1. Introduction
Classification of data into sensible groups is essential in a wide variety of fields, such as engineering, medical science, business, marketing and many more [
1,
2]. The most popular approaches for classifying objects into groups are discriminant analysis and clustering techniques [
2,
3]. Discriminant analysis is a supervised learning method in which the class labels are already defined and the aim is to find the data that have not been labeled [
2,
4]. In clustering, the problem is to group the unlabeled data into sensible groups. Hence, clustering is useful in applications where there is little prior information about the available data [
3]. Due to massive data generation in recent years, clustering has been found useful in various fields such as machine learning, pattern analysis, decision making, etc. [
5]. The popular clustering algorithms proposed in recent years include hierarchical clustering, partitioning clustering, mixture resolve clustering, fuzzy clustering, and so on [
2,
6]. The methods described above take into account all of the dimensions of the input data during learning. Dealing with high-dimensional datasets, on the other hand, can be more difficult due to the curse of the dimensionality problem [
7,
8]. As the dimensionality of the data grows, the data can become sparser, increasing the computational complexity of clustering [
5].
Even if the data are multidimensional, they can be expressed effectively in a union of low-dimensional space [
9]. In real-world scenarios, the high-dimensional data would also be distributed across several low-dimensional subspaces [
10,
11]. Then, the aim of subspace clustering is to identify these subspaces and segment the data based on their dissimilarity [
7,
12]. Algebraic methods, matrix factorization methods, statistical methods, and spectral clustering methods are the major types of subspace clustering techniques [
6,
13,
14]. Spectral clustering is simple to implement and can outperform traditional algorithms. Hence, it is the most popular method for high-dimensional data clustering [
15]. Depending on the type of affinity matrices derived from the data, various spectral clustering algorithms have been proposed.
Shi et al. proposed a normalized spectral clustering method which measures the dissimilarity between different groups and the similarity within the group using a normalized Laplacian matrix [
16]. Andrew et al. proposed another method with additional row normalization [
17]. Then, the sparse subspace clustering (SSC) algorithm proposed by Elhamifar et al. utilizes the self-expressiveness property of the data [
10]. The underlying theory behind the self-expressiveness property is that every data point lying in a particular subspace can be expressed as a linear combination of other data points that belong to the same subspace [
1,
10]. The SSC algorithm aims to find a sparse representation that corresponds to a minimal set of points belonging to the same subspace. Then, the solution of the optimization problem is used for spectral clustering [
10]. Liu et al. proposed subspace segmentation by low rank representation (LRR) [
18]. Similar to SSC, LRR also represents a given data point as the linear combination of other data points [
14] but instead of sparsest representation, LRR tries to find the low rank representation.
When dealing with higher dimensional signals, such as images, all the aforementioned methods map the 2D images into one-dimensional vectors. This approach is not so effective in capturing the spatial structure information of the images. To address this problem, instead of vectorizing the imaging data, a new approach called the union of free submodule (UoFS) model was proposed, which preserves the spatial structure of the 2D data [
18,
19]. In this model, images are stacked together in a third order tensor space. Kernfeld et al. proposed sparse submodule clustering (SSmC), which combines the UoFS model with the self-expressiveness property exploited in the SSC algorithm. In this, each image is interpreted as a linear combination of remaining images in the dataset [
20]. However, in SSmC, the correlation between images from the same submodule is not taken into account [
21]. To consider the inner correlation, the low rank structure of the multi-linear data is exploited in the sparse and low-rank submodule clustering method (SLRSmC) proposed by Piao et al. [
21]. Identical to the scalar product, the tensor product is utilized for constructing the submodule clustering method. SLRSmC, on the other hand, imposes a low rank constraint on each image in the tensor, rather than a tensor low rank constraint. Wu et al. resolved this problem by imposing a low tensor rank constraint using the tensor nuclear norm (TNN) [
19].
For enforcing the low rank constraint, the methods proposed in [
19,
20,
21] use
norm instead of
norm. This ensures that the optimization problem is convex since
norm is considered the convex surrogate of
norm [
22]. Relying on the UoFS model, many extensions of the work proposed by Wu et al. were developed with the objective of addressing real-world scenarios, such as noise, incomplete observations, and so on. Francis et al. proposed a tensor-based single stage optimization framework for clustering imaging data under incomplete observations [
6]. In this work, individual images with missing samples are fetched in sequence from the input data tensor for reconstruction. Further, reconstruction of the missing samples is carried out by the matrix completion [
6]. In another work, Johnson et al. replaced the low tensor multirank equivalent TNN by employing weighted tensor nuclear norm minimization (WTNN) for a more accurate low rank representation [
23]. Baburaj et al. proposed a noise robust tensor-based submodule identification approach, named re-weighted low rank tensor approximation and
regularization
to perform clustering in the presence of gross errors [
24], using the re-weighted tensor nuclear norm. An error term was introduced into the model to separate noise and data, which brings noise robustness to the clustering technique. Xia et al. proposed a subspace clustering method for multi-view data in which the representation tensor is learned by means of weighted tensor Schatten
p-norm minimization (WTSNM) [
25]. In another work, Wu proposed a clustering-aware Laplacian regularized low-rank submodule clustering (CLLRSmC) model that exploits the local manifold structure of the data [
26]. In this work, the nonlinear extension of the UoFS model which can adapt data drawn from a mixture of nonlinear manifolds was presented.
