
Multimodal Fusion of Voice and Gesture Data for UAV Control

Abstract
:1. Introduction
Contributions
- We propose a multimodal interaction integration system that provides intelligent interaction service support for command recognition by dynamically modifying the weights to fuse gesture and speech data to achieve the accurate output of UAV control commands in virtual environments.
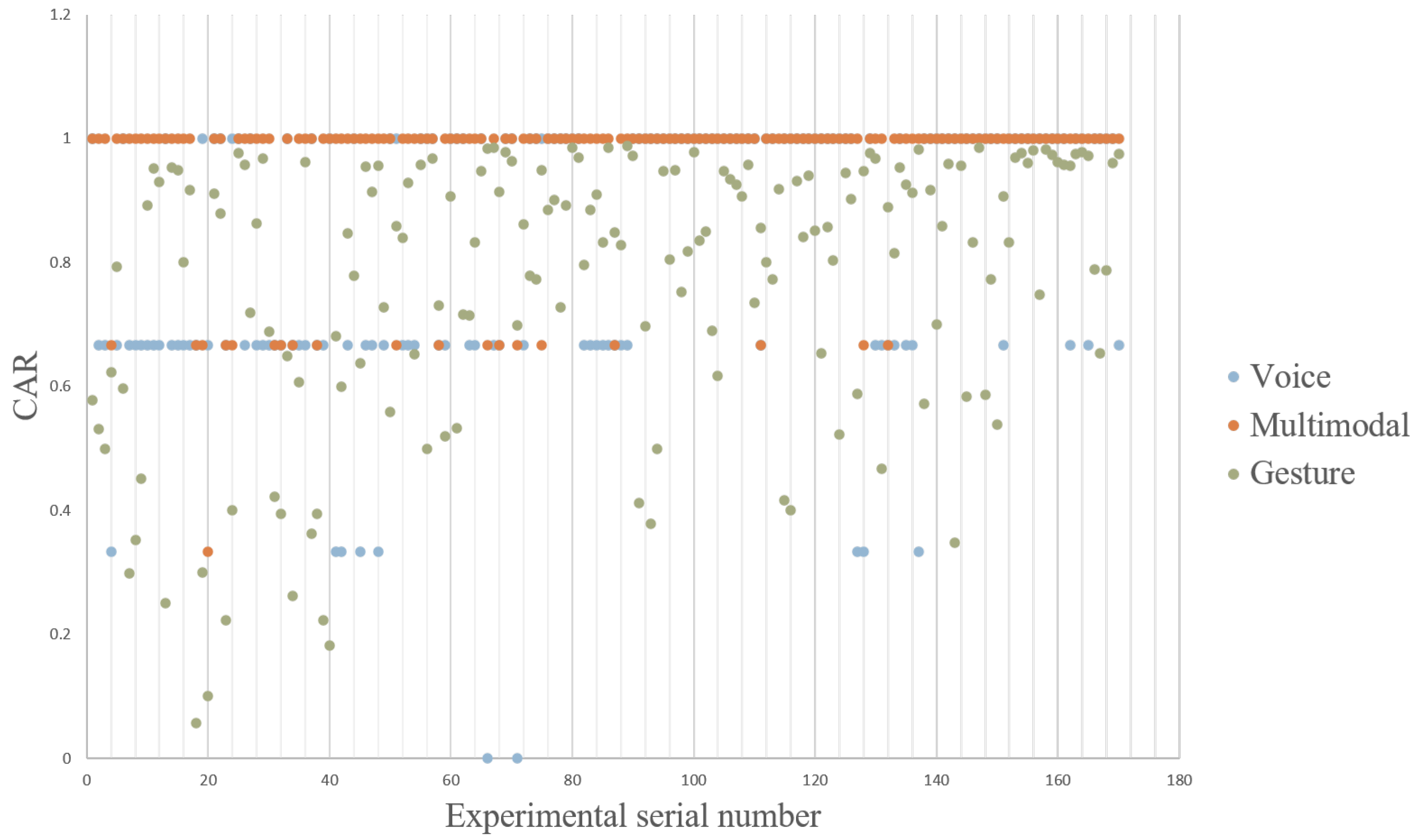
- We investigated gesture-only and speech-only command systems to highlight the respective advantages of these input modes. Meanwhile, we studied the integrated multimodal interaction system with an accuracy of 95.8824% to emphasize the synergy found when combining these modalities. This result is higher than the unimodal method and better than other fusion methods of the same type.
- We constructed the UAV flight simulation for the study of UAV mission operations and combined it with a human–machine efficacy questionnaire to verify the method’s validity.
2. Related Work
- Accepting operator inputs from separate devices.
- Accepting operator inputs as different modes and fusing the input to capture commands related to operator behaviors.
