Abstract
(1) Background: At present, the bio-inspired visual neural models have made significant achievements in detecting the motion direction of the translating object. Variable contrast in the figure-ground and environmental noise interference, however, have a strong influence on the existing model. The responses of the lobula plate tangential cell (LPTC) neurons of Drosophila are robust and stable in the face of variable contrast in the figure-ground and environmental noise interference, which provides an excellent paradigm for addressing these challenges. (2) Methods: To resolve these challenges, we propose a bio-inspired visual neural model, which consists of four stages. Firstly, the photoreceptors (R1–R6) are utilized to perceive the change in luminance. Secondly, the change in luminance is divided into parallel ON and OFF pathways based on the lamina monopolar cell (LMC), and the spatial denoising and the spatio-temporal lateral inhibition (LI) mechanisms can suppress environmental noise and improve motion boundaries, respectively. Thirdly, the non-linear instantaneous feedback mechanism in divisive contrast normalization is adopted to reduce local contrast sensitivity; further, the parallel ON and OFF contrast pathways are activated. Finally, the parallel motion and contrast pathways converge on the LPTC in the lobula complex. (3) Results: By comparing numerous experimental simulations with state-of-the-art (SotA) bio-inspired models, we can draw four conclusions. Firstly, the effectiveness of the contrast neural computation and the spatial denoising mechanism is verified by the ablation study. Secondly, this model can robustly detect the motion direction of the translating object against variable contrast in the figure-ground and environmental noise interference. Specifically, the average detection success rate of the proposed bio-inspired model under the pure and real-world complex noise datasets was increased by 5.38% and 5.30%. Thirdly, this model can effectively reduce the fluctuation in this model response against variable contrast in the figure-ground and environmental noise interference, which shows the stability of this model; specifically, the average inter-quartile range of the coefficient of variation in the proposed bio-inspired model under the pure and real-world complex noise datasets was reduced by 38.77% and 47.84%, respectively. The average decline ratio of the sum of the coefficient of variation in the proposed bio-inspired model under the pure and real-world complex noise datasets was 57.03% and 67.47%, respectively. Finally, the robustness and stability of this model are further verified by comparing other early visual pre-processing mechanisms and engineering denoising methods. (4) Conclusions: This model can robustly and steadily detect the motion direction of the translating object under variable contrast in the figure-ground and environmental noise interference.
1. Introduction
In nature, Drosophila, as a model organism, has evolved over millions of years to develop a robust and stable visual neural system that plays a vital role in its survival, and it has better motion sensitivity than humans [1,2]. Detecting the motion direction of the translating object has become one of the fundamental survival skills of Drosophila, which plays a significant role in daily behavior, such as avoiding predators, chasing prey, and so forth [3,4]. A variety of bio-inspired models are proposed based on motion-sensitive visual neurons of Drosophila [5], which are widely used in robots [6] and drones [7]. From biology to bio-inspired modeling and even to biomimetic applications, the physiological mechanisms of the Drosophila visual neural system provide many inspirations. The motion direction of the object, as one of the important motion features of the object, provides a basis for the higher-order neural structure (central brain) to make decisions [8]. The initial motion-directional detection model to express the behavioral and physiological characteristics of Drosophila is the elementary motion detector (EMD) [9], which is widely used in the fields of intelligent devices [10,11]. However, the detection performance of the EMD and a series of improved EMD-based models [12,13,14] under complex dynamic backgrounds is not satisfactory. With the revelation of the physiological mechanism of the motion-sensitive neurons of Drosophila, the LPTC has been shown to have a strong response to translating wide-field objects and the motion of local salient objects [15]. Subsequently, several bio-inspired models based on the LPTC have been put forward by mathematicians, which have proven to have excellent detection performance under complex dynamic backgrounds [16]. In the visual neural system of Drosophila, the retina and the optic lobe are two significant biological structures for detecting motion features and objects. The retina is responsible for perceiving the change in luminance and color information from the natural environment, while the optic lobe is a multi-layered structure responsible for processing the change in luminance and color information, and further detecting motion features and objects [17,18].
The visual neural system of Drosophila is a visual invariant, highly parallel, and multi-layer ganglion information processing model. The first-order visual neural structure is the retina, which consists of approximately 800 ommatidia in each ommateum. Each ommatidium consists of eight different photoreceptor cells, R1–R8, of which R1–R6 are responsible for perceiving a wide range of light and motion information, while R7 and R8 are responsible for perceiving the color information [19]. The second-order higher visual neural structure is the optic lobe, which includes the lamina, the medulla, and the lobula complex (including lobula and lobula plate). Firstly, in the lamina, a large number of the LMC neurons receive the signal from the R1–R6 neurons, which are highly sensitive to the change in luminance [20]. The LMC neurons mainly include two types, namely, L1 and L2. The L1 type of the LMC has a strong response to increased luminance, while the L2 type of the LMC has a strong response to decreased luminance [21]. Further, the inter-neurons in the lamina have the property of improving environmental disturbance [22] and the characteristic of the LI biological mechanism, which can improve motion boundaries [23]. Secondly, a great number of the transmedulla 3, 2, and 1 (Tm3, Tm2, and Tm1) and intrinsic medulla 1 (Mi1) neurons in the medulla receive the signal from the LMC. The Tm3 and Mi1 neurons are highly sensitive to increased luminance with the response of the Mi1 delayed relative to the Tm3, on the contrary, the Tm2 and Tm1 neurons are highly sensitive to decreased luminance with the response of the Tm1 delayed relative to the Tm2 [24]. Thirdly, the T4 neurons in the medulla have four sub-types, which are highly sensitive to increased luminance and receive signals from the Tm3 and Mi1 neurons [25]; additionally, the ON/OFF contrast pathways will be activated in the medulla [26]. Finally, the T5 neurons in the lobula of the lobula complex have four sub-types, which are highly sensitive to decreased luminance and receive signals from the Tm2 and Tm1 neurons [27]; after that, the LPTC and the lobula plate-intrinsic (LPi) neurons in the lobula plate of the lobula complex [28,29,30] are adopted to detect the motion direction of the translating object. Although the Drosophila-inspired visual neural model based on the visual neural circuits has made remarkable progress in detecting the motion direction of the translating object, the detection performance is not satisfactory in the case of visual contrast in the figure-ground and environmental noise interference. Furthermore, there is scant literature that comprehensively analyses and verifies this. This study proposes a bio-inspired visual neural model to resolve these challenges. In summary, the main contributions of this paper are as follows:
- (1)
- We utilize the spatio-temporal biological mechanism to suppress environmental noise and improve motion boundaries, which facilitate the subsequent detection of the motion direction of the translating object.
- (2)
- We adopt the contrast normalization mechanism and the contrast pathways to reduce the fluctuation in the response of variable contrast in the figure-ground.
- (3)
- The computing of Drosophila’s four-layer visual neural circuits demonstrates a compact and layered solution to robustly and steadily detect the motion direction of the translating object against variable contrast in the figure-ground and noise interference, which further approximates Drosophila’s visual neural detection capability.
The remainder of this paper is organized as follows. In Section 2, the related works are reviewed. In Section 3, the proposed bio-inspired model is introduced in detail. In Section 4, the experimental simulations and performance are analyzed based on the synthetic noisy visual stimulus sequence dataset. In Section 5, the proposed bio-inspired model is discussed and prospects for future research are presented. In Section 6, the proposed bio-inspired model is summarized.
2. Related Works
Over the years, numerous works based on the visual neural system of Drosophila have been presented. Some of the notable ones, including spatio-temporal biological mechanisms, bio-inspired motion direction detection models, and contrast neural computation, are discussed below.
2.1. Spatio-Temporal Biological Mechanisms
The spatio-temporal biological mechanisms work together to play a significant role in reducing background interference, which facilitates the subsequent detection of the motion direction of the translating object. The spatio-temporal biological mechanism has been shown to suppress environmental noise and improve motion boundaries, which is considered a suitable filter prior to motion and contrast information detection in the visual neural system of Drosophila [16,22]. The suitable filter mainly includes the spatial denoising mechanism [31] inspired by grouping-layer processing mechanisms [32] and the role of lateral excitation [33], and the spatio-temporal LI mechanism inspired by the biological neural system, i.e., the inhibition that occurs between the adjacent neurons [23]. The review of relevant literature is shown in Table 1.

Table 1.
Literature review concerning the spatio-temporal biological mechanisms.
2.2. Bio-Inspired Motion Direction Detection Models
To further incorporate the latest biological findings of the motion-sensitive neural mechanisms, the EMD model [9] has been optimized and several optimized models have been presented; additionally, according to the physiological mechanism of LPTC neurons, several LPTC-based bio-inspired models were presented. The relevant literature reviews are shown in Table 2.
