOC | Pascal visual object classes (object detection dataset) |
| ResNet | Residual Network [67] |
| RCNN | Regional convolutional neural network [253] |
| SOTA | State of the art |
| SSD | Single-shot detector [252] |
| SVM | Support vector machine |
| Swin | Shifted windows transformer [266] |
| TN(R) | True-negative rate |
| TP(R) | True-positive rate |
| VI | Visual inspection |
| ViT | Specific architecture of a vision transformer model published in [265] |
| VGG | Visual geometry group (model) [250] |
| WoS | Web of Science |
| YOLO | You only look once (object detection model) [68] |
Appendix A
| Web of Science Category | Exc. | Web of Science Category | Exc. |
|---|---|---|---|
| Engineering Electrical Electronic | Food Science Technology | ||
| Instruments Instrumentation | Mathematics Applied | ||
| Computer Science Information Systems | Medical Informatics | x | |
| Engineering Multidisciplinary | Nanoscience Nanotechnology | ||
| Materials Science Multidisciplinary | Nuclear Science Technology | x | |
| Chemistry Analytical | Oceanography | x | |
| Telecommunications | Operations Research Management Science | x | |
| Physics Applied | Psychology Experimental | x | |
| Engineering Civil | Thermodynamics | x | |
| Chemistry Multidisciplinary | Agricultural Engineering | ||
| Imaging Science Photographic Technology | Agriculture Dairy Animal Science | x | |
| Remote Sensing | x | Audiology Speech Language Pathology | x |
| Environmental Sciences | Behavioral Sciences | x | |
| Computer Science Interdisciplinary Applications | Biochemistry Molecular Biology | x | |
| Geosciences Multidisciplinary | x | Ecology | x |
| Construction Building Technology | Engineering Industrial | ||
| Engineering Mechanical | Health Care Sciences Services | x | |
| Multidisciplinary Sciences | Materials Science Textiles | ||
| Radiology Nuclear Medicine Medical Imaging | x | Medicine Research Experimental | x |
| Engineering Biomedical | x | Pathology | x |
| Astronomy Astrophysics | x | Physics Mathematical | x |
| Computer Science Artificial Intelligence | Physics Multidisciplinary | ||
| Mechanics | Physics Particles Fields | x | |
| Transportation Science Technology | Physiology | x | |
| Neurosciences | x | Quantum Science Technology | x |
| Energy Fuels | Respiratory System | x | |
| Acoustics | x | Robotics | |
| Oncology | x | Surgery | x |
| Engineering Manufacturing | Architecture | ||
| Mathematical Computational Biology | x | Chemistry Medicinal | x |
| Mathematics Interdisciplinary Applications | Dentistry Oral Surgery Medicine | x | |
| Metallurgy Metallurgical Engineering | Dermatology | x | |
| Optics | x | Developmental Biology | x |
| Green Sustainable Science Technology | Engineering Environmental | ||
| Biochemical Research Methods | x | Fisheries | x |
| Computer Science Software Engineering | Forestry | x | |
| Automation Control Systems | Gastroenterology Hepatology | x | |
| Computer Science Theory Methods | x | Genetics Heredity | x |
| Computer Science Hardware Architecture | x | Geriatrics Gerontology | x |
| Geography Physical | x | Immunology | x |
| Agriculture Multidisciplinary | Infectious Diseases | x | |
| Chemistry Physical | x | Marine Freshwater Biology | x |
| Engineering Aerospace | Materials Science Biomaterials | ||
| Environmental Studies | x | Medical Laboratory Technology | x |
| Materials Science Composites | Obstetrics Gynecology | x | |
| Medicine General Internal | x | Otorhinolaryngology | x |
| Physics Condensed Matter | x | Paleontology | x |
| Rehabilitation | x | Parasitology | x |
| Biotechnology Applied Microbiology | x | Peripheral Vascular Disease | x |
| Clinical Neurology | x | Pharmacology Pharmacy | x |
| Engineering Ocean | Physics Fluids Plasmas | x | |
| Materials Science Characterization Testing | Physics Nuclear | x | |
| Meteorology Atmospheric Sciences | x | Plant Sciences | x |
| Water Resources | x | Psychiatry | x |
| Geochemistry Geophysics | x | Public Environmental Occupational Health | x |
| Mathematics | Sport Sciences | x | |
| Neuroimaging | x | Transportation | |
| Agronomy | Tropical Medicine | x | |
| Cell Biology | x | Veterinary Sciences | x |
| Engineering Marine |
References
- Drury, C.G.; Watson, J. Good practices in visual inspection. In Human Factors in Aviation Maintenance-Phase Nine, Progress Report, FAA/Human Factors in Aviation Maintenance; 2002. [Google Scholar]
- Steger, C.; Ulrich, M.; Wiedemann, C. Machine Vision Algorithms and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Sheehan, J.J.; Drury, C.G. The analysis of industrial inspection. Appl. Ergon. 1971, 2, 74–78. [Google Scholar] [CrossRef] [PubMed]
- Chiang, H.Q.; Hwang, S.L. Human performance in visual inspection and defect diagnosis tasks: A case study. Int. J. Ind. Ergon. 1988, 2, 235–241. [Google Scholar] [CrossRef]
- Swain, A.D.; Guttmann, H.E. Handbook of Human-Reliability Analysis with Emphasis on Nuclear Power Plant Applications, Final Report; Sandia National Lab.: Albuquerque, NM, USA, 1983. [CrossRef]
- Drury, C.; Fox, J. The imperfect inspector. Human Reliability in Quality Control; Taylor & Francis: London, UK, 1975; pp. 11–16. [Google Scholar]
- Jiang, X.; Gramopadhye, A.K.; Melloy, B.J.; Grimes, L.W. Evaluation of best system performance: Human, automated, and hybrid inspection systems. Hum. Factors Ergon. Manuf. Serv. Ind. 2003, 13, 137–152. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Vom Brocke, J.; Simons, A.; Riemer, K.; Niehaves, B.; Plattfaut, R.; Cleven, A. Standing on the shoulders of giants: Challenges and recommendations of literature search in information systems research. Commun. Assoc. Inf. Syst. 2015, 37, 9. [Google Scholar] [CrossRef]
- Zheng, X.; Zheng, S.; Kong, Y.; Chen, J. Recent advances in surface defect inspection of industrial products using deep learning techniques. Int. J. Adv. Manuf. Technol. 2021, 113, 35–58. [Google Scholar] [CrossRef]
- Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar]
- Sun, X.; Gu, J.; Tang, S.; Li, J. Research progress of visual inspection technology of steel products—A review. Appl. Sci. 2018, 8, 2195. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using deep learning to detect defects in manufacturing: A comprehensive survey and current challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef] [PubMed]
- Nash, W.; Drummond, T.; Birbilis, N. A review of deep learning in the study of materials degradation. NPJ Mater. Degrad. 2018, 2, 1–12. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Q.; Luo, Y. A review of applications of visual inspection technology based on image processing in the railway industry. Transp. Saf. Environ. 2019, 1, 185–204. [Google Scholar] [CrossRef]
- De Donato, L.; Flammini, F.; Marrone, S.; Mazzariello, C.; Nardone, R.; Sansone, C.; Vittorini, V. A Survey on Audio-Video Based Defect Detection Through Deep Learning in Railway Maintenance. IEEE Access 2022, 10, 65376–65400. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Khan, W.; Serhani, M.A.; Al Jassmi, H. Bibliometric Analysis and Review of Deep Learning-Based Crack Detection Literature Published between 2010 and 2022. Buildings 2022, 12, 432. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Abu Talip, M.S.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2022, 133, 103989. [Google Scholar] [CrossRef]
- Hamishebahar, Y.; Guan, H.; So, S.; Jo, J. A Comprehensive Review of Deep Learning-Based Crack Detection Approaches. Appl.-Sci.-Basel 2022, 12, 1374. [Google Scholar] [CrossRef]
