Abstract
This paper focuses on studying a random effects semiparametric regression model (RESPRM) with separable space-time filters. The model cannot only capture the linearity and nonlinearity existing in a space-time dataset, but also avoid the inefficient estimators caused by ignoring spatial correlation and serial correlation in the error term of a space-time data regression model. Its profile quasi-maximum likelihood estimators (PQMLE) for parameters and nonparametric functions, and a generalized F-test statistic for checking the existence of nonlinear relationships are constructed. The asymptotic properties of estimators and asymptotic distribution of test statistic are derived. Monte Carlo simulations imply that our estimators and test statistic have good finite sample performance. The Indonesian rice farming data are used to illustrate our methods.
1. Introduction
A space-time panel dataset is a sample collected from a number of spatial units over time periods. Such data widely exist in various research fields. It is of great theoretical significance and practical value to conduct statistical modeling and analysis on space-time panel data. There are three branches of panel data which are defined as ordinary panel data, spatial panel data, and space-time panel data given the variety heterogeneities of existing panel datasets. The regression models established on basis of ordinary panel data are called ordinary panel data regression models. Ordinary panel data regression models date back to the 1950s when the pioneering paper (Bates et al. [1]) was published. After that, the theories and methods of ordinary panel data regression models have been greatly enriched and they are widely available in many fields, such as economics, management and environmental science, see Chamberlain [2], Baltagi [3], Arellano [4], Baldev and Baltagi [5], and Hsiao [6], among others. Panel data spatial regression models generated from the turn of this century when spatial econometrics literature has exhibited a particular interest in the specification and estimation of econometric relationships based on spatial panel data (Elhorst [7]). Panel data spatial regression models deal with the spatial correlations between different individual units in panel data models and their theories have been well developed and widely used, see Druska and Horrace [8]; Egger, Pfaffermayr, and Winner [9]; Kapoor, Kelejian, and Prucha [10]; Lee and Yu [11], etc.
Two problems hampering when modeling with space-time panel data are serial correlation and spatial correlation. Serial correlation lies between the observations of each spatial unit over time, and it is the domain of the voluminous time-series econometrics literature. Spatial correlation lies between the observations of the spatial units at each time period, and it is of the spatial econometrics literature, a subfield of econometrics for dealing with spatial interaction effects among geographical units such as individuals, firms, governments, etc. In order to overcome the defects that the panel data spatial regression models do not account for serial correlation and the ordinary panel data regression models account for neither spatial correlation nor serial correlation, people have tried to combine serial correlation and spatial correlations, and established panel data paramertic regression models with separable/nonseparable space-time filters, which are used to do researches on estimation, testing and empirical analysis. Elhorst [12] developed ML method of a panel data linear regression model with nonseparable space-time filters, while did not establish asymptotic properties of the estimators. Parent and LeSage [13] explored Markov Chain Monte Carlo methods of random effects panel data linear regression models with separable space-time filters, and the performance of the method was demonstrated by both Monte Carlo simulations and an applied illustration. Lee and Yu [14] studied MLE and its asymptotic properties of fixed and random effects panel data parametric regression models with separable space-time filters. Lee and Yu [15] provided QMLE and its asymptotic properties for a fixed effects panel data linear regression model with disturbances contained both separable space-time filters and nonseparable space-time filters. Baltagi et al. [16] derived several Lagrange Multiplier tests for panel data linear regression model with separable space-time fliters containing random effects. Cohen and Paul [17] analysed the influencing factors of public infrastructure investment on the costs and productivity of private enterprises on basis of 1982–1996 state-level U.S. manufacturing data by panel data parametric regression model with separable space-time filters.
All literature on panel data regression models with separable/nonseparable space-time filters mentioned above focuses on panel data parametric regression models. Although the theories and applications of these models have been well developed, they are often unrealistic in real situations for the reason that they fail to capture complex structure (e.g., nonlinearity) owing to lacking of flexibility. Moreover, the form of parametric regression models may be misspecified, and estimators based on misspecified models are able to cause inconsistency and even erroneous conclusions. Driven by these reasons, Zhao et al. [18] constructed semiparametric minimum average variance estimation method, and proposed a F-test statistic of partially linear single-index panel regression model with separable space-time filters, then proved the asymptotic properties of estimators and test statistic. Bai, Hu, and You [19] established weighted semiparametric least squares and weighted polynomial spline series estimation method for parametric and nonparametric component, respectively, of panel data partially linear varying-coefficient regression model with separable space-time filters, and then proved their asymptotic normalities.