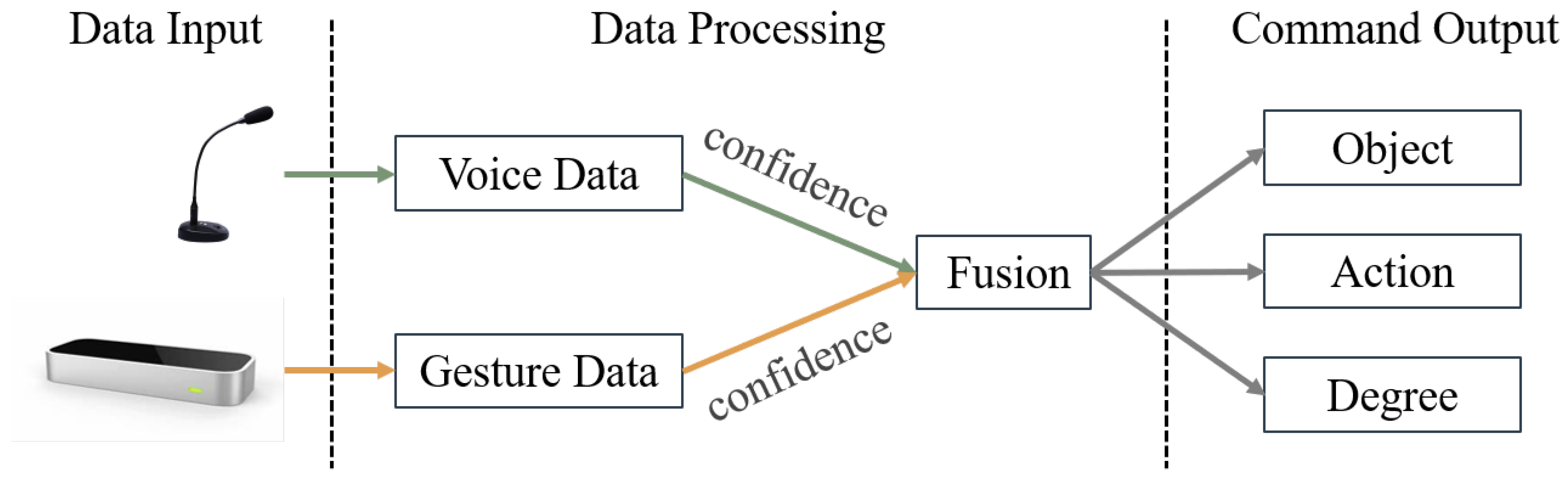
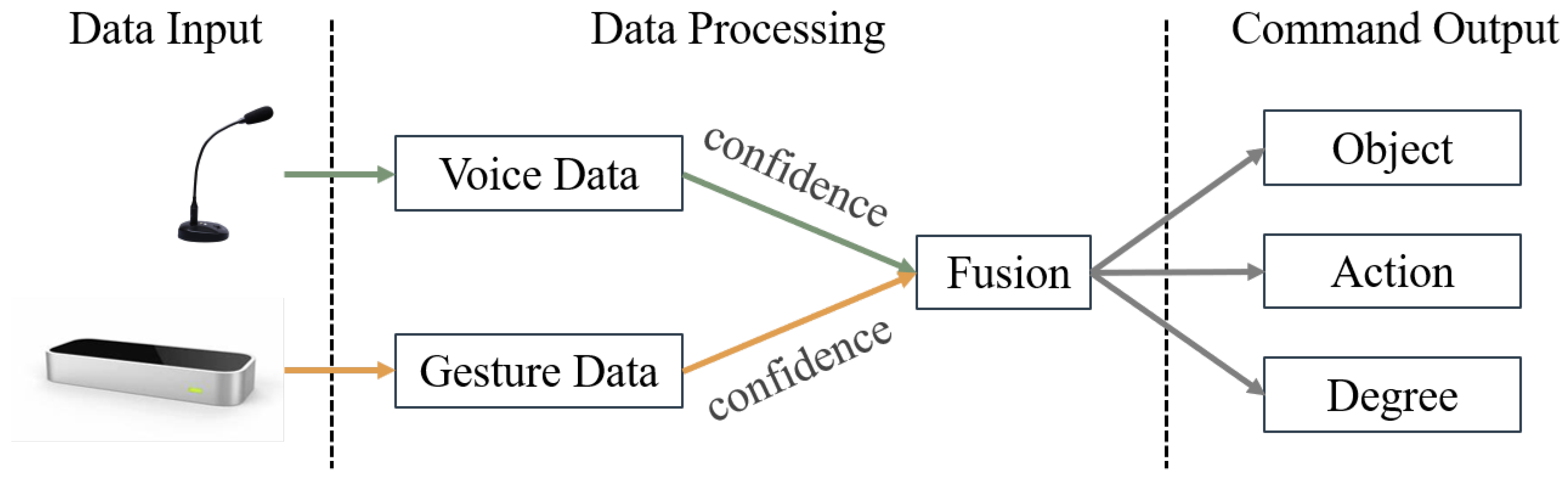
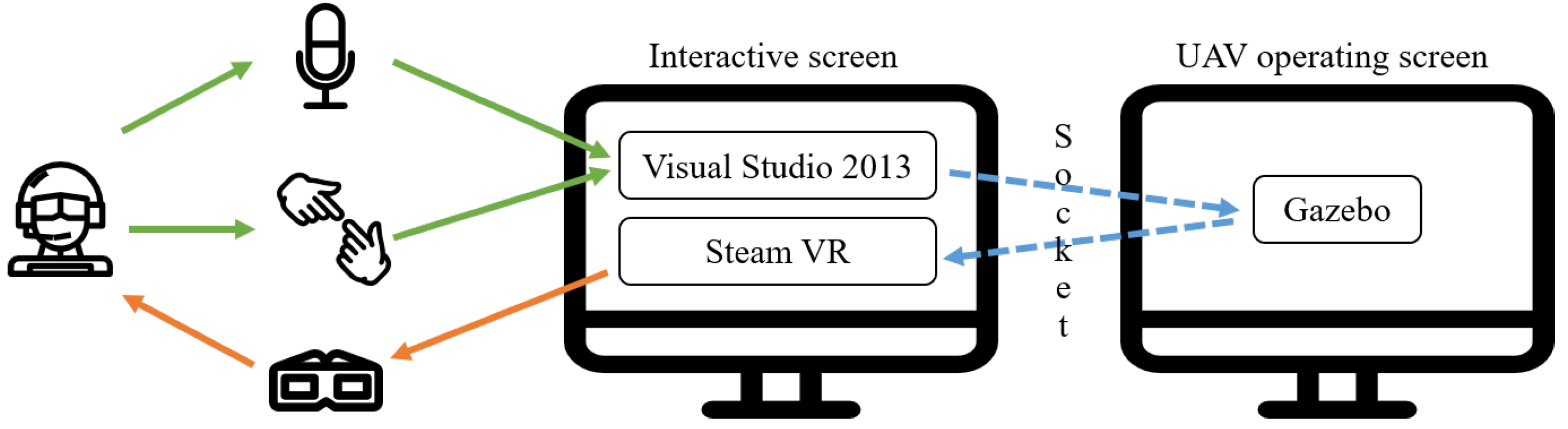
3. Multimodal Interaction Integration System
3.1. Voice Recognition
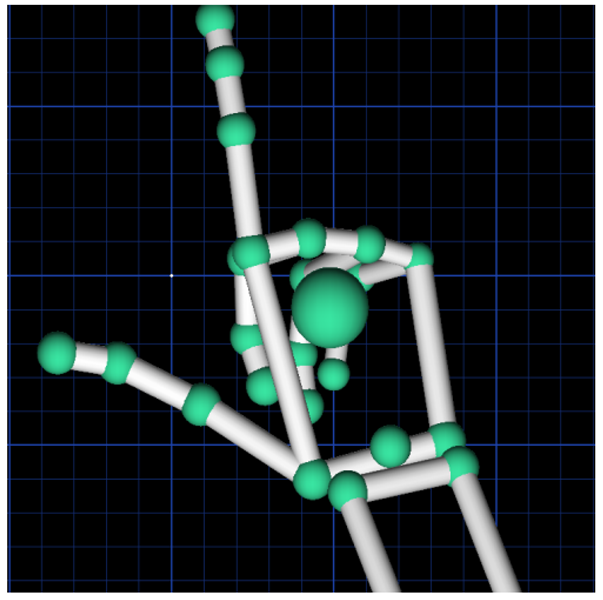
3.2. Gesture Interaction
3.3. Multimodal Fusion Interaction
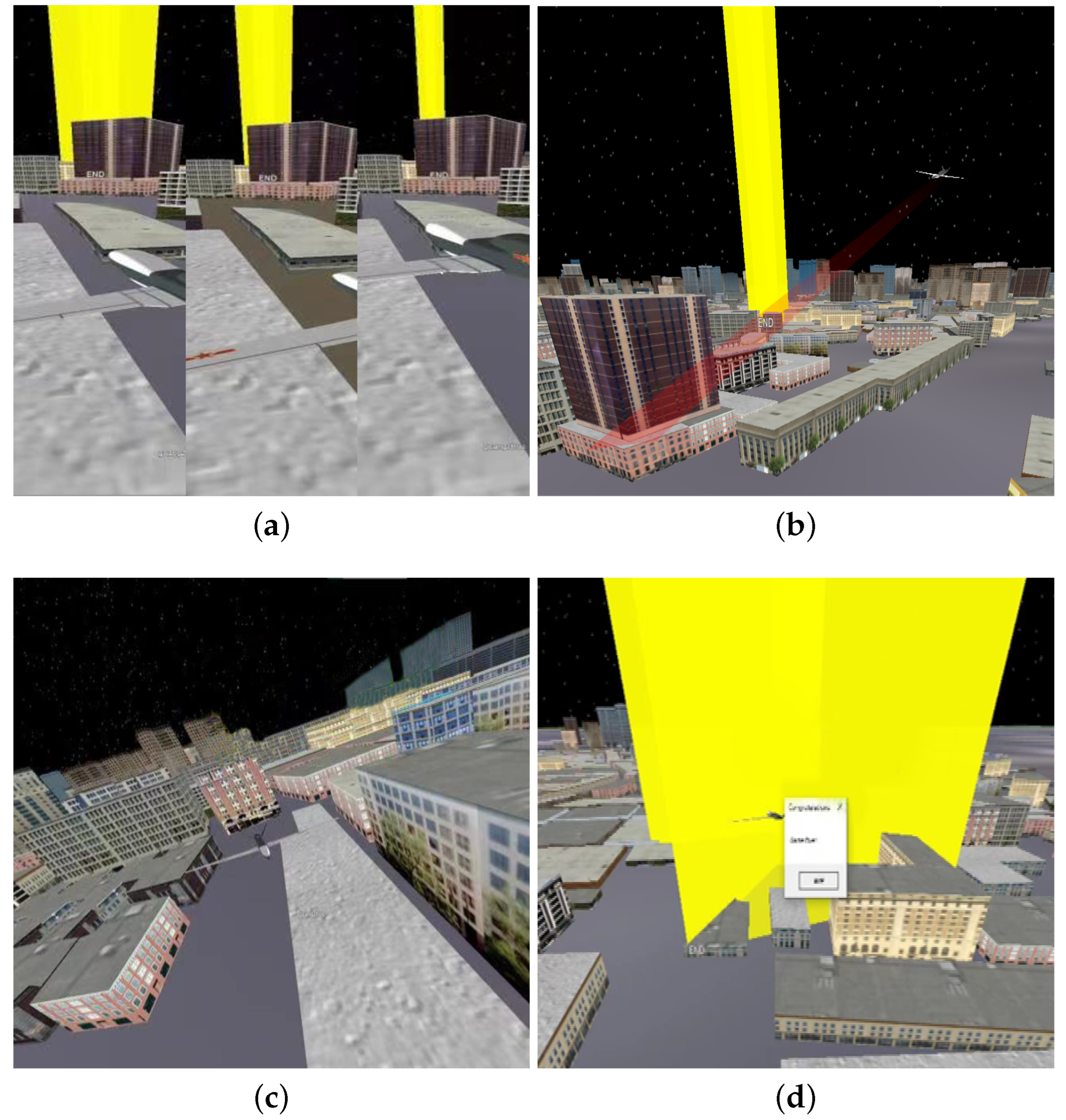
4. Experiments
4.1. Accuracy Test
- Insert : A command that is incorrectly added to the hypothetical script.
- Delete : A command that is not detected from the hypothetical script.
- Substitution : A command that replaces the hypothetical script.
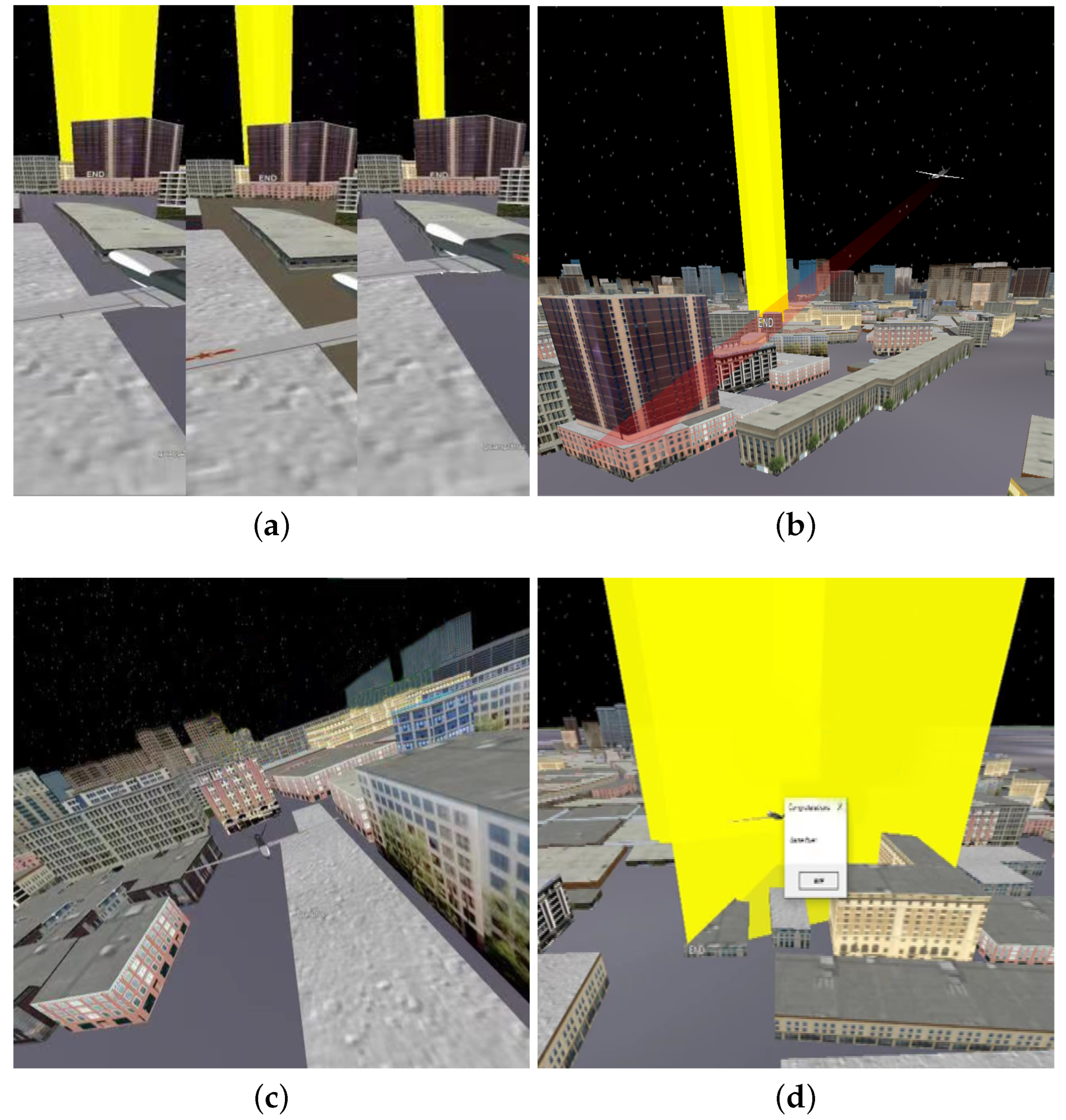
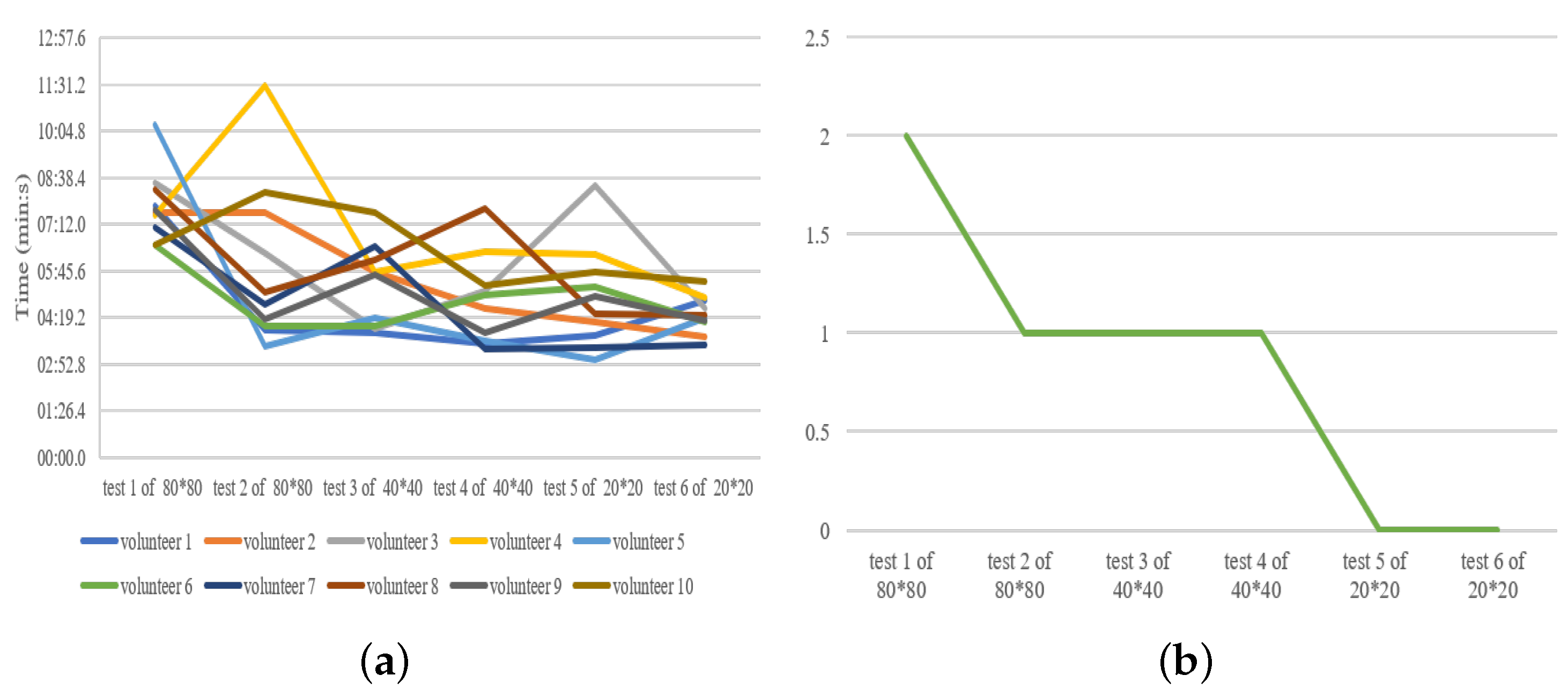
4.2. Human Factor Ergonomics Test
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alexander, G.H.; Paul, M. Gestures with speech for graphic manipulation. Int. J. Man-Mach. Stud. 1993, 38, 231–249. [Google Scholar]
- Kelly, S.D.; Özyürek, A.; Maris, E. Two Sides of the Same Coin: Speech and Gesture Mutually Interact to Enhance Comprehension. Psychol. Sci. 2010, 21, 260–267. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.; Billinghurst, M.; Baek, W.; Green, R.; Woo, W. A usability study of multimodal input in an augmented reality environment. Virtual Real. 2013, 17, 293–305. [Google Scholar] [CrossRef]
