Abstract
Unmanned aerial vehicles (UAVs), owing to their flexible coverage expansion and dynamic adjustment capabilities, hold significant application potential across various fields. With the emergence of urban low-altitude air traffic dominated by UAVs, the integrated aviation information network combining UAVs and manned aircraft has evolved into a complex space–air–ground integrated Internet of Things (IoT) system. The application of 5G/6G network technologies, such as cloud computing, network function virtualization (NFV), and edge computing, has enhanced the flexibility of air traffic services based on service function chains (SFCs), while simultaneously expanding the network attack surface. Compared to traditional networks, the aviation information network integrating UAVs exhibits greater heterogeneity and demands higher service reliability. To address the failure issues of SFCs under attack, this study proposes an efficient SFC recovery method for recovery rate optimization (ERRRO) based on virtual network functions (VNFs) migration technology. The method first determines the recovery order of failed SFCs according to their recovery costs, prioritizing the restoration of SFCs with the lowest costs. Next, the migration priorities of the failed VNFs are ranked based on their neighborhood certainty, with the VNFs exhibiting the highest neighborhood certainty being migrated first. Finally, the destination nodes for migrating the failed VNFs are determined by comprehensively considering attributes such as the instantiated SFC paths, delay of physical platforms, and residual resources. Experiments demonstrate that the ERRRO performs well under networks with varying resource redundancy and different types of attacks. Compared to methods reported in the literature, the ERRRO achieves superior performance in terms of the SFC recovery rate and delay.
1. Introduction
In recent years, with the continuous advancement of unmanned aerial vehicle (UAV) technology, the urban low-altitude air traffic industry dominated by UAVs has rapidly emerged. The integrated air traffic ecosystem combining UAVs and manned aircraft has evolved into a complex space–air–ground integrated network [1]. By the end of 2024, the number of registered civil UAVs in China exceeded 1.7 million units, encompassing more than 1800 different types [2]. Meanwhile, the number of manned aircraft has increased by 16.1% over the past five years [3]. On 29 March 2024, at the press conference for “Advancing the Construction of the Low-Altitude Flight Service Support System”, the Civil Aviation Administration of China (CAAC) emphasized that, whether manned or unmanned aircraft, their integration into the national airspace system for safe and efficient operation requires continuous improvement of the low-altitude flight service support system and enhancement of low-altitude navigation service capabilities [4]. The vast number of UAVs and manned aircraft generates substantial demand for air traffic services, and the diverse applications of UAVs also contribute to the multifaceted characteristics of air traffic services.
The aeronautical information network serves as a critical infrastructure supporting the efficient and safe operation of both unmanned and manned aircraft. However, traditional narrowband communication technologies and dedicated hardware-based network architectures have become inadequate to meet the rapidly growing and increasingly diverse demands of air traffic services [5,6]. In recent years, with the deep application of new-generation broadband communication technologies, such as 5G in the Internet of Things (IoT) field, their core advantages—including high data rates, low latency, massive connectivity, and high energy efficiency—have gradually become prominent [7,8,9]. In 2021, the CAAC released the “New Generation Aeronautical Broadband Communication Technology Roadmap for China’s Civil Aviation”, which explicitly focuses on promoting the international standardization of new-generation communication technologies, such as 5G/6G, in the civil aviation domain. The roadmap aims to integrate onboard broadband wireless communication, cloud computing, artificial intelligence, and information security technologies, fostering air–ground collaborative applications to provide various flight information transmission and exchange services. This effort effectively enhances air traffic safety, airspace capacity, and operational efficiency [10].
Cloud computing, edge computing, and network function virtualization (NFV) are key technologies for enabling aeronautical information networks to meet the communication requirements of 5G/6G application scenarios. By leveraging virtualization, standardized network functions are implemented on unified resource platforms, breaking the traditional tightly coupled hardware–software network architecture in aeronautical information networks. Through service function chains (SFCs), customized air traffic services are realized, transforming the traditional point-to-point aeronautical communication into a network-centric information exchange model. This not only reduces the operational costs of air traffic management but significantly enhances the flexibility of aeronautical information services [11,12,13,14]. However, as the isolation between network functions shifts from closed physical isolation to flexible logical isolation, the attack surface of SFC-based aviation information systems continues to expand. Coupled with the emergence of new attack patterns characterized by intelligent technologies, the cybersecurity threats facing aviation information systems have become increasingly severe [15,16,17,18,19]. For example, an attacker only needs to target a particular resource platform, causing all network functions running on it to be unable to provide normal services. Since these network functions may belong to different SFCs, the impact of such an attack can propagate through the SFCs to affect a wider range of aeronautical information services [20,21,22]. The SFCs that realize the data exchange services among air traffic participants are fundamental to ensuring unmanned and manned aircraft safety; their failure due to attacks can lead to severe consequences [23]. For instance, an SFC responsible for providing air traffic control services between controllers and pilots may become inoperative due to an attack, potentially causing flights to enter heavily congested controlled airspace. This could result in extensive flight delays in mild cases, and even flight collisions in severe cases [24]. Therefore, researching recovery strategies for the SFCs after attacks is of great significance to enhancing both security and safety in air traffic systems.
As shown in Figure 1, the aeronautical information network is a complex space–air–ground integrated network that incorporates satellites, unmanned aerial vehicles (UAVs), cloud servers, switching nodes, and air traffic participants. The switching nodes include ground routers, switches, and access points (APs), among others, while the air traffic participants consist of flights, UAVs, control centers, meteorological centers, and airlines, among others [25]. Under environments empowered by cloud computing, edge computing, and NFV, customized air traffic services are realized among air traffic participants via SFCs [26]. An SFC is a chained structure composed of virtual network functions (VNFs) and virtual links (VLs). During instantiation, the VNFs can be deployed on cloud servers, UAV platforms, and satellite platforms, while the VLs can be mapped onto wired or wireless links [27,28]. Figure 1a illustrates the deployment scenarios of three SFCs. SFC1 provides meteorological services from the meteorological center to UAV2, with its three VNFs deployed on Server1, Server3, and Server6, respectively. SFC2 offers air traffic control services from the surveillance center to UAV3, with its three VNFs deployed on Server5, Satellite6, and Satellite5, respectively. SFC3 delivers landing navigation services from the airport to Flight2, with its three VNFs deployed on Server1, Server2, and UAV1, respectively. When Server2 is attacked and becomes inoperative, all links connected to Server2 also fail, causing both SFC2 and SFC3 to be affected and fail. The failure of SFC2 is due to the deployment path of its VL passing through the attacked node, while SFC3 fails because VNF2 is deployed on the attacked node.
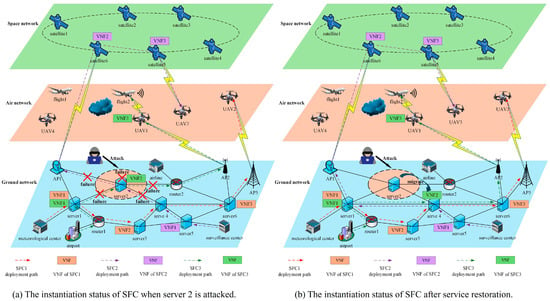
Figure 1.
The deployment and recovery process of SFCs in the aeronautical information network.
