
Cross-Scene Multi-Object Tracking for Drones: Leveraging Meta-Learning and Onboard Parameters with the New MIDDTD

Abstract
1. Introduction
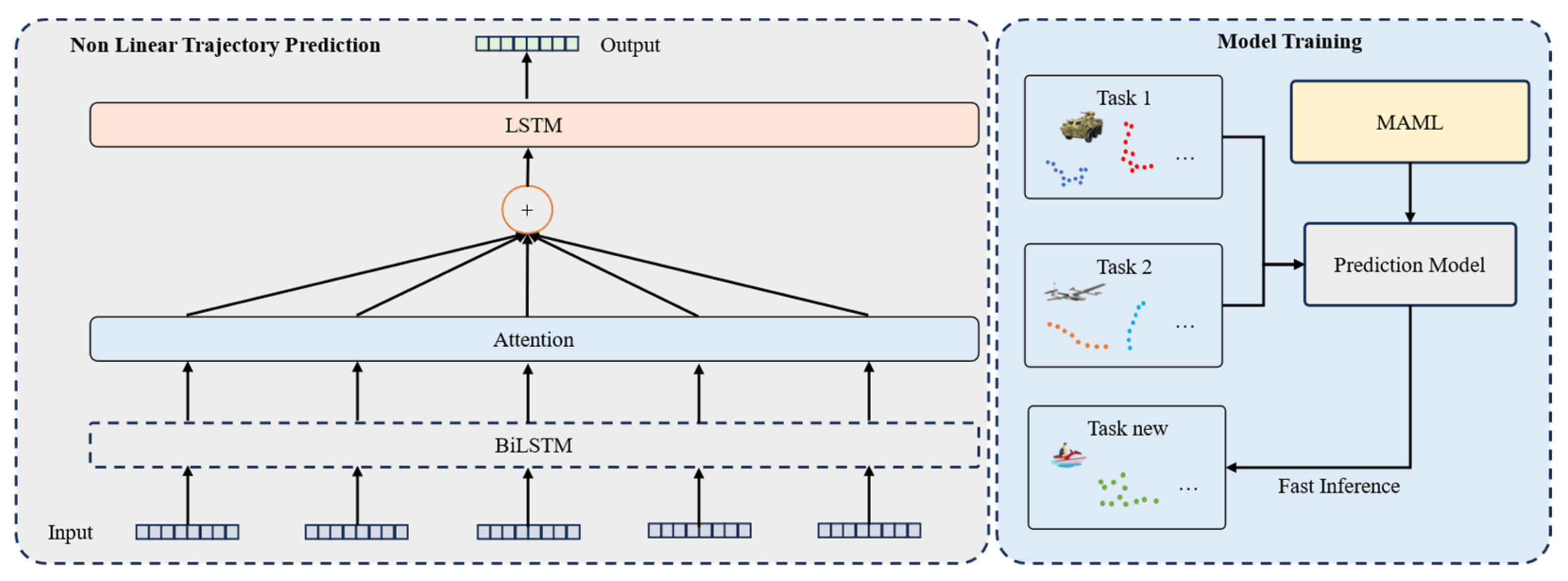
- The Model-Agnostic Meta-Learning (MAML) method is employed to enhance trajectory prediction capabilities. By leveraging the adaptability of MAML in quickly adjusting learned parameters to new tasks, more robust and generalized predictions for dynamic object movements are achieved, significantly improving performance in multi-target tracking scenarios.