- Geraint, J.; Nadia, B.; Roman, B.; Simon, J. Towards a situated, multimodal interface for multiple UAV control. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Anchorage, Alaska, 3–8 May 2010; pp. 1739–1744. [Google Scholar]
- Kensho, M.; Ryo, K.; Koichi, H. Entertainment Multi-rotor Robot that realises Direct and Multimodal Interaction. In Proceedings of the 28th International BCS Human Computer Interaction Conference (HCI), Southport, UK, 9–12 September 2014; pp. 218–221. [Google Scholar]
- Jane, L.E.; Ilene, L.E.; James, A.L.; Jessica, R.C. Drone & Wo: Cultural Influences on Human-Drone Interaction Techniques. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 6794–6799. [Google Scholar]
- Clifford, R.; McKenzie, T.; Lukosch, S.; Lindeman, W.R.; Hoermann, S. The Effects of Multi-sensory Aerial Firefighting Training in Virtual Reality on Situational Awareness, Workload, and Presence. In Proceedings of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Atlanta, GA, USA, 22–26 March 2020; pp. 93–100. [Google Scholar]
- Burger, B.; Ferrané, I.; Lerasle, F.; Infantes, G. Two-handed gesture recognition and fusion with speech to command a robot. Auton Robot. 2012, 32, 129–147. [Google Scholar] [CrossRef]