- Omar, I.; Khan, M.; Starr, A. Compatibility and challenges in machine learning approach for structural crack assessment. Struct. Health Monit. Int. J. 2022, 21, 2481–2502. [Google Scholar] [CrossRef]
- Chu, C.; Wang, L.; Xiong, H. A review on pavement distress and structural defects detection and quantification technologies using imaging approaches. J. Traffic Transp.-Eng.-Engl. Ed. 2022, 9, 135–150. [Google Scholar] [CrossRef]
- Qureshi, W.S.; Hassan, S.I.; McKeever, S.; Power, D.; Mulry, B.; Feighan, K.; O’Sullivan, D. An Exploration of Recent Intelligent Image Analysis Techniques for Visual Pavement Surface Condition Assessment. Sensors 2022, 22, 9019. [Google Scholar] [CrossRef]
- Ranyal, E.; Sadhu, A.; Jain, K. Road Condition Monitoring Using Smart Sensing and Artificial Intelligence: A Review. Sensors 2022, 22, 3044. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.M.; Kim, Y.G.; Son, S.Y.; Lim, S.Y.; Choi, B.Y.; Choi, D.H. Review of Recent Automated Pothole-Detection Methods. Appl. Sci. 2022, 12, 5320. [Google Scholar] [CrossRef]
- Zhou, H.; Xu, C.; Tang, X.; Wang, S.; Zhang, Z. A Review of Vision-Laser-Based Civil Infrastructure Inspection and Monitoring. Sensors 2022, 22, 5882. [Google Scholar] [CrossRef] [PubMed]
- Hassani, S.; Mousavi, M.; Gandomi, A.H. Structural Health Monitoring in Composite Structures: A Comprehensive Review. Sensors 2022, 22, 153. [Google Scholar] [CrossRef] [PubMed]
- Chew, M.Y.L.; Gan, V.J.L. Long-Standing Themes and Future Prospects for the Inspection and Maintenance of Facade Falling Objects from Tall Buildings. Sensors 2022, 22, 6070. [Google Scholar] [CrossRef] [PubMed]
- Luleci, F.; Catbas, F.N.; Avci, O. A literature review: Generative adversarial networks for civil structural health monitoring. Front. Built Environ. 2022, 8. [Google Scholar] [CrossRef]
- Mera, C.; Branch, J.W. A survey on class imbalance learning on automatic visual inspection. IEEE Lat. Am. Trans. 2014, 12, 657–667. [Google Scholar] [CrossRef]
- Tao, X.; Gong, X.; Zhang, X.; Yan, S.; Adak, C. Deep Learning for Unsupervised Anomaly Localization in Industrial Images: A Survey. IEEE Trans. Instrum. Meas. 2022, 71, 5018021. [Google Scholar] [CrossRef]
- Rippel, O.; Merhof, D. Anomaly Detection for Automated Visual Inspection: A Review. In Bildverarbeitung in der Automation: Ausgewählte Beiträge des Jahreskolloquiums BVAu 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–13. [Google Scholar]
- Newman, T.S.; Jain, A.K. A survey of automated visual inspection. Comput. Vis. Image Underst. 1995, 61, 231–262. [Google Scholar] [CrossRef]
- Li, K.; Rollins, J.; Yan, E. Web of Science use in published research and review papers 1997–2017: A selective, dynamic, cross-domain, content-based analysis. Scientometrics 2018, 115, 1–20. [Google Scholar] [CrossRef]
- Chin, R.T. Automated visual inspection: 1981 to 1987. Comput. Vision Graph. Image Process. 1988, 41, 346–381. [Google Scholar] [CrossRef]
- See, J.E.; Drury, C.G.; Speed, A.; Williams, A.; Khalandi, N. The Role of Visual Inspection in the 21 st Century. In Foundations of Augmented Cognition; Schmorrow, D.D., Fidopiastis, C.M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 61, pp. 262–266. [Google Scholar] [CrossRef]
- Brandoli, B.; de Geus, A.R.; Souza, J.R.; Spadon, G.; Soares, A.; Rodrigues, J.F., Jr.; Komorowski, J.; Matwin, S. Aircraft Fuselage Corrosion Detection Using Artificial Intelligence. Sensors 2021, 21, 4026. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Gao, J.; Zeng, Q.; Sun, Y. Multitype Damage Detection of Container Using CNN Based on Transfer Learning. Math. Probl. Eng. 2021, 2021, 5395494. [Google Scholar] [CrossRef]
- Chen, Y.W.; Shiu, J.M. An implementation of YOLO-family algorithms in classifying the product quality for the acrylonitrile butadiene styrene metallization. Int. J. Adv. Manuf. Technol. 2022, 119, 8257–8269. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, Y.; Zhou, M.; Jiang, K.; Shi, H.; Yu, Y.; Hao, N. Application of Lightweight Convolutional Neural Network for Damage Detection of Conveyor Belt. Appl. Sci. 2021, 11, 7282. [Google Scholar] [CrossRef]
- Wei, X.; Wei, D.; Da, S.; Jia, L.; Li, Y. Multi-Target Defect Identification for Railway Track Line Based on Image Processing and Improved YOLOv3 Model. IEEE Access 2020, 8, 61973–61988. [Google Scholar] [CrossRef]
- Kin, N.W.; Asaari, M.S.M.; Rosdi, B.A.; Akbar, M.F. Fpga Implementation of CNN for Defect Classification on CMP Ring. J. Teknol.-Sci. Eng. 2021, 83, 101–108. [Google Scholar] [CrossRef]
- Smith, A.G.; Petersen, J.; Selvan, R.; Rasmussen, C.R. Segmentation of roots in soil with U-Net. Plant Methods 2020, 16, 1. [Google Scholar] [CrossRef]
- Kuric, I.; Klarak, J.; Bulej, V.; Saga, M.; Kandera, M.; Hajducik, A.; Tucki, K. Approach to Automated Visual Inspection of Objects Based on Artificial Intelligence. Appl. Sci. 2022, 12, 864. [Google Scholar] [CrossRef]
- Selmaier, A.; Kunz, D.; Kisskalt, D.; Benaziz, M.; Fuerst, J.; Franke, J. Artificial Intelligence-Based Assistance System for Visual Inspection of X-ray Scatter Grids. Sensors 2022, 22, 811. [Google Scholar] [CrossRef]
- Fan, Z.; Li, C.; Chen, Y.; Wei, J.; Loprencipe, G.; Chen, X.; Di Mascio, P. Automatic Crack Detection on Road Pavements Using Encoder-Decoder Architecture. Materials 2020, 13, 2960. [Google Scholar] [CrossRef] [PubMed]
- Napoletano, P.; Piccoli, F.; Schettini, R. Anomaly Detection in Nanofibrous Materials by CNN-Based Self-Similarity. Sensors 2018, 18, 209. [Google Scholar] [CrossRef] [PubMed]
- Ulger, F.; Yuksel, S.E.; Yilmaz, A. Anomaly Detection for Solder Joints Using beta-VAE. IEEE Trans. Compon. Packag. Manuf. Technol. 2021, 11, 2214–2221. [Google Scholar] [CrossRef]
- Adibhatla, V.A.; Huang, Y.C.; Chang, M.C.; Kuo, H.C.; Utekar, A.; Chih, H.C.; Abbod, M.F.; Shieh, J.S. Unsupervised Anomaly Detection in Printed Circuit Boards through Student-Teacher Feature Pyramid Matching. Electronics 2021, 10, 3177. [Google Scholar] [CrossRef]
- Chandran, P.; Asber, J.; Thiery, F.; Odelius, J.; Rantatalo, M. An Investigation of Railway Fastener Detection Using Image Processing and Augmented Deep Learning. Sustainability 2021, 13, 12051. [Google Scholar] [CrossRef]
- Wang, T.; Yang, F.; Tsui, K.L. Real-Time Detection of Railway Track Component via One-Stage Deep Learning Networks. Sensors 2020, 20, 4325. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, M.; Ronay, A.; Lee, Y.T.T.; Law, K.H. Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning. Smart Sustain. Manuf. Syst. 2018, 2, 137–164. [Google Scholar] [CrossRef]
- Wang, P.; Tseng, H.W.; Chen, T.C.; Hsia, C.H. Deep Convolutional Neural Network for Coffee Bean Inspection. Sens. Mater. 2021, 33, 2299–2310. [Google Scholar] [CrossRef]
- Hussain, M.A.I.; Khan, B.; Wang, Z.; Ding, S. Woven Fabric Pattern Recognition and Classification Based on Deep Convolutional Neural Networks. Electronics 2020, 9, 1048. [Google Scholar] [CrossRef]
- Aslam, M.; Khan, T.M.; Naqvi, S.S.; Holmes, G.; Naffa, R. Ensemble Convolutional Neural Networks With Knowledge Transfer for Leather Defect Classification in Industrial Settings. IEEE Access 2020, 8, 198600–198614. [Google Scholar] [CrossRef]
- Chen, Y.; Fu, Q.; Wang, G. Surface Defect Detection of Nonburr Cylinder Liner Based on Improved YOLOv4. Mob. Inf. Syst. 2021, 2021. [Google Scholar] [CrossRef]
- Neven, R.; Goedeme, T. A Multi-Branch U-Net for Steel Surface Defect Type and Severity Segmentation. Metals 2021, 11, 870. [Google Scholar] [CrossRef]