- A novel approach for trajectory re-identification is introduced, utilizing Dempster-Shafer (DS) theory to effectively manage and combine uncertain information from multiple sources. This method enhances the accuracy of identifying reappearing targets in complex environments, thereby increasing the reliability of the tracking system.
- The MIDDTD is constructed as a comprehensive dataset specifically designed for air-to-ground multi-target tracking. This dataset integrates diverse scenes and detailed drone-specific parameters, including GPS and IMU data, which support the validation of advanced tracking algorithms and address the limitations of existing datasets focused primarily on pedestrian or vehicle targets.
2. Related Work
3. Method
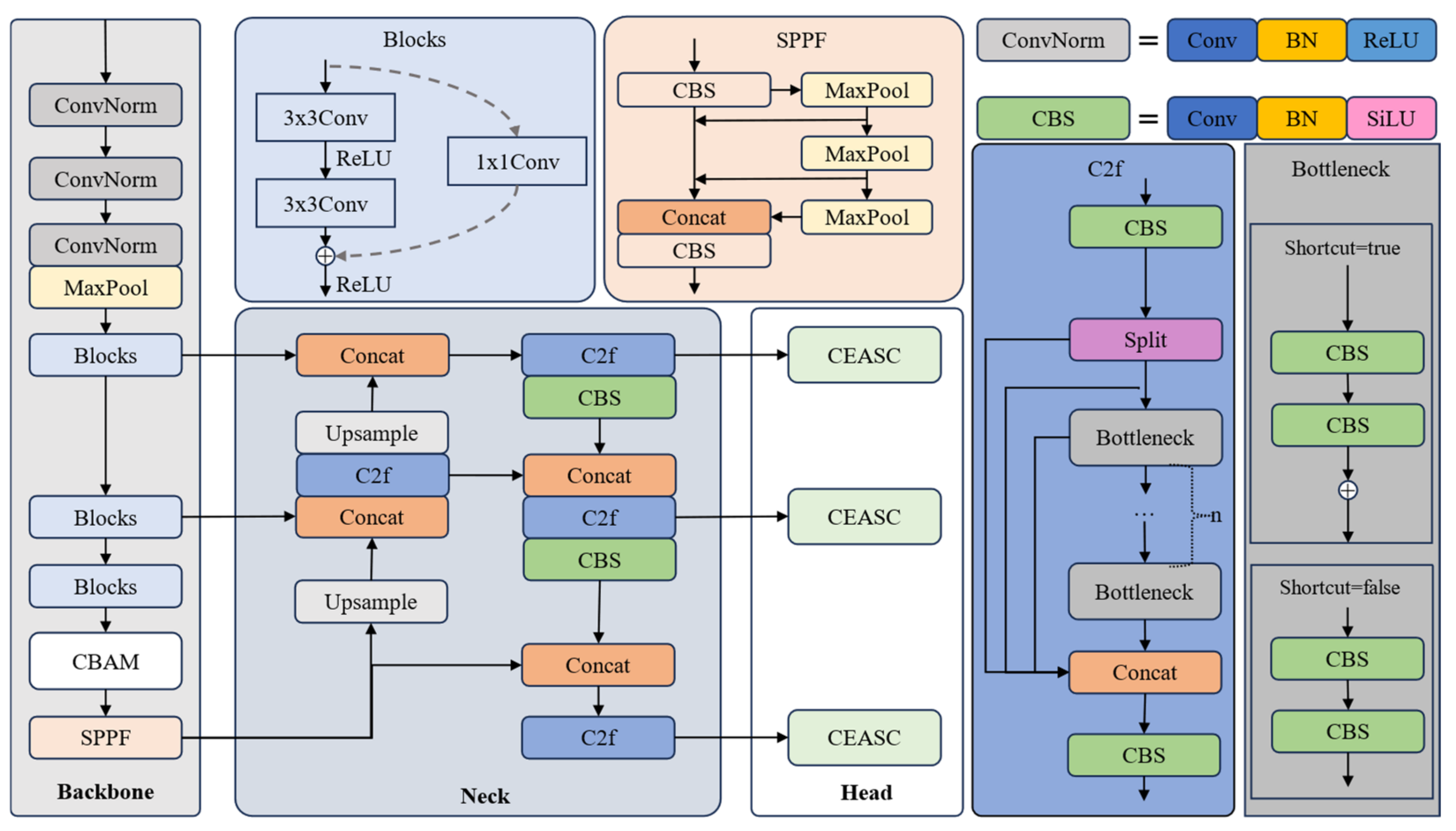
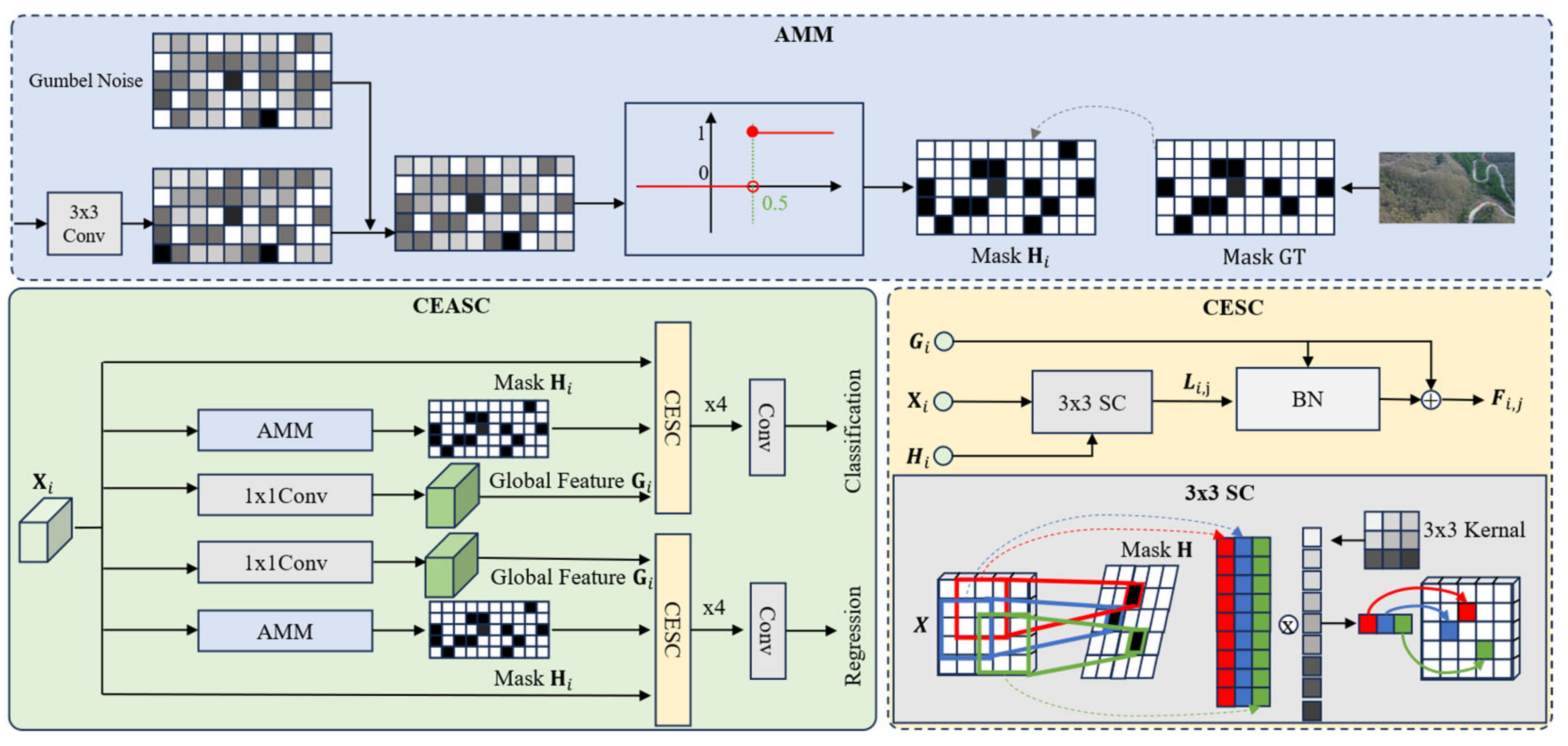
3.1. Detection
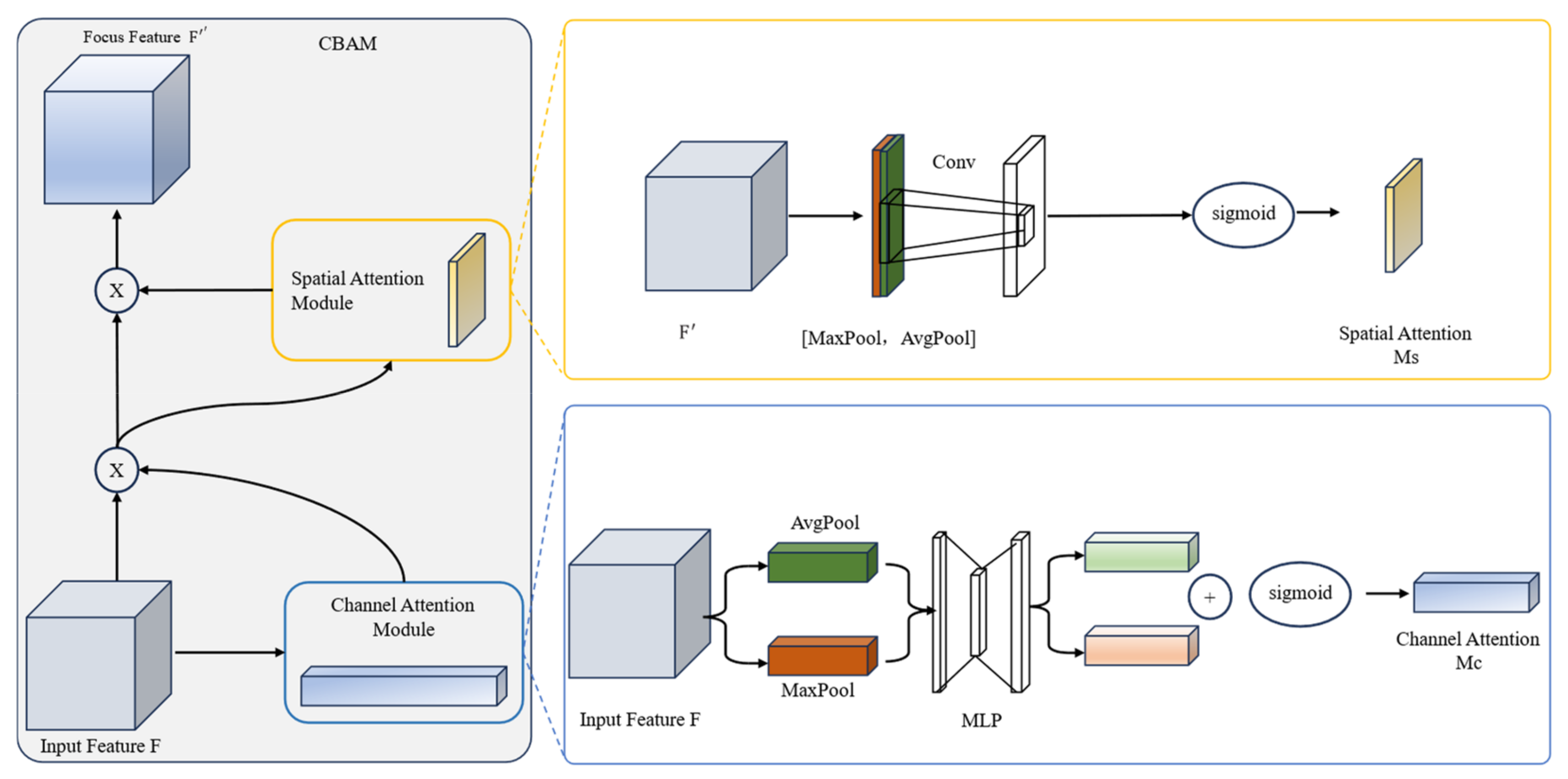
3.1.1. CBAM
3.1.2. CEASC
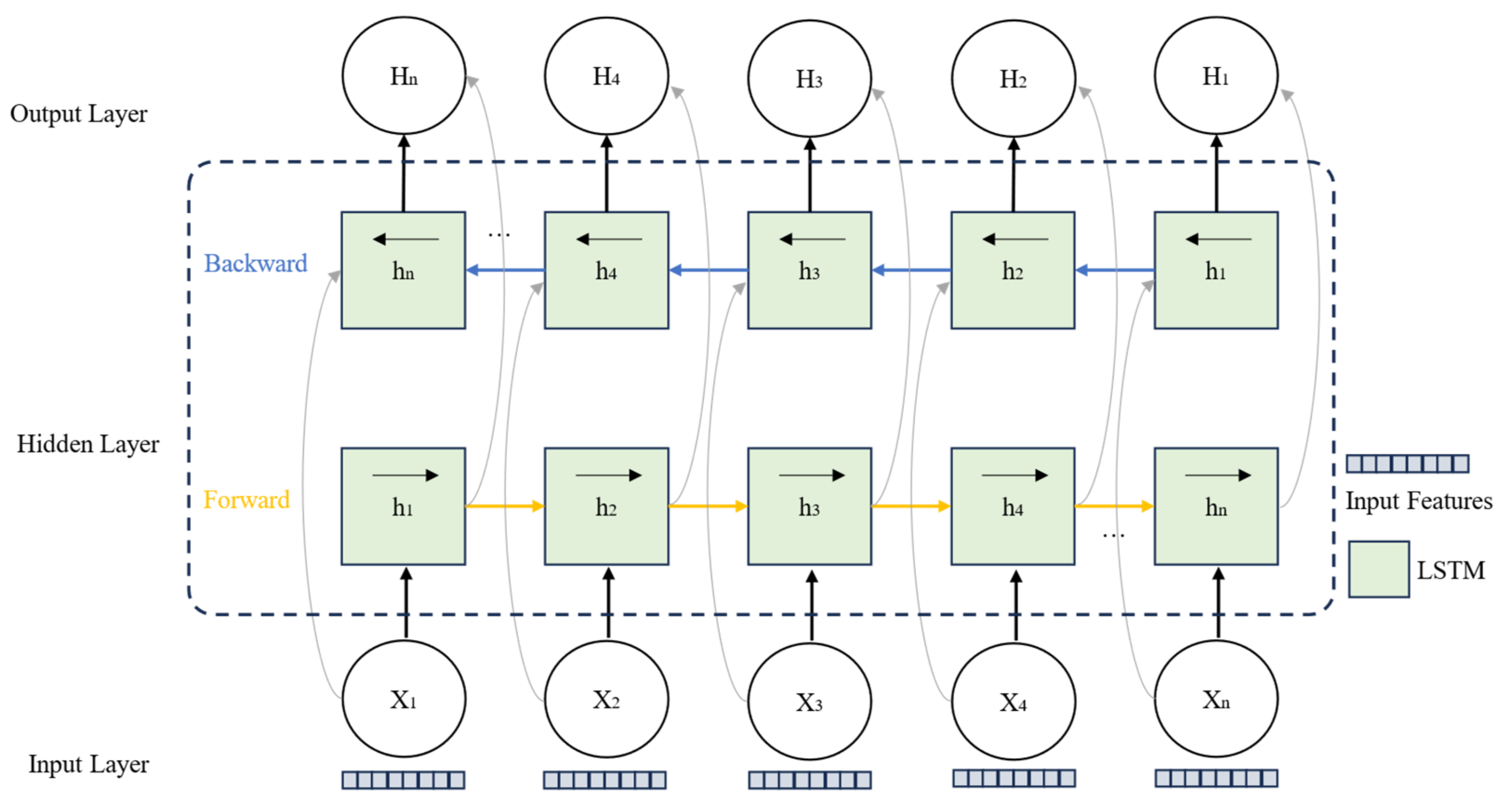
3.2. Trajectory Prediction
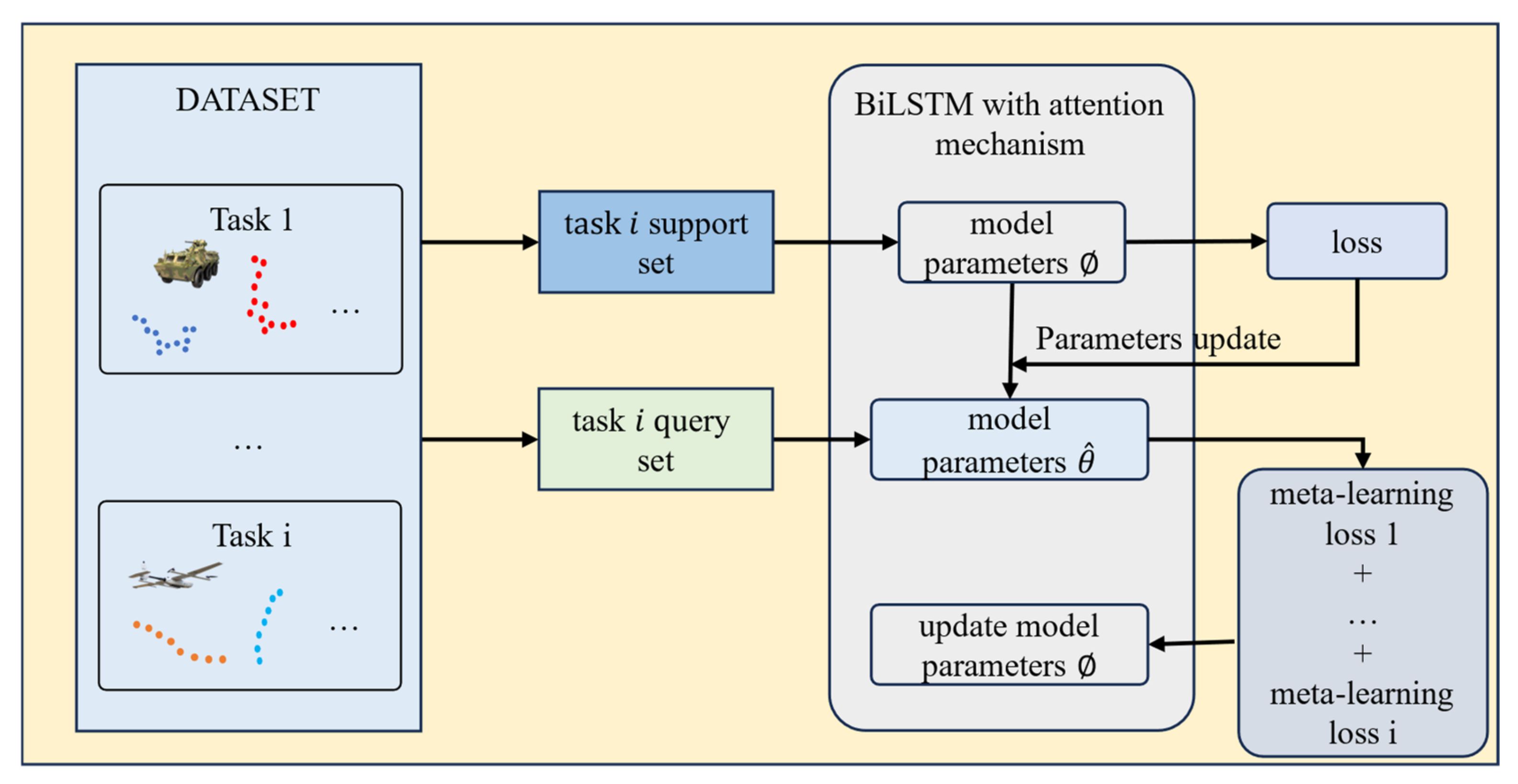
| Algorithms 1. The operational steps for the MAML-based trajectory prediction model. | |