Table 2.
Literature review concerning the bio-inspired motion direction detection models.
2.3. Contrast Neural Computation
To adapt to the highly variable natural environment, some related researchers proposed the environmental statistics method described earlier; nevertheless, the challenge of highly variable inputs had not been fully resolved [40,41]. Through the latest relevant investigations, contrast visual computation is presented to resolve this challenge, which includes the contrast normalization mechanism and the parallel contrast pathways; the relevant literature reviews are shown in Table 3. According to the relevant literature, this mechanism has not yet been verified in detecting the motion direction of the translating object.
Table 3.
Literature review concerning the contrast neural computation.
3. Methods
The proposed bio-inspired model is developed with formulation on four-layer neurons including the retina, lamina, medulla, and lobula complex, together with the model parameter configuration. Figure 1 depicts the network structure and legend of the proposed bio-inspired model, which consists of four-layer neurons. Firstly, the change in luminance is perceived by photoreceptors (R1–R6) in the retina neural layer. Secondly, the change in luminance is divided into parallel ON and OFF pathways by the LMC; the spatial denoising mechanism is adopted to suppress environmental noise; and the spatio-temporal LI mechanism is utilized to improve motion boundaries in the lamina neural layer. Thirdly, the ON and OFF signals are normalized and the parallel ON and OFF contrast pathways are activated in the medulla neural layer. Finally, the contrast and motion pathways converge on the LPTC in the lobula-complex neural layer to detect the motion direction of the translating object.
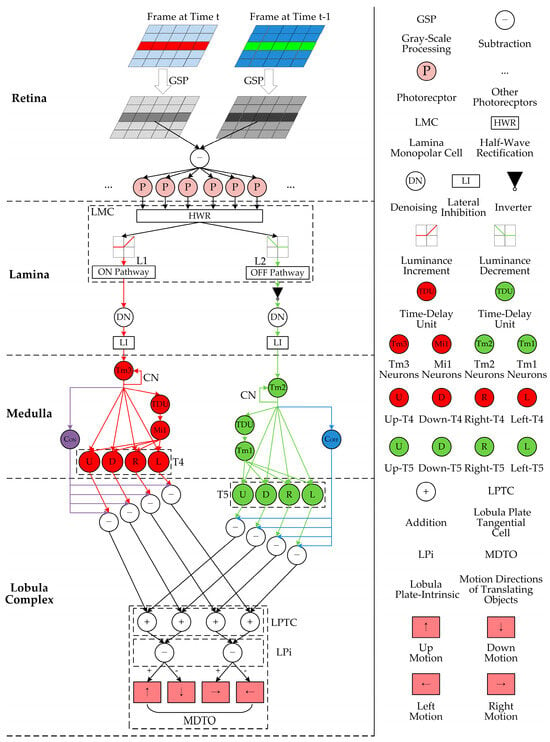
Figure 1.
Network structure and legend of the proposed bio-inspired model: the red and green pipelines represent ON and OFF motion pathways, respectively; the purple and blue pipelines represent ON and OFF contrast pathways, respectively.
3.1. Retina Neural Layer
In the retina neural layer, Drosophila has a compound eye structure, each compound eye includes numerous ommatidia, each ommatidium consists of several photoreceptors, and each photoreceptor corresponds to a pixel [47]. These photo- receptors (R1–R6) are able to perceive the change in luminance frame-by-frame and transmit it to downstream neurons for further processing. Specifically, this model adopts gray-scale processing [48,49] and the difference between two successive frames [16] to obtain the change in luminance (see GSP, ㊀, and P in the retina neural layer, shown in Figure 1).
3.2. Lamina Neural Layer
In the lamina neural layer, a large number of LMC neurons (L1 and L2) (see the dashed rectangular box LMC in the lamina neural layer shown in Figure 1) separate the change in luminance into parallel ON (L1) and OFF (L2) pathways, which encode increased and decreased luminance, respectively. The half-wave rectification (HWR) algorithm is used to divide the change in luminance into the ON and OFF pathways [43] (see HWR, ON Pathway, and OFF Pathway in the lamina neural layer shown in Figure 1). The ON signal corresponds to the L1 type of the LMC, while the OFF signal corresponds to the L2 type of the LMC, and the OFF signal is inverted (see ▼ in the lamina neural layer shown in Figure 1).
Afterward, the spatial denoising mechanism is used to suppress environmental noise, which includes two stages. In the first stage, the value of the passing coefficient is computed, which is defined in Equations (1) and (2):
where represents the average luminance change in ON and OFF signals, which represents the passing coefficient; represents the ON and OFF signals; and represents the weighting matrix of ON and OFF signals. The cluster excitation obtains a larger passing coefficient, while the isolated excitation obtains a smaller passing coefficient. Then, the normalized passing coefficient is calculated, which is defined in Equation (3):
where represents the normalized passing coefficient of ON and OFF signals and represents a small real number to prevent the denominator tending toward zero. In the second stage, the value of the signal is multiplied by the corresponding normalized passing coefficient and then transmitted, as defined in Equation (4):
where represents the ON and OFF signals after the denoising. Additionally, the threshold comparison is adopted to filter the decayed excitation, i.e., the isolated excitation.
Finally, each inter-neuron in the lamina neural layer receives the LI from its adjacent similar neurons, which can be achieved by the delayed propagation mode, and the relevant references verify its validity [33,35] (see LI in the lamina neural layer shown in Figure 1).
3.3. Medulla Neural Layer
In the medulla neural layer, the inter-neurons (Tm3, Tm2, Mi1, and Tm1) receive the ON and OFF signals, and the contrast normalization is calculated by a hyperbolic tangent tanh function (see Tm3, Tm2, and CN in the medulla neural layer shown in Figure 1), which is defined in Equation (5):
where represents the normalized ON and OFF signals, represents the ON and OFF signals after the early visual pre-processing, represents the baseline contrast sensitivity, and represents ON and OFF signals after the convolution, which are defined in Equations (6) and (7):
where represents the standard deviation and represents a two-dimensional Gaussian kernel. Furthermore, the medulla neural layer again splits the signals into parallel contrast and motion pathways. The local contrast signal is obtained by calculating the competition between the response of the central and the surrounding adjacent neurons (see CON and COFF in the medulla neural layer shown in Figure 1), which are defined in Equations (8) and (9):
where represents the local contrast signals of the ON and OFF pathways (see purple CON and blue COFF in the medulla neural layer of Figure 1) and represents the weighting matrix of the center-surrounding competition.
Next, the T4 neurons have integrated signals from the Tm3 and Mi1 neurons. At the same time, the T4 neurons have four sub-types, each of which is sensitive to one of the upward, downward, leftward, and rightward motion directions, i.e., have four different direction-selective responses. This model adopts the computing between the current and delayed normalized ON signals to separate the ON pathway into upward, downward, rightward, and leftward sub-visual pathways. The calculation formula of the separating operation of the T4 is defined in Equation 10:
where , , , and represent the signal of upward, downward, rightward, and leftward sub-visual pathways of T4 (see U, D, R, and L of the rectangular dotted box T4 in the medulla neural layer shown in Figure 1); represents the delayed normalized ON signal, which can be obtained by using the temporally delayed output from Tm3 [16,43] (see red TDU and Mi1 in the medulla neural layer shown in Figure 1); and represents the sampling distance in every pairwise detector.
3.4. Lobula-Complex Neural Layer
In the lobula-complex neural layer, the T5 neurons integrate signals from the Tm2 and Tm1 neurons in the medulla neural layer. At the same time, the T5 neurons have four sub-types, each of which is sensitive to one of upward, downward, rightward, and leftward moving directions, i.e., have four different direction-selective responses. The calculation formula for the separating operation of T5 is defined in Equation (11):
where , , , and represent the signal of upward, downward, rightward, and leftward sub-visual pathways in T5 (see U, D, R, and L of the rectangular dotted box T5 in the lobula-complex neural layer shown in Figure 1); represents the delayed normalized OFF signal, which can be obtained by using the temporally delayed output of Tm2 [16,43] (see green TDU and Tm1 in the medulla neural layer shown in Figure 1).
Afterward, the T4 and T5 sub-layers with the same motion direction are integrated into the LPTC in the lobula, namely, the responses of the same motion direction converge to the same sub-layer of the LPTC (see the rectangular dotted box LPTC in the lobula-complex neural layer shown in Figure 1). The calculation formula of the translating moving directions is defined in Equation (12):
where , , , and represent the signal of upward, downward, leftward, and rightward sub-visual pathways of the LPTC; and and represent the exponents of the ON and OFF signals.