- Qu, Z.; Mei, J.; Liu, L.; Zhou, D.Y. Crack Detection of Concrete Pavement With Cross-Entropy Loss Function and Improved VGG16 Network Model. IEEE Access 2020, 8, 54564–54573. [Google Scholar] [CrossRef]
- Samma, H.; Suandi, S.A.; Ismail, N.A.; Sulaiman, S.; Ping, L.L. Evolving Pre-Trained CNN Using Two-Layers Optimizer for Road Damage Detection From Drone Images. IEEE Access 2021, 9, 158215–158226. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, Y.; Yao, G.; Wei, F.; Wong, M. Autonomous Crack and Bughole Detection for Concrete Surface Image Based on Deep Learning. IEEE Access 2021, 9, 85709–85720. [Google Scholar] [CrossRef]
- Wang, D.; Cheng, J.; Cai, H. Detection Based on Crack Key Point and Deep Convolutional Neural Network. Appl. Sci. 2021, 11, 11321. [Google Scholar] [CrossRef]
- O’Byrne, M.; Ghosh, B.; Schoefs, F.; Pakrashi, V. Applications of Virtual Data in Subsea Inspections. J. Mar. Sci. Eng. 2020, 8, 328. [Google Scholar] [CrossRef]
- Ahmad, N.; Asif, H.M.S.; Saleem, G.; Younus, M.U.; Anwar, S.; Anjum, M.R. Leaf Image-Based Plant Disease Identification Using Color and Texture Features. Wirel. Pers. Commun. 2021, 121, 1139–1168. [Google Scholar] [CrossRef]
- Velasquez, D.; Sanchez, A.; Sarmiento, S.; Toro, M.; Maiza, M.; Sierra, B. A Method for Detecting Coffee Leaf Rust through Wireless Sensor Networks, Remote Sensing, and Deep Learning: Case Study of the Caturra Variety in Colombia. Appl. Sci. 2020, 10, 697. [Google Scholar] [CrossRef]
- Pagani, L.; Parenti, P.; Cataldo, S.; Scott, P.J.; Annoni, M. Indirect cutting tool wear classification using deep learning and chip colour analysis. Int. J. Adv. Manuf. Technol. 2020, 111, 1099–1114. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Jian, B.l.; Hung, J.P.; Wang, C.C.; Liu, C.C. Deep Learning Model for Determining Defects of Vision Inspection Machine Using Only a Few Samples. Sens. Mater. 2020, 32, 4217–4231. [Google Scholar] [CrossRef]
- Ali, L.; Jassmi, H.A.; Khan, W.; Alnajjar, F. Crack45K: Integration of Vision Transformer with Tubularity Flow Field (TuFF) and Sliding-Window Approach for Crack-Segmentation in Pavement Structures. Buildings 2023, 13, 55. [Google Scholar] [CrossRef]
- Rajadurai, R.S.; Kang, S.T. Automated Vision-Based Crack Detection on Concrete Surfaces Using Deep Learning. Appl. Sci. 2021, 11, 5229. [Google Scholar] [CrossRef]
- Hallee, M.J.; Napolitano, R.K.; Reinhart, W.F.; Glisic, B. Crack Detection in Images of Masonry Using CNNs. Sensors 2021, 21, 4929. [Google Scholar] [CrossRef] [PubMed]
- Mohammed, M.A.; Han, Z.; Li, Y. Exploring the Detection Accuracy of Concrete Cracks Using Various CNN Models. Adv. Mater. Sci. Eng. 2021, 2021, 9923704. [Google Scholar] [CrossRef]
- Stephen, O.; Maduh, U.J.; Sain, M. A Machine Learning Method for Detection of Surface Defects on Ceramic Tiles Using Convolutional Neural Networks. Electronics 2022, 11, 55. [Google Scholar] [CrossRef]
- Chaiyasarn, K.; Sharma, M.; Ali, L.; Khan, W.; Poovarodom, N. Crack detection in historical structures based on convolutional neural network. Int. J. Geomate 2018, 15, 240–251. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Al Jassmi, H.; Gocho, M.; Khan, W.; Serhani, M.A. Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef]
- Santos, R.; Ribeiro, D.; Lopes, P.; Cabral, R.; Calcada, R. Detection of exposed steel rebars based on deep-learning techniques and unmanned aerial vehicles. Autom. Constr. 2022, 139, 104324. [Google Scholar] [CrossRef]
- Woo, J.; Lee, H. Nonlinear and Dotted Defect Detection with CNN for Multi-Vision-Based Mask Inspection. Sensors 2022, 22, 8945. [Google Scholar] [CrossRef]
- Avdelidis, N.P.; Tsourdos, A.; Lafiosca, P.; Plaster, R.; Plaster, A.; Droznika, M. Defects Recognition Algorithm Development from Visual UAV Inspections. Sensors 2022, 22, 4682. [Google Scholar] [CrossRef] [PubMed]
- Stephen, O.; Madanian, S.; Nguyen, M. A Hard Voting Policy-Driven Deep Learning Architectural Ensemble Strategy for Industrial Products Defect Recognition and Classification. Sensors 2022, 22, 7846. [Google Scholar] [CrossRef]
- Ortiz, A.; Bonnin-Pascual, F.; Garcia-Fidalgo, E.; Company-Corcoles, J.P. Vision-Based Corrosion Detection Assisted by a Micro-Aerial Vehicle in a Vessel Inspection Application. Sensors 2016, 16, 2118. [Google Scholar] [CrossRef] [PubMed]
- Jin, W.W.; Chen, G.H.; Chen, Z.; Sun, Y.L.; Ni, J.; Huang, H.; Ip, W.H.; Yung, K.L. Road Pavement Damage Detection Based on Local Minimum of Grayscale and Feature Fusion. Appl. Sci. 2022, 12, 13006. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Walther, D.; Schmidt, L.; Schricker, K.; Junger, C.; Bergmann, J.P.; Notni, G.; Maeder, P. Automatic detection and prediction of discontinuities in laser beam butt welding utilizing deep learning. J. Adv. Join. Processes 2022, 6, 100119. [Google Scholar] [CrossRef]
- Kumar, G.S.; Natarajan, U.; Ananthan, S.S. Vision inspection system for the identification and classification of defects in MIG welding joints. Int. J. Adv. Manuf. Technol. 2012, 61, 923–933. [Google Scholar] [CrossRef]
- Alqahtani, H.; Bharadwaj, S.; Ray, A. Classification of fatigue crack damage in polycrystalline alloy structures using convolutional neural networks. Eng. Fail. Anal. 2021, 119, 104908. [Google Scholar] [CrossRef]
- Elhariri, E.; El-Bendary, N.; Taie, S.A. Using Hybrid Filter-Wrapper Feature Selection With Multi-Objective Improved-Salp Optimization for Crack Severity Recognition. IEEE Access 2020, 8, 84290–84315. [Google Scholar] [CrossRef]
- Kim, B.; Choi, S.W.; Hu, G.; Lee, D.E.; Juan, R.O.S. An Automated Image-Based Multivariant Concrete Defect Recognition Using a Convolutional Neural Network with an Integrated Pooling Module. Sensors 2022, 22, 3118. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Wang, Z.; Yang, G. Real-Time Tiny Part Defect Detection System in Manufacturing Using Deep Learning. IEEE Access 2019, 7, 89278–89291. [Google Scholar] [CrossRef]
- Dang, X.; Shang, X.; Hao, Z.; Su, L. Collaborative Road Damage Classification and Recognition Based on Edge Computing. Electronics 2022, 11, 3304. [Google Scholar] [CrossRef]
- Alqethami, S.; Alghamdi, S.; Alsubait, T.; Alhakami, H. RoadNet: Efficient Model to Detect and Classify Road Damages. Appl. Sci. 2022, 12, 11529. [Google Scholar] [CrossRef]
- Chandra, S.; AlMansoor, K.; Chen, C.; Shi, Y.; Seo, H. Deep Learning Based Infrared Thermal Image Analysis of Complex Pavement Defect Conditions Considering Seasonal Effect. Sensors 2022, 22, 9365. [Google Scholar] [CrossRef]
- Wang, D.; Xu, Y.; Duan, B.; Wang, Y.; Song, M.; Yu, H.; Liu, H. Intelligent Recognition Model of Hot Rolling Strip Edge Defects Based on Deep Learning. Metals 2021, 11, 223. [Google Scholar] [CrossRef]
- Schlosser, T.; Friedrich, M.; Beuth, F.; Kowerko, D. Improving automated visual fault inspection for semiconductor manufacturing using a hybrid multistage system of deep neural networks. J. Intell. Manuf. 2022, 33, 1099–1123. [Google Scholar] [CrossRef]
- Maeda, K.; Takahashi, S.; Ogawa, T.; Haseyama, M. Convolutional sparse coding-based deep random vector functional link network for distress classification of road structures. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 654–676. [Google Scholar] [CrossRef]
- Ahmad, A.; Jin, Y.; Zhu, C.; Javed, I.; Maqsood, A.; Akram, M.W. Photovoltaic cell defect classification using convolutional neural network and support vector machine. IET Renew. Power Gener. 2020, 14, 2693–2702. [Google Scholar] [CrossRef]