- Mohd, T.K.; Carvalho, J.; Javaid, A.Y. Multi-modal data fusion of Voice and EMG data for Robotic Control. In Proceedings of the 2017 IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), Columbia University, New York, NY, USA, 19–21 October 2017; pp. 329–333. [Google Scholar]
- Kandalaft, N.; Kalidindi, P.S.; Narra, S.; Saha, H.N. Robotic arm using voice and Gesture recognition. In Proceedings of the 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), UBC, Vancouver, BC, Canada, 1–3 November 2018; pp. 1060–1064. [Google Scholar]
- Chen, Y.; Zhao, H.; Chen, J. The Integration Method of Multimodal Human-Computer Interaction Framework. In Proceedings of the 2016 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 11–12 September 2016; pp. 545–550. [Google Scholar]
- Huang, J.; Jing, H. Research on gesture recognition in virtual interaction based on Leap Motion. Appl. Res. Comput. 2017, 4, 1231–1234. [Google Scholar]
- Shao, L. Hand Movement and Gesture Recognition Using Leap Motion Controller; International Journal of Science and Research: Raipur, Chhattisgarh, India, 2016. [Google Scholar]
- Fang, X.; Wang, Z.; Gao, J. Design of Gesture Interaction System Based on Leap Motion. Mach. Des. Res. 2020, 36, 128–132. [Google Scholar]
- Liu, Y.; Wang, S.; Xu, G.; Lan, W.; He, W. Research on 3D Gesture Interaction System Based on Leap Motion. J. Graph. 2019, 40, 556–564. [Google Scholar]