In this paper, we study estimation and testing of random effects semiparametric regression model (RESPRM) with separable space-time filters. By allowing a nonparametric component in parametric regression model with separable space-time filters, it can simultaneously capture the linear and nonlinear effects of covariates, spatial correlation of error structure, serial correlation of remainder error structure, and individual random effects. To the best of our knowledge, there is no related literature on this model. In this paper, we aim to study its profile quasi-maximum likelihood estimation (PQMLE) and hypothesis test methods, and then conduct systematic studies of the asymptotic properties and small sample performance for estimators and test statistic. Furthermore, we illustrate the proposed estimation and testing methods by using a real dataset.
The remainder of this paper is organized as follows. Section 2 introduces the RESPRM with separable space-time filters, and estimators for the model and test statistic for nonparametric component are constructed. Section 3 mainly provides asymptotic properties of estimators, asymptotic distribution of test statistic and conditional assumptions. Section 4 presents the finite sample performance of estimates and F-test statistic through Monte Carlo simulations. Section 5 illustrates the proposed methods by an application of Indonesian rice farming data. Conclusions are summarized in Section 6. The proofs of some important lemmas and theorems are given in Appendix A.
2. The Model, Estimation, and Testing
2.1. The Model
The RESPRM with separable space-time filters can be specified as:
where is an observation of the response variable for the ith spatial unit at the tth time period, , and are observations of and vectors of covariates, respectively, is an individual random effect which is assumed to be , is an error term, is a remainder error term which is weakly stationary sequence, is a random error term which is assumed to be , is a regression coefficient vector of , is an unknown link function, is the th element of spatial weights matrix, and are spatial correlation and series correlation coefficients, respectively. Furthermore, we denote , as the true parameter vector of and , respectively, and as the true value of nonparametric function of .
We find that separable space-time filters in our model result in a trade-off between the spatial correlation and serial correlation coefficients. According to Shi and Lee [20], it is not hard to obtain that the stationarity requires not only , but also , i.e., parameter space of and , see Figure 1.
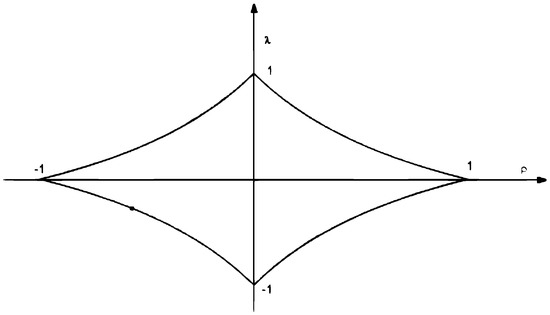
Figure 1.
The parameter space of and .
2.2. Estimation
Because that random effect could be regarded as time-invariant permanent spillovers (see Baltagi, Fingleton, and Pirotte [21]), the model (1) can be written in matrix form
where , , , , , , is a vector of ones, , is an identity matrix, W is an spatial weights matrix. Then we obtain the variance matrix of transformed error structure as follows
where
, and = . Therefore, the log-likelihood function of the new transformed model (4) is defined in (5)
where .
It is difficult to obtain the QMLE by maximizing (5) because that is unknown. Thus, we will combine PQML method and Working Independence theory (Cai [22]) to estimate unknown parameters and nonparametric function of the model. Working independence assumption is often used to deal with nonparametric/semiparametric regression models which exist correlation structures. By ignoring the correlation structure entirely, and pretending as if the data within a cluster were independent, the asymptotically most efficient estimator of nonparametric function is obtained (Lin and Carroll [23]). It has been widely used in various correlation structures of nonparametric/semiparametric models, such as Fan et al. [24], Fan and Zhang [25], and Tang and Liu [26], among others.
The estimation steps are as follows:
Step 1. By supposing that is known, the initial estimator of can be obtained. Let
where , is kernel function, is the determinant of , . In addition, denote , then we have and
where , , is the first derivative of . Let , then and
where , is a vector.