- Shin, H.K.; Ahn, Y.H.; Lee, S.H.; Kim, H.Y. Automatic Concrete Damage Recognition Using Multi-Level Attention Convolutional Neural Network. Materials 2020, 13, 5549. [Google Scholar] [CrossRef]
- Dunphy, K.; Fekri, M.N.; Grolinger, K.; Sadhu, A. Data Augmentation for Deep-Learning-Based Multiclass Structural Damage Detection Using Limited Information. Sensors 2022, 22, 6193. [Google Scholar] [CrossRef]
- Stephen, O.; Madanian, S.; Nguyen, M. A Robust Deep Learning Ensemble-Driven Model for Defect and Non-Defect Recognition and Classification Using a Weighted Averaging Sequence-Based Meta-Learning Ensembler. Sensors 2022, 22, 9971. [Google Scholar] [CrossRef]
- Chen, C.; Chandra, S.; Han, Y.; Seo, H. Deep Learning-Based Thermal Image Analysis for Pavement Defect Detection and Classification Considering Complex Pavement Conditions. Remote Sens. 2022, 14, 106. [Google Scholar] [CrossRef]
- Nagy, A.M.; Czuni, L. Classification and Fast Few-Shot Learning of Steel Surface Defects with Randomized Network. Appl. Sci. 2022, 12, 3967. [Google Scholar] [CrossRef]
- Dunphy, K.; Sadhu, A.; Wang, J. Multiclass damage detection in concrete structures using a transfer learning-based generative adversarial networks. Struct. Control Health Monit. 2022, 29. [Google Scholar] [CrossRef]
- Guo, X.; Liu, X.; Krolczyk, G.; Sulowicz, M.; Glowacz, A.; Gardoni, P.; Li, Z. Damage Detection for Conveyor Belt Surface Based on Conditional Cycle Generative Adversarial Network. Sensors 2022, 22, 3485. [Google Scholar] [CrossRef]
- Ogunjinmi, P.D.; Park, S.S.; Kim, B.; Lee, D.E. Rapid Post-Earthquake Structural Damage Assessment Using Convolutional Neural Networks and Transfer Learning. Sensors 2022, 22, 3471. [Google Scholar] [CrossRef]
- Chen, H.C. Automated Detection and Classification of Defective and Abnormal Dies in Wafer Images. Appl. Sci. 2020, 10, 3423. [Google Scholar] [CrossRef]
- Wu, X.; Xu, H.; Wei, X.; Wu, Q.; Zhang, W.; Han, X. Damage Identification of Low Emissivity Coating Based on Convolution Neural Network. IEEE Access 2020, 8, 156792–156800. [Google Scholar] [CrossRef]
- Stamoulakatos, A.; Cardona, J.; McCaig, C.; Murray, D.; Filius, H.; Atkinson, R.; Bellekens, X.; Michie, C.; Andonovic, I.; Lazaridis, P.; et al. Automatic Annotation of Subsea Pipelines Using Deep Learning. Sensors 2020, 20, 674. [Google Scholar] [CrossRef]
- Konovalenko, I.; Maruschak, P.; Brevus, V.; Prentkovskis, O. Recognition of Scratches and Abrasions on Metal Surfaces Using a Classifier Based on a Convolutional Neural Network. Metals 2021, 11, 549. [Google Scholar] [CrossRef]
- Xiang, S.; Jiang, S.; Liu, X.; Zhang, T.; Yu, L. Spiking VGG7: Deep Convolutional Spiking Neural Network with Direct Training for Object Recognition. Electronics 2022, 11, 2097. [Google Scholar] [CrossRef]
- Meister, S.; Wermes, M.; Stueve, J.; Groves, R.M. Cross-evaluation of a parallel operating SVM-CNN classifier for reliable internal decision-making processes in composite inspection. J. Manuf. Syst. 2021, 60, 620–639. [Google Scholar] [CrossRef]
- Meister, S.; Moeller, N.; Stueve, J.; Groves, R.M. Synthetic image data augmentation for fibre layup inspection processes: Techniques to enhance the data set. J. Intell. Manuf. 2021, 32, 1767–1789. [Google Scholar] [CrossRef]
- Al-Waisy, A.S.; Ibrahim, D.; Zebari, D.A.; Hammadi, S.; Mohammed, H.; Mohammed, M.A.; Damasevicius, R. Identifying defective solar cells in electroluminescence images using deep feature representations. PeerJ Comput. Sci. 2022, 8, e992. [Google Scholar] [CrossRef] [PubMed]
- Maeda, K.; Takahashi, S.; Ogawa, T.; Haseyama, M. Deterioration level estimation via neural network maximizing category-based ordinally supervised multi-view canonical correlation. Multimed. Tools Appl. 2021, 80, 23091–23112. [Google Scholar] [CrossRef]
- Konovalenko, I.; Maruschak, P.; Brezinova, J.; Vinas, J.; Brezina, J. Steel Surface Defect Classification Using Deep Residual Neural Network. Metals 2020, 10, 846. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, C.; Li, C.; Ding, S.; Dong, Y.; Huang, Y. Fabric defect recognition using optimized neural networks. J. Eng. Fibers Fabr. 2019, 14, 1558925019897396. [Google Scholar] [CrossRef]
- Mushabab Alqahtani, M.; Kumar Dutta, A.; Almotairi, S.; Ilayaraja, M.; Abdulrahman Albraikan, A.; Al-Wesabi, F.N.; Al Duhayyim, M. Sailfish Optimizer with EfficientNet Model for Apple Leaf Disease Detection. Comput. Mater. Contin. 2023, 74, 217–233. [Google Scholar] [CrossRef]
- Barman, U.; Pathak, C.; Mazumder, N.K. Comparative assessment of Pest damage identification of coconut plant using damage texture and color analysis. Multimed. Tools Appl. 2023, 82, 25083–25105. [Google Scholar] [CrossRef]
- Ksibi, A.; Ayadi, M.; Soufiene, B.O.; Jamjoom, M.M.; Ullah, Z. MobiRes-Net: A Hybrid Deep Learning Model for Detecting and Classifying Olive Leaf Diseases. Appl. Sci. 2022, 12, 10278. [Google Scholar] [CrossRef]
- Wu, L.; Liu, Z.; Bera, T.; Ding, H.; Langley, D.A.; Jenkins-Barnes, A.; Furlanello, C.; Maggio, V.; Tong, W.; Xu, J. A deep learning model to recognize food contaminating beetle species based on elytra fragments. Comput. Electron. Agric. 2019, 166, 105002. [Google Scholar] [CrossRef]
- Kang, D.H.; Cha, Y.J. Efficient attention-based deep encoder and decoder for automatic crack segmentation. Struct. Health Monit. Int. J. 2022, 21, 2190–2205. [Google Scholar] [CrossRef]
- Yuan, G.; Li, J.; Meng, X.; Li, Y. CurSeg: A pavement crack detector based on a deep hierarchical feature learning segmentation framework. IET Intell. Transp. Syst. 2022, 16, 782–799. [Google Scholar] [CrossRef]
- Andrushia, D.; Anand, N.; Neebha, T.M.; Naser, M.Z.; Lubloy, E. Autonomous detection of concrete damage under fire conditions. Autom. Constr. 2022, 140, 104364. [Google Scholar] [CrossRef]
- Wan, C.; Ma, S.; Song, K. TSSTNet: A Two-Stream Swin Transformer Network for Salient Object Detection of No-Service Rail Surface Defects. Coatings 2022, 12, 1730. [Google Scholar] [CrossRef]
- Su, L.; Huang, H.; Qin, L.; Zhao, W. Transformer Vibration Detection Based on YOLOv4 and Optical Flow in Background of High Proportion of Renewable Energy Access. Front. Energy Res. 2022, 10, 764903. [Google Scholar] [CrossRef]
- Oishi, Y.; Habaragamuwa, H.; Zhang, Y.; Sugiura, R.; Asano, K.; Akai, K.; Shibata, H.; Fujimoto, T. Automated abnormal potato plant detection system using deep learning models and portable video cameras. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102509. [Google Scholar] [CrossRef]
- Naddaf-Sh, M.M.; Hosseini, S.; Zhang, J.; Brake, N.A.; Zargarzadeh, H. Real-Time Road Crack Mapping Using an Optimized Convolutional Neural Network. Complexity 2019, 2019, 2470735. [Google Scholar] [CrossRef]
- Song, W.; Jia, G.; Zhu, H.; Jia, D.; Gao, L. Automated Pavement Crack Damage Detection Using Deep Multiscale Convolutional Features. J. Adv. Transp. 2020, 2020, 6412562. [Google Scholar] [CrossRef]
- Saleem, M.R.; Park, J.W.; Lee, J.H.; Jung, H.J.; Sarwar, M.Z. Instant bridge visual inspection using an unmanned aerial vehicle by image capturing and geo-tagging system and deep convolutional neural network. Struct. Health Monit. Int. J. 2021, 20, 1760–1777. [Google Scholar] [CrossRef]
- Chen, R. Migration Learning-Based Bridge Structure Damage Detection Algorithm. Sci. Program. 2021, 2021, 1102521. [Google Scholar] [CrossRef]