- Negrão, M.; Domingues, P. SpeechToText: An open-source software for automatic detection and transcription of voice recordings in digital forensics. Forensic. Sci. Int. Digit. Investig. 2021, 38, 301223. [Google Scholar] [CrossRef]
- Kalawsky, R.S. VRUSE—A Computerized Diagnostic Tool: For Usability Evaluation of Virtual Synthetic Environments Systems. Appl. Ergonimics 1999, 30, 11–25. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Syntax File for UAV Command Control |
|---|
| !start <VI>; |
| <VI>::=[<OD>][<AD>][<DD>]; |
| <OD>::=<UAVs>|<viewpoint>|<scene>; |
| <AD>::=<forward>|<back>|<left>...; |
| <DD>::=<large>|<middle>...; |
| <UAVs>::=[<id>]<UAV>; |
| <id>::=1|2|3...; |
| <UAV>::=UAV; |
| <viewpoint>::=current viewpoint position; |
| <scene>::=scene; |
| <forward>::=move forward; |
| <back>::=move back; |
| <left>::=move left; |
| <large>::=large scale; |
| <middle>::=medium scale; |
| Hand Posture | Recognition Results | Action description | Command Information | |
|---|---|---|---|---|
| Object |  |  | Static gesture in which only the index and middle fingers are extended, while the other three fingers are bent. | UAVs |
 |  | Static gesture in which only the thumb and index fingers are extended, while the other three fingers are bent. | Scene | |
