
CasTabDetectoRS: Cascade Network for Table Detection in Document Images with Recursive Feature Pyramid and Switchable Atrous Convolution

 ,
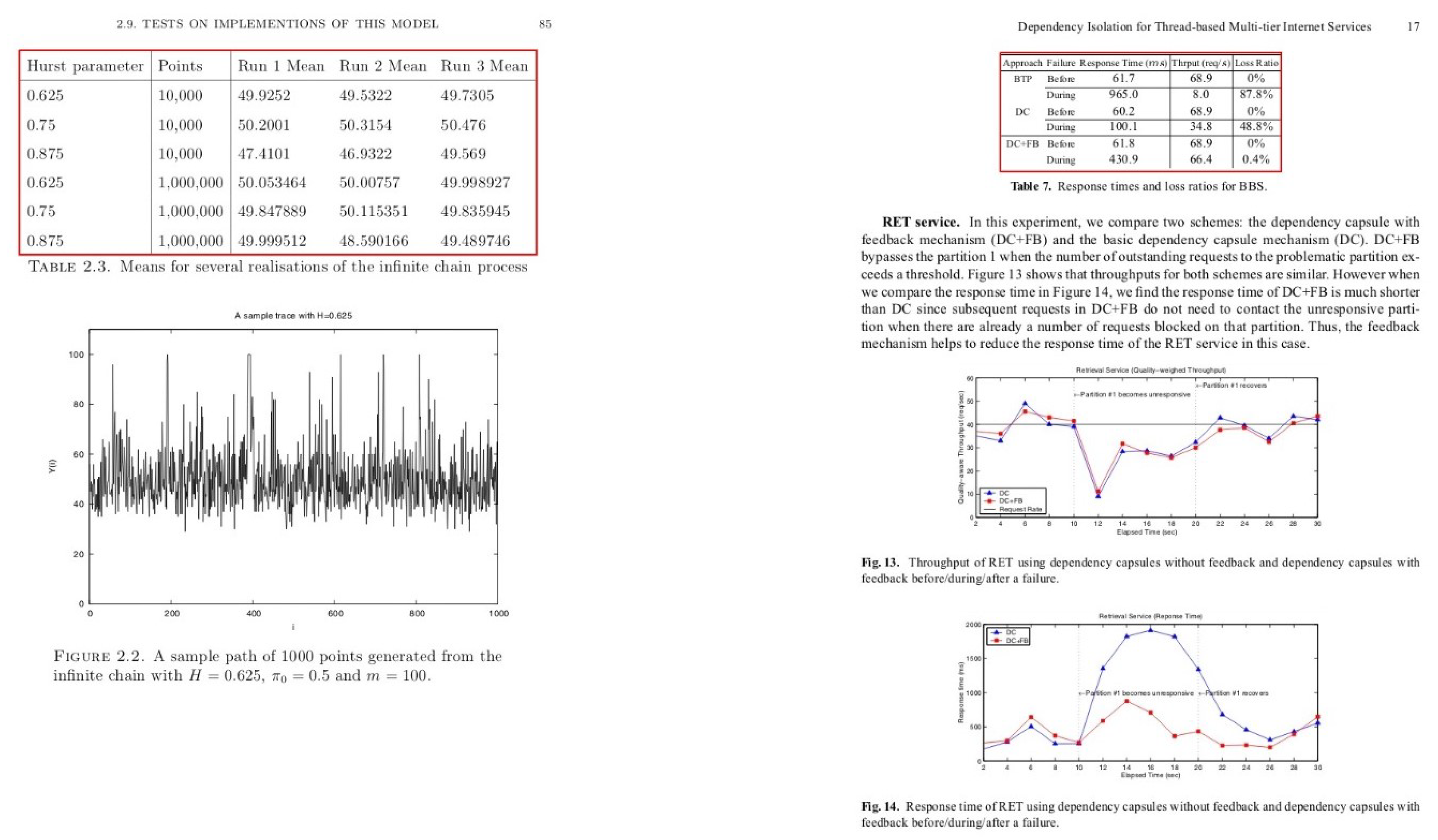
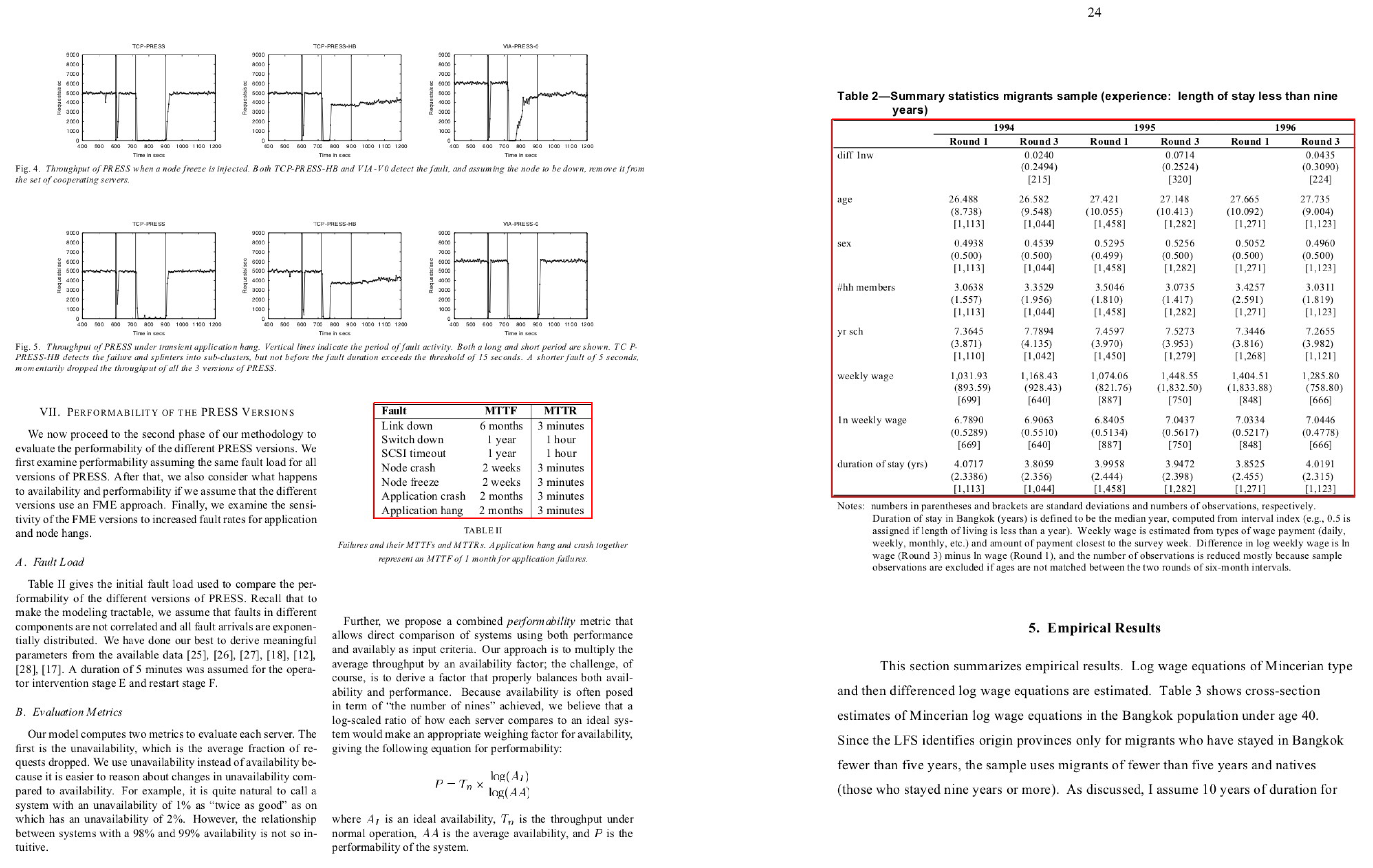
, 
 ,
, 
Abstract
:1. Introduction
- We present CasTabDetectoRS, a novel deepearning-based table detection approach that operates on Cascade Mask R-CNN equipped with recursive feature pyramid and switchable atrous convolution.
- We experimentally deny the dependency of custom heuristics or heavier backbone networks to achieve superior results on table detection in scanned document images.
- We accomplish state-of-the-art results on four publicly available table detection datasets: ICDAR-19, TableBank, Marmot, and UNLV.
- We demonstrate the generalization capabilities of the proposed CasTabDetectoRS by performing the exhaustive cross-datasets evaluation.