For the failed VNFs and VLs within an impaired SFC, service recovery is typically achieved through VNF migration and VL redirection [29]. Figure 1b illustrates the instantiation results of SFCs after service recovery, where the failed VL in SFC2 is redirected to the path “Server5—Server4—Server1—AP1—Satellite6”. Meanwhile, the failed VNF2 in SFC3 is migrated to Server4, and the failed VLs are respectively redirected to the paths “Server1—Server4” and “Server4—Server6—AP2—UAV1”. Different SFC recovery schemes inevitably result in varying recovery rates, recovery costs, and post-recovery SFC delay. Considering the high reliability and low delay requirements of aeronautical information services, developing an SFC recovery method that optimizes recovery rate and delay is the main challenge addressed in this work.
In aviation information networks integrated with UAVs, resource platforms include ground cloud servers, aerial UAV platforms, and space-based satellite platforms, thus exhibiting greater heterogeneity compared to the deployment and migration processes of the SFCs in traditional terrestrial networks. Additionally, considering the particularity and criticality of air traffic services, the SFCs in aviation information networks have higher requirements for reliability and latency. To address the failure problem of the SFCs in aeronautical information networks experiencing attacks, this paper first formally models the SFC recovery process from the perspectives of VNF migration and VL redirection. Then, an efficient SFC recovery method for recovery rate optimization (ERRRO) is proposed. Finally, experiments are conducted to evaluate the ERRRO’s performance under networks with different resource redundancy levels and various types of attacks, and to compare the ERRRO with other methods reported in the literature. The main contributions of this paper include the following:
(1) A formal modeling of the SFC recovery process in aeronautical information networks is developed, abstracting the physical network model, the SFC demand model, and the constraints of the SFC recovery process. Evaluation metrics for the SFC recovery methods are defined from the perspectives of service availability, cost-effectiveness, and quality, laying a theoretical foundation for the design of subsequent recovery methods.
(2) An SFC recovery method, named ERRRO, is proposed. It first determines the recovery sequence of the failed SFCs based on recovery cost. Then, it ranks the recovery priority of the failed VNFs by calculating and comparing their neighbor certainty. Finally, it determines the migration destination nodes for the failed VNFs through a topology-aware analysis of the physical network.
(3) Three groups of experiments verify that the ERRRO exhibits good performance under networks with different resource redundancy levels and various attack types. Moreover, a comparison with other published methods further demonstrates that the ERRRO outperforms them in terms of the SFC recovery rate and delay.
The remainder of this paper is organized as follows: Section 2 presents related work; Section 3 formalizes the SFC recovery process in aeronautical information networks; Section 4 introduces the detailed procedure of the proposed method; Section 5 explores the performance of the proposed method through three groups of experiments. Finally, Section 6 concludes the paper.
2. Related Work
As a national critical infrastructure to ensure the efficient and safe operation of UAVs and manned aircraft, the aeronautical information system is a typical cyber–physical system (CPS). The impacts of cyber-attacks on it can propagate from the cyber domain to the physical domain, posing significant threats to public safety and property. Therefore, its security issues have been a focus of both academia and industry. Ref. [8] reviews typical cyber-attacks on the aviation industry from 2001 to 2021, and summarizes the common attackers, attack motivations, and attack types. Ref. [30] analyzes security issues in the communication, navigation, and surveillance (CNS) systems within aeronautical networks, summarizes the vulnerabilities and potential attack vectors in various aviation protocols in the CNS, and emphasizes attacks based on software-defined radio. Ref. [31] categorizes network threats from the perspective of the aircraft into the Passenger Information and Entertainment Services Domain (PIESD), the Airline Information Services Domain (AISD), and the Aircraft Control Domain (ACD), analyzing the impact of cyber-attacks on the capabilities of components within these domains, and models existing attacks using the MITRE ATT&CK® framework.
With the empowerment of new technologies, such as cloud computing, NFV, and edge computing in aeronautical information networks, new cybersecurity threats targeting SFCs have also emerged. Ref. [15] analyzes the potential attack surfaces and threat vectors of SFCs based on the SFC framework and deployment cases, using a layered model to classify these threats. Ref. [32] classifies potential attacks on SFCs using the STRIDE model along three dimensions, intra-layer, inter-layer, and inter-administrative domain, and points out that attackers might breach logical isolation between the VNFs to launch co-residency attacks. Ref. [33] highlights that, while NFV technology enables rapid and low-cost network enhancement and expansion, shared infrastructure resources among different SFCs introduce security vulnerabilities.
A considerable amount of research has been conducted to address the network security threats that SFCs face, focusing primarily on defense mechanisms. Ref. [16] utilizes VNF aggregation technology to design an efficient and secure SFC deployment method optimized for delay, which reduces the risk of service interruption due to attacks without consuming redundant backup resources. Ref. [20] proposes an online reliability protection scheme for handling dynamic SFC requests in distributed cloud networks, employing VNF backup techniques to lower the failure probability of SFC services. Ref. [21] introduces a link protection algorithm based on column generation that enhances SFC security and reliability via VL backup mechanisms. Ref. [34] presents the concept of asymmetric dedicated protection for SFCs, and designs an efficient algorithm to address service function linkage, embedding, and protection problems. Ref. [35] proposes a reinforcement learning-based SFC scheduling strategy that improves the success rate of SFC requests while satisfying low latency and high reliability requirements. Ref. [36] develops a federated learning-based multi-domain SFC deployment backup algorithm that improves SFC survivability by considering isolation and privacy requirements across different network domains. Ref. [37] proposes a security-aware SFC deployment method aimed at load balancing and delay optimization, improving the acceptance rate of SFC requests with security demands. Ref. [38] presents an effective algorithm, called Optimal SFC Embedding and Protection, which reduces network resource costs by developing backup service function path identifiers and resource-aware Bellman–Ford cycles.
In addition, several studies focus on anomaly detection for SFCs. Ref. [39] proposes an end-to-end SFC anomaly detection architecture utilizing a self-attention-based encoder to capture the spatial correlations among the SFC components, detecting anomalies by comparing input data with reconstructed outputs. Ref. [40] presents a distributed teacher–student knowledge distillation framework to perform anomaly detection on each link containing the different VNFs. It uses spatial convolution combined with dilated convolution encoding to capture spatio-temporal dependencies in the SFC data and achieves model lightweighting through knowledge transfer between teacher and student networks. Ref. [41] introduces a feasible framework based on deep learning models that employs text convolutional neural networks and transformer bidirectional encoders to classify SFC faults, enabling rapid and accurate detection and identification of eight fine-grained categories of SFC faults.
However, no defense mechanism can completely prevent networks from being attacked. When an SFC suffers an attack and fails, to mitigate and eliminate the impact caused by the attack, some researchers have focused on the SFC recovery mechanisms. VNF migration is an effective way to rapidly restore the VNFs from failure states. Ref. [29] proposed an active recovery method based on an SFC attack graph and a double deep Q-network, designing three recovery modes for the failed VNFs and selecting any one of them by comparing recovery costs. Ref. [42] presented the Migration Joint Optimization of VNF Migration Cost and Network Energy consumption (MJOVME) algorithm, which adaptively calculates the migration cost and network energy consumption based on bandwidth and other required resources to determine the VNFs to be migrated, then uses a greedy algorithm to migrate the VNFs to the physical nodes with the largest residual resources. Ref. [43] proposed a rapid and adaptive VNF migration (RT) method based on multi-dimensional environment awareness. This method first computes the VNFs to be migrated using a resource-aware algorithm and then selects destination nodes by applying the TOPSIS algorithm considering residual resources and node latency. Ref. [44] introduced a learning-based two-stage algorithm (DLTSA) to solve the VNF migration problem. It determines the VNFs to migrate by comparing resource demands and employs a hybrid genetic evolutionary algorithm to select migration destinations. Ref. [45] proposed a functionality and traffic-aware heuristic algorithm (MRP) to optimize the VNF migration. Its core idea is to allocate the VNFs to appropriate nodes based on traffic-aware index functions, with priority given to the VNFs on nodes with greater computing resources. Ref. [46] developed a matching-game-based efficient recovery algorithm that reduces the time cost required for SFC recovery. Ref. [47] presented a migration-aware and fast-response algorithm to realize rapid migration and response for SFC requests. This algorithm optimizes the migration time while efficiently and flexibly selecting the migration schemes that best match the SFC according to the current network state.