Concurrently, the principle of sparse and low rank decomposition of matrices and tensors was applied to many research problems for noise removal. Shijila et al. proposed a unified framework of simultaneous denoising and moving object detection using low rank approximation [
27]. Jin et al. proposed an impulse noise removal algorithm named robust ALOHA, which employs a sparse and low rank decomposition of a Hankel structured matrix [
28]. They modeled impulse noise as a sparse component, then restored the underlying image while preserving the original image features [
28]. Similarly, Cao et al. proposed a subspace-based non-local low rank and sparse factorization (SNLRSF) method for hyperspectral image denoising [
29].
Since real-world data are heavily influenced by noise, which reduces clustering efficiency, and current techniques are unable to completely recover the data from noise, we propose a robust tensor based submodule identification technique with improved clustering capability, taking the following factors into account.
A robust tensor-based submodule clustering algorithm is proposed in this paper, which combines the clustering of 2D images with simultaneous noise removal in a single framework. Real-world data, such as images and videos, are frequently subjected to noise during acquisition, transmission, or due to limitations imposed by material and technological resources. The presence of noise affects the performance of clustering algorithms. To limit the effects of noise, existing methods usually include a global error term in their optimization problem. However, following this approach will not fully remove the noise encountered in individual images.
Hence, this work proposes a simultaneous noise removal scheme based on twisting the third-order input data tensor, which allows lateral image slices to become frontal slices of the twisted data tensor. Furthermore, images are extracted from this tensor data one by one, and each image is subjected to a sparse and low rank decomposition approach. Unlike the existing clustering methods, this procedure can find and eliminate the noise content in each of the images from the data, and a clean noise-free data tensor can be obtained for further clustering.
To better capture the low rankness and self-expressiveness property, induced TNN is integrated into the proposed method. Furthermore, regularization is incorporated into the submodule identification term because of its ability to induce more sparsity. An optimization problem is formulated that enables the proposed method to perform improved clustering, even in the presence of noise by employing the capabilities of induced TNN and regularization, as well as simultaneous noise removal using sparse and low rank decomposition.
3. Proposed Method
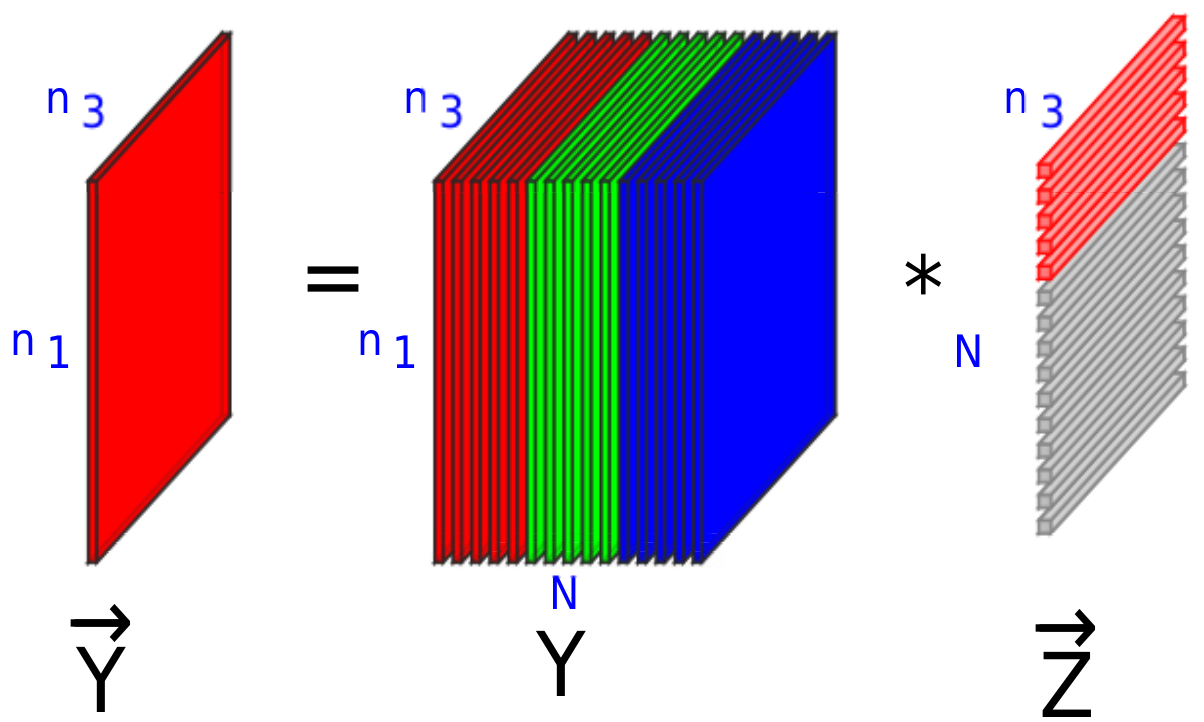
Under the UoFS model, making use of the self-expressiveness property, an image fetched from a submodule can be expressed as the