2. Related Work
2.1. Rule-Based Methods
2.2. Learning-Based Methods
2.3. Table Detection as an Object Detection Problem
3. Method
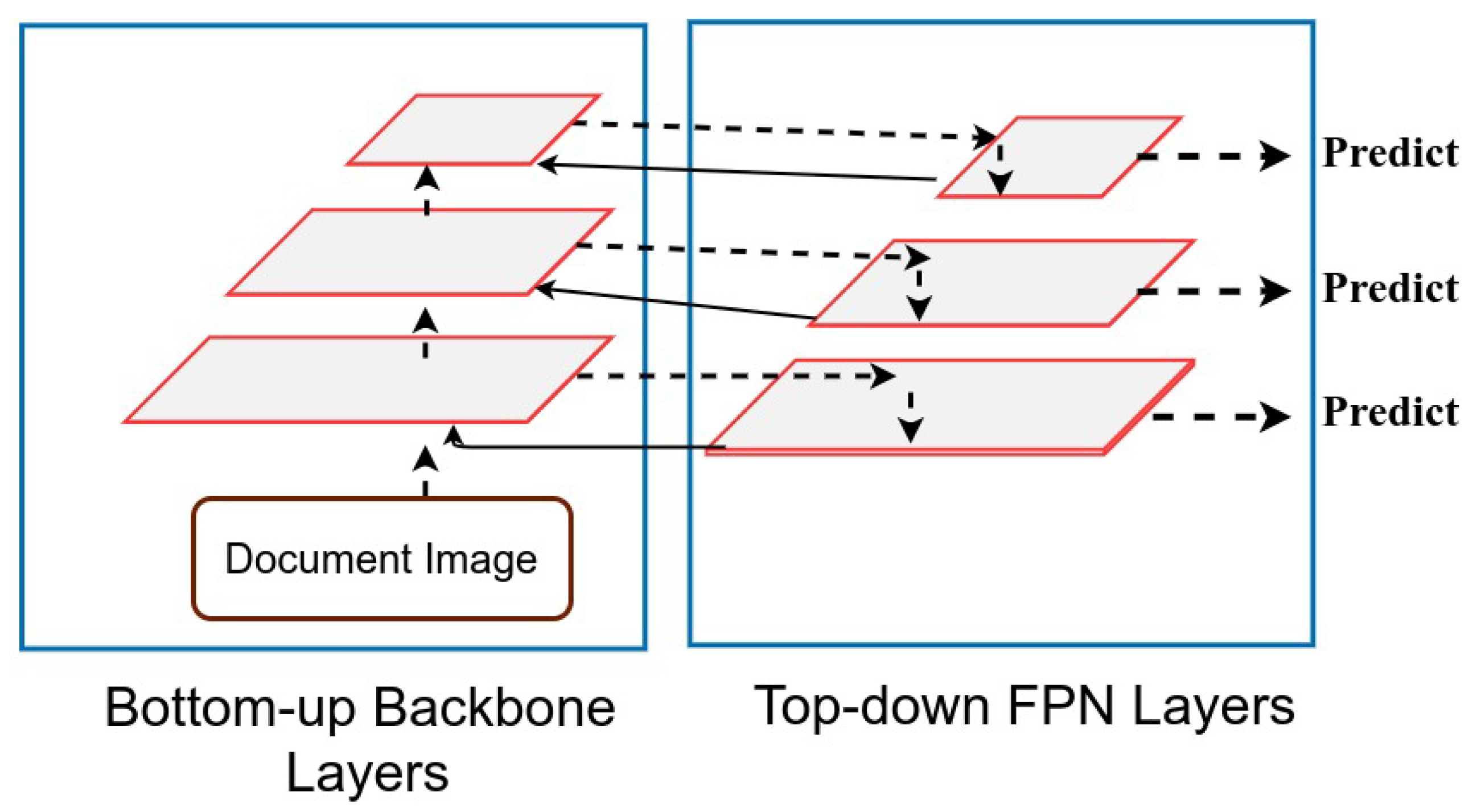
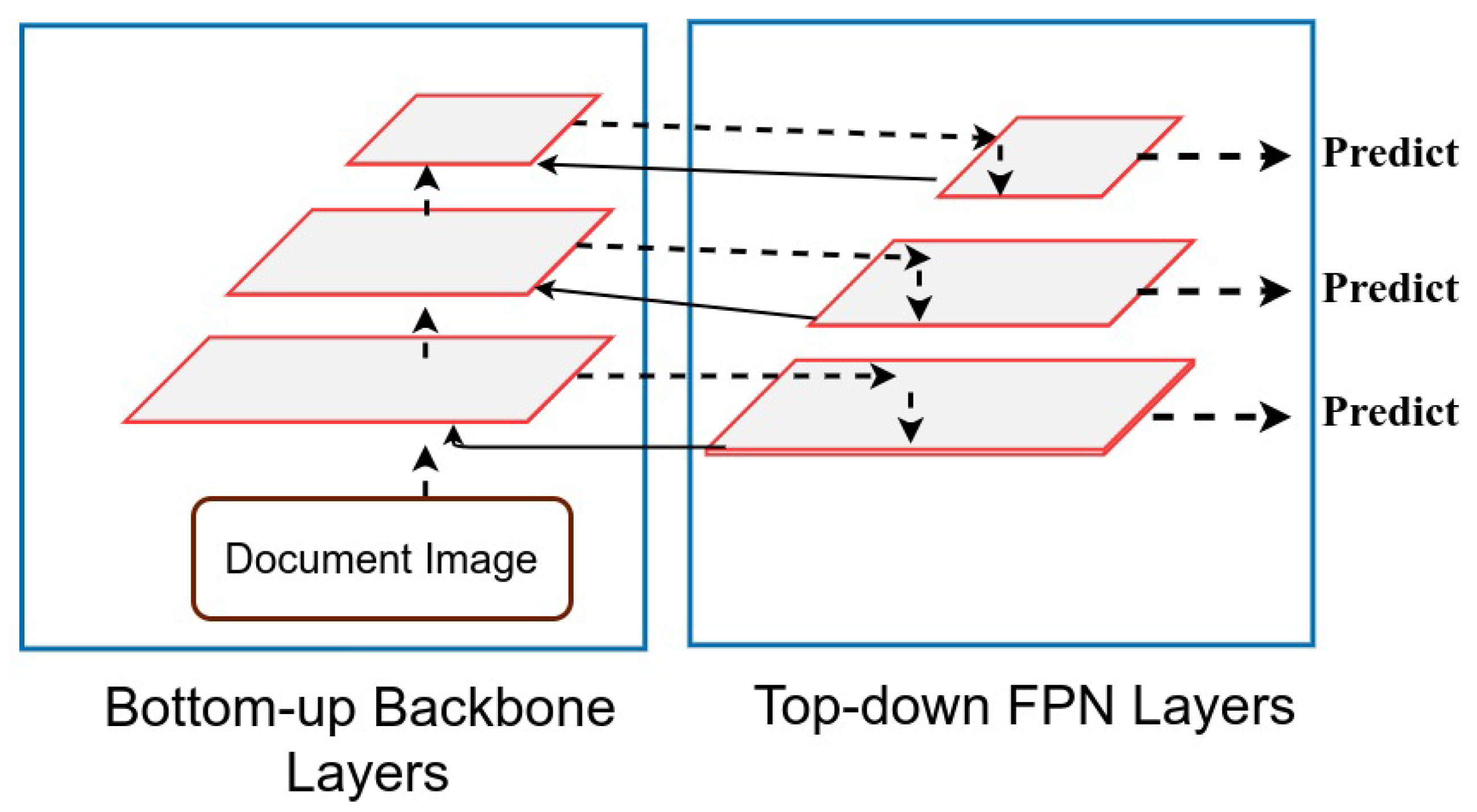
3.1. Recursive Feature Pyramids
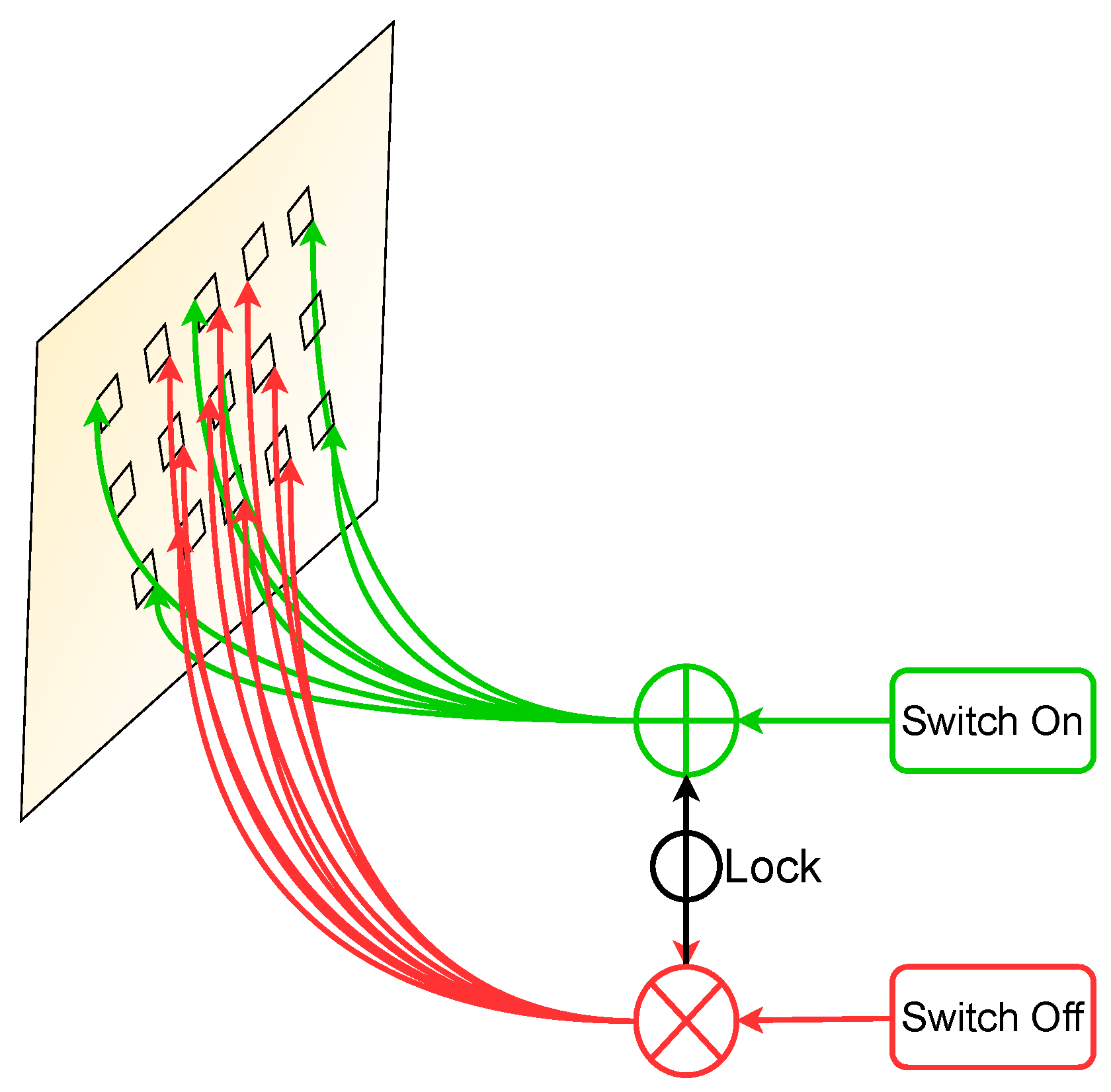
3.2. Switchable Atrous Convolution
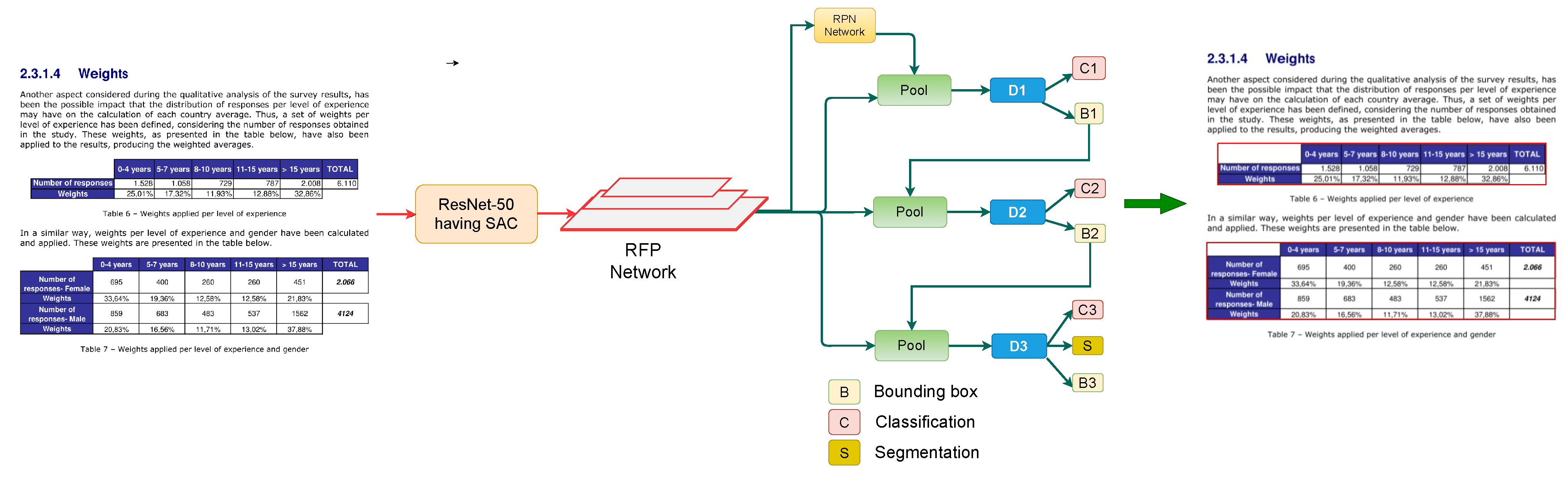
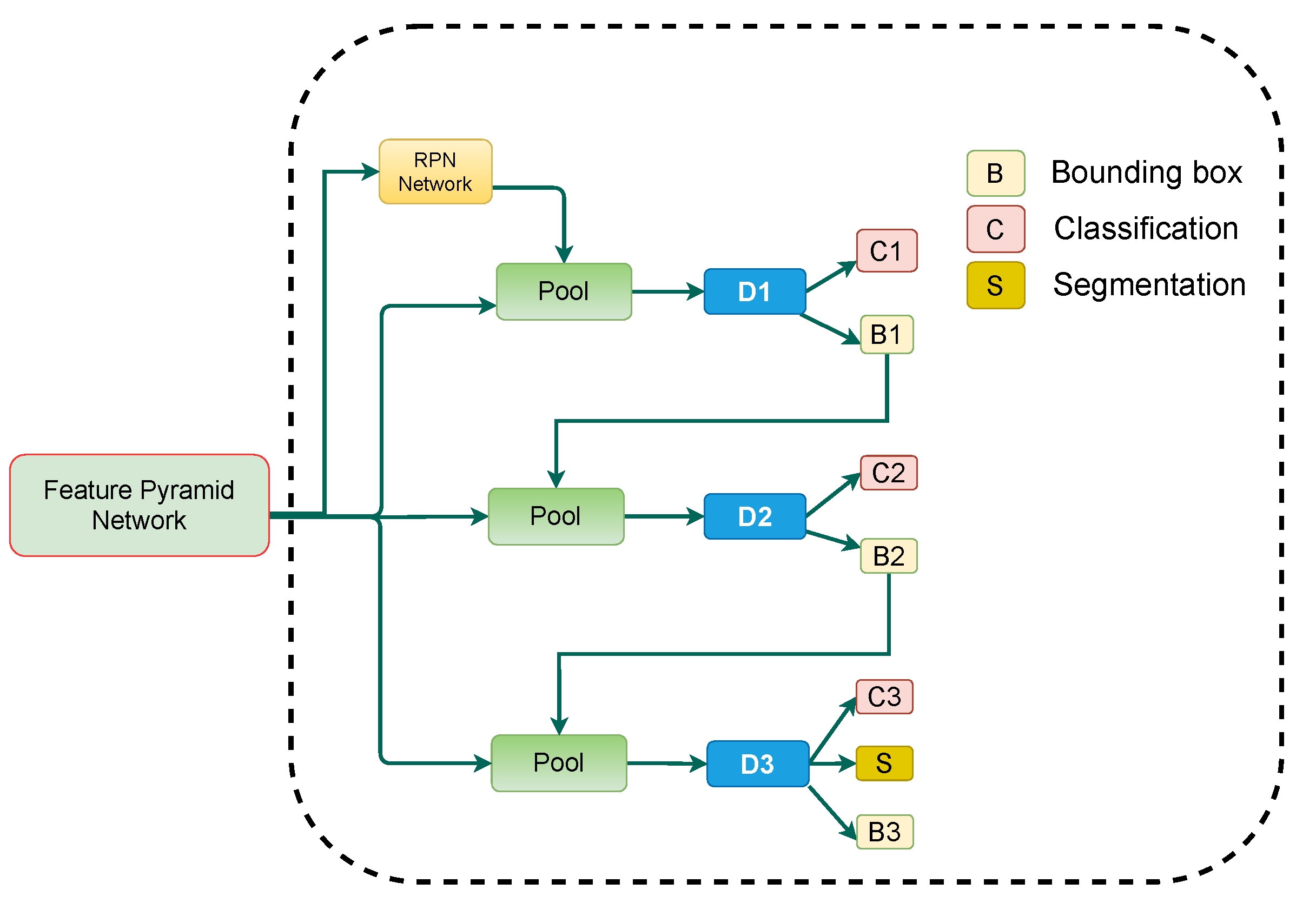
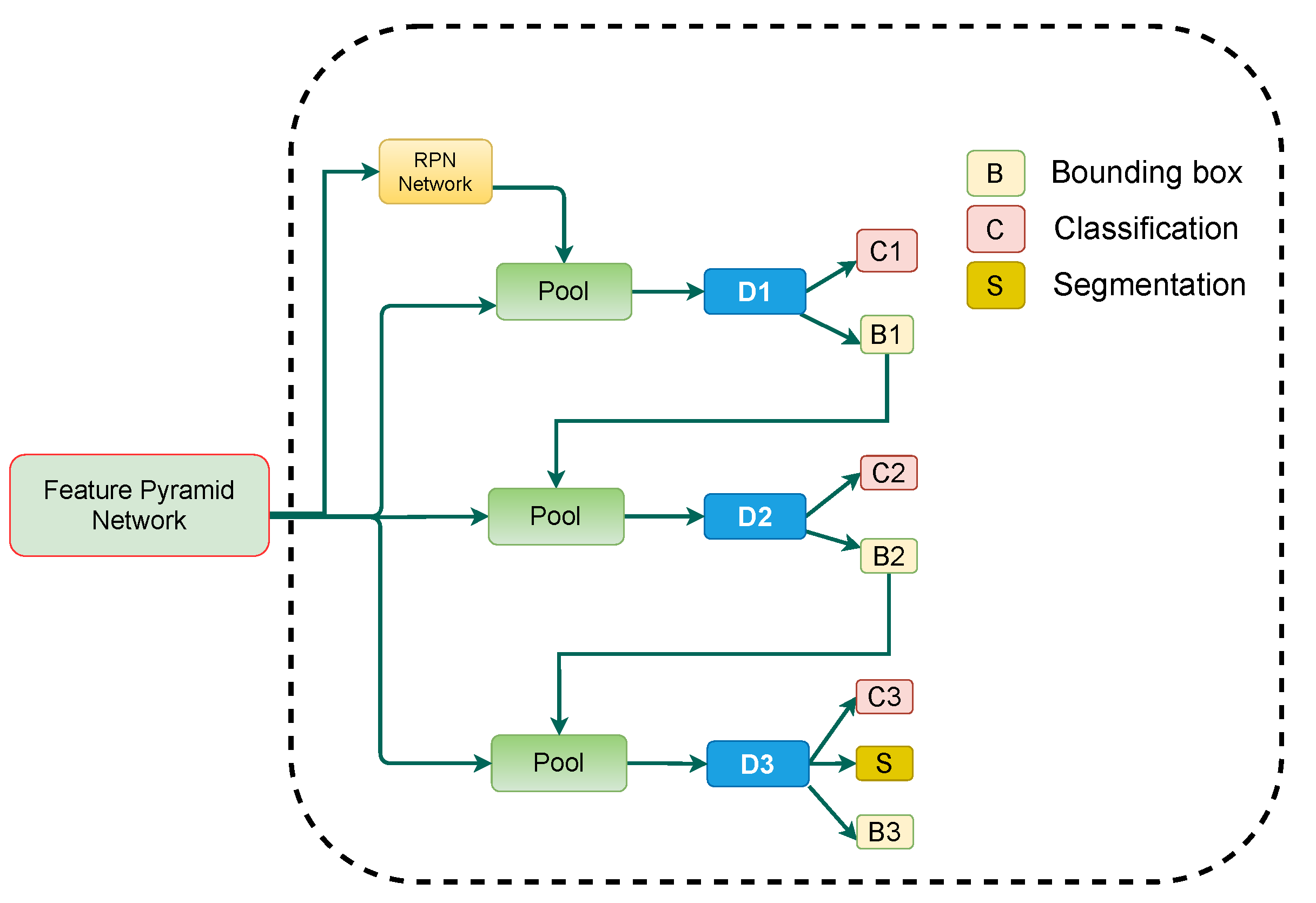
3.3. Cascade Mask R-CNN
4. Experimental Results
4.1. Datasets
4.1.1. ICDAR-17 POD
4.1.2. ICDAR-19
4.1.3. TableBank
4.1.4. UNLV
4.1.5. Marmot
4.2. Implementation Details
4.3. Evaluation Protocol
4.3.1. Precision
4.3.2. Recall
4.3.3. F1-Score
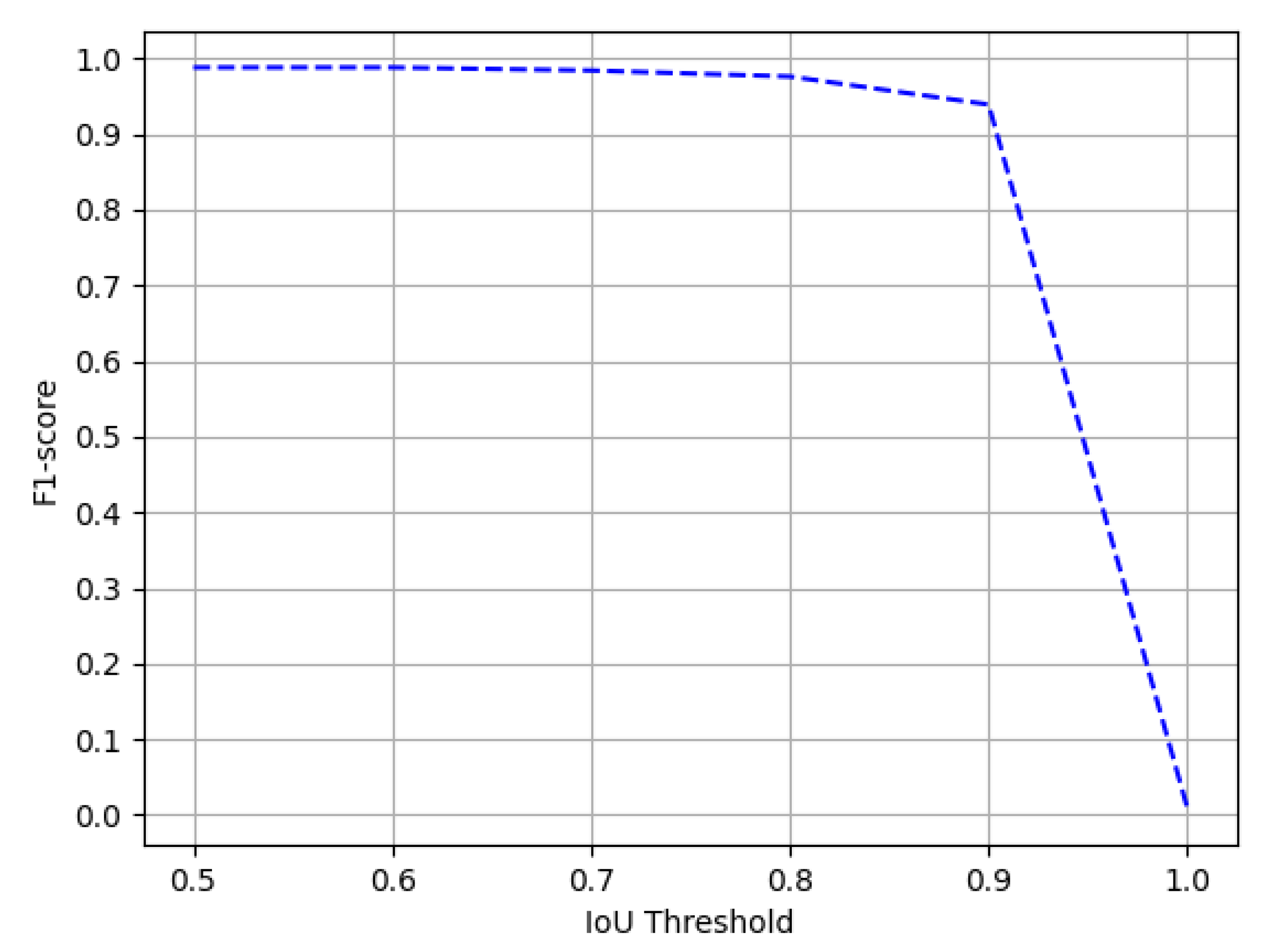
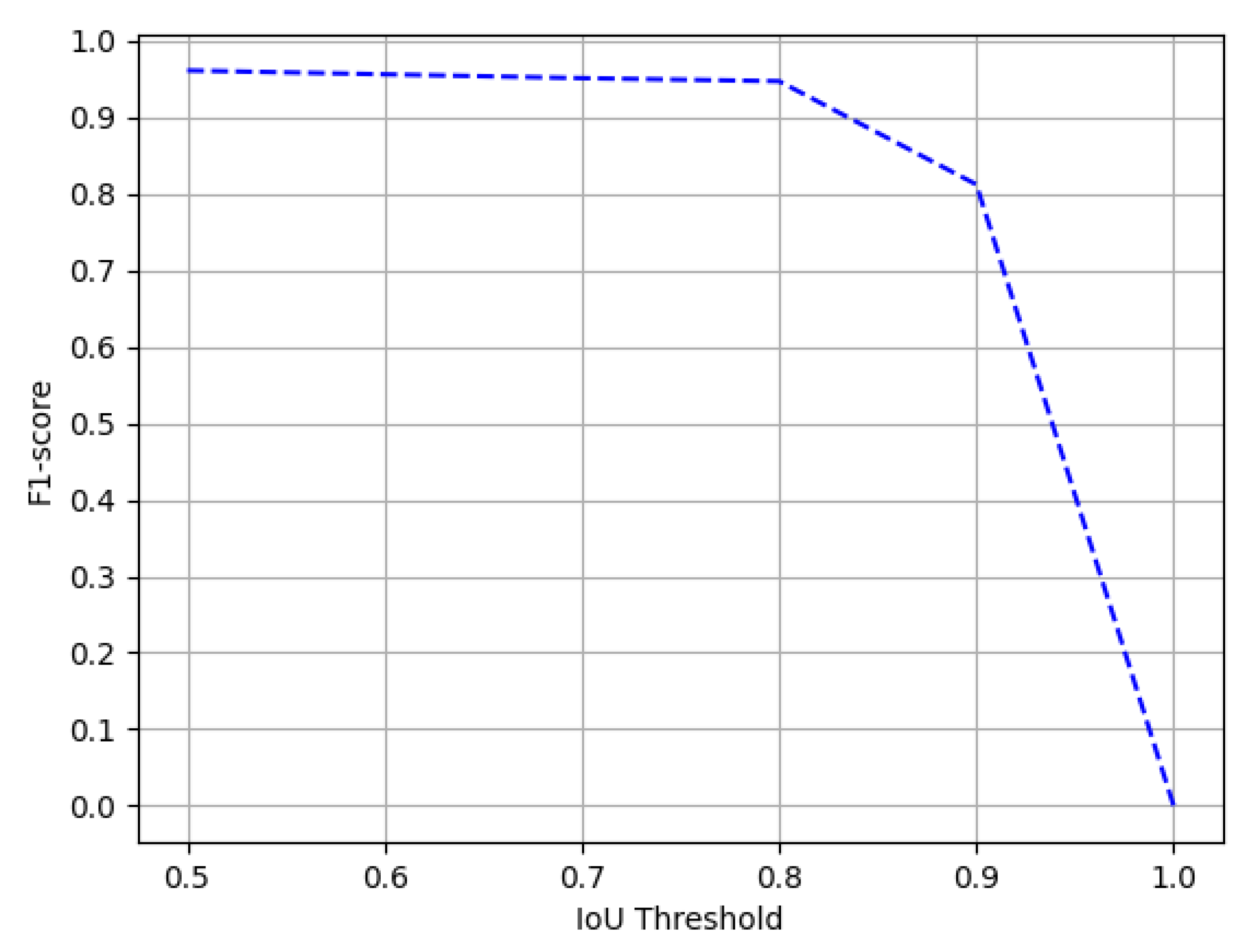
4.3.4. Intersection over Union
4.4. Result and Discussion
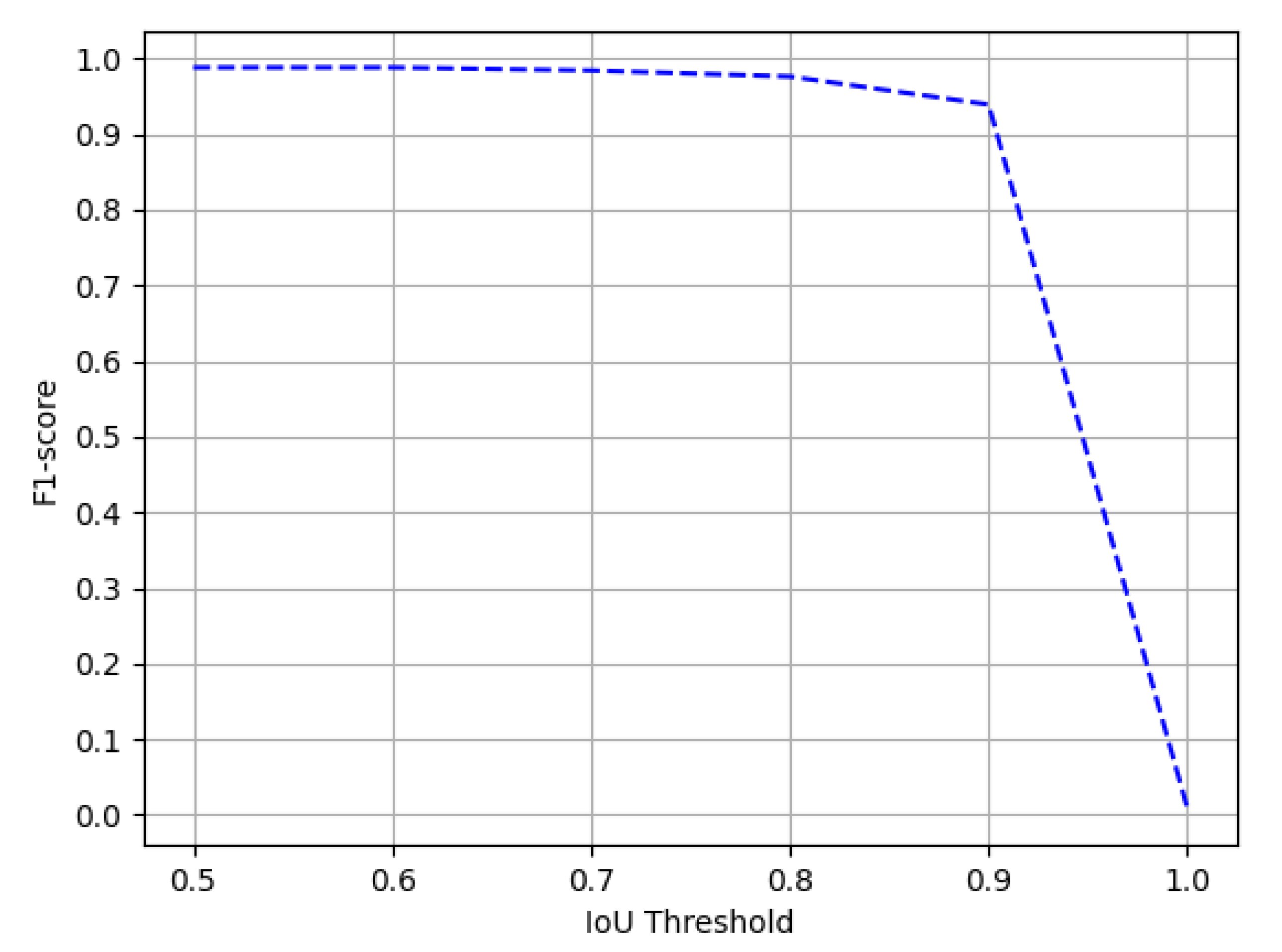
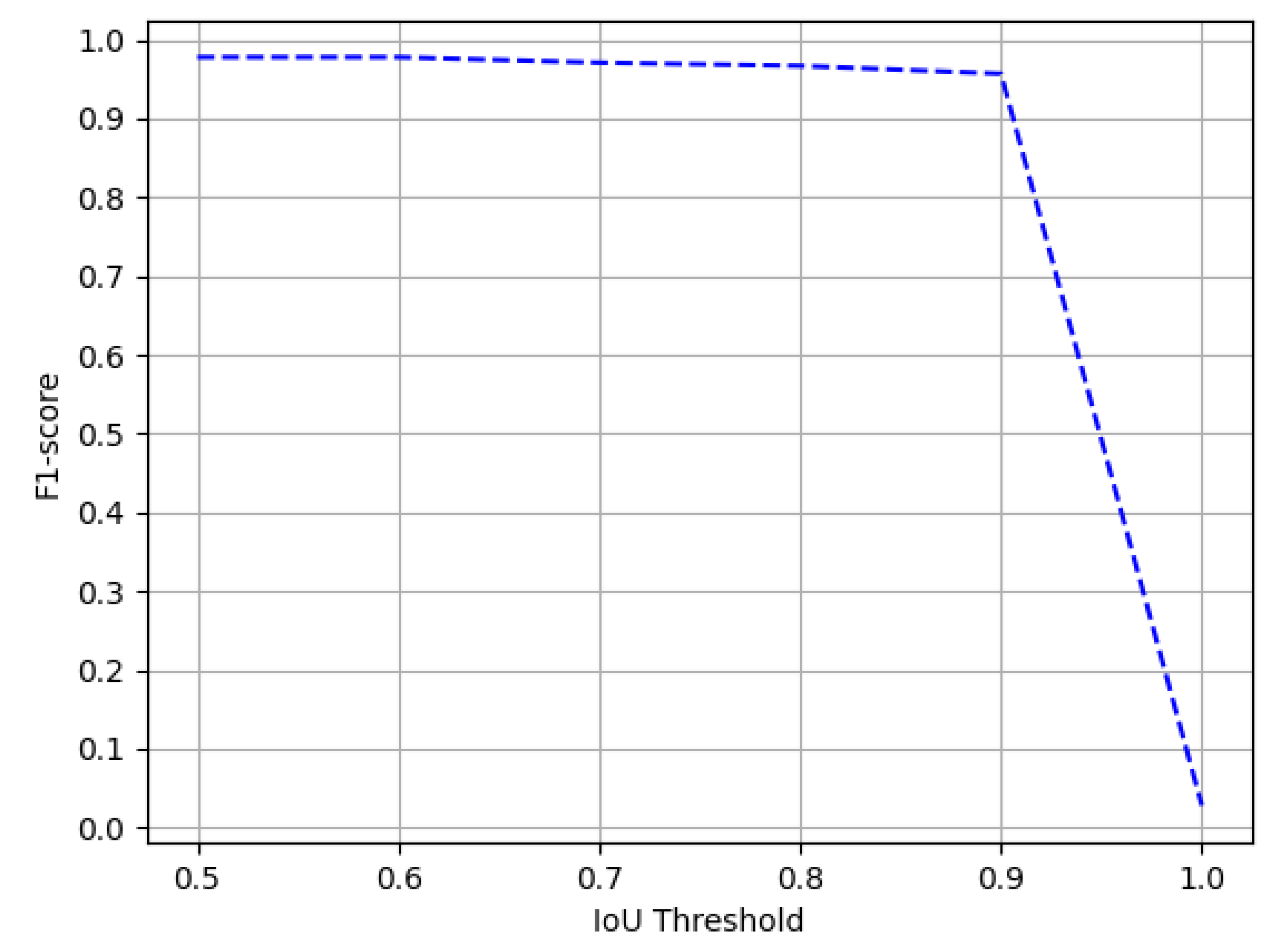
4.4.1. ICDAR-17 POD
Comparison with State-of-the-Art Approaches
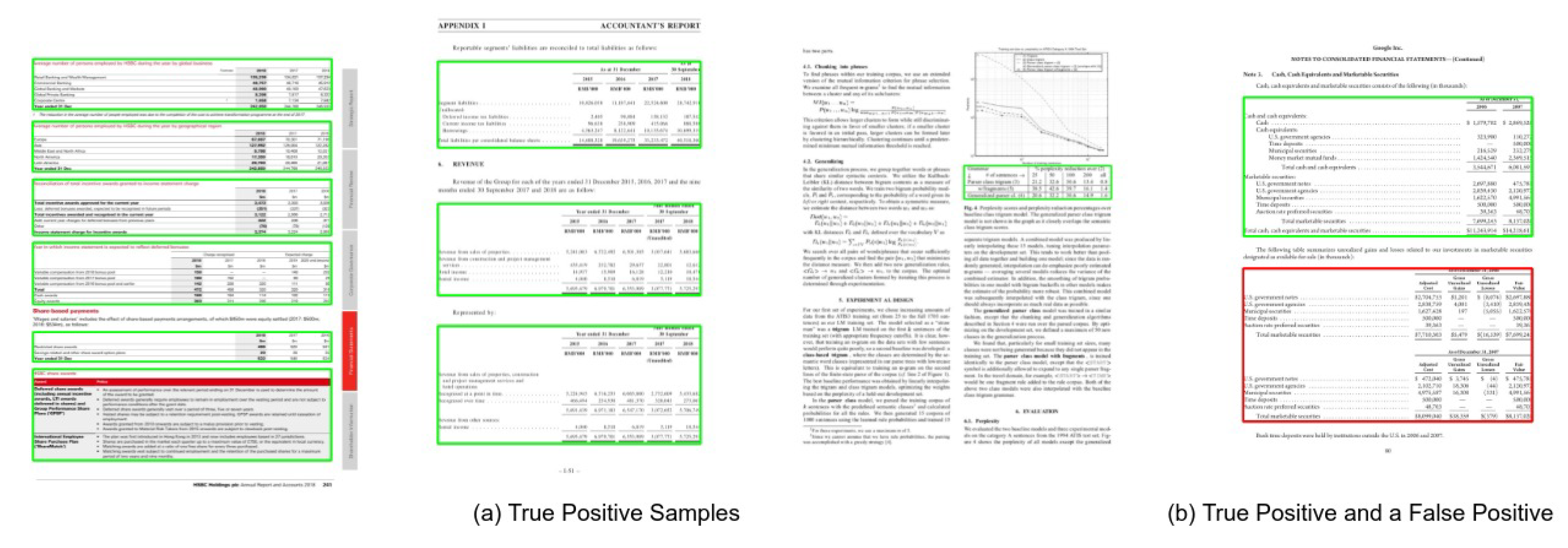
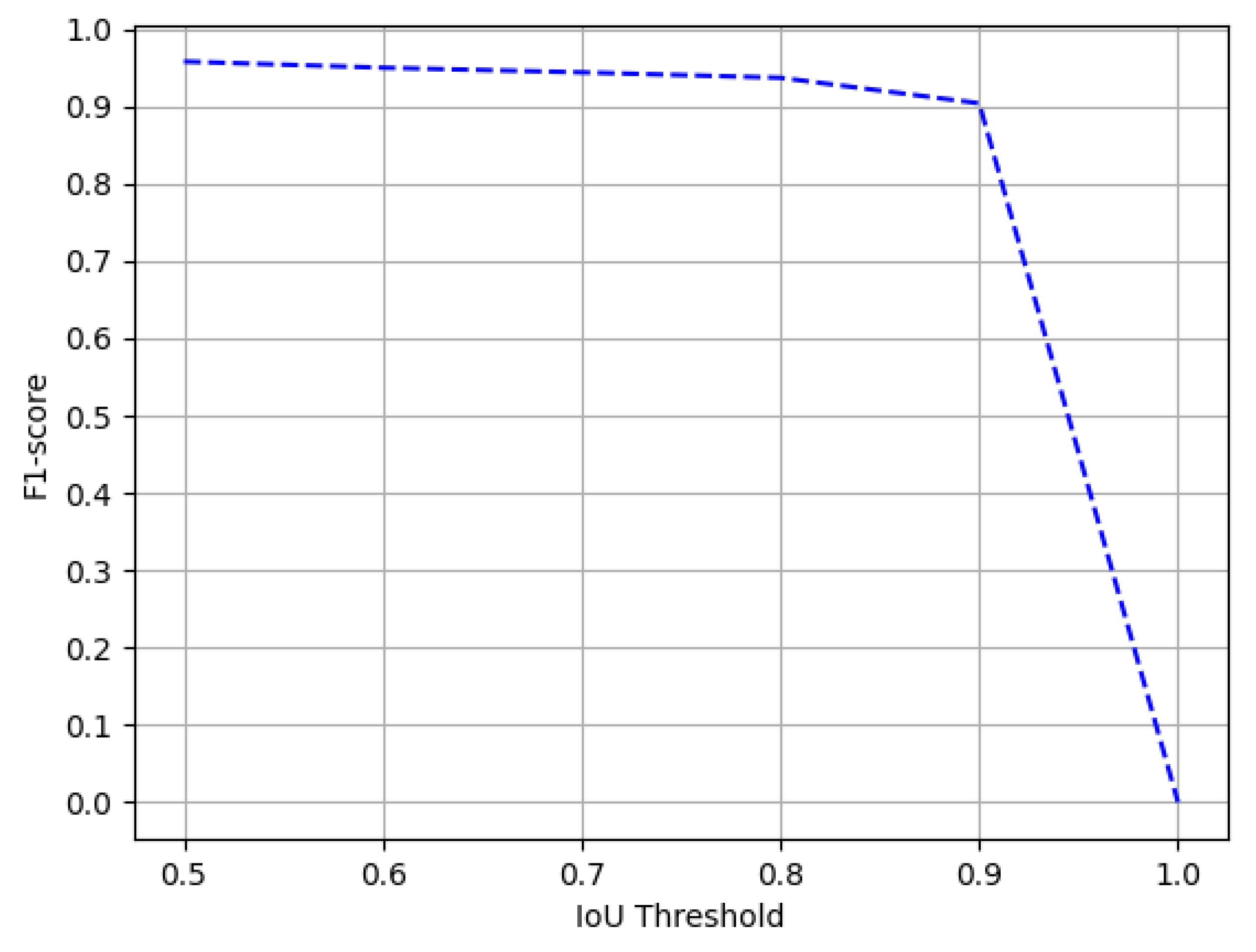
4.4.2. ICDAR-19
Comparison with State-of-the-Art Approaches
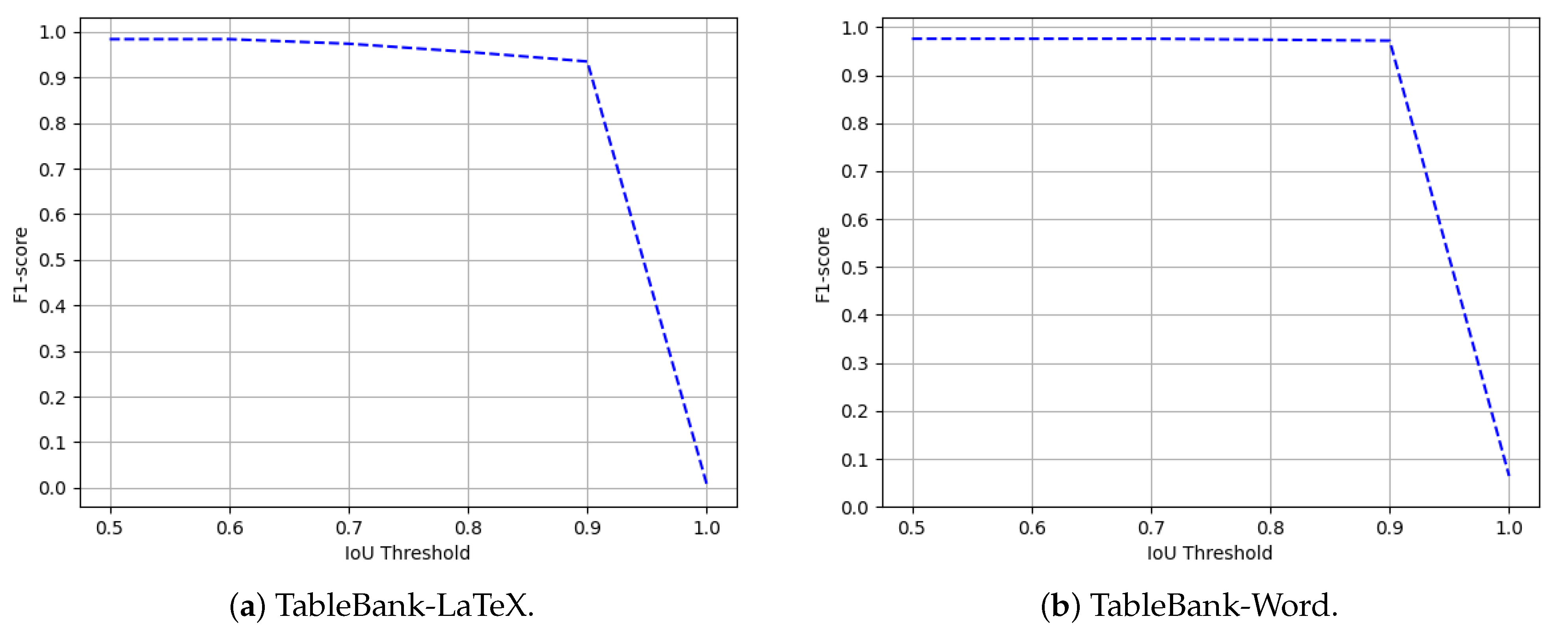
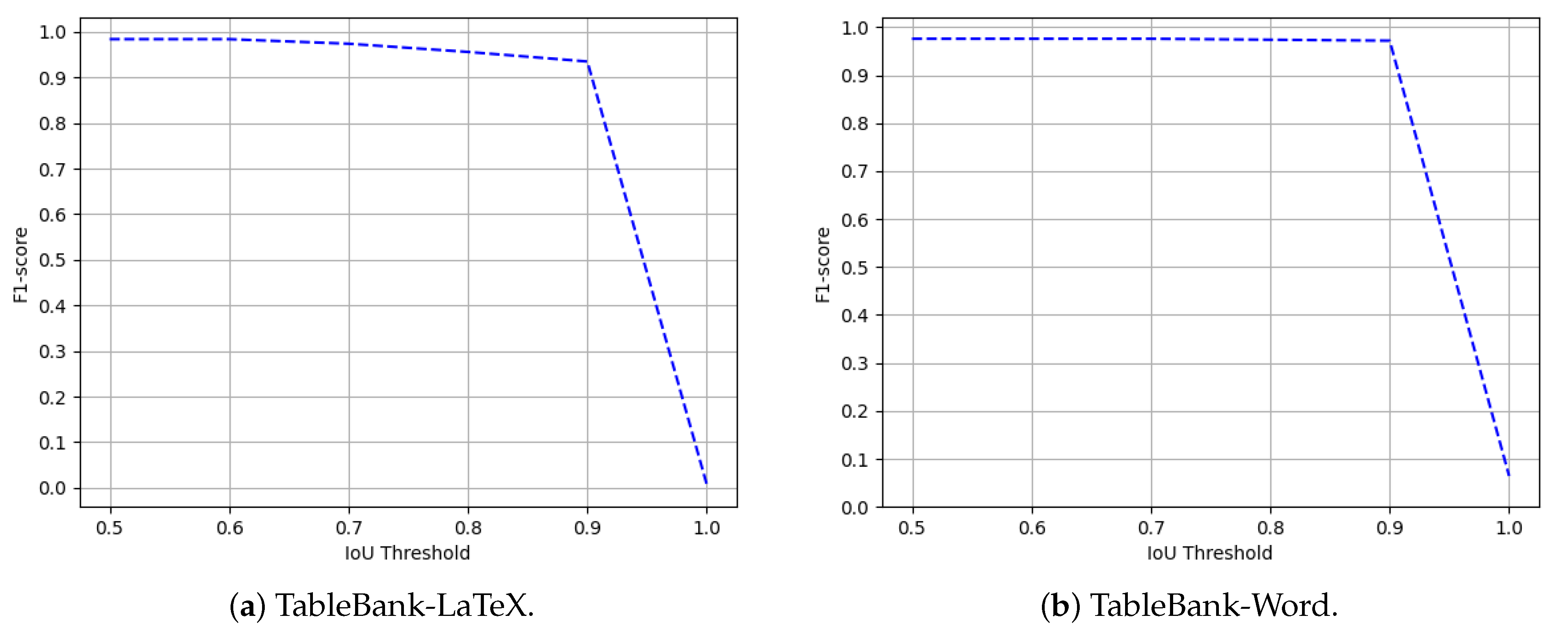
4.4.3. TableBank
Comparison with State-of-the-Art Approaches
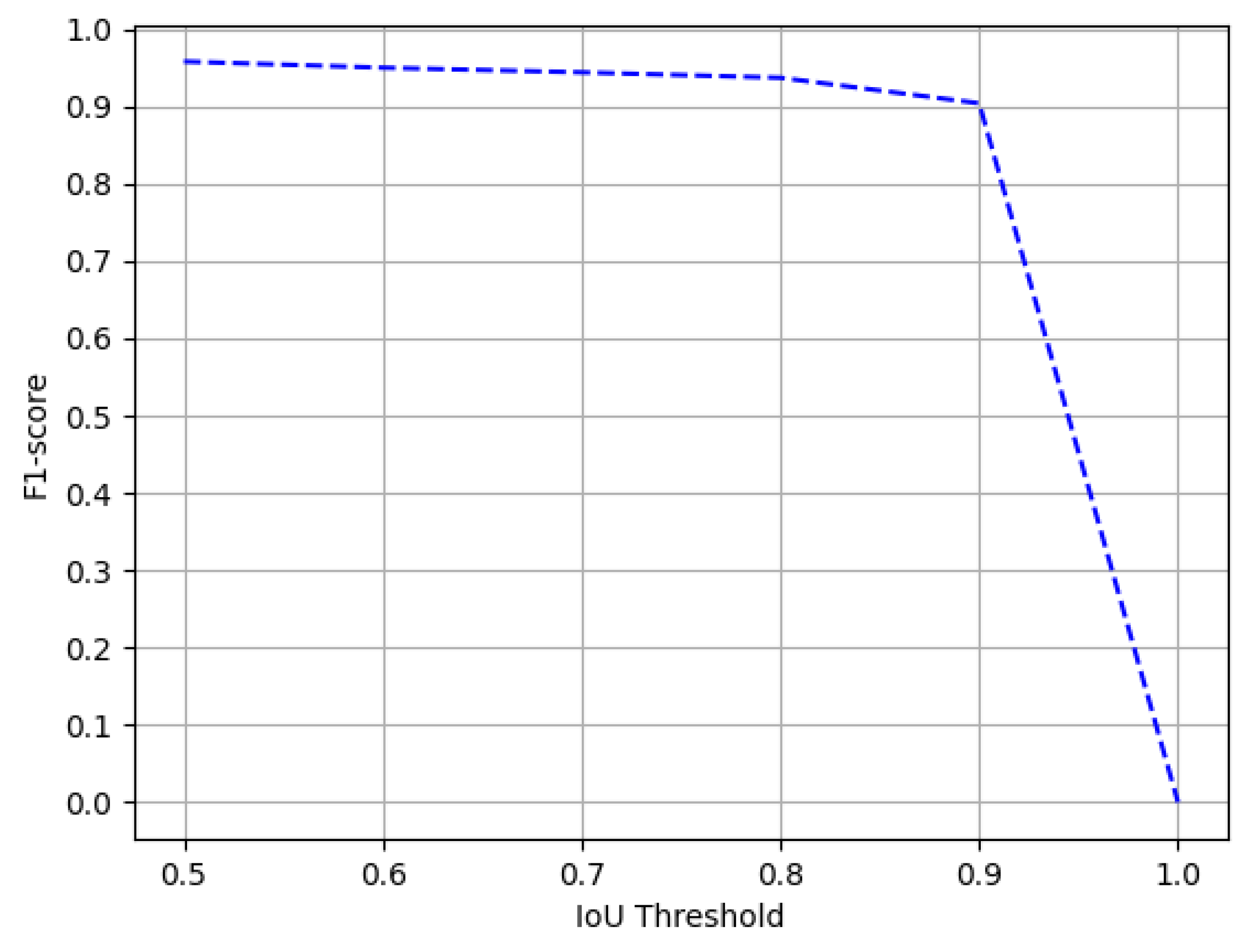
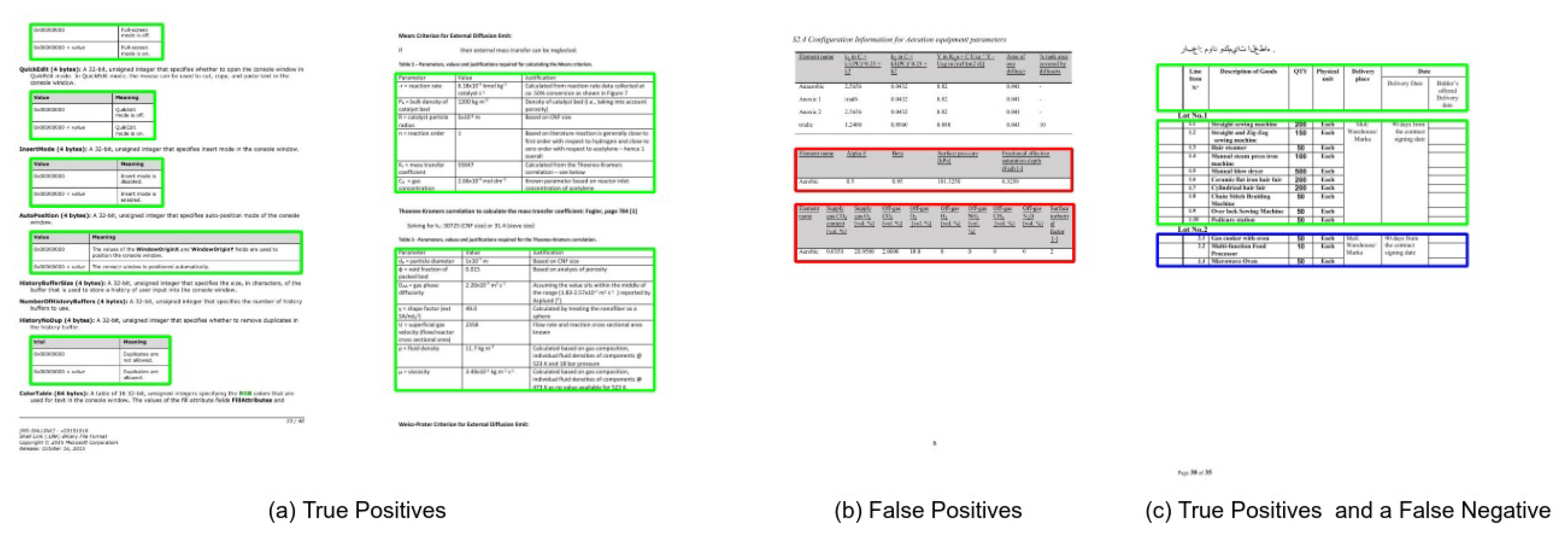
4.4.4. Marmot
Comparison with State-of-the-Art Approaches
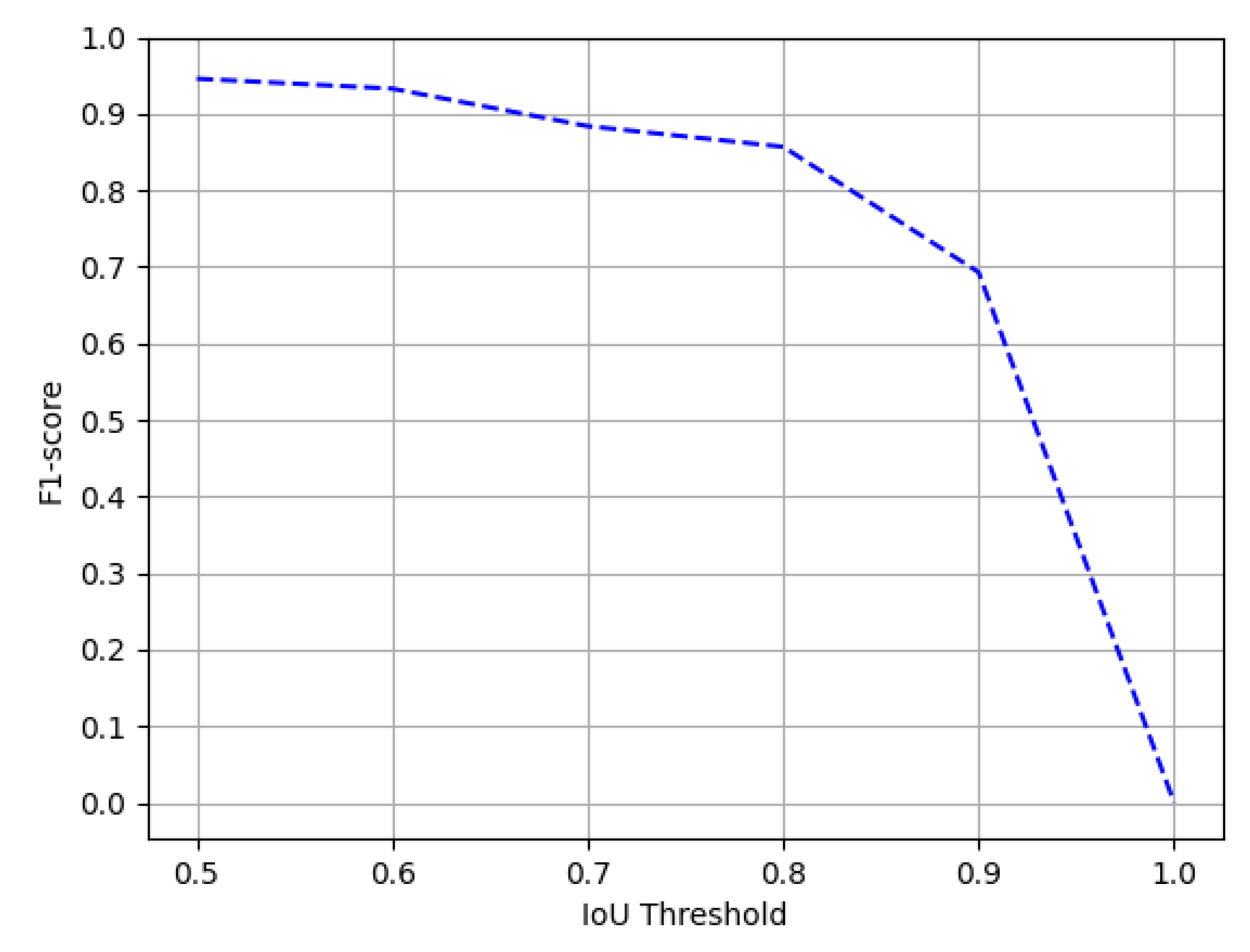
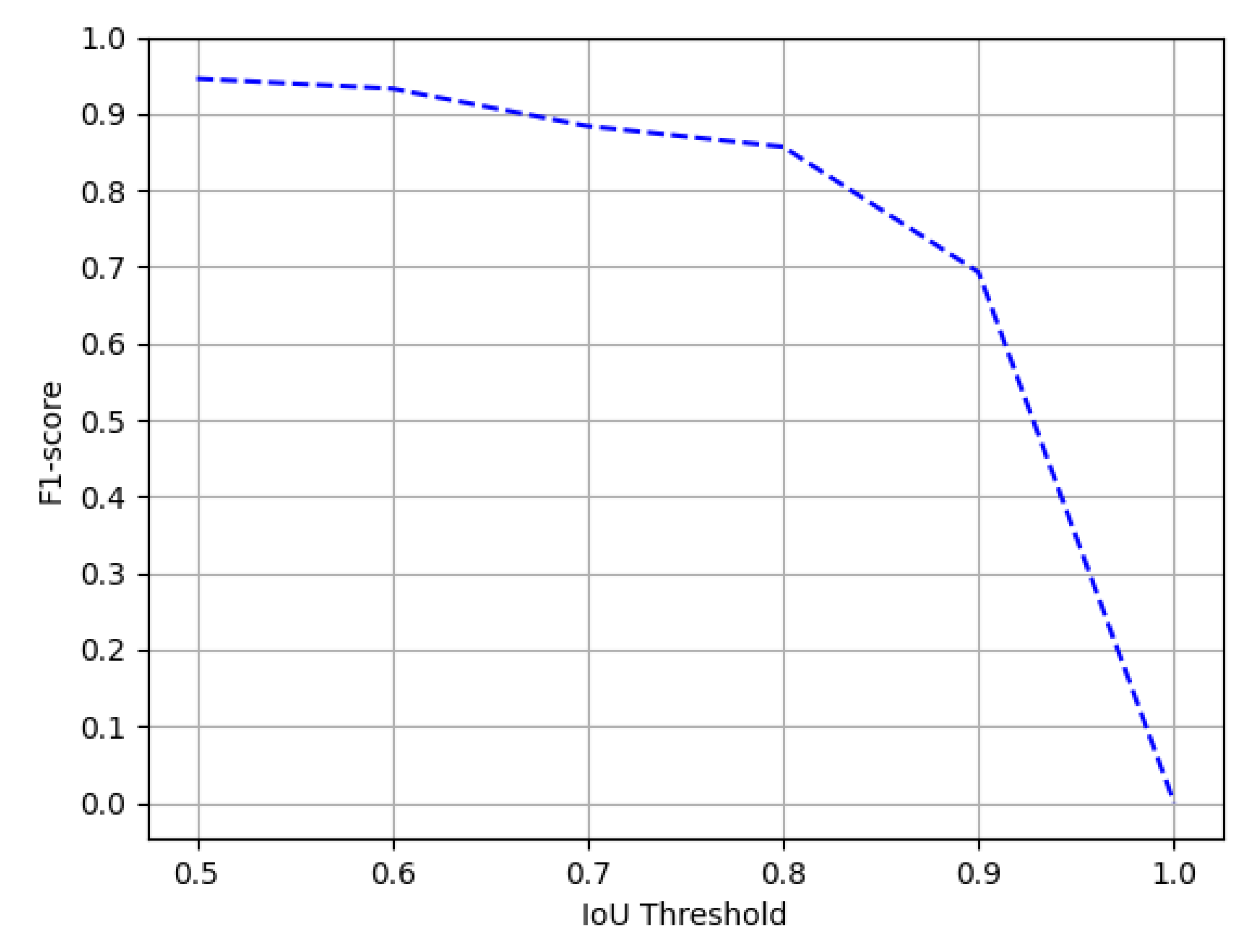
4.4.5. UNLV
Comparison with State-of-the-Art Approaches
4.4.6. Cross-Datasets Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gao, L.; Yi, X.; Jiang, Z.; Hao, L.; Tang, Z. ICDAR2017 competition on page object detection. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition. (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1417–1422. [Google Scholar]
- Bhatt, J.; Hashmi, K.A.; Afzal, M.Z.; Stricker, D. A Survey of Graphical Page Object Detection with Deep Neural Networks. Applied Sci. 2021, 11, 5344. [Google Scholar] [CrossRef]
- Zhao, Z.; Jiang, M.; Guo, S.; Wang, Z.; Chao, F.; Tan, K.C. Improving deepearning based optical character recognition via neural architecture search. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Hashmi, K.A.; Ponnappa, R.B.; Bukhari, S.S.; Jenckel, M.; Dengel, A. Feedback Learning: Automating the Process of Correcting and Completing the Extracted Information. In Proceedings of the International Conference on Document Analysis and Recognition Workshops (ICDARW), Sydney, Australia, 20–25 September 2019; Volume 5, pp. 116–121. [Google Scholar]
- van Strien, D.; Beelen, K.; Ardanuy, M.C.; Hosseini, K.; McGillivray, B.; Colavizza, G. Assessing the Impact of OCR Quality on Downstream NLP Tasks. In Proceedings of the ICAART (1), Valletta, Malta, 22–24 February 2020; pp. 484–496. [Google Scholar]