Step 2. Substituting (6) into (5), the approximate log-likelihood function is given by
By maximizing (7), the initial estimators of can be obtained as follows
Step 3. Substituting into (7), we get the concentrated log-likelihood function of and as
2.3. Testing
By allowing nonparametric component in a parametric regression model with separable space-time filters, it provides us the ability to explore potential nonlinear relationship lies between covariates and response variable. In order to check whether the parametric specification is correct, it is necessary to do the following hypothesis test
where are unknown parameters. Following Fan, Zhang, and Zhang [27], we obtain by PQML method, and is OLS estimator of the intercept and slopes in the linear regression of , is also obtained by PQML method. The resulting residual sums of squares under the null and alternative hypotheses, respectively, are as follows
To test the null hypothesis, we define generalized F-test statistic as follows:
The asymptotic distribution of is given in Section 3.
3. Asymptotic Property
To prove the asymptotic properties of PQMLE and asymptotic distribution of generalized F-test statistic proposed in Section 2, we need to establish some useful assumptions and lemmas.
3.1. Assumptions
In order to provide a rigorous theoretical analysis, we make the following assumptions.
Assumption 1.
(i) are nonstochastic variables and uniformly bounded (UB) in .
- (ii)
- There is a positive density function such that for any bounded continuous function , and is bounded away from zero on .
- (iii)
- are iid and .
Assumption 2.
(i)W is a row normalized and prespecified spatial weights matrix.
- (ii)
- B is nonsingular.
- (iii)
- B and are UB in both row and column sums in absolute value.
Assumption 3.
As , , , and , where is the Euclidean norm of matrix H, and is the determinant of matrix H.
Assumption 4.
The kernel function is a continuous density with compact support on , all odd order moments of K vanish. Further, is bounded, and are bounded and .
Assumption 5.
For any , we require that
where
, and
.
Assumption 6.
where , , , , , .
Remark: Assumption 1 concerns the features of covariates, random error term, and density function for the model (1). Assumption 2 provides the basic features of spatial weight matrix, it parallels Assumption 3 of Su and Jin [28] and Assumption 5 of Lee [29]. The assumption that B and are UB limits the spatial correlation to a manageable degree. Assumption 3 concerns the bandwidth sequence, it parallels Assumption 4 of Hamilton and Truong [30], and Assumption 7 of Ullah and Su [31]. Assumption 4 concerns the kernel function. Assumptions 5 and 6 are necessary for the consistency and asymptotic properties of the estimators.
3.2. Asymptotic Properties
From the model (4), we obtain the reduced form equation of Y as
Let , where . Denote a typical entry of by
, where is a typical column of .
Lemma 1.
Suppose that Assumptions 1–5 hold, then we have
The proof is given by Hamilton and Truong [30].
Lemma 2.
Suppose that Assumptions 1–5 hold, then we have
- (i)
- , where .
- (ii)
- There is a positive constant c such that for .
- (iii)
- There exists a positive constant c such that
The proofs is given by Ullah and Su [31].
Lemma 3.
Suppose that Assumptions 1–5 hold, then we have
The proof is given by Hamilton and Truong [30].
With the above lemmas, we then state main results as follows. Their detail proofs can be found in the Appendix A.
Theorem 1.
Suppose that Assumptions 1–5 hold, then we have .
Theorem 2.
Suppose that Assumptions 1–6 hold, then we have
where “” means convergence in distribution, is the average Hessian matrix (information matrix when e and b obey normal distributions), and .
Theorem 3.
Suppose that Assumptions 1–4 hold, then we have
where is the second derivative of , , and , , .
Theorem 4.
Suppose that Assumptions 1–4 hold, then we have
where , , , , is the support of and H is a bandwidth sequence, besides, note that when , we get , and hence .
4. Monte Carlo Simulation
4.1. Performance of the Estimates
In this section, we report the results of a small-scale Monte Carlo study which is aimed to evaluate the finite sample performance of PQMLEs. We use mean square error (), standard deviation (), and mean absolute deviation error () to measure the parametric and nonparametric estimation performance, respectively, where
, are Q fixed grid points in support set of z. Furthermore, we apply the rule of thumb method of Mack and Silverman [32] to choose the optimal width and let (see Su [33]).