| Initialize the weights of the Bidirectional Long Short-Term Memory (BiLSTM) network as , the attention mechanism parameters as , and the meta-learning optimization parameters (learning rates and ). | |
| 1. | Select a task from the task set . |
| 2. | Update the task-specific parameters from the support set : |
| 3. | Update the general parameters based on the query set : |
| 4. | On new task data , use the meta-learned parameters to quickly adjust with a small amount of data: |
| 5. | Input historical trajectory data: |
| 6. | Extract time-series features: |
| 7. | Calculate the time-step weights: |
| 8. | Sum the weighted hidden states: |
| 9. | Use a fully connected layer to generate future trajectory points: |
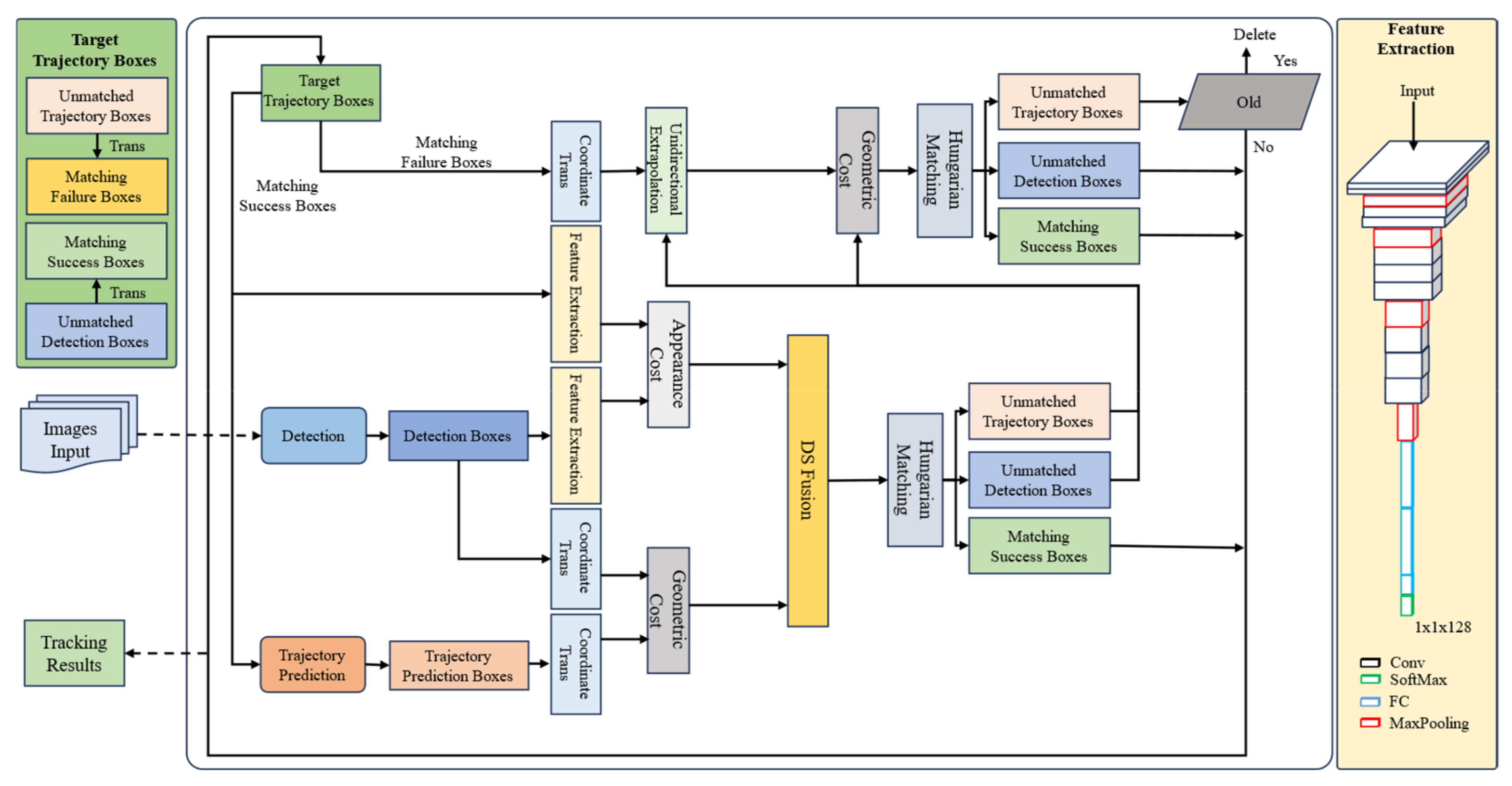
3.3. Re-Identification
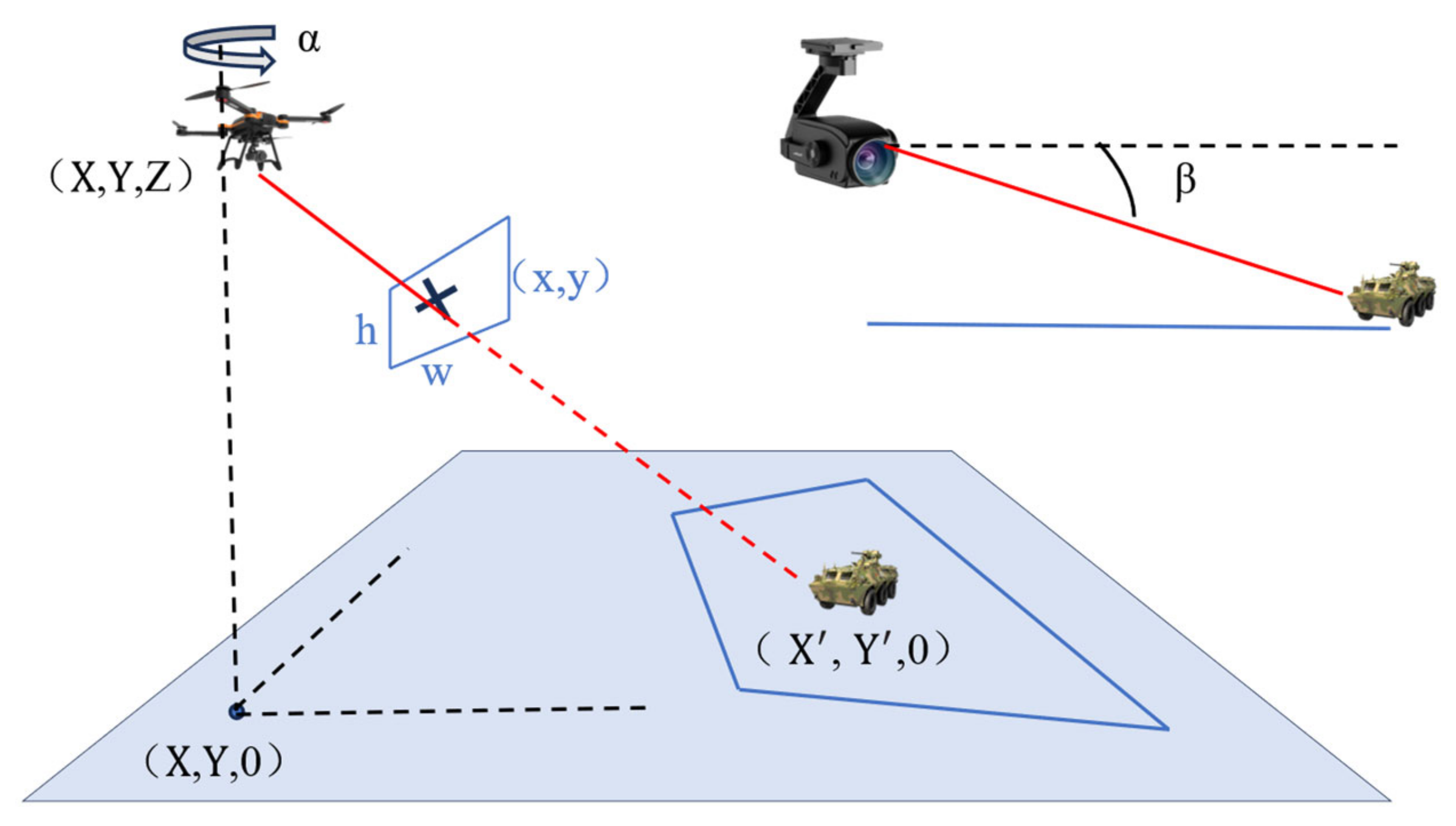
3.3.1. Unidirectional Extrapolation and World Coordinate Transformation
3.3.2. Information Fusion Association Based on DS Theory
- (1)
- Hypothesis Space: Define a hypothesis space that contains all possible target matching results.This represents whether two boxes belong to the same target.