- Kieninger, T.G. Table structure recognition based on robust block segmentation. In Document Recognition V; Electronic Imaging: San Jose, CA, USA, 1998; Volume 3305, pp. 22–32. [Google Scholar]
- Schreiber, S.; Agne, S.; Wolf, I.; Dengel, A.; Ahmed, S. Deepdesrt: Deepearning for detection and structure recognition of tables in document images. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1162–1167. [Google Scholar]
- Hashmi, K.A.; Liwicki, M.; Stricker, D.; Afzal, M.A.; Afzal, M.A.; Afzal, M.Z. Current Status and Performance Analysis of Table Recognition in Document Images with Deep Neural Networks. IEEE Access 2021, 9, 87663–87685. [Google Scholar] [CrossRef]
- Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Cascade Network with Deformable Composite Backbone for Formula Detection in Scanned Document Images. Appl. Sci. 2021, 11, 7610. [Google Scholar] [CrossRef]
- Smith, R. An overview of the Tesseract OCR engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; Volume 2, pp. 629–633. [Google Scholar]
- Prasad, D.; Gadpal, A.; Kapadni, K.; Visave, M.; Sultanpure, K. CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents. In Proceedings of the IEEE/CVF Conference Computer Vision Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 572–573. [Google Scholar]
- Agarwal, M.; Mondal, A.; Jawahar, C. CDeC-Net: Composite Deformable Cascade Network for Table Detection in Document Images. arXiv 2020, arXiv:2008.10831. [Google Scholar]
- Zheng, X.; Burdick, D.; Popa, L.; Zhong, X.; Wang, N.X.R. Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context. In Proceedings of the IEEE/CVF Winter Conference Applied Computer Vision, Virtual (Online), 5–9 January 2021; pp. 697–706. [Google Scholar]
- Afzal, M.Z.; Hashmi, K.; Liwicki, M.; Stricker, D.; Nazir, D.; Pagani, A. HybridTabNet: Towards Better Table Detection in Scanned Document Images. Appl. Sci. 2021, 11, 8396. [Google Scholar]
- Coüasnon, B.; Lemaitre, A. Handbook of Document Image Processing and Recognition, Chapter Recognition of Tables and Forms; Doermann, D., Tombre, K., Eds.; Springer: London, UK, 2014; pp. 647–677. [Google Scholar]
- Zanibbi, R.; Blostein, D.; Cordy, J.R. A survey of table recognition. Doc. Anal. Recognit. 2004, 7, 1–16. [Google Scholar] [CrossRef]
- Kieninger, T.; Dengel, A. Applying the T-RECS table recognition system to the businessetter domain. In Proceedings of the 6th International Conference on Document Analysis and Recognition, Seattle, WA, USA, 10–13 September 2001; pp. 518–522. [Google Scholar]