We use data generated from the following model
where , , , , , , , , and , respectively. In addition, we defined weights matrix as Rook matrix (see Anselin [34]). The simulation results of cases , and are presented in Table 1, Table 2, Table 3 and Table 4.

Table 1.
Results of parametric estimates under the model (12) with T = 10.
Table 2.
Results of parametric estimates under the model (12) with T = 20.
Table 3.
The medians and SDs of MADEs for nonparametric estimates under the model (12) with T = 10.
Table 4.
The medians and SDs of MADEs for nonparametric estimates under the model (12) with T = 20.
It is obvious from Table 1, Table 2, Table 3 and Table 4 that: (1) the of all parametric estimators are fairly small, which indicates the parametric estimators are approximately unbiased; (2) for fixed T, when N increases, the of , , , and decrease rapidly. For fixed N, when T increases, the behavior of parametric estimates is similar to the case where N changes with the fixed T. (3) The and of decrease as T or N increases. It presents that the nonparametric estimates are convergent.
Figure 2 shows the fitting image and 95% confidence intervals of under and , respectively, where the black short dashed line is the average fit over 2000 simulations by PQML method, the red solid line is the true values of , and the two black long dashed lines are the corresponding 95% confidence bands. By observing subgraphs of Figure 2, we know that shorter dotted line is fairly close to solid line and confidence band is narrow. These mean that nonparametric estimation procedure performances well under finite sample. To save space, we do not show the others cases under with , with and with of different N and T because they are similar with the case with .
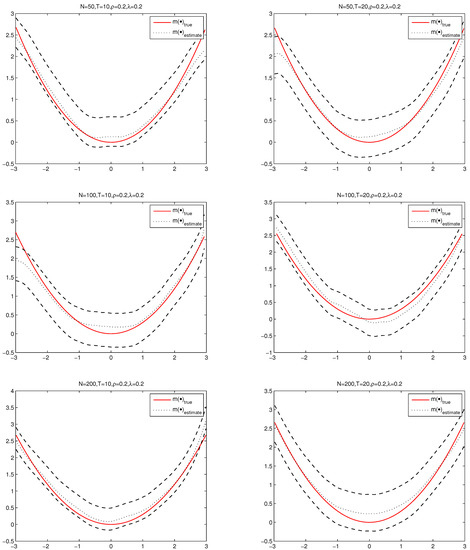
Figure 2.
The fitting images and 95% confidence intervals of with and .
4.2. Comparison of Results of Different Models
In this section, we will investigate the necessity of including nonparametric components, spatial correlation, and serial correlation if the real model is model (12). By deleting spatial correlation, serial correlation, and spatiotemporal correlations, respectively, in the model (12), we get the following three deleted models:
where all variables in above models are the same as the model (12). To save space, we only study the case that and . In addition, we set , and . By using PQML method in Section 2, the experimental results are presented in Table 5.
Table 5 reports Means, MSEs and s of parametric estimates in the models (12)–(15), where is growth rate of MSE on the basis of that in model (12). From Table 5, we get the following conclusions: (1) the means of parametric estimates in the real model get closer to the true values as the sample size increases. However, we find that the means of estimates of and in model (13), in the models (14) and (15) are very unstable, they do not converge to true values, respectively. Although the means of other parametric estimates get close to true values as the sample size increases, they still far away from true values and do not converge to true values. (2) In comparison with the real model, the MSEs of each parameter estimate in the deleted models increase. For most parametric estimates, they decrease with the increase in sample size except for and in the model (13), , and in the model (14), in the model (15). (3) The s of all parametric estimates are large, they do not decrease with the increase in sample size for some parametric estimates except for in the model (13)–(15) and in the model (13).
Table 6 reports the medians and SDs of MADEs, s, and s for nonparametric estimates of the models (12)–(15), where and are growth rates of median and SD, respectively, on the basis of that in the model (12). It can be seen from Table 6 that, in comparison with the real model, the values of medians and SDs of MADEs for nonparametric estimates of the models (13)–(15) increase rapidly, and do not decrease with the increase in sample size.
The above facts reveal that the efficiency of both parametric and nonparametric estimates depends on the correct specification of errors in (1)–(3), and violation of which can lead to inconsistency.