- Chun, C.; Ryu, S.K. Road Surface Damage Detection Using Fully Convolutional Neural Networks and Semi-Supervised Learning. Sensors 2019, 19, 5501. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Yu, Z.; Li, C.; Zhao, C.; Sun, Z. Automated Detection for Concrete Surface Cracks Based on Deeplabv3+BDF. Buildings 2023, 13, 118. [Google Scholar] [CrossRef]
- Kou, L.; Sysyn, M.; Fischer, S.; Liu, J.; Nabochenko, O. Optical Rail Surface Crack Detection Method Based on Semantic Segmentation Replacement for Magnetic Particle Inspection. Sensors 2022, 22, 8214. [Google Scholar] [CrossRef] [PubMed]
- Siriborvornratanakul, T. Downstream Semantic Segmentation Model for Low-Level Surface Crack Detection. Adv. Multimed. 2022, 2022, 3712289. [Google Scholar] [CrossRef]
- Chen, H.; Lin, H.; Yao, M. Improving the Efficiency of Encoder-Decoder Architecture for Pixel-Level Crack Detection. IEEE Access 2019, 7, 186657–186670. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X. A Performance Improvement Strategy for Concrete Damage Detection Using Stacking Ensemble Learning of Multiple Semantic Segmentation Networks. Sensors 2022, 22, 3341. [Google Scholar] [CrossRef]
- Shim, S.; Kim, J.; Cho, G.C.; Lee, S.W. Stereo-vision-based 3D concrete crack detection using adversarial learning with balanced ensemble discriminator networks. Struct. Health Monit. Int. J. 2023, 22, 1353–1375. [Google Scholar] [CrossRef]
- Meng, M.; Zhu, K.; Chen, K.; Qu, H. A Modified Fully Convolutional Network for Crack Damage Identification Compared with Conventional Methods. Model. Simul. Eng. 2021, 2021, 5298882. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, H.; Yang, Y. Deep Learning-Based Crack Monitoring for Ultra-High Performance Concrete (UHPC). J. Adv. Transp. 2022, 2022, 4117957. [Google Scholar] [CrossRef]
- Ali, L.; Khan, W.; Chaiyasarn, K. Damage detection and localization in masonry structure using faster region convolutional networks. Int. J. Geomater. 2019, 17, 98–105. [Google Scholar] [CrossRef]
- Dong, C.; Li, L.; Yan, J.; Zhang, Z.; Pan, H.; Catbas, F.N. Pixel-Level Fatigue Crack Segmentation in Large-Scale Images of Steel Structures Using an Encoder-Decoder Network. Sensors 2021, 21, 4135. [Google Scholar] [CrossRef] [PubMed]
- Jamshidi, M.; El-Badry, M.; Nourian, N. Improving Concrete Crack Segmentation Networks through CutMix Data Synthesis and Temporal Data Fusion. Sensors 2023, 23, 504. [Google Scholar] [CrossRef] [PubMed]
- Yu, G.; Dong, J.; Wang, Y.; Zhou, X. RUC-Net: A Residual-Unet-Based Convolutional Neural Network for Pixel-Level Pavement Crack Segmentation. Sensors 2023, 23, 53. [Google Scholar] [CrossRef]
- Loverdos, D.; Sarhosis, V. Automatic image-based brick segmentation and crack detection of masonry walls using machine learning. Autom. Constr. 2022, 140, 104389. [Google Scholar] [CrossRef]
- Pantoja-Rosero, B.G.; Oner, D.; Kozinski, M.; Achanta, R.; Fua, P.; Perez-Cruz, F.; Beyer, K. TOPO-Loss for continuity-preserving crack detection using deep learning. Constr. Build. Mater. 2022, 344. [Google Scholar] [CrossRef]
- Zhao, S.; Kang, F.; Li, J. Non-Contact Crack Visual Measurement System Combining Improved U-Net Algorithm and Canny Edge Detection Method with Laser Rangefinder and Camera. Appl. Sci. 2022, 12, 10651. [Google Scholar] [CrossRef]
- Shim, S.; Cho, G.C. Lightweight Semantic Segmentation for Road-Surface Damage Recognition Based on Multiscale Learning. IEEE Access 2020, 8, 102680–102690. [Google Scholar] [CrossRef]
- Ji, H.; Cui, X.; Ren, W.; Liu, L.; Wang, W. Visual inspection for transformer insulation defects by a patrol robot fish based on deep learning. IET Sci. Meas. Technol. 2021, 15, 606–618. [Google Scholar] [CrossRef]
- Shim, S.; Kim, J.; Lee, S.W.; Cho, G.C. Road damage detection using super-resolution and semi-supervised learning with generative adversarial network. Autom. Constr. 2022, 135, 104139. [Google Scholar] [CrossRef]
- Dong, J.; Li, Z.; Wang, Z.; Wang, N.; Guo, W.; Ma, D.; Hu, H.; Zhong, S. Pixel-Level Intelligent Segmentation and Measurement Method for Pavement Multiple Damages Based on Mobile Deep Learning. IEEE Access 2021, 9, 143860–143876. [Google Scholar] [CrossRef]
- Li, T.; Hao, T. Damage Detection of Insulators in Catenary Based on Deep Learning and Zernike Moment Algorithms. Appl. Sci. 2022, 12, 5004. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Y.; Zhang, Y.; Yu, J.; Zhu, Y. Embedded system for road damage detection by deep convolutional neural network. Math. Biosci. Eng. 2019, 16, 7982–7994. [Google Scholar] [CrossRef] [PubMed]
- Luo, Q.; Su, J.; Yang, C.; Gui, W.; Silven, O.; Liu, L. CAT-EDNet: Cross-Attention Transformer-Based Encoder-Decoder Network for Salient Defect Detection of Strip Steel Surface. IEEE Trans. Instrum. Meas. 2022, 71, 5009813. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, J.; Su, Z.; Zhou, Z.; Liu, L. Binary Neural Network for Automated Visual Surface Defect Detection. Sensors 2021, 21, 6868. [Google Scholar] [CrossRef] [PubMed]
- Konovalenko, I.; Maruschak, P.; Brezinova, J.; Prentkovskis, O.; Brezina, J. Research of U-Net-Based CNN Architectures for Metal Surface Defect Detection. Machines 2022, 10, 327. [Google Scholar] [CrossRef]
- Konovalenko, I.; Maruschak, P.; Kozbur, H.; Brezinova, J.; Brezina, J.; Nazarevich, B.; Shkira, Y. Influence of Uneven Lighting on Quantitative Indicators of Surface Defects. Machines 2022, 10, 194. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Y.; Luo, L.; Wang, N. AnoDFDNet: A Deep Feature Difference Network for Anomaly Detection. J. Sens. 2022, 2022, 3538541. [Google Scholar] [CrossRef]
- Park, S.S.; Tran, V.T.; Lee, D.E. Application of Various YOLO Models for Computer Vision-Based Real-Time Pothole Detection. Appl. Sci. 2021, 11, 11229. [Google Scholar] [CrossRef]
- van Ruitenbeek, R.E.; Bhulai, S. Multi-view damage inspection using single-view damage projection. Mach. Vis. Appl. 2022, 33, 46. [Google Scholar] [CrossRef]
- Zhao, G.; Hu, J.; Xiao, W.; Zou, J. A mask R-CNN based method for inspecting cable brackets in aircraft. Chin. J. Aeronaut. 2021, 34, 214–226. [Google Scholar] [CrossRef]
- Pan, X.; Yang, T.Y. Image-based monitoring of bolt loosening through deep-learning-based integrated detection and tracking. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 1207–1222. [Google Scholar] [CrossRef]
- Brion, D.A.J.; Shen, M.; Pattinson, S.W. Automated recognition and correction of warp deformation in extrusion additive manufacturing. Addit. Manuf. 2022, 56, 102838. [Google Scholar] [CrossRef]
- Salcedo, E.; Jaber, M.; Carrion, J.R. A Novel Road Maintenance Prioritisation System Based on Computer Vision and Crowdsourced Reporting. J. Sens. Actuator Netw. 2022, 11, 15. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A Wheat Spike Detection Method in UAV Images Based on Improved YOLOv5. Remote Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Huetten, N.; Meyes, R.; Meisen, T. Vision Transformer in Industrial Visual Inspection. Appl. Sci. 2022, 12, 11981. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, J.; Yu, Z.; Xie, S.; Ji, X.; Wan, Z. Real-Time Foreign Object and Production Status Detection of Tobacco Cabinets Based on Deep Learning. Appl. Sci. 2022, 12, 10347. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef]
- Tanveer, M.; Kim, B.; Hong, J.; Sim, S.H.; Cho, S. Comparative Study of Lightweight Deep Semantic Segmentation Models for Concrete Damage Detection. Appl. Sci. 2022, 12, 12786. [Google Scholar] [CrossRef]