In summary, the aeronautical information network functions as a data exchange system that provides real-time information support for UAVs and manned aircraft, where the running SFCs have stringent requirements on availability and delay. However, the existing SFC recovery methods mainly focus on optimizing recovery costs, with limited attention paid to optimizing recovery rate and delay. To address this issue, this paper proposes an SFC recovery method, named ERRRO, aiming to improve the recovery rate of the SFCs under attack in aeronautical information networks and to optimize the delay of the SFCs after recovery.
3. Formal Modeling
From a functional perspective, the aeronautical information network can be divided into two parts: the physical network and the SFC. The physical network provides hardware support functions, including resource platforms, such as cloud servers, UAVs, satellites, and switching nodes, responsible for data routing and forwarding. The SFC offers software service functions that need to be instantiated within the physical network. This section first formalizes the aeronautical information network from a functional layering perspective, then analyzes the constraint conditions of the SFC recovery process, and finally introduces the performance evaluation metrics for the SFC recovery methods. To further enhance the readability of this paper, the symbols used and their meanings are listed in Table 1.

Table 1.
Symbols and Their Meanings.
3.1. Physical Network
The physical network is abstracted as a weighted undirected graph G = (N, E), where N represents the set of physical nodes (ni ∈ N denotes the i-th physical node), and E represents the set of physical links (eij ∈ E denotes the physical link between nodes ni and nj). The set N includes a resource node set Nr ( ∈ Nr denotes the i-th resource node) and a switching node set Ne ( ∈ Ne denotes the i-th switching node). The resource node set Nr comprises cloud servers Ns ( ∈ Ns denotes the i-th cloud server node), UAVs Nu ( ∈ Nu denotes the i-th UAV node), and satellites Na ( ∈ Na denotes the i-th satellite node). The total computing resource of is denoted as Com(), the total storage resource as Sto(), and the processing delay as d(). When corresponds to a cloud server, UAV, or satellite, considering differences in power consumption and performance, the relationship between total resources and processing delay satisfies the formula presented in Equation (1).
The total bandwidth of link eij is denoted as b(eij), and the transmission delay as d(eij). Physical links connected to UAVs or satellites are wireless links, while the others are wired links. Denote as a wired link and as a wireless link. Considering channel capacity and propagation loss, the relationships between bandwidth and transmission delay for these two types of links satisfy the formula shown in Equation (2).
3.2. SFC
Let the set of SFCs be F, where fi denotes the i-th SFC (fi ∈ F). Let Vi denote the set of VNFs of fi, and Li denote the set of VLs of fi. Let represent the maximum allowable delay for fi, and Ii and Oi denote the source endpoint and destination endpoint of fi, respectively. Let vij denote the j-th VNF in Vi, and Com(vij) and Sto(vij) represent the computing resource demand and storage resource demand of vij, respectively. Let η(vij) denote the bandwidth change factor of vij, which represents the degree of network traffic change caused by the VNF; it is defined as the ratio of outgoing bandwidth to incoming bandwidth. Let lij denote the j-th VL in Li, and b(lij) denote its bandwidth demand. The bandwidth relationship of lij satisfies Equation (3), where b(li0) denotes the initial bandwidth of fi.
When a physical node is attacked and fails, the physical links connected to that node also fail, causing the VLs carried on these physical links to become unavailable. If the failed physical node is a resource node, then the VNFs hosted on it will also fail. Let binary variables S(fi), S(vij), and S(lij) represent the states of the SFC fi, the VNF vij, and the VL lij, respectively, where 0 indicates a normal state and 1 indicates a failure state. The relationship among S(fi), S(vij), and S(lij) is given by Equation (4).
Equation (4) expresses that the necessary and sufficient condition for fi to be in a normal state is that all its constituent VNFs and VLs are in a normal state.
3.3. Constraint Conditions for SFC Recovery
Before the attack occurs, it is assumed that all SFCs are deployed on the physical network and are in a normal operational state. Let the binary variable = 1 indicate that the VNF vij is deployed on physical node nk, and = 0 otherwise. Similarly, let the binary variable = 1 denote that the VL lij is deployed on the physical link ekm, and = 0 otherwise. Once an attack occurs, the affected SFCs transition into a failed state, and their corresponding VNFs and VLs also become failed. At this point, these failed VNFs and VLs must be migrated and redirected, respectively, in order to restore the SFC services. Let the binary variable = 1 represent the migration of the VNF vij to the physical node nk, and = 0 otherwise. Similarly, let the binary variable = 1 indicate that the VL lij is redirected on the physical link ekm, and = 0 otherwise. During the recovery process for the failed SFC fi, the VNF migration and the VL redirection must satisfy the following constraints:
Equation (5) indicates that each failed VNF in fi can only be migrated to one physical node. Equation (6) specifies that each failed VL in fi can be redirected over multiple physical links. Equation (7) states that each resource node can host multiple VNFs, while Equation (8) imposes that each physical link can carry multiple VLs. Equations (9) and (10) ensure that the occupied resources at each resource node do not exceed its total available resources. Equation (11) restricts the total occupied bandwidth on each physical link to be no greater than its total bandwidth capacity. Finally, Equation (12) requires the latency of fi not to exceed its maximum allowable delay.
3.4. Evaluation Metrics
To evaluate the performance of the SFC recovery methods, this paper adopts the following metrics:
(1) Long-term Average Service Recovery Rate Rs: This metric assesses the service availability performance of the SFC recovery method. It is calculated as shown in Equation (13).
where Tmax denotes the maximum number of attacks, represents the set of failed SFCs in the k-th attack, and denotes the set of successfully recovered SFCs in the k-th attack; || and || are the cardinalities of the respective sets.
(2) Long-term Average Service Recovery Cost Cr: This metric evaluates the economic efficiency of the SFC recovery method. The calculation is given by Equations (14) and (15).
Equation (14) computes the recovery cost Cr(k) for the k-th attack. The parameters α, β, and γ represent the weights of computing resources, storage resources, and bandwidth resources in the overall resource cost, respectively. The calculation is detailed in Equation (16). Here, hop(lij) refers to the number of hops after the redirection of the VL lij in the physical network. When designing the calculation methods for α, β, and γ, we consider that the scarcer the resource, the greater its assigned weight should be. Taking the computing resource weight α as an example in Equation (16), if the computing resources in the network are scarcer, the proportion of total computing resources to the total amount of all resources, denoted as , becomes smaller. Therefore, becomes larger, which means α becomes larger accordingly.
(3) Long-term Average Service Delay Dr: This metric measures the quality of service performance of the SFC recovery method. It is calculated as shown in Equations (17) and (18).
Equation (17) computes the average delay of the successfully recovered SFCs in the k-th attack. The numerator represents the sum of delays of the successfully recovered SFCs, where the first term accounts for the sum of processing delays at nodes, and the second term accounts for the sum of transmission delays over links.
4. Design of SFC Recovery Method
This paper considers the recovery of the failed SFCs through VNF migration and VL redirection. When designing the SFC recovery strategy, the following three issues need to be addressed:
(1) How to determine the recovery order of the failed SFCs? When a node in the physical network is attacked, it usually causes multiple SFCs to fail. The resources required to recover each SFC differ, and the SFC restored earlier typically has more resources available to choose from.