Next, the responses of the opposite motion directions inhibit each other by the LPi. This model adopts the sign-inverting operation to simulate the direction-opponent response (see the rectangular dotted box LPi in the lobula-complex neural layer of Figure 1). The calculation formulas of the vertical and horizontal direction-opponent responses of the LPi are defined in Equations (13) and (14):
where and represent the direction-opponent responses of vertical and horizontal; and represent height and width of the two-dimensional visual field in the retina neural layer; represents the upward motion and represents the downward motion; and represents the rightward motion and represents the leftward motion (see MDTO in the lobula-complex neural layer shown in Figure 1).
The pseudo-code of the proposed bio-inspired model is depicted in Algorithm 1, which shows the signal processing of the proposed bio-inspired model in detail.
| Algorithm 1. Proposed bio-inspired model |
| 1: Input: Visual stimulus sequences at continuous frames, . 2: Output: Motion directions of translating objects, and . 3: Procedure ProposedBioInspiredModel _CALCULATION(, ) 4: for num = from (, ) to (, ) 5: // 1. Retina neural layer 6: Compute the gray-scale successive frames and the change in luminance between every two successive frames 7: // 2. Lamina neural layer 8: Firstly, compute the ON and OFF signals by the HWR algorithm, get 9: Finally, compute the pre-processed ON and OFF signals by the early visual pre-processing in Equations (1)–(4), the threshold comparison, and LI, get 10: // 3. Medulla neural layer 11: Firstly, compute the normalized ON and OFF signals by Equations (5)–(7), get 12: Secondly, compute the local contrast ON and OFF pathway signals by Equations (8) and (9), get 13: Finally, compute the sub-visual signals of four different motion directions of the T4 by Equation (10), get // 4. Lobula-complex neural layer 14: Firstly, compute the sub-visual signals of four different motion directions of the T5 by Equation (11), get 15: Secondly, compute the integrated sub-visual motion and contrast pathway signals of the LPTC by Equation (12), get 16: Finally, compute the vertical and horizontal direction-opponent responses of the LPi by Equations (13) and (14), get and 17: return and 18: end for 19: End procedure |
3.5. Model Parameter Configuration
The parameter configuration of the proposed bio-inspired model is given in Table 4. All of the parameters are determined empirically by considering the functionality of the visual neural system of Drosophila.
Table 4.
The parameter configuration of the proposed bio-inspired model.
4. Results
In the experiments, the proposed bio-inspired model was set up in Visual Studio 2010 (The Microsoft Corporation, Redmond, WA, USA) using Intel Core i7-8700 and 3.20 GHz (12 CPUs) hardware. The synthetic visual stimulus sequences were generated by Vision Egg [49], and the noise was added to the synthetic visual stimulus sequences by OpenCV 2.4.9 (The Intel Corporation, Santa Clara, CA, USA). The performance of the proposed bio-inspired model was verified by the ablation study, the detection performance of translating objects in pure and real-world complex noise backgrounds, and further investigations.
4.1. Ablation Study
In this section, 10 groups of the synthetic pure visual stimulus sequences and 10 groups of the synthetic pure noisy visual stimulus sequences were adopted, the pure background is a solid image with a fixed gray value of 1, and the resolution of the pure background is 500 × 250 pixels × pixels. The translating object is a solid rectangle with a different gray value that varies between a maximum of 250 and a minimum of 25, and is taken every 25 gray values; the motion velocity of the translating object is 2000 pixels/second. In the upward/downward motion, the size of the translating object is 100 × 50 pixels × pixels. In the leftward/rightward motion, the size of the translating object is 50 × 100 pixels × pixels. Each synthetic pure visual stimulus sequence consists of 100 frames. Sample frames 40 and 80 from the 10 groups of the synthetic pure visual stimulus sequences are shown as dataset I in Figure 2. We adopted dataset I (no noise, only various contrasts in the figure-ground) to verify the effectiveness of the contrast neural computation. For dataset II, salt and pepper noise (SPN ratio: 0.01/0.02/0.03/0.04) or Gaussian noise (GN standard deviation: 10.0/20.0/30.0/50.0/80.0) were added based on Figure 2(a1–a4); sample frames 40 and 80 from the 10 groups of the synthetic pure noisy visual stimulus sequences with the upward moving object are shown in Figure 3; in the same way, the synthetic pure noisy visual stimulus sequences with the downward, leftward, and rightward moving object were obtained. We adopted dataset II (keep the figure-ground contrast constant, only various noises) to verify the effectiveness of the spatial denoising mechanism.

Figure 2.
Sample frames 40 and 80 from 10 groups of synthetic pure visual stimulus sequences. The light blue arrows represent the motion direction of the translating object. (a1–j1) represent the translating object in the upward motion; (a2–j2) represent the translating object in the downward motion; (a3–j3) represent the translating object in the leftward motion; (a4–j4) represent the translating object in the rightward motion. The gray values of the translating objects in , , , , , , , , , and are 250, 225, 200, 175, 150, 125, 100, 75, 50, and 25, respectively.

Figure 3.
Sample frames 40 and 80 from 10 groups of the synthetic pure noisy visual stimulus sequences with the upward moving object based on dataset II. The noise intensity in (a), (b), (c), (d), (e), (f), (g), (h), (i) and (j) are 0, SPN = 0.01, SPN = 0.02, SPN = 0.03, SPN = 0.04, GN = 10.0, GN = 20.0, GN = 30.0, GN = 50.0, and GN = 80.0, respectively.
In the ablation study, the proposed bio-inspired model without the ON and OFF contrast neural computation (i.e., Model 1) and the proposed bio-inspired model without the spatial denoising mechanism (i.e., Model 2) were adopted to verify the effectiveness of the proposed bio-inspired model. The experimental results of model responses based on dataset I are shown in Figure 4. The experimental results of the mean and standard deviation based on dataset I are shown in Figure 5. The experimental results of model responses based on dataset II are shown in Figure 6. The experimental results of the mean and standard deviation based on dataset II are shown in Figure 7.
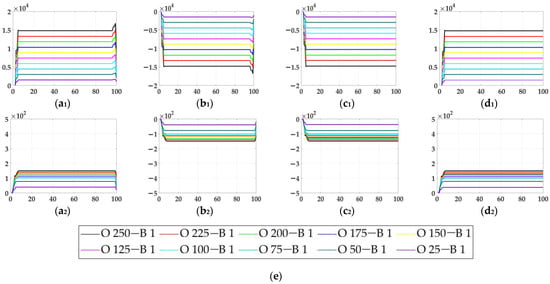
Figure 4.
The experimental results of model responses based on dataset I. Horizontal axis represents time in frames; vertical axis represents model responses. (a1,a2) represent the translating object in the upward motion; (b1,b2) represent the translating object in the downward motion; (c1,c2) represent the translating object in the leftward motion; (d1,d2) represent the translating object in the rightward motion. (a1–d1) represent the model responses of Model 1 and (a2–d2) represent the model responses of the proposed bio-inspired model; (e) represents the legend for (a1–d2). O represents the translating object and B represents the background.
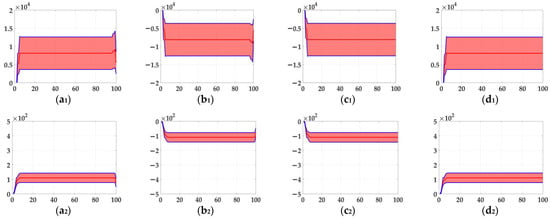
Figure 5.
The experimental results of the mean and standard deviation based on dataset I. Horizontal axis represents time in frames; vertical axis represents the mean and standard deviation. (a1,a2) represent the translating object in the upward motion; (b1,b2) represent the translating object in the downward motion; (c1,c2) represent the translating object in the leftward motion; (d1,d2) represent the translating object in the rightward motion; (a1–d1) represent the mean and standard deviation of Model 1; and (a2–d2) represent the mean and standard deviation of the proposed bio-inspired model.
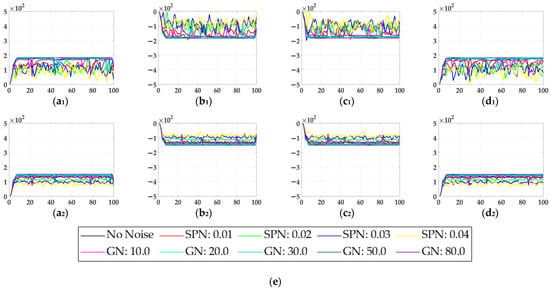
Figure 6.
The experimental results of model responses based on dataset II. Horizontal axis represents time in frames; vertical axis represents model responses. (a1,a2) represent the translating object in the upward motion; (b1,b2) represent the translating object in the downward motion; (c1,c2) represent the translating object in the leftward motion; (d1,d2) represent the translating object in the rightward motion; (a1–d1) represent the model responses of Model 2; and (a2–d2) represent the model responses of the proposed bio-inspired model. (e) represents the legend of for (a1–d2). SPN represents the salt and pepper noise; GN represents the Gaussian noise.