4.3. Performance of the Test
In this section, we aim to evaluate the power of hypothesis test proposed in Section 2.3. Consider the model (12), and the settings of and are the same as those in model (12). In addition, we only study the case that and . Then, the corresponding hypothesis is obtained as follows:
where , are values consisting of and . In particular, when , the above null hypothesis is exactly the true nonparametric function. As the value of increases, the true nonparametric function is increasingly farther from the null hypothesis. Figure 3 presents the true nonparametric functions with different -values. In this section, we conduct simulations that N = 100, T = 8, 16 under significant levels and 0.05, respectively. For each case, there are 1000 repetitions. Then, the powers of the hypothesis test are shown in Figure 4.
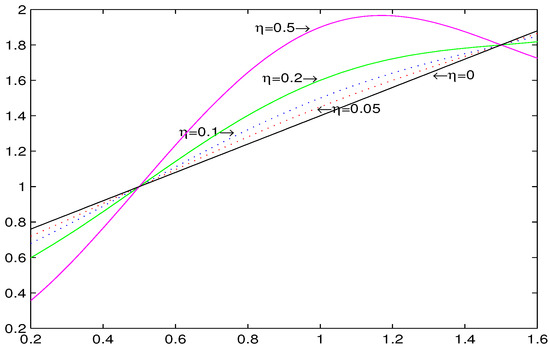
Figure 3.
Trajectories of with = 0, 0.05, 0.1, 0.2, and 0.5, respectively.
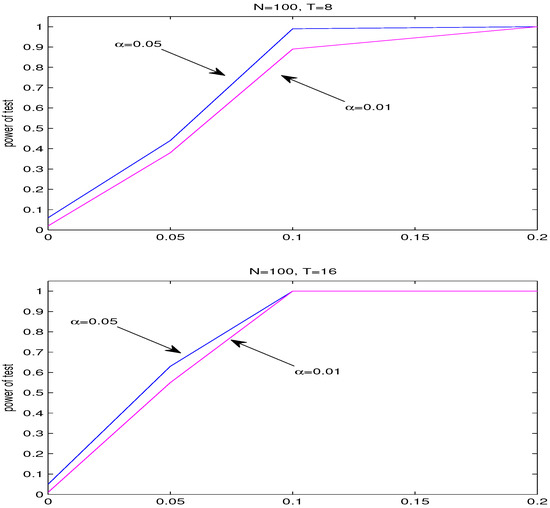
Figure 4.
Powers of the test with = 0.01 and 0.05, respectively, with sample size .
We get from the Figure 4 and Table 7 that: (1) while = 0, the power of the test is very close to the significance level. As the value of increases, the power of the test statistic increases considerably, which indicates that our test statistic is sensitive to the alternative hypothesis of the proposed test problem. (2) While the number of spatial units is the same, the power of F-test with T = 16 is higher than that with T = 8. This shows that the F-test statistic performance get better as sample size increases.
Table 7.
Powers of test with significance level .
5. Real Data Analysis
In this section, we will illustrate the prescribed estimation and testing methods by Indonesian rice farming dataset with N = 171 and T = 6 which is a quintessential example of large N and small T in the stochastic frontier literature(see detail for Feng and Horrace [35]). This dataset has five variables, one response variable and four covariates. The response variable is natural logarithm of output of Indonesian rice farming, and the covariates include high, mixed, seed, and land, which are defined in Table 8. The dataset is from the agricultural economic research center of the Ministry of agriculture of Indonesia and compiled by the Agro Economic Survey. Based on the panel data of related variables of 171 farms over 6 growing seasons (three wet and three dry seasons), we will explore the influencing factors of output of Indonesian rice farming by RESPRM with separable space-time filters.
Table 8.
Variables and their definitions.
In order to take the proposed RESPRM with separable space-time filters to Indonesian rice farming dataset, we apply the F-test statistic proposed in Section 2.3 to verify whether or not a nonlinear relationship between covariates and response variable exists. The test results are given in Table 9. From Table 9, we find that land (other covariates) has (have) significant nonlinear (linear) relationship with natural logarithm of output of Indonesian rice farming at significant level .
Table 9.
Results of F-test under significant level .