(2) How to determine the migration order of the VNFs? Within the same failed SFC, multiple VNFs may fail simultaneously, each with different resource demands and different deployment statuses of the adjacent VNFs. The VNFs migrated earlier usually have more candidate nodes that satisfy their resource demands.
(3) How to determine the destination nodes for VNF migration? During VNF migration, multiple candidate nodes may meet the resource requirements. Different selections of destination nodes will lead to differences in recovery cost and SFC delay.
In addition, regarding the issue of determining the redirection paths of the VLs, this paper adopts the k-shortest path algorithm as the solution. This method is simple to implement and can achieve shorter SFC deployment path lengths, thereby effectively reducing SFC latency. The specific procedure is as follows: first, physical links in the network topology that do not meet the VL bandwidth requirements are removed; then, the k-shortest path algorithm is used to calculate the shortest path between the two endpoints, which is taken as the redirection path.
To address the above three issues, this paper proposes three targeted algorithms: the SFC recovery order algorithm based on migration cost (ROMC), the VNF migration order algorithm based on neighborhood states (MONS), and the migration destination node selection algorithm based on topology awareness (MDNSTA). These three algorithms collectively form the ERRRO method proposed in this paper, and the detailed implementation process is illustrated in Figure 2. When a resource node in the physical network is attacked and fails, the ROMC algorithm is first used to identify the SFCs requiring recovery and to determine their recovery order based on migration cost. For each SFC to be recovered, it is checked whether there exist VNFs that need to be restored. If so, the MONS algorithm is executed to determine the VNF migration order; otherwise, the failed VLs are directly redirected using the k-shortest path algorithm. For each VNF to be migrated in a failed SFC, the MDNSTA algorithm is run to determine the destination node for migration, followed by redirection of the failed VLs using the k-shortest path algorithm.
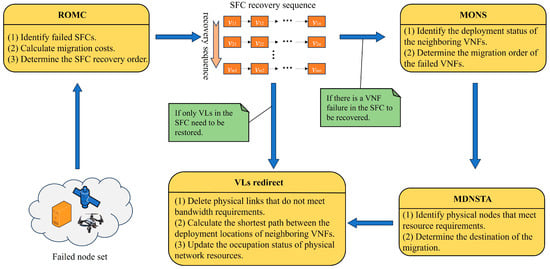
Figure 2.
Implementation process of the ERRRO.
4.1. ROMC
When a physical node is attacked and fails, multiple VNFs and VLs may also fail. If migration and redirection are conducted without considering the affiliation relationships among these failed VNFs and VLs, it may lead to partial restoration of some VNFs and VLs within an SFC while the SFC as a whole remains in a failed state. To effectively improve the service recovery rate, the ROMC algorithm restores services on an SFC-by-SFC basis while taking into account the affiliation relationships of the failed VNFs and VLs. Specifically, it prioritizes the migration and redirection of the failed VNFs and VLs within the same SFC, proceeding only to the next SFC after either the current one is successfully recovered or explicitly declared unrecoverable.
The ROMC algorithm first identifies the set of failed SFCs Ff by filtering according to the affiliation relationships among the failed VNFs and VLs. Then, it calculates the migration cost for each failed SFC, as described in Equation (19).
In Equation (19), the migration cost represents the total resource demands of all VNFs and VLs that need to be restored within the SFC fi, where the first term denotes the sum of the computing and storage resource demands of the VNFs to be recovered in fi, and the second term represents the sum of the bandwidth demands of the VLs to be recovered. Considering that the SFCs with lower resource demands are easier to recover successfully, the ROMC sorts the to-be-recovered SFCs in ascending order of migration cost, prioritizing the recovery process for the SFCs with lower migration costs. The detailed procedure of the ROMC algorithm is presented in Algorithm 1.
| Algorithm 1: ROMC |
| Input: The set Nf of failed physical nodes Output: The SFC sequence Rfs to be restored 1. for nk ∈ Nf 2. Calculate the VNFs set Vf deployed on nk; 3. for vij ∈ Vf 4. S(vij) = 1; 5. end for 6. Calculate the set Ef of links directly connected to nk; 7. for eki ∈ Ef 8. Calculate the VLs set Lf deployed on eki; 9. for lij ∈ Lf 10. S(lij) = 1; 11. end for 12. end for 13. end for 14. Define Ff = ∅; 15. for fi ∈ F 16. if sum(Vi) + sum(Li) > 0 17. S(fi) = 1; 18. Put fi into Ff; 19. Calculate Cost(fi); 20. end if 21. end for 22. Sort the elements in Ff in descending order according to Cost(f), and put the result in Rfs; 23. return Rfs; |
4.2. MONS
After identifying the specific SFC to be recovered, if multiple failed VNFs within them require restoration, the MONS algorithm is employed to determine the recovery order of these VNFs. Since the selection of migration destination nodes later on needs to consider the instantiation locations of the neighboring VNFs as well as the topology attributes of the physical network, the MONS algorithm prioritizes the recovery of the failed VNFs with higher neighbor certainty. The neighbor certainty is defined as the number of neighboring VNFs whose instantiation locations are determined. The detailed computation method is given by Equation (20).
It is important to note that, when a VNF is in a failed state, its instantiation location is uncertain until the migration is successfully completed; once the migration succeeds, the instantiation location becomes determined. Additionally, when calculating the neighbor certainty of the first and last VNFs in an SFC, since the source and destination endpoints of the SFC are fixed, a value of one is added in the formula to account for this.
However, within the same SFC, a VNF can have at most two neighboring VNFs—namely, the VNF immediately preceding it and the one immediately following it. Therefore, the different VNFs may have the same neighbor certainty. In such cases, the recovery order is further determined based on the resource demands of the VNFs. Since the VNFs with higher resource demands are more difficult to find suitable migration destination nodes, the MONS algorithm prioritizes the recovery of the failed VNFs with larger resource demands when their neighbor certainty is equal. When the migration of a certain VNF in fi fails, the algorithm introduces a fallback mechanism that releases all resources occupied by fi, including both the resources used for deployment and those occupied in previous migrations. The detailed procedure of the MONS algorithm is presented in Algorithm 2.
| Algorithm 2: MONS |
| Input: SFC fi to be restored Output: The VNF sequence Rvs to be restored 1. Save the failed VNFS in fi to the set Vif; 2. while Vif is not an empty set 3. for vim ∈ Vif 4. Calculate NC(vim); 5. Res(vim) = Com(vim) + Sto(vim); 6. end for 7. Screen the VNF set Vif1 with the maximal NC(vim) from Vif; 8. Screen the VNF vif with the maximal Com(vim) + Sto(vim) from Vif1; 9. Put vif into the sequence Rvs; 10. Run the MDNSTA algorithm on vif; 11. if vif migration was successful 12. Update the failed VNF in fi; 13. Remove vif from Vif; 14. Clear Vif1; 15. else 16. Release the physical resources occupied by fi; 17. end if 18. end while 19. return Rvs; |
4.3. MDNSTA
After identifying the specific VNF to be recovered, there may be multiple candidate destination nodes available in the physical network for migration. At this point, the MDNSTA algorithm is used to select the optimal destination node. The MDNSTA algorithm first filters the set Φ1 of resource nodes that satisfy the resource requirements of the VNF to be recovered. If Φ1 is empty, it indicates that there are no candidate nodes in the network meeting the VNF’s resource demands, and the algorithm outputs a recovery failure. If Φ1 is not empty, the algorithm then selects from Φ1 the subset Φ2 consisting of resource nodes with the highest topology proximity. The topology proximity of a node indicates the degree of fit between the node, when chosen as the migration destination for a certain VNF, and the deployment path of the SFC to be recovered. When the resource node acts as the migration destination node for the VNF vif to be recovered, its topology proximity Tk(vif) is calculated, as shown in Equation (21).