 | 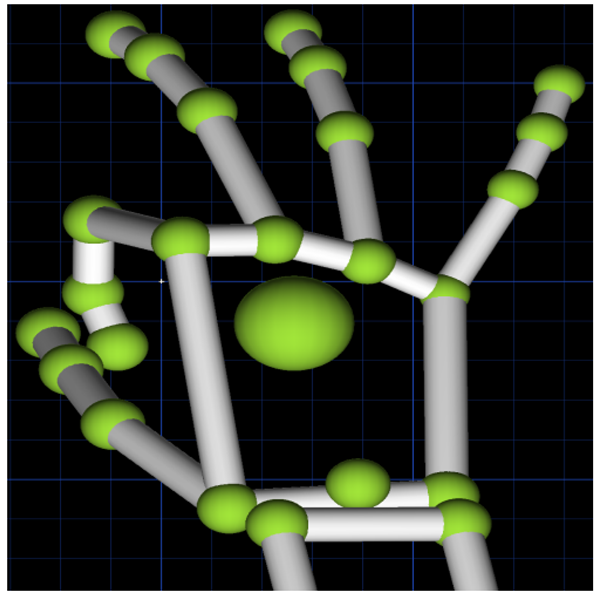 | Static gesture in which only the thumb and index fingers are bent, while the other three fingers are extended. | Viewpoint | |
| Action | 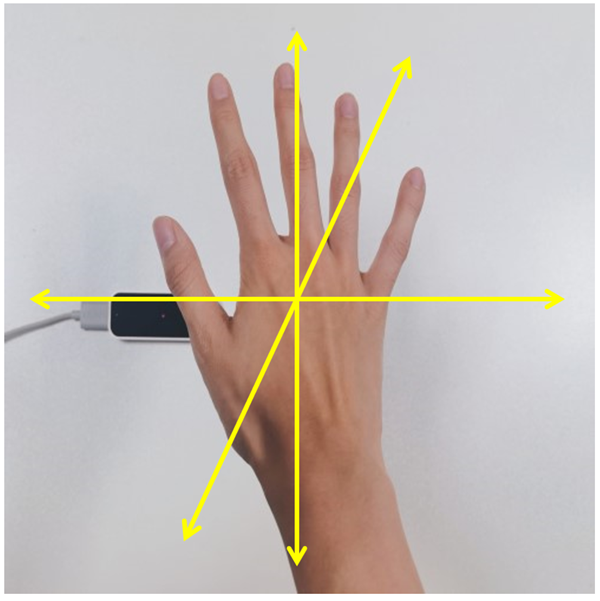 | 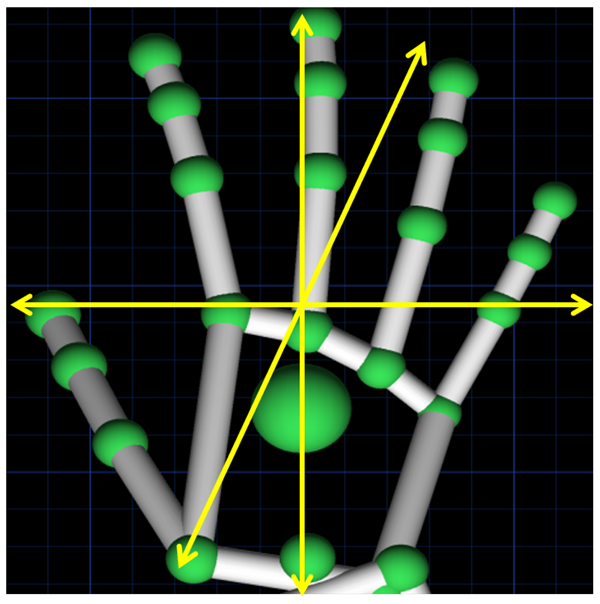 | Five fingers extended and moving forward, backward, left, right, up, or down in parallel movements. | Moving forward, backward, left, right, up, or down |
 | 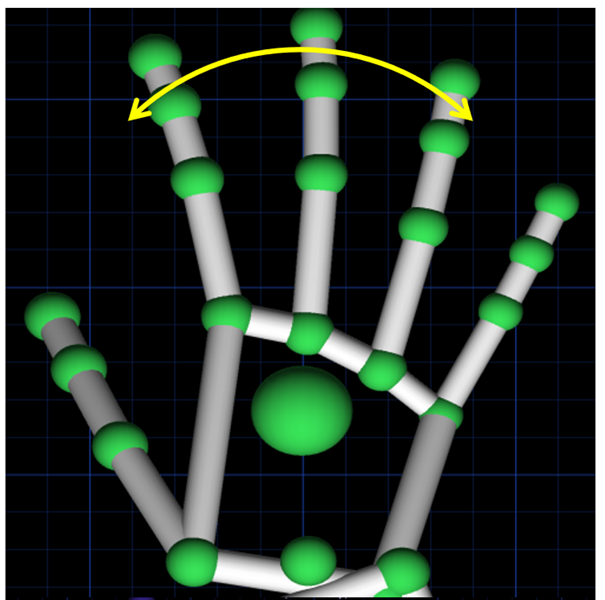 | All five fingers extended and rotating vertically. | UAV yaws to the left or right | |
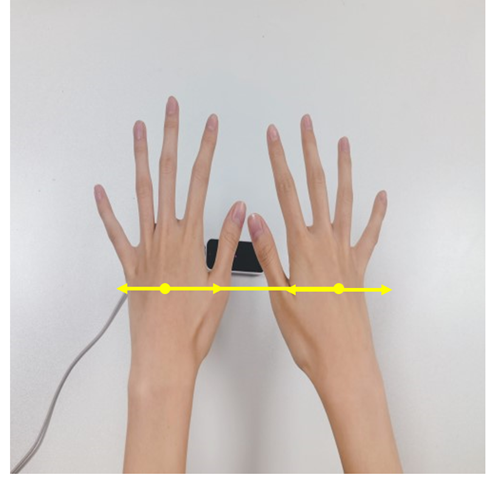 | 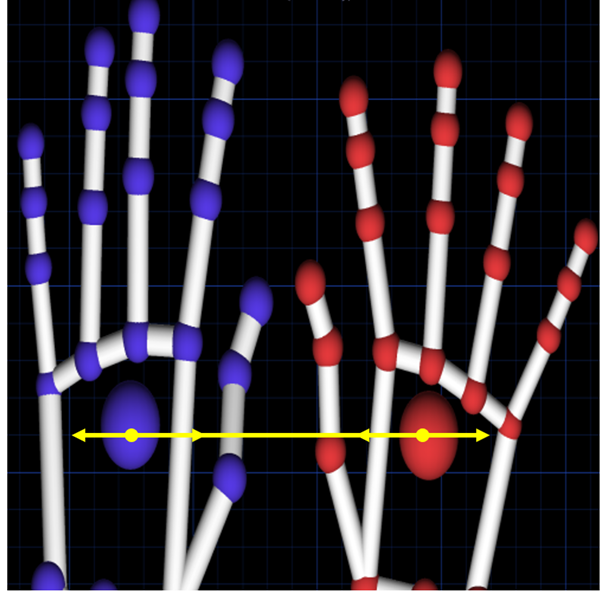 | The five fingers of both hands are extended, and the distance between the hands gradually increases or decreases. | Zooming in or out of the scene. | |
| Degree | _ | _ | The distance between the fingertips is small or large. | Ten or a thousand degrees |
| _ | _ | The yaw rotation angle is small, medium, or large. | 30 degrees, 45 degrees, or 60 degrees |
| Interaction Methods | Gesture | Voice | Multimodal |
|---|---|---|---|
| 76.9502% | 83.8264% | 95.8824% |
| Up | Down | Forward | Backward | Left | Right | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| All | Fault | All | Fault | All | Fault | All | Fault | All | Fault | All | Fault | |