- Shigarov, A.; Mikhailov, A.; Altaev, A. Configurable table structure recognition in untagged PDF documents. In Proceedings of the 2016 ACM Symposium Document Engineering, Vienna, Austria, 13–16 September 2016; pp. 119–122. [Google Scholar]
- Gilani, A.; Qasim, S.R.; Malik, I.; Shafait, F. Table detection using deepearning. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 771–776. [Google Scholar]
- Siddiqui, S.A.; Malik, M.I.; Agne, S.; Dengel, A.; Ahmed, S. Decnt: Deep deformable cnn for table detection. IEEE Access 2018, 6, 74151–74161. [Google Scholar] [CrossRef]
- Hashmi, K.A.; Stricker, D.; Liwicki, M.; Afzal, M.N.; Afzal, M.Z. Guided Table Structure Recognition through Anchor Optimization. arXiv 2021, arXiv:2104.10538. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2016, arXiv:1611.05431. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representationearning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. arXiv 2020, arXiv:2006.02334. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference Computer vision pattern Recognition, Salt Lake City, UT, USA, 30–31 January 2018; pp. 6154–6162. [Google Scholar]
- Itonori, K. Table structure recognition based on textblock arrangement and ruled ine position. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR’93), Tsukuba City, Japan, 20–22 October 1993; pp. 765–768. [Google Scholar]
- Chandran, S.; Kasturi, R. Structural recognition of tabulated data. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR’93), Sukuba, Japan, 20–22 October 1993; pp. 516–519. [Google Scholar]
- Hirayama, Y. A method for table structure analysis using DP matching. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–15 August 1995; Volume 2, pp. 583–586. [Google Scholar]
- Green, E.; Krishnamoorthy, M. Recognition of tables using table grammars. In Proceedings of the 4th Annual Symposium Document Analysis Information Retrieval, Desert Inn Hotel, Las Vegas, NV, USA, 24–26 April 1995; pp. 261–278. [Google Scholar]
- Huang, Y.; Yan, Q.; Li, Y.; Chen, Y.; Wang, X.; Gao, L.; Tang, Z. A YOLO-based table detection method. In Proceedings of the International Conference Document Analysis Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 813–818. [Google Scholar]
- Casado-García, Á.; Domínguez, C.; Heras, J.; Mata, E.; Pascual, V. The benefits of close-domain fine-tuning for table detection in document images. In International Workshop Document Analysis System; Springer: Cham, Switzerland, 2020; pp. 199–215. [Google Scholar]
- Arif, S.; Shafait, F. Table detection in document images using foreground and background features. In Proceedings of the Digital Image Computing: Techniques Applied (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar]
- Sun, N.; Zhu, Y.; Hu, X. Faster R-CNN based table detection combining cornerocating. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1314–1319. [Google Scholar]