t-linear combination of other images present in the same submodule, as shown in
Figure 1. Hence, for a third-order tensor
, there exists a coefficient tensor,
such that
[
6]. Further, the tensor multirank can be used to capture the self-expressiveness property [
19] using the tensor nuclear norm
, which is the tightest convex relaxation of the tensor multirank [
36]. Since the structure of the solution
also determines the performance of the clustering, a block diagonal structure is required for the coefficient tensor,
, which can reveal the compactness between the intraclass components and the separation between the interclass components [
8,
37,
38]. Hence, in the UoFS model, an f-block diagonal structure constraint is added [
19]. In addition, images which belong to a single submodule are highly correlated, while those that belong to different submodules are slightly correlated; to capture this, a dissimilarity matrix,
is defined, where each entry indicates the dissimilarity between two images. The entries of
,
are given by [
19]
Here,
and
represent the
and
lateral slices of the 3rd order tensor
, and
is the empirical average of all
[
19]. Once an optimum coefficient tensor
, is obtained, the clustering of data can be achieved using the spectral clustering technique in which the
entry of affinity matrix
can be calculated as [
17]
Incorporating all the factors mentioned above, the clustering problem is formulated into an optimization problem given by [
19]
where
,
and
represent the element-wise multiplication operator,
norm and Frobenius norm, respectively. Further,
represents the tensor nuclear norm (TNN) [
19]. In addition,
and
stand for the regularization parameters for the optimization problem.
Further,
norm is used in the submodule structure constraint term,
as well as in TNN of
in the above expression. The methods mentioned in [
19,
20,
21],
norm are used instead of
norm for imposing the low rank constraint. The strong acceptance of
minimization in sparsity-related problems is because of its convex nature and ability to provide the sparse solution with less computational bottleneck [
39]. However,
regularization is a loose approximation of
regularization, and the performance will be limited in many applications [
40,
41]. Hence, to improve the performance,
(
) regularization techniques can be employed. Therefore, in order to extract the sparsest structure for the vector
, from the observation
, the
regularization problem is represented by
where
,
. Then,
represents the
quasi-norm and is defined by,
.
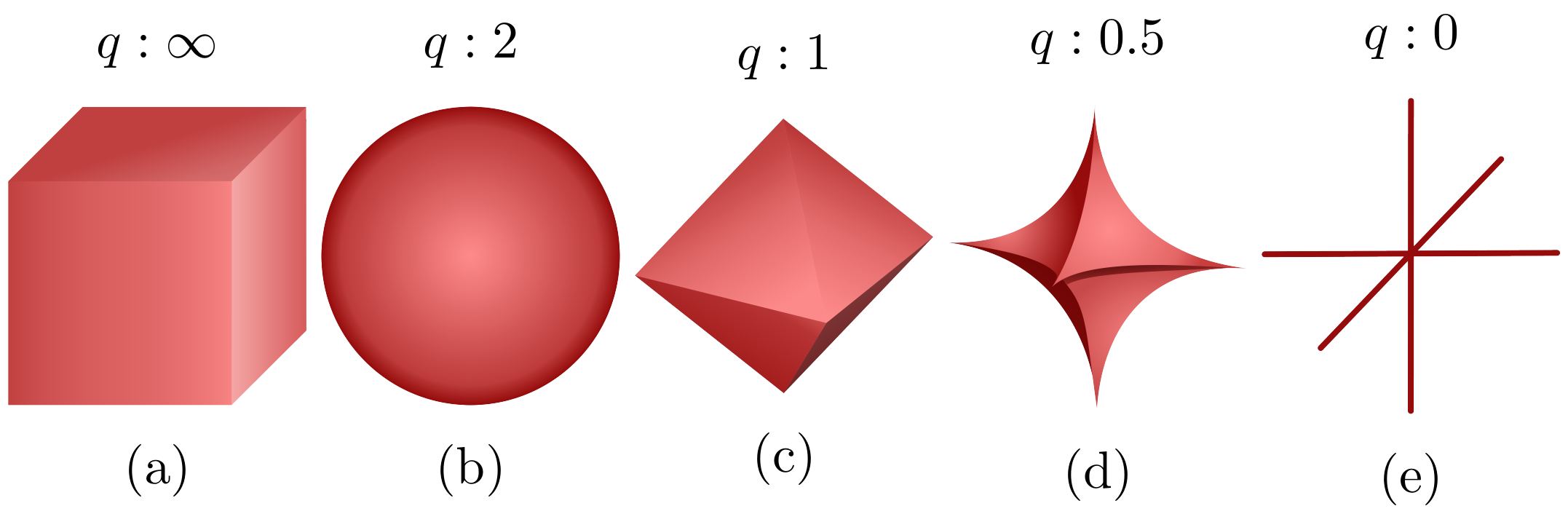
The unit ball representations of all the norms are illustrated in
Figure 2 in which
norm has the spherical shape, whereas in
norm, it is diamond shaped. It is obvious that
regularization provides a sparser solution compared to
norm since there is higher probability for the
line to coincide with the axes. However, as the value of
q is again reduced, the unit ball can assume the shape as shown in
Figure 2d.