| volunteer 1 | 15 | 0 | 11 | 0 | 49 | 0 | 0 | 0 | 2 | 0 | 23 | 0 |
| volunteer 2 | 13 | 1 | 10 | 0 | 31 | 0 | 0 | 0 | 0 | 0 | 13 | 0 |
| volunteer 3 | 15 | 0 | 16 | 0 | 28 | 3 | 0 | 0 | 10 | 0 | 24 | 0 |
| volunteer 4 | 12 | 1 | 13 | 0 | 35 | 2 | 0 | 0 | 1 | 0 | 17 | 0 |
| volunteer 5 | 21 | 0 | 15 | 0 | 40 | 0 | 0 | 0 | 3 | 1 | 20 | 0 |
| volunteer 6 | 13 | 1 | 15 | 0 | 31 | 2 | 0 | 0 | 1 | 0 | 14 | 0 |
| volunteer 7 | 17 | 1 | 12 | 0 | 21 | 0 | 0 | 0 | 5 | 0 | 9 | 1 |
| volunteer 8 | 17 | 0 | 16 | 0 | 30 | 1 | 3 | 0 | 6 | 0 | 23 | 0 |
| volunteer 9 | 12 | 0 | 10 | 0 | 36 | 2 | 0 | 0 | 2 | 0 | 14 | 1 |
| volunteer 10 | 12 | 1 | 12 | 0 | 24 | 0 | 0 | 0 | 4 | 0 | 15 | 0 |
| the overall | 147 | 5 | 130 | 0 | 325 | 10 | 3 | 0 | 34 | 1 | 172 | 2 |
| Category | Detail | Mode | Average | Variance | |
|---|---|---|---|---|---|
| 1 | Completion | The system supports volunteers in performing the complete task of manning a UAV for urban environment exploration. | 7 | 7 | 0 |
| 2 | Functionality | The system’s method of completing tasks, frequency of operation, and duration are reasonable. | 7 | 6.9 | 0.09 |
| 3 | Interactivity | The system allows volunteers to interact naturally and flexibly with the scene and the UAV in real-time, and where attention is focused more on the task than on the interactive interface and physical devices. | 7 | 6.8 | 0.16 |