- Qasim, S.R.; Mahmood, H.; Shafait, F. Rethinking table recognition using graph neural networks. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 142–147. [Google Scholar]
- Pyreddy, P.; Croft, W.B. Tintin: A system for retrieval in text tables. In Proceedings of the 2nd ACM International Conference Digit Libraries, Ottawa, ON, Canada, 14–16 June 1997; pp. 193–200. [Google Scholar]
- Pivk, A.; Cimiano, P.; Sure, Y.; Gams, M.; Rajkovič, V.; Studer, R. Transforming arbitrary tables intoogical form with TARTAR. Data Knowl. Eng. 2007, 3, 567–595. [Google Scholar] [CrossRef]
- Hu, J.; Kashi, R.S.; Lopresti, D.P.; Wilfong, G. Medium-independent table detection. In Document Recognition Retrieval VII; International Society for Optics and Photonics: Bellingham, WA, USA, 1999; Volume 3967, pp. 291–302. [Google Scholar]
- e Silva, A.C.; Jorge, A.M.; Torgo, L. Design of an end-to-end method to extract information from tables. Int. Doc. Anal. Recognit. (IJDAR) 2006, 8, 144–171. [Google Scholar] [CrossRef]
- Khusro, S.; Latif, A.; Ullah, I. On methods and tools of table detection, extraction and annotation in PDF documents. J. Information Sci. 2015, 41, 41–57. [Google Scholar] [CrossRef]
- Embley, D.W.; Hurst, M.; Lopresti, D.; Nagy, G. Table-processing paradigms: A research survey. Int. Doc. Anal. Recognit. (IJDAR) 2006, 8, 66–86. [Google Scholar] [CrossRef]
- Kieninger, T.; Dengel, A. The t-recs table recognition and analysis system. In International Workshop on Document Analysis System; Springer: Seattle, WA, USA, 1998; pp. 255–270. [Google Scholar]
- Cesarini, F.; Marinai, S.; Sarti, L.; Soda, G. Trainable tableocation in document images. In Proceedings of the Object Recognition Supported User Interaction Service Robots, International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; Volume 3, pp. 236–240. [Google Scholar]
- Kasar, T.; Barlas, P.; Adam, S.; Chatelain, C.; Paquet, T. Learning to detect tables in scanned document images usingine information. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1185–1189. [Google Scholar]
- e Silva, A.C. Learning rich hidden markov models in document analysis: Table ocation. In Proceedings of the 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 843–847. [Google Scholar]
- Silva, A. Parts That Add Up to a Whole: A Framework for the Analysis of Tables; Edinburgh University: Edinburgh, UK, 2010. [Google Scholar]
- Hao, L.; Gao, L.; Yi, X.; Tang, Z. A table detection method for pdf documents based on convolutional neural networks. In Proceedings of the 12th IAPR Workshop Document Analysis System (DAS), Santorini, Greece, 11–14 April 2016; pp. 287–292. [Google Scholar]