Here, hop(A,B) denotes the length of the shortest path between nodes A and B. The notation inst(∗) represents the instantiation node of the VNF ∗, forw(vif) indicates the first normal VNF positioned before vif (including the VNFs that have been successfully migrated), and beha(vif) represents the first normal VNF positioned after vif (also including the VNFs that have been successfully migrated). From Equation (21), it can be observed that, when selecting the migration destination node for vif, Tk(vif) measures the distance relationship between the candidate node and the instantiated nodes of forw(vif) and beha(vif) (or source endpoint and destination endpoint). The larger the value of Tk(vif), the smaller the sum of distances between the candidate node and the instantiated nodes of forw(vif) and beha(vif) (or source endpoint and destination endpoint). Consequently, after migrating vif, the deployment path length of fi becomes shorter, resulting in lower latency for fi.
Next, to reduce the “ping-pong effect” among the SFC traffic, the MDNSTA algorithm further filters from Φ2 the nodes set Φ3 satisfying the condition hop(Ii, nr k) > hop(Ii, forw(vif)). If Φ3 is empty, a fallback mechanism is introduced by setting Φ3 = Φ2. Finally, to minimize the delay of the SFC after successful recovery, the MDNSTA algorithm selects, from Φ3, the node with the lowest delay as the migration destination node. The detailed procedure of the MDNSTA algorithm is presented in Algorithm 3.
| Algorithm 3: MDNSTA |
| Input: VNF vif to be restored Output: The migration destination node 1. Screen the node set Φ1 that meets the resource requirements of vif; 2. if is empty(Φ1) 3. return restored failed; 4. else 5. for ∈ Φ1 6. Determine forw(vif); 7. Determine beha(vif); 8. Calculate Tk(vif); 9. end for 10. Screen the node set Φ2 with the maximal Tk(vif) from Φ1; 11. for ∈ Φ2 13. Calculate hop(Ii, ); 14. end for 15. Screen the node set Φ3 from Φ2 that satisfies hop(Ii, ) > hop(Ii, forw(vif)); 16. if is empty(Φ3) 17. Φ3 = Φ2; 18. end if 19. Screen the node with the minimum delay from Φ3; 20. end if 21. return ; |
5. Experimental Results and Analysis
This paper conducts three groups of experiments to verify the performance of the proposed ERRRO method as well as its performance differences compared with the other SFC recovery methods. The first group of experiments evaluates the performance of the ERRRO under varying resource redundancy levels in an aeronautical information network. The second group assesses the ERRRO’s performance under different types of attacked nodes. The third group compares the performance of the ERRRO with several existing methods, including the MJOVME algorithm [42], the RT algorithm [43], the DLTSA algorithm [44], and the MRP algorithm [45]. To eliminate the randomness effect caused by the selection of attack nodes, each group of experiments is performed 100 times, and the average of each run is taken as the final experimental result.
The simulation experiments were conducted using MATLAB R2024b. The experimental host is equipped with an Intel i9-13900HX CPU, an RTX 4060 GPU, and 16GB of RAM. A random connected network, named SubNetwork with 100 nodes, was generated to simulate the aeronautical information network. In the SubNetwork, each node is connected with a probability of 0.05, resulting in a total of 245 links. The network topology is illustrated in Figure 3. Within the SubNetwork, 40 nodes were randomly selected as cloud servers, 10 nodes as satellite platforms, 20 nodes as UAV platforms, and 30 nodes as wireless access points or switches. Links connected to satellite or UAV platforms are considered wireless links, while all other links are wired. A total of 1000 SFCs were generated and deployed in the SubNetwork according to the ESSFCD-DO method proposed in [12]. To ensure the availability of residual resources in the network for SFC recovery, each resource node was constrained with resource redundancy during the SFC deployment process. The resource redundancy level ε is defined as the ratio of the remaining available resources to the total resources at a resource node.
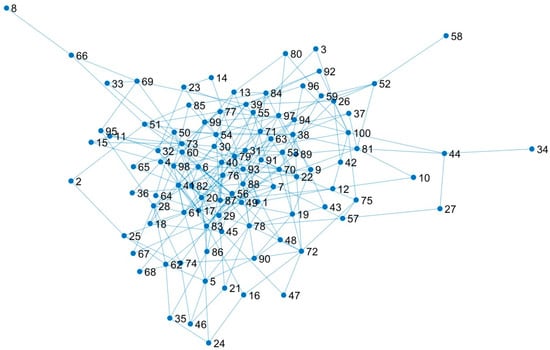
Figure 3.
Network topology structure of SubNetwork.
Each group of experiments conducts 30 attack iterations on the SubNetwork. In each attack, a new node is randomly selected to be attacked and added based on the state of the previous attack. The attacked node immediately fails, and all edges directly connected to it also become invalid. Subsequently, the SFC recovery method is executed to restore the failed SFCs within the SubNetwork. The parameter settings for the experiments are listed in Table 2, where U denotes a uniform distribution.
Table 2.
Simulation parameter.
5.1. Performance of the ERRRO in Networks with Different Resource Redundancy Levels
In the first group of experiments, the resource redundancy level ε was set to 0.1, 0.2, 0.3, and 0.4, respectively, during the deployment of the SFCs in the SubNetwork. Correspondingly, 347, 309, 271, and 232 SFCs were successfully deployed. Then, attack nodes were randomly selected from the set of physical nodes to carry out attacks, and the ERRRO procedure was executed. The experimental results are shown in Figure 4. The same set of attack nodes was used across networks with different resource redundancy levels.
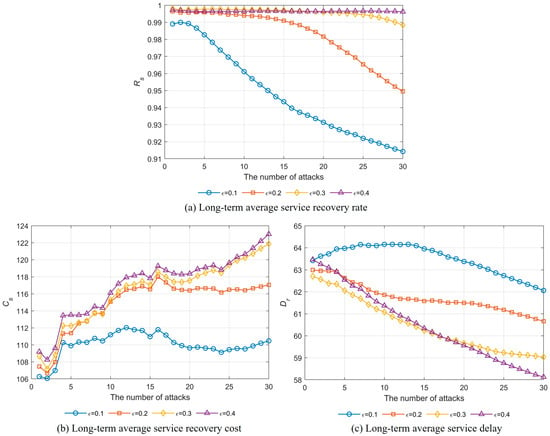
Figure 4.
The performance of the ERRRO in networks with different resource redundancy levels.
Figure 4a shows the long-term average service recovery rate Rs under different resource redundancy levels in the network. Firstly, it can be observed that Rs exhibits an overall decreasing trend as the number of attacks increases. This is because, as the number of failed nodes grows, the number of failed SFCs also increases, while the number of available destination nodes for the VNF migration decreases, thereby reducing the probability of successful SFC recovery. Secondly, Rs increases with the ε. This is because in networks with a larger ε, more node resources are available during the VNF migration, leading to a higher probability of successful SFC recovery. Finally, it can be seen that, in networks with different resource redundancy levels, the ERRRO maintains a recovery rate Rs above 0.91, demonstrating strong performance.