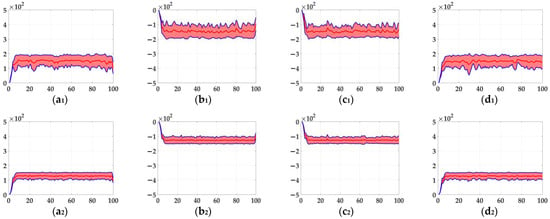
Figure 7.
The experimental results of the mean and standard deviation based on dataset II. Horizontal axis represents time in frames; vertical axis represents the mean and standard deviation. (a1,a2) represent the translating object in the upward motion; (b1,b2) represent the translating object in the downward motion; (c1,c2) represent the translating object in the leftward motion; (d1,d2) represent the translating object in the rightward motion; (a1–d1) represent the mean and standard deviation of Model 2; and (a2–d2) represent the mean and standard deviation of the proposed bio-inspired model.
Since the standard deviation is affected by the value of the variable itself, we adopted the dispersion of the coefficient of variation to further compare. The coefficient of variation, the inter-quartile range (IQR) of the coefficient of variation, and the sum of the coefficient of variation are defined in Equations (15)–(17):
where represents the coefficient of variation, represents the standard deviation, represents the mean value, represents the temporal coordinate, represents the inter-quartile range of the coefficient of variation, represents the upper quartile, represents the lower quartile, and represents the sum of coefficient of variation. The smaller the inter-quartile range, the better the statistical result; the smaller the coefficient of variation and the sum of the coefficient of variation, the better the statistical result. The experimental results of the coefficient of variation and the sum of the coefficient of variation based on dataset I comparison in Model 1 and the proposed bio-inspired model are shown in Table 5. The experimental results of the coefficient of variation and the sum of the coefficient of variation based on dataset II comparison in Model 2 and the proposed bio-inspired model are shown in Table 6.
Table 5.
The experimental results of the inter-quartile range and the sum of the coefficient of variation based on dataset I comparison in Model 1 and the proposed bio-inspired model. Bold indicates the best result.
Table 6.
The experimental results of the inter-quartile range and the sum of the coefficient of variation based on dataset II comparison in Model 2 and the proposed bio-inspired model. Bold indicates the best result.
From Figure 4 and Figure 5, we can draw the following two conclusions. (1) The proposed bio-inspired model and Model 1 have a high response to the translating object in the upward, downward, leftward, and rightward motions; furthermore, they can accurately detect the motion direction of the translating object. (2) In the upward/downward motion of the translating object, the horizontal response is approximately 0; furthermore, in the leftward/rightward motion of the translating object, the vertical response is approximately 0. From Table 5, compared with Model 1, we can draw the following two conclusions. (1) The inter-quartile range of the proposed bio-inspired model is reduced by 30.03%. (2) The sum of the coefficient of variation in the proposed bio-inspired model is reduced by 42.48%. In summary, the contrast neural computation of the proposed bio-inspired model effectively reduces the fluctuation in the model response under various contrasts in the figure-ground.
From Figure 6 and Figure 7, we can draw the following two conclusions. (1) The proposed bio-inspired model and Model 2 have a strong response to the translating object in the upward, downward, leftward, and rightward motions, and can accurately detect the motion direction of the translating object; furthermore, the fluctuation in the proposed bio-inspired model is significantly lower than that in Model 2. (2) In the upward/downward motion of the translating object, the horizontal response is small relative to the vertical response; furthermore, in the leftward/rightward motion of the translating object, the vertical response is small relative to the horizontal response. From Table 6, compared with Model 2, we can draw the following two conclusions. (1) The inter-quartile range of the coefficient of variation in the proposed bio-inspired model is reduced by 57.38%. (2) The sum of the coefficient of variation in the proposed bio-inspired model is reduced by 17.36%. In summary, the spatial denoising mechanism of the proposed bio-inspired model has the ability to suppress environmental noise and effectively reduces the fluctuation in the model response under different noise types with different intensities.
4.2. Detection Performance of Motion Directions of Translating Objects in Pure Noise Backgrounds
In this section, six kinds of comparable bio-inspired models (i.e., SotA models) including the EMD [9], TQD [12], FQD [13], FU [16], XU [38], and WANG [50] models were adopted to verify the detection performance of the proposed bio-inspired model; the value of the sampling distance (sd) of the EMD, TQD, and FQD models is 4, and the value of the parameter of the FU and XU models is shown in the references [16] and [38], and remains unchanged. To maintain consistency with the structure of other models, the WANG model adopts a combination of GPS, Gaussian blur, difference calculation, HWR, LI, and TQD, and the value of the sd is 4. SPN ratio (0.01/0.02/0.03/0.04) or GN standard deviation (10.0/20.0/30.0/50.0/80.0) were added based on Figure 2, as dataset III, i.e., sample frames 40 and 80 from 10 groups of the synthetic pure noisy visual stimulus sequences (SPN ratio: 0.04) with the upward moving object that is shown in Figure 8. The experimental results of model responses based on dataset III (SPN ratio: 0.04) are shown in Figure 9. The experimental results of the mean and standard deviation based on dataset III (SPN ratio: 0.04) are shown in Figure 10. The experimental results of the detection success rate based on the dataset III comparison for the six kinds of bio-inspired models and the proposed bio-inspired model are shown in Table 7. The experimental results of the inter-quartile range of the coefficient of variation based on dataset III comparison for the six kinds of bio-inspired models and the proposed bio-inspired model are shown in Table 8. The experimental results of the inter-quartile range and the sum of the coefficient of variation based on dataset III comparison for the six kinds of bio-inspired models and the proposed bio-inspired model are shown in Table 9.

Figure 8.
Sample frames 40 and 80 from 10 groups of the synthetic pure noising visual stimulus sequences with the upward moving object based on dataset III (SPN ratio: 0.04). The gray values of the translating objects (GVTO) in (a), (b), (c), (d), (e), (f), (g), (h), (i) and (j) are 250, 225, 200, 175, 150, 125, 100, 75, 50, and 25, respectively.
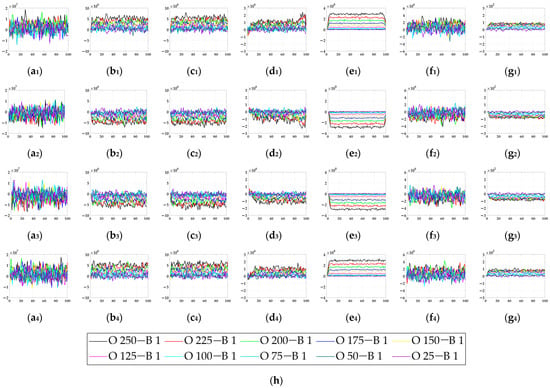
Figure 9.
The experimental results of model responses based on dataset III (SPN ratio: 0.04). Horizontal axis represents time in frames; vertical axis represents model responses. (a1–g1) represent the translating object in the upward motion; (a2–g2) represent the translating object in the downward motion; (a3–g3) represent the translating object in the leftward motion; (a4–g4) represent the translating object in the rightward motion. , , , , , , and represent EMD [9], TQD [12], FQD [13], FU [16], XU [38], WANG [50], and the proposed bio-inspired model, respectively; (h) represents the legend of (a1–g4). O represents the translating object and B represents the background.
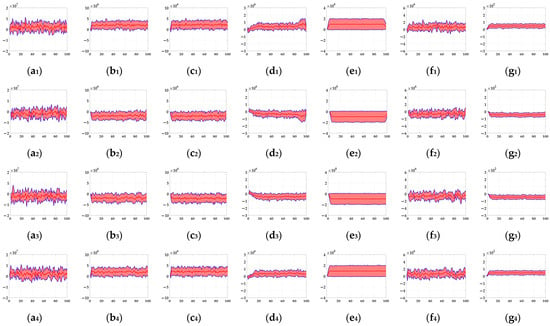
Figure 10.
The experimental results of the mean and standard deviation based on dataset III (SPN ratio: 0.04). Horizontal axis represents time in frames; vertical axis represents the mean and standard deviation. (a1–g1) represent the translating object in the upward motion; (a2–g2) represent the translating object in the downward motion; (a3–g3) represent the translating object in the leftward motion; (a4–g4) represent the translating object in the rightward motion. , , , , , , and represent EMD [9], TQD [12], FQD [13], FU [16], XU [38], WANG [50], and the proposed bio-inspired model, respectively.
Table 7.
The experimental results of the detection success rate (unit: %) based on dataset III comparison for the 6 kinds of bio-inspired models and the proposed bio-inspired model. Text in red, green, and blue are the first, second, and third best results.