Hence, the probability of achieving sparser solution is higher as the value of
q is changed from 0 to 1. For
, the solution will be sparser for a smaller value of
q. No significant change is observed in the performance for
[
39,
42,
43]. Hence,
regularization can be chosen as the optimum regularization method. In works such as [
19,
20,
21], TNN was used for imposing the low rank constraint in their optimization problem. For a tensor
, the expression for TNN with t-SVD
is given by [
19],
where in
and
are the orthogonal tensors. In addition,
is an f-diagonal tensor and
is its Fourier transform. As in Equation (
8), TNN uses the
norm to determine the absolute sum of the singular values in each frontal slice of the tensor
. However, in comparison to the
norm,
regularization yields a more sparse solution [
39,
43]. Hence, to obtain a more accurate low tensor rank representation,
regularization is incorporated, and the Equation (
8) can be rewritten as
where the above expression can be called
induced TNN. In TNN, the frontal slices of the tensor
contains
frontal slices, each slice being a diagonal matrix with singular values
, where
as entries. Then, we apply the half thresholding function proposed by Xu et al. over the vector
, and it can be expressed as [
39],
where
and
to
. Then, using the non linear half thresholding operator,
, we perform the expression given in Equation (
10) for all elements of
. The expression for the half thresholding operator
is given by
, where
denotes the threshold value [
39,
43]. After repeating the process for all frontal slices of
, the solution for
induced TNN is obtained. Furthermore, the solution’s detailed procedure is summarized and can be found in Algorithm 1.
In real-life contexts, imperfections in an image may occur in different circumstances, such as during acquisition, from any of the display systems or due to the constraints of both material and technological resources [
44]. In any of the ways, the presence of noise in the data may adversely affect the outcomes of the algorithms [
45]. The accuracy of the clustering algorithms could be improved if the data become noise-free. To meet this objective, each image is extracted by twisting the data tensor,
developed for the clustering model, and
return the twisted tensor [
46]. The
image is then transformed into the
frontal slice,
of the twisted tensor,
, where
to
N. This further allows each individual image to be taken in sequence by calling
, where
to
N. The removal of noise from an image can be achieved by the sparse and low rank matrix decomposition method and is already illustrated in
Section 2.1. The concept of removing noise from a single image is given in Equation (
3). Then, for
N number of images, Equation (
3) can be modified such that
To incorporate all the challenges aforementioned, proposed method integrates the following aspects into its optimization problem.
Compared to TNN, induced TNN is able to capture better low rankness. In addition, due to its inherent noise robustness and better ability to catch the property of self-expressiveness, induced TNN is introduced into the proposed method.
Compared to norm, norm regularization is able to capture the f-block diagonal structure in a better way such that the submodule structure constraint is modified using norm.
To meet the objective of noise removal, we use the tensor , where is the twisted version of the noisy data tensor . Afterwards, noise removal is carried out by employing the nuclear norm and norm minimization on each image to separate the noise content by combining the principles of sparse and low rank decomposition techniques. As a result, the underlying images are restored, and the sparse noise content is eliminated. This process delivers a noise-free data tensor for further clustering process.
Incorporating the aforementioned factors, the tensor,
is introduced into the proposed optimization problem such that
is the clean data tensor, where the noise removed images are stacked into its frontal slices,
. Another tensor,
is defined, where the eliminated sparse noise content from each image is stored into its frontal slices,
. In addition, the tensor,
is incorporated, where
is the twisted version of the clean data tensor
such that
is given for the clustering. Further, we employ variable splitting for
into Equation (
6) such that
and
[
21]. Combining all the above, the proposed optimization problem can be reformulated as
where
represents the
induced TNN and
represents
norm. Further,
,
and
denote the nuclear norm,
norm and Frobenius norm respectively. Finally,
is the twisted version of the noisy data tensor
. In the above expression,
,
,
and
denote the regularization parameters of the proposed optimization problem and among them,
and
balance the effect of low rank and sparsity constraints [
27]. The above constrained equation is transformed into a unconstrained one using the Augmented Lagrangian (AL) method [
19,
47] given by
where the tensors
,
,
and
are the Lagrangian multipliers, where
is the penalty parameter and
denotes the inner product [
27]. The above problem can be solved by iteratively minimizing the Lagrangian
over one tensor while keeping the others constant [
6].