Figure 4b depicts the long-term average service recovery cost Cs under different resource redundancy levels. Firstly, Cs shows an overall rising trend with increasing attack numbers. This is because, as the number of failed nodes increases, the VNF instantiation locations during the SFC recovery become relatively concentrated. If new resource nodes fail subsequently, the number of VNFs needing recovery in each failed SFC will increase, resulting in higher recovery costs. However, if the newly failed nodes are switching nodes without VNFs, the Cs exhibits fluctuations during its increase. Secondly, Cs increases with increasing ε, since networks with a larger ε have more successfully recovered SFCs, and thus incur greater recovery costs. Finally, the ERRRO keeps Cs below 124 across different resource redundancy levels, indicating good cost performance.
Figure 4c illustrates the long-term average service delay Dr in networks with different resource redundancy levels. Firstly, Dr generally decreases as the number of attacks increases. This is because the VNF migration during the SFC recovery leads to more VNFs instantiated on the same resource node, which shortens the SFC path length to some extent. Moreover, when ε = 0.1, the value of Dr first increases and then decreases, showing a trend inconsistent with the other three curves. This is because, at the early stage of attacks with ε = 0.1, there is very little resource redundancy in the network. As a result, the failed VNFs have fewer candidate nodes that meet their resource requirements when searching for migration destination nodes, making it difficult to find candidates that can reduce the SFC delay. Therefore, Dr gradually increases. As the number of attacks increases, some SFCs fail and cannot be recovered, releasing a large amount of resources. Consequently, new failed VNFs have more candidate nodes that satisfy resource demands when selecting migration targets, making it easier to find nodes that reduce the SFC delay. Thus, Dr gradually decreases. Secondly, Dr decreases with increasing ε since networks with a higher ε provide more candidate migration destination nodes that meet the VNF resource requirements, increasing the likelihood that the VNFs migrate to nodes with lower delay. Lastly, the ERRRO maintains Dr below 62 across varying redundancy levels, reflecting a favorable delay performance.
5.2. Performance of the ERRRO Under Different Attack Node Types
In the second group of experiments, the resource redundancy level ε was set to 0.2 during the deployment of the SFCs in the SubNetwork. Then, attack nodes were randomly selected from the sets of switching nodes, resource nodes, and physical nodes, respectively, to launch attacks. The ERRRO procedure was executed for each case, and the experimental results are shown in Figure 5.
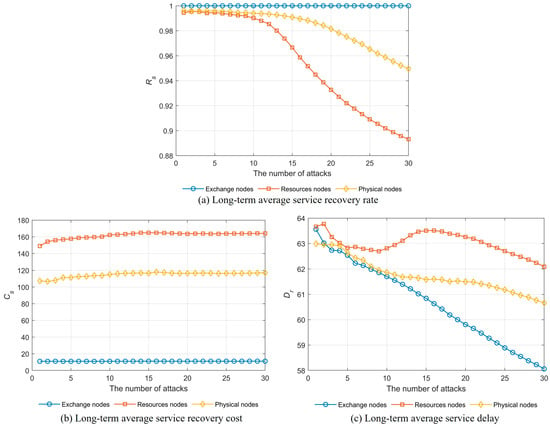
Figure 5.
The performance of the ERRRO under the different types of attack nodes.
Figure 5a presents the long-term average service recovery rate Rs under different types of attacked nodes. It can be observed that, when the attacked nodes are switching nodes, Rs is the highest, followed by physical nodes and resource nodes. This is because the failure of switching nodes does not cause VNF failures; during the SFC recovery process, only the VLs need to be redirected, resulting in the highest probability of successful service recovery. Additionally, the ERRRO maintains Rs above 0.89 across different attack node types, indicating good performance.
Figure 5b shows the long-term average service recovery cost Cs under different attacked node types. The lowest Cs occurs when the attacked nodes are switching nodes, followed by physical nodes and resource nodes. This is because resource node failures lead to both VNF and VL failures, and the recovery process requires computational resources, storage resources, and bandwidth, thereby incurring higher recovery costs. Furthermore, the ERRRO keeps Cs below 165 for all attack node types, reflecting favorable cost performance.
Figure 5c depicts the long-term average service delay Dr under various attacked node types. The lowest Dr appears when the attacked nodes are switching nodes, followed by physical nodes and resource nodes. This is because, when switching nodes fail, the SFC recovery process only alters the local instantiation path of the SFC without changing the VNF instantiation locations, so the SFC delay remains almost the same as before failure. Moreover, the ERRRO maintains Dr below 62 across different attack node types, demonstrating good delay performance.
5.3. Performance Differences Between the ERRRO and Other Methods
In the third group of experiments, the resource redundancy level ε was set to 0.2 during the deployment of SFCs in the SubNetwork. Then, attack nodes were randomly selected from the set of physical nodes to launch attacks. The ERRRO, MJOVME, RT, DLTSA, and MRP algorithms were executed, respectively, and the experimental results are shown in Figure 6.
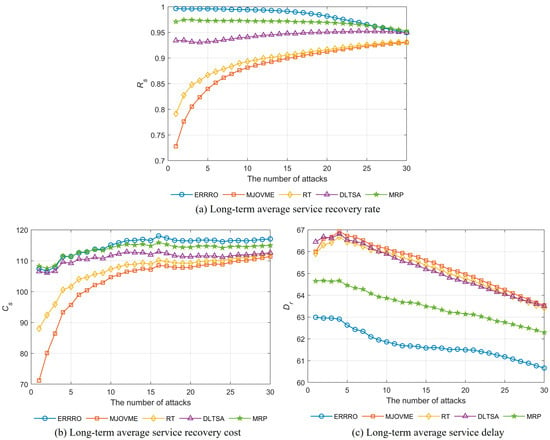
Figure 6.
The performance of the different SFC recovery methods.
Figure 6a shows the long-term average service recovery rate Rs of the different SFC recovery methods. It can be observed that, before the number of attacks reaches 25, the ERRRO achieves the highest Rs, followed by the MRP, DLTSA, RT, and MJOVME successively. After the number of attacks exceeds 25, the Rs values of the ERRRO and MRP tend to converge. This is because the ERRRO prioritizes the recovery of the SFCs with the lowest recovery cost, and when selecting migration destinations for the VNFs, it uses topology awareness to prefer nodes with the greatest topological proximity. As a result, the migrated SFCs are more likely to meet delay constraints, thereby improving the probability of successful recovery. Additionally, it can be seen that the Rs values of the ERRRO, MRP, and DLTSA either decline or stabilize as the attacks increase, while those of the RT and MJOVME show an increasing trend. This is due to the fact that, in the early stages of attacks, a considerable number of failed SFCs in the RT and MJOVME can successfully execute the VNF migrations and the VL redirections but fail to meet the delay constraints, resulting in low recovery rates. However, this also causes most surviving SFCs to have relatively relaxed delay constraints, thereby increasing the likelihood of successful recovery in subsequent attacks.
Figure 6b presents the long-term average service recovery cost Cs under the different SFC recovery methods. The MJOVME achieves the lowest Cs, followed by the RT, the DLTSA, the MRP, and the ERRRO. The performance ranking in terms of cost is roughly opposite to that of the recovery rate Rs, which is because the higher the SFC recovery rate, the more resources the failed VNFs and VLs consume, resulting in higher recovery costs.
Figure 6c illustrates the long-term average service delay Dr for the different recovery methods. The ERRRO attains the lowest Dr, followed by the MRP, DLTSA, RT, and MJOVME, with the DLTSA, RT, and MJOVME showing similar delay performance. This is because the ERRRO leverages topological proximity when migrating the VNFs, enabling better alignment of destination nodes with the original SFC deployment paths. Consequently, the path length of the recovered SFCs changes little compared to the pre-failure state, resulting in a lower delay Dr.