Therefore, we consider the model (1)–(3), and set , , is the ith observation of at tth growing season, are the ith observation of high, mixed, and seed at tth growing season, respectively, is land for the ith observation at tth growing season. equals 1 if farms i and j are in the same village, equals 0 otherwise (see detail for Druska and Horrace [8]).
The parametric estimates results of the model (1)–(3) for fitting Indonesia rice farming data are described in Table 10. Via Table 10, we find that: (1) show expectation of dummy variables for high, mixed, and seed have promotional effects on output of rice. (2) presents that the output of rice in different farm is relatively unstable and is affected by external fluctuations.
Figure 5 shows the results of estimation and corresponding 95% confidence intervals of , where the blue solid line is the average fit over 500 simulations, the red and green dotted lines are the corresponding 95% confidence bands. From Figure 5, we know that land has obvious nonlinear effects on output of rice, and output of rice increases with the increase in land.
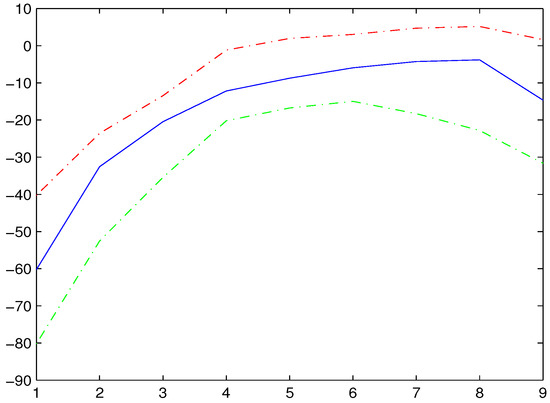
Figure 5.
and its 95% confidence intervals for the dataset of Indonesian rice farming in China.
6. Conclusions
In this paper, we study PQMLE and hypothesis test for RESPRM with separable space-time filters. The proposed model can simultaneously capture linear and nonlinear effects of covariates, spatial correlation of error structure, serial correlation of remainder error structure, and individual random effects. With the given conditional assumptions, asymptotic properties of PQMLE and asymptotic distribution of nonparametric components are proved. Monte Carlo simulations are applied to investigate the performance of estimators and test statistic under finite samples, and the results show that proposed estimators and test statistic are well-behaved under finite samples, and consistency of parametric estimates is hard to guarantee if spatial correlation and series correlation in the real model are ignored in some cases. In addition, the practicability of the proposed methods are also assessed by a real dataset.
This paper focuses only on RESPRM with separable space-time filters but does not account for spatially lagged response variables. How to extend our proposed estimation and testing methods to a random effects spatial lag semiparametric regression model with separable space-time filters is an open problem. In addition, we may combine generalized moment estimation method, quantile regression method and local linear method to estimate parametric and nonparametric components of the random effects spatial lag semiparametric regression model with separable space-time filters and RESPRM with separable space-time filters.
Author Contributions
Formal analysis, S.L. and B.L.; Methodology, S.L. and J.C.; Software and Writing-original draft, S.L.; Supervision, Writing—review & editing and Funding acquisition, J.C.; Data curation, B.L. All authors have read and agreed to the published version of manuscript.
Funding
This work is supported by National Social Science Fund of China (22BTJ024) and Natural Science Foundation of Fujian Province (2020J01170, 2022J01193).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
This section aims to prove some lemmas and theorems given by Section 3, before that, we provide two frequently used evident facts.
Fact 1. If the row and column sums of the matrices and are UB in absolute value, then the row and column sums of are also UB in absolute value.
Fact 2. If the row (resp. column) sums of are UB in absolute value and is a conformable matrix whose elements are uniformly , then so are the elements of (resp. ).
Proof of Theorem 1.
Define . By direct calculation, we have
and
To show the consistency of , we follow Lee [29] by showing the uniform convergence of to zero on a compact convex parameter space . By comparison with Lee [29], the difference is that our model setting is more complex. By White [36] (Theorem 3.4), it needs only to show
and
We first prove (A3). By direct calculation, we know that
and
where . As is UB, we know , and as , that is uniform convergence is proved.