- (2)
- Basic Belief Assignment (BBA): The belief assignment represents the degree of support for hypothesis , satisfying the following:
- (3)
- Belief (Bel): The belief represents the minimum degree of support for hypothesis , i.e., the total belief in and all of its subsets:
- (4)
- Plausibility (PI): The plausibility represents the possibility that is true, including all sets that support and those that overlap with other hypotheses:
- (5)
- Uncertainty: The difference between belief and plausibility reflects the uncertainty of the evidence:
4. Experiments
4.1. Datasets
Detailed Data Acquisition Process
4.2. Implementation Details
4.2.1. Detection Experiment
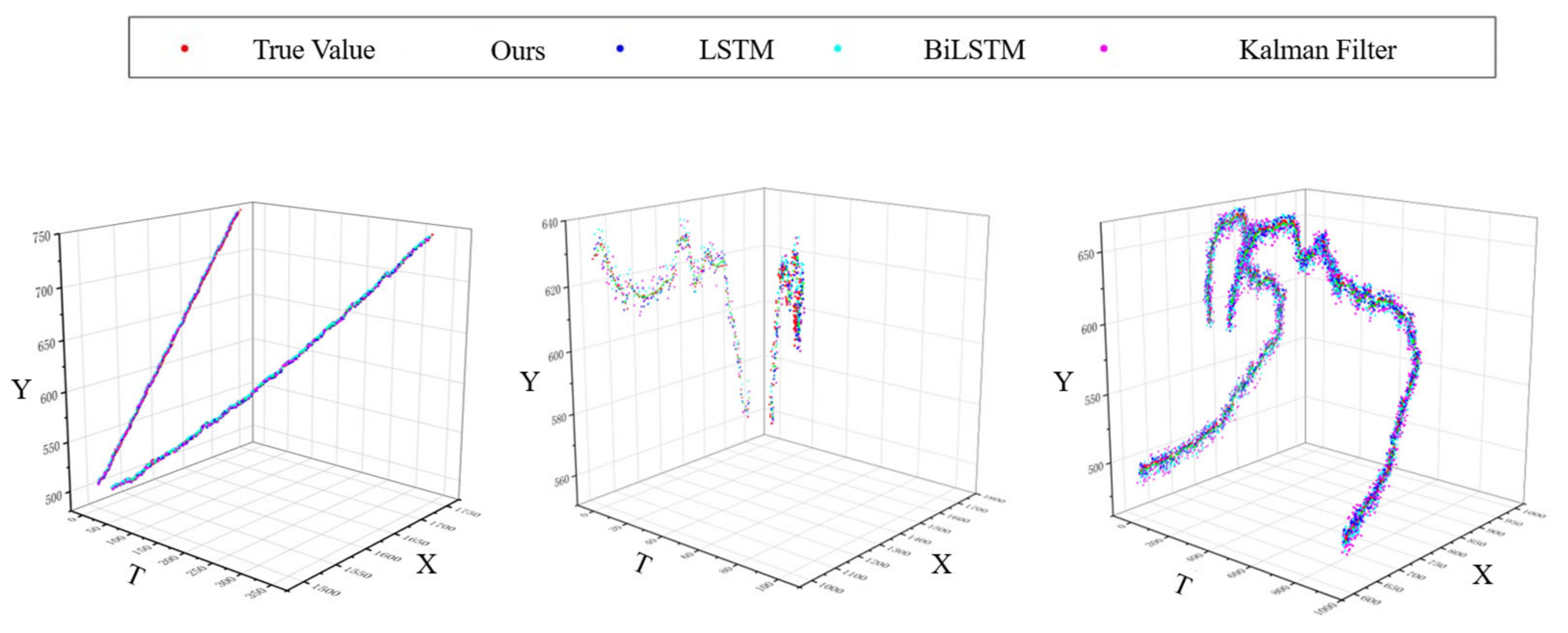
4.2.2. Trajectory Prediction Experiment
4.2.3. Re-Identification Experiment
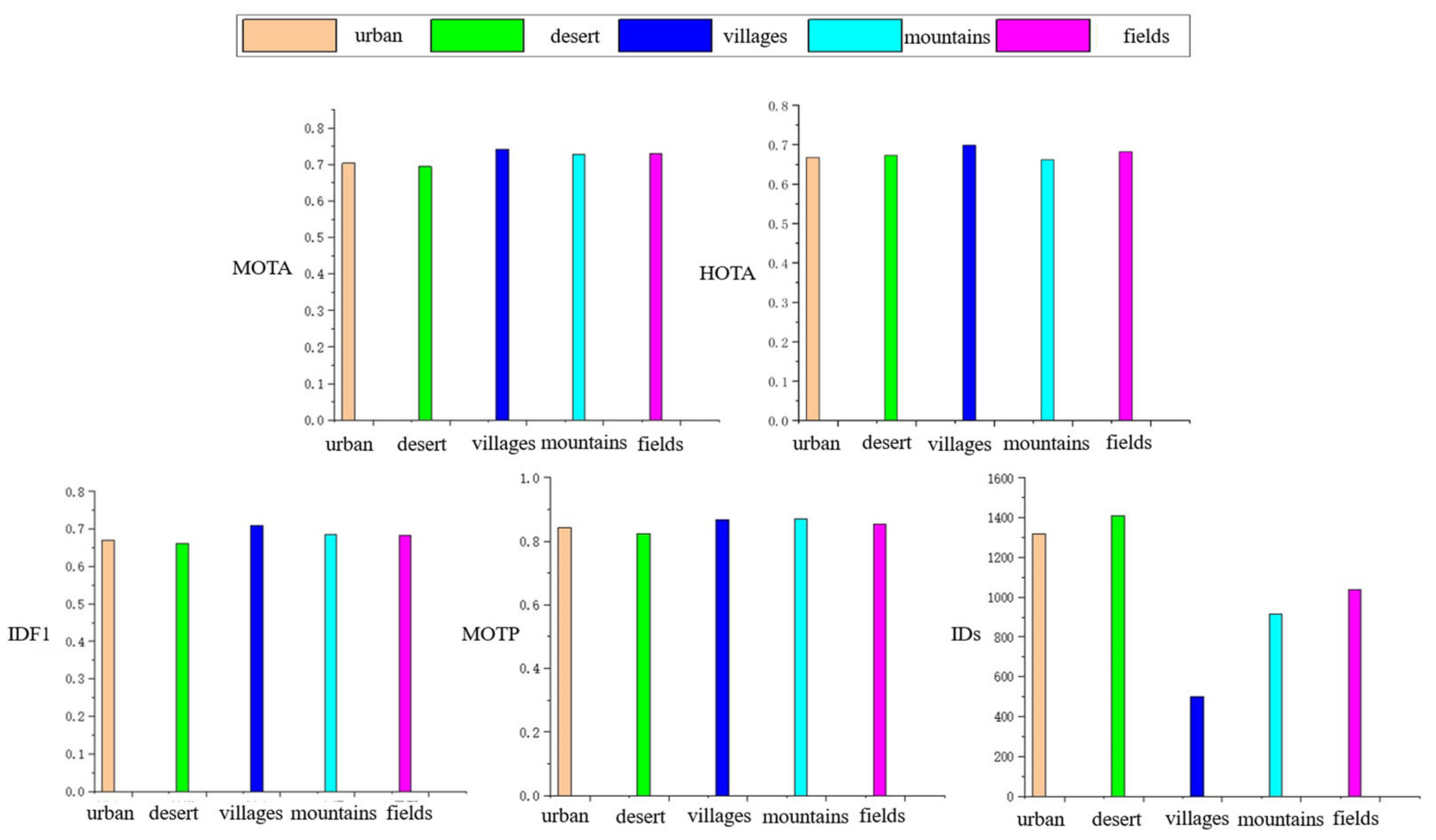
4.3. Ablation Study
5. Conclusions
- A multi-object tracking dataset from the air-to-ground perspective was constructed, containing multiple scenes and annotated with drone GPS coordinates, altitude, and payload attitude parameters. This provides an important foundation for the experiments in subsequent sections and sets evaluation benchmarks for experimental validation.
- A lightweight object detection method based on global context enhancement and layer-decoupling fusion was developed. As the core component of the multi-object tracking method in this paper, this approach improves the performance ceiling for subsequent multi-object tracking.
- A nonlinear trajectory prediction method based on an adaptive BiLSTM network was constructed, further optimizing multi-object tracking performance from the motion feature perspective.
- A target re-identification method based on coordinate data and knowledge fusion was developed. From the perspective of optimization problem solving, it converted and fused the target’s position and feature information, further enhancing the overall performance of multi-object tracking. These four approaches progressively build upon and complement each other, collectively improving the stability of the multi-object tracking system.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Moon, S.; Youn, W.; Bang, H. Novel deep-learning-aided multimodal target tracking. IEEE Sens. J. 2021, 21, 20730–20739. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple Online and RealtimeTracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. RealTime Multiple People Tracking with Deeply Learned Candidate Selection and Per-son Re-Identification. arXiv 2018, arXiv:1809.04427. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. ByteTrack: Multi-object tracking by associating e-very detection box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.Z. BoT-SORT: Robust associations multi-ped-estrian tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-centric sort: Rethinking sort for robust multi-object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9686–9696. [Google Scholar]