6. Conclusions
With the deep integration of new network technologies, such as cloud computing, edge computing, and NFV, into aeronautical information networks, the flexibility of air traffic services has been improved, while the network attack surface has also expanded. This paper addresses the problem of SFC failures caused by attacks on aeronautical information networks and proposes an SFC recovery method, named ERRRO. The ERRRO first employs the ROMC algorithm to calculate the migration cost of the failed SFCs and determines the recovery order based on the computed costs. Then, it uses the MONS algorithm to evaluate the neighbor certainty of each failed VNF within the SFCs to be recovered, establishing the migration order for the failed VNFs accordingly. Finally, the MDNSTA algorithm is applied to jointly consider topology attributes, delay, and the “ping-pong effect” of traffic in selecting the migration destination nodes for the VNFs. The experimental results demonstrate that the ERRRO consistently achieves superior performance across networks with varying resource redundancy levels, and effectively handles different types of attacks. Furthermore, compared with existing methods in the literature, the ERRRO exhibits advantages in terms of the SFC recovery rate and delay.
Author Contributions
Conceptualization, B.W.; methodology, Y.Y.; software, Y.Y.; validation, X.L.; formal analysis, Y.Y.; investigation, S.L.; resources, J.T.; data curation, S.L.; writing—original draft preparation, Y.Y.; writing—review and editing, B.W.; visualization, X.L.; supervision, J.T.; project administration, B.W.; funding acquisition, B.W. and J.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by National Natural Science Foundation of China under Grant 62472437, 62402520, and 62201610, China Postdoctoral Science Foundation under Grant Number 2024M752586, Young Talent Fund of Association for Science and Technology in Shaanxi under Grant 20240105, Shaanxi Provincial Natural Science Foundation under Grant 2024JC-YBQN-0620, Shaanxi Province Postdoctoral Research Funding Project under Grant 2023BSHYDZZ20, Youth Elite Scientist Sponsorship Program by China Association for Science and Technology under Grant 2024-JCJQ-QT-010.
Data Availability Statement
The datasets used and/or analyzed during the current study are available from the corresponding authors on reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IoT | Internet of Things |
| CAAC | Civil Aviation Administration of China |
| NFV | Network Function Virtualization |
| UAVs | Unmanned Aerial Vehicles |
| APs | Access Points |
| SFCs | Service Function Chains |
| VNFs | Virtual Network Functions |
| VLs | Virtual Links |
| ERRRO | Efficient SFC Recovery Method for Recovery Rate Optimization |
| CPS | Cyber–Physical System |
| CNS | Communication, Navigation, and Surveillance |
| PIESD | Passenger Information and Entertainment Services Domain |
| AISD | Airline Information Services Domain |
| ACD | Aircraft Control Domain |
| ROMC | SFC Recovery Order Algorithm based on Migration Cost |
| MONS | VNF Migration Order Algorithm based on Neighborhood States |
| MDNSTA | Migration Destination Node Selection Algorithm based on Topology Awareness |
References
- Li, A.; Hansen, M.; Zou, B. Traffic management and resource allocation for UAV-based parcel delivery in low-altitude urban space. Transp. Res. Part C Emerg. Technol. 2022, 143, 103808. [Google Scholar] [CrossRef]
- CCTV News Client. More Than 1800 Types of Civilian Unmanned Aerial Vehicles Have Been Registered in China, With a Production Volume Exceeding 1.7 Million. 2024. Available online: https://baijiahao.baidu.com/s?id=1819881521578769055&wfr=spider&for=pc (accessed on 8 April 2025).
- National Bureau of Statistics of China. Civil Aviation Routes and the Number of Aircraft in Service. 2023. Available online: https://data.stats.gov.cn/easyquery.htm?cn=C01 (accessed on 15 April 2025).
- Civil Aviation Administration of China. The Situation Regarding the Promotion of the Construction of the Low-Altitude Flight Service Guarantee System. 2024. Available online: http://www.caacnews.com.cn/special/2024NZT/8024/20191zbzy/202403/t20240329_1376986.html (accessed on 15 April 2025).
- Yang, J.; Sun, K.; He, H.; Jiang, X.; Chen, S. Dynamic virtual topology aided networking and routing for aeronautiCom ad-hoc networks. IEEE Trans. Commun. 2022, 70, 4702–4716. [Google Scholar] [CrossRef]
- Zhang, J. AeronautiCom mobile communication: The evolution from narrowband to broadband. Engineering 2021, 7, 431–434. [Google Scholar] [CrossRef]
- Papa, A.; von Mankowski, J.; Vijayaraghavan, H.; Mafakheriy, B.; Gorattiy, L.; Kellerer, W. Enabling 6G applications in the sky: AeronautiCom federation framework. IEEE Netw. 2024, 38, 254–261. [Google Scholar] [CrossRef]
- Ukwandu, E.; Ben-Farah, M.A.; Hindy, H.; Bures, M.; Atkinson, R.; Tachtatzis, C.; Andonovic, I.; Bellekens, X. Cyber-security challenges in aviation industry: A review of current and future trends. Information 2022, 13, 146. [Google Scholar] [CrossRef]
- Zhou, D.; Sheng, M.; Li, J.; Han, Z. Aerospace integrated networks innovation for empowering 6G: A survey and future challenges. IEEE Commun. Surv. Tutor. 2023, 25, 975–1019. [Google Scholar] [CrossRef]
- Civil Aviation Administration of China. Technology Roadmap for New-Generation Aviation Broadband Communication in China Civil Aviation. 2021. Available online: https://www.caac.gov.cn/XXGK/XXGK/TZTG/202105/t20210518_207630.html (accessed on 2 April 2025).