Table 8.
The experimental results of the inter-quartile range of the coefficient of variation based on dataset III comparison for the 6 kinds of bio-inspired models and the proposed bio-inspired model. Text in red, green, and blue are the first, second, and third best results.
Table 9.
The experimental results of the sum of the coefficient of variation based on dataset III comparison for the 6 kinds of bio-inspired models and the proposed bio-inspired model. Text in red, green, and blue are the first, second, and third best results.
To compare the detection performance of the bio-inspired models, we adopt the detection success rate for quantitative analysis, which is defined in Equation (18):
where represents the detection success rate. The experimental results of the detection success rate comparison for the six kinds of bio-inspired models and the proposed bio-inspired model are shown in Table 7.
From Figure 9 and Figure 10 and Table 7, we can draw the following three conclusions. (1) The EMD [9], TQD [12], FQD [13], FU [16], XU [38], WANG [50], and proposed bio-inspired models have strong responses to the translating object in the upward, downward, leftward, and rightward motions; however, they have some detection errors of varying degrees. (2) The detection performance of the proposed bio-inspired model is superior to the six kinds of comparable bio-inspired models in the detection success rate; surprisingly, in the ten sub-datasets of dataset III, eight sub-datasets achieve the first best results, one sub-dataset achieves the second best result, and one sub-dataset achieves the third best result. Specifically, the detection success rate of the proposed bio-inspired model is increased by 9.32%, 3.59%, 2.72%, 5.84%, 6.27%, and 4.51%, respectively. The average detection success rate of the proposed bio-inspired model is increased by 5.38%. Thus, the proposed bio-inspired model can robustly detect the motion direction of the translating object. (3) In the upward/downward motion of the translating object, the horizontal response is small relative to the vertical response; furthermore, in the leftward/rightward motion of the translating object, the vertical response is small relative to the horizontal response. From Table 8 and Table 9, comparing the six kinds of bio-inspired models, we can draw the following two conclusions. (1) In ten groups of experiments, the inter-quartile range of the coefficient of variation in the proposed bio-inspired model achieves three of the first results and four of the second results. The inter-quartile range of the coefficient of variation in the proposed bio-inspired model is reduced by 94.70%, 65.21%, 57.85%, 74.32%, -150.64%, and 91.16%, respectively. The average decline in the inter-quartile range of the coefficient of variation in the proposed bio-inspired model is 38.77%. (2) In 10 groups of experiments, the sum of the coefficient of variation in the proposed bio-inspired model achieves ten of the first results. The sum of the coefficient of variation in the proposed bio-inspired model is reduced by 66.41%, 51.01%, 48.88%, 55.89%, 60.82%, and 59.17%, respectively. The average decline in the sum of the coefficient of variation in the proposed bio-inspired model is 57.03%. To summarize, the proposed bio-inspired model can robustly detect the motion direction of the translating object and effectively reduces the fluctuation in the model response against variable contrast in the figure-ground and environmental noise interference, which verifies the most basic detection capabilities of the proposed bio-inspired model.
4.3. Detection Performance of Motion Directions of Translating Objects in Real-World Complex Noise Backgrounds
In this section, to further verify the detection performance of the proposed bio-inspired model in real-world complex backgrounds, we used a Samsung camera (8 megapixels) to collect 500 real-world scenes on campus and the institute, including trees, buildings, bicycles, and so on. Each real-world scene of the campus and the institute comprised 60 partially overlapping images that were stitched together with PTGui (New House Internet Services BV, Rotterdam, Netherlands) to obtain the panoramic real-world images [51]; the resolution of the panoramic real-world images is set to 2048 × 310 pixels × pixels. These panoramic real-world images are the backgrounds, and the translating object is embedded in the panoramic real-world background. The translating object is a solid rectangle with a different gray value that varies between a maximum of 250 and a minimum of 25, and is taken every 25 gray values. In the upward/downward motion, the size and the motion velocity of the translating object are 100 × 50 pixels × pixels and 2000 pixels/second. In the leftward/rightward motion, the size and the motion velocity of the translating object are 50 × 100 pixels × pixels and 2000 pixels/second. Each panoramic background consists of 40 groups of real-world visual stimulus sequences and each group of the real-world visual stimulus sequences consists of 100 frames, the resolution and frame rate of each group of the real visual stimulus sequences are 500 × 250 pixels × pixels and 30 fps. The motion velocities of the background in the leftward/rightward and upward/downward motion are 500 and 2000 pixels/second, respectively. The sample of panoramic real-world backgrounds (ID: 1–500) amongst dataset including 500 testing panoramic real-world complex backgrounds are shown in Figure 11. The SPN ratio (0.01/0.02/0.03/0.04) or GN standard deviation (10.0/20.0/30.0/50.0/80.0) were added based on Figure 11, as dataset IV; sample frames 40 and 80 from 10 groups of synthetic real-world complex noisy visual stimulus sequences from one sample (ID = 8) of dataset IV (SPN ratio: 0.04) are shown in Figure 12. The experimental results of the mean and standard deviation based on dataset IV (SPN ratio: 0.04) are shown in Figure 13. The experimental results, represented by violin- and box-type diagrams of the coefficient of variation based on dataset IV (SPN ratio: 0.04), comparison drawings for the six kinds of bio-inspired models, and the proposed bio-inspired model, are shown in Figure 14. The denser the distribution of the coefficient of variation is, the better the statistical result. The closer the coefficient of variation is to 0, the better the statistical result. Therefore, we hope that the height of the violin based on the coefficient of variation can be as narrow as possible, and the position of the violin based on the coefficient of variation can be as close to 0 as possible. In addition, the blue box in each violin represents a box-plot, which is used to characterize the dispersion degree of the coefficient of variation; the blue top and bottom of each box-plot represent the upper and lower quartile, the red line of each box-plot represents the median value, the black top and bottom line of each box-plot represent the upper and lower edges, and the red crosses represent outliers. The experimental results of the detection success rate based on the dataset IV comparison for the six kinds of bio-inspired models and the proposed bio-inspired model are shown in Table 10. The experimental results of the inter-quartile range of the coefficient of variation based on dataset IV comparison for the six kinds of bio-inspired models and the proposed bio-inspired model are shown in Table 11. The experimental results of the sum of the coefficient of variation based on dataset IV comparison for the six kinds of bio-inspired models and the proposed bio-inspired model are shown in Table 12.

Figure 11.
The sample of panoramic real-world complex backgrounds (ID: 1–500) amongst dataset IV, including 500 panoramic real-world backgrounds used in the tests. … represents other panoramic real-world complex backgrounds.


Figure 12.
Sample frames 40 and 80 from 10 groups of synthetic real-world complex noisy visual stimulus sequences from one sample (ID = 8) of dataset IV (SPN ratio: 0.04). The light blue arrows represent the motion direction of the translating object. (a1–j1) represent the translating object in the upward motion; (a2–j2) represent the translating object in the downward motion; (a3–j3) represent the translating object in the leftward motion; and (a4–j4) represent the translating object in the rightward motion. The gray values of the translating objects in , , , , , , , , , and are 250, 225, 200, 175, 150, 125, 100, 75, 50, and 25, respectively.
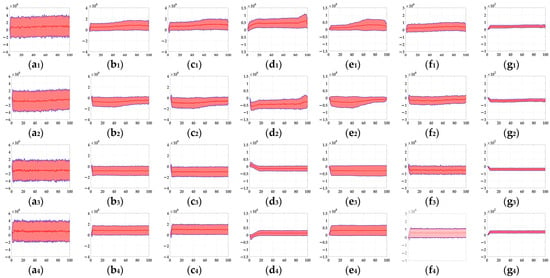
Figure 13.
The experimental results of the mean and standard deviation based on dataset IV (SPN ratio: 0.04). Horizontal axis represents time in frames; vertical axis represents the mean and the standard deviation. The red line represents the mean, the transparent red shadow represents the standard deviation, and the blue lines represent the addition and subtraction between the mean and the standard deviation; (a1–g1) represent the translating object in the upward motion; (a2–g2) represent the translating object in the downward motion; (a3–g3) represent the translating object in the leftward motion; (a4–g4) represent the translating object in the rightward motion., , , , , , and represent EMD [9], TQD [12], FQD [13], FU [16], XU [38], WANG [50], and the proposed bio-inspired model, respectively.