- Maggiolino, G.; Ahmad, A.; Cao, J.; Kitani, K. Deep oc-sort: Multi-pedestrian tracking by adaptive re-identification. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; IEEE: New York, NY, USA, 2023; pp. 3025–3029. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards Real-Time Multi-Object Tracking. arXiv 2019, arXiv:1909.12605. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V.; Krahenbuhl, P. Tracking Objects as Points. In Proceedings of the Computer Vision—ECCV 2020 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Yan, F.; Luo, W.; Zhong, Y.; Gan, Y.; Ma, L. Bridging the gap between end-to-end and non end to end multi-object tracking. arXiv 2023, arXiv:2305.12724. [Google Scholar]
- Li, S.; Liu, Y.; Zhao, Q.; Feng, Z. Learning residue-aware correlation filters and refining scale for real-time UAV tracking. Pattern Recognit. 2022, 127, 108614. [Google Scholar] [CrossRef]
- Zhang, F.; Ma, S.; Qiu, Z.; Qi, T. Learning target-aware background-suppressed correlation filters with dual regression for real-time UAV tracking. Signal Process. 2022, 191, 108352. [Google Scholar] [CrossRef]
- He, Y.; Fu, C.; Lin, F.; Li, Y.; Lu, P. Towards robust visual tracking for unmanned aerial vehicle with tri-attentional correlation filters. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 1575–1582. [Google Scholar]
- Mohamed, B.; Noura, J.; Lamaari, H.; Abdelkader, M. Strengthen aircraft real-time multiple object tracking with optical flow and histogram of oriented gradient provided HSMA implemented in low-cost energy VPU for UAV. In Proceedings of the 2023 3rd International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), Mohammedia, Morocco, 18–19 May 2023; pp. 1–5. [Google Scholar]
- Lusardi, C.; Taufique, A.M.N.; Savakis, A. Robust multi-object tracking using re-identification features and graph convolutional networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3868–3877. [Google Scholar]
- Bartoli, A.; Fusiello, A. PAS Tracker: Position, appearance- and size- aware multi-object tracking in drone videos. In Proceedings of the 2021 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2021; pp. 604–620. [Google Scholar]
- Zhang, Z.; Xu, Y.; Song, J.; Zhou, Q.; Rasol, J.; Ma, L. Planet craters detection based on unsupervised domain adaptation. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 7140–7152. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Reddy, R.; Venkata, C. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 18–20 November 2024; pp. 529–545. [Google Scholar]
- Du, B.; Huang, Y.; Chen, J.; Huang, D. Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13435–13444. [Google Scholar]
- Wang, W.; Tan, X.; Zhang, P.; Wang, X. A CBAM based multiscale transformer fusion approach for remote sensing image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6817–6825. [Google Scholar] [CrossRef]
- Bastidas, A.A.; Tang, H. Channel attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Liu, B.; Wang, M.; Foroosh, H.; Tappen, M.; Pensky, M. Sparse convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 806–814. [Google Scholar]
- Verelst, T.; Tuytelaars, T. Dynamic convolutions: Exploiting spatial sparsity for faster inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2320–2329. [Google Scholar]
- Yang, Z.; Li, Z.; Jiang, X.; Gong, Y.; Yuan, Z.; Zhao, D.; Yuan, C. Focal and global knowledge distillation for detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4643–4652. [Google Scholar]