- Wang, Y.; Wang, H.; Wei, X.; Zhao, K.; Fan, J.; Chen, J.; Hu, Y.; Jia, R. Service function chain scheduling in heterogeneous multi-UAV edge computing. Drones 2023, 7, 132. [Google Scholar] [CrossRef]
- Wang, X.; Shi, S.; Wu, C. Research on service function chain embedding and migration algorithm for UAV IoT. Drones 2024, 8, 117. [Google Scholar] [CrossRef]
- Zoure, M.; Ahmed, T.; Réveillère, L. Network services anomalies in NFV: Survey, taxonomy, and verification methods. IEEE Trans. Netw. Serv. Manag. 2022, 19, 1567–1584. [Google Scholar] [CrossRef]
- Jia, M.; Zhang, L.; Wu, J.; Meng, S.; Guo, Q. Collaborative satellite-terrestrial edge computing network for everyone-centric customized services. IEEE Netw. 2022, 37, 197–205. [Google Scholar] [CrossRef]
- Pattaranantakul, M.; Vorakulpipat, C.; Takahashi, T. Service function chaining security survey: Addressing security challenges and threats. Comput. Netw. 2023, 221, 109484. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, B.; Guo, R.; Tian, J.; Luo, P.; Li, D.; Li, X. Efficient and secure service function chain deployment method for delay optimization in air traffic information network. Sci. Rep. 2024, 14, 25829. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, B.; Tian, J.; Luo, P. Efficient SFC protection method against network attack risks in air traffic information networks. Electronics 2024, 13, 2664. [Google Scholar] [CrossRef]
- Tian, J.; Shen, C.; Wang, B.; Ren, C.; Xia, X.; Dong, R.; Cheng, T. EVADE: Targeted Adversarial False Data Injection Attacks for State Estimation in Smart Grid. IEEE Trans. Sustain. Comput. 2024, 10, 534–546. [Google Scholar] [CrossRef]
- Tian, J.; Shen, C.; Wang, B.; Xia, X.; Zhang, M.; Lin, C.; Li, Q. LESSON: Multi-label Adversarial False Data Injection Attack for Deep Learning Locational Detection. IEEE Trans. Dependable Secur. Comput. 2024, 21, 4418–4432. [Google Scholar] [CrossRef]
- Tian, C.; Cao, H.; Fu, Y.; Garg, S.; Kaddoum, G.; Hassan, M.M. Online and reliable SFC protection scheme of distributed cloud network for future IoT application. Comput. Commun. 2023, 208, 179–189. [Google Scholar] [CrossRef]
- Li, W.; Qu, L.; Liu, J.; Xie, L. Reliability-aware resource allocation for SFC: A column generation-based link protection approach. IEEE Trans. Netw. Serv. Manag. 2024, 21, 4583–4597. [Google Scholar] [CrossRef]
- Bondan, L.; Wauter, T.; Volckaert, B.; De Turck, F.; Granville, L.Z. NFV anomaly detection: Case study through a security module. IEEE Commun. Mag. 2022, 60, 18–24. [Google Scholar] [CrossRef]
- Lu, Y.; Jiang, C.; Tan, L.; Zhang, J.; Zhang, P.; Rong, C. UAV dynamic service function chains deployment based on security considerations: A reinforcement learning method. IEEE Internet Things J. 2024, 24, 39731–39743. [Google Scholar] [CrossRef]
- Guo, H.; Li, J.; Liu, J.; Tian, N.; Kato, N. A survey on space-air-ground-sea integrated network security in 6G. IEEE Commun. Surv. Tutor. 2021, 24, 53–87. [Google Scholar] [CrossRef]
- Liao, A.; Gao, Z.; Wang, D.; Wang, H.; Yin, H.; Ng, D.W.K.; Alouini, M.-S. Terahertz ultra-massive MIMO-based aeronautiCom communications in space-air-ground integrated networks. IEEE J. Sel. Areas Commun. 2021, 39, 1741–1767. [Google Scholar] [CrossRef]
- Li, T.; Wang, B.; Shang, F.; Tian, J.; Calo, K. Online Sequential Attack Detection for ADS-B Data Based on Hierarchical Temporal Memory. Comput. Secur. 2019, 87, 101599. [Google Scholar] [CrossRef]
- Yue, Y.; Cheng, B.; Liu, X.; Wang, M.; Li, B.; Chen, J. Resource optimization and delay guarantee virtual network function placement for mapping SFC requests in cloud networks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1508–1523. [Google Scholar] [CrossRef]
- Chintapalli, V.R.; Partani, R.; Tamma, B.R. Energy efficient and delay aware deployment of parallelized service function chains in NFV-based networks. Comput. Netw. 2024, 243, 110289. [Google Scholar] [CrossRef]
- Zhou, D.; Ji, X.; You, W.; Qiu, H.; Zhao, Y.; Xu, M. DDQN-SFCAG: A service function chain recovery method against network attacks in 6G networks. Comput. Netw. 2024, 254, 110748. [Google Scholar] [CrossRef]
- Dave, G.; Choudhary, G.; Sihag, V.; You, I.; Choo, K.-K.R. Cyber security challenges in aviation communication, navigation, and surveillance. Comput. Secur. 2022, 112, 102516. [Google Scholar] [CrossRef]
- Habler, E.; Bitton, R.; Shabtai, A. Assessing aircraft security: A comprehensive survey and methodology for evaluation. ACM Comput. Surv. 2023, 56, 1–40. [Google Scholar] [CrossRef]
- Madi, T.; Alameddine, H.A.; Pourzandi, M.; Boukhtouta, A. NFV security survey in 5G networks: A three-dimensional threat taxonomy. Comput. Netw. 2021, 197, 108288. [Google Scholar] [CrossRef]
- Zahran, B.; Ahmed, N.; Alzoubaidi, A.R.; Ngadi, A. Security and privacy issues in network function virtualization: A review from architectural perspective. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 475. [Google Scholar] [CrossRef]
- Wang, B.; Li, J.; Cao, S.; Guler, E.; Zheng, D. Security-aware service function chaining and embedding with asymmetric dedicated protection. IEEE Access 2024, 12, 53944–53957. [Google Scholar] [CrossRef]
- Yang, L.; Jia, J.; Lin, H.; Cao, J. Reliable dynamic service chain scheduling in 5G networks. IEEE Trans. Mob. Comput. 2022, 22, 4898–4911. [Google Scholar] [CrossRef]
- Qu, H.; Wang, K.; Zhao, J. Survivable SFC deployment method based on federated learning in multi-domain network. J. Supercomput. 2023, 79, 18198–18226. [Google Scholar] [CrossRef]
- Zhai, D.; Meng, X.; Yu, Z.; Hu, H.; Huang, T. A security-aware service function chain deployment method for load balance and delay optimization. Sci. Rep. 2022, 12, 10442. [Google Scholar] [CrossRef] [PubMed]
- Zheng, D.; Cao, X. Provably efficient service function chain embedding and protection in edge networks. IEEE/ACM Trans. Netw. 2024, 33, 178–193. [Google Scholar] [CrossRef]
- Chen, X.; Kou, J.; Li, H.; Zhang, Y.; Ma, J.; Li, C.; Tu, B. End-to-end anomaly detection of service function chain through multi-source data in cloud-native systems. Comput. Secur. 2025, 155, 104461. [Google Scholar] [CrossRef]
- Tang, L.; Xue, C.; Zhao, Y.; Chen, Q. Anomaly detection of service function chain based on distributed knowledge distillation framework in cloud–edge industrial internet of things scenarios. IEEE Internet Things J. 2023, 11, 10843–10855. [Google Scholar] [CrossRef]
- Guo, K.; Chen, J.; Dong, P.; Liu, S.; Gao, D. FullSight: A feasible intelligent and collaborative framework for service function chains failure detection. IEEE Trans. Netw. Serv. Manag. 2022, 19, 4546–4565. [Google Scholar] [CrossRef]
- Li, W.; Guo, J. Adaptive migration method for virtual network functionality in cloud and blockchain based integrated environment for handling socio-economic systems. IEEE Trans. Consum. Electron. 2024, 70, 6952–6964. [Google Scholar] [CrossRef]
- Shi, Y.; Wang, P.; Zhu, X.; Zhu, H. Reconfigurable digital satellite-borne base station design and virtual function fast migration algorithm. Sensors 2023, 23, 7591. [Google Scholar] [CrossRef]
- Yue, Y.; Tang, X.; Zhang, Z.; Zhang, X.; Yang, W. Virtual network function migration considering load balance and SFC delay in 6G mobile edge computing networks. Electronics 2023, 12, 2753. [Google Scholar] [CrossRef]
- Pham, T.M.; Nguyen, T.M. Function traffic-aware VNF migration for service restoration in an NFV-enabled IoT system. ICT Express. 2024, 10, 374–379. [Google Scholar] [CrossRef]
- Jia, Z.; Cao, Y.; He, L.; Li, G.; Zhou, F.; Wu, Q.; Han, Z. NFV-enabled service recovery in space-air-ground integrated networks: A matching game based approach. IEEE Trans. Netw. Sci. Eng. 2025, 12, 1732–1744. [Google Scholar] [CrossRef]
- Xie, J.; Zhou, R.; Sun, G.; Sun, J.; Yu, H. Fast recovery for online service function chaining interruption using adaptive migration. Cluster Comput. 2022, 25, 1321–1339. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).