We then prove (A4). Recall (A1) and By direct calculation, we know
then
where , . Conduct a random effects model , we know its log-likelihood function is as follows
where . Using the information inequality of above model, . In addition, is a quadratic function of and for given any . Next, we prove that strictly, i.e.,
Combined Assumption 5 and uniform convergence, is proved. □
Proof of Theorem 2.
By Taylor expansion of (5) at point , we obtain
where , and lies in between and . According to Theorem 1, we have . Denote
Therefore,
Next, we aim to prove
and
In order to prove (A5), we will show that all elements of converge to 0 in probability. It can be calculated that
where
is the true value of , is the first derivative of with respect to . Consequently, we get
Then, by mean value theorem, Assumption 2 and Fact 2, we easily get
Then we can similarly prove that (A5) holds.
In order to prove (A6), we follow the idea of Lee [29]. It is easy to obtain that the components of are linear or quadratic functions of e and their means are all . With Assumption 1, we have that is asymptotically normal distributed with 0 means by using the CLT for linear-quadratic forms of Theorem 1 in Kelejian and Prucha [37]. In the next step, we calculate the variance. Denote and as the third and forth moments of , respectively, be the ii-th element of A. By using the facts that , , it follows by direct calculation that
where
In particular, it is not difficult to know that when e and b obey normal distribution. This completes the proof. □
Proof of Theorem 3.
We follow the idea of Ullah and Su [31] to prove the theorem. The difference is that our error structure setting is more complex. Recall
then
Write , where is the first derivative of . By the second order Taylor expression, we obtain . Thus, we have
Thus, we get
and
where
For , write
Thus, we obtain
where , .
For , write , we can show that and
Combined (A9), Slutsky’s theorem and central limit theorem, we get
where , , and . □
Proof of Theorem 4.
It can be seen that
where and . For , it is obtained by Theorems 1–3 and direct calculation that
Similarly, we know that
where , and . For , it is obtained by Theorems 1–3 and calculation that
In addition, we obtain that
By Remark 3.4 in [27], under , we obtain
where , , , is the support of and H is a bandwidth sequence. □
References
- Bates, G.E.; Neyman, J. Contributions to the theory of accident proneness II: True of false contagion. Univ. Calif. Publ. Statist. 1952, 1, 255–276. [Google Scholar]
- Chamberlain, G. Multivariate regression models for panel data. J. Econom. 1982, 18, 5–46. [Google Scholar] [CrossRef]
- Baltagi, B. Econometrics Analysis of Panel Data; Wiley Press: New York, NY, USA, 2001. [Google Scholar]
- Arellano, M. Panel Data Econometrics; Oxford University Press: New York, NY, USA, 2003. [Google Scholar]
- Baldev, R.; Baltagi, B. Panel Data Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Hsiao, C. Analysis of Panel Data; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Elhorst, J. Spatial Econometrics: From Cross-Sectional Data to Spatial Panels; Springer Press: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Druska, V.; Horrace, W. Generalized moments estimation for spatial panel data: Indonesian rice farming. Am. J. Agric. Econ. 2004, 86, 185–198. [Google Scholar] [CrossRef]
- Egger, P.; Pfaffermayr, M.; Winner, H. An unbalanced spatial panel data approach to US state tax competition. Econ. Lett. 2005, 88, 329–335. [Google Scholar] [CrossRef]
- Kapoor, M.; Kelejian, H.; Prucha, I. Panel data models with spatially correlated error components. J. Econ. 2007, 140, 97–130. [Google Scholar] [CrossRef]
- Lee, L.; Yu, J. Estimation of spatial autoregressive panel data models with fixed effects. J. Econ. 2010, 154, 165–185. [Google Scholar] [CrossRef]
- Elhorst, J. Serial and spatial autocorrelation. Econ. Lett. 2008, 100, 422–424. [Google Scholar] [CrossRef]
- Parent, O.; LeSage, J. A space-Ctime filter for panel data models containing random effects. Comput. Stat. Data Anal. 2011, 55, 475–490. [Google Scholar] [CrossRef]