- Kavasidis, I.; Palazzo, S.; Spampinato, C.; Pino, C.; Giordano, D.; Giuffrida, D.; Messina, P. A saliency-based convolutional neural network for table and chart detection in digitized documents. arXiv 2018, arXiv:1804.06236. [Google Scholar]
- Paliwal, S.S.; Vishwanath, D.; Rahul, R.; Sharma, M.; Vig, L. Tablenet: Deepearning model for end-to-end table detection and tabular data extraction from scanned document images. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 128–133. [Google Scholar]
- Holeček, M.; Hoskovec, A.; Baudiš, P.; Klinger, P. Table understanding in structured documents. In Proceedings of the International Conference on Document Analysis and Recognition Workshops (ICDARW), Sydney, Australia, 20–25 September 2019; Volume 5, pp. 158–164. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks forarge-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference Computer vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Saha, R.; Mondal, A.; Jawahar, C. Graphical object detection in document images. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 51–58. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhong, X.; ShafieiBavani, E.; Yepes, A.J. Image-based table recognition: Data, model, and evaluation. arXiv 2019, arXiv:1911.10683. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focaloss for dense object detection. In Proceedings of the IEEE International Conference Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4974–4983. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residualearning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Analysis Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollar, P. Microsoft COCO: Common objects in context (2014). arXiv 2019, arXiv:1405.0312. [Google Scholar]
- Gao, L.; Huang, Y.; Déjean, H.; Meunier, J.L.; Yan, Q.; Fang, Y.; Kleber, F.; Lang, E. ICDAR 2019 competition on table detection and recognition (cTDaR). In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1510–1515. [Google Scholar]
- Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M.; Li, Z. Tablebank: Table benchmark for image-based table detection and recognition. In Proceedings of the 12th Language Resource Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 1918–1925. [Google Scholar]
- Shahab, A.; Shafait, F.; Kieninger, T.; Dengel, A. An open approach towards the benchmarking of table structure recognition systems. In Proceedings of the 9th IAPR International Workshop Document Analysis System, Boston, MA, USA, 9–10 June 2010; pp. 113–120. [Google Scholar]