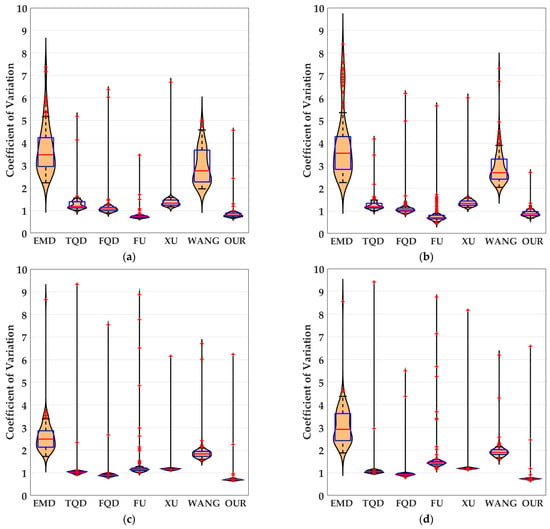
Figure 14.
The experimental results shown as violin- and box-type diagrams of the coefficient of variation based on dataset IV (SPN ratio: 0.04), comparison drawings for the 6 kinds of bio-inspired models and the proposed bio-inspired model: (a) represents the translating object in the upward motion; (b) represents the translating object in the downward motion; (c) represents the translating object in the leftward motion; (d) represents the translating object in the rightward motion. OUR represents the proposed bio-inspired model [9,12,13,16,38,50].
Table 10.
The experimental results of the detection success rate (unit: %) based on dataset IV, comparing the 6 kinds of bio-inspired models and the proposed bio-inspired model. Text in red, green, and blue are the first, second, and third best results.
Table 11.
The experimental results of the inter-quartile range of the coefficient of variation based on dataset IV, comparing the 6 kinds of bio-inspired models and the proposed bio-inspired model. Text in red, green, and blue are the first, second, and third best results.
Table 12.
The experimental results of the sum of the coefficient of variation based on dataset IV, comparing the 6 kinds of bio-inspired models and the proposed bio-inspired model. Text in red, green, and blue are the first, second, and third best results.
From Figure 13 and Table 10, we can draw the following four conclusions. (1) From Figure 11(a1–a4), the detection performance of the EMD [9] is not satisfactory. (2) From Figure 11(b1–f1,b2–f2,b3–f3,b4–f4), the detection performance of the TQD [12], FQD [13], FU [16], XU [38], and WANG [50] models can meet the basic detection performance, but there are still a few detection errors. (3) The detection performance of the proposed bio-inspired model is superior to the six kinds of comparable bio-inspired models in the detection success rate; surprisingly, in the ten sub-datasets of dataset IV, seven sub-datasets achieve the first best results and two sub-datasets achieve the second best results. Specifically, the detection success rate of the proposed bio-inspired model is increased by 10.82%, 3.33%, 3.15%, 4.16%, 6.05%, and 4.26%, respectively. The average increase in the detection success rate of the proposed bio-inspired model is 5.30%. So, the proposed bio-inspired model can robustly detect the motion direction of the translating object. (4) In the upward/downward motion of the translating object, the horizontal response is small relative to the vertical response; furthermore, in the leftward/rightward motion of the translating object, the vertical response is small relative to the horizontal response. From Figure 14, we can draw the following two conclusions. (1) In the upward motion, the height of the proposed bio-inspired model violin diagram is narrower than the EMD [9], TQD [12], FQD [13], XU [38], and WANG [50] models, but not that of the FU [16] model. In the downward motion, the height of the proposed bio-inspired model violin diagram is narrower than the EMD [9], TQD [12], XU [38], and WANG [50] models, but not that of the FQD [13] and FU [16] models. In the leftward motion, the height of the proposed bio-inspired model violin diagram is narrower than the six kinds of comparable bio-inspired models. In the rightward motion, the height of the proposed bio-inspired model violin diagram is narrower than the EMD [9], TQD [12], FQD [13], FU [16], and WANG [50] models, but not that of the XU [38] model. (2) In the upward/downward motion, the position of the violin diagram for the proposed bio-inspired model is closer to 0 than the EMD [9], TQD [12], FQD [13], XU [38], and WANG [50] models, but not closer than that for the FU [16] model. In the leftward/rightward motion, the position of the violin diagram for the proposed bio-inspired model is closer to 0 than for the six kinds of comparable bio-inspired models. From Table 11 and Table 12, we can draw the following two conclusions. (1) The inter-quartile range of the coefficient of variation in the proposed bio-inspired model is reduced by 84.83%, 10.02%, 23.23%, 27.52%, 64.32%, and 77.12%. The average decline in the inter-quartile range of the coefficient of variation in the proposed bio-inspired model is 47.84%. (2) The sum of the coefficient of variation in the proposed bio-inspired model is reduced by 71.49%, 66.47%, 64.78%, 64.45%, 69.49%, and 68.16%. The average decline in the sum of the coefficient of variation in the proposed bio-inspired model is 67.47%. Briefly, the proposed bio-inspired model can robustly detect the motion direction of the translating object and effectively reduces the fluctuation in the model response under various contrasts in the figure-ground of real-world complex noise backgrounds.
4.4. Further Investigations
To further estimate the performance of the proposed bio-inspired model, the spatial denoising mechanism is replaced by the difference of Gaussians (DoG) [22] (Model 3), fast-depolarizing slow-repolarizing (FDSR) [52] (Model 4), Gaussian filter (Model 5), mean filter (Model 6), or median filter (Model 7) based on two sub-datasets (SPN ratio: 0.04 and GN standard deviation: 80.0) of dataset IV, for further comparison. The DoG and FDSR as early visual pre-processing mechanisms have previously been validated for their role in filtering background interference [22,52]. Gaussian, mean, and median filters are standard engineering noise-filtering methods [53].
From Table 13, comparing Models 3, 4, 5, 6, and 7, we can draw the following two conclusions. (1) The inter-quartile range of the coefficient of variation in the proposed bio-inspired model is reduced by 76.26%, 34.46%, 28.32%, 25.86%, and −1.7%, respectively. The average decline in the inter-quartile range of the coefficient of variation in the proposed bio-inspired model is 32.64%. (2) The sum of the coefficient of variation in the proposed bio-inspired model is reduced by 47.64%, 25.48%, 33.69%, 26.96%, and 1.3%, respectively. The average decline in the sum of the coefficient of variation in the proposed bio-inspired model is 27.01%. From Table 14, comparing Models 3, 4, 5, 6, and 7, we can draw the following two conclusions. (1) The inter-quartile range of the coefficient of variation in the proposed bio-inspired model is reduced by 7.87%, −0.82%, −2.50%, 13.99%, and 4.65%, respectively. The average decline in the inter-quartile range of the coefficient of variation in the proposed bio-inspired model is 4.64%. (2) The sum of the coefficient of variation in the proposed bio-inspired model is reduced by −18.65%, −26.94%, −18.22%, 2.30%, and 1.57%, respectively. The average decline in the sum of the coefficient of variation in the proposed bio-inspired model is -11.99%. To summarize, for the salt and pepper noise (SPN ratio: 0.04), the performance of the proposed bio-inspired model is superior to that of Models 3, 4, 5, and 6, and is close to that of Model 7. For the Gaussian noise (GN standard deviation: 80.0), the performance of the proposed bio-inspired model obtains the third best result according to the inter-quartile range of the coefficient of variation; the performance of the proposed bio-inspired model is superior to Models 6 and 7 but inferior to Models 3, 4, and 5, according to the sum of the coefficient of variation.
Table 13.
The experimental results of the inter-quartile range and the sum of the coefficient of variation based on one sub-dataset (SPN ratio: 0.04) of the dataset IV comparison for Models 3, 4, 5, 6, 7, and the proposed bio-inspired model. Text in red, green, and blue are the first, second, and third best results.
Table 14.
The experimental results of the inter-quartile range and the sum of the coefficient of variation based on one sub-dataset (GN standard deviation: 80.0) of the dataset IV comparison for Models 3, 4, 5, 6, 7, and the proposed bio-inspired model. Text in red, green, and blue are the first, second, and third best results.