- Islam, M.M.M.; Kim, J.M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder-Decoder Network. Sensors 2019, 19, 4251. [Google Scholar] [CrossRef]
- Kumar, P.; Sharma, A.; Kota, S.R. Automatic Multiclass Instance Segmentation of Concrete Damage Using Deep Learning Model. IEEE Access 2021, 9, 90330–90345. [Google Scholar] [CrossRef]
- He, Y.; Jin, Z.; Zhang, J.; Teng, S.; Chen, G.; Sun, X.; Cui, F. Pavement Surface Defect Detection Using Mask Region-Based Convolutional Neural Networks and Transfer Learning. Appl. Sci. 2022, 12, 7364. [Google Scholar] [CrossRef]
- Kulambayev, B.; Beissenova, G.; Katayev, N.; Abduraimova, B.; Zhaidakbayeva, L.; Sarbassova, A.; Akhmetova, O.; Issayev, S.; Suleimenova, L.; Kasenov, S.; et al. A Deep Learning-Based Approach for Road Surface Damage Detection. Comput. Mater. Contin. 2022, 73, 3403–3418. [Google Scholar] [CrossRef]
- Zhou, S.; Pan, Y.; Huang, X.; Yang, D.; Ding, Y.; Duan, R. Crack Texture Feature Identification of Fiber Reinforced Concrete Based on Deep Learning. Materials 2022, 15, 3940. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Zha, B.; Sezen, H.; Yilmaz, A. Engineering deep learning methods on automatic detection of damage in infrastructure due to extreme events. Struct. Health Monit. Int. J. 2023, 22, 338–352. [Google Scholar] [CrossRef]
- Dais, D.; Bal, I.E.; Smyrou, E.; Sarhosis, V. Automatic crack classification and segmentation on masonry surfaces using convolutional neural networks and transfer learning. Autom. Constr. 2021, 125, 103606. [Google Scholar] [CrossRef]
- Hu, G.X.; Hu, B.L.; Yang, Z.; Huang, L.; Li, P. Pavement Crack Detection Method Based on Deep Learning Models. Wirel. Commun. Mob. Comput. 2021, 2021, 5573590. [Google Scholar] [CrossRef]
- Du, F.J.; Jiao, S.J. Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection. Sensors 2022, 22, 3537. [Google Scholar] [CrossRef]
- Li, L.; Fang, B.; Zhu, J. Performance Analysis of the YOLOv4 Algorithm for Pavement Damage Image Detection with Different Embedding Positions of CBAM Modules. Appl. Sci. 2022, 12, 10180. [Google Scholar] [CrossRef]
- Wang, L.; Li, J.; Kang, F. Crack Location and Degree Detection Method Based on YOLOX Model. Appl. Sci. 2022, 12, 12572. [Google Scholar] [CrossRef]
- Yang, Z.; Ni, C.; Li, L.; Luo, W.; Qin, Y. Three-Stage Pavement Crack Localization and Segmentation Algorithm Based on Digital Image Processing and Deep Learning Techniques. Sensors 2022, 22, 8459. [Google Scholar] [CrossRef]
- Yin, J.; Qu, J.; Huang, W.; Chen, Q. Road Damage Detection and Classification based on Multi-level Feature Pyramids. Ksii Trans. Internet Inf. Syst. 2021, 15, 786–799. [Google Scholar] [CrossRef]
- Xu, H.; Chen, B.; Qin, J. A CNN-Based Length-Aware Cascade Road Damage Detection Approach. Sensors 2021, 21, 689. [Google Scholar] [CrossRef] [PubMed]
- Mallaiyan Sathiaseelan, M.A.; Paradis, O.P.; Taheri, S.; Asadizanjani, N. Why Is Deep Learning Challenging for Printed Circuit Board (PCB) Component Recognition and How Can We Address It? Cryptography 2021, 5, 9. [Google Scholar] [CrossRef]
- Schwebig, A.I.M.; Tutsch, R. Intelligent fault detection of electrical assemblies using hierarchical convolutional networks for supporting automatic optical inspection systems. J. Sens. Sens. Syst. 2020, 9, 363–374. [Google Scholar] [CrossRef]
- Yan, S.; Song, X.; Liu, G. Deeper and Mixed Supervision for Salient Object Detection in Automated Surface Inspection. Math. Probl. Eng. 2020, 2020, 3751053. [Google Scholar] [CrossRef]
- Liang, H.; Lee, S.C.; Seo, S. Automatic Recognition of Road Damage Based on Lightweight Attentional Convolutional Neural Network. Sensors 2022, 22, 9599. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, Z.; Qiu, Y.; Zhai, X.; Wang, Z.; Xu, P.; Liu, Z.; Li, X.; Jiang, N. A New Road Damage Detection Baseline with Attention Learning. Appl. Sci. 2022, 12, 7594. [Google Scholar] [CrossRef]
- Lin, C.S.; Hsieh, H.Y. An Automatic Defect Detection System for Synthetic Shuttlecocks Using Transformer Model. IEEE Access 2022, 10, 37412–37421. [Google Scholar] [CrossRef]
- Abedini, F.; Bahaghighat, M.; S’hoyan, M. Wind turbine tower detection using feature descriptors and deep learning. Facta Univ. Ser. Electron. Energetics 2020, 33, 133–153. [Google Scholar] [CrossRef]
- Kim, H.; Lee, S.; Han, S. Railroad Surface Defect Segmentation Using a Modified Fully Convolutional Network. Ksii Trans. Internet Inf. Syst. 2020, 14, 4763–4775. [Google Scholar] [CrossRef]
- Zhang, Z.; Liang, M.; Wang, Z. A Deep Extractor for Visual Rail Surface Inspection. IEEE Access 2021, 9, 21798–21809. [Google Scholar] [CrossRef]
- Tabernik, D.; Sela, S.; Skvarc, J.; Skocaj, D. Segmentation-based deep-learning approach for surface-defect detection. J. Intell. Manuf. 2020, 31, 759–776. [Google Scholar] [CrossRef]
- Shi, H.; Lai, R.; Li, G.; Yu, W. Visual inspection of surface defects of extreme size based on an advanced FCOS. Appl. Artif. Intell. 2022, 36, 2122222. [Google Scholar] [CrossRef]
- Zhou, Q.; Situ, Z.; Teng, S.; Chen, W.; Chen, G.; Su, J. Comparison of classic object-detection techniques for automated sewer defect detection. J. Hydroinform. 2022, 24, 406–419. [Google Scholar] [CrossRef]
- Shin, H.K.; Lee, S.W.; Hong, G.P.; Sael, L.; Lee, S.H.; Kim, H.Y. Defect-Detection Model for Underground Parking Lots Using Image Object-Detection Method. Comput. Mater. Contin. 2021, 66, 2493–2507. [Google Scholar] [CrossRef]
- Urbonas, A.; Raudonis, V.; Maskeliunas, R.; Damasevicius, R. Automated Identification of Wood Veneer Surface Defects Using Faster Region-Based Convolutional Neural Network with Data Augmentation and Transfer Learning. Appl. Sci. 2019, 9, 4898. [Google Scholar] [CrossRef]
- Roberts, R.; Giancontieri, G.; Inzerillo, L.; Di Mino, G. Towards Low-Cost Pavement Condition Health Monitoring and Analysis Using Deep Learning. Appl. Sci. 2020, 10, 319. [Google Scholar] [CrossRef]
- Shihavuddin, A.S.M.; Chen, X.; Fedorov, V.; Christensen, A.N.; Riis, N.A.B.; Branner, K.; Dahl, A.B.; Paulsen, R.R. Wind Turbine Surface Damage Detection by Deep Learning Aided Drone Inspection Analysis. Energies 2019, 12, 676. [Google Scholar] [CrossRef]
- Allam, A.; Moussa, M.; Tarry, C.; Veres, M. Detecting Teeth Defects on Automotive Gears Using Deep Learning. Sensors 2021, 21, 8480. [Google Scholar] [CrossRef]
- Lee, K.; Hong, G.; Sael, L.; Lee, S.; Kim, H.Y. MultiDefectNet: Multi-Class Defect Detection of Building Facade Based on Deep Convolutional Neural Network. Sustainability 2020, 12, 9785. [Google Scholar] [CrossRef]
- Wei, R.; Bi, Y. Research on Recognition Technology of Aluminum Profile Surface Defects Based on Deep Learning. Materials 2019, 12, 1681. [Google Scholar] [CrossRef] [PubMed]
- Palanisamy, P.; Mohan, R.E.; Semwal, A.; Melivin, L.M.J.; Gomez, B.F.; Balakrishnan, S.; Elangovan, K.; Ramalingam, B.; Terntzer, D.N. Drain Structural Defect Detection and Mapping Using AI-Enabled Reconfigurable Robot Raptor and IoRT Framework. Sensors 2021, 21, 7287. [Google Scholar] [CrossRef] [PubMed]
- Siu, C.; Wang, M.; Cheng, J.C.P. A framework for synthetic image generation and augmentation for improving automatic sewer pipe defect detection. Autom. Constr. 2022, 137, 104213. [Google Scholar] [CrossRef]
- Chen, Q.; Gan, X.; Huang, W.; Feng, J.; Shim, H. Road Damage Detection and Classification Using Mask R-CNN with DenseNet Backbone. Comput. Mater. Contin. 2020, 65, 2201–2215. [Google Scholar] [CrossRef]