| 4 | Consistency | The system responds interactively in the way the volunteer expects, and the feedback is clear and easy to understand. | 7 | 6.7 | 0.41 |
| 5 | Learnability | The system is intuitive and easy to learn. | 7 | 6.8 | 0.16 |
| 6 | Usability | The system is intuitive and easy to use. | 7 | 6.8 | 0.36 |
| 7 | Comfort | The use of helmets, gestures, and voice control in the system did not make volunteers feel fatigued, nauseous, vertigo, or other discomforts. | 7 | 6.7 | 0.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, X.; Tan, Q.; Zhou, H.; Tang, D.; Lai, J. Multimodal Fusion of Voice and Gesture Data for UAV Control. Drones 2022, 6, 201. https://doi.org/10.3390/drones6080201
Xiang X, Tan Q, Zhou H, Tang D, Lai J. Multimodal Fusion of Voice and Gesture Data for UAV Control. Drones. 2022; 6(8):201. https://doi.org/10.3390/drones6080201
Chicago/Turabian StyleXiang, Xiaojia, Qin Tan, Han Zhou, Dengqing Tang, and Jun Lai. 2022. "Multimodal Fusion of Voice and Gesture Data for UAV Control" Drones 6, no. 8: 201. https://doi.org/10.3390/drones6080201
APA StyleXiang, X., Tan, Q., Zhou, H., Tang, D., & Lai, J. (2022). Multimodal Fusion of Voice and Gesture Data for UAV Control. Drones, 6(8), 201. https://doi.org/10.3390/drones6080201