- Xie, Z.; Zhang, Z.; Zhu, X.; Huang, G.; Lin, S. Spatially adaptive inference with stochastic feature sampling and interpolation. In Proceedings of the Computer Vision–ECCV 2020 16th European Conference Part I, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 531–548. [Google Scholar]
- Hartley, R. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Meireles, L.; Guterres, B.; Sbrissa, K.; Mendes, A.; Vermeulen, F.; Lain, L.; Smith, M.; Martinez, J.; Drews, P.; Filho, N.D. The not-so-easy task of taking heavy-lift ML models to the edge: A performance-watt perspective. In Proceedings of the SAC ‘23: 38th ACM/SIGAPP Symposium on Applied Computing, New York, NY, USA, 27–31 March 2023. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MOTA↑ | HOTA↑ | IDF1↑ | MOTP↑ | IDs↓ | FPS↑ |
|---|---|---|---|---|---|---|
| DeepSORT | 0.6498 | 0.5411 | 0.6541 | 0.8444 | 1304 | 7 |
| DeepOcSORT | 0.6509 | 0.6230 | 0.6691 | 0.8339 | 1207 | 6 |
| StrongSORT | 0.6497 | 0.6454 | 0.6492 | 0.8425 | 1258 | 7 |
| OcSORT | 0.6572 | 0.6182 | 0.6518 | 0.8344 | 1295 | 9 |
| BoTSORT | 0.6811 | 0.6344 | 0.6574 | 0.8429 | 1219 | 6 |
| ByteTrack | 0.6931 | 0.6554 | 0.6581 | 0.8391 | 1198 | 9 |
| Ours | 0.7246 | 0.6827 | 0.6883 | 0.8542 | 907 | 8 |
| Method | MOTA↑ | HOTA↑ | IDF1↑ | MOTP↑ | IDs↓ |
|---|---|---|---|---|---|
| DeepSORT | 0.6498 | 0.5411 | 0.6541 | 0.8444 | 1304 |
| DeepSORT+World Coordinates | 0.6655 | 0.5827 | 0.6703 | 0.8534 | 1205 |
| DeepOcSORT | 0.6509 | 0.6230 | 0.6691 | 0.8339 | 1207 |
| DeepOcSORT+World Coordinates | 0.6746 | 0.6403 | 0.6783 | 0.8342 | 1127 |
| StrongSORT | 0.6497 | 0.6454 | 0.6492 | 0.8425 | 1258 |
| StrongSORT+World Coordinates | 0.6541 | 0.6502 | 0.6654 | 0.8455 | 1068 |
| OcSORT | 0.6572 | 0.6182 | 0.6518 | 0.8344 | 1295 |
| OcSORT+World Coordinates | 0.6602 | 0.6355 | 0.6503 | 0.8410 | 1172 |
| BoTSORT | 0.6811 | 0.6344 | 0.6574 | 0.8429 | 1219 |
| BoTSORT +World Coordinates | 0.6791 | 0.6418 | 0.6681 | 0.8532 | 1003 |
| ByteTrack | 0.6931 | 0.6554 | 0.6581 | 0.8391 | 1198 |
| ByteTrack+World Coordinates | 0.7152 | 0.6760 | 0.6753 | 0.8487 | 1095 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Shen, X.; Zhang, Z.; Tao, C.; Xu, Y. Cross-Scene Multi-Object Tracking for Drones: Leveraging Meta-Learning and Onboard Parameters with the New MIDDTD. Drones 2025, 9, 341. https://doi.org/10.3390/drones9050341
Wang C, Shen X, Zhang Z, Tao C, Xu Y. Cross-Scene Multi-Object Tracking for Drones: Leveraging Meta-Learning and Onboard Parameters with the New MIDDTD. Drones. 2025; 9(5):341. https://doi.org/10.3390/drones9050341
Chicago/Turabian StyleWang, Chenghang, Xiaochun Shen, Zhaoxiang Zhang, Chengyang Tao, and Yuelei Xu. 2025. "Cross-Scene Multi-Object Tracking for Drones: Leveraging Meta-Learning and Onboard Parameters with the New MIDDTD" Drones 9, no. 5: 341. https://doi.org/10.3390/drones9050341
APA StyleWang, C., Shen, X., Zhang, Z., Tao, C., & Xu, Y. (2025). Cross-Scene Multi-Object Tracking for Drones: Leveraging Meta-Learning and Onboard Parameters with the New MIDDTD. Drones, 9(5), 341. https://doi.org/10.3390/drones9050341