- Zhang, J.; Cosma, G.; Watkins, J. Image Enhanced Mask R-CNN: A Deep Learning Pipeline with New Evaluation Measures for Wind Turbine Blade Defect Detection and Classification. J. Imaging 2021, 7, 46. [Google Scholar] [CrossRef] [PubMed]
- Dogru, A.; Bouarfa, S.; Arizar, R.; Aydogan, R. Using Convolutional Neural Networks to Automate Aircraft Maintenance Visual Inspection. Aerospace 2020, 7, 171. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Automated Multiple Concrete Damage Detection Using Instance Segmentation Deep Learning Model. Appl. Sci. 2020, 10, 8008. [Google Scholar] [CrossRef]
- Kim, A.; Lee, K.; Lee, S.; Song, J.; Kwon, S.; Chung, S. Synthetic Data and Computer-Vision-Based Automated Quality Inspection System for Reused Scaffolding. Appl. Sci. 2022, 12, 10097. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, Z. Automated Asphalt Highway Pavement Crack Detection Based on Deformable Single Shot Multi-Box Detector Under a Complex Environment. IEEE Access 2021, 9, 150925–150938. [Google Scholar] [CrossRef]
- Jang, J.; Shin, M.; Lim, S.; Park, J.; Kim, J.; Paik, J. Intelligent Image-Based Railway Inspection System Using Deep Learning-Based Object Detection and Weber Contrast-Based Image Comparison. Sensors 2019, 19, 4738. [Google Scholar] [CrossRef] [PubMed]
- Ramalingam, B.; Manuel, V.H.; Elara, M.R.; Vengadesh, A.; Lakshmanan, A.K.; Ilyas, M.; James, T.J.Y. Visual Inspection of the Aircraft Surface Using a Teleoperated Reconfigurable Climbing Robot and Enhanced Deep Learning Technique. Int. J. Aerosp. Eng. 2019, 2019, 5137139. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Lv, L.; Yao, Z.; Wang, E.; Ren, X.; Pang, R.; Wang, H.; Zhang, Y.; Wu, H. Efficient and Accurate Damage Detector for Wind Turbine Blade Images. IEEE Access 2022, 10, 123378–123386. [Google Scholar] [CrossRef]
- Wei, Z.; Fernandes, H.; Herrmann, H.G.; Tarpani, J.R.; Osman, A. A Deep Learning Method for the Impact Damage Segmentation of Curve-Shaped CFRP Specimens Inspected by Infrared Thermography. Sensors 2021, 21, 395. [Google Scholar] [CrossRef] [PubMed]
- Munawar, H.S.; Ullah, F.; Shahzad, D.; Heravi, A.; Qayyum, S.; Akram, J. Civil Infrastructure Damage and Corrosion Detection: An Application of Machine Learning. Buildings 2022, 12, 156. [Google Scholar] [CrossRef]
- Wang, A.; Togo, R.; Ogawa, T.; Haseyama, M. Defect Detection of Subway Tunnels Using Advanced U-Net Network. Sensors 2022, 22, 2330. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhang, S.; Yu, B.; Li, Q.; Zhang, Y. Defect Inspection in Tire Radiographic Image Using Concise Semantic Segmentation. IEEE Access 2020, 8, 112674–112687. [Google Scholar] [CrossRef]
- Wu, W.; Li, Q. Machine Vision Inspection of Electrical Connectors Based on Improved Yolo v3. IEEE Access 2020, 8, 166184–166196. [Google Scholar] [CrossRef]
- Kumar, P.; Batchu, S.; Swamy S., N.; Kota, S.R. Real-Time Concrete Damage Detection Using Deep Learning for High Rise Structures. IEEE Access 2021, 9, 112312–112331. [Google Scholar] [CrossRef]
- Lin, H.I.; Wibowo, F.S. Image Data Assessment Approach for Deep Learning-Based Metal Surface Defect-Detection Systems. IEEE Access 2021, 9, 47621–47638. [Google Scholar] [CrossRef]
- Shihavuddin, A.S.M.; Rashid, M.R.A.; Maruf, M.H.; Abul Hasan, M.; ul Haq, M.A.; Ashique, R.H.; Al Mansur, A. Image based surface damage detection of renewable energy installations using a unified deep learning approach. Energy Rep. 2021, 7, 4566–4576. [Google Scholar] [CrossRef]
- Yu, L.; Yang, E.; Luo, C.; Ren, P. AMCD: An accurate deep learning-based metallic corrosion detector for MAV-based real-time visual inspection. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 8087–8098. [Google Scholar] [CrossRef]
- Du, F.; Jiao, S.; Chu, K. Application Research of Bridge Damage Detection Based on the Improved Lightweight Convolutional Neural Network Model. Appl. Sci. 2022, 12, 6225. [Google Scholar] [CrossRef]
- Guo, Y.; Zeng, Y.; Gao, F.; Qiu, Y.; Zhou, X.; Zhong, L.; Zhan, C. Improved YOLOV4-CSP Algorithm for Detection of Bamboo Surface Sliver Defects With Extreme Aspect Ratio. IEEE Access 2022, 10, 29810–29820. [Google Scholar] [CrossRef]
- Huang, H.; Luo, X. A Holistic Approach to IGBT Board Surface Fractal Object Detection Based on the Multi-Head Model. Machines 2022, 10, 713. [Google Scholar] [CrossRef]
- Li, Y.; Fan, Y.; Wang, S.; Bai, J.; Li, K. Application of YOLOv5 Based on Attention Mechanism and Receptive Field in Identifying Defects of Thangka Images. IEEE Access 2022, 10, 81597–81611. [Google Scholar] [CrossRef]
- Ma, H.; Lee, S. Smart System to Detect Painting Defects in Shipyards: Vision AI and a Deep-Learning Approach. Appl. Sci. 2022, 12, 2412. [Google Scholar] [CrossRef]
- Teng, S.; Liu, Z.; Li, X. Improved YOLOv3-Based Bridge Surface Defect Detection by Combining High- and Low-Resolution Feature Images. Buildings 2022, 12, 1225. [Google Scholar] [CrossRef]
- Wan, F.; Sun, C.; He, H.; Lei, G.; Xu, L.; Xiao, T. YOLO-LRDD: A lightweight method for road damage detection based on improved YOLOv5s. Eurasip J. Adv. Signal Process. 2022, 2022, 98. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, T.; Yang, J. Image Recognition of Wind Turbine Blade Defects Using Attention-Based MobileNetv1-YOLOv4 and Transfer Learning. Sensors 2022, 22, 6009. [Google Scholar] [CrossRef]
- Wang, C.; Zhou, Z.; Chen, Z. An Enhanced YOLOv4 Model With Self-Dependent Attentive Fusion and Component Randomized Mosaic Augmentation for Metal Surface Defect Detection. IEEE Access 2022, 10, 97758–97766. [Google Scholar] [CrossRef]
- Du, X.; Cheng, Y.; Gu, Z. Change Detection: The Framework of Visual Inspection System for Railway Plug Defects. IEEE Access 2020, 8, 152161–152172. [Google Scholar] [CrossRef]
- Zheng, D.; Li, L.; Zheng, S.; Chai, X.; Zhao, S.; Tong, Q.; Wang, J.; Guo, L. A Defect Detection Method for Rail Surface and Fasteners Based on Deep Convolutional Neural Network. Comput. Intell. Neurosci. 2021, 2021, 2565500. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Sun, X.; Loh, K.J.; Su, W.; Xue, Z.; Zhao, X. Autonomous bolt loosening detection using deep learning. Struct. Health Monit. Int. J. 2020, 19, 105–122. [Google Scholar] [CrossRef]
- Lei, T.; Lv, F.; Liu, J.; Zhang, L.; Zhou, T. Research on Fault Detection Algorithm of Electrical Equipment Based on Neural Network. Math. Probl. Eng. 2022, 2022, 9015796. [Google Scholar] [CrossRef]
- An, Y.; Lu, Y.N.; Wu, T.R. Segmentation Method of Magnetic Tile Surface Defects Based on Deep Learning. Int. J. Comput. Commun. Control 2022, 17. [Google Scholar] [CrossRef]
- Chen, S.W.; Tsai, C.J.; Liu, C.H.; Chu, W.C.C.; Tsai, C.T. Development of an Intelligent Defect Detection System for Gummy Candy under Edge Computing. J. Internet Technol. 2022, 23, 981–988. [Google Scholar] [CrossRef]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. SDNET2018: An annotated image dataset for non-contact concrete crack detection using deep convolutional neural networks. Data Brief 2018, 21, 1664–1668. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Mraz, A.; Kashiyama, T.; Sekimoto, Y. Transfer Learning-based Road Damage Detection for Multiple Countries. arXiv 2020, arXiv:2008.13101. [Google Scholar] [CrossRef]
- Gan, J.; Li, Q.; Wang, J.; Yu, H. A Hierarchical Extractor-Based Visual Rail Surface Inspection System. IEEE Sens. J. 2017, 17, 7935–7944. [Google Scholar] [CrossRef]
- Grishin, A.; Boris, V.I.; Inversion, O. Severstal: Steel Defect Detection Dataset. 2019. Available online: https://kaggle.com/competitions/severstal-steel-defect-detection (accessed on 17 January 2023).