- Fang, J.; Tao, X.; Tang, Z.; Qiu, R.; Liu, Y. Dataset, ground-truth and performance metrics for table detection evaluation. In Proceedings of the 10th IAPR International Workshop Document Analysis System, Gold Coast, Australia, 27–29 March 2012; pp. 445–449. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Blaschko, M.B.; Lampert, C.H. Learning toocalize objects with structured output regression. In Proceedings of the European Conference Computer Vision, Marseille, France, 12–18 October 2008; pp. 2–15. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | IoU = 0.6 | IoU = 0.8 | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F1-Score | Recall | Precision | F1-Score | |
| DeCNT [20] | 0.971 | 0.965 | 0.968 | 0.952 | 0.946 | 0.949 |
| NLPR-PAL [1] | 0.953 | 0.968 | 0.960 | 0.958 | 0.943 | 0.951 |
| VisInt [1] | 0.918 | 0.924 | 0.921 | 0.823 | 0.829 | 0.826 |
| GOD [54] | - | - | 0.989 | - | - | 0.971 |
| CDeC-Net [12] | 0.931 | 0.977 | 0.954 | 0.924 | 0.970 | 0.947 |
| HybridTabNet [14] | 0.997 | 0.882 | 0.936 | 0.994 | 0.879 | 0.933 |
| CasTabDetectoRS (Ours) | 0.941 | 0.972 | 0.956 | 0.932 | 0.962 | 0.947 |
| Method | IoU = 0.8 | IoU = 0.9 | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F1-Score | Recall | Precision | F1-Score | |
| TableRadar [65] | 0.940 | 0.950 | 0.945 | 0.890 | 0.900 | 0.895 |
| NLPR-PAL [65] | 0.930 | 0.930 | 0.930 | 0.860 | 0.860 | 0.860 |
| Lenovo Ocean [65] | 0.860 | 0.880 | 0.870 | 0.810 | 0.820 | 0.815 |
| CascadeTabNet [11] | - | - | 0.925 | - | - | 0.901 |
| CDeC-Net [12] | 0.934 | 0.953 | 0.944 | 0.904 | 0.922 | 0.913 |
| HybridTabNet [14] | 0.933 | 0.920 | 0.928 | 0.905 | 0.895 | 0.902 |
| CasTabDetectoRS (Ours) | 0.988 | 0.964 | 0.976 | 0.951 | 0.928 | 0.939 |
| Method | Dataset | IoU = 0.5 | IoU = 0.9 | ||||
|---|---|---|---|---|---|---|---|
| Recall | Precision | F1-Score | Recall | Precision | F1-Score | ||
| CascadeTabNet [11] | TableBank-LaTeX | 0.972 | 0.959 | 0.966 | - | - | - |
| Li et al. [66] | TableBank-LaTeX | 0.962 | 0.872 | 0.915 | - | - | - |
| HybridTabNet [14] | TableBank-LaTeX | - | - | 0.980 | - | - | 0.934 |
| CasTabDetectoRS (Ours) | TableBank-LaTeX | 0.984 | 0.983 | 0.984 | 0.935 | 0.935 | 0.935 |
| CascadeTabNet [11] | TableBank-Word | 0.955 | 0.943 | 0.949 | - | - | - |
| Li et al. [66] | TableBank-Word | 0.803 | 0.965 | 0.877 | - | - | - |
| HybridTabNet [14] | TableBank-Word | - | - | 0.970 | - | - | 0.962 |
| CasTabDetectoRS (Ours) | TableBank-Word | 0.985 | 0.967 | 0.976 | 0.981 | 0.963 | 0.972 |
| CascadeTabNet [11] | TableBank-Both | 0.957 | 0.944 | 0.943 | - | - | - |
| Li et al. [66] | TableBank-Both | 0.904 | 0.959 | 0.931 | - | - | - |
| HybridTabNet [14] | TableBank-Both | - | - | 0.975 | - | - | 0.949 |
| CasTabDetectoRS (Ours) | TableBank-Both | 0.982 | 0.974 | 0.978 | 0.961 | 0.953 | 0.957 |
| Method | IoU = 0.5 | IoU = 0.9 | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F1-Score | Recall | Precision | F1-Score | |