5. Discussion
In the lamina neural layer, the spatial denoising mechanism is regarded as the early visual pre-processing, which can suppress environmental noise of the ON and OFF visual pathways. In the medulla neural layer, the non-linear instantaneous feedback divisive contrast normalization mechanism dynamically suppresses the neural signals to reduce local contrast sensitivity, and the parallel contrast pathways are activated. In the lobula-complex neural layer, the parallel motion and contrast pathways converge and the contrast pathways negatively affect the motion pathways to suppress the high-contrast optical flow. The proposed bio-inspired model performs feed-forward visual processing in a four-hierarchical neural network to denoise and encode polar motion and contrast information, respectively. The contrast neural computation and the spatial denoising mechanism are the main innovations of this modeling study because they act as an instantaneous, feedback, and dynamic normalization mechanism and environmental noise suppression for processing ON and OFF signals. There are ON and OFF contrast pathways to neutralize high contrast local ON and OFF motion-induced excitation for robust and stable model responses against variable contrast in the figure-ground of the pure and real-world complex noise backgrounds. To confirm the proposed bio-inspired model, we produced four datasets consisting of the translating motions of a rectangle object against the pure and real-world complex backgrounds with different noise types with variable intensities. To highlight the detection performance of the proposed bio-inspired model, comparative experiments were carried out. Comparative experiments consist of four sections. Firstly, the ablation study verifies the effectiveness of the contrast neural computation and the spatial denoising mechanism. Secondly, the pure background verifies the effectiveness of the proposed bio-inspired model under different noise types with variable intensities and different gray-scale objects against the same gray-scale background. Thirdly, the real-world complex background verifies the effectiveness of the proposed bio-inspired model under different noise types with variable intensities and different gray-scale objects against different real-world complex backgrounds. Finally, further investigations verify the performance of the proposed bio-inspired model under various contrasts in the figure-ground of real-world complex noise backgrounds. The experimental results verify the proposed bio-inspired model has better stability and robustness for detection in pure and real-world complex backgrounds with different noise types. Separating motion and contrast into ON and OFF pathways, the model works effectively to alleviate the response fluctuation against variable contrast in the figure-ground; furthermore, the spatial denoising mechanism makes the bio-inspired visual neural model more robust and stable in response to translating motion. Future research efforts may involve the following aspects:
- (1)
- The limitation of this study is that the baseline contrast sensitivity has an impact on the detection performance of the proposed bio-inspired model. Therefore, how to effectively determine the corresponding relationship between variable signals and the baseline contrast sensitivity is the focus of future research.
- (2)
- How to use the moving direction of the translating object based on LPTC neurons to detect the wide-field or local-salient object is one of the future research points.
- (3)
- Integrating the probability between layers of the LPTC-based bio-inspired model to further improve environmental interference is one of the future research points.
6. Conclusions
In this study, the LPTC is used as a research object to study its physiological mechanism and the existing computational model. We find that it can detect the motion direction of the translating object robustly and stably under a complex dynamic noise background; based on this biological vision paradigm, a bio-inspired visual neural model is proposed, which incorporates continuous computational neural layers from the retina to the lobula complex. Firstly, in the retina neural layer, the photoreceptors (R1–R6) are utilized to perceive the change in luminance. Secondly, in the lamina neural layer, the change in luminance is divided into parallel ON and OFF pathways, and the spatial denoising and spatio-temporal LI mechanisms are regarded as the early visual pre-processing, which can suppress environmental noise and improve motion boundaries. Thirdly, in the medulla neural layer, the non-linear instantaneous feedback divisive contrast normalization mechanism is adopted to reduce local contrast sensitivity; furthermore, the parallel contrast pathways are activated. Finally, the parallel motion and contrast pathways converge on the LPTC in the lobula-complex neural layer and the contrast pathway negatively affects the motion pathway to suppress the high-contrast optical flow. Variable contrast in the figure-ground and environmental noise interference are two major factors that affect the stability and robustness of the motion direction of the translating object detection. The proposed bio-inspired model not only has stable and robust performance in variable contrast in the figure-ground, but also has stable and robust performance in the noise background, with its performance to process both simultaneously, which further approximates Drosophila’s visual neural detection capability. Four groups of experiments were adopted to verify the robustness and stability of the proposed bio-inspired model under variable contrast in the figure-ground and environmental noise interference. We have consistently adhered to the study of how Drosophila utilizes a robust, stable, and lightweight visual neural system to process environmental information from a neuroscientific perspective, which can effectively enhance the current ability to build various bio-inspired visual neural models.
Author Contributions
Conceptualization, S.Z. (Sheng Zhang) and Z.L.; methodology, S.Z. (Sheng Zhang); software, S.Z. (Sheng Zhang); validation, S.Z. (Sheng Zhang), K.L., and Z.L.; formal analysis, Z.L.; investigation, K.L.; resources, S.Z. (Sheng Zhang); data curation, S.Z. (Shengnan Zheng); writing—original draft preparation, K.L.; writing—review and editing, K.L.; visualization, M.X.; supervision, S.Z. (Shengnan Zheng); project administration, M.X.; funding acquisition, K.L., Z.L., and S.Z. (Shengnan Zheng). All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China, grant number 62463021, and the Natural Science Foundation of Jiangxi Province, grant numbers 20242BAB25049, 20232BAB202003.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The code used to generate the results and figures is available in a Github repository, which can be accessed via the following link: https://github.com/szhanghh/Bio-inspired-model, accessed on 6 January 2025. The panoramic real-world dataset is available in a Github repository, which can be accessed via the following link: https://github.com/szhanghh/Model-dataset and https://github.com/szhanghh/Model-dataset2, accessed on 6 January 2025.
Acknowledgments
This research was supported by the National Natural Science Foundation of China and the Natural Science Foundation of Jiangxi Province.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, J.; Zhou, Z.; Kim, B.J.; Zhou, Y.; Wang, Z.; Wan, T.; Yan, J.; Kang, J.; Ahn, J.-H.; Chai, Y. Optoelectronic graded neurons for bioinspired in-sensor motion perception. Nat. Nanotechnol. 2023, 18, 882–888. [Google Scholar] [CrossRef]
- Shen, K.; Yang, Y.; Liang, Y.; Xu, L. Modeling Drosophila vision neural pathways to detect weak moving targets from complex backgrounds. Comput. Electr. Eng. 2022, 99, 107678. [Google Scholar] [CrossRef]
- Cheng, K.Y.; Frye, M.A. Neuromodulation of insect motion vision. J. Comp. Physiol. A 2020, 206, 125–137. [Google Scholar] [CrossRef]
- de Andres-Bragado, L.; Sprecher, S.G. Mechanisms of vision in the fruit fly. Curr. Opin. Insect Sci. 2019, 36, 25–32. [Google Scholar] [CrossRef]
- Fu, Q.; Wang, H.; Hu, C.; Yue, S. Towards computational models and applications of insect visual systems for motion perception: A review. Artif. Life 2019, 25, 263–311. [Google Scholar] [CrossRef]
- Bagheri, Z.M.; Cazzolato, B.S.; Grainger, S.; O’carroll, D.C.; Wiederman, S.D. An autonomous robot inspired by insect neurophysiology pursues moving features in natural environments. J. Neural Eng. 2017, 14, 046030. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Wang, H.; Bellotto, N.; Hu, C.; Peng, J.; Yue, S. Enhancing LGMD’s looming selectivity for uav with spatial-temporal distributed presynaptic connections. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 2539–2553. [Google Scholar] [CrossRef]
- Chen, Z.; Mu, Q.; Han, G.; Lu, H. Drosophila-vision-inspired motion perception model and its application in saliency detection. IEEE Trans. Consum. Electron. 2024, 70, 819–830. [Google Scholar] [CrossRef]
- Reichardt, W. Evaluation of optical motion information by movement detectors. J. Comp. Physiol. A 1987, 161, 533–547. [Google Scholar] [CrossRef]