Subproblem: The update expression for
is given by
The above expression can be transformed into the following form,
Solution to the above subproblem is obtained by,
where
is the threshold value. The operation of
is detailed in Algorithm 1.
| Algorithm 1 Tensor singular value half thresholding. |
Require:, threshold, Ensure:
Singular Value Half-thresholded, as optimal solution 1: 2: for i= 1 to do 3: 4: 5: 6: 7: 8: end for 9: , , 10:
|
Subproblem: The update expression for
is given by
Above equation can be decomposed into
expressions and the
kth frontal slice of
can be updated by
where
is the
frontal slice/matrix of
. The solution to the above subproblem is given by the halfthresholding operator [
42],
where
is the halfthresholding operator [
39]. Here,
is the
th element of
kth frontal slice/matrix of
.
Subproblem: The subproblem for updating
is given by
Above equation can be simplified as,
Finding the Fourier transform on both sides, the above equation can be rewritten as,
where
,
and
are the Fourier transforms of
kth frontal slice of
,
and
, respectively, and
indicates the slicewise multiplication [
19]. The analytic solution for the update of the
kth frontal slice is given by
Subproblem: In
subproblem, the update expression is given by,
Above expression can be considered an
N subproblems. Then, the update expression for
kth slice is given by,
Above expression can be solved using singular value thresholding,
is the singular value thresholding operator [
48].
Subproblem: Similarly, the update expression for
subproblem is given by
Solution for the
kth slice is given by,
where
is the shrinkage operator defined in [
27] and the expression is given by,
, where
represents the threshold value.
Solution for the above expression is given by,
Finally, the stopping criterion is measured by the following condition,
The overall algorithm can be summarized in Algorithm 2.
| Algorithm 2 Robust tensor-based submodule clustering for noisy imaging data. |
Require: Data: and parameters , , , , , Ensure: , 1: ==== 2: == 3: = and 4: , , , , , 5: while not converged do 6: ← Update using Equation ( 16) 7: ← Update using Equation ( 18) 8: ← Update using Equation ( 23) 9: ← Update using Equation ( 24) 10: ← Update using Equation ( 28) 11: ← Update using Equation ( 30) 12: = 13: = 14: = 15: = 16: = 17: Check the convergence using Equation ( 31) 18: 19: end while
|
4. Results and Discussions
The performance of the proposed method is evaluated on Coil20
http://www.cs.columbia.edu/CAVE/software/softlib/coil-20.php (accessed on 5 June 2021), MNIST
http://yann.lecun.com/exdb/mnist/ (accessed on 5 June 2021) and UCSD
http://www.svcl.ucsd.edu/projects/anomaly/dataset.htm (accessed on 8 June 2021) datasets [
19]. These datasets are widely used for clustering, completion, noise reduction, and moving object detection problems [
6,
19,
42]. The dimensions, number of classes and total number of images of these datasets have already been defined in various papers and can be found in [
6,
24] and so on. For comparison with the proposed method, other recent clustering methods, such as normalized spectral clustering [
16], SSmC [
20], SLRSmC [
21], SCLRSmC [
19], weighted tensor nuclear norm (WTNN) minimization [
23] and re-weighted low rank tensor approximation and
regularization, named
[
24], approaches are chosen. All the experiments are implemented and run on a personal computer with i5 - 4590 CPU at 3.30 GHz and 8 GB of RAM. The results are compared using the standard evaluation metrics such as the misclustering rate (MCR), adjusted Rand index (ARI), normalized mutual information (NMI) and purity [
6]. The definitions and expressions of MCR, ARI and purity can be found in [
6,
24]. Then, normalized mutual information (NMI) is obtained by normalizing the mutual information to a value between 0 and 1, where the value of 1 indicates perfect labeling. In addition, purity and ARI are upper bound measures whose values lie in the interval
[
24]. For those metrics, higher values indicate sound performance. In this work, the clustering results for MCR are represented by
, where
m is the mean,
is the standard deviation and smaller MCR value indicates improved performance [
6]. To simulate sparse noise in the data, we create an algorithm which generates noise values at random locations in the images. The amount of sparse noise applied to the data can be modified by this algorithm, and the amount of sparse noise added is shown as a percentage of the total pixels in the images of each dataset. In this work, the amount of sparse noise are varied from
to
for all the datasets.
We first present the experimental results obtained from the Coil20 dataset. For the Coil20 dataset, the values chosen for the regularization parameters are
and
. The proposed method exhibits a major improvement in its clustering efficiency, and furthermore improved evaluation metrics are obtained. The reason is that the proposed algorithm decomposes each image in the dataset into its sparse and low rank part. The sparse part represents the noise encountered, and the algorithm removes this sparse noise content. Consequently, the imaging data are free from noise and clean data are available for clustering at the same time.