| DeCNT [20] | 0.946 | 0.849 | 0.895 | - | - | - |
| CDeC-Net [12] | 0.930 | 0.975 | 0.952 | 0.765 | 0.774 | 0.769 |
| HybridTabNet [14] | 0.961 | 0.951 | 0.956 | 0.903 | 0.900 | 0.901 |
| CasTabDetectoRS (Ours) | 0.965 | 0.952 | 0.958 | 0.901 | 0.906 | 0.904 |
| Method | IoU = 0.5 | IoU = 0.6 | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F1-Score | Recall | Precision | F1-Score | |
| Gilani et al. [19] | 0.907 | 0.823 | 0.863 | - | - | - |
| CDeC-Net [12] | 0.906 | 0.914 | 0.910 | 0.805 | 0.961 | 0.883 |
| HybridTabNet [14] | 0.926 | 0.962 | 0.944 | 0.914 | 0.949 | 0.932 |
| CasTabDetectoRS (Ours) | 0.928 | 0.964 | 0.946 | 0.914 | 0.952 | 0.933 |
| Training Dataset | Testing Dataset | Recall | Precision | F1-Score | Average F1-Score |
|---|---|---|---|---|---|
| TableBank-LaTeX | ICDAR-19 | 0.605 | 0.778 | 0.680 | 0.865 |
| ICDAR-17 | 0.866 | 0.958 | 0.910 | ||
| TableBank-Word | 0.967 | 0.947 | 0.957 | ||
| Marmot | 0.893 | 0.963 | 0.927 | ||
| UNLV | 0.918 | 0.856 | 0.885 | ||
| ICDAR-17 | ICDAR-19 | 0.649 | 0.778 | 0.686 | 0.812 |
| TableBank-Word | 0.983 | 0.943 | 0.963 | ||
| Marmot | 0.965 | 0.952 | 0.958 | ||
| UNLV | 0.607 | 0.685 | 0.644 | ||
| ICDAR-19 | ICDAR-17 | 0.894 | 0.917 | 0.906 | 0.924 |
| TableBank-Word | 0.981 | 0.921 | 0.950 | ||
| Marmot | 0.925 | 0.956 | 0.940 | ||
| UNLV | 0.898 | 0.876 | 0.887 | ||
| UNLV | ICDAR-17 | 0.867 | 0.879 | 0.881 | 0.897 |
| TableBank-Word | 0.903 | 0.941 | 0.922 | ||
| Marmot | 0.874 | 0.945 | 0.908 | ||
| ICDAR-19 | 0.839 | 0.918 | 0.877 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. CasTabDetectoRS: Cascade Network for Table Detection in Document Images with Recursive Feature Pyramid and Switchable Atrous Convolution. J. Imaging 2021, 7, 214. https://doi.org/10.3390/jimaging7100214
Hashmi KA, Pagani A, Liwicki M, Stricker D, Afzal MZ. CasTabDetectoRS: Cascade Network for Table Detection in Document Images with Recursive Feature Pyramid and Switchable Atrous Convolution. Journal of Imaging. 2021; 7(10):214. https://doi.org/10.3390/jimaging7100214
Chicago/Turabian StyleHashmi, Khurram Azeem, Alain Pagani, Marcus Liwicki, Didier Stricker, and Muhammad Zeshan Afzal. 2021. "CasTabDetectoRS: Cascade Network for Table Detection in Document Images with Recursive Feature Pyramid and Switchable Atrous Convolution" Journal of Imaging 7, no. 10: 214. https://doi.org/10.3390/jimaging7100214
APA StyleHashmi, K. A., Pagani, A., Liwicki, M., Stricker, D., & Afzal, M. Z. (2021). CasTabDetectoRS: Cascade Network for Table Detection in Document Images with Recursive Feature Pyramid and Switchable Atrous Convolution. Journal of Imaging, 7(10), 214. https://doi.org/10.3390/jimaging7100214