- Ruffier, F.; Viollet, S.; Franceschini, N. Visual control of two aerial micro-robots by insect-based autopilots. Adv. Robot. 2004, 18, 771–786. [Google Scholar] [CrossRef]
- Chahl, J.S. Optical flow and motion detection for navigation and control of biological and technological systems. J. Mod. Opt. 2016, 70, 793–810. [Google Scholar] [CrossRef]
- Franceschini, N.; Riehle, A.; Nestour, A. Directionally Selective Motion Detection by Insect Neurons. In Facets of Vision; Springer: Berlin/Heidelberg, Germany, 1989; pp. 360–390. [Google Scholar] [CrossRef]
- Eichner, H.; Joesch, M.; Schnell, B.; Reiff, D.F.; Borst, A. Internal structure of the fly elementary motion detector. Neuron 2011, 70, 1155–1164. [Google Scholar] [CrossRef]
- Clark, D.A.; Bursztyn, L.; Horowitz, M.A.; Schnitzer, M.J.; Clandinin, T.R. Defining the computational structure of the motion detector in Drosophila. Neuron 2011, 70, 1165–1177. [Google Scholar] [CrossRef] [PubMed]
- Wei, H.; Kyung, H.Y.; Kim, P.J.; Desplan, C. The diversity of lobula plate tangential cells (LPTCs) in the Drosophila motion vision system. J. Comp. Physiol. A 2020, 206, 139–148. [Google Scholar] [CrossRef] [PubMed]
- Fu, Q.; Yue, S. Modelling Drosophila motion vision pathways for decoding the direction of translating objects against cluttered moving backgrounds. Biol. Cybern. 2020, 114, 443–460. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, X. Development of the Drosophila optic lobe. Cold Spring Harb. Protoc. 2023, 2024, pdb-top108156. [Google Scholar] [CrossRef]
- Zavatone-Veth, J.A.; Badwan, B.A.; Clark, D.A. A minimal synaptic model for direction selective neurons in Drosophila. J. Vis. 2020, 20, 2. [Google Scholar] [CrossRef]
- Zhu, Y. The Drosophila visual system: From neural circuits to behavior. Cell Adhes. Migr. 2013, 7, 333–344. [Google Scholar] [CrossRef] [PubMed]
- Stöckl, A.L.; O’carroll, D.C.; Warrant, E.J. Hawkmoth lamina monopolar cells act as dynamic spatial filters to optimize vision at different light levels. Sci. Adv. 2020, 6, eaaz8645. [Google Scholar] [CrossRef]
- Joesch, M.; Schnell, B.; Raghu, S.V.; Reiff, D.F.; Borst, A. ON and OFF pathways in Drosophila motion vision. Nature 2010, 468, 300–304. [Google Scholar] [CrossRef]
- Fu, Q.; Bellotto, N.; Yue, S. A directionally selective neural network with separated ON and OFF pathways for translational motion perception in a visually complex environment. arXiv 2018, arXiv:1808.07692. [Google Scholar] [CrossRef]
- Arkachar, P.; Wagh, M.D. Criticality of lateral inhibition for edge enhancement in neural systems. Neurocomputing 2007, 70, 991–999. [Google Scholar] [CrossRef]
- Behnia, R.; Clark, D.A.; Carter, A.G.; Clandinin, T.R.; Desplan, C. Processing properties of ON and OFF pathways for Drosophila motion detection. Nature 2014, 512, 427–430. [Google Scholar] [CrossRef] [PubMed]
- Maisak, M.S.; Haag, J.; Ammer, G.; Serbe, E.; Meier, M.; Leonhardt, A.; Schilling, T.; Bahl, A.; Rubin, G.M.; Nern, A.; et al. A directional tuning map of Drosophila elementary motion detectors. Nature 2013, 500, 212–216. [Google Scholar] [CrossRef]
- Bahl, A.; Serbe, E.; Meier, M.; Ammer, G.; Borst, A. Neural mechanisms for drosophila contrast vision. Neuron 2015, 88, 1240–1252. [Google Scholar] [CrossRef] [PubMed]
- Shinomiya, K.; Karuppudurai, T.; Lin, T.-Y.; Lu, Z.; Lee, C.-H.; Meinertzhagen, I.A. Candidate neural substrates for OFF-edge motion detection in Drosophila. Curr. Biol. 2014, 24, 1062–1070. [Google Scholar] [CrossRef][Green Version]
- Melano, T.; Higgins, C.M. The neuronal basis of direction selectivity in lobula plate tangential cells. Neurocomputing 2005, 65–66, 153–159. [Google Scholar] [CrossRef]
- Mauss, A.S.; Pankova, K.; Arenz, A.; Nern, A.; Rubin, G.M.; Borst, A. Neural circuit to integrate opposing motions in the visual field. Cell 2015, 162, 351–362. [Google Scholar] [CrossRef] [PubMed]
- Klapoetke, N.C.; Nern, A.; Peek, M.Y.; Rogers, E.M.; Breads, P.; Rubin, G.M.; Reiser, M.B.; Card, G.M. Ultra-selective looming detection from radial motion opponency. Nature 2017, 551, 237–241. [Google Scholar] [CrossRef] [PubMed]
- Lei, F.; Peng, Z.; Liu, M.; Peng, J.; Cutsuridis, V.; Yue, S. A robust visual system for looming cue detection against translating motion. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8362–8376. [Google Scholar] [CrossRef] [PubMed]
- Yue, S.; Rind, F. Collision detection in complex dynamic scenes using an LGMD-based visual neural network with feature enhancement. IEEE Trans. Neural Netw. 2006, 17, 705–716. [Google Scholar] [CrossRef]
- Zhu, Y.; Dewell, R.B.; Wang, H.; Gabbiani, F. Pre-synaptic muscarinic excitation enhances the discrimination of looming stimuli in a collision-detection neuron. Cell Rep. 2018, 23, 2365–2378. [Google Scholar] [CrossRef]
- Hong, J.; Sun, X.; Peng, J.; Fu, Q. A bio-inspired probabilistic neural network model for noise-resistant collision perception. Biomimetics 2024, 9, 136. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Wang, Y.; Wu, G.; Li, H.; Peng, J. Enhancing LGMD-based model for collision prediction via binocular structure. Front. Neurosci. 2023, 17, 1247227. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Peng, J.; Yue, S. A feedback neural network for small target motion detection in complex backgrounds. In Proceedings of the International Conference on Artificial Neural Networks (ICANN), Rhodes, Greece, 4–7 October 2018; pp. 728–737. [Google Scholar] [CrossRef]
- Wang, H.; Peng, J.; Yue, S. An improved LPTC neural model for background motion direction estimation. In International Conference on Development and Learning and on Epigenetic Robotics; ICDL-EpiRob: Lisbon, Portugal, 2018; pp. 47–52. [Google Scholar] [CrossRef]
- Xu, M.; Shi, J.; Zheng, S.; Han, L. Detection model of target motion direction simulating the optic lobe neural network of compound eyes. CAAI Trans. Intell. Syst. 2024, 19, 546–555. [Google Scholar] [CrossRef]
- Wiederman, S.D.; O’carroll, D.C. Biologically inspired feature detection using cascaded correlations of OFF and ON channels. J. Artif. Intell. Soft Comput. Res. 2013, 3, 5–14. [Google Scholar] [CrossRef]
- Clark, D.A.; Fitzgerald, J.E.; Ales, J.M.; Gohl, D.M.; Silies, M.A.; Norcia, A.M.; Clandinin, T.R. Flies and humans share a motion estimation strategy that exploits natural scene statistics. Nat. Neurosci. 2014, 17, 296–303. [Google Scholar] [CrossRef] [PubMed]
- Fitzgerald, J.; Clark, D. Nonlinear circuits for naturalistic visual motion estimation. eLife 2015, 4, e09123. [Google Scholar] [CrossRef]
- Drews, M.S.; Leonhardt, A.; Pirogova, N.; Richter, F.G.; Schuetzenberger, A.; Braun, L.; Serbe, E.; Borst, A. Dynamic signal compression for robust motion vision in flies. Curr. Biol. 2020, 30, 209–221.e8. [Google Scholar] [CrossRef] [PubMed]
- Fu, Q.; Yue, S. Bioinspired contrast vision computation for robust motion estimation against natural signals. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 18–22. [Google Scholar] [CrossRef]
- Li, Z.; Fu, Q.; Li, H.; Yue, S.; Peng, J. Dynamic signal suppression increases the fidelity of looming perception against input variability. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Fu, Q.; Li, Z.; Peng, J. Harmonizing motion and contrast vision for robust looming detection. Array 2022, 17, 100272. [Google Scholar] [CrossRef]
- Hua, M.; Fu, Q.; Peng, J.; Yue, S.; Luan, H. Shaping the ultra-selectivity of a looming detection neural network from non-linear correlation of radial motion. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Tuthill, J.C.; Nern, A.; Holtz, S.L.; Rubin, G.M.; Reiser, M.B. Contributions of the 12 neuron classes in the fly lamina to motion vision. Neuron 2013, 79, 128–140. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhao, J.; Hua, M.; Luan, H.; Liu, M.; Lei, F.; Cuayahuitl, H.; Yue, S. O-LGMD: An opponent colour LGMD-based model for collision detection with thermal images at night. In Proceedings of the International Conference on Artificial Neural Networks (ICANN), Bristol, UK, 6–9 September 2022; pp. 249–260. [Google Scholar] [CrossRef]
- Straw, A.D. Vision egg: An open-source library for realtime visual stimulus generation. Front. Neurosci. 2008, 2, 339. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Peng, J.; Yue, S. A directionally selective small target motion detecting visual neural network in cluttered backgrounds. IEEE Trans. Cybern. 2020, 50, 1541–1555. [Google Scholar] [CrossRef] [PubMed]
- Brinkworth, R.S.A.; O’Carroll, D.C. Robust models for optic flow coding in natural scenes inspired by insect biology. PLOS Comput. Biol. 2009, 5, e1000555. [Google Scholar] [CrossRef] [PubMed]
- James, J.V.; Cazzolato, B.S.; Grainger, S.; Wiederman, S.D. Nonlinear, neuronal adaptation in insect vision models improves target discrimination within repetitively moving backgrounds. Bioinspiration Biomim. 2021, 16, 066015. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Sodhi, S. Comparative analysis of gaussian filter, median filter and denoise autoenocoder. In Proceedings of the International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 12–14 March 2020; pp. 45–51. [Google Scholar] [CrossRef]















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).