Figure 3 shows the visual appearance of the simultaneous noise removal of a single image from the coil20 dataset with
sparse noise applied. The eliminated noise content from the noisy image is presented in
Figure 3c, and the recovered clean image is shown in
Figure 3d, respectively.
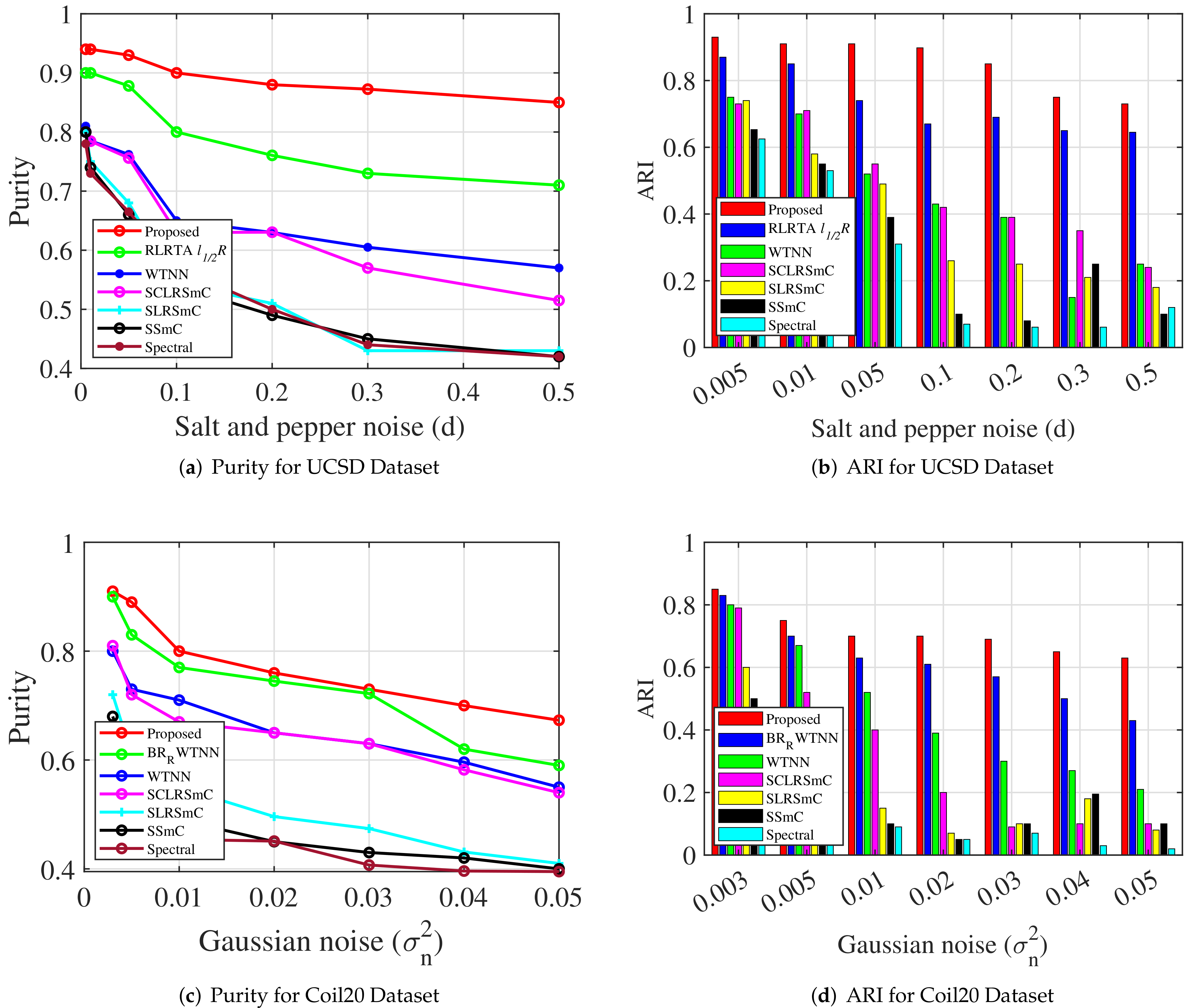
The proposed method is compared against state-of-the art clustering algorithms. The MCR values obtained using the Coil20 dataset for proposed method and other algorithms are summarized in the first section of
Table 1, with the best values shown in bold. Similarly, the compared results of purity, NMI, and ARI metrics using Coil20 dataset are shown in Figure 5a, Figure 5b and Figure 5c, respectively. Our method obtains better values of MCR, purity, NMI and ARI metrics, compared to the state-of-the-art methods. For
to
of sparse noise content, the MCR values of the proposed method are
and
(second and third row, last column of
Table 1), and these values are extremely small, compared to other algorithms. Similarly, purity and ARI values of the proposed method for
of sparse noise content are
,
and
, respectively (from Figure 5). Hence, it is evident from
Table 1 and Figure 5 that the proposed method outperforms other state-of-the-art clustering algorithms. The evaluation metrics of the proposed method indicate small decrements for noise values exceeding
and more, but the values are still better than its counterparts. Further, the noise-removed images achieved by the proposed method using the Coil20 dataset for various levels of sparse noise content are shown in
Figure 4. The eliminated sparse noise content from the noisy images in the dataset are clearly illustrated in the third row of
Figure 4.