- Lee, L.; Yu, J. Spatial penels: Random components versus fixed effects. Int. Econ. Rev. 2012, 53, 1369–1412. [Google Scholar] [CrossRef]
- Lee, L.; Yu, J. Estimation of fixed effects panel regression models with separable and nonseparable space-time filters. J. Econ. 2015, 184, 174–192. [Google Scholar] [CrossRef]
- Baltagi, B.; Song, S.; Jung, B.; Koh, W. Testing for serial correlation, spatial autocorrelation and random effects using panel data. J. Econ. 2007, 140, 5–51. [Google Scholar] [CrossRef]
- Cohen, J.; Morrison Paul, C. Public infrastructure investment, interstate spatial spillovers and manufacturing costs. Rev. Econ. Stat. 2004, 86, 551–560. [Google Scholar] [CrossRef]
- Zhao, J.; Zhao, Y.; Lin, J.; Miao, Z.-X.; Khaled, W. Estimation and testing for panel data partially linear single-index models with errors correlated in space and time. Random Matrices 2020, 9, 2150005. [Google Scholar] [CrossRef]
- Bai, Y.; Hu, J.; You, J. Panel data partially linear varying-coefficient model with both spatially and time-wise correlated errors. Stat. Sinica. 2015, 35, 275–294. [Google Scholar] [CrossRef]
- Shi, W.; Lee, L. Spatial dynamic panel data models with interactive fixed effects. J. Econ. 2017, 197, 323–347. [Google Scholar] [CrossRef]
- Baltagi, B.; Fingleton, B.; Pirotte, A. Estimating and forecasting with a dynamic spatial panel data model. Oxford. B Econ. Stat. 2014, 76, 112–138. [Google Scholar] [CrossRef]
- Cai, Z. Trending time-varying coefficient time series models with serially correlated errors. J. Econ. 2007, 136, 163–188. [Google Scholar] [CrossRef]
- Lin, X.; Carroll, R. Nonparametric function estimation for clustered data when the predictor is measured without/with error. J. Am. Stat. Assoc. 2000, 95, 520–534. [Google Scholar] [CrossRef]
- Fan, J.; Huang, T.; Li, R.Z. Analysis of longitudinal data with semi-parametric estimation of covariance function. J. Am. Stat. Assoc. 2007, 102, 632–641. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, W. Statistical methods with varying coefficient models. Stat. Inference 2008, 1, 179–195. [Google Scholar] [CrossRef]
- Tang, L.; Liu, Y. Estimation of generalized spatial lag semi-parametric varying-coefficient panel model with random effects. Stat. Res. 2018, 35, 119–128. [Google Scholar]
- Fan, J.; Zhang, C.; Zhang, J. Generalized likelihood ratio statistics and Wilks phenomenon. Ann. Stat. 2001, 29, 153–193. [Google Scholar] [CrossRef]
- Su, L.; Jin, S. Profile quasi-maximum likelihood estimation of partially linear spatial autoregressive models. J. Econ. 2010, 157, 18–33. [Google Scholar] [CrossRef]
- Lee, L. Asymptotic distributions of quasi-maximum likelihood estimators for spatial autoregressive models. Econometrica 2004, 72, 1899–1925. [Google Scholar] [CrossRef]
- Hamilton, S.; Truong, Y. Local linear estimation in partly linear models. J. Multivar. Anal. 1997, 60, 1–19. [Google Scholar] [CrossRef]
- Ullah, A.; Su, L. Profile likelihood estimation of partially linear panel data models with fixed effects. Econ. Lett. 2006, 92, 75–81. [Google Scholar]
- Mack, Y.; Silverman, B. Weak and strong uniform consistency of kernel regression estimates. Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete 1982, 61, 405–415. [Google Scholar] [CrossRef]
- Su, L. Semiparametric GMM estimation of spatial autoregressive models. J. Econ. 2012, 167, 543–560. [Google Scholar] [CrossRef]
- Anselin, L. Spatial Econometrics: Methods and Models; Kluwer Academic Press: Dordrecht, The Netherlands, 1988. [Google Scholar]
- Feng, Q.; Horrace, W. Alternative technical efficiency measures: Skew, bias and scale. J. Appl. Economet. 2012, 27, 253–268. [Google Scholar] [CrossRef]
- White, H. Estimation, Inference and Specification Analysis; Cambridge University Press: New York, NY, USA, 1994. [Google Scholar]
- Kelejian, H.; Prucha, I. On the asymptotic distribution of the Moran I test statistic with applications. J. Econ. 2001, 104, 219–257. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).