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection. IEEE Trans. Image Process. 2018, 28, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Özgenel, Ç.F. Concrete Crack Images for Classification; Mendeley: London, UK, 2018. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. Automatic Crack Detection on Two-Dimensional Pavement Images: An Algorithm Based on Minimal Path Selection. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2718–2729. [Google Scholar] [CrossRef]
- Huang, Y.; Qiu, C.; Yuan, K. Surface defect saliency of magnetic tile. Vis. Comput. 2020, 36, 85–96. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2014, arXiv:1411.4038v2. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tan, M.; Le V, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. PMLR 2019, 97, 6105–6114. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; Tao, X.; Fang, J.; imyhxy; et al. ultralytics/yolov5: V7.0—YOLOv5 SOTA Realtime Instance Segmentation; Zenodo: Geneva, Switzerland, 2022. [Google Scholar] [CrossRef]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads with Attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. Up-detr: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar]
- Bar, A.; Wang, X.; Kantorov, V.; Reed, C.J.; Herzig, R.; Chechik, G.; Rohrbach, A.; Darrell, T.; Globerson, A. DETReg: Unsupervised Pretraining with Region Priors for Object Detection. arXiv 2021, arXiv:2106.04550. [Google Scholar]
- Xu, M.; Zhang, Z.; Hu, H.; Wang, J.; Wang, L.; Wei, F.; Bai, X.; Liu, Z. End-to-End Semi-Supervised Object Detection with Soft Teacher. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. SimMIM: A Simple Framework for Masked Image Modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. BEiT: BERT Pre-Training of Image Transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. PMLR 2020, 119, 1597–1607. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved Baselines with Momentum Contrastive Learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow Twins: Self-Supervised Learning via Redundancy Reduction. PMLR 2021, 139, 12310–12320. [Google Scholar]
- Chen, X.; Xie, S.; He, K. An Empirical Study of Training Self-Supervised Vision Transformers. In Proceedings of the CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Bardes, A.; Ponce, J.; LeCun, Y. VICRegL: Self-Supervised Learning of Local Visual Features. Adv. Neural Inf. Process. Syst. 2022, 35, 8799–8810. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. PMLR 2021, 139, 8748–8763. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar] [CrossRef]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Li, C.; Yang, J.; Su, H.; Zhu, J.; et al. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. arXiv 2023, arXiv:2303.05499. [Google Scholar]
- Cai, Y.; Zhou, Y.; Han, Q.; Sun, J.; Kong, X.; Li, J.; Zhang, X. Reversible Column Networks. arXiv 2023, arXiv:2212.11696. [Google Scholar]
- Ren, T.; Yang, J.; Liu, S.; Zeng, A.; Li, F.; Zhang, H.; Li, H.; Zeng, Z.; Zhang, L. A Strong and Reproducible Object Detector with Only Public Datasets. arXiv 2023, arXiv:2304.13027. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]









| Category | Search Terms |
|---|---|
| DL-based computer vision | Deep Learning, Neural Network, Convolutional Neural Network, CNN, Transformer, Semantic segmentation, Object Detection |
| Automated visual inspection in industrial use cases | Industrial Vision Inspection, Industrial Visual Inspection, Vision Inspection, Visual Inspection, Damage Detection, Damage Segmentation, Error Detection |
| VI Use Case | Model | Count | References |
|---|---|---|---|
| Crack Detection | AlexNet | 1 | [90] |
| CNN | 1 | [86] | |
| EfficientNet | 1 | [91] | |
| ResNet | 1 | [92] | |
| VGG | 2 | [87,88] | |
| Damage Detection | AlexNet | 1 | [93] |
| CNN | 6 | [66,94,95,96,97,98] | |
| CNN LSTM | 1 | [99] | |
| EfficientNet | 2 | [100,101] | |
| Ensemble | 1 | [56] | |
| GAN | 2 | [102,103] | |
| MLP | 1 | [85] | |
| MobileNet | 1 | [104] | |
| ResNet | 4 | [105,106,107,108] | |
| VGG | 2 | [60,109] | |
| Completeness Check | ResNet | 1 | [51] |
| SSD | 1 | [89] | |
| Quality Inspection | CNN | 3 | [110,111,112] |
| DenseNet | 1 | [113] | |
| ResNet | 2 | [55,114] | |
| VGG | 1 | [115] | |
| Other | CNN | 1 | [65] |
| EfficientNet | 1 | [116] | |
| MLP | 1 | [117] | |
| MobileNet | 1 | [118] | |
| ResNet | 1 | [54] | |
| VGG | 1 | [119] |
| VI Use Case | Model | Count | References |
|---|---|---|---|
| Crack Detection | CNN | 8 | [47,59,62,126,127,128,129,130] |
| CNN LSTM | 1 | [122] | |
| Attention CNN | 1 | [120] | |
| Custom encoder–decoder CNN | 1 | [121] | |
| DeepLab | 3 | [131,132,133] | |
| Ensemble | 3 | [134,135,136] | |
| Fully convolutional network (FCN) | 2 | [137,138] | |
| Faster RCNN | 1 | [139] | |
| UNet | 6 | [140,141,142,143,144,145] | |
| Damage Detection | DenseNet | 1 | [146] |
| Faster RCNN | 1 | [147] | |
| GAN | 1 | [148] | |
| Mask RCNN | 2 | [149,150] | |
| ResNet | 1 | [48] | |
| SSD | 1 | [151] | |
| Swin | 1 | [123] | |
| Transformer | 1 | [152] | |
| UNet | 3 | [153,154,155] | |
| VAE | 1 | [49] | |
| ViT | 1 | [156] | |
| YOLO | 2 | [157,158] | |
| Completeness Check | Mask RCNN | 1 | [159] |
| YOLO | 1 | [160] | |
| Quality Inspection | YOLO | 1 | [161] |
| Other | Faster RCNN | 1 | [125] |
| UNet | 2 | [44,162] | |
| YOLO | 2 | [124,163] |
| VI Use Case | Model | Count | References |
|---|---|---|---|
| Crack Detection | AlexNet | 1 | [166] |
| DeepLab | 2 | [61,167] | |
| FCN | 1 | [168] | |
| Mask RCNN | 5 | [169,170,171,172,173] | |
| UNet | 1 | [174] | |
| YOLO | 5 | [175,176,177,178,179] | |
| Damage Detection | CNN | 7 | [180,181,182,183,184,185,186] |
| DETR | 1 | [187] | |
| EfficientNet | 1 | [188] | |
| FCN | 3 | [189,190,191] | |
| FCOS | 1 | [192] | |
| Faster RCNN | 10 | [193,194,195,196,197,198,199,200,201,202] | |
| Mask RCNN | 6 | [53,203,204,205,206,207] | |
| MobileNet | 1 | [39] | |
| RCNN | 1 | [45] | |
| SSD | 5 | [208,209,210,211,212] | |
| Swin | 1 | [164] | |
| UNet | 4 | [58,213,214,215] | |
| VGG | 1 | [216] | |
| YOLO | 16 | [41,57,217,218,219,220,221,222,223,224,225,226,227,228,229,230] | |
| Completeness Check | CNN | 1 | [231] |
| Ensemble | 1 | [232] | |
| Faster RCNN | 2 | [233,234] | |
| YOLO | 2 | [42,52] | |
| Quality Inspection | YOLO | 3 | [40,235,236] |
| Other | YOLO | 1 | [165] |
| Dataset Name | # Samples | Resolution | Learning Task | Class Distribution | B-Score | # Publications | References |
|---|---|---|---|---|---|---|---|
| NEU Surface Defect Database | 1800 | 200 × 200 | Classification | Rolled-in Scale 300 Patches 300 Crazing 300 Pitted Surface 300 Inclusion 300 Scratches 300 | 1.0 | 9 | [237] |
| SDNET 2018 | 56,000 | 256 × 256 | Classification | Crack 8484 Intact 47,608 | 0.51 | 6 | [238] |
| Crack Forest Dataset (CFD) | 118 | 480 × 320 | Segmentation | Crack 118 | 0.32 | 5 | [239] |
| Road Damage Dataset 2018 | 9054 | 600 × 600 | Object Detection | Longitudinal Crack, Wheel Mark 2768 Longitudinal Crack, Construction Joint 3789 Lateral Crack 742 Lateral Crack, Construction Joint 636 Alligator Crack 2541 Rutting, Bump, Pothole 409 Cross-Walk Blur 817 White-Line Blur 3733 | 0.75 | 5 | [211] |
| GRDDC 2020 | 21,041 | 600 × 600, 720 × 720 | Object Detection | Longitudinal Crack 8242, Laterial Crack 5480, Alligator Crack 10613, Pothole 7008 | 0.85 | 4 | [240] |
| Rail Surface Defect Dataset (RSDD) | 195 | 1024 ×* | Segmentation | Defect 195 | - | 4 | [241] |
| Severstal Dataset | 87,995 | 256 × 256 | Segmentation | Holes 1820 Scratches 14576 Rolling 2327 Intact 69,272 | 0.37 | 4 | [242] |
| Deep Crack | 537 | 544 × 384 | Segmentation | Crack 3.54% Background 96.46% | 0.34 | 3 | [243] |
| Crack Tree | 206/260 | 800 × 600 | Segmentation | Crack 206/1.91% Background -/98.09% | 0.32 | 3 | [243,244] |
| Özgenel Crack Dataset | 40,000 | 227 × 227 | Classification | Crack 20,000 Intact 20,000 | 1.0 | 3 | [245] |
| Crack 500 | 500 | 2560 × 1440 | Segmentation | Crack 4.33% Background 95.67% | 0.35 | 2 | [246] |
| Crack LS 315 | 315 | 512 × 512 | Segmentation | Crack 1.69% Background 98.31% | 0.32 | 2 | [243] |
| Aigle RN | 38 | 311 × 462, 991 × 462 | Segmentation | Crack 38 | - | 2 | [247] |
| Magnetic Tile Surface Dataset | 1344 | 196 × 245 | Segmentation | Blowhole 115 Break 85 Crack 57 Fray 32 Uneven 103 Intact 952 | 0.40 | 2 | [248] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hütten, N.; Alves Gomes, M.; Hölken, F.; Andricevic, K.; Meyes, R.; Meisen, T. Deep Learning for Automated Visual Inspection in Manufacturing and Maintenance: A Survey of Open- Access Papers. Appl. Syst. Innov. 2024, 7, 11. https://doi.org/10.3390/asi7010011
Hütten N, Alves Gomes M, Hölken F, Andricevic K, Meyes R, Meisen T. Deep Learning for Automated Visual Inspection in Manufacturing and Maintenance: A Survey of Open- Access Papers. Applied System Innovation. 2024; 7(1):11. https://doi.org/10.3390/asi7010011
Chicago/Turabian StyleHütten, Nils, Miguel Alves Gomes, Florian Hölken, Karlo Andricevic, Richard Meyes, and Tobias Meisen. 2024. "Deep Learning for Automated Visual Inspection in Manufacturing and Maintenance: A Survey of Open- Access Papers" Applied System Innovation 7, no. 1: 11. https://doi.org/10.3390/asi7010011
APA StyleHütten, N., Alves Gomes, M., Hölken, F., Andricevic, K., Meyes, R., & Meisen, T. (2024). Deep Learning for Automated Visual Inspection in Manufacturing and Maintenance: A Survey of Open- Access Papers. Applied System Innovation, 7(1), 11. https://doi.org/10.3390/asi7010011