Second, experiments are conducted on the UCSD dataset, and the obtained MCR values are provided in the second section of
Table 1. For lower noise content (
to
), the proposed approach achieves smaller MCR values as reported in
Table 1. For noise values such as
and
, the MCR values for the proposed method are
and
. In the same scenario, algorithms such as SSmC, SLRSmC and SCLRSmC fail to achieve good clustering results (
Table 1,
Figure 5d–f). WTNN shows improved results over the SSmC, SLRSmC, SCLRSmC and spectral methods for lower noise values, but its performance reduces when the noise content in the imaging data is increased. Among the methods we have compared, the
method shows the second best performance. The MCR metrics of this method are
to
for noise levels up to
. In all of the scenarios considered, the proposed approach outperforms the state-of-the-art methods significantly. In addition,
norm regularization effectively captures the f-block diagonal structure in a better way, and the self-expressiveness property of the submodules is preserved in the proposed method. A few images from the UCSD dataset, which was recovered by the proposed method under various noise levels, are shown in
Figure 4. The proposed method’s efficiency is also checked using the MNIST dataset [
19]. the MNIST dataset comprises images of handwritten digits from 0 to 9 with a resolution of
, where the number of images that belong to class is set as 30. The MCR metrics obtained for the proposed as well as the compared methods are summarized in last section of
Table 1. The proposed method produces better clustering results than the state-of-the-art methods.
To summarize, the proposed approach performs well and provides good clustering results, even with noise-corrupted data for these three datasets. Furthermore, it outperforms all of the clustering algorithms that we compare in this work throughout every case. The reasons for the improved performance are as follows: first, the proposed algorithm is a unified optimization framework that clusters imaging data while also eliminating noise from images. Furthermore, induced TNN, incorporated into the proposed method, provides better low rankness and maintains the self-expressiveness property of submodules. Second, the proposed method’s optimization equation demonstrates the benefit of regularization in providing better submodule identification. Finally, the simultaneous noise removal reduces the impact of noise on the clustering performance and provides clean data for further clustering. No other methods in the state of the art have a simultaneous noise reduction scheme in their optimization problem for extracting the noise content from individual images. In most of the approaches, a global error term is used in their optimization problems to reduce the effect of noise when clustering. However, it is just a partial solution that cannot be applied to all cases. On the other hand, the proposed method handles individual images in the dataset and removes the noise content simultaneously, which is the major contribution of the proposed method.
4.1. Analysis of the Proposed Method with Gaussian Noise and Salt and Pepper Noise
In order to further analyze the robustness of the proposed system, experiments were conducted on imaging data that were distorted by different types of noise [
49,
50]. For this study, we used Coil20 and UCSD datasets, and two cases were considered. In case I, images that are corrupted by salt and pepper noise were considered. Salt and pepper noise is a type of impulse noise, where the noise values include two extreme ranges of a pixel value [
28]. In one study, an impulse noise removal algorithm based on the sparse and low rank decomposition method was proposed in which impulse noise types were modeled as sparse components and the underlying image was restored with keeping the original features [
28]. In this work, salt and pepper noise of various noise densities (
d) were added. The noise density level considered are
to
. In the presence of salt and pepper noise, it was observed that the proposed method provides improved clustering performance as well as restoring the clean image with removed noise content. To substantiate, a few of the recovered images from the UCSD dataset are displayed in
Figure 6. In this, the first row represents the original images, the second row denotes the noise corrupted images of various noise densities and the last row represents the recovered images. Further, the MCR metrics under salt and pepper noise are presented in Case I of
Table 2. Similarly, purity and ARI metrics of our method and the compared methods for UCSD dataset are shown in
Figure 7a and
Figure 7b, respectively. In all cases, the proposed method outperforms the state-of-the-art algorithms that we compared.
In case II, images corrupted by Gaussian noise were used. Gaussian noise in images is most common when the lighting is low or the temperature is high [
27]. This can happen at any time during the capture or transmission process. In analysis, the noise variances considered are
,
,
,
,
,
and
. Case II in
Table 2 summarizes the MCR metrics of the proposed method and the compared methods.
Figure 7c,d shows the compared results of purity and ARI metrics, respectively. The obtained images of the proposed method under Gaussian noise are shown in the last four columns of
Figure 6. For noise variances up to
, our method successfully recovers the noise-free images, but for noise variance values of
or more, the recovered images have an over-smoothing problem. However, by fine-tuning the regularization parameters, this issue can be mitigated to a certain extent. Nonetheless, the compared methods generate inadequate clustering performance under the same scenarios. The second-best performance is achieved by the
approach. Then, WTNN performs reasonably to an extent for lower noise variances, but the results are deteriorated for higher noise values. In comparison to the above methods, the other methods do not perform as well. Hence, in the presence of Gaussian noise at different noise levels, the proposed method performs well and outperforms state-of-the-art clustering methods in general.
4.2. Parameter Tuning and Convergence Analysis
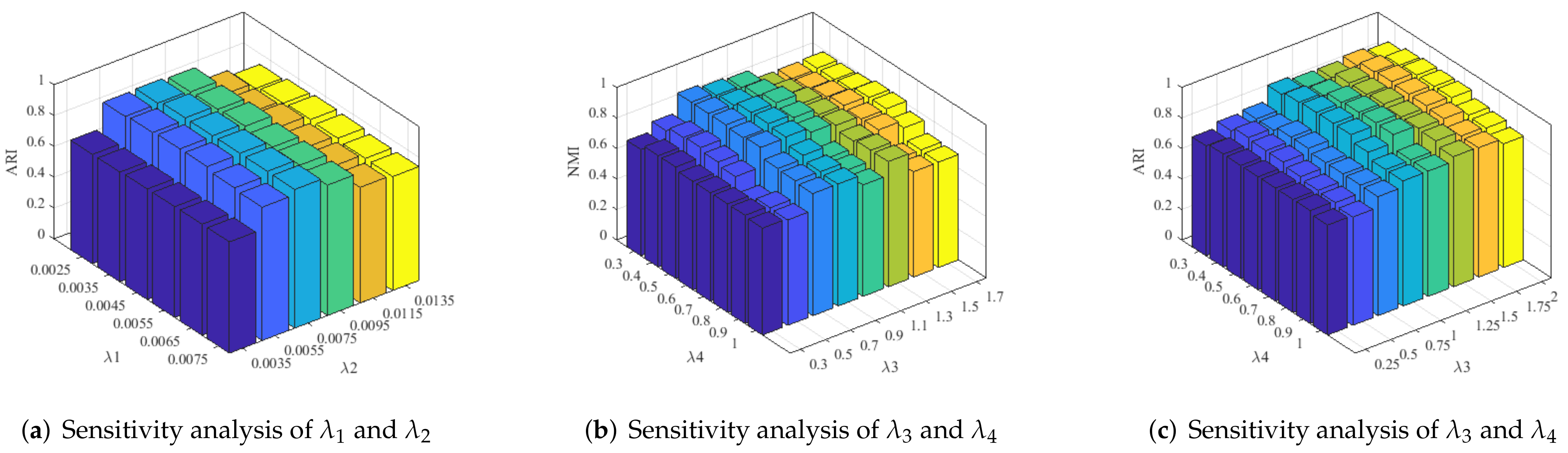
The sensitivity analysis of all regularization parameters against the evolution metrics NMI and ARI, and the convergence of the proposed algorithm are discussed in this section. The parameters
and
are tuned manually to obtain the best results from the range of (0.2–2.1).
Figure 8b,c illustrates graphs of the two metrics, NMI and ARI, with these regularization parameters. The graphs show that the proposed method provides good evaluation scores for
within the range of 0.70–1.5 and
in 0.25–0.95. The optimal values for the proposed method are found to be
and
within this range. However, to obtain good evaluation scores and visual quality when using different datasets, minor variations can be allowed in these values. Similarly, the parameters
and
balance the effect the submodule structure constraint term and representation error term, respectively. The optimal values for
and
are identified as
and
. The sensitivity analysis of
and
with respect to the ARI metric is shown in
Figure 8a.
Similarly, the proposed algorithm has a high convergence rate and converges quickly within 10–20 iterations. The proposed method’s convergence curves with the metrics NMI and MCR (with mean value
m) are plotted in
Figure 9a,b, respectively. The plots show that as the number of iterations increases, the change in NMI and MCR values converges to zero. In addition,
Table 3 shows the execution time required for the proposed method, compared to the existing methods. Since the proposed algorithm employs
regularization and
induced
, their solutions are to be computed iteratively. Furthermore, the proposed method employs nuclear and
norm minimization for the simultaneous noise removal of every image in the dataset. Therefore, an additional reasonable amount of time is consumed by the proposed method. This marginal increase in computational time can, however, be offset by the use of high-performance computing stations. In addition, the proposed method has six subproblems and four multipliers to update, as presented in Algorithm 2. In the proposed method,
induced TNN, nuclear and
norm minimization need more computational requirements.
update involves nuclear norm minimization on each slice, which requires
operations. In
update, where
, it requires
operations. Finally,
update requires
operations. Therefore, the total computational complexity of the proposed method is given by
operations, where
T represents the number of iterations. Hence, the proposed method offers moderate computational complexity.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}